
| |
|
|
| 首页 淘股吧 股票涨跌实时统计 涨停板选股 股票入门 股票书籍 股票问答 分时图选股 跌停板选股 K线图选股 成交量选股 [平安银行] |
| 股市论谈 均线选股 趋势线选股 筹码理论 波浪理论 缠论 MACD指标 KDJ指标 BOLL指标 RSI指标 炒股基础知识 炒股故事 |
| 商业财经 科技知识 汽车百科 工程技术 自然科学 家居生活 设计艺术 财经视频 游戏-- |
| 天天财汇 -> 科技知识 -> 为什么说NLP死了? -> 正文阅读 |
|
|
[科技知识]为什么说NLP死了? |
| [收藏本文] 【下载本文】 |
|
随着chatgpt等生成式AI的爆火,部分NLP的研究者表达了消极的态度,有什么具体的理由吗,我只是个学习语言学和人工智能的大一学生,有人可以解答一下… |
|
nlp本身没死,但nlp的研究现在确实有点麻烦。 因为chatgpt为首的transformer系模型,或者说LLM模型的成功说明了一件事:力大真的飞砖。 什么意思呢?比如以前某个ai方向效果不好,那第一反应当然是改进算法,改进模型,用更精妙的逻辑去处理,或者加点小trick。 但是现在呢,transformer系的模型以非常简单的逻辑达到了比你更好的效果,你疑惑为什么,然后就在论文里看到了那几千亿的参数、几十个TB的数据量和可以预想到的训练所需的大到恐怖的算力需求。 而这种东西,不是一个普通实验者能够掌握的。 如果这就是AI的未来的话,那就意味着小实验室能做的将非常有限。你再怎么费劲改进你的模型,效果总还是比不上它们――只因为你没有那么多训练数据和算力。更不要说这些模型可迁移性还特别强,人家哪怕不是专门做你的方向的,干你这个方向的活效果也比你设计的专门做这个方向的模型效果好。那你的研究还有什么意义呢? 你说你要改进transformer?好的,先不管你怎么做到的,总之你认为自己的新方法把参数需求从几千亿降到几十亿了,数据量也降到了500GB。一百倍诶,真厉害。现在请把权重炼出来以证明你的改进方式没有导致严重性能下降。然后你就傻眼了,因为手头的算力炼这个一百倍改良版的都炼不出。你一次都没炼成过,自己都不知道这方法到底行不行。 所以nlp本身仍会在大组织的推动下继续发展,但nlp研究也将变成只有它们才能做的事。普通研究者最多做点偏落地和应用的东西了。 (以上事情并不是一定会发生,只是说现在看来有这个趋势,然后有些人正是因为认同这个趋势而沮丧。至于我本人还是比较乐观的。原因和评论区的某位老哥说的差不多,技术和算力的发展总会带来新希望的。) ―――――――――――――――― 4.14更新 微软开源了个新的“低成本训练方案”,据说能让大部分人都大部分人都训练的起自己的chatgpt。给出的预估开销是Azure云9小时,合300美刀。那确实只要有必要都训练的起了。 所以嘛,发展总还是会带来希望的。 |
|
因为NLP的小镇做题家时代结束了,不光是NLP,整个AI领域都是如此。 2012-2022是黄金十年,各种数据集的出现,各种网络结构的提出,各种框架的开源。 老黄也挺给力,算力跟得上,关键是,需要的算力真不大,成本并不高。 一个实验室,一个学生一张卡,不够的话,几个学生串一串,几张卡一起跑,都能跑出足以发顶会的文章。 部分企业、科研机构也愿意博个名声好招揽人才,也给员工提供一些计算资源,搞点儿研究。 总之,有脑子和勤奋就行了。 现在呢?大模型已经给实验效果定了下限,你的方案要是干不过的话,根本没人看。 各大芯片厂商,也都在出端上推理方案,大模型的推理算力很快就可以满足,云端就更不用说了。 这就造成了大模型必然成为未来主流研究方向。 但是,大模型的训练成本极高,你在别人的基础上微调,小修小改,根本算不上什么成果,很难发出文章。 最终,这方面的研究受限于钱,很多很多的钱,让很多研究人员无缘参与了。 能出得起这个钱的科研机构和企业,注定是少数。 对此感到绝望的,多半是水平一般,被挤出的底层科研人员,也许本身也不适合搞研究。 相对比较牛的人,反而是开心的,因为他们可以争取到资源,做最火最顶尖的研究,并因此获得财富。 |
