
| |
|
|
| ����ƻ� -> �Ƽ�֪ʶ -> DeepMind ����ɽ�������ʽ����ģ�� Genie����ʲô���壿�� Sora ����ʲô��ͬ�� -> �����Ķ� |
|
|
[�Ƽ�֪ʶ]DeepMind ����ɽ�������ʽ����ģ�� Genie����ʲô���壿�� Sora ����ʲô��ͬ�� |
| [�ղر���] �����ر��ġ� |
|
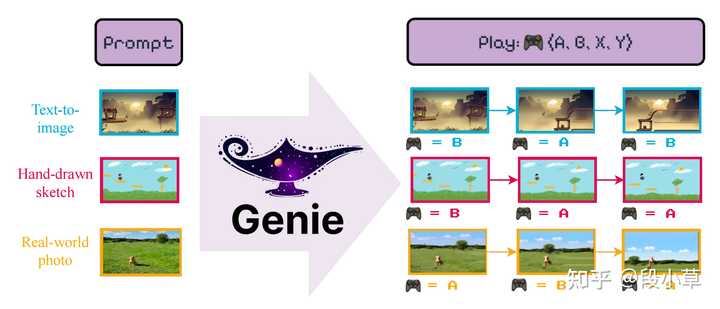
��Ŀ��վ�� https://sites.google.com/view/genie-2024/ �ոգ��ȸ趨��������ʽ AI ��ȫ�·�ʽ ���� ����ʽ�� |
|
Genie������������ڣ��ٴν�ʾ������ʽģ����ͨ��AGI��·�Ͻ�Ҫ���ӵ���Ҫ���á� ���Ķ���֮ǰ���������˼��һ�����⣺CV����ʽģ����ʲô�ã�Ҳ�����뵽��DALL-E��Stable Diffusion��Sora������ģ�ͣ�Ȼ��ش𣺡�����ʽģ�Ϳ��������������ݡ������ߡ�����ʽģ�Ϳ��Ը������ഴ���ý���ʲ������������ҿ�������ֻ������ʽģ�͵ij�����ֵ���������������ռ�ֵ�� CV����ʽģ�͵����ռ�ֵ���ڣ��������������Ը�С�Ĵ���ȥģ��������磬�Ӷ�����AI�㷨��ģ��������ѧϰ����������AGI�� ���Ҫ�������������仰����Ҫ�������µĹ۵㣺AI�㷨�����̶ܳȣ���ȫȡ��������ѵ����������ʵ�Ժ����ԡ�֮����NLP�����ܹ������GPT����ǿ���AI��������ΪNLP����Ļ����Ƚϼ�����ͨ���Ի���chat������ģ�����������CV��������Ļ���Ҫ���Ӻü�������������Ŀǰ��û����֪�ķ�ʽ����ģ�⣬���CV����ͺ��ѹ�����GPT������AI�������Ҫ��ϸ���������۵㣬���Կ���ȥ��д�����¡� л���أ���VALSE 2023�����������Ӿ���ͨ���˹����ܣ�GPT�ʹ�����ģ�ʹ���������606 ��ͬ �� 39 �������� |

|
|
��ʱ��д����CV���ٵ�����֮һ���ǹ��������ӵ�������� �����ӵ����������ǰ����������ķ�����Ҫ�����֡�һ�ǻ�����ʵ���ݲ�������������ռ�ʵ�ʳ������ݣ������佨ģΪ���ơ���Ƭ��mesh�������䳡��NeRF�������ݽṹ����֧�ָ��١����ģ����Ⱦ�����������ijɱ����Ƚϸߣ����Թ�ģ��������������ǰ���õ�3D���ݼ�����Habitat[1]���������2D���ݼ�����ģҪС�ü���������������Ȼ������ijЩ���ⳡ���������ڻ��߽־���������ͨ������ѧ���������������ͨ��3D��ģ������ʽ�㷨������GAN����ɢģ�ͣ��ȷ�ʽ��ֱ�Ӳ����������ݲ���Ⱦ3D����������������Ȼ�ܹ��������ɻ�������ProcTHOR[2]������������ԭ��ʵ��������ݷֲ���һ���棬ͼ����ͨ������Ӱ���㷨ѧϰ��artifacts����ʹ�������Թ۲���������Ӷ����Ա�֤������������ѵ����ģ�͵�Ǩ��������Ȼ�����������ַ�����������Ĵ�С����ʵ�Ȼ���������Ҫ������������AI�㷨�뻷���е����������廥���� ��������Ϊ������δ��3-5������CV��������Ҫ������û��֮һ��Genie�ij��֣����ҿ�����һЩϣ����������ʽģ���ܹ��������Ǹ���ع������ģ�����������ȻGenie��Ч�����Ƚϲ�[3]�������������㣬����������ȷ�ĵ�·�ϡ� ����˵˵��Sora�����𡣸���Sora��demo�жϣ�����Ϊ������ӵ�к�Genie�൱��ģ�������������Ҳ�ܹ�ͨ��prompt������δ����Ҫ�����ij�������ˣ�Genie����������Sora��һ���Ӽ���ֻ���ٶ�Ӧ�û��Sora���ϲ��١����������ţ�OpenAIҲ��Ͷ����ͬ�ķ���������ʱ��ͻᷢ��һ������������������������ǿ��ģ�͡� �ο�^Savva M, Kadian A, Maksymets O, et al. Habitat: A platform for embodied ai research[C]//Proceedings of the IEEE/CVF international conference on computer vision. 2019: 9339-9347.^Deitke M, VanderBilt E, Herrasti A, et al. Procthor: Large-scale embodied ai using procedural generation[J]. arXiv preprint arXiv:2206.06994, 2022.^Ŀǰ������Genie�ƺ����ڽϳ��Ľ������в��ܱ�֤�ȶ���ͬʱ���ɵ�ͼ�������ϲ����Ȼͼ���ϻ��������artifacts�� |
|
�Ҵ���������ĽǶ�˵һ�£���Ģ����Ҷ�����ɡ� |

