
| |
|
|
| 首页 淘股吧 股票涨跌实时统计 涨停板选股 股票入门 股票书籍 股票问答 分时图选股 跌停板选股 K线图选股 成交量选股 [平安银行] |
| 股市论谈 均线选股 趋势线选股 筹码理论 波浪理论 缠论 MACD指标 KDJ指标 BOLL指标 RSI指标 炒股基础知识 炒股故事 |
| 商业财经 科技知识 汽车百科 工程技术 自然科学 家居生活 设计艺术 财经视频 游戏-- |
| 天天财汇 -> 科技知识 -> OpenAI 视频模型 Sora 的推理生成成本多高? -> 正文阅读 |
|
|
[科技知识]OpenAI 视频模型 Sora 的推理生成成本多高? |
| [收藏本文] 【下载本文】 |
|
OpenAI,发他们的文生视频大模型,Sora了。。。 而且,是强到,能震惊我一万年的程度。。。 https://openai.com/sora 如果… |
|
从技术报告上看,Sora是基于latent diffusion的视频生成模型。首先会训练一个Video compression network,将视频编码到一个低维度的latent空间,这和SD使用一个VAE将512x512x3的图片编码成64x64x4的latent是类似的道理。然后会将latent转成patches,送入到基于transformer的扩散模型中。 |

|
|
|

|
|
如果假定这里的Video compression network的空间压缩率也是8x,patch size是4x4x4,那么对于1024x1024x32的视频(32帧的视频)其patch个数就为32x32x8=8192,就是说Transformer要处理的token长度大约是8k,如果去噪步数是20,那么就生成这样一段视频就相当于一次要生成160k的tokens,所需的计算量还是挺大的。 注:这里假定Video compression network没有在时序上压缩,即视频的帧数没有减少,只是图像的宽和高降采样了。 此外,实际上video transformer往往会采用分离的空间attention和时序attention,所以实际上网络的计算开销会少很多,具体可以见谷歌的ViViT[1] 参考^ViViT: A Video Vision Transformer https://arxiv.org/abs/2103.15691 |
|
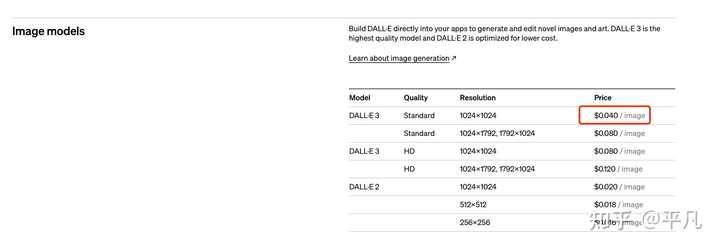
我来一个非常粗犷的计算。 Sora可以生成一分钟的视频,一分钟 = 60 秒, 一秒 = 24帧。 那一分钟就等于1440帧。 那一分钟的视频就等于生成1440张图片。 那生成一张图片呢,就按Dalle3的最便宜一档来算,为0.04刀。 |
|
|
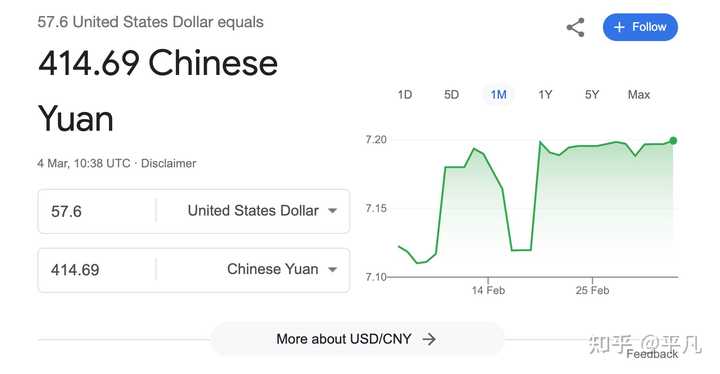
那1440*0.04刀= 57.6刀。 等于这么多。 |
|
|
这是很粗略的算,但不管怎么样,成本肯定很高,不然奥特曼不会嚷嚷着要融7万亿美元做芯片。 真心顶不住。 |
|
非常高。 初步估计: Sora 生成 1min video 的成本 是 GPT-4 生成 1k token 的 1500 倍。以 GPT-4 $0.06/1k token 的定价, 猜测 Sora 定价 1min video 需要约 $90。Sora 生成 1min video 时间会非常久。 以 8xA800 计算,需要 3 小时以上。 (可以用多台 A800 机器加速) 以 8xH800 计算,需要半小时。 详细推导过程参见: 成诚:浅谈 Sora 未来的千倍推理算力需求298 赞同 ・ 36 评论文章 |

|
|
