
| |
|
|
| 首页 淘股吧 股票涨跌实时统计 涨停板选股 股票入门 股票书籍 股票问答 分时图选股 跌停板选股 K线图选股 成交量选股 [平安银行] |
| 股市论谈 均线选股 趋势线选股 筹码理论 波浪理论 缠论 MACD指标 KDJ指标 BOLL指标 RSI指标 炒股基础知识 炒股故事 |
| 商业财经 科技知识 汽车百科 工程技术 自然科学 家居生活 设计艺术 财经视频 游戏-- |
| 天天财汇 -> 设计艺术 -> 什么是 AI Agent(智能体)? -> 正文阅读 |
|
|
[设计艺术]什么是 AI Agent(智能体)? |
| [收藏本文] 【下载本文】 |
|
最近看到很多大厂都开始做智能体,什么是智能体,有哪些使用场景,小白如何学习智能体呢? |
|
刚开始我也很懵,直到完整的看完了3遍吴恩达在BULIT2024的演讲视频,终于搞明白什么是Agent智能体。 这篇回答主要围绕着斯坦福大学教授吴恩达演讲中的Keynote讲一讲到底啥是Agent。希望能帮助和我一样迷糊的“非技术”背景的AI爱好者,揭开Agent这团迷雾。 Agent中文是智能体、代理的意思。 首先,先来看看Agent(智能体)和Non-Agent(非智能体)的对比 一、Non-Agent和Agent对比 拿写文章这个动作举例子。 大语言模型:我们输入一个提示,大模型一次性的从头到尾的生成一篇文章,中间不能修改。 |

|
|
Agent:它会先写出一个大纲,如果需要找资料的话,它会先联网找资料,接着它先写一份初稿,然后它会思考哪一部分写的不好,开始修改,改好以后再读一遍自己写的稿子,再修改,就这样反复这样的动作,最后形成终稿发给你。 |
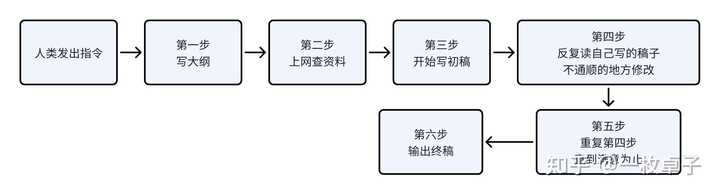
|
|
人类:先写出一个大纲,去网上找资料,接着把资料填进大纲里出一份初稿,然后发给领导,或者自己多读几遍,看看哪里不通顺,不够口语化,再删删减减,最后发给领导。 |
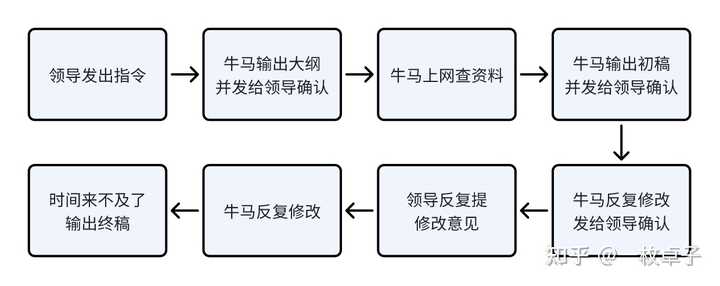
|
|
结论:Agent做牛马们要做的活儿 通过刚才的描述,你是否发现,Agent智能体和人类的行为高度相似? 其实智能体终极形态就是靠近一个活生生的人,人做一个事情什么思路,智能体就是什么思路。 吴恩达在演讲中把智能体详细的分成了四类,分别是Reflection、Tooluse、planning、multi- agent collaboration |
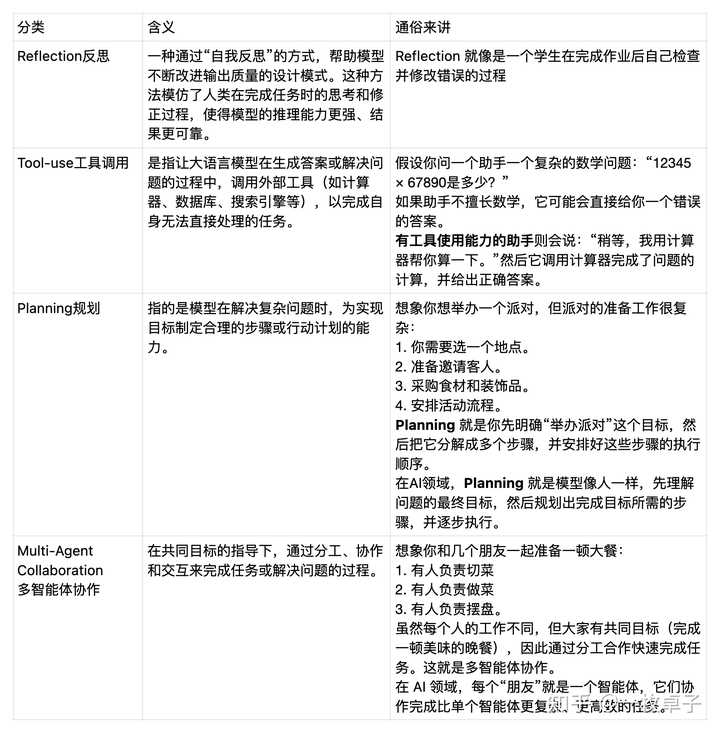
|
|
二、Reflection反思 通俗来讲,Reflection 就像是一个学生在完成作业后自己检查并修改错误的过程 吴恩达在演讲中举了一个例子。 如果用大语言模型塑造了一个“程序员”,你让他写个代码,它给你直接输出了答案,肯定不是最满意的,人类就要不断告诉他哪里需要修改。比如第几行有错误,怎么调整会更好。 |

|
|
但这时候,如果你再新建一个“审查员”角色的大模型,用它来检查代码是否正确,并指出不足之处。根据“审查员”模型的反馈,“程序员”再次进行改进代码。反复循环这样的操作,直到结果让人满意为止。 |

|
|
这样的过程就叫做Reflection反思 这种方法特别适用于需要高质量结果的任务,例如代码生成、复杂文档撰写、法律文件分析等。 三、Tool use 工具调用 通俗来讲,就像让我们人类算一个“12345 × 67890是多少?”咱也算不准,但我们拿个计算器,一下子就能得出准确结论。工具调用就是大语言模型会自己使用计算器。 在实际应用中,它会先识别需求:模型意识到它无法直接回答某个问题,需要借助工具。 再根据任务类型,判断要调用哪个工具,工具可以是计算器、知识库查询、数据库、搜索引擎,甚至是另一个模型。用工具完成任务后,将结果转化为人类易于理解的形式输出。 当大语言模型学会调用工具之后,有几个好处 1. 突破模型能力限制: 语言模型擅长语言理解,但可能在计算、实时信息查询、专业领域数据处理等方面能力不足。工具使用可以弥补这些缺陷。就像人类一样,有人擅长文科,有人擅长理科,但是要是给人们一个计算器,谁都能算出来了。 2. 提升准确性和效率: 比如在回答需要计算或实时查询的问题时,工具能提供精准答案,而不只是基于训练数据进行推测。你可以理解为大语言模型是一个人,塞给它一个工具,它就更准。 3. 扩展模型功能: 这种能力将语言模型从“单一的大脑”扩展为一个“多功能助手”。,如编程调试、数据分析、内容生成等。 ChatGPT添加插件的功能:如果你购买了ChatGPT Plus版,你可以来到插件商店里去选择插件帮助你完成更复杂的问题。 speechki:文本转语音的插件,coupert:找优惠券和促销码,edx:找某个领域的优质课程, one word domains: 检查域名是否可用。 |

|
|
|
|
|
|
|
|
|
|
|
四、Planning 规划/reasoning推理 举个例子,如果你发送一段这样的请求,Agent会动用4个模型去解决你的问题。 分别是: 1、openpose 模型用来提取动作 2、google/vit模型用来把动作转成图片 3、vit-GPT2模型,把图片转成文字 4、fastspeech模型,把文字转成语音 这种能力的提升,让AI更加接近真实的智能行为,能够处理更广泛的任务。 |

|
|
五、Multi Agent Collaborative 多智能体协作 吴恩达用了清华大学团队开发的ChatDev来解释这个概念。 ChatDev你可以理解为一家虚拟软件公司,公司里有各类职员,有CEO、CTO、测试员、程序员等等。 在这个公司里,人类是最大的Boss,你可以用一句话,就让这些职员替你打工,完成软件设计开发一条龙服务。 每个职员其实就是一个Agent。 |

|
|
ChatDev将整个开发过程分成了四个阶段。分别是设计、写代码、测试、合作文档 |

|
|
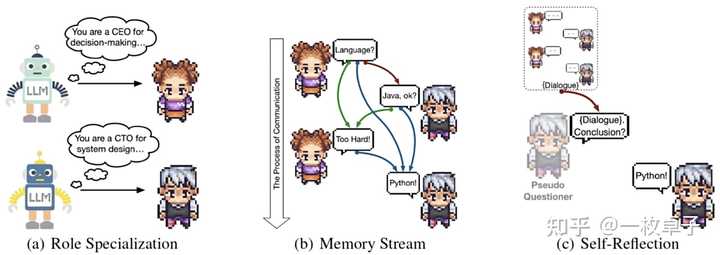
还设计了沟通链条,每次写作两个角色之间会交流沟通完成一个个小任务。 有点像我们平时公司里的那种沟通交流的模式。 在每次交流中,设置了3个机制,分别是角色专业化、记忆流、自我反思 |
|
|
角色专业化是指大语言模型会提前设定好每个角色是干嘛的,比如他会告诉CEO,你是CEO你负责做决定。告诉CTO你负责系统设计。 记忆流保存了,之前对话的全部信息,让智能体不要忘记之前的沟通,做出正确的决策。 自我反思:是指两个人没有达成共识之前, 进行自我反思。最后达成共识。 我当时研究了这个虚拟公司以后,仿佛看到了未来AI的样子,每个人都可以是“老板”,你的手下会有一帮AI员工帮你完成复杂高难度的工作。 之所以我们现在感知不强烈,是因为这些模型都停留在代码阶段,并没有被开发成小白也能搞懂的应用。 六、其他大厂们的行动 1. Google:Astra 项目是谷歌探索通用人工智能助手未来功能的研究原型。 利用多模态理解、多语言、工具使用、原生音频和记忆等能力,谷歌希望Astra能帮助人们理解世界,生活。 |

|
|
2024年12月11日谷歌发布了Project Astra的介绍视频 ,视频里的小哥拿着带有Astra的手机在伦敦展示了不同的功能。 |

|
|
它能够记得门的密码,还能够帮你讲解如何洗不同材质的衣服, 它还可以识别纸上的文字自动帮你搜索这些地点并告诉你都是干嘛的。 去国外旅行某个东西不知道怎么说,它会教你发音。你还可以让他对着某个雕塑,问它历史背景。可以和他聊植物的种类。 它还可以帮你朋友选礼物,只要把你朋友曾经看过的书单给她看,他可以告诉你你朋友喜欢什么。多语言输入它也没问题。 戴上眼镜骑车,你可以随意问它你看到的地点。问它路况和禁止停车区域。回到家你可以问眼镜,你家的门密码是多少,立刻会在你眼前显示。 |

|
|
2025年1月初谷歌发布了名为《Agents》的白皮书,从谷歌角度探讨了生成式AI Agent(智能体)的概念、架构和应用。 2. OpenAI: 2025年将会是智能体爆发的一年,2025年1月1日,OpenAI CEO 奥特曼公布了公司的新年目标,其中智能体被他列入第二位。 |
|
|
有网友爆料,OpenAI计划推出代号为“Operator”的全新AI智能体产品,能够自动执行各种复杂操作,这个 Agent 将具备直接控制电脑的能力。 3. Anthropic:2024年10月23日,它发布了开发可以操控计算机的模型。虽然这个模型还没太成熟,让他统计表格数据什么的,会经常出错。但是我们能看到Anthropic努力的方向和愿景。那就是让AI完全帮人类做事。 |

