
| |
|
|
| ����ƻ� -> �Ƽ�֪ʶ -> Ӣΰ�������Ƴ���ǿ AI оƬ���ɱ����ܺĽ�ǰ������ 25 ������Щ��Ϣֵ�ù�ע�� -> �����Ķ� |
|
|
[�Ƽ�֪ʶ]Ӣΰ�������Ƴ���ǿ AI оƬ���ɱ����ܺĽ�ǰ������ 25 ������Щ��Ϣֵ�ù�ע�� |
| [�ղر���] �����ر��ġ� |
|
�ųƽ���ȫ��ͷ���˹����ܣ�AI�������ߴ���Ӣΰ��2024 GTC AI���������ʱ��3��18����һ�����Ļ��������Ӣΰ��ʱ�������״������GTC�� |
|
B100ϵ�е�ǿ���Ǵ����Ԥ�ڵģ��������ûš� |

|
|
�Ϳ�����920�ܶ��̶��ϲ��������ˣ����䵱Ӯ�����¡� Ū����tsmc n3����Ĺ��գ�ȷʵ���ü��ꡣ�����ڵ��Ƕ���̬��ã�Ҳ��һ��ʱ�䡣 ����Ŀǰ����AI�IJ��첻��̫���ս���ϵı������Ǿ����ÿռ任ʱ����ˡ� |
|
Ϊ֪�����ṩ������Ϣ�� �ذ�����������Ҫ�����GPU����Ӣΰ�������Ƴ���ǿAIоƬ���ɱ����ܺĽ�ǰ������25�� ÿ���༭ ��½�� �ųƽ���ȫ��ͷ���˹����ܣ�AI�������ߴ���Ӣΰ��2024 GTC AI���������ʱ��3��18����һ�����Ļ��������Ӣΰ��ʱ�������״������GTC�ػ����£�Ҳ�Ǵ�ǰ������ΪӢΰ��Ҫ���ó�����һ��AIʢ�ᡣ ����ʱ����һ���磬Ӣΰ�ﴴʼ�˼�CEO����ѫ����������ʥ����SAP���Ľ�������Ϊ�������ߵ�1#AI��ᡱ��1#AI Conference for Developers���ݽ�������ѫ����������AIģ�͵���һ��оƬ��������Ӣΰ����ʽ�Ƴ���ΪBlackwell����һ��AIͼ�δ�������GPU����Ԥ�ƽ��ڽ�����Щʱ���� Blackwellƽ̨�ܹ������ڲ������Ĵ�������ģ�ͣ�LLM���Ϲ���������ʵʱ����ʽAI�����ɱ����ܺı�ǰ����25���� ����ý�屨����Ӣΰ��CEO����ѫ��GTC��������������ҵ��������������һ����ΪNIM���²�Ʒ��NIM���Ը�����ʹ�þɵ�Ӣΰ��GPU������������������˾����ʹ�������Ѿ�ӵ�е����ڸ�Ӣΰ��GPU���ò�Ʒ��ʹ���˹�����ģ�͵ij�ʼѵ������������������١��ù�˾�IJ������ù���Ӣΰ��������Ŀͻ�ע��Ӣΰ����ҵ�棬ÿ��GPUÿ����ȡ����4500��Ԫ������ѫ��ʾ�������������������䱸GPU�ıʼDZ������������˹����ܣ����������Ʒ����������С� ���⣬Ӣΰ��CEO����ѫ�����Ƴ���һ���˹����ܳ����������Ӣΰ�ﻹ����6G�о���ƽ̨���Ա���AI�����ƽ�����ͨ�š� Ӣΰ������AIоƬ ����ý������Ӣΰ������һ�����Ƴ���һ���˹�����оƬ�����������˹�����ģ�͵��������ù�˾������ʥ�������еĿ����ߴ������������һ��Ϣ����ֵ���оƬ������Ѱ������Ϊ�˹����ܹ�˾��ѡ��Ӧ�̵ĵ�λ�� ��OpenAI��ChatGPT��2022��ĩ�����˹������ȳ�������Ӣΰ��Ĺɼ��������屶�������۶������������ࡣӢΰ��ĸ߶˷�����GPU����ѵ���Ͳ������AIģ��������Ҫ������Meta�ȹ�˾�Ѿ���������ʮ����Ԫ������ЩоƬ�� |

