
| |
|
|
| 首页 淘股吧 股票涨跌实时统计 涨停板选股 股票入门 股票书籍 股票问答 分时图选股 跌停板选股 K线图选股 成交量选股 [平安银行] |
| 股市论谈 均线选股 趋势线选股 筹码理论 波浪理论 缠论 MACD指标 KDJ指标 BOLL指标 RSI指标 炒股基础知识 炒股故事 |
| 商业财经 科技知识 汽车百科 工程技术 自然科学 家居生活 设计艺术 财经视频 游戏-- |
| 天天财汇 -> 科技知识 -> 新架构mamba是否真的有用? -> 正文阅读 |
|
|
[科技知识]新架构mamba是否真的有用? |
| [收藏本文] 【下载本文】 |
|
目前arxiv上mamba相关论文有20篇左右了。经过简单的阅读,发现论文基本都是把mamba模块替换原先常用的vit或者cnn模块(占坑)。有没有实… |
|
说一个mamba的速度问题啊,它论文里那张selective scan和flash attention比较速度的图片非常有误导性,看起来好像句长小于2048的情况下两者持平,句长大于2048的情况下mamba更好。 论文的附录里提到,这个速度测试的参数是,scan和flash attention的输入输出维度均为1024,batch size为1,句长均为2的幂 这个速度比较有两个问题: scan和flash attention的输入维度相同,那么根本不可能是同参数量的比较,因为作为LM来说,transformer一层的参数量为 12×d_model2" role="presentation">12×d_model212 \times d\_model^2 ,而mamba一层的参数量为 6×d_model2" role="presentation">6×d_model26 \times d\_model^2 ,且scan运行在维度为 2×d_model" role="presentation">2×d_model2\times d\_model 的输入上。也就是如果保证同参数量,那么要么mamba的d_model是transformer的 2" role="presentation">2\sqrt{2} 倍,则scan的输入维度是flash attention的 22" role="presentation">222\sqrt{2} 倍;要么mamba的层数是transformer的2倍,则scan的输入维度是flash attention的2倍,且运行次数是flash attention的2倍。所以这两个kernel的同维度的比较并不是公平的,实际上mamba比transformer训练速度快的拐点可能要来到句长8192或者16384,否则都是transformer更快这个实验的句长都是2的幂,那么非2的幂的情况下呢?scan的速度会暴跌2到3倍,这也不能算bug,只能说大佬懒得处理这些边角的情况 以上两点基本上是大家觉得mamba训起来很慢的主要原因(坑),对结论有疑问的话自己做实验单测一下便知 |
|
肯定有用。 目前的神经网络基本只有4种架构:MLP、CNN、RNN、Transformer,或者以上架构的混合。以上4种架构都在历史上展现出了自己的巨大价值。 Mamba可以归类为RNN(SSM),Hyena是CNN,RWKV是RNN或Linear Transformer。 至于现在Arxiv上,把原有的架构换成Mamba发现效果不错,这基本属于水论文,但可以可视化一下说明Mamba为什么好。 现在RNN模型在语言建模上的Loss已经达到了和Transformer相当甚至更低的水平。在故事续写等任务上,RNN类模型可能更自然,但是在一些专门为Transformer设计的评价指标上(比如照抄前文)稍微差一些。整体能力水平和上限我认为不相上下。 最近有一些混合架构的模型出来,比如刚出的Jamba。 |
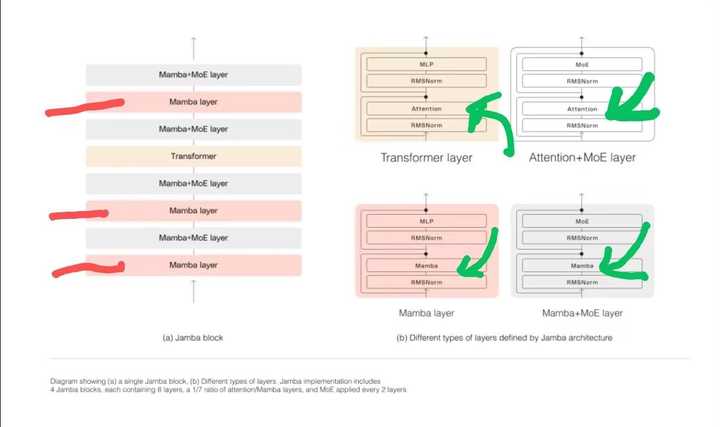
|
|
Jamba架构(盗图) 混合架构模型的潜力是被低估了。混合架构的模型可以发挥出各种架构的优势,扬长避短。在训练过程中,各个架构部分会学习到相应的特征,这可以提高模型的特征多样性。之前不够重视的原因可能是受到了Attention is all you need标题的误导,不过以现在的眼光来看,在正确初始化和训练的前提下,模型的架构越多样化,效果越好。 另外,在中国,如果你想尝试新的架构,可以考虑RWKV而不是Mamba,一个重要的原因是RWKV在中国有公司和客服,并且每年更新一代架构。在目前RWKV和Mamba性能相近的情况下,RWKV的外部优势是Mamba没有的。 对于真正有能力的研究者来说,我的建议是放下所谓的Mamba、RWKV和Transformer,去开发新一代的架构。AGI以哪种架构实现,现在还不一定呢。神经图灵机(NTM)上限很高,如果能解决并行训练问题,可能是AGI架构的有力候选者。 |
|
视觉方向,把tip的一个transformer块换成了ss2d那个架构。参数量上升,变慢1倍,不如原来的。 |
|
这方法在视觉领域本来就变相把网络加深了来涨点,计算量可能会减少,延时数据估计是不敢放出来的,用在图片上感觉都是水论文[飙泪笑],和一些用RNN混合CNN的架构处理图片(不是视频)的水文没本质区别。由于mamba视觉模型论文很少看,如果真的全方位的指标都能做的很好,欢迎打我脸。 放在NLP领域是真的想充当线性RNN变种,但感觉不如RetNet简洁,引入的离散化的设计完全没看懂,也不知道有什么必要。 |
|
说实话不如rwkv一根 https://www.zhihu.com/question/647212700/answer/3427664354?utm_psn=1757498475896709121 rwkv已经好几个企业用了,mamba有几个? man,what can i say,______ out |
|
借用苏神锐评RWKV的话,70%数据20%算力,架构只有10%吧。也许换一个别的也有这效果。 |
|
复现不了,缺少selective_scan_cuda包,pip install下载失败了 |
|
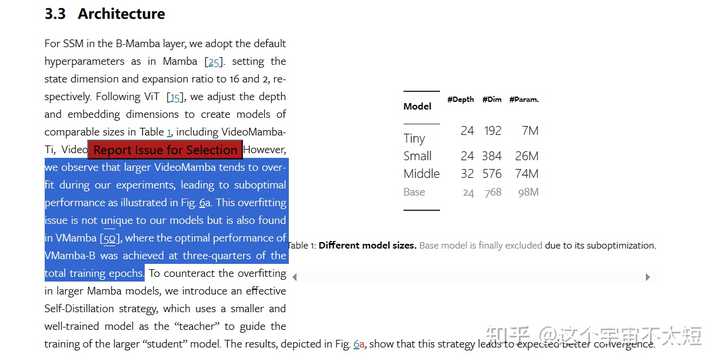
VideoMamba: State Space Model for Efficient Video Understanding (arxiv.org)?arxiv.org/html/2403.06977v2 最新paper,如果不是数据限制的话,感觉mamba的scalability不是很emmm..... |
|
|
update:当然我觉得新的可以替代的Transformer类架构最大的问题不在于如何设计一个新的架构(甚至可能这个架构早已被发表),而是在于是否有人愿意用足够大的资源证明这个架构在足够大的数据/算力/参数量下能够依旧类比/超越Transformer类模型的Scaling Laws。 所以在此非常敬佩RWKV的作者们 |

|
|
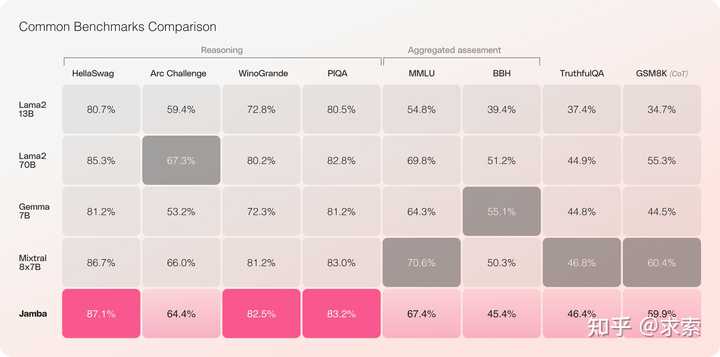
当地时间2024年3月28日,AI21 Labs首次推出基于Mamba的生产级模型,提供一流的质量和性能。希望未来有更多基于Mamba的大模型,而不是Transformer一家独大。 Jamba是世界上第一个基于Mamba的生产级模型。通过用传统Transformer架构的元素增强Mamba结构化状态空间模型(SSM)技术,Jamba弥补了纯SSM模型的固有局限性。提供256K上下文窗口,它已经在吞吐量和效率方面表现出显著的提高――这只是这种创新的混合架构可能实现的开始。值得注意的是,Jamba在广泛的基准上优于或匹配其尺寸类别中的其他最先进的模型。 |
|
|
在Apache 2.0下许可情况下,Jamba开放权重,开发者可以进一步优化和微调。 ? Jamba还可以从NVIDIA API目录中访问,作为NVIDIA NIM推理微服务,企业应用程序开发人员可以使用NVIDIA AI企业软件平台部署。 ? 主要特点第一个基于生产级Mamba的模型建立在新颖的SSM-Transformer混合架构上与Mixtral 8x7B相比,长上下文的吞吐量为3倍民主化访问一个巨大的256K上下文窗口唯一一款在单个GPU上容纳高达140K上下文的型号在Apache 2.0下以开放权重发布可在Hugging Face上获得,并即将登陆NVIDIA API目录Jamba提供两全其美 Jamba的发布标志着LLM创新的两个重要里程碑:成功地将Mamba与Transformer架构相结合,并将混合SSM-Transformer模型推进到生产级规模和质量。 ? 到目前为止,LLM主要建立在传统的Transformer架构上。虽然无疑是强大的,但这种架构有两个主要缺点: 大内存占用空间:Transformer的内存占用空间随上下文长度而缩放。这使得在没有大量硬件资源的情况下运行长上下文窗口或许多并行批次具有挑战性,限制了广泛的实验和部署机会。 ?随着上下文的增长,推理缓慢:Transformer的注意力机制随序列长度进行二次扩展,并减慢吞吐量,因为每个令牌都取决于之前的整个序列――将长上下文用例置于高效生产范围之外。 ? 由卡内基梅隆大学和普林斯顿大学的研究人员提出,Mamba恰恰解决了这些缺点,为语言模型开发开辟了新的可能性。然而,如果不关注整个上下文,这种架构很难匹配现有最佳模型的相同输出质量,特别是在召回相关任务上。 ? 为了捕捉Mamba和Transformer架构所能提供的最好的东西,AI21 Labs开发了相应的Joint Attention和Mamba(Jamba)架构。Jamba由Transformer、曼巴和专家混合(MoE)层组成,同时优化内存、吞吐量和性能。 |

