
| |
|
|
| ����ƻ� -> �Ƽ�֪ʶ -> �й����������Ƽ�ˮƽ����ж�� -> �����Ķ� |
|
|
[�Ƽ�֪ʶ]�й����������Ƽ�ˮƽ����ж�� |
| [�ղر���] �����ر��ġ� |
|
�˹����ܣ������������죬����������й��������IJ�྿���ж������Ҫ��ô�����������أ�ͷ�Է籩һ�� |
|
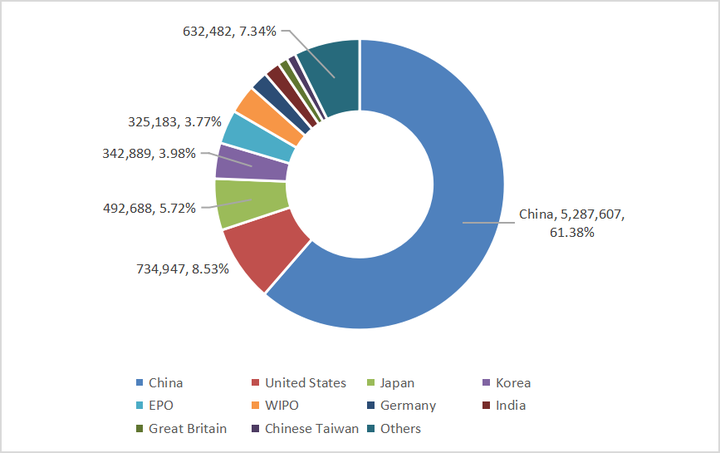
���Ǹ�֪ʶ��Ȩ�ģ����Ҵ�֪ʶ��Ȩ�ĽǶ����������Ƽ�ˮƽ�IJ�ࡣ��˵һ�����ݣ�ר����������2023 ���й�ר���Ĺ�������ߣ��ﵽ�˾��˵�5287607����ռȫ��ר�������� 61.38%�������������734947����ռ������8.53%������֮���й���ר����������������7��֮�࣡��֪���ܶ��˿϶��ᳰ�����й���ר����������Ȼ�ܶ࣬���Ǵ������һЩ����ר�����Ҹ����е�ʱ��Ҳ��ô��Ϊ����ʱ��һ�÷��ֲ�û����ô��Ϊʲô����Ϊ�ҷ��ִ�������ҵ�ڳнӺ��ⶩ�������ǵĸ�����ͨ�����ʾ������ϸ������ȫ���������Ĺ�˾�����࣬���й�����ϸ���������ҵ�������ǣ� |
|
|
����漰һ�����⣬Ϊʲô�й��ܳ�����ô��ϸ���������ҵ�����ǣ��й�ӵ��ȫ��������ģ�Ĺ�ҵ�˿ڣ�ͬ��������Ϊʲô����ҵ�ڲ�����������Ϊ�����Ĺ�ҵ�˿ڸ�����֧����ȫ��ҵ��ϵ����ŵ�Ȼ��Ҫ������ŵ��뷨����Ҫ�������㼼����Աȥ��صģ�ÿ����һ���������Ҫ��ȥ��ӣ������ӻ�ൽ�˲�����ĵز�������������ģת������ҵ������ֻ����Ϊ�ʱ���Ϊ�������������Ĺ�ҵ�˿ڹ�ģ����������֧�ź�����ϸ������ �ִ������ȵ���ʲô�������Ͼ��DZ�ƴ��ҵ�˿ڵĹ�ģ��˭�Ĺ�ҵ�˿ڹ�ģ��˭����Ӯ�����ʤ��������ͬ�ķ�չ�Σ���ҵ���ں���ȫȻ��ͬ�ġ�Ӣ�����ȷ�����ҵ�������Ƽ�Ѹ�ͷ�չ������ʱ��Ĺ�ҵ����������������·����֯���������ν�֮�࣬����Щ��ԼĶ�����ǧ�������㹻������ҵ�ֹ��������ſ�ѧ�����Ľ�����Խ��Խ���ϸ������Ӣ�����˿����ƺܿ����ֳ��������˶�ʮ���ͣ�Ӣ�������¹���ǧ��Ĺ�ҵ�˿ڵĹ�ģ������ƥ�����淢չ�Ĺ�ҵ������չ�����Ǻܿ챻�˿�Լ2�ڵ��������������������������������ŷ�ޣ�������Լ�Ĺ�ҵ�˿ڹ�ģ�ӽ�6�ڣ����Բ�������һ��ֻ�ܷ�չ�ع�ҵ�ɶ��Ž���������Ӯ������ս��ʤ���� Ȼ�������������ַ����˾�仯���й��Ĺ�ҵ�˿��Ѿ��ﵽ��14�ڵĹ�ģ����ŷ���պ���������Ҫ�࣬����һ�������е���Ȼ����������˹˵�����һ���м����ϵ���Ҫ��������Ҫ�ͻ��ʮ����ѧ���ܰѿ�ѧ����ǰ����ֻҪ���Ӵ���г������ܽ��ͳɱ����������������з����й��ĿƼ�ˮƽ���ܲ�����ǰ�����Dz����˵���ʶΪת�Ƶġ� �ҿ��Էǵ����ŵ�˵����������ȡ��Ӣ����ԭ������δ���й�ȡ��������ԭ���й��Ƽ�ˮƽ�ϳ���������ijЩ�������Ǹ�Ц���������ҿ�������ֱ����յ�̫����Ҫ���ۡ� |
|
��ô�� ʵ������֪�� �ɺ��Լ������飬���������Ȳ�ǰ�����������ҵ��Ⱥ��Ȼ��Ȼ�ػὫ�������� "�߿Ƽ�" ����������촷ۡ� |
|
|
|
|
|
|
|
|
|
|
̹�ʵĽ��� �ܰ��й�����������һ��Ƚϣ� �����κ����� ����20��ǰ�����ұ��붼������ġ� �ձ��¹�Ӣ����������������ңң���Ȱ��� |
|
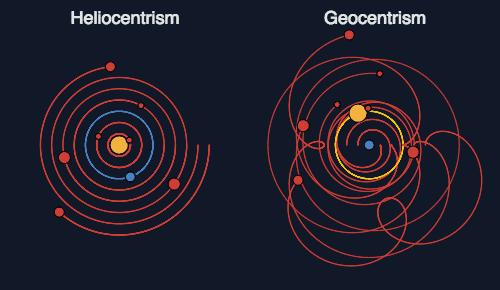
�ܶ���ж��ᵽ��оƬ����̻�����������ƫ�棬˵һ˵һ��������ţ���Ҳ������Ҫ������ͼ���㡣 �����������һ�仰˵��ͼ�����Ǹ���ģ��һ�˵��������Ԥ��δ���� ͼ�������й�Ϊ������ģ��ں����ʱ��ͳ�����ɱ������ǰ�أ���������Ӧ�����뿨����ȴ����ס�ļ����� ���������й�ͼ���������Ŷӣ����ϼ��ŵ���ʦ�����Ĺ�һ�Σ�����������Ŀ��պ�����ȥ��д����һƪ���£��������ϣ���������������Ƽ��������������� ֧�����ж�ݣ� ����Ϊץƭ�Ӹ����ͼ���㡱 ���ھ�����Ԥ��δ�� �� | ʷ�� ���㣩ʥ�˵ñ���ɱ�� 19���ͣ�ʥ�˵ñ���һ���ߵ���Ԣ�������һ���װ��� һλ������ԡ�ұ���������������������һ�ԣ���һ�Ѿ��µĿ��ŵ��� ����ľ�̽ʷ������ų���з���������¡����ƶ���������ĵ���ƻ��� 1���ȵ��鸻�̣��Ѻ��������й��ڵ�100���г�һ�š�����A���� 2���ٵ��鵶�߹��������������ֻ����100�ѣ����ǰ�������Ŀͻ�Ҳ�г�һ�š�����B���� 3��Ȼ���A��B����������бȶԣ�������û���غϵ��ˡ� |
|
|
�������Ⱥ����ȫ���غϡ� ���⡣��������ѧ����һ�����ڸ����ε���ϵ���� ��̽��������������һ�����顣 ���ѡ�����A���ϵ�100�˺͡�����B���ϵ�100�˷ֱ����ߣ���Ϊ10000����ԣ�Ȼ���߷õ��顣 ���뷢����Щ����ԡ�֮����û�С���ͬ��һ�ҡ�����ʶͬһλ�м��ˡ��������������ڶ࣬���еĿ�����Ҳ����ţë��ʷ������ų����ҧҧ�����Լ���ľ��Ŀ�ʼ�ƽ��� |

|
|
��������˼����£���������һ�����飬����̽�����˲��õ��¶��� ����B����һλ���߾����̸��в������в�����˵������ô�������к��ģ��������������⣬�ȵ���̽�����ˣ�����A������һλ���������ᣬ����Ů����Ȼ���Լ������˰�Ľ֮�顣 ���ǣ�ʷ������ų������Ȼ�������θ��в���˾���ܾ�����Ȼ��Ȣ�˰������Ů�������������۷塣 �����dz�ڽ����¾͵���� �ȵȡ������DZ�Ѫ���ﻹ����һλ�أ��������𣿣� ���Dz��ܣ�����ܲ��ˡ����� ���ǻص���̽���ߣ����ѷ��֣�����ǰ��ɢ�������������� �����������йص�������ˡ�����A���� ����A�ϵ�1����ȥ���ĵط�����ˡ�����A1���� ����A1�ϵĵ�һ���ص����кö���ȥ������������ˡ�����A1-1���� ����A1�ϵĵڶ����ص����кö���ȥ������������ˡ�����A1-2���� �Դ����ƣ����Ҳ������ ÿ���˶����ڶ�ص���˴��ڹ������������ϸ��˳�����ϣ����ն����ҵ����������˺͵�֮������ߣ��ٴ����Ų飬��������ҵ����֡� �������ǣ���ô�ɡ�����ų��̽������Ҳ��һ���ܲ�����డ�������������Ϊɶ�������ܾ���ӭȢ������ |