|
|
Sora�����ǣ������һ��prompt����������һ����ɭ���ﶥĢ������Ƶ��Ȼ�����ͻ���һ��ʱ���ڸ����ṩһ����Ģ������Ƶ�� Genie�����ǣ������һ�Ŷ�Ģ���Ľ�ͼ������һ����Ϸ�ֱ���Ȼ��ͼƬ�ᶯ������������������ֱ��IJ�������һ�µġ� �����б����ϵIJ�ͬ��Sora�Ƕ˵��˵ģ����ṩprompt�����ṩ��Ƶ���м�û�н�����Genie�ṩ�˽����Ļ��ᣬ�������㲻ͣ�������㹻��������ͣ������Ƶ�ͻ�һֱ������ ��Ҳ��Genie���ֵ���ԴGenerative Interactive Environment������ʽ�ɽ����������� Generative����ʽ˵������Ƶ������һ���֣�Interactive�ɽ���������˵����Ϸ�ֱ���Environment��������Genie��˵������ģ�ͣ�������֡�Ŀɽ���������ģ�͡� |

|
|
����1ͼƬ |

|
|
����1������Ƶ |

|
|
����2ͼƬ |

|
|
����2��Ƶ |

|
|
����Դ���Щ��Ƶ���ҵ��ܶ���Ϥ����Ӱ������궷��֮��ġ� |

|
|
�dz�������Ʒ�� ��û�������Կ�ǹ����������Ƶ���������ʵ�֣��ǿ����ڶ�ά��������֤���������ģ���Ƿ�������ⱻ���١���Ƭ���������͵�����������ԣ���ͬ�������Ϳ���Ǩ�Ƶ�3ά����� |
|
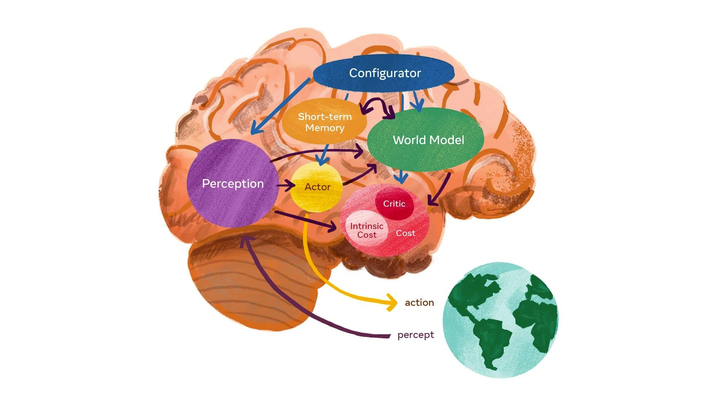
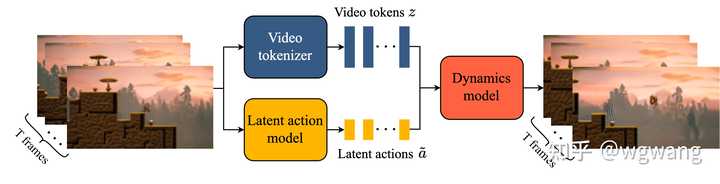
ʡ������ȫ����Ƶѵ������������ʵ����/ͼ���ɿɽ�������������2D�����Ϸ�IJ������� Genie[1] ����ST-Transformer�ܹ����ǵ�һ�����ලѧϰ�´ӻ�������Ƶ��ѵ�������Ŀ����ɽ���������ģ�ͣ�ѵ���ز��dz���20��Сʱ�Ĺ���������Ϸ��Ƶ���ݼ��� Genie����ͨ���ı����ϳ�ͼ����Ƭ����ͼ�ȷ�ʽ�����������������ɿ��ƶ������������硣Genie����11�ڲ��������Ա���Ϊһ�ֻ���������ģ�͡�����һ��ʱ����Ƶ tokenizer��һ���Իع鶯��ѧģ�ͣ�autoregressive dynamics model���Լ�һ�����ҿ���չ��DZ�ڶ���ģ�ͣ�latent action model / LAM����ɡ�Genie������û����ʵ������ǩ�����������ض�Ҫ�������£����û���֡Ϊ��λ�����ɵĻ����н��в��������⣬ͨ��ѧϰ����DZ�ڶ����ռ䣬������ѵ�����ܹ�ģ��δ��������Ƶ��Ϊ�� Agent��Ϊδ��ͨ�� Agent ��ѵ����ƽ�˵�·�� |