|
|
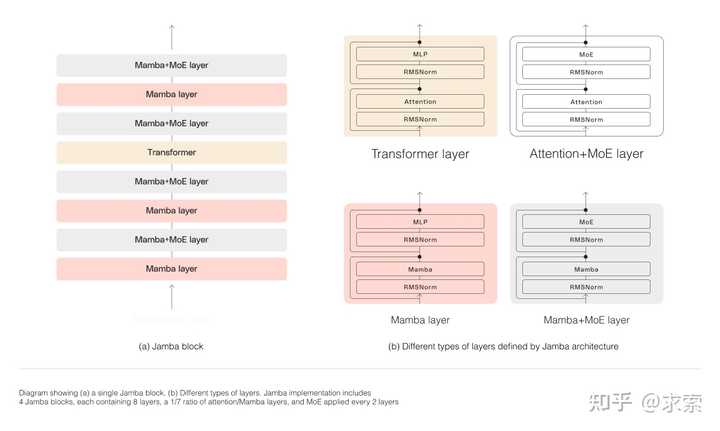
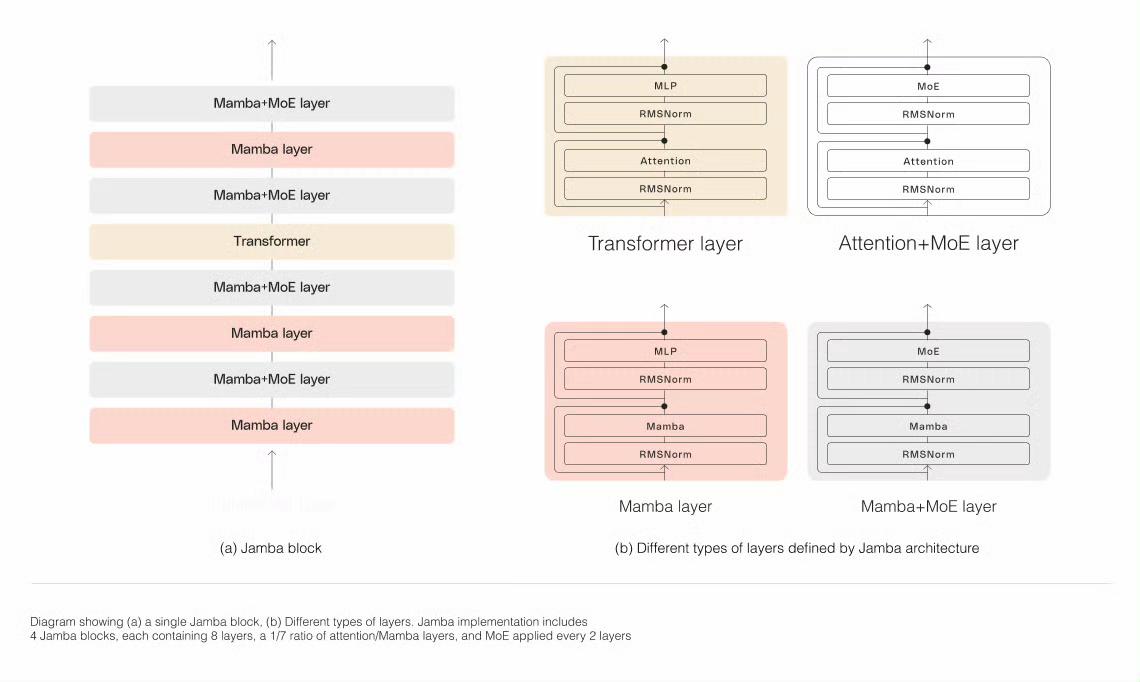
Jamba的MoE层允许它在推断时仅利用12B(可用52B参数),其混合结构使这些12B有源参数比等效尺寸的仅变压器模型更有效。 ? 虽然有些人尝试过缩放Mamba,但没有人将其缩放超过3B参数。Jamba是第一个达到生产级规模的同类混合架构。 使用Jamba Architecture进行规模建设 需要一些核心建筑创新才能成功扩展Jamba的混合结构。如下图所示,AI21的Jamba架构采用块和层方法,允许Jamba成功集成这两种架构。每个Jamba块都包含一个注意力或Mamba层,然后是多层感知器(MLP),每八个总层中产生一个变压器层的总体比率。 |
|
|
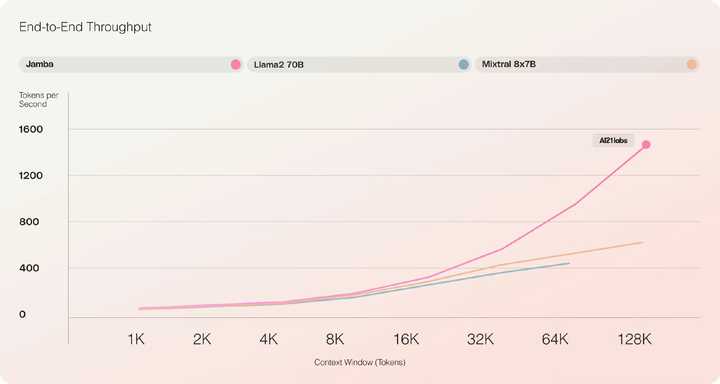
第二个特点是利用MoE来增加模型参数的总数,同时简化推理中使用的活动参数数量――导致更高的模型容量,而不会匹配计算要求增加。为了在单个80GB GPU上最大限度地提高模型的质量和吞吐量,优化了MoE层和使用的专家的数量,为常见的推理工作负载留出足够的内存。 ? 前所未有的吞吐量和效率 根据初步评估,Jamba在吞吐量和效率等关键测量方面表现出色。虽然其初步表现已经达到了令人印象深刻的里程碑,随着社区通过实验和优化进一步推动这项新技术,这些基准只会继续改进。 ? 效率 在长上下文中提供3倍的吞吐量,使其比Mixtral 8x7B等尺寸可比的基于变压器的模型更有效。 |
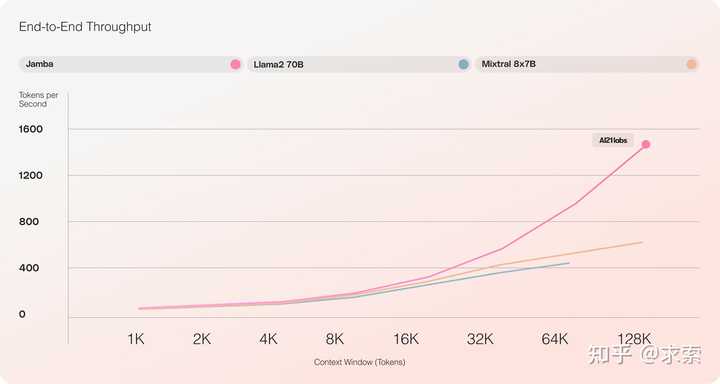
|
|
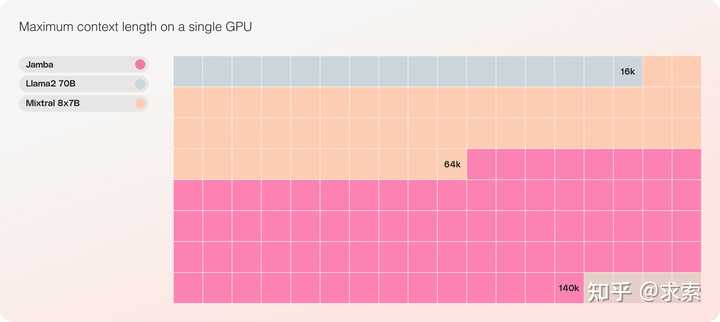
?成本 ?Jamba可以在单个GPU上容纳140K上下文,与目前其他类似规模的开源模型相比,提供更易于访问的部署和实验机会。 预计这些已经令人鼓舞的收益将随着未来的优化而进一步加强,例如更好的MoE并行性、更快的Mamba实现等。 |
|
|
? 开始使用Jamba构建 您可以开始在Hugging Face上与Jamba合作。作为基本模型,Jamba旨在用作微调、培训和开发定制解决方案的基础层,并应添加护栏,以便负责任和安全使用。指令版本将很快通过AI21平台提供测试版。 模型:https://huggingface.co/ai21labs/Jamba-v0.1 介绍:https://www.ai21.com/jamba 博客:https://www.ai21.com/blog/announcing-jamba |
|
What can I say? Mamba out! 顺便没想到居然是 CV 先把 mamba 给水起来了( |
|
Mamba视觉实用效果:速度提升2.8倍,内存能省87% 号称「全面包围 Transformer」的 Mamba,推出不到两个月就有了高性能的视觉版。 本周四,来自华中科技大学、地平线、智源人工智能研究院等机构的研究者提出了 Vision Mamba(Vim)。 |

|
|
论文地址:https://arxiv.org/pdf/2401.09417.pdf项目地址:https://github.com/hustvl/Vim论文标题:Vision Mamba: Efficient Visual Representation Learning with Bidirectional State Space Model 效果如何呢?在 ImageNet 分类任务、COCO 对象检测任务和 ADE20k 语义分割任务上,与 DeiT 等成熟的视觉 Transformers 相比,Vim 实现了更高的性能,同时还显著提高了计算和内存效率。例如,在对分辨率为 1248×1248 的图像进行批量推理提取特征时,Vim 比 DeiT 快 2.8 倍,并节省 86.8% 的 GPU 内存。结果表明,Vim 能够克服对高分辨率图像执行 Transformer 式理解时的计算和内存限制,并且具有成为视觉基础模型的下一代骨干的巨大潜力。 |

|
|
接下来我们看看论文内容。 Mamba 的提出带动了研究者对状态空间模型(state space model,SSM)兴趣的增加,不同于 Transformer 中自注意力机制的计算量会随着上下文长度的增加呈平方级增长,由于 SSM 擅长捕捉远程依赖关系,因而开始受到大家追捧。 在此期间,一些基于 SSM 的方法如线性状态空间层(LSSL)、结构化状态空间序列模型(S4)、对角状态空间(DSS)和 S4D 都被研究者提出来,用于处理各种序列数据,特别是在建模远程依赖关系方面。 Mamba 将时变参数纳入 SSM 中,并提出了一种硬件感知算法来实现高效的训练和推理。Mamba 卓越的扩展性能表明它在语言建模方面是 Transformer 有前途的替代品。 然而,到目前为止,研究者还尚未在视觉任务中探索出通用的基于纯 SSM 的骨干网络。 受 Mamba 在语言建模方面成功的激励,研究者开始设想能否将这种成功从语言转移到视觉,即用先进的 SSM 方法设计通用且高效的视觉主干。然而,由于 Mamba 特有的架构,需要解决两个挑战,即单向建模和缺乏位置感知。 为了应对这些问题,研究者提出了 Vision Mamba (Vim) 块,它结合了用于数据依赖的全局视觉上下文建模的双向 SSM 和用于位置感知视觉识别的位置嵌入。 与其他基于 SSM 的视觉任务模型相比,Vim 是一种基于纯 SSM 的方法,并以序列方式对图像进行建模。与基于 Transformer 的 DeiT 相比,Vim 在 ImageNet 分类上取得了优越的性能。此外,Vim 在 GPU 内存和高分辨率图像的推理时间方面更加高效。 方法介绍 Vision Mamba (Vim) 的目标是将先进的状态空间模型 (SSM),即 Mamba 引入到计算机视觉。 Vim 的概述如图 2 所示,标准的 Mamba 是为 1-D 序列设计的。为了处理视觉任务,首先需要将二维图像转换成展开的 2-D patch 。式中 (H, W) 为输入图像的大小,C 为通道数,P 为图像 patch 的大小。接下来,需要将 x_p 线性投影到大小为 D 的向量上,并添加位置嵌入得到如下公式: |
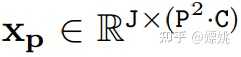
|
|
|
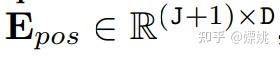
|
|
|
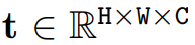
|
|
|
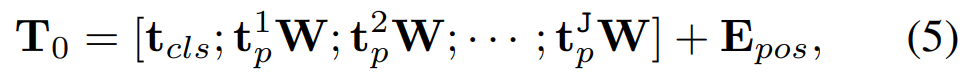
|
|
Vim 块 原始的 Mamba 块是为一维序列设计的,不适合需要空间感知理解的视觉任务。Vim 块集成了用于视觉任务的双向序列建模,Vim 块如上图 2 所示。 Vim 块的操作算法如下所示。 |