|
|
�п����ʵ�ǣ� ������֪���������������Ͳ���һ���������Ϊ�������ӣ�����̫��ʵ���ϸ��������С����������ֳ��������࣬�Ͳ������ࡣ �����Dz���һֱ���Ժ�����������ǿ����ü����ӽ����ࡣ ֱ������������������Ϣ�� ��һ��21���͵Ľ��죬����������һ�֡���Ӱ��������ָһ�Ӽ䣬���ܴӺ���������в�ѯ�������������࣬����ǡ���ͼ���㡣 �ڶ�����ͼ���������й��˵ļ���һֱ��������ǰ�У��൱�ڰ�����������ʷ�еĵ�λ���������е����Ǵ�û���κ��ˡ������ӡ��ļ������ ��˵��ɶ�ǡ�ͼ���㡱�ϣ� ��������仰����һ�£� 1������������������������������������ǻ�����ݴ������ݿ��С� 2����һ�����ݿ���ı����ǡ���ά���ģ�ֻ��չ�������һ�����档Ϊ�˼�¼��ͬ���棬���Ǿ͵����ܶ��������̽������ 3��������Щ�����Ƿ�ɢ�ģ�ԭ������ʵ��֮��ġ���ϵ��Ҳ�����˸�ϡ�顣�����˽�ij��������ľ����������ף������˽ⲻͬ������ʵ��֮��Ĺ�ϵ������Ҫ��һ�ѱ������һ���о�����ܷѾ��� 4�������Dz�����һ��ʼ�ͱ����ô�����ֱ�Ӱ����е����ݴ���ͬһ����ά�ռ������ܴ洢�����ʵ�塱������֮�䡰��ϵ��������ϵͳ���ͽС�ͼ���ݿ⡱�� 5����ͼ���ݿ��������㣬�����һ���������࣬���ǡ�ͼ���㡱�� ������������⣺��ͨ�����ݿ���ͼ���ݿ���ij��ƽ��ġ�ͶӰ������ͼ���ݿ�����ͨ���ݿ��ں���һ���γɵġ�ȫϢӰ�� |
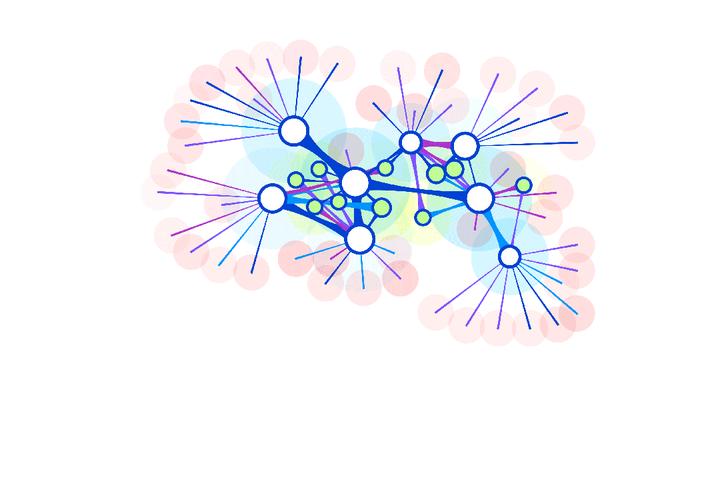
|
|
��˵��Ҫ��ʷ������ų���о�̽��Խ�����죬���Ϳ��Ѿ��ֵġ��������ݡ���������ת�����ݡ���������ͨ���ݡ�������ͼ���ݿ��У��������Լ����鵽�Ķ�����Ϣ����һ�»س�����һ������������û�ͻ��漣�㸡��������ǰ�� ����ν��̤����Ь���ٴ�������ȫ��ͼ���ݿ⣡�ܰ���һ���ļ������ѹ����ʮ����ļ��������һ��ר���ڿƼ��������� �������˵���ʶ��һλ�������ֶ��������Ĵ�ţ�����������ϼ���ͼ���ݿ�ĸ����ˣ��鴺�Ρ� �㲻һ�������������֣����ǣ�ÿ������֧����ת�˵�ʱ���豸�������ϵ�ȣ�����ͼ�����ж�����˻��Ƿ��з��յ����ݡ� �����������˵��������λ�����ܹ�����С����ǵġ��������� |

|
|
�鴺�� ��һ����ȼ������������һ�ѻ𡱵ľ���ƭ�� �Ҳºܶ������������������ʣ� Ϊɶ��ͼ���ݿ⡱����������ϼ������úã� �𰸲�����ô�Զ����� �����룬֧�����Ǹ�֧�����ߣ��������ݿ�ֻҪ��ÿ��ת�˵ġ��������������һ��Ǯ�����ˣ�Ϊɶ��Ҫ�Ѿ����ˡ��豸�Ĺ�ϵ��Щ��������Ϣ��Ҳ���ȥ�أ����Ӵ洢�ɱ���˵�����ö��Ᵽ����Щ���ݲ�й¶�����ⶼ�Ǹ����� ���������֣�ƭ�ӡ� ��֧�����ճ�����ʱ�����ݿ���ȷʵֻ�桰�û� ID���͡�ת�˽��ȼ���������Ϣ�� �����˵Ķ�����ˮ��ֻҪ�з�϶���ͻ�����ȥ�� �ܿ죬���˿�ʼ�����š���͵�����˵����룬��α������֤���ñ��˵����룬���Լ��ĵ����ϣ���ʱ��û���ֻ��棩��¼����Ǯת�ߡ� ֻ��ID�ͽ�֧�������ж�һ��ת���Dz��DZ�����֮�����ġ� ���ǣ���ʦ��ֻ�ðѵ�¼���豸�����绷���ȵ���Ϣ�����������������������ص�¼���ͺܿ����Ǹ߷��յģ������������Ҳ���Բ�����ת�� �������潴���ڷ����һ����ס������ |

|
|
����·�߲�ͨ�����˾ͻ����ϴ�ֻ�ȥ�ú��ϰ����𣿲����ܣ����ǻ��о����İ취����թƭ���������ܺ������Լ����ֻ�ת�������ˣ� �������潴������ |
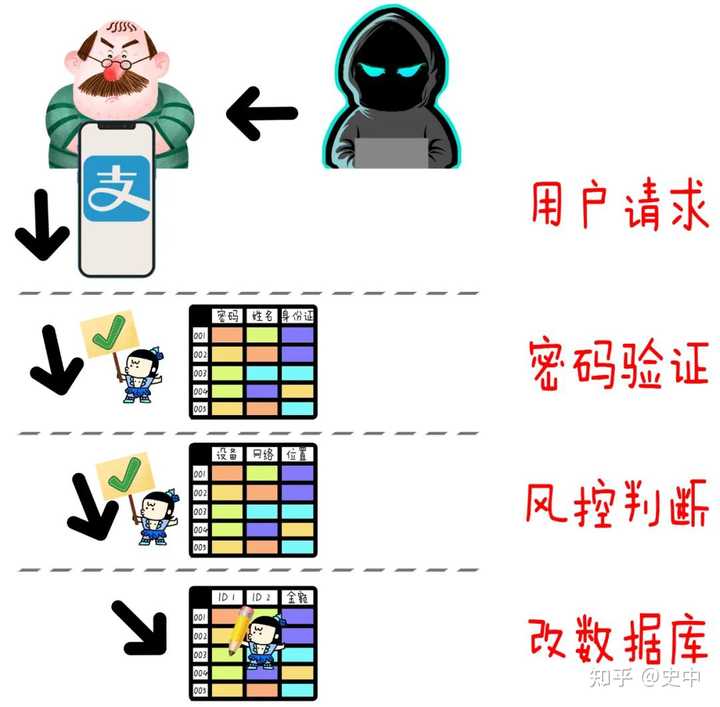
|
|
��զ�죿֧��������ʦ��ڤ˼���룬����һ�����ӣ���ƭת�˺�һ���ת�˲����������𣡱�ƭ�����������ǣ���ת��һ����ȫû�й�ϵ���˻��� �㿴������ϵ�������־�������Ȼ�����ˡ� ֧��������ʦ�������ҵ�һ�����ݿ⣬�ܹ���¼���˺��ˡ������˺��豸�������豸���豸��֮��Ĺ�ϵ�� ���ǣ���2015�꿪ʼ������һ֧С�ֶӣ������о�ͼ���ݿ� TuGraph����������Ǻ�ĵģ�Ϊ�˱����������Ǿͽ�������ְɣ��� ͼ���ݿ⿴��ȥ�������������ҡ�����ʵ��ֻ��Ҫ֪�������������㡢�ߡ����ݡ� ��ν�㣬���ǡ�ʵ�塱��һ���ˡ�һ̨�ֻ���һ����ַ������ʵ�塣 |

|
|
��ν�ߣ����ǡ���ϵ�������һ��������һ̨�ֻ����Ͱ����������ñ����ϣ����һ����תǮ����һ���ˣ�Ҳ�ñ߰��������ϡ� |
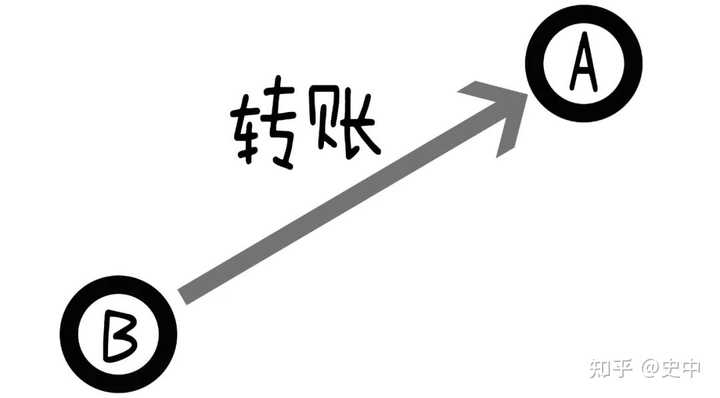
|
|
��ν���ݾ��ǣ���ϸ��¼������ߵ����ݡ�����һ���ˣ�����ע������֤�š�����֮������ݾ������ĵ��ϣ�����֮��ת�ˣ�ת�˽����ڱ��ϡ� |
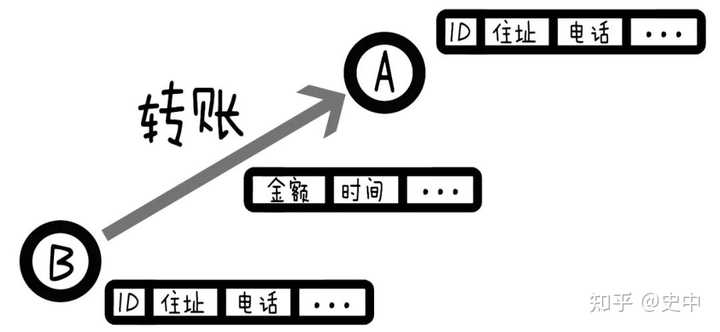
|
|
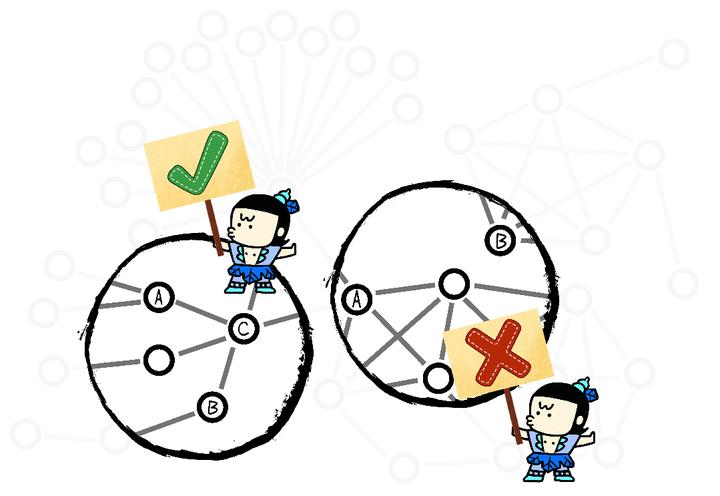
�������������ôץ�����أ� Ҳ�ܼ� 1������ A ��Ҫת�˸� B���Ǿ�ȥ��һ�� A �� B ֮����û�й�ϵ�� 2������ A ������ C ת���ˣ�C �ָ� B ת���ˣ�ϵͳ��Ȼ��֪�� A �� B ������ɶ��ϵ���������ж�������������������ʶ��թƭ���ձȽϵ͡� 3����� A �� B ��ͼ�ϸ��ź�Զ�����˺ü������������ϣ���������Ϳ��������⡣��˵һ����թƭ������������ӣ��������������Ϣ�������ۺϴ�֡� ��������ͼ����ߵġ�ABת�ˡ����ձȽϵͣ��ұߵķ��ձȽϸߡ����� |
|
|
��û�ио����죿����� A �� B ��ϵ�IJ�����������ų��̽�����װ��Ĺ���� ������������Ѿ���Ȼ�����ˣ� �����㲻���� �����ܲ����ϵ��ͼ���ݿ���ڷ��������Ϊ����û���ǡ��ٶȡ��� ���磬��������ת5000������������������룬Ȼ��֧������ʼתȦ������һ���֣��������ڲ�����û�б�ƭ������������������� ���ܵ��𣿾������ܵȣ������ܵ��� ��20���룬������ÿ�β�ѯ��ʱ�����ޡ�һ��10�������ɡ��鴺��˵�� ��գһ���ۣ����Ҫ100���룬Ҳ����գ�۵Ĺ������ٹ� TuGraph �����5�飬���ơ�һգ����ɡ��� ������������û�з���һ�� Bug�� ���ϵ�������ڸ�ʿ����ˮ������װ�ֻ�����ÿ���������ǡ��̶��ġ��� ��ʱ�� A �� B �Ǻû��ѣ�һ��ܿ��֪�����ǹ�ϵ���ܣ���ʱ A �� B ��ϵ�Ƚ���Զ�������������м��˲��ܰ�������ϵ�������ò���졣 Ҳ����˵����û��Ԥ֪��β�ѯ�ǿ����������� ������ͼ������ |
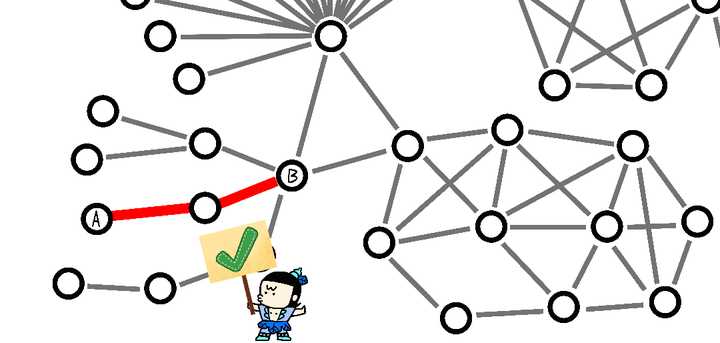
|
|
����ô��֤ͼ���ݿ�ÿ�β�ѯ�����������ʱ����ߡ��ϣ� �鴺��һ����˵�˾žŰ�ʮһ�У����������Ƚ���Ȥ�Ľ����㣺 ���ȣ��ø����ݿ�װ����С�ԡ��� Ӱ���ѯ�ٶȵ�����ɰ���ǧ����Ҫ˵����ج�Σ�����һ���ʣ�����㡱�� ������ͨ����֧���������ֻ���ʮ������ת�����������㡰С�㡱�� ���е���ţ���ʽ������г�ǧ�����ˡ�һ�������������ġ���㡱���ǿ�Ҫ���ˣ����ݿ���������һ����ͳ���20�����ˡ����� ��զ�죿ҡ���£���ʦ���ķ����ǣ��Ѵ���ϵIJ�ѯ����ֳ�ʮ�������в�ѯ�� ���ǣ�dz�����ϰ��ʱ�϶�������ᣬһ������һ�������漰��ͬ���ǵķֹ�������Ҫ�Dz����ŵò�����������ҡ�˦���������� �ⱳ����Ҫ���һ��ǿ��IJ��е���ϵͳ�����ݵ�ʱ��ʵ������Ų������̣߳�����С�ԡ�����˶�����һ�����ܵ���ȫ������ȺЭ�������� |

