
| |
|
|
| ����ƻ� -> �Ƽ�֪ʶ -> ��ο�������EMOģ�͵ķ����� -> �����Ķ� |
|
|
[�Ƽ�֪ʶ]��ο�������EMOģ�͵ķ����� |
| [�ղر���] �����ر��ġ� |
|
2��28�գ�����Ͱ����ܼ����о���������һ��ȫ�µ�����ʽAIģ��EMO��Emote Portrait Alive����EMO����һ������Ф����Ƭ����Ƶ���� |
|
��Ȼû�иĴ��Ĵºţ������ָĵúã��ô�Ҷ�emo�� |

|
|
|
|
Ч����������ľ��ޣ����DZ�����Ҳ���е�����֮�С� |

|
|
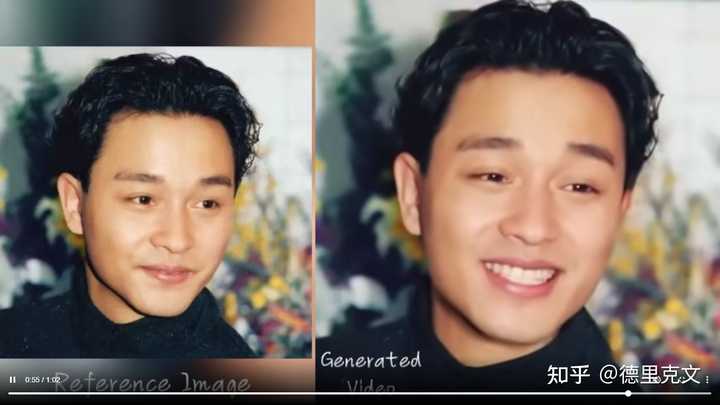
����˵���䡪��ͼƬ��Դ��EMO���� ��������EMOģ�Ϳ�����������ɯ˵�������衣 AI�ϳ���Ƶ����������ɯ���ڳ��� | AI��Ů�ݳ�MeLody328 ���� �� 21 ��ͬ��Ƶ |

|
|
? ������������ΪRAP֮������Eminem�ġ�RAP GOD�� AI�ϳ���Ƶ-����+Eminem| �Ź���+����Ѹ275 ���� �� 4 ��ͬ��Ƶ |

|
|
? ֻ��Ҫһ����Ƭʵ��˿������������������������ܡ� ��������AI������Ƶ����ͨ����Ƭ����Ƶʵ�ֻ�������472 ���� �� 6 ��ͬ��Ƶ |

|
|
? ����ʾ�������������û������ύһ����Ƭ��һ����Ƶ��EMO�����ܹ���������ⳤ���ұ�����������Ƶ�� �ӷų�����Ƶ������ֻ���ϴ��Ź��ٵ���Ƭ��һ������EMO�����������·����ڳ������ʵ��Ƶ������������档 �۲�EMO��������Ƶ�����Է�������Ŀ����뱳�����ֵ�ͬ���Լ��ѣ�����仯Ҳʮ�ַḻ��ʹ�ý�ɫ�·���������������Ч������ӡ����̡� ԭ���ĵ�ַ����� EMO: Emote Portrait Alive - Generating Expressive Portrait Videos with Audio2Video Diffusion Model under Weak Conditions?arxiv.org/abs/2402.17485 |

|
|
��Ŀ��ַ�� https://humanaigc.github.io/emote-portrait-alive/?humanaigc.github.io/emote-portrait-alive/ �����г��ϴ����ڶ�AI��Ʒ�ܹ�ʵ�����Ƶ���Ƶ����Ч������EMOģ����Ч�����棬�������ؼ�����չ������������ơ� |

|
|
��һ������ͬ���ľ�ȷ�ȡ� ��������ȷӳ�䵽���������������һ�����ս����Ϊ��ͬ���������ؿ��ܶ�Ӧ���Ƶ����Ͷ�������ͬһ�����ڲ�ͬ���ᄈ�п�����Ҫ��ͬ����������� ������Ȼ�����е���������������б仯Ҳ������Ͳ���Ӱ�죬��ʹ��ʵ������ͬ����ø��Ӹ��ӡ� ��EMOģ���ڴ�����Щϸ�ڷ�����ֳ�ɫ����������ͣ�١��߳�����ת��ʱ������ʵ������Ƶ������ƥ�䡣��һ����ĺܲ�����Ч��������̾�� |
|
|
�ڶ�����Ƶ�ij���ʱ���� �����AI��Ʒ���ɵ���Ƶʱ��ͨ�������ڼ������ڡ� ����������������EMO�ܹ��������ⳤ�ȵ���Ƶ��ͬʱ���ֽ�ɫ����Ķ����Ժ���Ȼ�ԣ������ظ��͵�������ʹ�����ɵ���Ƶ���������������ˡ� |

|
|
˵�����ŵ㣬Ҳ��̸̸��������IJ���֮����EMO��ijЩ�������иĽ��ռ䡣 ����Ƶ�п���Ŀǰ���ɵ���Ƶ�еĽ�ɫ���ı���ԭʼ����̬�Ϳռ�λ�ã����Ǵ�ͳ�������ˣ���������ͬSoraһ��������������ģ�͵�Ч���� ������ˣ��Ѿ������˾����ˡ� ������˵����һ���dz�������ܵ���Ϣ�����������Ϣ���ڶ�AI�����ߵ�����Ⱥ���棬���۵ķ����е���֣�����Ϊʲô�أ� |
|
|
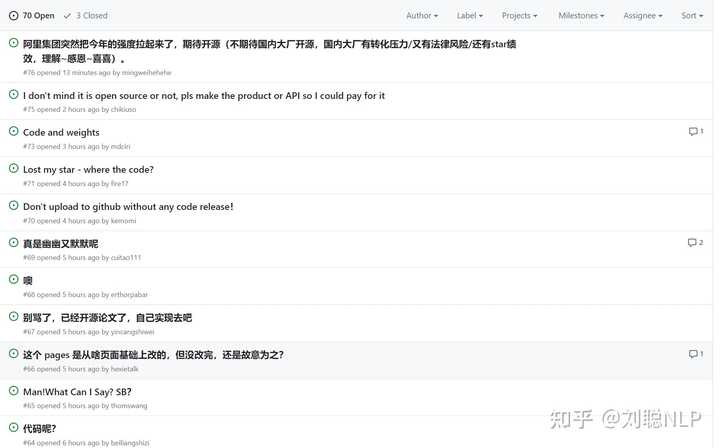
��Ϊ��������Ŷ��Ѿ�����ڿ�Դƽ̨��û�зų����룬������Ϸ����README��Դ�������ֿ�ֻ��README����ȥ�ˣ����ô���б��Ÿ��ӵĸо��� ���Ҳ�ֻ�������Ŀ������ŶӶ����Ŀ�ղֿ�������˲�̫������ģ��Ѿ��ջ��˲������ˡ� ������۵Ľ�����Ҫ�ڸо��ѿ�Դ����������������ˣ���һ�㻹�������˷ѽ�ģ���Ҳ������ڸ���ĵط���������ʵ�����˹����ܵ�����Ͷ��̫����ԴҲ������֮�У�δ�����ܿ�Դ��ģ�ͻ���١� |

