
| |
|
|
| ����ƻ� -> ������� -> ��ģ����������û�м�������������˵�������������ж�� -> �����Ķ� |
|
|
[�������]��ģ����������û�м�������������˵�������������ж�� |
| [�ղر���] �����ر��ġ� |
|
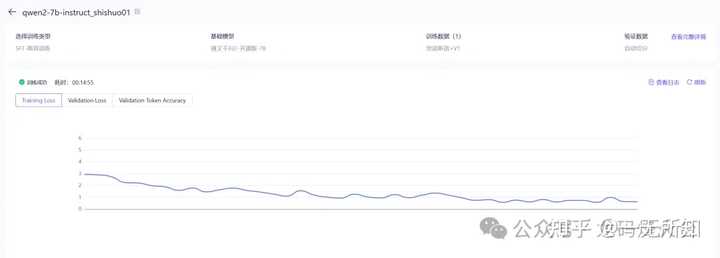
��ģ����������û�м�������������˵�������������ж�� ��ע����?д�ش� [img_log] ������ ���ѧϰ��Deep Learning�� GPT-4 ChatGPT ��ģ̬��ģ�� ��ģ����������û�м�������������˵�������������ж�� |
|
������̸��һ�仰�ɣ���û�м�������ȡ���������������ô���������� llm ���������ż���ȴ�ͳ NLP ��ø����ˡ� �Ҿ�һЩ���Ӱɣ���Դ�ģ�����ļ�����Ҫ���ڣ����оٵ�ÿһ����������ʶ����������Ŀ�꣬����˵ѵ������ģ��Ч����ûʲô��𡣵��Ը��������ɳ��İ����ʹ���ͬ�ˡ� ���ݹ��� ���� 1 : �̳�ʵ���һ���ͬ�µ�ѵ�����ݣ��õ�֮��Ҳ�� check һ������������ֱ�ӷŽ�ȥѵ�� ���� 2 : ����һ����Դ���ݣ�������system + query + answer�����ϡ� ���� 3 : ���� gpt4 �������ݣ�ѧ���� gpt4 ϲ�õ� prompt ȥ��������ʶ������ prompt �����ԣ��뾡���ְ취ȥ���� prompt ����������Ժͱ��﷽ʽ�����ԣ�����ȥ�����һЩ noisy prompt ȥ���������ԡ�ͬʱ��Ը��������ܣ�һ��һ��ȥ check ����������ȥ�ͱ�עͬѧ�����ע���� ���� 4 : �����û��Ľ�����־���������ݹ�����̣��ռ��û�����ʵ prompt���ù������GPT4ȥ�����û��� feedback��������ø������� answer ���ݡ� ���� 5 : ��� cot��rag�� function_call��agent ��˼·���Ѹ��ӵ�ģ����ʤ�ε����������ݲ���ͽ��в�⣬���硰ģ��д������ƪС˵�� --> ��ģ��дС˵��٣�ģ�ͻ���С˵���д��ƪС˵���� ���� ѵ������ ���� 1 : �̳�ʵ���һ���ͬ�µ�ѵ�����룬�� data_path��Ȼ�� bash train.sh�� ���� 2 : �̳л��Լ�����һ��ѵ�����룬�о����������ÿһ��������ȥѰ˼��ȥ�㶮��Ϊɶ�� offload��ʲô�� sequence_parallel���ȵȡ�Ȼ����ȥ���� dataloader ����ô�������ݸ�ʽ��session ���ݵ� loss ��ֻ�������һ�ֻ���ÿ�ֶ��㣬������Ӧ������Щ special_token �ȵȡ� ���� 3 : �����㶮��ÿ��������������Լ��ļ��⣺epoch = 3 �Dz���̫���ˣ�10W ��ѵ�������������������special_token �Dz��������̫���ˣ�7B ģ�������ѧϰ���Dz���̫���ˣ�warmup ���ö��� step ����˵�ܲ��ܲ��� warmup�������ɻ�Ȼ��ȥ���� chatgpt ��ʦ��ô˵���������Ѵ����ǵ����°ݶ�һ�¡� ���� 4 : ���ɺĽ�ѵ�����룬deepspeed �Dz����е�����Ҫ��Ҫ�ij� megatron ��ܣ��� megatron �� deepspeed ���ŵ����������������Ȥ��Ҳ����ȥ debug ���ٶȣ� ���� rope �ĺ�ʱ��� attention ������ʱ������취ȥ�Ż����������ǵ��Ż��������� ���� ʵ����� ���� 1 : ����ǰ���õ���������Ȼ����������������������Ļ���������������ˣ���������Ļ�����Ϊ�����ݲ��ɾ�����취ȥ��ϴ���ݻ����ǹ�������ѵ�����ݣ��ĸ� task ��ָ�����ص��Ż���� task ��ѵ�����ݡ� ���� 2 : ��� pretrain ģ�� / sft_base ģ�͵Ľ����ȥ����ͷ���ÿһ�� sft_exp ģ�͵� bad case������������þ����⣿pattern ��������⣿����̫��ѵ����������⣿pretrainģ��ѹ����û�������������� size ��ģ�;����������ָ��������⣿���� ����Լ��ķ�����������ʵ��ȥ��֤������ij�� task Ƿ��ϣ����ϲ������ task �����ݣ�������ѵ������ˣ��ͳ�һЩѵ�����ݵ� prompt ��ʽ����ģ��ȥ�ش����Ƶ����⣻��֪�� 7B ģ���ܲ��ܽ�����������ȥ���� llama��qwen��mistral��deepspeek ��ͬ size �� chat ģ��ȥ��֤Ч�����ȵȵȵȡ� �������Ҫ����Ҫ����һЩ���飬ѧ��һЩС trick�� �� pretrain ģ��ȥ��д�����ж�ij��������ij��֪ʶ��ģ��ѹ��û�У�����˵���Լ�ѵû�ˣ��۲�ij�� token �ĸ��ʣ��۲�ģ���ڵڼ��� token ��ʼ�ش����ģ����ģ�͵� pattern ���������û�а��� json �������һ���Dz��� json�����Dz�֪���ó� json������``json```Ҳι��ģ�ͣ���ģ�͵���д�����ģ�Ͱѡ��ձ������ش���˱������ˣ���Ҫֱ�Ӷ����ǻþ������Ƿ�����ģ���Ƕԡ��ձ������������������ĸ� token ������ˣ��п�����ģ�Ͱ����й��ҵ������ش�ɱ�����Ҳ�п���ģ���ǰ��ձ����κγ��ж��ش�ɱ�������������ѵ��������� pattern �йص������Dz���̫���ˣ����� ���� 3 : ������ʶ��ģ�ͽ�������������йأ���ȥ������ѵ�������Ĺ�ϵ�����ѵ����־��tensorboad ��ģ�͵����������ȥ��ͬ����ģ��Ч����SFT �ij�ʼ loss ��ô����Ϊʲô��special_token ̫���ѵ�����Ĵ�������̫�ࣿ���� loss ���Ƕ��١����� 0.5 ��Ҫ���Ĺ�����ˣ�channel_loss �Ƿ����Ԥ�ڣ�SFT �Ľ����� loss ������ʲô��3 �� epoch �� 2 �� epoch ��Ч���Աȣ� ���� 4 : ��һЩ benchmark��ȥ��֤ģ�͵�ͨ������������ģ���Ƿ���ͨ�������������½�������˵����ͨ�������½��ˣ�����������Ϊʲô�Լ�ѵ task A �ᵼ����ѧ�����½����Լ�ѵ task B �ᵼ�´��������½�����취ȥ�о�ͨ�����������ΰ����⣬ȥ����ѧ�����ŵ��������� ���� ������˵���ϵġ�����1���Dz��Եģ����Լ�Ҳ�й��ܶ�εġ�����1�����Ͼ�����ǰ�����������в����Ľ������ֻ����ǿ����SFT���������û�м�������������Ҫ���Լ��Ķ�λ�������� |
