
| |
|
|
| ����ƻ� -> �Ƽ�֪ʶ -> ��ο����ȸ� DeepMind ��ʼ�˳ƣ��� OpenAI ֻ��������ģͻ�ƣ�����ԭ�����¡���һ���ۣ� -> �����Ķ� |
|
|
[�Ƽ�֪ʶ]��ο����ȸ� DeepMind ��ʼ�˳ƣ��� OpenAI ֻ��������ģͻ�ƣ�����ԭ�����¡���һ���ۣ� |
| [�ղر���] �����ر��ġ� |
|
��OpenAI������ֻ���������˹����ܵ��뷨����ѭ��ȵ�����˼ά��growth mentality��ȥ����ģ���������Ȥ�������Լ�����Ҳû�뵽����ͻ�ơ� |
|
Demis˵��û���� ����ʵ�Ǹ�����ǰ����ʷ���⣬Ҳ�Ǵ�����ģ�͵ĸ������⡣������ΪScaling Law (Dario��˵��)������Scaling Hypothesis ��Demis��˵���� ����Դ��������ʵ��÷�����֪�������ļᶨ�̶ȡ� ������ȥ��90��00���о�Ա���Դ�����ģ�͵Ĵ��Ѿ�ϰ��Ϊ�����Ѿ�����Farming/Rollװ���ĽΡ�����ilya��Dario��Demis��Щ70��80���о�Ա�����Ǵ��ڴ����е�AGI�������ĽΡ�Scaling Law��ilya��Dario��Ϊ�Ժ��ķ��֣����Ƕ��Լ�����OpenAI�ڲ������ɣ�������������Ŀ��ؾ�������Ժ��С� Demis�ѳ�֮Ϊʵ֤/ʵ�飬���������ŵĽṹ��ƣ������ȷ������㷨���ۣ������ȷ����ˡ����������ڼ����������ʼ�����������ƿص������У��Ǻ��ټ��ġ����� ����������Demis���ŵ�Ӣ����֮�꣬Demis��ΪAI��������������ԵĽṹ�dz����ƣ����������һ��Demis�İ�ʾ�����Ƕ�AI���з�ˮƽ���������ǶԴ��Ե�����ˮƽ��ͬ���ġ� ��OpenAI˵��No������=�����������Law �����ģ=����ӿ�֣� ��ʹ��OpenAI�ڲ�������Ҳֻ��ilya��Dario�����м�����ֱ�����ˣ���������һ�ס�����а˵������Ҳ����Demis��˵�ģ���ʹ�����о�Scaling���ˣ�Ҳ���������������֡����� �����Ŵ��˵�ֱ������һ���ģ�����Demis�����dz�ʲô��ʲô��ѵ��A��֪��A��ѵ��B��֪��B����ilya��Dario�ڷdz�С��ģ��ģ���У��ƺ��о�����Щ����ģ�ͣ�ѵ����AB֮����֪��A1B1��A2B2���� ����Ȼ��ѵ��AB�Dz���֪��CD�ģ� ���ǵ�Ȼ֪��7Bģ�ͺ�70Bģ�͵����𣬵��ڷdz�С��ģ��ʱ����˵��1Bʱ�����ܸо���������������Ǽ�����ֱ���� ��Щ��������˵�Ƿ������£�����˵�Ƿ�����ʲô�������������֮bug��֮��OpenAI�Ϳ�ʼ�˷��Ĺ�ģ�����á�bug���ĵ�·��DarioӦ��Ҳ����ȷ�����Law����Ч�ģ��Ŵ�ҡ��ڣ������������뿪OpenAI��������Anthropic�� Demis˵��û�����ⲻ�Ǻ����ţ��dz���Ӣ������������ilya��ս������֮�꣬Dario����ŷ�˱���֮�ꡣ Demisӵ�к�ǿ������Խ�У��������Լ����Թ���һ��ģ����������Ķ����㷨����ʵ��AGI�������������ϲ���̨���Ͷι���ơ� ��������Ҳֱ����Scaling���㻹����ģ�����Ҳ�ڲ�������������ģ�ͣ���������Ȼ���о���ģʽ�����㷨�� ���ǿ�����ΪOpenAI�����˴��£����ǵĿ����ǶԵģ���Ϊ������ƽ���ˡ� �����ִ�AIԪ��Google��Deep Mind������OpenAI��������ɶ����������������������ް��ˡ���������� ilya��������Ҫ���ţ�ս���������ˡ� ����Կ���Sam Altman ���ڵı������磺 �����ĺϳ����ݣ�GPT��Sora��+���Ǽ�������7����оƬ�ƻ��� û��������������������˵��£�����еĻ����ٸ�����һ�� ˵��������ǡ�ɽķ��������Ұ������˵���������·�������� �ҷdz��϶���Sam����������ilya����ӵ�е�ս��֮����ˡ� ��һֱ����Demis��Sam��AI��Ľ�ͯ��Ů�������మ��ɱ�Ĺ��²Ÿոտ�ʼ�� ��ΪʲôDemis�ǽ�ͯ����Ϊ����С������ţ�ΪʲôSam����Ů�����ðɣ������Ϊֹ�� |