|
|
����� Sora ��Ϊͼ��/��Ƶ���ɣ�Genie ���˽����ԣ�Ҳ��������/ͼ�����������˿ɽ��������磬Ҳ��֤�������ɹ����У�ģ���ܹ���һ���̶�������ռ������֮��Ļ�����ϵ�� |
|
|
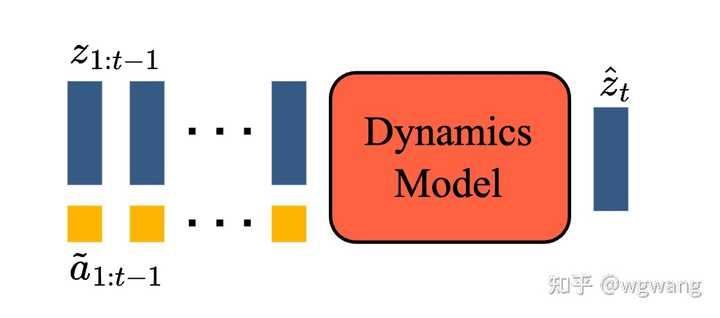
Genie���������ؼ������ һ��DZ�ڶ���ģ�ͣ�LAM���������ƶ���Ƶ֮֡���DZ�ڶ�����һ����Ƶ tokenizer����ԭʼ��Ƶ֡ת��Ϊ��ɢ�� token��һ����̬ģ�ͣ����ݵ�ǰ֡�� token ��DZ�ڶ���Ԥ����һ��֡�� ����ģ�ͷ�Ϊ�����ν���ѵ��������ѵ����Ƶ tokenizer��Ȼ��ѵ��DZ�ڶ���ģ�ͺͶ�̬ģ�͡� |
|
|
Genie ��ȱ�ݣ� Genie���ܻ��������ʵ��δ������������ LLMs �Ļþ�����������ʱ�ձ�ʾ��ȡ���˽�չ������Ȼ�ܵ��ڴ����ƣ�ֻ�ܼ�ס 16 ֡�������ڳ����ڱ���һ�µĻ�����Genie Ŀǰ�������ٶ�ԼΪÿ�� 1 ֡��������Ҫδ���Ľ�������ʵ�ָ�Ч��֡���ʽ��н����� �Ҿ��� Genie ���������ڣ�֤��ģ�͵�ȷ���Դ���Ƶ/ͼ����ѧϰ����һ���������������˵ Sora ֻ�������˿��Ʒ��Ϲ������Ƶ����ô Genie �����һ���������˿��Խ����Ļ���������������У��ж�����Ҳ�кͻ���Ҫ��֮����ϰ�����ײ�Ƚ��������������ġ�����������ô��ȷ������ȷ��ͨ��ѧϰ/Ԥ������� ���� Genie �������Լ�˵�ģ�Genie �����岻ֹ���ڿ����ô�����鵽�Լ�������Ϸ����Ȥ�������ڿ���ѵ��ͨ�� Agents��ͨ���ڸ�����Ƶ����ֻ�Ǻ����Ϸ��Ƶ����ѧϰ������ Agents ����ģ������δ��������Ϊ����������ʼ֡��Ԥ�ⲻ��ѧϰ�����еĻ���������Ϊ���� �ο�^https://sites.google.com/view/genie-2024/ |
|
�ȸ��������ͨ������ģ�����������OpenAI������Ϊ����ǰ���췢����SoraҲ�ų�������ģ������World Simulators���������ȸ��Genie���ӽ���ͳ�����ϵ�����ģ��[1]����������ģ�͵Ľ��ܣ���ϸ�ɲο�������ʦ�����£����ʲô��world models/����ģ�ͣ��������˼�dz�Խ��֪ģ�ͣ���Ҫ��ģ�����������仯�������� |
|
|
��ô�Ƚ��д����Ե�����ģ�����У� �Ӿ��Իع�ģ�ͣ����Ӿ�����Ϊ���ģ�ͨ���Իع�ѧϰ�ķ�ʽ�Ի���������ƵΪ���壩���н�ģ���Ӷ�ѧϰ��һ���ܱ��������ģ�͡����������У��ȸ�Genie[2]��������LVM[3]��˳���ƹ�һ�����ǽ��ڵĹ���DeLVM[4]����θ�Ч����LVM�� ��������ƺ���Σ�DeLVM���Իع��Ӿ�ģ�͵ĸ�Чѵ������12 ��ͬ �� 0 �������� ������Ƶģ�ͣ���Sora�Լ��ı��⡰Video generation models as world simulators����˵��openaiϣ��ͨ����Ƶ���ɴ�ģ�����������������ͨ��ģ������ |
|
|
�Ա�ѧϰ������Yann Lecunһֱ�ڳ���������ģ��·������������������V-JEPA[5]��ͨ���Ա�ѧϰ�ķ�ʽѧϰ��Ƶ�ij���������������˲�̫��������·��ֻ��ѧϰ�����м������û��ֱ�������������� |
|
|
�ο�^Yann LeCun on a vision to make AI systems learn and reason like animals and humans https://ai.meta.com/blog/yann-lecun-advances-in-ai-research/^Genie: Generative Interactive Environments https://arxiv.org/abs/2402.15391^Sequential Modeling Enables Scalable Learning for Large Vision Models https://arxiv.org/abs/2312.00785^Data-efficient Large Vision Models through Sequential Autoregression https://arxiv.org/abs/2402.04841^V-JEPA: The next step toward Yann LeCun��s vision of advanced machine intelligence (AMI) https://ai.meta.com/blog/v-jepa-yann-lecun-ai-model-video-joint-embedding-predictive-architecture/ |
