
| |
|
|
| 首页 淘股吧 股票涨跌实时统计 涨停板选股 股票入门 股票书籍 股票问答 分时图选股 跌停板选股 K线图选股 成交量选股 [平安银行] |
| 股市论谈 均线选股 趋势线选股 筹码理论 波浪理论 缠论 MACD指标 KDJ指标 BOLL指标 RSI指标 炒股基础知识 炒股故事 |
| 商业财经 科技知识 汽车百科 工程技术 自然科学 家居生活 设计艺术 财经视频 游戏-- |
| 天天财汇 -> 科技知识 -> 英伟达发布 Blackwell GPU 架构,最强 AI 加速卡 GB200 年底上市,有何重要意义? -> 正文阅读 |
|
|
[科技知识]英伟达发布 Blackwell GPU 架构,最强 AI 加速卡 GB200 年底上市,有何重要意义? |
| [收藏本文] 【下载本文】 |
|
[图片] 腾讯科技讯 3月19日消息,据国外媒体报道,英伟达备受期待的GTC大会周一在美国圣何塞会议中心正式开幕。为巩固其作为人工智能公司首选供应商的… |
|
AI春晚GTC开幕,皮衣老黄再次燃爆全场。 时隔两年,英伟达官宣新一代Blackwell架构,定位直指“新工业革命的引擎” ,“把AI扩展到万亿参数”。 |

|
|
作为架构更新大年,本次大会亮点颇多: 宣布GPU新核弹B200,超级芯片GB200Blackwell架构新服务器,一个机柜顶一个超算推出AI推理微服务NIM,要做世界AI的入口新光刻技术cuLitho进驻台积电,改进产能。 …… |

|
|
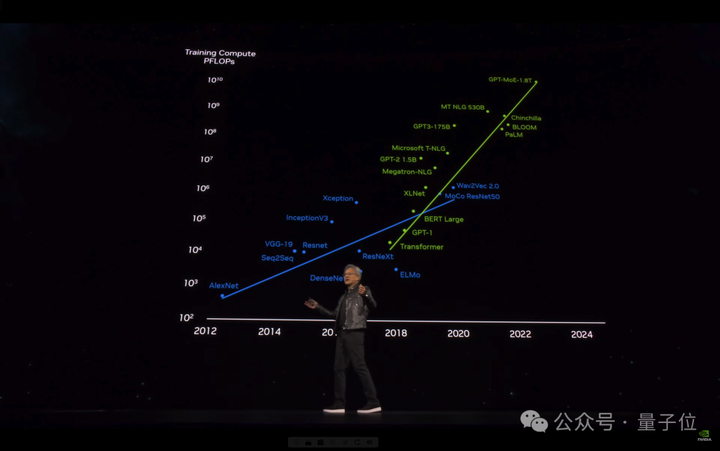
8年时间,AI算力已增长1000倍。 老黄断言“加速计算到达了临界点,通用计算已经过时了”。 我们需要另一种方式来进行计算,这样我们才能够继续扩展,这样我们才能够继续降低计算成本,这样我们才能够继续进行越来越多的计算。 |

|
|
老黄这次主题演讲题目为《见证AI的变革时刻》,但不得不说,英伟达才是最大的变革本革。 GPU的形态已彻底改变我们需要更大的GPU,如果不能更大,就把更多GPU组合在一起,变成更大的虚拟GPU。 Blackwell新架构硬件产品线都围绕这一句话展开。 通过芯片,与芯片间的连接技术,一步步构建出大型AI超算集群。 4nm制程达到瓶颈,就把两个芯片合在一起,以10TB每秒的满血带宽互联,组成B200 GPU,总计包含2080亿晶体管。 没错,B100型号被跳过了,直接发布的首个GPU就是B200。 |

|
|
两个B200 GPU与Grace CPU结合就成为GB200超级芯片,通过900GB/s的超低功耗NVLink芯片间互连技术连接在一起。 两个超级芯片装到主板上,成为一个Blackwell计算节点。 |

|
|
18个这样的计算节点共有36CPU+72GPU,组成更大的“虚拟GPU”。 它们之间由今天宣布的NVIDIA Quantum-X800 InfiniBand和Spectrum?-X800以太网平台连接,可提供速度高达800Gb/s的网络。 |

|
|
在NVLink Switch支持下,最终成为“新一代计算单元”GB200 NVL72。 一个像这样的“计算单元”机柜,FP8精度的训练算力就高达720PFlops,直逼H100时代一个DGX SuperPod超级计算机集群(1000 PFlops)。 |

|
|
与相同数量的72个H100相比,GB200 NVL72对于大模型推理性能提升高达30倍,成本和能耗降低高达25倍。 把GB200 NVL72当做单个GPU使用,具有1.4EFlops的AI推理算力和30TB高速内存。 |

|
|
再用Quantum InfiniBand交换机连接,配合散热系统组成新一代DGX SuperPod集群。 DGX GB200 SuperPod采用新型高效液冷机架规模架构,标准配置可在FP4精度下提供11.5 Exaflops算力和240TB高速内存。 此外还支持增加额外的机架扩展性能。 |