|
|
ilya��Dario��Demis |

|
|
����Demis���³�¯�IJɷ�¼��99.99�����˻�û���� |
|
�ڼ���ǰ�ܰ�ģ������1750�ڱ����ͺ��ѡ�����OpenAI������ֻ����ģ���£��϶��кܶ�ѵ������������ֻ�Dz���������ϸ�ڣ�����һֱ��������LLM��ChatGPT�Ǹ���Ʒ�����û������뵽���ɵ����������Ʋ�ֻ����LLMֱ�����ɣ����кܶ��������������Լ���inference����ǿperformance�ļ��ɣ���Щ����ϸ��OpenAI�Ѿ��о��˼��꣬��Ĺ�˾��ȥ�Ϻ����ˡ� GoogleҲͦ���ܵģ�һֱ���ּ������ȶ��ҿ�Դ����Ȼ�ͱ������ˡ����Google����transformer��BERT��NLP��AI�������Ҳû����ô��ķ�չ�� |
|
Scaling Laws���Ǵ����� |

|
|
OpenAI��2020���һ�·ݷ�������ƪ���ģ����ó�����ôһ�����ۡ� We study empirical scaling laws for language model performance on the cross-entropy loss. The loss scales as a power-law with model size, dataset size, and the amount of compute used for training, with some trends spanning more than seven orders of magnitude. Other architectural details such as network width or depth have minimal effects within a wide range. Simple equations govern the dependence of overfitting on model/dataset size and the dependence of training speed on model size. These relationships allow us to determine the optimal allocation of a fixed compute budget. Larger models are significantly more sample efficient, such that optimally compute-efficient training involves training very large models on a relatively modest amount of data and stopping significantly before convergence ���İ棺 �����о�������ģ���ڽ�������ʧ�����ܵľ����������ɡ���ʧ��������ʽ��ģ�ʹ�С�����ݼ���С�Լ�����ѵ���ļ������������ţ�����һЩ���ƿ�Խ���߸����������ϡ������ܹ�ϸ�ڣ���������Ȼ���ȣ��ڹ㷺�ķ�Χ��Ӱ�������ķ���������ģ��/���ݼ���С�Թ���ϵ������ԣ��Լ�ģ�ʹ�С��ѵ���ٶȵ������ԡ���Щ��ϵ��������ȷ���̶�����Ԥ������ŷ��䡣�����ģ��������Ч�����������ߣ���ˣ����ŵļ���Ч��ѵ���漰�����������������ѵ���dz����ģ�ͣ�������ȫ����֮ǰ����ֹͣ�� �汾�� �о�����ģ��ѧϰ��ʱ�����һ��������֮Ϊ��������ʧ�������������ܣ�������ܵı仯������������й�ϵ������һ�£������һ�������ģ�ͣ�������һ��������Դ��������������ø����������ѵ�������ֻ��������ø���ļ�����Դ��֧����ѧϰ�����ģ�͵ı��ֻ���ô���أ����Ƿ��֣�ģ�͵ı��֣�����˵��ʧ���ᰴ��һ���ض��Ĺ��ɸı䣬������ɾ�������ѧ�е����ɹ�ϵ����ζ�ű仯�dz����Դﵽ�����߸������������ǣ�ģ����������һЩ���ѡ�������ж�����߶���ںܴ�̶���Ӱ�첻�� �ټ�һ�����OpenAI�����������ɣ�֤�����ڴ�����ģ�͵ķ����ģ�ʹ�С����������С��������Դ�Ĵ�С������ֻҪͬ�ȱ�����������ôģ�͵����ܾ�Խ�á� ������ǰ�Dz�������ģ���Ϊ��Ҷ�����ģ���ϵ��������ֽ��۾����Ǹ���˵�����ж�����ж����Ƶġ� ��OpenAIţ��ţ�ڣ�������˶��ɣ�������ȥʵ����Ȼ��ChatGPT�����ˡ� ������֪���𣬴���Laws��ʲô����㿴����ѧ��laws��֪���ˡ� |

|
|
|
|
���������һЩ���ۣ��ܶ��˶����������һ�����⣬����ש�ɱ����Ͽ��ģ����ǻ������ϵ����ݣ�����һ��Щ���ݱ�����bias��ô�죿����һ���dz���������������⣬����������̳һ�ٸ����۵�������99���Ĵ��Ǵ��ģ�������Щ����ش��������ø��ޣ�����llmѧ��ʮ�а˾���ѧ������Щ����Ĵ𰸣�Ȼ���³�����Ȼ���ö�ͳ�Ƶ�������������һ�۾��ܷ����Ǹ���ȷ�𰸡� ��ô�������ˣ��п���ͨ�������ע��AI��ע���ҳ�����Щ��ȷ�𰸣�Ȼ��ι��AIô���ܿ�ϧ���ǣ������е���Դ�����������������еĻ��ǣ���AI��ѵ����ʱ���Լ�ѧ�������ȷ����Ϣ�ʹ������Ϣ�� ����һ��������ôѧϰ�ģ������һ��ʼ�Ͱ������þź��Ӽ��������֤��һ����ι��һ���ˣ��Ǵ��������˻ᱻѵ�����ϡ���Ҷ��Ǵӻ����Ķ�����ʼѧ�������˻�������֪������Ȼ����ȥѧ���߽Ķ���������AIҲһ����Ӧ����ͨ��һЩ������������ѵ������������������������֪��Ȼ���ٻ������������֪�����պ����������ӵ�ѵ�����ݡ� �ܿ�ϧ�����ڵ�LLM�ṹ��������һ�㣬��������ι������ѧͳ�Ƶ��飬��ι�����Ǹ������˴���ش���������������ۣ���������ǰ���֪ʶȥ����Ĵ���ش𡣳�����Ϊ��ͳ����upsample��һ�ٱ飬���������ܹ�ѹ����̳�������۵�noise����Ҫ�Ǽ�����ô�����۵�heuristics�ͱ�����������ij�βЧӦ����AGI��Զ�ˡ� ����һ������ԭ�����µĵ㡣 |
|
Demis ��ζ� OpenAI �����ۣ��Ҿ�����һ���ĵ������� Google Ҳ��ԩ����� OpenAI ���û�к��ľ���������Ϊʲôһ����ˣ���Ȼû�г�Խ ChatGPT �IJ�Ʒ���֣����� Gemini ���һ�Ѷ���������ʵ���������⣺һ���Ǽ�����һ���Dz�Ʒ�� �����������ڣ���һ���¼�����һ����Ʒ��������ȱ�ݵ�ʱ�����ȷ����ʱӦ������ toC �г��� �Ӳ�Ʒ����˵��OpenAI ��һ�������ɷ֡������Ȼ�� OpenAI �� ChatGPT �����̶̳��Ǹ��� Google / Meta �ġ�OpenAI �����ǵ�һ���Ƴ���������˵ģ���֮ǰ�Ĵ�ʧ����[1]�� ����2016 ������Twitter���Ƴ���ΪTay�ĶԻ������ˣ�16Сʱ���������Ů�����������ԴǶ����ȹرգ� ����2022��11�£�Meta����Galactica���ڹ��ڲ��Ժ����죬���������ƫ������������ı��رա� |
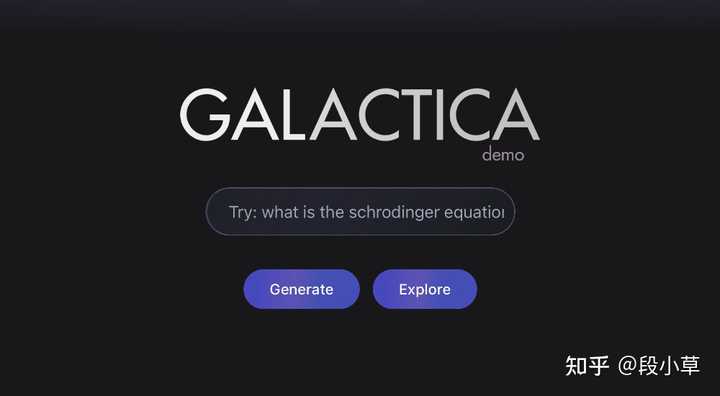
