
| |
|
|
| ����ƻ� -> �Ƽ�֪ʶ -> Ϊʲô���ѧϰ����Ԫ����y��kx2+b��һ��������أ� -> �����Ķ� |
|
|
[�Ƽ�֪ʶ]Ϊʲô���ѧϰ����Ԫ����y��kx2+b��һ��������أ� |
| [�ղر���] �����ر��ġ� |
|
���ڵ����ѧϰÿ����Ԫ�м�������y=kx+b�Ӽ������Ϊʲô���������һ��x�Ĵη��أ� |
|
�ܺõ����⣬��ʵ�ϣ���һ����С���������Quadratic Neural Networks��ר�ž����о�������˵����һ�������硣���˲��ţ�ǡ�ö����С������һ���о����ڴ���һ����ܡ���һ��������ѧ����Ҫ��Fenglei Fan��CUHK���������������ۣ���Zirui Xu��CVS Health��������������㣩��Grigorios G Chrysos��UW�CMadison���ߴ����������ۣ�����Ҳ�������������һЩ����С�Ĺ��ס� 1. ���ܽ��ƶ�����Universal Approximation�� ��ʵ�ϣ��ɶ������������ܽ��ƶ���[1], һ���ɼ���Ԫ y=ax+b" role="presentation">y=ax+by=ax+b �������dz��õļ�����Ϳ����γɶ����⺯�������⾫�ȵ���ϡ�Ҳ����˵�����ݵĸߴι�ϵ����������Ż��������ǿ��Ա���ϵģ�����Ŀǰ�����������������˼���Ԫ����Ҫԭ�� Ȼ����һ��û�������κ�prior knowledge��������һ������õ��𣿸ߴι�ϵ���Ż����������ٵ������ǣ�����ͨ��SGD���õ���optimal��һ����ӳ�����ĸߴι�ϵ������Ŀɽ�����������Ҳ������һ�����⡣����������NN��ȫ����һ���ںУ����Dz�����������������һЩprior������������ṹ/����������ߴι�ϵ�� 2. �ߴ������� Quadratic NNs�����ھ����������Ķ��ι�ϵ��Ŀ�꣨�Լ������м�״̬����mapping�����ǣ�ʵ�����ھ����������ĸߴ������������е������Ѿ����˷dz������ع��������ǹ���һ�£���CV��backbone neural network����Ҫ�����¼�����ʽ�� ��1��ע�������ƣ�Attention�����������ݱ�������һ��input adaptive weight��Ȼ��������Ƶ����ͨ���� y=Att(X)×Wx" role="presentation">y=Att(X)��Wxy = Att(X) \times Wx ��������ViT��Attention CNN�ȵ� ��2��˫���Գػ���Bilinear-Pooling��: �ڳػ�������ߴι�ϵ�� ��3�����������磨Quadratic Neural Networks���� y=XTAX+WX+b" role="presentation">y=XTAX+WX+by = X^TAX+WX+b ��4������ʽ�����磨Polynomial Neural Networks���� y=∑i=0nkiXi" role="presentation">y=��i=0nkiXiy =\sum_{i=0}^{n} k_iX^i��������P-nets�ȡ� �Դˣ�����������һ��github repo�� https://github.com/miniHuiHui/awesome-high-order-neural-network?github.com/miniHuiHui/awesome-high-order-neural-network �����о���ÿһ��Ĵ������� 3. ���������� ����һƪpaper�������QuadraNet, ��ƪ���������˶����������ڼ���������������ߴ�����������ƣ��Լ������ṩ���µ����������ռ����Neural Architecture Search��Ӱ�졣��ƪ���»����ASP-DAC 2024 ��Best Paper Nomination. ���ȣ�����ͼ��������Ԫ���и�ǿ��representation capacity����ӹ���ɵġ� |