|
|
最终成为包含32000 GPU的分布式超算集群。 老黄直言,“英伟达DGX AI超级计算机,就是AI工业革命的工厂”。 将提供无与伦比的规模、可靠性,具有智能管理和全栈弹性,以确保不断的使用。 |

|
|
在演讲中,老黄还特别提到2016年赠送OpenAI的DGX-1,那也是史上第一次8块GPU连在一起组成一个超级计算机。 |

|
|
从此之后便开启了训练最大模型所需算力每6个月翻一倍的增长之路。 |
|
|
GPU新核弹GB200 过去,在90天内训练一个1.8万亿参数的MoE架构GPT模型,需要8000个Hopper架构GPU,15兆瓦功率。 |

|
|
如今,同样给90天时间,在Blackwell架构下只需要2000个GPU,以及1/4的能源消耗。 |

|
|
在标准的1750亿参数GPT-3基准测试中,GB200的性能是H100的7倍,提供的训练算力是H100的4倍。 |

|
|
Blackwell架构除了芯片本身外,还包含多项重大革新: 第二代Transformer引擎 动态为神经网络中的每个神经元启用FP6和FP4精度支持。 |

|
|
第五代NVLink高速互联 为每个GPU 提供了1.8TB/s双向吞吐量,确保多达576个GPU之间的无缝高速通信。 |

|
|
Ras Engine(可靠性、可用性和可维护性引擎) 基于AI的预防性维护来运行诊断和预测可靠性问题。 Secure AI 先进的加密计算功能,在不影响性能的情况下保护AI模型和客户数据,对于医疗保健和金融服务等隐私敏感行业至关重要。 专用解压缩引擎 支持最新格式,加速数据库查询,以提供数据分析和数据科学的最高性能。 |

|
|
在这些技术支持下,一个GB200 NVL72就最高支持27万亿参数的模型。 而GPT-4根据泄露数据,也不过只有1.7万亿参数,一台能同时运行16个GPT-4。 |

|
|
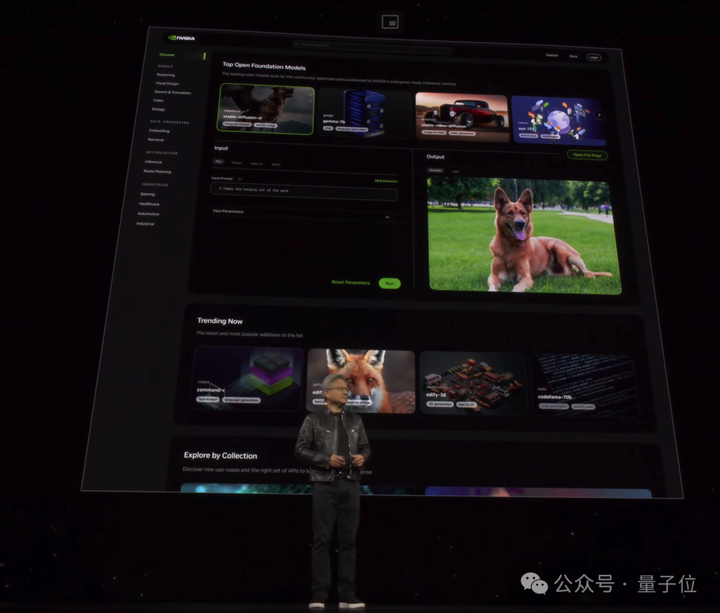
英伟达要做世界AI的入口 老黄官宣http://ai.nvidia.com页面,要做世界AI的入口。 任何人都可以通过易于使用的用户界面体验各种AI模型和应用。 同时,企业使用这些服务在自己的平台上创建和部署自定义应用,同时保留对其知识产权的完全所有权和控制权。 |
|
|
这上面的应用都由英伟达全新推出的AI推理微服务NIM支持,可对来自英伟达及合作伙伴的数十个AI模型进行优化推理。 |

