
| |
|
|
| ����ƻ� -> �Ƽ�֪ʶ -> ��ô��Ӣΰ��3��19�ոշ������Ǹ��ֲ���GpuоƬ�����ڸ��˵ĸо�������F22������ʱ��һ�����? -> �����Ķ� |
|
|
[�Ƽ�֪ʶ]��ô��Ӣΰ��3��19�ոշ������Ǹ��ֲ���GpuоƬ�����ڸ��˵ĸо�������F22������ʱ��һ�����? |
| [�ղر���] �����ر��ġ� |
|
ɾ�����ñ����ţ��������� |
|
��ǰ�������������꣬������AIоƬ�ڴ�ģ��ѵ����ʵ�û�����������Ҳ��ֻ����������һ�롣�������Ľ��죬������˾���ڵĹ��ڻ�����������ڲɹ��N��910B���������ͨ���������Բ��ԡ��������ֵ������ζ�����������鶼�����ˣ����Ȼ���ܸо���⣿ |
|
��Ҫ�Ƿ�������װ���ʼDZ����棬�õ��������Сʱ����˽��GPT-4��оƬ���Dz���������������ð˸��N����һƬӢΰ���F22ʱ���� ������ŵ��Ķ�����FP4�ٶȶ�������PPT�ˡ� |
|
�����û�°ɣ�ȥ�����Ŵ������Ѷ˽���4090��ʱ���㲻�Ʒ���Ӣΰ�������gpu����Ʒ��ˣ��ϸ�����ý��֪�����ڴ���ת��Ϊ�N���ˣ������������������ö�������ñ����˱����ˡ����� |

|
|
|
|
˵���ijЩ�˷ιܵĻ�������Ȧ��ô�����ˣ������ڻ��ǿ�������PPTдʲô����ʲô���ͻ������ˡ� ֻ����ΪӢΰ���Ǽ�������˾��������Щ�������������˶��ѡ� ����Ȧ������CPU�Կ���Щ��PPT����ν����������һ�㶼�����ۣ������������: һ��ʵ���������ǵ��ض����������������˺ܶ��֣�ȡ��õ��������Աȣ��㲻��˵����٣���Ϊ�˼�ʵ��������ܳ����������ǵ����û�������ʵ����ͨ����Ҫ���ۿۣ��������Ե�ƻ�������У�������û�־á� ����ר������һ���Ա���һ���ر�������Ŀ�������ԳƶԱȣ����������������úܸߣ�����������ߺܶ࣬��ʵֻ��һ���棬�ϻƼ��Լ��������ӡ� �������ö��ϣ�����������ɢ�ȡ���������������������PPT���������ܣ�������Щ��˵��һ�������� ���Ƴ�û�еõ��������֮ǰ�����������߱Ͼ�����ƿ���ģ���Ӣ�ض�14nm++++++����������㣬Ҳ����סAMD���Ƴ����ơ� ʵ��������ϻƷ����IJ�Ʒ���������ж��ϣ�����û�дﵽ�������ܱ�֮ǰ������ʮ���ķ��ȣ����ް�PPT���������ݺÿ���ֻ��������ݴ������ԡ� |
|
�Ҿ�����2020��9��15�գ��ǻ����������������֪����������������ƽʱ�ڻ�Ϊ�ڵ����ļ�����Ĭ�������� ��ʱû����Ϊ2023�����ó�7nm�����ֹ۵�Ҳ������Ϊ�и�14nm������800uˮƽ��оƬ�����ˣ�����ó���7nm��9000s����˵�����涼�ܴﵽ9000��ˮƽ��������ȫ�����к��ġ�����ҵ������ֹ۵Ĺ��ƶ�Ҫ��һ�㡣 �����Ҳ������ú���⡪�����������Ѿ���7nm������910B���ͼ��������������°���������꣩������920��������ò�����˵�Ļ���910B������J10��F22��������J8��F22�� û�б�Ҫ����ֵľ�������壬����B200���ˮƽ��оƬ����7nm����ңԶ��7nm�ľ�����ܶ���100��/cm2��5nm��150�ڣ�3nm��180�ڣ�2nm�����ԣ���200�ڡ����֮��14nmֻ��30�ڣ�����7nm��2nm�IJ�û��14nm��7nm�IJ��� �����������ģ�����ȫû����˵�����ֲ�࣬�������ֲ����Ҫ�ǹ�ȥ�Ļ���Ӱ���˻�Ϊ���з����ࡣĿǰ�����Ѿ���������ô�������ϵ��ٶȻ�dz��Ŀ졣 �����ż���һ���ʱ�����������ѹ�����ʤ�ܣ�SORA�����һ�ڸ�����Ƶ��Ҳ����������������Ĵ�� |
