
| |
|
|
| 首页 淘股吧 股票涨跌实时统计 涨停板选股 股票入门 股票书籍 股票问答 分时图选股 跌停板选股 K线图选股 成交量选股 [平安银行] |
| 股市论谈 均线选股 趋势线选股 筹码理论 波浪理论 缠论 MACD指标 KDJ指标 BOLL指标 RSI指标 炒股基础知识 炒股故事 |
| 商业财经 科技知识 汽车百科 工程技术 自然科学 家居生活 设计艺术 财经视频 游戏-- |
| 天天财汇 -> 科技知识 -> 如何看待与Open AI合作的最新机器人成果Figure 01? -> 正文阅读 |
|
|
[科技知识]如何看待与Open AI合作的最新机器人成果Figure 01? |
| [收藏本文] 【下载本文】 |
|
官网给出的机器人参数有:Height5'6" Payload:20KG Weight:60KG Runtime:5HR Speed:1.2M/S Sy… |
|
已知image 10Hz且说"setpoints",推断反馈控制频率只有10Hz,每次推理20个pose的chunk,这样每个pose间只有5ms,就可以很丝滑。 已知中间层级的动作是24-DoF,其中包括手腕位姿6-DoF(注:机械臂的自由度大于6,但手腕位姿至多6自由度),结合视频推断每只手是2+4的配置,大拇指两个关节fully actuated,其他四个手指两个关节under actuated末端关节柔性地跟随主动关节运动,可省去力控。 Limitation: 人形机器人并没有走,实际上和灵巧双手差不多。 灵巧双手并没有多少双手配合,实际上和灵巧手差不多。 灵巧手只是简单抓取放下(pick-place),实际上和平行夹爪机械手差不多。 存在behavior selection,如果behavior定义得很细比如抓苹果、抓盘子、苹果交到另一只手都是单独的behavior,那并没有什么技术突破,可能也就是action频率高了更丝滑。目测这些behavior都是人类动捕迁移过来的。 |

|
|
|

|
|
|
|
Figure 01 在 2024 年 1 月就展示了泡咖啡。这次展示的“语音与推理能力”对任何用过 GPT-4 的人来说都不奇妙,与机器人互动的“世界”非常简单,机器人从预先训练的动作中选取一项、拾取若干可识别的孤立对象,没什么值得惊讶之处――尤其是在你考虑到这种演示视频通常是多次拍摄大量素材、从中选取的情况下。 Figure 01 的神经网络每秒 10 次处理内置图像、每秒 200 次生成 24 自由度动作,例如腕部姿势、指关节角度。该神经网络从记录人动作的视频提取统计数据。一些回答者关注的“模仿了人的各种多余小动作,看起来超过这个时代的机器所能”大概不是计划中的机能,而是意外的副产物,对完成任务无特殊贡献。 在 2024 年 3 月 13 日发布的 Figure 01 演示视频的第 59 秒处,机器人先放下装有垃圾的筐,再将这筐拿起来递向人,这可能意味着训练数据里缺少人通过转动手臂与手腕改变手中物体方向的画面;在该视频 1 分 37 秒处,机器人在盘子抖动时轻推盘子下的筐,这也和“一般人”在类似情况下的反应明显不同[1]。 对于“撒手扔苹果”,Figure 01 不需要理解惯性、理解引力,看人撒手的动作并提取其关节运动数据就可以了。 你可以预期,Figure 01 能一边答非所问一边做出准确度不一的肢体动作。现存人工智能是怪异的,它们经常做出人预料之外的怪异举动,在有身体可用时更是如此。 这类问题下,照例有一些回答者大惊小怪“未来已来”、“人类XXOO”。Figure AI 自己的表态与时间表要谨慎得多: 在今后 1 到 2 年内,他们会“展示”人形机器人的进步,“最终”展示能在日常生活中发挥作用的人形机器人。他们的远期目标是在全球部署 100 亿台人形机器人、代替人从事体力劳动。他们认为人形机器人相对适合在为人设计的建筑物里执行制造、物流、仓储、零售等任务。这不代表他们不能做非人形机器人。参考^一些对机器人颇为乐观的欧美网民善意推测机器人是看到盘子抖动而“不知所措、尝试去扶”。但是,你觉得让你扶的话你扶的对象是盘子还是装盘子的筐? |
|
看demo视频,我个人觉得亮点主要还是在系统层面,智能这块基于llm, vlm的agent研究已经有很多了,但是直接在机器人上做到这么连贯确实很牛。figure01把智能和本体操作结合的很好,反应很快也准确。当然,毕竟是自己内部拍的demo视频,不排除是个调试了很多遍,终于成了一遍的演示。 |
|
OpenAI机器人发布,由多模态大模型驱动 随着技术的飞速发展,人工智能领域迎来了革命性的进步。OpenAI的GPT-4作为最新一代的大型语言模型,不仅在虚拟空间中展现出惊人的智能,更是开始走向实体世界。最新的进展是,这一高端智能模型已经拥有了可以操作的实体载体。 昨晚,人形机器人行业的佼佼者Figure AI发布了一则视频,引起了广泛关注。视频中,他们的机器人Figure 01在OpenAI的先进模型支持下,展示了其与人类进行自然对话交互的能力。 |