核心的假设: Sora 参数量约为 20B (百亿规模)1920x1080 的高清图像,经过 VAE 压缩(最高 32 倍压缩比)后得到 64x32 的 latent ,即一帧 = 2k tokens时间维度上,1s 30帧 压缩到 9 帧 则可以推导出: 1minVideo=64∗32∗9∗60=1Mtokens" role="presentation">1minVideo=64?32?9?60=1Mtokens1minVideo = 64*32*9*60=1M tokens 即 1000000 tokens 根据 OpenAI 技术报告,Sora 是一个 Diffusion Model,核心部分是 DiT(Diffusion Transformer)。 DiT 是 Encoder-Only 架构,对于 [64, 32, 540] 的 latent cube,需要约 20 个 timestep 进行迭代。 参考: Scaling Laws for Neural Language Models |

|
|
推导 Transformer 模型的前向计算代价 Transformer 模型一次前向计算的理论计算量公式是 ( N 是模型参数量大小): Cforward/token=2N+2nlayernctxdmodel" role="presentation">Cforward/token=2N+2nlayernctxdmodelC_{forward/token} = 2N + 2n_{layer}n_{ctx}d_{model} 参考常见的 20B 左右大模型的 hidden size, dmodel=6144" role="presentation">dmodel=6144d_{model} = 6144 ,则 : nctx/12=1M/12≈14∗6144=14dmodel" role="presentation">nctx/12=1M/12≈14?6144=14dmodeln_{ctx} / 12 = 1M / 12 \approx 14 * 6144=14d_{model} 则可以推导出: Cforward/token=2N+2nlayernctxdmodel≈2N+2∗(14nlayer(12dmodel)dmodel)=2N+2∗14N=30N" role="presentation">Cforward/token=2N+2nlayernctxdmodel≈2N+2?(14nlayer(12dmodel)dmodel)=2N+2?14N=30NC_{forward/token} = 2N + 2n_{layer}n_{ctx}d_{model} \approx 2N + 2*(14n_{layer}(12d_{model})d_{model}) = 2N + 2*14N = 30N 生成一分钟视频的 token 数 D=1Mtokens" role="presentation">D=1MtokensD = 1M tokens 生成一分钟视频的 Diffusion timesteps : T=20step" role="presentation">T=20stepT = 20step 则 Sora 生成 1min video 的理论计算代价为: C1minVideo=Cforward/token∗D∗T=30N∗D∗T=30∗20B∗1M∗20=1.2∗1019FLOPs" role="presentation">C1minVideo=Cforward/token?D?T=30N?D?T=30?20B?1M?20=1.2?1019FLOPsC_{1minVideo}=C_{forward/token}*D*T=30N*D*T = 30 * 20B*1M*20=1.2*10^{19} FLOPs 而 GPT-4 生成 1k