|
�ҷ����������Ǻ���Ϣ�� ��һֱ��һ���۵㣬 �����ֿ�ʼ����������ʱ�� �й��Ͳ�����... ... x86��ô����С�ͻ��ģ������ֿ�ʼ��ARM���x86�ˣ��� |

|
|
����Ϊ��̨x86��PowerС�ͻ����ܸ��Ƚ��� ��������Ϊ�������ĸ���������... ... |

|
|
�й���ȱ�绹��ȱ������ |
|
NVIDIA��оƬ�������ûʲô���µģ�����һ��Blackwell��������������û��ȥ��GH200��������... B100/B200��Ҫ��ͨ���Ƚ�������ˮоƬ���ﵽ���������Ƴ̶�û����2��ǰ��H100��N4��������Ȼ��N4��BlackwellҲ������ʲô�����Եģ�������صļܹ�����Ҳǡǡ˵�����Ƴ̵Ľ����Ż��ˣ���˵�뵼�幤����ʵ�Ǹ������˲��ǡ� �ϻƶ�˵�ˣ����ľ������־����ǰ��Ϳͻ�оƬ����Ҳ����Ϊ���NV�����в����Ҳ˵��ƿ������оƬ��NVIDIA����Ǻ���CUDA������оƬ�������������������Ӱ�Ȩ��ֱ��ͨ��������ķ�ʽֱ�ӡ�͵�ߡ�CUDA���Dz����ϻ���ŵ�����... |
|
���ƹ����ϵ�����ûʲô�����ġ��������Ҿ�������Զ����ֳ�����������Ŀ��Եģ�������о������� |
|
��̫�����ˣ� ���2020��9��оƬ��� ����Ϊ�й�����������7nmоƬ����Ҫ5-10�꣬ �����һ�����»�Ϊ�Ų�����ô�ã������˲�̫�ã��ص�����һ������710A�ij���50�ֻ���֧����������оƬ����ϣ���� �Դ���������710A���Ҿ������й���оƬս�������ˣ��������ڲ���֮���ˡ� ���2023��9�»�Ϊmate60�ͷ����ˣ� ���̵ģ���ȥ�ֻ�������ƣ�ֻ��оƬ�Ļ���2���ʱ�䣬̫�����ˡ� �����й��Ѿ�������5nmоƬ�ˣ� ���NV��оƬ��4nm�� �ֲ��������ֻ�����������ĵط��� �Ƴ̲��������ӣ��Ǿ��Ƕ���� ����û���Ŷ��ϵĻ����������ܿ��Զ��ϵġ� оƬ֮ս����Ѿ�ȷ���ˣ����Dz���̫��ע���ˣ����Ź����˼��֪꣬���ϻ���ִ����Ĵ���⣺ �������������оƬ���й��Dz��DZ�ƭ�ˣ� |
|
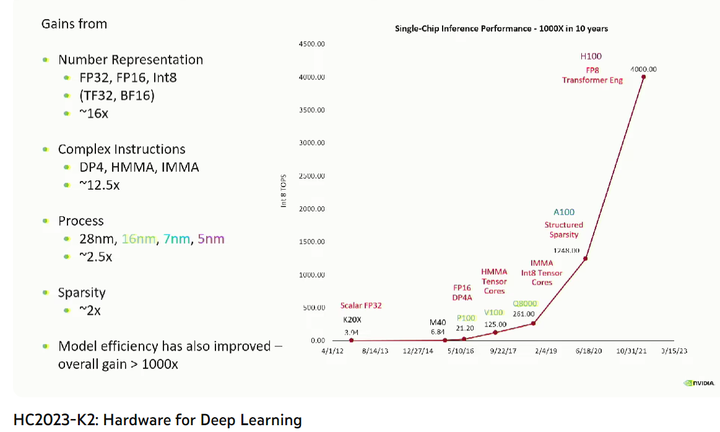
ǡǡ�෴�����췢�����gpu��������Щ����Ԥ������һ���콢Ʒ������hbm�ͷ�װ�ĸĽ������������㿴��fp32���������ˣ��ϻƶ���fp4��������fp16�Ա��ˣ�������������� fp32��fp4�ɲ�Ӧ����8����������Ӧ����8�����η����������� û�кڿƼ����а����߰��ʮ��nv���Ѿ��������������ˡ� ���ͼ��ǰ����NVIDIA��ϯ�ܹ�ʦBill Dally�ı��棬��ȥʮ��(2012 - 2022) �Ƚ��Ƴ̴�28nm��5nm������������ֻ��2.5�������������Ħ�������Ѿ��������ˣ�������Ҫ���ף�200��)�����ݾ��Ƚ��ͺ�npu��������������治��nv�� ��Ԥ��δ��nv����npu���;������ݼ�������Ҳ���cuda��̬��������ĸ��ѣ���Ϊcuda��Ϊcuda core����õIJ��Ǹ�tensor core�õģ� cuda������̬Ҫ����Խ��Խnpu����tensor core���Ǹ���ʷ���� |
|
|
|
|
