
| |
|
|
| 首页 淘股吧 股票涨跌实时统计 涨停板选股 股票入门 股票书籍 股票问答 分时图选股 跌停板选股 K线图选股 成交量选股 [平安银行] |
| 股市论谈 均线选股 趋势线选股 筹码理论 波浪理论 缠论 MACD指标 KDJ指标 BOLL指标 RSI指标 炒股基础知识 炒股故事 |
| 商业财经 科技知识 汽车百科 工程技术 自然科学 家居生活 设计艺术 财经视频 游戏-- |
| 天天财汇 -> 科技知识 -> 为什么我们提到的网速在上传、下载时要除以8? -> 正文阅读 |
|
|
[科技知识]为什么我们提到的网速在上传、下载时要除以8? |
| [收藏本文] 【下载本文】 |
|
比如100M,为什么算下来,上传、下载时只能用到12.5M/S?那为什么当初说网速时,不直接用除以8之后的值,为什么要给个乘以8的数字?剩下的7/8,… |
|
这个问题的深层关系是:计算机和通信是两个不同行业,有不同的关注点。 在通信业,我们关心的是数据如何从A传到B。那么,作为二进制数据,只能表达1和0的bit是天然的基础单位。而且这个bit,刚好还能和物理层面的脉冲信号相互对应(严格来说,脉冲信号是和码元才是一一对应,和bit是成比例对应。不过为了不过多引入其他诸如编码、码元进制等概念,就先这么说吧)。接下来做什么信号衰减、信号干扰、信噪比、信号转发之类的东西,都很方便。所以,通信行业拿着一个设备说我这台设备收发速率是“100bps”,实际上它想说的是:说这台设备一秒钟能收发/处理“100个信号”――当然,我们从计算机的角度来说,就是它一秒钟收发/处理“100个bit”――但这两种说法虽然意思相近,但实质内涵是有不同的。 但是在计算机业,虽然我们关注的也是1和0组成的二进制数据,但我们其实关心的是这些1和0所表达的含义。那么,一般情况下,只能存1和0的一个bit是表达不了什么特别有意义的内容的。所以,一般都用8个bit捆成一个byte来作为基础单位――好歹一个byte,存字符能放得下一个ascii字符,存数值能存0-255。甚至很多时候,我们还觉得一个byte也不够用,就继续捆成2byte、4byte、8byte来用。 所以,isp运营商,作为通信业中的一员,他们在采购设备、设计规划通信网络等等时候,自然使用的是通信业的概念和指标。 而你在计算机里看到的和显示的数据,自然又是按照计算机习惯的标准来。 看了不少其他回答,好像还是有不少觉得就是个除八乘八的单位转换问题。 那我就补充一下一些不被人注意到的小历史吧。 其实bit这个概念,要远远早于计算机出现的年代。大家看过谍战片,都应该对特工们偷偷发电报的那个滴滴答答的情节有印象吧?那里的每个滴答,就是一个bit,分别代表1和0(专业称谓是:dit和dah――不要问他们两和1/0到底谁代表谁,因为那个年代,人们不习惯用数字来代表二进制)。 而实际上,bit的出现,就是跟随远程电报业而出现的。最早的电报,大约在鸦片战争年代,大约在洋务运动年间传入了中国。到了甲午年代,我们看历史书上常见的什么“xxx通电下野”之类的“通电”,其实就是“通过电报广而告之”的操作――也就是说在那个年代,中国也已经有了完善的(有线)电报网络了。 而在那个年代,因为都是人工按出来的滴答,业内关注的速率其实不是bps,而是bpm(每分钟多少bit)。我的某位长辈,建国初期先是当通信兵,后来进入邮电。他们当年的职业技能大赛的永远不变的一个项目,就是比谁的bpm更高(包括发报和听报)。 说完了bit的起源,那就说说编码――因为大家都关心的是内容,而不是bit: 在电报盛行的那个年代,国际上最通行的字符编码就是摩尔斯码――大家熟知的代表紧急情况的SOS就是。但应该极少人留意到,摩尔斯码它就不是8bit代表一个字符的。它甚至已经极为超前的使用上了变长编码――英文字符1-4bit,数字统一是5bit。说来有意思,我当年宿舍有个哥们,在研究透彻了unicode编码后,顿悟,大赞这种变长编码乃前无古人后无来者的登峰造极之作。然后,捉狭的我就打印了份摩尔斯码表给他…… 而另一个我们熟知的编码:ASCII码,有两点冷知识:首先是它不是一个8bit编码,而是一个7bit编码。其次就是,它的出现同样早于计算机。所以,是的,它最早也是用于电报业的。它之所以能替代摩尔斯码,主要是那个年代电报公司已经基本不再用人工按出滴答了,已经是按键盘上的字母,然后机器自动转换为滴答编码发送,所以定长(便于机器处理)且能容纳更多字符的编码自然就更受欢迎。 那么,到了计算机出现后,就终于出现1byte=8bit了吗?不好意思,还是没有。早期计算机,1byte=Nbit的N的范围,从7-10都有――应该不会有比7小的(毕竟连ascii码都放不下的,造出来也不大可能受欢迎),但可能有更冷门的会超过10也说不定。而受此影响。在早期就出现的计算机编程语言:C和C++的标准文件中,同样明确说了这是留给各厂商自行决定的:A byte is composed of a contiguous sequence of bits, the number of which is implementation defined. ――这个规定至今尚存。 而我所知道最早的,明确规定了8bit为基础单位的,应该是互联网协议规范里(记得它用的还不是byte这个词,而是octet――而octet这个词,本身就来源于拉丁文的8)。自那以后,为了便捷的接入互联网,以及便捷的处理互联网报文,大家才逐步开始逐步把软硬件设计统一到1byte=8bit这个关系上――具体时间点应该不早于80年代早期。 所以,8这个比例关系,实际上出现得非常非常非常晚(和通信业相比),只不过因为互联网大流行以及之后的兼容性处理,导致人们对它极为熟悉而已。 总之,在通信业看起来,你们多少个bit捆起来,那都是你们的事――当年摩尔斯码一统天下的时候,老子就是按bit来算的。现在互联网席卷一切,老子当然还是按bit算。说得难听点,莫尔斯码一统天下的时间,可比互联网长多了。所以,城头变幻大王旗,谁知道以后会不会又有个什么大流行的编码变成100bit呢?不过就算真的有那么一天,我相信通信业的兄弟还是会给我们一句话:老子还是按bit算。 |