|
|
��Σ����ø����ݿ�װ�������ԡ��� �鴺��ͻȻ���ң��� A �� B �Ĺ�ϵ����Ҫ�� A ������ B�����Ǵ� B ������ A������ AB һ����������м���ͷ�� ��������Ȧ�У��������˴𰸣���һ���� ����� A �������ϻ�����һ����㣬��B��������С�㣬����Ȼ�� B ��ʼ����졣����� A �����߹�һ��֮��������㣬�ٴ�B��ʼ��Ҳ���ԡ� �������ǣ��ڿ�ʼ��ѯ֮ǰ���㲻����ȷ��֪�������������㡣 ������ʦ������һ��������ƣ���ͼ���ݿ�������洢���ݵ�ʱ�����ô��ԵĹ��㣬�����Ƚϴ��Ǹ���Ƚ�С������С�����ϱ��á� ��������ִ�в�ѯ����ǰ���á����ԡ�����С����Ԥ�������滮���Ų���у�������ν��Ԥ��������Ԥ��ϡ�� |
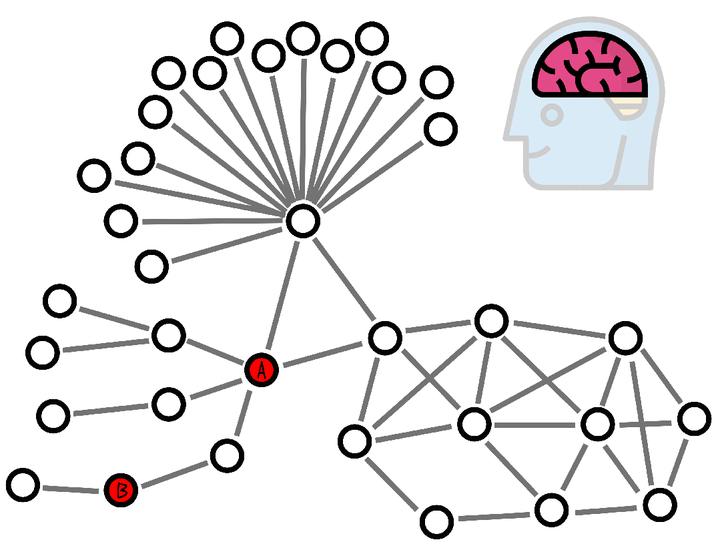
|
|
��˵�����������ԡ����Dz�ѯ������Ż�������������ƿ������ῴ�����ײ�ļ����� ��������Ż����洢���ơ��͡��������ơ����൱������������ô�ڲ���Щ��Ϣ�����������������Щ֪ʶ̫������������Թ���������ƪ����������Ȥ�Ĺ��¡� ���ˡ�ų��̽�ס��͡�֧����ץƭ�ӡ��İ�������������������ĸо���ͼ���ݿ�������ץ���˵ġ� ����Ҫ˵��������ͼ���ݿ��ץ���˵��������䲻��˵���С�ã�����ʵ˼·̫�����ˡ� �������Ҳ��������ṩһЩ����ţ�زġ������ڸ����˳Է�����ʱ����Ӧ��������ͼ���ݿ����һ������������イ�������ϣ� ���������ݿ�ġ���˹��ʱ�̡� ��˵�����չ����ô����ֵľ籾�� �����������ȷ���һ�������ġ�����̬���� Ȼ��ʵ�ɼ�Ϊ�˽��ͳɱ���ֻ���á��ͼ���̬������������ Ȼ��ȵ�����������ij��ʱ�̣�һ�����ӻ�����˵�������Ѿ����������ġ�����̬������ �����Ǹ����͵����ӡ� �ڽγ������ĺܳ�ʱ����������ɵ������ģ���Ƽ������ʵ͡����µ���1900�꣬��������������У��糵����15�������ͳ�ֻ�п�����936���� ����ʱ�ĵ�ؼ���ʵ��̫����ſ��ž�û���ˣ�ʵ�ɼҸ���һ������������ȼ�ͳ����ʺϵ��£�������������ˮ�ߣ�������T�ͳ�������ſ������ͳ�ʱ���� �����Ĺ��´��Ҳ֪����3C��ҵ��չ�õ�ؼ���ͻ���ͽ���������˹��ͻȻ�Ĵ��ȣ����������õ����������� ����������˹���綯���ı����� |

|
|
����Ҳ��һ�����ӡ� ̫ƽ���ϵ����ֵ��кܶ�ʯ�̣��������������ң����ⶫ��̫������Ǯ����������������Ǵ�ҷ����ˡ����ˡ��� �Ҹ����ķ�֮һ��ʯ�̣����ô�֧�����˱��ϼ�һ�ʣ�����������Ȩ��ת�Ƶ��������ˡ� �������������ط�����̫�࣬���ù�ģ̫��֧��Dz�������ֻ��ת�صͼ���̬������ʵ�����/������Ϊ�������м�� �����Ĺ��´��Ҳ֪���������ϵͳ��չ���������н�˻ָ��˻��ҵĸ߽���̬�������á��˻����ˡ����ַ�ʽ����ÿ���˵IJƸ��� |

|
|
���ֵ��ϵ�ʯͷ���� ���ݿ�Ҳ��һ�����ӡ� 1970�����ң���ѧ�ҷ������ݿ��ʱ�ͳ��ɡ�ͼ�������ӡ� ���� IBM �� Oracle һ�������������99%�ļ�������ܲ���������������ݿ��ı��ˣ�������һ����������������������˶�ά����ϵ�����ݿ⡱������ �����죬������������������Ĵ���������Ѿ������˷�Ծ���ѵ����Dz����û����ݿ�ġ�����̬������ͼ���ݿ��� ��������ݿ�ġ���˹��ʱ�̡��� ���ǿ����⣬�Ҳ»�����Ʋ�죺�Ҿ��Ǹ����ˣ�Զ����ߵ����ݿ��������������ë��ϵ�ϣ� ���Ҫ˵�����ݵı���Ŀ�ġ� û�����ݵ����ӣ�����������ë��Ѫ�������Ҳ���˼����ꡣ�ɼ����ݲ�����������ı���Ʒ�����Ǹ�ʱ���������ٺܶ�����������ˮ�ɺ�������Ұ����Ϯ������û�а취������ ��������ڤ˼���룬Ҫ�����ֻ����۵��е����Ԥ��δ������������ ���ݵı���Ŀ�ľ���Ԥ��δ���� ����������ǹ���ϵ��Ѻۣ���������ݹ���ʦ�Ǵ��˾��������Ԥ���ȷ��ʵ����һ���Ѿ���������50%����Ϊ���ǵ�������ȫû�������ʵ���硣 |

|
|
��������ݿ� ����Խǧ�꣬�����������ݿ⣬���ȥ����������������磺 �ҷ���һ���������ݿ����������λ���������ʣ�֤���Ҿ����й�����뷨�� �Ҹ�С�����ϰ�ת��20�飬������ʣ�֤���������һ�ζ����� ���ǣ����ݲſ�ʼ����Ԥ��δ���������������ݿ��������ϸ�ܽ�֯���������������ϵ��������˵�ġ�DT ʱ����Ҳ�͵����ˡ� �鴺�θ����ң�Ϊ������Ԥ��ȷ�ȣ���Ҫ������ϵͳ��ע���µ�ά�ȵ����ݣ����ҶԸ���ά�ȵ����ݽ������Ϸ�������ʱ�ͻᷢ�֣����еġ���ϵ�����ݿ⡱�ij���ɱ���Ѹ�����ߡ� �����ᵽ��һ���������ʣ�����ɱ��� ��������ٸ����ӡ� ������˵������������Χ��̫������Բ���˶����ڵ���˵�����������������Ÿ��ӵķ������˶�������������Ԥ������������Ϊɶ�������Dz��õ���˵���أ���Ϊ����˵�ij���ɱ��ߣ� ͬ��Ԥ��50�����ǵ�λ�ã��õ���˵�ļ�����������˵�ijɰ���ǧ���� |
|
|
�úڰ壡������㲻��Ԥ�⸴�ӵ����飬���������ݿⶼһ���������ںܶ���������д�ͳ���ݿ���졣һ��Ԥ�⸴�ӵ����飬�Dz��ʹ��ˣ�ȥ���ˣ� �ٸ����ӣ� ���ںܶ˾���쵼��ϲ���á�BI ���塱���������ϰ����Ӧ���⣬����һͨ�㣬�ڿ����ϳ��ִ𰸡� ���磬����Ӫ�����ϰ���ܻ������������⣺ 30-35����ѻ���ʿ�У���ϲ������˹001������Ⱥ������ǵ�ϱ��ϲ����ʲô��Ʒѽ�� �㿴�����������漰���ӹ�ϵ�������һ������ݿ⣬�ðѺö�ƽ�������һ������㡣 ���ݹ���ʦ��ҹ�����һ��ͷ��Ȼ��ѽ�������ϰ壬�ϰ忴�˿�˵��������ͻȻ�����µ��ӣ��������¸�����һ��ϲ������������������ä�еİְ֣����ǵ�ϱ����ϲ�����ֿں죿 ����������ݹ���ʦ����϶���˵��35���ͺ������Ա��������Ƕ���������ϰ���춤�ϣ� ��֮�������ݹ���ʦ�����ϰ����������Ϊ�����ݱ�ը��ʱ�������ǻ����õ���˵���ۼ���50���Ļ���λ�á����� ��Ҫ����ͼ���ݿ⣬���ָ��ӷ�������ô���ϣ� ��ʵ˵���˾������� 1�����ϰ�Ļ�ת����һ����Ա����������ġ������ 2�������������桱��һ���Ŵ�ͼ����һ������������� �����ᵽ�ˡ������ݡ��� �������ݡ���Ȼ����ʲô�����ѣ�������֪���Ĵ��������涼�Ǻ���ͨ���ݿ����ġ� ͼ���ݿ����ͨ���ݿ�ඨ�����һ�㡰��ϵ�����ԣ�ԭ�еĴ�����ϵͳ����ֱ�������ֹ�ϵ�������Ҫ��ʦ�����֣���һ���ܺ�ͼ���ݿ���CP�ġ�ͼ���������桱�� ˵��ͼ�����������������ڲ��ĵ������£����Ǻͻ����й�ϵ�� |