��Gpuһ��������������ƽ̨�����ˣ�������������϶����й�ҩ�衣 ����һ��оƬ���ѡ��ֲ���û�����Ʒ������ԭ�ӵ����ǿ�����������ģ����������ڰ�һ��оƬ�����Լ����������֧���� �������ǽ�����оƬ��������������������������ԭ���Ǽ�ʮ������ȷ��ȣ�������ô��Ҳ�������Ǵ�������ˣ��������˿��õ����Ʒ������һ�㲻������ȣ��ͳ��˺������˷ܼ��� ��ô��������̬�� |
|
������֪��������ÿ����ʡ�������� ÿ��ˢ֪�����ܰ����ҵ�ȥʵ���Ҽ�����ש�Ķ�����Ψһ�����в��㣬�����λ�����ڰ��й���˼֮��ɵ����¾����ˡ� ˵������Ϊ�ṩ�����ǵ� 910B ����ƽ̨�����ˣ��������뻪Ϊ����һ����Ǩ�����д��롣����˵����������ڣ����ǵ�������¡�2020 ��ʱ�������������벻��������������Ϲ����ļ���оƬ�ġ� ��Ϊ���ֵ�������Ҳͦ���ģ������ϻ��ǹ���Ӧ���Ʋ�ǰҪ����˼���Ʋú���Ҫ����˼��ʵ�����е������ѹ��������л�Ϊ��Ȼ�ܺã�������ӵ�еġ���Ϊ������ҵ��������̫���ˡ� |
|
����һЩ�����������������dz���ҩ�裬�������ֺ����ֺ�Ц�� �����ڲ���ʶ���뵼���ҵ��AI����������ȫ���ľ����ã�δ��̫��֪����˰ɡ��� ����һ��˵����Щ�˶���ҵ��չ��״�л������˽��� �����������й�����Ƽ�ս��Խ��Խ��Ĺؼ���ҵ��ս����ҵ����ʵ���嵥����Щ�˳���ҩ�裻 �����ս��Ʋ��ж��Ƚ��Ƴ̴�������Ϊ��˼������оƬһ�������Ѳ�����Щ�˳���ҩ�裻 �������߶˼��㿨�������й����ۣ���ͼͨ����ͼͨ����ס�Ƚ������ķ�ʽ����й��ĿƼ��з�����Щ�˻��dz���ҩ�裻 �����������ʲô����� ����9000s��ճ�������������CPU/GPU�ںˣ����������Ѿ�ͻ��ǧ�� Ӣΰ���ԼҵIJƱ���ͨ���У�����Ϊ��˼��Ϊ����ǿ�������֡��� ��Ϊ��˼�ĕN��ϵ��AI���㿨�Ѿ��ڴ��ģ��������������һ�����������вɹ��� ���δ�����ҵ�Ѿ�ȫ�涯Ա�������뺣˼פ����Աͨ��Э������ɕN����̬�´������ӵ��ع��� ֪���ϻ��д�ҵ������˵���������ɹ��N�ڻ���Ҫ����ͷ�������ɣ����ڷ���Ҫ���ĕN���ܲ��ܰ�ʱ�����Ҳ�Ҫ�Ǽۣ� ��Щ��ҵ�ڻ����϶��Ѿ����˾���֪��һЩ֪����ý��������ר�ⱨ����������ij��ͷ�µ��N��910ϵ�е�����������ˡ�������Ȼ������Ϣδ��ȷ�� |
|
|
�������ߣ�Ӣΰ����������Ӧ���Ʋõ��˸��Ʒ�����Ҳ����ձ��Ե��������������� ����˵ʵ�������˵���ڴ�ͻ��������ϡ�Ӣΰ�����ܽ����IJ�Ʒ���Ҳδ�ء� Ӣΰ������һ����Ʒ�ǿ����Ʋõ������ߣ���Ȼ������һЩ�ؼ����ܣ�����������Ҳ�������ȥ�� ��˵���ף������˸�ֻ��һ���档 �ؼ��������ڣ�������ô�㣬�������ܲ����ȶ����������ܻ��ܲ�������������Ӣΰ��������ҵ���ܲ���˳����չ�� ҵ�������Ժͳ���������������Щ���ǹ��ڴ��ǵ��ص㡣 ����˵���N��AI���㿨���ģ�����������Ʋõ�Ч��Խ��Խ���������������á� �����Ϲ�������AIоƬ����ν���Ʋá������˺�Ӣΰ�������������CUDA��̬�����ǰװװ��г��ø���˼�N�ڡ� ijЩ�����츴����A4ֽ�ƻ�Ӫ�̻����������ڿ���������������A4ֽ��ȷ�����ƻ���Ӣΰ����й����������ڡ� ����������ʾ���ھ�ȫ����ֹ�й��������Ҫ����ѵ�������˹�����ģ�͵���������������ЩӰ�죿1047 ��ͬ �� 69 ���ۻش� |
|
|