|
|
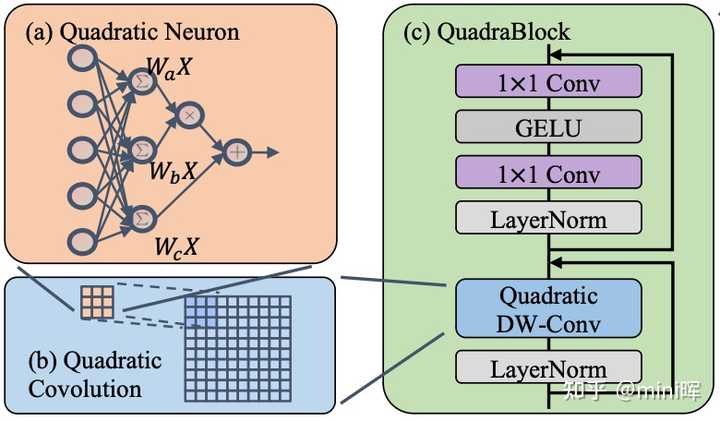
��������֤��������������������ViT�ı�����һ�����������磬 ��ΪSelf-attention�ļ�����Ա�дΪySelf−Attention(i,c)=∑j∈Ωi∑c′=1CA(x)i→jTV(c′,c)x(j,c′)," role="presentation">ySelf?Attention(i,c)=��j�ʦ�i��c��=1CA(x)i��jTV(c��,c)x(j,c��),y_{Self-Attention}^{(i,c)} = \sum_{j \in \Omega_i}\sum_{c'=1}^CA(x)_{i\rightarrow j}T_V^{(c',c)}x^{(j,c')}, ���� A(x)" role="presentation">A(x)A(x) ��Q��K��˶�������Q��K���ʶ�������x��һ�����Ա任�� ����һ�����̼�������һ������Ķ�����Ԫ�����ľ��������Swin Transformer�е�Self- Attention��������ΪSelf-Attention�ı������ھ�pixel���spatial�ϵĸߴι�ϵ������һ���ں��˶�����Ԫ��depth-width convolutionͬ�����������Ը��Ӷ�������һ���ߴι�ϵ��ȡ����ô����������ͬ�ļ����ģ������������ȣ�����FFN��ļ����ܶȣ��������������������Ϣencoding�� |
|
|
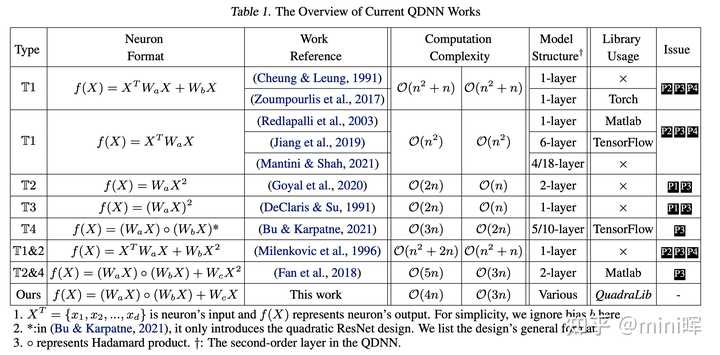
QuadraNet�Ļ����ṹ4. ����������ļ���ͼ��� ��������ǰ��һƪ����QuadraLib�ṩ��һ��Quadratic Neural Networks�ļ���⣬�Ը��ָ����Ķ������������˷��࣬��������㸴�Ӷȣ���������������Ӧ�ķ�������ƪ���»����MLSys 2022 ��Outstanding Paper Award�� |
|
|
��ƪ�����л��״�����˶Զ�����Ԫ�еĶ�������һ������LoRa�ķֽ⣬�Դﵽ���ŵļ��㸴�ӶȺ�ģ�����ܵ�Tradeoff������Զ���������ļ������Ȥ��������ϸ��һ����ƪ���¡� Reference: [1] Hornik K, Stinchcombe M, White H. Multilayer feedforward networks are universal approximators[J]. Neural networks, 1989, 2(5): 359-366. [2] Xu, C., Yu, F., Xu, Z., Liu, C., Xiong, J., & Chen, X. (2023). QuadraNet: Improving High-Order Neural Interaction Efficiency with Hardware-Aware Quadratic Neural Networks.arXiv preprint arXiv:2311.17956. (ASP-DAC 2024 Best Paper Nomination) [3] Xu, Z., Yu, F., Xiong, J., & Chen, X. (2022). Quadralib: A performant quadratic neural network library for architecture optimization and design exploration.Proceedings of Machine Learning and Systems,4, 503-514. |