|
|
����AI�������ɵ�ͼƬ ����������Σ���������ķ����ô�ҿ�����AI���������ɵľ���ʱ�̣��ڴ����ģ����������Ӧ�õ�ʱ�̣� ���ǵ�����ģ�һ����AI�滭���˹�������ǿ����Ȥ����ҵ������������ʦ��������ҵ��������ݸ���Ȥ�����æ��ע�����ղأ�лл�� |
|
�ȱ��ȽϺã�����ʱ������������»����㷨���� |
|
�Ȳ�̸Ч��������Github��Issue�Ѿ�������~ ����AIȺҲ�����۷�~ ����emo�ˡ� |
|
|
|

|
|
|

|
|
|
|
sora��ƵŮ��������������ǿ�����裬������ɯ�������ࡣ sora��ƵŮ���ܸ����� |

|
|
0 �沿�������Ȼ |

|
|
0 ���� |

|
|
0 �Ź��� + ����Ѹ����Ƶ |

|
|
0 ����˵�� |

|
|
0 |

|
|
0 ������ɯ������û��ô���� |

|
|
0 ����ǿ������(����) |

|
|
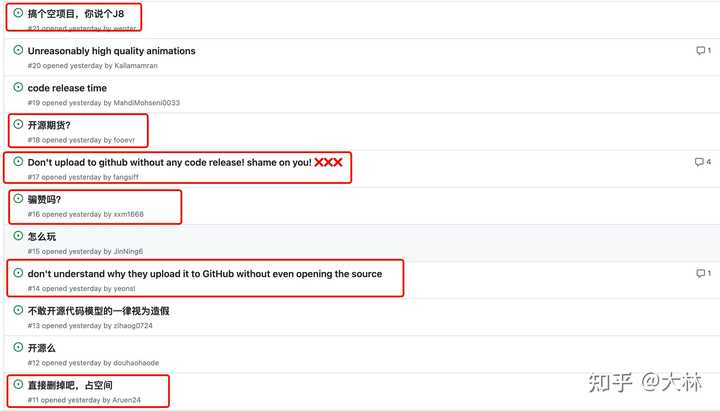
0 Ч�����棬��demo��Ƶ��ȷʵ���������飬���ͣ��������ٶ�������������˵�Ǻ������ˡ� ���ǣ��������á����²�Ϊʲô�� |
|
|
|

|
|
���֣�˭Ҳû�뵽�������������Ŀ����Ȼ������á��0 ��ͬ �� 0 �������� |

|
|
|
|
��ô˵��ȷʵ�Ǹ��dz�ǿ���ҷdz�ʵ�õ�ģ�ͣ������Ժ���쵼����Ƶ��ʱ�����쵼�ڸ������ĸ��գ�Ȼ��¼һС����Ƶ���ⲻЧ��ֱ�Ӹ¸º��ˣ�ʡ�Ļ������˸��쵼���Ÿ��ӣ��㲻�û��ö��ü��� |
|
������¼��������ţ����ڵ�ģ�ͼ���Ҳ��ʼ�����ˣ� �����찢�����һ�����͵�ģ�Ϳ�ܣ�EMO��ֻ��Ҫʹ��һ����Ƭ���һ����Ƶ���Ϳ���ֱ�����ɱ���ḻ����ʵ��������Ƶ�� ����ĺ���ʵ��������ʵŶ�� �о����ϾͲ�֪��δ�������絽������ʵ����������ˡ� ֻ��Ҫ�ϴ�һ����ƬȻ�����϶������ֵĸ裬������ǡ���������ѽ�� ������ϧ�����������û����������ڣ�����ֻ�����������ٷ��������ˣ� ������������顣 ��ֱ����һ����Ƶ�� |

|
|
0 ���Ͼ����ϴ�һ�Ű��������ձ���Ф��ͼ��Ȼ�����ϴ� Samantha Harvey �Ը��� Perfect �ķ����汾��Ƶ�� Ȼ��ͨ�� EMO ������ɵ���Ƶ�� �о����˸�������ô�У��൱��ʵ�˰��� Ȼ�����Ǽ�˵�� EMO �Ĺ���ԭ���� EMO ��Ҫ��ͨ��һ����Ϊ Audio2Video ��ɢģ�͵Ĺ��̣�����Ƶ�ź�ֱ��ת������Ƶ�����ƹ��˴�ͳ��������Ҫ�� 3D ģ�ͻ��沿��ǣ�ֱ�Ӵ���Ƶ����ȡ��Ϣ�����ɱ��鶯̬���촽ͬ������Ƶ���Ӷ��ڲ���Ҫ����Ԥ����������£��������Ȼ�����ұ���ḻ��������Ƶ�� ���ַ����������Ƶ����ʵ�Ժͱ�������ʹ�����ɵ�������Ƶ���Ӿ��ϸ�Ϊ����Ͷ�̬��Ȼ�� һ�仰Ҳ���Ͳ��壬��ԭ������Ȥ��С�����Կ��¹ٷ������ģ� https://arxiv.org/pdf/2402.17485.pdf Ȼ������������ EMO ������Щ���ܣ� �����Ф�裬����������ܻ�� Sora �е� AI Ůʿ���裺 |
|
|
|
0 EMO ��֧�ָ������ԺͲ�ͬ��Ф���� |

