
| |
|
|
| 首页 淘股吧 股票涨跌实时统计 涨停板选股 股票入门 股票书籍 股票问答 分时图选股 跌停板选股 K线图选股 成交量选股 [平安银行] |
| 股市论谈 均线选股 趋势线选股 筹码理论 波浪理论 缠论 MACD指标 KDJ指标 BOLL指标 RSI指标 炒股基础知识 炒股故事 |
| 商业财经 科技知识 汽车百科 工程技术 自然科学 家居生活 设计艺术 财经视频 游戏-- |
| 天天财汇 -> 设计艺术 -> 3DGaussianSplatting技术的影响会有多大? -> 正文阅读 |
|
|
[设计艺术]3DGaussianSplatting技术的影响会有多大? |
| [收藏本文] 【下载本文】 |
|
3D Gaussian Splatting于2023年8月末获得 SIGGRAPH 2023(计算机图形学及互交技术顶会) 最佳论文,是一种用于实时渲… |
|
最近在跟3DGS,准备开一个学习笔记系列。 初步计划包含: 阅读论文源码:框架源码:CUDA前项传播源码:CUDA反向传播源码修改 考虑到各个平台对高斯原理的讲解分析已经非常全面,而对于CUDA代码部分的讲解非常少,因此我们将不按顺序进行更新,先从CUDA代码的修改开始,从后往前进行。 2024.1.9第一次更新:第五节源码修改部分,我们向原本gaussian-splatting中加入了深度监督,文章见主页,项目连接如下 diff-gaussian-rasterization-depth?github.com/leo-frank/diff-gaussian-rasterization-depth |
|
2023年6月,苹果宣布iPhone 15 Pro可用来拍摄“空间视频”(Spatial Video/Photo),并可在其空间计算设备Apple Vision Pro上呈现。每个人能对“此情此景”进行立体记录和体验的广阔前景,引发了关于“3D拍摄”技术、XR生态发展与未来交互的新一轮讨论。 在持续降低3D内容生产与消费门槛的技术浪潮中,元象宣布推出3D拍摄与混合编辑插件工具XVERSE 3D-GS UE Plugin,将国际最前沿的三维重建技术率先引入中国,免费供所有人使用。 |

|
|
0 元象3D拍摄混合编辑插件下载地址:https://github.com/xverse-engine/XV3DGS-UEPlugin “3D拍摄”比苹果“空间视频”更进一步,具备立体记录、多端呈现、沉浸交互的独特优势,在功能上: 任意手机拍摄覆盖场景各方向的10分钟视频或百张照片,AI将自动生成“带景深”的高清3D空间。 用户可在手机、电脑或VR等多种终端设备上实时浏览和分享,也支持漫游、俯瞰等多种交互。 创作者可在虚幻引擎中进一步混合编辑,在空间中加入虚拟角色、动画、灯光、特效及运镜等进行混合渲染,创造虚实融合的全新3D体验。 |

|
|
该插件基于今年8月图形学顶级会议SIGGRAPH 2023最佳论文提出的基于3D高斯抛雪球法的实时辐射场渲染算法(3D Gaussian Splatting for Real-Time Radiance Field Rendering,下称3D-GS)研发而成。 3D-GS被普遍认为是三维重建领域的“爆炸性”新技术,是多种创新集大成者,克服了此前大热的NeRF(神经辐射场)算法和传统三维重建所面临的工序繁琐、耗时、难以兼容、需专门设计硬件、渲染开销大等老大难问题,实现渲染质量、渲染速度、训练速度三者兼得,为3D拍摄-生成-剪辑-呈现流程节约了大量时间和花销,并保持了卓越渲染品质。 3D拍摄可广泛应用于家居、零售、文化、旅游、营销等不同行业与场景,并根据业务需求进行快速定制。 |

|
|
0 元象致力于打造AI驱动的3D生产与消费一站式工具,未来将持续迭代3D拍摄技术与功能,推动3D内容普及与XR行业发展,迈向“定义你的世界”愿景。 |

|
|
3D拍摄 降低生产门槛 我们身处的真实世界,是一个立体的、可自由探索和交互的3D空间,但我们缺乏“记录”这个立体世界的方法。2D的照片只能记录单一视角信息,2.5D的视频可记录连续视角信息,但无法以新视角回看,也无法编辑空间。 元象3D拍摄提供了一种更高维度的“记录”方法,不再有视角和交互方式限制,你能以任意视角回看和漫游,并进一步编辑,创造专属于你的3D空间。 |
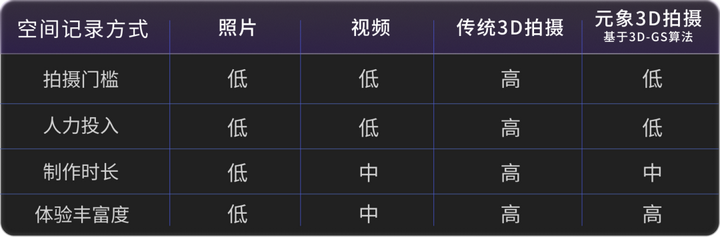
|
|
不同记录方式优劣势对比 多端呈现 降低消费门槛 借助元象自研“端云协同”3D互动技术,3D拍摄内容可在任意终端上打开。小到一个房间,大到整个城市,都能以小程序或H5形式,在手机、PC、VR头显等多类终端上体验和分享。 |

|
|
移动端:手机扫码 即刻体验 PC端:元象“端云协同”引擎支持PC端即开即用。 兼容虚幻引擎实时渲染,可供游戏或泛3D内容开发者打包发布为exe或录制视频。在线体验链接:https://uat-h5.xverse.cn/3DGS/dev/3DGS/check.html Windows可执行程序下载链接:https://github.com/xverse-engine/XV3DGS-UEPlugin/releases/download/v1.0.0/pack_win_exe.zip VR或MR端:元象插件未来将支持直接打包生产VR/MR应用,敬请期待。 开发者可免费下载使用该插件,元象也为企业客户提供3D拍摄一站式定制服务。欢迎洽谈。 |

|
|
3D拍摄技术发展史 1. 经典传统方法 - Photogrammetry工作流 传统3D拍摄方法被称为Photogrammetry工作流,它的输入是一系列照片,输出是一系列点云或3D模型信息,利用三维重建方式,为场景中的每个模型建模,再通过资产清理、减面、重拓扑、重烘焙等一系列工序生成标准PBR模型资产,最后在3D引擎中重新搭建场景。 |

|
|
|
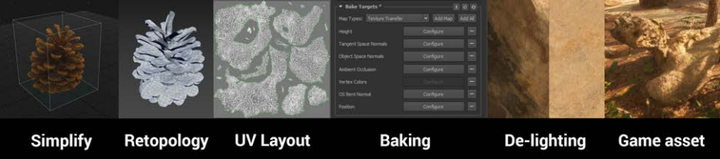
|
|
Photogrammetry工作流 该方法历经多年发展,在《FIFA》、《刺客信条》等3A大作中广泛应用,对自然界常见资产也有成熟资产库,但其资产制作和摆放大量依靠人工,难以自动化,人力成本高。根据场景大小和材质不同要求,单个场景可能需要数周或数月人力。 2. 新视角合成算法 - NeRF 新视角合成算法(Novel View Synthesis)只关心如何生成新视角图像,无需重建模型,从而推动了3D自动化生成。 其早期代表DIBR(Depth Image based Rendering),基于深度图和Warping变换合成新视角,渲染效率尚可,但场景构建成本高,效果易出现瑕疵。 |

|
|
DIBR合成示意 2020年在ECCV会议上横空出世的NeRF(Neural Radiance Field,神经辐射场渲染)带来了颠覆性变革。它利用多层感知机(Multi-layer Perceptron,简称MLP)学习整个场景的辐射场分布,并采用独特可微体渲染机制,实现了2D图像的MLP监督,不仅极大降低场景构建成本,还实现照片级渲染品质,一定程度上解决了画质问题。 |
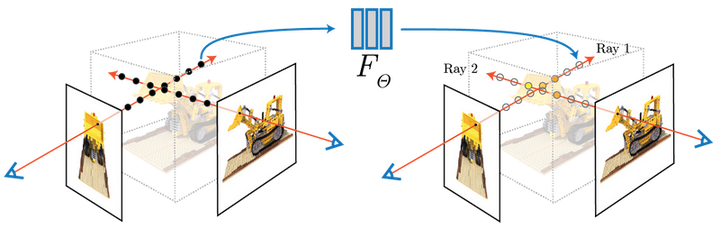
|
|
NeRF工作原理 NeRF掀起了三维重建与新视角合成算法的研究热潮,如Mip-NeRF增强了抗锯齿处理,提升渲染品质。Instant-NGP和Plenoxel仅少量牺牲重建品质,就实现了更高效表示和训练加速。但始终没有一个方案,能兼顾渲染质量和渲染/训练速度。 3. 新视角合成算法 - 3D-GS 3D-GS让其成为可能。 它来自图形学顶级会议SIGGRAPH 2023的五篇最佳论文之一,通过从2D图像样本中学得3D场景表示,实现了接近照片级别精度的实时渲染,一步解决渲染画质和效率两大难题。 3D-GS采用显式点云表示,其渲染过程类似于计算机图形学中的光栅化管线,但使用高斯点(或简单理解为椭圆体)进行光栅化,密度(半透明度)峰值位于中心。随着远离中心的增加,密度逐渐减小,呈现出类似高斯分布效果。多个高斯点使用EWA Volume Splatting算法渲染(见下图)。 |
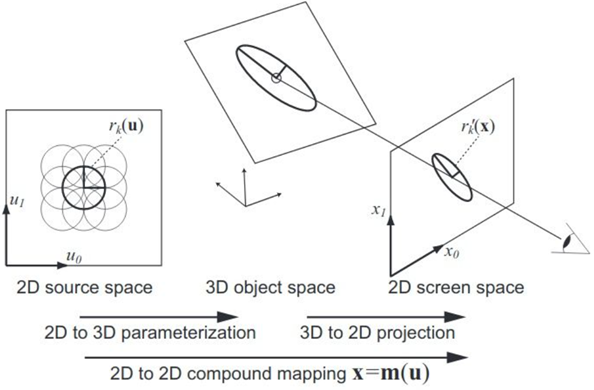
|
|
当高斯点数量增加到百万级别,一个精致3D场景初步显现。 |

|
|
700万个高斯点表示的场景 在场景构建和优化过程中,3D-GS巧妙利用预处理数据(计算输入图像位姿,SFM过程)时生成的稀疏点云作为场景初始化表示,结合其高效的可微瓦片渲染(Tiled-based Rendering),实现快速优化。场景构建和优化完成,3D-GS即可对场景进行高质量和实时渲染。 |
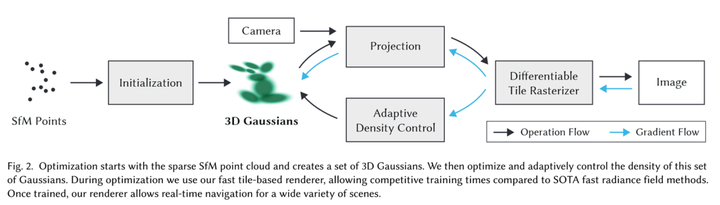
|
|
3D-GS优化流程图元象3D拍摄工作流 基于3D-GS算法,元象搭建了全新3D拍摄工作流,包括三大部分。 |