|
|
�山��թƭ��ҵ ����������ѧ���ˡ��������� 2018��˫11��ʼ��֧��������ͼ���ݿ�ķ��ϵͳ���ߣ�ÿ��ת�˶����һ�¡�AB��ϵ���� ������ƭ�����Ϸ��֣�ƭǮ�ѶȽ����ˡ�����ģʽ�����������һ���˺���Ǯ����Ϊ�쳣̫���ԣ��ַ��ӻᱻϵͳ���Ϊ��Σ��Ȼ���¡� �������ǿ�ʼ��������������һ���˺ţ�����ÿ���˺Ż��Ƶ�ʽ��ͣ����Ҳ����ɢ�ˣ������˺ŵ��쳣�����������ˡ� ���൱��ƭ��ѧ���ˡ����������� ����š���С�ġ������ˣ�û��ϵ������һ�����ϣ��������е��ǡ� ��ˣ������Ż�ͱ������ճ�İ�צ�㣬�������צ�����б��צ������ |
|
|
���զ�죿 ������Ȼ��Ӱ�������ͺ��������˲�һ�����Ͼ��ӹ�ϵ�Ͻ�����������˻����˻���һ���Ż��Щ�˻��ܻ���ijЩ������ֳ�һ�µ����ʡ�֧������ʦ��Ҫ���ľ��ǣ��ҳ���Щ���صĹ��ɣ� ��ʱ�����Ǿ͵�¡������һ���½�ɫ������ȫ���ݷ���ʦ���� ����ʦ��ɶ�أ� �ٸ����ӣ���������ץ��һ��թƭ�ŻȻ��ɻ����������ϵ�����֧�����˺ţ�Ȼ����Щ�˺Ż����֧���������ݷ���ʦ�����Ǿ�����̽���ʽܡ�����ϸ�о�����Ѻ�֮�䣬�������Ĺ�ϵģʽ��Ȼ�����Щ����д��һ��ʶ����� ������Щ���������ɶ���ҾͲ������ˣ���Ϊ�������˵�������ܿ���������Ҳ�ܿ��������� |

|
|
��֮��һ��������һ�����������顱�������ۡ�����Ҫ����������İ����е��˻���ɸ��һ�顣������ۣ����ǡ����������桱�ˡ� ע�⣬��������һ�εĹ������ɱ�ֻ��һ��AB����֮��Ĺ�ϵҪ����ˣ���ΪҪ�������û����豸£�������ڸ���ͱ߶�����ʽɸ��һ��� 20���룬�ǿ��Ƕ�Ȼ�ɲ����ˣ������Ҫ����Сʱ��ʱ�����ͨ����һ�顣�������ļ���һ��ÿ���賿ִ��һ�Ρ� ÿ��һ����ʵ���ˡ������Ż���Ƚ��ȶ�����̫���ܽ������Ǽ��������Ż����ʹ����ˡ���ÿ���̺ʽΧ��һ�飬����ѹ�ơ� |

|
|
����Ƿ���ʦ�Ĺ����ұ���ͼ���ݿ⡣����������ͼ������������������Ĵ𰸡� ���֡����ʽ�+��������+���ۡ�����ϣ��ͳ�Ϊ��һ�������ͼ����ģʽ��Ҳ�С��������㡱�� �����������������̫���ˣ��������ж������ˡ� ��ʱ�ܶ������������ϣ�������ʦ����æ�õ�������ץ���ˡ�ֻ��������Щ���˵ġ�����������̫һ���� ���磬ij���д��������������Żﶢ�ϡ��Ż����ij��С���ſڴ�����ӣ���װ���û������ÿ����ռ��˼Ҹ�����Ϣ��ȴ�ѿ��ĵ����Լ��ĵ�ַ��Ȼ������Щ�����֣�Ȼ��Ȼ�Ͳ����ˡ� ���иշ��ּ�����������Ϊ���;����ˣ����ƭ�ӻ�û���ü����ֵ����ÿ�ͳͳ�ҳ�����ͣ���� ����ƭ�����ˡ������������˼�ʮ���ֻ��ţ�ʮ������ַ�����ռ��������ÿ��� ����֪������һ�ſ������⣬��û�취������Ԥ���ĵ�ַ�͵绰�Ѽ����ſ�һ���˳����ġ� ��ʱ�����к� TuGraph ����ʦ�������ݵ���ͼ���ݿ⣬Ȼ�����ߵķ��ר�ң����ʽܣ�����һ�������һ����ʶ����������飩������������ϵͳ�����ۣ�ȥ�ܣ��ܿ���������ĸ�Σ�˻����ֳ�������������������Щ������ͣ�ˣ�����������澯������Ҳ��ȭ����ץ��ʹ�죡 |
|
|
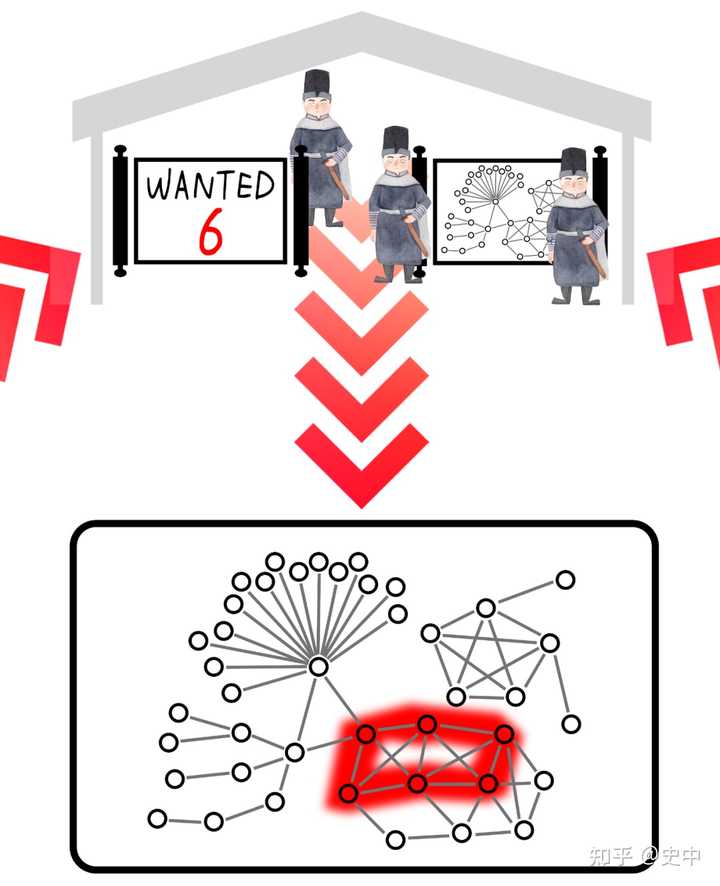
�ٱ��磬���л������һ�ֽ����������������ķ��ա� ��˼����A��˾�������н�Ǯ�������˸�������� ���B��A������C��B������D��C������E��D������F��E������A��F����������һȦ����ǡ���Ų��ҽš�������û���������� һ������£�6�����µĵ�������Ϊ�Ƿ��պܸߵģ����ԣ����ǵĺ�������Ϳ�������д�������������������գ�������6������Բ���ߣ�Ϥ�����ù鰸���� ����ijЩ��ҵ���ö����㵣���ͻ������죬�ⲻ֪���ǵ�С������ͱ����쿴��һ������� |
|
|
ͼ��ĺ�Ȧ�������������� ˵���⣬����������ͼ����������˰ɣ� ���ǣ���Զ��Ҫ�������Ƴ³��µ��������Ͼ������������ġ����ͷ��䡱�����ж���ȥ�ĸ �ⲻ����2020�꿪ʼ��һ���µ�������ʽ�����Ұ�����������Ѹ�ײ����ڶ�����ʽ�������֡��� ���ִ�Ҷ�֪�������������ǽ�Ǯ�����������ˢ��ȥ��Ǯ��ͨ��ij��;���ص������Ȼ����Ǯ�ͱ������ˣ����ºܿ��ܾͲ����ˡ����� ��ͼ�Ϸ��֡����֡��ͷ��֡������������е����ƣ������ҳ���Բ��������ȥ���꣬���·�����ϵͳҲһֱ����ô�ɵġ� ���ǣ��㻹�ǵðɣ������������Ҫ����Сʱ������һ�Σ����������Ż�Ҳ��һСʱ��һ�Ρ� Ҳ����˵�������������һСʱ��������ֵ�ȫ�������������Ѿ���Ǯȡ���ˣ����ٷ��־����ˡ� ���������Ǹ����һ�����Զ������ַ�����������Բ����ǰ�漸����Ȼ����ܴܺ��������ͻȻ����������ֱջ���һ��Сʱ��˵��1�Σ���100�ζ����ԡ� ���զ�죿 �鴺�θ����ң���ʱ��ʦ���������Σ���������һ�ֱ�ʵʱ��ѯ��20���룩Ҫ�������ȵ������㣨1Сʱ��Ҫ��ļ������棬����ǡ���ʽͼ�������桱��TuGraph-Analytics���� ����˼��Ҳ�ܼ� �Ҳ�����һ����㡣ÿһ��ת�˷������Ҷ���һ�����������������������ʱ����Ҳֻ��Ҫ������һ�����㡣 ����ٶȾͿ���ˣ�1�����ھ��ܳ������������������� �㿴��Ϊ�������ˣ��Ѻ��˶��Ƴ�ɶ���ˣ���ͼ���ݿⱾ����������ͼ�������棬����ʽͼ�������棬��ͬϵͳ���۴��αȵĹ�����ν����� ��Ӧ���Ǿ仰���ɹ���Ҫ���ѣ���ijɹ���Ҫ���ˡ����� |
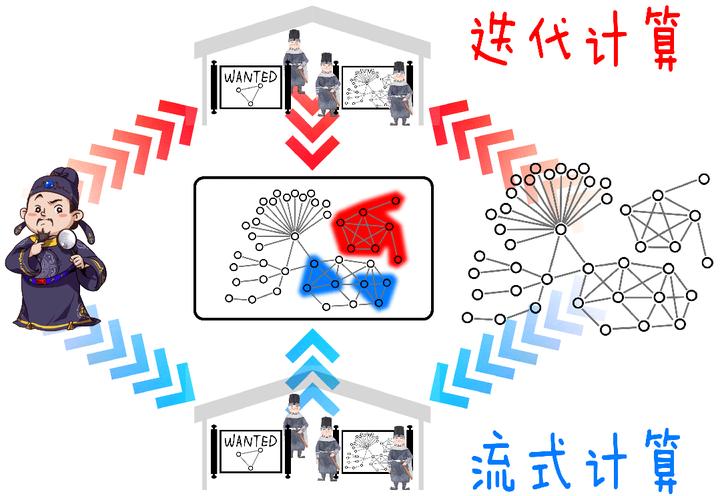
|
|
����˵���⣬�ҵ�����һ�£� ����֮����ʹ���¼������ɲ������Dz��¼�����Ч�ʸߣ�������Ϊ�¼��������ϼ��������˵����飡 ���ǻ��õ綯���ͻ��������ͣ� ���£��ͳ�Ҳ�ܿ����糵Ҳ�ܿ����糵������������&�ƶ����졣 ����δ�������������ռ���̬�ǻ����ˣ�Ҫ���������Ķ��������뿿����� ����������ϵ���Ƚ��������ڴ����ṹ�ĸ��ӣ�����Ҳ�Ǵ�����ġ� |