|
我们提到的网速在上传、下载时要除以8,是因为网络带宽的单位和数据传输速度的单位不同。 使用不同的单位主要是因为历史和技术上的原因。在网络通信的早期,比特是用来衡量信号传输速率的基本单位,因为它直接对应于二进制数据传输中的一个信号脉冲。而在计算机存储中,字节成为了更自然的单位,因为它可以容纳一个字符(如一个字母或数字)的信息。 虽然这确实给用户带来了一些不便,需要进行单位换算,但这两种单位在各自的领域都已经非常根深蒂固。不过,随着技术的发展和用户需求的变化,一些服务提供商和软件已经开始以更直观的单位(如MB/s或GB/s)来显示速度,以减少用户的换算负担。 网络带宽的单位是比特/秒(bit/s),而数据传输速度的单位是字节/秒(Byte/s)。1字节(Byte)等于8比特(bit),所以网络带宽要除以8,才能得到实际的数据传输速度。 例如,100M的宽带,其网络带宽为100Mbit/s,实际的数据传输速度为100Mbit/s / 8 = 12.5MB/s。 此外,在实际的网络传输中,还会存在一些损耗,比如网络拥塞、网络延迟、网络繁忙等等。所以,实际的数据传输速度可能会比理论值更低。 因此,为了获得更准确的估计值,我们将带宽的实际速度除以8,以获得更准确的估计值。 以下是网络带宽和数据传输速度单位换算的公式: 下载速度(Byte/s)= 上传速度(Byte/s)= 网络带宽(bit/s) / 8 当然在国内目前 上传速度,往往要比下载速度更慢一点,这个在早期可能是因为技术问题,如ADSL就是非对称数字用户线路,但是目前都是光纤网络的情况下,100M带宽,其实在光纤模式下是可以做到对称的,但是可能是出于商业的考虑,上行带宽更多的倾向到了 IDC 那边,下行带宽卖给家庭用户,运营商实现了一个利益最大化。 希望我的回答可以帮助到有需要的朋友,最近开发了一个 低成本通配符证书签发平台 CertSvc 通配符证书_泛域名证书_SSL证书签发托管平台?certsvc.com/ |
|
|
可以签发通配符证书并实现证书自动运维续签,欢迎大家使用。 |
|
网速属于信号传输层面,信号在数字化下都是1和0来表示,每个可能是1或者0的信号是一个bit,所以信号传输层面就用所谓『小b』,也就是每秒多少bit。 上传、下载是信息存储层面,信息在计算机系统中的存储因为历史原因实际上并不能单独存一个bit,你要存就要至少存一个byte,也就是8个bit,所以存储层面通常就用byte而不说bit。既然byte和bit两个都是b字辈的,为了区分通常将byte称为『大B』,上传、下载就说『大B』,也就是每秒多少Byte。 因为一个Byte包含8个bit,所以『小b』速度除以8就是『大B』速度。 客观上是一个速度,只是好比同样的速度,你可以说每秒1米,也可以说每秒10分米,而已。 |
|
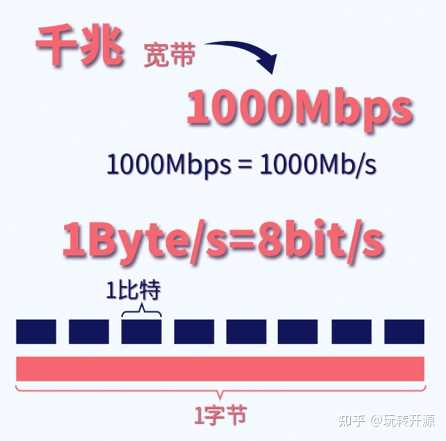
因为单位不同。就像 1 公里每秒 = 1000 米每秒。 硬件网速的单位是 Mbps(注意 b 的大小写),全称 Megabit per seconds,读作「兆 比特 每秒」。运营商宣传的时候用的是这个单位,比如「千兆宽带」指的是 1000 Mbps 的宽带。 而下载速度的单位是 MB/s,全称 Megabyte per seconds,读作「兆 字节 每秒」。软件中显示下载速度用的是这个单位。 也就是 b 代表 bit,是一个小单位;而 B 代表 Byte,是一个大单位,换算倍率是 8 倍。 |
|
因为通信和计算机是两个行业。 在通信行业,确实是用比特/秒来表示网络传输数据的能力,这是完全合理的。 就像你买热水器,厂商只会标称瓦数,而不会标称烧水时间一样。 你想知道烧水时间,可以测也可以自己估算。 网络也是一样。提供商只能标称比特/秒,没办法告诉你具体传输文件的速度。 因为这取决于你具体的用法(具体的通信协议以及协议具体的参数),比如同样的网络,你传输一大堆小文件和传输一个把小文件打包后的大文件速度是完全不同的。 具体多少,够不够用,你只能自己实测。 你是我总不能什么东西都实测一遍吧?确实是这么回事,所以很多时候我们需要估算够不够用,最简单的办法是网络带宽除以8,把比特换算成字节,得出理论最大传输速度。 当然这个理论最大值其实也没有多大意义的,因为实际用起来怎么样要看具体情况。 如果你有足够的生活经验,自己估算一下够不够也不是不行(比如带宽100M还是200M其实不是多大的事。) 我自己算不明白那怎么办? 你可以找专业人士然后提供更详细的信息,由他们帮你估算呀。 谁是专业人士呢,一个就是厂商,比如热水器厂商可能会贴心的告诉你,这个是单人用的,这个是家庭用的,这个是公共浴室用的。(你问运营商的话运营商也可以告诉你100Mbps大概能干什么,200Mbps大概能干什么) 如果你信不着厂商(因为厂商确实会从有利于自己的方面来给你算),也可以自己花钱雇专业人士呀。比如热水器的问题你就可以找装修公司咨询,他们会根据你具体怎么用算出多大瓦数的热水器适合你。 比如带宽的问题你也可以找我们,我们做项目的时候也会估算带宽,100个用户多少,1000个用户多少。但是绝对不是1000个用户的项目就是100个用户的十倍。 说到底,网络提供商使用比特/秒作为单位标称自己的服务/产品没有任何问题。 你用简单的除以8来估算自己够不够用,那是你自己的事。 |