|
|
ͼƬ��Դ����Ƶ��ͼ ��һ��AIͼ�δ���������ΪBlackwell����BlackwellоƬ��ΪGB200�����ڽ�����Щʱ����Ӣΰ�������ø�ǿ���оƬ�����ͻ����Դ̼��¶��������磬����˾��������������������������ǰһ���ġ�Hopper��H100оƬ�����Ʋ�Ʒ�� ��Hopper�ܰ�����������Ҫ�����GPU����Ӣΰ����ϯִ�йٻ���ѫ��һ�ڸù�˾�ڼ����������ݾ��еĿ����ߴ���ϱ�ʾ����������һ�̺����У�Ӣΰ��ɼ��µ�����1%���ù�˾���Ƴ�����ΪNIM�Ĵ�������������������AI�IJ���Ϊ�ͻ��ṩ������������ľ������м��ʹ��Ӣΰ��оƬ����һ�����ɡ� Ӣΰ��߹ܱ�ʾ���ù�˾����һ��Ψ����ͼ��оƬ�ṩ��ת��Ϊ��������ƻ����ƽ̨�ṩ�̣�������˾�����ڴ˻����Ϲ��������� ��Blackwell��������һ��оƬ������һ��ƽ̨�����ƣ�������ѫ��ʾ�� Ӣΰ����ҵ���ܲ�Manuvir Das�ڽ��ܲɷ�ʱ��ʾ���������۵���ҵ��Ʒ��GPU������������Ϊ�˰��������Բ�ͬ�ķ�ʽʹ��GPU����Ȼ������������Ȼ���������������ı���ǣ������������������ҵ����ҵ�� Das��ʾ��Ӣΰ��������������������κ�Ӣΰ��GPU�����г�����������Щ���ܸ��ʺϲ�������ǹ���AI���Ͼ�GPU����������ǿ����ߣ�����һ����Ȥ��ģ�ͣ���ϣ�����Dz�������������������NIM�У����ǻ�ȷ�����������������е�GPU�����У�������Ϳ��Ը��Ǻܶ��ˣ���Das˵���� Blackwellӵ����������Լ��� Ӣΰ��ÿ�������һ����GPU�ܹ���ʵ�����ܵķ�Ծ����ȥһ�귢��������AIģ�Ͷ����ڸù�˾��Hopper�ܹ���ѵ���ģ��üܹ�������H100��оƬ����2022�������Ƴ��� |

|
|
ͼƬ��Դ����Ƶ��ͼ ��Ϥ��Ӣΰ��ƣ�Blackwellӵ����������Եļ���������֧�ֶ��10���ڲ�����ģ�ͽ���AIѵ����ʵʱLLM������ ȫ����ǿ���оƬ��Blackwell�ܹ�GPU��2080�ڸ��������ɣ������������Ƶ�̨����4���������죬����reticle����GPU��Ƭ��10 TB/���оƬ��оƬ��·���ӳɵ���ͳһ��GPU�� �ڶ���Transformer���棺�����Blackwell Tensor Core������TensorRT-LLM��NeMo Megatron����е�Ӣΰ���Ƚ���̬��Χ�����㷨��Blackwell��ͨ���µ�4λ����AI֧��˫���ļ����ģ�ʹ�С���������� �����NVLink��Ϊ��������ڲ����ͻ��ר��AIģ�͵����ܣ�����һ��Ӣΰ��NVLinkΪÿ��GPU�ṩ��ͻ���Ե�1.8TB/s˫����������ȷ�����LLM֮����576��GPU֮��������ͨ�š� RAS���棺Blackwell֧�ֵ�GPU����һ��ר�����棬ʵ�ֿɿ��ԡ������Ժͷ����ԡ����⣬Blackwell�ܹ���������оƬ�����ܣ����û���AI��Ԥ����ά��������Ϻ�Ԥ��ɿ������⡣���������ȵ��ӳ�ϵͳ��������ʱ�䣬����ߴ����ģAI�ĵ��ԣ�ʹ�����������������������£���������Ӫ�ɱ��� ��ȫ�˹����ܣ��Ƚ��Ļ��ܼ��㹦�ܿ��ڲ�Ӱ�����ܵ�����±���AIģ�ͺͿͻ����ݣ���֧���µı����ӿڼ���Э�飬�����ҽ�Ʊ����ͽ��ڷ������˽������ҵ������Ҫ�� ��ѹ�����棺ר�ý�ѹ������֧�����¸�ʽ���ӿ����ݿ��ѯ���ṩ���ݷ��������ݿ�ѧ��������ܡ�δ�����꣬����ҵÿ�껨����������Ԫ�����ݴ������棬��Խ��Խ�����GPU���١� |