|
举个例子。在蒸汽机出来之前,当年很多器械都是马来驱动的,动物那个马。所以当年有专门的研究机构来研究怎么在短时间内培养出最强壮的马,是当时的热门研究项目(斯坦福早年就是干这个起家的),属于核心科技。然后蒸汽机出来,马的育种沦落成贵族的玩具,具备审美价值,不再具备更广泛意义的经济价值。 这个类比对chatgpt前的nlp和chatgpt后的nlp也是适用的。 之前做summarization本身就是一个大项,还有专门的startup来干这个,后面的技术价值成百上千万美元。现在随便找个python脚本,call一下gpt4,成本10美分不到。 失落感?必然的。随着llm进一步发展,失落的人还会更多。 |
|
简单做个比喻,就是以前大家都是能过提升自己的格斗技巧来相互切搓。好,现在突然来了一个巨人,告诉大家说,我可以直接把地板揍出一个大窟窿。你们再练10年,也赶不上我了。好,如果你想赶超我,首先,得把自己练得像我一样壮。但是,要练得这样强壮,需要很多钱,吃很多营养的东西。普通武术家都很穷,于是,就开始担心了。结果,希望能干点实事的人,只有抱着这个巨人的大腿,说,“哥们,借我一个肩膀,让我fine-tune一下呗” |
|
首先同意有的回答提到的,chatgpt之前学术界和工业界之间已经存在比较大的gap,学术界很多论文热衷于在开源数据集上实现新的sota,而工业界很多应用仍然还是以Bert的魔改版本为主来应用到NLP的各种业务中,虽然NLP各个细分任务都有新的工作出来,但也可以说Bert出来之后到chatgpt出现,NLP没有太大的实质进展。从工业界来说,对比cv,nlp的落地应用很尴尬,因为nlp提供的能力很难满足很多应用场景的需求,就比如说chatbot,端到端的学术研究很多,但是落地的一个没有,因为可控性太差,而且常识推理能力也比较弱,后处理兜底的工作量还不如用rule base。 另外企业非常关心成本问题,虽然使用bert finetune需要标的数据量,几千条也能做特定领域任务,但是几千条也是钱,而且再换个场景,还得继续标数据。prompt tuning出来后,few shot leaening开始有一些应用场景,但效果还难以满足很多业务需求,更多还是停留在研究领域。 ChatGPT的出现,使得NLP的能力直接提升了几个数量级,主要体现在几个维度:1.节省成本:输入几个示例,不需要要finetune,就能得到细分任务的可用结果;2.涌现出推理能力:我认为这个能力非常重要,也是chatgpt明显区别于以往chatbot的标志,它能做鸡兔同笼,能写代码,这种能力是之前很难想象的,就是chatbot居然开始会“思考”了;3.强大的上下文能力和语义理解能力,之前的chatbot聊几句就聊飞了,而chatgpt给你感觉一直在围绕你的所想在聊;4.多任务处理能力:以往的生成模型,可能写诗很厉害,但就不能写代码,可能创作现代文厉害,就不能创作古文。而chatgpt属于全能选手,能力覆盖领域远远超过了之前的模型。 以上,集这么多优点于一身的chatgpt,对NLP领域带来的不仅仅是细分领域任务的极大挑战,还有更重要的是,在大模型越发加剧学术界和工业界差距的同时,NLP领域应该如何面对这种变革,也对自身的研究思路进行变革,利用大模型的能力,更小的平替模型?显然这些还都不是答案,拥抱变化吧!NLP的大航海时代说不定才刚刚开始! |
|
传统那套小作坊式的NLP已经死了, 未来不是单打独斗的个人主义英雄时代, 而是抱团的割据战, 这是小作坊,个人英雄主义者们对复杂系统缺乏敬畏的必然结果 |
|
明明是发展得更好了,你们到底是要解决问题还是只是想摸鱼混饭? |
|
仅仅是NLP死了吗?可以说除了GPT之外的所有传统ML都死了。就像机器学习搞死了统计模型一样,GPT也搞死了机器学习。 新时代学GPT的人看老一辈做传统模态识别,去噪,CV,NLP,回归分类决策等等模型的人就和看孔乙己会写8种回字一样。 在GPT的统制下,所有传统方法都已经不重要了。当然GPT还有可能把这些传统算法的肢体吃掉一些变成自己肌肉的一部分。 一将功成万骨枯,GPT起来了,所有做传统模型的人都倒下了,但他们还得顽强的说着我也懂GPT,就想风烛残年的老妈妈桑一样来招揽客人。 |
