
| |
|
|
| ����ƻ� -> �Ƽ�֪ʶ -> RWKV��Mamba��recurrence���ģ������ܹ�����transformer�� -> �����Ķ� |
|
|
[�Ƽ�֪ʶ]RWKV��Mamba��recurrence���ģ������ܹ�����transformer�� |
| [�ղر���] �����ر��ġ� |
|
RWKV��Mamba��recurrenceģ�Ͷ�������״̬���ƣ������״̬�Ĵ�С�Ǻ㶨�ġ����ֺ㶨��С��״̬�㹻��¼���е���ʷ��Ϣ���������к������ӵġ� |
|
���˽�һ���¡�mamba������������Ϊ������Ϊlanguage modelʱ��ʡȥ��transformerƵ���ľ��������ֱ����һ��hidden state������Ϣ������ϵ��ģ������transformer�Ȳ��ˣ��������ҵ�����ƴ�㣬ͬ�Ȳ������������ô����û����Խtransformer���Ѿ����Ƿ����ˡ� |
|
��recurrence������״̬��������δ�����ܻ���transformer���ر����ڻ����ˡ������������м�����Դ����Դ���Ƶ�Ӧ�ó����¡������ͨ�����ܲ��ǿ���ס������ʷ��Ϣ�������ں㶨������С��״̬����֧��ͨ�����ܣ�����LLM����ʱʹ�õ�ȫ����ʷ��Ϣ����transformer���Ը������ڵĻ�е��ԭʼ��Ϣ������������������ڼ�¼���ʵ����Σ����Թ���������Ҳδ�������ر���Ч�������������ҵ����˹���ļ�����Դ���� �����е����������ܳ�Ϊͨ�����ܵ����������������㶨��С���ڲ�״̬��ȫ����֧��ͨ�����ܡ�һ����Ϊ����������ڳ�����ĺ̵ܶ�ʱ����Ԫ��ͻ���������������ﵽ������ʼ��Ԫ��ͻ����Ŀ���٣����ഺ��֮����Ԫ�����ȶ������������䡾1,2�����������Ƥ����Ԫ���������ڼ��١�3������ͼ1������Ƥ��һ�㱻��Ϊ�Ǻ������ͨ����������صĴ��Բ��֡�������recurrenceȷʵ�ձ���ڣ���������ÿ����Ԫ��ÿ��ͻ���ȶ����Լ�����ʷ״̬�� |

|
|
�������Ժ�Ů�Ե���Ԫ�������ǵȾ������ȣ������䣨���Ա�ȣ�18-105 �꣩�ĺ�����ϵ����3�� �������ܵ�ͨ���Բ�������ס������ʷ��Ϣ���෴�أ�����һ���˾�������ס����ϸ�ڡ��˵ĸй�ģ̬�������������������Ӿ����������˶����Լ�ס�����Ӿ�ϸ�ڣ������������ܻ�����һ��ëүү��ȫ��ϸ������˵�˵���Ȼ���Դ���������һ���˿���һƪ���¼�ǧ�ֵ�С˵��������ȥ������ʱ�侫�����Ļ���Ҳ������һ�ֲ���ؼ�סÿ�λ����෴��ס��ֻ�Ǿ��ʵ���ڡ�ijЩ��Ҳ��֪��ʲôԭ��ͼ�ס��Ҫ�㡣����ӵ��һ�����Ż����ġ��ԴӶ��ڵ����ڵ���Ϣ��������ɸѡ�ļ���ϵͳ�������ⲿ�̼�������״̬��Ӱ������Ч����������һЩ��ټ��䣬����һ����˵�������˵��û̫���Ӱ�졣Ϊ�˸��ø���ؼ�¼��ʷ��Ϣ�����и�����������һ���������ؼ�����Ϣ�������������ء�����������Ϣ����Ҫ�ԣ���ʶ�ܿ��Ƶ�����Ƕ�Ǽ��顢��취���и��ֹ����������п��ܣ����������������ļ��䡢����ֻ���Ժ���˼�������ǻ�������ֹ��ߣ����ñʼǡ��鼮��Ӱ���¼�ȽϿ۵ؼ�¼��Ҫ��ʷ��Ϣ�����ñ�ֽ���㡢����ģ�͡����Ʊ����Ŀ�ѧʵ��ȵ��ڽ����������б�Ҫʱ������Լ��㲻������������˽�����������������������е����пƼ����ƶȡ��Ļ������ȳɹ���������һ�����͵ģ��Ǵ���ͨ���������������������������ʵ����ʵ�������Ľ�������ԣ�Ϊʲô�˹�ͨ�����ܣ�AGI��һ��Ҫ�����ڲ�ֱ�Ӽ�ס������ʷ��Ϣ��һ��Ҫ���ڲ�ֱ�ӽ��и���������������˵���ظ�֮ǰ���������ݡ���������������״̬��ģ�Ϳ��Կ����ϴ洢������ʷ��ģ�鲢��֮��Ϊ����ʹ����ʵ�֣���������Ч�ʸ��ߡ� ʵ�õ�С�ͻ�ͨ������ϵͳ����Ҫ���������ɺ����ϳ�ʱ������������Լ���������ģ�ͣ��������⡢����������������ӵ����Ч�ļ���������������Ϳ��Ա�������LLM�в���Ҫ�Ķ��η��ļ���Ҫ���ټ�����Դ����Ŀǰ��LLM��Ҫ���Իع����Ϊʵ���ֶΣ���������ʷ�洢�ڼ����ڴ��У�û�ж�AIģ�ͣ������磩�ڲ�����ϵͳ��Ҫ��Ϊʲô��������Ч�����Ǽ�����ԴҪ���С���ı����ݣ�������ͼ�����ݣ���Ȼ�е��������Զ��˵ĸ���Ϣ�ܶ����ԣ�ͼ���е���Ч��Ϣ�ܶȺܵͣ�����˵������˵��ͬ����Ϣ��ʱͼ�����ݻ��ܶ������������ֵ�ֱ��ȫ���洢��ʹ��ʱȫ������ʵʱ�����У������ڵ�ʱ�ļ���ˮƽ�£���������ʵ�ֶ�����ѵ������Ч��ͬ�ȹ�ģ�Ӿ���ģ�ͣ����ں��Ӿ��Ķ�ģ̬��ģ��Ҳ��Ȼ����������⡣�����η����ļ�����ԴҪ������LLM�����ij������ơ��Լ��Գ������ƻ��Ƶ�����Sora�ļ�����ԴҪ����ơ�Altaman��7�������ۣ�����˵�����ַ�����ļ���ʹ洢��Դ������������ʵ��Ӧ�ó����в�һ�������㣬���������ƶ��Ļ����˻��е�Դ���ƣ����ص����ƶ˼����ģʽ�ڲ�������ʱҲ������⣬���Դ����ƶϣ�δ����ʵ��Ӧ�ó����У������ڲ�״̬��������ģ�Ϳ��ܻᳬԽ���еĻ���������ʷ�����Իع��Transformer������ ����һֱ��ϣ��AIϵͳֱ��ͨ���ڲ���������ȥ�洢�����һ��ִ���Ҳ���ţ�ֻҪ����ϵͳ�Ĵ洢������������ôֱ�Ӽ�¼������ԭʼ���ı�����Ƶ����Ϣ��Ϊ�۶��գ�Ӧ�û���������AGI���ԡ�Ŀǰ��RAGΪ�����ĸ�������������չLLM�ļ��������Ϣ��������Ӧ������һЩ������ϣ��δ����������LLM���������Ҳ��չ�γ�һ���õij��ڼ���ϵͳ�� ��ӭ������ʽ�Ľ���������ָ���� ��1��Ackerman, S. (1992). The Development and Shaping of the Brain, In Discovering the brain. ��2���˵���Ԫ������6��֮������Ͳ����ˣ���û�п�������绷���仯��Ӱ�죿 ��3��Wall?e, S., Pakkenberg, B., & Fabricius, K. (2014). Stereological estimation of total cell numbers in the human cerebral and cerebellar cortex.Frontiers in human neuroscience,8, 508. |
|
����û�п��ܣ�������Ҫһ���Ƚ�solid�Ĺ�����֤�����ƶ��� �ټ������ӡ� ��ɢģ�ͺ�������ˣ�������ͼ����������GAN����ͳ�ε�λ��ֱ��OpenAI����Ƴ�GLIDE��DALLE2���Լ���Դ��Stable Diffusion����ɢģ��һ���ӻ�����������GAN�����������ջƻ������������ȥ��ѡʲô�ܹ���ͼ�����ɣ����������Ƽ�����Diffusion��������GAN�� GPT-1���ȳ��������Ǻ���ȸ��BERTѹ����һͷ����������Ȼ���Դ�������BERT��ν�켫һʱ�����Ǻ���OpenAI����Ƴ�GPT-2��GPT-3�Լ����ڵ�ChatGPT��decoder-only��GPT��Ϊ�˴�ҵĹ�ʶ����BERT�Ѿ����������� ���ԣ��Ҿ��ú������ѹGPTһͷ�ļܹ�һ���DZ�Ȼ�ģ�������Ҫ��һ���Ƚ�ţ�Ĺ������ƶ�������֮ǰ���һֱ�þ����DDPM�����ڱȽ�SOTA��SD3����Rectified Flow���������Rectified FlowҲ�������������� ����ͼ֮SD3������transformerʱ��79 ��ͬ �� 9 �������� Ŀǰ��RWKV��Mamba��Ȼ��һЩ��չ�������Ҹо�û��ô���˾��ޣ����Ի����ȹ���һ��ɡ� |
|
