
| |
|
|
| ����ƻ� -> �Ƽ�֪ʶ -> AI �Dz����Ѿ�����Χ����һ���ϵ���Ϸ�� -> �����Ķ� |
|
|
[�Ƽ�֪ʶ]AI �Dz����Ѿ�����Χ����һ���ϵ���Ϸ�� |
| [�ղر���] �����ر��ġ� |
|
�˹���������ô�����Ӧ�õ�ʵ������ƫƫѡ����Χ������ս���ࡣ�����Ǹ������⡣������Ϸ�ڶ��ǵ�����������Ļ���ֵ�������˴�С�����������顣�ӽ��Ҫ��Ϊ�� |
|
aiû�лٵ���Χ�塱��һ����Ϸ��Ҳû�лٵ������Χ���л����Ȥ�ġ������ԡ������ҿ�����ȷ˵��ai�ٵ��������˶��������ߵ��Ļ������ ��aiʱ����ǰ��aiʱ���Ժ��Ҷ���ż������Χ��ѡ�ֵ�ֱ���������������Ը��ܵ����й��ڷ�Χ������ ��֮ǰ������������ڶ������Ƿdz���η�ģ���ȻҲ����ֱ��������ijһ�ֵĺû����������϶�����ѧϰ��������֮������ָ�����������ֱ��Ϊ��̬���������Ҷ������ٿ���Ļ�ˡ��������ٷ��Լ��أ���˵ȫ�ڿ����Է���ʤ���ǵ���˵���������������ͽ�������ϵ۵�����һ���� ���ɣ�����ai��û��������ΪΧ���ϵۣ�����ai�Լ���ս��ʱ���������ֱ�ʤ������Ŀ�����ֱذܵľ����ˣ������Ƕ�������˵�����Ѿ����ϵ�û�ж�������������ඥ��ѡ�ֵĶԾ��Ǵ�����£����ڸ�����һȺѧ������ʦ��ǰ�Դ𰸡����� ���գ����Dz��ò����ϣ�ԭ�����������������ԭ��ֻ���������ֶ���֮��ŷ�����żȻ��ԭ�������ӵ����֣���ai��ǰȴҲ�Ѿ�ͬ������һ����������ԭ�����Ļ�������ݻ��ˣ���Ȼ��Щ���ֵij�����ΪҲ����������һ�£����ʹ�һȥ�������� ��Ȼ����ʹ������������̳��Χ������Ժ��ǻ�ٰ죬����Ҳ���ǻ������Χ�������˶��᳤�ڴ�����ȥ����ʦ�ǻ�����Դ𰸣���ƴ˭����ai��ֻ�ǶԹ�������˵�����������ӵ��Ļ������Ѿ�������ɫ��һȥ������ Χ��Ҳֻ��aiʱ������Ӱ���ѣ�����滭�����֣�����һ�����ᾭ�������Ĺ��̣�������������Ϊ������Щ�������Ļ���Ʒ�����ᱻai����ѧģ�������������DZ�Ȼ�����ơ� Ҳ��δ����ʮ���Ժ������Ľ���������ûʲô��ϵ�ˡ����� |
|
������������Σ�ա� �ڰ�������ճ�����ʱ����һ��Ҳ��ΪAI��Χ�岻����̫��Ӱ�졣 һ�Ǵ�ͳ�ı����������ij��ֲ�����Ӱ�����ܡ� ��������֮���������������IJ�����ʱ��������ϵļ�������ʡ� ������֮���ҷ��������������IJ�ͬ�ˣ�AI�����������ְҵ���ֵ������ġ� �����ķ�����Ȼ����Ӱ���ᄊ�����ᄊѡ��Ҳ������������Ϊʦ�� ����ְҵΧ�壬�ܶ��ˮƽ���������жϵ�ʱ��Ҳ����ŵĿ�һ��AIʤ�ʡ�����͡��� �ص����潲�ĵڶ��㣬��Ϊ������Ŀ��������֮������������Ǻ���Ҫ��Ҳ�Ǻܾ��ʵġ���������˲Żᶮ�ã���ν����֮һ�֡����ļ�ֵ������ʤ����ת���������־�Ȼ������������ʤ�������Ĺ�ͷ������˵��жϣ� ��������ȼ�ղŻ�����������Ľ�ţ�����Χ��Ȧ�������Ļ��ij��ԡ�������������λ���������ͣ������ڵ���֮�ϣ�һ��֮������������ ��ϧAI��ʱ�������ˣ������������������֮�ϡ� ɽ����縧�������������У���֮�������ν���硣 �Ʋ���AI�������װ����������ʤ���½����� �㲻֪�������������֪���Ǹ������ǶԵġ� �����µ��ǣ���Ķ���Ҳ�������� ��̸����Դ�� ��Ԫ���������ǡ��ɾ�һ�δ��档 ��Ҫ֪��������·�����ë���ģ���������ǿ��ġ�����Դ�ijɹ���������٣�ǡǡ�����ڲ��ֵ������������ڲ��ֵ�������������ġ� ���������º�Ҳ̹�У�������������һ��ʧȥ���侲�� ��ν����ţ�����»�������Դ��ľ��ʵ������ս��ʦǿ�֣�������ð�������³���Ԫ���֣��������ǻ����������������Դ�������˵����������·����ʵ�ֳ����� ��������AI����һ�����ܵ���ʦ�Ͷ��֡���Ԫ����������λ���£�AI��ʾ��ʤ��һ·���������Ƿ�������������·�ϼ���ǰ���أ� AI�ij��ֲ������µ�����Դ��ǡǡ���ڶ�ɱ����Դ�� ��AIʱ����������Ҫ���Լ��ķ�ʽ�������Ҫ������Դ��ľ��ʵ����������� AI�Dz����Ѿ�����Χ�壬�ҽӴ�����ְҵ���֣�����������ˮƽ���Dz������ԡ� �����ܿ�����������ߣ�����ְҵ���֣�����AI��ǰ��ȥ�˷�â�� ֻϣ����Ȼ��ս��һ�ߵ��������ܹ����ҽ�ţ�����ס��ʿ�����ĺ����롣 |
|
�ǡ� �ڿ½��������������ʱ����Ҳû����Χ����군�� ���ǵ������꣬���ʼ�á�AI���϶ȡ�Ϊָ�����Χ��ѵ�� �������еĶ������ֶ������ˡ�ҪôѧAI��Ҫô����ʼ����䡱���ص�ʱ�� ���Ҿ���Χ���Ѿ��군�ˡ� ��Ȼ�����������ֵز��ˣ������군������ʲô�أ� �����϶��Ǵ���Ϸ�������ľ�����Ŀ��ƾʲôwar3���Ǽʡ��۹������군�� Χ�岻���군�� �������·����Ķ����þɶ����군����ʲô������ ���۲���ǧ������ |
|
˵ʵ�����ٲ��ٵIJ���˵���������ٲ������ˡ� ԭ����������帴�̣�����һ���о����⣬���ڴ�������帴�����ڶԴ𰸡� �Ͳ��ò�˵��Χ��Ĺ������ڱ�ͣ��˵������Ѿ�Խ��Խ�������ˡ� �ټ�������AI���У����Ҹ������������������������Ѿ�Խ��Խ���ˡ� |
|