|
|
输入:用户拍摄的场景视频 输出:重建的3D-GS模型 现有挑战使用门槛很高:原始算法无成熟软件包,用户难以直接使用。 算法不成熟:原始算法重建成功率低,显存占用率高,不支持大场景等。 元象提供两种方案降低生产门槛:云重建方案:元象将3D拍摄算法整体自动化。用户只需使用3D拍摄服务上传拍好的场景视频或照片,AI算法自动完成3D空间构建。该方案对小白用户非常友好,他们无需了解算法细节,只需关注输入和输出。相关AI训练服务API将在未来逐步开放。 本地重建方案:元象也提供基于Windows的本地重建工具,开放多组算法参数和不同场景下的较优预设组,方便用户根据不同场景需求定制3D拍摄方案。要求用户具有较强性能的本地运行环境(如NVIDIA独立显卡)。该工具也将在未来逐步开放。 两种方案生产的3D拍摄资产都可以直接用于后续工作流。 元象三大算法优化:提升算法鲁棒性:原始算法从拍摄到重建都有不小的失败率,在高分辨率图像上易发生崩溃。元象优化了重建中最易导致失败的SFM流程(Structure-from-motion),融合最新、最稳定的SFM算法,排查和修复了其他导致问题的Bug,整体提高了生成成功率。元象还提供标准拍摄指南文档,从源头规避风险,未来计划推出拍摄APP彻底解决该问题。 降低算法性能要求:原始算法要求24GB以上显存运行,消费级显卡门槛为4090。元象对算法管线进行深度工程优化,仅需8GB显存即可运行,常见的NVIDIA 30、40或少量20系列即可使用本地3D拍摄方案。 适配超大规模场景:算法未适配超大规模场景生成,元象通过算法拓展性优化,使其实能在超大场景中适应性地学习整体表示、并支持自动分块与合并。在降低算法性能要求基础上,计算消耗仅为少量增加,而非原本的成倍增加,而非原本的成倍增加,从而实现记录超大场景。 |

|
|
输入:重建的3D-GS模型 + 新的视角(相机位置) 输出:新视角对应的图像 现有挑战原始算法无法保证实时稳定性:场景越大、渲染速度越慢,无法保证稳定的实时渲染。 原始算法只支持在Cuda PC上运行,不支持移动端、VR等多终端运行。 元象两大算法优化: 保证算法实时渲染:为实现各种场景实时渲染,元象引入LOD(Level of Detail )机制对场景进行八叉树划分。在预处理阶段,对划分后每个节点中的3D-GS点云合并,生成多级LOD。在运行时,通过相机距离和屏占比,结合八叉树信息,筛选出合适层级的LOD点云渲染。通过限制每一帧渲染的点云数量上限,保证渲染帧率稳定,即使针对超大规模航拍场景也能保证稳定实时渲染。 |

|
|
大场景航拍实时渲染 2. 支持多端呈现 移动端:提供自动化工具,将3D拍摄资产无缝接入元象“端云协同”管线,无需在意场景大小或终端性能,可将精美的超大场景通过小程序/H5形式在任何手机上打开。PC端:首先可通过元象端云协同引擎技术在PC网页端即开即用。我们也兼容了在虚幻引擎(Unreal Engine)中进行实时渲染,通过混合编辑插件在虚幻引擎中导入3D拍摄资产,实现在虚幻引擎中实时渲染,也可打包为可执行文件(如exe),即开即用。若需产出视频,可简单通过录屏软件直接录制,或使用虚幻引擎Sequencer渲染高质量视频。VR或MR端:元象未来将支持直接打包生产VR/MR应用,敬请期待。 |

|
|
现有挑战 原始算法不支持混合编辑。混合编辑需要在重建的3D-GS模型上,叠加新的3D内容,如虚拟角色、动画、灯光、特效及运镜等。这要在保证呈现端性能的同时,进一步引入图形渲染引擎能力。 元象混合编辑插件多项功能 基于虚幻引擎(Unreal Engine)研发,适配常见开发习惯,让开发者能趁手、随心改造3D空间,满足多样化场景需求。目前基础功能已开放,更多进阶功能和特效模板将持续迭代。 可以像传统美术资产一样旋转、平移、缩放: |
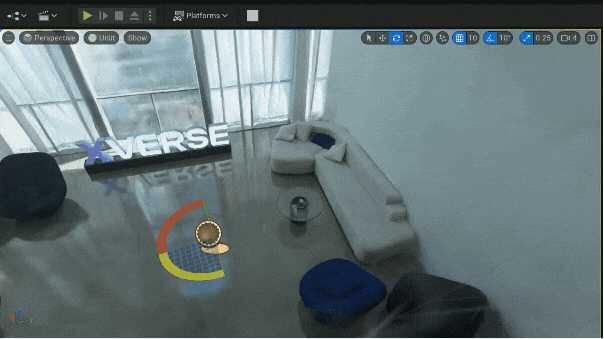
|
|
可以裁剪掉不想要的部分: |
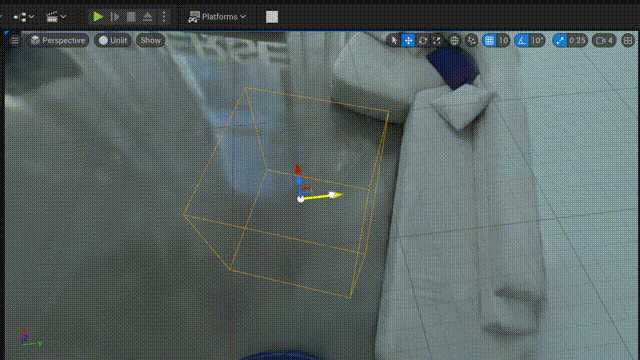
|
|
支持整体后处理,比如整体颜色调整: |

|
|
支持重新打光: |
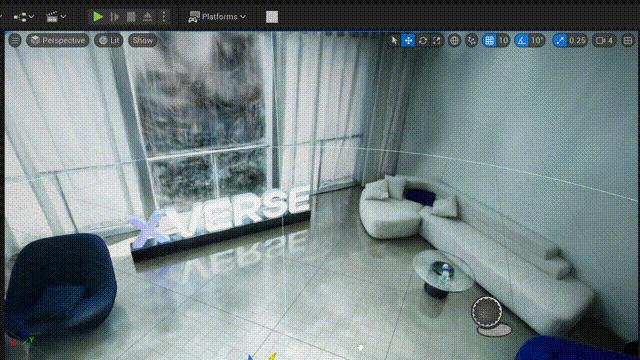
|
|
插件基于虚幻引擎粒子特效系统Niagara开发,可在场景上便捷开发新特效,元象也提供多个现成特效模板,可一键选用,如下是破碎和燃烧特效示例: |

|
|
|

|
|
未来展望 尽管已经实现了“王炸”效果,3D拍摄算法依然面临一些挑战。在生产端,算法处理弱纹理、透明度和动态物体方面仍显得相对薄弱;在呈现端,全平台支持尚未完全实现;在混合编辑上,对进一步编辑、去光、重新照明等细节处理相关的算法还需要深入研究。 引用 [1]https://unity3d.com/files/solutions/photogrammetry/Unity-Photogrammetry-Workflow_2017-07_v2.pdf [2]Quixel Megascans:https://quixel.com/megascans/ [3]Jonathan T. Barron, Ben Mildenhall, Matthew Tancik, Peter Hedman, Ricardo Martin-Brualla, and Pratul P. Srinivasan. Mip-nerf: A multiscale representation for anti-aliasing neural radiance fields. arXiv: Computer Vision and Pattern Recognition, 2021. [4]Thomas Müller, Alex Evans, Christoph Schied, and Alexander Keller. 2022. Instant Neural Graphics Primitives with a Multiresolution Hash Encoding. ACM Trans. Graph. 41, 4, Article 102 (July 2022), 15 pages. https://doi.org/10.1145/3528223. 3530127 [5]Alex Yu, Sara Fridovich-Keil, Matthew Tancik, Qin-hong Chen, Benjamin Recht, and Angjoo Kanazawa. Plenoxels: Radiance fields without neural networks. arXiv preprint arXiv:2112.05131, 2021. [6] Kerbl B, Kopanas G, Leimkühler T, et al. 3d gaussian splatting for real-time radiance field rendering[J]. ACM Transactions on Graphics (ToG), 2023, 42(4): 1-14. [7]Ben Mildenhall, Pratul P. Srinivasan, Matthew Tancik, Jonathan T. Barron, Ravi Ramamoorthi, and Ren Ng. NeRF: Representing scenes as neural radiance fields for view synthesis. ECCV, 2020. [8] EWA Volume Splatting |
|
0. 笔者个人体会 3D GS在NeRF领域已经掀起了一股浪潮,然后又很快席卷到了SLAM领域,最近已经看到很多3D GS和SLAM结合的开源工作了。 今天笔者将为大家分享帝国理工学院戴森机器人实验最新开源的方案Gaussian Splatting SLAM,这也是第一个将3D GS应用到增量3D重建的工作,速度为3 FPS。 下面一起来阅读一下这项工作,文末附论文和代码链接~ 1. 效果展示 Gaussian Splatting SLAM以3 FPS实时重建高保真3D场景。对于每帧RGB图像,增量地构建3D高斯曲线,并联合优化相机位姿。左图是光栅化的高斯,右图是阴影化的高斯。特别注意,电线这样的细结构还有透明物体,甚至都可以用高斯线表示出来。 |

|
|
可以看一下具体的重建效果,这个精度还是很高的。 |

|
|
其他的定性重建效果,渲染质量非常高了。 |

|
|
2. 具体原理是什么? Gaussian Splatting SLAM首先使用针对3D高斯的直接优化来公式化3DGS的相机跟踪,实现具有大范围收敛的快速和鲁棒的跟踪。然后利用高斯分布的明确性质,引入几何验证和正则化来处理增量3D稠密重建中出现的模糊性。 整个SLAM系统使用3D高斯作为唯一表示,统一了SLAM的所有组件,包括跟踪、建图、关键帧管理和新视图合成。 |
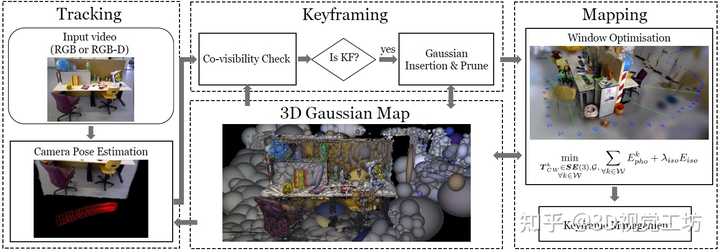
|
|
3. 和其他SOTA方法对比如何? TUM数据集上的定位精度对比,精度比其他NeRF SLAM高。但由于没有回环,Gaussian Splatting SLAM定位精度还是不如ORB-SLAM2,不知道加上回环效果如何。 |
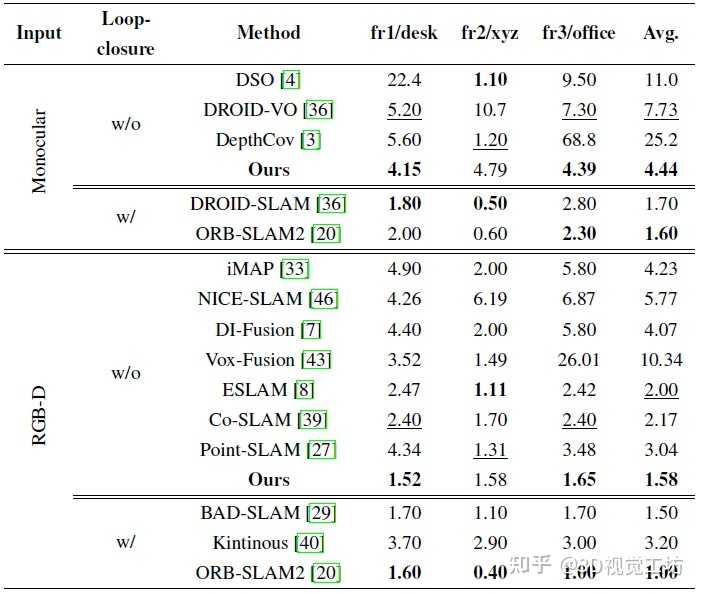
|
|
建图渲染的定量对比,这个速度真的快。 |
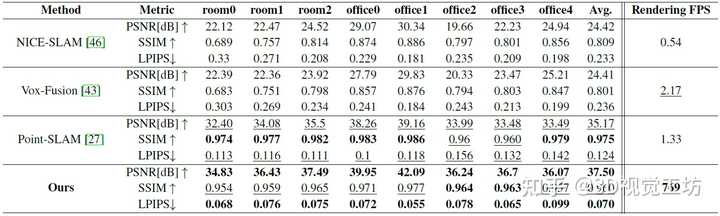
|
|
对更多实验结果和文章细节感兴趣的读者,可以阅读一下论文原文~ |
|
正在尝试将该技术与游戏结合起来~ |
|
3D场景编辑通过文本直接修改场景建模,广泛用于VR/AR、3D建图、游戏建模等应用。但传统的3D编辑方法依赖网格和点云,很难描绘复杂场景,NeRF方案渲染质量高但是速度很慢。最近3D Gaussian Splatting可谓大火,极大提高了NeRF的渲染速度,目前还在不停地刷新各大任务。感兴趣的读者可以抓紧探索3D Gaussian Splatting在其他CV任务上的应用,目前仍有很大研究空间。 原文链接:Gaussian Splatting杀疯了!最新开源的超强3D场景编辑! |

