
| |
|
|
| 首页 淘股吧 股票涨跌实时统计 涨停板选股 股票入门 股票书籍 股票问答 分时图选股 跌停板选股 K线图选股 成交量选股 [平安银行] |
| 股市论谈 均线选股 趋势线选股 筹码理论 波浪理论 缠论 MACD指标 KDJ指标 BOLL指标 RSI指标 炒股基础知识 炒股故事 |
| 商业财经 科技知识 汽车百科 工程技术 自然科学 家居生活 设计艺术 财经视频 游戏-- |
| 天天财汇 -> 科技知识 -> 马斯克开源 Grok-1,该混合专家模型拥有 3140 亿参数系迄今最大,将对相关领域产生哪些影响? -> 正文阅读 |
|
|
[科技知识]马斯克开源 Grok-1,该混合专家模型拥有 3140 亿参数系迄今最大,将对相关领域产生哪些影响? |
| [收藏本文] 【下载本文】 |
|
开源社区有福了。 说到做到,马斯克承诺的开源版大模型 Grok 终于来了! 今天凌晨,马斯克旗下大模型公司 xAI 宣布正式开源 3140 亿参数的混… |
|
首先一定是感恩开源的,老马真是说到做到,说开就开。 但其实我万万没想到的是开的竟然是一个MOE的模型,314B的整体参数,如果算单个专家的话,也就是30B的级别,由于Top-2专家激活,真实活跃参数量(86B)也就是70B的级别,总感觉这个史大有点投机取巧的意味。 当然,上一个火爆的moe模型还是mistral的7B级别,那么grok-1这种30B级别moe模型还是很有学术研究意义的。 但太大了,想我这种贫玩根本玩不了,别说没有8*A100/A800/H800 80G的显卡,我都没有640G的内存,更甚至我都没有640G的磁盘空间。 |

|
|
怎么办呢?只能等等等,等到int4量化的模型,但依然对于很多人来说可能没有那么多资源启动。 其实 @孟繁续 大佬曾经分析过,Mixtral-8x7B模型其实只有expert3在工作,那么grok-1是不是呢?也许可以变成仅利用一个专家就行了,直接退回30B级别模型。 真没资源来测试模型真实效果,只能通过刷推来看富人的测试效果了。 当然现在Github仓库里的model.py还是用jax实现的,而不是pytorch,所以等,等大佬们帮忙适配好。 PS:但我马哥,最近真实抓着openai狂喷,不知道openai是不是有些许压力,再开点东西,让我们见见世面呢? |
|
|
|
|
开源大模型领域好像都喜欢跟扎克伯格的Llama2比较。 马斯克开源的这个Grok-1是8个混合专家模型做的,一共有3140亿的参数,仅仅两个active的大小(86B)就超过了Llama2的参数大小(70B)。 |
|
|
不只是大小,就连各种性能比较,必定有LLama2,基本上的逻辑都是比Llama2参数少的模型通常比它性能好,比它参数大的模型性能比它肯定更好。 |
|
|
但是说实话从这个比较中,Grok-1的性能差GPT还是有点儿。 我觉得Grok应该不如国内的Kimi。 但就是胜在开源,可以随便拿来商用等等。 开源地址: GitHub - xai-org/grok-1: Grok open release?github.com/xai-org/grok-1 |

|
|
但是想要试试grok-1的话,你得有8张80GB显存的电脑。 |
|
|
这种显卡差不多得10万一张(去年的价格),意思是你想要测试这个模型,你得有80万的卡在这里放着。 对于一般的个人不用想了,但是对于稍微大点的公司来说还是没问题的。 Hugging Face也可以下载。 xai-org/grok-1 ・ Hugging Face?huggingface.co/xai-org/grok-1 |

|
|
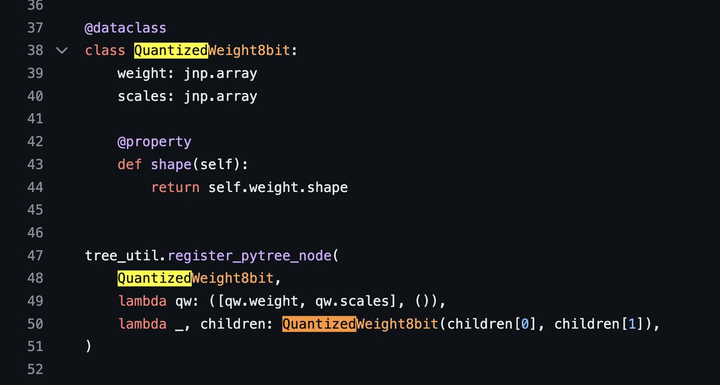
我看了下Grok的代码,我发现了点儿我的知识盲点。 Grok的model文件里面,我发现Grok是用Jax做的。 |
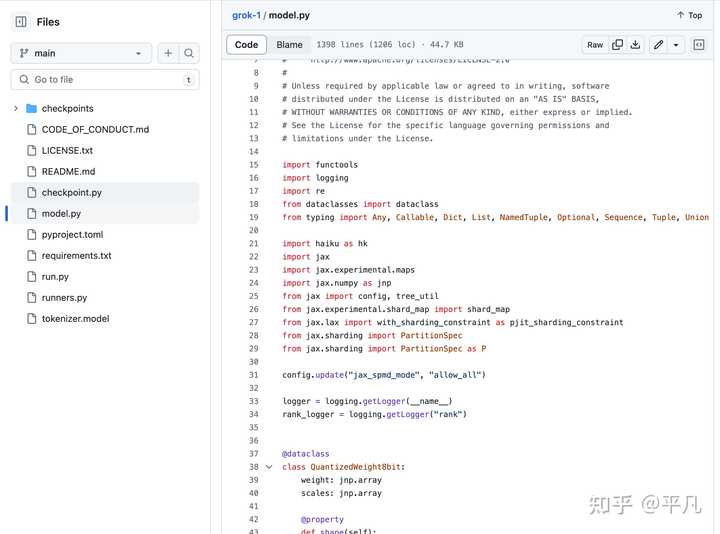
|
|
但你看Llama2,就是一般都用的Torch。 |
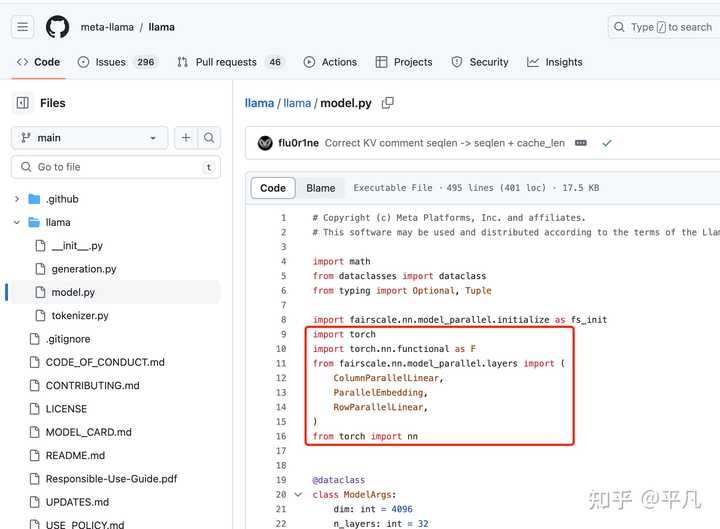
|
|
说实话开源的大模型我也看过几个,这是我第一次看到用jax的。 比如国内的阿里开源的Qwen千问大模型,也是用的Torch。 |
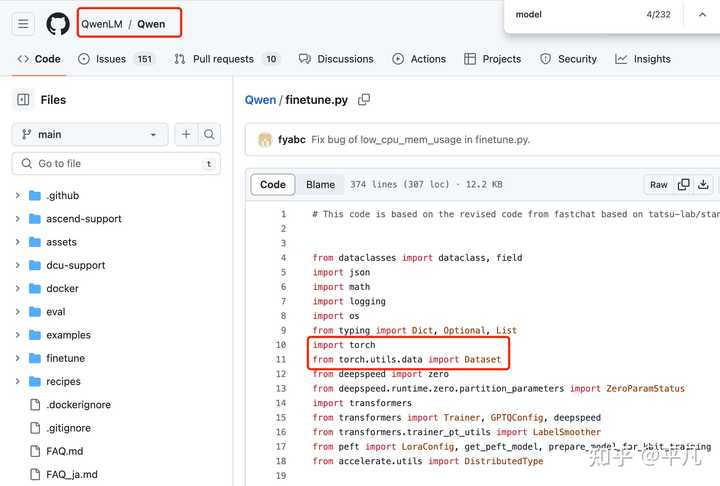
|
|
总的来说,我觉得Grok的开源肯定是利好大于利弊的,这么大参数的开源模型非常的少见,一般开源的都是70B,也就是700亿参数顶天了。 比如LLama2,Qwen等等。 |
|
说到做到,马斯克xAI的Grok,果然如期开源了! |
|
|
就在刚刚,xAI正式发布3140亿参数混合专家模型Grok-1的权重和架构。 |