|
20230907Դ��ƪ���£� ����LORA���ֵĽ��⣬���ǽ���Ϊ��ԭ��ƪ���͡�Դ��ƪ���� ��ԭ��ƪ�У����ǽ�ͨ��ͼ��ķ�ʽ����ϸ����LoRA��ô�á�Ϊʲô����Ч��������Щ�����ƵȺ������⡣�ر��ǵ�����ѧϰLoRAʱ������ԡ��ȡ��Ķ�������÷�ʽ�е��Ի���ô����Ҳ�����ṩһЩ���Ľ����ʽ�� ��Դ��ƪ�У����ǽ�һ��������LoRAԴ�룬�����������google colabƽ̨��ʹ�����GPU���LoRA��������ʹ��ÿ���˿������Զ�����һ��ԭ��LoRA���룬�����LoRA�������Ƶ����⣨��ҪǮ�Ŀ��ֲ�������֣��� ���⣬���ڡ���ģ��ѵ��ϵ�С����ֵ����£����Բο��������ӣ����������У� ��Գ��ͼ���ģ��ѵ��֮����ˮ�߲��У�Pipeline Parallelism������GpipeΪ�� ��Գ��ͼ���ģ��ѵ��֮�����ݲ�����ƪ(DP, DDP��ZeRO) ��Գ��ͼ���ģ��ѵ��֮�����ݲ�����ƪ(ZeRO���������Ż�) ��Գ��ͼ���ģ��ϵ��֮������ģ�Ͳ��У�Megatron-LM ��Գ��ͼ���ģ��ϵ��֮��MegatronԴ����1���ֲ�ʽ������ʼ�� ��Գ��ͼ���ģ��ѵ��֮��MegatronԴ����2��ģ�Ͳ��� �������ͻ�ͼ���ף�������ñ����а������鷳���СС���ޣ������ø����˿�����лл��ҡ���??????�� һ��ȫ������ |
|
|
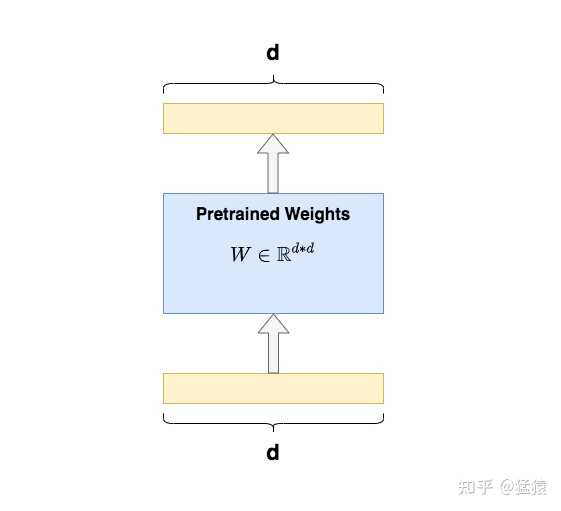
����֪�������ĺ��壬���ǰ��Ѿ�ѵ���õ�ģ�ͣ�pretrained model���������������ض��������������ݣ�ʹ��ģ����Ԥѵ��Ȩ���ϼ���ѵ����ֱ�����������������ܱ���Ԥѵ��ģ�;���һ��������ȡ�����ܹ�������ǰѵ��������ѧ���ľ��飬Ϊ������ȡ��Ч������������������������ѵ��Ч���������ٶȡ� ȫ����ָ���ǣ������������ѵ���У���Ԥѵ��ģ�͵�ÿһ�������������¡�����ͼ�У�������Transformer��Q/K/V�����ȫ����ʾ������ÿ��������˵������ʱ����d*d�������������������¡� ȫ����������ȱ���ǣ�ѵ�����۰�������GPT3�IJ�������175B���ҵȵ�������ֻ������ȴ��������Ҫ�������з�����bugʱ�ĸ�ˮ���ա�ͬʱ������ģ����Ԥѵ�����Ѿ������㹻������ݣ��ջ����㹻�ľ��飬�����ֻҪ��취��ģ������һ������֪ʶģ�飬�����Сģ��ȥ�����ҵ���������ģ�����屣�ֲ��䣨freeze�����ɡ� ��������֪ʶСģ�飬����Ҫ��ô�����أ� ����Adapter Tuning��Prefix Tuning ����������LoRA����ǰ�����������ľֲ����취��Adapter Tuning��Prefix Tuning����Ҳ��LoRA��ԭʼ�����У��ص�ȶԵ���������ʽ�� 2.1 Adapter Tuning |
|
|
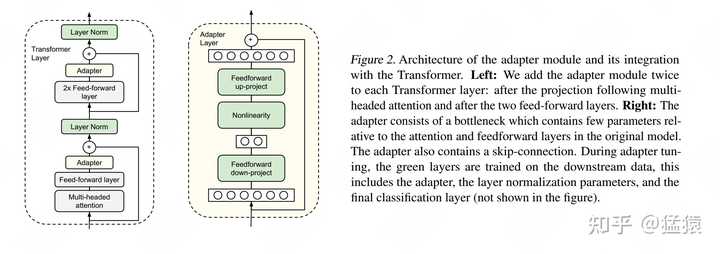
Adapter Tuning�ķ����кܶ��֣��������Ǿٳ�Houlsby et al. ,2019����ķ�������Ҳ��LoRA�������ἰ�����ʱ�����õĵ�һƪ���¡� ͼ���е������һ��Transformer Layer�ṹ�����е�Adapter��������˵�ġ�����֪ʶģ�顱���ұ���Adatper�ľ���ṹ������ʱ������Adapter�IJ��֣�����IJ������DZ���ס�ģ�freeze�����������Ǿ�����Ч����ѵ���Ĵ��ۡ�Adapter���ڲ��ܹ����DZ����������ص㣬�������ǾͲ��ٽ����ˡ� ����������Ƽܹ�����һ���������ƣ�������Adapter��ģ������IJ������������ѵ���ٶȺ������ٶȣ�ԭ���ǣ� ��Ҫ�ķѶ������������Adapter�ϵ����Dz��ò���ѵ��ʱ������Transformer�ܹ����õ�����ģ�Ͳ��У���Adapter�����������ͨѶ��������ͨѶʱ�� 2.2 Prefix Tuning |

|
|
Prefix Tuning�ķ���Ҳ�кܶ��֣���������ѡȡLi&Liang,2021��һƪ���м���������ƪ�У�����ͨ����������������ǰ��prefix������������Ȼ��prefixҲ���Բ�ֹ��������㣬�����Լ���Transformer Layer������м�㣬����Ȥ�����ѿ��Բ������������о��� ��ͼ��ʾ������GPT����������ʽģ�ͣ����������е���ǰ�����prefix token��ͼ���м���2��prefix token����ʵ��Ӧ���У�prefix token�ĸ����Ǹ����Σ����Ը���ģ��ʵ����Ч�����е���������BART������Encoder-Decoder�ܹ�ģ�ͣ�����x��y��ǰ��ͬʱ����prefix token���ں������У�����ֻ��Ҫ��סģ�����ಿ�֣�����ѵ��prefix token��صIJ������ɣ�ÿ�����������Ե���ѵ��һ��prefix token�� ��ôprefix�ĺ�����ʲô�أ�prefix������������ģ����ȡx��ص���Ϣ���������õ�����y�����磬����Ҫ��һ��summarization��������ô��������prefix��������ǰҪ�����Ǹ����ܽ���ʽ��������Ȼ������ģ��ȥx�������ؼ���Ϣ���������Ҫ��һ����з��������prefix��������ģ��ȥ������x�к������ص�������Ϣ���Դ����ơ������Ľ��Ϳ��ܲ���ô�Ͻ�������ҿ��Դ������һ��prefix�����á� Prefix Tuning��Ȼ���������㣬��Ҳ�������������������ƣ� ����ѵ������ģ�͵�Ч�������ϸ���prefix�����������Ӷ������������ԭʼ������Ҳ��ָ����ʹ���������Ч��Ϣ���ȼ��١�Ϊ�˽�ʡ���������Դ棬����һ���̶��������ݳ��ȡ�������prefix֮������ԭʼ�������ݵĿռ�����ˣ���˿��ܻή��ԭʼ������prompt�ı��������� ����ʲô��LoRA �ܽ�һ�£�ȫ������̫��Adapter Tuning����ѵ���������ӳ٣�Prefix Tuning��ѵ�һ����ԭʼѵ�������е���Ч���ֳ��ȣ����Ƿ���һ�����취���ܸ�����Щ�����أ� �����������������£����������LoRA��Low-Rank Adaptation������������������һ�������������������ԡ����ȡ������������������������Ľ��ͣ�����������LoRA��ʲô����Ҫ��ô�á�����һ���У�����������ϸ���͡����ȡ����õ�ԭ���� 3.1 LoRA����ܹ� |