��Ϸ���Լ����棬�������ǵ�����ʧ��ʲô�� ��ʵAI�ٵ��IJ���������Ϸ��������������һ������ ����Ľ�����������׳���� �Ҳ���Χ�壬��������ȫ�Ҷ��������� ���������е��˽���ˣ���������������������İ�� ������ϲ���������� �ҵ�һ�������������Ĵ������Ǵ���үү���� ��үү�����ǵ��ص�����ȦҲ��С������ ��һ���Һ����������鷿������ �������ţ������ң���֪�����ڵ�����˭�����µ�һô ��û��˵���ھ������������ˡ����µ�һ���������������Ĵʻ� ��˵��֪�������������ⲻ����ij���µ����ô ��˵���ԣ�����ij����ȥ�μ�����ʡ��Ĵ�����û����Χ������������������һ������ij�ң��һ�ר��ȥ��ij�ң���������һ�̣�ȷʵ�Ǹ����֣�����ķ��ڷ������������죬������˵������ǰ���Ϻ���������һ�������ĸ��֣�Ӯ��������Ͷ�ء�������֪�����Ǹ��˽к��ٻ����� ��˵���Ǻ��ٻ�������������µ�һô�� �������磨��ǰ�������ٻ�ȷʵ�����µ�һ����֪��Ӯ�˶��ٸ��ھ������Ǿż����ʱ���и������˺�ճ����ˡ����ͺ��ٻ������ˣ���һ���������ﲫɱ��һ�����ϣ��������Ϻ��ٻ���ͷ��β��������ͷ��û̧����һ�£���������������������ˣ��������ֽ�����������������18�ꡣ�� �������ⷬ������ʱ�����Ǽ¶��ġ����ڻ�ͷ�����ⷬ������ĺ�������С˵������ζ�� ��ʱ���Ҳ����ÿ�ʼ�룺 �ҵ�ʱ�����ǰ��ϵ������Ǿ���ͬ�������кü�������ǿ������ѧУ�Ĺھ��Ǹ���һ����͵�ѧ�����һ��ǵ��������۾����߸����ݵģ���š���������Ľ��Ѿͳ������ɡ����ǵ�ˮƽ�Ҷ����˽⡣ �����йھ����ж�ǿ�أ��Ͳ�֪���ˣ�����˵ʡ�ھ���ȫ���ھ��������������������ߣ��ͺ�ճ��������µ�һ������ʱ�������У����˽����ĸ��Ҳ����һ˿˿������ �ܶ�����ҿ�����������ġ��˿��С�����������ڴ���˵������еĸ��ֺ�Ŀ���������µ�һ������������һ��ɽ�壬ӭ��������ǣ���һ�������ߵ�ɽ�塣��ʱ��������У��������µĸ��� |

|
|
|

|
|
���˵ĵط������н����� �������˹��ɵģ��Ƕ��������Ҽ���̽���������㽣������dz�ݡ� û�о��������������Dz��˽����ָо��� �ҹ����ָо��� ������̬ ��Ȼ��ֻ��һ���μӹ�����ѧУ�����ij������� �������ֱ���ʱ�Ͷ��ֲ�ɱ�ĸ��ܣ�����һ���� �ʾ���֭��ʹ��������������ȥ��ܶ��� ��Ȼȫ�̶���ƴ����ȥ�����˽�Է����뷨 ��������̷���������Ҳ�ڲ��ϵ���ʶ�Լ� �����������ǿһ��Ķ��֣���Ȼ�³������ַ���Ϊʤ��ʱ��������˶��Լ��Ŀ��� ��ԭ���Ҳ�ֹ���������ҿ��Ը�ǿ���� ���ֿ�������Ա����Կ�и�����������ֱ��ֵһ�� �����Ǽġ�ʤ�����������ֿ��Լ����� ����ǧӮ�˵��ˣ����������ָо� ��Ϊ�Լ���ƭ�����Լ��� ���˶����Լ��ļ��ޣ����Զ���������ͻ��Զ�����������ĸ��� �����������ǵ���Ӱ��Ҳ�������ǵ���Ӱ ��Ϊ�����DZȡ����Ҽ��ޡ�����һ����εġ����༫�ޡ������� �������㽺������������ǽ�����Դ���� ��ai�ij��֣��ٵ�����һ�� 2006�꣬�������͵�ʱai����һ���壬����Ǻ��塣 �ҷdz������üǵã���ʱ����̨��������˵��������ķdz�ǿ�������ﵽ��������ŵ�ˮƽ �ԣ��ǻ��������Ȼ����ai�����µ�һ������ȣ����ǻ�����һ�������ź����� ���ǻ��ai����Ӥ��ˮƽ�� ��������սʤŷ�ھ���ʱ�������dz�Ц�� ��Ӯ��ŷ�ھ�Ҳ����˼˵������ʲôˮƽ������ ����2016�꣬����ʯ�Լ����ai�ˣ���������Ӯ��һ�̡����Կ½��˵����Ӯ�� �����2017�꣬��������ֱ�����˿½�һ����ͷ�� �½���� �����˶��ޱȵõ�ʧ�� ��Ϊ����û�� ���Ƕ����о������������Ȥ �ܴ�̶����Ƕ�˭�ǵ������µ�һ����Ȥ �������ڴ�Ҷ�Ĭ���ˣ�ai�������������µ�һ���пᵽû���κνƱ����� ���йھ���������һ��֮������֮�ϰ��� �ܶ��˶�ϲ���á������ij��֣�Ҳû���ð���������ʧ���������� �������������ʵ��ǡ�� �˲���ͱ��ӱ����ܣ�û���� ��Ϊ�����Ƕ�������������̽�� ������ʼ���������������������������ڳ���ǧ �������ð���������ʧ�ģ������ǻ��� ����һ�죬�������ܽ��˰���8�룬7���ʱ�Ͳ��������˹�ע�ɼ��� ��Ϊ���Ѿ���������������ͻ�ƣ����ǿƼ��ľ����� ������������Ѿ�ʧȥ�˼�ֵ Χ�壬�����������һ�� ����ܶ���˵�ģ����ڵĸ��ֶ��ڱ�ai������ �ȵ��Ѿ����Ƕ����գ����Ǽ������� �������յļ��ޣ�Ҳ�ʹ�ʧȥ�˼�ֵ ����Ҳ�ʹ���ȥ �⣬��������ʧ�������ԭ�� |
|
�����ô˵�أ������ǡ���ıȷ��ɡ��ñ�Perelman�ü��η����㶨3ά�Ӽ��������Ժ�ȷʵ��ѧ���3ά�ӲµĹ�עֱ���½��ˡ������ǰ������ں������á���Ȼ��������ѧ�һ�����Ϊ�ҵ�һ�����˵�֤�������к���Ҫ�ļ�ֵ�ġ� ������Ϊһ������һ��ˮƽ�ģ���ѧ��������˵����ȥ�˽�һ��20������ѧ�ҹ���3ά�Ӳµ���ʷ����Ȼ�����������д�µ���ѧ���ģ���Ҳ��һ�֣����������Եģ���Ȥ�� �������Ƶĵ�������ҵ��������˵��AI������û��̫��Ĺ����ϵ���ս���෴��ҵ�������ǽ���AI��ø�ǿ�ˡ������ܳ��ǿ�ҵ���ְҵ�������֡��Ͱ���������ʽ�����������ֹ�����λ�������֣�����ʯ���½࣬���ܵ��˲�С�ĸ���Ӱ�졣����ʯֱ������ѧ�忪ʼ�����Ͱ�Χ�嵱��һ������������������ʤ���������������������ܼ�������塣�½�ô���Լ�ȥ���������Bվ��Ƶ�ɡ��������ڵ��뷨���������ǡ�Χ���������塱�ˡ� |
|
