
| |
|
|
| ����ƻ� -> �Ƽ�֪ʶ -> CVPR 2024 ����Щֵ�ù�ע�Ĺ���? -> �����Ķ� |
|
|
[�Ƽ�֪ʶ]CVPR 2024 ����Щֵ�ù�ע�Ĺ���? |
| [�ղر���] �����ر��ġ� |
|
CVPR 2024 ����Щֵ�ù�ע�Ĺ���? ��ע����?д�ش� [img_log] ģʽʶ�� ������Ӿ� ���ѧϰ��Deep Learning�� CVPR �˹�����? CVPR 2024 ����Щֵ�ù�ע�Ĺ���? |
|
CVPR2024: Residual Denoising Diffusion Models |

|
|
���ǽ��в����뵽��ɢģ�ͣ������ͳһ�ɽ��͵�ͼ��ͼ��ֲ��任��ܡ��в�ȥ����ɢģ�ͣ�RDDM���ѹ������룩�� ���ߣ�Jiawei Liu, Qiang Wang, Huijie Fan*, Yinong Wang, Yandong Tang, Liangqiong Qu* ��λ���п�Ժ�����������ƴ�������ѧ��������������۴�ѧ Residual Denoising Diffusion Models?arxiv.org/abs/2308.13712 |

|
|
https://github.com/nachifur/RDDM?github.com/nachifur/RDDM |

|
|
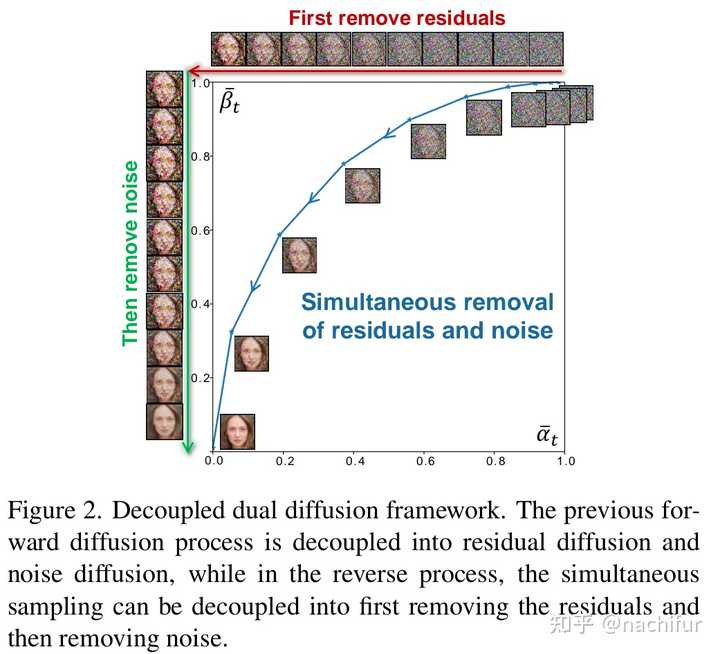
����һ���µ�˫��ɢ���̣�����ͳ�ĵ�һȥ����ɢ���̽���Ϊ�в���ɢ��������ɢ������˫����ɢ���ͨ������в�����������ͼ��ָ�����Ļ���ȥ�����ɢģ�ͣ���չΪͼ�����ɺͻָ���ͳһ�Ϳɽ��͵�ģ�͡� |

|
|
������˵�����ǵIJв���ɢ��ʾ��Ŀ��ͼ���˻�����ͼ��ķ�����ɢ������ȷָ��ͼ��ָ��ķ������ɹ��̣���������ɢ��ʾ��ɢ�����е�����Ŷ����в����ȿ���ȷ���ԣ�������ǿ�������ԣ�ʹ��RDDM�ܹ���Ч��ͳһ���в�ͬȷ���Ի������Ҫ�����������ͼ�����ɡ��ָ������롢��ȫ������ͼ�е�(b)���зŴ�ͼ����ʹ��MulimgViewer�� |

|
|
����ͨ��ϵ���任֤�������ǵIJ���������DDPM��DDIM�IJ���������һ�µġ� |

|
|
�������һ������·���ص����ɹ��̣��Ը��õ����ⷴ����̡� |
|
|
ֵ��ע����ǣ����ǵ�RDDMʹ��ͨ�õ�UNet��L1��ʧ��batchsize 1���Ϳ��������Ƚ���ͼ��ָ����������������ṩ�����Ԥѵ��ģ�ͣ��Թ�����һ��̽����Ӧ�úͿ������ǵĴ��¿�ܡ� ps�������ͽ���RDDM������ϸ���ܣ�����Ҳ����һ�����ơ� |
|
���Ÿ�B��������ȶȣ�����˵һ�������û��ͶCVPR����ΪͶ���ڼ��������ҵ����Կ��ԣ�֮ǰ���ķ�������Ŀ��ԺУ������Ҫ�ӵ�֡�������Ҫ��һ���ţ�Ҳ������һ��"�����ӽ�"����������Ǹĸ嵽�и�ɡ� �ҽ����֤̫����ѵijɹ������ǵĹ�������ʮ������ġ�����Ҳ֪����һЩ������ʧ�ܵ���Ϣ����л��Ⱥ����Ļ�鲻Ը�⿴����ʹ����ǻ��ڵײ�Ŀ��У�ѡ�������˼��������ң�������Ц��Y1S1���ǵĹ���Ҳͬ��ʮ�����㣬Ҳʮ�ֵ����ģ��кܶ���ֵ��ѧϰ�ĵط��� ��ʵ�Ҿ���CVPR�����Ǻ������ĺ���������Ȼ���ź����Ҷ������£������Ҹо�����˵���Ӧ���Ǹ������ˡ�ѧ������˵����ӣ�����AC�������³�"ѡ��"Ҳʹ������Domain�Ŀ�ζ������ĥ�� ������Σ����������ѧ����һ�����볡ȯ��Ҳ�ܶ��Լ����ʱ���Ŭ����һЩ����������ÿ���˵Ľ��࣬������popular�̶��Dz�һ���ġ�Ŭ���˺ܶ��û������ʵ�������㲢û������������ÿ���˶����Լ��Ľ����ģʽ�� ����ϲ����һ�仰����MEGALO BOX�У��ϲ��Ͷ�Joe˵��һ��"���ʵ���ǻ����ʵ��"�� ���Լ������Ͱɣ� |