|
销售产品的时候,都会选择对自己有利的方式进行营销。 实际上Mbps完全可以统一成MBps,把小bit改成大Byte,更有利于统一传播。 但Mbps是MBps的8倍,用户听起来感官上就要快很多。 实际上同样的事情也存在硬盘容量上,系统软件厂商用的是1024,而硬盘厂商用的是1000,1PB硬盘就差了126TB容量。 |
|
其实根本的区别在于传输与存储。 对于通信传输来说,每传一个比特都要控制电平,比如高电平表示1,低电平表示0,因此交换机或网卡的以太网数据接口是按照比特位来做电平转换的,所以用bit来计量传输速率。 但对于数据存储,不管是机械磁盘、ssd、还是ROM、Flash、RAM内存等,最小的物理存储单元是字节,在c语言里一个结构至少是按byte来“对齐”来在内存中存取,所以业界是按byte来计量存储量。 |
|
运营商在合同中的约定网速,也是从家中光猫到运营商网络接入点的网速,单位是Mbps(Mb/s)(兆比特每秒),常见的签约网速有100Mbps、200Mbps、300Mbps、500Mbps和1000Mbps等。 下载网速:使用者的手机APP、计算机软件等接收数据的实际网速,单位是MBps(MB/s)(兆字节每秒),如下载软件上显示下载速度为20MB/s。 |
|
|
两者关系:签约网速与下载网速的单位不同。每8比特为1字节,也就是1Byte=8bit,是1:8的对应关系。(补充一个例子:1000除以8,1000Mbps≈125MB/s≈125MBps)。 |
|
为什么mps换算成kmph的时候要除以3600 |
|
你再对比一下1T硬盘只有931G? 最本质的原因是100Mbps比12.5MBps显得多。商业心理暗示牛掰。 其次才是专业原因: bit(字节)是数字信号/计算机领域最小单位。 Byte(字符)是计算机领域最小(可读)有效单位:1Byte=8bit 之所以跟可读有关,拉丁语系ascii编码是8bit,有255种非0可能数值,可编码表达所有拉丁字母和符号。(外行可以类比摩斯码,计算机8bit可以表达所有英文字符,中文需要16bit) 颜色编码也是8位的。 另外早期处理器是8位的(现在流行是64位),存储(ram,rom)也是8位的。 当然,计算机可以处理单个bit操作,但Byte是最常用的。 计算机领域的K,M,G,T是二进制的。换成十进制1K=1024。但硬盘厂商是按十进制的1000倍数来标注容量,就是坑钱传统。 |
|
因为数据流没有字长这东西 |
|
原本1字节(Byte)等于7比特(bit),后来还是增加了1比特。 这是一个换算的比例,不是只取八分之一。 相当于人民币兑换美元的关系。 CNY=USD7.2" role="presentation">CNY=USD7.2CNY = \frac{USD}{7.2} 总不能说,剩下的6.2/7.2去哪里了? 在数字计算和网络通信中,1字节(Byte)等于8比特(bit)。 SByte/s=Sbps8" role="presentation">SByte/s=Sbps8 S_{\text{Byte/s}} = \frac{S_{\text{bps}}}{8} 其中: (Sbps表示网速,单位为比特每秒(bps),SByte/s表示文件传输速度,单位为字节每秒(Byte/s或B/s)。" role="presentation">表示网速,单位为比特每秒()表示文件传输速度,单位为字节每秒(或)。(Sbps表示网速,单位为比特每秒(bps),SByte/s表示文件传输速度,单位为字节每秒(Byte/s或B/s)。(S_{\text{bps}}表示网速,单位为比特每秒(bps),S_{\text{Byte/s}}表示文件传输速度,单位为字节每秒(Byte/s 或 B/s)。 |

|
|
一个比特(bit)可以表示2个可能的状态(0或1)。如果我们有 n个比特,那么我们可以表示的不同状态的数量 2n次幂。 ASCII码表(美国标准信息交换码)定义了128个字符,包括英文字母、数字、标点符号以及控制字符。这些字符使用7位二进制数来表示,范围从0000000到1111111,即从0到127。 本来,2的7次幂为128。 原始的ASCII码只使用了7位来表示128个字符[1],但8比特提供的256个可能的值(从00000000到11111111)为表示字符提供了更大的空间,包括扩展ASCII码,它使用了第8位来扩充字符集,使得可以表示更多的符号和国际字符。 相当于是,1字节等于7比特,是刚刚好,超了就不行。 1字节等于8比特,就是超了也不怕。 1字节可以等于9比特、10比特、20比特,都可以。 但在实际应用中,8比特已经足够用于字符表示,并且提供了处理效率和资源使用的良好平衡。 