
| |
|
|
| 首页 淘股吧 股票涨跌实时统计 涨停板选股 股票入门 股票书籍 股票问答 分时图选股 跌停板选股 K线图选股 成交量选股 [平安银行] |
| 股市论谈 均线选股 趋势线选股 筹码理论 波浪理论 缠论 MACD指标 KDJ指标 BOLL指标 RSI指标 炒股基础知识 炒股故事 |
| 商业财经 科技知识 汽车百科 工程技术 自然科学 家居生活 设计艺术 财经视频 游戏-- |
| 天天财汇 -> 科技知识 -> 2024年了diffusion还有什么可做的? -> 正文阅读 |
|
|
[科技知识]2024年了diffusion还有什么可做的? |
| [收藏本文] 【下载本文】 |
|
2024年了diffusion还有什么可做的? 关注问题?写回答 [img_log] 计算机视觉 深度学习(Deep Learning) 数据模型 Diffusion 2024年了diffusion还有什么可做的? |
|
纯属brainstorm,欢迎大家一起探讨。我会尽可能举一些具体例子来分析。部分点在我之前的一个相关回答中也有,大家可以移步参考: 这个回答对之前的回答做进一步的补充完善。我们通过“数据、模型、优化”三个角度,再加上能做的“任务”,可以将diffusion models的全流程解剖一下,然后一个一个来看,个人比较看好的方向加粗标出: 数据生成图像的分辨率生成特定领域图像模型压缩模型网络架构文本编码采样优化对齐特定人类偏好推理任务视频生成Instruction-Based Editing数据 “数据”角度主要还是关注生成图像的一些特性,比如说生成图像的resolution、domain等等。 生成图像分辨率 关注生成图像的“分辨率”其实就是做“High-Resolution Image Synthesis”,个人一直认为属于是“简单但难解的工程问题”,原因很简单,分辨率成倍增大,生成模型要生成的像素点就需要以2次方倍的速度增加。 经典的例子一般通过优化压缩模型或者是采用“生成 + 超分”来做。 对于前者来说,比较经典的例子就是Stable Diffusion了,将DDPM在pixel space的diffusion process直接搬到VQGAN的隐空间里做,大家都很熟悉了,这里就不再展开。 |

|
|
Stable Diffusion的模型架构图个人感觉这里一个可能的点是怎样优化压缩模型,采用更激进的下采样策略,同时又能保证压缩模型带来的精度损失在可接受的范围内,来实现更高分辨率的生成。举个具体例子,Stable Diffusion的VQGAN目前是将512×512的图像,压缩至64×64的latent feature(下采样8倍),假设我们能够拿到这样一个“超级压缩模型”,能够实现512×512到16×16(下采样32倍),那么直接拿Stable Diffusion这一套去用,理论上就能实现2048×2048的更高分辨率生成。 “生成 + 超分”的范式可以关注近期清华 + 智谱AI做的Cogview 3,目前已经能做到最高2048×2048的生成,超分阶段采用了Relay Diffusion,Relay Diffusion是关于diffusion models的noise scheduling来增强高分辨率生成的工作,挺有意思的,而noise scheduling又属于比较小众的赛道,这一块也还有研究空间。 |

|
|
Cogview 3的结果 关于Relay Diffusion以及Cogview 3的解析,可以参考我的文章: 生成特定领域图像 这一块其实涉猎面就挺广的,“特定领域”(specific domain)指的可以是特定“美感”的图片,也可以是灰度图像、线稿图、医疗图像这类专业领域的图片。近期的Playground v2.5其实也是基于这个motivation开展工作的,对比证明了SDXL生成“特定背景下”的图片仍然面临困难: |

|
|
Playground v2.5的motivation 能做的点,一方面是方法,虽然说Civitai上面众多的SD插件已经证明了LoRA微调是比较有效的方案,但是training-free solution还可以研究;另一方面就是生成什么domain的图像,这就涉及这样做具体有什么应用价值,以及故事应该怎么讲的问题。 近期有一些做生成医疗图像的工作,尚不清楚其具体应用价值,不过也一同分享出来,有需要的朋友可以参考。例如LLM-CXR: |
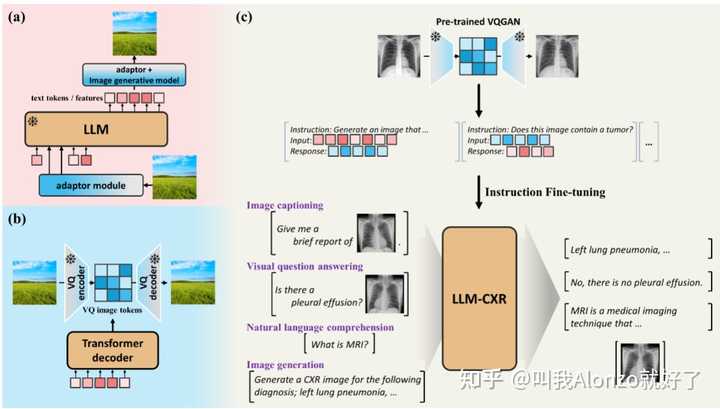
|
|
LLM-CXR的方法流程图 MedXChat: |
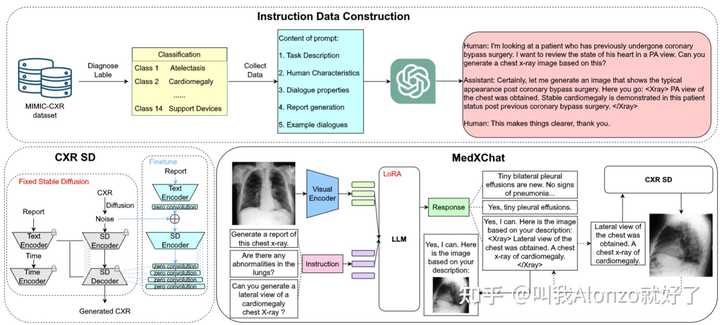
|
|
MedXChat的方法流程图模型 模型上主要还是按照现有主流latent diffusion models的设计,分为压缩模型、网络架构、文本编码三块,加上模型采样过程的优化。 压缩模型 压缩模型本质是一个图像压缩问题,即怎样尽可能多地节约数据容量,同时又能够保证数据精度的损失可以接受。正是因为这样,懂压缩模型的人其实相对较少,怎样能结合生成的特点设计压缩模型,其实还有较大研究空间。 近期的一些相关研究,例如Wuerstchen,提出级semantic compression将图像在像素空间的信息加入到latent diffusion models中: |
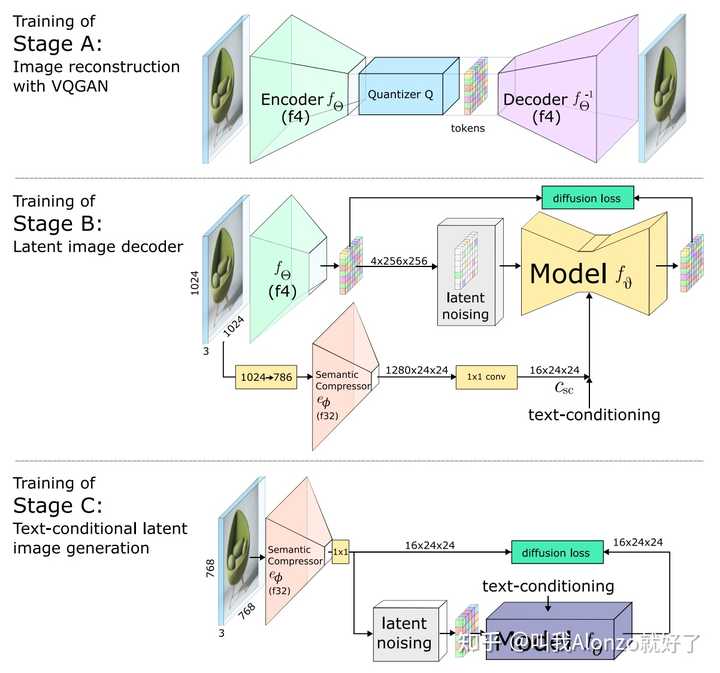
|
|
Wuerstchen的方法流程图 另外近期的Stable Diffusion 3也在压缩模型上做出了改进,将VQGAN latent feature的channel数量增大了,从而减少压缩模型编码-解码过程中的精度损失,其重构性能在多个指标上都有显著提升: |
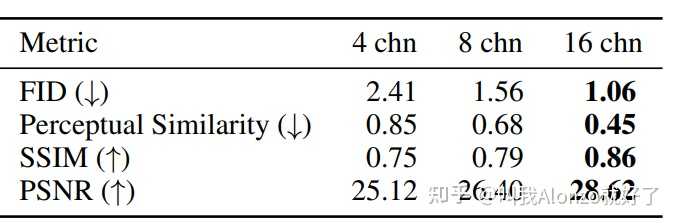
|
|
Stable Diffusion 3改进后VQGAN的重构性能 尽管如此,现有的改进都偏工程化,压缩模型方面仍有较大的改进空间。关于Stable Diffusion 3的具体分析,可以参考我的往期文章: 一文解读:Stable Diffusion 3究竟厉害在哪里?18 赞同 ・ 2 评论文章 |

