
| |
|
|
| 首页 淘股吧 股票涨跌实时统计 涨停板选股 股票入门 股票书籍 股票问答 分时图选股 跌停板选股 K线图选股 成交量选股 [平安银行] |
| 股市论谈 均线选股 趋势线选股 筹码理论 波浪理论 缠论 MACD指标 KDJ指标 BOLL指标 RSI指标 炒股基础知识 炒股故事 |
| 商业财经 科技知识 汽车百科 工程技术 自然科学 家居生活 设计艺术 财经视频 游戏-- |
| 天天财汇 -> 科技知识 -> 英伟达发布最强 AI 芯片 B200,性能提升 30 倍,该产品有哪些特性?对 AI 领域意味着什么? -> 正文阅读 |
|
|
[科技知识]英伟达发布最强 AI 芯片 B200,性能提升 30 倍,该产品有哪些特性?对 AI 领域意味着什么? |
| [收藏本文] 【下载本文】 |
|
NVIDIA 表示,新的 B200 GPU 拥有 2080 亿个晶体管,可提供高达 20petaflops 的 FP4 算力,而 GB200 将两个 … |
|
LLM任务可能要告别16bit浮点数做矩阵乘法计算的时代了。 Blackwell架构的Tensor Core支持FP4,可以让MoE模型的训练和推理受益。 To supercharge inference of MoE models, Blackwell Tensor Cores add new precisions, including new community-defined microscaling formats, giving high accuracy and ease of replacement for larger precisions. The Blackwell Transformer Engine utilizes fine-grain scaling techniques called micro-tensor scaling, to optimize performance and accuracy enabling 4-bit floating point (FP4) AI. This doubles the performance and size of next-generation models that memory can support while maintaining high accuracy. 这里提到的microscaling format应该是如下论文提出的方法,作者来自微软、AMD、英特尔、Meta、NVIDIA和高通,说明这个格式已经在业界形成了一定共识。之前FP8对整个Tensor进行统一scale,但是Tensor level Scaling被证明对于低于8bit的格式来说是不够的,因为这些格式的动态范围有限。所以缩放粒度要下降到更小的的sub-blocks of tensors,也就是Microscaling Data Formats。 Microscaling Data Formats for Deep Learning 另外,跨机的集合通信也可以用SHARP协议支持FP8。 The NVIDIA NVLink Switch Chip enables 130TB/s of GPU bandwidth in one 72-GPU NVLink domain (NVL72) and delivers 4X bandwidth efficiency with NVIDIA Scalable Hierarchical Aggregation and Reduction Protocol (SHARP)? FP8 support. The NVIDIA NVLink Switch Chip supports clusters beyond a single server at the same impressive 1.8TB/s interconnect. Multi-server clusters with NVLink scale GPU communications in balance with the increased computing, so NVL72 can support 9X the GPU throughput than a single eight-GPU system. 使用FP8梯度来做通信,这个之前MSRA的人已经做了一些验证。 Transformer Engine 2.0会支持FP4,期待一下第一个用FP4训练出来的MoE大模型。 评论区有人指出参数还是存储成高精度的。这里在补充一下混合精度训练概念:矩阵乘法的计算虽然用低精度数据格式完成,但是梯度计算结果会累加到高精度的参数上,有的非矩阵乘法计算还是会用高精度。具体细节可以参考我上面的知乎文章。 |
|
Blackwell B200 GPU,是如今世界上最强大的AI芯片,旨在「普惠万亿参数的AI」。 |

|
|
本来,H100已经使英伟达成为价值数万亿美元的公司,赶超了谷歌和亚马逊,但现在,凭着Blackwell B200和GB200,英伟达的领先优势还要继续领先。 老黄表示――「H100很好,但我们需要更大的GPU」! 新的B200 GPU,从2080亿个晶体管中能提供高达20 petaflops的FP4性能。(H100仅为4 petaflops) 而将两个B200与单个Grace CPU相结合的GB200,则可以为LLM推理工作负载提供30倍的性能,同时大大提高效率。 比起H100,GB200的成本和能耗降低了25倍! |

|
|
Blackwell芯片和Hopper H100芯片的尺寸比较 这种额外的处理能力,就能让AI公司训练更大、更复杂的模型,甚至可以部署一个27万亿参数的模型。 更大的参数,更多的数据,未来的AI模型,无疑会解锁更多新功能,涌现出更多新的能力。 现在,老黄拿在手里的,或许是100亿美元。 |