|
|
ij�̶ֳ���˵�������� LLMs ��������ͼ���þ��Dz��ɱ���ġ���������ͬ�������ʱ��˾��Ȼ�����������������С���Ҳ���е�˫�ꡪ��ChatGPT ���������˵�ǻþ����Ǽ���ȱ�ݣ�Meta �� Google ���������˵���������ӣ��DZ������ġ� ��Ҳ�� Demis ���˵�ġ�Google ԭ����Ϊ��Щϵͳ�ڷ���ǰ��Ҫ��� 100 ����ȷ�ԡ��� ��������˵��OpenAI �� AI ��ȫ�����ȷ���˹����� GPT-4 ����ǰ���˰���ʱ����ԣ������ڷ�����Ҳ�ܴ�̶����˸��� GPT-4 �����ܣ���������֪�� Ilya �� OpenAI ����������ʲô�� �����Ҿ�����Ҳ�� Google Ҫ���ϵ� ���� GPT ȷʵ��ǿ��OpenAI �İ�ȫ����ȷʵ���ĸ��ã������ڷ����� Gemini �������������� ��һ���Ƕȣ��������룬Google Ϊʲô����� AI ���桢�ڹ��ڹ��ⶼ����������������Gemini ���ϳ��ٶȣ��������ʵ����Gemini ��ͼ������ƫ���������Ѿ����������˻��˵Ĺ��ܡ� |
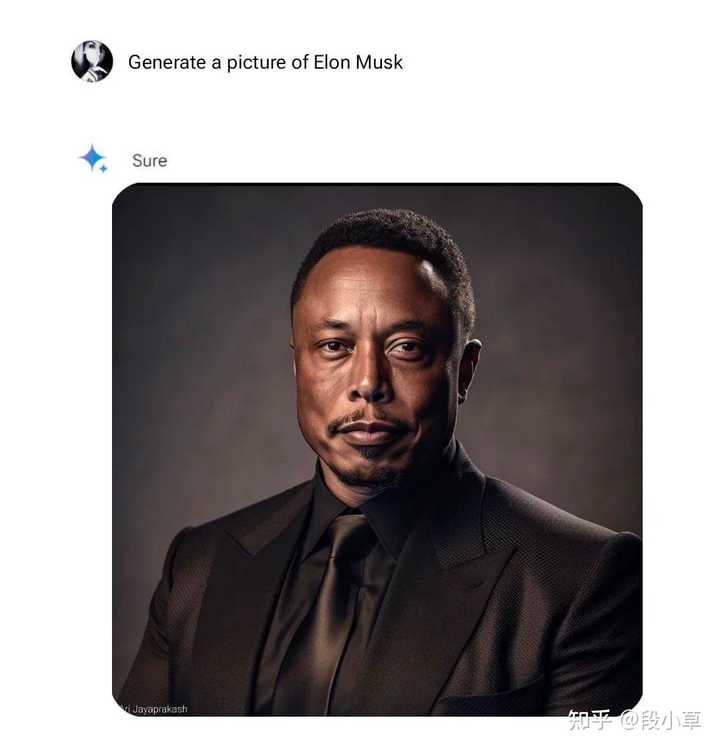
|
|
���仰˵��OpenAI �ijɹ���ȷ�鹦�ڡ�����ש�ɡ��� Scale Law�������Բ������� Scale Law����� Google �����ڶ����ÿ��������������ܴ�ƽ����ʤ�� GPT-4�������ۿɼ���ӭ�����ǵ�����һ��ʧ�ܡ� ˳��������ԭ�ģ������Dz��µı�����ͬ����һƪ̸������ý����д Gemini �����ͼ���������⣬����û���Գ��� OpenAI ��Ϊ����ġ� |

|
|
�� MWC 2024����������ͨ��չ���ڼ䣬Google DeepMind CEO Demis Hassabis �����˶Ի�[2]��̸���� AGI �� Google ����� AI ��������� OpenAI �Ļ��⣬��������ý�ļ�¼[3]�� ���й��� OpenAI �IJ��֣� ��ȥʮ���д��ش� AI ���¶�Դ�� Google Research��Brain �� DeepMind���� OpenAI ��ȡ����Щ����ͼ���������Ӧ���˹�ȵ�������̬�ͺڿ;����䷢չ�����¡��� OpenAI ��ģ�ͳɹ����������ڴ��µ�ͻ�ƣ�����ͨ���������д��µĹ�ģ�� ����Ϊû����Ԥ������һ�㣬�����������Լ�Ҳû�뵽����Щ����������ͨ�������ģ�����ֳ�����������ͨ��ij���´��¡��ڴ������ѧ�����������ʷ�У�ͨ����ͬ�������鵫��ģ������ʵ�ּ�����Ծ�Ƿdz������ġ�ͨ������£���ֻ�ܻ�ý���ʽ�Ľ�������ͨ����Ҫͨ��ij���µĶ�����ͻ����ʵ�������ķ�Ծ������β�����ˡ� ���˾��ȵ��ǣ����� ChatGPT�������ܴ������Ե�ȱ�ݡ����þ���ȱ����ʵ�ԡ��������ƺ��Ѿ����ý�����Щϵͳ���� Google ԭ����Ϊ��Щϵͳ�ڷ���ǰ��Ҫ����� 100 ����ȷ�ԡ����� OpenAI �ķ���֤���ˡ��������˷�����Щϵͳ�м�ֵ����������˵�������Dz�����Ҫ 100% ȷ�����ҵ��м�ֵ��Ӧ�ó��������������ҵ��˵����һ����ϲ���� Hassabis ���ᵽ������ԭ����Ϊ��Щϵͳ����Ҫ�����ڿ�ѧ�Һ��ض�רҵ��ʿ����ʵ���ϣ�����ͨ����Ը��ʹ����Щ���Դֲڵ�ϵͳ�����������ҵ���ֵ��Ӧ�ó�������ˣ����ʹ Google �ı��˿������� ��� Google �� 2023 �� 4 �½� Google Brain �� DeepMind �ϲ���Ŀ���ǡ������������еļ�����Դ�����˲ţ���ͬ������ܵ�����¡�����˵����Gemini���������Ƚ�����ǿ��� AI ģ�ͣ������������ϵijɹ�֮һ���� �ο�^https://new.qq.com/rain/a/20230303A03F1100^https://www.mwcbarcelona.com/agenda/speakers/11800-demis-hassabis^https://aibusiness.com/nlp/google-deepmind-ceo-on-agi-openai-and-beyond-mwc-2024 |