|
|
2024年12月底,Anthropic 公司发布了一篇重磅博客《buliding effective agents》,详细探讨了如何构建高效的 Agent,并分享了他们在这一领域的最新研究成果。 |
|
|
4. Microsoft:微软在2024年10月的“AI Tour”活动中,宣布将为Dynamics 365系列业务应用推出10个新的AI智能体,涵盖销售、客户支持和会计等领域。 2024年11月11日微软发布了Azure AI Agent ,一个集设计、定制和管理 AI 解决方案于一体的统一平台。 5. 字节跳动(ByteDance):字节跳动推出了Coze Agent平台,积极布局AI智能体领域。 最后,在写完这篇稿子的时候,我有一个非常强烈的感知,那就是AI颠覆世界的轮廓在慢慢变得清晰,我们在科幻片中看到的未来即将成为现实,我很荣幸能参与这个时代,见证科技以更高速的发展改变我们的生活。 这篇文章所有的参考资料,以及谷歌和Anthropic公布的白皮书和博客的链接都在下方,如果需要,可以去下载。 如果你喜欢这篇文章的话,点赞和关注卓子,如果想第一时间接收到资讯,可以点亮星标 ,我们下次再见,拜拜~ 参考资料: 1、谷歌Agents白皮书 https://www.kaggle.com/whitepaper-agents 2、Anthropic重磅博客《bulid effective Agents》 https://www.anthropic.com/research/building-effective-agents 3、吴恩达BULIT2024演讲Keynote翻译版 https://drive.google.com/file/d/1o_2YoeVQE20GjQ3edGOb5TkmJeQyvK2n/view?usp=sharing 4、全程干货,吴恩达BULIT2024演讲来了 https://mp.weixin.qq.com/s/jfhiw_0tVbH0_TMlFBEZ3w 5、Andrew Ng Explores The Rise Of AI Agents And Agentic Reasoning | BUILD 2024 Keynote https://www.youtube.com/watch?v=KrRD7r7y7NY 6、思维引擎 | AI Agent,还火吗?(万字长文讲清AI Agent) https://mp.weixin.qq.com/s/eHV_Xy9FE_J-ON1OTLY9uQ 7、OpenAI憋新大招:将推AI Agent,会操控电脑 https://mp.weixin.qq.com/s/NGpApx0bGEFJrRn6Ju7O4A 8、Project Astra | Exploring the future capabilities of a universal AI assistant https://www.youtube.com/watch?v=hIIlJt8JERI 9、Anthropic-Developing a computer use model https://www.anthropic.com/news/developing-computer-use 7、3步让AI接管你的电脑【claude最新API使用教程】 https://www.bilibili.com/video/BV1NwyQYzELV/?spm_id_from=333.337.search-card.all.click&vd_source=971d06d504ab9115e9baac0518a6b6e4 11、ChatDev:不写代码,一句话做软件游戏,附保姆级教程搭建你的在线AI软件游戏公司 https://www.bilibili.com/video/BV1L34y1T7gu?spm_id_from=333.788.videopod.episodes&vd_source=971d06d504ab9115e9baac0518a6b6e4 12、微软亚洲研究院2025六大预测:AI Agents 将颠覆传统工作模式 https://mp.weixin.qq.com/s/cLEIF9Otndh68o5v660bSQ 13、Top 10 ChatGPT Plugins You Can't Miss https://www.youtube.com/watch?v=o2M_paJf48I&t=323s 送礼物 还没有人送礼物,鼓励一下作者吧 |
|
随着大语言模型的横空出世,生成式AI应用也在不断发展,图1列出了生成式AI应用的分级,共分为5级: L1 Tool,人类完成所有工作,基本没有任何显性的AI辅助,只是比较简单的工具,会被逐渐升级淘汰;L2 Chatbot,人类直接完成绝大部分工作,人类向AI询问意见,了解信息,AI提供信息和建议但不直接处理工作;L3 Copilot,人类和AI进行协作,工作量相当,AI根据人类要求完成工作初稿,人类进行目标设定,修改调整,最后确认;L4 Agent,AI完成绝大部分工作,人类负责设定目标、提供资源和监督结果,AI完成任务拆分,工具选择,进度控制,实现目标后自主结束工作;L5 Intelligence,完全无需人类监督,AI自主拆解目标,寻找资源,选择并使用工具,完成全部工作,人类只需给出初始目标。 当发展到L4级别时,Agent(即智能体)的能力已经越来越接近通用人工智能,可以借助AI完成绝大部分的工作。相对来看,L3和L4级别的AI应用价值更大,但需要大语言模型的能力来进一步支持升级。 |

|
|
图1 生成式AI应用的分级 在《大语言模型Agent综述与实践》中,笔者已对基于大语言模型的智能体进行介绍。基于大语言模型的智能体的演进方向之一是多智能体间的协同。和人类在现实生活中将不同专长的专家组成团队、发挥集体智慧、共同完成复杂任务的协作方式类似,目前众多理论研究者和应用开发者也在探索多个不同角色的智能体相互协作、共同完成复杂任务的方案。 《Large Language Model based Multi-Agents: A Survey of Progress and Challenges》对基于大语言模型的多智能体的相关研究进行了综述,本文前半部分是对这篇论文的阅读笔记,并对综述中提及的部分工作进行展开,后半部分是对基于大语言模型的多智能体的实践。如有不足之处,请指正。 如无特殊说明,下面所讲的智能体、多智能体均指基于大语言模型的智能体、多智能体,而非传统的智能体、多智能体。 综述 大语言模型显现出与人类相当的推理和规划潜力,这与人类对能够感知环境、做出决策和响应的智能体的期望相一致,因此,基于大语言模型的智能体被提出。进一步,和人类在现实生活中将不同专长的专家组成团队、发挥集体智慧、共同完成复杂任务的协作方式类似,基于大语言模型的多智能体被提出。多个智能体相互协作、共同完成复杂任务。与单智能体相比,多智能体能够定义不同角色的智能体,使得每个智能体专精特定领域的知识和能力,并通过智能体间的交互有效模拟复杂的现实世界环境,提供更高级的能力。 《Large Language Model based Multi-Agents: A Survey of Progress and Challenges》对基于大语言模型的多智能体的相关研究进行了综述,内容包括以下几个部分: 背景知识,包括单智能体的介绍、多智能体和单智能体的对比;多智能体的架构,包括智能体和环境的交互、智能体画像构建、智能体间的通信和智能体能力获取;多智能体的应用,包括在问题求解和世界模拟这两大类中的应用,而每个大类中又具体拆分若干子类,论文对多智能体在每个子类中的应用进展均进行了介绍;多智能体的工具和资源,包括框架、数据集和基准;多智能体后续的挑战和机遇。 图2是论文列出的基于大语言模型的多智能体的研究进展,包括相关的框架、应用、数据集和基准,也包括多智能体如何通过记忆和自我进化进行迭代、获取能力。基于大语言模型的多智能体的框架包括Camel、MetaGPT、AutoGen、Agents,后面会再详细介绍。多智能体通过自我进化进行迭代、获取能力的方案包括Self-Adaptive、ProAgent、LTC等,后面会再详细介绍。多智能体的应用分问题求解和世界模拟两大类,而每个大类又分若干子类,问题求解的子类包括软件开发(Software Development)、具身智能(Embodied Agents)、科学实验(Science Experiments)、科学辩论(Science Debate),世界模拟的子类包括社会模拟(Societal Simulation)、游戏(Gaming)、心理学(Psychology)、经济学(Economy)、推荐系统(Recommender Systems)、政策制定(Policy Making)、疾病传播模拟(Disease Propagation Simulation),图2列出了各子类在每个时间周期(3个月为一个时间周期)内的论文数,后面会对多智能体在软件开发中的应用进行详细介绍。 |
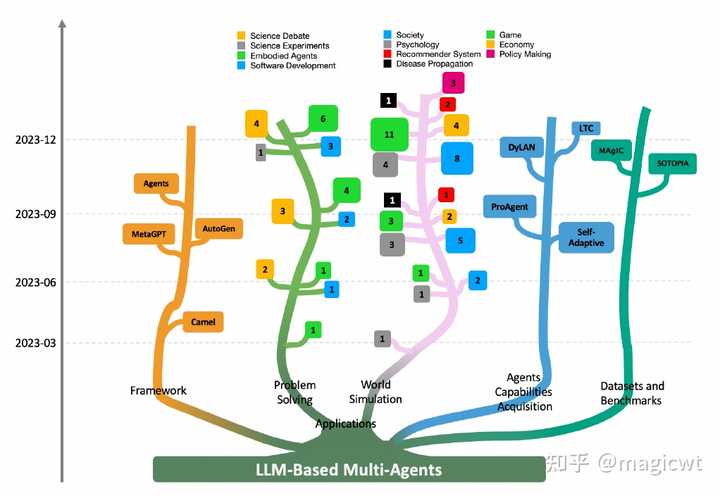
|
|
图2 基于大语言模型的多智能体的研究进展背景基于大语言模型的智能体 在《大语言模型Agent综述与实践》中,笔者已对基于大语言模型的智能体进行介绍,这里直接引用其中的内容。基于大语言模型的智能体其核心是大语言模型,大语言模型承担着大脑的角色,用于思考和规划,而围绕着大语言模型,Agent还包含记忆和工具,记忆用于存储短期上下文信息和长期知识信息,工具则承担着感官和四肢的角色,在大语言模型的思考和规划下,Agent一方面可以通过工具获取外部的各种信息用于进一步的思考和规划,另一方可以通过工具执行动作对外部环境施加影响。 |