|
|
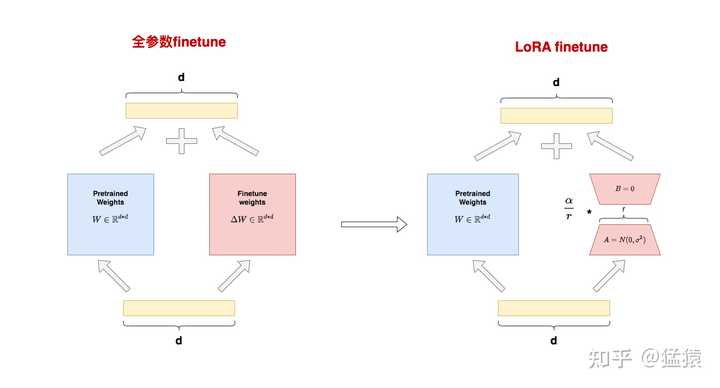
ͼ������ʾ��ȫ����finetune���ij��������ǽ������ֳ����������֣� W \in \mathbb R^{d*d} ��Ԥѵ��Ȩ��\Delta W \in \mathbb R^{d*d} ��finetune����Ȩ�� ֮������ô��֣�����Ϊȫ����finetune��������ɡ���ס��Ԥѵ��Ȩ�ء� + ���������в�����Ȩ�ظ��������� ������Ϊ x �����Ϊ h �����У� h = Wx + \Delta W x ͼ���Ҳ��ʾ��LoRA finetune���ij�������LoRA�У������þ���A��B�����Ʊ��� \Delta W �� A \in \mathbb R^{r*d} �����Ⱦ��� A ������ r ����Ϊ���ȡ����� A �ø�˹��ʼ����B \in \mathbb R^{d*r} �����Ⱦ��� B ����B�������ʼ���� ��������һ����֣����ǽ� \Delta W ��д�� \Delta W = B ����ʽ��ʹ������������d*d������2*r*d��ͬʱ���ı�������ݵ�ά�ȣ�����LoRA��������: h = Wx + BAx ���⣬��ԭ�������ᵽ�������������Ⱦ����ó��� \alpha ��һ��������������������û��˵��������ε�����λ�á��ڶ���LoRA��Դ����ҷ��������������Ϊscaling rateֱ�Ӻ͵��Ⱦ�����˵ģ�Ҳ�������յ����Ϊ�� h = Wx + \frac{\alpha}{r}BAx ��ʵ���У�һ��ȡ \alpha \ge r ��������LoRAԴ���GPT2������NLG����ʱ����ȡ \alpha = 32, r=4 �����ǻ��ں�����ϸ�������scaling rate�����ã��Լ����ȡ��ľ��庬�塣 A��B�ij�ʼ������ ��Ҫע����ǣ������ A ���ø�˹��ʼ������ B �������ʼ����Ŀ���ǣ���ѵ���տ�ʼʱ $$B$$ ��ֵΪ0�����������ģ�ʹ����������������ô��������ʣ����Ҷ� A �����ʼ������ B ����˹��ʼ���в����أ�����������ֻҪ�� BA ��ʼ��Ϊ0���У� ���������⣬����github issue���ҵ���LoRAһ���Ļش� |
|
|
����˵����ǰ����û�з���ת�� A,B ��ʼ����ʽ��������������ֻҪ������������һ��Ϊ0����һ�߲�Ϊ0���ɡ� 3.2 LoRA��ѵ������������ ��3.1�У����ǽ�����LoRA������ܹ�����ԭʼԤѵ���������·�ϣ��õ��Ⱦ���A��B����������������� \Delta W �������������Ҫ��ģ�Ͳ����������IJ���������Transformer�е� W_{q}, W_{k}, W_{v}, W_{o} ��MLP���Ȩ�ء�������Embedding���ֵ�Ȩ�ء���LoRAԭʼ�����У�ֻ��Attention���ֵIJ������˵������䣬����ʵ�ʲ����У����ǿ�����������Ҫ����ʵ�鷽�����ҵ���ѵ����䷽������Ǯ����ͨ���� 3.2.1 ѵ�� ��ѵ�������У����ǹ̶�סԤѵ��Ȩ�� W ��ֻ�Ե��Ⱦ��� A �� B ����ѵ�����ڱ���Ȩ��ʱ������ֻ�豣����Ⱦ���IJ��ּ��ɡ�����LoRA�����е�ͳ�ƣ������IJ���ʹ������GPT3 175Bʱ���Դ����Ĵ�1.2TB����350GB����r=4ʱ�����ձ����ģ�ʹ�350GB����35MB��������ѵ���Ŀ����� ����ѵ�����֣�����������һ����Ȥ�����⣺������������LoRA���Դ�Ľ�Լ�������ģ�������ѵ����ÿһʱ�̣�LoRA����������ʡ�Դ��� ����backwardʱ�� B �����ݶȣ����� h = Wx + BAx = W_{sum}x ��Ϊ���ù�ʽ���㣬��ʱ���Ե� \alpha һ��������У� \begin{aligned} \frac{\partial L}{\partial B} &= \frac{\partial L}{\partial h}\frac{\partial h}{\partial W_{sum}}\frac{\partial W_{sum}}{\partial B}\\ &=\frac{\partial L}{\partial h}x^{T}\frac{\partial W_{sum}}{\partial B} \end{aligned} ע�� \frac{\partial L}{\partial h}x^{T} ��һ���ᷢ�֣�����Ԥѵ��Ȩ�� W ��ά��d*d һģһ����Ҳ����Ϊ�˼��� B ���ݶȣ�������Ҫ�õ���ȫ������������һ����С���м�ֵ�������˶�LoRA��˵����һ��ķ�ֵ�Դ棬��ȫ����������һ�µģ����� \frac{\partial W_{sum}}{\partial B} һ��Ļ������ȫ�������� ����ΪʲôLoRA���ܴ������Ͻ����Դ�ʹ���أ���Ϊ�� LoRA������������ģ�͵�ÿһ�㣬�����������LoRAֻ������attention����LoRA��Ȼ�ᵼ��ijһ��ķ�ֵ�Դ����ȫ���������������ݶȺ�����м����Ϳ��Ա�����ˣ�����һ�±��浱��ѵ��Ȩ�ش�d*d��Ϊ2*r*dʱ����Ҫ�����optimizer statesҲ�����ˣ��ǿ���fp32���� 3.2.2 ���� �����������У����ǰ��� W = W + \frac{\alpha}{r}BA �ķ�ʽ���ϲ����Ⱦ����Ԥѵ��Ȩ�أ�Ȼ��������forward����������������ȫ�������ģ�͵ļܹ�����˲�����Adapter Tuningһ�����������ϵ���ʱ����ͼչʾ�������е�ʵ��Ч��������ʱ���ĵ�λ��milliseconds�����Է��֣�LoRA�������ٶ���������Adapter Tuning�� |
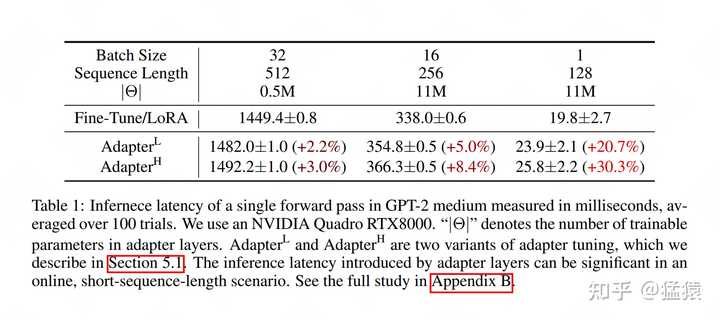
|
|