|
|
新一代性能巨兽,深夜重磅登场 凭借H100成为全球市值第三大公司的英伟达,今天再次推出了性能野兽――Blackwell B200 GPU和GB200「超级芯片」。 |

|
|
它以著名数学家David Blackwell(1919-2010)命名。他一生中对博弈论、概率论做出了重要的贡献。 |

|
|
老黄表示,「30年来,我们一直在追求加速计算,目标是实现深度学习和AI等变革性突破。生成式AI已然成为我们这个时代的标志性技术,而Blackwell将是推动这场新工业革命的引擎」。 「我们认为这是个完美的博弈概率」。 全新B200 GPU拥有2080亿个晶体管,采用台积电4NP工艺节点,提供高达20 petaflops FP4的算力。 与H100相比,B200的晶体管数量是其(800亿)2倍多。而单个H100最多提供4 petaflops算力,直接实现了5倍性能提升。 |

|
|
而GB200是将2个Blackwell GPU和1个Grace CPU结合在一起,能够为LLM推理工作负载提供30倍性能,同时还可以大大提高效率。 |

|
|
值得一提的是,与H100相比,它的成本和能耗「最多可降低25倍」。 过去,训练一个1.8万亿参数的模型,需要8000个Hopper GPU和15MW的电力。 |

|
|
如今,2000个Blackwell GPU就能完成这项工作,耗电量仅为4MW。 在GPT-3(1750亿参数)大模型基准测试中,GB200的性能是H100的7倍,训练速度是H100的4倍。 |

|
|
GB200由2个GPU、1个CPU、一个主板组成 全新芯片其中一个关键改进是,采用了第二代Transformer引擎。 对每个神经元使用4位(20 petaflops FP4)而不是8位,直接将算力、带宽和模型参数规模提高了一倍。 与此同时,英伟达还推出了第五代NVLink网络技术。 最新的NVLink迭代增强了数万亿参数AI模型的性能,提供了突破性的每GPU双向吞吐量,促进了无缝高速通信。 |

|
|
这也就是第二个关键区别,只有当你连接大量这些GPU时才会出现:新一代NVLink交换机可以让576个GPU相互通信,双向带宽高达1.8TB/秒。 这就要求英伟达打造一个全新的网络交换芯片,其中包含500亿个晶体管和一些自己的板载计算:拥有3.6 teraflops FP8处理能力。 在此之前,由16个GPU组成的集群,有60%的时间用于相互通信,只有40%的时间用于实际计算。 |

|
|
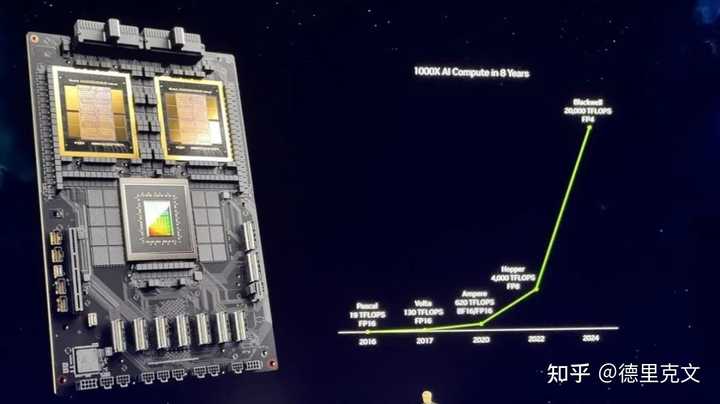
英伟达正在用Blackwell增加FP4和FP6 另外,Blackwell还配备了RAS引擎。 为了确保可靠性、可用性和可维护性,Blackwell GPU集成了专用引擎和基于AI的预防性维护功能,以最大限度地延长系统正常运行时间并最大限度地降低运营成本。 老黄表示,「过去8年,计算规模扩展已经增加了1000倍」。 |

|
|
网友:新的摩尔定律诞生了! 网友们纷纷惊叹,Blackwell再一次改变了摩尔定律。 英伟达高级科学家Jim Fan表示:Blackwell,城里的新野兽。 - DGX Grace-Blackwell GB200:单机架计算能力超过1 Exaflop。 - 从这个角度来看:老黄交付给OpenAI的第一台DGX是0.17 Petaflops。 - GPT-4-1.8T参数在2000张Blackwell上可在90天内完成训练。 新摩尔定律诞生了。 |