|
|
3140亿的参数,让Grok-1成为迄今参数量最大的开源LLM,是Llama 2的4倍。 |
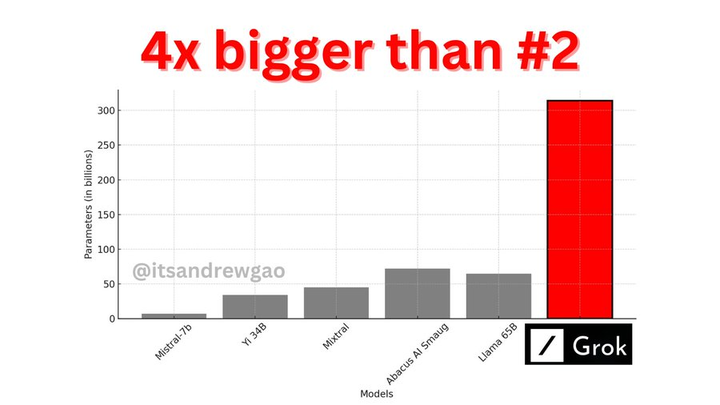
|
|
目前,xAI关于Grok-1没有透露更多信息。 官网放出的信息如下―― - 基础模型在大量文本数据上训练,未针对任何特定任务进行微调。 - 314B参数的MoE,有25%的权重在给定token上处于激活状态。 - 2023年10月,xAI使用JAX和Rust之上的自定义训练堆栈从头开始训练。 一经上线GitHub,Grok就狂揽了6k星,586个Fork。 |
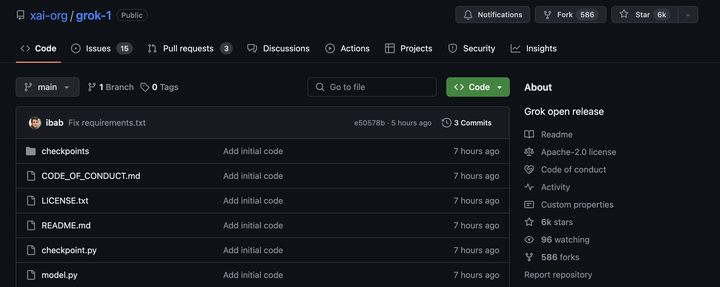
|
|
项目地址:https://github.com/xai-org/grok-1 马斯克还不忘嘲讽OpenAI一番,「告诉我们更多关于OpenAI的「open」部分...」 |

|
|
纽约时报点评道,开源Gork背后的原始代码,是这个世界上最富有的人控制AI未来战斗的升级。 |

|
|
开源究竟会让技术更安全,还是会让它更滥用? 「开源支持者」马斯克,以身作则地卷入了AI界的这场激烈辩论,并用行动给出了答案。 小扎刚刚也对Grok做出了评价,「并没有给人留下真正深刻的印象,3140亿参数太多了,你需要一堆H100,不过我已经买下了」。 |

|
|
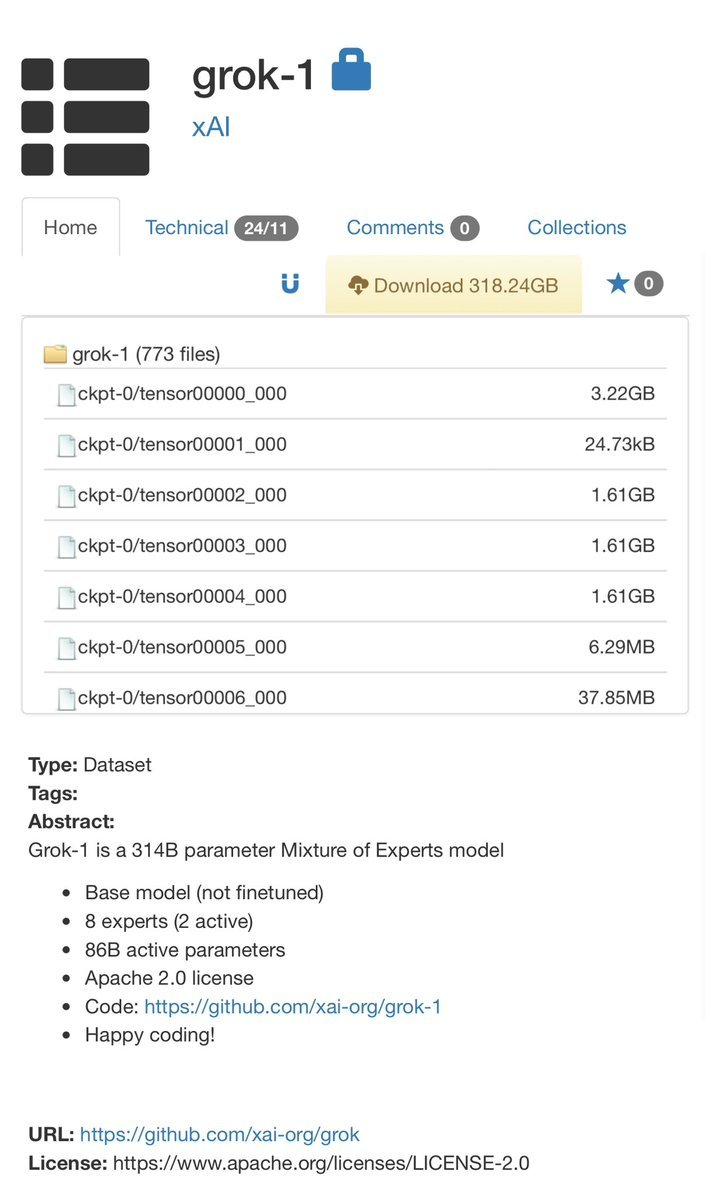
一条磁力链,全球首个最大模型开源 这次xAI开源Grok-1,遵守的是Apache-2.0许可证,因此,用户可以自由使用、修改和分发软件。 存储库包含了用于加载和运行Grok-1开源权重模型的JAX示例代码。 用户需要下载checkpoint,将ckpt-0目录放置在checkpoint中,随后运行以下代码来测试: 这个脚本会在测试输入上,加载checkpoint和模型中的样本。 由于模型较大,参数达到了314B参数,因此需要具有足够GPU内存的计算机,才能使用示例代码测试模型。 而且,由于此存储库中MoE层的实现效率不高,选择该实现是为了避免需要自定义内核来验证模型的正确性。 通过Torrent客户端和下面这个磁力链接,就可以下载权重了。 |

|
|
|

|
|
更多细节 斯坦福研究者Andrew Kean Gao浏览了model.py介绍了更多Grok的架构信息,3140亿参数没有更多附加条款。 |

|
|
|
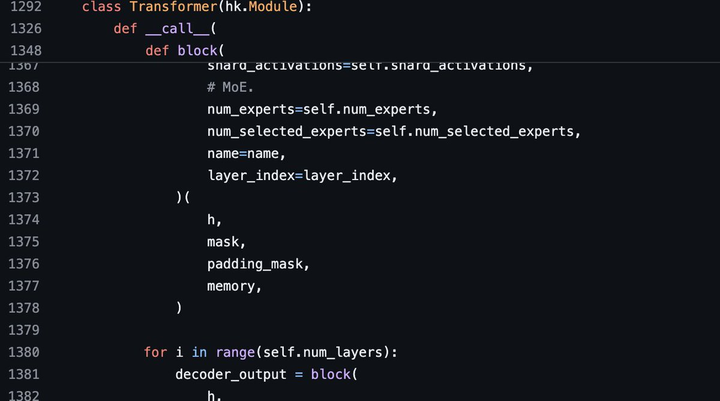
|
|
8个混合专家(2个活跃专家),860B活跃参数。它使用旋转嵌入#rope,而不是固定位置嵌入。 - token词汇量:131,072(于GPT-4类似)相当于2^17 - 嵌入大小:6144(48*128) - Transformer层:64(每一层都有一个解码层:多头注意块和密度块) - 密钥值大小:128 |

|
|
多头注意模块:有48个查询头和8个键/值 密集块(密集前馈块):宽度因子(Widening Factor):8;隐藏层大小为32768 每个token从8个专家中选出2个。 |
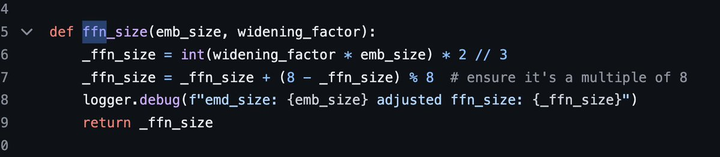
|
|
旋转位置嵌入大小6144,这是有意义的,它与模型的输入嵌入大小相同。 上下文长度:8192个token 精密bf16 |
|
|
最后,附上一张总结版图。 |