|
|
Figure 01机器人 从视频可见,Figure 01具有高度灵活的操作能力和出色的沟通流畅度,其表现让人难以区分机器人与真人的差别。 这一激动人心的成就发生在Figure AI获得OpenAI、微软、英伟达等行业巨头投资仅仅几周之后。这不仅展示了OpenAI的多模态大模型在拥有实体载体后的潜力,同时也预示了未来人形机器人与人类生活的无缝融合。 Figure 01:最懂你的人形机器人? OpenAI的多模态大模型赋予了Figure 01前所未有的智能。现在,它能够轻松识别桌面上的各种物品,如苹果、沥水架、水杯和盘子,这些对它来说毫无难度。 |

|
|
物品识别能力 当你感到饥饿,Figure 01能迅速理解你的需求,递给你一个苹果。 |

|
|
递苹果动作 它不仅能完成任务,还能在捡拾垃圾的同时,解释为什么会给你一个苹果。在多模态大模型的帮助下,Figure 01能够理解桌面上唯一的食物――苹果。 |

|
|
垃圾捡拾及解释 在人类的指令下,Figure 01还能够帮助做家务,比如收拾餐具,这使得它成为家庭生活中的得力助手。 值得一提的是,所有这些复杂的功能都是由单一的神经网络实现的。 背后的驱动力:多模态大语言模型 OpenAI的多模态大语言模型(MLLM)相较于传统模型,展现了一系列惊人的新能力。例如,它能够基于图片创作诗歌,进行无需OCR的数学推理等。这些能力表明MLLM可能是实现通用人工智能的关键途径。 学术Fun已经推出了多模态模型的整合包,供大家尝试使用: 图像理解大模型CogAgent整合包 |
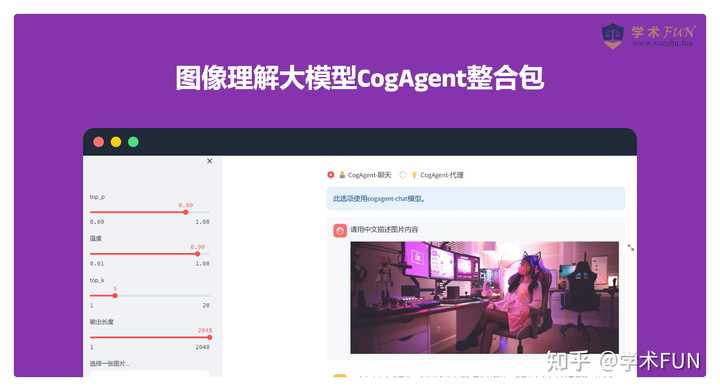
|
|
CogAgent视觉语言模型 CogAgent是基于CogVLM改进的视觉语言模型,CogAgent-18B模型具有110亿的视觉参数和70亿的语言参数。 它在各种经典跨模态基准测试中取得了领先的全面性能,包括VQAv2、OK-VQ、TextVQA等。CogAgent在图形用户界面操作数据集如AITW和Mind2Web上的表现也远超现有模型。 除了CogVLM的所有功能外,CogAgent还提供了: 支持更高分辨率的视觉输入和对话式问答,支持高达1120×1120像素的图像输入。 拥有视觉Agent能力,在任何图形用户界面截图上为给定任务提供行动计划和具体操作指引。 增强了图形用户界面相关问答能力,能够处理关于任何图形用户界面截图的问题,如网页、PC应用和移动应用等。 通过改进预训练和微调流程,提高了OCR相关任务的处理能力。 |
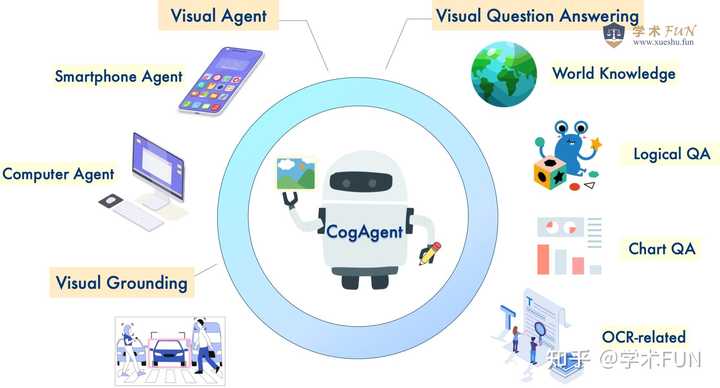
|
|
CogAgent能力展示通义千问多模态图片对话大模型一键整合包分享 |