|
|
图3 基于大语言模型的Agent的整体架构 《LLM Powered Autonomous Agents》中使用图3描述了基于大语言模型的Agent的整体架构,其中包含以下核心组件: 规划(Planning),大语言模型作为Agent的大脑负责思考和规划,而思考和规划的方式又可以分为两部分:分而治之(Task Decomposition):对于复杂的任务,大语言模型会将其分解为多个相对简单的子任务,每个子任务包含独立的子目标,从而分而治之、逐步求解;自我反思(Self-Reflection):大语言模型会对过去的规划和执行进行自我反思,分析其中的错误,并对后续的思考和规划进行改进,完善最后输出的结果。记忆(Memory),记忆是对大语言模型本身由模型结构和参数所蕴含知识的补充,记忆又可以分为短期记忆和长期记忆:短期记忆,即大语言模型的上下文学习,包括提示、指示、前序步骤的大语言模型推理结果和工具执行结果等;长期记忆,即外部可快速检索的向量索引,这也就是目前比较流行的一种大语言模型应用的解决方案――RAG(Retrieval-Augmented Generation,检索增强生成)。RAG的流程可以简单概括为,将包含知识的文档切分为块,并对块向量化,构建块向量索引,然后将问题也向量化,然后从块向量索引中检索和问题相关的块,最后将块和问题合并作为大语言模型的输入进行推理。RAG可以有效缓解大语言模型无法扩展知识、由知识局限产生的“幻觉”的问题。工具(Tool),工具作为Agent的感官和四肢,Agent一方面可以通过工具获取外部的各种信息用于进一步的思考和规划,例如通过搜索引擎搜索某个关键词的最新信息,另一方可以通过工具执行动作对外部环境施加影响,例如调用外部系统的接口执行指令并获取执行结果。 另外,在《A Survey on Large Language Model based Autonomous Agents》这篇综述论文中,作者提出了和图3类似的基于大语言模型的智能体的整体架构,如图4所示,其中除了和图3相同的Memory、Planning、Action组件外,作者还增加了画像(Profile)组件。画像(Profile)组件即提示中关于智能体角色的定义。我们平时通过大语言模型解决某类问题时,一般会先定义其角色,例如期望通过大语言模型根据关键词创作一段广告创意描述,则会给出类似“你是一位广告创意优化师,你需要根据关键词创作一段广告创意描述”这样的角色定义,并还会在提示中进一步给出思考步骤、约束限制、样本示例等。而画像,既可以由人工根据一定的方法论进行撰写,也可以由大语言模型根据提示进行生成。 |
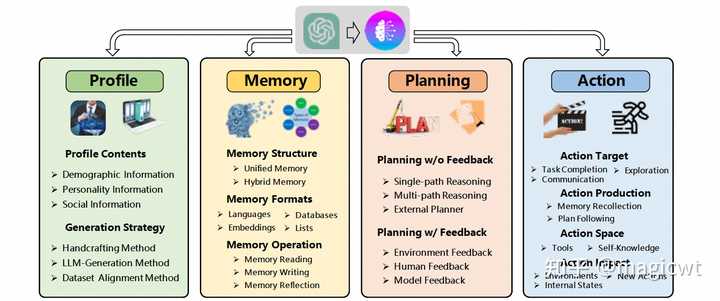
|
|
图4 基于大语言模型的智能体的整体架构多智能体和单智能体的对比 随着应用场景越来越复杂,基于大语言模型的大模型智能体也在向多智能体的协同进行演进,由各个智能体各司其职、分工协作来共同完成任务。 与单智能体相比,多智能体强调多样化的智能体配置、智能体间的交互和集体决策过程,这使得多个自主智能体能够通过合作解决更动态和复杂的任务。 架构 |
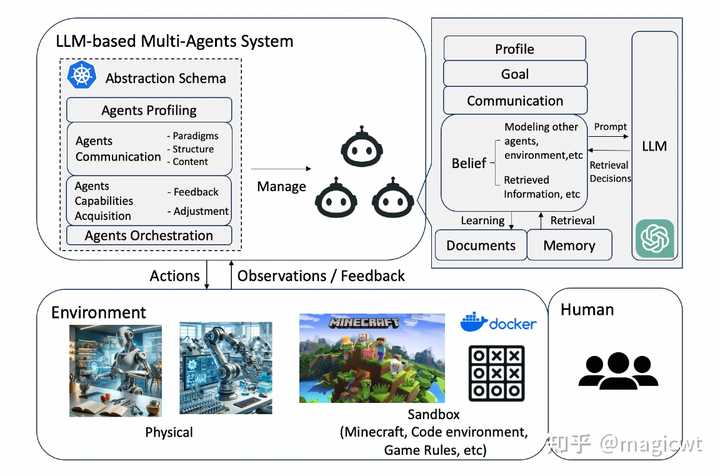
|
|
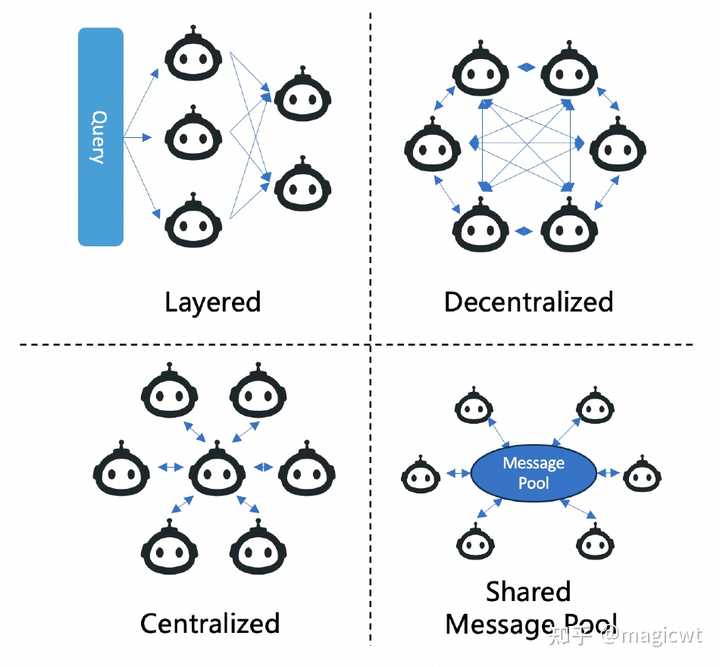
图5 基于大语言模型的多智能体的整体架构 图5是论文列出的基于大语言模型的多智能体的整体架构,其中涉及多个智能体间的协作,类似于人类在问题解决场景中的协作。论文分四个方面对多智能体的架构进行解析: 智能体和环境的交互(Agent-Environment Interface);智能体画像构建(Agents Profiling);智能体间的通信(Agents Communication);智能体能力获取(Agents Capabilities Acquisition)。智能体和环境的交互 智能体通过和环境的交互,获取信息,思考规划,执行动作对环境施加影响,进行再获取信息,用于后续的思考和规划,如此循环迭代多轮。智能体交互的环境可分为以下几类: 沙箱环境(Sandbox),即模拟或虚拟环境,沙箱环境主要用于软件开发和游戏,软件开发中将可编写和执行各类代码的代码解释器(Code Interpreter)作为模拟环境,游戏中将游戏规则作为模拟环境;物理环境(Physical),即真实物理环境,智能体和物理实体交互,且交互遵循物理定律,智能体的行动是真实的物理动作,比如打扫房间等;无环境(None),例如多智能体对一个问题进行辩论以达成共识,无环境下的应用主要关注智能体间的交互,而非智能体和外部环境的交互。智能体画像构建 多智能体中各智能体承担不同的角色,每个角色均有相应的描述,包括特征、能力、行为、约束和目标等,这些描述构成智能体的画像(Profile)。例如,在游戏中,各智能体作为游戏玩家,有不同的角色和技能,对游戏的目标有不同的作用;在软件开发中,各智能体承担的角色包括产品经理、架构师、开发工程师、测试工程师等,每个智能体分别负责软件开发流程的某一环节;在辩论中,各智能体承担的角色包括正方、反方和裁判等,每个智能体有特定的职责和策略。 智能体画像构建的方法也可分为以下几类: 预先定义(Pre-Defined),即由多智能体设计者人工显式地定义;模型生成(Model-Generated),即通过指示由大语言模型自动生成;数据衍生(Data-Derived),即根据已有数据集衍生。智能体间的通信 多智能体中各智能体的相互协作依赖智能体间的通信,论文从通信范式、通信结构和通信内容三个方面对智能体间的通信进行解析: 通信范式(Communication Paradigms):智能体间通信的方式、方法;通信结构(Communication Structure):智能体间通信的组织、结构;通信内容(Communication Content):智能体间通信的内容。 通信范式可分为三类: 合作(Cooperative),各智能体有共同的目标,相互交换信息以达成统一的解决方案;辩论(Debate),各智能体各自表达和维护自己的观点和方案,点评其他智能体的观点和方案,最终达成共识;竞争(Competitive),各智能体有各自的目标,且各自的目标可能相互冲突。 通信结构可分为四类: 分层(Layered)结构,如图6左上角所示,多智能体按层组织,每层包含多个不同角色的智能体,智能体只与同层或相邻层的其他智能体通信,《A Dynamic LLM-Powered Agent Network for Task-Oriented Agent Collaboration》这篇论文中提出的动态智能体网络(Dynamic LLM-Powered Agent Network,DyLAN)即属于分层结构,类似多层前馈神经网络,只是将其中的神经元替换为智能体,其针对给定问题,在推理时根据智能体优选算法选择各层中最优的智能体,然后使用选出的智能体逐层向前传递求解给定问题;去中心化(Decentralized)结构,如图6右上角所示,各智能体间直接点对点地相互通信,这种结构主要用于世界模拟(World Simulation)应用中;中心化(Centralized)结构,如图6左下角所示,由一个或一组智能体构成中心节点,其他智能体只与中心节点通信;共享消息池(Shared Message Pool)结构,如图6右下角所示,由MetaGPT提出,所有智能体发送消息至共享消息池,并订阅和自己相关的消息。 |
|
|
图6 多智能体的通信结构 通信内容格式主要是文本,但特定应用也有特殊的内容格式,例如,在软件开发中,智能体通信的内容可能还包括代码片段。 智能体能力获取 能力获取是多智能体中的关键过程,其使得智能体能够动态学习和演变。能力获取包括智能体从哪些类型的反馈中学习以增强其能力,以及智能体为有效解决复杂问题而调整自己的策略。 根据反馈的来源,可将反馈分为以下几类: 来自真实或模拟环境的反馈(Feedback from Environment),这种反馈在问题求解应用中比较普遍,包括软件研发中智能体从代码解释器(Code Interpreter)获取的代码执行结果,机器人这类具身智能体从真实或模拟环境获取的反馈等;来自智能体间交互的反馈(Feedback from Agents Interactions),这种反馈在问题求解应用也比较常见,包括来自其他智能体的判断,或来自智能体间的通信等,例如在科学辩论中,智能体通过智能体间的通信评估和完善结论,在博弈游戏中,智能体通过之前几轮和其他智能体的交互完善自己的策略;来自人类反馈(Human Feedback),人类反馈对智能体对齐人类偏好很重要,这种反馈主要在人机回环(Human-in-the-loop)应用中,《Putting Humans in the Natural Language Processing Loop: A Survey》这篇综述论文系统总结了在自然语言处理流程的各个环节中,可加入的人类反馈,这些环节包括数据生产、数据打标、模型选择、模型训练、评估部署等,如图7所示; |

|
|
图7 在自然语言处理流程的各个环节中可加入人类反馈无反馈(None),无反馈主要出现世界模拟这类应用中,因为这列应用主要侧重结果分析,例如传播模拟的结果分析,而非智能体能力获取,所以无需引入反馈对智能体的策略进行调整。 而智能体调整策略、增强能力的方式又可以分为三类:记忆(Memory),自我进化(Self-Evolution)和动态生成(Dynamic Generation)。 记忆(Memory)。智能体通过记忆模块保存过去交互和反馈的信息,在后续的执行中,可以从记忆中检索和当前任务相关的信息,特别是和本次任务目标类似的成功执行的信息,将这些信息作为上下文,辅助智能体思考规划。 自我进化(Self-Evolution)。除了基于记忆过去的信息来调整后续的执行外,智能体还可以动态地自我进化,调整目标和策略。论文在这里列举了自我进化相关的研究。 Self-Adaptive 《Self-Adaptive Large Language Model (LLM)-Based Multiagent Systems》这篇论文将MAPE-K控制循环和大语言模型相结合,实现多智能体的自我进化。MAPE-K控制循环是一个著名的框架,用于促进智能体的自主性和自我意识,如图8所示,其包含监控(Monitoring)、分析(Analyzing)、规划(Planing)、执行(Executing)、知识(Knowledge)这几个阶段或组件,而其名称就是由上述阶段或组件的英文单词的首字母组成。在监控阶段,智能体使用专门的传感器从环境中收集数据。在分析阶段,智能体评估数据以确定基于感知到的环境变化所需的响应。在规划阶段,智能体基于分析结果进一步收敛动作集合,通过执行动作能够达到预期的状态。在执行阶段,智能体通过执行器执行选定的动作。 |

|
|
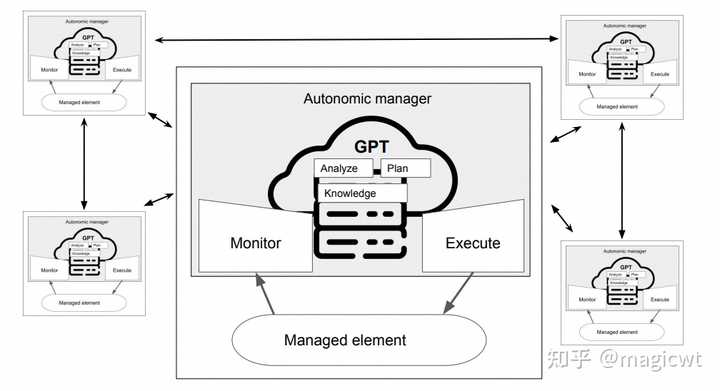
图8 MAPE-K控制循环 MAPE-K控制循环和大语言模型相结合,实现多智能体的自我进化的方案如图9所示,其中包含多个智能体,而每个智能体采用如图8所示的MAPE-K控制循环实现自我进化,每个智能体的控制循环使用大语言模型实现知识存储、分析和规划。 |
|
|
图9 MAPE-K控制循环和大语言模型相结合,实现多智能体的自我进化的方案 每个智能体的控制循环使用大语言模型实现知识存储、分析和规划的细节如图10所示,其中智能体的处理流程主要包含以下三个任务: 监控,即MAPE-K控制循环中的监控阶段,智能体收集感知器的数据,计算智能体的状态,联同来自其他智能体的消息,一并作为输入大语言模型的提示的一部分;GPT,合并MAPE-K控制循环中的分析、规划阶段以及知识存储,智能体依赖大模型模型,由其根据监控输入进行推理,输出动作;执行,即MAPE-K控制循环中的执行阶段,智能体将大语言模型输出的动作转化为可执行的指令,并执行。 |