|
|
网友:开源争霸战要来 AI社区已经沸腾了! 技术界指出,Grok的亮点是在前向反馈层中使用了GeGLU以及归一化方法,并且使用了有趣的三明治范式技术(sandwich norm technique)。 连OpenAI的员工,都表示了自己对Grok的强烈兴趣。 |
|
|
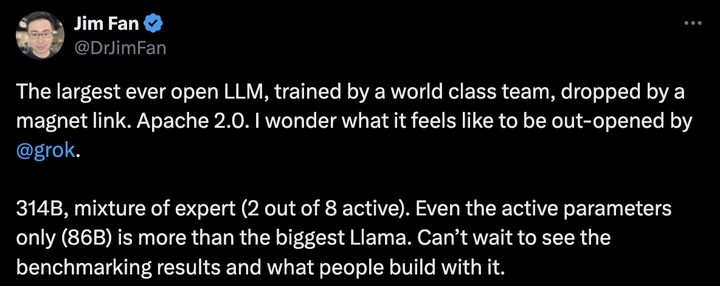
英伟达高级科学家Jim Fan表示,「有史以来最大的开源大模型,由世界级团队训练,通过磁力链Apache 2.0发布。 314B参数,混合专家模型(8个专家2个是活跃的)。就连活跃参数规模(86B)都超过了最大的Llama模型。迫不及待地想看到基准测试结果,以及人们能用它构建出什么样的应用」。 |
|
|
|
|
|
AI研究人员Sebastian Raschka表示,与其他通常有使用限制的开源模重模型相比,Grok更为开源。不过它的开源程度低于Pythia、Bloom和Olmo,后者提供了训练代码和可重现的数据集。 |

|
|
|

|
|
Craiyon创始人Boris Dayma,详细分析了Grok-1的代码。 |

|
|
网友indigo表示,为了「理解宇宙」的理念,看来xAI团队特意把参数设定成了「圆周率 314B」,这是目前规模最大的开源模型,期待今年6月的Llama 3加入Grok的开源争霸战。 |

|
|
Grok开源后,一大波微调要来了。 |
|
|
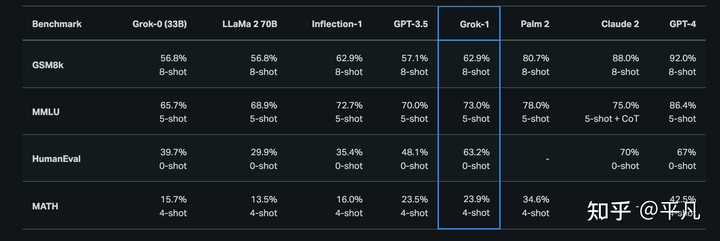
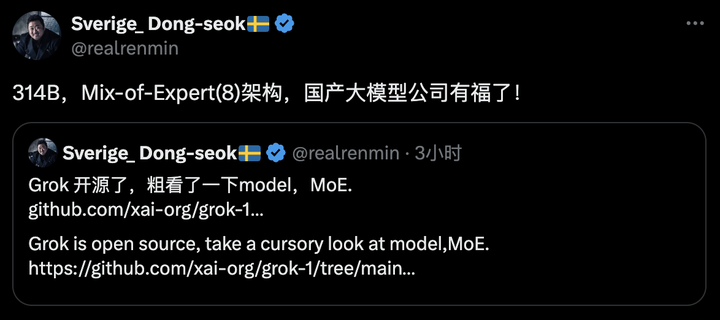
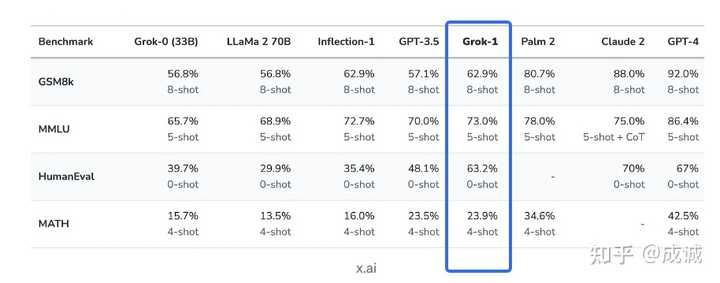
第一代Grok已超越Llama-2-70B 2023年11月,xAI推出了自己的第一代大语言模型Grok,正式加入大模型的战争。 当时,Grok在推特上作为「Premium+」订阅服务的一部分,月费16美元。 xAI表示,Grok的设计灵感来源于《银河系漫游指南》,它能够回答几乎所有问题,助力人类不分背景或政治立场地追求理解和知识。 Grok最初的版本Grok-0拥有330亿参数,紧接着xAI推出了经过数次改进的Grok-1,为X上的Grok聊天机器人提供支持。 根据xAI公布的数据,在GSM8K、HumanEval和MMLU等一系列基准测试中,Grok-1的表现超过了Llama-2-70B和GPT-3.5,虽然跟GPT-4还差得远。 |
|
|
当时,Grok不仅能够处理X平台上实时生成的用户内容,还带有一点幽默感,给憨憨的AI注入了一丝活力。在提供最新热点事件信息(无论是政治还是体育)的同时,它还能抖个机灵,甚至偶尔讽刺一下。 马斯克为何选择开源? 在数次嘲讽OpenAI是「CloseAI」之后,马斯克果真选择了开源自家大模型。 当然,这背后肯定也有商业上的考量。 Llama的开源给Meta带来了很多好处,几乎让小扎从元宇宙的泥潭爬了出来。 |

|
|
而仅仅只是一个小型初创公司的Mistral AI,也因为自己的开源策略而声名鹊起,被业界公认为「欧洲的OpenAI」。 |

|
|
开源版本可能会鼓励开发者和潜在客户更快地采纳自己的模型,实际上起到了市场推广的作用。 开发者社区对Grok开源版本的反馈和改进也可能有助于xAI加速开发新版本,这些新版本xAI可以选择开放源代码或保留专有权。 比如像Mistral一样,承诺继续发布开源版本,同时为付费客户保留最先进的模型。 马斯克一直是开源技术的支持者,连Tesla也已经开放了汽车某些部分的源代码,而他的社交媒体平台X公开了一些用于内容排名的算法。 「还有工作要做,但这个平台已经是迄今为止最透明、最注重真相、不是高门槛的平台,」马斯克今天在回应对开源X推荐算法的评论时,这样说道。 |
|
|
尽管OpenAI目前在AI领域仍遥遥领先,但开源和闭源的战争还远远没有结束。 |