|
|
贾扬清回忆道,「我记得在Meta,当我们在一小时内(2017年)训练ImageNet时,总计算量约为1exaflop。这意味着有了新的DGX,理论上你可以在一秒钟内训练ImageNet」。 |

|
|
还有网友表示,「这简直就是野兽,比H100强太多」。 |

|
|
另有网友戏称,「老黄有效确认GPT4是1.8万亿参数」。 |

|
|
所以,GB200的成本是多少呢?英伟达目前并没有公布。 此前据分析师估计,英伟达基于Hopper的H100芯片,每颗的成本在25,000美元到40,000美元之间,整个系统的成本高达200,000美元。 而GB200的成本,只可能更高。 新超算可训万亿参数大模型 当然,有了Blackwell超级芯片,当然还会有Blackwell组成的DGX超算。 这样,公司就会大量购入这些GPU,并将它们封装在更大的设计中。 GB200 NVL72是将36个Grace CPU和72个Blackwell GPU集成到一个液冷机架中,可实现总计720 petaflops的AI训练性能,或是1,440 petaflops(1.4 exaflops)的推理性能。 它内部共有5000条独立电缆,长度近两英里。 |

|
|
它的背面效果如下图所示。 |

|
|
机架中的每个托盘包含两个GB200芯片,或两个NVLink交换机。一共有18个GB200芯片托盘,9个NVLink交换机托盘有。 老黄现场表示,「一个GB200 NVL72机架可以训练27万亿参数的模型」。 此前传言称,GPT-4的参数规模达1.8万亿,相当于能训练15个这样的模型。 |

|
|
与H100相比,对于大模型推理工作负载,GB200超级芯片提供高达30倍的性能提升。 |

|
|
那么,由8个系统组合在一起的就是DGX GB200。 总共有288个Grace CPU、576个Blackwell GPU、240 TB内存和11.5 exaflop FP4计算。 |

|
|
这一系统可以扩展到数万个GB200超级芯片,通过Quantum-X800 InfiniBand(最多144个连接)或Spectrum-X800ethernet(最多64个连接)与800Gbps网络连接在一起。 |

|
|
配备DGX GB200系统的全新DGX SuperPod采用统一的计算架构。 除了第五代NVIDIA NVLink,该架构还包括NVIDIA Bluefield-3 DPU,并将支持Quantum-X800 InfiniBand网络。 这种架构可以为平台中的每个GPU提供高达每秒1,800 GB的带宽。 除此之外,英伟达还发布了统一的超算平台DGX B200,用于AI模型训练、微调和推理。 它包括8个Blackwell GPU和2个第五代Intel Xeon处理器,包含FP4精度功能,提供高达144 petaflops的AI性能、1.4TB的GPU内存和64TB/s的内存带宽。 这使得万亿参数模型的实时推理速度,比上一代产品提高了15倍。 用户还可以使用DGX B200系统构建DGX SuperPOD,创建人工智能卓越中心,为运行多种不同工作的大型开发团队提供动力。 目前,亚马逊、谷歌、微软已经成为最新芯片超算的首批用户。 亚马逊网络服务,将建立一个拥有20,000 GB200芯片的服务器集群。 |