|
|
Qwen-VL模型 Qwen-VL是阿里云研发的大规模视觉语言模型。它能够处理包含图像、文本、检测框的输入,并生成文本和检测框作为输出。Qwen-VL模型的特点包括: 强大的性能:在多种多模态任务的标准英文评测中取得了卓越成绩。 多语言对话模型:自然支持英文、中文等多语言,能够识别图片中的中英双语长文本。 多图交错对话:支持多图输入和比较,实现指定图片问答和多图文学创作等。 首个支持中文开放域定位的通用模型:可以通过中文开放域语言表达来进行检测框标注。 细粒度识别和理解:相比于其他模型,Qwen-VL使用了更高的448分辨率,提升了文字识别、文档问答和检测框标注的精度。 |
|
|
Qwen-VL演示 整合包下载地址:https://xueshu.fun 请继续关注学术Fun,我们将提供更多AI资源和最新资讯! |
|
一个非常丝滑的大型缝合怪。系统里面每一个环节其实都有不少研究,但是在一台Humanoid上缝合到这个程度的还不多。当然主要原因也包括现在能用的机器人系统就不多。 如果把Figure换成一个固定基座机械臂,一样的任务就会显得平平无奇,机械臂+平行钳+vlm的缝合在外行看来都快审美疲劳了。现在放出来的人形机器人灵巧操纵的视频都只爱给一个正面镜头,很难让人不怀疑机器人是不是自己站着……(文人相轻) |
|
RT-1/2应该是采用了大量真实机器人产生的大量操作视频(印象中他们是用很多台机器人收集了十多个月),再加上他们更新迭代出来的VLM大模型,从指令直接到动作,通过transformer架构训练出来的,泛化性好很多。 而Figure的演示,仅仅针对厨房特定几个task,泛化和通用并未验证,并不能据此直接说比RT-2牛逼很多。 |
|
暂时听到各路研究学者的反馈:“麻了” |
|
简单说视觉能力加ai给了他场景判断能力和执行能力 这也是通用ai的可怕之处 |