此外,随着Unicode和UTF-8等编码的发展,使用一到四个8比特字节(即1到4个字节)可以表示全球几乎所有的字符和符号,这进一步证明了8比特作为基础单位的有效性和灵活性。 附:为什么一个字节是8位?(中译) 作者:鲍勃・贝默 我最近收到了来自巴西西门子公司员工泽诺・路易斯・艾恩森・纳达尔的一封电子邮件。 他问:“我的算法老师问我和我的同事们‘,为什么一个字节有八位?’这有技术上的答案吗?” 当然,对于一个叫做泽诺的人,我无法抗拒回复,这个名字让人想起了古代的那位老师。 一些被抄送此回复的人认为这是一份有用的文档,所以(既然已经做了艰难的工作)我决定将其作为历史的一部分添加到我的网站上。 我在工作上已经落后了,但我就是无法抗拒回答你关于“字节”为什么有八位的问题。 答案是有些字节有,有些字节没有。 但这需要解释,如下所述: 如果计算机完全以二进制方式工作(很久以前有些计算机确实是这样),并且只做二进制数的计算,那么就不会有字节的概念。 但要使用和操作字符信息,我们必须为这些符号编码。而这些在打孔卡片的时代就已经被了解了。 IBM的打孔卡片(也存在其他种类)有12行80列。 每列被分配给一个符号,我在这里使用“符号”一词,尽管现在由于计算机被用于许多新的方式,它们有了更花哨的名称。 列是从上到下编号的,依次为12-11-0-1-2-3-4-5-6-7-8-9。在0到9行中的打孔代表数字0-9。一组列可以被称为一个“字段”,而这样一个字段中的数字可以带有一个加号(数字单位位置的顶行12多一个打孔)或减号(就在该数之下的11行多一个打孔)。 然后他们开始需要字母表。 这是通过在数字1-9上加上12打孔来实现字母A至I,加上11打孔来实现字母J至R。 对于S至Z,他们在数字2至9上加上0打孔(跳过了0-1组合――3x9=27,但英文字母表只有26个字母)。12、11和0打孔被称为“区”,你会注意到今天它们潜伏在最高的4位中。记住,这比那些相同字符的二进制表示要早得多。 第一个额外收获是,没有任何0-9打孔的12和11打孔给我们提供了字符+和-。 但当时没有代表其他标点符号,甚至没有代表句号(点,句点)的IBM或电信设备。在早期的电报中可以看到这一点,人们会说“I MISS YOU STOP COME HOME STOP”。 “STOP”代表了机器没有的句号。 然后标点符号和其他标记有了打孔组合,但要做到这一点,一列中必须有3个打孔。 在大多数情况下,第三个打孔是额外的“8”。 通过这种方式,加上10个数字、26个字母和11个其他字符,IBM得到了47个字符。UNIVAC由于使用不同的打孔卡片(圆孔而不是矩形,90列而不是80列)得到了大约54个字符。 但这些大多是商业字符。当FORTRAN出现时,他们需要例如“除号”符号和“=”符号,以及商业集合中没有的其他符号。所以他们不得不为科学和数学工作使用一套替代规则。一套FORTRAN卡片会在工资支付中引起混乱! 对于许多早期的计算机来说,这些打孔卡片被用作输入和输出,由于可表示的字符总数不超过64,为什么不用每个字符6位来表示它们呢?对于用于电报机的6轨打孔带也是如此。 在这个时期,我来到了IBM工作,并看到了64个字符限制造成的所有混乱。 特别是当我们开始考虑文字处理时,这将需要大写和小写字母。将26个小写字母加到现有的47个上,就得到了73个――比6位能表示的多9个。 我甚至提出了一个建议(考虑到STRETCH,这是我所知道的第一台有8位字节的计算机),这将把打孔卡字符代码扩展到256个[2]。 有些人认真对待了它。我认为这是一种恶作剧。 所以有些人开始考虑7位字符,但这很荒谬。 有了IBM的STRETCH计算机作为背景,处理64字符字可分为8的组(我在沃纳・布赫霍尔茨博士的指导下设计了字符集,他确实是为8位分组创造了“字节”这个术语)。 [3]制定一个通用的8位字符集,能够处理多达256个字符,似乎是合理的。 在那些日子里,我的口头禅是“2的幂是魔法”。 因此,我领导的小组开发并提出了这样的提案[4]。 当这个进展被提交给负责正式化ASCII的标准组织时,这是一个过于巨大的进步,所以他们暂时停留在了7位集上,或者是一个8位集,上半部留给未来的工作。 IBM 360使用了8位字符,虽然不是直接使用ASCII。 因此,布赫霍尔茨的“字节”在各处流行起来。 我本人并不喜欢这个名称,因为很多原因。设计中有8位并行移动。但随后出现了一个新的IBM部件,内部和磁带驱动器中都用了9位进行自检。我在1973年向媒体曝光了这个9位字节。但早在那之前,当我在1965-66年为法国的Cie. Bull公司领导软件操作时,我坚持要求用“octet”(八位组)一词代替“字节”。 你可以注意到,我当时的偏好现在成为了首选术语。 这是由新的通信方法证明的,它们可以并行传输16、32、64甚至128位。 但一些愚蠢的人现在由于这种并行传输,称之为“16位字节”,这在UNICODE集中是可见的。 我不确定,但也许这应该被称为“hextet”(十六位组)。 但你会注意到,我仍然是正确的。 2次幂仍然是魔法! 