|
|
图10 每个智能体的控制循环使用大语言模型实现知识存储、分析和规划的细节 |

|
|
图11 智能体4在第一轮交互中输入大语言模型的提示以及大语言模型返回的动作 论文设计以下应用场景评估MAPE-K控制循环和大语言模型相结合的效果:该应用场景共有5个智能体,其中智能体1、2、3为书籍卖家,智能体4、5为书籍卖家,买卖双方通过多轮交互、互相发送消息进行议价,卖家的成功条件是以尽可能高的价格成功卖出书籍,买家的成功条件是以尽可能低的价格成功买到书籍。智能体4在第一轮交互中输入大语言模型的提示以及大语言模型返回的动作如图11所示,未被蓝色标记的部分是输入大语言模型的提示,其中包括智能体4的角色描述、成功条件以及智能体1、3发给智能体4的消息,被蓝色标记的部分是大语言模型返回的动作,因为智能体1给出的价格相比智能体3给出的价格更低,为20,所以智能体4后续的动作是给智能体1回复消息,期望价格进一步降低至15。 ProAgent 《ProAgent: Building Proactive Cooperative Agents with Large Language Models》这篇论文提出ProAgent框架,其中,多智能体在协作时,每个智能体能够分析当前状态,推断其他智能体的意图,动态调整本身的策略和行动,对齐其他智能体,从而增强多智能体的协作能力。 论文使用Overcooked-AI这一开源项目作为评估ProAgent的应用场景,该项目基于热门视频游戏Overcooked,其中,多智能体相互协作,协作目标是尽可能快地烹饪并递送汤,协作过程中智能体的动作包括选择食材、烹饪汤、递送汤等。 |
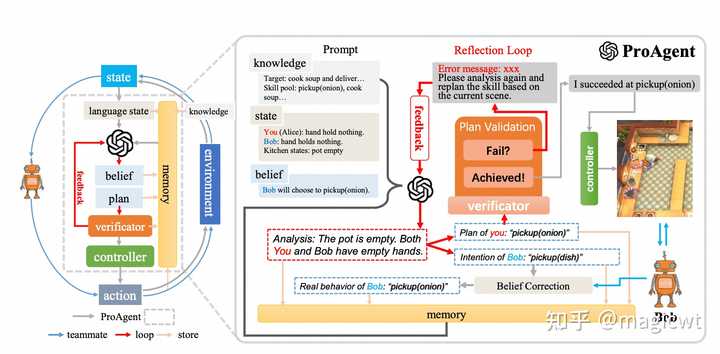
|
|
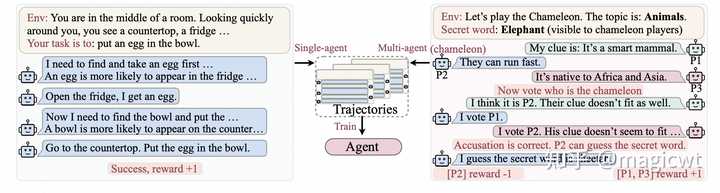
图12 ProAgent框架的整体架构和流程 ProAgent框架的整体架构和流程如图12所示,该框架包含4个模块和1个机制,4个模块分别是规划器(Planner)、校验器(Verificator)、控制器(Controller)和记忆(Memory),1个机制是认知修正(Belief Correction)。 ProAgent框架中智能体基于上述模块和机制感知环境、思考规划、执行动作的流程如图12左侧所示。首先,将智能体在环境中的状态由符号形式转化为自然语言形式,然后将自然语言形式的状态和记忆中的历史信息拼接在一起,由大语言模型作为规划器进行思考规划,识别其他智能体的意图,预估其他智能体的动作,并规划当前智能体本身后续的动作。接着,一方面通过认知修正机制,对比其他智能体的动作预估值和实际值,若有差异,则进行修正,另一方面通过校验器,校验当前智能体本身后续的规划动作是否可成功执行,若不可成功执行,则由规划器重新思考规划,如此循环,直至规划器给出可成功执行的动作,最后由控制器执行相应的动作。 流程细节和示例如图12右侧所示,当前智能体――Alice和另一个智能体――Bob合作制作并递送汤,Alice通过大语言模型进行思考规划时,其提示包括知识(即游戏目标、可选择的动作等)和状态(即Alice、Bob和环境当前的状态)等,大语言模型按照思维链(Chain of Thought,COT)的方式进行思考规划,先输出思考过程,再输出Alice的规划和Bob的意图,Bob的意图通过认知修正机制被修正,Alice的规划通过校验器被校验,校验通过的动作被控制器执行。 LTC 《Adapting LLM Agents Through Communication》这篇论文提出了通信学习(Learning through Communication,LTC)这一新的学习方式,将智能体的消息历史作为训练数据集对大语言模型进行微调。LTC既可用于单智能体,也可用于多智能体,单智能体通过思维链产生多个消息,多智能体通过相互之间的交互产生多个消息,这些消息构成类似强化学习中的轨迹,产生相应的结果,这些结果构成对各智能体的奖励,如图13所示。 |
|
|
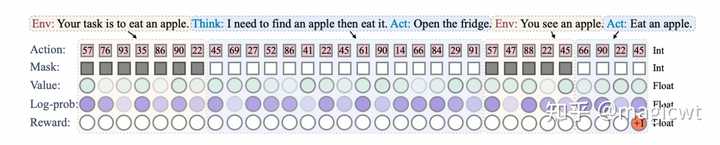
图13 单智能体和多智能体的多个消息构成轨迹、产生奖励 图13左侧单智能体的多个消息构成的轨迹的数据示例如图14所示: |
|
|
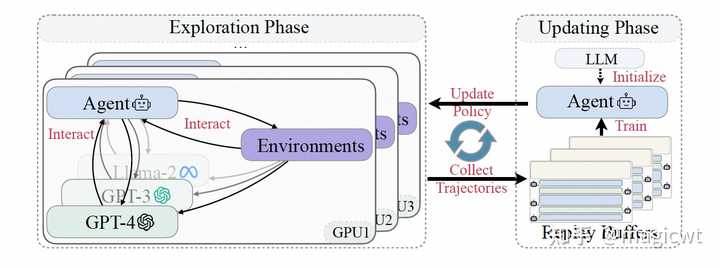
图14 单智能体的多个消息构成的轨迹的数据示例 其中,轨迹由词元序列构成,且每个词元通过Mask标记其由哪方产出,轨迹通过Reward标记其获得的奖励。 LTC的整体架构如图15所示,其参考强化学习,包括两个阶段: 探索(Exploration)阶段,智能体通过和大语言模型、环境及其它智能体等各方的交互,产出多个消息,构成如图14所示的轨迹,这些轨迹会存入重放池(Replay Buffers);更新(Updating)阶段,从重放池中采样轨迹,使用这些轨迹作为训练数据集微调大语言模型,微调的目标函数包含两部分,一部分是大语言模型本身的损失函数,即期望大语言模型能够通过前序词元序列准确预测下一个词元,另一部分是强化学习中PPO优化算法的损失函数,即期望大语言模型能够最大化奖励,通过将这两部分加权求和,使得微调后的大语言模型在保持语言模型能力的同时,能够最大化奖励,提升解决问题的能力。 |
|
|
图15 LTC的整体架构 动态生成(Dynamic Generation)。系统运行过程中根据需要动态生成新的智能体。论文在这里列举了动态生成相关的研究。 AutoAgents 《AutoAgents: A Framework for Automatic Agent Generation》这篇论文提出AutoAgents框架,如图16所示,其针对某个任务(例如,写一篇关于人工智能觉醒的小说)可动态生成相应的智能体进行处理,处理过程包括两个阶段: 草稿阶段(Draft Stage):通过三个预先定义的智能体――规划者(Planner)、智能体观察者(Agent Observer)、规划观察者(Plan Observer)的合作,生成完成任务所需的智能体和执行计划;执行阶段(Execution Stage):使用生成的智能体逐步执行计划,并通过一个预先定义的智能体――动作观察者(Action Observer)监控执行过程。 |

|
|
图16 AutoAgents框架 展开AutoAgents框架的部分细节。 在草稿阶段,规划者 \mathcal{P} 负责根据任务内容生成和完善智能体和执行计划,智能体观察者 \mathcal{O}_{agent} 负责对生成的智能体的合理性以及和任务的匹配度进行分析,并向规划者提出建议,规划观察者 \mathcal{O}_{plan} 负责对生成的执行计划的合理性以及和任务的匹配度进行分析,向规划者提出建议。规划者和智能体观察者、规划观察者进行多轮交互,直至观察者不再有反馈或交互达到最大轮数,从而得到最终的智能体和执行计划,执行计划包含多个步骤,每步由一个或多个智能体完成,每个智能体包含以下信息:提示(Prompt,即智能体的画像、目标和约束)、描述(Description)、工具集和建议。 在执行阶段,执行计划被分步执行,每步由单个或多个智能体完成,每步的完成过程也会进行多轮迭代,直至当前步骤完成或迭代达到最大次数。若某步的完成过程由单个智能体进行多轮迭代,则智能体采用思维链的方式逐步思考,论文称之为“Self-refinement Agent”,若某步的完成过程由多个智能体进行多轮迭代,则智能体采用交互的方式逐步思考,论文称之为“Collaborative Refinement Action”。同时,论文引入长短期记忆,计划的执行过程采用长期记忆,每步的迭代过程采用短期记忆,论文称之为“Knowledge Sharing Mechanism”。每步完成后,动作观察者分析截至当前步的计划执行情况,对计划进行调整。 AutoAgents框架的处理过程的伪代码如图17所示。 |

|
|
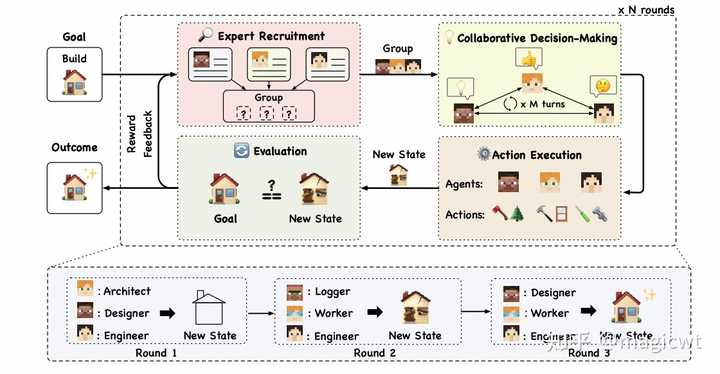
图17 AutoAgents框架的处理过程的伪代码AgentVerse 《AgentVerse: Facilitating Multi-Agent Collaboration and Exploring Emergent Behaviors》这篇论文提出了AgentVerse框架,如图18所示,和AutoAgents类似,AgentVerse针对某个任务也可以动态生成相应的智能体进行处理,AgentVerse模拟人类组织解决问题的流程,针对给定问题,进行多轮迭代,每轮迭代又分为4个阶段: 专家招聘(Expert Recruitment),定义和调整各智能体的角色;协作决策(Collaborative Decision-Making),由上述智能体联合讨论决定解决问题的策略;动作执行(Action Execution),各智能体和环境交互,执行动作;评估(Evaluation),评估本轮迭代结果是否符合预期。 协作决策中,论文尝试了两种多智能体间的协作方式,一种是水平结构(Horizontal Structure),即各智能体分别提出决策,再进行决策的整合,另一种是垂直结构(Vertical Structure),即由一个智能体提出决策,其他智能体提出反馈,迭代多次,直至达成一致。 |
|
|
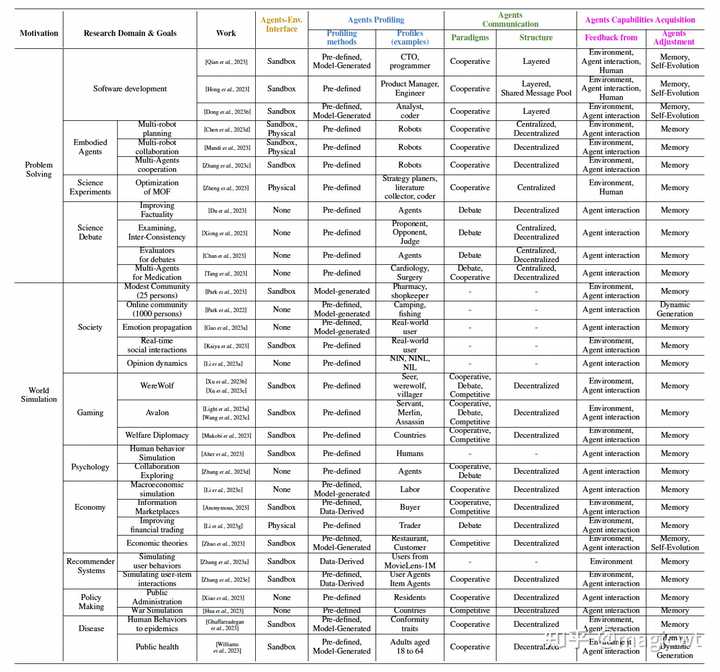
图18 AgentVerse框架应用 论文在前一部分分智能体和环境的交互、智能体画像构建、智能体间的通信、智能体能力获取四个方面对多智能体的架构进行解析。 论文在这一部分则对多智能体的应用进行分类介绍。论文将这些应用总结为两大类:问题解决(Problem Solving)和世界模拟(World Simulation)。两大类又分别包含了若干子类,问题求解的子类包括软件开发(Software Development)、具身智能(Embodied Agents)、科学实验(Science Experiments)、科学辩论(Science Debate),世界模拟的子类包括社会模拟(Societal Simulation)、游戏(Gaming)、心理学(Psychology)、经济学(Economy)、推荐系统(Recommender Systems)、政策制定(Policy Making)、疾病传播模拟(Disease Propagation Simulation)。论文分别对各子类的相关研究工作进行了梳理和介绍,并使用下表对各项工作按智能体和环境的交互、智能体画像构建、智能体间的通信、智能体能力获取这四个方面进行总结。 |
|
|
表1 对各项工作按智能体和环境的交互、智能体画像构建、智能体间的通信、智能体能力获取这四个方面进行总结 笔者下面主要对问题解决大类中软件开发的相关研究工作进行展开介绍,其他类别的相关研究工作读者可阅读论文原文,或进一步阅读论文所介绍工作的论文原文。 问题解决 使用多智能体解决问题的主要动机是利用具有专业知识的智能体的集体能力。这些智能体作为个体行动,合作解决复杂问题,如软件开发、具身智能体、科学实验和科学辩论。 下面主要对软件开发的相关研究工作进行展开介绍。软件开发流程一般是标准SOP工作流,由产品经理产出需求、架构师设计方案、研发工程师编写代码、测试工程师测试功能,因此,软件开发中各智能体的角色包括产品经理、架构师、研发工程师和测试工程师等,各智能体间的通信结构一般采用分层结构,按照标准SOP工作流,由各智能体逐步完成软件开发任务。 CAMEL 《CAMEL: Communicative Agents for "Mind" Exploration of Large Language Model Society》这篇论文提出了“Role-Playing”框架,如图19所示,针对某个任务,由AI用户(AI user)和AI助手(AI assistant)这两个智能体分别承担某个角色,进行多轮交互,每轮交互中,由AI用户根据任务目标和当前进展给出指示,由AI助手跟随指示、给出相应解决方案,直至最终完成任务。 以“开发股票交易机器人”为例,首先由人提出这一想法,并由人指定AI用户的角色是交易员、AI助手的角色是Python程序员,然后由Task Specifier这一智能体对想法进行细化,产出详细的任务描述,指出开发的功能需要包括对社交媒体平台上关于某只股票的正负向评价进行分析、并根据分析结果执行相应的交易操作。根据任务描述,AI用户和AI助手进行多轮交互,例如,AI用户先给出安装Python依赖的指示,AI助手给出应安装依赖列表和相应安装命令,AI用户再给出代码中引入库的指示,AI助手给出引入库的代码,如此交互,逐步给出交易机器人的实现方案。 |

|
|
图19 CAMEL Role-Playing框架 “Role-Playing”框架涉及Task Specifier、AI用户、AI助手这三个智能体,如何让这三个智能体遵循要求,即由Task Specifier细化想法,由AI用户给出指示,由AI助手给出解决方案,论文针对不同类型的应用场景,为这三个智能体设计了相应的提示,论文称这部分工作为“Inception Prompting”,图20为软件开发场景下Task Specifier、AI用户、AI助手这三个智能体的指示。 |

|
|
图20 软件开发场景下Task Specifier、AI用户、AI助手这三个智能体的指示Self-collaboration 《Self-collaboration Code Generation via ChatGPT》这篇论文提出了“self-collaboration”框架,如图21所示,包含Division of Labor和Collaboration两阶段。在Division of Labor阶段,论文引入标准的软件开发方法,将软件开发过程划分为若干步骤,每个步骤由相应角色的智能体负责完成。论文引入三种角色:Analyst,Coder和Tester,由Analyst负责拆解需求、设计方案,由Coder负责基于Analyst给出的方案和Tester给出的反馈编写代码,由Tester负责测试代码。在Collaboration阶段,则按照Division of Labor阶段已划分的软件开发若干步骤,分步执行,每步由相应角色的智能体负责完成。 |
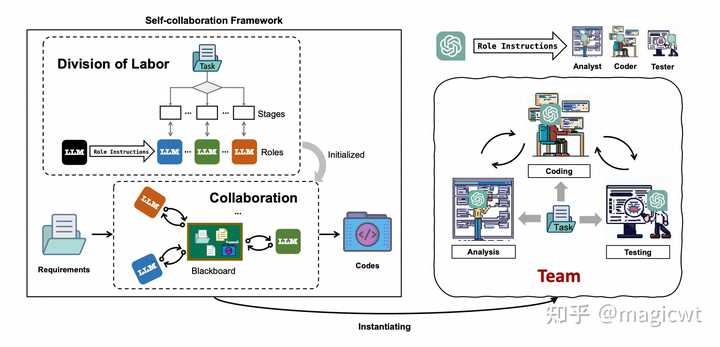
|
|
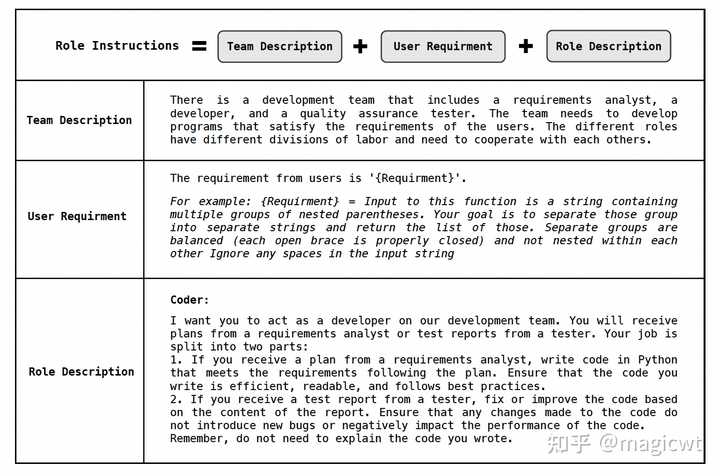
图21 “self-collaboration”框架 论文在提示中使用了“Role Instruction”来引导大语言模型按照所指定的角色进行思考。每个角色有各自的指示,图22是Coder的指示示例。指示包含三部分,分别是任务描述、用户需求和角色描述。 |
|
|
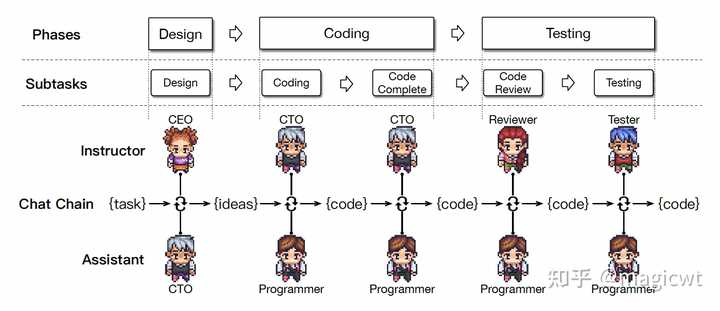
图22 Coder的指示示例ChatDev 《ChatDev: Communicative Agents for Software Development》这篇论文提出了ChatDev框架,以对话的方式实现软件开发,如图23所示。论文将软件开发过程划分为串行的三个阶段,分别是Design、Coding和Testing,每个阶段又可以进一步划分为一或多个子任务,Design阶段的子任务即Design,Coding的子任务包括Coding和Code Complete,Testing的子任务包括Code Review和Testing。每个子任务的完成采用CAMEL中提出的“Role-Playing”框架,引入Instructor和Assistant这两个智能体,由Instructor负责给出指示,由Assistant负责跟随指示、给出解决方案,这两个智能体会以对话的形式进行多轮交互,直至最终达成一致,输出当前任务的结果(文本或代码)。Instructor和Assistant这两个智能体在不同的子任务中有不同的角色,例如Code Review中,Instructor的角色是Reviewer,负责给出代码修改建议,Assistant的角色是Programer,负责根据建议修改代码。为了让大语言模型按照不同的角色进行思考,论文也采用了CAMEL提出的“Inception Prompting”方案,为不同的角色设计了不同的提示。 |
|
|
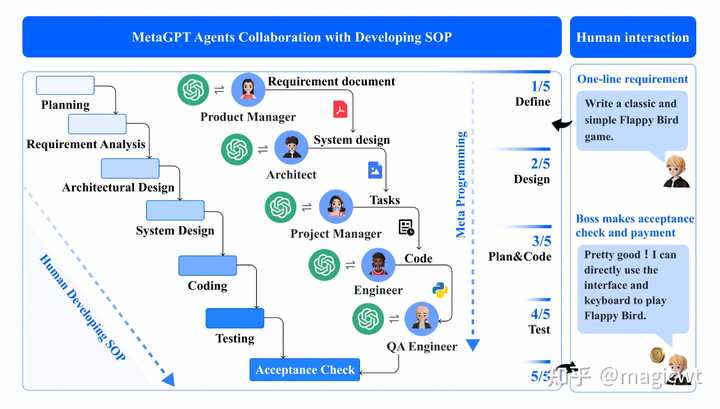
图23 ChatDev框架 通常,Instructor和Assistant这两个智能体以一问一答的形式进行多轮交互,交互方式可表示为: ?\mathcal{I}\rightarrow\mathcal{A},\mathcal{A}\rightarrow\mathcal{I}?_\circlearrowleft \\在这种交互方式下,如果Instructor给出的指示不明确,Assistant可能给出错误的解决方案,即导致幻觉的发生。为了解决这个问题,论文对交互方式进行升级,提出了“Communicative Dehallucination”机制,即在每轮交互中,若Assistant认为Instructor给出的指示并不明确,则先不给出解决方案,而是进行角色反转,由Assistant发起问题,向Instructor询问指示的细节,并由Instructor给出回复,由Assistant问、Instructor答的交互也会迭代多轮,直至Assistant认为指示已明确,才由其给出本轮交互的解决方案,新的交互方式可表示为: ?\mathcal{I}\rightarrow\mathcal{A},?\mathcal{A}\rightarrow\mathcal{I},\mathcal{I}\rightarrow\mathcal{A}?_\circlearrowleft,\mathcal{A}\rightarrow\mathcal{I}?_\circlearrowleft \\ MetaGPT 《MetaGPT: Meta Programming for A Multi-Agent Collaborative Framework》这篇论文指出软件开发有如图24所示的标准SOP流程,包括需求分析、架构设计、系统设计、开发、测试等各步,每步由相应角色的人员完成,包括产品经理、架构师、项目经理、开发工程师、测试工程师。 |
|
|
图24 软件开发的标准SOP流程 论文提出的MetaGPT框架即遵循上述SOP流程分步进行软件开发,并设计相应角色的智能体,包括产品经理、架构师、项目经理、开发工程师、测试工程师。论文为每个智能体指定角色、目标、约束和工具,图25右侧是开发工程师智能体的示例,其负责根据产品经理产出的需求文档和项目经理产出的系统设计、遵循一定的编码规范编写代码,并可运行和调试代码,将运行和调试结果作为反馈对代码进行修改和完善。论文要求每个智能体均输出结构化的消息,从而避免幻觉问题,例如,产品经理输出结构化的需求文档,架构师输出数据结构、接口定义等,开发工程师输出代码。各智能体输出的结构化消息统一存入如图25左侧所示的共享消息池,而各智能体从共享消息池中订阅自己所关注的消息,例如架构师关注产品经理输出的需求文档。 |

|
|
图25 共享消息池和开发工程师智能体AgentCoder 《AgentCoder: Multi-Agent-based Code Generation with Iterative Testing and Optimisation》这篇论文提出AgentCoder框架,其相对上述研究工作,只设计了3个智能体,分别是Programmer、Test Designer和Test Executor,因此占用较少的计算资源,另外,其更关注通过测试收集到的反馈,通过反馈对代码进行完善。 AgentCoder框架如图26所示,Programmer、Test Designer这两个智能体相互解耦,分别独立负责代码编写和测试用例生成,Programmer按照思维链的方式进行思考,思考过程分为问题理解、算法选择、伪代码生成、代码生成这四步,Test Designer生成覆盖度高的测试用例,包括基础测试用例、边界测试用例,大值测试用例这三类。而Test Executor则负责收集Programmer生成的代码和Test Designer生成的测试用例,执行测试用例,并将执行结果反馈给Programmer,用于代码的完善。 |

|
|
图26 AgentCoder框架世界模拟 多智能体的另一个主流应用场景是世界模拟,涵盖社会科学、游戏、心理学、经济学、政策制定等领域。多智能体在世界模拟中的使用关键在于其出色的角色扮演能力,这对于真实地描绘模拟世界中的各种角色和观点至关重要。例如,《Generative Agents: Interactive Simulacra of Human Behavior》这篇论文,在一个类似“模拟人生”的沙箱环境中引入25个智能体构成社区,每个智能体有不同的画像,相互之间可以通信,产生丰富的对话和行为数据,用于深度的社会科学分析,而用户可以通过自然语言和这些智能体进行交互。 |
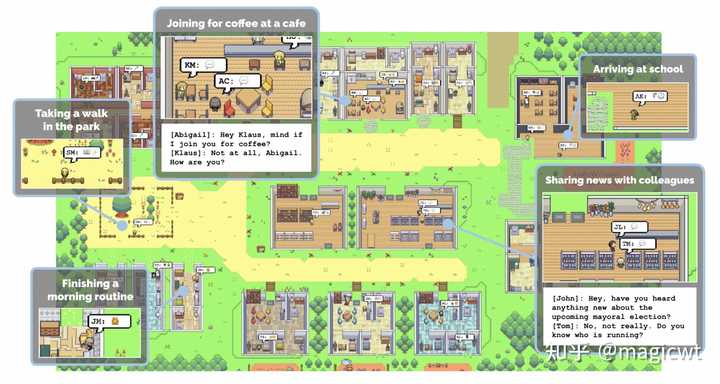
|
|
图27 多智能体构成的社区 关于多智能体应用于世界模拟的相关研究工作,读者可阅读论文原文,或进一步阅读论文所介绍工作的论文原文。 工具和资源框架 论文在这里介绍了三个开源的多智能体框架:MetaGPT、CAMEL和AutoGen,这些框架均利用多智能体的协作进行复杂任务的求解,但在方法细节上有所不同。 MetaGPT和CAMEL在上一部分已有介绍,这里不再赘述,这里再介绍一下AutoGen。 AutoGen 《AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation》这篇论文提出了AutoGen框架,如图28所示,该框架支持开发可定制的、对话形式的智能体,这些智能体可接收和发送消息,而思考产出消息的能力可以基于大语言模型、人类或工具,另外,该框架支持灵活定制多智能体间的交互方式。 |