|
|
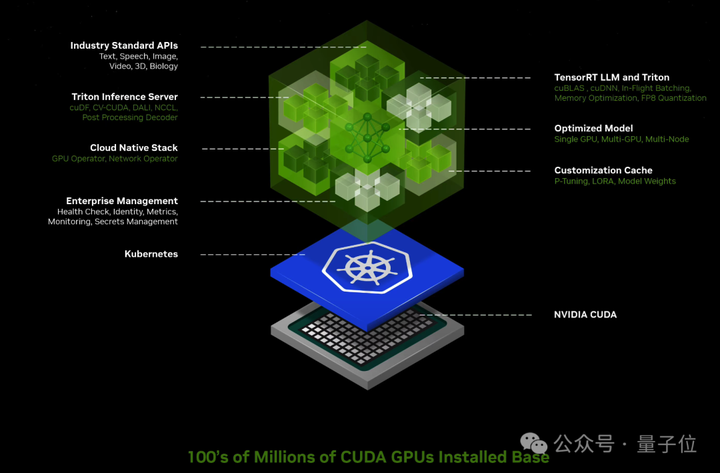
此外,英伟达自己的开发套件、软件库和工具包都可以作为NVIDIA CUDA-X?微服务访问,用于检索增强生成 (RAG)、护栏、数据处理、HPC等。 |
|
|
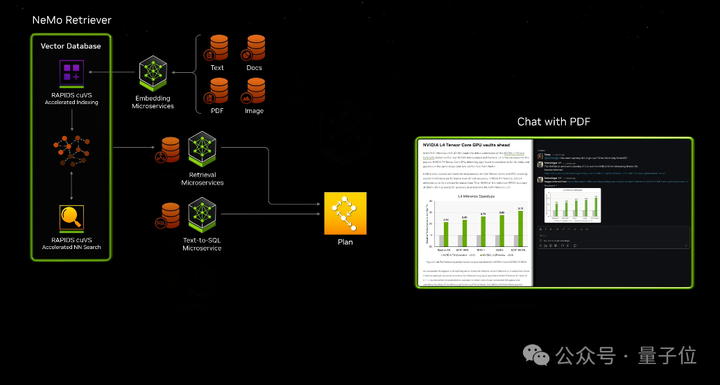
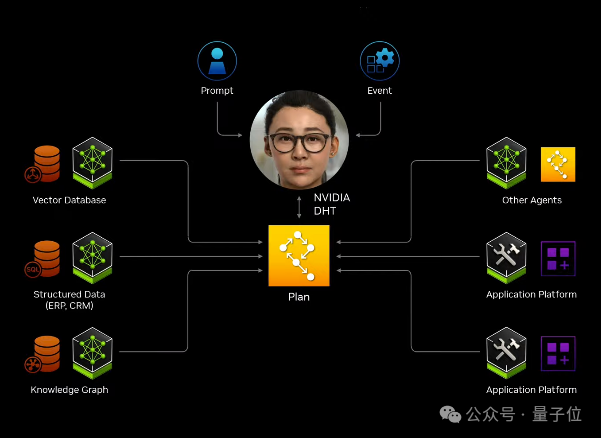
比如通过这些微服务,可以轻松构建基于大模型和向量数据库的ChatPDF产品,甚至智能体Agent应用。 |
|
|
|
|
|
NIM微服务定价非常直观,“一个GPU一小时一美元”,或年付打五折,一个GPU一年4500美元。 从此,英伟达NIM和CUDA做为中间枢纽,连接了百万开发者与上亿GPU芯片。 什么概念? 老黄晒出AI界“最强朋友圈”,包括亚马逊、迪士尼、三星等大型企业,都已成为英伟达合作伙伴。 |

|
|
最后总结一下,与往年相比英伟达2024年战略更聚焦AI,而且产品更有针对性。 比如第五代NVLink还特意为MoE架构大模型优化通讯瓶颈。 新的芯片和软件服务,都在不断的强调推理算力,要进一步打开AI应用部署市场。 当然作为算力之王,AI并不是英伟达的全部。 这次大会上,还特别宣布了与苹果在Vision Pro方面的合作,让开发者在工业元宇宙里搞空间计算。 |

|
|
此前推出的新光刻技术cuLitho软件库也有了新进展,被台积电和新思科技采用,把触手伸向更上游的芯片制造商。 |

|
|
当然也少不了生物医疗、工业元宇宙、机器人汽车的新成果。 |

|
|
|

|
|
以及布局下一轮计算变革的前沿领域,英伟达推出云量子计算机模拟微服务,让全球科学家都能充分利用量子计算的力量,将自己的想法变成现。 |

|
|
One More Thing 去年GTC大会上,老黄与OpenAI首席科学家Ilya Sutskever的炉边对谈,仍为人津津乐道。 当时世界还没完全从ChatGPT的震撼中清醒过来,OpenAI是整个行业绝对的主角。 如今Ilya不知踪影,OpenAI的市场统治力也开始松动。在这个节骨眼上,有资格与老黄对谈的人换成了8位―― Transformer八子,开山论文《Attention is all you need》的八位作者。 他们已经悉数离开谷歌,其中一位加入OpenAI,另外7位投身AI创业,有模型层也有应用层,有toB也有toC。 这八位传奇人物既象征着大模型技术真正的起源,又代表着现在百花齐放的AI产业图景。在这样的格局中,OpenAI不过是其中一位玩家。 而就在两天后,老黄将把他们聚齐,在自己的主场。 |