|
�����ڲ��ÿ����Ҹ��˹۵㵥���Ӿ����ලģ�ͻ������죬�����ڲ�������Ƚϴ��ͻ�ơ� Genie�����ϻ���һ��������Ƶ����ģ�ͣ�ֻ���������������ͨ���ලѧϰ����latent action���������ˣ����������latent action�ռ��Сֻ��8�������Genie���ľ����ˣ���ʵ����������������8��С�Ŀռ��ܱ���ġ� �Ҹ��˾����Ӿ����ɻ��ǿ��ö�ģ̬��·�ߣ��������ı����������ɡ�OpenAI������Image GPT��������ת�����ɹ��Ķ�ģ̬ģ��CLIP��DALLE���Լ����ڵ�Sora��������õ�֤���� ֮ǰ�켫һʱ���Լල�Ӿ�ģ����moco��simclrֻ�ܳ�Ϊ���������backbone��������������CLIP��DALLE��SDȴ�Ѿ���Ϊ�������������� ������������غ���������������Ȼ������һ�����õ�ѡ�� �����վ��OpenAI�� |
|
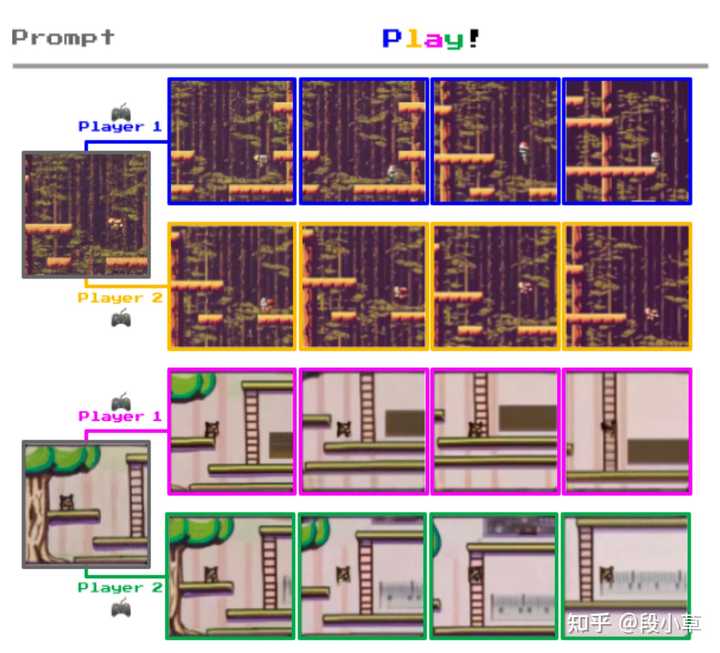
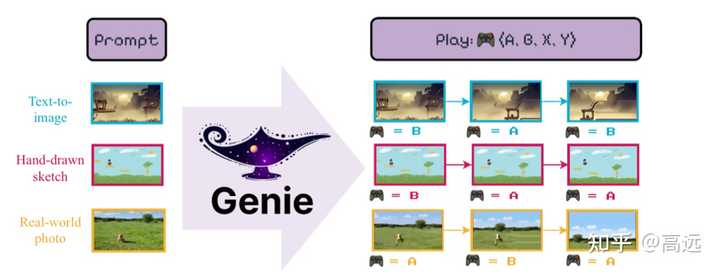
��ǰһ����ģ�ͣ��� AI ֱ������һ���ɽ����ij����������֮��AI ֱ������ 2D ��Ϸ����������������Ҫȥд�ˣ��ο���ͼ�� |
|
|
Դ�����ġ�Genie��Generative Interactive Environment�� ��Ҫ�ر�ǿ�����ǣ����ģ�Ͳ�����������һ��Ԫ�ع���Ϸ������ã��������ģ�ͱ������������Ϸ����IJ��ּ��㹦�ܣ�������ֱ��ͨ�� T0 ʱ�̵Ļ��� + �û��������ָ��������Ԥ�� T1 ʱ�̵Ļ��棬�Ӷ��ṩһ���ɻ����ij�����������Ҫ�����һ����Ϸ���������������Ϸ���汾���ļ�������Ȼ�����Ա�����ʽ����������ˣ���������һ�ο��� �����Ȳ�����ߺ����ģ�Ϳ��Խ����ȥ RL ������ѵ��������������⡣����Ҳ�ᵽ����ģ����DZ����δ���� Agent �ṩ�����ޣ��Ľ��������������Ҳ�� Google ̽����ģ�͵Ķ�������Ȼ�����ܸо�����Щ����ζ�����Ͼ� AI ѵ����Ϊ�˺������ֵ���롣��ô��� AI ѵ���ij�����������һ�� AI ���ɵģ����е���������ζ���ˡ� ֵ��ע����ǣ����ģ�ʹ���ʹ���� ViT ��Visual Transformer��ģ�͡�û�������������� Transformer �ֳ����ˡ�ǰ��ʱ�䱬��� SORA �Ĺؼ��ṹ DiT��Diffusion Transformer��Ҳ�õ��� Transformer������ Transformer Խ��Խ����ͳһ AI �� �㷨����ʦֻ��Ҫ�ͼӲ����� + ���ݵ�ζ���ˡ� ��֮����ģ�ͽ�һ���ؿ�������ʽ AI �Ŀ����ԣ�����δ�����и�������ʽ AI ���ⷢ���ij�������ֵ���ڴ��� |
|
����һ���������Ƶ����һ��ð������������뷨�ǣ��Ժ��ҿ��ܻ��кö�ö������ڳ���������ֵܵ���Ϸ������ �Ҹо���Щ2D����world��Ƶö�ͦ�ÿ�������ٽ�Ϲؿ����ϰ����ֵ��ˣ�������Ӧ�úܲ���G�� ǰ���쿴���궷�����ư漴����½PS��Switch����������ؿ����һ���Сʱ��ĸо��������е��ź��ľ��ǣ��ؿ���Ȼ����Щ��Ϥ�Ĺؿ������δ����������������������������ս�Ե���Ϸ��˵���������Ϸ�����ٴ��Ի��أ� |