|
|
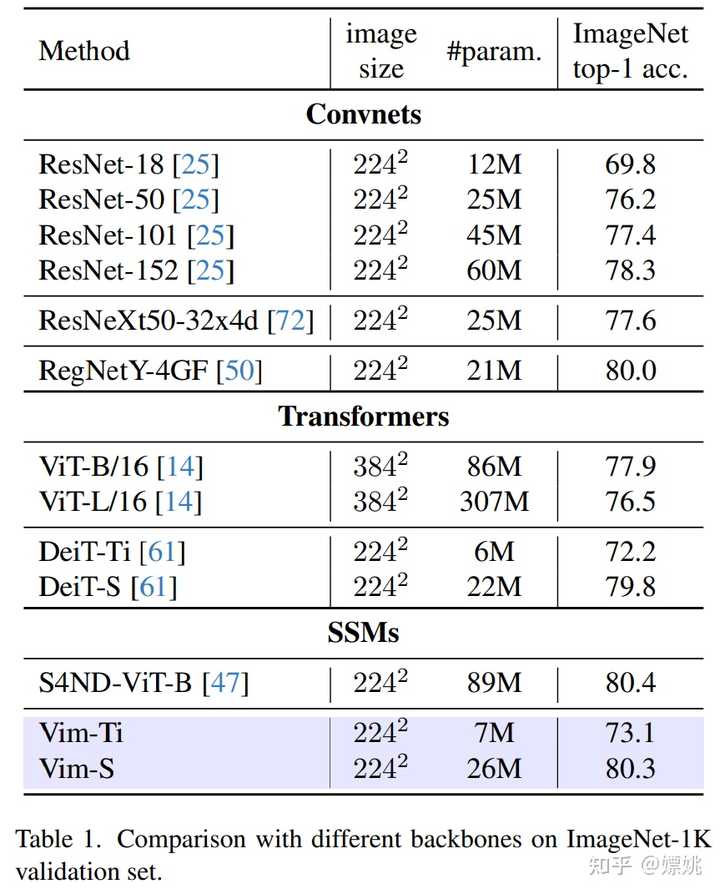
架构细节 架构的超参数如下: L:块数D:隐藏状态维度E:扩展状态维度N:SSM 维度 遵循 ViT 和 DeiT,该研究首先采用 16×16 内核大小的投影层来获得非重叠 patch 嵌入的一维序列。随后直接堆叠 L 个 Vim 块。默认情况下块数 L 设置为 24,SSM 维度 N 设置为 16。为了与 DeiT 系列模型大小保持一致,该研究将小( tiny)尺寸变体的隐藏状态维度 D 设置为 192,将扩展状态维度 E 设置为 384。对于小(small)尺寸变体,该研究将 D 设置为 384,将 E 设置为 768。 实验 该研究在 ImageNet-1K 数据集上对 Vim 进行了基准测试。 图像分类 表 1 将 Vim 与基于 ConvNet、基于 Transformer 和基于 SSM 的骨干网络进行了比较。与基于 ConvNet 的 ResNet 相比,Vim 表现出更优越的性能。例如,当参数大致相似时,Vim-Small 的 top-1 准确率达到 80.3,比 ResNet50 高 4.1 个百分点。与传统的基于自注意力的 ViT 相比,Vim 在参数数量和分类准确率方面都有相当大的优势。与高度优化的 ViT 变体(即 DeiT )相比,VimTiny 比 DeiT-Tiny 高 0.9 个点,Vim-Small 比 DeiT 高 0.5 个点。与基于 SSM 的 S4ND-ViTB 相比,Vim 以减少 3 倍的参数实现了类似的 top-1 准确率。 |
|
|
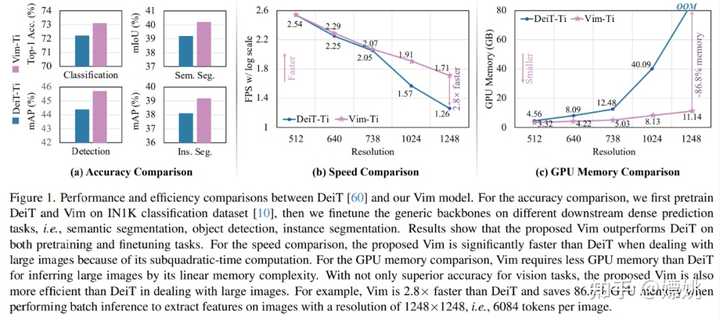
图 1 (b) 和 (c) 比较了小型 Vim 和 DeiT 的 FPS 和 GPU 内存。随着图像分辨率的提高,Vim 在速度和内存方面表现出更好的效率。具体来说,当图像大小为 512 时,Vim 实现了与 DeiT 相似的 FPS 和内存。当图像大小增长到 1248 时,Vim 比 DeiT 快 2.8 倍,并节省 86.8% 的 GPU 内存。Vim 在序列长度上的线性扩展的显著优势使其为高分辨率下游视觉应用和长序列多模态应用做好了准备。 |
|
|
语义分割 如表 2 所示,Vim 在不同尺度上始终优于 DeiT:Vim-Ti 比 DeiT-Ti 高 1.0 mIoU,Vim-S 比 DeiT-S 高 0.9 mIoU。与 ResNet-101 主干网络相比,Vim-S 以减少近 2 倍的参数实现了相同的分割性能。 |
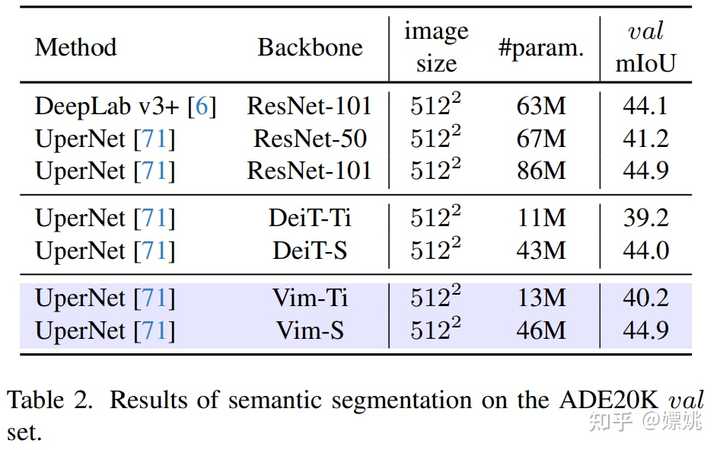
|
|
为了进一步评估研究方法在下游任务上(即分割、检测和实例分割)的效率,本文将骨干网与常用的特征金字塔网络(FPN)模块结合起来,并对其 FPS 和 GPU 内存进行基准测试。 如图 3 和图 4 所示,尽管该研究在主干网上附加了一个 heavy FPN,但效率曲线与纯主干网(图 1)的比较结果相似。 |
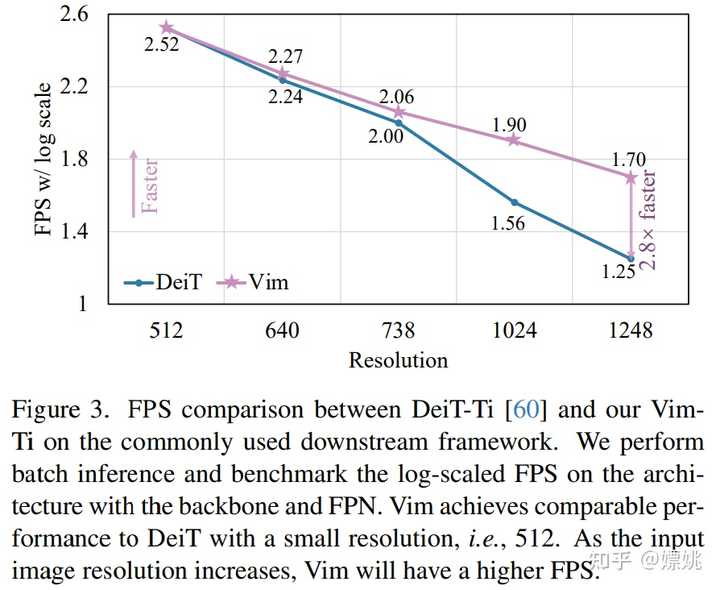
|
|
|
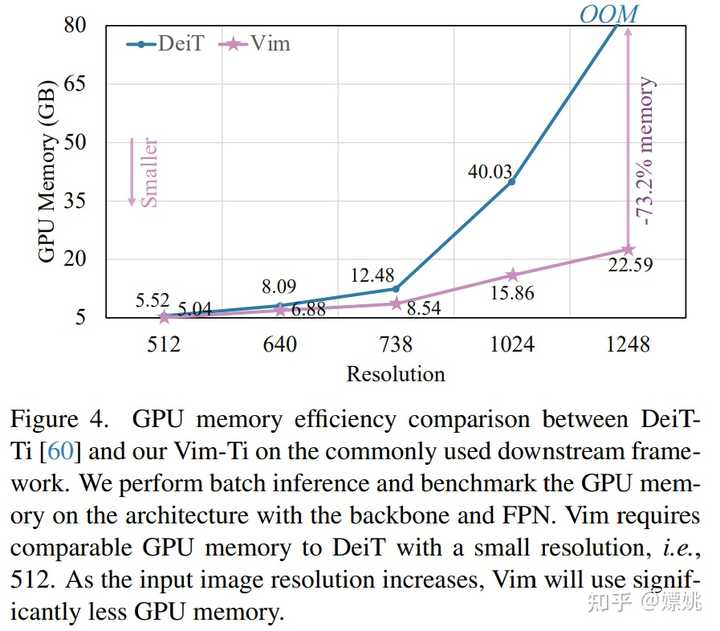
|
|
目标检测和实例分割 表 3 使用 Cascade Mask R-CNN 框架对 Vim-Ti 和 DeiT-Ti 进行了比较。Vim-Ti 超过 DeiT-Ti 1.3 box AP 和 1.1 mask AP。 |
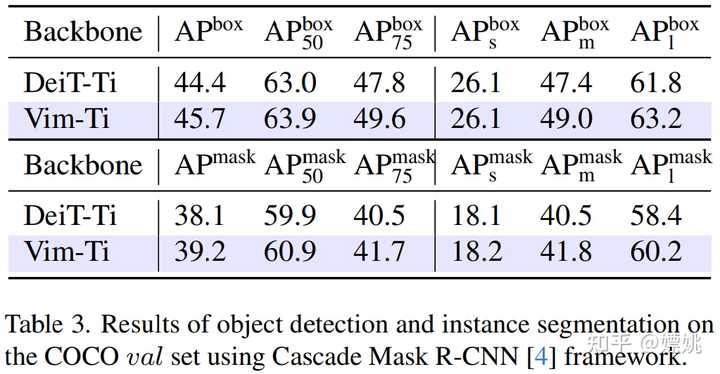
|
|
下图为可视化结果:本文方法可以捕获图像中非常大的物体,这是 DeiT-Ti 等无法做到的。 |