参考^Computer History Vignettes By Bob Bemer I recently received an e-mail from one Zeno Luiz Iensen Nadal, a worker for Siemens in Brazil. He asked "My Algorythms teacher asked me and my colleagues 'Why a byte has eight bits?' Is there a technical answer for that?" Of course I could not resist a reply to someone named Zeno, after that teacher of ancient times. Some people copied on the reply thought it a useful document, so (having done the hard work already) I add it to my site as further bite of history. I am way behind in my work, but I just cannot resist trying to answer your question on why a "byte" has eight bits. The answer is that some do, and some don't. But that takes explaining, as follows: If computers worked entirely in binary (and some did a long time ago), and did nothing but calculations with binary numbers, there would be no bytes. But to use and manipulate character information we must have encodings for those symbols. And much of this was already known from punch card days. The punch card of IBM (others existed) had 12 rows and 80 columns. Each column was assigned to a symbol, a term I use here although they have fancier names nowadays because computers have been used in so many new ways. The columns, going down, starting from the top, were 12-11-0-1-2-3-4-5-6-7-8-9. A punch in the 0 to 9 rows signified the digits 0-9. A group of columns could be called a "field", and a number in such a field could carry a plus sign for the number (an additional punch in top row 12 of the units position of the number), or a minus sign (an additional punch in row 11 just under that). Then they started to need alphabets. This was accomplished by adding the 12 punch to the digits 1-9 to make letters A through I, the 11 punch to make letters J through R. For S through Z they added the 0 punch to the digits 2 through 9 (the 0-1 combination was skipped -- 3x9=27, but the English alphabet has only 26 letters). The 12, 11, and 0 punches were called "zones", and you'll notice them today lurking in the high-order 4 bits. Remember that this was much prior to binary representations of those same characters. The first bonus was that the 12 and 11 punches without any 0-9 punch gave us the characters + and -. But no other punctuation was represented then, not even a period (dot, full stop) in IBM or telecommunication equipment. One can see this in early telegrams, where one said "I MISS YOU