|
|
网络架构 网络架构方面不得不提Diffusion Transformer,既然2024年初OpenAI的Sora、StabilityAI的Stable Diffusion 3都不约而同采用了这一架构;同时,PixArt系列的工作也一直采用的是这一架构,更加证明了其可行性。这些AI巨头的动作势必会带动一系列基于Diffusion Transformer的工作。 |
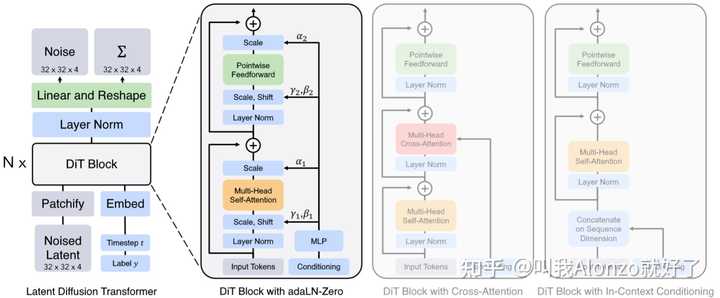
|
|
Diffusion Transformer的模型架构图 关于Diffusion Transformer的具体解读,可以参考我的往期文章: Diffusion Transformer Family:关于Sora和Stable Diffusion 3你需要知道的一切69 赞同 ・ 4 评论文章 |

|
|
文本编码 文本编码这一块其实是个人比较看好的发展方向,因为目前NLP社区大语言模型的发展也非常快,而大多数diffusion models还是沿用以往工作的CLIP或者T5-XXL来做文本编码。如何将LLM跟diffusion models做结合,以及结合后有什么应用价值,目前的工作还不多,例子可以参考ACM MM 2024的SUR-Adapter: |

|
|
SUR-Adapter的模型架构图 另外值得一提的是,在DALL-E 3的带领下,Re-captioning基本上已成为了现有方法的标配,Cogview 3更是借助GPT-4V的多模态能力通过Visual QA的方式升级了Re-captioning的设计,随着GPT系列多模态能力的进一步增强,通过对GPT做一些prompt engineering拿到更多文本数据,也还大有文章可做。 采样 采样主要考虑两个方面,一个提升采样质量,二是加速采样。 第一点属于理论性要求比较高的工作,参考Classifier Guidance和Classifier-Free Guidance,有一定研究难度,但是idea如果work的话也具有巨大的普适价值。 第二点其实是目前主流的趋势,基本上都是基于Progressive Distillation来做。具体工作可以参考:SDXL-Lightning、Stable Cascade、SDXL Turbo、Cogview 3等等,具体不再过多展开。 关于Diffusion Distillation,可以参考我的往期回答: 现如今的知识蒸馏领域,在多模态方面有什么可以做的点子?4 赞同 ・ 0 评论回答 |
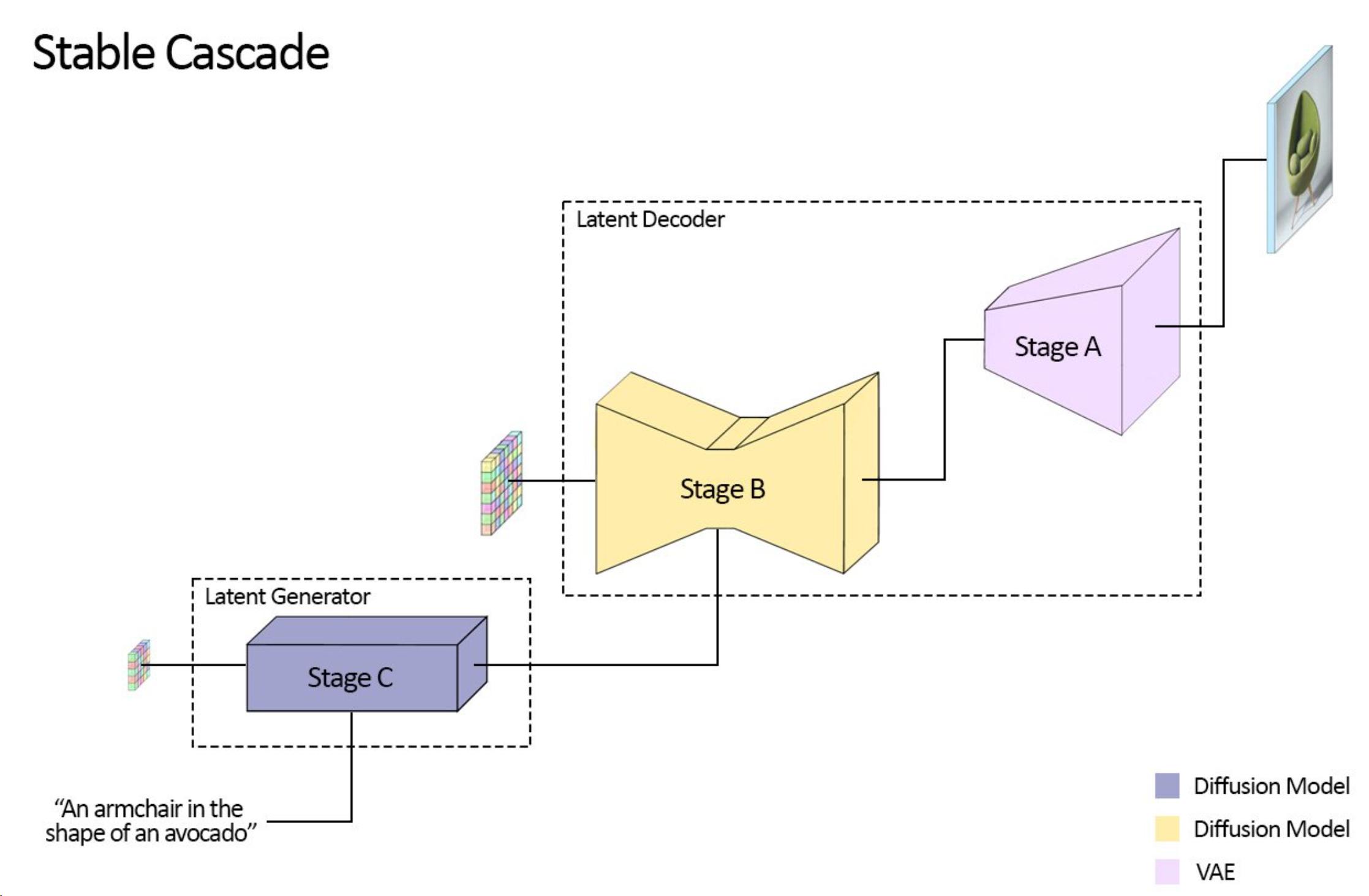
|
|
优化 优化方面个人认为其实也是大有可为的,现有方法大多还是沿用标准的MSE loss,而NLP社区LLM在强化学习方面的研究已经很多了,其实其中可以借鉴的点还比较多。 对齐人类特定偏好 说到LLM结合强化学习,大家第一印象想到的肯定是RLHF。事实上RLHF能做的事情有很多,可以增强样本质量、跟人类偏好做对齐,甚至是跟特定领域对齐,做domain adaptation,等等。 而反观图像生成社区,diffusion models跟强化学习结合的工作其实还不多,比较有名的工作可以参考DDPO。这方面由于我对强化学习不太熟悉,仅做分享,但从LLM研究的视角来看,在scaled up diffusion models的大趋势下,RLHF想必一定也能有它的用武之地。 推理 推理方面是个人感觉比较有意思的,相关的工作也还不多。例如名字比较有趣的MiniGPT-5,同样也是“LLM + Diffusion”的工作,可以看下它能做的一个例子: |
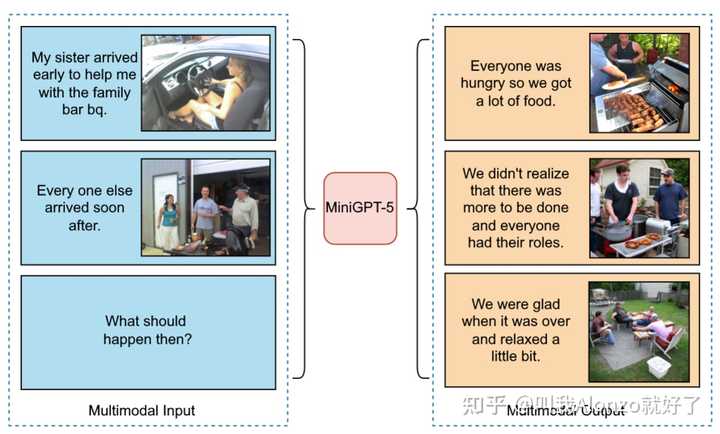
|
|
MiniGPT-5的结果例子 为什么说“推理”值得去做?个人认为效果如果能够实现图像维度的信息推理,那么就将In-Context Learning又上升了一个高度,具体能做的事情其实很多,比方说Text-to-Comic Generation,能够生成漫画(如果一致性能保持好的话);Storybook Generation,等等。这些任务如果做得足够好,或许会有新的文生图任务定义,甚至能产生可观的商业价值。 任务 任务上更多的是其他数据模态的生成,或者是文生图的任务变式来考虑。 视频生成 视频生成自然不用多说了,年初OpenAI放出的Sora,势必会带来一个视频生成的风口,带动一系列这方面的研究。另一方面,根据个人的调研结果,目前视频生成的工作还不多,仍有较大挖掘空间。关于视频生成的顶会文章,可以参考我GitHub repo收录的paper list: Video Generation Paper List?github.com/AlonzoLeeeooo/awesome-video-generation |