|
|
|

|
|
|

|
|
|

|
|
工业3D视觉(结构光、缺陷检测、三维点云)、SLAM(视觉/激光SLAM)、自动驾驶、三维重建、事件相机、无人机等近千余篇最新顶会论文 |
|
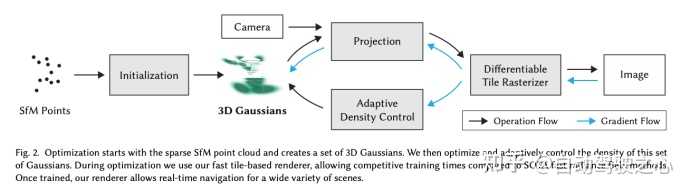
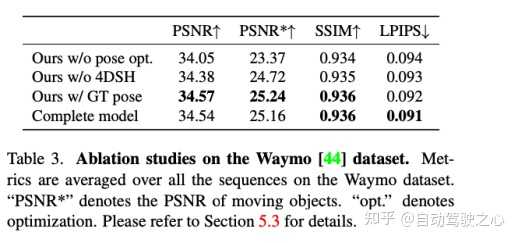
Street Gaussians的动机在自动驾驶领域,动态街景重建有着重要的应用场景,比如数据生成、自动标注、闭环仿真等。由于对重建质量和效率有较高的要求,这方面的技术仍旧临着巨大的挑战。对于单目视频建模动态城市街景的问题,近期方法主要是基于NeRF并结合跟踪车辆的姿态,从而重建出高真实感的视图。然而训练和渲染速度慢、对跟踪车辆姿态精度需求高,使其在很难真正被应用起来。我们提出了Street Gaussians,这是一种新的显式场景表示方法,可以解决所有这些限制。关注知乎@自动驾驶之心,第一时间获取自动驾驶感知/定位/融合/规控等行业最新内容 开源链接: Street Gaussians for Modeling Dynamic Urban Sceneshttps://zju3dv.github.io/street_gaussians/方法简介在Street Gaussians中,动态城市街道被表示为一组3D高斯的点云,每个点云与前景车辆或背景之一相关联。为了模拟动态前景物体车辆,每个物体模型都用可优化的跟踪姿态进行建模,并配有动态球谐函数模型来表现动态外观。这种显式表示可以轻松地组合物体车辆和背景,进而允许进行场景编辑操作。同时拥有极高的效率,可以在半小时完成训练,渲染速度达到133FPS(1066x1600分辨率)。实验表明,Street Gaussians在所有数据集上优于现阶段SOTA方法。此外,提出了前景目标位姿优化策略(初始位姿来自跟踪器),与使用真值姿态所达到性能相当,也验证了Street Gaussians的高鲁棒性。背景介绍静态场景建模 ?基于场景表达的不同,我们可以将场景重建分为volume-based和point-based。volume-based的方法,用MLP网络表示连续的体积场景,已经取得了令人印象深刻的渲染结果。同时比如Mip-NeRF360、DNMP等也将其应用场景扩展到了城市街景 。point-based的方法,在点云上定义学习神经描述符,并使用神经渲染器执行可微分的光栅化,大大可以提高了渲染效率。然而,它们需要密集的点云作为输入,并在点云稀疏区域的结果相对模糊。最近的一项工作3D Gaussian Splatting (3D GS),在3D世界中定义了一组各向异性的高斯核,并执行自适应密度控制,以仅使用稀疏的点云输入实现高质量的渲染结果。我们可以把3DGS理解成介于volume-based和point-based的中间态,所有同时拥有volume-based方法的高质量,也拥有point-based方法的高效率。然而,3DGS假定场景是静态的,不能模拟动态移动的对象。 动态场景建模。 ?可以从不同的角度来实现动态场景建模,从目标角度,可以在单个对象场景上构建4D神经场景表示(比如HyperReel ),从场景角度,可以通过在光流(如Suds)或视觉变换器特征(Emernerf )监督下的实现场景解耦。然而,这些方法均无法对场景进行进行编辑,限制了其在自动驾驶仿真中的应用。还有一种方式,使用神经场将场景建模为移动对象模型和背景模型的组合(比如NSG、Panoptic Neural Fields),然而,它们需要精确的对象轨迹,并且在内存成本和渲染速度上存在问题。 算法建模考虑到自动驾驶场景中都是通过车载相机得到图像序列,我们希望构建一个模型,可以生成任意时间和视角的高质量图像。为实现这一目标,我们提出了一种新颖的场景表示,命名为"Street Gaussians"。如图所示,我们将动态城市街景表示为一组点云,每个点云对应于静态背景或移动车辆。这种基于点的表示可以轻松组合多个独立的模型,实现实时渲染以及解耦前景对象以实现场景编辑。我们提出的场景表示可以仅使用RGB图像进行训练,同时结合车辆位姿优化策略,进一步增强动态前景的表示精度。 |
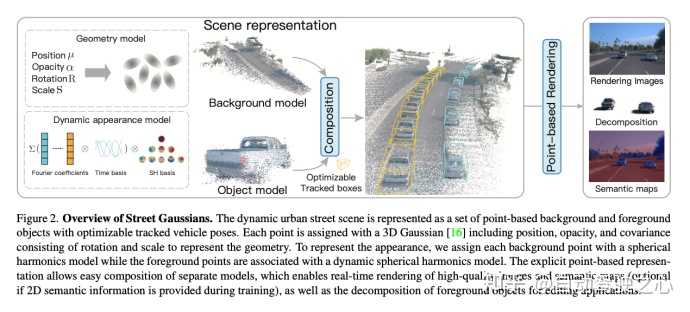
|
|
静态背景建模针对静态背景,使用基本的3DGS方式建模,即我们世界坐标系中一组点来表示背景模型,每个点分配有一个3D高斯分布,以平滑地表示连续的场景几何和颜色。高斯参数包括协方差矩阵和位置向量(表示均值)。与3DGS一样,为了避免在优化过程中出现无效的协方差矩阵,每个协方差矩阵进一步缩减为缩放矩阵和旋转矩阵,其中缩放矩阵由其对角元素表征,而旋转矩阵被转换为单位四元数。除了位置和协方差矩阵之外,每个高斯分布还分配有一个不透明度值和一组球谐系数来表示场景几何和外观。为了获得视图相关的颜色,球谐系数还会乘以从视图方向投影的球谐基函数。为了表示3D语义信息,每个点还附加有一个语义特征。 |
|
|
动态前景建模针对包含多辆移动前景物体车辆的场景,我们将每个对象用一组可优化的姿势(初始位姿可以来自某个跟踪器,比如CasTracker)和一组点云表示,其中每个点分配有一个3D高斯分布、语义和动态外观模型。前景对象和背景的高斯属性相似,不透明度和尺度矩阵的定义相同,然而它们的位置、旋转和外观模型均不同。每一个前景对象的3DGS模型,定义在该对象的local坐标系下。我们通过前景对象的RT矩阵,可以将前景对象和背景的模型统一到世界坐标系下。仅使用球谐系数简单表示物体外观不足以模拟移动车辆的外观,如图所示,因为移动车辆的外观受到其在全局场景中位置的影响。如果使用单独的球谐来表示每个时间的对象,会显著增加存储成本,我们的解决方案是引入了4D球谐模型,通过用一组傅里叶变换系数来表示球谐系数,当给定任意时间t,可以通过逆傅立叶变换来求出对应的球谐系数。基于这种方式,我们将时间信息编码到外观中,而且不增加额外存储成本。 |

|
|
渲染过程要渲染Street Gaussians,我们就需要聚合每个模型对最终结果的贡献。以前的方法中,由于神经场表示方式,需要复杂的raymarching 方式进行组合渲染。相反,Street Gaussians可以通过将所有点云拼接起来,并将它们投影到2D图像空间来进行渲染。具体来说,在给定渲染时间点的情况下,我们首先计算球谐系数,并根据跟踪的车辆姿态将前景对象点云转换到世界坐标系,然后将背景点云和变换后的前景对象点云拼接起来形成一个新的全场景点云。效果评估我们在Waymo和KITTI数据集上都进行了实验来评估我们的方法合成新视角的能力,不论定性和定量结果表明,相比之前的工作,我们的方法可以渲染出渲染高质量图片,并在各项指标上均有有显著提升。 ?下图是从定性角度,分别在waymo和kitti数据集上对比目前已有方法,无论背景还是前景目标,我们的方法在细节的渲染上均有大幅提高。 |

|
|
|

|
|
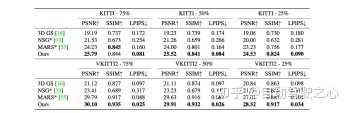
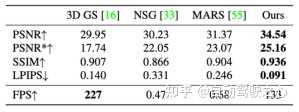
?同时我们在kitti和waymo上定量对比了重建指标,我们的方法也大幅领先已有方法。 |
|
|
KITTI数据集 |
|
|
Waymo数据集下游任务Street Gaussians可以被应用到很多下游任务当中,包括场景的前背景解耦、场景的可控编辑、语义分割等。丰富且高质量的下游任务适配,大大提高了Street Gaussians的应用上限。 ?我们的模型可以实现场景前背景解耦,细节上相比之前的方法有明显提升。 |