|
|
|
|
Jamba, the world’s first production-grade Mamba based model from @AI21Labs - combines transformer and mamba - MoE layers allow it to draw on just 12B of its available 52B parameters at inference - massive 256K context window - 140K context on a single GPU - Apache 2.0 blog: https://ai21.com/blog/announcing-jamba… @huggingface: https://huggingface.co/ai21labs/Jamba-v0.1… @nvidia NGC (coming soon): https://catalog.ngc.nvidia.com/ai-foundation-models… This is a wild week for AI |
|
个人愚见,CNN的地位仍然不可撼动。目前最大的挑战者Transformer在过去几年的演化之后,也仅仅是有与CNN平齐的实力,也谈不上全面碾压。况且ViT的具体源码实现里patch embedding还是用Conv2d实现的,换言之Transformer骨干几乎还是不可避免地要在第一阶段用Conv-baesd stem。 Mamba只能说,当下赶热度水论文做个噱头还行,但是不是真的革命性进展,还需要很长的时间来验证。 |
|
hi man what can i say |
|
和我自己写的transformer在MiniPile上跑了5b tokens做对比,结果还是比不过transformer |
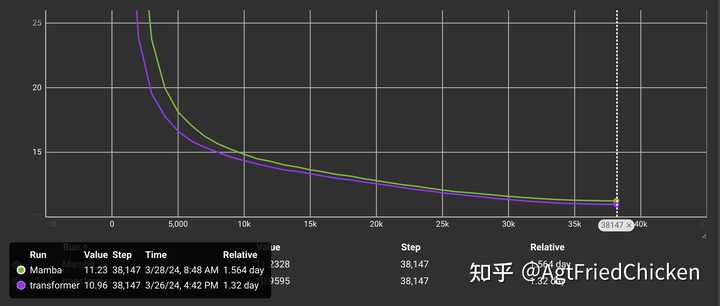
|
|
|
|
反正多了一个积木 把以前的作品部分积木换成新积木,讲个故事,在特定数据集某个指标达到SOTA就是一篇新论文。 |
|
Mamba 是一个新兴的架构,在自然语言处理、机器学习和其他领域引起了广泛关注。它在许多方面都具有优势,包括: 更高的效率:Mamba 可以比传统的 Transformer 架构更快地训练和运行。更强的性能:Mamba 在许多任务上都取得了最先进的成果。更高的灵活性:Mamba 可以很容易地扩展到新的任务和领域。 然而,Mamba 也有一些潜在的缺点,包括: 缺乏成熟度:Mamba 仍然是一个相对较新的架构,尚未经过大规模的生产环境验证。缺乏可解释性:Mamba 的内部机制可能难以理解和解释。 总体而言,Mamba 是一个很有前途的新架构,有可能在许多领域产生重大影响。然而,它仍然需要进一步的研究和开发才能达到其全部潜力。 以下是关于 Mamba 的一些具体研究结果: 在自然语言处理领域,Mamba 在机器翻译、文本摘要和问答等任务上取得了最先进的成果。在机器学习领域,Mamba 在图像识别、语音识别和自然语言生成等任务上取得了最先进的成果。在其他领域,Mamba 也取得了一些初步的成功,例如在化学和生物学领域。 目前,Mamba 仍然是一个相对较新的架构,尚未经过大规模的生产环境验证。然而,它在许多任务上都取得了最先进的成果,表明它具有巨大的潜力。随着 Mamba 的进一步研究和开发,它有可能在许多领域产生重大影响。 以下是一些关于 Mamba 未来发展的预测: Mamba 将在自然语言处理、机器学习和其他领域得到更广泛的应用。Mamba 将与其他架构,例如 Transformer 相结合,以创建更强大的模型。Mamba 将用于开发新的应用程序和服务。 Mamba 的未来发展充满希望,它有可能改变我们与计算机交互的方式。 |
|
最近看到很多报道,介绍了AI下一步发展的瓶颈在哪里,包括奥特曼在内的人士普遍认为电力,或者广泛来讲的能源供给会是AI进一步普及应用的阻力。有一种说法是AI的尽头是光伏和储能。 今天刚好读了下Mamba架构的Paper,有感而发,目前虽然LLM或者VLM在语言理解和视觉的分析方面已经达到了类人的能力,但是底层依赖的是巨大的电力消耗和GPU算力供应。Lecunn在一次采访中讲到,一个 GPU 的功耗在五百瓦特到一千瓦特之间,而人脑的功耗约为25瓦特,GPU 的功耗远远高于人脑的功耗,但人脑所处理的算力表现,需要十万或上百万瓦特的 GPU 才能与之匹敌。 看了上述的描述,大家可能都跟我一样有一个疑问,为什么目前基于硅基所产生的智能,各种大模型的应用的消耗远远高于人脑? 我认为一个重要原因是当前以Transformer为基础的模型结构,虽然在生物学上已经可以一定程度模拟人脑,在很多Paper有相关的论证,比如下图介绍的是Transformer类人脑海马体的设计。 |
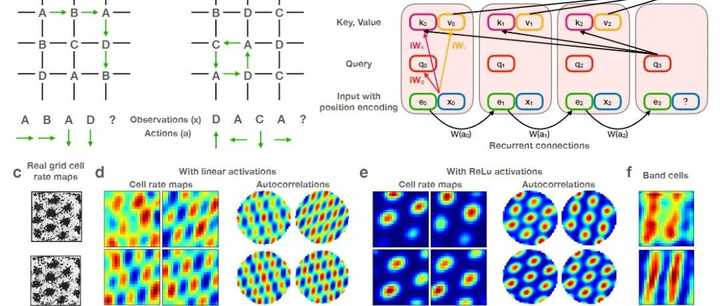
|
|
但是Transformer这种基于Attention机制的N方计算复杂度基础模型并不经济。于是,接下来的技术演进方向之一是就是如何通过更经济的基础模型架构简化Transformer这种模式,并且达到更好的效果,最近有很多相关工作,比如Flash Attention。Mamba可以看作非常有希望的一个新基础模型结构,后续会有更多类似的工作,在数学层面优化智能构建的模式,降低能源的消耗。 接下来看下Mamba是怎么做到的。分为三个方面: 1.一种时序数据的选择机制 |
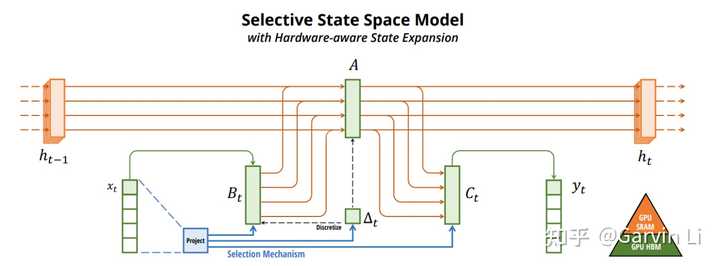
|
|
Transformer结构是大力出奇迹的模式,每次训练和推理需要把历史所有数据都遍历一遍,而Mamba结构每次输入的数据是对历史数据的提炼和总结。这一点其实更与人脑的记忆活动类似,因为我们在记忆存储的时候也是基于关键片段的总结的。 2.硬件感知算法:通过算法减少HBM的IO压力,提升整体计算速度。 3.全新的架构设计 |
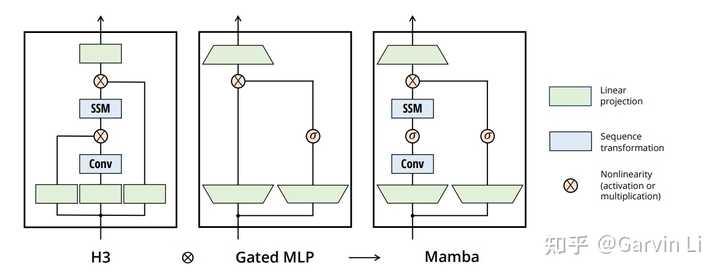
|
|
在数学公式层面通过简化架构达到驱动的计算效果。 看了大概内容后,对新的更经济的模型架构应用还是充满期待的,不过如何突破当前Transformer已经形成的软硬件生态,是需要解决的问题。未来应该会有更多先进的基础架构模型诞生,从硬件、引擎、框架各层,如何更快捷的适配,对于AI工程能力是个大考。 |
|
本文将为大家介绍“RSMamba: Remote Sensing Image Classification with State Space Model”(基于状态空间模型的遥感图像分类),性能SOTA,代码已开源。 |

|
|
Title: RSMamba: Remote Sensing Image Classification with State Space ModelPaper: https://arxiv.org/abs/2403.19654Code: https://github.com/KyanChen/RSMamba 01 /导读/ 遥感图像分类是各种遥感理解任务的基础,卷积神经网络(CNNs)和Transformers的最新进展显著提高了分类精度。然而,遥感场景分类仍然是一个重大挑战,特别是考虑到遥感场景的复杂性和多样性以及时空分辨率的可变性。全图像的理解能力可以为场景区分提供更精确的语义线索。本文介绍了RSMamba,这是一种新颖的遥感图像分类架构。RSMamba基于状态空间模型(SSM),并采用高效、硬件感知设计的Mamba实现,它整合了全局感受野和线性复杂度建模的优点。为了缓解原始Mamba只能建模因果序列,不能适应二维图像数据的缺点,文中提出了一种动态多路径激活机制来增强Mamba处理非因果数据的能力。值得注意的是,RSMamba保持了原始Mamba的内在建模机制,但仍在多个遥感图像分类数据集上表现出优越的性能。 02 /引言/ 遥感场景的复杂性和多样性,加上时空分辨率的变化,给自动遥感图像分类带来了重大挑战。深度学习具有自主从数据中挖掘有效特征并以端到端的方式输出分类概率的能力。在网络架构方面,主要可以分为CNNs和注意力网络。前者通过二维卷积操作逐层抽象图像特征。后者通过注意力机制捕获整个图像局部区域之间的长距离依赖性,从而实现更强大的语义响应。一定程度上,遥感图像分类精度严重依赖模型具备处理复杂多样的遥感场景和变化的时空分辨率影响的能力。基于注意力机制的Transformer能够从整个图像的有价值区域获取响应,为这些挑战提供了最佳解决方案。然而,随着输入序列长度的增加或网络的加深,其注意力计算的平方复杂性在建模效率和内存使用方面带来了重大挑战。状态空间模型(SSM)可以通过状态转换建立长距离依赖关系,并通过卷积计算执行这些转换,从而实现近线性复杂性。Mamba通过将时变参数引入到简单的SSM中并进行硬件优化,对训练和推理都非常高效。Vim和VMamba已经成功地将Mamba引入到二维视觉领域,在多个任务中实现了性能和效率的良好平衡。 本文介绍了RSMamba,一种用于遥感图像分类的高效状态空间模型。RSMamba基于Mamba实现,但引入了动态多路径激活机制,以缓解Mamba只能在单一方向上建模,且对位置不敏感的限制。值得注意的是,RSMamba被设计为保留原始Mamba块的内在建模机制,只在块外引入非因果和位置敏感的改进。具体来说,图像被划分为重叠的补丁令牌,添加位置编码形成序列。并构造了三个路径副本,即前向、反向和随机。这些序列通过使用共享参数的Mamba块建模以包含全局关系,然后通过不同路径的线性映射进行激活。 本文的主要贡献可以总结如下: i) 提出了RSMamba,一种基于状态空间模型(SSM)的高效全局特征建模方法用于遥感图像分类。该方法在表征能力和效率方面具有显著优势,可以作为处理大规模遥感图像解释的可行解决方案。 ii) 具体来说,引入了一个位置敏感的动态多路径激活机制,以缓解原始Mamba仅限于建模因果序列,并对空间位置不敏感的限制。 iii) 在三个不同的遥感图像分类数据集进行了全面的实验,结果表明,RSMamba比其他基于CNN和Transformers的分类方法表现出显著优势。 03 /方法/ State Space Model 状态方程: |
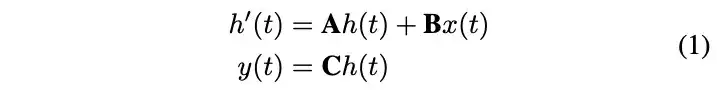
|
|
离散化: |
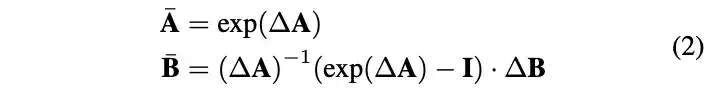
|
|
|

|
|
|
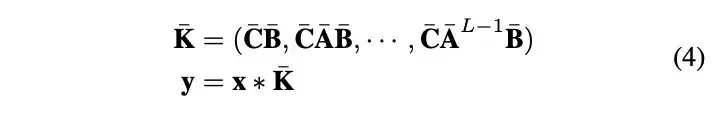
|
|
RSMamba |

|
|
RSMamba将2-D图像转化为1-D序列,并使用多路径SSM编码器捕获长距离依赖关系,如图所示。给定一幅图像,使用一个二维卷积核将局部区域映射到像素级的特征嵌入。随后,特征图被展平成1-D序列。为了保留图像内部的相对空间位置关系,引入位置编码,整个过程如下, |