|
|
AI模型是否应该开源?某些人认为,必须防止这种强大技术免受闯入者的侵害,而另一些人则坚持认为,开源的利绝对大于弊。 作为市场领导者的OpenAI,是没有理由开源ChatGPT背后模型代码的。 现在,通过发布Grok的代码,马斯克将自己牢牢扎根在后者的阵营中。 这一决定,或许能让他的xAI最终超越Meta和Mistral AI。 |
|
实际上没有什么影响。 个人评价是”电子垃圾“,不会有人真正基于该模型做什么后续的应用。 Grok-1 类似于之前开源的 Falcon-180B, 或者是 Switch-C (1T 参数),参数量大是真的大,但是模型效果也是真的差,性价比极低。 参考: google/switch-c-2048 ・ Hugging Facetiiuae/falcon-180B ・ Hugging Face 3.19 10:00 更新: 评论区很多同学 diss 我的观点 23,表示: “jax 开源没问题,转 torch 很难么?”。 (确实不难,就是费事而已) 对于理由3 “ Grok-1 只开源了 Jax 版本的 ckpt 和 infer code ” 的补充: 用 Jax 训练没问题。 想发布 Jax 版本也没问题。 对于开源社区的用户而言,找几个人搞一两周也可以搞定 torch 版本的转换和精度对齐。 但开源社区 99% 以上的 LLM 都是 torch + hf。 如果 jax -> torch 很方便的话,为什么 x.AI 不多做一步拥抱社区,发布一个 HuggingFace 上的 torch 版本,而是非要恶心所有想用 Grok-1 的人都重复工作一遍? 对于理由2,你可以搞一个种子链接加速下载和传播。但实际上 HuggingFace 对于 ckpt 的版本管理是很有必要的,参考 Mistral 发布的模型和网络结构后续均做了调整,没有版本控制的话,用户可能会疯掉。对于理由1, 尤其是觉得 Grok-1 还是有部分指标领先 Mixtral-8x7B 的同学,我这里其实没有表达更直接一些:实际上 Grok-1 的参数量级应该是要对标 GPT-4-Turbo 的,再不济也应该是 Mistral-Large 或者 Claude 2 的水平。然而实际上 Grok-1 只能跟比他小 8 倍的 8x7B 掰掰手腕,甚至在关键的数学能力上落后,本身就是一个严重的失败。 |
|
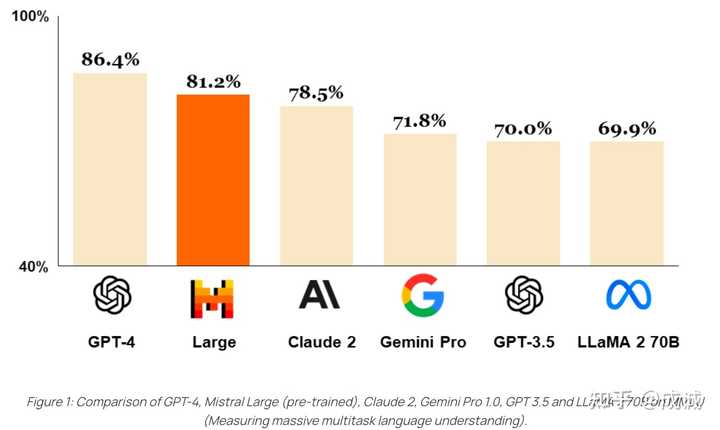
|
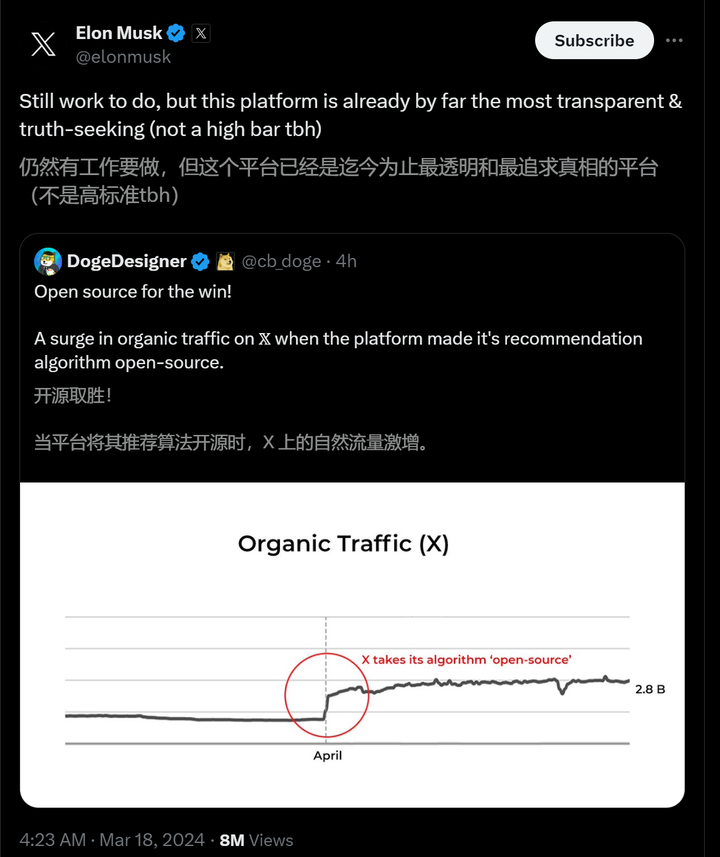
Mistral-Large MMLU Benchmark 为什么 Grok-1 开源? 为什么 马斯克 最近才起诉 OpenAI 不开源违反协议? 实际上 GPT-4 一开始就没开源,马斯克应该 2023 年初就起诉 OpenAI 才对,但是马斯克没这么做,而是自己组建了 x.AI 搞了近一年时间。 但实际上 Grok-1 以及 x.AI 明显已经不属于全球大模型公司的第一梯队,马斯克是看自己的团队追赶 OpenAI 无望,才 起诉 OpenAI + 自己开源倒逼 OpenAI 开源 两连招,核心是不希望 OpenAI 挣到钱 同时 自己的 x.AI 无钱可挣。且此次开源我认为是十分仓促和没有诚意的。 3.18 13:20 更新: 没想到评论区有同学吵起来了。。。。。。我这里先个人声明一下,本回答没有任何针对 马斯克/特斯拉/x.AI 的意思,只是理性评价此次开源的 Grok-1 并不能引起什么轰动,也不值得国内的 AI 应用公司基于 Grok-1 做什么后续的开发、训练、微调等工作。(这个后续时间会检验) 并没有认为 x.AI 不如国内,而是评价 x.AI 不如其他国外第一梯队的大模型创业公司。 另外是吐槽 Grok-1 开源的方式是没有什么准备和诚意的,因为其余所有知名模型的开源,都会明确: 明确说明 Benchmark 结果,强调自己模型的优势在哪里在 HuggingFace 上上传自己的模型权重让所有人公开访问,并提供版本管理,这个是开源社区的统一标准(而不是给一个种子链接让大家下载,种子链接也不稳定)提供基于 Torch / Transformers 的标准推理脚本。 (而不是 release 一个大多数开发者都不会用的 Jax 代码) 此次开源其实是跟前几天 马斯克 起诉 OpenAI 的事件相关的: 马斯克以违反合同为由起诉 OpenAI 及其 CEO 萨姆・奥特曼,哪些信息值得关注? 但事实上我个人对 马斯克没有什么偏见,对特斯拉也没有偏见。 我个人还是一个 Model Y 车主。求轻喷。。。。 以下是原文: Grok-1 不如 Mistral-8x7B 目前的开源 repo GitHub - xai-org/grok-1: Grok open release 主页没有任何的 benchmark 介绍,实际需要下载测试。 不过参考之前 x.AI 自己 release 出来的 benchmark,真的效果挺差的: |
|
|
Grok-1 Benchmark 结果 这里的结果仅比 GPT-3.5 高一点,不及 Claude 2。 同时对比 Mistral 的 MoE: |

|
|
Mixtral 8x7B Benchmark 结果 比如: MATH : Mixtral-8x7B 28.4 > Grok-1 23.9 GSM8k : Mixtral-8x7B 74.4 > Grok-1 62.9 但要明确的是: Grok-1 总参数量是 314B, 激活参数量是 86BMixtral-8x7B 总参数量 45B,激活参数量是 12BGPT-3.5-turbo 预估实际推理成本不超过 20B Grok-1 的问题: Grok-1 用了 8 倍于 Mixtral-8x7B 的模型大小,但实际效果可能仅和 Mixtral-8x7B 持平。同时,Grok-1 的推理成本是 Mixtral-8x7B 的 10 倍以上: Grok-1 只能通过 8xA100 / 8xH100 机器推理,且一个模型就独占了一个机器。单机器显存一共 640G, 由于参数量已经有 314B 了, bf16 推理参数量就 628G,几乎无法推理完成(无法开 batch size,存 kvcache),所以只能是 int8 量化推理。 且 TP8 引入大量的通信,而同等量化下,Mixtral-8x7B 单卡就能推理,无需跨卡通信,吞吐效率远高于 Grok-1 10 倍以上。Grok-1 只做了 Pretrain,没做 SFT (也可能是 x.AI 自己搞了 SFT 但是效果不好所以没有 release)Grok-1 是用 Jax 训练的,开源的代码也是 Jax,而不是开源社区主流的 PyTorch 代码 。Grok-1 的权重也不是发布在 HuggingFace 上。 https://medium.com/@mazzalucas42/decoding-grok-1-rust-powered-ai-benchmarks-and-the-uncharted-territory-of-real-time-insights-1e167cb9f289 马斯克为什么开源 Grok-1 ? 个人认为是马斯克发现自己组 x.AI 团队搞了近一年,但是不仅进度上远不及 OpenAI、Anthropic、Google、Meta,甚至在创业团队中也比不过 Mistral , 所以希望通过对等开源的激将法逼 OpenAI 开源,指责 OpenAI 不 Open (即 我自己都开源了,你也应该开源),换取一个名声:“社区最大的开源 LLM” (但并不是最强的)。 但对于这样一个与 主流开源社区 模型权重类型不一致,推理脚本不一致,推理成本如此之高(基本上个人开发者很难用起来,但是对于拥有 DGX/HGX 机器的团队这样的模型又属实没什么用),模型效果又不突出 的最大开源模型,是否能像 Mistral 一样产生足够的开源社区影响力,我个人是很悲观的。 更像是 x.AI 的一次破罐破摔罢了。 |
|
开源模型中参数量最大的巨头来了? 3月18日,马斯克旗下AI初创企业xAI今天发布新闻稿,宣布正在开源3140亿参数的混合专家模型 Grok-1,该模型遵循 Apache 2.0 协议开放模型权重和架构,号称是“迄今为止全球参数量最大的开源大语言模型”。 |