|
之前大家其实也一直想要有一个端到端模型能解决所有nlp问题,但是发现效果很差。所以只能够定义为很多nlp子任务,用这些子任务的排列组合能够满足大部分需要nlp的场景。openai告诉大家llm就是这个端到端的可行的解决方案之后,之前的研究范式也就成为了过去式。 但是,这个新的范式下也有很多值得探索的问题,比如人类对齐、可控生成、模型加速等等。就我个人而言,我比较感兴趣的就是提高整个模型的可信赖度。因为相较于以前的范式中每个子组件是有清晰设计的,现在llm的透明度是显著降低的。所以,我们现在应该关心何时我不该信任模型的输出,何时模型会被坏人利用,何时模型会生成不良的价值观? |
|
NLP没有死,但是大部分NLPer不愿意接受NLP的研究走向 “prompt策略 as baseline”,而后与prompt策略相结合进行策略迭代的现实,所以大部分NLPer未来会变得不值钱。 现在大部分NLPer的认知还停留在“prompt策略就是产品经理干的活”,殊不知,BERT时代的国内互联网大厂里,最牛的算法工程师、上线产出最猛的算法工程师往往不是代码最牛的、刷论文最多的,而是最懂业务逻辑的那些人。 今天这一幕,就很像2018年BERT出来后,很多NLPer非常抗拒,坚持魔改BERT的model structure是一样的道理。 事情的本质没有变,NLPer还是要解决NLP的问题,但客观上来说,现在大部分NLP问题都不需要训模型,但需要非常好的prompt策略,或prompt策略与规则、训模型相结合去联合做事情会高效很多。 可惜目前我接触下来的候选人,非常两极化。 要么是prompt工程玩的花里胡哨,懂得去持续理解业务逻辑,但由于缺乏NLP的背景,不懂怎么做算法,做个基线还行,想正儿八经的做策略迭代,或去解决纯prompt策略搞不定的算法问题就扛不住了。 要么是抗拒prompt工程,本来搞点prompt策略迭代迭代,不需要GPU机器,半天就能搞定的事情,非要抓数据搞数据标注和finetune,甚至刷paper去了。理解不了业务需要什么,分不清good/bad badcase的形态,建立不起来无偏的策略迭代通路。这种在大厂常被戏称为“学院派”,这类往往基线和迭代都做不好。 我预判,未来NLPer依然会非常值钱,并且是越懂应用层的NLPer会越值钱。大模型预训练层的需求卷完后,杀手级应用层的NLP需求才会是NLPer水涨船高的真正高潮。 理由很简单,参考下2018年之后的不同技能分层的算法工程师的市场薪资变化路径吧,搜广推这三个字还没凉透。说多了得罪人,懂的都懂。 目前,大模型时代下具备应用层算法核心竞争力的NLPer,凤毛麟角,比做大模型基础设施层的要稀缺的多。 与prompt策略相结合的NLP算法,玩好了上限会比单纯的训大模型可观的多,玩法也比大部分想象中的丰富的多。 如果你觉得你是个脑子灵活、眼里有光的NLPer,既有BERT时代培养下来的良好的算法迭代方法论,又非常乐于接受时代的变化,希望做出杀手级的算法驱动的应用,欢迎撩我:) |
|
以前搞NLP,拼的是个人研究者的水平 ―― 对模型的设计,对算法的优化,对数据的理解。 现在GPT大模型一出来,直接用巨大的参数量和算力降维打击。对于钱多的大厂来说,如果模型效果不好,那就涨参数,堆算力。模型都是同样的配方,给它参数翻个100倍,算力加个20倍,往上堆就完事儿了。至于模型和算法,你想改都不让你改,毕竟你没法证明你改了之后是变好了还是变差了。这就导致,虽然大厂在NLP上投入的钱越来越多,但钱都流进了高性能计算、量子计算、以及芯片厂的口袋,而研究算法和模型NLP-er根本就赚不着这个钱了。 |
|
可以类比经济活动中的垄断 产业界巨头拥有的算力资本恰巧在本问题上可以发挥规模效应――大模型 使学术界在算力出奇迹方法论可行的前提下无法参与竞争 问题是; 魔改一下就水篇论文 一年水成千上万论文的虚假繁荣 难道才是好的吗 也不是说学科问题已经解决完了 不影响那些静心搞研究的真学者 |