��Ϊһλ���������֡����ڵ�ǿ��ѧϰ��AlphaGo��Ӧ���������ߣ����������Ļش�һ��������⡣ ���ֳ��ģ���רҵ��Ա�������м��AlphaGo�㷨�ķ������������Ҳ��ͨ�����������ܽ�������AlphaGo�Ĵ��¿�ܡ� ����һ�ˣ������ս�ս֮�ʣ��������ɣ����ձ���Ժ�������ң���ѹһ���̳���������ܡ� ����һ�ˣ���������̨֮�ϣ�����������ھ���֮������ֱ�ϣ�ɨ��һ�ڵ��֣������ʥ�� ����һ�ˣ�����̳����֮�У���������������ȴ����ʯ��ͳ��һ�������ֻȡ��Ŀ�� �������� ��������һƬ������û�����̣�ȴ����ɱ�������ֵ�����ȴ���������������������������콾������������Ƿdzɰ�תͷ�գ�AI�Ծ�Ӣ�ۡ��� ��������������Χ������룬Ҳ�����е��츳�ɣ�����ʮ����Ѿ���ù����ʡ�����Ǿ����������п�֮��ȥ����������ְҵ��ǰ����ѵ��Ȼ���첻����Ը������һ���3�£�һ�ж����ˣ�һֻ�������������������ķ���������һ�н�������ʱ�����¶����������AlphaGo�ij��ֶ�������ζ��ʲô��ֻ֪��Χ����Ҳ�����Լ�����Ϊ�������֡�ǧ����ͬ�֡����ǻ۵߷��ˡ��̼ǵ��Ǹ����ϣ��ҳ�ҹ���ߣ����ջ��Dz��ò����ţ�Χ���Ѿ������ס����ܡ��� ��ʱҲ��Ҳ��˭Ҳû���뵽�����ڷ�����AI���´�����Χ�塣��Ϊ����������Χ���Ѿ�����ĺ�ꣻ����Ϊһ��������Ϸ��Χ��ȴ�ֻ����˵ڶ�����AI�����˱��𰸣���Χ���������ѩ��Ϊ������ˣ�ͬʱҲ�ô��ѧϰΧ����ż���ͣ�ֻ��˵����ʧ����֪�Ǹ�����ֻ�ǿ�ϧAlphaGoֻ֪�����ȴ������ν̣��������ܱ������Լ����뷨�������ܹ��������������ѪҺ������硣 |

|
|
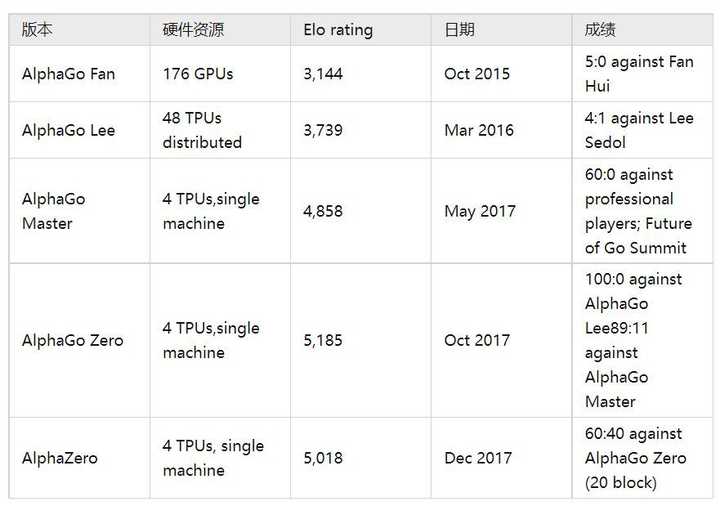
Image ����»�����Ϊ�������е�һ�����ӡ��߿����Ŷ���ֻ���ĺ��棬�Һ�����ԥ�����AIרҵ�����ڴ�ѧ��Ҳ�Ӵ������������ԭ�����㷨��Ϊ֮��������������������������֮�С� ����֮���ٶȽӴ�AlphaGo���п���ǧ���������Լ�¼�� һ��AlphaGoϵ�з�չ���� AlphaGoϵ�н����˶�μ��������뷺������Ҫpaper���£� Mastering the game of Go with deep neural networks and tree searchMastering the game of Go without human knowledgeMastering Chess and Shogi by Self-Play with a General Reinforcement Learning AlgorithmMastering Atari, Go, Chess and Shogi by Planning with a Learned Model ���е�һƪ�dz���AlphaGo���Ѿ��ﵽ�����ඥ�����ֵ�ˮ�����ڶ�ƪ����������AlphaGo Zero����ȫ����������֪ʶ���Ѿ��ﵽ������������ĸ߶ȡ�����ƪ�ǽ�AlphaGo Zero���㷨�����ģ�Ǩ�Ƶ���Chess ��Shogi�ϡ�����ƪ���Ƿ�����MuZero�� ������AlphaGoϵ�е�ʵ���Աȣ����Կ���ģ�ͺ���Ҫ��������Ҳ���ɺ��ӡ� |
|
|
Image ��������ֻ�������Χ���ǰ��ƪ���ġ� ��������AlphaGo �ٶȷ�����ƪ���£����ֳ��ڵ�AlphaGo��Զ��ֻ��Ӧ��������ĶԾ����ݣ���ѧϰ��ʽ��������ʽ��������������������ͬ��֮������Ʋ�DeepMind�Ŷ�������㷨���֮ǰһ����һЩ����������˵��С����������ŶӺ�������֮һ�ĻƲ�ʿ��ҵ��6�θ��֣���Ҳ�Ͳ���Ϊ���ˡ� �ع�����ѧ��Ĺ��̣�������Ҫ���䲢�������һЩ�ֲ��Ķ�ʽ�ͻ���������Ȼ����ʵս�������Լ���������������ʵս������ÿ��һ��ǰ�����Ƕ�Ҫ������һ����ʽ��������ʽ��Ҫ���ಽ����ԱȺ������Լ���������ж���һ������㡣����Щ�ڳ��ڵ�AlphaGo�ж����ҵ���Ӧ�IJ��֣� ���䶨ʽ�ͻ�����������������Ծ����ݽ��мලѧϰʵսѵ�������Բ�����ʽ����������ֵ�������������С�����Rollout Policy�������ؿ��������� ���������ϸ������ 1. ���� ������Χ���Ѿ��кܶ������ʷ�ˣ�������Χ������������ռ���ֲ��������Ѷȣ����Ե�ˮƽһֱ�����룬��ǿҲ����ҵ����ֵ�ˮ����AlphaGo��ճ���֮ǰ�����������Զ��²���������һ�����˵Ļ��� ������ԣ������Χ����Ƴ�һ������������ô�������Լ��250����150����Ҫ����������infeasible�ģ������ǿ��Դ���ȺͿ������ֽǶ���������������� ��� ����ʹ�� position evaluation��������������������ÿ���ڵ㣬������ֵ��ȡ���������������������ַ����ڹ����������Ϸ�ж�ȡ����superhuman��Ч��������Χ���У������临���ԣ�����intractable�ġ� ���� ��ÿһ���ڵ㣨״̬���������䶯�������� Monte Carlo rollouts �������������߶�ʮһ��һ·�����磬��ͷsample��β��ͨ���ܶ�ε�rollouts���ܹ��õ���Ч�� position evaluation�����ַ��������������Ϸ��ȡ����superhuman��Ч��������Χ����Ҳֻ�ܴﵽҵ��Ͷε�ˮƽ��һ��������ķ�����MCTS����һ��value function��ָ��rollouts���úõ�action��sample�ĸ��ʸ���ͬʱ����rollouts�Ľ��У�value functionҲ�ڱ��Ż������ַ����ܹ��ﵽҵ��߶ε�ˮƽ��Ҳ�����е���÷����� 2. ������ AlphaGo�Ŀ��Ӧ���ۺ�����������idea�����Ҳο����������ֵ�ѧϰ˼�����̡���������ͼ��ʾ�� |
|
|
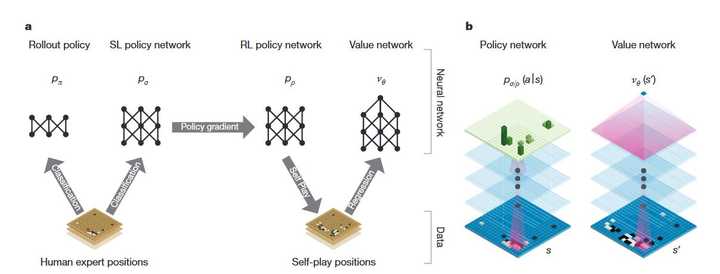
Image ���ȿ�bͼ�����߽�����CV�ķ���������ֿ���һ��19×19" role="presentation">19��1919\times 19��ͼ������13���CNN�У��Դ����Զ���ȡ״̬������ aͼչʾ�����幤����ܣ���Ϊ4�����֣� �������������ලѧϰ��ѵ��һ����������pσ" role="presentation">p��p_\sigma����Ԥ�������߷���ѵ��һ��������������pπ" role="presentation">p��p_\pi��֮������rollouts����RL�ķ�������pσ" role="presentation">p��p_\sigma�Ļ����Ͻ����Բ���ѵ�����õ���ǿ�IJ�������pρ" role="presentation">p��p_\rho����pσ" role="presentation">p��p_\sigma����ѵ��һ����ֵ����vθ" role="presentation">v��v_\theta�������������״̬�� ��������м������Ե����ʣ����磺ΪʲôҪѵ������������������rollouts��Ϊʲôrollouts�еĶ���ѡȡҪ�� pσ" role="presentation">p��p_\sigma�������Ǹ���ǿ���pρ" role="presentation">p��p_\rho���ҿ����ķ����� 3. CNN������ȡ policy network��value network�����붼��һ��19×19×48" role="presentation">19��19��4819\times 19\times 48����������value network��Ҫ��������һ����������ʾ��ǰ�ֵ��ķ����ӡ���48��ֱ��ʾ���������� |