|
|
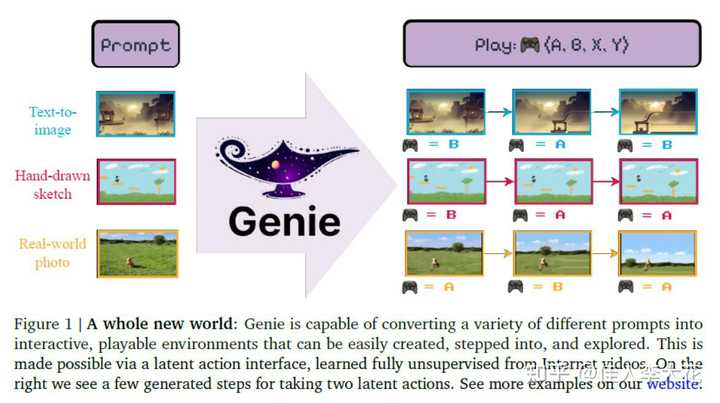
���ĵ�YY���ˣ����������˼ҵ����ġ����µĵ�һ��ͼ�����������˵ĸ�����genie�����ġ������硱�� |
|
|
����һ�£��������һ�仰��һ��ͼ����һ����Ƭ�ʹ����һ��С���磬�������������������ͬ�����顣 �����ʾ��ͼ�������С���ÿ������ﶼ��һ����ͬ�ij�����һ���Ǵ��������ɵ�ͼ��һ�����ֻ�IJ�ͼ������һ������ʵ�������Ƭ��Ȼ��Genie�������ħ��ʦһ��������Щ��������˿������С��Ϸ����ͼ���ұߣ�����Կ�������ͬ�İ�ť�����硰A���͡�B����������Ϸ������ͬ�Ķ�������������ڵ���������Ϸ�����������Ϸ�����Լ���һ��ͼƬ����һ�仰��������ġ� ��Ч��ȷʵ�㹻�ſᣬ��ϸ��һ��ģ�͵ļ������֣��Ҿ���Genie��Ŀǰ���еĴ�ģ������Ҫ�м�����ͬ�� Genieѧϰ��������Ƶ��ȴ����������ǻ�ע�͵Ķ������ݡ����ܹ�ͨ��ѧϰDZ�ڵĶ����ռ����ÿһ֡������Ҫ������ȷ�Ķ�����ǩ������Ŀǰ��ģ���Ƕ������ලѧϰ���ලѧϰ�ķ�����̫��ͬ��Genie������������ͼ�����Ƶ������Ҫ���ǣ����ܹ�������ɽ���������Ļ������û���������Щ�����н���֡���Ŀ��ƣ�Ҳ����˵���û��ǿ��Կ��ƻ����з�����ÿһ�����Genieʹ�õĺ�������ǻ��ڿռ�ʱ��Transformer�ܹ�������һ�������Transformer�����ڴ�����Ƶ�Ⱦ���ʱ��Ϳռ�ά�ȵ����ݣ���ֻ������̬ͼ��Ĵ�ͳTransformerģ���кܴ�ͬ��Genie����һ���Իع�Ķ�̬ģ�ͣ�����Ԥ����Ƶ����һ֡������ģ���ܹ��ڸ�����ǰ֡��DZ�ڶ���������£��Զ�Ԥ����һ֡�����ӡ�Genieչʾ�������Ӽ�����Դ������£���ܹ��ܹ���ֵ���չ�����մﵽ��11�ڲ���������ʾ�����Ŀ���չ���Լ��������ģ���ݼ���������Genie�ڲ�ͬ�Ļ�������2Dƽ̨��Ϸ�ͻ�������Ƶ����չʾ��ģ�͵�ͨ���ԣ�������δ��������Ƶ�Ͻ�������Ϊģ��ѵ����������δ�����ܳ�Ϊһ��ͨ�������塣 �Ҿ��ùȸ���һ�־����������硰�㼡�⡱��չʾ��������ȷʵ�ܹ����漣�� ����Ƶ���ɵĽǶ���˵���Ҳ�����ΪGenie����ʤ��Sora�����������ɵ���Ƶ��ֱ�����Ӱ�ť��ȷʵ��һ��������Ĵ��£���ÿ���˶��ܳ�Ϊ��Ϸ���ʦ�� ����Ŀǰ����Ϸ����Ч�����Ҳ���������������Ԫ���棬ϣ���ȸ��ٽ��������������ؼ�2D��Ϸ��Ȼ���������ڵ��г�������ֱ������3D������������ʵ���� |
|
��ſ���һ�¹ٷ����ģ���Ȼ����������Ƶ������ Genie ��һ���� Sora ����˵����������Ƶģ��·�߲���dz����ģ�͡� |