|
|
?我们的模型支持便捷的场景编辑,如下图分别是车辆增加、替换和交换的编辑操作。 |

|
|
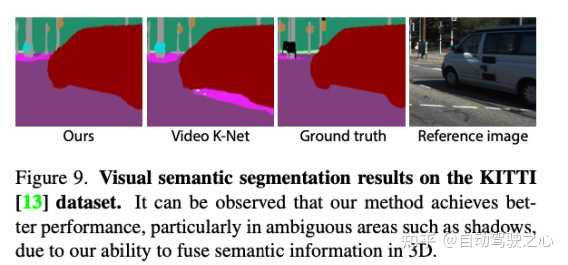
?我们的模型还支持拓展到语义分割任务,依靠我们的建模方式,我们对于前景目标的分割更加细腻。 |
|
|
方法总结我们提出来了Street Gaussians,这是一种新颖的用于建模复杂的动态街道场景的表征方法,它能够高效地重建和渲染出高保真度的城市街道场景,并且支持实时渲染。我们开发了一种优化跟踪姿态的策略,配合一个4D球谐函数模型外观模型来处理移动前景的动态车辆。我们在几个具有挑战性的数据集上进行了全面的比较和消融实验,展示了我们方法的最新最先进性能以及所提出组件的有效性。 |
|
|
|
|
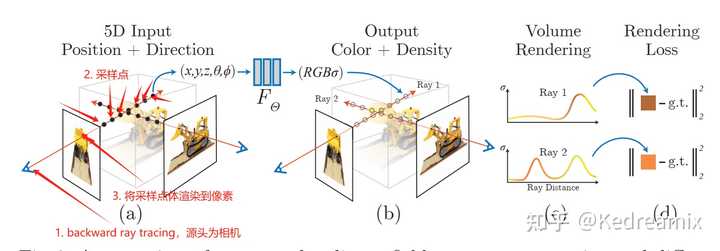
今天想介绍的是ZJU带来的3DGS的首篇综述A Survey on 3D Gaussian Splatting 这是论文链接 arXiv:2401.03890,结合一些资料,趁这个机会好好学习一下3DGS,加油入坑!!! 首先说一些自己的理解,3DGS之所以爆火,很大程度在于他的实时性,而这一部分极大程度得益于他定制的算法与自定义 CUDA 内核。除此之外,Gaussian Splatting根本不涉及任何神经网络,甚至没有一个小型的 MLP,也没有什么 "神经"的东西,场景本质上只是空间中的一组点。在大家都在研究数十亿个参数组成的模型的人工智能世界里,这种方法越来越受欢迎,令人耳目一新。它的想法源于 "Surface splatting"(2001 年),说明经典的计算机视觉方法仍然可以激发相关的解决方案。它简单明了的表述方式使Gaussian Splatting特别容易解释,这也是为什么在某些应用中选择它而不是 NeRFs。 我也在不断的学习3DGS,做了一个知识库,大家也可以多多关注,我会不断的更新: 引言 INTRODUCTION NeRF自从2020年开始,在多视角合成中做出来巨大的贡献,他利用神经网络,实现了空间坐标到颜色和密度的映射的,然NeRF的方法是计算密集型的,通常需要大量的训练时间和大量的渲染资源,特别是高分辨率的输出。 |
|
|
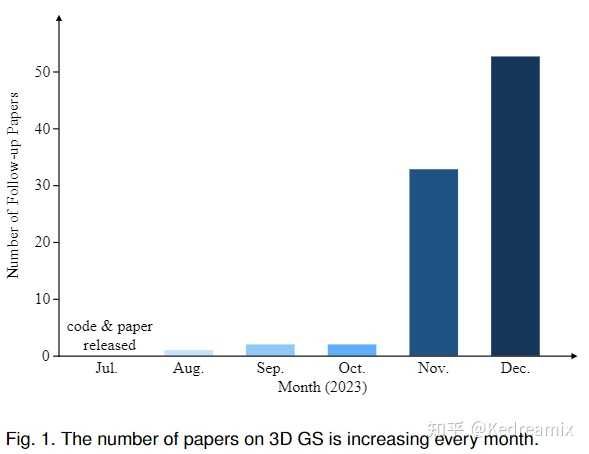
NeRF 针对这些问题,3DGS出现了,3DGS 采用显式表示和高度并行的工作流程,有利于更高效的计算和渲染,其创新在于其独特地融合了可微分管道和基于点的渲染技术的优点,通过用可学习的 3D 高斯函数表示场景,保留了连续体积辐射场的理想特性,这对于高质量图像合成至关重要,同时避免了与空白空间渲染相关的计算开销,这是传统 NeRF 方法的常见缺点,而3DGS很好的解决了这个问题,在不影响视觉质量的情况下达到了实时渲染。 论文中也发现,自3DGS出现以来,2023年有很多的论文在arXiv中挂出来,所以基于此也写了这样一个综述,同时促进3DGS领域的进一步研究和创新 |
|
|
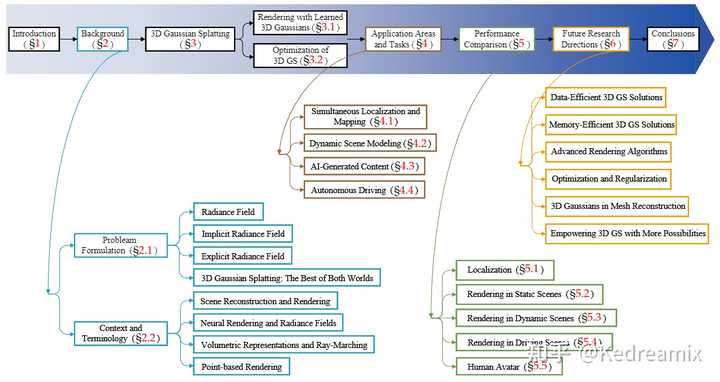
The number of papers on 3D GS is increasing every month. 以下是论文架构的图,论文的大概架构如下所示,可以看到这篇综述撰写的一个逻辑,还是非常好的,接下来,我会顺着这个架构进行解读论文来学习 第2部分:主要是一些问题描述和相关研究领域的一些简要的背景第3部分:介绍3DGS,包括3DGS的多视角的合成和3DGS的优化第4部分:3DGS 产生重大影响的各种应用领域和任务,展示了其多功能性第5部分:对3DGS进行了一些比较和分析第6、7部分:对一些未来的开放性工作进行总结和调查 |
|
|
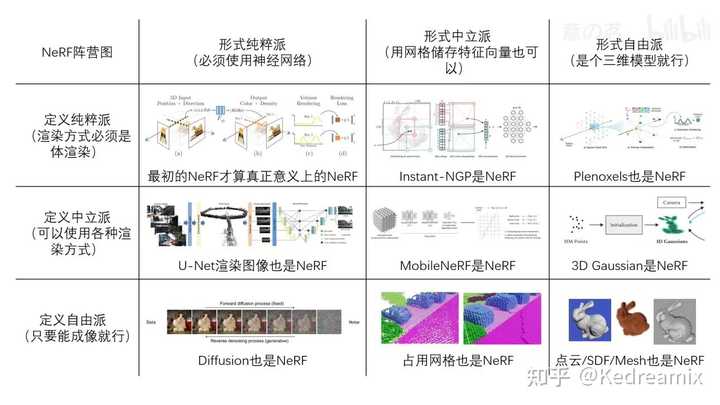
Structure of the overall review. 背景 BACKGROUND 背景主要分两部分讲解 辐射场的概念:隐式和显式有关辐射场的场景重建、渲染等领域相关介绍问题定义辐射场 辐射场是实际上是对三维空间中光分布的表示,它捕捉了光与环境中的表面和材质相互作用的方式。从数学上来说,辐射场可被描述为一个函数$L:\mathbb{R}^5\to\mathbb{R}^+$, 其中$L(x,y,z,\theta,\psi)$将点$(x,y,z)$和球坐标下的方向$(\theta,\phi)$映射为非负的辐射值。辐射场有显示表达和隐式表达,可用于场景表示和渲染。 隐式辐射场 隐式辐射场是辐射场中的一种,在表示场景中的光分布时,不需显式定义场景的集合形状。这里面最常见的就是NeRF,使用神经网络来学习连续的体积表示。在NeRF中,使用MLP 网络用于将一组空间坐标 $(x, y, z)$ 和观察方向 $(\theta,\phi)$ 映射到颜色和密度值。任何点处的辐射不是显式存储的,而是通过查询神经网络实时计算得出。因此,该函数可以写成: L_\text{implicit}(x,y,z,\theta,\phi)=\text{NeuralNetwork}(x,y,z,\theta,\phi) 这种方式的好处是构建了一个可微且紧凑的复杂场景,但是由于我们总是需要对光线进行采样和体渲染的计算,会导致计算负载比较高。 显式辐射场 与隐式不同的是,显示是直接表示光在离散空间结构中的分布,比如体素网格或点云。该结构中的每个元素都存储了其在空间中相应位置的辐射信息,而不是像NeRF一样去执行查询的操作,所以他会更直接也更快的得到每个值,但是同时也需要更大内存使用和导致较低的分辨率。通常我们可以表示为: L_\text{explicit}{ ( x , y , z , \theta , \phi ) }=\text{DataStructure}[(x,y,z)]\cdot f(\theta,\phi) 其中,DataStructure可以是网格或点云,而$f(θ, ?)$是一个根据观察视线方向修改辐射的函数。 3D Gaussian Splatting (两全其美) 3DGS通过利用3D 高斯函数作为其表示形式,充分利用了显示辐射场和隐式辐射场的优势。这些高斯函数被优化用于准确表示场景,结合了基于神经网络的优化和显式结构化数据存储的优点。这种混合方法能进行高质量渲染,同时具有更快的训练和实时性能,3D高斯表达可表示为: L_{\mathrm{3DGS}}(x,y,z,\theta,\phi)=\sum_{i}G(x,y,z,\mu_{i},\Sigma_{i})\cdot c_{i}(\theta,\phi) 其中 $G$ 是具有平均值 $μ_i$ 和协方差 $Σ_i$ 的高斯函数,$c$ 表示与视图相关的颜色。 显式与隐式的理解 这里放一张理解显示隐式图像的图片,我还是觉得相当不错的 |
|
|
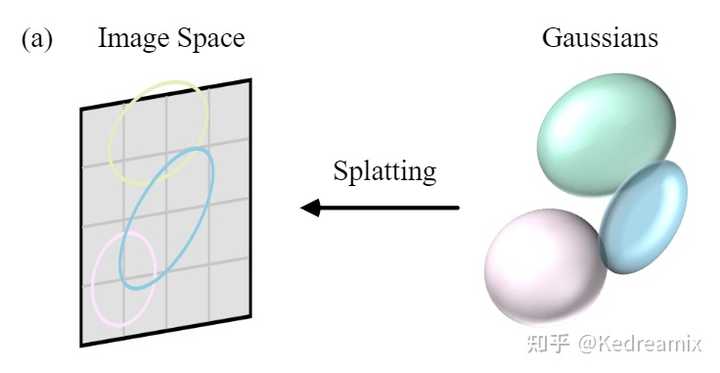
显式隐式表达 背景和术语 许多技术和研究学科与 3DGS 有着密切的关系,以下各节将对此进行简要介绍。 场景重建与渲染 场景重建:从一组图像集合或其它数据建立场景的三维模型。 渲染:将计算机可读取的信息(如场景中的3D物体)转化为图像。 早期技术基于光场生成逼真的图像,运动结构(SfM)与多视图立体匹配(MVS)算法通过从图像序列估计3D结构来增强光场。 神经渲染和辐射场 神经渲染:将深度学习与传统图形技术结合生成逼真的图像。早期方法使用CNN估计混合权重或纹理空间解决方案。 辐射场:一种函数表达,描述从各方向穿过空间各点的光的量。NeRF使用神经网络建模辐射场。 体积表示和光线行进 体积表达:不仅将物体和场景建模为表面,还将其其建模为充满材料或空白空间的体积。这样可以对如雾、烟或半透明材料进行更精确的渲染。 光线行进:是体积表达渲染图像的技术,通过增量跟踪穿过“体”的光线来渲染图像。NeRF引入重要性采样和位置编码增强合成图像的质量,虽然能得到高质量的图像,但这一方法计算量大。 基于点的渲染 基于点的渲染是一种使用点而非传统多边形来可视化3D场景的技术。该方法特别适用于渲染复杂、非结构化或稀疏的几何数据。点可以通过添加额外属性,如可学习的神经描述符来进行增强,并且可以高效地进行渲染,但这种方法可能会出现渲染中的空洞或混叠效应等问题。3DGS通过使用各向异性高斯进行更连贯的场景表达。 用于显式辐射场的3DGS 3DGS能够实时渲染高分辨率的图像,并且不需要神经网络,是一个突破。 这一块主要围绕两块进行讲解 3DGS的前向过程3DGS的优化过程学习3D高斯函数进行新视角合成 假如现在有一个场景,目的是生成特定视角下的相机图像。NeRF对每一个像素使用光线行进和采样点,影响其实时性;而3DGS将3D高斯投影到图像平面,称为“泼溅”,如下图所示。然后对高斯进行排序并计算每个像素的值。NeRF和3DGS的渲染可视为互逆关系。 |
|
|
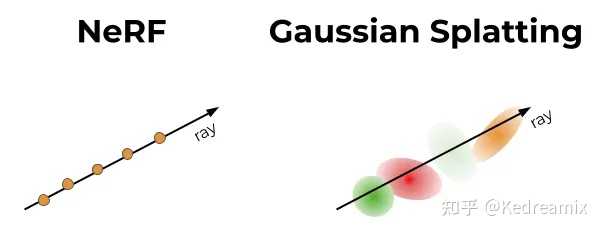
3DGS的Splatting 泼溅 这里面有个点很有意思,为什么说是互逆关系,我参考了知乎的一篇文章3D Gaussian Splatting中的数学推导的说明,我觉得这个说的还不错。 首先,我们回忆一下体渲染的这个事情。假设读者跟我一样是从NeRF才接触体渲染的,那么回顾一下NeRF中,沿着一个像素,发出一条射线,然后这条射线“射向体数据”(在NeRF里就是沿着光线进行采样,然后查询采样点的属性)的过程。这个过程可以归结为一种backward mapping。 所以很自然的,会有一种forward mapping的办法。形式上,就是将整个“体数据”投影到此时位姿所对应的图像平面。这种办法的前提就不能是用NeRF那种隐式表达了,需要一些显式的表达才能支持这样直接的投影。例如以三个顶点长成的三角面基元(primitive),然后将这些许多的三角面直接投影到成像平面上,判断哪些像素是什么颜色,当有多个三角形投影时,根据他们的“深度”来判断前后顺序,然后进行熟悉的alpha compositing。当然也会有其他基元,例如小的平面表示等等。 无论是backward mapping还是forward mapping,这个过程都涉及到将连续的表示变成离散的。在backward mapping里,是对场进行采样;在forward mapping里,是需要直接生成出基元,这也是一种连续化为离散。为了理解在这个过程中,高斯分布为什么重要,我们需要牵扯到信号与系统中的概念。与混过数字信号处理考试不同的是,我们要清楚此时引入信号与系统里的工具的目的是什么。回想刚才三角面基元的情景,在实际情境中,我们其实都接触不到“连续”的表达,比如三角面,我们只会记录它的三个顶点。当投影完成后,我们只能做一些有限的操作来阻止“锯齿”,例如对结果进行一个模糊操作,这些操作一般都是局部的。我们这样做的目的,本质是“希望用离散的表达来重建原来的信号,进一步在重建好的信号上进行“resampling”。如果我们对处理后的结果,视觉上看起来没什么混叠或者锯齿上的问题,那就说明我们“resampling”是成功的。 从下图也可以看到NeRF和Gaussian在概念上的区别,左边是NeRF沿着光线查询连续 MLP,右边是Gaussian一组与给定光线相关的离散的高斯分布 |
|
|
|
|
|
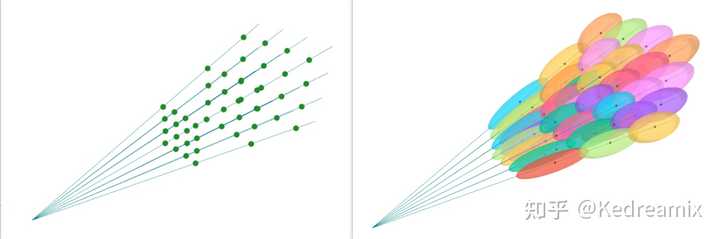
difference between NeRF and Gaussian Splatting 首先简单介绍一下,3DGS是如何表示真实场景的,前面也有提过,在Gaussian Splatting中,3D世界用一组3D点表示,实际上是数百万个,大致在0.5到5百万之间。每个点是一个3D高斯,具有其独特的参数,这些参数是为每个场景拟合的,以便该场景的渲染与已知数据集图像紧密匹配,接下来就介绍他的属性。 |