|
|
图像芯片。。。。。。,图像。。。。。。 |
|
这个只是一个demo,并且没有看到新的东西。 视觉语言动作模型是基于已有的RT-2的这类框架,涌现能力和泛化能力其实都没有得到验证。 另外动作端的操作本质上来说是Pick and place,灵巧手基本也是当成一个dof的夹爪,但凡他们达到拿着刀切苹果的地步都算突破了,所以其实看看就好不用惊慌 |
|
视频看着像合成的 |
|
不会有人还以为chatGPT的实现逻辑只能用于文本吧 机器人为什么就不能用类似方法训练自己的动作, 学习怎么和人类一样进行躯体表达? 很多人的回答里面,对于机器人思路还留在传统方式中。。。 基于大模型原理,和标准化的机器人框架,按人类的要求进行激励和标记,让它自己做一些乱七八糟的动作,自己学习,自己记忆有价值的动作。这才是最可怕的,它会快速的迭代和进步,还有人怀疑是合成的视频。。。你真的是个大聪明。 |
|
不管实际水平如何,将来必然会在AGI的史书上留下一笔 |
|
这绝对是具有里程碑式的意义。也指明了未来的方向。标志正式进入了“AGI大模型+”的时代。特斯拉的最新版智能驾驶系统也已经从各种功能代码替换成了大模型 |
|
大势所趋。 利用大模型所具有的常识和推理决策能力来做任务规划,是22年底就开始的趋势,而且效果可以说相当不错。这使机器人具有了完成复杂任务的决策能力,并显示出了比较可靠的泛化能力。 所以说ai真的会改变世界,可惜架不住很多人不信啊。。。 |
|
机器人系统组成包括: 传感器-感知器-决策规划器-控制器-执行器。 |
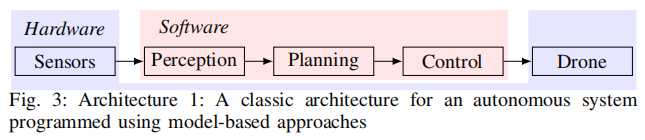
|
|
感知是前提,解决“是什么”,包括定位、建图和状态估计,实现pixel-to-state; 决策规划是中枢,根据感知的状态,进行任务决策、路径规划、轨迹优化,实现state-to-action; 控制是底层,解决“控得住”,包括位置控制和姿态控制,实现tracking control action command; 这次Figure 01就是把感知和规划用大模型做了,实现端到端pixel-to-action,类似这样子: |