|
|
「不是一个芯片,更像一个平台」 自从ChatGPT于2022年底掀起AI热潮以来,英伟达的股价已经上涨了五倍之多,总销售额增长了两倍多。 因为英伟达的GPU对于训练和部署大型AI模型至关重要,微软、Meta等大公司都已纷纷豪掷数十亿购买。 如今各大公司和软件制造商还在争先恐后地抢购Hopper H100等芯片呢,GB200就已经出了。 老黄表示,Blackwell不是一个芯片,而是一个平台的名称。 从此,英伟达不再是芯片供应商,而更像是微软、苹果这样的平台提供商,可以让其他公司在平台上构建软件。 英伟达副总裁Manuvir Das表示,GPU是可销售的商业产品,而软件,是为了帮人们用不同的方式使用GPU。 虽然英伟达现在仍然售卖GPU,但真正不同的是,英伟达现在有了商业软件业务。 |
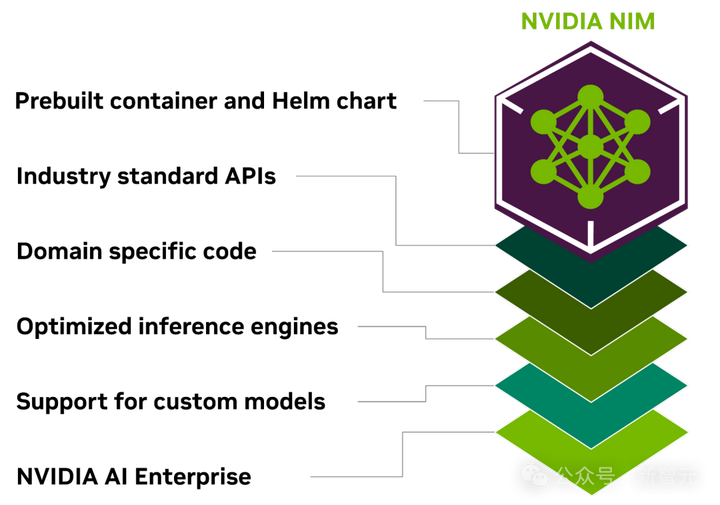
|
|
新软件NIM,代表着英伟达的推理微服务。 NIM使得在英伟达的任何GPU上运行程序都变得更容易,即使是可能更适合部署但不适合构建AI的旧GPU。 也就是说,假如一名开发者有一个有趣的模型,希望向人们推广,就可以把它放到NIM中。英伟达会确保它可以在所有的GPU上运行,这样模型的受众就大大扩展了。 NIM使得部署AI变得更容易,这就更加增加了客户使用英伟达芯片的粘性。 并且,与新AI模型的初始训练相比,NIM的推理需要更少的算力。 这样,想要运行自己AI模型的公司,就能运行自己的AI模型,而不是从OpenAI等公司购买对AI结果的访问权。 |

|
|
需要购买基于英伟达服务器的客户,需要注册Nvidia企业版,每个GPU每年需要花费4,500美元。 英伟达将与微软或Hugging Face等人工智能公司合作,确保他们的人工智能模型经过调整,可以在所有兼容的英伟达芯片上运行。 然后,使用NIM,开发者可以在自己的服务器或基于云的英伟达服务器上,高效运行模型,而无需冗长的配置过程。 Das介绍说,在自己调用OpenAI的代码中,他只替换了一行代码,就指向了NIM。 另外,NIM软件还将帮助AI在配备GPU的笔记本电脑上运行,而不是在云端的服务器上。 |

|
|
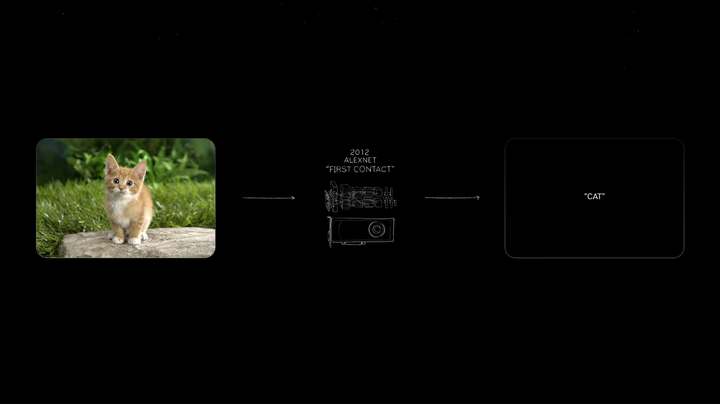
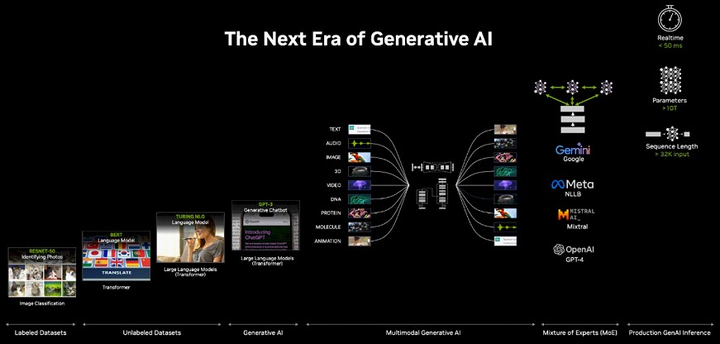
NIM支持跨多个领域的AI用例,包括LLMs、视觉语言模型(VLM)以及用于语音、图像、视频、3D、药物发现、医学成像等的模型。 AI API就是未来的软件。在未来,所有LLM都可以从云端获取,从云上下载,运行它的工作站。 终极生成式AI模型 而现在,整个行业都已经为Blackwell准备好了。 2012年,将一只小猫的图片输入,AlexNet识别后输出「cat」,让世界所有人为之震惊,并高呼这改变了一切。 |
|
|
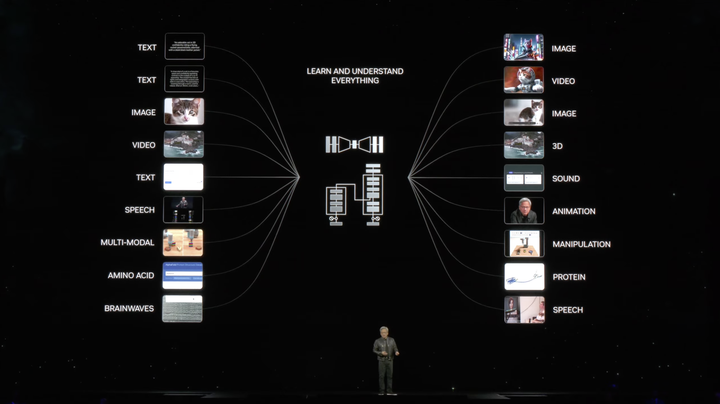
而现在从三个字「cat」输出10 million 像素成为了可能。仅用了10年时间,我们就可以识别文本、图像、视频。 万物都皆可数字化。 |
|
|
网友表示,老黄向我们展示了GenAI的终极游戏:多模态输入――多模态输出。 「这是我们总有一天都会使用的最终模型。它可以获取任何模态并生成任何模态。同时,它还能在没有每个部件的情况下工作」。 |