|
|
要论在整个AI界的影响力、号召力,在这一刻,无论是“钢铁侠”马斯克还是“奥特曼”Sam Altman,恐怕都比不过眼前这位“皮衣客”黄仁勋。 直播回放: https://www.youtube.com/watch?v=Y2F8yisiS6E ―完― @量子位 ・ 追踪AI技术和产品新动态 深有感触的朋友,欢迎赞同、关注、分享三连?'?' ? ? |
|
翻了一眼两年前H100发布时候写的 两年时间天翻地覆,大模型横空出世,整个AI芯片、Infra的很多底层逻辑都发生了天翻地覆的变化。作为一个骨灰级N吹,继续给大家梳理一下正确姿势。白皮书还没出,先说一些大面上的,之后再更新。 算力提升放缓,显存提升加速。抛开茫茫多老黄吹牛逼的烟雾弹,实打实的算力提升大概只有2.5倍,以往NVidia每一代产品的算力提升都是5倍左右。这个并不是NVidia没有能力继续暴力提算力,而是大模型横空出世之后,显存的重要性相比带宽的重要性急剧提升。我去年一整年几乎都是在鼓吹显存的重要性(英伟达的破绽) NVidia过去的整个产品战略都是围绕算力需求规划的,保持算力按照黄氏曲线增长是过去这么多代产品一直坚持的,每一代产品差不多提升4~5倍的算力,确保吃尽工艺和架构创新的红利空间。这个节奏过去这么多大算力AI芯片的冲击下基本没有动摇过。 过去一年对NVidia而言是混乱的一年,这种混乱估计还会持续一段时间,因为大模型带来了显存需求的暴涨和算力重要性的下滑,无论是H100 VNL还是H200都是过去闻所未闻的形态。L40S这一类传统意义上的推理卡在今天的大模型推理市场也是毫无性价比,惨遭滑铁卢。 B200本质上也是这个旧的产品路线和新需求交叉的产物。自然而然,产品升级的重心要放到显存维度,未来甚至需要在互联和显存维度再塑造一个新的黄氏曲线。 AMD凉了。老黄还是比较有魄力,做了双die合封。双die模拟一个die虽然有一些隐性的NUMA问题,不过这个问题在A100时候L2分裂成两个的时候就已经存在了,倒也问题不大。但AMD的短期优势转瞬即逝,本来靠着chiplet在大模型横空出世的阶段能快速堆到8个HBM,通过8个HBM3打NVidia的6个HBM,哪怕H200升级成6个HBM3E也仍然有一定的优势。 但随着NVidia也开始双die合封,也变成8个HBM,还是HBM3E,甚至把海力士的8GT/pin的频率拉满,直接挤光牙膏做到8TB/s的内存带宽,AMD短期优势算是瞬间没了,毕竟HBM3E的产能都被NVidia抢光了,未来随着海力士进一步升级成36GB+1.2TB/s的HBM,显存应该能飙到288GB+9.6TB/s,Intel的falcon shores画的饼也是差不多这个规格,不过估计Intel还是会跳票。 缓存带宽估计需要配平。H100的L2带宽大致只有12TB/s,而B200的内存带宽已经到这个当量了,L2带宽得显著提升才能发挥作用,要不然会跟很多DSA芯片一样会出现比较多不配平产生的利用率的问题,这个可以等白皮书出来仔细看看。B200芯片内部应该花费了不少资源去做这方面的配平调整,相反算力调整可能没那么急迫。只不过双die合封了自然已经被动有了2倍提升了,再稍微有个30%的提升,纸面算力已经提升了2.5倍了。 NVidia的大模型战略仍然是全面高端卡。虽然显存重要性很高,但大模型全场景存在非常变态且激烈分化的算力密集部分和访存密集部分。因此老黄的策略就是把算力和显存都做到最高端,这样放到算力密集的场景,B200是算力最高的,放到访存密集的场景,B200是访存最高的。这个策略其实挺无敌的。尤其AMD的MI300X短暂地让NVidia地产品在显存层面处于第二的位置时,老黄是急切地想重回这个维度的第一。所以未来也一样,每个指标都会有一定升级,谁跟他卷某个指标,他反过来快速迭代这个指标。 当然这个战略也有破绽,这样反过来导致算力密集的场景显存是过剩和浪费的,访存密集的场景算力又是过剩和浪费的,尤其在大模型这么撕裂的场景下。我在LLM推理到底需要什么样的芯片?(2) 里也提到过,今天跟NVidia卷就应该把这种撕裂的场景做成异构,来打这种全面高端的同构形态。 抛弃x86可能有点激进。