|
|
RSMamba并未像ViT那样使用[CLS]标记来聚合全局表示。相反,该一维序列被输入到多个动态多路径激活的Mamba块中,用于建模长距离依赖关系。随后,通过对序列平均池化得到类别预测所需的密集特征。这个过程可以迭代地描述如下, |
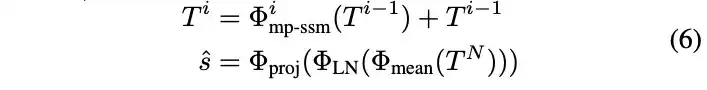
|
|
Dynamic Multi-path Activation 原始的Mamba用于对1-D序列进行因果建模,为了增强其对2-D数据的处理能力,引入了一个动态多路径激活机制。重要的是,这种机制为了保留原始Mamba块的结构,仅在块的输入和输出上操作。具体来说,复制了三份输入序列,建立了三个不同的路径,即前向路径、反向路径和随机路径,并利用一个参数共享的普通Mamba混合器分别对这三个序列中的标记之间的依赖关系进行建模。随后,我们将序列中的所有标记恢复到正确的顺序,并使用一个线性层来压缩序列信息,从而建立了三个路径的门控。然后,这个门被用来激活三种不同信息流的表示,如上图所示。第i个块的过程如下所述, |
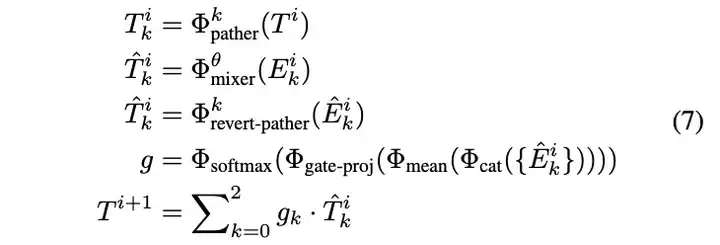
|
|
Model Architecture |
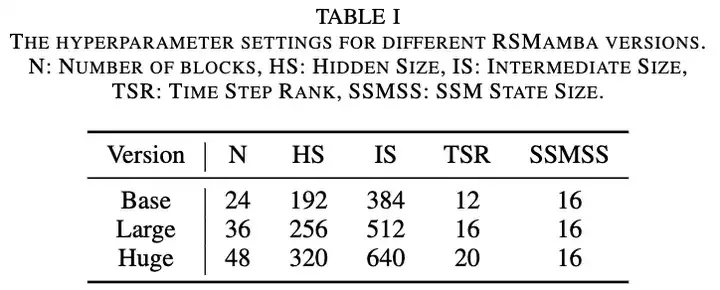
|
|
04 /实验/ 为了评估所提出方法的效果,在三个不同的遥感数据集上进行了广泛的实验:UC Merced土地利用数据集(UC Merced),AID,和NWPU-RESISC45数据集(RESISC45)。每个数据集都包含不同的地物类别和图像数量。 |

|
|
05 /结论/ 本文引入了一种新的状态空间模型用于遥感图像分类,称为RSMamba。RSMamba同时利用了CNN和Transformer的优点,特别是它们的线性复杂性和全局感受野。RSMamba引入了一个动态多路径激活机制,以减轻原始Mamba中固有的单向建模和位置不敏感的限制。RSMamba保持了Mamba的内部结构,并提供了灵活性,可以轻松扩展参数以适应各种应用场景。在三个不同的遥感图像分类数据集上进行的实验评估表明,RSMamba可以超越基于CNN和Transformer的其他最先进的分类方法,具有作为下一代视觉基础模型的主干网络的巨大潜力。 |
|
?xT: Nested Tokenization for Larger Context in Large Images 公和众和号:EDPJ(进 Q 交流群:922230617 或加 VX:CV_EDPJ 进 V 交流群) |