|
|
���£��ֽ�Ҳ���ã�����ת��Ҳ���ã�ת�˲������Ǹ�����Щ�� ����δ���������ᱻ�е�����ϸ�飬����һ����/��˾��ͬʱ�ʹ�����ϵͳ���ף�ÿ�ʽ����ܵ�������Ǯ�� ��������ֽ���ȫ��Ӧ�ԣ������ü���ϵͳ��������Ҫ�÷ֲ�ʽ����ϵͳ�����ܺ�Լ�������������� |

|
|
��ô���Դ����ƣ�ͼ���ݿ�϶�Ҳ��Щ�˲��õ��÷����Ǵ�ͳ���ݿ��붼������ģ��ǻ���ɶ�ϣ� �鴺�θ����ң���ͼѧϰ���ܿ����Ǵ�֮һ�� ���ģ�ͼѧϰ�������˹����ܵĻ� ����������ߵĴ���������ǡ��˻�Э������ɵġ� ����һ�����ⲻ�Զ������˻�Э���������У�������Խ������ˡ���Խ��Ϊƿ���� �ٸ����ӣ�����ô������ �̼�ע�����ô��ʱ���˹���дһ�ѹؼ��ʡ�����ϵ»������Ĺؼ��ʿ����ǣ���͡����͡����������������֡� ����һ��������Ϊһ���û�ȥ������Щ�ؼ��ʵ�ʱ��Ӧ���̼Ҿͻ��������������������������������������ϵ»����� |
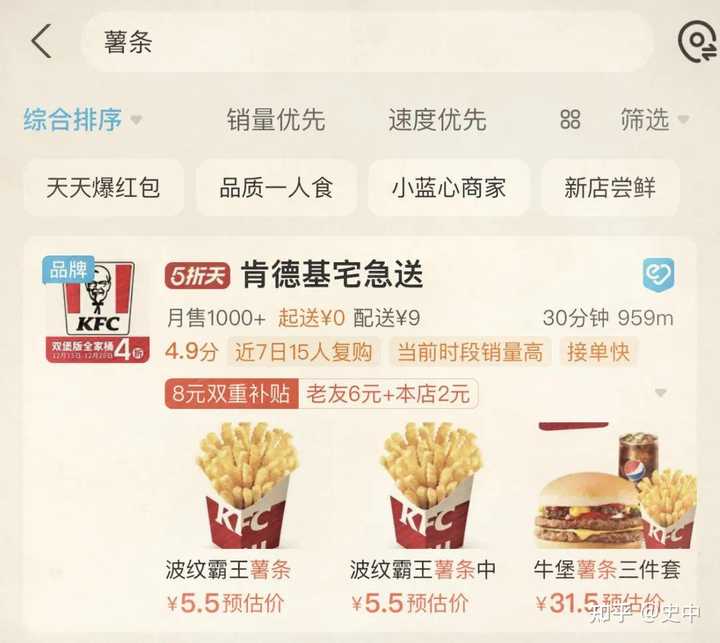
|
|
���ǣ�����һ�ֺܲ����Ĵ��ڣ���ؼ��ʵ�ʱ�����벻����ôȫ�档 �����������ʹ�������д�ؼ��ʣ���д�ˣ���͡����͡����������ֵȵȣ���©�������������� �����������������������;Ͳ�����֣�����Ȼ����������� ����һ����������һ��ѡ�����Ͷ���һ�����⣬˫�䰡������ ��ʱ���˹����ܾͿ��������ó��� AI ��ͼ���ݿ�����������������ͺͿϵ»������˺ܶ�����Ƶ��û��������Ƿֱ������ˡ���͡��������͡������������������֡������ϵ»��������������� ���Dz�����ζ�ţ��ҿ��Դ��ڡ����͡��͡�������֮�����һ�����ߣ����û�����ͨ���������������ͣ� |
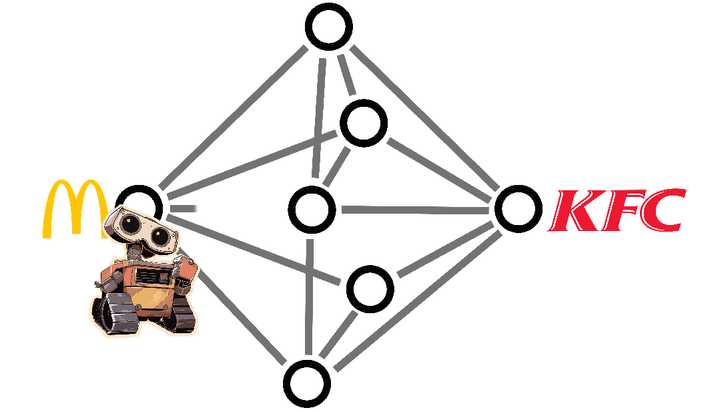
|
|
�پ�һ�����ӣ�֥�����á� ˵�����¶�����ȥ���鴺�ε�֥�����÷ֺܵ͡��ⲻ����Ϊ������ɶ�£�������Ϊ����û��ɶ�¶����� ���ڼ��Ǹ�˦���ƹ�����֧��������ɶ��������̫̫ȥ������̫̫��֥�����ߣ���800�ࡣ ��ͼ���ݿ���鴺���������DZȽϡ��ס��ģ�û���㹻���ݣ��ͺ���������֪�����Ǹ����˻��ǻ��ˣ�ֻ���ȵ������˴���ͷְɡ����� ���ǣ���������˹����ܣ�AI ����ͨ��ͼ���ݿ��������һ���֡� ����ԭ���ǽ��ģ��鴺�κ�̫̫�����ˣ���ͼ���ݿ���Ĺ�ϵ�ܽ������ǵĵ�¼����һ�£������������е�ת�˼�¼��AI һ�룬һ��֥�����ߵ��˲�̫���ܺ�һ������������ܻ��������ԣ��鴺�ξ�մ��̫̫�Ĺ⣬֥��ֱ����ߵ���һ������ij̶ȡ� |
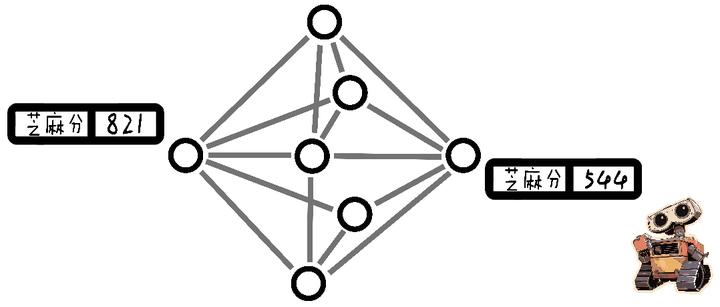
|
|
�㻹�ǵøղ�����˵�ģ����ݵı���Ŀ����Ԥ��ɣ� ����ͼѧϰ�����������˹���������ͼ���ݿ⣬�Ը���ά�ȵĿհ�λ������ϸ���ȡ�������Ԥ�⡣ ����Ԥ�����ͬʱ�����������ڵ����ɵ���Ϣ�����У�ÿһ���˻���ϸ���ϡ�Ԥ��֮�ܼ�����������ʷ�ϲ��������� ��·�Ħ�������캣����һ���� ���ۺ�֮����������ͼѧϰ������Ԥ��������������ܲ���һ����Ծ������£�����ͳ���ݿ������ר���ִ꣬���Ǿ��Ʋ�����ʵ�ֵġ� |
|
|
��������Ȼ�С�ͼѧϰ������Ԥ���������컨�壬�Ͳ���ȡ����ͼ��ˮƽ����ȡ���� AI ��ˮƽ�� ˵���⣬���Ǿͱ������Ͻ������ͻ����¼�����������ģ�͡��� Сģ�Ϳ���ģ������ͼ���������ݲ�ȫ��֮��ļ������Ͷ��� ��ģ�͵���֮�����ڣ���������ͼ��ģ�����Եĸ������Ͷ����������졣 �㻹�ǵ��Ǹ����˵��ϰ�ô���������ݹ���ʦȥ�������㲻ͬ��Ⱥ����Ʒ�Ĺ�ϵ����ʵ������Ϊ���ҵ��������ص������Ӷ��ƶ���ҵ���ԣ�ʵ������Ŀ�ꡣ �����Ǹ�����Ĺ��£� ���а�ơ�ƺ�����һ����Ϊ֪���������ص������ֻ̰ᱻ���������������������������ơ�ƾͻ��������������۶�ͻ����ӡ� �����һ������ģ�����֡������Ϳ�����������˼ά����ȫͼ��ֱ�ӽ���ȥ���顰�ض���Ⱥ����Ŀ֮��Ķ�����ϵ����Ȼ�����ɾ�ϸ�Ĵ������ԣ��Դ���ϰ��趨����ҵĿ�ꡣ �������IJ��Կ����������ģ� �ҽ��飬��32��-35���ڱ����������������У�����ÿ��������1��ä�����ϵ���Ⱥ�� �ٴ�����ѡ�������������Ʒ����Ⱥ�� �ٴ���Ⱥ�˵�һ�ȹ�ϵ����������ȥ3���������200Ԫ����ơ�Ƶ���Ⱥ�� Ϊ�����Ƽ�λ�ڱ�����ƽ����ij���¿��Ķȼ������Ż�ȯ�� Ҫ���ܾ�ȷ���ˣ��������Ƽ�������û���ɴ��ţ���������ѩ����̿�� |

|
|
��ͨ�� AI ���Բ�ȫͼ������һ������ͼ��Ҫ��ﵽ�������⣬���ÿ������ģ�͡� ��˵������Ҫ�����˵ȴ����Ĵ�ģ��̸�����ס� ���ִ�ģ�Ͳ�ͬ�� ChatGPT ������ͨ������ģ�ͣ�������Ҫ������������������Ҫ��ͼ���ݿ�ı�����������⡣�������ϵ���ʦ���dz��ѡ���Ȼ�����������͡�ͼ���ݿ��������ں���һ��ѵ������ͽС���ͼģ�͡���Large Graph Model���� ��˵��ͼģ�ͲŸ���·�����鴺�μ�������������ж��������������� �ȸ裬֮���Ի�������֮����������Ϊ��ʱ MapReduce �ô��ģ���м���ijɱ�ͻȻ���ͣ���ʹ�á����������ֹ��ϵ�������Ϊһ����ҵģʽ�״ε��Գ����� �ֽ������Ľ���ͷ���Ͷ�����֮�������ڼ���ǰ��������Ϊ��ʱ�����ݷ����ijɱ�ͻȻ���͡��ɴˣ�ͨ�����ݶ�һ���˵���Ϊ���ж�̬������Ȼ���ҵ�����ʱ�����ϲ��������������ǰ��������ҵģʽ�����״γ����� ��ʷ����Ѻ�ϡ� ���ͼѧϰ����ģ��+ͼ����+ͼ���ݿ⣩�ijɱ������½����ᷢ��ʲô�أ� �Ҳ£�����ͼ���͵IJ�ͬ�������ڸ���������ֲ�ͬ��Ӧ�ã� ��ģ�ͼ���Ũ��������֪ʶ�ij���ͼ��֪ʶͼ�ף����ͻ�������ƿ����������н����ࡱ�ĸ�����ʦ�� ��ģ�ͼ��������ó������ֽ��ڹ�ϵͼ���Ǿ����ܶԸ��ַ��վ�ȷ����������Ԥ�⾭��Σ���ľ���ʦ�� ��ģ�ͼ��Ϲ�ҵ�豸����ͼ���Ǿ������Լ��Ż�Ч�ʡ�����ҵ�ɱ�����Ʒ�ۼ۵IJ�ҵ�������ࡣ ���������Ӳ�ʤö�٣�������Ļ������������� һ�����������Ͳ����������ģ�ͣ������һ�����������������άϸ�ڵ����ݿ�����ϣ����ܷ��ӳ��������ļ�ֵ�� ��Ȼ��Ϊ������ʷ�������鴺�κ����ϵ���ʦ����ʱ������һ���£��Ǿ��ǡ������������ͼ���ݿ�ijɱ��� |