其实一个很重要的细节是NVidia这次的DGX推的是DGX GB200而不是DGX B200,以前的DGX A100、DGX H100都是x86 CPU的标准服务器挂了8张GPU,并且在GPU侧做了复杂的网络和NVLink互联。Grace+GPU的形态是从22年的GH200开始的,实际上这就是个全NVidia私有化的方案了。其实GH200那个一排机柜的“A single GPU”虽然真的是个力大砖飞的秀肌肉形态,但市场上确实没什么水花。 今年感觉老黄是铁了心想再试试把x86从数据中心里抹掉,把DGX的品牌都跟这个全定制的CPU+GPU的组合形态绑定了。当然还是留了HGX B200给下游服务器厂商继续供应常见的x86服务器形态,估计也是怕走太激进翻车了。 CPU+GPU其实除了完全私有化外,对用户而言,唯一的好处是CPU和GPU之间800GB/s的互联带宽,相比PCIe的64GB/s肯定是高了不少。要说收益肯定有,但大多不是什么痛得不行的痛点。实在想不出有什么场景值得用户放弃x86来拥抱NV纯私有化方案,感觉还是存疑的。 其实今天NVidia天天在NVLink-Network层面秀肌肉,但互联网厂商一般还是买它的单机节点,自己搞交换机搭网络拓扑。全面拥抱NV纯私有化的大盒子方案实际上还是有很大的阻力的。 其实即使是NVidia,也一样要遵循整个生态竞争的逻辑,我之前在芯片生态的竞争逻辑也阐述过,NVidia的扩张和重塑的权力一定是要有利于关键需求的,NVLink得以成为事实标准,是因为GPU之间的PCIe互联软件已经没法优化了,值得入NVLink,但其他层面还远没到这个程度。 NVidia在16年的时候就尝试过和IBM合作踢掉x86,不过最后是IBM在风中凌乱了。今天NVidia市值已经是Intel十倍了,又跃跃欲试想踢掉x86,其实还是有点激进的。 NVIDIA追求全面私有化其实进一步打开了围绕标准化体系的第二套方案的空间。对于今天所有NVidia的竞争者而言,围绕标准化体系打造一个松散的白盒方案会非常有生态竞争力。比各自为战和NVIDIA一样打造全面私有化方案有效得多。 NVIDIA的竞争力其实越来越依赖脱离标准化体系的私有方案,和标准化体系差异化会越大,围绕标准化体系也就可以差异化竞争。围绕x86的整套体系其实Intel是最有号召力的,可惜Intel完全没有脑子,CXL搞什么莫名其妙的一致性,还不如带宽拉起来,天下群雄就自然围绕在Intel周围了,怒其不争。 当然了,今天大模型把竞争拉到了数据中心的尺度,可以架构取舍的空间也比从前大的多,NVIDIA在这个尺度下要保持竞争力,必然需要坚持这种全面高端的战略,确保各个指标都冲到极致,反过来也会在不同场景下出现巨大的浪费,而这就是竞争者在标准化体系下的空间。 |
|
所有的关键内容,就是: 卖卡, 卖很多卡(机柜), 打包卖很多很多卡(数据中心) B200 GPU,包含 2080 亿个晶体管,提供高达 20 petaflops的 FP4 算力。 将两个 GPU 与单个 Grace CPU 结合在一起的 GB200 可以为 LLM 推理工作负载提供 30 倍的性能,同时还可能大幅提高效率。与 H100 相比,它“可将成本和能耗降低多达 25 倍”。 老黄说,训练一个 1.8 万亿参数模型之前需要 8,000 个 Hopper GPU 和 15 兆瓦的功率。如今,只需要 2,000 个 Blackwell GPU 就可以做到这一点,而功耗仅为 4 兆瓦。嗯,训练速度提升了4倍。 在具有 1750 亿个参数的 GPT-3 LLM 基准测试中,老黄说, GB200 的性能是 H100 的 7 倍,看起来,两个 B200组成的 GB200,并未提供了8倍的性能,多卡并联还是有损失的。 新的下一代 NVLink 交换机可让 576 个 GPU 相互通信,具有每秒 1.8 TB 的双向带宽。 FP6 FP4 这两是冲着推理去的了, FP6和 FP8性能竟然一致,那么 FP6的价值何在?为什么要有 FP6? FP4是 FP8性能的两倍。FP4的好处,其实是提升了带宽,通过为每个神经元使用 4 位而不是 8 位(因此,我之前提到的 FP4 的 20 petaflops),使计算、带宽和模型大小加倍。 |