|
如果把NLP当作工具,研究NLP没有以往那么容易了。无论研究哪个领域,都得至少达到LLM的准确率。这导致其它模型很难再出成果,而且大家都研究LLM,竞争就更激烈了。 如果把LLM当作智能,NLP才刚刚起步。虽然LLM很强,但它强大的原因几乎是个未解之谜。即使最顶尖的研究者也尚未发现很好的可解释性方法。因此LLM领域也有非常多值得研究的方向,举几个我认为很重要的方向: LLM的factual knowledge存在哪个位置?LLM In-context learning的机制是什么?LLM multitask learning的机制是什么?LLM 为什么会产生幻觉?Instruction tuning前后的模型有什么变化,导致LLM可以提升指标?COT的机制是什么? 这些问题即使是最顶尖的研究者也没研究明白,而且重要性被严重低估。就连OpenAI都认为增加模型scale和数据量是目前提升指标最有效率的方案。但我认为大力出奇迹不是AGI的解法,understanding LLM才是。 我整理的值得读的LLM paper list,看了不后悔: https://github.com/zepingyu0512/awesome-llm-papers-interpretability |
|
说句题外话,题主赶紧结束你的语言学的学习,这东西学得越多越有害 |
|
题主说部分NLP研究者表达了消极的态度,哪部分呢? 猜测一下,可能有这三部分: 1、NLP领域的传统算法研究者 NLP的早期阶段主要由传统的机器学习算法统治,比如朴素贝叶斯、支持向量机(SVM)、随机森林和决策树等等,这在处理基本的NLP任务没什么问题,但是在处理复杂语言结构和捕捉上下文信息方面就遇到了瓶颈。 深度学习的出现标志着NLP的重大转折。2003 年,Yoshua Bengio等人提出神经网络概率语言模型,但受限于算力当时未能激起太多浪花;2013 年,得益于 Word2vec的高效实现,十亿词的语料库在单机上一天也能训练完毕,词向量开始在各个领域广泛应用。再后来,显卡强大的算力和深度学习互相结合,继续引领着经验主义方法取得辉煌成就。2014 年的序列到序列(Sequence-to-Sequence)学习开启了机器翻译的新范式;2015年的注意力机制(Attention Mechanism)逐渐成为处理长程依赖的标配;2018年的BERT更是把自然语言处理技术推到了新的历史高度,开启了大规模预训练模型的新时代。借用强化学习大师Richard Sutton在评论文章 The BitterLesson [苦涩的教训])中的话来说: “the only thing that matters in thelongrusisthe leveragingofcomputation" (从长期来看,真正重要的事情是有效利用算力) 这确实是几十年大浪淘沙留下来的肺腑之言。 在transform架构的基础上,语言模型(LMs)已经成为NLP领域的新时代。特别是由GPT-n模型所代表的LMs,具有生成连贯、具有上下文意识的文本响应的能力。利用无监督学习,它们能够处理各种NLP任务,根本不需要进行大量微调或明确监督。 LLMs通过为模型提供对语言的深层次理解和生成类似人类文本的能力而改变了这一领域。这些模型在文本完成、摘要、翻译甚至创意写作等任务上都表现得很出色。完全可以说,LLMs主导者NLP的世界,所以,如果说传统的NLP已死,一定程度上也不为过。 2、个人研究者和中小机构 很多模型和算法变得越来越重了,尤其是超大规模的预训练模型需要天量的计算资源,个人研究者和中小机构注定无缘。 3、对NLP的学术研究抱有极大工业幻想的人 关于NLP的基准测试有个公开的秘密:当今NLP基准测试的目的是发表论文,而不是推动NLP的实际应用。基准测试的目标是提供一个公平的评估环境,使研究人员能够客观地比较不同算法在各种任务上的性能,进而推动技术的进步。但如果目的变成了发论文,就会导致一些研究过于关注在基准测试上的性能提升,而忽略了实际应用中的效果和泛化能力。 对于NLP的产业从业者来说,听到“哇,我刚刚在两个迭代中解决了一个价值几千万的NLP问题!”可比“哇,我的模型在指令理解方面的鲁棒性提升了一个百分点!”兴奋多了。 |