|
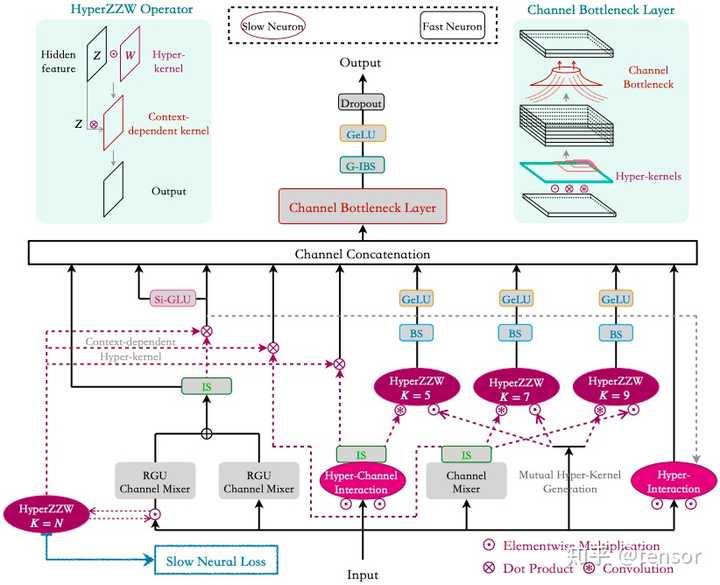
��¥����һ�����ǵĹ�������Ȼ����CVPR 2024 Rejected... �ù�����proposal��ʽ�����2022��10�·ݣ���ģ�ʹ��ȫ���㿪ʼ���м侭������ǧ��ħ��... ��ǰ���İ汾�д���һ�����ƣ���arXivֻ�ų����IJ���...��ҳ�����ƣ�����ֻ�ܼ����ڽ��ܼܹ�ϸ�ڡ���¼����15ҳorz��Ͷ�帽¼��11ҳ HyperZ?Z?W Operator Connects Slow-Fast Networks for Full Context Interaction https://arxiv.org/pdf/2401.17948.pdf?arxiv.org/pdf/2401.17948.pdf ��SSM/Mamba�Ĺ�ϵ�� ��ʵSSM�ĺ���Ҳ��long conv����ͨ���ṹ����������������ˣ���������ͨ��һ��С�͵�MLP���ɴ�����ʽ�����ˡ���SSMͬ�ڵĹ�����֮Ϊcontinuous convolutional networks������FlexNet��CCNN�� ����Hyena/Mambaֻ����������data-dependent gating����˼��Դ��self-attention��������2022�����ʶ��context-dependent weights����Ҫ�ԣ���Ȼ�����Ƚ����� ����slow and fast networks�ĸ�����Դ��1990s����1987�꣬Hinton�������������slow and fast weights�ĸ���������ڱ��泤�ڼ���long memory�Ͷ��ڼ���short memory��Jurgen��1992�����ʹ��һ��slow network������һ��fast network��Ȩ�أ�����ΪFast Weight Programmer (FWP)������Ĺ�����hypernetwork...����related works�����˸�¼�С�������Jurgen�ܽ�Ĺ���FWP����ع����� Neural nets learn to program neural nets with with fast weights (1991)?people.idsia.ch//~juergen/fast-weight-programmer-1991-transformer.html ������Hinton��2019���presentationһ�ڣ� |

|
|
���������һ���µ�����ܹ�Terminator������������в�ѧϰ�Լ�����������Ը��Ӷȵ�self-attention���±��֣�������������˺ܶ���ӱ��ģ��ȥ���ѵ��Terminator�����⣬���ǵļܹ���normalization����Ҳ�����˸��£�����ȥ����ߵĿ�ѵ��Affine�����Լ�Momentum� ��һ����ResNet�����У�����ǿ�����Dzв�ѧϰ���Ա��������˻������ǽ���ݶ���ʧ���⡣Ȼ����PlainNet���������˻���ԭ��һֱδ�ҵ���������Ϊ��Դ���ڴ�ͳCNN�ձ���õ���֧�ṹ��С�����ˣ���ᵼ��ÿһ���������ȡ�������������������������avg pooling layer���õ�ȷ�����������������в����ӵ��������ڿ���ͨ������һ���������������һ����������Ϣ��ʧ�����в��ֻ�ܻ����������⣬���Ȳο�Figure 2��������¼�н�����������ӻ������������ͼ��Ȩ�غ��ݶ���Ϣ�ȡ�¶һ�㣺���Ǽܹ������������ݶ���ʧ���⣬��Ϊdz���ݶ�ֵ������ݶ�ֵ��Ҫ���ֳ��ݼ����ơ� �ڶ���Ϊ���������Ұ����ټ�������ģ��ͨ����ʹ���м��²����㣬max pooling��Figure 