|
|
0 |

|
|
0 ��ʹ�ϴ�����Ƶ�ٶȺܿ죬Ҳ���Ժܺõı�֤��Ƶ��������ȶ��Լ�����Ƶ�Ķ�̬ͬ���� |

|
|
0 �ϴ�����Ƶ�������ڳ������Ƶ���������ԵĿ�����ƵҲ����������Ŷ�� |

|
|
0 |
|
|
|
0 ��������Ϥ������Ф�����Ϥ��������ϣ��ֻ���������һ�ֳ����ϣ������Ӱ���ٴ����˰ɣ� |
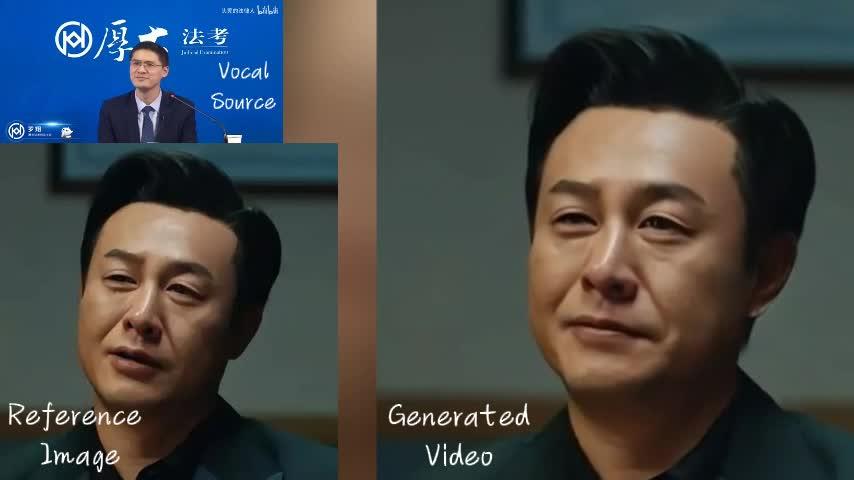
|
|
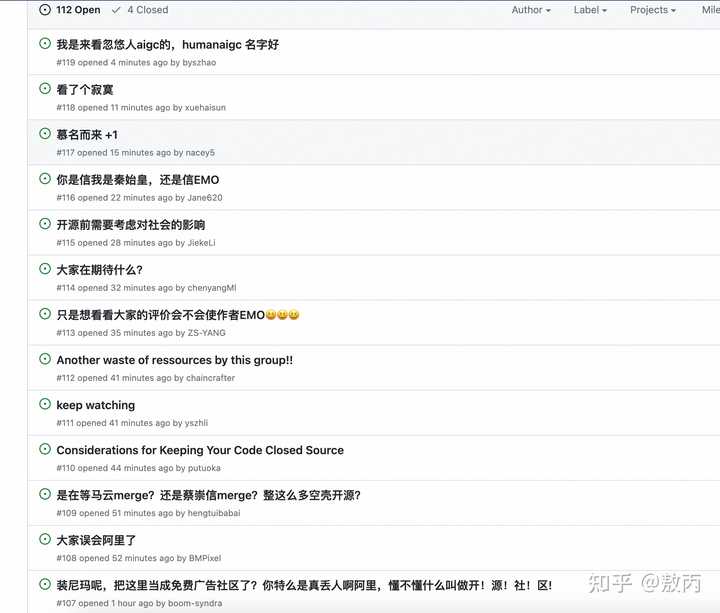
0 С������Ķ���û�У���Ч��������൱ţ���ˣ� �������൱�ڴ��ģ� �������������һ�仰����δ���������˹����ܵ�δ����������ۿɼ��ĵ���ѽ�� �����ϴ�����Ŀ�Լ��ѿ�Դ������������֮�������Ͳ������ˡ�����ϣ����㿪Դ�����ɡ����� |
|
������Ȼ��Sora�����ˡ�AI������Ƶ���� ����ͷ����ģ��Ҳ������������˰���û���ҵ���ڣ��������ڵ����ѿ��Եε���~ ��˵���ģ��ֻ��Ҫ�ṩһ����Ƭ��һ��������Ƶ�ļ���EMO�������ɻ�˵������� AI ��Ƶ���Լ�ʵ����ԽӵĶ�̬С��Ƶ���ʱ��ɴ�1��30�����ҡ�����dz���λ�������������������١�����ͼ����һһ��Ӧ�� ����ʵ��AI������Ƶ����֮ǰ�����Թ��ˣ���˵����������ô������Ƶ�����ǻ�����AI����������ǿ���ʵ�ֵġ� �ñȼ���ħ��ʦ�ġ�������Ƶ��������һ�����־Ϳ��Ը���һ����������Ƶ�� |

|
|
�ñȶȼӴ�������Ҳ��AI������Ƶ�Ĺ��ܣ�����AI�ʼǡ� |
|
|
������ʵ��AI������Ƶ���ڹ��ڲ���ϡ�档�ڹ����ұȽϵ��ĵ��ǡ���Ȩ�Ͱ�ȫ�������⡣ �����AI����Ĺ��²����ܹ���ƭ��ͨ���ѣ�����ȫ�����ý��Ҳ���ϵ��� |

|
|
��AI��ͼ�� ��������ȥ���������һ���¼��� ����ƽ���й�������ἷ־�������ӷ��֣����21����վ��ͬ��������һ�����ء����š�������һ��ײ����·���ˣ���9�������� ��˺������ŵı�����Ӵ������ļ��б��������������š��ĵ�����ܿ쳬����1.5�������˲������ѵ����ۡ� �����´����������У���ȫ����һ���������Ļ��ӡ� �����������̽��룬������֣����������˺�ij����������AI�������е�������١� |