|
|
ͼƬ��Դ����Ƶ��ͼ Blackwell GPU����Ӵ�������������ľ�����ϳ�һ����̨���������оƬ����������Ϊһ����ΪGB200 NVLink 2�������������ṩ���÷����������72��Blackwell GPU������ּ��ѵ��AIģ�͵�Ӣΰ�ﲿ���� ����ѷ���ȸ衢���ͼ��Ľ�ͨ���Ʒ����ṩ��GB200�ķ��ʡ�GB200������B200 Blackwell GPU��һ������Arm��Grace CPU��ԡ�Ӣΰ���ʾ������ѷ���������һ������20000��GB200оƬ�ķ�������Ⱥ�� Ӣΰ��û���ṩ�¿�GB200����ʹ��ϵͳ�ijɱ����ݷ���ʦ���ƣ�Ӣΰ�����Hopper��H100оƬ�ɱ���2.5����4����Ԫ֮�䣬������ϵͳ�ijɱ��ߴ�20����Ԫ�� Ӣΰ���������� Ӣΰ�ﻹ������������Ӣΰ����ҵ��������������һ����ΪNIM��Ӣΰ�����������²�Ʒ��NIM��ʹ�ýϾɵ�Ӣΰ��GPU����������������AI�����Ĺ��̣���ø��Ӽ���������˾����ʹ�����Ѿ�ӵ�е����ڸ�Ӣΰ��GPU������AIģ�͵ij�ʼѵ����ȣ���������ļ����������١�������Щϣ�������Լ���AIģ�ͣ������Ǵ�OpenAI�ȹ�˾����AI�����Ϊ�������ҵ��˵��NIM���������ǵĵ������֡� Ӣΰ��IJ����������������Ӣΰ��ķ������Ŀͻ�ע��Ӣΰ����ҵ�棬ÿ��GPUÿ������ɷ�Ϊ4500��Ԫ�� Ӣΰ�ォ������Hugging Face��AI��˾������ȷ�����ǵ�AIģ���ܹ������м��ݵ�Ӣΰ��оƬ�����С�������߿���ʹ��NIM�����з�����������ƶ˵�Ӣΰ��������ϸ�Ч����ģ�ͣ����跱�������ù��̡� ������ԭ������OpenAI�Ĵ����У���ֻ���滻һ�д��룬����ָ���Ӣΰ���ȡ��NIM���ɡ���Das˵���� Ӣΰ���ʾ����������������AI���䱸GPU�ıʼDZ����������У����ǽ������ƶ˷������� ÿ�վ��������ۺϵ�һ�ƾ���������Ϣ �����������������������ݽ����ο���������Ͷ�ʽ��飬ʹ��ǰ���ʵ���ݴ˲����������Ե��� |
|
������NIM��һ�����������������û���GPU���١� ÿ��GPUÿ����ȡ����4500��Ԫ? ��ô�� ��������ڴ�˾Ӧ�û����һ��GPU���ܹ�˾�� Ȼ��GPUʹ���ƽ�汾NIM��ѵ������ �ܹ�˾ͨ�����ӹ�˾������������ʽ���ӹ�˾֧�����á� ����ϻƲ鵽�ˣ���Ҳֻ�������ӹ�˾�� ����ÿ��GPU���ں���������۸�������4500��Ԫ��Ҳ�������˹�����ڵ�GPUѵ���ɱ���һ��Ҳ��Ҳ���Խ�Լ��ʮ������ ���Ǯ�͵��������Ʋ�˰�ˡ� |
|