|
|
Image ͨ����Щ�������ܹ���ȷ������ֵĵ�ǰ״̬��ֵ��һ����ǣ�AlphaGo����ֻ���ǵ�ǰ���棬���������ǰ���ֵ���ʷ��Ϣ�������ܹ���ȡ�����ḻ������������ij�̶ֳ����ܹ����ݶ��ֵķ������һЩ������ ������Щ�ɻ�ǰ����֮��Ҳ����ʱ����Ϣѽ��Ϊʲô����RNN֮���ģ�͡��²�����ΪΧ������ɢ�˶����м��ʱ���ϵ��ǿ�� 4. SL of policy networks �����õ��������������ݼ�KGS������16����̶Ծ����ݣ�����Щ���ײ�ֳ�position-action����һ֡һ������ݾͿ�������ѵ���ˡ����ǵ�Χ������ԣ���������������� ͬһ���������֮����к�ǿ������ԣ������Ǵ��ҳ�ȡ������Щ��DQN�еľ���طż���Χ����жԳ��ԣ�������������ݶ�����reflections and rotations���Ӷ�Ҳ�����ݼ����������� ���������ݼ���ʹ��mini-batch�ķ�ʽ���мලѧϰ��ÿ�γ�ȡm������ {sk,ak}k=1m′" role="presentation">{sk,ak}k=1m��\left\{s^{k}, a^{k}\right\}_{k=1}^{m^{\prime}}���������� Δσ=αm∑k=1m∂log⁡pσ(ak∣sk)∂σ" role="presentation">����=��m��k=1m?log?p��(ak�Osk)?��\Delta \sigma=\frac{\alpha}{m} \sum_{k=1}^{m} \frac{\partial \log p_{\sigma}\left(a^{k} \mid s^{k}\right)}{\partial \sigma}�� ���ֻʹ�õ�ǰ״̬��ǰ���֣���ȷ�ʿ��Դﵽ 55.7%" role="presentation">55.7%55.7\%��������������ʷ��������Ϣ�����Դﵽ 57.0%" role="presentation">57.0%57.0\%�����������������ˮƽ44.4%" role="presentation">44.4%44.4\%����10���ٷֵ��ȷ�������������ϵ����ּ�Ϊ����������ͼa��ʾ�� |

|
|
Image ���⣬������ĽṹԽ���ӡ�Խ�Ӵ�Ԥ��ȷ�ʾ�Խ�ߣ�������ʱ��ȴ��������rollout����Ҫ������Ҷ�ν��У����ٶ�Ҫ��ϸߣ���������ر�ѵ����һ���������ӵ�rollout���� pπ(a∣s)" role="presentation">p��(a�Os)p_{\pi}(a \mid s)������������������˼��ʱ������ ����С�������ͬ��֮� 5. RL of policy networks and value networks ������ⲿ����Ҫһ����ǿ��ѧϰ����������Ȥ�����ѿ������Ķ�������ʦ�ġ�����dz��ǿ��ѧϰ�����Ǻܺõ����Ŷ�� |

|
|
��� ����dz��ǿ��ѧϰ:ԭ������ ���� ��39.18 ȥ����? ����method���ֵĽ�˵��policy networks �� value networks ��Ҫ����ѵ����Ρ� policy networks �����Ѿ�ѵ������SL���� pσ" role="presentation">p��p_\sigmaΪ pρ" role="presentation">p��p_\rho�����������Բ��ĵķ�������������ֵ��һ����ǣ��Բ��ķ�����Ȼ��ʷ��Զ�����Ѿ���֤���ںܶ�����Dz�work�ģ�DeepMind�Ŷ���һ���������һ�ָ�Ϊͨ�õ�ǿ���㷨���PSRO��������Կ��ҵ���һƪ���£� PSRO������ܣ�A Unified Game-Theoretic Approach to Multiagent Reinforcement Learning40 ��ͬ �� 14 �������� |

|
|
Ϊ�˷�ֹ����ϣ�����ÿ�δ�ǰ�������������ѡһ����Ϊ���ֽ��жԿ�������� zt=±1" role="presentation">zt=��1z_t=\pm 1 ����ʾ�����dz���ѵ����ÿ�ֵ�������Ϊ�� Δρ∝∂log⁡pρ(at∣st)∂ρzt" role="presentation">���ѡ�?log?p��(at�Ost)?��zt\Delta \rho \propto \frac{\partial \log p_{\rho}\left(a_{t} \mid s_{t}\right)}{\partial \rho} z_{t} �����Ѿ����� value networks ֮��baseline����0��Ϊ vθ(s)" role="presentation">v��(s)v_{\theta}(s)����������Ҳ��Ϊ�� Δρ=αn∑i=1n∑t=1Ti∂log⁡pρ(ati|sti)∂ρ(zti−v(sti))" role="presentation">����=��n��i=1n��t=1Ti?log?p��(ati|sti)?��(zti?v(sti))\Delta \rho=\frac{\alpha}{n} \sum_{i=1}^{n} \sum_{t=1}^{T^{i}} \frac{\partial \log p_{\rho}\left(\left.a_{t}^{i}\right|s_{t}^i\right)}{\partial \rho}\left(z_{t}^{i}-v\left(s_{t}^{i}\right)\right) ���⣬����Ӧ����ÿһ��֮��ͳһ����һ���Ż�����ÿ�����кܶ�ʱ�䲽t, ÿ��ʱ�䲽��Ӧһ�����״̬st" role="presentation">sts_t�����յ�ʱ�䲽Tʤ����������ʱ����������������£�Ҳ���ǻع�ͷ����ֽ�� r(sT)" role="presentation">r(sT)r(s_T) ����ǰ��ÿ��ʱ�䲽��Ӧ�� st" role="presentation">sts_t �ϣ�����һ�����ݶ� (st,zt)" role="presentation">(st,zt)(s_t,z_t)�����ʹ������ݶ��½�����Щ���ݶ� (st,zt)" role="presentation">(st,zt)(s_t,z_t) �����Ż��� ���������� RL ������������Ϸ�е����ܣ��Ӷ�����������ʷֲ����� [��ʽ] ��ÿ���������в����������潻��ʱ��RL ������������ SL ��������ı�����ʤ�ʳ��� 80%��������Ե�ʱ��ǿ��Ŀ�ԴΧ����� Pachi �����˲��ԣ�����һ�����ӵ����ؿ������������� KGS �������� 2 λ��ÿ��ִ�� 100,000 ��ģ�⡣��ȫ��ʹ��������RL ��������Ӯ������ Pachi �� 85% �ı����� value networks ����һ����ֵ���� vp(s)" role="presentation">vp(s)v^p(s)���ú���Ԥ��˫��ʹ������ p ������Ϸ��λ�� s �Ľ��: vp(s)=E[zt∣st=s,at…T∼p]" role="presentation">vp(s)=E[zt�Ost=s,at��T��p]v_p(s)=\mathbb{E}\left[z_{t} \mid s_{t}=s, a_{t \ldots T} \sim p\right] ��������£���֪�������淨�µ����ż�ֵ���� v∗(s)" role="presentation">v?