|
��ʱ�ǿ��Եģ� kx2+b" role="presentation">kx2+bkx^2+b ���Կ�����Gated Linear Unit����������� һ����ʽ��GLUΪ�� GLU(x)=f(x)⋅σ(g(x))" role="presentation">GLU(x)=f(x)?��(g(x))GLU(x)=f(x) \cdot \sigma(g(x)) ������ f" role="presentation">ff �� g" role="presentation">gg ��linear transformation�� σ" role="presentation">��\sigma һ��Ϊ�����Լ�� ������ǽ� σ" role="presentation">��\sigma ����Ϊidentity�������GLU����Ա�Ϊ f(x)⋅g(x)" role="presentation">f(x)?g(x)f(x) \cdot g(x) ���ٻ���Ϳ��Խ��Ƶõ� һ������ x" role="presentation">xx �Ķ�����ʽ�� ͬʱ�������GLU������Ϊ�����Ͱ����������ˣ���˿��Կ�����һ��������transformation�� Simple Baselines for Image Restoration?arxiv.org/abs/2204.04676 ֮ǰһƪ����ͼ��ԭ��ģ��������ľ������Ƶ�˼·�����õ�GELU���Կ�����GLU��������ʽ���ٽ�GLU���õ�SimpleGate�� ��Ȼ�����ʽ�����Լ�����չ���俴��һ��attention����� x" role="presentation">xx �������ڲ�ͬscale�ģ��� y=k⋅x1⋅x2+b" role="presentation">y=k?x1?x2+by=k \cdot x_1 \cdot x_2 +b ������Կ����ǿ�scale���attention��һ����ʽ��������Բο�������ƪ������SimpleGate����һС�ڣ�Simplified Channel Attention�� ���ƵĻ���������ƪ�����е�Multiplication based Channel Attention�� CVPR 2021 Open Access Repository?openaccess.thecvf.com/content/CVPR2021/html/Wei_Shallow_Feature_Matters_for_Weakly_Supervised_Object_Localization_CVPR_2021_paper.html |

|
|
|
|
��̫��ͬ¥��GLU�Ǹ��۵㣬GLU��������linear transform����ˣ�kx2��ͬһ��linear transform�����Σ�û�����µ���Ϣ��������xƽ������������ÿ��ά�ȶ�������������ֱ��ѧx��������ǿ�� |
|
Ϊʲô���ѧϰ����Ԫ�Ļ�����ʽ������ʹ�����Ժ���y=kx+b�ټ��ϼ�����������Dz��ø��ߴη�����ʽ����y=kx2+b�Ӽ������ ��˵�����������������Խ�ı�ʾ�ܹ����ͬ�����ܣ�ΪʲôҪ���ӻ��ء�����ReLU������ܼ���ͬ����ʵ�ã�Ҳ�㷺Ӧ�õ����ѧϰ�� ��Ȼ�����Ҫѧ��ʽ̽�֣����ǿ��ԴӶ����У��������ԭ���㸴�����Լ�ģ�ͷ��������ȷ�������ء����������ѧϰģ�͵����ּ���ҵ�һ��������Ч�����ݸ���������ά�ּ�������Ժ����÷�����ƽ��㡣 ��ģ�͵ı��������Ƕȳ����������ϣ���������һ�����ز��Ҿ����㹻����Ԫ����������磬ʹ�ü�����ӳ��ӷ����Լ�����ѱ�֤�����Աƽ��κθ��ӵĺ��������ǻ���ͨ�ý��ƶ����Ľ��ۡ�����ӳ��y=kx+b�������ʽ��������ͨ��������Ͷ���������ϣ�������ѧϰ����Ϊ���ӵķ����Թ�ϵ������֮����ʹ�ǻ��ڼ�����ӳ�����Ԫģ�ͣ��ڶ��ṹ��Ҳ�ܹ�����dz����ӵĺ����� ���ǵ�����Ч�ʣ�y=kx2+b����ʽ�����˸��ߵļ��㸴���ԡ������ѧϰѵ�������У��Ż��㷨�����ݶ��½�������Ҫ������ʧ��������ģ�Ͳ������ݶȡ�������x�ĸߴ���ʱ���ݶȼ�����ø��Ӹ��Ӻͼ����������ⲻ�������˵��ε����ļ���ɱ���������Ӱ��ģ�͵������ٶȺ��ȶ��ԡ���ʵ���У�Ϊ��ʹģ��ѵ���ں�����ʱ������ɣ������ֽϺõ����ܣ�����ģ�͵ļ���Ч���Ƿdz���Ҫ�ġ� ��ģ�ͷ��������ĽǶȿ��ǣ�ʹ�ø��ߴη���ģ�Ϳ��ܵ��¹�������⡣�������ָģ����ѵ�������ϱ������ã�����δ�����������ϱ��ֽϲ����x�ĸߴ�����ζ��ģ�ͱ�ø����ӣ������ײ���ѵ�������е��������������䱳�����ʵ��ϵ�������ή��ģ�����������ϵ�Ԥ����������ˣ���ģ�����ʱ��ҪȨ��ģ�͵ĸ��ӶȺͷ��������� ʵ���еĿ����Ժ�����Ҳ��һ����Ҫ���ء���Ȼ��������̽����ͬ��ʽ����Ԫ�ǿ��ܵģ����ڴ����ʵ��Ӧ���У�������ӳ����Ϸ����Լ�����Ѿ��ܹ��ṩ���õ����ܡ����⣬���ѧϰ�����е��о���ʵ���Ѿ������˴�����������ģ�͵ľ���ͼ��������������Чѵ��ģ�͡��������ϵȡ����ַḻ��֪ʶ��Ϊʹ�ñ���ʽ����Ԫ�ṩ��ǿ���֧�֡� ����Ŀǰ��������ܹ�����������ӳ��ӷ����Լ��������ƣ�����ѧ�о��ı����Dz���̽���ͳ��ԡ�ʵ���ϣ����о���̽��ʹ�ò�ͬ���͵���Ԫ�ͼ��������������ʽ��Ԫ�������������RBF����Ԫ�ȣ�����Ӧ�ض���Ӧ����������ģ�����ܡ���Щ������ijЩ�ض�����¿��ܻ�������ܵ���������Ҳ�����������ᵽ����ս�� |

|
|
|

|
|
|

|
|
|

|
|
|
|
��Ϊ�鷳��˭֪���Ǽ��η��Ĺ�ϵ���������Ѽ��㣬�������ͷ�����������ݡ�����ƽ�������ģ��������ͱ���NaN�ˡ� |
|
û�п�����ص����ף�������һЩֱ�۵ĸ��ܡ����ȣ���ӹ����y=kx+b��һ������ӳ�䡣��ô���������һ��ģ����һ�����ʲô�����أ�����Ϊ�Ǽ�Ȩ��ϡ����������Ҫ��һ�ָ����ܷ����Եķ�ʽȥ��ϼ�Ȩ��Ψ��ʹ������������ϡ���Ȼ����ܻ���ΪʲôҪ�����ԣ���Ϊһ�����������ԣ����ǾͿ��Ը������ҵ����ŵ㡣��Σ���Ҷ�֪���������Ƿ�����ӳ�䣬��ô���ַ����Կ���������ķ������𣿴���ȷ��������Եļ�������кܶ࣬������ʵ���ǣ���ʹֻ���ڼ��������ʩ�Ӳ�ͬ�ķ����ԣ��������綼�ܿ������ɿز��������Ҵ���ıȷ�������ֱ����x��0.5�η��������������Ҫ�ڼ����֮ǰ������Ӹ��ӵķ����ԣ���ôҪ�ﵽ�����Ż��Ľ���ͻ�����ѣ���Ϊ���ӵĺ������Ͼ��Ǹ�����������������ʵ����Ʋ���ļ��뷨�����۵�ǰ��û��������������Ժͷ����Եĵ�������Ϊ���DZ��뿼�ǵġ� ���߾�������¥�����ᵽ�ı��������⣬���ʹ���˶��ε�ӳ�䣬���������һЩֵ���������ԣ���Ϊ�ݶ�ͼһ���ᷢ���ܴ�ı仯��������Ϊ�����״�������Ӷ�䡣���ʱ����������Ӧ�õ��Ż��㷨��������ϣ��Ǿ���������ֲ����ŵ㡣 |