|
|
老黄很贴心,知道各个搞大模型的公司,不是一卡一卡地买的。 老黄将36个 cpu 和72个 gpu 打包,封装到一个液冷机架中。大模型公司可以更方便的“批发” 一个液冷机架及所包含的 cpu 和 gpu 一起,叫做 GB200 NVL72。按照某米的宣传方式,这里必须再宣传一下,一个液冷机架共有 5,000 根单独的电缆,近两英里长。这么长的电缆,还是值很多很多钱的!所以,GB200 NVL7肯定不便宜 老黄说, GB200 NVL72可以提供 720 petaflops的训练算力和1.4 exaflops推理算力。各位,算力不足恐惧症的大厂们,有福了。 老黄的 GB200 NVL7搞个几个会去,大模型杠杠的! |

|
|
GB200 NVL72 以机架级设计连接 36 个 Grace CPU 和 72 个 Blackwell GPU。GB200 NVL72 是一款液冷机架级解决方案,拥有 72 个 GPU NVLink 域,充当单个大型 GPU,可为万亿参数 LLM 推理提供 30 倍的实时速度。 GB200 Grace Blackwell Superchip 是NVIDIA GB200 NVL72的关键组件,使用 NVIDIA? NVLink?-C2C 互连将两个高性能 NVIDIA Blackwell Tensor Core GPU 和一个 NVIDIA Grace CPU 连接到两个 Blackwell GPU。 |