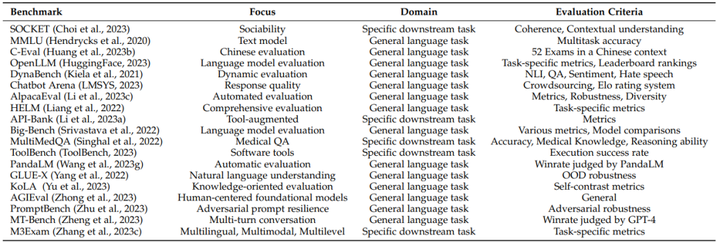
|
|
19个流行的基准测试 总之,Transformer架构和基于互联网文本的自监督预训练已经成为主流了,NLP也应该回归到正常的研究阶段。在这个阶段,要关注的是产业化效率,因为训练和提供大型语言模型的成本在迅速增加,甚至超过了摩尔定律的预测。提升效率,工业化NLP才是未来的大势所趋。 传播先进文化、推动社会进步,蒙您欢喜,不要忘记点赞、分享、关注@清华大学出版社 IT专栏 哦~ |
|
来源 | 新智源 ID | AI-era 过去十年间,仅靠简单的神经网络计算,以及大规模的训练数据支持,自然语言处理领域取得了相当大的突破,由此训练得到的预训练语言模型,如BERT、GPT-3等模型都提供了强大的通用语言理解、生成和推理能力。 前段时间,斯坦福大学大学教授Christopher D. Manning在Daedalus期刊上发表了一篇关于「人类语言理解和推理」的论文,主要梳理自然语言处理的发展历史,并分析了基础模型的未来发展前景。 |

|
|
论文获取链接:https://direct.mit.edu/daed/article/151/2/127/110621/Human-Language-Understanding-amp-Reasoning |

|
|
论文作者Christopher Manning是斯坦福大学计算机与语言学教授,也是将深度学习应用于自然语言处理领域的领军者,研究方向专注于利用机器学习方法处理计算语言学问题,以使计算机能够智能处理、理解并生成人类语言。 Manning教授是ACM Fellow,AAAI Fellow 和ACL Fellow,他的多部著作,如《统计自然语言处理基础》、《信息检索导论》等都成为了经典教材,其课程斯坦福CS224n《深度学习自然语言处理》更是无数NLPer的入门必看。 NLP的四个时代第一时代(1950-1969) NLP的研究最早始于机器翻译的研究,当时的人们认为,翻译任务可以基于二战期间在密码破译的成果继续发展,冷战的双方也都在开发能够翻译其他国家科学成果的系统,不过在此期间,人们对自然语言、人工智能或机器学习的结构几乎一无所知。 当时的计算量和可用数据都非常少,虽然最初的系统被大张旗鼓地宣传,但这些系统只提供了单词级的翻译查找和一些简单的、基于规则的机制来处理单词的屈折形式(形态学)和词序。 第二时代(1970-1992) 这一时期可以看到一系列NLP演示系统的发展,在处理自然语言中的语法和引用等现象方面表现出了复杂性和深度,包括Terry Winograd的SHRDLU,Bill Woods的LUNAR,Roger Schank的SAM,加里Hendrix的LIFER和Danny Bobrow的GUS,都是手工构建的、基于规则的系统,甚至还可用用于诸如数据库查询之类的任务。 语言学和基于知识的人工智能正在迅速发展,在这个时代的第二个十年,出现了新一代手工构建的系统,在陈述性语言知识和程序处理之间有着明确的界限,并且受益于语言学理论的发展。 第三时代(1993-2012) 在此期间,数字化文本的可用数量显著提升,NLP的发展逐渐转为深度的语言理解,从数千万字的文本中提取位置、隐喻概念等信息,不过仍然只是基于单词分析,所以大部分研究人员主要专注于带标注的语言资源,如标记单词的含义、公司名称、树库等,然后使用有监督机器学习技术来构建模型。 第四时代(2013-现在) 深度学习或人工神经网络方法开始发展,可以对长距离的上下文进行建模,单词和句子由数百或数千维的实值向量空间进行表示,向量空间中的距离可以表示意义或语法的相似度,不过在执行任务上还是和之前的有监督学习类似。 