|
��Ϊʲô���Ǵ��ڻ��ϼ���ֱ�ӻ�ȥ�������������ɻ���������һȦ�ٵ��ϼ��أ� |
|
�����ƽ����û�취���������������Ǹ������о���̫����ѽ�� Ҫ�������о������ԡ��ѵ�����ʡȥ�����ô��Ҳ��������ʵ�顣 ��������ֵ��Χ�е��֪�������������� ֱ���ϸо��������ǰ�����Ŵ�Ȼ�����һ��ŵĸ�����������Ӧ��Ч��������������ߺ���ѧ�� |
|
��Ϊ��Ч�ҿ����� |
|
��Ϊһ�κ�����������Ļ����� ͨ�����relu ���Ա�Ϊ������ ��˵�����ֿ��Խ��ͼ��㿪�� �ٵ��Ӽ��� |
|
���ѧϰ�����Ԫ������һ���ļ����������Ȱ���������ݣ�x������һ������k�����ټ���һ������b����Ȼ����ͨ��һ������������������������������ģ���õ���Ӧ���ָ��ӵ����ݡ� ���ᵽ�����x�Ĵη���������������������������˷����߸��߽����㡣ȷʵ���������ģ�ͱ�ø����ӣ����������ӵ����ݡ��������ѧϰ�У�ͨ���������������ķ������ﵽ���Ч�����������Ӹ���ļ�������ʹ�ø����ӵļ������������Ϊ��Щ�����Ѿ���֤���ںܶ������϶����ֵúܺá� |
|
���Կ��Լ��㣬 �������㷨ʱ������ʹ�����ԣ� �������ѧϰ�������Ƿ��࣬����ѵ��һ��С��ģ�͡� �����и��ڰ壬С������Ƭ������ߣ�����С������Ƭ�����ұߣ��м仮һ��ֱ�߾Ϳ���ʵ�֡����Ծͻ�ֱ�ߡ�����Ӹ�Сèһ�����Ļ����ٻ�һ��ֱ�ߡ� ������������ߣ������ɾ���һ����һ��������㳬�������ˡ� ps1: �����Կ��ر��ʺ������˷������е�y=kx ps2:����֮���ִֹ������ⶼ������ԡ� ���˿�������һ���ԡ� |
|
¥�Ϻܶԣ��ڲ�������Ԫ��Ŀ������±���һ�������������������� |
|
���Ե��鷳 |
|
��Ϊ����������y=x^2������������ǵȼ۵� |
|
������ͨ�����Dz�Ը�⣬�����漰���Ӷ��ѵ㡣 |
|
���ޱ�Ҫ��____ |
|
�������ѧϰ�������õ�����Ҫ��Դ���ṩ�˷����ԡ������ϣ�ֻҪ�����㹻��ķ����ԣ��Ϳ�������κε���ѧ���ߣ�����������ѵ�������ճ������⣬������⡢����ȣ�Ҳ�������Ӷȸ��ߵĴ�ģ�ͣ�Ҳ�ǿ��Կ�����һϵ�е���ѧ���ߣ�Ȼ������ģ�ķ�����ģ������������Щ�ճ��������ѧ���ߡ� |
|
������Ϊ����һ�κ������ܽ�ģһ�����κ�����Ҳ��������һ�ε�����Ϳ���ģ��һ����ε������ˡ����Ƕ���Ԫ����û��ģ��һ�����ε����簡�� ����˵�������������Ȼ����������1+1+...ƴ����һ�������������Dz��ܱ�2ƴ�����ġ� |
|
|
| [�ղر���] �����ر��ġ� |
| ��һƪ���� ��һƪ���� �鿴�������� |
|
|
|
| ��Ʊ�ǵ�ʵʱͳ�� ��ͣ��ѡ�� ��ʱͼѡ�� ��ͣ��ѡ�� K��ͼѡ�� �ɽ���ѡ�� ����ѡ�� ������ѡ�� �������� �������� ���� MACDָ�� KDJָ�� BOLLָ�� RSIָ�� ���ɻ���֪ʶ ���ɹ��� |
| ��վ��ϵ: qq:121756557 email:121756557@qq.com ����ƻ� |