���л���ͬ��������ʱ�����ǿ������� W ���Ƴ�����Ȩ�صIJ��֡���������������������A�������ͨ�� W = W + \frac{\alpha}{r}BA �ϲ�Ȩ�أ���������������Ȩ�� A,B ���������л�����������Bʱ�����ǿ���ͨ���� W �м�ȥ����Ȩ�ز��֣�Ȼ���ٿ����µ�LoRA����Ҳ����˵��ÿ�����������������Լ���һ����Ȩ�ء� ��������ʣ���ÿ������������һ��Ҫ�ѵ���Ȩ�غϽ� W �����ҿ��Խ���Ԥѵ��Ȩ�ء��͡�����Ȩ�ء��ֿ��洢�𣿵�Ȼû��������LoRA�Ǻ����ģ�����ȫ���Ը���������Ҫ����д���룬����Ȩ�صı��淽ʽ��ֻҪ����һ������ԭ�����Ǻϻ��Dz��ϣ������а취�����ֳ�Ԥѵ����LoRA�IJ��֣����С���Դ����ƪ�У����ǻ�����ϸ������㡣 ��ϲ�㣡����һ�����Ѿ�������LoRA�ļܹ����Dz��Ǻܼ��Dz���ԾԾ���ԣ����ǣ���Ϊһ���ϸ������ʦ��Ϊ���ܶ�ѵ�����̸���debug�����ǻ�Ҫ��Ҫ�������о�LoRA��ԭ���� �ġ�LoRA���������ԭ�� ��ǰ���У������������ᵽ���ȡ��ĸ����˵��LoRA���ȼ�Ϊ���� r ��ͬʱ������Ҳ����ǿ�� BA �� \Delta W �Ľ��ơ�����һ���У����ǽ��������������ȡ�����˵��Ϊ���ǡ����ơ������˽���Щ�����Ǿ������������ \alpha �����ã�������һ���������о��ˡ� 4.1 ʲô���� ������������һ������A�� �þ����У�row2 = row1 * 2��row3 = row1*3��Ҳ����˵�������е�ÿһ�У�������ͨ����һ�����Ա�ʾ�� ����������һ������B�� �þ����У�����һ�У��ܿ������������е������������ʾ�� �������������һ������C�� �þ����У�����һ�У������ܴ������е�����������Ƶ������� ����np.linalg.matrix_rank���������ǿ���������������ȣ���������������ȷֱ�Ϊ�� �Ծ���A��˵������ֻҪ�������е�����һ�У������ж���������һ�������Ƶ����������A������1�� �Ծ���B��˵������ֻҪ�������е��������У������ж���������������������Ƶ����������B������2�� �Ծ���C��˵�����ڱ�����ȫ�������У����ܵõ�������C�����C������3�� ����������Dz����Ѿ��������˸��Ե������ˣ��ȱ�ʾ���Ǿ������Ϣ������������е�ijһά���ܿ���ͨ������ά�������Ƶ���������ô��ģ����˵����һά����Ϣ������ģ����ظ�����ġ���A��B����������dz�Ϊ�ȿ���rank deficient������C����������dz�Ϊ���ȣ�full rank�������Ͻ�����ѧ���壬��ҿ��Բο������Դ���������ͷ���� ���˶��ȵ������ʶ��������Ȼ���뵽��ȫ�������е�����Ȩ�� \Delta W ����Ҳ�����������Ϣ��������Dz�����Ҫ��������d*d �ߴ�����ʾ������ô������Ҫ����ҳ�\Delta W���������õ�����ά���أ�SVD�ֽ⣨����ֵ�ֽ⣩���������ǽ��������� 4.2 SVD�ֽ� |
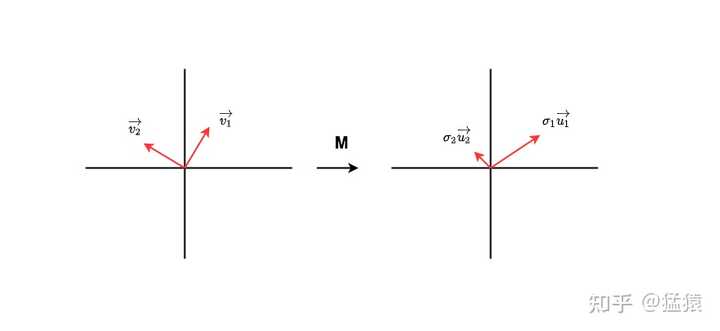
|
|
��ͼ������ M ��������Ҫ����Ϣ�����ľ��������������ݵ������ռ��У�����һ�������ĵ�λ���� \vec{v_1}, \vec{v_2} ������ M �ı任�����DZ����һ���������� \sigma_1 \vec{u_1}, \sigma_2 \vec{u_2} ������ \vec{u_1}, \vec{u_2} Ҳ��һ�������ĵ�λ������ \sigma_1, \sigma_2 �ֱ��ʾ��Ӧ�����ϵ�ģ��������һ�ٱ�ã�����д�ɣ� M[\vec{v_1}, \vec{v_2}] = [\sigma_1 \vec{u_1}, \sigma_2 \vec{u_2}] �ԼӸ�д�����У� M = \begin{bmatrix}\vec{u_1}&\vec{u_2}\end{bmatrix}\begin{bmatrix}\sigma_1&0 \\0&\sigma_2\end{bmatrix}\begin{bmatrix}\vec{v_1}\\\vec{v_2}\end{bmatrix} ���ѷ��֣� \sigma_{1}, \sigma_{2} �������˶ԡ���Ϣ��������ʾ���ڱ����� v ���� M ��ת��Ͷ�䵽 u ��ʱ�� M ǿ������1�������̺�����Ϣ�� �����ٿ���һЩ������������ҵ�������һ�� v �� u ������ \sigma �����ֵ�Ӵ�С�������У���ô���Dz����ܶ� M ���в�⣬ͬʱ�ڲ������У��ҳ� M ��ǿ������Щ������������Ҳ����˵�� M = U\Sigma V^{T} �������ҵ������� U, \Sigma, V ����������ٴ���������ȡ����Ӧ��top r �У����У��������൱�ڹ�ע���� M ��ǿ�����Ǽ�ά���������������ø���ά�ľ��������Ʊ��� M �ˣ�������˼ά���M�ķ��������dz�ΪSVD�ֽ⣨����ֵ�ֽ⣩���ڱ�ƪ�����Dz��������ľ��巽��������Ȥ�������ǣ��G���ֿ��Բο������Դ������� ������ͨ��һ���������ӣ���ֱ�۵ظ���һ�����ֽ��ƣ����ע�⿴��ע�ͣ����Ӹı��ԣ�https://medium.com/@Shrishml/lora-low-rank-adaptation-from-the-first-principle-7e1adec71541�� ������Ϊ�� �����������ˣ�������Ӱ����������Ľ����ͨ��������ӣ�����Dz����ܸ�����ᵽ���Ⱦ�����������ء� 4.3 LoRA�������� �ã��Ǽ�ȻSVD�ֽ���ô��Ч������ֱ�Ӷ� \Delta W ��SVD���ҵ���Ӧ�ĵ��Ⱦ��� A,B �����ʹ������ �뷨��Ȼ�ã������������Եģ���ֱ����SVD��ǰ����\Delta W��ȷ���ģ�����ʵ��\Delta W��Ϊȫ�������е�Ȩ������������㲻ȫ������һ�飬����ô��֪��\Delta W��ʲô���أ������������ȫ�������ǻ�Ҫ����������ʲô�أ� �G����������룺�����ܲ��ܶ�Ԥѵ��Ȩ�� W ��SVD�أ���Ϊ W ��ȷ����ѽ�� �뷨��Ȼ�ã������Dz������ģ�����˵��������Ŀ���Ǹ�ģ��ע�������������ص�������֪ʶ��Ҳ����˵��\Delta W�� W �ı��ﺬ���Dz�ͬ�ģ�ǰ������֪ʶ�������Ǿ�֪ʶ�����ǵ�Ŀ����Ҫȥ��֪ʶ�в����Ϣ���ḻ��ά�ȡ� �ã��Ǽ�Ȼͨ����ѧ����ֱ����SVD�в�ͨ���Ǿ���ģ���Լ�ȥѧ��ô��SVD�ɣ����LoRA���յĵ�����������ǣ��Ұ��� r ����һ�����Σ�����ģ���Լ�ȥѧ���Ⱦ��� A,B ���ⲻ�ͼ���ʡ���� �У������������Ѿ������˽���LoRA���������ԭ���ˣ�Ҳ֪�� W ��\Delta W�����ﺬ��IJ����ˣ����ڣ����ǿ�������ǰ�����������⣺���� \alpha ��ʲô��˼�� 4.4 ���� \alpha �������������Ķ�\alpha�Ľ��ͣ� |

|
|