|
|
数字化的目的是让所有的目标都能成为机器学习的目标,从而让它们都能被AI生成。 比如,数字孪生地球,可以很好地帮助我们了解全球气象气候的变化。 |

|
|
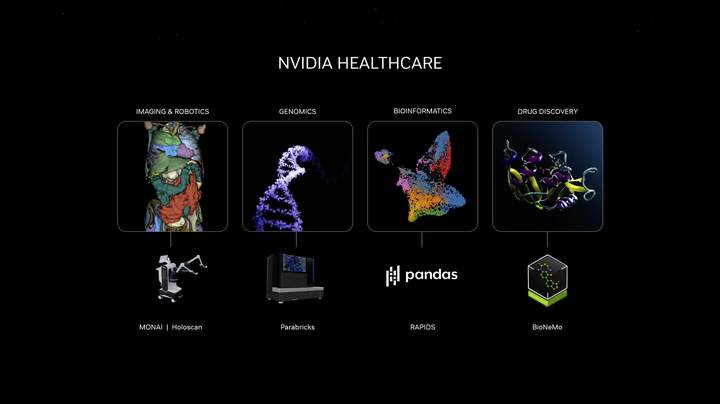
将基因、蛋白质、氨基酸数字化,可以让人类去理解生命的力量。 |
|
|
在大会接近尾声时,活动迎来了一个小高潮:Wall-E机器人也登台表演了。 |

|
|
而生成式AI的未来应用不仅于此。 现在,有了世界最强的处理器Blackwell,新一轮技术革命即将开启。 |
|
|
|
|
FP16 -> FP8 -> FP4 1-bit LLM is the future |
|
性能提升30倍,难怪有媒体说它是“AI核弹”!简单进行比较,单个B200的“算力”是它的前代产品H100的整整5倍。 |

|
|
B200芯片这是一款具有革命性的高性能计算产品,这个硬件性能的提升太及时了,要知道就在近日,来自MIT FutureTech的研究人员发表了一项关于大模型能力增长速度的研究。 该研究结果表明,大型语言模型(LLM)的能力以惊人的速度增长,大约每8个月翻倍,这一增速远超传统的摩尔定律预测。 由于LLM的能力提升在很大程度上依赖于算力的增强,而摩尔定律代表着硬件算力的发展,也就是说,随着时间的推移,终有一天人类的硬件设备,将无法满足LLM所需要的算力。 然而,令人没想到的是,才过几天,英伟达的最新B200芯片就以其卓越的性能,特别是在处理大型模型方面的算力,展现出了比LLM能力增长更快的硬件提升速度。 |
|
|
这一突破性的进展不仅满足了当前LLM对算力的迫切需求,还为未来更复杂模型的运行,提供了坚实的硬件基础。 B200芯片的推出,无疑是对目前大模型算力需求快速增长的回应,这也确保AI技术能够在满足基本硬件条件的情况下持续发展,不受算力限制的束缚。 性能的提升 B200芯片拥有2080亿个晶体管,这一数字是上一代H100芯片的两倍多。晶体管数量的增加直接关联到芯片处理能力和效率的提升。 |