2018年,超大规模自监督神经网络学习取得了重大成功,可以简单地输入大量文本(数十亿个单词)来学习知识,基本思想就是在「给定前几个单词」的情况下连续地预测下一个单词,重复数十亿次预测并从错误中学习,然后就可以用于问答或文本分类任务。 预训练的自监督方法的影响是革命性的,无需人类标注即可产生一个强大的模型,后续简单微调即可用于各种自然语言任务。 模型架构 自2018年以来,NLP应用的主要神经网络模型转为Transformer神经网络,核心思想是注意力机制,单词的表征计算为来自其他位置单词表征的加权组合。 Transofrmer一个常见的自监督目标是遮罩文本中出现的单词,将该位置的query, key和value向量与其他单词进行比较,计算出注意力权重并加权平均,再通过全连接层、归一化层和残差连接来产生新的单词向量,再重复多次增加网络的深度。 |
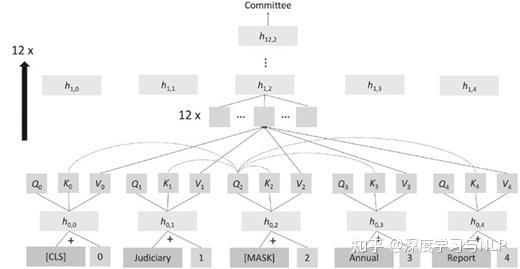
|
|
虽然Transformer的网络结构看起来不复杂,涉及到的计算也很简单,但如果模型参数量足够大,并且有大量的数据用来训练预测的话,模型就可以发现自然语言的大部分结构,包括句法结构、单词的内涵、事实知识等。 prompt生成 从2018年到2020年,研究人员使用大型预训练语言模型(LPLM)的主要方法就是使用少量的标注数据进行微调,使其适用于自定义任务。 但GPT-3(Generative Pre-training Transformer-3)发布后,研究人员惊讶地发现,只需要输入一段prompt,即便在没有训练过的新任务上,模型也可以很好地完成。 相比之下,传统的NLP模型由多个精心设计的组件以流水线的方式组装起来,先捕获文本的句子结构和低级实体,然后再识别出更高层次的含义,再输入到某些特定领域的执行组件中。 在过去的几年里,公司已经开始用LPLM取代这种传统的NLP解决方案,通过微调来执行特定任务。 机器翻译 早期的机器翻译系统只能在有限的领域中覆盖有限的语言结构。 2006年推出的谷歌翻译首次从大规模平行语料中构建统计模型;2016年谷歌翻译转为神经机器翻译系统,质量得到极大提升;2020年再次更新为基于Transformer的神经翻译系统,不再需要两种语言的平行语料,而是采用一个巨大的预训练网络,通过一个特别的token指示语言类型进行翻译。 问答任务 问答系统需要在文本集合中查找相关信息,然后提供特定问题的答案,下游有许多直接的商业应用场景,例如售前售后客户支持等。 现代神经网络问答系统在提取文本中存在的答案具有很高的精度,也相当擅长分类出不存在答案的文本。 分类任务 对于常见的传统NLP任务,例如在一段文本中识别出人员或组织名称,或者对文本中关于产品的情感进行分类(积极或消极),目前最好的系统仍然是基于LPLM的微调。 文本生成 除了许多创造性的用途之外,生成系统还可以编写公式化的新闻文章,比如体育报道、自动摘要等,也可以基于放射科医师的检测结果生成报告。 不过,虽然效果很好,但研究人员们仍然很怀疑这些系统是否真的理解了他们在做什么,或者只是一个无意义的、复杂的重写系统。 意义(meaning) 语言学、语言哲学和编程语言都在研究描述意义的方法,即指称语义学方法(denotational semantics)或指称理论(heory of reference):一个词、短语或句子的意义是它所描述的世界中的一组对象或情况(或其数学抽象)。 现代NLP的简单分布语义学认为,一个词的意义只是其上下文的描述,Manning认为,意义产生于理解语言形式和其他事物之间的联系网络,如果足够密集,就可以很好地理解语言形式的意义。 LPLM在语言理解任务上的成功,以及将大规模自监督学习扩展到其他数据模态(如视觉、机器人、知识图谱、生物信息学和多模态数据)的广泛前景,使得AI变得更加通用。 基础模型 除了BERT和GPT-3这样早期的基础模型外,还可以将语言模型与知识图神经网络、结构化数据连接起来,或是获取其他感官数据,以实现多模态学习,如DALL-E模型,在成对的图像、文本的语料库进行自监督学习后,可以通过生成相应的图片来表达新文本的含义。 