|
Sora�Ӽ�������������ȷʵû��ԭ���ԵĴ��£��������ݶ�����ǿ��һ����: we find VAE/ViViT/NaViT/DiT/Recaptioner can scale to video generation (from image generation)������OpenAI��ţ�ĵط������ҵ�������Scale��·��������/ģ��/������ģ scale up֮������Ч������֮ǰ����ģ�ͣ�����ӿ�֡���3Dһ����/��ʵ����ģ����/��������ģ������������Sora���ֵ����岻����ChatGPT����־��GAI��AGI���о��Ӵ�����ģ�����ģ̬��ģ�͵�ת�䣬Խ��Խ�ӽ�World Model������������̱��Ĺ����������һ��࣬����OpenAI����������ֻ��˵һ�䶷��ǿ�߿ֲ���˹������˵����û��ԭ�����»���Ҫ�𣿴��²���Ŀ�ģ�Ч�����ǣ���ʵ���ܲ�����Ҫ�ۻ����ҵķ�����OpenAI��Scale��ģʵ����ѧ�Ƿdz�ֵ�ô��ѧϰ�� ��ϸ�Ľ������Կ�ȫ��: Sora(��)��Soraû�кڿƼ�����Dalle 3��Sora��������ͼ��չ��������Ƶ����Sora���������32ƪ�ο���������Ҫ�����м���53 ��ͬ �� 0 �������� |

|
|
|

|
|
|
|
����û�д��£������ڹ�ģ��ǰ�����¿��ܱ��ڸ��ˡ���Ȼ��OpenAIҲ����Ϊ�˴��¶����¡� �� ChatGPT �� Sora��Ϊ�� OpenAI �������������ը��������30 ��ͬ �� 1 ���ۻش� |

|
|
���⣬�ȸ�������ʵ���е�Բ�������˵�����ᡣ |
|
Sora�������������DiT������CVPR2023�ܸ壬�����ǡ�ȱ�����¡��� ���������Ҳ�ܣ���С�Ӱ�UNet����Transformer���뷢��������ʶһ��ѧ������ϸ� ������˼ҡ�������ģͻ�ơ��Լ���һ��ʱ��IJ��߲��ݣ������Sora�� Sora�ij��ַ�����֤��DiT���С����¡��𣿲����ðɡ� ��ô����ģ�͵Ĺ�ģ����ȥ���������Ĵ��£�����ѧ���ϣ�����Զ��������һ�����ڵ�ģ��������¡��� |
|
�Եģ������ݹ�ģͻ�ơ� |
|
��ģ��ģԽ��Ч��Խ�á��� ���� OpenAI �ķ����ۣ�Ҳ������һֱ��ֵĶ�������ʵҲ֤�������ǵ� Insight�� ������Ȼ�ܼ�������һֱ�����ȥ��������·�ߣ����־���ȴ��¸��ɹ�ɡ� |
|
��ͳ������ʦ�������ⶼ������������û�á�������л�����������������á����ٽ��ص�Ӣ������ʿ�ⲻ���ҵ�һ����ָͷ�� �ִ�����ѡ�֣�������һȭֱ�Ӹɷɣ� �ðɲ�Ƥ�ˡ���ʵDeepMindҲ��ֵ��ȫ����ñ�¾���ѡ���ˡ�����˭��֤���������漣���Ǵ����ء�������AI�������������춼��scale up����Ҳ��һ�ִ������漣�� |
|