�����Ѿ�������ԣ�֪����ijЩ�˻����⸴�����N��û���á������Ƴ̱��������������ڸ�Ц�� Mate60/Mate X5����������ͻ��ǧ��ijЩ�˻����⸴�������оƬ�����������ڰ���� ����Щ�ˣ�������9000s����ǰ����������ڣ�������9000s���������ǡ�����������������������������ǡ�δ������һ����һ������������·���������������ҩ�ɾȡ� �Ҳ�˵�й���оƬ�뵼��ؽ�����ȫ������һ��˵������ֻ���ǹ����г���������ȫ���������뵼�������û���������ҵ��ռ�ݹ����г��ã� ����Ӣΰ�����·�����GPU��Ʒ����ʵ��ûɶ��˵�ġ� �����Ƴ̻�����ƣ���ʵ��û��̫���ͻ�ƣ������Ƚ���װ�е㿴ͷ�� ӲҪ˵��������ɶ��־�����壬�ǿ��ܷ���˵���Ƚ��Ƴ̷�չԽ��Խ�ѣ���������˵���������ˣ�Ц~ ��˵��Ҳ����Ӣΰ���һ�η�����ν���˵���GPU���������ǵ�һ�α����飬Ҳ���ǵ�һ������һƪ����ҩ����˳��� һ��ǰ�������Ƶ����ӣ���ʱ������ô˵�ģ� �����ڵķ�չ����������ڰ뵼���ҵ������ǰ���ֹ۲���ì�ܡ� ����ǡ���෴���Ҳ�ֹһ��ǿ����������ɥ�IJ����ʵ���嵥��������ȷʵ�Թ�����ز�ҵ����˲�С����������ڿ�ȴΪ��������ṩ��������Ҫ���г��ռ䡣 �Ҿ�˵���һ��ɣ�Ҫ�÷�չ���۹⿴���⡣Ӣΰ��Ŀǰ�ijɾ�ȷʵ��ǿ������˼AIоƬ�ܳ嵽����һ��ˮƽ��δ���ѵ����������� �Ҹ�����Ϊ��δ�����ڰ뵼���ҵ����չ׳��������оƬ����̬���������γ�����ϵͳ���뵼���ҵ���ľ����dz��ܣ�û��Ҫ����һʱ�� Ӣΰ�� GTC ��ᷢ�����˵�����GPU����Ϊ AI ��չ������Щ������?www.zhihu.com/question/591133606/answer/2949444247?utm_psn=1754441372701224960https://www.zhihu.com/question/591133606/answer/2949444247?utm_psn=1754441372701224960 ����ǰ��2021�����2022�꣬���ƵĻ�����֪��һ����ظ��� ����ɥ�IJ����ʵ���嵥��������ȷʵ�Թ�����ز�ҵ����˲�С����������ڿ�ȴΪ��������ṩ��������Ҫ���г��ռ䡣 ֻҪ���Dz�������ʤ�ۡ��͡������ۡ��ɱ�˫�ۣ�ֻҪ������������ѹ����־�����յ�ʤ���ؽ��������ǣ� ���ڻع�ͷ����ǰ������⾰����ҵ���Ѿ����־�仯�� �����뻪Ϊ���ж��Ƚ��Ƴ̴���������조����������������ͱ���족�ĺ���׳� |
|
|
|

|
|
��Ϊ��Ȳ���뵼���ҵ������Ŭ����ע������ʷ�ᣡ ��о���ʡ������洢�ȵȹ��ڰ뵼���ҵ������ͷ��ҵ���ڶ̶�������ʵ������ʷ�ԵĴ��Խ��ͬ���Ǽ����ѵá� ֪��ijЩ�ɻ��ڸ����䳰�ȷ������β���ĸ����������������ȵ����й��� ��Ȼ��ˣ����Ҿ͡����ڡ�һ�ѣ� ������7nm�Ƴ̲������յ㣬DUV�������ع�������5nm��δ�������һ�������� ��̻���Ȼ�ѣ���˵����Ҳֻ����������ļ����豸�� ���漰��������������߶��£��������Ӵ��г���ι���£����������ٶȱ�ijЩ��Ԥ��Ŀ�Ķࡣ ��ʵ�ϣ����������Ѿ��й�����̻��������ܣ���Ϊ�Լ�����һ����ҵ���Ѿ�Ͷ��EUV��ؼ����з��� �����赲����ʷ������ǰ��ijЩ����С�����Ϊ����Ӧ�˹���һ�仰�� ��ݺ���������Ц�������� |
|
��Ϊһ��������������F22���Ⱳ�Ӷ�������Զ��F22����������Ŀ�����Ӣΰ���Կ�����˵���˰�������������װ���豸���ǿ������ⱳ�����ġ� |