|
|
国内有没有这样做的呢?多的是! |
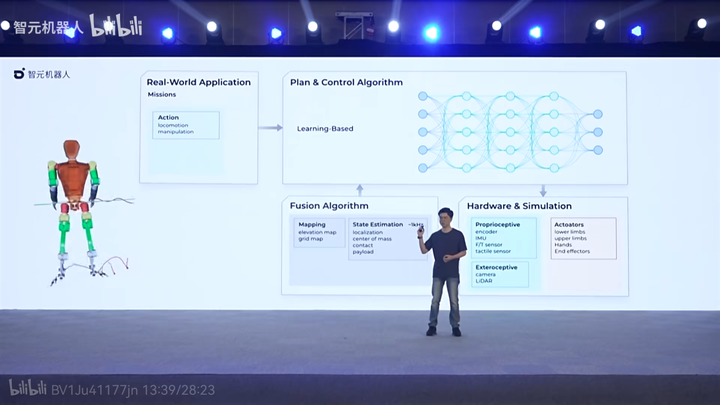
|
|
MLLM大模型+机器人,能实现机器人革命吗? 不能,机器人的核心是AI大脑,目前的AI还是“大力出奇迹”,人类还没有发现AI的“牛顿定律”。 |
|
|
|
|
我们可以有请 @稚晖 来回答这个问题。 如果我没有猜错的话,稚晖君正在做的AI机器人的理想就应该是这样。 我认为出现这样的机器人是很正常的(符合目前科技水平的)。 因为本质就是将agent结合起来,图像识别将看见的变成文字,然后LLM接收指令再依据图片转换过来的文字信息,生成api指令。 最后机器人再根据API指令完成相应的动作等等。 |
|
首先我们了解一下Figure AI这家公司: Figure AI是一家成立于2022年,由Brett Adcock创立的领先的人工智能机器人公司,专注于开发第一款具有商业价值的自主人形机器人,旨在多样化应用于制造、物流、仓储和零售行业。公司总部位于加利福尼亚州的硅谷心脏地带――旧金山湾区的Sunnyvale,处于技术创新和发展的前沿????。 公司的旗舰产品,Figure 01人形机器人,旨在执行广泛的任务,展示了人类般的灵巧性与先进AI技术的融合。这一开创性的方法不仅旨在解决劳动力短缺、执行不受欢迎或不安全的工作,还旨在显著提高全球供应链运作的效率??。 到2024年初,Figure AI已成功吸引了大量投资以资助其雄心勃勃的项目。目前,公司已筹集资金达8.5亿美元,显示出投资界对其的强烈信心。其中一个值得注意的融资轮是由微软和OpenAI领投的5亿美元投资,可能将Figure的估值近乎19亿美元。这反映了对Figure AI能力的高度期待和信念,以其自主人形机器人革新该领域??。 除了其突破性产品外,Figure AI的执行团队汇聚了具有深厚专业知识的资深专业人士。创始人兼CEO Brett Adcock在科技创业领域拥有成功的记录,之前创立了Vettery和Archer Aviation。公司的首席技术官Dr. Jerry Pratt是机器人学领域的杰出人物,拥有二十多年的人形机器人经验,进一步加强了公司在推进自主人形技术方面的领导地位??。 Figure AI的商业模式围绕将人形机器人部署到实际应用中,首先聚焦于仓库解决方案。这一战略重点在于自动化结构化、重复性高且往往危险的任务,标志着可能改变行业运作方式的转型,旨在提高生产效率和安全性??。 随着Figure AI继续发展和扩大其能力,它代表着将AI和机器人技术集成到劳动力中的一大飞跃,不仅有望重塑行业,也为未来的自主人形技术创新铺平了道路。 所以,Figure AI与OpenAI不仅仅是技术上的合作,而且OpenAI是Figure AI的投资方。 AI的快速进步必然要进入商业和工业领域,否则在商业上是不可持久的,类似Devin这样致力于创造知识劳动力,比如软件工程师,Figure AI通过人形机器人,利用AI创建体力劳动力,这些劳动力可以象人类一样工作,并在AI的加成下,可以与人类同事协作共同完成任务,未来可期。 |
|
互联网的本质是连结。 人工智能的本质是加速。 我其实不太关注figure01的具体功能,我关注的主要有两点: 1.demo是1.0倍速播放的,说明背后对于高频采样的计算已经没有问题,后面看是否公布具体训练和推理的硬件参数,如果推理侧4090就能驱动,那真也算一个小里程碑了 2.openai与figure13天就实现了这样的效果!13天!一个Young human baby 有可能眼睛都还没睁开与学会观察世界!如果视频保真,并非遥控的话,那么欢迎来到机器人加速时代,终结者西部世界未来可期! |
|
简单吧,说几点 一,微软是重要赢家,这些机器人赚了钱,都要分微软一些 Figure AI 利用微软的 Azure 云服务进行人工智能基础设施、培训和存储,这是纯纯多模态,还有 每台机器人 24 小时的视觉记录呢。 而且,通过 Open AI ,它可能又获得了下一个超级硬件的操作系统入场券。 |

|
|
二,没有 OpenAI 的时候人家也很牛逼,毕竟,此前已经有波士顿动力这样的公司辛勤耕耘了 N 多年,输送了大量人才给行业。 有了 OpenAi 的多模态,他们更容易理解人类了。 为了实现快速、灵活且精确的机器人动作,Figure AI为Figure 01设计了一款高效的神经网络。 2024年1月,Figure 01 就掌握了制作咖啡的技能,这一成就得益于端到端神经网络的引入,使得机器人能够自主学习和纠正错误,仅需 10 小时的训练; |

|
|
2024年2月,Figure 01实现在仓库中工作的行为,自主完成了一个典型的物流环节任务――搬运空箱,Figure 01已经在执行真实的物理世界任务,拥有自主导航、识别箱子和任务优先级排序的能力,且这些能力能够迁移推广至其他类似的任务当中。 三,既然部署了 OpenAI 的多模态, 它应该是部分“闭环运算”在本地,部分学习能力在云上。也就是说,一台机器人学会的东西,所有机器人都会了。而 figure01 被设计的目的就是取代人类劳动。 之前大家一直抱怨-如图 |