|
|
Video Generation GitHub Repo部分截图Instruction-Based Editing Instruction-Based Editing其实属于文生图的一个任务变式,这一任务自从CVPR 2022的InstructPix2Pix之后,连续两年的CVPR都收录了大约30篇左右的相关工作,而InstructPix2Pix在两年之内也是收获了小600个引用,足以证明这一方向的价值。其本质原理其实也类似前文中说到的“推理”。 |

|
|
InstructPix2Pix中展示的Instruction-Based Editing的结果例子 关于Instruction-Based Editing的具体研究,可以参考我的往期回答: 对于“扩散模型中的图像编辑”方向,可以推荐论文和相应的开源代码吗?9 赞同 ・ 3 评论回答 |

|
|
上述提及文章均已附上超链接,其他文生图顶会文章,在我的GitHub repo中均有收录,有需要的朋友可以参考: Text-to-Image Generation Paper List?github.com/AlonzoLeeeooo/awesome-text-to-image-studies |
|
diffusion for classification(??????? diffusion这种生成模型,既然知道了标签和图像的关系,那么能否直接用来分类呢? https://arxiv.org/abs/2305.15241?arxiv.org/abs/2305.15241 这种分类是否鲁棒呢?我们能否直接给这种分类器的lipschitz常数求出来呢?以及能否直接求出它们鲁棒性的下界呢? https://arxiv.org/abs/2402.02316?arxiv.org/abs/2402.02316 |
|
目前Diffusion Model不管是从方法还是应用层面都是有很多可以做的,下面介绍一下扩散模型的最新研究趋势(与大模型结合,高效训练,MoE范式,其他应用),更多算法和应用细分方向可参考这篇扩散模型综述。 LLM+Diffusion 复杂文生图-RPG 文章链接:https://arxiv.org/abs/2401.11708 代码地址:https://github.com/YangLing0818/RPG-DiffusionMaster Diffusion框架介绍 当前文生图模型研究一个很重要的问题就是面对复杂的,组合的(compositional)条件输入时,生成的图片会丢失部分文本语义甚至导致错误的语义表达,为此我们提出了下面这个RPG框架。用LLM来去控制文生图过程能够很好的解决这类问题,是一个非常值得研究的方向。 |
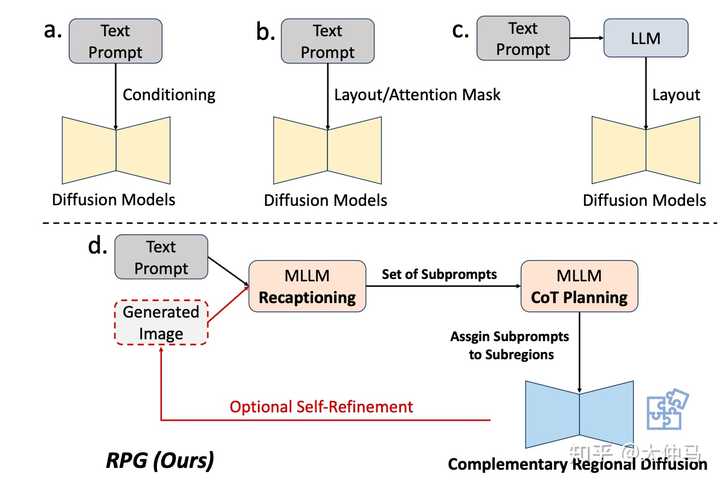
|
|
我们联合斯坦福、Pika Labs提出了一个全新的training-free生成范式RPG (Recaptioning-Planning-Generating):利用多模态大语言模型(MLLMs)强大的跨模态理解,分析和规划能力对扩散模型的生成和编辑进行指导,从而极大提高在复杂场景下生成图片的图文对齐程度。在一些特别复杂的文本条件下我们的生成结果能够超越SDXL和DALL-E 3等模型。除此之外,RPG还能结合不同的大模型结构和任意扩散模型(SDXL、ControlNet等)。 |