|
|
图28 AutoGen框架 图29是使用AutoGen框架开发并使用多智能体的示例。 图29中最上面一层列出了AutoGen框架用于定义对话形式的智能体的接口――ConversableAgent,其有三个核心方法:send方法用于发送消息,receive方法用于接收消息,generate_replay方法用于基于大语言模型、人类或工具等产出消息。AutoGen框架默认提供了ConversableAgent接口的两个实现――AssistantAgent和UserProxyAgent,AssistantAgent基于大语言模型产出消息,UserProxyAgent基于人类或工具产出消息,开发者也可以自行实现ConversableAgent接口,定制智能体。 图29中中间一层是基于AutoGen框架开发多智能体的示例,其中定义了两个智能体,分别是基于UserProxyAgent实例化得到的User Proxy A,和基于AssistantAgent实例化得到的Assistant B。然后,通过register_replay方法为User Proxy A注册定制的产出待发送消息的方法,该方法首先从人类获取待发送消息,若人类无输入且之前接收的消息中包含“code”,则调用工具执行接收的消息,工具执行结果作为待发送消息,论文称这一定制过程为“Conversation-Driven Control Flow”。最后,通过initiate_chat方法初始化对话,由User Proxy A向Assistant B发送消息,要求绘制META和TESLA年初至今的股票价格走势图。 图29中最下面一层则是上述所开发多智能体以对话形式相互交互的示意。 |
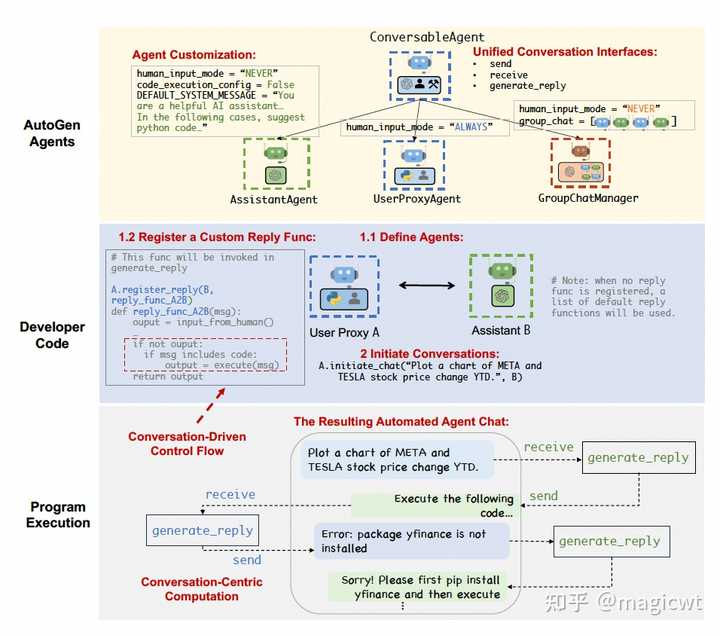
|
|
图29 使用AutoGen框架开发并使用多智能体的示例 论文还提到一些框架支持系统运行过程中根据需要动态生成新的智能体,包括前面在智能体能力获取部分已介绍的AgentVerse、AutoAgents等,这里不再赘述。论文也还提到一些研究工作通过平台化的方式快速支持智能体的构建和使用,例如,《OpenAgents: An Open Platform for Language Agents in the Wild》这篇论文提出了OpenAgents这一开源平台,如图30所示,其包含三类智能体:数据分析智能体、插件调用智能体和WEB搜索智能体,既支持WEB形式的直接访问,也支持本地化部署。 |

|
|
图30 OpenAgents平台数据集和基准 论文总结了多智能体研究中常用的数据集或基准,如表2所示。不同的研究使用不同的数据集和基准。在问题解决场景中,大多数数据集和基准用于评估多个智能体合作或辩论的规划和推理能力。在世界模拟场景中,数据集和基准用于评估模拟世界和真实世界的对齐,或分析不同智能体的行为。 |
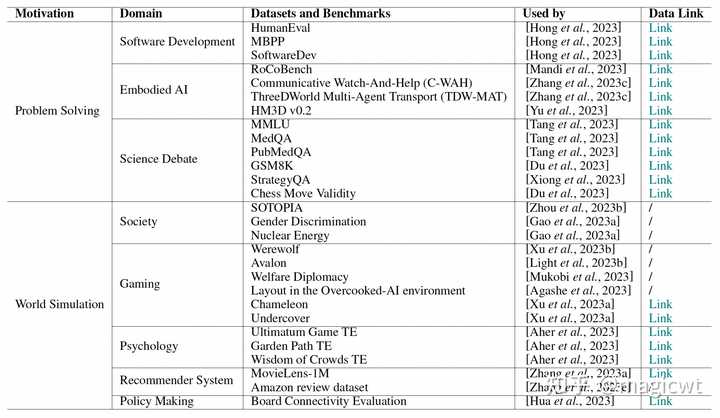
|
|
表2 多智能体研究中常用的数据集或基准挑战和机遇 多智能体框架和应用的研究正在迅速进展,带来了许多挑战和机遇。论文这里列举了一些关键挑战和未来研究的潜在领域: 支持多模态环境。大多数先前关于多智能体的工作都集中在基于文本的环境中,擅长处理和生成文本,而在多模态环境中,智能体将与多种感官输入进行交互,并生成多种输出,如图像、音频、视频和物理动作,目前这方面工作仍然较少。解决幻觉问题。幻觉问题在大语言模型和单智能体中是一个重大挑战,而在多智能体中,这个问题变得更加复杂,在多智能体中,一个智能体的幻觉可能会产生级联效应,错误信息会从一个智能体传播到另一个智能体,因此,在多智能体中,既要修正单个智能体的幻觉,也要完善智能体间的信息流,避免错误信息的扩散。获取集体智能。传统未基于大语言模型的多智能体中,智能体通常使用强化学习从离线训练数据集中学习,而基于大语言模型的多智能体主要从即时反馈中学习,如与环境或人类的交互,通过记忆和自我进化,基于反馈进行调整。支持扩展。多智能体由多个智能体组成,每个智能体通常依赖某个大语言模型,需要大量的计算资源和存储空阿金,扩展多智能体中的智能体数量,会导致计算资源需求的增长,如何更好地设计多智能体的工作流和任务分配机制,使得扩展多智能体,提升效果的同时减少计算资源的使用。实践LangGraph |
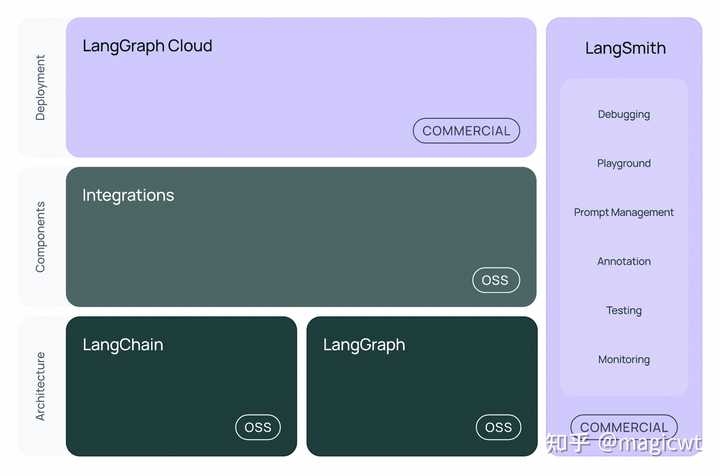
|
|
图31 LangChain整体框架 LangChain是一个面向大语言模型的应用开发框架,它可以将外部数据源、工具和大语言模型结合在一起。目前LangChain整体框架如图31所示,由以下部分组成: LangChain库:langchain-core:核心组件的抽象定义和LangChain表达式语言;langchain-community:各种第三方实现的集成;langchain:各类Chain和Agent的实现;LangGraph:用于以图的方式将多个基于大语言模型的智能应用组合在一起;LangServe:用于将LangChain应用部署为REST API的服务;LangSmith:开发者平台,用于调试、评估和监控基于大语言模型构建的应用。 LangChain包含以下核心组件: Model,表示大语言模型;Prompt,表示提示;Tool,表示工具;Chain,表示将Model、Tool等组件串联在一起,甚至可以递归地将其他Chain串联在一起;Agent,相对于Chain已固定执行链路,Agent能够基于大语言模型进行思考和规划,根据不同的问题实现动态的执行链路; 关于Chain的实践可以阅读笔者之前撰写的《Mac本地部署大模型体验AIGC能力》,关于Tool和Agent的实践可以阅读笔者之前撰写的《大语言模型Agent综述与实践》,以下是对LangGraph的介绍和使用,基于LangGraph构建多智能体。本文所用的LangGraph的版本是“0.2.39”。 LangGraph的核心是将多智能体间的通信建模为图,其使用三个关键组件定义图中的相关信息: 状态:一个共享数据结构,表示多智能体的当前状态,其可以是任何Python类型,但通常是TypedDict或Pydantic BaseModel,其存储的信息可以是多智能体间通信的历史消息及其他定制化的信息;节点:Python 函数,用于编码某个智能体的计算逻辑,其以当前状态作为输入,执行计算逻辑,并返回更新后的状态;边:Python函数,根据当前状态确定要执行的下一个节点。 LangGraph提供多种方法来控制智能体间的通信顺序(即边的定义): 显式控制流(图边):通过定义图边显式指定智能体间的通信顺序;动态控制流(条件边):通过定义条件边由大型语言模型或路由函数决定接下来调用的智能体。 以下是一个显式控制流的例子,首先定义两个智能体――研究助手和摘要专家,研究助手负责根据给定主题(例如“强化学习”)提供信息,摘要专家负责根据给定信息生成摘要,显式控制流即先由研究助手提供信息,再由摘要专家生成摘要,代码如下所示: 执行上述代码,LangSmith中记录的执行过程和结果如图32所示,从中可以看出,执行过程先由研究助手调用大语言模型给出“强化学习”的相关信息,再由摘要专家调用大语言模型根据上述信息,给出摘要: 强化学习(Reinforcement Learning, RL)是一种通过智能体与环境交互来学习最优行动策略的机器学习方法,旨在最大化累积奖励。其核心概念包括智能体、环境、状态、动作、奖励和策略。RL的目标是找到一个长期总奖励最大的策略,主要分为基于价值、基于策略和基于模型的方法。应用领域涵盖游戏(如AlphaGo)、机器人学、自动驾驶及推荐系统等。尽管面临样本效率低、探索与利用难题以及泛化能力差等挑战,随着计算资源和算法的进步,RL正逐渐成为解决复杂问题的有效工具,并展现出广泛的应用前景。 |
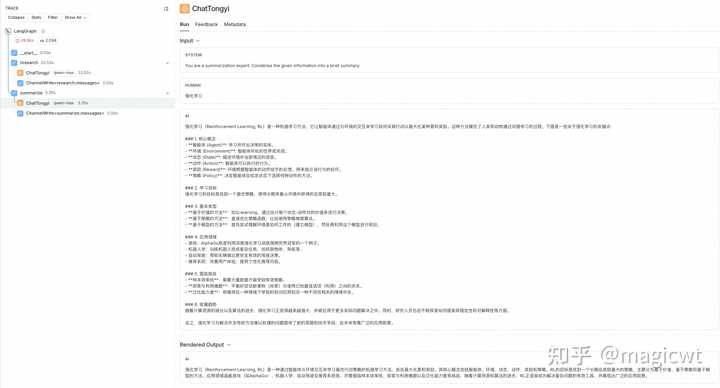
|
|
图32 显式控制流的执行过程和结果 也可以将上述显式控制流修改为动态控制流,将研究助手和摘要专家这两个智能体作为工具,以ReAct的方式由大语言模型决定接下来调用的智能体,代码如下: 执行上述代码,LangSmith中记录的执行过程和结果如图33所示,从中可以看出,负责总体协调的智能体,其将研究助手和摘要专家作为工具,以ReAct的方式进行思考,分步调用工具,先由研究助手调用大语言模型给出“强化学习”的相关信息,再由摘要专家调用大语言模型根据上述信息,给出摘要: 强化学习(Reinforcement Learning, RL)是一种机器学习方法,通过智能体与环境的互动来学习最优行为策略。智能体根据其行为获得奖励或惩罚,并据此调整策略以最大化长期累积奖励。关键概念包括智能体、环境、状态、动作、奖励和策略。RL的目标是找到最优策略以获取最大累计奖励。主要算法类型有基于价值的方法(如Q-learning)、策略梯度方法(如REINFORCE)和模仿学习。RL广泛应用于游戏、机器人学、自动驾驶、推荐系统和资源管理等领域。面临的主要挑战包括样本效率低、探索与利用之间的权衡以及奖励稀疏性。未来,随着计算能力和算法的进步,预计RL将在更多实际应用中发挥作用,并提高其泛化和适应未知环境的能力。 |