(s)v^*(s)����ʵ���У�����ʹ�� RL �������� pρ" role="presentation">p��p_\rho �����Ʋ��Եļ�ֵ���� vpρ" role="presentation">vp��v^{p_\rho}��ʹ��Ȩ��Ϊ θ" role="presentation">��\theta �ļ�ֵ���� vθ(s)" role="presentation">v��(s)v_\theta(s) �����Ƽ�ֵ������vθ(s)≈vpρ(s)≈v∗(s)" role="presentation">v��(s)��vp��(s)��v?(s)v_\theta(s) \approx v^{p_\rho}(s) \approx v^*(s)�������������������������Ƶļܹ�����������ǵ���Ԥ������Ǹ��ʷֲ�������ͨ��״̬-����� (s,z)" role="presentation">(s,z)(s,z) �Ļع���ѵ����ֵ�����Ȩ�أ�ʹ������ݶ��½�����С��Ԥ��ֵ vθ(s)" role="presentation">v��(s)v_\theta (s) ����Ӧ��� z ֮��ľ����� Δθ=αm∑k=1m(zk−vθ(sk))∂vθ(sk)∂θ" role="presentation">����=��m��k=1m(zk?v��(sk))?v��(sk)?��\Delta \theta=\frac{\alpha}{m} \sum_{k=1}^{m}\left(z^{k}-v_{\theta}\left(s^{k}\right)\right) \frac{\partial v_{\theta}\left(s^{k}\right)}{\partial \theta} ��������һ������ϵ����⣬������λ����ǿ��صģ��������һ�ӣ����ع�Ŀ����Ϊ������Ϸ�����ġ��������ַ�ʽ�� KGS ���ݼ��Ͻ���ѵ��ʱ����ֵ�����ס����Ϸ������������ƹ㵽�µ�λ�ã��ڲ��Լ���ʵ���� 0.37 ����С MSE������ѵ������Ϊ 0.19��Ϊ�˻���������⣬����������һ���µ����Ҷ������ݼ������а��� 3000 �����ͬ��λ�ã�ÿ��λ�ö���һ����������Ϸ�в�����ÿ����Ϸ���� RL �������������֮����У�ֱ����Ϸ�������Ը����ݼ���ѵ������ѵ���Ͳ��Լ��� MSE �ֱ�Ϊ 0.226 �� 0.234����ʹ�ÿ��� rollout ���� pπ" role="presentation">p��p_\pi �����ؿ��� rollout ��ȣ���ֵ����ʼ�ո�ȷ��ʹ�� RL �������� pρ" role="presentation">p��p_\rho �� vθ(s)" role="presentation">v��(s)v_\theta (s) �ĵ�һ����Ҳ�ӽ��� Monte-Carlo rollouts ��ȷ�ԣ���ʹ�õļ����������� 15,000 ���� ѵ��Ч������ͼ�� |

|
|
Image 6. Searching with policy and value networks ���ϣ�ѵ�������Ѿ������������Ѿ��õ���һ����ǿ�IJ������� pρ" role="presentation">p��p_\rho��һ�������������� pπ" role="presentation">p��p_\pi��һ����ֵ�������� vθ" role="presentation">v��v_\theta ������ͽ�֮��װ����ʵ��һ��ǿ���Χ��AI�� |
|
|
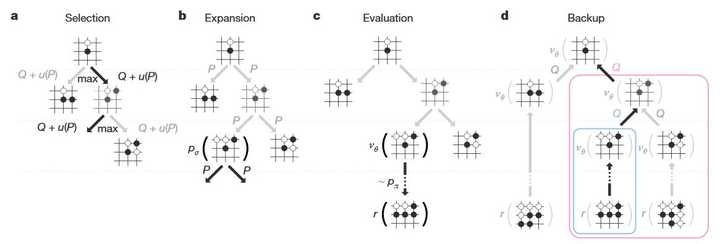
Image �����������̾�����ͼ��ʾ�� a: ÿ��ģ��ͨ��ѡ����������ֵQ�ı��Լ�ȡ���ڴ洢�ĸñߵ��������P�Ľ������� u(P) ����������b: Ҷ�ӽڵ����չ�����½ڵ��ɲ������� pσ" role="presentation">p��p_\sigma ����һ�Σ�������ʴ洢Ϊÿ���������������Pc: ��ģ�����ʱ������Ҷ�ڵ㣩��Ҷ�ڵ��ں����ַ�ʽ����������ʹ�ü�ֵ���� vθ" role="presentation">v��v_\theta����ͨ��ʹ�ÿ����Ƴ����� pπ" role="presentation">p��p_\pi ���Ƴ����е���Ϸ������Ȼ��ʹ�öԾֽ�� r" role="presentation">rr ������������d: �Ըö����·������� r" role="presentation">rr �� vθ" role="presentation">v��v_\theta ��ƽ��ֵ������Q AlphaGo �� MCTS �㷨����ͼ���н���˲��Ժͼ�ֵ���硣��������ÿ���� (s,a)" role="presentation">(s,a)(s,a) �洢һ��������ֵ Q(s,a)" role="presentation">Q(s,a)Q(s,a)��һ�����ʼ���N(s,a)" role="presentation">N(s,a)N(s,a)��һ��������� P(s,a)" role="presentation">P(s,a)P(s,a)�� ��ÿһ�������£�һ��ʼ��״̬��Ϊ��״̬��Ȼ��Ӹ�״̬��ʼģ�⡣��ÿ��ʱ�䲽t��ѡ��һ������ a_t�� a_{t}=\operatorname{argmax}_{a}\left(Q\left(s_{t}, a\right)+u\left(s_{t}, a\right)\right) ���� u(s, a) \propto \frac{P(s, a)}{1+N(s, a)}���Դ�������̽�������㡢���ʴ������ٵĶ��������ģ�δ��չ�Ľڵ㣬�������չ��Ҳ����b������������һ�����⣺ΪʲôҪ�� p_\sigma ����Ԥ�⣬�����þ����Բ��ĺ����ǿ��� p_\rho�أ�ԭ�������߾���ʵ�鷢�֣������߷�Ԥ������p_\sigma ��Ȼ��ǿ�����߱����õ�̽���ԣ�����ʺ�����ģ�⡣ ����Ըýڵ���������� V\left(s_{L}\right)=(1-\lambda) v_{\theta}\left(s_{L}\right)+\lambda z_{L} ������ģ������бߵ���Ϣ�� \begin{aligned}&N(s, a)=\sum_{i=1}^{n} 1(s, a, i) \\&Q(s, a)=\frac{1}{N(s, a)} \sum_{i=1}^{n} 1(s, a, i) V\left(s_{L}^{i}\right) \end{aligned} ���� s_L^i �ǵ� i ��ģ���Ҷ�ڵ㣬1(s,a,i) ��ʾ�ڵ� i ��ģ���ڼ��Ƿ�����˱� (s,a)��������ɺ��㷨�Ӹ�λ��ѡ����ʴ��������ƶ��� �������Ժͼ�ֵ������Ҫ�ȴ�ͳ��������ʽ�༸���������ļ��㡣Ϊ����Ч�ؽ� MCTS ��������������ϣ�AlphaGo ʹ���첽���߳��������� CPU ��ִ��ģ�⣬���� GPU �ϲ��м�����Ժͼ�ֵ���硣 AlphaGo �����հ汾ʹ���� 40 �������̡߳�48 �� CPU �� 8 �� GPU������ʵ����һ���ֲ�ʽ�汾�� AlphaGo���������˶�̨������40 �������̡߳�1202 �� CPU �� 176 �� GPU�� 7. �ܽ� �Ӹ��ּ����Ͽ�����һ�汾��AlphaGo����˺ܶ����������˼·�����ɹ���֮������DL��RL�ȿ���У�ȡ���˺ܺõ�Ч���� ����ʱ�����Ͽ�����Ӧ�û�û�л�������ʯ��Ҳ����˵����һ�汾��û�дﵽ���׳�Խ�����ˮ������ʲô�ú�����Zero�ﵽ��ǰ��δ�еľ����أ� ͨ���Աȷ��֣�AlphaGo Zero��ܶ���һ�汾����Щ�������IJ��ֶ����˺ܴ�ĸĶ���ʹ֮���ʺ�AI��ѧϰ����-->��������-->��Խ���࣬�����AlphaGoϵ�еĽ������̡� ����AlphaGo Zero ֮ǰ����ƪ���Ļ�û������ʲô��ֻ�DZ����е�ģ�������������¼��������������о�DeepMind�µĺô�һ���塣 Ŀǰ�������Ѿ������˺ܶ���ϷAI������֮�����ܹ�ѵ������ôǿ�����кܴ�һ����ԭ������ӵ�д���������ר�����ݡ��������Լ���һЩ���飬��RLѵ�������У�����һ��ʼ�����Ǻ�ƽ���ģ�Խ������Խ���͡�Ҳ����˵������ܹ���ר��������һЩָ�����ܹ�������ѵ�����̣���ʡ������ ���� AlphaGo Zero �У����߳����������������ݣ���AI��ȫ�����Բ��Ĵ��㿪ʼѧ�������������ֻ����Ҫ���һ��superhuman��Χ��AI��������AI����û��Ҫ����������ΪʲôҪ���һ���أ�����һ����ԭ�������������Ϊ�������ֶ�̫�����ˣ��Ͼ��������ֺܶ�����ǧ�������ܽ��µĶ�ʽ���Ǵ��ģ��������� AlphaGo Zero �����ޡ�������֮�⣬���ǰ���յ�ͨ��èGato�Լ���Ⱥ��ţ�⼸��ɵ��£�Ҳ��DeepMind��һ��ʼ����־��ͨ���˹����ܣ�Χ��ֻ����������һ��ʵ�鳡�����ѡ� �弸�����⻰��Gato�ճ�����ʱ��Ҳ����һ��������ϸ�������֣���Ȼȷʵ��ǿ�����о���ͨ���˹����ܹ�ϵ����ʵ����������transformerǿ��ı���������ʵ��ͬһ��Ȩ����ɶ����������²�Ӧ��������ע����������ʶ���������ͣ�Ȼ����Ҫ��ijһ������з�����Ӧ����֮������Ӧ��������������ʶ������������ô�棬����ָ���ԣ�����ɲ��س���ͨ�á������С�representation is all you need���ȽϺ��ʣ���������dz����Ҳû�����о������˵������һ��Ҫ�����ң��ڱ�������ѧϰ (�ֶ���ͷ)�� ��С���ֳ�Զ�ˣ��ع����⡣ AlphaGo Zero ��Ҫ������������Ľ��� �����ලѧϰ���֣�ֱ���Բ���ѵ������ȡ������AlphaGo�е�SL�μ�������Ϣ�ϲ����ԡ���ֵ���磬�������㷨����ѵ�� �������ν��ܸĽ��IJ��֡� 1. ��������Ϣ ��ԭ�ȵ�AlphaGo�У�������һ�� 19\times 19\times 48 �����������������ǰ���ֵ���ʷ��Ϣ����ʵ������Щ��Ϣ��������ģ��������ӵġ���������Ϣ����ͨ�����ӵ�λ���жϳ���������ȥ�������е�������Ϣ���������Ϊ 19\times 19\times 17 ��һ��17�㣬ǰ16��ֱ��ʾǰ���ֵľ���״̬�����һ���ʾ��һ�ָ�˭�¡� ������������Ϣ����ζ����Ҫ���������Ϣ��ȡ������ǿ���������߽�ԭ�е�CNN��Ϊ�˲в������磬�ṹ���£� |

|
|
Image 2. �ϲ����缰���㷨 Zero�������е������������һ�����磺(p,v)=f_\theta (s)������p��ʾ��һ����ĸ��ʷֲ���v��ʾ�Ե�ǰ״̬��������������ѵ���й����о�������MCTS�� |
|
|
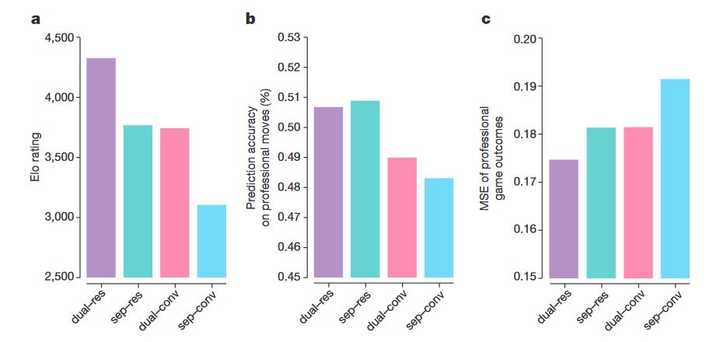
Image ����ΪʲôҪ������ϲ���������������һ��ͼ�����Ⱥ�����ResnetҪ����CNN���������ǵ��������������������Կ������ϲ���������ʵ���Լ�����ֽ����Ԥ���϶�Ҫ���ڷֿ������磬�����ڶ����������з���Ԥ�����Բ�һ��������˸о���Ҳ�����ƣ��Ͼ���AI��˵����Dz˹��� �������AlphaGo��ѵ�����̣���ʵ������AC��ܡ���������һ���µ��뷨����MCTS�ܹ�������һ����ǿ�IJ��� \pi�����Ҹ��ݶԾֽ�����Եõ�һ��������������ֵz����ô��ȫ�����Ż�������ʹ�������������������õĽ���� |
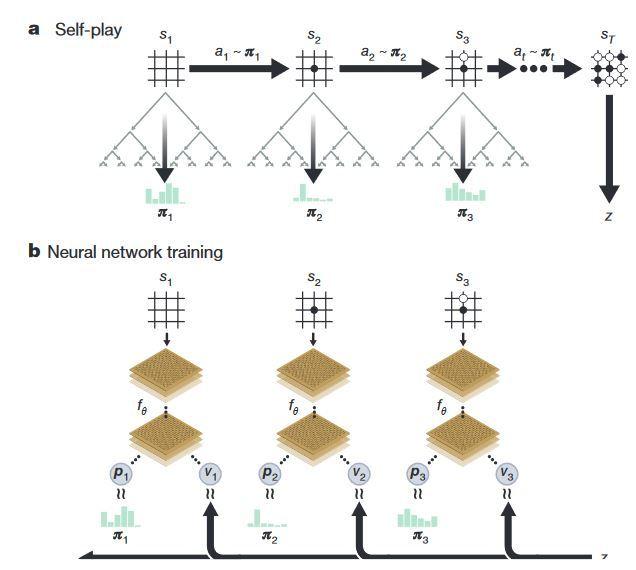
|
|
Image ����ͼ��ʾ��aͼ��ʾ�Ƚ���һ���Բ��ĶԾ֣�����ÿһ����MCTS������ǿ���� \pi ���ӣ�ֱ������ʤ��������ʤ����Ҳ��������һ�ֵ����ݼ���ͨ����bͼ��ʾ���Ż��������һ�ε���������ʧ�������£� |
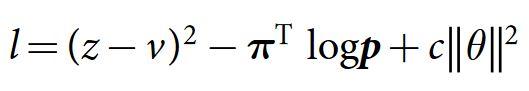
|
|
Image ���������ص�˵��MCTS�Ĺ��̡���ʵԭ��������ǰ���еij���AlphaGo�������������ͼ�Dz���Ҳ���ú��� |

|
|
Image ������Ҫ���������� ��Ϊֻ��һ�����磬��������ʵ�Ԥ�����϶����ʲ��ó���AlphaGo��Ҷ�ڵ��������ʹ����Monte Carlo rollouts���������Ƶ���ֽ������Ӷ��õ���ʤ���ʣ�Ȼ�����ַ�����ʵ���dz���������Ҫ����ѵ������Ȼ�����ʣ�����ת��������������v������Ҷ�ڵ㣬����ʤ���ѷ������Ż���Щv�� ����IJ������£� a. Select: ÿ��ģ��ӵ�ǰ�����Ӧ�ĸ��ڵ�s��ʼ�����ϵ�����ѡ��Q(s,a)+U(s,a)���Ķ���a����������һֱ����������Ҷ�ӽڵ�����̽����� b. Expand and Evaluate: ��MCTS����Ҷ�ӽڵ�ʱ��˵��֮ǰ̽�����������Ҳû�м���ȥ�����ڵ�ǰ״���¸������������ˣ���ôû����ʷ����MCTS�����չ���Ҷ�ӽڵ��أ�NN���ṩ�˰������ѵ�ǰ��s������NN��NN����Եõ�һ��p��v��ͨ��NNָ��MCTS�������졣 c. Backup: ��һ���������Ҫ�������徭����������move���и��¡����ǵ�ô��ÿ��move�洢����һ��move�������ջ�ʤ��ʤ���Ƕ��٣����Ե����̽�����Ҫ������и��¡� d. play: �����ģ����̺����ͨ�����ʵõ��У� [��ʽ] , �� ���¶Ȳ�����temperature parameter���������Կ��Ʀеķֲ������Ȼ��Ǹ����ͣ�ͨ��������������NN���õĽ���ѧϰ�� 3. ����Ч�� |