|
|
|

|
|
在这个范式中,RPG提出了三个核心策略,如下图所示: |

|
|
RPG框架示意图 1. Recaption:通过MLLMs的跨模态分析和理解能力将复杂任务划分为几个简单的子任务,在我们的生成范式中,即将描述复杂场景的句子分解为包含单个实体或属性的多个子关键句,同时对关键句内容进行进一步补充,以进一步提高生成的质量。 2. Plan: 利用MLLMs CoT reasoning强大的分析和规划能力将整个复杂场景分解为多个互补的子区域,同时为每个子关键句规划并分配合适的子区域。我们进一步使用了高质量的in-context examples 去提升多模态大语言模型对整个场景分区的合理性与准确性,使其更加符合人类审美。 3. Generate: 我们创新性地提出了Complementary Regional Diffusion,即在sample过程的每一步中对每个子关键句分别进行生成其子区域对应的latent,这些子区域latents经过resize之后进行拼接,并结合Base prompt(对复杂场景的概述)生成的latent,进行加权融合,从而在sample过程中进行逐步的融合优化,最终生成与文本高度对齐同时各区域和谐一致的图片。新的扩散模型结构如下: |
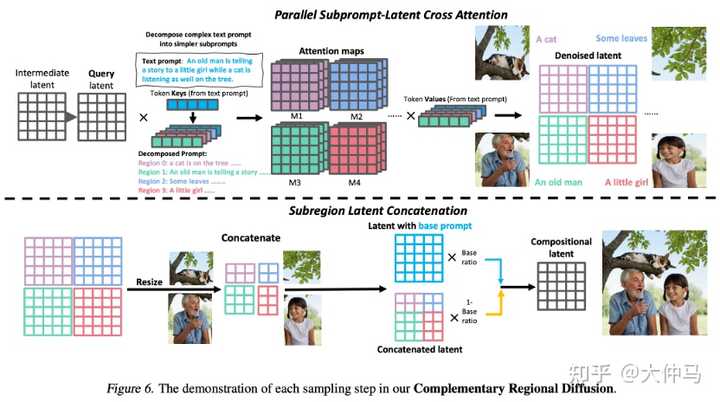
|
|
多轮编辑框架介绍 RPG同时能泛化到图像编辑任务上,将图像生成和图像编辑任务在一个框架里统一起来,如下所示: |
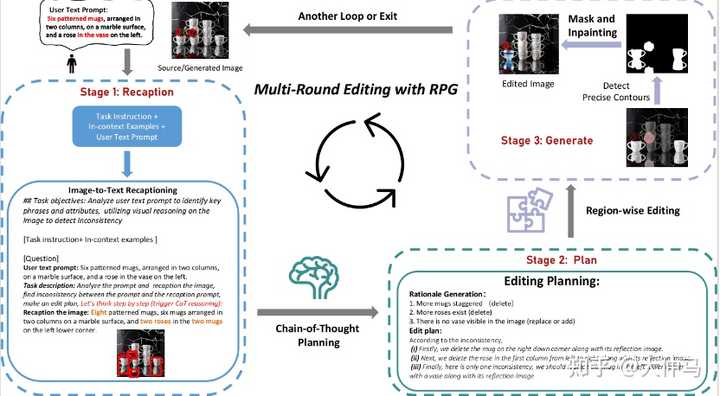
|
|
多轮编辑->统一生成编辑任务 1. Recaption: 通过MLLMs的跨模态推理能力精确识别出图片中的实体及属性,并与输入图片对应的text prompt进行对比,利用大语言模型的分析能力,找出两者间不一致的实体或属性。 2. Plan: 利用MLLMs CoT reasoning 强大的分析和规划能力,针对图片和文本不一致的部分制定step-by-step edit plan. 我们使用高质量的人工编辑流程作为in-context examples来进一步提高模型的规划能力,从而提高编辑流程的准确性。 3. Generate: 与生成任务不同,在编辑任务中,我们提出了Contour-based Regional Diffusion. 这里我们首先根据step-by-step edit plan 来获得编辑对象,使用text-grounded contour 获得编辑对象的精确轮廓,之后采用mask-and-inpainting 的方法实现准确编辑。 如下图所示,在复杂场景的精确编辑任务中,我们的范式在多个方面超越了当前SOTA的编辑方法,如instruct-pix2pix 以及 prompt2prompt。 |

|
|
图像编辑结果对比 |

|
|
多轮编辑 本文还有很多技术细节,后续会再更新此帖,也欢迎大家关注项目地址 https://github.com/YangLing0818/RPG-DiffusionMaster 高效的训练策略-SADM(CVPR 2024) 当前扩散模型的训练都是基于单个样本,这样的训练范式使模型不太能快速收敛到真实数据分布,我们提出了一种新型的structure-aware的扩散模型训练框架-SADM(和之前的方法对比如下)。该方法在每个batch训练中不仅关注到单个样本的拟合情况,还会将batch中样本间pair-wise的manifold structure(内积)也进行重建。 |

|
|
SADM和之前训练策略的对比 训练框架的示意图如下: |

|
|
我们不仅从structure-level角度对扩散模型训练进行改进,还提出了一种对抗式训练策略,让模型对数据分布的拟合更加鲁棒,成功在各项图像生成指标上超越之前所有的方法,还大大提升了Diffusion Trasformer (DiT)的性能。 |
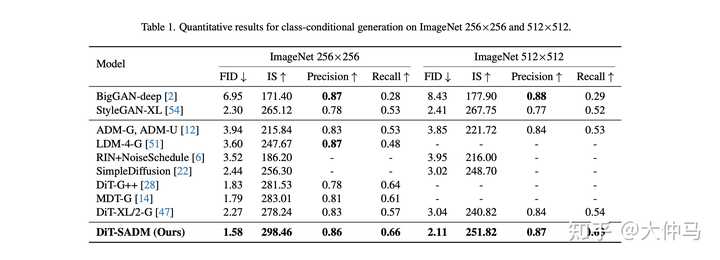
|
|
扩散模型MOE范式-RealCompo 文章链接:RealCompo: Dynamic Equilibrium between Realism and Compositionality Improves Text-to-Image Diffusion Models 代码链接:GitHub - YangLing0818/RealCompo: RealCompo: Dynamic Equilibrium between Realism and Compositionality Improves Text-to-Image Diffusion Models RealCompo是一种新的文本到图像生成框架,旨在利用文本到图像和布局到图像模型的优势,增强生成图像的逼真度和组合性。该框架无需额外的训练,易于迁移,提出了一种直观且新颖的平衡器,在去噪过程中动态平衡两种模型的优势,使任何模型都可以直接使用,无需额外训练。大量实验证明,RealCompo在多对象组合生成方面始终优于最先进的文本到图像模型和布局到图像模型,同时保持了生成图像的逼真度和组合性。 |
|
|
优化生成图像的组合性的一个实用方法是将每个对象的布局提供为扩散模型的额外输入。使用布局作为约束T2I模型的另一个条件,这些布局到图像(L2I)模型具有精确控制特定对象在特定位置生成的能力。例如,GLIGEN采用门控自注意力来训练模型,利用布局的全面信息。尽管这些L2I方法改善了对象定位和计数错误的弱点,但其生成结果的逼真度不尽人意。相比之下,T2I模型可以生成具有高逼真度的对象,但是难以遵循文本提示关于对象数量和位置的要求。L2I模型和T2I模型之间存在显著的互补空间。 |