2չʾ���²����������ƻ�������Ľṹ��������ͬ���������Ϣ��ʧ����ˣ����ǵĽṹ����ʹ���м��²����㡣 ���ϣ�Ϊ����ÿһ�㾡���ܼ�����Ϣ��ʧ�����������full context interaction�����ָ����ģ����ÿһ���ܹ�ͬʱ�ۺ�ȫ�ֺ;ֲ���Ϣ����ǿ������ȡ������Ϊ��ʵ��full context interaction��������Ҫ���֧�ṹ�ʹ�����ˡ�����ǰ�ߣ���Figure 3��ʾ�����ǹ����˶��֧��Slow-Fast Neural Encoding (SFNE) block�����ں��ߣ��������ʹ��С��MLP��Ϊslow networkȥ���ɴ�����ʽ�����ˣ���Ϳ��Ա��������˴����IJ�����ը���⡣ ������֮ǰ�ܶ����self-attention�����е�attention matrix��������ɼ���ֵ���ɵ�context-dependent fast weights��attention matrix����һ��������ʽȨ�ؾ���������Ը������붯̬�仯�� ���ģ�self-attention���Ƶ�ȱ�����ʱ��Ϳռ��ϵĶ��θ��Ӷȡ���Ȼ֮ǰ���������ڽ����临�Ӷȣ���������Ȼ������ͨ��query-key��ʽ����attention matrix�� ���壬Ŀǰ��vision transformer��Ȼ��Ҫ��ͼ�ֳ�patches�ټ������patch֮���attention scores����Ȼ�����ַ�ʽ���õ�ÿ�����صķ�������pixcel-level scores. ���ϣ����������HyperZ?Z?W operator�������Եõ�context-dependent fast weights������ֻ�����Ը��Ӷȡ���ͨ���Դ�����ʽ�����˺���������ͼ���е�������pixcel-level scores������ϸ���뿴���ġ� ���������ĵ�������Ҫ���ס��������SFNE block�Ĺ����� |
|
|
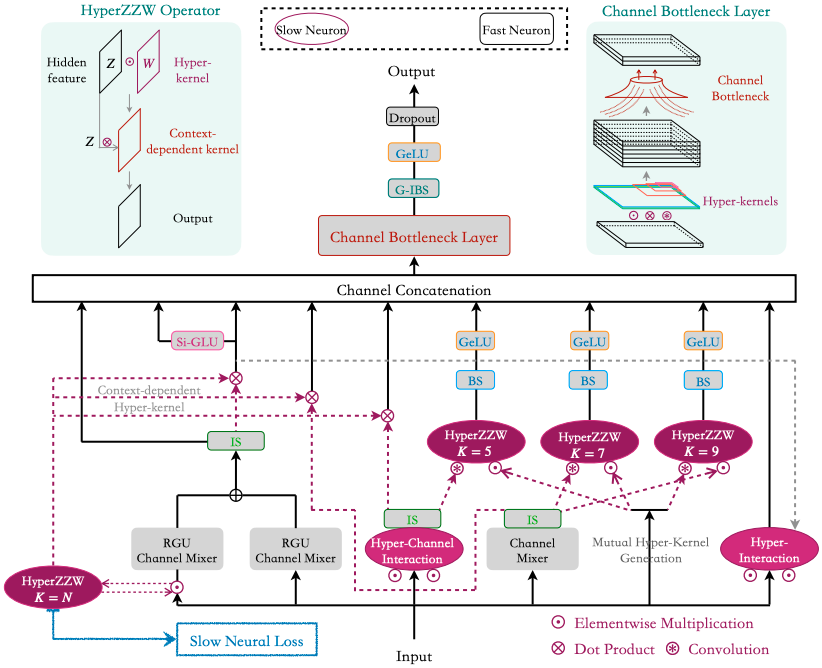
Slow-Fast Neural Encoding (SFNE) ����ͼ��ʾ������Ҫ�ṹ��Ϊ�IJ� Input -> Channel Mixers -> Global and Local HyperZZWs -> Channel Concatenation -> Channel Bottleneck LayerChannel Mixers ����������ͬģ�飺RGU��GLU����չ; Hyper-Channel Interaction��ͬ��Ƕ��HyperZZW������Կ�����channel attention�ĸ���Ч�汾�������һ���MLP����Ϊ�����Global and Local HyperZZWs�е�dot product and convolution opeartions��channel-wise��������Ҫ���Ƕ�ͨ����Ϣ���н��������ң�channel mixers��ߵ�instance standardization���Ա�֤����ά��(B)�Ϳռ�ά��(H,W)�Ķ����ԡ� 2. HyperZZW (K=N) ����ȫ��������ȡ������δʹ�þ�����������Ϊ�������dot product���Ǵ�ͳ���ڻ������ڵľ�����HyperZZW (K=5-7-9) ���оֲ�������ȡ�� 3. ��ͨ��ά���϶�ȫ�������;ֲ���������concat�����ǵĿ��ӻ������ʾ��ȫ���������ڲ�����Ĵ��Խṹ�����ֲ��������Ա�������ϸ�ڣ��ر���ʹ��С�����ˡ� 4. Channel Bottleneck Layer. ��ͼչʾ����һ���ŷ�֧�ṹ�����ÿһ���channel��������9���ѵ����SFNE block��ʹ��channel�����ﵽ20000�����Dz��ɽ��ܵġ���ˣ�����ͼ���Ͻ���ʾ�����Ƕ�channel������ѹ������������channel=C��concat��Ϊ9C��Channel