|
|
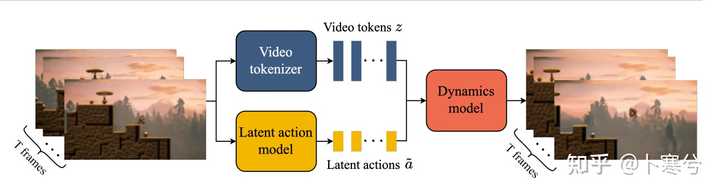
Genie: Generative Interactive Environments ��˵��Genie �Ǹ���һ�ų�ʼͼ���һ�顰DZ�ڶ�������latent actions������һ����Ƶ��������DZ�ڶ����Ǻ��ģ�����Ϊһ��������ʹ��ģ�����ɵ���һ֡ͼ���ǿɿصģ��û�����ָ��������������ʲô����/���顰����ȥ��������ǹȸ�Ϊʲô��֮Ϊ�ǽ���ʽ������ģ�͡� �Ҿ�����Ҳ�� Genie �� Sora ��������Ƶ�������ĵط��� ���� Sora ������ text-to-video ģ�ͣ��û��ṩһ������������ģ��֮��ʲô�����Ʋ����ˣ����ɵ���Ƶ��ʲô���ģ���ȫ��ģ���Լ��� prompt �����������������Ҳ����˵��������Dz��ɿصģ���û��ָ����Ƶ��������Ҫ�ķ�ʽ���ɡ� Genie ͨ��ѵ��һ����DZ�ڶ���ģ�͡�ѧϰ������Ƶ֮֡�����ϵ�� |
|
|
ģ�Ͱ��������ؼ���ɲ��֣� latent action model �������ƶ�ÿ��֮֡���DZ�ڶ�����video tokenizer����ԭʼ��Ƶ֡ת������ɢ�� tokens��dynamics model������һ��DZ�ڶ�����ȥ��Ƶ֡�� tokens��Ԥ����Ƶ����һ֡�� ѵ����ֻ��Ҫ�õ���Ƶ���ݣ������ල�ķ�ʽ��ģ����ѧϰ��һ����Ƶ����Щ�����ǿɿصģ������ƶϳ�����DZ�ڶ���������Կ��� Genie ģ����������ķ�ʽ�� �������Σ�ģ�����ṩ�ij�ʼͼ���ָ���Ķ���˳�����ϵ�Ԥ����һ֡ͼ�� |