|
|
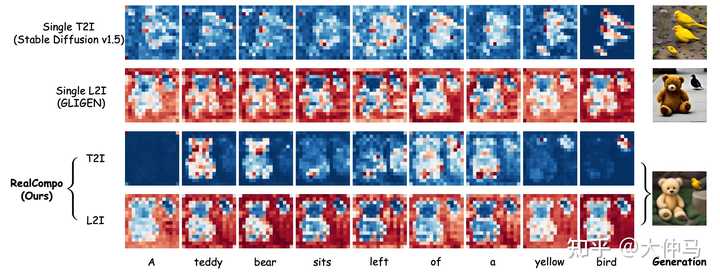
为此,本文引入了一个通用的无需训练的文本到图像生成框架RealCompo,该框架利用了一个新颖的平衡器,在生成的图像中实现了逼真度和组合性的动态平衡。 首先利用了LLM(大语言模型)的上下文学习能力来推理出重要对象的布局,并从输入文本提示中实现属性和对象的“预绑定”。然后,引入了一个创新的平衡器来整合预训练的L2I和T2I模型。该平衡器被设计为通过分析每个模型在每个去噪步骤的交叉注意力图来自动调整预测组合的各个系数。这种方法可以整合两种模型的优势,动态平衡生成图像的逼真度和组合性。虽然存在用于合并多个扩散模型的方法,但它们在使用上缺乏灵活性,因为它们需要额外的训练,并且缺乏推广到其他场景和模型的能力。 本文的方法是第一个以无需训练的方式执行模型组合的方法,可以在任何模型之间实现平滑的过渡。作者进行了大量实验,展示了RealCompo在生成具有逼真度和组合性的图像方面的出色性能。如图所示,RealCompo以动态平衡的方式结合了T2I和L2I模型的优势。通过整合布局信息,它将精确的对象定位注入到T2I模型中,同时保持了每个标记的交叉注意力图中对每个对象焦点的特性。这确保了生成高度逼真的图像。 |
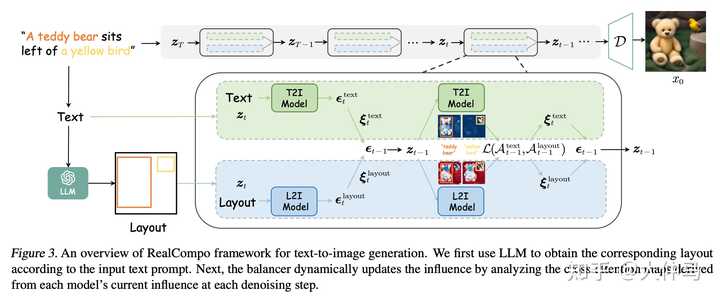
|
|
同时,它保持了L2I模型对每个标记的交叉注意力图中框外特征的关注,展示了强大的定位能力和生成图像中组合性的最佳实现。RealCompo使T2I和L2I模型能够保持各自的优势,同时弥补彼此的不足。 本文是文本到图像生成领域首次通过动态实现生成图像的逼真度和组合性之间的平衡来增强生成图像的质量。RealCompo具有选择任意L2I或T2I模型的能力,可以自动平衡它们以实现协同生成。相信RealCompo开辟了可控和具有组合性的图像生成的新研究视角。 主要贡献总结如下: ? 引入了一个新的无需训练且易于转移的文本到图像生成框架RealCompo,通过平衡生成图像的逼真度和组合性,增强了组合式文本到图像的生成能力。 ? 在RealCompo中,设计了一个新颖的平衡器,在每个去噪时间步中动态地组合来自T2I和L2I模型的输出。它为组合式图像生成提供了新的视角。 ? 通过与先前的最先进方法进行广泛的定性和定量比较,证明了RealCompo在生成多个对象和复杂关系方面的性能显著提高。 实验结果: |
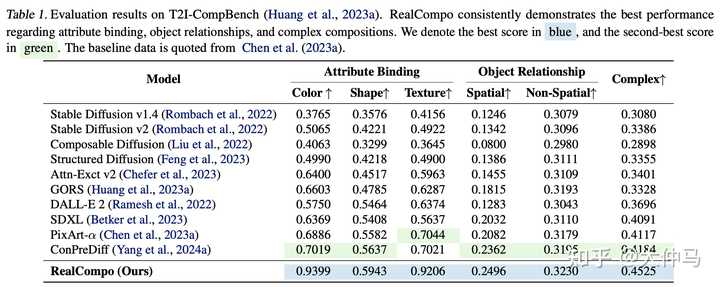
|
|
与当前优秀的L2I模型GLIGEN和LMD+相比,可以在保持对象属性匹配和生成位置正确的情况下实现高水平的逼真度。将这归因于动态平衡方法,使得T2I模型能够在布局独立时最大化其语义生成能力。表1中呈现的定量结果表明,RealCompo在文本到图像生成的组合生成任务中取得了最佳性能。 |
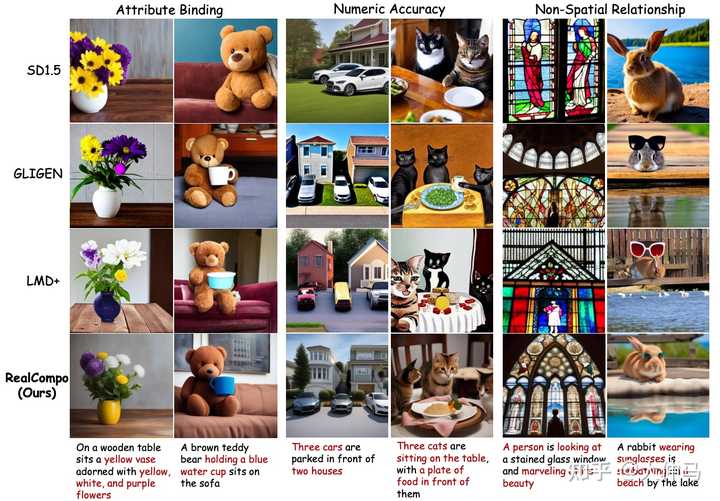
|
|
结果展示梯度分析: 选择了 RealCompo v3 和 v4 来分析在公式 11 中去噪过程中梯度的变化。如下图 所示,使用相同的提示和随机数种子来可视化对应于每个模型版本的 T2I 和 L2I 的梯度大小变化。观察到 RealCompo v4 的梯度大小变化在去噪过程的早期阶段更加明显。我们认为,TokenCompose 通过使用分割mask微调模型来增强多对象生成的组成能力,与基于布局的多对象生成相互冗余,并且 TokenCompose 的对象定位不一定在边界框内。因此,RealCompo 必须在预去噪阶段专注于平衡 TokenCompose 和布局的定位,因此其梯度与 RealCompo v3 相比不稳定。此外,由于 LayGuide 在定位能力上较 GLIGEN 弱,RealCompo v4 在某些罕见情况下生成的对象填充边界框较少的问题,如前所述。 |
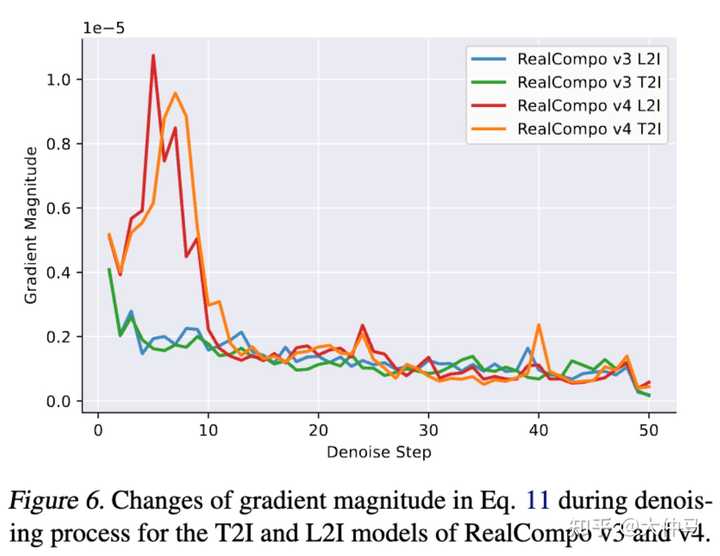
|
|
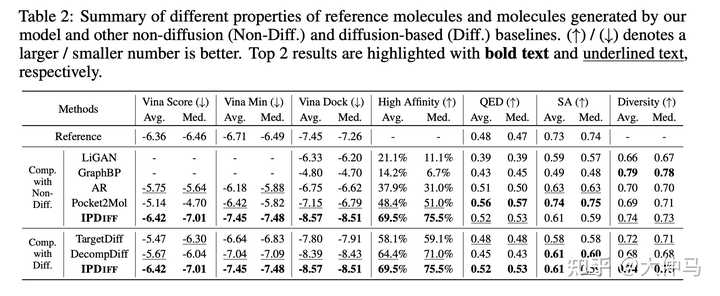
AI for Science中的应用-IPDiff(ICLR 2024) 文章链接:Protein-Ligand Interaction Prior for Binding-aware 3D Molecule... 代码链接:https://github.com/YangLing0818/IPDiff 扩散模型在SBDD任务中有了越来越多的应用,本方法首次将protein-ligand中的交互先验加入到扩散模型的前后向过程中,并提出prior-conditioning和prior-shifting两种策略进行更好的binding-aware的3D分子生成。 |