Bottleneck Layer�Ὣ��ѹ����2C�����������Ƕ�����һ��ѹ��ϵ������ο����ġ� 5. ���ǻ���SFNE������RGU�ĺͽ���channel concatenation. ����������������֧��Si-GLU��hyper interaction�����ǿ��������Ӻ��ټ������Ͳ����������������ģ�����ܡ���ʵ������Ҳ��Ϊ����ǿfull context interaction������������Ϣ��ʧ�� ���ǵļܹ��ڶ�����ݼ��ϳ���֮ǰbaselines�����ұ��ֳ��������ԣ�����������������ֵ����������ģ�Ͳ����ȡ�Ȼ�������ڼ�����Դ���ƣ����������ImageNet�ϵ�ʵ�� (��Ҳ�DZ�reviewers rejection����Ҫԭ����ȻAC�����Ӧ�ù���̽��zz)����ʵ��������rebuttal��û����ȷָ������Ȼ����reviewers��ACҲû�����������ڣ��Ǿ���global HyperZZW�е�dot product�ǻ������������������������ (ImageNet��ҪA100...���Ҽ���ɱ���ʱ���е�)���������ֻ�ܲ�������Ϊ96*96�Լ�length=16000����Ȼ����Ҳ��self-attention���ڵ����⣬��Ϊ����õ���attention matrix (L*L)��Ȼ��Ҫ��Value (L*D)����dot product�� �����Ȥ��ͬѧ���Բ鿴����ϸ�ڡ�����������ʱ���Խ��������ע��������£� HyperZ?Z?W Operator Connects Slow-Fast Networks for Full Context Interaction0 ��ͬ �� 0 �������� |
|
|
˽�Ż�Email: harviezzw@gmail.com |
|
��ӭ��ҹ�ע������CVPR2024�ϵ������Լ��������Ƶ���ɹ���Panacea�� �������ӣ�https://arxiv.org/abs/2311.16813 ��ҳ���ӣ�https://panacea-ad.github.io/ Github���ӣ�https://github.com/wenyuqing/panacea ��ӭ�ο�demo��վ���Լ��Ķ�ԭ���˽�������飬Ҳ��ӭ��������github���������� ����֪���Զ���ʻ�������ݵ��д���������ôAIGC ���Ǿ��ѵĹ�����Ϊ�Զ���ʻ�ϳ����ݡ��������µĹ�����������������������һ��ȫ�µ�����ģ������Panacea��Ϊ�Զ���ʻ�ϳɸ������ģ�����ע�Ķ��ӽ���Ƶ���ݣ��ƶ��Լ�����ķ�չ�� Panacea: �����Զ���ʻ�Ķ��ӽǺͿɿ���Ƶ���� �Զ���ʻ����Ը���������ע��ѵ�����������������������������һ�ִ��µķ�����Panacea�����������ɶ��ӽ��ҿɿصļ�ʻ������Ƶ���ܹ��ϳ����������Ķ�����������ע��������������Զ���ʻ�Ľ�����������Ҫ�����塣 Panacea����������ؼ���ս����һ���ԡ��͡��ɿ��ԡ���һ����ȷ��ʱ����ӽǵ�һ���ԣ����ɿ���ȷ�����ɵ���������Ӧ�ı�ע���롣Panacea����˴��µ�4Dע�������ƺ����ε�����������ʵ��һ���ԣ���ͨ��ControlNet����������ͼ��BEV�����֣��Խ��о�ȷ���ƣ��Ӷ���֤�ɿ��ԡ�Panacea��nuScenes���ݼ������˹㷺�Ķ��ԺͶ������������֤�����������ɸ��������ӽǼ�ʻ������Ƶ�����ǿ������������������ƶ����Զ���ʻ����ķ�չ����Ч����ǿ��ѵ�����ݼ������������Ƚ���BEV��֪������ѵ���� Panacea����ʲô�� Panacea��һ����ɫ����Ƶ���������������ϳɸ������ģ��ɿصģ����ӽ��Զ���ʻ��Ƶ������������ʹPanacea ���������ϳɴ������б�ע�ĸ�������Ƶѵ�����ݡ�������������������Ƶ���ݼ����ṩ�����µĺϳ����������һ��п��Խ�ͼƬ���ݼ�����Ϊ��Ƶ���ݼ����Ӷ��ٽ�������Ƶ��BEV��֪�����ķ�չ�����⣬PanaceaԽ��������ʵ����ɿ���ʹPanacea��Ϊ��ʵ�����ʻģ���һ������ѡ�� ����չʾ��Panacea�Ĺ㷺��;�� 1. ����BEV�����ͼ���������кϳɶ��ӽ���Ƶ, ������������Ƶ���ݼ���������֪�������ܡ� |

|
|
2. ͨ����ʼ֡��BEV�������ɶ��ӽ���Ƶ�������н���ͼ������ݼ�����Ϊ��Ƶ���ݼ����ٽ�������Ƶ�ĸ�֪�����ķ�չ�� |

|
|
3. �ɱ����Կ��Ƶ���Ƶ���ɣ���������ʱ��ͳ���������ģ�⺱�������ȳ������������ݵĶ����ԡ� |
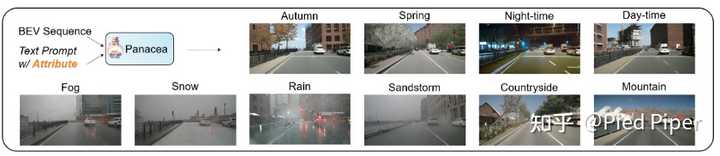
|
|
Panacea���ʵ���������ܣ� Panacea����Stable Diffusion (SD) [1] ģ��������ȻSDģ����ͼ�����ɷ�����ֳ�ɫ�������������в�ͬ��ͼ��֮֡��ȱ��Լ������ֱ��Ӧ��������һ�µĶ��ӽ���Ƶ��Panacea��ȡ��һ�����µļܹ���һ�����ڷֽ��4Dע������UNet������ͼ��b����ʾ��ּ��ͬʱ�����������ӽ���Ƶ���С�������ɢģ�͵�����ά��ΪH �� (W �� V) �� T �� C������C����DZ�ڱ����ά�ȡ�������ӽ���Ƶ�����ؿ���ƴ�����ڵ��ӽǣ������ǹ��еĶ��ӽ�������һ�¡���ͼ��a��չʾ��Panacea������ѵ����ܡ�Panacea��һ�����η�������ʼ�κϳ���ʵ�Ķ��ӽǼ�ʻ����ͼ�����Ľ���ʱ������չ��Щͼ���Դ�����Ƶ���У��������η�����������������ɵ���Ƶ���������⣬Panacea����ControlNet [2] ��ע��BEV����, ����ͼ��c����ʾ���������Щ�������֮�⣬Panacea��������ͨ���ı���������������ʱ��ͳ���������ȫ�ֳ������ԵĶ���ԣ�Ϊ�����ض������ṩ���û��ѺõĽ��档 |
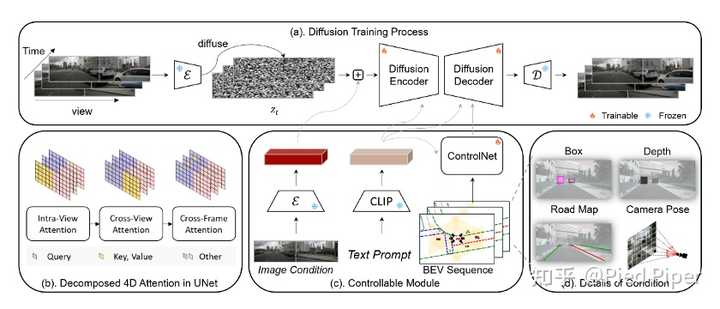
|
|
��������ϸ����Panacea�ļ�������ģ�飺 �ֽ��4Dע�������ƣ� ���ڷֽ��4Dע����UNetּ��ʵ�ֿ��ӽǺͿ�֡��ģ��ͬʱȷ������Ŀ����ԡ����ӽ���Ƶ���ɵ�һ����ֱ�����صķ������ܲ�����ȫ��4D��HWVT��ע������Ȼ�������ַ�����Ҫ������ڴ�ͼ�����Դ�������˼�ʹ�����Ƚ���A100 GPU����������ˣ�Panacea������һ�ָ���Ч�ļܹ�����Ϊ�ֽ��4Dע������ѡ���Եر�������ؼ���ע���������������ӽ�֮���ע�����Ϳռ�����ʱ��Ƭ��֮���ע������ �������е��ӽ��ڿռ�ע���������������������µ�ע����ģ�顪�����ӽ�ע�����Ϳ�֡ע����������ʵ��֤�������ַֽ��4Dע�������������ںϳ�����Ķ��ӽ���Ƶ��ͬʱ����������Ŀ����Ժ�Ч�ʡ� ���η����� Ϊ���������������Panacea��һ�����������ε�ѵ�����������̡�ͨ������ʱ���֪ģ�飬PanaceaҲ������Ϊ���ӽ�ͼ�����������У��Ӷ�ʵ��������Ƶ���ɵ�ͳһ�ܹ�����ѵ�������У�����ѵ��һ��ר�����ڶ��ӽ�ͼ�����ɵ�Ȩ�ء�Ȼ��ͨ��������ͼ������ɢ����ƴ����һ��ѵ���ڶ�����Ƶ����Ȩ�ء�ֵ��ע����ǣ�����ڶ���ѵ���У�Panaceaʹ����ʵͼ����������ɵ�ͼ����Ϊ���������ַ���ʹѵ�����̾����뵥����Ƶ���ɷ����൱��Ч�ʡ������������У�����ͼ��Panacea����ʹ�õ�һ�ε�Ȩ�ز������ӽdz�ʼ֡, ��������Щ��ʱ���ʼ֡��ʹ�õڶ��ε�Ȩ�أ�����һ�����ӽ���Ƶ�����ֽ��ռ���ʱ��ϳɹ��̽�ź���������������������������Ƶ����ʵ�ԡ� |