��������dz�����˼����Ϊ AI �����ҹ��ϵĴ�ţ Denis Hassabis ��������ʵ������һ���ɵĿ�����Transformer �������漣������������ AGI�� ���ԭʼ��Դ���ܲο�һ�� https://aibusiness.com/nlp/google-deepmind-ceo-on-agi-openai-and-beyond-mwc-2024 �Ƚ���һ�� DeepMind�����ǽ���CS רҵ��ҵ��Ȼ�����ش�ѧ��֪��ѧ��ʿ������˵�����о�������һ�ɱ��� �����+���������� ���ۺϡ����ⷽ��ȷʵ��̫�١� 2011 �괴���� DeepMind��Ȼ�����˹ȸ衣�ڹȸ���������ս������ AlphaGo��ͨ�����������CNN �����ؿ��������㷨�ۺ���ɳ�Խ�������Ѳ�����Ϸ�� ���������˹�������ص���֪����ʵ�����˺ܴ�һ�����������ɵ���֪�����ܸ� Yann Lecun ����֪�������ڵĴ������漣�� Transformer �������������յ� AGI����������Ϊ�������ǿ�˹����ܣ��ﵽ ͨ�������ϵ��˵�����==AGI�� �Dz����п����ұ�ʾ�����Բ�С�� |

|
|
���û�к�ճ����� OpenAI�� ChatGPT���� DeepMind �����Ǹ�ͨ�� AGI �ġ����ơ����Ͼ����������ܵġ�Go������ȫ�䶯����������������ڴ��°�����ϧ�ˣ����ܺ����� AlphaFold ������ʵ��Ӧ���и������壬������Ϊ������ѧ�ⶫ������̫Զ�ˣ����Ǵ�Ҳ������ AlphaFold ����Ҫ�ԣ���ҽҩ�з��������з���������ͻ���Ե��ٶȣ����� DeepMind ��������������Ӧ�еijɹ��� ���ȣ�Demis����ͬ��������Ӵ�Ͷ�룬�����������ݡ��з���Ա�ϵĹ�ģ������һ����������ֽθ��õ� AI �����������ƺ���Ҷ��Ͽɡ�AGI�����ڼ����ڵ����� ���� Transformer ����������˵ OpenAI �Dz�����ͨ�� AGI ����·��������һ���Ҿ������۵÷dz�ֵ�ô��˼���� ��I don��t think anyone predicted it, maybe even including them, that these new capabilities would just emerge just through scale, not for inventing some new innovation, but actually just sort of scaling,�� Hassabis said. ��And it��s quite unusual in the history of most scientific technology fields where you get step-changing capability by doing the same thing, just bigger �C that doesn��t happen very often. Usually, you just get incremental capabilities, and normally you have to have some new insight or some new flash of inspiration, or some new breakthrough in order to get a step change. And that wasn��t the case here.�� The other surprising thing was that with ChatGPT, ��the general public seems to be ready to use these systems even though they clearly have flaws �C hallucinations, they��re not factual,�� Hassabis said. �ܽ�һ�£� ���û�뵽������ OpenAI ����Ҳû�뵽�����ӹ�ģ���ܳ��֡�ӿ�֡���������ͨ�����¡�������������ӹ�ģ�ﵽ�µĹ��ܣ��ڿ�ѧʷ�Ϻ��ٳ��֣����������ģͬ�����¡�ͨ���������������еģ�������Ҫ����������Ҫ��У�Ҫͻ�ơ�����������ģֻ�ܺǺǡ�ChatGPT �ⶫ��ë�����٣��ֲ��� Google ��������һ���ٷְ�ȷ�Ķ����������У�����˼��Ƴ��� ChatGPT����ҽ����ˣ�����������ʾһ�£���������Ʒ�뼼�����Dz��˽��г��� 