|
|
Representing a 3D world 3D高斯的属性: 一个3D高斯主要包括,中心(位置)$x,y,z$的均值$μ$、不透明度 $α$、3D 协方差矩阵 $Σ$ 和颜色 $c$(一般是RGB或者是球谐(SH)系数)。 其中$c$与视角有关,$c$ 由球谐函数表示。所有属性均可学习,都可以通过反向传播来学习和优化。 视域剔除:给定特定的相机姿态,该步骤会判断哪些高斯位于相机的视锥外,并在后续步骤中剔除之,以节省计算。 Splatting泼溅:实际上只是3D高斯(椭圆体)投影到2D图像空间(椭圆)中进行渲染。给定视图变换 $W$ 和3D协方差矩阵$\Sigma$,我们可以使用使用以下公式计算投影 2D 协方差矩阵 $\Sigma^{\prime}$ \Sigma^{\prime}=JW\Sigma W^\top J^\top 其中 $J$ 为投影变换中仿射近似的雅可比矩阵。 像素渲染:如果不考虑并行,采用最简单的方式:给定像素 $x$ 的位置,与其到所有重叠高斯函数的距离,即这些高斯函数的深度。这些可以通过观察变换 $W$ 计算出来,形成高斯函数的排序列表$N$。然后进行alpha混合,计算该像素的最终颜色: C=\sum_{i\in\mathcal{N}}c_i\alpha_i^{\prime}\prod_{j=1}^{i-1}\left(1-\alpha_j^{\prime}\right.) 其中 $c_i$ 是学习到的颜色,最终的不透明度 $\alpha_i^{\prime}$ 是学习的不透明度 $\alpha_i$ 与高斯的乘积: \alpha_i'=\alpha_i\times\exp\left(-\frac12(x'-\mu_i')^\top\Sigma_i'^{-1}(x'-\mu_i')\right) 其中 $x'$ 和 $μ'_i$ 是投影空间中的坐标,同时我也找了个gif来可视化了一下Gaussian Splatting对位置p的影响: |

|
|
3DGS 如果仔细看的话,我们会发现,实际上这个公式和多变量正态分布的概率密度函数十分相像,是忽略了带有协方差行列式的标准化项,而是用不透明度来加权。 (2\pi)^{-k/2}\det(\boldsymbol{\Sigma})^{-1/2}\exp\biggl(-\frac12(\mathbf{x}-\boldsymbol{\mu})^\mathrm{T}\boldsymbol{\Sigma}^{-1}(\mathbf{x}-\boldsymbol{\mu})\biggr) 不过如果考虑并行的话加快速度,这种列表排序实际上很难并行化,所以很有可能这个渲染程度比NeRF还慢。为了实现实时渲染,3DGS也做了一个tradeoff,3DGS做出了一些让步来适应并行计算。 |
|
|
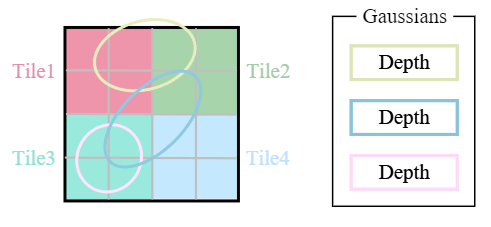
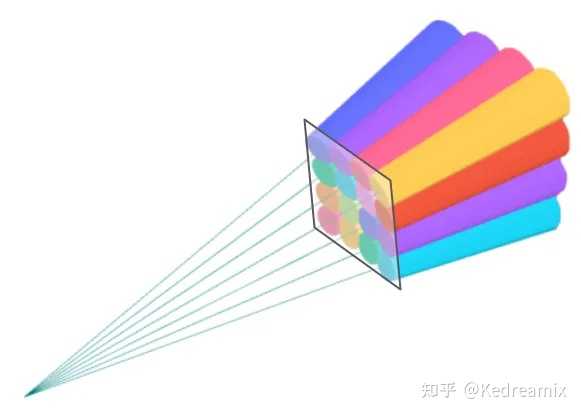
Tiles(Patches) Tiles (Patches):为避免逐像素计算出现的成本,3DGS改为patch级别的渲染。具体来说,首先将图像分割为多个不重叠的patch,称为tile,每个图块包含 16×16 像素,如下图所示。3DGS然后确定tile与投影高斯的相交情况,由于投影高斯可能会与多个tile相交,需要进行复制,并为每个复制体分配相关tile的标识符(如tile的ID)。(不用判断每个像素与高斯的距离,而是判断tile就简单多了) |
|
|
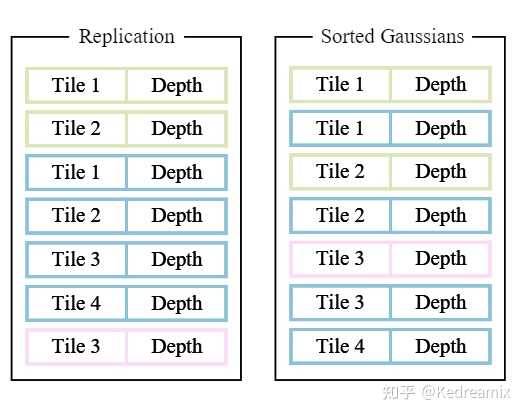
从下图可以看到排序的结果,在排序中,高位是tile的ID,低位就是深度,一起进行排序,下面的图是AI葵视频的结果,还是很好理解的 |
|
|
3DGS排序 |
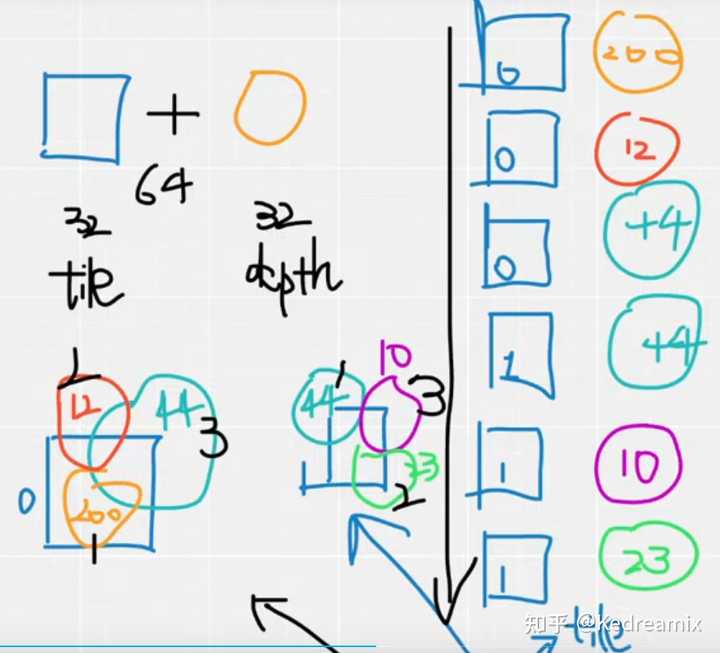
|
|
3DGS排序例子(AI葵) 并行渲染:复制后,3DGS(对应字节的无序列表)结合包含了相关的tile ID(对应字节的高位)和深度信息(对应字节的低位),如上图所示。由于每一块和每一像素的计算是独立的,所以可以基于CUDA编程的块和线程来实现并行计算,同时有利于访问公共共享内存并保持统一的读取顺序。排序后的列表可直接用于渲染(alpha混合),如下图所示。 |

|
|
并行渲染 总的来说,3DGS在前向过程中做出了一些近似计算,以提高计算效率并保留图像合成的高质量。 3DGS的优化 学习到这里,我们可能会有一个问题,怎么可能在空间中的一堆圆球中得到一个像样的图像的,确实是这样,如果没有进行优化,在渲染的时候就会出现很多伪影,从下图你可以看到。 |