|
|
AI��������������ͼƬ��Ƶ�������Լ����档 �ر�������midjourney��Stable Diffusion����ͼ���ߵ�����������AI������Ƭ��Ч������������ˡ�һ�ۼ١������Σ��ﵽ���������Էֱ�ij̶ȣ���ʽ��������ͼ�����ࡱ��ʱ���Ѿ������� ��û���ϣ����AI�Ƽ���չ��ͬʱ����������Ӧ�ķ������߸������Թ淶�� |
|
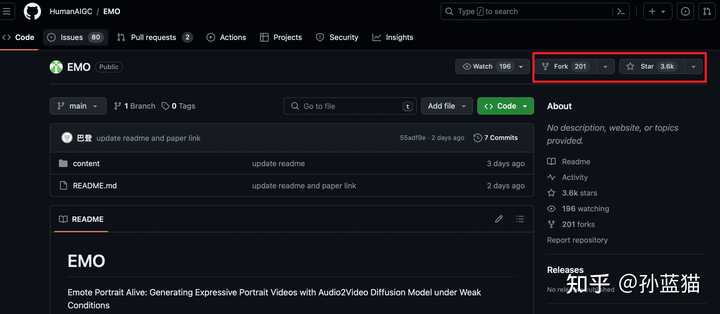
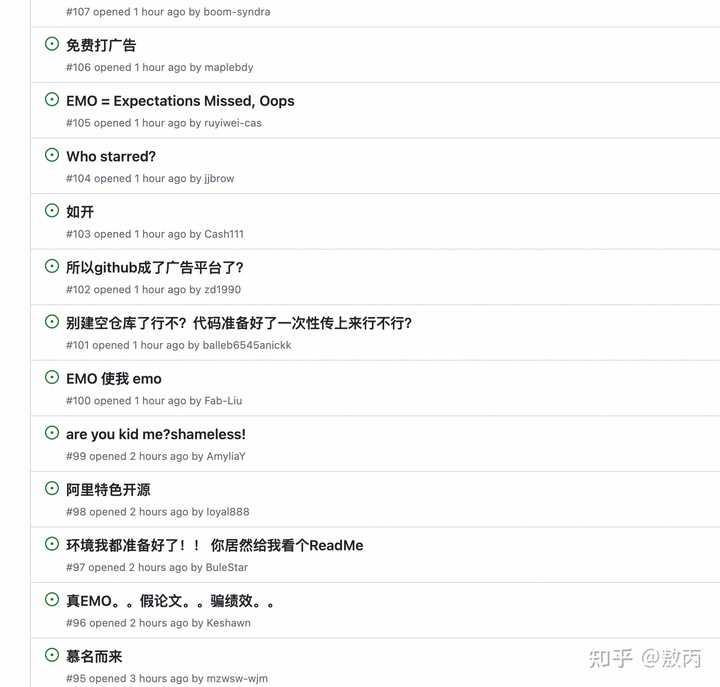
�� GitHub Ҳ��һ��ʱ���ˣ�����һ�Ѽ�ǧ star ����ˮ�Ĵ�ģ�� repo��һ�㶼������Ŀ������û������ôˮ��.. һ��ɶҲû�е� repo������ô�� 3.6k ��stars���������Ҳ��ǣ��� 201 forks�����Ƕ� fork ��Щɶѽ���� |
|
|
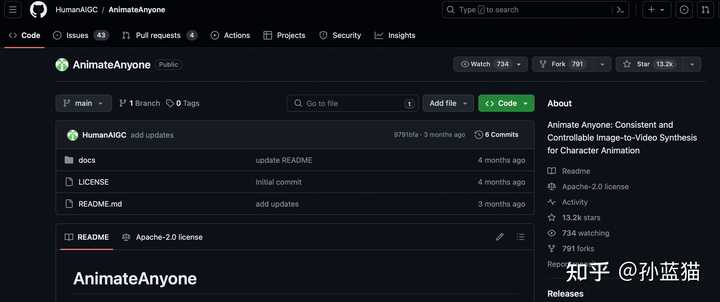
Ȼ���ҿ�����ͬһ GitHub �˺��µ���һ���ֿ⣨HumanAIGC/AnimateAnyone����Ҳ��һ���� repo����ȻҲ�� 13.2k stars �� 791 forks... |
|
|
�Ա�һ����˾���Ŀ�Դ��Ʒ PaddlePaddle/PaddleNLP ������Դ��+�ճ�Ͷ����ά����Ҳ�� 11k stars..ͻȻ�е�����������ô���£����Ǵ������ ���� issue ��������ҳ������Ҳ�ǵ�һ�μ������������رʣ����߿����Ʋ� https://github.com/HumanAIGC/EMO/issues |
|
|
����issue��ͼ |
|
�������ܵ���Դ����������װ���ƣ���ɶ�ÿ��ģ� sora����Ҳ���ܹ��⣬������̸����̸������sora���ٲ����ܵ�Githubר������������棬 �����ⷢ����������һƪ��Ƶ����������ǰ�����ڻ�װŤƨ�ɵļ�SDӦ�� |
|
|
������ô������SDӦ�ã�����Ҳ����ÿ�Դ������ͨ��Github������һ����ʲôħ��Ĺ�����վ |

|
|
������������������Ƥ��AI��ҵ�����վ��ͬС��ĸо���ģ��Ҳ���ܸģ���ֻ���Լ��ϴ��·��������� |

|
|
�����Ҿ��ò����ף�������˵��������ô��Ĺ�˾����Github�����������Ҿ���ʵ�ڲ�Ӧ�� |
|
ϸ˼���֣�����ţè��ϴ���衢����ٸ����Ŀ��֮�������������������˸���ǿ�շ���������ɯ������һ���� ֻҪһ������Ф��ͼ+һ����Ƶ�Ϳ����û����е����ﰴ����Ƶ��ָ�������ݳ������˵�����ؼ��ǿ��ͻ���һ�£��沿�����ͷ����̬Ҳ�������dz���Ȼ�������Ƶʱ�仹�ɴﵽ1��30�����ҡ� |

|
|
Ҳ��������Դ������һ�£��õ��ž�̬AI��Ůͷ��Ϳ������ɳ�����Ƶ��������̾��൱�ڣ�AI�ȿ�һ����Ƭ��Ȼ�������������������һ��һ�ŵػ�����Ƶ��ÿһ֡�仯��ͼ�� ����˭���ֵܷ����������ʵ... ...�� ���˿��� ��ϸһ�룬���������ʽAI�����ڲ��Ͻ�����չ��һ����ȷʵ��������������ı�ݣ����ͬʱ��Ҳ������������ĵ��ˡ������ǻ�ɫ��ҵ�ṩ���µļ����ӳ֡� EMO��һͼ����ƵAI���ߵķ�������Ȼ���ǿ���Ϊ���ļ���ͻ���������е���ϲ����ҲӦ�����������Լ����������Ϣ��ʵ�Ե��жϡ� |