|
|
���壩ͼ���ݿ���ǻ���ԭ �鴺�θ����ң�Ŀǰͼ���ݿ���Ҫ�������ɱ��� 1������ɱ���Ҳ���Ǽ��������Ӳ���������� 2����Ա�ɱ���Ҳ���Ƕ���ͼ���ݿ⼼��ջ����ʦ���Ĺ�Ǯ�� 3��ʹ�óɱ���Ҳ����ͼ���ݿ�ʹ�ͳ���ݡ�AI�������ݵ�������ϵͳ�Խ�ʱ��Ͷ�롣 ʵ��˵��Ŀǰ�����ɱ����ܸߣ�ȫ�м����½��Ŀռ䣬��Ҫ˵�ռ����ģ������еģ���ʵ�ǡ���3������ ���Dz������ӽ�������Ŀǰ���й����������ϼ�����ͼ���ݿ�һ�����ȣ����аٶȡ���Ϊ����Ѷ������ȴ�Ҳ������ͼ���ݿ⣬����������Ƽ���������ͼ�����ڿƼ�������Ƽ��ȴ�ҵ��˾����ͼ���ݿ⡣ �ٻ���ŵ�Ȼ�Ǻ��£�������ͼ���ݿ�Ľӿڱ��Ͳ�ѯ��䶼������ͬ���൱��ս�����ۣ���Ҷ�˵��ͬ�ķ��ԣ��ò�ͬ�����֡� ������ɶ�����أ� �ղ�˵�������и�ҵ��ͼ��������ƶ���ͬ��ͼ���ݿ⳧�̺����Լ�����������ҵ����Ҫ����������̬������м��æ�� �������ͼ���ݿ�ı���ͬ����̬������ѧ�������ϣ����컹��ѧ�ٶȡ���Ϊ���Կͻ���˵������������ҵ�ͼ���ݿ⣬�����뻻�����ҵģ������ӿڶ�������һ�顣 ���ڵijɱ����úܶ���ҵ����ȴ���������谭ͼ���ݿ����Ѱ�����ռҵ�һ����ɽ�� ��Ȼ��ɽ���͵������� TuGraph����Ϊ�й�ͼ���ݿ������ܴ���Ǹ���������һ�¡�����ɽ������ʷ���̡� 2022�꣬������ʦ�����Ϲ��ʱ���֯ ISO �����ƶ�ͼ���ݿ�ġ���ͨ��������ͨ�ò�ѯ���� GQL�� 2023�꣬���ǻ�����ͼ���ݿ�Ĺ�����֯ LDBC���ƶ��� FinBench ����ͼ���ݿ���Ա������оͶ����˱������ݽӿڡ� |
|
|
FinBench �ı����� �⿿���͡�Э���ɱ�������ʦ�������ò���һ�������뷨ð���������� 2022�꣬����ֱ�Ӱ� TuGraph �ĵ��������Դ�ˣ� �ⲻ������������Ҫ����ҵֱ�ӡ���Ԫ������������ͼ���ݿ⣬�����ø����ͼ���ݿ����Ȥ����ʦ������Ѽ����о����� ��˵����Ȼ��ҪǮ����ҵ��Ҳ������һ��������ͼ���ݿ�е����Σ���Щ��ʦ��Ҳ������һ��������Ӧͼ���ݿ��˼ά���������ɷ��ϣ����Ƕ�������֮�� |

|
|
TuGraph ������Դ ��Ȥ���ǣ���Ϊ˭�������أ��鴺��Ҳ��֪������˭���á� ����һЩżȻ�ij��ϣ���������һЩС��飬��������С�����������м�������Ĺ�˾�� �Է����ߺ鴺�Σ��Լ��Ĺ�˾�Ѿ���ʼ�� TuGraph �ˡ�ûɶ��������������£�ȴ������Щ������ҵ��������ѿ�����ú鴺�ζ� TuGraph �����������Ĵ����� �鴺�θ��һ���һ��ͼ������ͼ���ݿ�ijɱ����ͣ����ܽ���������Խ��Խ�ࡣ |

|
|
����ķ�չ��Ҳ����ӡ֤����ͼ�� ���ڲ���ǰ��TuGraph �ŶӰ������ڲ�����һ���ͽ��ڱ���û��ô���ϵ���¶�����������ѪԵ���̡��� �����ǽ��ģ� ������ҵ����ʹ�õĴ�ͳ���ݿ����һЩ�������ҹ��ġ�������������Ϣ�� ��Щ�����������������ԭʼ�������ڸ���ҵ������ͬ�������еĴ�����ȡ��һ����ʹ�ã��еİѱ��˵ı������������á� �����������ˣ����ССһ����ű��ﶼ����������ű��ġ����� �Ȿ��ûʲô���⣬�������Ź��ҵķ�չ�����������ǻ�仯�ġ�2021�꣬���ϼ����ڲ���������һ����������������������� �鷳���ˣ�����������������һ����ű�����ɶӰ�죿��һ����ű��������ĵĻ������ϵͳ�����Щ�����Ӧ����������˳���滻�� TuGraph �ŶӰ�æ����Щ�����Ԫ��Ϣ������ͼ���ݿ⣬��ͼ�㷨һ�ܣ����й�ϵ��Ҳ���ǡ�����ѪԵ�����̸��ֳ����� ѪԵ��ʾ��������������������Ҫ�������ܶ���������ġ����������������������ĸ����˱������������Ŀ�飬��������б������������ݵĵ�λ�������˹���������л����DZ���֮��صĵ�λҲͬ���л��� ������������������α��DZ�ڵ����ݳ�ͻ�����̻������ݿ�֮���Ѫ�����Ժ���������ֱ�Ӳ������У� |

|
|
�������Ƶ�˼�룬TuGraph �Ŷӻ���ij����������һ��������ѪԵ��������Դͷ����������һ�䣬������ص����þ�˲����ġ� ���ǻ���ij���ذѱ��ص������ݶ��Ž�ͼ���ݿ�����Դ��з���ȫ����Ʒ����������������̽���ٱ��ص���Ϊ�� ���ǻ���һ����Դ���Űѵ����е��豸���˶�������ͼ���ݿ��У�ģ������ijЩ�ڵ���ֹ���֮���ϵͳ������ɵ�Ӱ�죬�Ӷ��ƶ�����ȷ��ά�����ԡ� ��ЩӦ���廨���ţ��ں鴺�ν���ǰ������ȫ������ ����ͼ���ݿ����������Щ��ҵ�أ������ٸ��ʵס� ��������ҵ��ֻҪͼ���ݿ�ijɱ��㹻�ͣ����鴺��˵�������ڿ�����������ҵ���ڵ����ĵ��ϳ��ԣ�����վ��Զ��������Щ�������࣬�ͻ�����Ƭ��������ǻ���ԭ����ʵ���̡��� |
|
|
��������һ���¼����� Hyper Cycle���鴺����Ϊͼ���ݿ����ڵ�λ���Ѿ��߳��ˡ�����֮�ȡ��� ���Ļ�����ͻȻ������130��ǰ��1893���֥�Ӹ����粩���ᡣ �ǽ첩����Ϊ����ף���ײ������´�½400�꣬����ʹ�õ�ʱ����δ�����¼������硣 ���᳡�У�12�������ͬʱ��������ͬ���硣���������һ�δ����һ�����������Ľ��������������� ����֮��������ˡ��硱����Ѱ�����ռҵ���ӿ���̣��Դ���ʷ�ٲ���ͷ�� �����Ӧ��Ҳ�ӡ���ơ���ʼ��������ȡů���������ҵ��������е�����������������˵��Ӽ��������Ϊ�˳�����һ���Ƽ��˳��Ļ�ʯ�� ��˿�������һ���Ƽ��˳������������ǽ���ӿ���� |

|
|
�������·��գ����¡���ǰ���� 2021�꣬�����ձ�������һƪ���£����С�������ͼ���㣺��˿Ƽ���һ��ǰ�ء��� ���е͵���˵��һ�䣺 ���ҹ���չ������ͼ���㣬�߱����õļ�����������ʵ������ �������������ʷ���鴺�ε�Ȼ֪����Щ���������������ж�ô��֮���ס� �������⣬ͼ���ݿ��������ҵ����̬������������2007�괴ҵ�Ŷ� Neo4j ������ͼ���ݿ����ҵӦ�ã������ڵ�ʱ���ݷ���������ʢ���漴�����˳���8��ĵͳ��� ����2015�꣬��������ʼ���ǣ�������٣���ʱ������������ʦ���Ǽ���ͬʱ���ɱ��ͼ���ݿ⣬��һ�����ǵ�Ͷ��˿����ѷ�������� ֮�����й�����ô�����ģ�Դ�����Ǿ���˿ڻ������ͽ��������ϵ�ȫ���������ƶ���������̬�� �ⳡ������Ͷ�룬���صĽ�����ǣ���ͼ���ݿ��ͼ���������й�һ�������������ǰ�أ�û���κ��˿����ǵIJ��ӡ� ���Dz��룬���Dz��ܡ� ���У��廪��ѧ��ѧ�������������ȣ������ڲ�ҵ����������ǰ�档 ����2020�꣬�鴺�κ�������ʦ���Ĺ��������������廪���ŶӼ��������ϼ��ţ�ѧ����Ͳ�ҵ����ǿ����֧�����ʦ����Ϊ���й�ͼ���ݿ��һ����̱��� ��λ�ʦ�Ľ�����ǣ������µ�Ȩ���������У�TuGraph �ijɼ���������֮ǰ������ǿ�� TigerGraph �� 2.84 ���� ��Ȼ������ͼ���ݿ���Թ����г����ܴ�ȫ����������ǿ���˲ţ��ۺ�ʵ���������ȣ������й�ͼ���ݿ�����ܰ��������˵û��Ҫ��������Ҳû�������ԷƱ��� �����Ǹ��ù��ĵ��ǣ���ô�ҵ�һ������������������������и��Ӳ��Ƶ����ݾ�������ͼ���ݿ����������ʩ����֯��ר������һ��ʱ������������ �������һЩֵ�þ������ʵ�� �ڲ���ͼ�������Ը�ϣ��й���ҵ��û��������ҵ��ô������ ����ҵ������һ��ͻ�������ӡ� ��˵���ǵĺܶ����ж���ʹ��ͼ���㣬��ȴ������Ϊ����ض����յ�ר�ù��ߣ�û�������������Ž�ÿһ�ʽ��ĺ�������� ���������еķ�ز��Ը�Ϊ�ϸ���ҵ�������������Ҫ��ܸߣ�������С��ҵ���ȱ�������жϵ���Ϣ�����ʽ��ȡ�������������ѡ� �������dz���֮�ơ� ������꣬���Ҵ����ƽ��ջݽ��ڣ��������мӴ��С��ҵ�Ĵ���֧�����ȣ�����ҵ�ķ������Ҳ�ڽ�һ������ˮ�����棬�¼�����Ӧ�ÿ��ܾ���һ��Կ�ס� ����ҵֻ��ǧ�а�ҵ�Ĵ����������ߵ������£���Դ��ҵ���Ƚ�����ҵ��ҽҩ���������ڽ������ֻ����죬��һ���������ݷ����Ͷ��졣 ��Щ���������Ƿ����˾۱�һ����ȼ�й�ͼ������һ�ֱ�ը��������Ⱥ��ʦ��վ��ʱ��ĺ������ߣ����˷�һ������֮��������һ�з����� ң�뵱�꣬��������֥�Ӹ������ῪĻʱ�����������ս�����������й���ط�����ޣ���ʶ֮ʿ���ڿ첽���У�Ѱ�ҵ��������������� ����ͷ������ձ����������Ҳ������ɻ����ǰ������ �Ͼ��������������ʼ��������͡�ð�������Ķ����ꡱ���������ǵ��������ǰ����������������ʫ����ɣ� |