|
|
���ԣ��ڹٷ������IJ����п��Կ���������һ��˳����ͬ��DZ�ڶ���������£�����ͼ��prompt��ͬ��ģ���ܹ�������Ϊһ�µ���Ƶ�� ���磬����4����Ƶ�� latent actions ����{6, 6, 7, 6, 7, 6, 5, 5, 2, 7}�����������һ����ǰ����Ծ������ |

|
|
|

|
|
|

|
|
|

|
|
��Ȼ��ʵ��Ч������Genie ���ɵ���Ƶ���ܳ���������Ŀǰѧϰ��DZ�ڶ���������Ҳ���ޣ��ٷ��������ᵽĿǰlatent action�������趨Ϊ 8������������������ֻ������һЩ����Ϊģʽ�� ��������˵�������������˼�ĵط��������� AI ��Ƶ���ɱ���˿ɿصģ�ͨ���ɽ����ķ�ʽ���û�����༭����һ�����Ա༭��Ƶ�� ��Ȼ����������Ҫ�䵽ģ��ѧϰlatent actions��������Σ��������Ƽ��������Ӻ�һ�㻯����Ƶ�����С����ڹٷ���ʾ����Ҫ��������Ϸ�ͻ����˳����У����Ҵ���ʾ����Ƶ��������������Ϊģ�Ͷ��DZȽϼģ��������ʵ���������磩�� ���ԣ���������ģ���������磬����˵��Ϊ��ν�ġ�����ģ�͡���δ�����ܻ���Ҫ�䵽���ڴ���������ѵ���ϣ���ȻҲ��Ҫ�����ģ�ͣ�ĿǰGenie����������11B����������Genie �����ܹ�Ҳ���õ� Transformer���ֱ���ͨ�� scale up ���ģ�͵�ѧϰ����������Ҳ���Dz����ܡ� |

|
|
���Ǻ�OpenAI��Sora�����ˡ����ܣ��ȸ������Ƴ������°��Gemini����Сʱ֮��OpenAI�ͷ����˹�˾������Ƶ����ģ�͡���Sora������������һ�°�Gemini�ķ�ͷȫ������ȥ�ˡ� ����һ�����ң��ȸ�������Ƴ��ɽ���ʽ����ģ��Genie�� Genie��Generative Interactive Environments����һ�� 110 �ڲ����Ļ�������ģ�ͣ�����ͨ������ͼ����ʾ���ɿ���Ľ���ʽ���������ݹ������ܣ�Genie��һ���ɻ�������Ƶѵ�����Ļ�������ģ�ͣ��ܹ��Ӻϳ�ͼ����Ƭ������ͼ�����������Ŀ��棨�ɶ������ƣ����硣 |