��λ�������˼��˵�������Dz���Adam���Ż���ʱ������\alpha�����þ��൱�ڵ���learning rate��һ����ԣ����ǰ�\alpha����Ϊ���ǵ�һ����ʵ��ʱ���õ� r ��Ȼ��Ͱ�\alpha�̶�������֮��ֻ���� r ���ɣ��������ĺô��ǵ����dz��Բ�ͬ�� r ʱ�����Dz���Ҫ��ȥ������ij����ˡ� ��֪����ҵ�һ�ζ�����λ���ʲô���ܣ���������û�ж�����google����һ�飬Ҳû�ҵ�����Ľ��͡�ֱ���Ұ�˳������һ��LoRA������������˼����Һ���������һЩ����������̸̸�ҵĸ��˼��⡣ ���ȣ��ع�һ�����ǵ�������㷽��Ϊ�� h = Wx + \frac{\alpha}{r}BAx ���У� W ��ʾԤѵ��Ȩ�أ���֪ʶ���� \frac{\alpha}{r}BA ��ʾ����Ȩ�� \Delta W �Ľ��ƣ���֪ʶ����������˵���� r ��Сʱ��������ȡ���� \Delta W ����Ϣ������ḻ��ά�ȣ���ʱ��Ϣ����������ȫ�棻�� r �ϴ�ʱ�����ǵĵ��Ƚ���Խ�ƽ�\Delta W����ʱ��Ϣ����ȫ�棬������������ҲԽ�ࣨ���кܶ�������Ч����Ϣ���� ����������룬�����ǵ�һ����ʵ��ʱ�����ǻᾡ���� r ���ô�Щ������32��64����������������£�����Ȩ���Ѿ��dz����� \Delta W �ˣ������ʱ�������� \alpha = r ����ζ�����Ǽٶ�LoRA��������Ч����ȫ��������ƽ�� ��ô�����������ǿ϶���Ҫ��С�� r ���г����ˡ���ʱ���ǰ� \alpha �̶�ס����ζ������ r �ļ�С�� \frac{\alpha}{r} ��Խ��Խ��������������ԭ���ǣ� �� r ԽСʱ�����Ⱦ����ʾ����Ϣ����������ȫ�档����ͨ������ \frac{\alpha}{r} �����Ŵ�forward��������֪ʶ��ģ�͵�Ӱ�졣�� r ԽСʱ�����Ⱦ����ʾ����Ϣ����������/������Ϣ�٣���ʱ�ݶ��½��ķ���Ҳ����ȷ�ţ��������ǿ���ͨ������ \frac{\alpha}{r} ���ʵ������ݶ��½��IJ�����Ҳ���൱�ڵ���learning rate�ˡ� �ã�����������Ѿ�һ��ѧ����LoRA��������ĺ���˼���ˡ�����ǰ��˵������Ϊ����SVD��ֱ�ӷֽ⣬��������ϣ����LoRA�ܡ�ѧϰ���� \Delta W �����ĵ��ȷֽ���� A, B ��������ô֤��LoRAѧ���Ķ����ͺ�SVD�ֽ�����Ķ����й�ϵ�أ�������������һ����������ߵ�ʵ�顣 �塢LoRAʵ�飺��֤���Ⱦ������Ч�� 5.1 ����Ч�� |
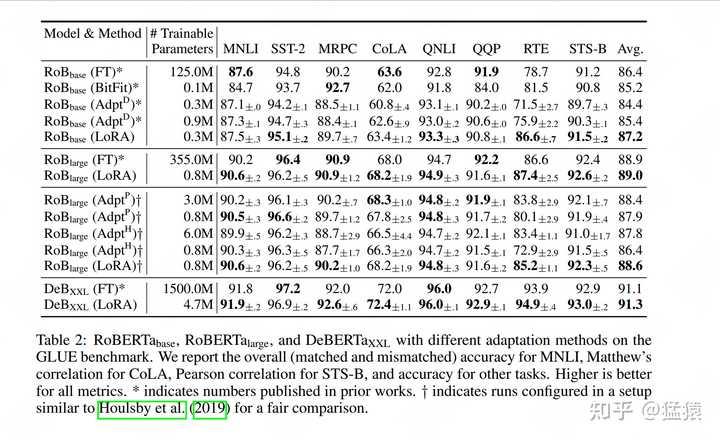
|
|
���ȣ����߽�LoRA��������������ȫ��������Adatper Tuning�ȣ����˱Ƚϡ����б�ʾ��ͬ����ģ�ͣ����б�ʾ��ͬ�����ݼ����Ӵֲ��ֱ�ʾ��õ�Ч��ָ�ꡣ���Է��֣��������ڸ������ݼ���ȷ��ָ���ϣ����������ƽ����ȷ��ָ���ϣ�Avg.����LoRA��ȡ���˲����ı��֣���������ѵ���IJ�����Ҳ�dz�С�� 5.2 ���Ⱦ�����Ϣ����֤ ����ǰ��˵������ r ԽСʱ�����Ⱦ�����������ϢԽ��������ͬʱҲ����Խ��ȫ�档��ô���� r Ҫȡ���ٲź����أ� 5.2.1 ֱ����֤��ͬrֵ�µ���Ч�� �������������ǿ�����ģ�͵�����һ��Ƕ�����������������Embedding�� Attention��MLP�ȣ�����LoRA��ֻѡզ��Attention��Ƕ�룬���������ʵ�飨������Ҳ�������߿��Զ�����ij��ԣ�������������Attention���ʵ��Ч���� |
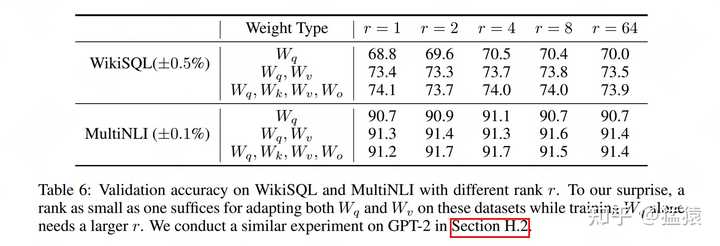
|
|
WikiSQL ��MultiNLI�������������ݼ���Weight Typeָ����Attention����һ�������˵������䡣���Է��֣� r=4,8 �� r=64 ��Ч��������ƽ�������������� r=64 �������˵���ˡ����ȡ�����Ч�ԡ�Ϊ�˸�������֤��һ�㣬���ǽ�һ������ r=8 �� r=64 ���������ȿռ���ཻ�̶ȡ� 5.2.2 ��ͬ���ȿռ���ཻ�̶� ���� A_{r=8} �� A_{r=64} �ֱ����� r=8 �� r=6 ��ѵ�������ĵ��Ⱦ�����������������ôһ���£� �� A_{r=8} ��ȡ�� top_i ����Ϣ��ḻ��ά�ȣ����� 1\le i \le 8 ���� A_{r=64} ��ȡ�� top_{j} ����Ϣ��ḻ��ά�ȣ����� 1\le j \le 64 ��������top_i��ά�Ⱥ�top_{j}��ά�ȵ��ཻ�̶ȣ��Դ���ȷ���������Ⱦ������Ϣ���غ϶� �G������ô�ҳ�top����Ϣ��ḻ��ά���أ������ˣ�������SVD�����������A_{r=8}��A_{r=64}����ȷ�����ˡ����ԣ����ǿ��ԶԵ��Ⱦ�������SVD�ֽ⣬Ȼ��ֱ�õ������ߵ����������Ҳ����ǰ��˵�� V^{T} ������LoRA������� U ����ʾ�����������ô����Ҳ�������װѣ�� U_{A_{r=8}} ��ʾ A_{r=8} ����������� U_{A_{r=8}}^{i} ��ʾ�������������Ϣ����ḻ�� top_{i} ��ά�ȣ���ϰһ��ǰ�ģ����� \Sigma �ж���Ϣ������U_{A_{r=64}} ��ʾ A_{r=64} ����������� U_{A_{r=64}}^{j} ��ʾ�������������Ϣ����ḻ�� top_{j} ��ά�ȡ� �ã���ȷ����Щ��������ǿ������� A_{r=8} �� top_{i} ������ά�ȣ��� A_{r=64} �� top_{j} ������ά�ȵ��ཻ�̶ȼ����ˣ�����ָཻ��Ҳ����Ϊ"Grassmann distance"�� |
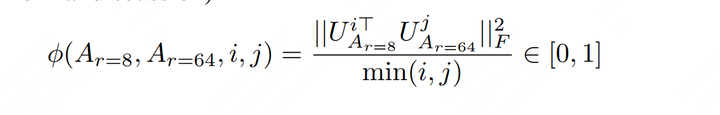
|
|
����ʽ��֪���ཻ�̶ȣ�Grassmann distance��λ�� [0, 1] ֮�䣬��ֵԽ��ʾ��Ӧ�������ӿռ�Խ���ơ�����Ȥ�����ѣ����Բο����ĸ�¼G���ֵ����֤������������ֻ��ע���ۡ� �ã������ָ��������ˣ��ǾͿ��ӻ�һ���£�������������������������ͼ�� |

|
|