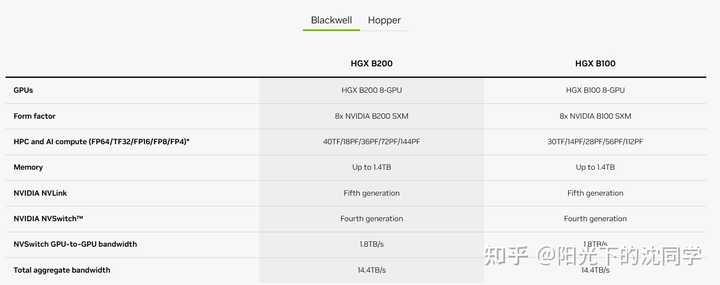
�ܽ�һ��������ĺ������� 1��Ӣΰ���Ƴ�ȫ����ǿ��оƬBlackwell Blackwell�ij��ֱ�־���ڶ̶�8���ڣ�Ӣΰ��AIоƬ�ļ�������ʵ��������1000������ʷ�Գɾ� 2016 �꣬��Pascal��оƬ�ļ���������Ϊ19 teraflops��������Blackwell�ļ��������Ѿ��ﵽ�� 20000 teraflops �ϻ����ݽ��о����ƣ����Ҫѵ��һ��1.8���ڲ�������GPTģ�ͣ���Ҫ8000��Hopper GPU������15���ߵĵ�������������90�� �����ʹ��GB200 Blackwell GPU��ֻ��Ҫ2000�ţ�ͬ����90��ֻ�����ķ�֮һ�ĵ��� ��ֻ��ѵ��������Token�ijɱ�Ҳ����֮�������� Blackwell��2080�ڸ��������ɣ�����̨����4nm�Ƴ� ֧�ֶ��10���ڲ�����ģ�ͽ���AIѵ����ʵʱ������ģ�ͣ�LLM������ ����reticle����GPU��Ƭ��10TB/���оƬ��оƬ��·���ӳɵ���ͳһ��GPU Blackwell ��ͨ���µ�4λ����AI֧��˫���ļ����ģ�ʹ�С�������� ����ѷ�������ȸ�ͼ����������ṩBlackwell֧�ֵ��Ʒ�����֮�� GB200 Grace Blackwell����оƬ������2��B200оƬ��4��die����Grace CPU��϶��� �����H100��������ģ����������30����ͬʱ�ܺ�ֻ��25��֮һ 2��Ӣΰ���Ƴ�AI��ĿProject GR00T�������λ����� 3��̨�����Synopsys������Ӣΰ������̼��� 4��Ӣΰ���Ƴ�������NIM�����û���������������Ӣΰ��GPU����AI���� |

|
|
Blackwell����Ӣΰ�������Ƴ���AIͼ�δ�������GPU������������°���ᷢ�� Blackwellƽ̨�ܹ������ڲ������Ĵ�������ģ�ͣ�LLM���Ϲ���������ʵʱ����ʽ AI�����ɱ����ܺı�ǰ������25������������Ŀ��� ��ӵ��1750�ڲ�����GPT-3��ģ�ͻ������У�GB200��������H100��7����ѵ���ٶ���H100��4�� B200GPU����Ҫ����֮һ���Dz����˵ڶ���Transformer���� ��ͨ����ÿ����Ԫʹ��4λ��20 petaflops FP4��������8λ��ֱ�ӽ�����������������ģ�Ͳ�����ģ����һ�� DGX Grace-Blackwell GB200���������ܵļ�����������1 Exaflop ����ѫ������OpenAI�ĵ�һ̨DGX��0.17 Petaflops GPT-4��1.8T��������2000��Blackwell�����90���ѵ�� |
|
|
��������оƬʹ����192GB��HBM3E�ڴ� |

|
|
Ӣΰ���������Ͷ��AI��ҩ Ӣ����˾Relation Therapeutics������һ��ͨ����ȡDNA�Ը����������Ĵ�������ģ�ͣ������Ǵ�����ҩ�Ĺؼ����� �����˾�������3500����Ԫ�������������ʣ���DCVC��NVIDIA��Ӣΰ��ķ���Ͷ�ʲ��� NVentures ������Ͷ Ӣΰ�ﻹ��ʾδ�����ص�Ͷ��ͨ�û����ˣ������λ������ܹ����ı�����������Ƶ�����ֳ���ʾ��Ϊ�������գ���������д�������ȡ�ض���ͨ�ò��� Ӣΰ���ڴ����˵��Project