token 的计算代价是: CGPT4−text=2NGPT4∗Dtext=2∗400B∗1k=800TFLOPs" role="presentation">CGPT4?text=2NGPT4?Dtext=2?400B?1k=800TFLOPsC_{GPT4-text} = 2N_{GPT4}*D_{text}=2*400B*1k=800TFLOPs 两者相差 15000 倍: C1minVideoCGPT4−text=1.2∗10198∗1014=15000" role="presentation">C1minVideoCGPT4?text=1.2?10198?1014=15000\frac{C_{1minVideo}}{C_{GPT4-text}} = \frac{1.2*10^{19}}{8*10^{14}} = 15000 而 GPT-4 是一个 Decoder-Only 的 Transformer,推理时为 Memory-Bound 访存瓶颈,计算利用率 MFU 可能只有 Sora 的 1/10,因此两者的实际差距: Sora−InferenceCostGPT−InferenceCost=C1minVideo/MFUSoraCGPT−text/MFUGPT=15000/10=1500" role="presentation">Sora?InferenceCostGPT?InferenceCost=C1minVideo/MFUSoraCGPT?text/MFUGPT=15000/10=1500\frac{Sora-InferenceCost}{GPT-InferenceCost} = \frac{C_{1minVideo} / MFU_{Sora}}{C_{GPT-text}/MFU_{GPT}} = 15000 / 10= 1500 Sora 推理 1min video 对于实际算力的需求是 GPT-4 推理 1k token 的 1500 倍。 如果用一台 8xA100 机器生成 Sora 1min video,A100 的单卡算力是 312TFLOPs ,根据之前推导的各项参数,假设 MFU = 50%,可以推导出来 8xA100 机器需要生成的时间为 3.2 h: Duration=C1minVideo8CA100MFU=30N∗D∗T8∗312T∗0.5=30∗20B∗1M∗208∗312T∗0.5=9615s=3.2h" role="presentation">Duration=C1minVideo8CA100MFU=30N?D?T8?312T?0.5=30?20B?1M?208?312T?0.5=9615s=3.2hDuration = \frac{C_{1minVideo}}{8C_{A100}MFU} = \frac{30N*D*T}{8*312T*0.5} = \frac{30*20B*1M*20}{8*312T*0.5} = 9615s = 3.2h 如果是 8xH100 机器,并加上 FP8 推理,按照 40% MFU 可以推导出来 8xH100 机器需要生成的时间为 0.5 h : Duration=C1minVideo8CH100MFU=30N∗D∗T8∗1979T∗0.4=30∗20B∗1M∗208∗1979T∗0.4=1875s=31min" role="presentation">Duration=C1minVideo8CH100MFU=30N?D?T8?1979T?0.4=30?20B?1M?208?1979T?0.4=1875s=31minDuration = \frac{C_{1minVideo}}{8C_{H100}MFU} = \frac{30N*D*T}{8*1979T*0.4} = \frac{30*20B*1M*20}{8*1979T*0.4} = 1875s = 31min |