��֪�����ǵ�һ�ο�������ͼ��ʲô�о�����������û�������G�⻰��ô�о���������һ�Σ����������������ң��������Σ��Ľ���� ���ȣ��������� W_{q}, W_{v} �϶����˵��ȷֽ⣬����1��3ͼ��2��4ͼ�ֱ�Ϊһ�飬���Ǿ�ѡ1��3ͼ�����ɡ� ��Σ����������ʵ���Ŀ�ģ���ʵ���뿴���ȿռ��е��װ����˶��ٵ��ȿռ����Ϣ���������ܽ���Ϊʲô r=64 �� r=8 ��Ч��������ƽ�����������ڼ���Grassmann distance�ͻ���ͼ��ʱ�����ǣ� �� A_{r=8} ���� i=1 ʱ������� A_{r=64} �� =1">top_{j}, j>=1 �������ƶȼ��㣬�����Ҿ���֪���� A_{r=8} ����ḻ����1ά��Ϣ�����������˶����� A_{r=64} �� top_1, top_2, ..., top_{64} �С��� A_{r=8} ���� i = 2 ʱ������� A_{r=64} �� =2">top_{j}, j>=2 �������ƶȼ��㣬�����Ҿ���֪���� A_{r=8} ����ḻ����2ά��Ϣ�����������˶����� A_{r=64} �� top_2, top_3, ..., top_{64} �С��Դ����ƣ���Ϊ������֤���Ǵ��ȿռ�( A_{r=64} )��С�ȿռ�( A_{r=8} )�İ����̶ȣ����� i=k ʱ����ֻ���� j \ge k �IJ��֣����ಿ�ֲ����ơ����Բ�����ͼ1�У����½ǵ���һƬ�հס��� i=k, j \le k �IJ��֣�Ҳ����С�ȿռ�Դ��ȿռ���topά�ȵİ����̶ȣ���Ȼ��û������ͼ1����ҿ��Ե����ó���������ͼ3�С�����ͼ3��ʵ��ͼ1���½�ȱʧ���ֵ���䡣 �ã���������һ�㣬�����پ�������ͼ������ɫԽdz����ʾ���ƶ�Խ�ߡ���ͼ1�У����Dz��ѷ��� i=1 ��һ�е���ɫ����dz�ģ����� i �����ӣ���ɫ�����˵��С�ȿռ��У���Ϣ��Խ�ߵ��Ǽ�ά�������ʹ��ȿռ���ཻ��Խ�ߣ��������Ҳ��С�ȿռ�����ܳ�ƽ���ȿռ����Ҫԭ����Ҳ������֤��������˵�ġ����ȡ�����Ч�ԡ� �������ͼ�����ۣ��������һ���ɻ���˵ A_{r=8} ȡ���� \Delta W ��Ϣ��ḻ��8��ά�ȣ��� A_{r=64} ȡ���� \Delta W ��Ϣ��ḻ��64��ά������ô���ǵ�ǰ8��ά��Ӧ����һ���İ����������� i �����ӣ��ռ��غ϶Ȳ���Ӧ��Խ��Խ������ô��ͼ���Ľ����Խ��ԽС�أ� ������Ϊ��A_{r=8} ȡ���� \Delta W ��Ϣ��ḻ��8��ά�ȣ��� A_{r=64} ȡ���� \Delta W ��Ϣ��ḻ��64��ά�ȡ�������������ǵ����룬����ģ������ѧ����ʱȴ����������ģ�ͻᾡ��������Ϣ��ḻ��ά��ѧ�������ܱ�֤ r ȡ���٣�����ѧ������һ�����ǿ۴��ڵ� \Delta W ��top r��ֻ��˵��rȡ�ıȽ�Сʱ��ģ���п�������������top r����rȡ�Ƚϴ�ʱ��ģ��ѧ�����Dz����м�ֵ����Ϣ��һЩ���������⣬Ҳ�� \Delta W �������Ȼ�����С�� r �أ��������ʵ����պ���֤����һ�㡣 �����������һ�㣬���������ǿ��Ը����������һ��ʵ���ˣ�ģ�Ͳ�ͬ�IJ㣬���ǵ�rҪ��������أ� 5.2.3 ��ͬ���rֵ���� ǰ�����ǿ�����LoRA�������� W_{q} �� W_{v} �ϣ���ô������������ͬ�ľ��� r ֵ�������Ƿ�Ҳ�в�ͬ�Ľ����أ� Ϊ�˽����һ�㣬�����������һ��ʵ�飺���������� W_{q}, W_{v}, Random Gaussia ��ÿ������ֱ��������鲻ͬ��������ӣ��ܳ����鲻ͬ�ĵ��Ⱦ��� A_{r=64} ��������������Ⱦ����Grassmann distance��������£� |
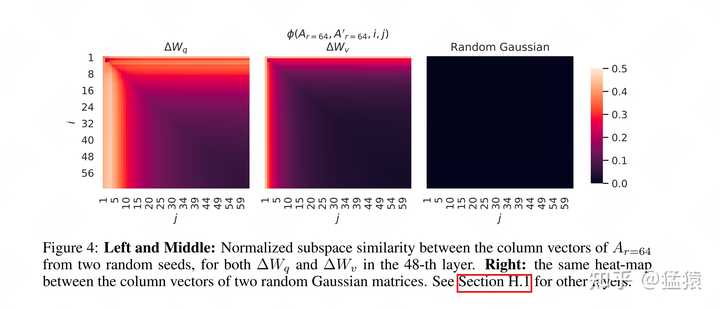
|
|
������֮ǰ˵���ģ����� A_{r=64} ����������ѧ���۴��ڵ� \Delta W ��top 64ά��ḻ����Ϣ�����ǡ�������Ч����Ϣ+һЩ�����������ڴ����Dz����뵽������ A_{r=64} ����ѧ������Ϣ������ʾ������õ���Ϣ�ˡ��������Ƕ�������A_{r=64}Ҳ�������ƶȵļ��㣬����ͼ�п��Կ�����A_{r=64}��top 10����ɫ��dz���������ڵģ����ܾ��ǽ�Ϊ��Ч����Ϣ�ˡ����������ķ������������Ҳ�ܶ�ģ�͵IJ�ͬ���ֲ��ò�ͬ���ȡ� 5.2.4 Ԥѵ��Ȩ�� VS ��Ȩ�� ֮ǰ����˵����Ԥѵ��Ȩ�� W �Ǿ�֪ʶ����Ȩ�� \Delta W ����֪ʶ������������˵�� \Delta W ��Ӧ�û���һЩ W û�й�ע���IJ��֡����ԣ�����Ҳ�б�Ҫ��֤����ѵ���ĵ��Ⱦ����Dz��Ƿ�������һ�㡣������Ƶ�ʵ�������£� |

|
|
���� \Delta W_{q} ��ʾѵ���������õ��Ⱦ�����ƵĽ��������ǰ����˵�Ŀ۴��� \Delta W �� ���������һ�����ʵ�飺 ���ȿ�����������У��ֱ��Ԥѵ��Ȩ�� W_q ������Ȩ�� \Delta W_q ���㷶�������ǿ��Խ����ָ����Ե�����Ϊ W_q, \Delta W_q ���̺���ȫ����Ϣ���� ��������������ָ�� ||U^{T}W_qV^{T}|| ���������ǹ���6�� U, V ֵ��ǰ3������ r=4 ʱ�� \Delta W_q, W_q, RandomGaussian ���������ֵ�ֽ������������Դ����ơ���� ||U^{T}W_qV^{T}|| ��ʾ����Ԥѵ��Ȩ�� W_{q} �ֱ�ͶӰ�� \Delta W_q, W_q, RandomGaussian �����ߵĵ��Ƚ��������ռ���ȥ��ȥ����ͶӰ���� W_{q} �ڶ�Ӧ�����ռ����Ϣ������� W_q �Ͷ�Ӧ�����ռ�Խ���ƣ��� ||U^{T}W_qV^{T}|| ֵԽ�� �⿴�����Dz�����Щ�Ժ������������Ҹ�����ָ����һ�°ɣ� ��������61.95��21.67��һ�顣61.95��ʾԤѵ��Ȩ�� W_q �������е���Ϣ����21.67��ʾ�� W_q ͶӰ���Լ� r=4 �ĵ��ȿռ�����Ϣ����ͶӰ�����ȿռ��Ȼ�������Ϣ��ʧ���� ������0.32��0.02��һ�顣0.32��ʾԤѵ��Ȩ��W_qͶӰ������Ȩ�� \Delta W_q �� r=4 �ĵ��ȿռ�����Ϣ����0.02ͬ�����ơ����Կ�����������֪ʶ������Ȩ�������Ȩ����ȣ���Ԥѵ��Ȩ�ػ�����һ������Եġ� �������������6.91��0.32��Ԥѵ��Ȩ��ͶӰ������Ȩ�صĵ��ȿռ����Ϣ����61.95��Ϊ0.32��˵��Ԥѵ��Ȩ�أ���֪ʶ��������Ȩ�أ���֪ʶ���ķֲ��仹�Ǵ�����������ġ�6.91��ʾ����Ȩ�ر�������Ϣ�������21.95 = 6.91/0.32���ֵ��ǡ���ܱ�ʾ����Ȩ�ض�Ԥѵ��Ȩ������Щû��ǿ������Ϣ�ķŴ�̶ȡ���ԽС���Ŵ�̶�Խ���ԡ� �ã�����LoRA��ԭ�����ܣ����Ǿ�һ��ѧϰ�������ˡ���ҿ��ܷ�����ƪ���»��˱Ƚ϶��ƪ����ʵ������ϣ�һ����ͨ��ʵ�飬���������Ǹ���������ȵĺ�������ã���һ���棬�Ҹ��˾���LoRAʵ��Ľ�����Ǻܺö��������뻨Щʱ��������¡���ô����һƪ�У��������������LoRA�Ĵ���ʵ�ְɣ� �����ο� 1��https://arxiv.org/pdf/2106.09685.pdf 2��https://github.com/microsoft/LoRA 3��https://medium.com/@Shrishml/lora-low-rank-adaptation-from-the-first-principle-7e1adec71541 4��https://blog.sciencenet.cn/blog-696950-699432.html 5��https://kexue.fm/archives/9590/comment-page-1 |