|
|
|
|
���������F22�ı���������Цһ�찡�������������������������� F22��սΨһս����2023��2��5�ջ����й�������������һֻ�� ������������������������Цһ�ᡭ�� ��ģ�������̫��С���ˡ� ��Ҫ�������ŵ����� ��оƬ����ԭ��û�д�ı仯������£����еIJ������������϶������Ͷ��ϡ� ���GPU��Ϊһ�ѶѼ���оƬ�Ӵ���ͨ���� ��ͻᷢ�֣��ڼȲ����Ʒ��ȣ��ֲ����ƹ��ʣ��������������Ҳ���ù���Ǩ���ۼ۵�ǰ���£�������������GPU��ʵ���ǰ�ԭ�����GPU֮���·�ؿ���Ȼ��ŵ�һ���װ� Blackwell�ܹ�ʵ���ϱȽ��ѵĵط�������̨�����4NP�Ƴ̹��ա� ��������ͻص�����һ���ĵط��ˣ��ȹ���EUV��̻��ɡ� �����������ûɶ���ظеġ� ����������ǵ����ڸ��������ۣ����ڻ�����������֮��Ķ�����������ɶ�ÿֲ��ģ� |
|
F22һ���ڵ�������ǻ����˵� GPU��û���Ӧ�þ��������� ��ô��GPU������ˢ���ÿ����ǰ����ϰࣿ ����������Ԫ���棬�����ִ����رң������ִ�gpu ������ʱȺ�����裬̸���ʱ������ɢ�� �ⲻ�ǵ�һ�Σ�Ҳ���������һ�Ρ� |
|
F22�����߶�û�ˣ������Ŵ���F22�ɵ�ʱ�����������۷壬����ô����Ӣΰ��Ҫ�۹��� |
|
2019�껪Ϊ��������Ӣΰ���AIоƬʱ���������û�ио��˷ܣ���ô���ھͲ�Ӧ�øо���⣻�����ʱ���ǶԻ�Ϊ�䳰�ȷ�������Ҳ��Ӧ�øе���⡣ |
|
���ĸ�ʱ��㣬���Ҽ�ס 1997��9��7��F22�� 2005��12��15��F22�γ���ս������ʼ���� 2011��1��11��J-20�� 2017��3��9����������J-20��ʽ���� �й��Ĺ���ѹ������й���Σ�յ�ʱ�� ��06-10��5�� �����й�������ʱ�̣��й��ľ��°����ߺͰ��������������ʱ�� ������ϰ��տ��ܻ�Ȼ������������ʱ�������ż���Ҳ����Σ�ա� �����ǵ�10�겿���ڳ�����11�겿�����ձ������ɻ��ص�ʱ������˼������⧲������� �ں��ϺͿ��н����ͷ����й��ľ����ٴ��γɡ� Ȼ������������������û��ͼ�20�� ���ǵ��ķ����ˣ�����֪��������j-20�ij��֣���ʹF-22�����ٶ࣬�����ٹ㣬δ��3-5�����������Ҳû�а취���й�ʵ���ƿ�Ȩ�ưԡ� �������ϻ�Ӣΰ���GPU����������Կ���12��ĵ��㵺Σ���͡����հ�����Լ��������Ȩ����������ǩ���� ���ǵ��ģ����Dz��پ��� ���������꣬һ������Ͳ�������������ɢ�� һ�ж��й��ķ����������Ϊ��Ц��Ц���� ��ӭ��λ�������Ľ��������������ڷ� |
|
����ϴ���Ʒ���ľ���һ����ˮоƬ*2+��Ƶ��+25%die���������+�����Ż��� 50��Ϸ�콢�Դ�����24G�����4090����40%�����������ɡ� �ҳ���ȷʵ����Ϊ���ڴ�ȯ��ý��Ϊ�˳�������̫�����ˡ� ��������3*2��FP4����2.5=15������15���� |
|
���ðɡ����� �ۺϹ��ġ��Ƴ��������о���H100û��̫���ԵĽ��� H100�dz������Ƴ̵ĺ�����B100��������������һ��1000w��ʲô��������1.5p�յ��������ӡ� Ȼ��ʹ����int8/fp8���ܣ�תͷ�ְ�fp64����һ����ʣ ʲô��������ˮ��666 |
|
��Ȱ�㻹�����������ɣ� ��ǰ������ǻ�֪�ܶ����¡� �����������ֻ�ᳪңң���ȡ� |
|
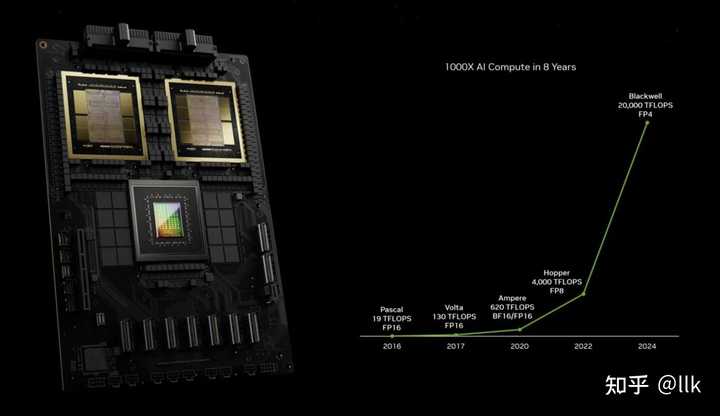