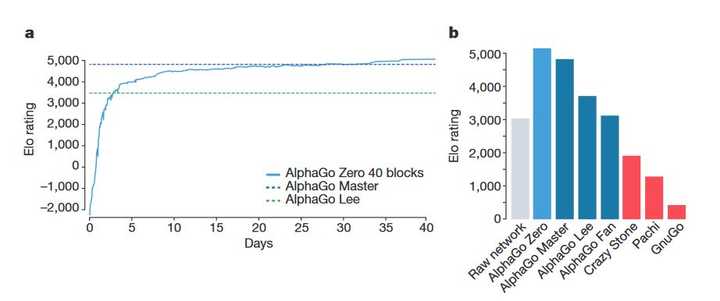
|
|
Image Elo�ȼ�������������г��õ�һ�������ֶΣ�������������ʯ��Elo�ȼ��ִ����3600�֣���������ܵ�AlphaGo Lee��Լ��3800�֣�����Ȼ��������ˮ�������ಢ���Ǻ����ᡣȻ������Zeroȴ�Ѿ��ﵽ��Լ5200�֣�����ǧ������������ʦ�����֮������������ԶԶδ�ܴ�����ңԶ���磡 ��Zero�Բ��ĵĹ����У������˴��������δ������з���Ҳ���˺ܶ�����ԭ�е��з�����������½����������Ҳ�������֡� |

|
|
Image �����������еĵ�һ�֣�����ִ�ס����뷲�Ƕ�Χ����һЩ�˽�����Ѷ�����������һ����·��������һ�м����伺�����������˺ڷ����ƣ�������ȥ���ֽ������ӵĻ��ᡣһ���䣬��������ԭ�������Χ��������ռ�Ч�ʡ� |

|
|
Image �������еĵڶ��֣�����Ϊ��������ʷ�Ͼ���ˮƽ��ߵ�һ�֡�����һֱ��Ϊ����ƺŲ�̫��࣬�����С�ǧ�ŵ�һ���塰��Ϊ���ʡ���һ�ֿ½�ִ���³���һ�ֶ�·��̣����������������AI�ĸ����о������������AI�����ɱ�У����Դ�Zero�Ծɱ���ĸ������������ȵ����Ž⣬�·���˵ ���α��������� �ġ���Ϊ���ֵ�һ����� AlphaGo�ij��ֶ�����������һ�����£�����Χ��磬������ǻ����ԵĴ�������������ֱ���Ϊ��ʤ��ʦ����һ����361����㣬���ص��Dz��ƹ��ܵ��������ģ���ս����ս���ļ�����ײ���Ǿ�����������������档�������ĺ�AIʱ�������ȴ�Ѿ��������AI���µ�һ�����ԣ�˭���ǵ������������Ľ����� ����һ�ˣ������ս�ս֮�ʣ��������ɣ����ձ���Ժ�������ң���ѹһ���̳���������ܡ� ����һ�ˣ���������̨֮�ϣ�����������ھ���֮������ֱ�ϣ�ɨ��һ�ڵ��֣������ʥ�� ����һ�ˣ�����̳����֮�У���������������ȴ����ʯ��ͳ��һ�������ֻȡ��Ŀ�� �������� ��������һƬ������û�����̣�ȴ����ɱ�������ֵ�����ȴ���������������������������콾������������Ƿdzɰ�תͷ�գ�AI�Ծ�Ӣ�ۡ��� ǧ���ɣ�����±�Ǩ��������������Ͼ��Ķ��ǵ�˺ɱ����ʿ���ĵ�ִ�ţ����С�����Χ���Ų��������! ������ʮ��֮�����Dz���������ǧ����������ʦŻ����Ѫ�����������ļ�����ֻ����ÿ�ζԾ�֮����AI��ʦҪһ�����֡���һ�ݱ�� AlphaGo�������Ҷ�ʱ������λá����������������ڤڤ֮���������⣬���������Ϊ������Ҳ����Ӵ�����һ����Ȥ���ֳ����ǻ۵����� ��������Ƽ�һ��������ʿ�Ĵ��Ǻ�һ�ν����������ʷ�Ŀ�����Ƶ����ɴ���һ�������Dz���׳�����λá� |

|
|
��� ����Դ����¼ Χ���ʦ��ʷ���ﴫ�� ���� ���� ��21.20 ȥ����? 2022��6��3�ո��� ��֪�ѷ�ӳ�õ���̫��רҵ�ʻ㣬���������⡣����ܿ�רҵ�ʻ㣬��ͨ�����Լ�����һ������AlphaGo�����ڻ��ơ���������ж�רҵ֪ʶ����Ȥ�����ѣ�����Ҳ�Ƽ�һ�����õ�ǿ��ѧϰ���Ŷ�� |

|
|
��� ����dz��ǿ��ѧϰ:ԭ������ ���� ��39.18 ȥ����? �����Dz���˵�� AlphaGoϵ���õ�����ѧϰ���㷨��ʵ���϶����Էֳ�������ѵ�����̺Ͳ��Թ��̣���ʵҲ�Ͷ�Ӧ������ƽʱ��ѵ���ͱ���ʱ�ĶԾ֡� ����AlphaGo ����AlphaGo�Ŀ����ʵ������������ɡ����ǽ�Χ�忴��һ��ս������ô�������ֿ��Էֱɣ� ����ָ�Ӻ;��ߵĽ������������磩�����������Ƶľ�ʦ����ֵ���磩����̽��ս�����Ƶ�ʿ���������������磩 ����֮�����ϣ��Ӷ������˴ﵽ������������ˮƽ�ij���AlphaGo ѵ������ һ��ʼ�����������е�����ѵ�����ǡ����������е��·����ý�����ʿ��ѧ��ģ���������ӣ����������жԾֵ�ʤ�����þ�ʦѧ��������ֵ���ʽ�� ����һ����ɺ��������ﵽ������ְҵ���ֵ�ˮ����ʿ��Ҳ�ﵽ��������ͨҵ�����ֵ�ˮ����ʦ����ʽ�ж�Ҳ����һ��ȷ�ȡ� ��ô����Ϳ�ʼ�ý����;�ʦͨ�����Ҳ�����ѧϰ������������أ����Ƚ����ᡱӰ�����������ܺ���ǰ���Լ����ģ���������Ƕ��Ĺ����е�ÿһ������ʦ�������Ա�ĬĬ���������жϡ���һ�����ˣ������;�ʦ��ʼ���̡�ͨ���Ծֽ�������������Լ�ÿһ�����߷������һ���ѯ��ʦ��������Ծ�ʦ�ж�ʧ���ľ��������ϴ�ĸ��ģ��Ա�������õ���ϣ�ͬʱ��ʦҲ˼���Լ��жϵ�ʧ�����Լ����жϸ������Ծֽ���� ͨ������ѭ���������̣������;�ʦ�����������˺ܴ�������� ���Թ��� ��ѵ��������ɺͿ�����ʽ��ʼ�����ˡ���ʱ��ɲ���ѵ����������һ�����Լ�����ֱ�Ӽ��ž���ս�� ��һ�������£����Ƚ��������������õ��з�ϸϸ���ã����ؿ�������������˼��������������ߣ�����֮�����ʲô���棿Ȼ����֮���ܵľ��涼������ʦ����������Ϊ�˷�ֹ��ʦ�ж�ʧ���������ɳ��ܶ�ʿ��ȥ̽�����ƣ��������Լ�����ȫ�֣�MC rollouts�����ٸ��߽������������ۺϾ�ʦ��������ʿ����̽�飬�������յ��жϣ����ӡ� ��˵�ĺã�������Ƥ����������������߱���������̫ǿ�������������֮�£����ǾͿ��Ի������ඥ�����֡� AlphaGo Zero ����AlphaGoͨ�����ž���ս�����ʤ��������֮��һ��������ŵ����ˣ�����Zero��Zero��Ϊһ��������ţ���м������ЩȺŹ�����飬��һ���˾��ܱ���һȺ�����û��ã�һ�����ڡ�����Zero����ѱ����Ϊ�����϶��Ǵ�����û��������������ʦ���¶�����ֻ����ѧ���⺢�ӣ���С�Ͱ�װx�����������װ���ˡ� |