|
|
现在,不用抱怨了,扫地洗碗的活,也有 AI 干了。 Figure 01身高167.64厘米,体重59.8千克,最大负重能力为20千克,移动速度可达每秒1.2米。将来会进一步加强。 是不是比你聪明还比你能干? |
|
模拟世界训练和端到端视觉大模型必然是后面机器人控制,自动驾驶等的终极解决方案,这完全符合人脑的处理逻辑,也符合第一性原理,不接受反驳,时间会证明一切。 目前基于激光雷达和各种传感器,感知,规划和控制三阶段的自动驾驶和机器人解决方案只是阶段性的工程方案 |

|
|
【深度解析:Open AI赋能下的人工智能里程碑――Figure 01机器人革新进展】 最近,人工智能与机器人技术发展迎来了一项极具颠覆性的成果――与Open AI合作研发的Figure 01人形机器人。这款引人瞩目的创新型机器人凭借其先进的人工智能系统与独特的多模态交互能力,引发了业界广泛关注,堪称划时代之作,或将重新定义人形机器人在现实生活中的角色和应用场景。 Figure 01的核心亮点: 超越传统感知与决策边界 ? 视觉与语言的认知融合:Figure 01配备的大型预训练多模态模型赋予了机器人理解周围环境的能力,能够实时接收摄像头图像并将语音转录成文本,结合过往图像记忆进行对话处理。它可以依据当前环境描述自己的视觉体验,并通过“看”和“听”的结合,实现对诸如“我饿了”这样复杂、模糊指令的理解,进而采取恰当的实际行动,比如从桌子上选取并传递一个苹果。 |

|
|
高速精准的运动控制与自主学习 ? 实时决策与敏捷操作:Figure 01的运动控制系统基于transformer神经网络构建的visuomotor transformer策略,以每秒10次的速度接收图像输入,并以每秒200次的速率输出24自由度的动作指令,涵盖手腕姿态与手指关节的角度变化。这种设计使得机器人能够快速做出反应,甚至完成如在任意位置操纵可变形袋子这样对精度要求极高的任务。 ? 高效训练与快速迭代:尽管官方尚未公布全部技术细节,但据透露,Figure 01的部分动作仅通过端到端训练在短短10小时内便得以完成,这可能得益于高效的示教学习以及其他先进的机器学习算法的应用。 |

|
|
强大的综合性能指标 ? 实体规格与性能参数:Figure 01身高约为5英尺6英寸(约1.68米),有效负载达到20公斤,自重60公斤,续航时间为5小时,行走速度可达1.2米/秒。采用全电力驱动系统,确保了长时间稳定工作的同时具备足够的力量和机动性。 商业化前景与社会影响 ? 产业革命的催化剂:随着Figure 01展示出的强大功能和学习能力,人们普遍认为此类先进技术的商业化进程将对诸多产业带来深远影响,从制造业、服务业到家庭生活,都将可能被人工智能驱动的机器人所改变。 Figure 01人形机器人不仅是Open AI与合作伙伴在人工智能与机器人技术交叉领域的璀璨结晶,更是迈向通用型人工智能(AGI)道路上的一个显著里程碑。它的诞生不仅反映了当下科研团队在探索机器智能边界的决心与成就,也为未来的机器人产业发展描绘了一个激动人心的蓝图。随着更多技术细节的披露与市场化推广的推进,Figure 01及其背后的创新技术将愈发引发全球范围内专业人士和公众的关注。 |