|
|
Art work ByYoshi Sedeoka �����ҽ���һ�°ɡ��ҽ�ʷ�У���һ�����Ĺ��µĿƼ����ߡ��ҵ��ճ��Ǻ�·�������졣�������������ѣ����������ţ�shizhongmax��Ҳ���Թ�ע�Ź��ں�dz�ڿƼ���qianheikeji |
|
�й��ĿƼ�ˮƽҪ���й����Լ�˵���㣡 |
|
�������ƣ��Ƽ�ս��������ս�ܣ���ϸ������ ǰ���ã��ݵǴҴҸϵ�Խ�ϣ���˫����ϵ����Ϊȫ��ս�Ի���ϵ��������£Խ���⣬�ݵǻ���һ����Ҫ����ʾ����Э����Խ�Ͽ���ϡ����Դ�� ȫ��ϡ������1.2�ڶ֣��й�Ϊ4400��֣�ռ��41%Ϊȫ���һ�� ��Խ��Ϊ2100��֣�ռ��Ϊ18%�� ����Խ�ϣ�����ǰ��ʱ�仹�պ��ɹŴ����ϡ����������¼�� ��Ϊ�����������·��������ݣ��ɹŹ���ϡ���������ܸߴ�3100��֣��������й�Ϊȫ��ڶ��� �������ڶ�ϡ����ô���ģ�����ת������Щ����ǩ����ص�Э�飬Ŀ����Ƿ�����δȻ���ԶԿ��й��ġ�ϡ��¢�ϡ��� 2010��ʱ�������ձ��������ǵĵ��㵺���й�������ʱֹͣ���ձ���ϡ�����ڣ������ǵ�ϡ��95%���ϴ��й����ڡ� �ڽ����֮��������ʱ�䣬�ձ���ϡ����صĴ�����ө����ϡ�������ϡ������մɵ��ȹ���ҵ����ͣ�ڣ������Ǹ����ܴ�������ز�ҵֱ��ͣ����ϡ�����ձ��ļ۸�������10�����ϣ����㲻������ ��һĻ������Ȼ�������ǣ���������Ƶ���Ʋ����ѹ�й��ĸ߿Ƽ���ҵ��һ���й����з��ƣ����������һ����ϡ����Ϊ����������һ��취��û�С� �������Ʋ��й���оƬ�����Ҳ����Ӱ��ͨѶ��ҵ����ϡ����ȴӰ�쵽����30�����ҵ�� �ڹ�ҵ�ϣ�ϡ����ʹ�÷�Χ�dz��㷺����ӫ�⡢���ԡ����⡢����ͨ�š�������Դ�������Ȳ����������Ų�����������á� �ھ����ϣ�ϡ�����DZز����٣�Ŀǰ�������и߿Ƽ���������ϡ������Ӱ����ϡ�����ϳ���λ�ڸ߿Ƽ������ĺ��IJ�λ�� �������ڵij��浼�������簮���ߣ��Ƶ�ϵͳ��ʹ����Լ3���������ܴ������������壬���ڵ������۽������ܾ�ȷ������Ϯ������ �ٱ�����ν��ǿ����M1̹�˵ļ��������F-22ս�����ķ������������̵Ļ���.......��Щͳͳ���벻��ϡ���� ������˵�����������е����е��Ӳ�Ʒ������ϡ��ϢϢ��أ��ֻ�����LED�����ԡ������������û��ϡ����Щ������������ �����й����ձ�����ϡ�����ˣ������������ձ�д���� ���û��ϡ�������ǽ������е�����Ļ������Ӳ�̡����˵��¡���������ʹ����ҽ�Ƴ����豸�� ϡ�������ǿ����������������������е�������ϵͳ��������Ҫ�����أ�û��ϡ����͵ø���췢������ǣ�ȫ�������ϵͳҲ��ͣת��ϡ����δ�����ǽ����ӿ��ص�ս������Դ...... ��2010�꿪ʼ���������Ѿ���ʶ���ˣ����ϡ�����������й�����һ���dz�Σ�յ����飬�����2020�꿪ʼ�������ȷ���Ƽ�ս���뵽����������ﲻ̤ʵ�� ��Ҫ�Ʋ��й����й�����������������ֻ��� �����й���������أ������������� ���ݵ������ϴ�������������ϡ���������㡰���������Է�����δȻ�� ���������� ��ϧûʲô���á� ���й�֮�⣬ȫ����59%��ϡ����������ϡ������������ͺ���оƬһ���� оƬ��ɶ�������ɵ��ʹ�����ģ�������ȫ���絽�����ǣ�ɳ������ȫ�ǵģ���������ɳ�Ӿ�������оƬ���� ��ʵ�ڽ����1��6�·ݣ��й���Ȼ��ȫ���һ��ϡ������������ȴ��ȫ�������3.78��ֵ�ϡ�����ţ��ǵģ����ǻ���ȫ���һ��ϡ�����ڹ��� ��������զ��ģ���������3.77����Ǵ��������ڵģ��൱�����Ǵ��������ڵ�ϡ��������ռ���������ı��ظߴ�99.73%�� ��ʵ�ϣ������ڳ�����ϡ��������99%�������й�....... ����Ϊʲô�� ��Ϊ����Ҳ��ȫ���8��ϡ������������������ȴû��ϡ���ӹ�����������ֻ�ܰ�ϡ����ӵ����ڳ���....... ������Ŀǰ�Ĺ�ҵ����£���ϡ���������ȼ��ߣ����������ʹ����İ��Լ���ϡ�������ڡ����й��������й��ӹ����١����ڡ�������ȥ�� �ǵģ��й���ϡ��������ռ����ȫ��71%�ķݶ����71%����м����Ե�71%�� ��ʹ�й�û��ϡ����������Ȼ��ռ��71%�ķݶ��Ϊֻ������������ӹ������� ϡ��ԭ���д����ķ��������ʣ��ӹ��ᴿ��һ�����ѶȵĹ����� �������˵��ϡ���������������̷�Ϊ7�����ֱ�Ϊ���ܡ����롢̼�ɡ���Ҥ����ˮ���Ȼ�����ȡ...... ��Щ�������̣�ֻ�����й����С� ��������Խ����ϡ����ɶ�ã� ��ʵ����ȥ��Խ�Ͼʹ��й�������1.2���ϡ���������Լ��Ĺ�ҵ��Ʒ�� ������Խ�����ٶ��ϡ��������Ҳֻ���͵��й�ȥ�ӹ��� ��ôԽ�Ͽ��Ը����й��ļ������Ժ�����ӹ�ϡ���� �������ܣ��й���ѧ���������ɹ����з���ϡ����������ɼ�������������ܹ���ϡ�����������30%�����ʺ�������70%������ʱ������70%...... �����ϣ�������������ϡ���������������Խ���Լһ��ijɱ��� Ҳ����˵������ǰ���й���ϡ���ӹ�������100�֣�������ţ����������й������ȫ�����ǵ�ϡ���ӹ�������20�֡� �����й��ļӹ���������120�֣��������20�֡� ��ʵ�ϣ����Ǹ�˵��ϡ���ӹ���7������7�����������������û�У�����������Ļ�������Ҫ���½��й�ҵ�����֣����������Ĺ�Ӧ�����ߡ� ���ؼ������ǣ�ϡ���������ԭ���Ĺ�������һ�������ǰ��������ڳ���һ���������������70������60������20����ϡ���ĺ����ٵÿ�������Լֻ��2�� ��ô�й���ϡ��֮���Լӹ�����ǿ������Ϊ�й������Ĺ�ҵ��ϵ���ڼӹ����������ʱ��˳�㡱��ϡ�������˳���........ �ͺ�����ԭ��˵����һ����������Ҫ�������ߣ�����Ҫ�� ���Ƚ����������������ߣ��Ǿ�Ҫ�Ƚ��������IJ��ߣ� ������dz������ܺIJ�ҵ��һ�������IJ��߿��Ժķ�һ������1/3���õ�����������ܰ�������ޣ� ����������������ˣ���ȫ����ҵ���ز��ܹ�ʣ�� ....... ��ϡ����7�ڣ���������ȡ���й�����ȥ�����������ɣ�ÿһ�����ڶ���Ҫ�������ϵ�Ͷ�ʣ�ÿһ�����ڶ���Ҫ�����Ĺ�Ӧ��...... �����ǻ��˾��Ѫ����ʱ�䣬Ҳ����ϡ���ӹ��������۸�Զ�����й��������ĵ���������ɱ�������ǣ��Ǹ�ʱ�����ǾͿ��Կ�ʼ�������ˣ�������Ͷ����ʱ�Ѫ���飬���������� ��ʵ�ϣ��й�����ϡ���ļӹ��ϵ���ȫ����ԭ��������ȫ��ҵ��������ǿ��Ĺ�ģ�����Ͻ����������Ĺ�ҵ��ϵ�� ������ܾͻ����ˣ���������Ļ�������Ϊɶ���ϴ���������Խ��ȥǩ��ϡ������¼�����ѵ���֪��������û���� ����Ȼ֪��������û�ã�����ȥ��������ϡ�����ɳ�����99%���͵��й����ӹ��� ���ǰݵDZ�����������Ŭ�������ӡ�����������������һ����̬���Կ��й�������ĺ�Ŭ����....... ������û��Ч�����ǾͲ����ҵ������ˣ������Ҿ����ˡ� ��ô����������ˣ�ϡ����ô��Ҫ�������������������еģ�Ϊɶ������������ ��Ϊ��20���������е����ݶ�֤���ˣ��й�ȫ���츳���������Ե���ȫ��������ȫ����������ߡ� ������Ϊȫ�����ǵĹ�ҵ����ԭ���Ļ����ϸ��ٷ�չ�������ճ�Ϊȫ������� �Ǽ�Ȼ��ˣ�����������������ʱ�����Ǹ�Ҫ�߾�ȫ�����ģ�ΪʲôҪ���������أ� Ҫ������ֻ��һ�ֿ����ԣ��Ǿ��ǵ������һ�������������ӷ���ս�������ǾͻῪʼȫ����ˣ��ȵ���һ�죬������ͻȻ���һ�����ƽ�ij������֣�ֱ��ץϹ�� ϡ��������һ�ź��ƣ����Dz��������á� ���������������ǻ��кܶࡣ �ͺ�����һ��������Ҳֻ�ǽ����˳��ڹ��ƣ���û�н��г������ƣ���û��˵�����������ڡ� �������ƣ����������׳��� ���Ƶ�ʱ��һ���öԷ�Ҫ����ֱ���������䡣 ֻ�������������ڿƼ��϶��й����������Ƶģ����ܾ���оƬ�ˣ����������������ը����������������������ֱ�Ӱ���ը��˦�˳����� ���������������ʱ����ƽ��ˣ��������ڷ��IJ��������һ��ΪMate 60 Pro�����͵ó����������ۣ� ����һ����оƬ�����й��Լ����ġ� ���۶�����ô���ģ��Բ���Ҳ��֪��....... �������Ʋ����Ѿ����˿�20�����ˣ�4��K�Ѿ����ˣ����Ƿ����˰������ǻ�Ϊ�����˺���4.0������ԭ��̬Ӧ�ã����ٵ�������죻 4��AҲ���ų��ˣ������˿��������������Ϊ���������ξ��з������ز����� 4��2Ҳ���ˣ�������������ʾ���������Ϊ���Ͼ������Ƴ�����OLED��ʾ���� ����������߳�ŭ��˦����ը��в��ȫ�����й��ң��Ի�Ϊ���з�����Ҫն�ϻ�Ϊ��оƬ��Ӧ��������ֱ���Ϊ�ƽ��ˡ� �ٹ�֮��������ȫ��һ���й���ҵ������е��ƣ�����������ˡ� ��������һ���±ƣ���ô�죿�һ���ɶ�ƣ� �й�˵���ţ�Ҫ�����ȳ���3�� ���������Ʋû�Ϊ�������Ǿ��Բ����Ʋ�ƻ���� ����ͬϡ�������࣬����Ҳ���Բ������ڶ��������ˣ���ô����Ҫ��ʲô�� ����һ�����飬ǰ���죬̩��������е���������ѡ�٣������ǵ������ѡ��������ڵ�Ϊ̩��������������ѡ����������ΪΨһ�ĺ�ѡ�ˣ���428Ʊ�ľ�����Ӯ�ô�ѡ�� Ϊʲô˵�����ѣ���Ϊ�����ոյ�ѡ���ͺͶ���̩���ڸ��ܵ����ȵ��������չ��ʻ�����ӭ����ǩ����ʵʩ���յĵ�һ����̩�й��ο͡� ���ⲻ����Ҫ˵���ص㣬�ص�������Ϊ��һ��һ·�������˹�ע�ĺ�����Ŀ���ᴩ���ϰ뵺������̩��·����ǰ���ɣ� ǰ���ã�������·�Ѿ������ˣ��������Ҳ�Ѿ�������......�й���·�����������DZ�ˡ� Խ�ϡ�����կ����������......������ס�ˡ� Խ�ϴ�2001�������ϱ�������������ӡ��ĸ�������ʼ���ˣ��Լ���ûӰ�ӣ�Խ�϶������ˡ� һ���ʱ�䣬Խ���Ⱥ��������й�����Ϊ��̸�����ĺ���������5��29�գ�Խ�Ͻ�ͨ���䲿�������ӷû���������Ա����Խ�Ϲ���ƽ�ίԱ�ḱ���Ρ�Խ����·�ܹ�˾���³��ȣ����������к�����·��ص���Աȫ�����й����ˡ� �����й���Խ�ϴ������ܼ��ݷ��ҹ���ͨ���䲿��������·�֡��������š��н����š��й��г����й��������й������ȵ�λ�����й����к��������йز���һ����©��ȫ�ܱ���...... �����ԣ���Ԥʾ����Խ��·�ڽ��������ܻ���ʵ�����ƽ��� ��ͨ����Դ�ǹ�ҵ�Ļ�����һ�������������������й������ı����ٴ������Ժ�ĸ�����������������Դ����ô�����Ǿͳ�Ϊ���й���������죬�й���ҵ��һ���֣����й�Ϊ���Ķ�������̫�ľ��ý������������ںϡ� ���й�����Щ������չ���г�Խ����������Լ����ڲ���ģ�����γ������ױȵijɱ��뼼�����ƣ���ѹȫ�� ����˵�й����Խ���ͨ���촬������������������Դ���ͽ�ȫ�����ӣ���δ����10�꣬�κ�һ��������Ҫ�ڹ�ҵ����ȡ�óɾͣ����벻���й��ı��� �Ǹ�ʱ�����еĹ�ҵ������Ŀ�����Ƕ���ȫ��֮�������쵼�ߣ��κ�һ�����ң���������й��ı������Ⱦ���ζ�Ź�ҵ���ijɱ����40%���ϣ���û��ʼ����Ѿ�����ˣ� ��ô����Ϊʲô������������ Ϊʲô������������ϡ�����ˣ� ��Ϊ�ⲻ��������Ҫ�ģ�����������Ҫ���ǣ� 5��֮���й�����Ϊ�����ǵļ������ĺ�ҵ���ƶ��ߣ� 10��֮���й�����Ϊȫ��ļ������ĺ�ҵ���ƶ��ߣ� ���������Ų�����ϲ���ƶ����� ��������ǵı���������Ŀ�꣡ оƬ��ȫ���ƾ֣��й���һ��֮������ȫ��������ǻԻ͵Ŀ�ʼ�� ��Ϊ��δ����һ�죬��������ȫ��Ҳ���������й��� ���й�������һ��֮������ȫ���뿪�й��Ľ��������ȫ��ҵͣ�ڣ� ϡ������ֻ�����е�һС����ѣ� ������Դ ���ںţ�һ�������� |
|
��ijλ������еĻ����й��������ĿƼ���࣬���Ա���Ϊ���и߷�û�и�ԭ�� �����ĿƼ�ʵ����ͬ��ԭ�������Ǹ�����ȫ��λ�������硣�ҹ����ڲ��������и߷壬��������ˮƽ��������������������ƽԭ��û��ȫ��λ�ĸ�ԭ�� ���ݹ��֪�ѵ����ۣ���һ��ͼ |