|
|
ѵ������ Zeroֱ�ӾͿ�ʼ�����Ҳ��ġ���һ�������£�����Zero�����Լ���ֱ����㣬Ȼ����ϸ���ú����ؿ��������������ӣ�����һ������һ���������ơ���һ�����ˣ�Zero��ʼ���̣���һ���Ż��Լ���ֱ������ֱ���������ú�����������ͬ��һ���Ż��Լ������������������������Ľ���ͶԾ�ʤ�����Ǻϡ� ��������ţ������Ŭ�����ܿ������ܹ������ž���ս�ij������ڵ���Ħ���� ���Թ��� Ӧ��һ�����ԣ���������Σ�������ܶ��������Ķ�����Щ�е�ѧ������ν�ġ���Ͱˮ���������Ĵ��ж��dz������أ���Ҫ�������ǿ����ؾ������ǻ�����㣬��ƽʱһ�����¡������Zero����ʵд�գ�����֮ʱ���˲���Ҫ���Ǹ����Ż����������⣬������˵û���κ������Ƶ�����֮�䣬����һ�С� ����ʹ�� Zhihu On VSCode ���������� |
|
�౦��һ�㿴�� �౦��ô��������Alpha Go��ʵ�����������ڻ����Գ�Խ�� ��������ʵľͺ���ô˵�أ��һش���ܶ���ˣ��Ͳ����ܳ�Խ �㲻���ܣ�����ô�ܹ���Alpha Go���� û�������п��ܳ�Խ�����������dz�Խ���� ���˶��²������һ���AI�£��Dz��Ǹ�Ц�� �����ò����ϣ��Ҳ��ò����� ���������ʵ������Ϊ����AI�Ժ����˾�ķ��� Ȼ��Ҳ�ر����ģ�����ô���۶����ԣ����Ҿ������ڵ�Χ���Ǽ���֮���ĵ� ��ʵ���Ǿ����и��̲�һ����Ȼ�����ǵĶ��ֵ��ڸ����dz��� �����ܷ��ս̲��ϵIJο���ȥ���� ��ú��˴�ö��ˣ�������Ǻ϶Ⱦߣ�ʤ�ʾߣ��ͺ��п���Ӯ ��ò���ʤ�ʾͻή�� �����ϴ�����Ӯ�ˣ��������� �˿϶�Ҳ���е�����ڣ�����ʵ��������ȷʵҲ�Ƿdz��ľ� AIѵ���ķ�ʽ���ʺ��ҵģ���û�а취 �����кܶ������ң�˵���ڶ���AI��������������������ʲô�أ� ���ʵ����ˣ������ģ�����ǰ����˵���Լ�������˵ ����������Dz�������� ��������Ϊʲô����������أ� ����ʲô������ ����ʲô������ ��Χ����ʲô������ �ҿ�������ʲô���� �Ҳ�֪����ʲô���� ���·��� �Ϳ����·��� ��û��ʲô����ѽ �Ҷ�����ȥ˵���Լ���ȥ˵�����ְҵ��ʲô���� �Լ�������ȥ˵���Լ� �����ھ�˵��С���Ӷ����ԣ���������ͦ����˼�� ��Ϊ��Ϸ��������ͦ����˼��һ����Ϸ �����������ѵľ�һ��������������������� �����������˵ �����������ֻ��˵��ʽ�������ܶ��¶�û������ �����������ҵ����� ��ȷʵ�ʵ����� �ܶ����ⶼ�ʵ����� ��Ҳ��Ѱ�ң���AI���д��ˣ�������������� ����˵Ϊ���¸��õ��� ��Ҳ����Ҫ���� �����ƽ��Ժ�����ô�� �������Ҳ���������е� �������Ӧ���dz���Ա���е� ����ɶҲ˵���� �岻�ϻ� ���� |
|
�������������˽�ӹ����С˵������ֽ��������������ˣ������ڹ����ۺ����նྫ�ɣ���ͨ��һǹ���ܸ�����ˣ��������ֲ��������У�����Ҳ��������������ѧ�䣬����û�䣬����û�䣬����ʱ�����ˡ� �㵱Ȼ����˵�������������������䰡�������ܿ����ִ�ᰡ����ֹʹ�û����������ˣ����������û�������ǣ���һ��һ��������������ֵ��������û��ѽ�� ai��Χ���Ӱ��Ҳ������������ưɡ�������Ȼ����ѧϰ���գ�����֮����Ȼ���Ծ��ʲ��ģ���ֹai���������𣿵��ǡ������뵽��������ӣ��Ҷ�������ܹ��������ǵĸ��ܡ� ���ǣ������վ���û���˵ģ�ʱ�����ǻ�����ģ���������δ�����������������Ԥ�ԣ�����ʹ����������Լ�����֫���и������һ�죬���е��˶���ĿҲ��ӭ��Χ�����ڵĴ����� ����ʵ��һ��ͦ����˼�ı��⣬������������д�����ٹ۵��һ��ģ�û�о��ԵĶԴ��� |
|
�Ҳ���Χ��Ҳ˵����AI�㲻���ǻ���Χ�塣������֪������һ�����顣 ����֪��������ش��ĵ�һ����ҵ��ʲô�� ��ơ�������ơ� �����ĺô����Ǽ���������һ�㡣�ڼ�����ռ���ǰ���������þ�ҵ��רҵ����Ϊ���и�ҵ����Ҫ��ơ������Ļ�ơ� ��ʱ����ȥ��ٻ���¥���ῴ��ÿ����̨�鶼��һ�����˻�ƣ�ÿ��¥�����һ��¥���ƣ���������¥����һ���ܻ�ƣ�ÿ�������°�����л���Ǿͻ������Լ����˱�һ��ȥ�����Ҷ��ˣ��dz����֡���Ƶ������������ۻ�Ա���������ɣ���Ů���ӵ���ѡרҵ�� ������ῴ����������ר��ְԺУ�����˻��רҵ������ϻ��л����ѵ�࣬����ʴ�����ѵ�త�š���Ϊ�����ȷʵ��Ҫ�����ij�����ƣ� ����������ռ��ˣ���������ϵͳ����Ҳû�С������ơ����ַֹ��ˣ���ר��ְ�Ļ��רҵ���������������ˮ���ٻ���¥������Ҳ�Ӷ���ʮ�˵Ĵ����ת��Ϊ�������˵�С���ҡ������ܶ�С��ҵ����û�л�ƣ��ϰ�ϱ����Excel�����˾��ˡ� ���ڻ�ƻ��Ǻ���Ҫ������ҵCFO�����Ǹ�excel��������ע����ʦ����ʦ����Ȼ�����ҵ���н���������Ͳ����û���ˣ�����������ʧҵ�ˡ� ������ߵ�ְҵ���У����л��רҵ������ҵ���Ѿ�û����ȥ���»��ҵ���ˡ� ҽѧ���棬�����ĵ�ͼ��Ӱ��ơ��������Ѿ�����ʹ�õ����Զ�������ˣ���˵��һ�����ǻ�����Ҫ��Ա��Ŀǰ�ܶ�ְ�������������͡���Ȼ��ְ����û�����ڵģ���ô�ͼ�����Ƹ��ְ�����������˾����ˡ� ���ԣ�Χ��ѡ��Ҳ����̫�������ڱ���̭��·�ϣ����Dz����µ��� |
|
|
| [�ղر���] �����ر��ġ� |
| ��һƪ���� ��һƪ���� �鿴�������� |
|
|
|
| ��Ʊ�ǵ�ʵʱͳ�� ��ͣ��ѡ�� ��ʱͼѡ�� ��ͣ��ѡ�� K��ͼѡ�� �ɽ���ѡ�� ����ѡ�� ������ѡ�� �������� �������� ���� MACDָ�� KDJָ�� BOLLָ�� RSIָ�� ���ɻ���֪ʶ ���ɹ��� |
| ��վ��ϵ: qq:121756557 email:121756557@qq.com ����ƻ� |