我们目前还处于基础模型研发的早期,但未来大多数信息处理和分析任务,甚至像机器人控制这样的任务,都可以由相对较少的基础模型来处理。 虽然大型基础模型的训练是昂贵且耗时的,但训练完成后,使其适应于不同的任务还是相当容易的,可以直接使用自然语言来调整模型的输出。 但这种方式也存在风险: 1. 有能力训练基础模型的机构享受的权利和影响力可能会过大; 2. 大量终端用户可能会遭受模型训练过程中的偏差影响; 3. 由于模型及其训练数据非常大,所以很难判断在特定环境中使用模型是否安全。 虽然这些模型的最终只能模糊地理解世界,缺乏人类水平的仔细逻辑或因果推理能力,但基础模型的广泛有效性也意味着可以应用的场景非常多,下一个十年内或许可以发展为真正的通用人工智能。 参考资料:https://direct.mit.edu/daed/article/151/2/127/110621/Human-Language-Understanding-amp-Reasoning |
|
简单的道理来说,就是一力降十会 你辛辛苦苦研究出来优化的模型和结构也好,在大公司的海量的硬件和数据面前,被秒得连渣都不剩。 如今的机器学习,早就变成了一场数据集和资本(硬件)的军备竞赛 |
|
吴恩达2023年初有过一篇专访,给小数据模型站台的,意思非常直白,“很多领域的客户就这么点数据, 我们需要的是在数据量很少的情况下,也能很好工作的模型”。 NLP过去不少“小模型”派,玩的就是这套东西, 他们做的就两件事 1w条以内标记好的数据,这模型在对应领域能work。 在一个相对通用的领域,用一个基础模型(可能百万级数据),再加上1w条以内标记好的细分领域的数据,这模型能work。 |
|
我们实验室就是做nlp的,今年年初all in 大模型,光今年AAAI就中了4篇......大模型来了nlp能研究的东西更多了,也更有价值 |
|
最早Andrew Ng发的教学视频就提到了解决overfitting与其改你model不如多去收集点数据。大公司用辛辛苦苦收集清理的数据加上堆硬件加速学习,学校和小作坊很难赶得上。 不过好多年前学校和工业界就已经分开了,学校做的花里胡哨的玩具在公司根本用不了。有没有gpt这波,学校也都是在opensource data上自娱自乐,影响不大。 但最悲观的是中文nlp还会死在最前面,数据质量太差,很多内容都没了。督工前几天讲到这个真的深表赞同。 诶,我写的感觉对研究人员很不友善 此回答不针对任何人,只是对我自己研究的一点反思。当初的流程是读各种文章,然后看了下引用的开源数据,想想有什么新问题,举例子证明一下实际用途,再解决一下,做实验和现有方法比比。发文章是的确能发,但是先有数据后有问题的路子你也知道实际能有多大用处.. 做有价值的研究我觉得是很难的,实际问题有时候要靠遇到,不是自己硬想出来的。读书时间有限,早点发够文章毕业要紧。锻炼一下讲故事的能力,语言,画图能力。做cs的动手能力也要有,code好好写,能开源经得起同行复现。祝研究顺利。 |
|
|
| [收藏本文] 【下载本文】 |
| 科技知识 最新文章 |
| 百度为什么越来越垃圾了? |
| 百度为什么越来越垃圾了? |
| 为什么程序员总是发现不了自己的Bug? |
| 出现在抖音评论区里边的算命真不真? |
| 你认为 C++ 最不应该存在的特性是什么? |
| 为什么 Windows 的兼容性这么强大,到底用了 |
| 如何看待Nvidia禁止使用翻译工具将cuda运行 |
| 为何苹果搞了十年的汽车还是难产,小米很快 |
| 该不该和AI说谢谢? |
| 为什么突破性的技术总是最先发生在西方? |
| 上一篇文章 查看所有文章 |
|
|
|
| 股票涨跌实时统计 涨停板选股 分时图选股 跌停板选股 K线图选股 成交量选股 均线选股 趋势线选股 筹码理论 波浪理论 缠论 MACD指标 KDJ指标 BOLL指标 RSI指标 炒股基础知识 炒股故事 |
| 网站联系: qq:121756557 email:121756557@qq.com 天天财汇 |