STOP COME HOME STOP". "STOP" stood for the period the machine did not have. Then punctuation and other marks had combinations of punches assigned, but there had to be 3 punches in a column to do this. In most case the third punch was an extra "8". In this way, with 10 digits, 26 alphabetic, and 11 others, IBM got to 47 characters. UNIVAC, with different punch cards (round holes, not rectangles, and 90 columns, not 80) got to about 54. But most of these were commercial characters. When FORTRAN came along, they needed, for example, a "divide" symbol, and an "=" symbol, and others not in the commercial set. So they had to use an alternate set of rules for scientific and mathematical work. A set of FORTRAN cards would cause havoc in payroll! With many early computers these punch cards were used as input and output, and inasmuch as the total number of characters representable did not exceed 64, why not use just 6 bits each to represent them? The same applied to 6-track punched tape for teletypes. In this period I came to work for IBM, and saw all the confusion caused by the 64-character limitation. Especially when we started to think about word processing, which would require both upper and lower case. Add 26 lower case letters to 47 existing, and one got 73 -- 9 more than 6 bits could represent. I even made a proposal (in view of STRETCH, the very first computer I know of with an 8-bit byte) that would extend the number of punch card character codes to 256 [1]. Some folks took it seriously. I thought of it as a spoof. So some folks started thinking about 7-bit characters, but this was ridiculous. With IBM's STRETCH computer as background, handling 64-character words divisible into groups of 8 (I designed the character set for it, under the guidance of Dr. Werner Buchholz, the man who DID coin the term "byte" for an 8-bit grouping). [2] It seemed reasonable to make a universal 8-bit character set, handling up to 256. In those days my mantra was "powers of 2 are magic". And so the group I headed developed and justified such a proposal [3]. That was a little too much progress when presented to the standards group that was to formalize ASCII, so they stopped short for the moment with a 7-bit set, or else an 8-bit set with the upper half left for future work. The