|
|
Motivation |
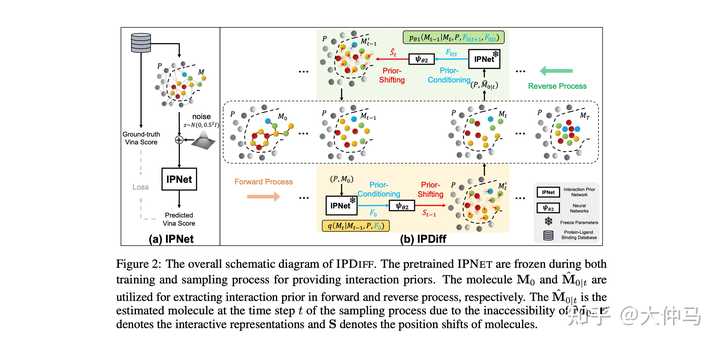
|
|
IPDiff框架图 |
|
|
IPDiff超越之前的Diffusion和非Diffusion方法 |
|
可控生成 正好来宣传一下我们的新综述,20页原文,249篇参考文献 TL;DR(太长不看版总结) 利用文本生成图片(Text-to-Image, T2I)已经满足不了人们的需要了,近期研究在T2I模型的基础上引入了更多类型的条件来生成图像,本文对这些方法进行了总结综述。 论文: https://arxiv.org/abs/2403.04279?arxiv.org/abs/2403.04279 代码: https://github.com/PRIV-Creation/Awesome-Controllable-T2I-Diffusion-Models?github.com/PRIV-Creation/Awesome-Controllable-T2I-Diffusion-Models 摘要 在视觉生成领域迅速发展的过程中,扩散模型已经彻底改变了这一领域的格局,通过其令人印象深刻的文本引导生成功能标志着能力方面的重大转变。然而,仅依赖文本来调节这些模型并不能完全满足不同应用和场景的多样化和复杂需求。鉴于这种不足,许多研究旨在控制预训练文本到图像(T2I)模型以支持新条件。在此综述中,作者对关于具有 T2I 扩散模型可控性生成的文献进行了彻底审查,涵盖了该领域内理论基础和实际进展。我们的审查从简要介绍去噪扩散概率模型(DDPMs)和广泛使用的 T2I 扩散模型基础开始。然后我们揭示了扩散模型的控制机制,并从理论上分析如何将新条件引入去噪过程以进行有条件生成。此外,我们提供了对该领域研究情况详尽概述,并根据条件角度将其组织为不同类别:具有特定条件生成、具有多个条件生成以及通用可控性生成。 |
|
|
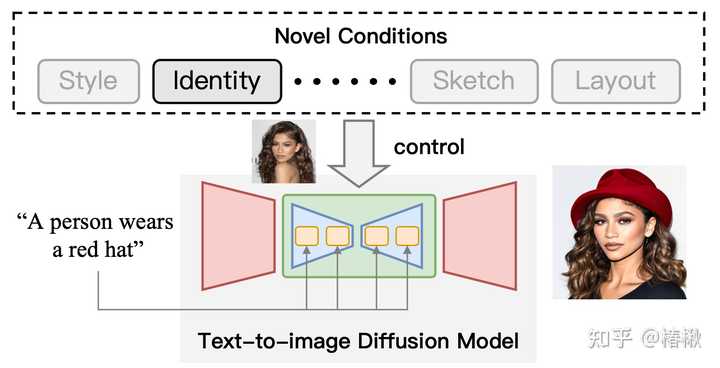
利用T2I扩散模型可控生成示意图。在文本条件的基础上,加入“身份”条件来控制输出的结果。 分类体系 |

|
|
可控生成的分类。从条件角度来看,我们将可控生成方法分为三个子任务,包括具有特定条件的生成、具有多个条件的生成和通用可控生成。 利用文本扩散模型进行条件生成的任务代表了一个多方面和复杂的领域。从条件角度来看,我们将这个任务分为三个子任务(参见图2)。大多数研究致力于如何在特定条件下生成图像,例如基于图像引导的生成和草图到图像的生成。为了揭示这些方法的理论和特征,我们根据它们的条件类型进一步对其进行分类。 利用特定条件生成:指引入了特定类型条件的方法,既包括定制的条件(Personalization, e.g., DreamBooth, Textual Inversion),也包含比较直接的条件,例如ControlNet系列、生理信号-to-Image。多条件生成:利用多个条件进行生成,对这一任务我们在技术的角度对其进行细分。统一可控生成:这个任务旨在能够利用任意条件(甚至任意数量)进行生成。 如何在T2I扩散模型中引入新的条件 细节请参考论文原文,下面对这些方法机理进行简要介绍。 条件得分预测(Conditional Score Prediction) |
|
|
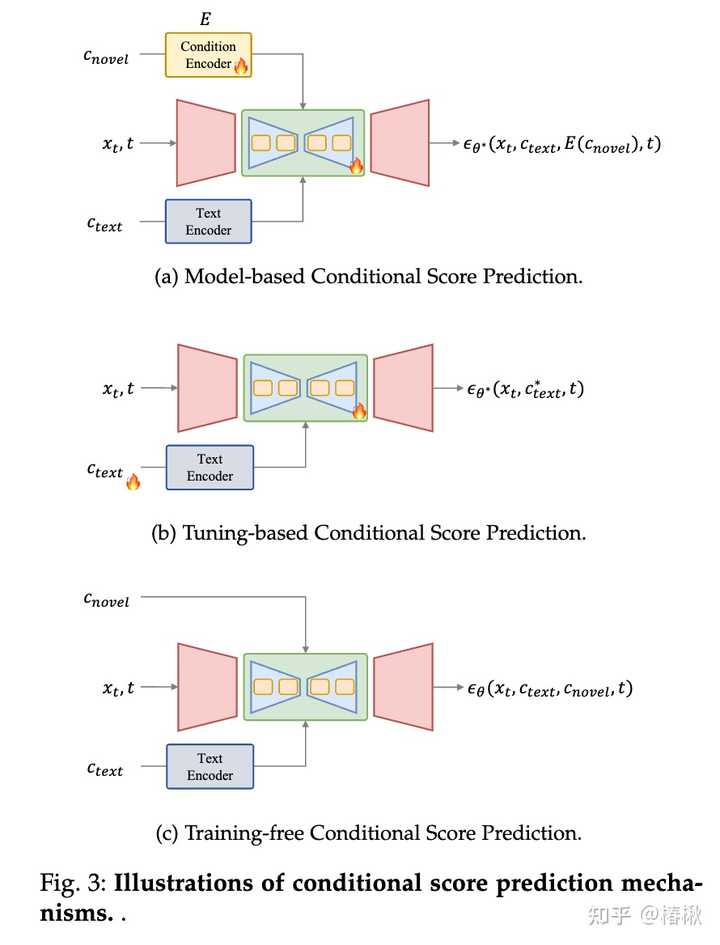
在T2I扩散模型中,利用可训练模型(例如UNet)来预测去噪过程中的概率得分(即噪声)是一种基本且有效的方法。在基于条件得分预测方法中,新颖条件会作为预测模型的输入,来直接预测新的得分。其可划分三种引入新条件的方法: 基于模型的条件得分预测:这类方法会引入一个用来编码新颖条件的模型,并将编码特征作为UNet的输入(如作用在cross-attention层),来预测新颖条件下的得分结果;基于微调的条件得分预测:这类方法不使用一个显式的条件,而是微调文本嵌入和去噪网络的参数,来使其学习新颖条件的信息,从而利用微调后的权重来实现可控生成。例如DreamBooth和Textual Inversion就是这类做法。无需训练的条件得分预测:这类方法无需对模型进行训练,可以直接将条件作用于模型的预测环节,例如在Layout-to-Image(布局图像生成)任务中,可以直接修改cross-attention层的attention map来实现设定物体的布局。条件引导的得分评估 |
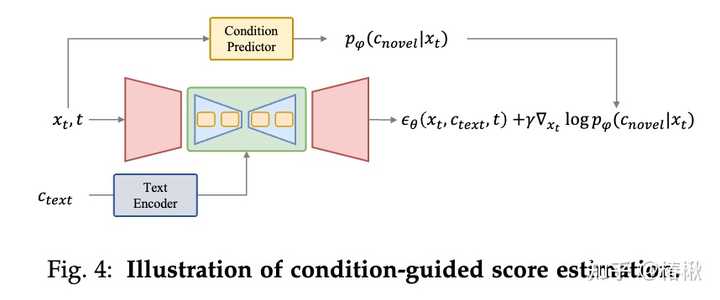
|
|
条件引导估的得分估计方法是通过条件预测模型(如上图Condition Predictor)反传梯度来在去噪过程中增加条件指导。 利用特定条件生成 |