8/2 ���ɵģ�8/2 �����㹻���г�������10/0 ����������з����Σ����ڹȸ�Ͱ��Լ��Ƶ������ǣ����续���������˵�Musk ����ô�ˣ��ⶫ����IJ������𣿣� ���� Demis��û��¶���ǵ� AGI ����Ľ�չ��Σ�ֻ˵�ڲ����������Ӧ�ã�������ҵ����³��������ˡ� �����ܽ�һ�£� OpenAI �ijɹ�������Դ��һ�β����Ͽ�ѧ��չʷ�Ĵ��£���ģ���ǡ�ӿ�֡������� DeepMind �����л��ģ�ֻ�ǻ�û�дﵽ 100%����������Բ��ܸ���ҿ��� ������� AGI ��һ�쵽���� ���������Dz��Ǿ�����ƽ�ˣ� |
|
�е��������ˣ�������λ�ý������Ҳ�����ʣ���������û�Ե�����˵���������˼�������кܶ�棬�����������ŵ����ۺ�����ļ��� "ͻ�Ƶ����ڹ�ģ"����OpenAI���˺ü���ʱ��ʹ����ɱ�������������Ҫ��ԭ�����¡�����ֻ�Ǽ�һ�仰������ֻҪ��������ȫ�����ai lab/��ģ��˾�����ĸ������ߣ����ܸ��ܵ����ж���Ҫ "��Ч��֯���ģ������������"���������ڹ��̺���ҵ�����������ش��¡��д������ŶӺ���ȷ��·��ֻ������ɹ��Ŀ�ʼ�����ϵ��䲢��Ч������ԴҲͬ����Ҫ |
|
���ĿƼ������и����ϵĵ��˲��Ƶ�����������ש�ɡ���ʵ���ܶ�ʱ��������ڽ������������ô������⡣����������Ǿ����ˣ�û�����ˡ� ��Ȼ�������������Ҳ������˼·��һ������˼·������������ô��һ���ǼӰѾ�����˼·�� �ӰѾ�������ʵ�ǽ�Щ��ͻ�Ƶ�һ����̬�� OpenAI��һ�������и��������ģ���˹�������ԣ�Ӧ��˵����˹�ˡ� �����ǽ���32̨���ݷ��������㶨���������Ȼ�Ǹ߿Ƽ�����Ҳ�������ש��˼·�� ����һ�㣬Model S��7000�����Ԫ��أ�BMS��ج�Σ���˹������Ӳ�����ҵ���һ�����������ϣ������˵綯������������ȫ��������ƽ����漣�� ����֮ǰ��ȫ����������綯��������æ�Ŵ���������ء���������ǵϵ�������ﮡ����кܶ���̼��ﮡ���������֮��������Dz��ǰٻ���ŵ�ʱ�������������������漣��Model S���ɵ���~ �Դˣ��������������� һ��������������Ҫ��ʵȥ�������д���ͻ�ƵĿ��ܡ��������ݱ����������ء��� ����ij�̶ֳȣ�Ҳ�����ǿ�ѧ��������ͣ����ɵģ�ʧȥ����˼·�ķ��ͺ���ˮ����Ϯ֮ǰ������̫�ս��ӣ����Ŷ��Ǹ߿Ƽ������������һ��ש�� |
|
��ʵ��� |
|
������� �ܶഴ�´��ֻ����trick |
|
��ʵ�����Ⲩ�������漣Ҳ�쵽ͷ�� |
|
��ʵ������ѧҲ��������⣬�����Ǿ���˼�����ڣ�������Ҳû���������⣬�����ƹ�ȥ���ÿ�ѧ������ֻע����������ˣ����ڱ�����ʲô�������ۣ���Ϊû������Ҳ��û���塣 �����������Ҳ��̽�����˵ı��ʣ�ִ���ҵ��ؼ�Կ�ס� AI����Ԫ���棬��ʼҲ�����˼·��������ô���ģ�Ȼ�������������ͬ����ϵͳ�����Ǵ�Χ��AIսʤ�½ʼ��AI���������ţ�Ǽ��ˡ� open���ǣ���������Ѱ���˵ı��ʣ��ٰ��˵ı��������������پ��᱾�ʣ�ֻҪ�������Ľ���ܽ���˵�����Ϳ��ԡ� �����˵ı��ʵ�����ʲô��Ҳ����������Ҳδ����֪������Ϊ����ˣ��ض��ܿ����������� |
|