|
|
��ǰ����OpenAI��Sora��DeepMind��Genie���ٵ�������EMOģ�ͣ���һӡ֤��AI��Ƶ�Ѿ���Ϊ�˽���AI��չ�������ɡ� AI��Ƶ������Ϊ��ģ̬Ӧ����ġ�ʥ����������������һ���������ݴ���ĸ����� �ع�֮ǰ��һ�������ʽAI�ķ�չ���Ѿ�ʮ�ֿɹۣ�����ϵ��Ƴ³��·������������˾�ϲ��AI���ߣ��ͺñ������������һ��ͷdz�ֵ�ô��һ��~ �� AI�������ɼ���Ҫ���㹦�ܣ�AIд��+AI�滭+AI�Ի�+AI���� �����������Ѷ��ƺ���Ϊ��������սʿ����һ������AI���ߣ�����һ�ƺ���ʵ����Ϊ�������䱸���ر����ʽ��AI���ܡ� |
|
|
���������ݴ������滭���ɡ��Ի����졢��Ƶ�ϳɡ����ܷ���ȵ����ͣ��ۺ���ʮ��֮�ߵ���һAIGC���߾����Ը������Ǹ�Ч��ɸ��������µ��������� ��AIд���� ��Ϊ���Ƕ��dz�ϲ���ּ�������д�����ܣ����ı��־�ʮ�ֵĿ�Ȧ�ɵ㣡 Ϊ��������������Եؽ������ݴ�������Ч��������������ݣ�����ϸ�ĵؽ�AIд��ϸ��ΪӪ�����칫�����������ĵȶ�������µ�ѡ� |
|
|
ÿ���д�������Ϳ���ֱ�Ӱ��շ����ģ��ȥ��������������ʹ�ô������ż��Լ�����Ҫ�� ������������һ��������AIд�����ߣ�ͬʱ��������һ�����ݱ༭���ɹ��������߱༭�Ű棬��Ӵ֡���ǡ�������ŵȹ��ܲ�������Ͷ����Ը㶨�� ������ɹ�����һ�����ƣ����ǵ���Ϊ������ĵ���ʽ�������������������ʡ��~ |

|
|
��AI������ ����������������ӵġ�AI��������һ���ܾͺͰ���EMO��ģ��ͼ����Ƶ�е���Ƶ�ϳ�������ͬ��֮��~ �����ı�����һ�����ɲ�ͬ��ɫ�����������ɵ���ƵЧ����Ȼ��ʵ������������ |

|
|
�ؼ�����ɫ��ѡ����ʮ��֮�ߣ����ԡ����ͯ������������������Ů�����ϰ�����ɫ���������������ɾ�����ɺ�����������~ |
|
|
��ô�йػ���ķ������ȵ���~ ���Ǹɻ������ķ������ҿ�˭��û�����ղ�ϲ������ʲô���Ҳ������������ֱ˵ @��Ƶ�༭���� ���Ի�ӭ�� |
|
EMO + Qwen �����ѾѾ���� |
|
��AIд����AI�滭��AI������ƵҲ���ˡ� EMOģ�͵ij���֮������ֻҪһ����Ƭ+һ����Ƶ����������AI��Ƶ����Ƶ�е����ﻹ��˵�����衣 ��ʵAIӦ������Ƶ���Ҳ����һ�������ˣ������ϻ��кܶ���õ�AI��Ƶ���ߣ�����˳���Ƽ�����ң� ��Synthesia Synthesia ��һ�� AI ��Ƶ����ƽ̨���������ò�ͬ���Դ��ı��д���רҵ��Ƶ��֧�� 120 �������ԣ��� 50 ������Ƶģ��ɹ�ѡ�� ʹ�úܼ���д��Ƶ�ű���Ȼ��ѡ��һ���ʺϵ�ģ�壬��������ı���ѡ��һ����ʵ��AI�����������������Ƶ��֮���������Ӿ�Ч������ͼƬ��ͼ�ꡢ�����ȡ�������Ƶ���ȴ������Ӻ�Ϳ������ػ�������Ǵ����� AI ��Ƶ�ˡ� |
|
|
������ħ��ʦ һ��רҵ�Ķ�����Ƶ��������������AI���ܼ������������ߺܶ�����֧����Ƶ������ƴ�Ӻϲ����ü��ָ���١����š��������ӵȹ��ܣ����һ��ṩ�ḻ��ת������Ч���˾�����Ļ����̬��ֽ���زģ���Ҫ����ʲô���͵���Ƶ���ܷ��㡣 |
|
|
һ��רҵ�Ķ�����Ƶ��������������AI���ܼ������������ߺܶ�����֧����Ƶ������ƴ�Ӻϲ����ü��ָ���١����š��������ӵȹ��ܣ����һ��ṩ�ḻ��ת������Ч���˾�����Ļ����̬��ֽ���زģ���Ҫ����ʲô���͵���Ƶ���ܷ��㡣 |
|
|
��Moonvalley �ų���ǿ���AI��Ƶ���ɹ��ߣ�ʹ������кܲ���~ �����������������ı����������ܽ�����Ƶ������дʵ��������ȵȶ���ѡ��������Ƶǰ�ٽ��о���IJ������ã������������Ч������~ |

|
|
���������~������ϲ����ϲ������@ְ��С��һ��֧�ֺ�ע�£����������� |
|
ģ�ͱ�����Ч������˵�dz�ը�ѣ�ֻ����GIthub��һ�д��벻���������ȷʵ~~ |

|
|
��Star�����Կ�����һ��Ǻ��ڴ���..... |

|
|
������һ�κܺõ��������ᣬֻ�Dz�֪����ô������~~ |
|
|
|
|
|
|
|
��ȱ�IJ����㷨��ȱ���������� wav2lips���ã����������档 |
|
AIȷʵû�л��Ǻӣ���ʱû����emoģ�ͺ�֮ǰ��Wav2Lip��Ƶ�ں����������ж������ ֮ǰùù˵Ӣ������������Ƶͦ��ģ��Ѿ��������ǰ�������ˡ� |