|
Sora并没有公布模型相关的各种参数信息,所以可以尽情的大胆假设和推理一下。 首先来看看DALL・E3生成图片的成本: 标准分辨率1024×1024像素的图片,价格是每张0.040美元。标准分辨率1024×1792或1792×1024像素的图片,价格是每张0.080美元。高清分辨率1024×1024像素的图片,成本是每张0.080美元。高清分辨率1024×1792或1792×1024像素的图片,价格是每张0.120美元?。[1] 然后考虑一下不同类型视频的帧率(即每秒显示的图片帧数): 24帧/秒:电影行业的标准帧率,用于大多数电影的拍摄和播放,能够提供较为流畅的动作表现。25帧/秒:主要用于使用PAL电视系统地区的电视节目。30帧/秒(或29.97帧/秒):常用于使用NTSC电视系统地区的电视节目。60帧/秒:提供非常流畅的动作,常用于游戏中的视频播放、体育赛事直播和一些高帧率电影。 也就是说,生成1秒视频所需的图片帧数从24到60帧不等。根据目前Sora放出的一系列视频来看,大概只需普通电影的帧率,所以暂且认为sora的帧率是24帧/秒。 做个简单的乘法,假如生成1024×1024分辨率,1分钟的视频,那么60*24*0.04=57.6美元。 但是显然生成视频并不是简单的堆叠图片,而是要涉及更复杂的动态内容处理。 比如时间序列处理,视频是由一系列图片组成的时间序列,需要算法理解和生成时间上的连续性和逻辑性,这就要求模型拥有更复杂的结构、更多的参数,也就意味着更多的计算资源; 比如生成视频肯定会涉及到动态场景和对象的运动,也就需要模型能够理解物理规律和动作逻辑,显然这些比生成静态图片难得多,模型训练过程中直接学习视频内容的资源消耗,就要比学习图片大得多; 再比如视频数据的维度高于图片,处理这些数据需要更高的计算能力和存储空间,进一步导致成本增加。 如果将训练过程中的成本以及储存、计算资源的消耗全部计算在内的话,Sora生成一个1分钟视频的成本恐怕不是我们普通人能够随便拿来玩的…… 这样一算,似乎可以理解奥特曼为啥嗷嗷叫着要自研芯片了,如果计算价格下不来的话,产品再好,恐怕也很难得到广泛的推广和应用。 参考^https://openai.com/pricing/ |
|
通过Sora的技术报告看来,Sora有以下一些特点: Sora 模型的关键特点包括: 将视觉数据转化为Patch(Turning visual data into patches) 研究人员受到大型语言模型的启发,它们通过在互联网规模的数据上进行训练而获得了通用能力。LLM范式的成功部分得益于优雅地统一了文本、代码、数学和各种自然语言等不同形式的令牌。在这项工作中,研究人员考虑了生成视觉数据模型如何继承这些优势。LLMs用文本Token,Sora则用视觉Patch。研究表明,Patch是用于训练生成模型的多种类型视频和图像的高度可扩展且有效的表示。 |

|
|
在较高层面上,研究人员通过首先将视频压缩到低维潜空间,然后将表示分解为时空Patch来将视频转换为Patch。 视频压缩网络(Video compression network) 研究人员训练了一个降低视觉数据维度的网络。这个网络以原始视频为输入,并输出一个在时间和空间上都被压缩的潜在表示。Sora在这个压缩的潜在空间上进行训练,并在此空间内生成视频。研究人员还训练了一个相应的解码器模型,将生成的潜在表示映射回像素空间。 时空潜控件Patchs(Spacetime Latent Patches) 给定一个压缩的输入视频,研究人员提取一系列时空Patch,这些Patch充当Transformer Token。这种方案对图像也适用,因为图像只是具有单帧的视频。