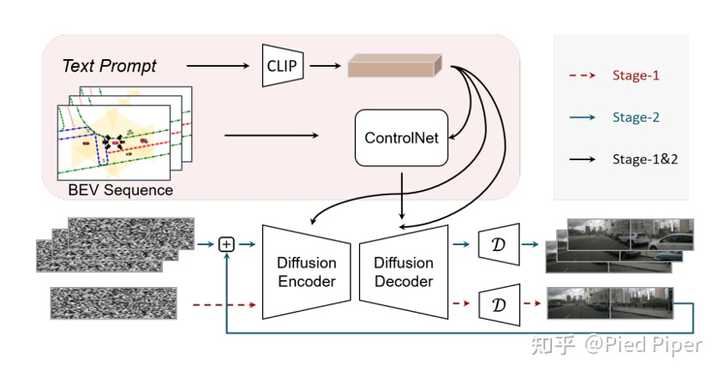
|
|
�ɿ������뷽���� Panaceaģ����Ϊ�ٽ��Զ���ʻϵͳ����ƣ� ��˺ϳ���Ƶ�Ŀɿ��Գ�Ϊһ���ؼ����ԡ�Panacea��������������źţ�һ���Ǵ����ȵ�ȫ�ֿ��ƣ������ı����ԣ�һ����ϸ���ȵIJ��ֿ��ƣ��漰BEV�������С� ������ȫ�ֿ���ʹPanaceaģ���ܹ����ɶ����Ķ��ӽ���Ƶ������ͨ����CLIP���� [3] ���ı���ʾ���ɵ�UNet��ʵ�ֵģ����ַ���������Stable Diffusion��ʹ�õķ�����������Stable DiffusionԤѵ��ģ�ͣ�Panacea�ܹ������ı���ʾ�ϳ��ض��ļ�ʻ������ Panaceaģ�͵�ϸ���Ȳ��ֿ����������������עһ�µĺϳ������� Panacea ����BEV����������Ϊϸ���ȿ����źš�������˵������ʱ��ΪT��BEV���н���ת��Ϊ����ͼ����ȡ������Ԫ�أ�������߽���������ͼ����·ͼ�������̬Ƕ�롣 Ȼ����Щ����Ԫ�ؽ���ɾ���19��ͨ���IJ��ֿ���ͼ��10��������ȣ�3�����ڱ߽��3�����ڵ�·ͼ���Լ�3�����������̬Ƕ�롣��Щ19ͨ��ͼ��ͨ��ControlNet���ɵ�UNet�С�ֵ��ע����ǣ�Panacea���������������̬��Ϊ�����������Ա����ȷ�ؿ��ƺϳ���Ƶ���ӽǡ� ʵ����� ��Panacea��������µļ�ʻ�������ɷ�����FVD ��FID �Ͻ��бȽϣ����±���ʾ�� Panaceaʵ����139��FVD��16.96��FID����Щָ�궼�������������ж��֣�����������Ƶ�ķ�����DriveDreamer�ͻ���ͼ��Ľ��������BEVGen��BEVControl�� չʾ��Panacea������Խ������������ |
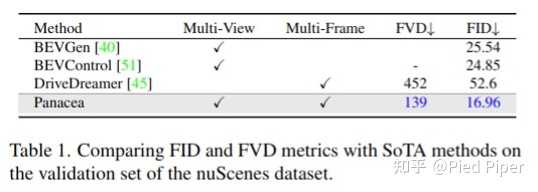
|
|
������������ָ�����⣬Panacea ����ȡ��֪����ָ�������������ɿ��ԣ�����StreamPETR [4]������ʹ��Panacea����nuSences��������֤����Ȼ��ʹ��Ԥѵ����StreamPETRģ�������ɵ���֤���ϲ��Ը�֪���ܡ�����ʵ���ݵĸ�֪������ȵ�������ܿ������ں�����������������ź�BEV����֮��Ķ���̶ȣ��ɿ��ԣ������±���ʾ��Panaceaʵ����68%��������ܣ�ͻ�Գ�������Ƶ��BEV�����źŵ�ǿ��������������⣬Panacea�ij�ʼ�κϳɵĶ��ӽ�ͼƬ��Ҳʵ����72%��������ܡ� |
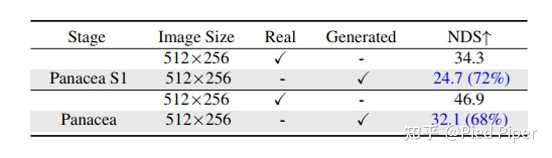
|
|
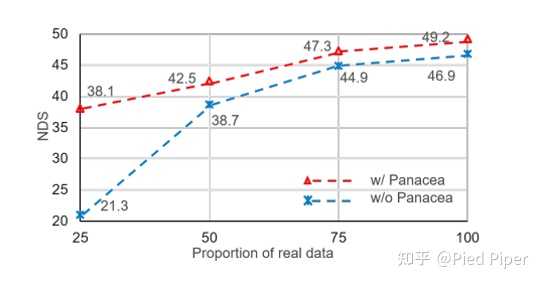
��������֤���ϵ������⣬Panacea����Ҫ��������������������������עѵ��������������ʹ��Panacea��nuScenes�ϳ�һ���µ�ѵ�����ݼ�Gen-nuScenes������ΪStreamPETRģ�͵ĸ���ѵ����Դ�����±���ʾ��ʵ��������������Gen-nuScenes��ѵ����StreamPETRģ��ȡ����36.1%��nuScenes���÷�(NDS)���ﵽ��ʮ�ֿɹ۵�����ʵnuScenesѵ����ѵ����ģ�����77%��������ܡ�����Ҫ���ǣ������ɵ���������ʵ���ݽ�ϣ�ʹStreamPETRģ�͵�NDS��ߵ���49.2���Ƚ�ʹ����ʵ����ѵ����ģ�߳�2.3�㡣 |