��ϸ���Ͳ�����ÿֲ��ˣ����귢����Blackwell��������ĸ��ߴ��Ħ�����ɲ��������ˣ�֮ǰNVIDIA�Ŀ���չ��GPU�ܹ�����Ħ�����ɿ�ν�ݿ����࣬�ô�������������������NVIDIA���������оƬ�������Ի���һ�ʴ��������ص㶼��DGXϵͳ�ϣ�Ҳ����оƬ�ڲ�����Ħ��������չ������ͷ��������չ��Ҫ��оƬ�以��������ˡ���һ����������������������û����������ô���ţ���NVIDIAչʾ��8����AI����������1000X����Ҫ���������ݾ��ȣ����ʼ�����ܼ����FP64��FP32��FP16����FP8��FP4�� |
|
|
ʵ�������һ��ֻ��2.5�������� ������оƬ�以�����ֳ����ࣺ һ����D2D,Ҳ����ͨ��interposerʵ��die֮�以��������һ���Ǹ��ٲ��нӿڣ������ṩTB����Ĵ���������������TSMC��CoWoS��Intel��EMIB�ȣ����췢����Blackwell���Dz���D2D������die������װ�������ṩ10TB/s�Ĵ����� |

|
|
��һ�����NVLinkΪ������оƬ�以����ҵ���Ƴ��ľ���UCIe����Blackwell�Ѿ��ݽ���������ˣ�����NVLink SwitchоƬ�������ṩ7.2TB/s�ܴ�����֧��GPU����������չ�� |

|
|
��Ȼ������һ���Dz���Infiniband��Ethernet���к�����չ����Щһ�������NVIDIA��DGXϵͳ�� �ܶ���֮�����ڶ���NVIDIA�ľ����ߣ����ղ��������⣬��ƴ���ص��ڻ�����������die�ڻ���������Ƭ�以�����������绥���������ɸ��ߴ�����ϵͳ���ǹؼ��� |
|
����Ϣ��������Ѫ��̫���� ����Ϣ����������Ѫ���� ����һֱ����������Ѫ���� �⼸���ܿ����� �ⲻ�Ǻ����� ��ζ�������ľ��鼴����� ��ó��ս��ʱ�Ϳ�ʼ����bossս�������� ����2023�꣬�������ڿ����˹������ܿ���bossѪ���� ���������ǿ�˭����һ�� |
|
��4nm��������7nm���������е�5nm������ȥ������9000s��ˮƽ�㡣 ����һ�飬����ʮ�鶥���в��У��ֲ���3��ǰ������Ħ�г����������г����������ڶԷ������γ������ܳ�����������Ȼ���㣬���ܲ�ס����ܱ����� ����оƬ�ˣ�����ƴ�ķ�������Դ��˵���˾��Ƿ����������ɣ��й���µľ��DZȷ����������ҷ������ģȫ���һ��������ȫ���һ������Ӣΰ�����춥�ǿƼ������ܺıȱ����Ǹ�ʮ���������õ綥��ȥ���͵��ˡ� ������ô��糵�����������š� |
|
�ϸ��������ⶫ������gpu����pcie�������ʡ� ��˵�ⶫ����ͼ�������� |
|
��ѻƬս�������죬��ȥ��ʮ�ϰ��꣬�й��ڸ�������������ž�IJ�࣬������֮������쿴����GPU���Ҫ��Ķࡣ������Щ���ֱ��Ӱ�����������ʳס�С�����й����й����ߡ��쵼���ڹ�ȥ��ʮ�궼������һ����ֻ��־塢��������������˼���ǽ������Ͳ�����֪���Ϸ�˼�ˡ� ���⣬����й��������Ҫ���ÿֲ�����������������Ҫ��̷�˼����ô����һ�ٶ������Ϊɶ��ȥ���أ� |
|