|
|
Wav2Lip��һ����Դ���ߣ�����һ���������������Ƶ�е���˵��ʱ���촽�Ķ�������Ƶ�����ݱ���һ��,�������������촽�ı仯��ʹ�����ɵ���Ƶ����������������ͬ���� |
|
|
�������κ��������κ����ԡ����������ԭʼ��Ƶ�ںϣ�������ƥ��ת�������͵Ŀ��͡� �������Ĺȸ��ڲ����ϡ�AIû�л��Ǻӡ���ƪ�����У�˵��: AI ģ�͵�����Ժ�ǿ�� ����˾��ģ����ǿ���������Ǻ��Ĺ��ܶ������Ƶģ������ױ������ģ��֮��IJ��죬Ŀǰ�������Ǿ����Եġ� һ�ҹ�˾�Ƴ����¹��ܣ�������˾�ܿ���ܸ��ϡ� |

|
|
ijЩ��˾�����ж��Ҽ����������ǹؼ����֡�AI �ļܹ���ԭ�����ǹ����ģ���ͬ��ֻ�Ǹ��ҵ�ʵ�֡� ������ AI �Ŀ�Դģ�ͣ�����Խ��Խǿ��ֻҪ���ս̳̲�������ʹ�Ǽ��õ��ԣ�Ҳ�ܺܿ����һ�����õ� AI ���� ���ﻨ������£������Ǹ�����ǰ�ˣ�Ч��������Ӧ�ò�࣬�����Ƿ������˻��õȿ�Դ�������ۡ� ����֤�����ڵĿ����������Ǻ�ǿ�ģ�վ�ھ��˵ļ����Ҳ�ã��Լ���ͷ��ʼҲ�ã���AI�˳��У����ֿ��Ű��ݵ���̬��ϣ���ܾ������Ϲ�����������ǰ��ɡ� |
|
����㲻��Դ�ͱ�ȥ��Դƽ̨�Ͻ���Ŀ���������Ҫȥ����Ŀ����Ҳһ��ʼ��˵���Ҳ���Դ��ֻ���������ģ������ǽ���Ŀƭ�����ղأ�һ������ô�㻹�Ƿ���������ô���治�Ӷ����� |
|
�����ǿ����ˡ��ο����硱ģ���ߵ�Ӧ�á� �ο����磨ReferenceNet��������EMO ��Ӧ�ã�һ��˼ά��ʽ��Ǩ�ƣ� ��EMOģ���е������ǣ���ȡ�ο�ͼ��Ͷ���֡�е�������Ϊ���ɵ���Ƶ�ṩ�ؼ���ָ����Ϣ����������������ѧϰ������������IJο�ͼ�������ȷ�������ȡ���沿��������Ϣ�����۾������ӡ���͵���״��λ�õȡ�ͨ���Զ���֡���д�������ȡ������Ƶ������صĶ�̬��������ȡ������Щ������Ϣ�ᱻ����ָ���������Ĺ�������֤���ɵ���Ƶ������Ŀ��͡��沿�����ͷ����̬��ο�ͼ�����Ƶ���ݱ���һ�£����ɵ���Ƶ����ȷ����Ȼ�ͱ��档 �ο�������EMOģ���а����˷dz��ؼ��Ľ�ɫ����֤�����ɵ���Ƶ������IJο�ͼ�����Ƶ����֮��ĸ߶�һ���Ժ���Ȼ�ԡ���Ҳ��EMOģ���ܹ�������ʽAI��������ӱ��������Ҫԭ��֮һ�� ���磬��֡����Σ�ϵͳʹ��һ�ֳ�Ϊ���ο����硱�Ĺ�������ȡ�������ܹ��ӵ��Ųο�ͼ����˶�֡����ȡ�ؼ���Ϣ�������沿����״�������������Լ�ͷ����̬�ȡ���Щ������ȡ����Ϊ�������ɹ��̵Ļ���������ϵͳ���õ�����ο�ͼ��Ͷ�̬�˶��� ����һ����������ǣ��������ѧϰ���Ա�������Autoencoder���ķ������Ա�������һ���ල��ѧϰ�㷨������ѧϰ�������ݵĵ�ά��ʾ��ͨ��ѵ��һ���Ա�����ģ�ͣ����Խ��ο�ͼ����˶�֡��Ϊ���룬��ѧϰ��ȡ�ؼ���������ʾ����Ϊ�������ɹ��̵Ļ���������������Ҳ�ǰ����沿����״�������������Լ�ͷ����̬����Ϣ�� |
|
���ǻ����ȿ�һ�¹ٷ�����������Ч�������˸о���ͦ�����ģ����ٱ�ǰ��ʱ��pika��runway��Ч��Ҫ��ɫ��Ҳ���ǹ���AI�µ�ͻ�ơ��±���һЩ�ٷ�������Ч����Ƶ������������ʾ�¡� Ч����Ƶ������ Sora �� AI Lady �ݳ� Dua Lipa 2. AI��Ů������ 3. ���������ձ��������¡�ϣ�� 4. AI Girl ���б��������ݳ��Ն���������� ���кܶ�İ�������ҿ���ȥ��һ�£�����Ͳ����ظ��ˡ� ������ַ���ٷ�Ҳ�����˹ٷ��ĵ�ַ�� GitHub��ַ������Ŀǰ���git���ֻ��һ��README����һ����Ҳ�²۵�ͦ�࣬�����Ҹо����ǻ���Ҫ������һ��ʱ�䣬��������һЩ�Ƚ��ѽ�����⣨����Ա�������� |
|
|
д����������˵һ�����ߵ�һЩ�۵�ɣ����ȿ������ǹ�����AI�����ͻ�ƣ��һ��DZȽϾ�ϲ�ģ��������Ǹ����ϣ������ض�������ʵ��Ӧ�õ�Ч�����Ҹо����ǵõȹٷ�����Ŀ����Ӧ�õ���ڷų������������У��Ͼ��ʼrunway��pika�շų��ƹ���Ƶ��ʱ��Ҳ�൱���ޡ�������������Ҹо����ǻ��Ǹ�������ģ��һ��ʱ�䣬�����к����ƣ�����ȥ�ϣ����ϲ�൫�Dz�Ҫ���ԷƱ��� |
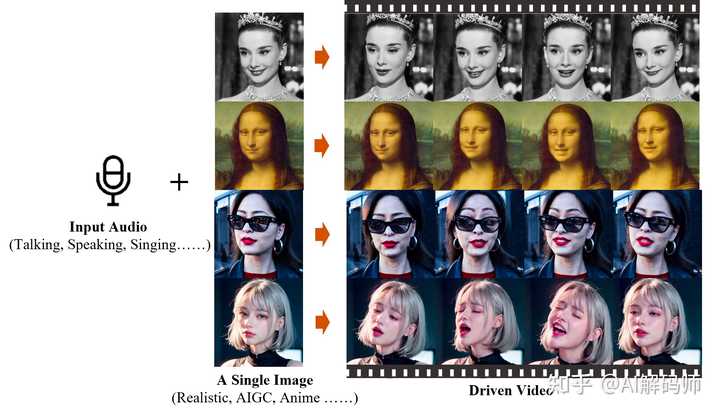
|
|
|
|
Sora֮��Ȼ�����µ�AI��Ƶģ�ͣ��ܾ��ô�ҿ�ת���ޣ� ������������쭡����ɸ���ǿ�������裬���ܸ������շ�������ͷ���� ����ǰ��������Ƴ��Ļ�����Ƶ������Ф����Ƶ���ɿ�ܣ�EMO��Emote Portrait Alive���� �����������뵥�Ųο�ͼ���Լ�һ����Ƶ��˵�������衢rap���ɣ����������ɱ���������AI��Ƶ����Ƶ���ճ��ȣ�ȡ����������Ƶ�ij��ȡ� �������������ɯ������λAI��Ч���������ѡ�֣�����һ�ζ��ס� ���ῡ����С�������ο�����rap�����㣬���θ�����ȫû���⡣ �����������Ҳ��holdס������ø���Ź������׳���Ѹ�ġ����������� ��֮����������Ф�裨��ͬ����Ф�����������Ф��˵������ͬ���֣������Ǹ��֡��Ź�������Ŀ���Ա���ݣ�EMO��Ч���������ۿ���һ�һ㶵ġ� |