|
|
���⣬��ͼչʾ��Gen-nuScenes���һ�µ���ǿStreamPETR�ڸ�����ʵ���ݱ����µ����ܡ���Щ�����֤ͬ����Panaceaģ�����ɿɿصĶ��ӽ���Ƶ���ݵ�ǿ�����������Լ������ǿ�������� |
|
|
����֮�⣬Panaceaģ�ͻ�����ͨ��ʹ����ʵͼ����Ϊ����������ͼ������ݼ�����Ϊ��Ƶ���ݼ����������������ڴٽ�������Ƶ�ĸ�֪�����ķ�չ����С����ʾ��NDS������5.8�㣬�������������ơ� |

|
|
�ܽ��չ�� Panacea ǿ��Ŀɿض��ӽ���Ƶ�����������Զ���ʻ�����ش����塣���зֽ��4Dע����ģ����Ը�Ч��ȷ��ʱ��Ϳ��ӽǵ�һ���ԣ�������ѵ�����Կɽ�һ���������������Ҳ����ʹPanaceaͬʱ��������������Ƶ���ݼ��Լ���ͼƬ���ݼ�����Ϊ��Ƶ���ݼ������ֹ��ܡ���ֵ��ע����ǣ�Panacea�ó��������ֿ����źţ��Բ������о�ȷ��ע����Ƶ������ʵ�鶼֤����Panacea�����ɸ���������ע���õĶ��ӽǼ�ʻ������Ƶ�����ǿ����������Щ��Ƶ�dz������������ͼ�Ӿ���֪�з������ã���������ʵ�����ʻģ����Ҳ��ʾ��ǰ������δ����Panacea��ϣ�����ϸ��������Ŀ����źţ�Ҳ��DZ����Ϊ��ʵ������Զ���ʻģ������ [1] Andreas Blattmann, Robin Rombach, Huan Ling, Tim Dockhorn, Seung Wook Kim, Sanja Fidler, and Karsten Kreis. Align your latents: High-resolution video synthesis with latent diffusion models. In CVPR, pages 22563�C22575. IEEE, 2023. 2, 3, 5 [2] Lvmin Zhang and Maneesh Agrawala. Adding conditional control to text-to-image diffusion models. CoRR, abs/2302.05543, 2023. 2, 3, 6, 12 [3] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. In ICML, volume 139 of Proceedings of Machine Learning Research, pages 8748�C8763. PMLR, 2021. 5 [33] Aditya Ramesh, Prafulla Dhari [4] Shihao Wang, Yingfei Liu, Tiancai Wang, Ying Li, and Xiangyu Zhang. Exploring object-centric temporal modeling for efficient multi-view 3d object detection. CoRR, abs/2303.11926, 2023. 2, 3, 6, 12 |
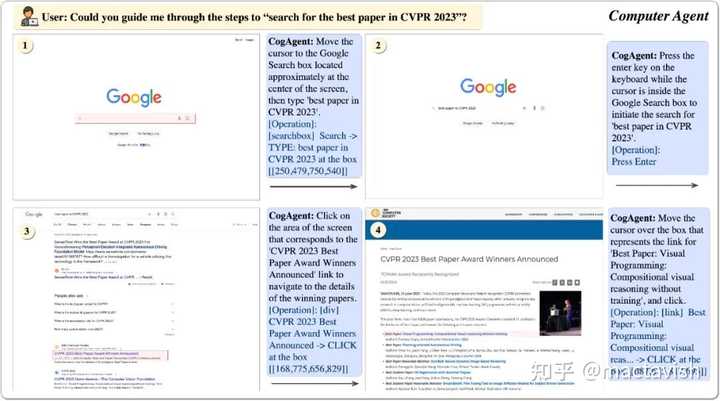
��������Ԥѵ��ģ�ͣ�LLM����Agent�ǵ������ŵ��о����⣬�߱����õ�Ӧ��ǰ�������ǣ�һ�����ص������ǣ�������LLM��ģ̬����ֻ�ܽ���������ʽ�����롣 ����ҳagentΪ����WebAgent �ȹ�������ҳHTML��ͬ�û�Ŀ�꣨���硰Can you search for CogAgent on