|
|
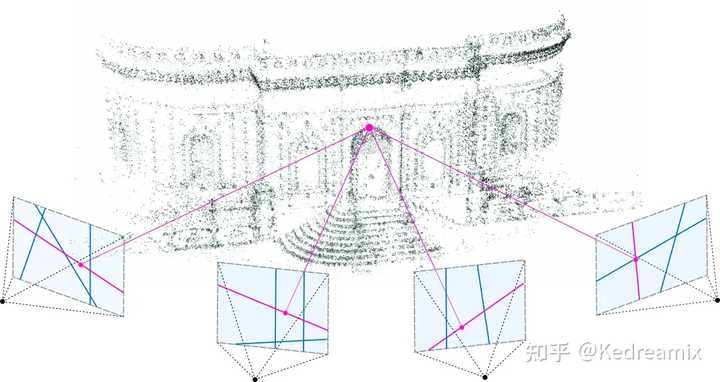
An example of renders of an under-optimized scene 3DGS的核心是3D高斯集合的优化过程。一方面需要通过可微渲染来使高斯符合场景纹理,另一方面表达场景需要的高斯数量是未知的。这分别对应参数优化与密度控制两步,这两步在优化过程中交替进行。优化过程中,需要手动设置很多超参数。 参数优化 Parameter Optimization损失函数:图像合成后,计算渲染图像与真实图像的差异作为损失: \mathcal{L}=(1-\lambda)\mathcal{L}_1+\lambda\mathcal{L}_{D-SSIM} 其中 $λ$ 是权重因子。与 NeRF 的损失函数略有不同,由于光线行进成本高昂,NeRF 通常在像素级别而不是图像级别进行计算,而3DGS是图像级别的。 参数更新:3D高斯的多数参数可通过反向传播直接更新,但对于协方差矩阵 $\Sigma$来说,需要半正定矩阵(这里面是一个定义,应该是多元正态分布的协方差矩阵是一个半正定矩阵),直接优化可能会产生非半正定矩阵,而只有半正定矩阵才有物理意义。因此,改为优化四元数$q$和3D向量$s$。将协方差矩阵分解: \Sigma=RSS^\top R^\top 其中$R$与$S$分别由$q$和$s$推导得到的旋转和缩放矩阵。 $S$是一个对角缩放矩阵,含有3个参数 $R$是一个3x3的旋转矩阵,通过旋转四元数来表示 对于不透明度$α$, 其计算图较为复杂:$(q,s)\to\Sigma\to\Sigma^{\prime}\to\alpha$。为避免自动微分的计算消耗,3DGS还推导了$q$与$s$的梯度,在优化过程中直接计算之。 密度控制 Density Control初始化:3DGS建议从SfM产生的稀疏点云初始化或随机初始化高斯,可以直接调用 COLMAP 库来完成这一步。。然后进行点的密集化和剪枝以控制3D高斯的密度。当由于某种原因无法获得点云时,可以使用随机初始化来代替,但可能会降低最终的重建质量。 |
|
|
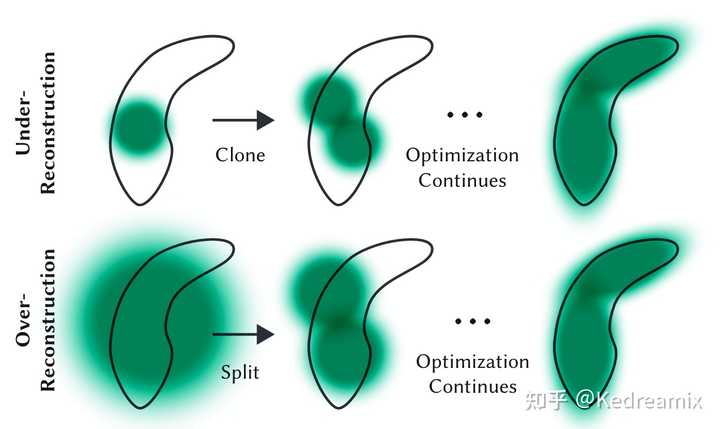
A sparse 3D point cloud produced by SfM, means initialization 点密集化:在点密集化阶段,3DGS自适应地增加高斯的密度,以更好地捕捉场景的细节。该过程特别关注缺失几何特征或高斯过于分散的区域。密集化在一定数量的迭代后执行,比如100个迭代,针对在视图空间中具有较大位置梯度(即超过特定阈值)的高斯。其包括在未充分重建的区域克隆小高斯或在过度重建的区域分裂大高斯。对于克隆,创建高斯的复制体并朝着位置梯度移动。对于分裂,用两个较小的高斯替换一个大高斯,按照特定因子减小它们的尺度。这一步旨在在3D空间中寻求高斯的最佳分布和表示,增强重建的整体质量。 这一部分的意义是什么呢,,因为SGD只能对现有点进行调整,但是在完全没有点或点太多的区域,很难找到好的参数,所以这就是点密集化的作用。 点的剪枝:点的剪枝阶段移除冗余或影响较小的高斯,可以在某种程度上看作是一种正则化过程。一般消除几乎是透明的高斯(α低于指定阈值)和在世界空间或视图空间中过大的高斯。此外,为防止输入相机附近的高斯密度不合理地增加,这些高斯会在固定次数的迭代后将$\alpha$设置为接近0的值。该步骤在保证高斯的精度和有效性的情况下,能节约计算资源。 |
|
|
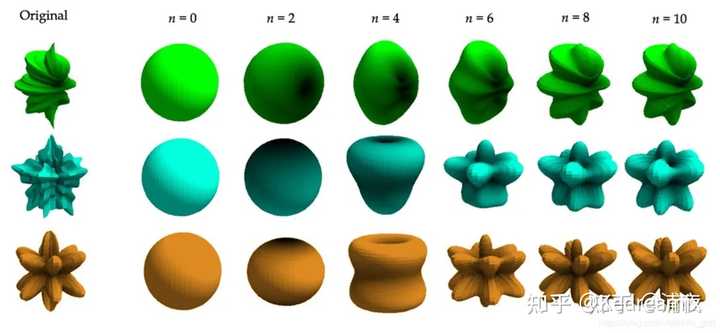
Adaptive Gaussian densification scheme. 用SH系数来表示颜色 在计算机图形学中,用球谐函数(Spherical Harmonics,简称SH)表示视角相关的颜色起着重要作用,最初是在Plenoxels中提出的。他能表示非兰伯特效应,比如金属表面的高光反射。不过这样也不是一定的,实际上也可以使用3个RGB值表示颜色,然后使用Gaussian Splatting。 图形学全局环境光照技术与球谐函数息息相关,我们的环境光来源四面八方,可以理解为一个球面函数,当模拟漫反射环境光,我们用一张环境贴图进行采样,对每一个点进行半球采样出在这个像素上的颜色,球谐光照简单来说就是用几个系数存取了整张环境贴图包围在球上法线方向所对应的的颜色信息。在渲染过程中传入球谐系数。在模型上根据对应的法线信息,从球谐函数中获取对应的颜色信息。 球谐函数是定义在球面上的特殊函数,换句话说,可以对球面上的任意点计算这样一个函数并得到一个值。 这里我们简单理解一下,SH,球谐函数,归根到底只是一组基函数,至于这组基函数是怎么来的,不管他。简单点来说,每一个函数都可以由多个基函数组合起来,如果我们有很多基函数,我们可以通过对应的权重系数复原出原来的函数,不过本质上还是一个有损压缩,不一定那么准确,不过如果基函数越多,复原的函数越准确,但是计算量也变大了。 在球面基函数中,最多的就是球谐函数了。球谐函数有很多很好的性质,比如正交性,旋转不变性(这边就不介绍了)。正交性说明每个基函数都是独立的,每个基函数都不能用别的基函数加权得到。当SH的系数用的越多,那么表达能力就越强,跟原始的函数就越接近。(如果更详细的了解可以看看一些原理,我主要是宏观的了解SH是什么,简单理解就是他是一种颜色的表示) |
|
|
当用来描述不同方向光照的SH基函数,我们一般用二阶或者三阶,比如下面的例子就是3阶的 |

|
|
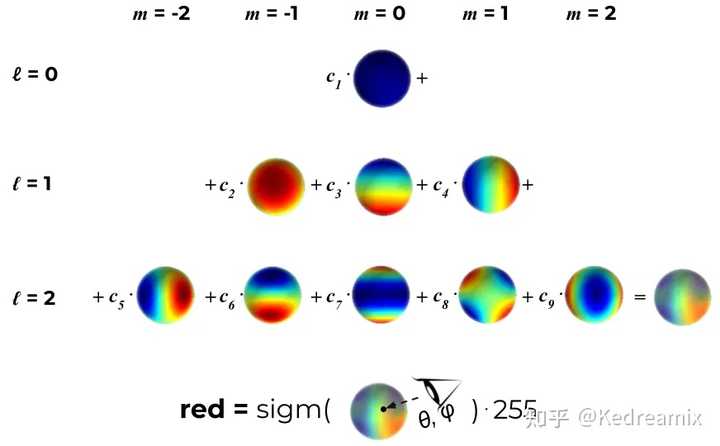
下面展示的是一个$l=2$和3阶的球谐函数,一共包括9个学习系数,我们可以根据点的视角得到相关颜色,可以看到最后是red红色分量。 |
|
|
得到l=2和9个学习系数的点的视角相关颜色(红色分量)的过程 3DGS 流程 最后根据论文的图来总结一下3DGS的流程 |