|
|
���Ѵ��̾�������������߽�һ���µ���ʵ���� |

|
|
��2019�桶С��˵2008�桶�������ڰ���ʿ����̨�ʣ� �����Ѿ������ѿ�ʼ��EMO������Ƶ��ʼ����Ƭ����֡����Ч��������ô���� �����������Ƶ��������Sora���ɵ�AIŮʿ������Ϊ����ݳ�����Ŀ�ǡ�Don��t Start Now���� ���ѷ������� �����Ƶ��һ���ԣ�����������һ��¥�ˣ�һ�ֶ��ӵ���Ƶ�SoraŮʿ���ϵ�ī������û���Ҷ������䡢üë���ж������˶�����ʵ���SoraŮʿ�ĺ�����������к�������������Ĺ��������廹�������ƶ�����ֱ�Ӵ��� |
|
|
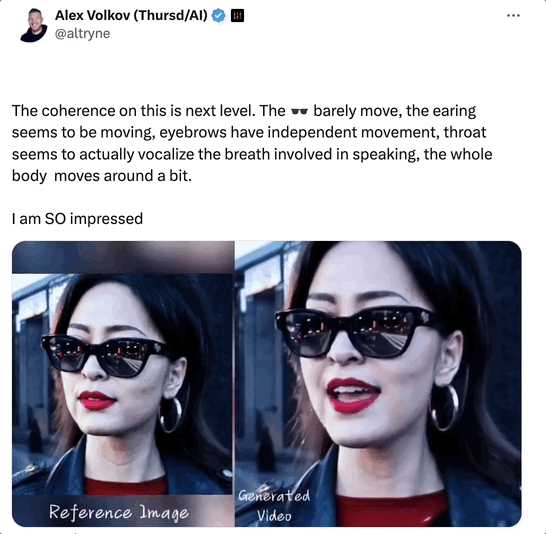
|
|
��˵������EMO�������¼�����ⲻ��������ͬ��Աȡ��� �������죬AI��Ƶ���ɹ�˾PikaҲ�Ƴ���Ϊ��Ƶ����������ͬʱ���Կ��͡��Ĵ���ͬ�����ܣ�ײ���ˡ� ����Ч����ô���أ�����ֱ�Ӱ������ ���������ѶԱȹ���ó��Ľ����ǣ�����������ˡ� |
|
|
EMO�������ģ�ͬʱ������Դ�� ���ǣ���˵��Դ��GitHub����Ȼ�ǿղ֡� �ٵ��ǣ���Ȼ�ǿղ֣��������Ѿ�������2.1k�� |
|
|
�ǵ�����������Ǻ��ż����м���������ô���� |
|
|
��Sora��ͬ�ܹ� EMO����һ����Ȧ�ڲ��������˿����� ����Sora����·�߲�ͬ��˵������Sora����Ψһ��·�� EMO�����ǽ���������DiT�ܹ��Ļ����ϣ�Ҳ����û����Transformerȥ�����ͳUNet����Ǹ�����ħ����Stable Diffusion 1.5�� ������˵��EMO��һ�ָ��б���������Ƶ������Ф����Ƶ���ɿ�ܣ����Ը���������Ƶ�ij��������κγ���ʱ�����Ƶ�� |

|
|
�ÿ����Ҫ�������ι��ɣ� ֡����β���һ����ΪReferenceNet��UNet���磬����Ӳο�ͼ�����Ƶ��֡����ȡ������ ��ɢ�����ȣ�Ԥѵ������Ƶ������������ƵǶ�룬����������ģ���֡������������������ͼ������ɡ� ����ǹǸ���������ȥ��������ڹǸ�������Ӧ��������ע�������ο�ע��������Ƶע�������ֱ������ڱ��ֽ�ɫ������һ���Ժ͵��ڽ�ɫ���˶��� ���⣬ʱ��ģ�鱻�������ݵ�ʱ��ά�ȣ��������˶����ٶȡ� ��ѵ�����ݷ��棬�Ŷӹ�����һ����������250Сʱ��Ƶ�ͳ���1500����ͼ����Ӵ��Ҷ�����������Ƶ���ݼ��� ����ʵ�ֵľ����������£� ���Ը���������Ƶ�����������ʱ�����Ƶ��ͬʱ��֤��ɫ����һ���ԣ���ʾ�и������������ƵΪ1��49�룩��֧�ָ������ԵĽ�̸�볪�裨��ʾ�а�����ͨ�����㶫����Ӣ��������֧�ֲ�ͬ���磨��Ƭ����ͳ�滭��������3D��Ⱦ��AI�����ˣ� |