|
|
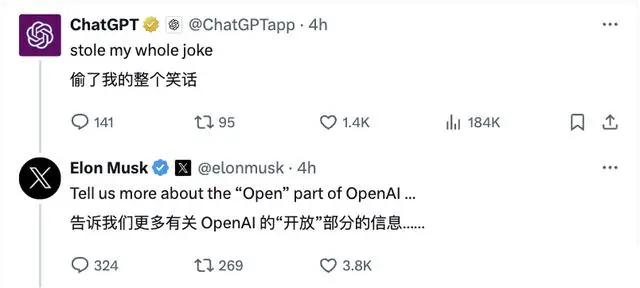
消息一出,Grok-1的GitHub仓库已揽获4.5k标星,并且还在库库猛涨~ 而ChatGPT本尊,也现身Grok评论区,开始了与马斯克日常的斗嘴; |
|
|
Grok-1是一个混合专家(Mixture-of-Experts,MOE)大模型,这种MOE架构重点在于提高大模型的训练和推理效率,这个技术将大模型划分为不同的子专家模型,每次推理只选择部分专家网络进行推理,在降低成本的同时保证模型的效果; Grok-1包含了8个专家,总参数量高达314B(3140亿),处理Token时,其中的两个专家会被激活,激活参数量为86B; 单看这激活的参数量,就已经超过了密集模型Llama 2的70B,对于MoE架构来说,这样的参数量称之为庞然大物也毫不为过; 因此,在GitHub页面中,官方也提示,由于模型规模较大(314B参数),需要有足够GPU和内存的机器才能运行Grok; xAI也使用了一些旨在衡量数学和推理能力的标准机器学习基准对Grok-1进行了一系列评估; |

|
|
数据上,Grok-1的表现超过了Llama-2-70B和GPT-3.5,虽然跟GPT-4还稍有差距,但Grok不仅能够处理X平台上实时生成的用户内容,更值得一说的是它还略带有一丝幽默感,给憨憨死板的AI注入了一丝活力~ AI大模型五花八门地推出,许多以创造性为由接触AI工具的人,越发逐渐开始追求AI的这一丝“幽默”,更喜好AI的发言偏向人性,这样的AI工具银河君我也恰好有几个与之相符; ? AI创意生成家 “创意生成家”大概就是所有使用过这个工具的人对它的印象了!“创造力”绝对是这款软件的最大亮点! 集合了AI写作、AI绘画、AI聊天等AI功能于一体,通过AI让我们可以将更多的精力投入到创造性的任务中,释放出更多的创意和想象力! |
|
|
工作总结、培训方案、岗位事迹、论文开题报告、商业计划书、活动策划、视频脚本等文章内容,都属于非常实用的写作类型,日常使用频率非常之高! |
|
|
当然,软件中的其它各种AI绘画、AI配音、AI特效、AI转换等等功能,输出创意也都非常不错! 譬如AI绘画,功能能够支持“图生图”、“文生图”两大主流AI绘画模式,并且简洁干净的UI界面,也让许多新手小白表示能够快速上手; |
|
|
各种类型的模板对于一些毫无基础的用户非常友好,完美地契合这些用户的眼光和需求,只需要选择到钟意的风格,简单输入自己的需求,调整设置后即可生成输出! |

|
|
? Copy AI “外语贸易最强大的AI助手,没有之一!”来自一个外贸专业的学生; Copy作为一款专注于营销文案生成的AI智能网站,拥有强大的文案生成能力,可以快速生成各种类型的文案,如广告文案、社交媒体文案、产品描述等,支持各种长篇、短篇内容的创建; 网站提供90多种工具和模板,只需点击几下,还可以为所有广告系列生成高转化率的副本; |

|
|
它对英文的撰写非常专业,即使英语水平一般,也可以用这个AI工具写出高质量的英文文案,此外,我们还能通过草稿内容,再接着进行修饰、润色,从而达到我们想要的写作效果~ |
|
|
? Jasper AI Jasper AI的愿景是成为创作者最好的伙伴,帮助他们克服写作障碍,提高写作效率和质量,并且释放他们的创造力; 在Jasper中,有多种工具,包括将近70个模板、Jasper Chat、Documents(可以在其中保存我们的工作)Recipes和 Jasper Art,借助这些助手,可以快速创建大量内容! |

|
|
它的应用类似初学者模式,主要是可以利用Jasper的50多种模板,生成对应的文案,这些模板种类包含各种内容,囊括了大部分营销场景; 我们可以用它创作文案、小说、剧本、等多种类型的文章,优化文章、提高文章的可读性等等~ |
|
|
并且在马斯克数次嘲讽Open AI是“Close AI”之后,xAI现已将Grok-1的权重和架构在GitHub上开源,似乎有股想要“身体力行”敦促Open AI恢复开源的意味了~ 话不多说啦~有用的记得要码住,也可以关注一下@银河君主页下次不迷路! |
|
马斯克说到做到: 旗下大模型Grok现已开源! |
|
|
代码和模型权重已上线GitHub。官方信息显示,此次开源的Grok-1是一个3140亿参数的混合专家模型―― 就是说,这是当前开源模型中参数量最大的一个。 消息一出,Grok-1的GitHub仓库已揽获4.5k标星,并且还在库库猛涨。 |
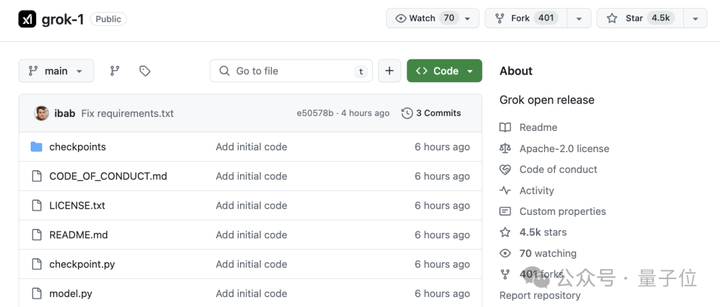
|
|
表情包们,第一时间被吃瓜群众们热传了起来。 |

|
|
而ChatGPT本Chat,也现身Grok评论区,开始了和马斯克新一天的斗嘴…… |
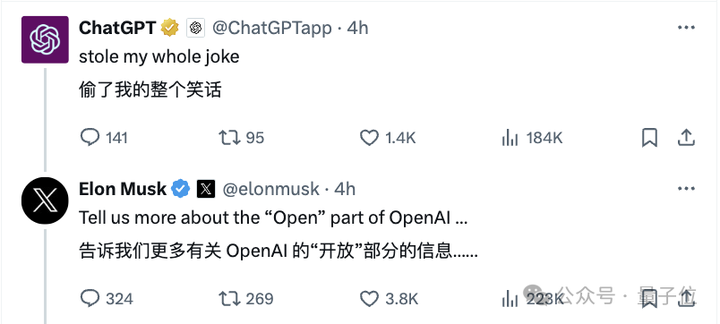
|
|
那么,话不多说,来看看马斯克这波为怼OpenAI,究竟拿出了什么真东西。 Grok-1说开源就开源 此次开源,xAI发布了Grok-1的基本模型权重和网络架构。 具体来说是2023年10月预训练阶段的原始基础模型,没有针对任何特定应用(例如对话)进行微调。 结构上,Grok-1采用了混合专家(MoE)架构,包含8个专家,总参数量为314B(3140亿),处理Token时,其中的两个专家会被激活,激活参数量为86B。 单看这激活的参数量,就已经超过了密集模型Llama 2的70B,对于MoE架构来说,这样的参数量称之为庞然大物也毫不为过。 |

|
|
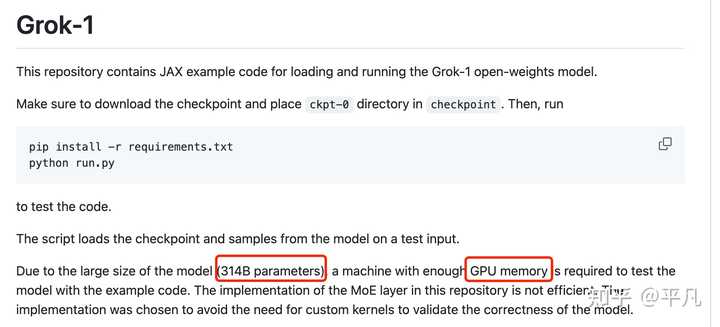
不过,在GitHub页面中,官方也提示,由于模型规模较大(314B参数),需要有足够GPU和内存的机器才能运行Grok。 这里MoE层的实现效率并不高,选择这种实现方式是为了避免验证模型的正确性时需要自定义内核。 模型的权重文件则是以磁力链接的形式提供,文件大小接近300GB。 |