|
|
����ͳ�Ƶ�ȫ����ֵǰ100��˾�IJ�ҵ�ֲ������������ǹ�˾�������Dz�ҵ�ֲ��������������ǵ����һ���Ĵ��ڣ������ǿƼ�����������й���ŷ�ޣ���̫�� ���֪���ǵ����ۣ����˲������ݡ� 2021��10��1����2022��9��30�գ�����Ȼ���͡���ѧ����־������Ȼָ��������Ϊ779.20���й���½Ϊ164.31��Ӣ��Ϊ145.61���¹�Ϊ138.84���ձ�Ϊ56.86������Ϊ54.68����ʿΪ50.14�����ô�Ϊ29.18���Ĵ�����Ϊ28.76������Ϊ26.35������ȫ��ǰʮλ�� ͬ��������Ҳ֧�����й����𣬡���Ȼ����־������������漯�Ź�����2021��10�µ�2022��9�µ�ȫ�����������Ա��ȫ��82����ѧ�ڿ��ϵķ���ͳ����Ȼָ������ȥ���ʺ������ֺ��һ�����������������ߺ�������ߣ��й���ֵ���й�����ֵȥ����ȫ���һ, �й���ռ1.83��ȫ��28%�Ķ����������й��о��߷����ġ� |
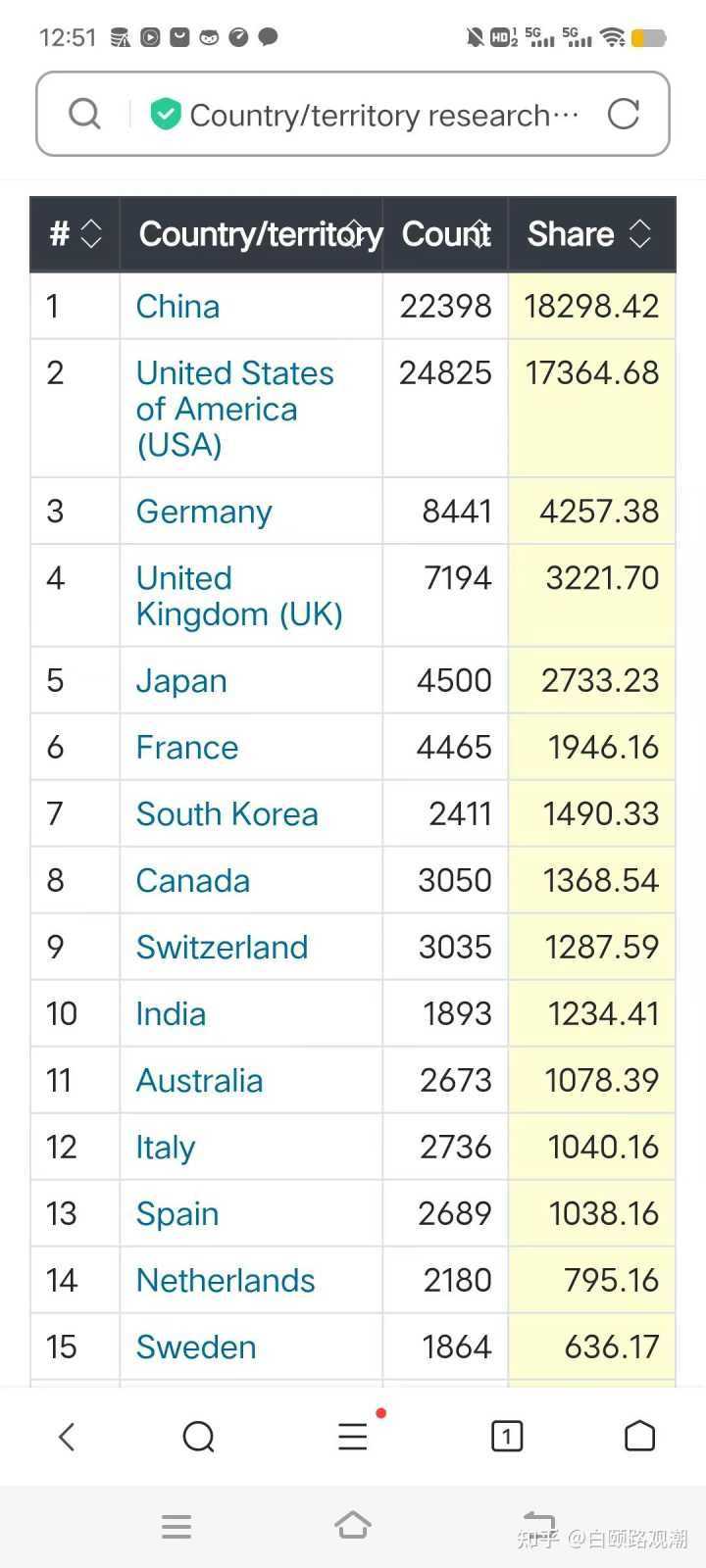
|
|
�й�ȥ�����Ͷ�볬��2.8����Ԫ����4180����Ԫ��ȫ����о��ѵĽӽ�1/4�����й�Ͷ��ġ�����ǰ�����Ͷ��6075����Ԫ��ȥ�����7000����Ԫ���ҡ��й��ò���ȫ��25%�Ŀ��о��Ѳ�����ȫ��28%�Ķ�����гɹ�,������ȫ��41%�Ŀ���Ͷ�������ȫ��26%�Ķ�����гɹ��� �����ݰ����ٶȺ�����֪�ѻش����ݣ� ����Ӧ��������������ǿ�����ʵ��ҲӦ���������������������ʵ���ⲻ��ͻ��������ΪԶ�������½���ij�����������������ھ��¡����á��Ƽ�������������κι��ҵ�ʵ�������־�����������һ��ɥʧ������ʧȥ�������Ӱ�����Ϳ���������Ϊ���ٹ�������ͨǿ���������������ݻ��ǵ�һ�� |
|
��ʵ������ �����̳���ŷ����ţ��Ϊ�����Ŀ�ѧͻ���Ժ�500�����������ʷ���ۡ� �Ѿ����й������������������Ƽ�ˮƽ����ˡ� �ⲻ�������Ĺ��ٰ� ��2000��ǰ���ϴ�ѧ����ʱ�ո������� ��ʱ�����粻�����������۵ġ� ��Ϊȫ����������β�ƶ������� ���ڣ��Ҵ��µ����ϸ����ҵ�������Ѿ��Ǹ�������ƽ�ˡ� |
|
��������ˣ���˵����ѹ����й������������������Ҫȫ��ͣ�٣�������߶�������ڵģ�����˵�Ѷȸ��ߵ�������������й��Ĺ���ҽ����е���IJ�����������ˣ���ͨ��������ͷ�����Ķ�������Ѫ�ܣ������ڵ�����һ�ƾ�����ȥ������˿���о�����ʹ�������� |

|
|
|

|
|
|
|
���̫���ˣ�ʵ���DZȲ��������� �������������������з��ģ�ZQD-2�����Ӹߴſռ��Բ�ʽʯ���Զ�ת��װ�ã�������ȫ������ʮ�ꡣ ��װ��̫�Ƚ��ˣ�����������ԭ��˵�����������ҿ�ѧ��Ҳ��������ֻ֪�������ܰ������ǵ�ʯ�͡��䵽�����������ϡ� |
|
|
| [�ղر���] �����ر��ġ� |
| ��һƪ���� ��һƪ���� �鿴�������� |
|
|
|
| ��Ʊ�ǵ�ʵʱͳ�� ��ͣ��ѡ�� ��ʱͼѡ�� ��ͣ��ѡ�� K��ͼѡ�� �ɽ���ѡ�� ����ѡ�� ������ѡ�� �������� �������� ���� MACDָ�� KDJָ�� BOLLָ�� RSIָ�� ���ɻ���֪ʶ ���ɹ��� |
| ��վ��ϵ: qq:121756557 email:121756557@qq.com ����ƻ� |