|
|
与用于推理的相同数量的H100 Tensor Core GPU相比,全新的GB200 NVL机架级系统具有36个Grace Blackwell超级芯片,性能提高了30倍。 这意味着一台服务器的AI推理能力相当于一个超级计算机,极大地加速了AI技术在实际应用中的部署和运行。 对AI领域的意义 硬件的提升,带来的必然是更多的可能性。 在未来五年的时间内,我们预计将进入一个全新的信息处理时代,其中文本、图像、视频和语音等多种形式的数据,也许都能够实时输入到大语言模型(LLM)中。 计算机就能够直接接入所有信息源,并通过多模态交互不断地进行自我学习和改进。 而这,需要的就是巨量的算力。 |

|
|
只要能投入足够的计算资源,在所有的数据都被加载进大语言模型(LLM)后,构建超越人类智能的通用人工智能(AGI)就可能实现。 在不远的未来,我们可能只需使用简单的自然语言,就能与计算机进行有效沟通,并且实现我们想要的各种需求。 生成式AI在未来可能会演变为一种宏观世界层面的操作系统。 未来是创意的世界,只需要有足够的创意,人工智能就能够利用人类的历史积累智慧,想方设法把创意变为现实。 结语 硬件性能的提升,如果用人类来做类比,就好比我们拥有了一副能够适应更长时间工作需求的健康身体,以及一个反应更加迅速、思维更加敏捷的大脑。 这个身体不仅能够承受更高强度的工作压力,还能在面对复杂问题时迅速做出决策和响应。 正如一个经过良好训练的运动员,才能够在竞技场上展现出更加超凡的耐力和速度,英伟达B200芯片的推出,为AI领域带来了类似的飞跃。 |

|
|
在AI的世界里,芯片性能的提升,意味着计算机能够更快地处理和分析大量数据,更有效地训练复杂的机器学习模型,以及更实时地响应不断变化的计算需求。 这种硬件上的突破,为AI技术的发展打开了新的可能性,使得我们能够更加自信地迈向未来,探索那些曾经因为算力限制而难以触及的领域。 正如一个健康的身体是实现个人潜能的基础,强大的硬件性能也是推动AI技术进步和创新的基石。 随着高性能硬件的涌现,我们可以期待AI在未来将如何改变世界。 我是德里克文,一个对AI绘画,人工智能有强烈兴趣,从业多年的设计师!如果对我的文章内容感兴趣,请帮忙关注点赞收藏,谢谢! |
|
在各种IT巨头纷纷下单之余,他们未来的命运我不好揣测。 但是我知道的是,卖金铲子的皮衣老黄的确是赚麻了!! |

|
|
嘿嘿嘿 |
|
|
| [收藏本文] 【下载本文】 |
| 科技知识 最新文章 |
| 百度为什么越来越垃圾了? |
| 百度为什么越来越垃圾了? |
| 为什么程序员总是发现不了自己的Bug? |
| 出现在抖音评论区里边的算命真不真? |
| 你认为 C++ 最不应该存在的特性是什么? |
| 为什么 Windows 的兼容性这么强大,到底用了 |
| 如何看待Nvidia禁止使用翻译工具将cuda运行 |
| 为何苹果搞了十年的汽车还是难产,小米很快 |
| 该不该和AI说谢谢? |
| 为什么突破性的技术总是最先发生在西方? |
| 上一篇文章 下一篇文章 查看所有文章 |
|
|
|
| 股票涨跌实时统计 涨停板选股 分时图选股 跌停板选股 K线图选股 成交量选股 均线选股 趋势线选股 筹码理论 波浪理论 缠论 MACD指标 KDJ指标 BOLL指标 RSI指标 炒股基础知识 炒股故事 |
| 网站联系: qq:121756557 email:121756557@qq.com 天天财汇 |