Mamba �� RWKV �@�ģ�ͱ��|���� Linear RNNs��Transformers �ԏ� 2016 ������ԁ��������T�� ConvS2S ��� Non-linear RNNs���ɞ� NLP �I��Ľy��ģ�͡���� Mamba �� RWKV �@�ģ���ܳ�Խ Transformers���@��ζ�� Linear RNNs �� Non-linear RNNs ߀Ҫ���������һֱ������ǣ���� Linear RNNs ������N����ʲ�N�ς����o�ɠ����� RNNs ��ģ���� LSTM������ Linear RNNs �� Non-linear RNNs ��һ�ݾ��Dž����������^С��߀���ԁK���\�㡣��� Linear RNNs ������߀�������N Linear RNNs ��ֱ����������ģ�͡����c���}�ˣ��ґ��� Linear RNNs ���ܲ���ij�Nȱ�ݣ����ܿ��Ԅ��Εr���΄գ������� NLP �I��߀�ǵÿ� Transformers�����⣬�F�� Non-linear RNNs [1] Ҳ���ԁK���\���ˣ����S RNNs �ĕr���ֻ��ˡ� [1] Yi Heng Lim, Qi Zhu, Joshua Selfridge, & Muhammad Firmansyah Kasim (2024). Parallelizing non-linear sequential models over the sequence length. In The Twelfth International Conference on Learning Representations. |
|
��������棺RWKV���й��ģ�Transformer�������ģ���ô��սʤ����Ҫ������־�������Լ����硣 ���а棺��RWKVΪ���������Դ�ģ����Ȼ�кܶ�Ľ����������кܶ����ݿ����о�����transformer�ĺ��������������2022�����ҾͶ��Ѿ�������ˡ� �棺ѡ���������ȶ���transformer��û�м������գ�����̽�������Կ������ҵ��ָ�ꡣ δ���棺����ģ�ͻṲ�棬RWKV��Ϊһ������rnn����Ȼ�ʺϺܶ����г���������ģ������ɫ�����ݳ���ѡ�� |

|
|
RWKV��Mamba�ȵݹ�ģ���ܷ����Transformer�����������Eagle 7B���ǻ���RWKV�ܹ��ġ�Eagle 7B ��һ�� 7.52B ������ģ�ͣ������ǻ��� transformer �ܹ������ǻ��� Recurrent Neural Network ��RNN��RWKV-v5������7Bģ�ͣ������ɱ����� 10-100 ��+�����Ա�ѹ������Ҳ���Ǹ���Ч��������չ�ļܹ����ɽ����˹����ܳɱ��������ٶԻ�����Ӱ�졣�� Mamba һ����������ע�����ģ���ӿ����������̣������������������Ĵ��ڡ�����Ȥ���Է����������£� Eagle 7B��������Ի����Գ�Խ����7Bģ�ͣ������7Bģ��3 ��ͬ �� 0 �������� ��Mamba�����ţ���������ΪҪȡ��Transformer������������û�б�accepted��Ŀǰ���������߶�û�б��ֳ�ȡ��Transformer��̬�ơ� RWKVģ��ͨ�����RNN��ʱЧ�Ժ�Transformer�IJ��м�����������ͼ��ģ��ѵ���ٶȺ�����Ч�ʷ���ʵ�����ƽ�⡣RWKV����ʱ��˥��������Ϊע�������Ƶ�һ����ʽ����ͨ����������ͨ�����ģ������ǿģ�͵���������ʹ������ijЩ�����ϱ��ֳ�ɫ ��RWKV�ڲ�ͬ�����ij��Ⱥ�ģ�ʹ�С�������չʾ��һ��������������������ѵ���ٶ��ϱ�GPT�죬��ʾ����1 + 1 > 2����Ч�� �� Mambaģ������ͨ��״̬�ռ�ģ�ͣ�SSM�������Transformer�ڴ������������ʹ��ģ����ʱ�ľ����ԡ�Mambaͨ��ʹ��ʱ��SSM�����������ԡ���Ƶ�ͻ�����ѧ�ȶ���ģ̬�дﵽ�����Ƚ���SOTA�����ܣ�����ʾ���ڴ������������縴�ƺ��ɵȣ��ͳ����������ϵ����� ��Mambaģ�͵����������������״̬�ռ�����ʾ�ʹ���������Ϣ�����ַ�����ijЩ������ܹ��ṩ�ȴ�ͳTransformer���ߵ����ܺ�Ч�ʡ� Ȼ��������RWKV��Mamba��ijЩ������ʾ������Խ�ԣ��������Ƿ�����ȫȡ��Transformer���д��۲졣Transformerģ��������㷺��Ӧ�á��������̬ϵͳ�ͳ����ĸĽ�����Ȼ������������������λ��RWKV��Mamba���ٵ���ս֮һ����α���ģ�͵ij��ڼ�����������ʧЧ�ʣ��������ڴ����dz����ӵ���������ʱ�����⣬��Щģ�͵���Ч��Ҳ�������ض���������ݼ� �� RWKV��Mamba�ȵݹ�ģ���ڽ��Transformer��ijЩ���Ʒ���չʾ��DZ������������ѵ��Ч�ʡ����������кͶ�ģ̬�����档Ȼ������Щģ���Ƿ��ܹ������з��泬ԽTransformer������Ҫ��һ�����о�����֤�������ѧϰ�������Ľ����ǵ����ģ��µ�ģ�ͼܹ����Ż����������ƶ�����������ķ�չ����ˣ�δ�����ܻ��и����ģ�ͳ��֣���һ���ƶ���߸����е�ģ�ͼܹ��� |

|
|
|

|
|
|
|
��mamba��������rwkv��ġ���ͨ�˱���mamba |
|
���ܣ���Ϊtransformer����encoder��decoder��������rnnֻ��һ��decoder���Ӿ��������ڻ���cnn��vit��������û��rnnʲô�£��������� �Թ��������ص��������棬�ҷ��ִ���ƺ�����̫��������rnn������attention�� �ϸ���˵������attention���Ǵ�ͳattention�ľ������֣�����encoder��decoder����������rnn��ʵ��attention + causal mask�ľ������֡� ��Ȼ����Ϊ������ģ�͵ijɹ������ڴ�Ҹ�����decoder onlyģ�͡����ڴ�����ģ��Ϊʲô����decoder only�ļܹ�������Ȥ��С�����Բο���֮ǰ��һƪ�ش� Ϊʲô���ڵ�LLM����Decoder only�ļܹ���74 ��ͬ �� 5 ���ۻش� �ص�����rnn������attention������ ���ȣ�����rnn�������ָ����ȥ����ͳrnn�еķ������������Ӷ�֧�ֲ��м��㣨��������parallel scan��������attention�������ָ����ȥ��softmax���Ӷ�����ԭ�����г���ƽ���ļ��㿪���� �������ߵij����㲻ͬ����decoder�ܹ��ı����£�����attention + causal mask���Ա��������rnn����ʽ��ֻ��״̬�ռ����������������˾����Կ�����һ������״̬�ռ�������� ��������rnn״̬�ռ��С�����ľ����ԣ���ҿ��Բο�����һƪ�ش� Ŀǰ�Ƿ�����սTransformer�����ͼܹ���24 ��ͬ �� 17 ���ۻش� ��RWKV������RNN����RetNet������attention��Ϊ�������߶���ͨ��rnn�ķ�ʽ��kv cache����ѹ����Ȼ����q���м�����Ϣ�� ���������ָ��˥������һ���ȼ��ɣ�ǰ��ѹ������exp(k)��vԪ����˵õ���������������ѹ������k��v����õ��ľ���ǰ��ͨ��q����Ԫ�������������Ϣ������ͨ��q���о�����������������Ϣ�� ���ԣ�����attention + causal mask��һ�������rnn�����Է�������rnn�������ǵ�ļ��ɣ������ſػ��ƣ�����Ȥ��С�����Բο� @sonta ��GLA���ġ� Ŀǰ����������attention�������rnn�������¼������ơ���һ������attention��״̬�ռ�����Ի���ѹ��������Ϣ��ѹ�����ڶ�������attention������ʵ�ֿ��Բ�ȡchunkwise���������ֲ�ʹ�þ���˷�������������attention���Ա�����ͷע��������ƣ������������С� �����ƪ�ش�û����������attention������rnn����˼����Ϊ���ߵļ���·�߷dz��ӽ�������������������ơ� ����Ĺ�������������ϻ�������ע�����������ģ����recall�����ϵı��֡���ν�ǣ�������Ƥ����������������������� ���⣬��Ϊ���Ǿ������ֵ�attentionʵ�ڹ���ǿ��Ҫ֪��������attention�Ĵ�����ģ���Ѿ��ɹ������г�����չ��1M�������� ��attention�����ϵͳ�Ͻ������в��и���Ȥ��С��飬���Բο���֮ǰ��һƪ�ش� Megatron-LM �� Context Parallel �Ĺ���ԭ����ʲô��37 ��ͬ �� 10 ���ۻش� ��ô��������scaling�����ǣ�����̫���ǰϵͳ����Ŀ������������������ŵģ�It is easy to make a smart model cheaper. It is hard to make a cheap model smarter. |
|
�����Ȼش�Ϊʲôѡ���� SSM �Լ� Mamba �ܹ�����չ����ȫ�ݹ�ģ�ͣ� �ݹ�ģ�ͣ�Recurrent Model����һ�����ڴ����������ݵ������磬����ͨ����ģ�͵IJ�ͬʱ�䲽֮��ά��һ�������ڲ�״̬���������С���Щ�ڲ�״̬����ģ�͡���ס��֮ǰ����Ϣ��������Щ��Ϣ���ڵ�ǰ��δ���ľ��ߡ�����͵ĵݹ�ģ�������ǵݹ������磨RNN���� ����ѡ����SSM��Mamba�ܹ�֮���Ա���Ϊ�ݹ�ģ�͡� �ڲ�״̬��ά���������ڴ�ͳRNN����Щ�ܹ�ͨ��ά��һ��״̬������״̬������ģ�͵IJ�ͬʱ�䲽֮�䴫����Ϣ����ʹ��ģ���ܹ��ڴ�����ǰ����ʱ�����ǵ�֮ǰ����������Ϣ���Ӷ�ʵ�ֶ����еĶ�̬�������Իع����ʣ�Mamba������ѡ����SSM�ܹ�ͨ�������Իع飨autoregressive����ʽ�������У��������ɵ�ǰԪ��ʱ������֮ǰ��Ԫ�ء�������������ǰ״̬�����ɹ��̱������ǵݹ�ġ������������ݣ���Щģ���ܹ����ʱ�䲽�����������ݣ�����ÿһ���������ڲ�״̬������������״̬���µĹ����ǵݹ�ģ�͵ĵ������������������������봫ͳ��RNN��ȣ�ѡ����SSM��Mamba�ܹ�ͨ������Ч��״̬�������»��ƣ��ܹ�������������ϵ������ڴ���������������Ҫ������ͨ��������ƵĻ��ƣ���ѡ����״̬�ռ䣩�Ż�����Ϣ�ı�������ǣ�ʹģ���ܹ��ڱ���Ч�ʵ�ͬʱ�������dz��������С� ע�����2�Իع����ʣ�������ͬʱע���Իع�͵ݹ�������Իع�ģ�͵ĺ��������ǵ�ǰʱ�̵����������֮ǰһ������ʱ�̵���������Dz�û��˵������������ʱ�̡� |

|
|
�ûص����⣬�Իع��Transformer��attention�����Ǻ��ģ���Ŀǰ������LLM˼·��������transformer�ṩ�˽ϺõIJ���ѵ��������attention+�Իع�͵���������������ѵ���Σ����Բ��д���������Transformer��ѵ��ʱ���Խ��յ������������У���˿���ͬʱ��������������λ�õ���ע��������ʹ��ѵ��������Ը�Ч�������Σ��������л��������������ı����������л�����ʱ��ÿ����һ����Ԫ�أ�����Ҫ���ǵ�֮ǰ�������ɵ�Ԫ�ء�����ζ��������ÿ����Ԫ��ʱ����Ҫ���¼���ע���������������ٶ���Խ�������kv cache�������������������⣩��ôΪʲô���е�Transformer���ϵݹ���Իع�������ʱ��ͱ��뿼��֮ǰ���е�ʱ���أ� ���ȣ��Իع鲻һ����Ҫ����֮ǰ����ʱ�̣�����transformer������Ƶ�ʱ����Ǽ����������е�attention���������ƿ��ܲ�û�п��ǵ�δ��������Ҫ��������������ʱ��Ч�ʵĵ����⣬��Ȼͨ��һЩ�Ľ�����kvcache��Ҳ���Ի���������⣬��������ġ� ��Σ��Իع�Transformerģ���ڴ��������ı����ɵ���������ʱ������֮ǰ����ʱ�̵������Ҫ����Ϊ��������ȫ����ע�����������������еij������������������ѡ��ӳ��Transformer�ܹ���һ���������ƣ��ܹ�ֱ�Ӽ�����������������λ��֮��Ĺ�ϵ�����������Ǿ�������ơ� ���������ԣ�Ϊ���������ȷ����������ı���ģ�ͱ��뿼�������������ı��������ġ�������������ɵĴʻ㣬Ҳ��������֮ǰ���ɵ����ݣ�ȷ�������ɵ��ı������ܹ���֮ǰ���ı���Ȼ�νӡ��������������⣺�����о���������Ҫ��Խ�����븴�ӵ�������ϵ�����е�ǰ������������������൱ңԶ�IJ�����ء�ȫ����ע��������ʹ��ģ���ܹ�ֱ�ӿ�����Щ�����������������ǽ������ڽ��ڵ���ʷ��������ʵ�ָ����ϵ������Ҫ�ο�����֮ǰ�ᵽ�����ʡ��Իع�Transformerͨ������֮ǰ����ʱ�̵���Ϣ�������һ���⣬ȷ�����ɵ������������ϵ�ȷ�Ժ������ԡ�����ȫ��һ���ԣ������ɸ��ӵ��ı��ṹʱ����Ҫ���������������һ���ԣ������Ҫ��ģ�����Ⲣ���������ı�����������Ϣ���������������������ʻ��ַ�����Ϣ��Ҳ������Զ������Ϣ����ȷ���������ݵ������Ժ��ᄈ����ԡ��Իع�ģ��ͨ������֮ǰ����ʱ�̵������������ά�������һ���Ժ������ĵ�����ԡ� �����Ȼ���д�����ѵ���δ�������Ч�ʣ������Իع�ģ�͵������Σ�����ÿһ���������������֮ǰ���в�����ۻ���������ʹ���������̱�Ϊ�����л��ġ�Ϊ��������һ�������ģ����Ҫ���¿��ǰ�������������ڵ�������ǰ��Ϣ����ȷ�����ɵ������Ժ�ȷ�ԣ��Ӷ�����transformer�IJ���������Ϊ�Իع��ԭ��������ʱ����ַ��ӡ� �����Իع�Transformerģ�ͣ���vit����ͨ��һ�������������������ͨ�������������ٶ���ǰԪ�ص�����������������ٶȡ���Щģ����ͼ�ڱ�������������ͬʱ���������ɹ����б������л������IJ��������Ӷ��ӿ������ٶȡ��Ӿ�������ʹ�õ�����Transformerģ�Ͳ����ǻ����Իع����ƣ��������Dz�����Ϊ�Իع���������л������������������̻�������Щģ�Ͱ������������Ӿ�Transformer��ViT������������Transformer�Ľṹ�������ڴ���ͼ����ࡢĿ���⡢ͼ��ָ������ʱͨ�����÷��Իع鷽ʽ�� ��ô�Ӿ�Transformer��ViT��/���Իع�Transformerģ�͵��ص㣬�Լ����������ٶ������mamba�𣿣����д����������������Σ�����ģ�Ͳ���������ǰ����������ɵ�ǰ���������˿��Բ��д����������ݣ��������˴����ٶȡ�ȫ��ע�������ƣ���Щģ������Transformer��ȫ��ע������������ͼ���ڵ�ȫ��������ϵ��������˳�������ͼ���ÿһ���֣���������⸴�ӵ��Ӿ������dz���Ч�������ڶ����Ӿ������Իع�Transformerģ�ͱ��㷺Ӧ���ڶ����Ӿ�������ͼ����ࡢĿ���⡢ͼ��ָ�ȣ�չ���˼��õ�����Ժ����ܡ� һ���棬���Ӿ������У�vit��ȫ����ע�������Ʊ���������һ���ܹ�CNN�ڲ����������������������һ���������ƣ��ر����ڴ������ģ���ݼ���������ģ��ʱ������������cnn��û���������´�����˵����Ҳ��ͳһ�Ŷ�ģ̬ģ�͡���Ŀǰ������˵transformer��ȫ������CNN����Ϊ���Ӿ�������������ҽѧͼ��ָ�����cnn���ֻ�������transformer������̸mamba����transformerΪʱ���硣 һ���棬����Щ���Իع���Ӿ�Transformerģ�ͣ������ٶ���Ҫ������ģ�ʹ�С���������ݵķֱ����Լ�Ӳ�����ܣ����������Իع�ģ���������������л���������Ҫ������mamba���������ģ������ٶ���һ���Ʋ������ڡ����������������羫�ȣ������Ӿ�������ʱҲ�������ԣ�����Ҳ̸����"��Ļ���transformer"�� |
|
|
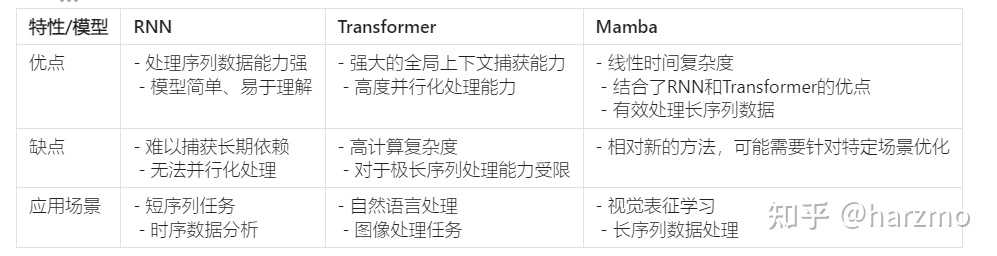