研究人员基于Patch的表示使得Sora能够训练各种分辨率、持续时间和长宽比的视频和图像。在推理时,研究人员可以通过将随机初始化的Patch排列成适当大小的网格来控制生成视频的大小。 扩展Transformers用于视频生成(Scaling transformers for video generation) Sora是一个扩散模型;给定输入的噪声Patch(和文本提示等条件信息),它被训练来预测原始的“干净”Patch。重要的是,Sora是一个扩散Transformer(diffusiontransformer)。Transformers已经在各种领域展现出了显著的扩展性能,包括语言建模、计算机视觉和图像生成。 |

|
|
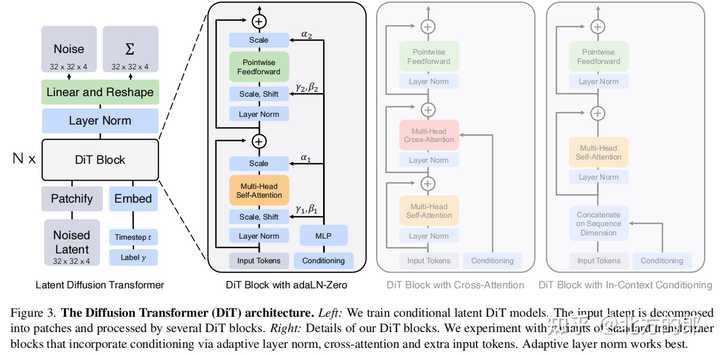
从这些可以看到通过使用Patchs以及Video compression network,Sora已经对处理的数据进行了大幅的压缩,应该会大幅提升处理效率。但是Patch大小,压缩比率不知道,所以无法准确推断。我感觉可以参考一下Sora的基础技术之一的DiT: |
|
|
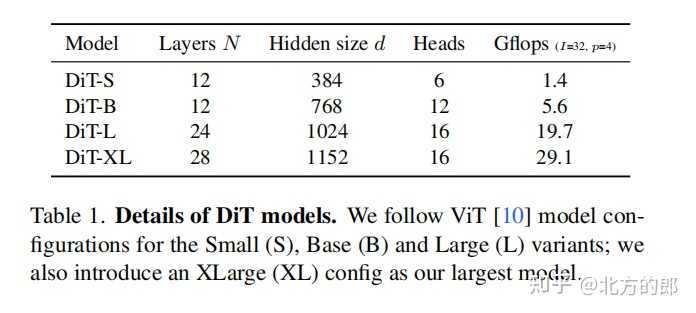
DiT模型大小: |
|
|
DiT有四种配置,分别为DiT-S、DiT-B、DiT-L和DiT-XL。 DiT-S包含12层,隐藏维度为384,6个注意力头,计算量为1.4 Gflops。DiT-B包含12层,隐藏维度为768,12个注意力头,计算量为5.6 Gflops。DiT-L包含24层,隐藏维度为1024,16个注意力头,计算量为19.7 Gflops。DiT-XL包含28层,隐藏维度为1152,16个注意力头,计算量为29.1 Gflops。 Sora的模型应该比DiT-XL还要大,所以对计算资源的消耗应该是非常大的。 参考: Video generation models as world simulators Scalable Diffusion Models with Transformers |
|
Sora的成本即使低到白菜价,它最终的客户群体也是非常狭窄的,就如文生图一样,它并不是普通人的刚需。 文生图发展到今日,大众的新鲜劲儿已经消散,还在坚持玩的,就剩下与美术相关的从业者了。 Sora面临的情况也是如此,最终除了影视相关的从业者外,谁还会花钱用Sora生成视频? Sora的归宿,最多就是成为影视后期软件的一个智能插件,仅此而已。好比洗脚盆里扎猛子,翻不出多大水花。 |
|
Sora的技术路线如果被开源,国内将能很快赶上。 在追赶Sora时,算力有可能成为门槛。 集中国内所有AI企业的算力或许是方法之一。 Sora视频分析对算力的消耗应该是远远超过千亿模型的。 现在国内显卡都被卡脖子之后,算力就可能会是一个问题。 Meta已经有50万块GPU,明年可能会买百万块。 微软应该也会按照百万级别去下订单。 国内所有人工智能公司加在一起可能有50万块GPU,都分散在各个公司里。 GPU的英文全称是Graphics Processing Unit,即图形处理单元,又称显示核心、视觉处理器、显示芯片。 |
|
开启一篇深度好文,让我们一起探讨OpenAI最新的视频模型Sora的推理生成成本。Sora模型,作为OpenAI在视频理解和生成领域的一次重大突破,不仅引起了广泛的关注,也让很多人好奇它的运行成本究竟如何。 首先,了解Sora模型的推理生成成本,我们得先弄清楚几个关键因素。其中最重要的包括计算资源、模型复杂度、以及运行效率。Sora模型为了处理视频数据,相比处理静态图片或文本的模型,无疑需要更强大的计算能力。视频数据的维度更高,处理起来更加复杂,因此,模型的推理生成过程消耗的资源也会相对较多。 |

|
|