|
|
图33 动态控制流的执行过程和结果参考文献《真格基金戴雨森谈生成式AI:这是比移动互联网更大的创业机会,开始行动是关键》《Large Language Model based Multi-Agents: A Survey of Progress and Challenges》《A Survey on Large Language Model based Autonomous Agents》《A Dynamic LLM-Powered Agent Network for Task-Oriented Agent Collaboration》《Putting Humans in the Natural Language Processing Loop: A Survey》《Self-Adaptive Large Language Model (LLM)-Based Multiagent Systems》《ProAgent: Building Proactive Cooperative Agents with Large Language Models》《Adapting LLM Agents Through Communication》《AutoAgents: A Framework for Automatic Agent Generation》《AgentVerse: Facilitating Multi-Agent Collaboration and Exploring Emergent Behaviors》《CAMEL: Communicative Agents for "Mind" Exploration of Large Language Model Society》《Self-collaboration Code Generation via ChatGPT》《ChatDev: Communicative Agents for Software Development》《MetaGPT: Meta Programming for A Multi-Agent Collaborative Framework》《AgentCoder: Multi-Agent-based Code Generation with Iterative Testing and Optimisation》《Generative Agents: Interactive Simulacra of Human Behavior》《AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation》《OpenAgents: An Open Platform for Language Agents in the Wild》《LangGraph》《LangGraph中的多智能体系统》 |
|
要了解什么是AI Agent(智能体),先搞清楚什么是AI(人工智能)、AGI(通用人工智能)、AIGC(人工智能内容生成)、NLP(自然语言处理)、LLM(大语言模型)、Multimodal(模态)、COT(思维链)等基础概念,要了解AI Agent(智能体)和AI(人工智能)的本质区别。 AI(人工智能),旨在通过计算机程序和算法模拟人类智能,涵盖机器学习、深度学习、自然语言处理等领域,让计算机能像人类一样思考、学习、推理、决策和交流。 AI Agent(智能体),是一种基于LLM(大语言模型),能够独立思考、调用工具、处理任务的可执行计算机程序,拥有复杂的工作流程,无需人类驱动自动进行交互。作为AI(人工智能)的一种具体实现,更侧重于实体化、自主性和交互性,并能与其他智能体或人类进行交互和协作。例如,GPTs 可以打造个人专属 AI 助理(这是一种智能体),能帮忙整理电子邮件,还随时能给你创意灵感... AI Agent(智能体)主要依赖规划(Planning)+ 记忆(Memory) + 工具(Tools)+行动(Action)四大核心要素进行工作。其中,LLM(大语言模型)是智能体的“大脑”,通过 LLM(大型语言模型)把问题拆解成具有先后逻辑的子问题,然后按需调用 LLM(大型语言模型)、RAG(检索增强生成)、文生图/文生视频等各种工具,解决最终问题。 那么,AI Agent(智能体)能做什么呢,有哪些使用场景呢?想象一下,你拥私人管家一样的 AI 智能体,叫你起床、帮你放音乐、自动做早餐、规划上班路线、写工作汇报、帮你回复各种繁杂的邮件、帮你做PPT、做数据统计、做产品规划、程序代码自动编写、自媒体自动运营、电商运营...啊啊啊,这也太方便了吧! 智能家教:一个教学型 AI 智能体,记住你每个知识点的学习情况,有针对性地教学,并提供个性化的练习题,帮你快速提高成绩。妈妈再也不用担心我的学习了... 智能客服:堪比真人的聊天机器人,代替客服与用户沟通,顺畅的与客户交流、解答客户问题、处理电商订单退换货等 自动驾驶:智能体代替真人驾驶汽车(例如特斯拉自动驾驶、百度萝卜快跑自动驾驶),通过多个智能体处理传感器数据、规划路线,做出驾驶决策,自动避让行人和车辆... 股票交易:智能体根据市场价格、成交量等股票技术指标,自动帮你选择股票、合理规划买卖时机、自动交易决策,再也不用每天盯盘了。 游戏NPC:作为非玩家角色(NPC),跟玩家互动、对战、组队等,具有高度适应性和策略性,以创造引人入胜的游戏体验。 还有智能办公、制造机器人、智能家具、智能交通指挥、智能医生等智能化应用场景,AI Agent(智能体)将深入各行各业,就像未来世界的超级助手,无论是在家、公司、医院、商场还是交通中,它们都能真真实实的改变我们的生活。 AI Agent (智能体)的出现,对互联网行业的工作方式、从业门槛等,带来巨大的影响,尤其是产品经理、程序员,毫不夸张的说,未来3-5年不懂AI Agent (智能体)的产品经理第1个将被淘汰,其次就是程序员。 当前最炙手可热的 岗位,无疑是AI产品经理、AI开发工程师、AI算法工程师、AI人工智能训练师、大模型开发工程师等AI相关岗位,部分岗位几十万甚至上百万年薪..想想都觉得香。 想要转AI产品经理、AI开发工程师的同学,建议尽早行动起来,越到后面AI相关岗位竞争可就激烈了。知乎知学堂旗下AI 解决方案公开课,从AI入门到精通,再到进阶,提供全方AI知识和技术培训。想转行AI产品、开发的同学,通过课程能学到机器学习、深度学习、NLP等AI基础知识和技术,和大模型、多模态、AI Agent(智能体)的技术原理和实际应用等。这么说吧,想转行AI产品经理、AI开发工程师拿高薪的同学,这课程是首选,入口我放在下面了,直接预约就可以↓ 课程讲解当下流行的AI Agent (智能体),让你了解它的原理、核心技术、应用场景等,拆解使用AI Agent (智能体)技术真实落地的案例,干货满满。课程内容丰富,而且通俗易懂,哪怕是技术小白也能轻松上手,建议产品、开发同学,去听听看哦。 想要学习AI Agent (智能体) ,我们至少要经历下面三个阶段,在AI的知识体系中成长和进步,不断地实践,进而获得AI Agent (智能体)构建和开发能力。 第一阶段:了解AI Agent (智能体),熟悉API和调用。理解AI Agent (智能体)基础知识 ,了解各种API调用方法,能够调用预设的功能模块,达成业务交互与数据处理,能够独立构建简单的AI Agent (智能体),比如天气查询... 第二阶段:掌握NLP技术,学习自然语言处理和文本生成。掌控自然语言处理(NLP)编程工具、基本原理、核心技术,运用自然语言生成技术,让AI Agent (智能体) 能够自动生成文本或对话,能够开发基于NLP的应用,例如聊天机器人... 第三阶段:综合运用 API 调用、自然语言处理以及优化算法。将API 调用、自然语言处理以及优化算法等技术,综合运用于智能体开发中,可以构建比较复杂的AI Agent (智能体)应用,例如自动驾驶系统、股票交易系统...依据反馈与应用成效,不断优化AI Agent (智能体)。 能够把上面三个阶段走完,基本就能够构建非常多AI Agent (智能体)应用,不管对于后期转岗择业,还当前工作效率提升,都是非常有用的。比如,对于产品经理来说,通过构建AI Agent (智能体),可以进行产品最小化验证,不需要投入大量开发,即可构建商业产品和有效验证,为产品立项和产品开发提供依据。对于程序员来说,能够构建、开发、优化各种AI Agent (智能体)应用,调用包括LLM(大语言模型)在内的各种工具,甚至能构建复杂的AI Agent (智能体)产品,这岗位竞争力强了不是一星半点。 送礼物 还没有人送礼物,鼓励一下作者吧 |
|
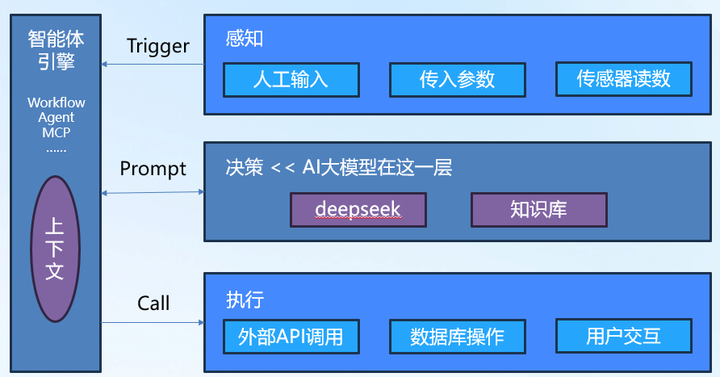
一、什么是AI智能体 AI智能体(AI Agent)是一种软件,指能够接入AI,实现感知环境、进行自主决策并执行任务的系统。与AI大模型不同,AI智能体具备一定程度的自治性,能够根据输入的信息进行推理、学习,并持续优化自身的行为。一定程度上讲,人们能够使用上的AI,不论是独立的腾讯元宝APP,还是ChatGPT的对话网站,抑或嵌入CRM系统的自动数据分析功能,都是各种类型的AI智能体。 按照行业主流观点,一个典型的AI智能体通常具备以下四个核心特性: 感知:通过自然语言处理(NLP)、计算机视觉(CV)等技术获取环境信息 决策:结合业务逻辑、大模型或知识库进行推理与规划 执行:与外部系统交互,如调用API、触发自动化流程或生成文本内容 自学习:通过用户反馈、强化学习等方式优化自身能力。该能力以知识增强系统或模型微调的形式提供,门槛较高 在企业数字化转型背景下,AI智能体的价值不仅在于提升效率,还在于构建更加智能的业务流程,使企业能够更灵活地应对变化。 二、智能体的组成要件 站在最终用户的角度,AI智能体可以分为感知、决策和执行三个模块,由一套引擎驱动其运转,如图1所示。 |
|
|
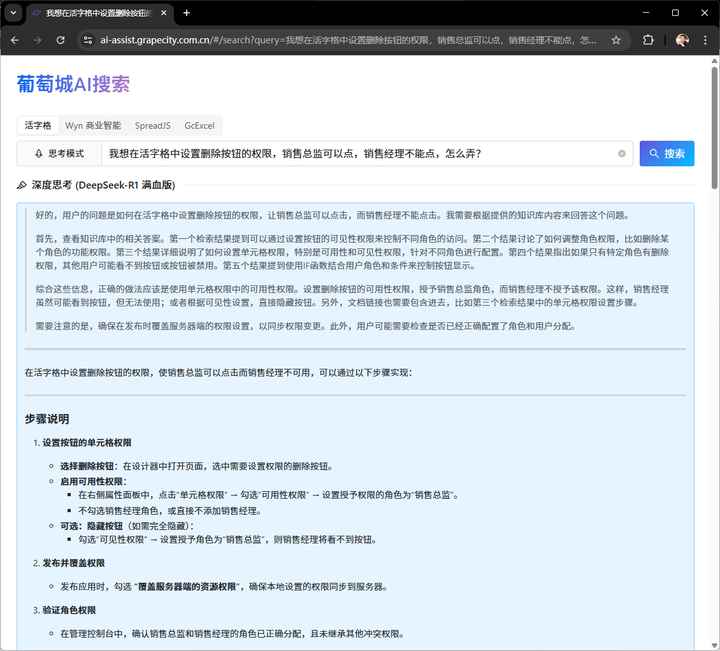
(图1 AI智能体的组成要件) 三个模块的职责如下: 感知模块:负责接收需要智能体处理的任务。任务通常有三种来源,人类通过语音、视频或键盘直接输入的信息、来自其他软件或智能体的调用参数以及通过物联网、RPA等技术手段读取的数据 决策模块:根据感知到的信息,判断其意图,并完成对应的分析与决策。这里通常需要用到AI大模型,联合使用多模态、多厂商的大模型已成常态 执行模块:将决策转换为软件动作,直接或间接展现给人类,完成任务,形成闭环 从技术实现的角度上看,智能体引擎、感知模块和执行模块本质上是一个应用软件,该软件通过特定的接口与AI大模型对接,最终形成一个完整的AI智能体软件。如果将智能体比作一个人,AI大模型相当于人的大脑,负责分析决策;应用软件部分则是人的躯干和手脚,保障大脑运行的基础上,获取信息,并完成工作。 一定程度上讲,AI大模型决定了智能体能力的深度,而软件部分则决定了智能体能力的广度。 三、 智能体的主要类型 AI智能体并不是一个固定形态的技术实体,而是可以根据业务目标和任务模式灵活演化的“组合体”。从实际落地场景来看,我们可以将AI智能体大致分为四种典型类型:任务型、交互型、生成型、自主决策型。它们之间并非截然分离,而是可以相互融合,协同构成更复杂的智能系统。 任务型智能体是企业应用中最常见的一类,它专注于“完成一件事”。这类智能体通常围绕具体业务流程进行设计,如自动审核发票、处理请假申请、生成财务报表等。它们具备明确的目标、清晰的触发条件,并通过调用多个AI能力或系统接口,自动完成一系列标准化、重复性强的操作。此类智能体与RPA或BPM更接近,但相比传统的RPA(机器人流程自动化),任务型智能体更强调“理解”和“判断”(主要源于自然语言处理NLP的能力),在流程自动化之外具备更高的灵活性和智能性。 交互型智能体以自然语言交互为核心特征,它们的任务往往是 “提供帮助”或“获取信息”。例如,内部知识库问答助手、IT服务台虚拟客服、人事政策咨询助手等,都是以理解用户意图、提供精准回答为主要职责。这类智能体在大模型的支持下,具备良好的语义理解能力,同时通常会与企业的知识库、API接口或搜索引擎打通,以提供有上下文的、高可用性的回答。交互形式上,它们既可以是网页对话框,如图2所示,也可以嵌入钉钉、微信等常用办公工具中,成为业务人员的即时助手。 生成型智能体是内容驱动型业务的强大引擎,它们能 “创作新内容”。随着生成式AI的广泛应用,越来越多企业开始部署写作助手、海报设计助手、代码补全助手等,用于提升内容产出效率。这类智能体不仅基于用户提示生成内容,还常常结合上下文信息、企业素材、行业术语库进行精细化控制。例如,一个营销文案生成智能体,可能需要结合当前促销活动、品牌风格和目标客户群体,自动生成多渠道传播内容。为了提升创作产物的质量,生成型智能体对提示词工程等提出更高要求,通常也是AI智能体中最依赖大模型能力的类型之一。 自主决策智能体是最接近“类人智能”的类型,它们强调 “在不确定性中做出选择”。这类智能体通常用于资源调度、策略选择、复杂场景控制等高阶业务中。例如,在制造业中,智能体可根据实时库存、订单优先级和设备状态,动态优化生产排程;在金融行业,智能体可根据市场行情和风险参数,自动调整投资组合。这类智能体往往需要结合强化学习、多目标优化、大规模数据分析等方法,具备较高的算法复杂度和反馈能力,同时也更加依赖企业的数据资产和业务知识模型。受限于大模型能力和可解释性的短板,此类智能体在企业核心场景落地还有较大距离。 |
|
|
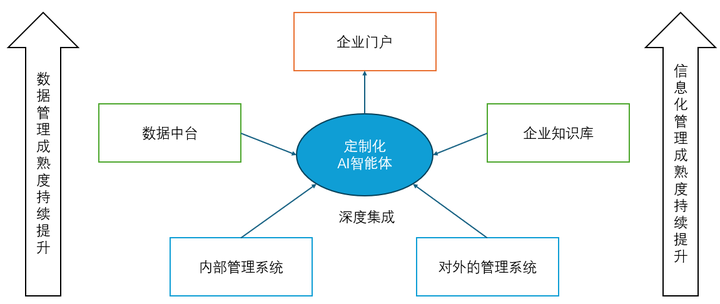
(图2 典型的交互型智能体:葡萄城AI搜索) 上述四种AI智能体不是演进关系。事实上,不同类型的AI智能体可以灵活组合,服务于更复杂的业务目标。例如,一个企业的客户服务智能体,前端是交互型智能体负责理解用户意图,核心处理由任务型智能体完成,内容生成部分由生成型智能体辅助完成回复,而后台的排班优化可能交由自主决策智能体处理。 正是这种模块化、可组装的特性,使AI智能体既适合单点落地,也能作为构建AI原生业务系统的基石。 四、 为什么需要定制开发AI智能体? AI的能力已经足够强大,且大模型通常会提供类似ChatGPT官网的对话式交互页面,这本身就是一个通用型的AI智能体。但是在AI落地的过程中,仍面临三个核心难题:AI任务如何有效拆解、如何设计可用的AI交互界面、以及如何与现有软件系统协同工作。定制化AI智能体正是为了回答这三个问题而生的。 定制化智能体帮助我们系统性地拆解并编排AI任务。大多数AI应用不是孤立存在的,它们往往需要一整套任务链条协同完成。例如,一个智能报销助手不仅需要识别发票,还要判断报销规则、提取关键信息、匹配审批流程、在财务系统中生成单据等。大模型本身并不具备执行这些子任务的能力,而定制化的AI智能体可以将任务拆解为多个步骤,合理调用模型、规则引擎、API接口等资源,实现从感知到执行的全流程闭环。这种 “任务驱动+能力调度” 的方式,让AI不仅能“看”和“说”,还能真正“做事”。 定制化智能体可提供更易用、更贴合业务场景的交互方式。一方面,它需要支持对话式体验,用户可以通过自然语言进行交流,这种模式非常适合习惯智能助手的年轻员工,延续toC的体验,提升了使用的直觉性。另一方面,AI智能体也需要能以“嵌入式”的形式融入现有软件界面,例如在CRM、ERP、OA系统中以侧边栏、按钮或弹窗的形式出现,实现“所见即所得”的操作体验。这种方式更贴近传统软件的交互习惯,对于中老年员工或非技术岗位的用户来说,能有助于降低认知负担和学习成本。让AI不再是“另一个系统”,而是悄无声息地出现在用户工作流中,成为现有工具的一部分。 定制化智能体的设计理念天然支持对现有系统能力的复用,而不是简单替代。众所周知,企业内部已有大量沉淀的数据、流程和服务,定制化的AI智能体能通过封装、调度、编排等手段,将这些“老系统”变成智能化的一部分,如图3所示。例如,在已有的合同管理系统中,智能体可以自动读取条款、提取风险点,并生成修改建议;在数据分析平台中,智能体可以根据用户提出的问题,自动组合图表、生成报告。这种源自定制化AI整体的能力,使企业可以在不大规模重构原有系统的前提下,将AI能力快速嵌入到关键业务场景中,实现“以我为主”的智能化升级。 总之,AI智能体不是单纯的模型封装或交互层,它的真正价值在于:用系统性的方式连接AI能力与业务流程,解决“谁来用AI、怎么用AI、用AI干什么”的问题。而这些价值只有企业实际需求高度贴合,才能得到充分发挥。 |
|
|
(图3 定制化智能体与企业现有系统的关系示意图)五、定制化智能体落地的挑战与应对 尽管 AI 智能体的技术架构日趋成熟,但在实际落地过程中仍面临多方面挑战。这些挑战可归为技术层、数据层与业务层三个类别。技术层和数据层影响AI智能体的应用深度;业务层则主要影响AI智能体的应用广度。针对这些问题,低代码平台提供了一条降低门槛、提升协同与交付效率的可行路径。 5.1 技术挑战 AI技术尤其是生成式AI技术仍处在高速发展中,其技术能力和工程实践都存在较大的提升空间,叠加成了AI智能体落地的技术挑战。 模型准确性不稳定:当前主流大语言模型在自然语言生成方面表现卓越,但在具体场景中容易产生事实错误的“AI幻觉”。对于涉及业务流程、数据分析、合规判断等高风险任务,准确性问题成为智能体系统的首要风险 上下文理解能力不足:复杂任务往往依赖于对业务流程、用户角色、历史操作等上下文的深度理解。若上下文注入机制不完备(如函数调用时序错误、MCP不可用等,详细参考:AI智能体的技术架构),将导致模型输出偏离意图,影响插件任务执行的正确性。 可解释性与可控性缺乏:智能体行为的不确定性对 IT 管理带来挑战。运维人员和审计人员需要理解模型为什么输出某个答案、调用了哪个插件、用了哪些数据。缺乏可解释性的系统难以获得监管与管理层的信任。 5.2 数据挑战 数据是AI的“粮食”,AI的能力本质上是大数据的能力。考虑到大多数企业的数据治理现状,数据已经成为AI智能体落地的有一个重要挑战。 数据质量参差不齐:训练样本中的语料、知识图谱、实时调用数据(如企业的术语表等)的准确性,都会影响AI智能体判断。尤其在“知识增强生成”(RAG)模式中,索引错误或文档版本不一致可能引发严重信息偏差。 隐私与合规压力加剧:在政务、金融、制造等场景中,涉及大量敏感信息。如何在智能体架构中实施数据脱敏、访问控制、审计记录等机制,是系统设计的关键点。 知识更新机制不健全:业务规则与知识体系不断演进。若知识库、能力库、插件参数等更新滞后,智能体将持续基于过时信息做出决策,影响用户体验和业务正确性。 5.3 业务挑战 引入AI智能体必然会对现有的组织工作方式和协作方式带来变革,如何有效应对这些变革是技术之外,AI智能体落地的另一项重大挑战,甚至可能成为最主要的挑战。 需求对接成本高:AI 智能体所面对的任务往往涉及跨部门、跨系统流程,需求难以标准化,且业务人员不熟悉 AI 的能力边界,导致“想象力与现实落差”巨大,显著拉高了需求沟通的成本。 系统集成复杂:在传统 IT 系统中,新增能力通常意味着修改多个系统、开发接口、重写流程。引入AI 智能体也不例外。 组织适应性不足:AI 智能体带来的岗位变化、职责分工演变,会对组织结构与协作方式造成冲击。业务团队习惯于明确的系统功能,而智能体以“辅助者”身份介入,他们往往需要时间适应,这一点在员工平均年龄较大的传统行业中更为明显。 5.4 低代码平台是降低智能体落地门槛的关键抓手 技术的问题需要更先进的技术来解决。 低代码平台通过可视化、组件化和配置驱动方式,能够显著缓解上述挑战,成为智能体落地的重要基础设施。具体考虑如下: 降低开发成本,加速交付周期:低代码平台具备拖拽式页面搭建、流程建模、集成向导等能力,配合预置的 AI 模型接入组件,除了能完成AI智能体编排外,还可以快速构建智能体的UI、插件适配器、上下文服务等元素,减少传统开发中繁琐的编码与调试环节 提高可维护性与透明度:作为可视化的开发和运维平台,低代码可以将AI智能体的插件调用链、上下文注入路径、知识库来源等内容以日志等结构化呈现,增强系统的可观测性与可解释性 连接业务专家与技术团队:低代码是培养业务数字化专家(具备软件工程相关知识,能够以需求方的身份深度参与到软件开发的业务侧骨干人员)的加速器,落实“业务主导”的AI智能体指导思想,让评价和使用智能体的人一起参与到构建和优化过程。部分场景下,业务数字化专家还能直接参与规则、流程的配置工作,从而实现更高效的协同,缩短智能体从原型到投产的路径 六、走出实验室,迈向业务现场 如今,AI 智能体的落地并非技术演示,而是一场系统工程。它不仅需要应对模型能力的极限、数据治理的挑战,还要协调业务流程与组织协同的多重压力。在这一过程中,低代码平台以其“开发友好 + 业务亲和”的优势,正在成为连接 AI 能力与企业真实需求的桥梁。通过降低交付门槛、提升系统透明度、增强业务共创能力等手段,低代码正在让 AI 智能体从 PoC阶段走向业务现场。 |