google������ΪLLM�����룬�Ӷ����LLM����һ��������Ԥ�⣨��������ť�������ı����� Ȼ����һ����Ȥ�Ĺ۲��ǣ�������ͨ���Ӿ���GUI�����ġ� ���磬���һ����ҳ��������һ������Ŀ��ʱ��������ȹ۲�����GUI���棬Ȼ�������һ����ʲô�����ͬʱ��GUI��Ȼ��Ϊ���˻�������Ƶģ������HTML���ı�ģ̬�ı�����GUI��Ϊֱ�Ӽ�࣬���ڻ�ȡ��Ч��Ϣ�� Ҳ����˵����GUI�����£��Ӿ���һ�ָ�Ϊֱ�ӡ����ʵĽ���ģ̬���ܸ���Ч�����ṩ������Ϣ������һ���أ��ܶ�GUI���沢û�ж�Ӧ��Դ�룬Ҳ���������Ա�ʾ����ˣ����ܽ���ģ�Ľ�Ϊ�Ӿ�Agent����GUI�������Ӿ�����ʽֱ�������ģ�����������⡢�滮�;��ߣ�����һ����Ϊֱ����Ч���߱����������ռ�ķ����� �Դˣ���������˶�ģ̬��ģ��CogAgent������ʵ�ֻ����Ӿ���GUI Agent����ͼչ�����乤��·���������� |
|
|
CogAgentģ��ͬʱ���ܵ�ǰGUI��ͼ��ͼ����ʽ�����û�����Ŀ�꣨�ı���ʽ�����硰search for the best paper in CVPR 2023������Ϊ���룬����Ԥ����ϸ�Ķ������Ͷ�Ӧ����Ԫ�ص�λ�����ꡣ |
|
|
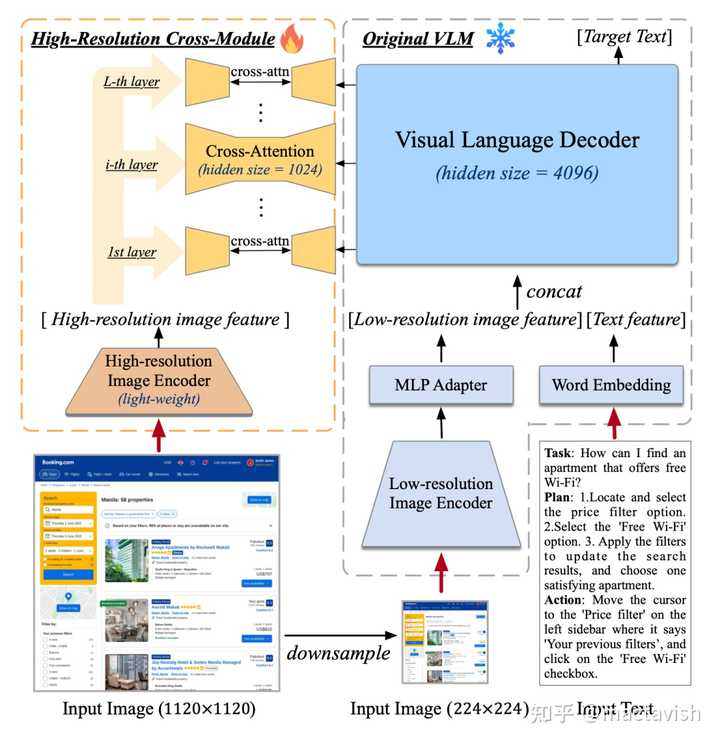
Ϊ��ʹģ�;߱��Ը߷ֱ���ͼƬ���������������Կ���~720p��GUI��Ļ���룬���ǽ�ͼ������ķֱ��ʴ��������1120��1120��������ģ��ͨ��С��500*500���� Ȼ�����ֱ��ʵ������ᵼ��ͼ�����м����������������Գ��ܵļ�����Դ濪��������Ҳ�����ж�ģ̬Ԥѵ��ģ��ͨ�����ý�С�ֱ���ͼ�������ԭ��֮һ�� �Դˣ�����������������ġ��߷ֱ��ʽ���ע����ģ�顱����ԭ�еͷֱ��ʴ�ͼ���������4.4 B���Ļ����ϣ������˸߷ֱ��ʵ�Сͼ�������(0.3 B������ʹ�ý���ע����������ԭ�е�VLM�������ڽ���ע�����У�����Ҳʹ���˽�С��hidden size���Ӷ���һ�������Դ�����㿪���� ����������÷�������ʹģ�ͳɹ�����߷ֱ��ʵ�ͼƬ������Ч�������Դ�����㿪���� ������ʵ���У����DZȽ��˸ýṹ��CogVLMԭʼ�����ļ�������������������ֱ�������ʱ��ʹ����������ķ�����with cross-module����ɫ����������������ļ��������ӣ�����ͼ�����е����������Թ�ϵ�� �ر�ģ�1120��1120�ֱ��ʵ�CogAgent�ļ��㿪����FLOPs����������490��490�ֱ��ʵ�CogVLM��1/2��ҪС����INT4�������������У�1120��1120�ֱ��ʵ�CogAgentģ��ռ��Լ12.6GB���Դ棬�����224��224�ֱ��ʵ�CogVLM���߳�����2GB�� ��������չʾһ����ԭ������ʵ�� |
|
|
|
|
��Ŀ��CLOVA: A Closed-LOop Visual Assistant with Tool Usage and Update ���ӣ�https://arxiv.org/pdf/2312.10908.pdf ����˱ջ�ѧϰ��ܣ�����tool-usage visual assistants ������ʹ�� tool�������� |
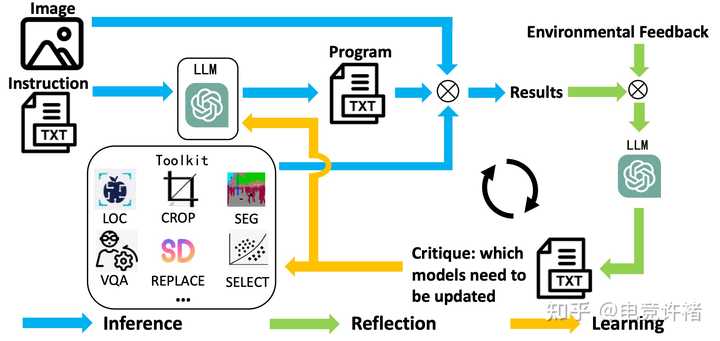
|
|
|
|
|
| [�ղر���] �����ر��ġ� |
| ��һƪ���� ��һƪ���� �鿴�������� |
|
|
|
| ��Ʊ�ǵ�ʵʱͳ�� ��ͣ��ѡ�� ��ʱͼѡ�� ��ͣ��ѡ�� K��ͼѡ�� �ɽ���ѡ�� ����ѡ�� ������ѡ�� �������� �������� ���� MACDָ�� KDJָ�� BOLLָ�� RSIָ�� ���ɻ���֪ʶ ���ɹ��� |
| ��վ��ϵ: qq:121756557 email:121756557@qq.com ����ƻ� |