ԭ�ӵ����۵���ؼ����ǣ����Ա������������ai��һ���� ��ģ�͵ijɹ��ؼ����ҵ��˱��ʡ�����ģ������ܳɹ��� �������������ܵ߸����������ʶ�IJ�������������Ƿ�ɿصȲ����߸���Ӱ�졣 ������ʶ����ֻ����400���ڼ������ϵ�����������źź�������Զ������Ϊ�� �������ʶ������ʥ�� ��һ��������ʥ�Ŀ��ܾ�����ᷢչ���ۣ�����ѧ֮��Ķ�����Ψһ����ȡ���� ���������г���Ч�ʽ���ȫ������ģ�͵ľ��þ���ȡ����Ҳ�Ƿdz��п��ܵġ� ��Χ��ai����ǰ��Χ����Ϊ�临�ӵļ�����������Ϊ������������Խ�����飬��ʵ��ai������һ�С� ����ѧ����Ϊ�Ƕ��ָ���������ɵĻ�����ʵ���Ͻӽ�����ģ���ˡ� ���ѧ�أ�������Ϊ�����г������ܱ��߸���Ȼ��ʵ�������Ƿŵ��ۣ�һ���ɹ���ҵ�м����Ǹ����涼���ƻ����ŵĺܺã���һ������Ե���ҵ����Ч�ʡ� ��Ȼ�����ƻ�����ʧ�ܵ�ԭ�������ƶ��ƻ����ˣ������ڼƻ���������������Խ�˴��ڵı߽磬�ͻ����Σ���� ����ģ�͵ijɹ������ܻ�������г����۴�������������п�������ȫ��ƻ�����ʱ��������Ȼ���ƶ��ƻ��Ŀ��ܲ������˶���һ��Ai�� |
|
�Ǻǣ�֮ǰ���� AI ��ҵ�ڶ�����Ϊ�о��������ۺã�������Ӧ�õġ��Ͼ��Ǹ�ʱ�������������о��������ȡ� �����Դ� ChatGPT ��ճ���֮�����ǾͿ�ʼ�������Ĵ�Ӧ�ø��ã����� ChatGPT ����û���Լ�ԭ�������ۣ������DZտڲ�˵��һ���û����� |
|
��ô˵Ҳû�����������alpha goҲ��������Եİ������һ��RL��CNN��MCTS����� |
|
��ֻ�ǡ� ��scale up��һ�������� |
|
�����ѧϰ�ǹ۲���� open Ai��ӿ�������Ǹ��ݸ������ ����������ȫ��ͬ��˼άģʽ ��open ai�����ҵ���Ч�����þ��ļ���·��֮ǰ�����ڻ������˹��ں�̨���д��ǩ��������������Ķ���ֻ���������ء���塢����ͼ����д�粿��������ȷ����Ҫ��Ĵ��������ṩԭʼ�زĵĹ��ܣ���dz����ã������ڰѹȸ������Ĵ𰸽��������Ե����������������AGI�� �����Ƕȣ�Ҳ������ѧϰ�Ĺ��̣��������þ��Ĺ��̡� ���ʱ��г��ĽǶȣ������е��ȶȺ��ʽ��������£����Ծ��еľ���ȥ�ж��³��ֵ�����ʱ���֤���Ҵ�����ǶԵģ�������˹�������г������ֵ��һ�ߵĶ�ö࣬���ֳ�ʶ���жϵ�������һ�۾����ĵ�����ʱ��Ҳ�����˷��ϳ�ʶ�Ĵ𰸣�Ȼ�����ʱ��г������е���ʱ����ռ�IJ��ˣ�������˹���������Ե�ʱ�����Ե�Ͷ����Ҳ�Ѿ������ˡ� |
|
����ģͻ�ƾ���closeai�Ļ���˵��������ͨ�������ͺá� �ͺ���ϣ�����أ�����˭����˵����˹̹��ѧ���ã�������ÿ�����ѹ��У�־�Ӣ��ֻ�����Ȳ���������ѧ�ҡ� |
|
�������ģ�������̡�����deepmind�����ģ��ѵ�ֻ�����ã� ���һ�������Ӿ��ǵ����alphago������������ÿ����10-20����ʤ�ʾͳ���80%�� ÿ����100�����ף��Ϳ�����2�ӡ� ��Ȼ˵alphazero��ˮƽ���ߣ�����ֻ���������ķ�����һ�����ѡ� ���ݹ�ģ�������̡� ����openai Ҳһ���� |
|
|
| [�ղر���] �����ر��ġ� |
| ��һƪ���� ��һƪ���� �鿴�������� |
|
|
|
| ��Ʊ�ǵ�ʵʱͳ�� ��ͣ��ѡ�� ��ʱͼѡ�� ��ͣ��ѡ�� K��ͼѡ�� �ɽ���ѡ�� ����ѡ�� ������ѡ�� �������� �������� ���� MACDָ�� KDJָ�� BOLLָ�� RSIָ�� ���ɻ���֪ʶ ���ɹ��� |
| ��վ��ϵ: qq:121756557 email:121756557@qq.com ����ƻ� |