|
|
3DGS 流程 Structure from Motion:使用SfM从一组图像中估计出点云,可以直接调用 COLMAP 库操作 |

|
|
Structure from Motion Convert to Gaussians:将每个点建模成一个 3D 高斯图像。从 SfM 数据中,我们能推断出每个高斯图像的位置和颜色。但如果是要得到更高质量的表征的话,还需要对每个高斯函数进行训练,以推断出更精细的位置和颜色,并推断出协方差和透明度。 Training:与神经网络类似,我们使用随机梯度下降法进行训练,但这里没有神经网络的层的概念 (都是 3D 高斯函数)。 训练步骤如下: 用当前所有可微高斯函数渲染出图像根据渲染图像和真实图像之间的差异计算损失根据损失调整每个高斯图像的参数根据情况对当前相关高斯图像进行点的密度控制 步骤 1-3 比较简单,下面我们稍微解释一下第 4 步的工作: 如果某高斯图像的梯度很大 (即它错得比较离谱),则对其进行分裂或克隆如果该高斯图像很小,则克隆它如果该高斯图像很大,则将其分裂 如果该高斯图像的 alpha 太低,则将其删除 这么做能帮助高斯图像更好地拟合精细的细节,同时修剪掉不必要的高斯图像。 Differentiable Gaussian Rasterization:3D Gaussian Splatting实际上是一种光栅化的方法,将数据成像到屏幕上,与其他方法相比,他有两个特点 快 可微 主要步骤如下: 针对给定相机视角,把每个 3D 高斯投影到 2D。按深度对高斯进行排序。对每个像素,从前到后计算每个高斯在该像素点的值,并将所有值混合以得到最终像素值。3DGS Limitations 优点 高品质、逼真的场景快速、实时的渲染更快的训练速度 缺点 防止模型优化中的“破碎”的高斯:点太大、太长、冗余等更高的显存使用率 (4GB 用于显示,12GB 用于训练)更大的磁盘占用 (每场景 1GB+)与现有渲染管线不兼容~~只能重建静态场景(但是好像现在动态的Gaussian也出来了,所以这个不算缺点了)~~应用领域和任务 APPLICATION AREAS AND TASKS同时定位和建图(SLAM) SLAM需要让设备实时理解自身位置并同时为环境建图,因此计算量大的表达技术难以应用。 传统SLAM使用点/surfel云或体素网格表达环境。3DGS的优势在于高效性(自适应控制高斯密度)、精确性(各向异性高斯能建模环境细节)、适应性(能用于各种尺度和复杂度的环境)。 动态场景建模 动态场景建模需要捕捉和表达场景随时间变化的的3D结构和外观。需要建立能精确反映场景中物体几何、运动和视觉方面的数字模型。4D高斯泼溅通过扩展3D高斯溅射的概念,引入时间维度,使得可以表达和渲染动态场景。现在也有一些方法在研究在动态场景中的一些编辑的功能,与3DGS进行交互。 AI生成内容(AIGC) AIGC是人工智能自动创建或极大修改的数字内容,可以模仿、扩展或增强人类生成的内容。 3DGS的显式特性、实时渲染能力和可编辑水平使其与AIGC高度相关。例如,有方法使用3DGS与生成模型、化身或场景编辑结合,如3DGS-Avatar。 自动驾驶 自动驾驶的目标是在无人干涉的情况下导航并操作车辆,其主要目标是安全而高效地感知环境、做出决策和操作执行器。 其中,感知和理解环境需要实时重建驾驶场景,精确识别静态和动态物体,并理解其相互关系和运动。动态驾驶场景中,场景还会随时间连续变化。3DGS可以通过混合数据点(如激光雷达点)将场景重建为连贯表达,有利于处理数据点变化的密度,以及静态背景和动态物体的精确重建。 性能比较 PERFORMANCE COMPARISON 在这一部分,针对3FGS在上述的领域上的一些性能评估。 性能基准:定位 数据集:Replica。 基准算法:Gaussian-SLAM、GS-SLAM、SplaTAM、GSS-SLAM。 评估指标:均方根误差(RMSE)、绝对轨迹误差(ATE),测量传感器运动轨迹上真实位置与估计位置欧式距离的均方根。结果:基于3D高斯的SLAM方法能超过基于NeRF的密集视觉SLAM。 |
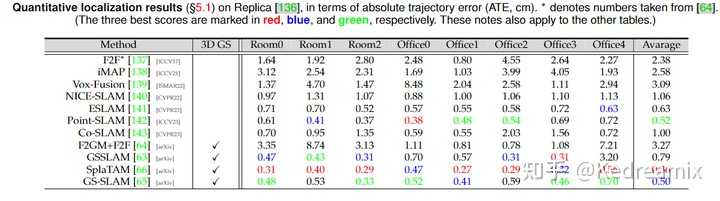
|
|
性能基准:静态场景渲染数据集:Replica。基准算法:Gaussian-SLAM、GS-SLAM、SplaTAM、GSS-SLAM。评估指标:峰值信噪比(PSNR)、结构相似性(SSIM)、学习的感知图像patch相似性(LPIPS),衡量RGB渲染性能。结果:基于3D高斯的方法能超过基于NeRF的方法。 |
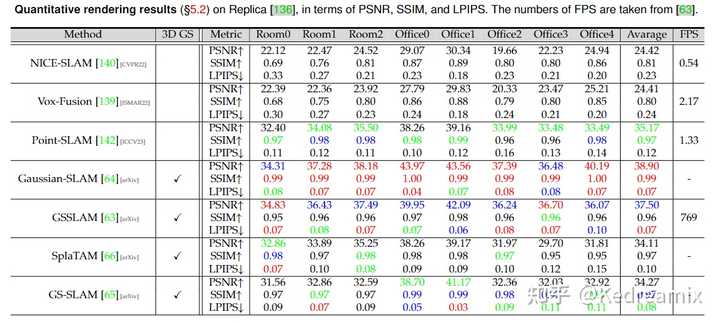
|
|
性能基准:动态场景渲染数据集:D-NeRF。基准算法:CoGS、4D-GS、GauFRe、4DGS。评估指标:PSNR、SSIM、LPIPS, 用于衡量RGB渲染性能。结果:3DGS能大幅超过基于NeRF的SOTA。但静态版本的3DGS对动态场景的重建是失败的。 |
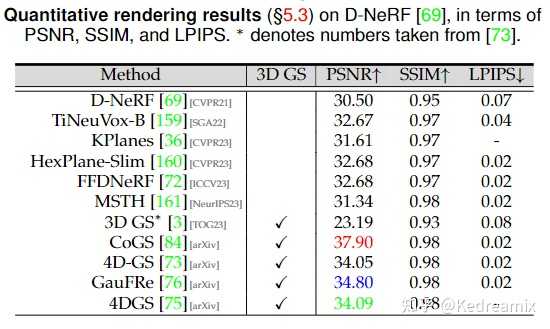
|
|
性能基准:驾驶场景渲染数据集:nuScences。基准算法:DrivingGaussian。评估指标:PSNR、SSIM、LPIPS*(LPIPS× 1000), 用于衡量RGB渲染性能。结果:3DGS方法能大幅超过基于NeRF的方法。 |
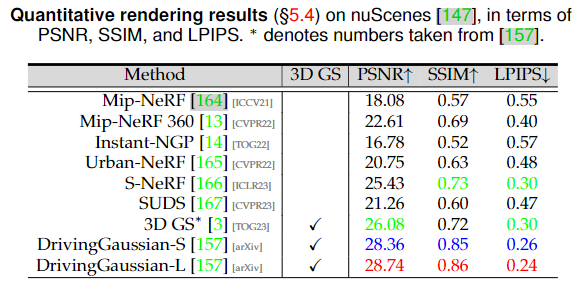
|
|
性能基准:数字虚拟人 该任务的目标是从给定的多视角视频渲染人体化身模型。 数据集:ZJU-MoCap。基准算法:GART、Human101、HUGS、3DGS-Avatar。评估指标:PSNR、SSIM、LPIPS* (LPIPS×1000) ,用于衡量RGB渲染性能$_{9}$结果:基于3DGS的方法能在渲染质量和速度上均有优势。 |
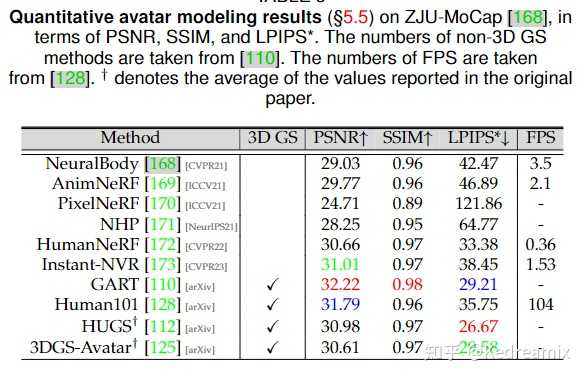
|
|
未来研究方向 FUTURE RESEARCH DIRECTIONS数据高效的3DGS解决方案:从少样本中进行新视图生成和场景重建很重要。目前的方法有探究引入深度信息、密集概率分布、像素到高斯的映射来促进该能力,实际上就是引入更多的信息。。此外,在观测不足的区域,3DGS会产生伪影,可尝试在这些区域进行数据插值或积分。存储高效的3DGS解决方案:3DGS的可扩展性较差,在大尺度环境中需要大量的存储。需要优化训练阶段和模型的存储利用,而对于NeRF来说只需要存储学习到的MLP参数。可以探索更多高效的数据结构和先进的压缩技术,如Light-Gaussian等先进的渲染算法:目前3DGS的渲染算法较为简单直接,可见性算法会导致高斯深度/混合顺序的剧烈切换,需要实施更先进的渲染算法,更好模拟光与材料属性的复杂相互作用。可结合传统计算机图形学的方法。此外,还可探索逆渲染。优化与正则化: 各向异性高斯虽然有利于表示复杂几何体,但可能产生不希望的视觉伪影。例如,特别是在具有视角依赖外观的区域,大的3D高斯可能导致弹出伪影,突然出现或消失的视觉元素打破了沉浸感。使用正则化可以增加收敛速度,平滑视觉噪声或提高图像质量。此外,3DGS中大量的超参数也会影响3DGS的泛化性。在3DGS的规则化和优化方面存在相当大的探索潜力。3D高斯在网格重建中的应用:可探索3DGS在网格重建中的潜力,从而缩小体积渲染和传统基于表面的方法的差距,以便提出新的渲染技巧和应用。赋予3DGS更多可能性: 尽管3D GS具有显著潜力,但3DGS的全范围应用仍然未被充分挖掘。一个有前景的探索方向是用额外的属性增强3D高斯,例如为特定应用定制的语言和物理属性。此外,最近的研究开始揭示3D GS在多个领域的能力,例如相机姿态估计、捕捉手对象互动和不确定性量化。这些初步发现突出了跨学科学者进一步探索3D GS的重要机会。参考文献 REFERENCESKerbl, B., Kopanas, G., Leimkühler, T., & Drettakis, G. (2023). 3D Gaussian Splatting for Real-Time Radiance Field Rendering. SIGGRAPH 2023.Mildenhall, B., Srinivasan, P. P., Tancik, M., Barron, J. T., Ramamoorthi, R., & Ng, R. (2020). NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis. ECCV 2020.Zwicker, M., Pfister, H., van Baar, J., & Gross, M. (2001). Surface Splatting. SIGGRAPH 2001Luiten, J., Kopanas, G., Leibe, B., & Ramanan, D. (2023). Dynamic 3D Gaussians: Tracking by Persistent Dynamic View Synthesis. International Conference on 3D Vision.Zwicker, M., Pfister, H., van Baar, J., & Gross, M. (2001). EWA Volume Splatting. IEEE Visualization 2001.Yu, A., Fridovich-Keil, S., Tancik, M., Chen, Q., Recht, B., & Kanazawa, A. (2023). Plenoxels: Radiance Fields without Neural Networks. CVPR 2022.A Comprehensive Overview of Gaussian SplattingIntroduction to 3D Gaussian SplattingSample Representation《3D Gaussian Splatting for Real-Time Radiance Field Rendering》3D高斯的理论理解【论文笔记】A Survey on 3D Gaussian Splatting |
|
本文分享4D生成方向新工作,由北京交通大学和得克萨斯大学奥斯汀分校共同完成的“4DGen: Grounded 4D Content Generation with Spatial-temporal Consistency”,文章使用Gaussian Splatting实现了高质量的4D生成。 文章主页:https://vita-group.github.io/4DGen/ 论文地址:https://arxiv.org/abs/2312.17225 开源代码:https://github.com/VITA-Group/4DGen |

|
|
研究背景 尽管3D和视频生成取得了飞速的发展,由于缺少高质量的4D数据集,4D生成始终面临着巨大的挑战。过去几篇工作尝试了Text-To-4D的任务,但依然存在两个主要问题: 由于输入依赖于单视角的图片或者简单的文本描述,并不能保证得到精准的4D结果,需要花费大量的时间进行反复调整。尽管采用了Hexplane作为4D的表征,基于NeRF的方法在高分辨率和长视频上的渲染所需要的计算时间和显存占用是难以接受的。即使采用了一个超分辨的后处理网络,依然会有模糊和闪烁的结果。 为了解决上述问题,4DGen定义了“Grounded 4D Generation“新型任务形式,并且设计了新的算法框架实现高质量的4D内容生成。 任务定义 过往的4D生成工作是“one click“的方式,并不能对生成的结果进行有效的控制。4DGen提出了“Grounded 4D Generation“的形式,通过利用视频序列和可选的3D模型作为4D生成的控制信息,可以实现更为精准的4D内容生成。用户可通过输入视频序列或3D模型来约束4D结果的运动和外观;当用户仅提供单张图片作为输入时,可借助预训练好的视频生成模型来得到视频序列;当用户未提供3D模型时,可通过单张图片重建3D模型来作为起始点。 |
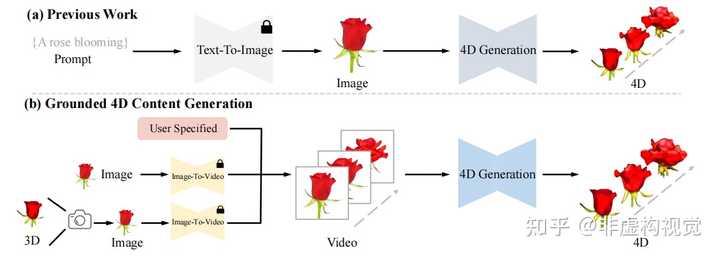
|
|
方法介绍 4DGen框架的输入起始点为用户给定或者模型生成的视频序列,对于任意的单张图片,借助多视角生成模型(multi-view diffusion model),可以得到不同视角的图片。4DGen通过对第一帧多视图进行三维重建,得到初始的静态3D Gaussians作为4D生成的起始点。 由于4D数据的匮乏,需要尽可能的从先验模型中蒸馏信息。4DGen将每一帧生成的多视图作为2D伪标签,并且采用多视图生成的点云作为3D点的伪标签来监督训练过程。 因为多视图生成具有ill-posed的特点,得到的伪标签在不同视角之间,不同时序之间存在不连续性,需要引入时间和空间上的一致性损失函数进行约束。相较于拟合多视图DDIM采样得到的图片,score distillation sampling(SDS)是根据先验的扩散模型对场景表达进行似然估计。4DGen依据正面视角计算任意视角图片在Zero123模型上的SDS损失,用于提升空间上的连续性。为了缓解闪烁问题,4DGen引入了无监督的时间平滑约束。通过计算平面的平滑损失和Gaussians不同时刻的平滑损失,有效提升了时间上的一致性。 |
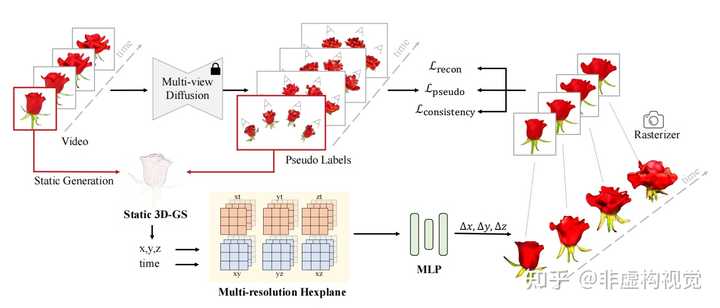
|
|
实施细节 4DGen的 4D表达采用了4D Gaussian Spaltting的方式,通过一个多分辨率Hexplane对每个Gaussian进行编码。将6个时空平面的特征进行相加,并经过一个额外的MLP解码得到对应Gaussian在不同时刻的位置偏移量。 训练上采用三阶段方式,第一阶段对场景进行静态建模,第二阶段利用2D和3D的伪标签进行动态场景的初步建模,第三建模利用平滑损失增强模型的细节和连续性。 所有实验可以在一张RTX3090上完成,对于2.5万个Gaussians只需45分钟的训练,对于9万个Gaussians训练2小时可以得到更加好的细节效果。 实验结果 4DGen可以实现不同视角、不同时间的高质量图片渲染。相较于对比方法在细节表达、噪声去除、颜色还原、时空连续性等方面有显著提升。更多视觉效果可以参考项目主页。 |