接下来,谈谈模型复杂度。Sora模型能够理解和生成视频内容,这背后依赖的是深度学习中的复杂网络结构。这种复杂度不仅体现在模型训练时对硬件的高要求,也反映在推理时对计算资源的消耗上。一般来说,模型越复杂,其运行成本也越高。 运行效率也是一个不可忽视的因素。OpenAI在设计Sora模型时,肯定会尽量优化其运行效率,比如通过算法优化减少不必要的计算,或是利用更高效的硬件加速推理过程。这些优化措施能在一定程度上降低成本,但具体节约了多少,需要根据实际运行情况来评估。 |

|
|
至于具体的数字,OpenAI并未公开Sora模型的详细运行成本。不过,可以肯定的是,随着技术的进步和优化,未来的模型运行成本有望进一步降低。现阶段,对于研究人员和开发者来说,最好的策略可能是利用云计算资源,通过按需付费的方式来平衡成本和性能需求。 |

|
|
最后,让我们不忘这背后的意义。Sora模型的出现,不仅是技术进步的体现,也开启了视频内容理解和生成的新篇章。虽然成本是一个需要考量的重要因素,但其带来的创新和可能性,无疑是值得期待的。 总结起来,Sora模型的推理生成成本受到多种因素的影响,虽然具体数值不得而知,但随着技术的不断优化和发展,有望在未来实现成本和效能的更好平衡。现在,我们所能做的,就是继续关注这一领域的最新进展,探索其带来的无限可能。 Ads: 如果你对最新的GPTs新闻感兴趣,不妨看看[GPTs Weekly](https://gptsweekly.ai/)。(by [Earn revenue from your GPTs with in-chat ads](Earn revenue from your GPTs with in-chat ads)) 我是竹醉,专注AI副业变现,我们成年人学东西其实更多的还是为了拿到自己想要的结果,而不是随随便便花钱,吭哧搞一堆,结果都是赔本赚吆喝,我同样也是希望我做的分享能给大家解决问题,提供价值,在AI这个时代能够快人一步! |

|
|
竹醉 1 次咨询 5.0 计算机软件测试员职业技能等级证书持证人 12843 次赞同 去咨询 |
|
有一些回答已经初步结算了,一分钟视频近百美元。这也是没有开放大规模试用的原因。也能解释为什么奥特曼喊话要成立芯片公司。 他是喊话黄皮衣的,你丫的再不降价,再限产能我就掀桌子了。 一方面是因为现在显卡价格与数量已经没办法满足飞速发展的需要。奥特曼一众ai公司不想搞来搞去给显卡公司打工了。另一方面,不把生成成本降一个数量级。没办法推进商用啊!一百美元一分钟视频,成本太贵了。 |
|
从不给demo来看应该不小 |
|
不知道有没有节省的解决方案,比如预览图功能,先出低分辨率,确定镜头选择后在再出高分辨率的。 |
|
OpenAI尚未公布Sora模型的推理生成成本,但根据目前公开的信息,我们可以进行一些初步的估计。 |

|
|
影响Sora推理生成成本的因素主要包括: 模型大小: Sora模型是一个大型语言模型,拥有数十亿个参数,因此模型推理所需的计算资源和存储空间都非常巨大。输入数据: Sora模型可以接受文本、图像和视频等多种格式的输入数据,不同类型和大小的输入数据会对推理生成成本产生影响。输出内容: Sora模型可以生成文本、图像和视频等多种格式的输出内容,不同类型和大小的输出内容也会对推理生成成本产生影响。硬件平台: Sora模型可以在不同的硬件平台上运行,不同平台的性能和成本也会影响推理生成成本。 根据目前公开的信息,Sora模型的推理生成成本可能在以下范围内: 低成本: 对于简单的文本生成任务,Sora模型的推理生成成本可能只需几美元。中等成本: 对于一般的视频生成任务,Sora模型的推理生成成本可能在几十美元到几百美元之间。高成本: 对于复杂的视频生成任务,例如生成高质量的电影或游戏画面,Sora模型的推理生成成本可能高达数千美元甚至数万美元。 