GR00T��Ӣΰ��Isaac ������ƽ̨���ߵİ����¿����� ����ѫ�ƣ���Project GR00Tƽ̨�ṩ֧�ֵĻ����˽������Ϊ��ͨ���۲�������Ϊ��������Ȼ���Բ�ģ�¶�����ʹ�����ܿ���ѧϰЭ���ԡ�����Ժ��������ܣ��Ӷ���Ӧ��ʵ���粢����֮���������Բ���������������� Ӣΰ��Ͷ�ʵ�AI������ҵ�dz��࣬�ܶ���ҵ����Ӣΰ���Ͷ�� Ӣΰ����ȫ�淢��+Ͷ��AI |

|
|
���Ҵ��Ҫ֪�����������AI�´��������Ӣΰ���CUDAƽ̨ Ӣΰ��IJ��Ծ�����ƽ̨�������Ӵ��������̬���ú�������ͻ�� Ӣΰ�������������������ž�Ľ�����ݣ�CUDA �����е���Ҫ��ɲ��֣�����ʹCUDA�����Ʒ���֣�Nvidia �ṩ�����Ϳ�ķ�ʽҲ���������ǹ���һ���dz��ɿ�����̬ϵͳ Ӣΰ����ҵ�Ļ��Ǻӱ�������� ����1GPU�Ѿ��ӽ�����CP �����������Ϸ���豸��չ��Ϊͨ�ü����� Ϊȫ��Ĺ���վ���������ͳ���������ṩ���� ����ʮ��ǰ��CPU������ר�ô����������������м������� ���Ǹ�ʱ�����Կ������ڼӿ� Windows��Ӧ�ó�����2D��״�Ļ����ٶȣ���û��������; ������GPU�Ѿ���Ϊҵ�����������λ��оƬ֮һ ����ѧϰ�����ܼ�������������GPU�Ĵ������� GPU�ķ�չ�dz���Ԥ�� Ӣΰ��֮ǰ��ΪAMD��Ӣ�ض�����Ϊ����ͨ����ͨ������ѷ�������Ƽ��㹫˾���Ǿ������� AMD��2022��6�£����Ƴ�CPU+GPU�ܹ���Instinct MI300����ʽ����AIѵ���� ��ȥ��6�£��ֹ�����MI300X��MI300A����AI������ Ӣ�ض���ȥ������״�չʾ���������ѧϰ�ʹ��ģ�����˹�����ģ�͵�Gaudi3ϵ��AI ��������Ԥ�ƽ���2024������ ��Ϊ��ȥ��8����ʽ�����ˡ��N��910��AIоƬ����MindSpore��ȫ����AI������ ����2023���Ƴ����������Ƶ�оƬ�ͼ���ϵͳ������˹����� (AI) ���������ʽ AI �����Ż��� Microsoft Azure Maia AI ������ ����ѷ��2013���Ƴ���Nitro1оƬ����AWS��������������оƬ���ƶ˳��̣���ӵ����·оƬ���ŷ���оƬ���˹��ǻۻ���ѧϰ����оƬ3����Ʒ�� Ӣΰ����Ҫ���ϵ�Ŭ�����ܲ����ڶྺ�����ֳ�Խ������һֱ������������ ������Ŀǰ������Ӣΰ���AIоƬ��ʱû�ж��� |
|
�ɱ�����25����Ӧ�þ��������������x������ǰ����25��������һ��оƬ������Ч���ߣ���������Ŀûɶ�ã��ҷ���ȥ��ԭ�����ᡣ һ����� ��Ȼ������Ŀд����ţ���� ��������ԭ������ܵġ� B200 ӵ��2080�ڸ�����ܣ�ǰһ��H100��H200ϵ��оƬֻ��800�ڸ���B200����̨����4NP�����Ƴ̣�����֧��10���ڲ�������AIģ�͡����֮�£�OpenAI��GPT-3��Ϊ1750�ڸ�������ɣ�����˵Ӣΰ����¿�оƬ������������ҵ������λ��B200����оƬ���ṩ20 