|
|
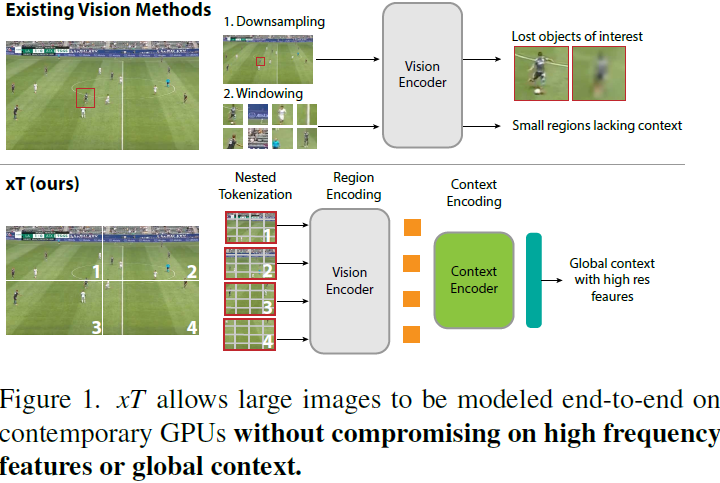
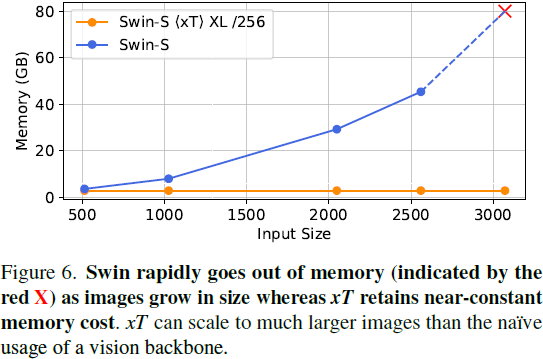
目录 0. 摘要 3. 背景 3.1. 长上下文模型作为上下文编码器 3.2. 线性注意机制 4. 方法 4.1. 嵌套标记化 4.2. 区域编码器 4.3. 上下文编码器 5. 实验 0. 摘要 现代计算机视觉流水线处理大图像通常采用两种次优的方式之一:降采样或裁剪。这两种方法都会导致图像中信息和上下文的显著丢失。在许多下游应用中,全局上下文与高频细节一样重要,例如在真实世界的卫星图像中;在这种情况下,研究人员不得不做出舍弃哪些信息的尴尬选择。我们引入了 xT,这是一个简单的视觉 Transformer 框架,它有效地聚合了全局上下文和局部细节,并且可以在当今的 GPU 上端到端地建模大尺度图像。我们选择了一组经典视觉任务中的基准数据集,这些数据集准确反映了视觉模型理解真正大型图像并在大尺度上合并细节的能力,并评估了我们的方法在这些任务上的改进。通过引入针对大型图像的嵌套标记化(Nested Tokenization)方案,结合通常用于自然语言处理的长序列长度模型,我们能够在具有挑战性的分类任务上将准确度提高多达 8.6%,并将上下文相关分割中的 F1 分数提高 11.6%。 项目页面:https://github.com/bair-climate-initiative/xT |
|
|
3. 背景3.1. 长上下文模型作为上下文编码器 xT 利用了最初设计用于文本的长上下文模型,以便在大型图像之间混合信息。这些方法将上下文长度延伸到超出 transformer 的典型限制。以下我们简要回顾了作为我们上下文编码器的两种技术:Transformer-XL [3] 和 Mamba [9]。 Transformer-XL 使用循环将先前的信息通过先前的隐藏状态传递到未来的窗口。这种效应通过深度传播,因此能够处理长度为 L 的序列的 N 层 transformer 可以很容易地扩展到处理长度为 NL 的序列。 序列 τ 的第 n 层的每个隐藏状态 h^n_τ 是从前一层的隐藏状态 h^(n?1)_(τ?1) 和 h^(n?1)_τ 计算的,如下所示: |
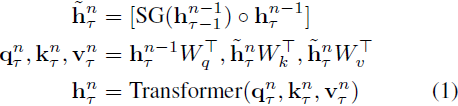
|
|
其中 SG 代表停止梯度。这与原始的 Transformer 相同,只是键和值 k^n_τ , v^n_τ 是使用前一个序列的隐藏状态 h^(n?1)_(τ?1) 以及当前序列的隐藏状态 h^(n?1)_τ 来计算的,使用了交叉注意力。这种机制允许隐藏状态 h^n_τ 在层之间循环。在序列之间应用停止梯度让信息在不承受完整序列反向传播所带来的内存成本的情况下传播。 状态空间和 Mamba。 3.2. 线性注意机制 具有多头自注意力的标准 Transformer 块对于完全全局上下文的序列长度 L 需要二次内存。这在有限的 GPU 内存面前并不理想。HyperAttention [12] 是一种注意机制,其复杂度与序列长度几乎呈线性关系。它通过首先使用局部敏感哈希(Locality Sensitive Hashing,LSH)找到注意力矩阵的大条目来减少朴素注意力的复杂性。然后,将这些主导条目与矩阵的另一个随机抽样子集结合起来,用于近似朴素注意力的输出。当长程上下文对应关系稀疏时,这种方法特别有帮助。 |
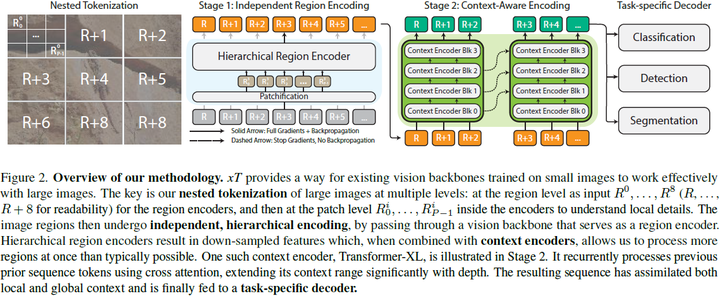
|
|
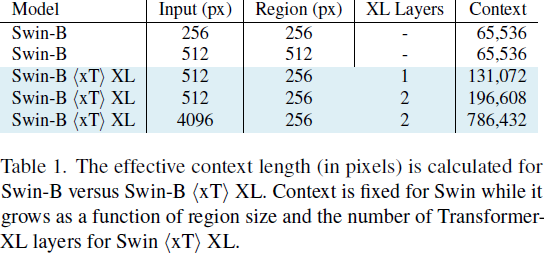
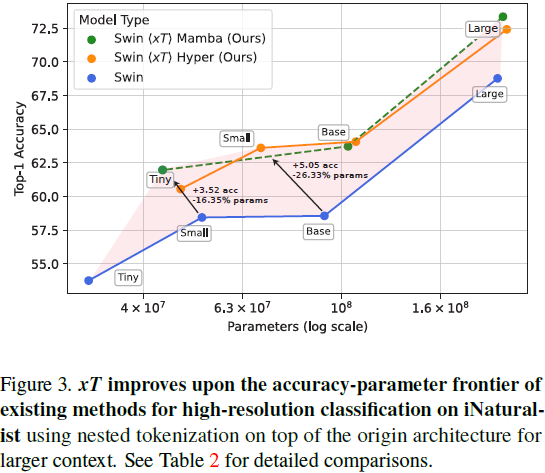
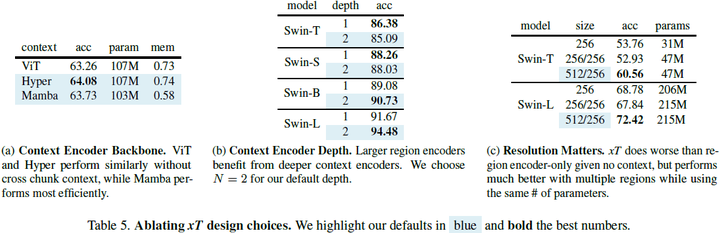
4. 方法4.1. 嵌套标记化 给定形状为 αH×βW 的大输入图像,我们首先将图像细分为 H×W 的区域,以便我们的区域编码器能够充分处理它们。每个区域 R^i 都被进一步分成 P 个补丁(patch),R^i_0,...,R^i_(P?1),通过区域编码器骨干来为每个区域提取特征。当区域大小 H×W 不能整除图像大小时,这些区域是非重叠的,并且在实例化时进行零填充。通常我们的图像和区域是正方形的,因此我们使用简化的符号来表示我们的管道参数。我们将接收尺寸为 αR×αR 的图像并将其细分为 R×R 的区域的管道称为 αR/R 设置。标准设置是 512/256 或 4096/512,其中我们分别将图像分割为 2×2 和 8×8 个区域。 4.2. 区域编码器 我们从一个用于典型小图像尺寸 H×W 的图像模型开始训练,通常是 224×224 或 256×256。区域编码器独立地为每个区域 R^i_(1...P) 生成特征图。我们的区域编码器是分层视觉 Transformer,其序列长度从开始处理时减少,并且小于等于等效长度的各向同性 ViTs [5] 生成的长度。因此,我们能够比使用其他体系结构时将更多区域特征组合在一起,因为我们的序列长度减少了 4 倍或更多倍。当 GPU 内存允许时,我们同时为所有区域计算特征。然而,当图像太大,以至于其所有组成区域无法全部放入 GPU 内存时,我们会逐个处理每个区域。 4.3. 上下文编码器 输出的区域特征按行主序(row major order)连接形成一个序列。在 xT 框架中,上下文编码器是一个轻量级的序列到序列模型,可以在长序列长度上进行注意。关键是,我们将上下文编码器限制为具有近线性的内存和时间成本。这种设计使得 xT 能够查看大图像中许多其他区域,否则在内存中是不可行的。这显著扩展了现有视觉模型的感受野,同时在内存成本和参数数量上只有边缘增加。 我们的方法主要在两种情况下发挥作用:当我们的区域特征序列完全适合(fit)上下文编码器的上下文长度时,以及当它不适合时。在第一种情况下,我们只是一次性处理所有内容。我们使用标准的二维位置嵌入,将其添加到嵌套区域特征中。 我们尝试了三种具有线性 “注意力” 机制的上下文编码器:使用 HyperAttention 的 LLaMA 风格的架构(称为 Hyper),以及 Mamba。这两种设置分别称为?xT? Hyper 和?xT? Mamba,其中?xT?是将区域编码器选择与上下文编码器相结合的操作符。 当我们的输入序列不适合整个上下文长度时,我们需要额外压缩我们的区域,以保持未来区域的上下文信息。我们尝试了一种使用 HyperAttention、一种线性注意力形式和绝对位置嵌入的 Transformer-XL 的派生版本。我们将此设置表示为?xT? XL。在撰写本文时,Mamba 没有用于实现 XL 风格循环的有效内核,因此我们无法将 Mamba 应用于此设置。 有效感受野计算我们提供了 Swin?xT? XL 设置的有效感受野的计算。在第 7.1 节进一步对其进行了消融实验。 在上下文编码器中,我们将 C 个区域的特征连接成一个 “块”(chunk),因为我们的特征比来自分层区域编码器的输入要小。Transformer-XL 上下文编码器由于使用 HyperAttention 而具有降低的注意力内存需求,进一步改善了适合一个 “块” 的区域数量。每个区域都会关注这个块中的所有其他区域,并且它们还可以访问上一个块的隐藏状态,以便模型中的上下文流动。在 Transformer-XL 中,上下文随深度的增加而增加。 因此,我们可以计算我们在小图像上仅使用标准模型 query 所实现的上下文增强。如果我们使用输入大小为 R(通常为 256)的区域编码器,并收到大小为 αR×βR 的大图像,则我们将有 αβ 个区域可用于我们的上下文编码器。然后,我们通过增加块的大小增加上下文的长度,增加因子为 C,也从我们的循环内存中增加块(chunk)的大小,增加因子为 N,即上下文模型的深度。这些值在表 1 中进行了计算,并在图 4 中进一步可视化。 总的来说,我们的上下文以因子 αβNC 倍增。然而,请注意 αβ 和 C 之间存在着一个权衡,因为增加输入图像的大小会限制我们从区域特征中创建的块的大小。 |
|
|
|
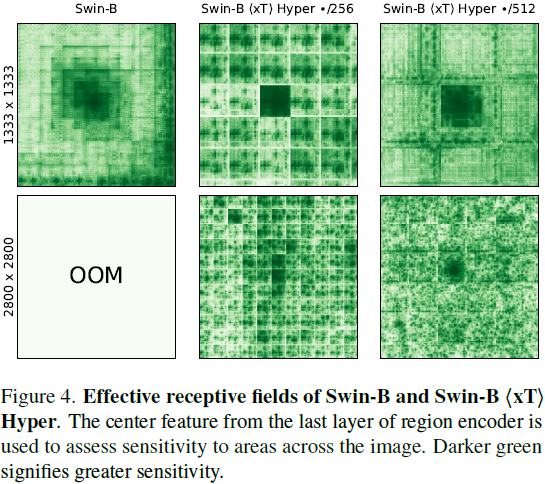
|
|
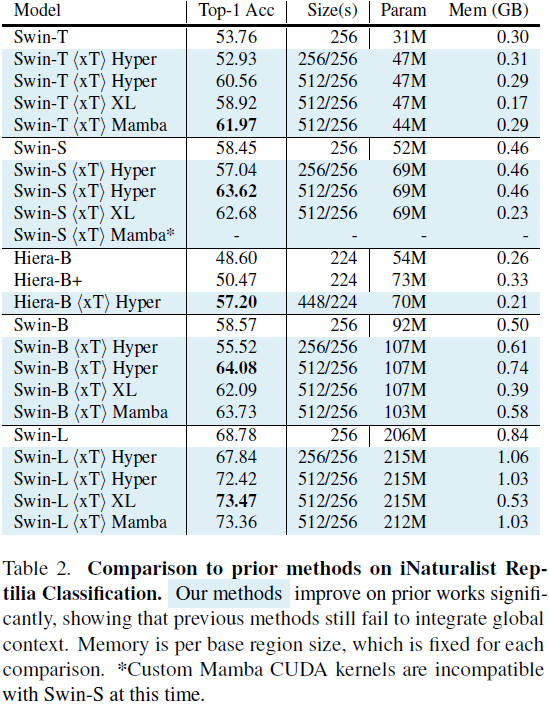
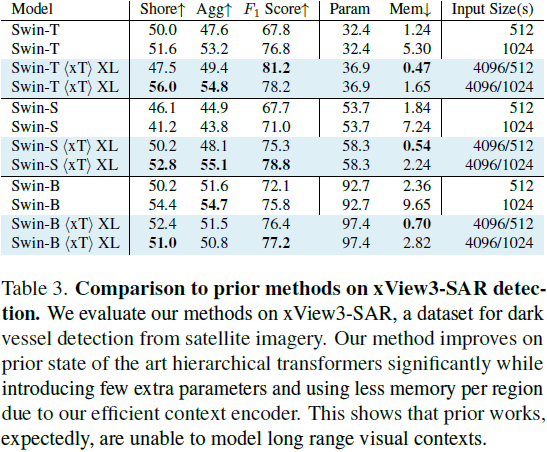
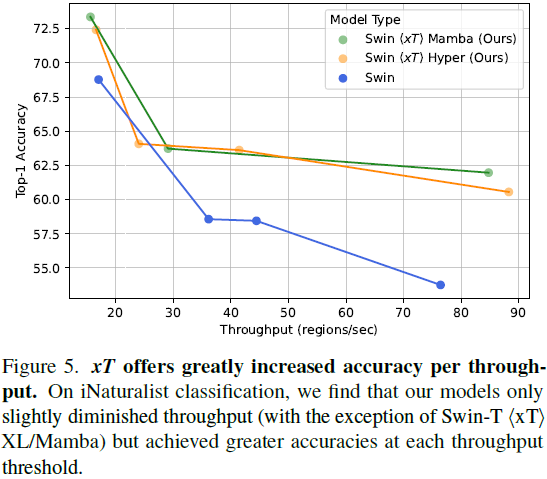
5. 实验 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
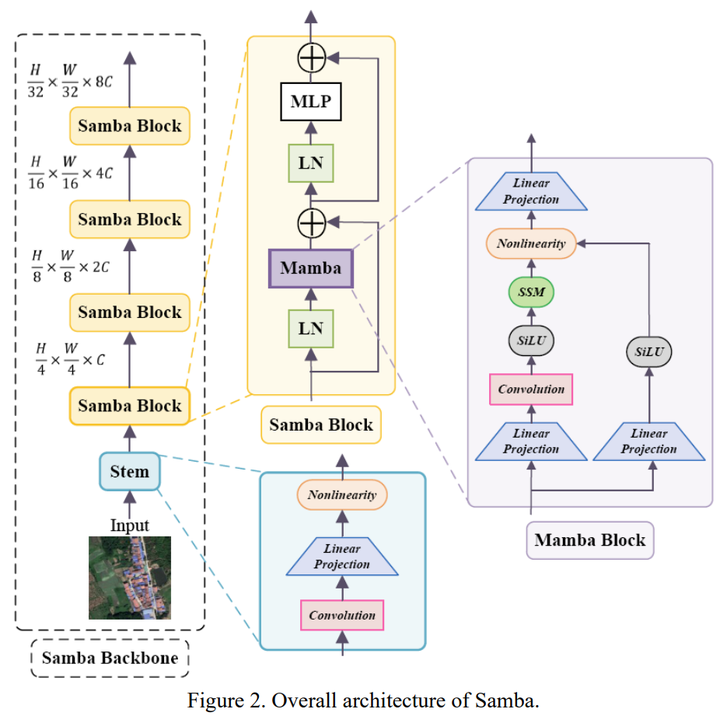
先说结论:新架构mamba在遥感高分辨率图像语义分割中展现了优势。 在这里向大家介绍我方(西交利物浦大学、利物浦大学、CSIRO)的最新工作:Samba: Semantic Segmentation of Remotely Sensed Images with State Space Model。我们提出了一个高分辨率遥感图像的语义分割框架Samba,在LoveDA数据集中指标超过了CNN-based和ViT-based方法,证明了Mamba在遥感高分图像中作为新一代backbone的潜力,为遥感语义分割任务提供了mamba-based方法的表现基准。据我们所知,Samba是第一个将状态空间模型(Mamba)运用到遥感图像语义分割任务中的文章。 文章和代码都已开源,目前在不断迭代中,欢迎各位大佬引用和star?,批评指正。 文章: 代码: 摘要 高分辨率遥感图像对常用的语义分割方法提出了挑战,如卷积神经网络(CNN)和Vision Transformer(ViT)。基于CNN的方法难以处理这种高分辨率图像,因为它们的感受野受限,而ViT面临处理长序列的挑战。受到状态空间模型(SSM),也叫Mamba,能够有效捕获全局语义信息的启发,我们提出了一个针对高分辨率遥感图像的语义分割框架,命名为Samba。Samba利用编码器-解码器架构,其中Samba块作为编码器用于多级语义信息的有效提取,而UperNet作为解码器。我们在LoveDA数据集上评估了Samba,并将其性能与表现最佳的CNN和ViT方法进行了比较。结果显示,Samba在LoveDA上取得了杰出的表现。这表明,所提出的Samba框架是SSM在遥感图像语义分割中的有效应用,为这一特定应用中基于Mamba技术的设定了新的性能基准。 模型架构 |
|
|
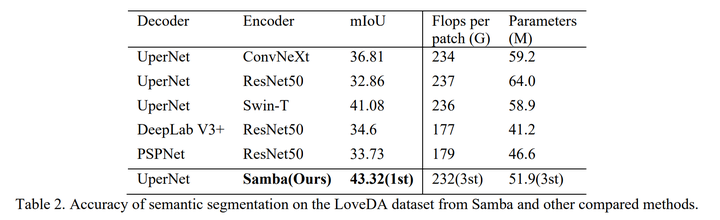
详见arxiv文章。 对比实验 在公平的实验设置下(详见文章),Samba架构的语义分割准确度优于CNN-based方法以及ViT-based方法。 |
|
|
结论 本文介绍了一个基于Mamba的新型语义分割框架Samba,被设计用于高分辨率遥感图像的分割。它标志着Mamba在该领域的首次融合。通过在LoveDA数据集上评估其性能,Samba超越了最先进的CNN-based和ViT-based的方法,设立了新的性能基准,并展示了Mamba架构在高分辨率遥感图像语义分割中的有效性和潜力。 |
|
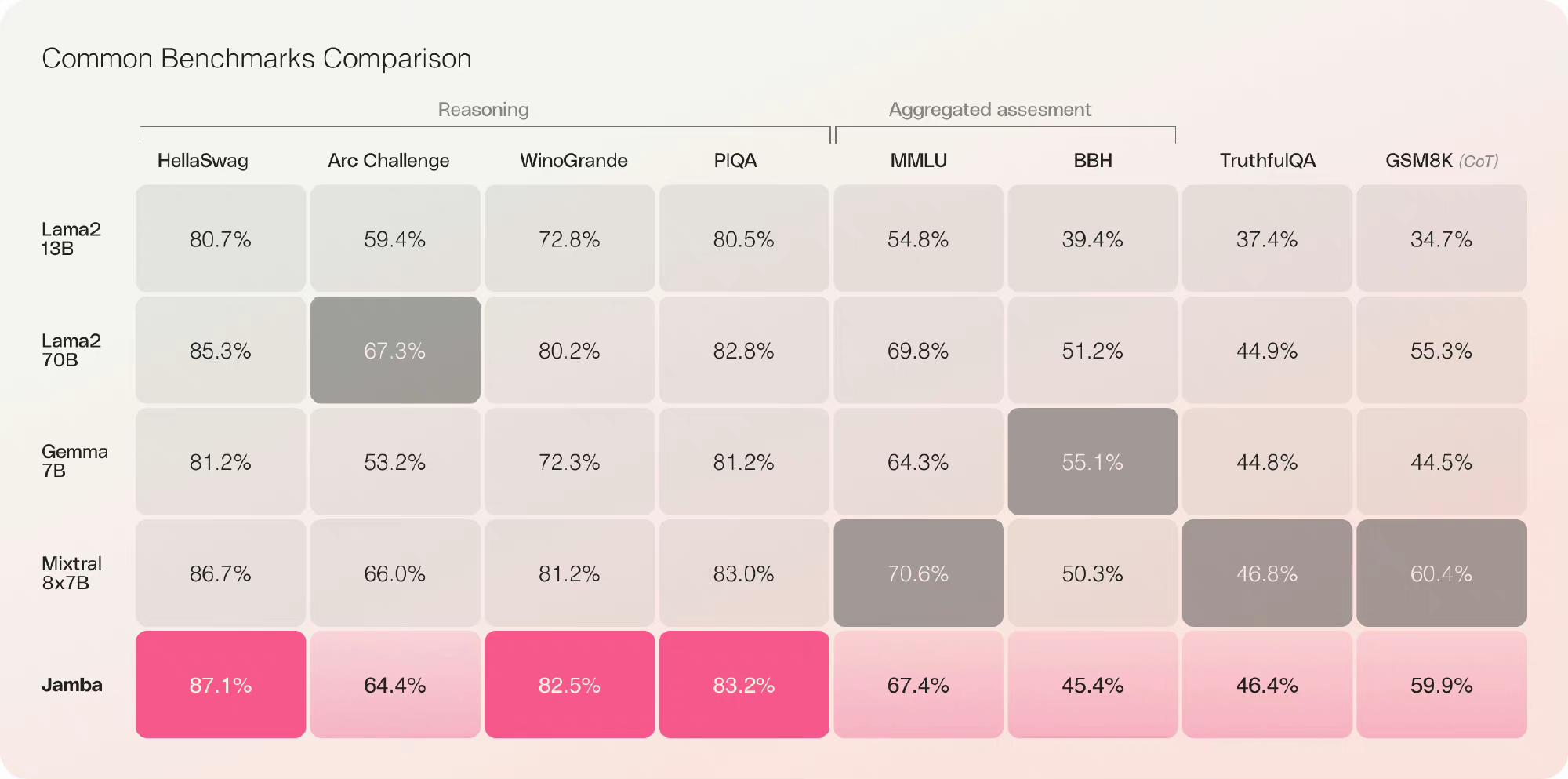
语言模型里,融合了Mamba架构的精髓,还结合了Transformer的特性,混合巨兽以520亿的庞大参数量诞生。Jamba平衡了模型的质量和运行效率,兼顾了高吞吐量与低内存需求,大规模语言处理变得更加高效,在处理语言理解的深度和广度上,Jamba展现出强大的能力,能够消化256,000个令牌的上下文信息,对传统模型巨大超越。 初步的性能评估还不错,即使与Mixtral 8x-7B相比,Jamba在整体性能上也毫不逊色。特别是在处理128,000个令牌的长文本时,吞吐量竟然是Mixtral的三倍之多,Jamba在处理大量数据时的速度远超同类,Jamba只需要单块NVIDIA A100 GPU就能处理高达140,000的上下文,这在效率与成本效益方面树立了新的标杆,堪称同等规模模型中的翘楚。 就连Mamba架构的原始设计者也被Jamba的卓越表现所打动,兴奋地将其称为“大新闻”,足以证明Jamba在推动语言模型技术发展上的重要地位。 |
|
|
|