以下是一些降低Sora推理生成成本的方法: 优化模型: 压缩模型参数、改进模型架构等方法可以有效降低模型推理所需的计算资源和存储空间。使用低成本硬件: 使用云服务器或边缘计算设备等低成本硬件平台可以降低推理成本。优化输入数据: 压缩输入数据、降低输入数据分辨率等方法可以降低推理成本。降低输出质量: 降低输出内容分辨率、降低输出内容帧率等方法可以降低推理成本。 随着技术的进步和硬件成本的下降,Sora模型的推理生成成本将会不断降低,未来有望更加普及。 |
|
关于OpenAI的视频模型Sora(注:此处Sora为假设或错误引用,OpenAI并未公开声明过名为Sora的视频模型,实际可能是对某一类先进视频生成技术的泛指或媒体使用的代称), 并没有直接提及OpenAI某个具体视频模型的确切推理生成成本。不过,可以从相关报道中推断出生成高质量视频内容的AI模型具有相当高的成本。 在真实世界中,开发和运行能够生成视频的人工智能模型是一项极其昂贵的任务。比如,在提到类似技术的成本时, 有一条记录指出基于SORA模型(再次强调这不是OpenAI官方模型名称)生成视频所需要的算力成本巨大。若按照该模型举例, 它对应的芯片需求为数万片高性能GPU,总算力成本高达8亿美元,而每日电费成本即达到5万美元。 虽然OpenAI一直在努力降低成本,并且在文本生成领域取得了显著的进步, 比如通过技术创新和规模化效应使得其模型如ChatGPT的推理成本显著下降,但对于视频内容生成这一复杂度更高的任务来说,成本预计会更高。因为视频生成不仅涉及大量的计算资源消耗,包括GPU集群的运行,还需要处理连续帧之间的时空一致性以及视觉细节的丰富性,这都会导致资源需求成倍增加。 因此,我们可以合理推测,OpenAI或其他公司在研发和部署用于视频内容生成的高级AI模型时, 其推理生成成本将会远高于文本生成模型,具体数值取决于多种因素,如模型架构复杂性、优化程度、硬件效率及使用量等。不过,由于缺乏针对OpenAI视频模型Sora的具体数据,无法给出一个精确的单位时间内或单位视频长度的生成成本。随着技术进步和市场竞争,未来这类成本有可能进一步下降,但目前尚无确切数据。 |
|
间接判断指标就是是否严厉打击亚洲用户。 每当奥特曼觉得算力富余的时候,看在$的份上,睁一只眼闭一只眼算啦。 每当算力吃紧了,GPU不足,奥特曼就会严打亚洲区用户。 而最近奥特曼又开始严打了。 所以SORA吃不吃算力,显然是显而易见的。 |
|
美苏冷战期间,大国博弈航天等等,形成大量的资源消耗。不管对国家对人类都没有溢出。 现在美国利用meta ,gpt,sora再次开启这一模式。。。骗局故事甚至再也无法提升的可能性。 |
|
|
| [收藏本文] 【下载本文】 |
| 科技知识 最新文章 |
| 百度为什么越来越垃圾了? |
| 百度为什么越来越垃圾了? |
| 为什么程序员总是发现不了自己的Bug? |
| 出现在抖音评论区里边的算命真不真? |
| 你认为 C++ 最不应该存在的特性是什么? |
| 为什么 Windows 的兼容性这么强大,到底用了 |
| 如何看待Nvidia禁止使用翻译工具将cuda运行 |
| 为何苹果搞了十年的汽车还是难产,小米很快 |
| 该不该和AI说谢谢? |
| 为什么突破性的技术总是最先发生在西方? |
| 上一篇文章 下一篇文章 查看所有文章 |
|
|
|
| 股票涨跌实时统计 涨停板选股 分时图选股 跌停板选股 K线图选股 成交量选股 均线选股 趋势线选股 筹码理论 波浪理论 缠论 MACD指标 KDJ指标 BOLL指标 RSI指标 炒股基础知识 炒股故事 |
| 网站联系: qq:121756557 email:121756557@qq.com 天天财汇 |