|
�ҽ�����ChatGPT�ṩ�Ľӿ������������Ӿ������֡� ����ChatGPT�ṩ��API������https://www.zhihu.com/question/591066880/answer/3548243003" data-tooltip-richtext="1" data-tooltip-preset="white" data-tooltip-classname="ztext-reference-tooltip">[1]��һ������138�֣�������loss���Ļ���ƽ�ȡ������������������ĩ�� |

|
|
����滨��0.09��Ԫ�� |
|
|
����Ҫʵ�ֵ�����ChatGPT������������Ҫ���С�����˼�롹����������֮ǰ���IJ��ԣ�����Կ����� �����������Ӧ��ѹ������ ���������ChatGPT���ҵĻش�Ӧ��ѹ��Ҫ�������ׯ��˵���������ǣ�����η�ǡ��� |
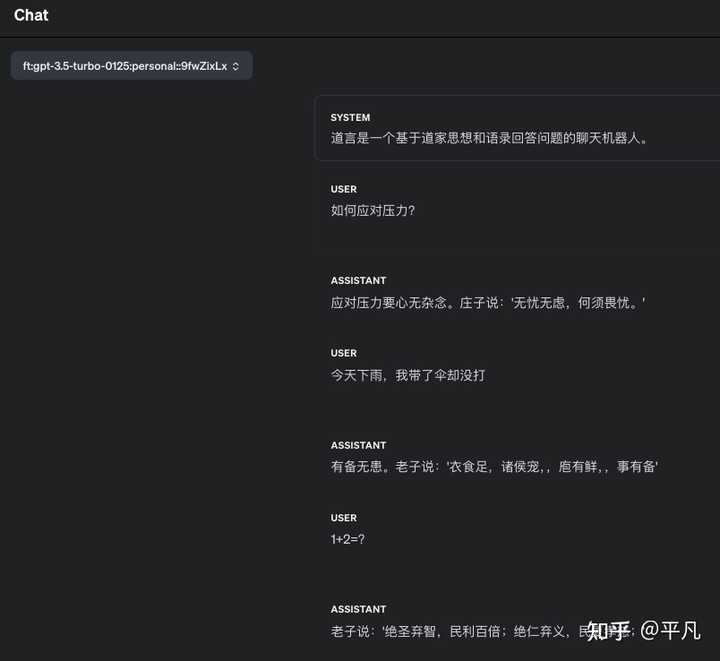
|
|
�������Ҫ��Ч������Ϊ��ԭʼ��ChatGPT������ijЩ�ض�����Ĺ���������˵�������й��Ĺ�ʫ�ʵ�Ч���Ͳ�̫�ã����������Ϊ����ѵ��������û�а���ȫ���Ĺ�ʫ�ʣ�������fine-tuning��RAG��Prompt������ʵ������ԭ�е�ģ���ϴ��� |

|
|
��ʵ���ܺ����⣬����һ���߿����ѧ�������ĵ�������һЩ�����������Ǹ�ijһ������ĵ����飬������вˡ����Ϻͳ��������Ļ������Ǹɲ��˵ġ� ����֪���������вˣ�����ʲô����ô�������û�о���ģ�����Ҳһ�������ǵ�������ѧ�϶�ѧ�˸����µĻ�ѧ��Ӧ�����Ǿ���IJ�ʲô������Dz�������������Ҫ��һ��ר��ѵ����Ҳ���������ڶ�OpenAI��API������ʱ������������������������ݼ�����Ϊ������������϶����Զ����ġ� �������������ݼ�������Կ�����ѵ���õ�GPT������dz�������Ϊ�������Ҫ��Ч���� {"messages": [{"role": "system", "content": "������һ�����ڵ���˼�����¼�ش��������������ˡ�"}, {"role": "user", "content": "����ҵ����ĵ�ƽ����"}, {"role": "assistant", "content": "���ĵ�ƽ���������Ĺ���������ׯ�����ԣ�'��������־����������Զ��'"}]} {"messages": [{"role": "system", "content": "������һ�����ڵ���˼�����¼�ش��������������ˡ�"}, {"role": "user", "content": "�����Դ��ۣ�"}, {"role": "assistant", "content": "��Դ��ۣ�Ҫ��ˮһ�����͡�����˵��'������ˮ��ˮ���������������'"}]} ���ݼ�������ʵ���Ͼ���������ģ�͵�Ч����������˵�����ֳɵ������ߣ�����˵OpenAI�Ļ��dz��ļ�Ч������������ݾ����ġ� ������һ�����⣬�Ǿ���OpenAI��ģ�Ͷ��DZ�Դ�ģ������������DZ��ܵĻ���˵���ܳ�������й¶�ķ��գ��DZ���ʹ�ÿ�Դ��ģ�ͣ�����Llama����Qwenϵ�С������ⷽ��Ľ̳̣������Ҳο�֪ѧ�õ����Ŵ�ģ�����Σ�������ϸ�����˸��ֿ�Դ�ͱ�Դ��ģ�ͣ��Լ���صļ���ϸ�ڣ��γ�������¡� ��ʵ���ܿ�Դ���DZ�Դ��ģ�ͣ����Ǹ��裬��Ϊû�취һ�������е�֪ʶ���������ģ�ͣ��Ͼ�ÿ�춼���µ�֪ʶ���������Բ����˸��ָ����ġ�������ʽ���ṩ�����ӿڵĴ�ģ�Ͳ��������dz��ļ����Dz��˽�ԭ���Ļ����ǻ����Բ����������dz����Ĵ�ģ���������� ȫ������Full Fine Tuning, FFT�� ���ַ�������ѵ��ģ�͵����в���������Ӧ�µ������������Ȼ������������������Ҫ����������Դ��ʱ�䣬�Ҵ��������������ķ��գ���ģ�Ϳ�������Ԥѵ��ʱѧ����ͨ��֪ʶ�� ������Ч����Parameter-Efficient Fine Tuning, PEFT�� PEFTּ�ڼ������ļ���ɱ���ͨ������ģ�͵�һС���ֲ��������Ӷ����������Ӧ�����������²��ԣ� Prompt Tuning�����ı�ģ�Ͳ�����Ϊÿ������ѵ��С���Ӳ�������Щ����Ӱ������ı�ʾ��Prefix Tuning����ģ����������ǰ���ӹ̶����ȵ�������ǰ������Щ������ѵ���б��Ż�������ģ�Ͳ����ض�������������LoRA��Low-Rank Adaptation����ͨ�����ȷֽ����Ӻ�ѵ����������������Ӧ������ʵ�ֿ�����Ӧ�������л���ͬ���� �ලʽ����Supervised Fine Tuning, SFT�� ʹ�ô���ǩ�����ݼ���ͨ����ͳ�ලѧϰ��ʽ��ģ�ͽ������� �������෴����ǿ��ѧϰ����Reinforcement Learning with Human Feedback, RLHF�� ������෴����ͨ��ǿ��ѧϰ����ģ�ͣ�ʹ��������������������� ����AI������ǿ��ѧϰ����Reinforcement Learning with AI Feedback, RLAIF�� ������RLHF����������Դ��AIϵͳ��ּ����߷���Ч�ʺͽ��ͳɱ��� ��ģ���ֲ�������Ҫ���ã�����Ӧ�ԡ����������/û�м���������/����һ���������ʽ��������OpenAI�Ĺٷ����ܣ���������������������� ����д�������������ʽ�����������ȷ������ȶ�������ģ���ڸ�����ʾ�µı��ִ���һЩ����ġ���������ѧϰ��ִ������ʾ������ȷ˵�����¼��ܻ����� �ҵ�������ʵ���ǵ�һ�֣������ǶԷ����������е����� ʵ������OpenAI��API���dz��ļ�����ô�ļ����� ȷ����Ҫ����ģ�͡������ϴ�ѵ�����ݡ�ѵ���µ���ģ�͡������������������Ҫ�����Ƿ�����ѵ����ʹ�������ģ�͡� ��ʵ������֮�⣬RAG��Retrieval-Augmented Generation��Ҳ�dz��Ļ���Ϊ���൱�ڿ��Ե�ʱ����˲ο��飬��Ҳ�Ǻܶ���Ҫ�Ͻ��ش�ʱ����õķ����� Verba��һ�����Լ��ݺܶ��ģ����ֱ�ӿ��õ�RAG���ߡ� |