|
|
|
|
|
|
|
|
|
|
古人已经告诉我们答案了。 夫,何罐吾言? |
|
Mamba是一种新的开源软件基础设施或框架,主要用于数据分析和科学计算领域。它基于Conda环境管理和Jupyter Notebook等工具,旨在提供一个更高效、更易用的环境管理系统。 Mamba的核心优势在于其速度和效率。由于它使用了C++重写的一些关键组件,因此在处理复杂的环境管理和包依赖关系时,相比于传统的conda命令,mamba能够更快地解决这些问题。 对于经常需要管理复杂Python环境、处理众多库依赖的研究者和开发人员来说,Mamba确实是一个非常有用的工具。然而,具体是否有用还要取决于用户的具体需求和场景。如果你的工作流主要集中在简单的Python项目或者你并不常遇到环境配置问题,那么可能感觉不到Mamba带来的显著变化。但对于大型团队协作、多项目并行开发以及大规模数据分析任务而言,Mamba的引入无疑会提高工作效率。 |
|
论文标题:TimeMachine: A Time Series is Worth 4 Mambas for Long-term Forecasting (这篇的标题应该是在模仿PatchTST的标题:A time series is worth 64 words: Long-term forecasting with transformers) 作者: Md Atik Ahamed, Qiang Cheng 机构:肯塔基大学(UKY) 论文链接:https://arxiv.org/abs/2403.09898 Cool Paper:https://papers.cool/arxiv/2403.09898 代码:https://github.com/Atik-Ahamed/TimeMachine TL;DR:本文提出了一个名为TimeMachine的模型,通过4个Mamba状态空间模型来有效地进行多变量时间序列的长期预测,同时保持线性可扩展性和低内存消耗。 关键词:长期时间序列预测(LTSF),选择性状态空间模型(SSSM),通道混合(Channel Mixing)、通道独立(Channel Independence |