|
|
Personalization(定制化):定制化任务旨在捕捉和利用概念作为生成条件行可控生成,这些条件不容易通过文本描述,需要从示例图像中进行提取。如DreamBooth,Texutal Inversion和LoRA。Spatial Control(空间控制):由于文本很难表示结构信息,即位置和密集标签,因此使用空间信号控制文本到图像扩散方法是一个重要的研究领域,例如布局、人体姿势、人体解析。方法例如ControlNet。Advanced Text-Conditioned Generation(增强的文本条件生成):尽管文本在文本到图像扩散模型中起着基础条件的作用,但该领域仍存在一些挑战。首先,在涉及多个主题或丰富描述的复杂文本中进行文本引导合成时,通常会遇到文本不对齐的问题。此外,这些模型主要在英语数据集上训练,导致了多语言生成能力明显不足。为解决这一限制,许多工作提出了旨在拓展这些模型语言范围的创新方法。In-Context Generation(上下文生成):在上下文生成任务中,根据一对特定任务示例图像和文本指导,在新的查询图像上理解并执行特定任务。Brain-Guided Generation(脑信号引导生成):脑信号引导生成任务专注于直接从大脑活动控制图像创建,例如脑电图(EEG)记录和功能性磁共振成像(fMRI)。Sound-Guided Generation(声音引导生成):以声音为条件生成相符合的图像。Text Rendering(文本渲染):在图像中生成文本,可以被广泛应用到海报、数据封面、表情包等应用场景。 多条件生成 |