|
|
当然,如果你的钱很多很多,老黄粉不仅长大了,还有钱了的话 那么,老黄还可以提供更多的“超级盒子” 就像超人一样,超级盒子很牛逼,很大,很强,也很硬,这就是DGX Superpod。 NVIDIA DGX SuperPOD? 是一种 AI 数据中心基础设施,使 IT 能够毫不妥协地为每个用户和工作负载提供性能。作为NVIDIA DGX? 平台的一部分,DGX SuperPOD 为最具挑战性的 AI 工作负载提供领先级的加速基础设施和可扩展性能,并取得了经过行业验证的结果。 比如,这一个超级盒子,可以包含有8个机架,总共 288 个 CPU、576 个 GPU、240TB 内存和 11.5 exaflops 的 FP4 计算。 |

|
|
老黄语录:“当有人说 GPU 时,我看到的是这一点。两年前,当我看到 GPU 时,它是 HGX。它重 70 磅,包含 35,000 个零件。我们的 GPU 现在包含 600,000 个零件和 3,000 磅。这有点像碳纤维的重量法拉利”。从核弹,变成了法拉利,也许是受了某米的影响?【狗头保命】 |
|
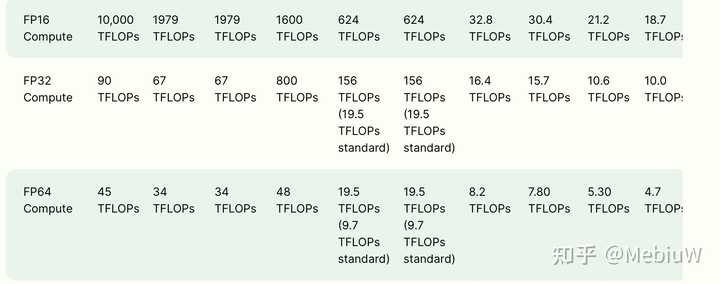
虽然Blackwell发布之前还在期待有没有黑魔法,不过目前看来Nvidia可能也进入到正常更新的局面了,Blackwell的提升基本于等于芯片规模的增加。 |
|
|
Blackwell 208B的总晶体管对比上一代的80B提升了2.6倍,然后在定精度的情况下,Tensor性能是2.5倍,传统的Vector 性能提升34%。然后考虑到功耗的提升和变化不大的工艺,那么基本从规模上,Blackwell把大部分新增的晶体管拿去做了Tensor性能,然后获得了比较正常的一个提升幅度。亮点的话这次引入的FP4,所以极限Tensor速率翻倍了。很好奇下一代,以及下下一代是不是分别引入2bit和1bit的运算支持了? 所以总体来说就是Tensor性能强无敌,传统Vector 性能真的很一般。 这货完全是个NPU,而不是GPU之类的。 |
|
|
另外比较有意思的是这回Blackwell是两个芯片胶水到一起的,从实际图片来看两个芯片的封信微乎其微,看起来和Apple的M2 Ultra用的可能是类似的封装技术, 10TB/s的通信速度说可以逻辑上看成一个统一的架构。但是具体10TB/s够不够不太好说,一方面Intel Sapphire Rapids那里一个D2D 0.5TB/s总共20条也是10TB/s,感觉10TB/s对于GPU不一定够。 另一方面HBM的速度就8TB/s了,内部通信这个量级总觉得有点少。 |

|
|
|

|
|
|
|
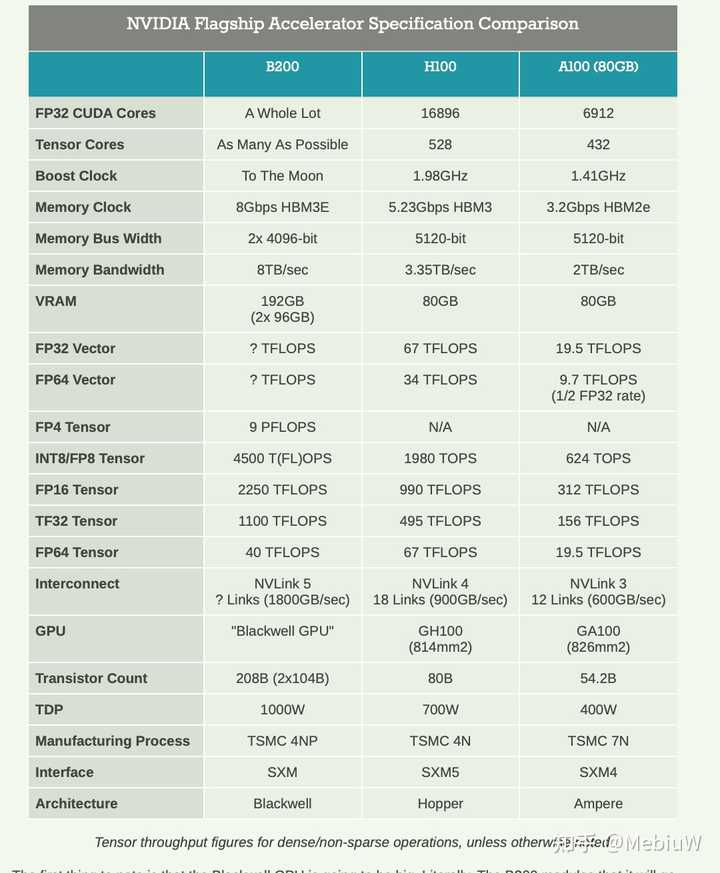
有两个重要意义: 摩尔定律开始失效了。 单位面积内的芯片算力被锁死在了 H100 量级。因此从 B200 开始, GPU 要沿着堆料的方向增大芯片面积了。其他 GPU 厂商有追赶上来的机会,一旦技术(工艺)突破到 H100 水平,后续的芯片就主要聚焦在多芯片封装、芯片间互联、节点间互联 通信等工程优化了。B200 仅比 H100 加速 13% 实际大模型应用中都是稠密计算(即使是 MoE,也是稠密计算 matmul),所以我们剔除掉浮夸的 with sparsity 虚标算力,实际的各芯片算力对比: |