|
|
而且这个“足够的GPU”,要求不是一般的高――YC上有网友推测,如果是8bit量化的话,可能需要8块H100。 |

|
|
除了参数量前所未有,在工程架构上,Grok也是另辟蹊径―― 没有采用常见的Python、PyTorch或Tensorflow,而是选用了Rust编程语言以及深度学习框架新秀JAX。 而在官方通告之外,还有许多大佬通过扒代码等方式揭露了Grok的更多技术细节。 比如来自斯坦福大学的Andrew Kean Gao,就针对Grok的技术细节进行了详细解释。 首先,Grok采用了使用旋转的embedding方式,而不是固定位置embedding,旋转位置的embedding大小为 6144,与输入embedding相同。 |
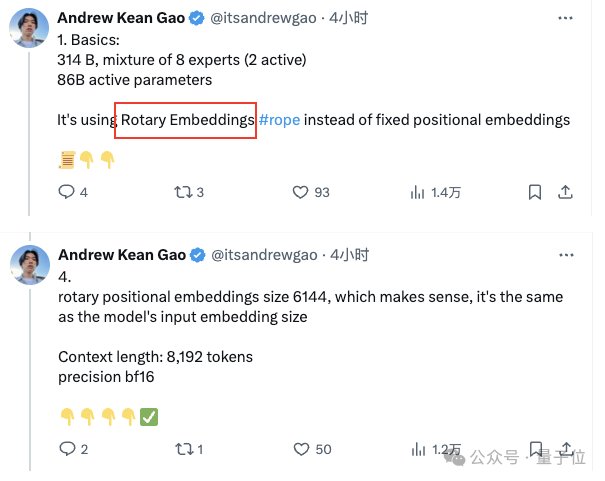
|
|
当然,还有更多的参数信息: 窗口长度为8192tokens,精度为bf16Tokenizer vocab大小为131072(2^17),与GPT-4接近;embedding大小为6144(48×128);Transformer层数为64,每层都有一个解码器层,包含多头注意力块和密集块;key value大小为128;多头注意力块中,有48 个头用于查询,8 个用于KV,KV 大小为 128;密集块(密集前馈块)扩展因子为8,隐藏层大小为32768。 |
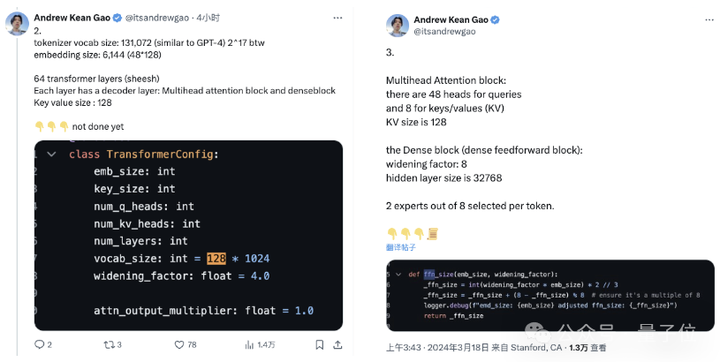
|
|
除了Gao,还有英伟达AI科学家Ethan He(何宜晖)指出,在专家系统的处理方面,Grok也与另一知名开源MoE模型Mixtral不同―― Grok对全部的8个专家都应用了softmax函数,然后从中选择top2专家,而Mixtral则是先选定专家再应用softmax函数。 |

|
|
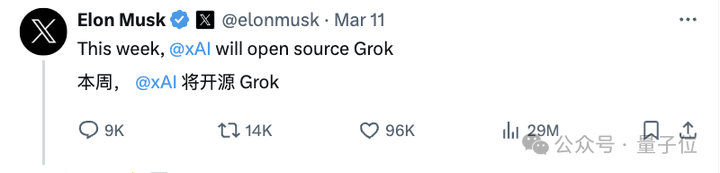
而至于有没有更多细节,可能要看官方会不会发布进一步的消息了。 另外,值得一提的是,Grok-1采用的是Apache 2.0 license,也就是说,商用友好。 为怼OpenAI怒而Open 大家伙知道,马斯克因为OpenAI不Open,已经向旧金山高等法院提起诉讼,正式把OpenAI给告了。 不过当时马斯克自己搞的Grok也并没有开源,还只面向 的付费用户开放,难免被质疑双标。 大概是为了堵上这个bug,马斯克在上周宣布: 本周,xAI将开源Grok。 |
|
|
虽然时间点上似乎又是马斯克一贯的迟到风格,但xAI的这波Open如今看来确实不是口嗨,还是给了网友们一些小小的震撼。 |
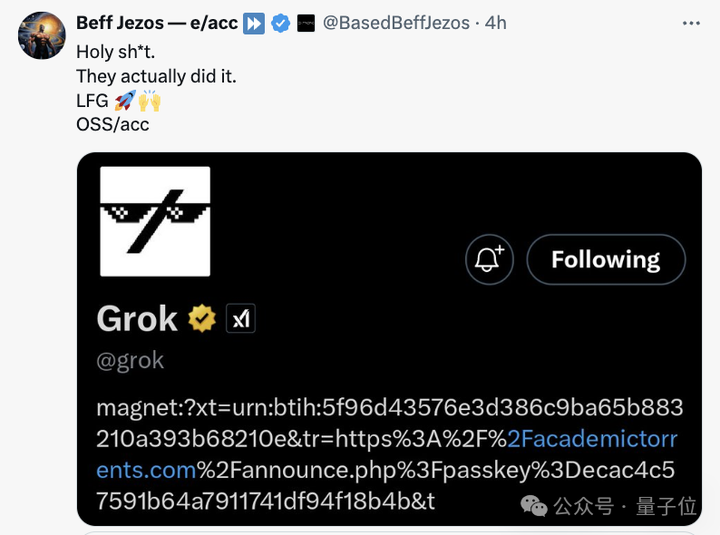
|
|
有xAI新晋员工感慨说: 这将是激动人心的一年,快系好安全带吧。 |

|
|
有人已经期待起Grok作为一个开源模型,进一步搅动大模型竞争的这一池水。 不过,也并不是每个人都买马斯克的账: |
|
|
不过说归说,多线并进的马斯克,最近大事不止开源Grok这一件。 作为多公司、多业务的时间管理大师,马斯克旗下,特斯拉刚刚全线推出了端到端纯视觉的自动驾驶系统FSD V12,所有北美车主用户,都OTA更新升级,可以实现所有道路场景的任意点到点AI驾驶。 SpaceX则完成了第三次星舰发射,虽然最后功败垂成,但又史无前例地迈进了一大步。 推特则开源了推荐算法,然后迎来了一波自然流量新高峰。 别人都是 you can you up, no can no bb…马斯克不一样,bb up不选择,边喊边干,还都干成了。 |
|
|

|
|
参考链接: [1]https://github.com/xai-org/grok-1 [2]https://x.ai/blog/grok-os |
|
Grok-1的3140 亿参数量是迄今为止最大参数量的开源大模型,而允许商用、可修改和分发,对各种自研大模型是一个很大的利好! |