|
|
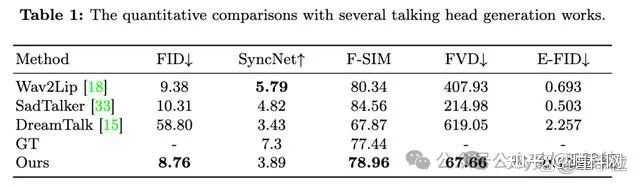
�ڶ����Ƚ���Ҳ��֮ǰ�ķ����нϴ�����ȡ��SOTA��ֻ�ں�������ͬ��������SyncNetָ������ѷһ� |
|
|
��������������ɢģ�͵ķ�����ȣ�EMO����ʱ�� ��������û��ʹ���κ���ʽ�Ŀ����źţ����ܵ��������������ֵ��������岿λ��һ��DZ�ڽ�������Dz���ר���������岿λ�Ŀ����źš� EMO���Ŷ� ���������EMO������Ŷ�����Щ�ˡ� ������ʾ��EMO�Ŷ�������Ͱ����ܼ����о�Ժ�� ���߹���λ���ֱ���Linrui Tian��Qi Wang��Bang Zhang��Liefeng Bo�� |

|
|
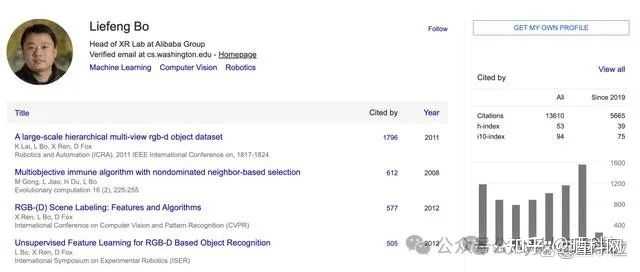
���У����з壨Liefeng Bo������Ŀǰ�İ���Ͱ�ͨ��ʵ����XRʵ���Ҹ����ˡ� ���з沩ʿ��ҵ���������ӿƼ���ѧ���Ⱥ���֥�Ӹ��ѧ�����о�Ժ�ͻ�ʢ�ٴ�ѧ���²�ʿ���о����о�������Ҫ��ML��CV�ͻ����ˡ���ȸ�ѧ������������13000�� �ڼ��밢��ǰ��������������ѷ����ͼ�ܲ�����ϯ��ѧ�ң����ּ��뾩�����ֿƼ�����AIʵ��������ϯ��ѧ�ҡ� 2022��9�£����з���밢� |
|
|
EMO�Ѿ����ǵ�һ�ΰ�����AIGC�����Ȧ�ijɹ��ˡ� |
|
|
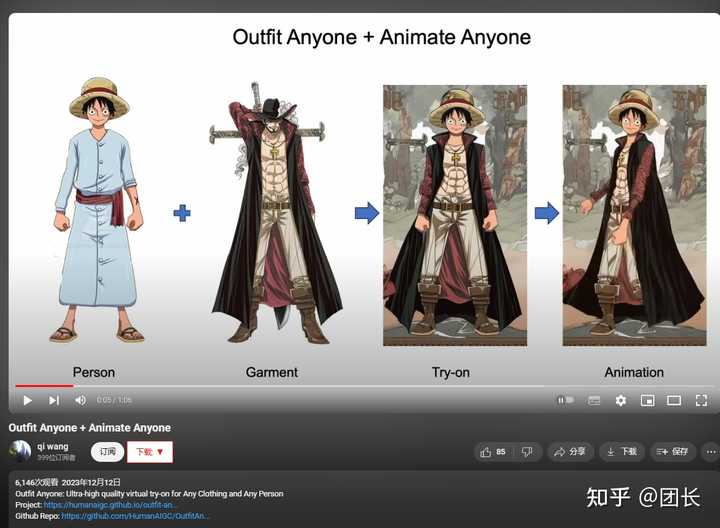
��AIһ����װ��OutfitAnyone�� |

|
|
������ȫ����СèС��������ϴ�����AnimateAnyone�� ������������� |
|
|

|
|
����Ƴ�EMO�����������ڸ�̾����������Щ�������������ϵġ� |

|
|
��֮�������롰����AIһ���籾�����������Ӱ��Խ��Խ���ˡ� |

|
|
One More Thing Sora�������ı���������Ƶ�ϳɵĶ���ʽͻ�ơ� EMO��Ҳ������Ƶ��������Ƶ�ϳ�һ���¸߶ȡ� ���߾�������ͬ������ܹ���ͬ��������һ����Ҫ�Ĺ��ԣ� �м䶼û�м�����ʽ������ģ�ͣ�ȴ����һ���̶���ģ�����������ɡ� ���������Ϊ������Lecun��ֵġ�ͨ������������Ϊ������ģ�������˷���ע��Ҫʧ�ܵġ��۵���㣣���֧����Jim Fan�ġ���������������ģ�͡�˼�롣 |

|
|
��ȥ���ַ���ʧ���ˣ������ڵijɹ�������������Ի���ǿ��ѧϰ֮��Sutton�ġ���ɬ�Ľ�ѵ�����������漣�� ��AI�ܹ�������һ��ȥ���֣������ǰ������Ƿ��ֵ�����ͻ���ԵĽ�չ����ͨ����������ģ��ʵ�� ���ģ�https://arxiv.org/pdf/2402.17485.pdfGitHub:https://github.com/HumanAIGC/EMO �ο����ӣ�[1]https://x.com/swyx/status/1762957305401004061 ��Դ��Aya�˹������Ź��ں� |
|
|
| [�ղر���] �����ر��ġ� |
| ��һƪ���� ��һƪ���� �鿴�������� |
|
|
|
| ��Ʊ�ǵ�ʵʱͳ�� ��ͣ��ѡ�� ��ʱͼѡ�� ��ͣ��ѡ�� K��ͼѡ�� �ɽ���ѡ�� ����ѡ�� ������ѡ�� �������� �������� ���� MACDָ�� KDJָ�� BOLLָ�� RSIָ�� ���ɻ���֪ʶ ���ɹ��� |
| ��վ��ϵ: qq:121756557 email:121756557@qq.com ����ƻ� |