|
|
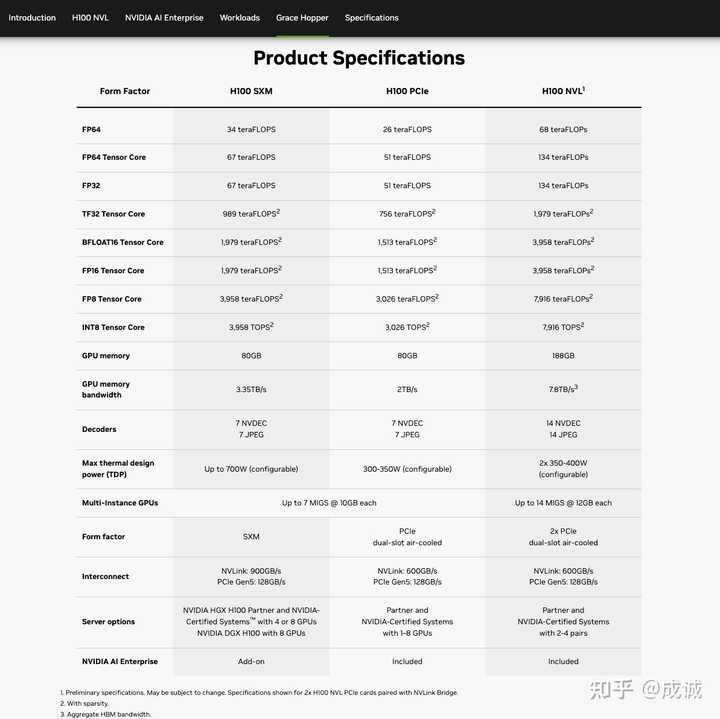
B200 和 H100、A100 各精度算力对比 由于 B200 实际上是两块芯片拼起来的,单位面积内(SM)的算力需要除以二。以 LLM 目前最主要的训练方式 BF16 精度为计算单元,实际上 B200 的加速效果: \frac{FLOPs_{B200/SM}}{FLOPs_{H100/SM}} = \frac{2250 TFLOPs / 2}{989TFLOPs} = \frac{1125}{989} = 1.137 B200 是大号的 H100 NVL 可能大部分人不知道 H100 的 NVL 型号(实际上也没人买)本质上就是由两块 H100 SXM 拼起来的: |
|
|
H100 NVL 是 B200 的雏形 而 B200 沿着这条路做的更极致了一些, 且 NVIDIA 只发布拼接后的芯片可能也是为了掩盖单芯片算力提升不明显的问题。 B200 是否具有性价比优势? 目前还不清楚 B200 的售价。但从生产成本上, B200 的成本至少是 H100 的两倍以上。得到的性能收益也是两倍多。如果保持利润率不变的话,很难说 B200 比 H100 更具性价比。 同时,我们已知在 H100/H800 刚生产的前半年里, H100 的故障率很高(超过 10%),直到现在也有 3% - 5% 的故障率/年。 而作为能耗大户、8 卡 B200 等于 16 卡 H100 的新芯片,故障率是否会更高就不得而知了。 只知道之前 NV 做过 16 卡的 A100/H100 ,但因为太不稳定并没有推广开,流行的仍是 8 卡的 DGX/HGX-H100。 FP4 算力是否能成为下一代 LLM 训练标配? 除了芯片拼接,B200 的另一大特色是支持 FP4 的 Tensor Core,在 FP8 基础上算力又翻了一倍。其实 FP8 的 LLM Training 还没有成为主流, 大部分的 LLM 训练还是用的 BF16 混合精度。 FP8 的 AMP 需要非常定制化、非常小心的给每一个 Weight 计算设置不同的、自适应调整的 Scaling 参数,相关的工作有: https://github.com/Azure/MS-AMPFP8-LM: Training FP8 Large Language Models 且除了 Matmul,很多计算用 FP8 都会造成数值溢出,以至于 FP8 的 AMP 会插入更多的 Cast,实际加速效果并不是 BF16 的 2 倍(算力是 2 倍),仅能到 40% 左右。 顺带提一句,早期(2022年及之前)很多复现 GPT-3 的工作的 LLM 训练都非常难以收敛(Bloom、OPT 等),核心的问题就是用 FP16 精度训练,而非 BF16 (后者的表示范围更大,精度更低),以至于发生频繁的数值溢出。 因此,未来 FP4 是否能用于 LLM Training,个人表示是十分怀疑的。至少目前学术界也没有一个有说服力的方案 (Pretrain,而非 QAT)。 NVIDIA 在宣传 FP4 的时候,也主要是宣传推理效果加速,推理确实可以支持 FP4/INT4 量化推理,但需要承受一定程度的效果损失。 GB200 推广了新的互联方式 B200 本身在芯片层级就进行了拼接 (2x H100),而 GB200 在两个 GPU 间高速互联的设计也不是新东西了,而是沿用了之前的 GH200 的设计: |
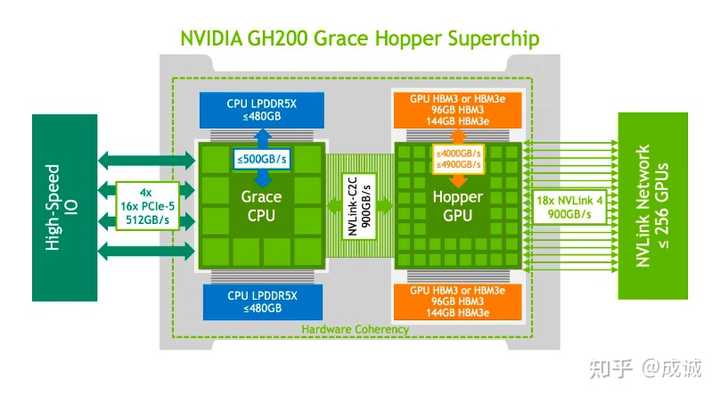
|
|
GH200 芯片互联架构 至于 GB200-NVL72 更是一个超大杯的多芯片互联,将 36 个 GB200 用超高速的 NVLink 进行连接,1800 GB/s (x72) 的互联带宽 远超之前 DGX-H800 机器之间的 3.2Tb/s (8 GPU 共享)IB 网络带宽。 实际总互联带宽是: GB200-NVL72 130TB/s Bandwidth >> DGX-H100 0.8TB/s Bandwidth 分配到单芯片的互联带宽是: B200 1800GB/s Bandwidth >> H100 100GB/s Bandwidth 注: 上述互联带宽都是双工累加。 而 GB200-NVL72 比 9 台 8xH100 机器快很多倍的主要原因也是因为它的互联带宽快了很多倍,并行效率大幅提升。 对未来的影响 实际上 芯片拼接、增大互联带宽 并不是一个很难的技术。 在 B200 的单位面积算力见顶的当下,NVIDIA 也开始走堆料、堆互联的路线了。 因此可以估计,一旦一个芯片厂商在单芯片的制程、算力可以比肩 H100 的情况下,发展到 B200、GB200-NVL72 只是一个工程问题,而不是一个技术突破问题。 这个消息对于非 NVIDIA 的 GPU 厂商而言是一个好消息,追赶的目标变得固定了。 参考: NVIDIA Blackwell Platform Arrives to Power a New Era of ComputingNVIDIA HGX AI Supercomputing PlatformNVIDIA Grace Blackwell GB200 SuperchipNVIDIA Grace Hopper Superchip Data SheetNVIDIA DGX B200 DatasheetNVIDIA H100 Tensor Core GPUNVIDIA A100 GPUs Power the Modern Data Center |
|
|
| [收藏本文] 【下载本文】 |
| 科技知识 最新文章 |
| 百度为什么越来越垃圾了? |
| 百度为什么越来越垃圾了? |
| 为什么程序员总是发现不了自己的Bug? |
| 出现在抖音评论区里边的算命真不真? |
| 你认为 C++ 最不应该存在的特性是什么? |
| 为什么 Windows 的兼容性这么强大,到底用了 |
| 如何看待Nvidia禁止使用翻译工具将cuda运行 |
| 为何苹果搞了十年的汽车还是难产,小米很快 |
| 该不该和AI说谢谢? |
| 为什么突破性的技术总是最先发生在西方? |
| 上一篇文章 下一篇文章 查看所有文章 |
|
|
|
| 股票涨跌实时统计 涨停板选股 分时图选股 跌停板选股 K线图选股 成交量选股 均线选股 趋势线选股 筹码理论 波浪理论 缠论 MACD指标 KDJ指标 BOLL指标 RSI指标 炒股基础知识 炒股故事 |
| 网站联系: qq:121756557 email:121756557@qq.com 天天财汇 |