petaflops��AI���ܣ���ǰ��H100��5���� Ӣΰ��ÿ���껻�ܹ�����μܹ�����һλ��ѧ����������������BIackwell�ܹ�����Ʒ��B200��GB200�� Ӣΰ�ﻹ��ʾ GB200 ���������� B200 Blackwell GPU ��һ������ Arm �� Grace CPU ��ɣ�����������ģ�����ܱ� H100 ���� 30 �����ɱ����ܺĽ��� 25 ��֮һ �ϻƻ��ٸ����� ���Ҫѵ��һ��1.8���ڲ�������GPTģ�ͣ���Ҫ8000��Hopper GPU������15���ߵĵ�������������90�졣�����ʹ��Blackwell GPU��ֻ��Ҫ2000�ţ���90��ֻҪ4���� ʵ��˵����û���������������ô����25���ģ� ���ϻƵ����ӣ��ܺ���������15/4=3.75���� ���Ǽ۸��ˡ� ��h100��̨n4��800�ھ���ܡ�Gb200������B200+һ��ARM GPU��̨����N4���գ���2080�ھ���ܡ� 2080/800=2.6������ܷ���2.6�������ܷ���2.5������GB200��һ��ARM�ܹ���GPU�����������ϼܹ������������Աȡ��ǰ��ϻ�˵�ġ�8000��2000����ôһ��GB200������H100��4����Ҳ����˵����B200����2x2.5=5��H100����ô���ARM��GPU��3��H100�� ���ڸ����뷨�������ARM��GPU����������ARM GPU+һ��B200������3+3+2.5=8.5���� ���ˣ��ع����⡣��GB200�ļ۸��أ�����̨���繤�ճ����ˣ������۸��½�����������Ҳ��20-30%����30%�㡣��ȼ�����ʱ��7�ۡ�����װ��������һ�ɱ����ˣ�ARM����Ȩ�ѡ��ȡ��Ҿ��㵥λ����ܼ۸��ˡ� Ҳ����˵GB200�ۼ��� H100��2.6������������4�����ܺ���4/15�����ʱ���һ��������90��ijɱ��ǡ� �ܺ�x�۸�3.75x4��2.6=5.769231�� ����ɱ������ý��ͣ�������Ҳ���������´���Ļ����dzɱ����Ǵ��ŵ�Ѱ������´�����ֻ��3.75������ ��Ȼ����Ҳ�����ˡ�д25���� ���˺��ĵ�оƬ���������⣬Ӣΰ�ﻹ������GB200 NVL72 Һ�����ϵͳ�����а��� 36 �� GB200 Grace Blackwell ����оƬ��Ӣΰ���ʾ��������������;����ͬ������ H100 Tensor Core ͼ�δ�����Ԫ��ȣ�GB200 NVL72 ���������ߴ� 30 �����ɱ����ܺĽ��Ͷ�� 25 ���� �ҷ���һ�¡�36��GB200��������72��B200������ͬ������H100(36��)���ɱ����ܺĽ������25���� ���Ǻüһ�������ʽ��ô�ȣ� ��Ȼ��ˡ������� GB200��H100�ɱ����ܺĸ��ƶ��25���� ��������밴B200��H100�ܺĽ���25�������� |
|
|
| [�ղر���] �����ر��ġ� |
| ��һƪ���� �鿴�������� |
|
|
|
| ��Ʊ�ǵ�ʵʱͳ�� ��ͣ��ѡ�� ��ʱͼѡ�� ��ͣ��ѡ�� K��ͼѡ�� �ɽ���ѡ�� ����ѡ�� ������ѡ�� �������� �������� ���� MACDָ�� KDJָ�� BOLLָ�� RSIָ�� ���ɻ���֪ʶ ���ɹ��� |
| ��վ��ϵ: qq:121756557 email:121756557@qq.com ����ƻ� |