RNN�����ʺϴ�������ʱ���������Ե����ݣ���������ʶ�𡢹�Ʊ�۸�Ԥ��ȡ����ڴ����϶̵�����������Ч���Ϻã����ڴ�������������ʱ�������ݶ���ʧ��ը���⣬���ܻ��ܵ����ơ�Transformer��������ǿ���ȫ�������IJ��������Ͳ��д����������ر��ʺ�����Ҫ������������Ϣ��������������롢�ı�ժҪ ��˾���һͳ����ģ̬��RepLK��ͳ����UniRepLKNet��ImageNet 88%��ʱ��Ԥ��SOTA�������Ч�� - ֪�� (zhihu.com) (23 ��˽�� / 3 ����Ϣ) ������� Mamba ģ�� Selective State Spaces? - ֪�� (zhihu.com) ����ģ��VMamba���߸��Ӿ�Transformer����һ������Backbone�� - ֪�� (zhihu.com) Mamba��ϸ���ܺ�RNN��Transformer�ļܹ����ӻ��Ա� (qq.com) |
|
��ʽ������˽�ͳ��δ���ܹ� Convolutional neural network will be great again! ��2022���Ҿ���ʶ���������͵�RNN LSTM CNN����������ڼ�����Դ�����������Ը��ƣ���Ȼ�����ܹ�Ҫ��������transformer��CNN�IJ�ͬ�������ֳ����� Ȼ�������������Դ�ٽ�һ��������ôδ��������ܹ�����ʲô��������AI machine�Ĺ�ϵ������Σ� �ص����⣬��������transformer�����ܴ��������ı��hh 2016 DeepMind AlphaGo -> 2023 OpenAI ChatGPT -> 2030 ? ? |
|
�����ã�RWKV��Mamba�ȵݹ�ģ�ͣ�recurrence models�����������ԵĻ��ƣ�����������Ե�һЩ�������סһЩ�� ͬʱ�������������Ϣ����ʾʱ������һЩ��ǰ�����Եij��ڼ��䡣 �Ȼ�Ǻõġ����ǣ�Ϊɶ�о��������г��ϻ��� Tansformer ���ܹ�ע�أ� RWKV��Mamba�ȵݹ�ģ�ͣ�recurrence models����ȷ�Ƚ� RWKV��Receptance Weighted Key Value����Ȼ��ijЩ�����봫ͳ��Transformerģ��������֮��������������һ�������Transformerģ�͡� RWKV��һ�ֽ����Transformer��RNN�ŵ���������ѧϰ����ܹ�����ʵ���˸߶Ȳ��л���ѵ�����Ч��������������ʱ�临�Ӷȣ��ڴ���������ʱ���ֳ����ڴ�ͳTransformer�����ܡ� RWKVģ�͵Ĺؼ�����������ע�����㣬�������봫ͳTransformerģ�͵���Ҫ������RWKV�У���ע������self-attention�����滻Ϊλ�ñ��루Position Encoding����TimeMix����ǰ�����磨Feed-Forward Network��FFN�����滻ΪChannelMix����Щ�Ķ�ʹ��RWKV�ڱ���Transformer��Ч����ѵ����ͬʱ��Ҳ�ܹ�������ʱ���ֽϵ͵ļ�����ڴ渴�Ӷȡ� ��ˣ�RWKV���Ա���Ϊһ�ֶ�Transformer�ܹ�����չ��Ľ����������Transformer�����˼�룬��ͨ�����µķ�ʽ�����Transformer�ڳ����д����ϵ�һЩ�����ԡ�����RWKV������Transformer��һЩ���ĸ����ʹ��Ƕ��㡢���һ����Layer Normalization�����������ģ��ͷ��������ע�������ƺ�������ʵ���봫ͳTransformer������ͬ�� ��һ�����Ҫ����Ҫ����Ϊ����ʹ�� AI �����ƾ��ǡ�һ�����Ӳ��붯��Խ��Խ������Խ��Խ�������� ���ԣ�������ܽ����Խ��Խ�����������⣬���� Transformer ģʽ�IJ�Ʒ�ᱻ�û������Ͽ塣 ���� AI ��ҵ���յļ����ǡ���������Դ���˵IJ�Ҫ��Ҫ�ġ��������չ��Ǽ��衣 ��˵ RWKV RWKVģ��ͨ������صļܹ���ƣ��ܹ��ڱ���״̬��С�㶨��ͬʱ����Ч�ش��������С������������ģ����ÿ��ʱ�䲽������״̬���������µ���Ϣ��ͬʱ����������Ҫ����ʷ��Ϣ�����ֻ���ʹ��RWKV�ڴ���������ʱ���ܹ����ֽϵ͵ļ��㸴�Ӷȣ��������Դ���Ļ���������Ҫ�� Ȼ��˵ Mamba Mambaģ���������ѡ����״̬�ռ�ģ�ͣ�SSM����������ģ�������ݶ�̬�ع��˺ʹ�����Ϣ������ζ��Mamba�����ڴ���������ʱ��ֻ��ע�Ե�ǰ��������ص���Ϣ���Ӷ����Ч�ʡ�Mamba��������ijЩ�������Ѿ������˻���LLaMa��ģ�ͣ���ʾ�����ڴ��������з����DZ���� Ȼ���� ������Щ�ݹ�ģ���������Ͼ��д��������е�����������ʵ��Ӧ���У������Ƿ��ܹ���ȫ�����ܡ�Transformerģ�ͻ���Ҫ���Ƕ�����ء� Transformerģ��������NLP�������Ѿ�ȡ���������ijɹ����䲢�л�������������չ������ʹ���ڹ�ҵ��õ��˹㷺Ӧ�á� ������л�������������չ�����ԣ�������ҵ�ᆳ��˵��Scaling laws���������ͱȽ�������ҵ�����ʱ������ͼ������ϣ��Ҿ�֪����Ͷ���˶���Ǯ�����߶����������� �Ҿ�����߶���ģ�����ܡ����Ѷ���ѵ��ʱ�䡢�����ṩ������Դ���ģ����ܶ�ģ�ʹ�С�������������������Ӱ�죬Ҳ�ܰ����������������Ե�����֮�䣬����һ������ѧ���ɵ�ģ�͡� ���ߣ���ֱ��һ���˵��Tanrsformer ģ���������Ϻù�Ӧ�������ʺ����Կ���������Ӧ�ʱ��г��ij�ϫ���ɡ� ���ݹ�ģ����Ȼ�������������ƣ�����ʵ��Ӧ���п�������ѵ���Ѷȴ���������������⡣ һ��ѵ���Ѷȴ����������㣬����ֻ��������Ӣ��˾�;�Ӣ������Ա��������������˶����Կ������dz����������г��������۸��ض�����cartel���� ���ң����ڸ��ӵ���������Ҫ�ظ�֮ǰ�������ݵ����ݹ�ģ�Ϳ���������ս����������ͨ����Ҫģ�;���ǿ��ļ������������ݹ�ģ�͵�״̬��С�Ǻ㶨�ģ�������������������������ϵı��֡� �����ᵽ�ˣ���֮�����ܡ������Ч�ʺͳɱ��ܸߡ���������Ϊ��ԭ�����һ���֡� Ȼ�����Ⲣ����ζ�ŵݹ�ģ�����������������ǿ�����Ҫ�ض�����ƺ��Ż������������Щ�����ϵ����ܡ� �ܵ���˵��RWKV��Mamba�ȵݹ�ģ���ڴ��������з���չ�ֳ���DZ�������Ƿ�����ȫ��ԽTransformerģ�ͻ���Ҫ�����ʵ֤�о���ʵ��Ӧ������֤�� ��ʵ��Ӧ���У�ѡ������ģ������ȡ���ھ��������������Դ�����Լ�ģ�͵Ŀ���չ�Ե����ء� ����Ҫ���ǣ���һ�� Tanrsformer�����ʱ��г����ƶ�������һ����ʲô��˭֪���أ� |
|
RWKV��Mamba��recurrenceģ���ڴ����ض������Ͽ��ܻ���ֳ�ɫ���������ڴ������г���������ϵ�����м�������ϸߵ�����ʱ�����ǵ�״̬���������������б���һ���̶ȵļ��䣬���ں���������ʹ�á�Ȼ�������ڸ����ӵ���������Ҫ����������ʷ��Ϣ��Ҫ���ڼ����������Щģ�Ϳ��ܻ��ܵ����ơ����֮�£�transformerģ���ڴ��������к�������ʱͨ�����ֽϺã���Ϊ������������ע�������������������еij�����������ϵ�������̶ܹ���С״̬�����ơ���ˣ����ڲ�ͬ������ѡ���ʺϵ�ģ��ȡ��������������Լ�����ļ�������������� |
|
|
| [�ղر���] �����ر��ġ� |
| ��һƪ���� �鿴�������� |
|
|
|
| ��Ʊ�ǵ�ʵʱͳ�� ��ͣ��ѡ�� ��ʱͼѡ�� ��ͣ��ѡ�� K��ͼѡ�� �ɽ���ѡ�� ����ѡ�� ������ѡ�� �������� �������� ���� MACDָ�� KDJָ�� BOLLָ�� RSIָ�� ���ɻ���֪ʶ ���ɹ��� |
| ��վ��ϵ: qq:121756557 email:121756557@qq.com ����ƻ� |