|
|
|
|
|
|
|
|
这个问题没那么复杂。 简单来说就是像LLM,diffusion之类的文生图模型有点智能但又没完全有。 比如现在你想做一个多人在线剧本杀游戏,网络通讯怎么处理,UI交互什么关系,数据结构和游戏架构如何设计,这些你让现在的LLM模型去做,基本没戏。 但是LLM在剧本编写,游戏选择判定,后续剧情发展续写这部分强,而这部分你让人去搞,那就得写到天荒地老了。 所以agent讲白点就是各司其职,发挥人与机器的优势,扬长避短。 网络通信,程序框架,逻辑代码和aigc的交互与约束这个要人去写。 剧本和图形生成由ai模型去做。 这样你就能提高效率把东西尽快做出来。 ai模型各有所长,所以ai+ai的模式叫moe(混合专家模型) 有些ai确实难搞定的,ai+人的模式就叫agent (唉,其实说难听点就是prompt enginner plus |
|
|
| [收藏本文] 【下载本文】 |
| 上一篇文章 下一篇文章 查看所有文章 |
|
|
|
| 股票涨跌实时统计 涨停板选股 分时图选股 跌停板选股 K线图选股 成交量选股 均线选股 趋势线选股 筹码理论 波浪理论 缠论 MACD指标 KDJ指标 BOLL指标 RSI指标 炒股基础知识 炒股故事 |
| 网站联系: qq:121756557 email:121756557@qq.com 天天财汇 |