IBM 360 used 8-bit characters, although not ASCII directly. Thus Buchholz's "byte" caught on everywhere. I myself did not like the name for many reasons. The design had 8 bits moving around in parallel. But then came a new IBM part, with 9 bits for self-checking, both inside the CPU and in the tape drives. I exposed this 9-bit byte to the press in 1973. But long before that, when I headed software operations for Cie. Bull in France in 1965-66, I insisted that "byte" be deprecated in favor of "octet". You can notice that my preference then is now the preferred term. It is justified by new communications methods that can carry 16, 32, 64, and even 128 bits in parallel. But some foolish people now refer to a "16-bit byte" because of this parallel transfer, which is visible in the UNICODE set. I'm not sure, but maybe this should be called a "hextet". But you will notice that I am still correct. Powers of 2 are still magic! https://web.archive.org/web/20170403130829/http://www.bobbemer.com/BYTE.HTM^R.W.Bemer, "A proposal for a generalized card code of 256 characters", Commun. ACM 2, No. 9, 19-23, 1959 Sep -- Computing Reviews 00025 Early public hint of 8-bit bytes to come.^R.W.Bemer, W.Buchholz, "An extended character set standard", IBM Tech. Pub. TR00.18000.705, 1960 Jan, rev. TR00.721, 1960 Jun -- Computing Reviews 00813^R.W.Bemer, H.J.Smith, Jr., F.A.Williams, "Design of an improved transmission/data processing code", Commun. ACM 4, No. 5, 212-217, 225, 1961 May -- Computer Abstracts 61-1920 ASCII in its original form. |
|
通信行业的速率观测维度是bit,比特。 软件行业的速率观测维度是byte,字节。 一字节等于八比特。 电信运营商属于通信行业,它们和你宣传百兆光纤的时候,指的是Mbit,而你电脑的速率单位,是Mbyte。 |
|
因为网络传输的不一定是字节流。当然在everything over IP的今天基本上也可以认为99%的网络传输的就是字节流了…… 其实除以8都不对,因为真实的传输数据量还要扣除IP头部分,只是太小了可以忽略不计…… |
|
运营商卖你12.5M的带宽,他们可能觉得不好意思。 100m,1000m多大气~ 回归正题:1个字节有8位,剩下的应该跟硬件电气知识相关了。劝退了。 |
|
|
| [收藏本文] 【下载本文】 |
| 科技知识 最新文章 |
| 百度为什么越来越垃圾了? |
| 百度为什么越来越垃圾了? |
| 为什么程序员总是发现不了自己的Bug? |
| 出现在抖音评论区里边的算命真不真? |
| 你认为 C++ 最不应该存在的特性是什么? |
| 为什么 Windows 的兼容性这么强大,到底用了 |
| 如何看待Nvidia禁止使用翻译工具将cuda运行 |
| 为何苹果搞了十年的汽车还是难产,小米很快 |
| 该不该和AI说谢谢? |
| 为什么突破性的技术总是最先发生在西方? |
| 上一篇文章 下一篇文章 查看所有文章 |
|
|
|
| 股票涨跌实时统计 涨停板选股 分时图选股 跌停板选股 K线图选股 成交量选股 均线选股 趋势线选股 筹码理论 波浪理论 缠论 MACD指标 KDJ指标 BOLL指标 RSI指标 炒股基础知识 炒股故事 |
| 网站联系: qq:121756557 email:121756557@qq.com 天天财汇 |