|
|
|
|
视频很惊艳,是不是突破的关键,一在于成功率,二在于是不是事先排练的。 如果事先排练过,相同的物体,固定的动作,这事儿不太难。 如果拿苹果10次,掉2次,这技术离实用还差五个数量级。 做一下技术栈分解: 1 语音识别命令,生成文字。 2 计算机视觉识别,框出物体,物体带文字标签。比如 obj1 苹果 红色。 3 物体间形成连接,生成层次。一般建立一个树,每个连接带一个介词。比如 桌子-框-苹果1 -苹果2 -苹果3 4 讲前三步的自然语言集中在一起,生成一串伪代码,伪代码语法事先定义好,类似: 将 obj1 放到 obj2 prep1. prep1可代表 之上 or 里面 or 等等 5 然后就是规划和控制的事情了。 这部分可以用规则方法,也可以加入强化学习加速或预生成,也可以监督学习。 这些事情是否可以直接端到端训练完成 当然可以 如果让这个机器人,给一个固定指令“拿苹果”,再给一个跟随模仿人拿苹果的控制输出,作为训练集,训练几十几百次,这个动作应该能学会了。 只是拓展应用范围差点。 更务实可行的方式,还是分阶段,各自训练。 最后集中在一起,再进行少量微调。 从技术逻辑来说,这条路能全链路走通。 难点还是开头说的那两个。 拿苹果不难,拿鸡蛋就比较难了,端满杯水也需要特殊训练。 在这个桌子可以,在一个透明玻璃的桌面下面也有一堆苹果的桌子,就可能会想穿过玻璃去拿。在一个桌面是镜子且桌子上有一堆镜子的桌子上,AI就更容易混淆了。 ai本质的困难,还是在于完全依赖训练的数据,而训练数据难以穷举。 但只要找到足够的限定的场景,机器人应用前景还是光明的。 这个场景是什么呢? 尤其是家庭场景下,有符合要求的需求吗? |
|
刚看了视频。 假装口吃也太刻意了吧! I .. I think I did pretty well. 还有填充词, chatgpt 在我印象中是不会使用填充词的。但在视频中非常自然地出现了 ah。 当然不排除特殊训练的版本。 我觉得更像一个寻找投资人的广告, 实际效能有待观察。 再者, 日本也太拉了, 钻研人形机器人几十年。这种成果竟然不是日本公司做出来的。 |
|
在figure1出现前,有多少人在说“openai只能搞文娱,搞不了工业革命”?现在回旋镖来了,只是暂时还没有结结实实地砸到他们脸上而已。 对于星舰也一样,第三次试飞最终失败了,但已经让史上最大火箭达到了轨道速度,然而依然有很多人揪着“失败”两个字说风凉话。 这种死鸭子嘴硬抱团取暖的人,真到了被现实打脸的时候,跪得比谁都快。 |
|
猜测: 1.或者采用语音识别转成text,或者直接LAM(Large Audio Model) ?2.每次语音输入大概30 words(大约50个token),从接收完语音,语音识别(或LAM的tokenizer)+LLM识别至少3秒 ?3.执行命令过程中,会频繁采集场景图片(物体+动作状态),auto regression的方式生成下一个动作(这里不需要文本和image做cross attention,所以,不大需要image patching,很有可能是image->encode->embedding->one token) ?4.采样频率:10Hz(10张图片tokens),控制频率:200Hz(200组动作tokens), ?整个action大概持续10秒。 5.对images和text都会进行记忆和存储 |
|
|
| [收藏本文] 【下载本文】 |
| 科技知识 最新文章 |
| 百度为什么越来越垃圾了? |
| 百度为什么越来越垃圾了? |
| 为什么程序员总是发现不了自己的Bug? |
| 出现在抖音评论区里边的算命真不真? |
| 你认为 C++ 最不应该存在的特性是什么? |
| 为什么 Windows 的兼容性这么强大,到底用了 |
| 如何看待Nvidia禁止使用翻译工具将cuda运行 |
| 为何苹果搞了十年的汽车还是难产,小米很快 |
| 该不该和AI说谢谢? |
| 为什么突破性的技术总是最先发生在西方? |
| 上一篇文章 下一篇文章 查看所有文章 |
|
|
|
| 股票涨跌实时统计 涨停板选股 分时图选股 跌停板选股 K线图选股 成交量选股 均线选股 趋势线选股 筹码理论 波浪理论 缠论 MACD指标 KDJ指标 BOLL指标 RSI指标 炒股基础知识 炒股故事 |
| 网站联系: qq:121756557 email:121756557@qq.com 天天财汇 |