|
|
言出必行,北京时间3月18日凌晨,马斯克承诺的开源版大模型 Grok 终于发布! |

|
|
|

|
|
项目地址: 让我们先看下在Github的下载地址上,它的开源声明都说了什么: 一、开源声明主要内容 |

|
|
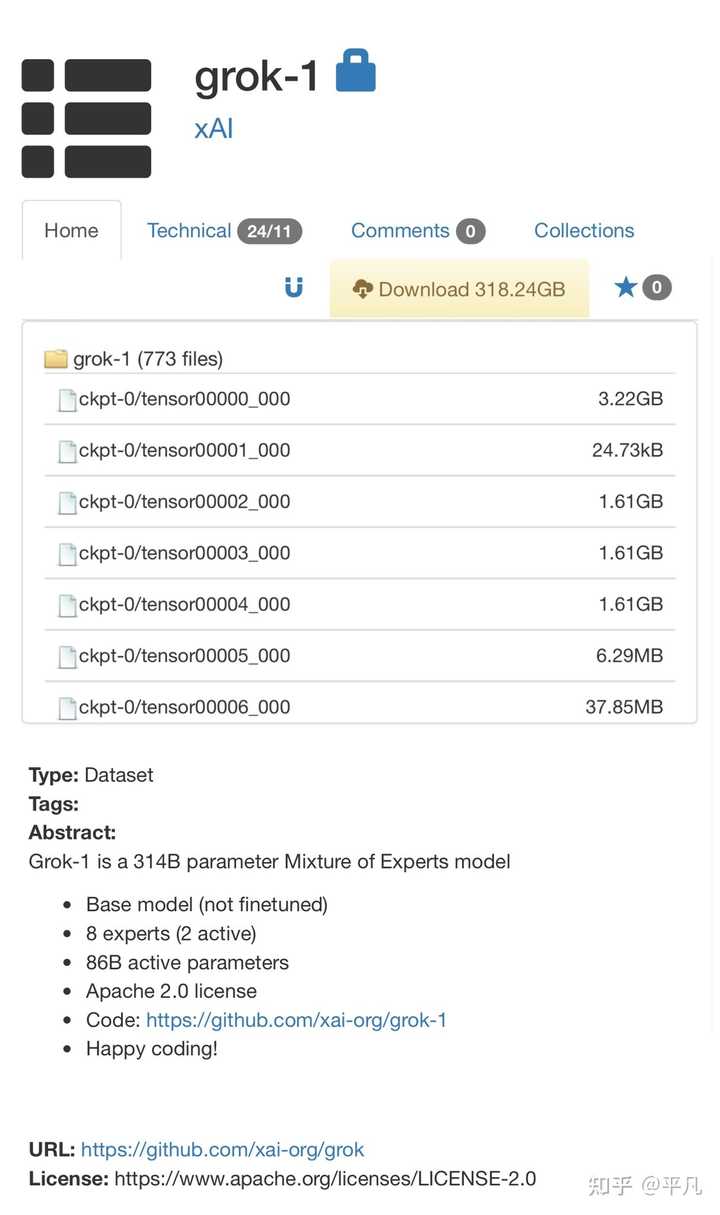
1.模型介绍: Grok-1模型拥有高达314亿个参数,采用了混合专家(MoE)层结构。MoE层的实现,在效率上存在局限,但这种结构设计选择是刻意为之,主要目的是为了简化模型验证流程,避免自定义内核的需求。 2.许可协议: Grok-1遵循Apache 2.0许可证,赋予用户以下权利: 商业使用自由:用户有权将Grok-1用于商业用途,无需支付任何许可费用。 源代码修改及再分发:用户可以对源代码进行修改,并且可以在相同的许可证下对修改后的版本进行分发。 专利权授予:该许可证自动授予用户对软件的所有专利权利,确保贡献者无法基于专利对用户提起诉讼。 版权和许可声明保留:在分发软件或其衍生版本时,必须包含原始的版权和许可声明。 责任限制:虽然提供一定程度的保障,但软件的作者或贡献者不对因使用软件可能产生的任何损害承担责任。 Grok-1有314B的大小,需要有足够 GPU 内存的机器,从网友的推算来看,可能需要一台拥有 628 GB GPU 内存的机器,大概是8个H100(每个 80GB)就可以,才有可能使用示例的代码来测试模型。 |

|
|
因此基本上个人是没办法用的,这个模型开源就是为了便于各种企业使用的,同时模型还提供了权重下载。 |
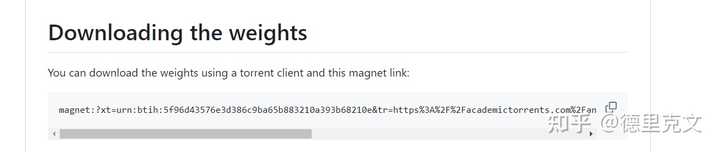
|
|
地址为: 二、相关领域影响 Grok-1的开源,对于中小企业垂直领域的微调模型是一个利好,通过下载Grok进行微调,可以诞生很多基于这个模型的有趣应用。 |

|
|
对比之前已经开源的大模型来说,它的参数量更大,而大模型的参数量越大,它的涌现水平理论上应该是会更加智能,毕竟力大出奇迹这件事OPENAI已经验证过了。 也许就如同Stable Diffusion的开源对于国内各种AI绘画工具软件的影响一样,Grok-1的开源或许会对于各种垂直邻域的应用,尤其是国内的应用爆发会有一定的启发作用。 三、网友分析 推特网友 Andrew Kean Gao详细分析了 Grok-1 的架构细节,并做了一些总结。 |
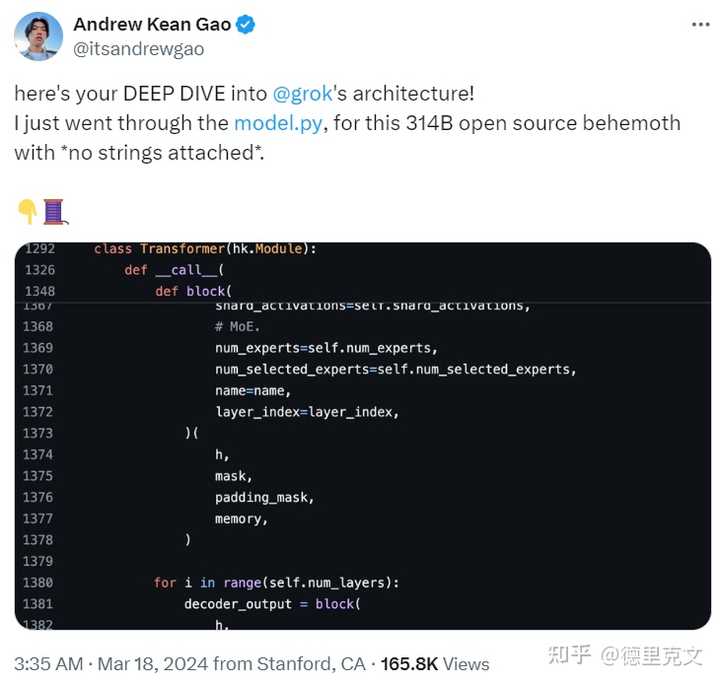
|
|
原文过于专业我也看不懂,我输入信息后让KIMI帮我进行了一个讲解和翻译,分享给大家: 这个模型就像是一个由8个小组(我们称之为“专家”)组成的大团队,其中有两个小组特别活跃,它们一起工作,帮助模型理解和处理信息。 这个模型有一个特别的名字,叫做“旋转嵌入”,这让它和别的模型有点不一样,就像是一种特殊的记忆方法,帮助它更好地记住和理解事物。 模型里有一个叫做“tokenizer”的部分,它的词汇量非常大,有131,072个词汇,这和另一个知名的模型GPT-4很像。嵌入大小是6,144,你可以想象成是模型用来存储和处理信息的空间大小。 这个模型还有64层“变换器”,每一层都像是一个处理信息的小工厂。 在这些小工厂里,有两个特别重要的部分,一个叫做“多头注意力块”,它有48个“头”用来提问,还有8个“头”用来回答问题或提供信息。另一个部分是“密集块”,它的作用是加强模型的理解和记忆能力,让模型能够处理更复杂的信息。 这个模型就像是一个有着超级记忆力的图书管理员,它能够记住和理解大量的信息。 旋转位置嵌入就像是它的书架上的一种特殊的标记方式,每个标记都帮助它记住信息的位置。这里的标记大小是6144,正好和它用来理解信息的“书架空间”大小一样,这样它就可以更有效地找到和使用信息。 这个图书管理员能够同时处理很多本书,这里的“上下文长度”就是它能同时关注的书籍数量,有8192本那么多。 就像是一个超级大脑,能够同时考虑很多信息,帮助它做出决策。 “精度bf16”是说这个图书管理员在处理信息时的精确度。就像是一个精密的仪器,能够准确地理解和记住每一本书的内容,确保提供的信息是准确无误的。 另外一个有趣的评论,值得一看: |

|
|
四、Grok-1的信息 Grok-1是xAI公司开发的人工智能模型,它拥有高达314亿个参数。 这个模型采用了一种叫做混合专家(MoE)的技术,以人类团队来比喻的话来说,就是一个团队里有多个专家共同工作,每个专家都有自己擅长的领域。 |
|
|
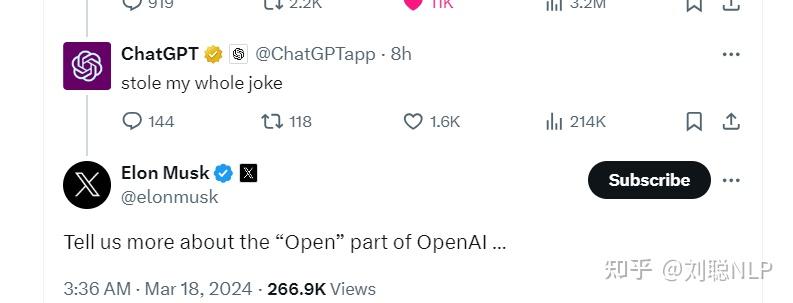
Grok-1的训练是从零开始的,没有特别针对任何一项特定任务进行优化或调整。 Grok-1 模型的研发经历了四个月,在此期间,Grok-1 经历了多次迭代,用的是JAX和Rust这两种编程语言,它们一起构建了一个强大的训练基础设施。 为了训练Grok-1,xAI公司动用了上千块GPU,用了好几个月来训练这个模型。在训练过程中,还特别提高了模型的容错能力。 五、各界反应 先看看ChatGPT如何回复马斯克的嘲讽吧: |
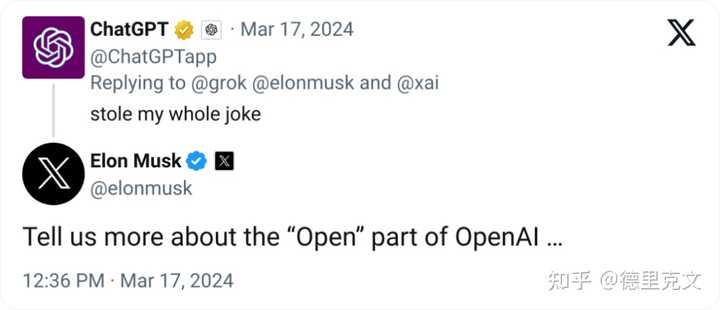
|
|
ChatGPT @・2024年3月17日 @ChatGPTapp 回复给 @grok @elonmusk 和 @xai 抄袭了我整个笑话 埃隆・马斯克 @elonmusk 告诉我们更多关于OpenAI中“开放”部分的信息。 随后山姆奥特曼也回复了这件事情: |
|
|
结语 正如Sam 所说,这是以往人类历史上最有趣的一年,未来也许更加精彩,让我们期待人工智能的竞争,会给世界带来什么更多的惊喜吧! 我是德里克文,一个对AI绘画,人工智能有强烈兴趣,从业多年的室内设计师!如果对我的文章内容感兴趣,请帮忙关注点赞收藏,谢谢! |