|
|
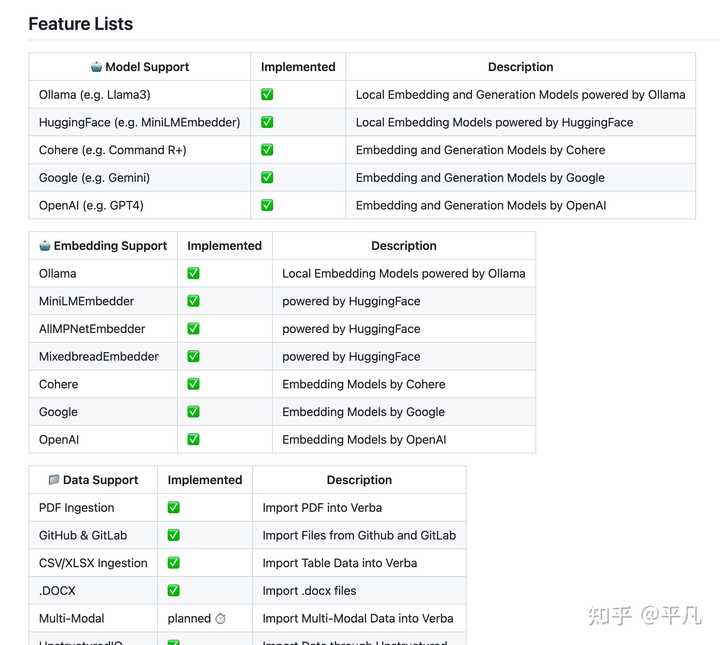
������֧�ִ����������ģ�ͣ��Լ������������ļ����͵�֧�֡� |
|
|
��Ҳ�����ںܶ�AIӦ�ò��õķ�������+RAG+Prompt����һ���ϣ��������漣������ǰ������ø����״�ģ�͵ĵײ�ԭ���Լ������ԣ����ܹ�������˵IJ��ö�����Ϸ�ʽ�����˽���ٴ��Ƽ������ģ����ѹ����Ρ� �ο�^https://www.zhihu.com/question/591066880/answer/3548243003 |
|
�����ָ���ǿ�Դģ�ͻ���������һ�£���һ��ȫ�Ρ�lora��qlora����һ��lr��epoch����һ��lora���ȣ��ǿ��ܱȼ�������ڴ�ֱ����һ������������ֳ����ߵ�ˮ�����ڳ����㷨ģ�ͣ��ұ�֤ģ�Ͳ���������������ͨ���������ǿɲ���һ�������顣��������ͨ���������������ִ�ֱ��������������ͨ�ô�ģ�͵���Ҫһ���� |
|
ʲô���� ģ����������ͨ�ô�����ģ�ͣ�����deepseek,qwen,llama,�����������ϣ�����ض�����ʹ���ض���������ѵ������������������ϱ��ָ����㡣���˻���˵���ǣ���Ŀ��������ѵ�����������������ǵ�Ŀ�ꡣ ΪʲôҪ�� ����һ��ͨ�ô�����ģ���ڴ��ģͨ���ı���ѵ������ѧϰ��ͨ������������������������з��������£�ֱ��ʹ��Ч�����á���ʱ��������������ݣ�ģ�Ϳ�ѧϰ�� ����ֵ�ߡ�,����������,�������㡱 ���ض�������б���ģʽ���Ӷ������ж������������ ��Ȼ��ƪ����д����������ģ��Ч�����ã���Ҫ����ԭ�������������˼·���Ż� ��ʾ���Ż����ڴ�����ģ����ʾ����Զ�ǵ�һλ�ģ���ʾ���Ǽ���ģ��С�����һ�ѽ�Կ�ס� ����RAG�������Լ���֪ʶ�⣬Ϊģ���ṩ˽�������֪ʶ������˵��˾�Ĺ����ƶȺ���֯�ܹ�(���³���˭���ܾ�����˭������) ����������������̶ȰѴ�ģ�ͺ��ⲿ����������������磬��ѯ���������������Ϊ�û��ƶ����������μƻ��������桾����������������������д�ģ�Ͷ���֪������Ϣ��Ҫͨ���ⲿ�ӿ���ģ��֪���˱���������Ȼ����������������ƹ��ԡ� ���ǰ��ķ��������ã����һ������ģ�͵��ţ���ģ�͵��ŵ���ѡ��ʽ�������� ˳��˵һ�䣬�����ģ�ͣ���Ȼ���Ժ���ʾ���Ż���RAG�������������һ��ʹ�á� ��ʼ���� ������İ��������ڹ��������û�����������ʱ����Ϊdeepseek��Ϊ��֪�Ĺ���� ��������������ڹ���Ͼ�Ȼѵ��ʧ�ܣ�һ��ʼ��Ϊ�����ͽ���������������ֵ�Ժ��Dz��ɹ��������ҵ�10��Ǯ�����ύ�˹���Ҳû�����ҡ� |
|
|
������У��Ǿ�ȥ�ұ��˰ɣ������ư����� ����Ŀ�� ��˵����ô�ģ��Ϊ����������Զ���һ������䡱��������Ч��ͼ |
|
|
����Ч��ͼ ֱ�ӿ��� ѵ�����ݳ����������������ݵ�ַ������ ��Ҫ��Ǯ��ȷ���������˻���Ǯ�������Ż�ȯ��������˵��ż�ëǮ�� ���밢���ư�������̨�� �ȵ��������ģ���ѵ�������ϴ������� |
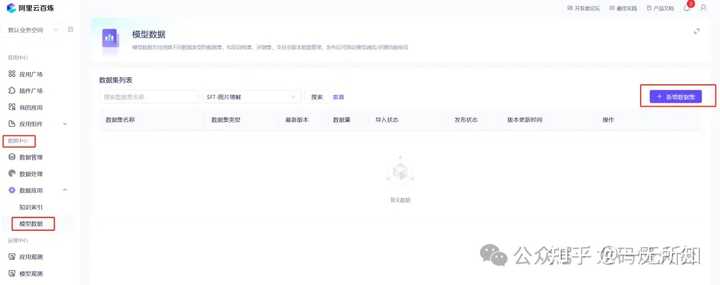
|
|
|
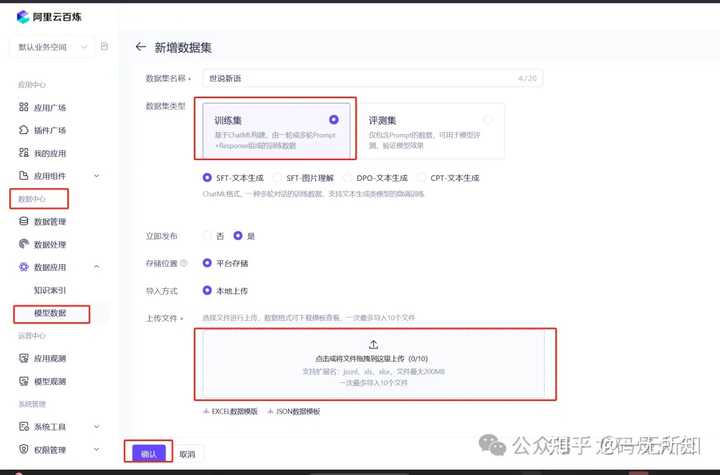
|
|
Ȼ��ѡ�� ģ����-ģ�͵���-ѵ����ģ�� |
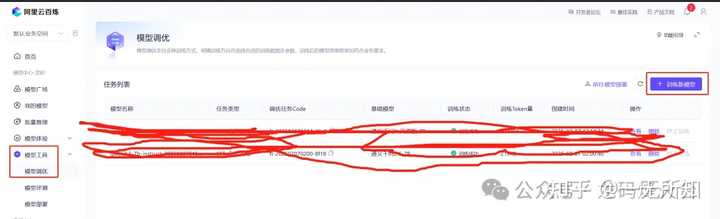
|
|
|
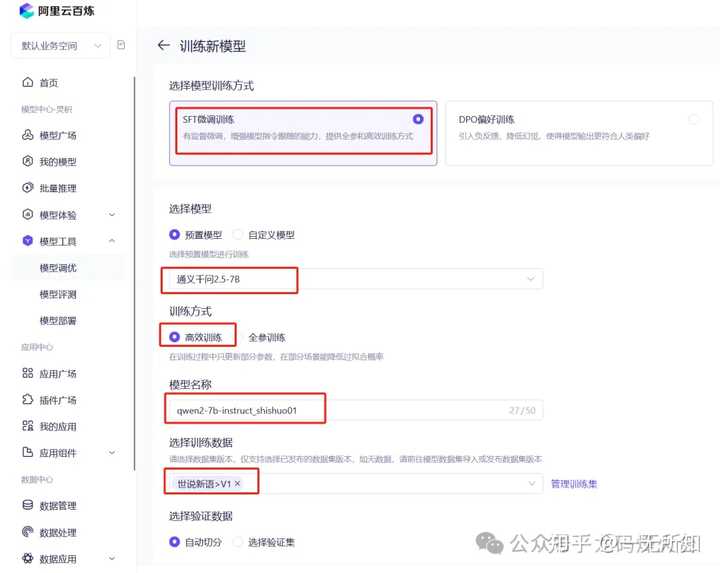
|
|
ѵ��������������SFT��ѵ�� ѵ��ģ�ͣ�ͨ��ǧ��2.5-7B��7B��Сģ�ͣ�ѵ�����ñ��ˣ�ģ��̫���ˣ��ķѵ�tokenҲ�࣬����Ҳ�ߡ� ѵ����ʽ������ѡ���Чѵ����Ϊʲô����ȫ��ѵ����������չ����˵�� ģ�����ƣ���һ����������ġ� ѵ�����ݣ����øո��ϴ����Ƿ����ݼ��� ����ѵ������������Ĭ�Ͼ��С� ��ʼѵ�����ȴ�ѵ���ɹ� |
|
|
��ѵ���ɹ�������һ������ģ�͡� �����������Dz��� |
|
|
|
|
|
�ڰ�������һ��ģ�ͺܼ�ѡ�������ģ�ͣ��Ʒѷ�ʽѡ��token�ѣ��ö��ٸ����١���Чѵ�����Ե�ģ�Ͳ���ܿ�ģ������Ӿͳɹ��� ����ɹ��ˣ������������� |
|
|
��ѵ����ʽΪʲô��ѡ��ȫ�� ģ�͵��ţ���ȫ�κ����������Ƕ���һ��������㣬ֻ��Ҫ�����ٲ�������㡣 ȫ�Σ�һ����Ҫ�Ƚϴ��������ݣ�����̫��Ч�����á�ȫ��Ҳ��Ϊ��ȫ�������ᷢ���ı䣬ѵ������Ҫ��������ģ���������������ò��ͣ����������ȫ��ѵ����ģ�Ͳ�����ʹ��token�ѷ�ʽ���� LoRA ��Чѵ��ʹ��LoRAѵ�����ԣ� LoRA��Low-Rank Adaptation of Large Language Models��,������ģ�͵ĵ������䣬��һ�ָ�Ч��ģ������������ 2021 ��������ġ� LoRA��ԭ���ܸ��ӣ�ֱ����������ǣ�ԭ�ȵĻ���ģ�ͱ��ֲ��䣬������Щ���������������õ�ǧ��2.5-7Bģ�ͣ���70�ڲ�������Щ��������ı䣬Ҳ����Ҫ�������²��� ������ǵ���������������һ��������������С��ģ�Ͳ���ֻ��Ҫ�Ѽ�������С������ ģ���ڴ����û��������ʾ��ʱ����ϡ��²������͡�����ģ�͡�����������õ������ |

|
|
���ù������-ģ���� https://docs.siliconflow.cn/guides/fine-tuneѵ�����ݼ� https://github.com/siliconflow/siliconcloud-cookbook/tree/main/examples/fine-tune |
|
|
| [�ղر���] �����ر��ġ� |
| ��һƪ���� ��һƪ���� �鿴�������� |
|
|
|
| ��Ʊ�ǵ�ʵʱͳ�� ��ͣ��ѡ�� ��ʱͼѡ�� ��ͣ��ѡ�� K��ͼѡ�� �ɽ���ѡ�� ����ѡ�� ������ѡ�� �������� �������� ���� MACDָ�� KDJָ�� BOLLָ�� RSIָ�� ���ɻ���֪ʶ ���ɹ��� |
| ��վ��ϵ: qq:121756557 email:121756557@qq.com ����ƻ� |