���ҹ���ֻ��̤��߿Ƽ���ҵ�ͷ��ֹĴ����������ƺ͵�������û�á� оƬ��ҵ����һ����������˲ű��ҹ��࣬�ʱ����ҹ�������ʶ����ҹ��ߵ���ҵ����������ӡŷ�����˲ſ����á����й���оƬ��ҵ���ʵ��˻�Ҫ�������ͬ�е��ڽǡ������ҵ�Ѿ���ɲ�ҵ�Ľ��裬�����IJ�Ʒ�������ܴﵽ20%���ҹ����㿪�����������˲Ż�Ҫ���ٲ�ʱ�����ʣ�����Ӱ�����⡣ ˵���ף��߿Ƽ���ҵ������500����Ƥ����ֻҪ����һ������������ܵ�ʮ���������Ӱ����ճ������������������� Jim Keller���оƬ�ܹ���ʦ��ƻ��A4��A5������������ƻ�������ֻ�CPU���ܰ���֮λ��AMD K8��Zen�ܹ�����AMD����������Ϯ��Ϸ������֤�������ĸ���˾���ĸ���˾��оƬ������ͻ���ͽ������ҹ�����о���ʻ���Ϊ�ɶ��Թ�Ȩ����̫�߲����⣬���ݹ�����Ϸ����2021�꣬�����ֻ�ƣ���ϯ��������ִ�ƹ�˾���³�������� ��һ����������ҵ�������Ƿdz���ġ������Ϊ���־����ҶȽ����ʺ��ƶȡ�������ϵ��Լ��������չ��ħ���ֻ���Ӱ���Ρ� |
|
���գ�������Ŀ��Ӣΰ��GTC����ٴΡ�ȼ���Ƽ��硱��Ƥ�����ͻ���ѫ������ʷ�ϡ���ǿ��GPU���������� |

|
|
����ѫ���� Blackwell GPU ʱ�����꣬Ӣΰ�������һ��Blackwell�ܹ�����λֱָ���¹�ҵ���������桱 ������AI��չ�����ڲ������� �������Ƴ���Ϊը�ѵġ�AI�˵���Blackwell�ܹ���B200���Լ�������2��B200���ܸ�ǿ���GB200ϵ�У���H100��ȣ�GB200�ijɱ����ܺĸ��ǽ�����25������һ����֮�����ɽ�AI�����������µĸ߷塣 ����ѫ����һ��������������������Ӣΰ��ǿ����з�ʵ������Ԥʾ��AI������δ���������貶�Ŀ�� ������֪��Ӣΰ�� CEO ����ѫ��ǿ��һ�����ͣ���������������ս��ĥ���������͡� ������Ӣΰ������һ��AIоƬBlackwell�ķ�����ҵ�����Ħ�����ɵ������ٴα������˷���˼⡣ ����������Ħ��������Ϊ�뵼����ҵ��չ�Ļƽ��������ż���������ķ��ٽ�����Ȼ�������ž���������С���ٽ�㣬Ħ�������ƺ�������ʧȥ������Ĺ�� ���ڣ�Ӣΰ��˴η�������ص�ת�ƣ�Ҳ�ƺ�Ԥʾ����ҵ��չ���������ڴӵ�һоƬ������������ת���оƬЭͬ��ϵͳ���Ż�����·���� �ع�Ӣΰ��ķ�չ���̣������չ��GPU�ܹ�������Ħ������������ã���ͬ���������������漣�� |
|
|
ͼԴ��Ӣΰ��GTC�����������Ϸ����Ļ�����£�����AI��������������Ӣΰ�ﶼ����Խ�ļ���ʵ������������ҵ�ķ�չ������Ȼ��������Ħ�����ɵ���ʧЧ����������оƬ�ڲ��ľ���������������������ܵķ�ʽ���Ѿ�����������ѡ� ���⣬Blackwell�ķ�����������һ���Ƶ��������֡�����Ӣΰ���ڷ������϶���оƬ����������һ�ʴ����������ǿ��Դ��п���һЩ���ߣ��������ǰ����Ʒ��Blackwell�����ܺ�Ч���϶����������������������������Ѿ������ǵ������������������������ʵ�ֵġ� �෴���ǣ�Ӣΰ�����ע��оƬ�������Ż�����̬ϵͳ�Ĺ�����ͨ������оƬ��Ļ������ܣ���ʵ�ָ���Ч�ļ����ͨ�š� �� ���DZ��뷢��һЩ�¼�����ʹ֮��Ϊ���ܡ�������ѫ��ʾ��Ӣΰ����������˹�����оƬ�����̽����δֹͣ�� ���䣬��һת��ı�����Ӣΰ�������ҵ��չ���Ƶ���̶��졣��Ħ��������ʧЧ�ı����£���������оƬ�ڲ������������Ѿ����������������ļ���������ˣ�Ӣΰ�ォ����ת���˶�оƬЭͬ��ϵͳ���Ż���ͨ������оƬ��Ļ������ܣ���ʵ�ָ���Ч�ļ����ͨ�š� ���ѿ�����DGXϵͳ���Ƴ�������Ӣΰ����һս�Եľ������֣�DGXϵͳ�����ṩ�˸߶�ϵͳ���ҿ���չ��ƽ̨����ͨ���Ż�оƬ��Ļ������ܣ�ʵ����AI����ĸ�ЧЭͬ�� ��Щ�꣬�ڶ���ҵʼ����̽Ѱһ�֡������Ļ������������������ǵ�ǰȫ��ҵ�������ٵ�һ��ո����ս����оƬ�以����Ҫ��Ϊ���ࣺ |