|
|
多条件生成任务旨在根据多种条件生成图像,例如在用户定义的姿势下生成特定人物或以三种个性化身份生成人物。在本节中,我们从技术角度对这些方法进行了全面概述,并将它们分类以下类别: Joint Training(联合训练):在训练阶段就引入多个条件进行联合训练。Continual Learning(持续学习):有顺序的学习多个条件,在学习新条件的同时不遗忘旧的条件,以实现多条件生成。Weight Fusion(权重融合):用不同条件微调得到的参数进行权重融合,以使模型同时具备多个条件下的生成。Attention-based Integration(基于注意力的集成):通过attention map来设定多个条件(通常为物体)在图像中的位置,以实现多条件生成。 通用条件生成 除了针对特定类型条件量身定制的方法之外,还存在旨在适应图像生成中任意条件的通用方法。这些方法根据它们的理论基础被广泛分类为两组:通用条件分数预测框架和通用条件引导分数估计。通用条件分数预测框架:通用条件分数预测框架通过创建一个能够编码任何给定条件并利用它们来预测图像合成过程中每个时间步的噪声的框架。这种方法提供了一种通用解决方案,可以灵活地适应各种条件。通过直接将条件信息整合到生成模型中,该方法允许根据各种条件动态调整图像生成过程,使其多才多艺且适用于各种图像合成场景。通用条件引导分数估计:其他方法利用条件引导的分数估计将各种条件纳入文本到图像扩散模型中。主要挑战在于在去噪过程中从潜变量获得特定条件的指导。 应用 引入新颖条件可以在多个任务中发挥用处,其中包括图像编辑、图像补全、图像组合、文/图生成3D。例如,在图像编辑中,可以利用定制化方法,将图中出现猫编辑为特具有定身份的猫。其他内容请参考论文。 总结 这份综述深入探讨了文本到图像扩散模型的条件生成领域,揭示了融入文本引导生成过程中的新颖条件。首先,作者为读者提供基础知识,介绍去噪扩散概率模型、著名的文本到图像扩散模型以及一个结构良好的分类法。随后,作者揭示了将新颖条件引入T2I扩散模型的机制。然后,作者总结了先前的条件生成方法,并从理论基础、技术进展和解决方案策略等方面对它们进行分析。此外,作者探索可控生成的实际应用,在AI内容生成时代强调其在其中发挥重要作用和巨大潜力。这项调查旨在全面了解当前可控T2I生成领域的现状,从而促进这一充满活力研究领域持续演变和拓展。 |
|
扩散模型(Diffusion Models)的发展趋势与前景分析 序号发展趋势相关论文论文结论通俗解读1模型深度与广度增加"Deep Unsupervised Learning using Nonequilibrium Thermodynamics"扩散模型可以通过增加网络深度提高生成质量更多的层次,更细腻的画笔,画作更逼真2条件生成能力强化"Denoising Diffusion Probabilistic Models"条件扩散模型在图像生成、文本到图像等任务上表现优异给定条件,模型能生成更符合要求的内容3跨模态生成"High-Resolution Image Synthesis with Latent Diffusion Models"扩散模型开始探索文本、图像、音频等多种模态的联合生成一句话,一幅画,一首歌,全方位的艺术创作4效率与速度提升"Elucidating the Design Space of Diffusion-Based Generative Models"研究者正在优化扩散模型的计算效率和生成速度生成更快,等待更少,创意无限5可解释性与可控性增强"Diffusion Models Beat GANs on Image Synthesis"与GANs相比,扩散模型在可解释性和可控性上有优势更容易理解模型的工作原理,生成过程更透明6无监督与半监督学习"Score-Based Generative Modeling through Stochastic Differential Equations"扩散模型在无监督和半监督学习领域有巨大潜力利用未标记数据,让模型自己学习并生成新内容7多领域应用拓展"GLIDE: Towards Photorealistic Image Generation and Editing with Text-Guided Diffusion Models"扩散模型正在拓展到图像编辑、化学分子设计等多个领域不只是生成,还能编辑和优化,应用更广泛8伦理与隐私关注"On the Dangers of Stochastic Parrots: Can Language Models Be Too Big?"随着模型能力的增强,对伦理和隐私的关注也在增加技术强大,但也要用得好,用得对 相互关系总结: 随着研究的深入,扩散模型在模型深度与广度、条件生成能力、跨模态生成、效率与速度、可解释性与可控性、无监督与半监督学习以及多领域应用等方面都呈现出积极的发展趋势。然而,随着模型能力的增强,对伦理与隐私的关注也成为一个不可忽视的问题。这些方面共同推动着扩散模型的发展,并在实际应用中展现出巨大的潜力。 参考文献: "Deep Unsupervised Learning using Nonequilibrium Thermodynamics" by Sohl-Dickstein et al."Denoising Diffusion Probabilistic Models" by Ho et al."High-Resolution Image Synthesis with Latent Diffusion Models" by Rombach et al."Elucidating the Design Space of Diffusion-Based Generative Models" by Nichol & Dhariwal."Diffusion Models Beat GANs on Image Synthesis" by Dhariwal & Nichol."Score-Based Generative Modeling through Stochastic Differential Equations" by Song et al."GLIDE: Towards Photorealistic Image Generation and Editing with Text-Guided Diffusion Models" by Nichol et al."On the Dangers of Stochastic Parrots: Can Language Models Be Too Big?" by Bender et al. 参考文献中文翻译: Sohl-Dickstein等人的《使用非平衡热力学的深度无监督学习》Ho等人的《去噪扩散概率模型》Rombach等人的《基于潜在扩散模型的高分辨率图像合成》Nichol和Dhariwal的《阐明基于扩散的生成模型的设计空间》Dhariwal和Nichol的《扩散模型在图像合成上超越GANs》Song等人的《通过随机微分方程的基于分数的生成建模》Nichol等人的《GLIDE:迈向文本引导扩散模型的真实感图像生成与编辑》Bender等人的《关于随机鹦鹉的危险:语言模型会太大吗?》 |
|
Diffusion 才刚开始啊,还什么都不是呢。怎么就没东西可以做了呢? Diffusion Models(扩散模型)在业内比较大的共识有以下几个方面。比如 1. 多模态的应用: 怎么样结合文本和图像生成,就是类似于 Sketch-Guided Text-to-Image Diffusion Models 这种的,还有目前 Sora 的探索方向,这不都是在研究吗?Sora 这方向,不一定就是终极形态啊,乍一看挺惊艳,但是细细一想,是不是跑偏了也不一定啊 2. 对自然语言的理解 扩散模型在图像生成任务中超越了传统的生成对抗网络(GAN),并且在生成高质量图像方面取得了显著的进展。 但是,这一轮生成式 AI 之所以窜出来这么快,就是“对理解层的果断放弃”啊,简单点说,就是不使用提示词就不能理解啊啊啊啊! 应该用自然语言就能交互才对吧?至少也应该做到Dall-E 的水平吧? 3. 加速和效率改进: 针对原始扩散模型采样速度慢的问题,大家不是也在探索如何加速扩散模型的采样过程,例如通过Analytic-DPM、Extended-Analytic-DPM和DPM-Solver等方法。这也是 2024 年能做的啊 4. 训练方法的改进:例如Diffusion ODE的极大似然训练直接优化扩散潜在空间(DOODL)最小信噪比加权策略(Min-SNR-γ)自注意力引导(SAG扩散模型的量化(Q-Diffusion)SVDiff:紧凑参数空间的扩散微调DiffFit:简单参数高效的微调扩散概率模型基于最优传输(DPM-OT) 能做的,需要做的,太多了 5. 可控生成: 研究如何生成可控的输出,Controllable Generation 做不好,这 Diffusion 也容易走进死胡同里呀, 例如通过EGSDE(Efficient Guided Sampling for Diffusion Models)等方法来实现对生成内容的更精细控制。文本引导的生成有没有更接近自然语言的方法?通过迭代修改文本到图像扩散模型的一个额外输入token的嵌入向量,将生成的图像朝着给定的目标类别进行导引,这目前也只有 Dall-E 做的好啊,其他都不行。不过 Dall-E “功夫在诗外”类别或属性引导:通过使用类别标签或属性描述来引导扩散模型,可以生成具有特定类别或属性的图像。例如,可以在带类标签的数据集上训练扩散模型,或者使用预训练的分类器作为引导信号,以提高生成图像的准确性和质量。编辑和微调技术:在生成过程中,可以使用编辑技术对特定区域或特征进行微调,以满足用户的特定需求。包括但不限于通过在生成过程中引入蒙版(Mask),可以遮盖或修改图像的某些部分,从而实现更精细的控制。条件扩散模型:就是Conditional Diffusion Models,通过在训练和生成过程中引入额外的条件信息,如文本、类别标签或其他模态的输入,来控制生成过程。还有交互式生成:根据各种输入进行迭代优化。这个得跟“多模态”一起玩儿。没“多模态”就没啥可交互的东西。所以又说回来多模态引导:文本、图像、音频啊,我看日本还有个变态的,根据气味的,来以实现跨模态的可控生成 6. 理论建立和算法改进: 所以,这个事情肯定不是一个人一家公司或者一个团队能做成的,整个行业都要从理论和算法的角度对扩散模型的能力进行分析,并建立基本的共识,这样才能确保所有公司“打的是同一个副本”,防止最后散沙一片。每个公司做成的事情,最后能拼接成一个统一的地图。 我为了这个事还弄了一本书,重新学数学,然而我这个岁数精力已经不足了,天天烦心事太多,已然无法集中注意力学习了。 7. 与其他研究领域的结合: 毕竟,这东西最终是要拿来用的,不管是十年,二十年还是五十年,你不能和别人相结合。弄个空中楼阁,自己薅自己头发是不能飞起来的。 我刚才看 @CHAD 提到了一个 RF-Diffusion 的概念,我查了一下,这是在MobiCom '24会议上,刚提出的概念,利用时间-频率扩散模型(Time-Frequency Diffusion Model)来生成无线电信号。这项研究由Jingao Xu、Guoxuan Chi、Zheng Yang、Chenshu Wu、Jingao Gao、Yunhao Liu和Tony Xiao Han共同完成。 大概意思是,RF-Diffusion的核心思想是将扩散模型(Diffusion Model)应用于无线信号的生成,以此来增强无线信号数据的多样性和丰富性。 我算是涨了见识了,所以要坚持写东西,做交流,这太重要了。 RF-Diffusion 大概的意思是说, 在无线通信系统中,信号的多样性和复杂性对于提高系统性能、增强信号的鲁棒性以及提高频谱利用率等方面都至关重要。RF-Diffusion通过模拟信号在时间-频率域内的扩散过程,生成新的无线电信号样本。这种方法可以有效地扩充无线信号的数据集,尤其是在有限的实测数据情况下,通过数据增广技术可以提高无线通信系统的训练和测试效果。 我查了一下,RF-Diffusion可能涉及以下几个关键步骤,不过我水平有限,一知半解的先罗列出来: 信号表示:首先,需要将无线电信号转换为适合扩散模型处理的表示形式,例如将其转换为时频域的表示。模型训练:使用大量的无线电信号样本来训练扩散模型,使其能够学习信号在时间-频率域内的统计特性信号生成:训练完成后,模型可以生成新的信号样本,这些样本具有与训练数据类似的统计特性,但在细节上是独一无二的。性能评估:生成的信号样本需要在无线通信系统中进行测试,以评估其对系统性能的影响,包括信号的可检测性、误码率、抗干扰能力等。 也就是说, RF-Diffusion的研究为无线信号处理领域提供了一种新的数据增广方法。通过生成更多样化的信号样本,可以更好地模拟和应对实际无线环境中的各种情况,从而提高系统的整体性能和可靠性。 你看这尼玛多高科技? 所以,diffusion model 能做的事情还很多很多 |
|
我自己觉得一堆可以做的,甚至我当做博士方向了。博士第一年,diffusion相关,中了CVPR。 |
|
世界模型是个方向,可以看一下黄冠老师团队的工作 |
|
当然是结合NLP一起做啦。还有很多可以做的,结合NLP的各个子任务 |
|
减少diffusion的计算开销和存储开销。 提高diffusion生成的图像的视觉质量。 |
|
|
| [收藏本文] 【下载本文】 |
| 科技知识 最新文章 |
| 百度为什么越来越垃圾了? |
| 百度为什么越来越垃圾了? |
| 为什么程序员总是发现不了自己的Bug? |
| 出现在抖音评论区里边的算命真不真? |
| 你认为 C++ 最不应该存在的特性是什么? |
| 为什么 Windows 的兼容性这么强大,到底用了 |
| 如何看待Nvidia禁止使用翻译工具将cuda运行 |
| 为何苹果搞了十年的汽车还是难产,小米很快 |
| 该不该和AI说谢谢? |
| 为什么突破性的技术总是最先发生在西方? |
| 上一篇文章 下一篇文章 查看所有文章 |
|
|
|
| 股票涨跌实时统计 涨停板选股 分时图选股 跌停板选股 K线图选股 成交量选股 均线选股 趋势线选股 筹码理论 波浪理论 缠论 MACD指标 KDJ指标 BOLL指标 RSI指标 炒股基础知识 炒股故事 |
| 网站联系: qq:121756557 email:121756557@qq.com 天天财汇 |