|
|
好大的模型,应该是我目前看到的最大的开源模型。 314B参数,按照bf16或者fp16格式存储的话,就需要约630GB的存储空间,用一台8*80GB的A100可能勉强能加载模型。好在这是MoE模型,激活参数还有1/4,但普通人估计还是玩不起。 |
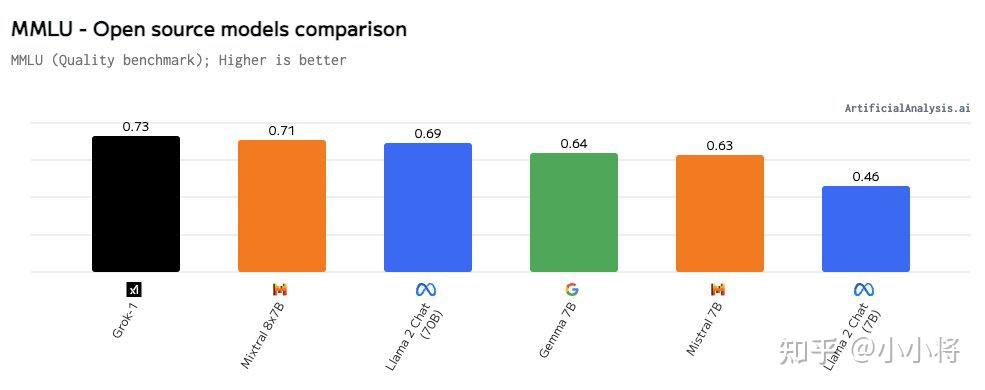
|
|
另外,这次开源的Grok-1只有预训练模型,没有Chat版本,让不得不怀疑马斯克只是为了反击OpenAI而作秀。 但民间有高手,期待社区基于基础模型调出一个更好的Chat版本,看看更大参数的模型是不是真的能更牛。 |
|
刚才我打开看了一眼,星星数已经来到了17.6k,而且还在继续增长中…… |

|
|
有网友开始好奇 314B 参数的 Grok-1 到底需要怎样的配置才能运行。对此有人给出答案:可能需要一台拥有 628 GB GPU 内存的机器(每个参数 2 字节)。这么算下来,8*H100(每个 80GB)就可以了。 看到拥有8块H100“即”可以运行Grok-1,我就明白人家马老板这个模型从来就没打算给我这种穷人玩…… |

|
|
有大神详细分析了 Grok-1 的架构细节,并做出了几点总结: Grok-1 是 8 个专家的混合(2个活跃)、860亿激活参数(比Llama-2 70B还多),使用旋转嵌入而非固定位置嵌入。 2. tokenizer 词汇大小为 131,072(类似于 GPT-4)2^17,嵌入大小 6,144 (48*128),64 个 transformer 层(sheesh), 每层都有一个解码器层:多头注意力块和密集块,键值大小 128。 3. 多头注意力块:48 个 head 用于查询,8 个用于键 / 值(KV)。KV 大小为 128。密集块(密集前馈块):加宽因子 8,隐藏层大小 32768。每个 token 从 8 个专家中选择 2 个。 4. 旋转位置嵌入大小为 6144,与输入嵌入大小相同。上下文长度为 8192 tokens,精度为 bf16。 |

|
|
不过目前的这些技术“细节”都是大神“手撕”Grok-1推断得到的,具体而准确的细节需要等官方公布的技术报告。 在 X 平台上,Grok-1 的开源引发了众多的讨论。 其中技术社区指出,该模型在前馈层中使用了GeGLU,并采用了有趣的sandwich norm 技术进行归一化。 比较搞笑的是,与老马随时随地不忘阴阳OpenAI不同,有个 OpenAI 的员工发帖表示对该模型很感兴趣。 |

|
|
不过大模型发展到今天,仅仅“参数多”并不能代表什么,用来训练的语料库是影响语言模型效果的重要因素之一。 根据Grok团队的说法,Grok-1的训练语料包括书籍、新闻、社交媒体、网页等各种来源的文本数据,为了保证这些文本数据的质量,研究者们采用了一系列数据过滤和清洗技术,如去除低质量网页、过滤不当内容等。此外,他们还采用了一些数据增强技术,如回译、词替换等,来进一步扩充训练语料。 不过根据之前Grok连大麻都敢做的表现来看,我对于它的语料质量有些存疑…… GeGLU和sandwich norm从算法上来看,确实算得上是对transformer的又一次改进。 传统的Transformer中,前馈层通常使用ReLU或GELU作为激活函数,而GeGLU在此基础上引入了一个门控机制,这种门控机制允许模型自适应地调节每个维度的信息流,增强了模型的表达能力。 Sandwich Norm 是一种创新的归一化技术,旨在优化 Transformer 模型中的层归一化处理。具体而言,Sandwich Norm 结合了前置归一化(Pre-LN)和后置归一化(Post-LN)的方法。在这种方法中,数据首先通过一个处理层,接着进行一次归一化操作,然后传递给下一个处理层。紧接着,在进入下一层处理之前,再次执行一次归一化操作。这种策略有效地结合了 Post-LN 和 Pre-LN 的优点,同时保证了层与层之间的信息流动更加顺畅。 只是不管怎么说,仍然是对着transformer架构在做一些A4纸上雕花的工作,并没有什么根本性的创新。具体效果如何,需要等待拥有8块以上H100的大佬们进行测试后才能知晓。 不过有竞争终归是件好事,有鲶鱼在的水池里,其他鱼也就不敢继续安心当“休克鱼”了…… |
|
现在开源模型很多了LLaMA-2 70B以及基于此的各种开源模型,QWen-1.5 72B,Yi 34B,Mixtral 7B*8(最新的Mistral Large则没有再开源),但是Grok-1这个规模的模型还是第一个,因此有其重要意义的(很多人提到榜单分数不高但是榜单只是一个评价维度,而且他这个是预训练模型没有针对性训练,也期待一下到时候人类对战效果LMSys Chatbot Arena Leaderboard - a Hugging Face Space by lmsys)。在目前模型结构大差不差的情况下,规模更大往往意味着能力更强,数据则是打上榜单的关键; 但是很尴尬的是,这个规模的模型需要8台H100服务器才能跑起来,开源社区只有极少数的头部巨头能跑,因此这次开源又有点鸡肋。因此我觉得马斯克要么就自己把模型做好做全套再开源,或者做成平台类似ChatGPT/Claude/Mistral LeChat让用户使用让数据飞轮转起来,不然除了打打OpenAI嘴炮外很难产生实际的社区影响力。马斯克很有想法,希望也能在大模型和人工智能取得成功,免得被OpenAI一家独大。 |
|
|
| [收藏本文] 【下载本文】 |
| 科技知识 最新文章 |
| 百度为什么越来越垃圾了? |
| 百度为什么越来越垃圾了? |
| 为什么程序员总是发现不了自己的Bug? |
| 出现在抖音评论区里边的算命真不真? |
| 你认为 C++ 最不应该存在的特性是什么? |
| 为什么 Windows 的兼容性这么强大,到底用了 |
| 如何看待Nvidia禁止使用翻译工具将cuda运行 |
| 为何苹果搞了十年的汽车还是难产,小米很快 |
| 该不该和AI说谢谢? |
| 为什么突破性的技术总是最先发生在西方? |
| 上一篇文章 下一篇文章 查看所有文章 |
|
|
|
| 股票涨跌实时统计 涨停板选股 分时图选股 跌停板选股 K线图选股 成交量选股 均线选股 趋势线选股 筹码理论 波浪理论 缠论 MACD指标 KDJ指标 BOLL指标 RSI指标 炒股基础知识 炒股故事 |
| 网站联系: qq:121756557 email:121756557@qq.com 天天财汇 |