|
|
标题和作者摘要 由于捕获长期依赖性、实现线性可扩展性和保持计算效率的困难,长期时间序列预测仍然具有挑战性。 推出了 TimeMachine,这是一个创新模型,它利用 Mamba(一种状态空间模型)来捕获多元时间序列数据中的长期依赖性,同时保持线性可扩展性和较小的内存占用。 TimeMachine 利用时间序列数据的独特属性来产生多尺度的显着上下文线索,并利用创新的集成 quadruple-Mamba 架构来统一对通道混合(channel-mixing)和通道独立(channel-independence)情况的处理,从而能够有效地选择内容进行预测 不同尺度的全局和局部上下文。 在实验上,TimeMachine 在预测准确性、可扩展性和内存效率方面实现了卓越的性能,并使用基准数据集进行了广泛验证。 Q: 这篇论文试图解决什么问题? A: 这篇论文介绍了一个名为TimeMachine的创新模型,旨在解决长期时间序列预测(Long-term Time-Series Forecasting, LTSF)的挑战。LTSF在多个领域如天气预报、异常检测、能源、农业、工业和国防资源规划等任务中至关重要。尽管已经开发了许多LTSF方法,但它们通常只能实现以下一个或两个期望属性: 捕获多变量时间序列(Multivariate Time Series, MTS)中的长期依赖关系。随着数据量的增加,模型参数的数量呈线性可扩展性。计算效率或在边缘计算中的适用性。 论文指出,同时实现这些理想属性仍然是一个挑战。特别是,捕获长期依赖关系对于LTSF至关重要,但现有的线性模型(如DLinearer和TiDE)虽然具有竞争力的性能和线性复杂度,但它们依赖于多层感知器(MLPs)和线性投影,可能无法很好地捕获长期相关性。而基于Transformer的模型(如iTransformer、PatchTST和Crossformer)虽然能够通过自注意力机制捕获长期依赖关系并提高LTSF的准确性,但它们通常受到二次复杂度的限制,限制了它们的可扩展性和适用性。 为了解决这些问题,TimeMachine模型利用Mamba,一种状态空间模型(State-Space Model, SSM),来捕获多变量时间序列数据中的长期依赖关系,同时保持线性可扩展性和小内存占用。该模型通过创新的四重Mamba架构来统一处理通道混合和通道独立情况,有效选择不同尺度的全局和局部上下文内容进行预测。实验结果表明,TimeMachine在预测准确性、可扩展性和内存效率方面均取得了优越的性能。 Q: 有哪些相关研究? A: 这篇论文提到了多个与长期时间序列预测(LTSF)相关的研究领域和具体方法,可以归纳为以下几类: 非Transformer基础的监督学习方法: 经典时间序列方法,如ARIMA、VARMAX、GARCH和RNN。基于深度学习的MLP和CNN方法,例如DLinear、TiDE和RLinear,使用多层感知器(MLPs)和卷积神经网络(CNNs)来实现。 基于Transformer的监督学习方法: iTransformer、PatchTST、Crossformer、FEDformer、stationary和autoformer等,这些方法将时间序列转换为标记序列,并利用自注意力机制来发现任意时间步骤之间的依赖关系。 自监督表示学习模型: 使用非Transformer基础模型(例如TS-TCC)和基于Transformer的模型(例如时间序列Transformer和TS-TCC)来学习时间序列的有用表示,用于下游任务。 论文还提到了一些具体的模型和方法,包括但不限于: Autoformer:一种结合自注意力和分解Transformer的模型,用于长期序列预测。Informer:一种高效的Transformer模型,用于处理长时间序列数据。Scinet:一种利用样本卷积和交互来进行时间序列建模和预测的方法。TimesNet:一种用于一般时间序列分析的Temporal 2D-Variation建模方法。 此外,论文还提到了Mamba模型,这是一种具有选择性扫描能力的状态空间模型(SSM),TimeMachine模型正是基于Mamba构建的。Mamba模型能够捕获长期依赖关系,并且具有线性时间复杂度,使其成为处理长期时间序列预测的有力工具。 Q: 论文如何解决这个问题? |
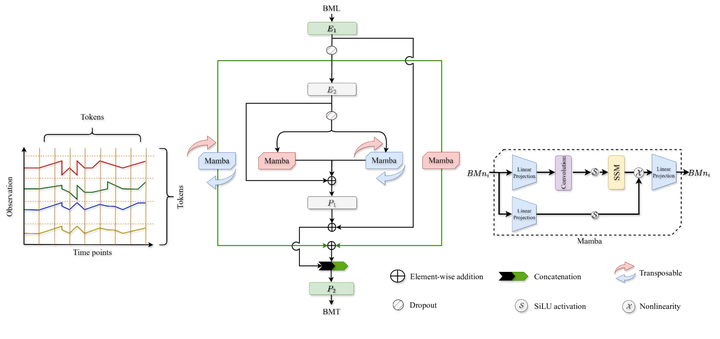
|
|
TimeMachine中间所示:方法包含了四个Mamba,其中2个专门的Mamba能够处理每个分支中的转置信号数据。左图,多元时间序列输入右图,提供了一个Mamba结构的详细放大视图。Mamba能够接受一个形状的输入,同时提供与输出相同的形状。 A: 论文通过提出一个名为TimeMachine的创新模型来解决长期时间序列预测(LTSF)的问题。TimeMachine模型的核心特点和解决策略如下: 利用Mamba模型:TimeMachine模型使用Mamba,一种状态空间模型(SSM),来捕获多变量时间序列(MTS)数据中的长期依赖关系。Mamba模型具有线性时间复杂度,能够有效地处理长序列数据。多尺度上下文线索:TimeMachine通过连续分辨率降低或下采样生成两个尺度的上下文线索。第一层在高分辨率下工作,而第二层在低分辨率下工作。在每个尺度上,模型使用两个Mamba模块来从全局视角捕获通道混合情况下的上下文线索,以及从全局和局部视角捕获通道独立情况下的上下文线索。集成四重Mamba架构:TimeMachine采用一个创新的架构,将四个Mamba模块集成在一起,以统一处理通道混合和通道独立的情况。这种设计使得模型能够根据MTS数据的特点灵活地采用两种处理方式。输出投影:模型通过两个多层感知器(MLPs)P1和P2将Mamba模块的输出标记投影到所需的序列长度上,以生成最终预测。实验验证:TimeMachine在多个标准基准数据集上进行了广泛的实验验证,包括Weather、Traffic、Electricity和ETT数据集。实验结果表明,TimeMachine在预测准确性、可扩展性和内存效率方面均优于或可与当前最先进的方法相媲美。内存占用和可扩展性:TimeMachine模型展示了较小的内存占用,并且能够随着输入序列长度的增加而线性地增加可学习的参数数量,这表明了其在处理更长序列时的可扩展性。 通过这些策略,TimeMachine模型能够有效地解决LTSF中的挑战,同时保持了计算效率和内存效率。 Q: 论文做了哪些实验? |
|
|
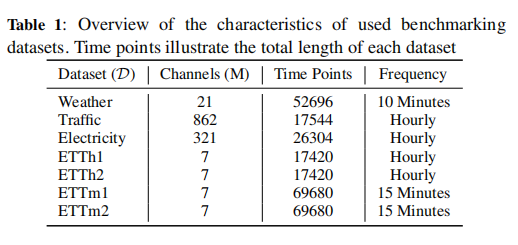
数据集 |
|
|
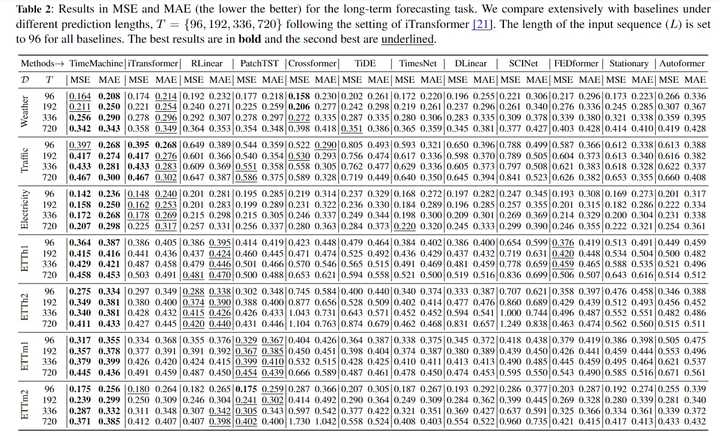
实验结果,输入96,预测{96,192,336,720} |
|
|
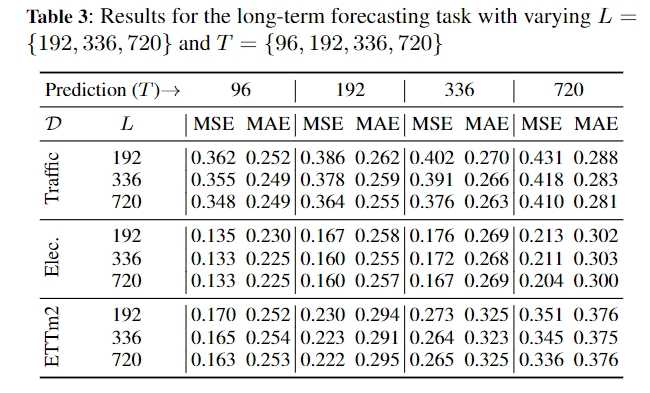
实验结果,纵列:输入长度{192,336,720},横:输出长度{96,192,336,720} |
|
|
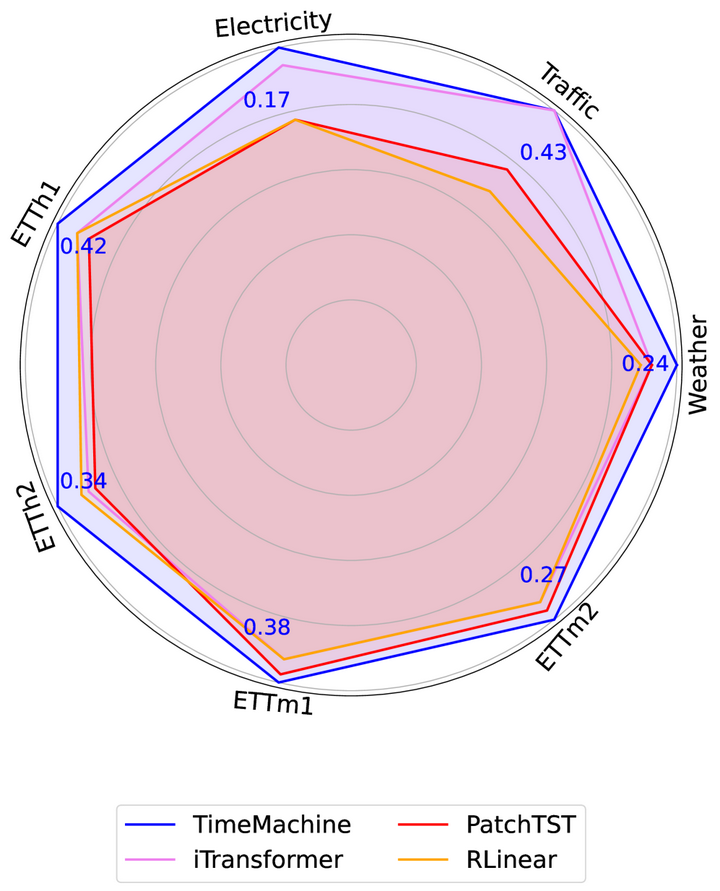
雷达图(96步性能比较) A: 论文中进行了一系列实验来验证TimeMachine模型在长期时间序列预测(LTSF)任务中的性能。以下是实验的主要组成部分: 基准数据集:作者在多个广泛认可的基准数据集上评估了TimeMachine模型,这些数据集包括Weather、Traffic、Electricity以及四个ETT(Electricity Transformer Temperature)数据集(ETTh1, ETTh2, ETTm1, ETTm2)。这些数据集涵盖了不同的领域和时间点数量,以测试模型在不同条件下的表现。性能比较:TimeMachine与其他11个最先进的模型进行了比较,包括iTransformer、PatchTST、DLinear、RLinear、Autoformer、Crossformer、TiDE、Scinet、TimesNet、FEDformer和Stationary。性能指标包括均方误差(MSE)和平均绝对误差(MAE),这些指标用于衡量预测准确性。不同预测长度:作者在不同的预测长度(T = {96, 192, 336, 720})下测试了TimeMachine模型,并设置了不同的输入序列长度(L = 96),以评估模型在不同预测范围的表现。扩展性测试:通过改变输入序列长度(L = {192, 336, 720}),作者评估了TimeMachine模型处理更长序列的能力,以及模型在不同长度下的可扩展性。内存占用和可扩展性:作者测量了TimeMachine模型和其他基线模型的GPU内存使用情况,以比较它们的内存效率。此外,还展示了模型在不同输入序列长度下的可学习参数数量,以证明其线性可扩展性。消融研究:为了展示模型中各个组件的有效性,作者进行了消融研究,包括对MLP参数(n1, n2)、dropout率、残差连接、Mamba的局部卷积宽度、状态扩展因子(N)和维度扩展因子(E)的敏感性分析。定性结果:作者提供了TimeMachine模型与第二名表现最好的方法之间的定性比较,通过可视化预测结果来展示模型在实际时间序列数据上的表现。 这些实验结果表明TimeMachine在预测准确性、可扩展性和内存效率方面均取得了优越的性能,并且能够适应不同长度的时间序列数据和不同特性的多变量时间序列预测任务。 |
|
|
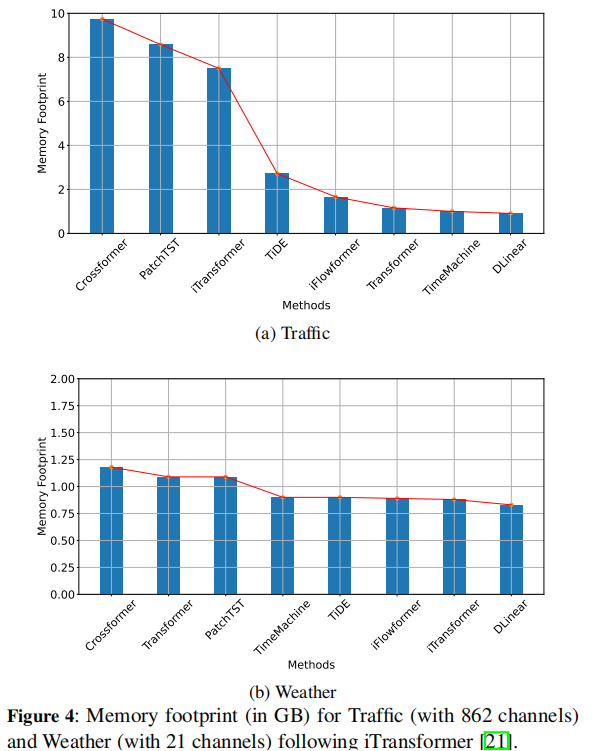
内存占用比较 |

|
|
可扩展性(时间窗长度与参数量的关系)Q: 总结一下论文的主要内容 A: 这篇论文主要内容的总结如下: 问题陈述:长期时间序列预测(LTSF)是一个重要但具有挑战性的任务,尤其是在捕获长期依赖关系、实现线性可扩展性和保持计算效率方面。 TimeMachine模型:为了解决这些挑战,论文提出了一个名为TimeMachine的新型模型,该模型基于Mamba状态空间模型(SSM),旨在捕获多变量时间序列数据中的长期依赖关系,同时保持线性可扩展性和小内存占用 方法论: 多尺度上下文:TimeMachine通过连续分辨率降低生成多尺度上下文线索,以捕获全局和局部的依赖关系。集成四重Mamba架构:模型结合了四个Mamba模块,以统一处理通道混合和通道独立的情况,有效选择不同尺度的上下文内容进行预测。输出投影:使用多层感知器(MLPs)将Mamba模块的输出标记投影到目标序列长度上,以生成最终预测。 实验验证: 在多个标准基准数据集上评估了TimeMachine的性能。与多个先进的基线模型进行了比较,包括Transformer和非Transformer模型。进行了消融研究,以验证模型组件的有效性。 结果:TimeMachine在预测准确性、可扩展性和内存效率方面均显示出优越的性能。 未来工作:论文提出了未来可能的研究方向,包括自监督学习、多任务学习、模型解释性、实时预测、长期依赖关系的深入分析等。 代码可用性:论文提供了TimeMachine模型的代码实现,可供研究社区进一步探索和验证。 总体而言,这篇论文介绍了一个创新的时间序列预测模型,通过结合先进的架构和技术,有效地解决了LTSF中的一些关键问题,并在多个数据集上展示了其有效性。 |
|
|
| [收藏本文] 【下载本文】 |
| 科技知识 最新文章 |
| 百度为什么越来越垃圾了? |
| 百度为什么越来越垃圾了? |
| 为什么程序员总是发现不了自己的Bug? |
| 出现在抖音评论区里边的算命真不真? |
| 你认为 C++ 最不应该存在的特性是什么? |
| 为什么 Windows 的兼容性这么强大,到底用了 |
| 如何看待Nvidia禁止使用翻译工具将cuda运行 |
| 为何苹果搞了十年的汽车还是难产,小米很快 |
| 该不该和AI说谢谢? |
| 为什么突破性的技术总是最先发生在西方? |
| 上一篇文章 下一篇文章 查看所有文章 |
|
|
|
| 股票涨跌实时统计 涨停板选股 分时图选股 跌停板选股 K线图选股 成交量选股 均线选股 趋势线选股 筹码理论 波浪理论 缠论 MACD指标 KDJ指标 BOLL指标 RSI指标 炒股基础知识 炒股故事 |
| 网站联系: qq:121756557 email:121756557@qq.com 天天财汇 |