|
|
量化对比上,4DGen采用了不同时序图片和参考图片的CLIP距离来衡量生成质量,采用CLIP-T衡量不同时间下的图像连续性。4DGen在多项指标上明显优于过往方法。 |
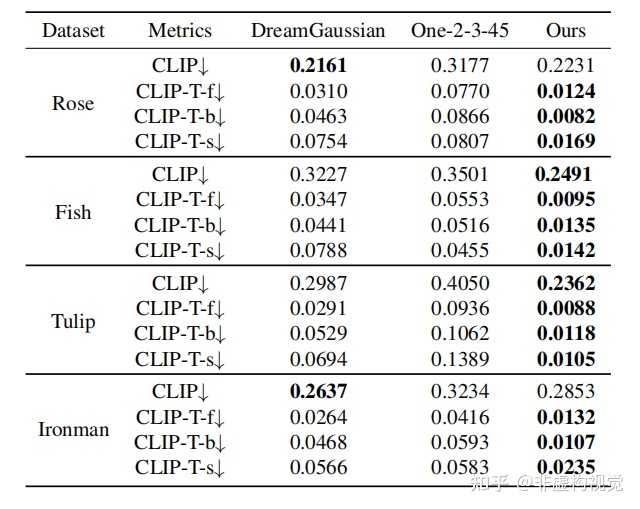
|
|
总结 4DGen定义了“ Grounded 4D Generation“的任务形式,通过视频序列和可选3D模型的引入提升了4D生成的可控性。通过高效的4D Gaussian Splatting的表达,2D和3D伪标签的监督和时空的连续性约束,使得4DGen可以实现高分辨率、长时序的高质量的4D内容生成。 |
|
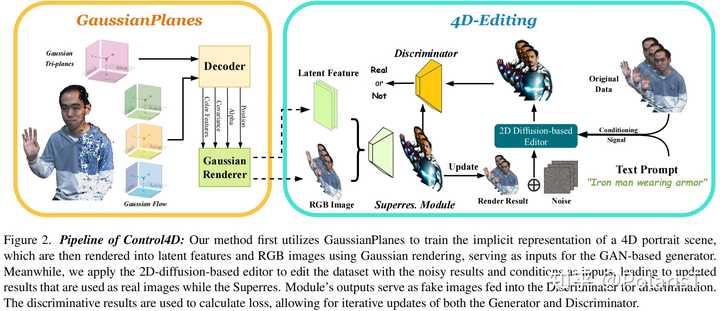
https://control4darxiv.github.io/ 论文链接:https://arxiv.org/abs/2305.20082 介绍 实现的功能:给定多视角的人像动态视频+一段文本,输出肖像中人物被编辑后的视频结果。 论文方法整体的overview如下面的视频所示:先用多视角视频训练作者提出的4D表示GaussianPlanes,重建出原始人物的4D肖像视频,然后利用2D扩散模型+作者提出的4D GAN编辑框架迭代优化前面的4D表示,最终得到被编辑后的4D肖像视频。由于Gaussian Splatting的存在,整个训练过程的收敛速度相比以前基于动态NeRF的工作要快了好几倍。 背景&贡献点4D编辑的主要难点在于保证时空一致性以及生成结果的高视觉质量。将常见的3D表示+SDS的组合替换成4D+SDS是很显然的思路,但是这么做存在两个问题。动态NeRF等4D表示需要沿着光线进行密集采样,显著增加了在4D场景中进行编辑所需的时间。目前的T2I扩散模型在编辑不同的图像时缺乏一致性,这种不一致性在4D编辑中更为明显(因为生成结果会随不同的空间视角和时间的推移而变化),这使得4D编辑极具挑战性。贡献点作者提出了一个高效鲁棒的4D表示GaussianPlanes来进行4D编辑。作者引入了一个4D生成器,它可以从2D T2I编辑模型中学习知识,可以减少不一致的监督信号的影响,并提高4D编辑的质量。在所提出的GaussianPlanes和4D生成器的基础上,作者实现了Control4D,一种新的4D肖像文本编辑框架,它可以在数分钟内训练完毕,实现高质量的渲染,并确保时空一致性。整体方法 |
|
|
Pipeline of Control4D 第一阶段是利用多视角人物视频训练一个4D表示GaussianPlanes,训练完毕后,这个4D表示即可较好地重建出该特定人物的4D动态效果。 下一阶段是执行4D-Editing编辑框架的训练。 GaussianPlanes的Decoder解码出每个时空中高斯点的各项属性,随后利用Gaussian Splatting即可快速渲染出低分辨率RGB图像。除了RGB图像,作者还从这些平面表示中query+decode+render得到低分辨率Latent feature maps。将隐特征图+RGB图像一起输入超分辨率模块中即可得到最终的Render Result。 得到Render Result后,即可利用一个现成的2D扩散模型对这些视频帧进行text-guided的编辑并输出编辑后的视频帧结果。 最后,作者将edited frames作为real,而rendered frames作为fake去训练判别器和生成器(此时将整个4D表示+超分辨率模块视为生成器),用这种对抗生成的训练方式来促使4D生成器从2D扩散模型中蒸馏得到编辑所需的知识,以及稳定地收敛到2D扩散模型的生成数据分布中去。 GaussianPlanes in 3D为了增强鲁棒性,作者提出了一种空间三平面分解来表示高斯点的属性。虽然高斯点之间保持独立,但它们的属性在空间域中是结构化且低秩的,这有助于降低噪声,提高Gaussian Splatting的鲁棒性。 |
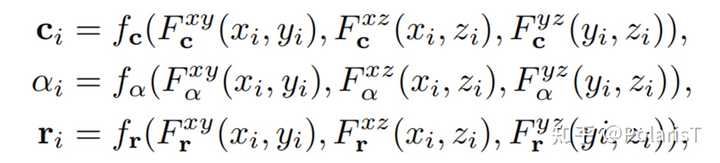
|
|
从Planes中查询高斯点的属性的过程f_c,f_α,f_r 是用来聚合来自三个平面特征以预测特定属性的MLP。不分解尺度因子 s ,这是因为分裂的高斯点会突然使尺度因子减半;不分解中心位置 x ,这是因为每个点的中心位置用于查询属性本身。GaussianPlanes in 4D为了引入Gaussian Splatting,作者将第一帧的高斯点云视为标准空间,通过对标准高斯点云的形变来表示不同时间下的四维场景。这种方式可以增强时序一致性,因为高斯点云在任何时候都与它的标准空间保持关联。为了进一步规整高斯点在空间和时间上的flow,作者采用了Tensor4D(CVPR 23,刘烨斌老师组的前置研究)提出的基于时空平面的分解方法,将第 i 个高斯点的flow属性分解到9个时空feature planes上。 |
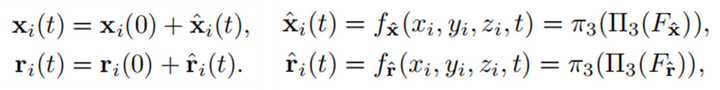
|
|
得到t时刻高斯点属性的过程通过空间三平面分解和基于四维平面的分解,作者构造了4D Gaussian Splatting,可以在保持效率的同时保持时空一致性。4D Editing with GaussianPlanes本的方法不是利用编辑后图像直接对4D repre.提供监督,而是通过GAN学习连续的生成空间,建立GaussianPlanes和动态编辑图像之间的联系。4D生成器可以有效地从editor中蒸馏出知识,并判别渲染图像(fake)和编辑图像(real)。随后, GaussianPlanes在连续生成空间中利用对抗损失进行优化。 |

|
|
利用GaussianPlanes+4D编辑框架进行训练的过程第一阶段超分模块的输入是渲染图像+隐特征图+渲染图像的全局特征,损失函数是对抗损失。第二阶段超分模块的输入是渲染图像+隐特征图+编辑后图像的全局特征,损失函数是对抗损失+感知损失。第三阶段超分模块的输入是渲染图像+编辑后图像的局部特征+编辑后图像的全局特征,损失函数是对抗损失+感知损失+L1损失。实验我们主要在动态Tensor4D数据集上进行实验,该数据集利用4个摆放在固定位置的RGB相机捕获动态的上半身人体视频。该数据集中每个样本视频的时长为1-2分钟。在我们的实验中,我们从完整的视频中提取2秒的片段,包括50帧,用于4D重建和编辑。静态场景下的定性比较 下图中第一行是本文方法的结果,第二行是InstructNeRF2NeRF的结果。 |

|
|
动态场景下的定性比较 下图中第一行是baseline方法(只用Dataset Update的方式迭代训练一个4D表示实现编辑)的结果,第二行是本文方法的结果。 |

|
|
更多结果 |

|
|
定量比较 |
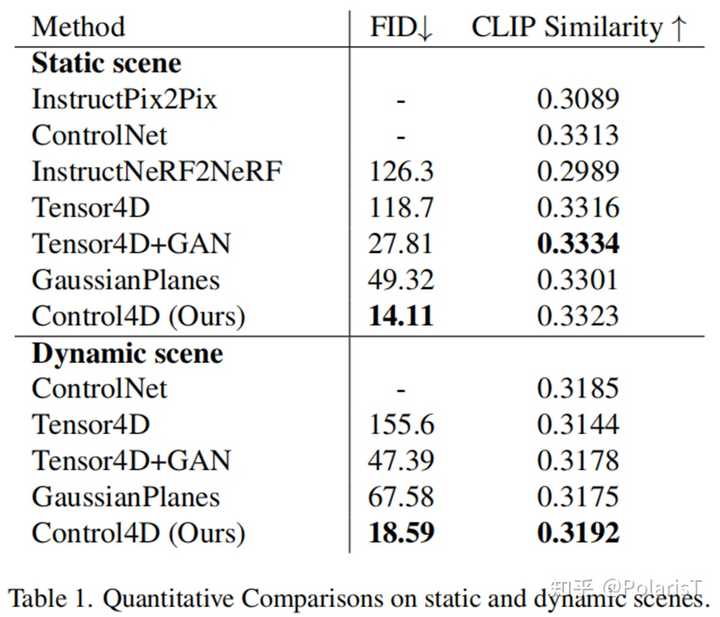
|
|
Tensor4D是4D表示的baseline,Tensor4D+GAN是指在Tensor4D基础上引入本文提出的GAN训练方式来实现编辑,GaussianPlanes是本文提出的4D表示(主要是和Tensor4D进行对比),Control4D其实就是GaussianPlanes+GAN+整体训练框架,主要是和Tensor4D+GAN进行对比。结论Control4D是一种在动态4D场景中进行高效、高保真和时间一致编辑的新方法,它利用了一个高效的4D表示GaussianPlanes和一个基于二维扩散模型的editor。GaussianPlanes利用平面分解来构造Gaussian Splatting,保证了4D编辑的效率和鲁棒性。为了解决基于扩散模型的编辑引起的不一致性,Control4D利用GAN策略从扩散先验中蒸馏出一个连续的生成空间,避免了直接用离散编辑后图像对GaussianPlanes 进行优化。实验结果表明 Control4D在实现逼真和一致的4D编辑方面十分有效,超过了以前现实世界场景编辑的方法,这是基于文本的图像编辑(特别是在动态场景)领域的一个重大进展。局限性由于使用了标准空间+flow的表示,我们的方法可能无法有效地处理快速和广泛的非刚性运动。我们的方法受到ControlNet的约束,它只支持大粒度的编辑,无法执行更加精细的编辑。我们的方法需要对编辑过程进行迭代优化,不能在一个步骤中完成。 如果觉得本文的分享对你有帮助,可以给作者点个关注哦~ 谢谢你的支持与鼓励,未来我会定期分享更多关于3D生成与编辑相关的论文。 |
|
个人认为现阶段最优雅的重建技术,虽然现在的还在整个领域都在快速迭代,但是证明传统算法也可以比肩甚至超越神经网络。不过我觉得未来GS会在SLAM有更大发展空间,目前来说基于算法的模型还是比基于神经网络的模型鲁棒的多,很适合SLAM。我是觉得训练NeRF的方法或架构有哪里不对,使用了隐式表示,数据集只有几十张图片,神经网络加起来十几层,靠着过拟合来记住坐标信息,而过拟合可以解决的问题可能都可以通过可微优化来解决。但想找个新方法感觉还挺难的。有错望大佬指正。 |
|
|
| [收藏本文] 【下载本文】 |
| 上一篇文章 下一篇文章 查看所有文章 |
|
|
|
| 股票涨跌实时统计 涨停板选股 分时图选股 跌停板选股 K线图选股 成交量选股 均线选股 趋势线选股 筹码理论 波浪理论 缠论 MACD指标 KDJ指标 BOLL指标 RSI指标 炒股基础知识 炒股故事 |
| 网站联系: qq:121756557 email:121756557@qq.com 天天财汇 |