|
|
ͼԴ��Ӣΰ��GTC��� ��һ����D2D��Die-to-Die����������ͨ��interposer���н�㣩ʵ��оƬ��die֮��Ļ����� ���ֻ�����ʽһ���Ǹ��ٲ��нӿڣ��ܹ��ṩTB����Ĵ�����ʹ��оƬ�����ݴ������Ѹ�١�������������TSMC��CoWoS��Intel��EMIB�ȡ� Ӣΰ�����Blackwell�Ͳ�����D2D����������die������װ���Ӷ��ṩ�˸ߴ�10TB/s�Ĵ���������һ�����У�Chiplet��������Ϊͻ����ͨ�������Chiplet������һ�𣬿���ʵ�ָ��ߵ����ܡ����͵Ĺ��ĺ�������ơ� ��һ��������NVLinkΪ������оƬ�以��������NVLink��һ�ָ����ܡ����ӳٵ�оƬ�以�������������Ҫ����GPU��CPU֮������ӡ� |

|
|
ͼԴ��Ӣΰ��GTC�����ͨ���ṩ���١�ֱ�ӵ�����ͨ�����������������ݴ���Ч�ʺͼ������ܡ� ���ż����IJ��Ϸ�չ��ҵ���Ƴ���UCIe��Universal Chiplet Interconnect Express��������Ҳ��һ�ֿ��ŵ�оƬ�以������ּ���ƶ�Chiplet�����Ĺ㷺Ӧ�úͷ�չ�� ���У�Blackwell�Ѿ��ݽ���������������NVLink SwitchоƬ�������ṩ7.2TB/s���ܴ�����֧��GPU����������չ���Ӷ���������ģ�ļ������� ���⣬����һ���Dz���Infiniband��Ethernet���к�����չ�ļ�����Infiniband��Ethernet�����ֲ�ͬ�����缼����������оƬ�以����Ҳ��������Ҫ���á� |

|
|
ͼԴ��Ӣΰ��GTC���Infinibandͨ�����ڸ����ܼ����з�����֮��Ļ�������Ethernet������Ӧ�����ն��豸�Ļ����� ��Щ����ͨ���ṩ��ͬ�����紫�����Ժ����ƣ�ΪNVIDIA��DGXϵͳ�ṩ��ǿ��ĺ�����չ������ʹ��ϵͳ�ܹ����������ģ�����ݺͼ������� ����������оƬ�以�������ķ�չ�ͽ������ڰ뵼����ҵ���зǷ����壬���硰�ٻ�ǧ�⡱��ʢ���� ������D2D��NVLink�Լ�Infiniband��Ethernet�ȼ������ڲ�ͬ�̶����ƶ���оƬ�以�����ܵ�������Ϊ������ҵ�ķ�չע�����µĻ����� ͬʱ������Chiplet�����IJ��Ϸ�չ��Ӧ�ã�δ��оƬ�以������������ʵ�ָ��Ӹ�Ч�����Ϳɿ������ݴ��䣬Ϊ�������ܵ�������Ӧ�õĴ����ṩ����֧�֡� ����ƪ�����ޣ�����Ӣΰ��GTC�����Ƚ�����ô��...... ���˽����뵼����ҵ��̬������������ע���ǡ� �����ֽ���ÿ�ܣ�����ʱ����~ |

|
|
���������Լ��ѷ��һ�����ԣ� ΰ�����Ʒ���ǿ����������ǿ��������ɵġ� Ըÿһλ�뵼���ҵ�߿��ԡ��� ��ͷ�ս���ͬ�۹��ã� |
|
һ����ҵ�ϵĶ��� ���������ɱ��ߣ���ô���ҵ�����ۣ���Ҫ��AMD��������� �����ʲô���µġ��� |
|
|
| [�ղر���] �����ر��ġ� |
| ��һƪ���� ��һƪ���� �鿴�������� |
|
|
|
| ��Ʊ�ǵ�ʵʱͳ�� ��ͣ��ѡ�� ��ʱͼѡ�� ��ͣ��ѡ�� K��ͼѡ�� �ɽ���ѡ�� ����ѡ�� ������ѡ�� �������� �������� ���� MACDָ�� KDJָ�� BOLLָ�� RSIָ�� ���ɻ���֪ʶ ���ɹ��� |
| ��վ��ϵ: qq:121756557 email:121756557@qq.com ����ƻ� |