|
|
�ڹ�ȥ�ļ��������ʽ�˹����ܿ�ʼ���֣���Щģ���ܹ�ͨ�����ԡ�ͼ��������Ƶ������ӱ�Ҹ��д����Ե����ݡ��ȸ��Genie��һ���·�ʽ��������ʽ����������Genie����ͨ���÷�ʽ�����Դӵ���ͼ����ʾ���ɿɽ����ġ�����Ļ����� Genie�Ǵ�һ����������������������Ƶ�Ĵ������ݼ���ѵ�������ġ���Ҫ��ע2Dƽ̨��Ϸ�ͻ����˼�������Ƶ��������ͨ�õģ�Ӧ���������κ����͵������ҿ�����չ������Ļ��������ݼ��� Genie�Ķ���֮�����ڣ����ܹ����ӻ�������Ƶ��ѧϰ��ϸ�Ŀ��ơ�����һ����ս����Ϊ��������Ƶͨ��û�й�������ִ�еĶ����ı�ǩ������û�й���Ӧ�ÿ���ͼ�����һ���ֵı�ǩ��ֵ��ע����ǣ�Genie����ѧϰ�۲�����Щ����ͨ���ǿ��Կ��Ƶģ����һ��ƶϳ������ɵĻ����б���һ�µĸ���DZ�ڶ�������ע�⣬��ͬ��DZ�ڶ����ڲ�ͬ����ʾͼ��������β���������Ϊ�ġ� |

|
|
ֻ��Ҫһ��ͼƬ�����ܴ���һ��ȫ�µĽ�����������Ϊ���ɺͲ�������������˸����·�ʽ�Ĵ��ţ����磬���ǿ��Բ������Ƚ����ı���ͼ������ģ�ͣ�������������ʼ֡��Ȼ�����Genie����Щ��ʼ֡����������������������ʹ��Imagen2����ͼ��ͨ��Genie�����ǻ������� |

|
|
Genie �������IJ�ֹ��ˣ���������Ӧ�õ���ͼ�����������صĴ������� |

|
|
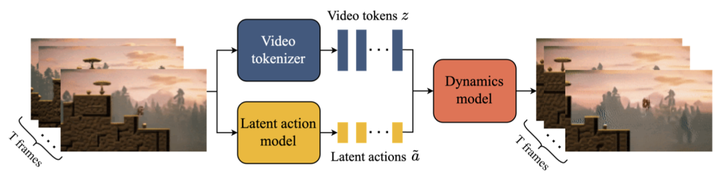
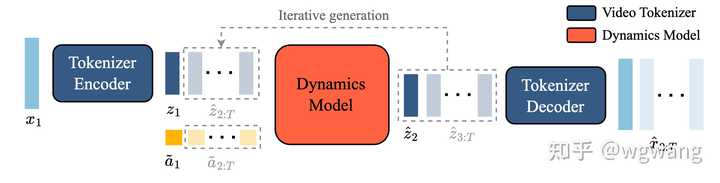
Genie����ѵ��ͨ��������Ҳ��Ӱ�졣��ǰ�Ĺ����Ѿ���������Ϸ�������Գ�Ϊ�����˹��������������Ч���鳡�������ھ����ܵ�������Ϸ���������ơ�����Genie��δ�����˹����������������һ������ֹ���ġ������ġ����ɵ������н���ѵ���� Genie�������� Genie�����ǵ�һ�����ޱ�ǩ�Ļ�������Ƶ�����ල��ʽѵ��������ʽ������������ģ�Ϳ��������������ġ���ͨ���ı����ϳ�ͼ����Ƭ������ͼ�����Ķ����ɿص��������硣ӵ��110�ڲ�����Genie���Ա���Ϊ��һ����������ģ�͡� Genie��Ҫ�������������DZ�ڶ���ģ�ͣ�Latent Action Model ��LAM������Ƶ�ִ�����Video Tokenizer������̬ģ�ͣ�Dynamics Model���� Genie��ģ�ͽṹ������ʾ�� |

|
|
Genie�� ֡��Ƶ��Ϊ���룬ͨ��Video Tokenizer�����DZ��Ϊ��ɢ��token ����ʹ��Latent action Model �ƶ�ÿ֮֡���DZ�ڶ��� ?��Ȼ�����߶������ݵ�Dynamicds model�У��Ե�����ʽΪ��һ֡����Ԥ�⡣ Latent action Model�Ľṹ������ʾ�� |
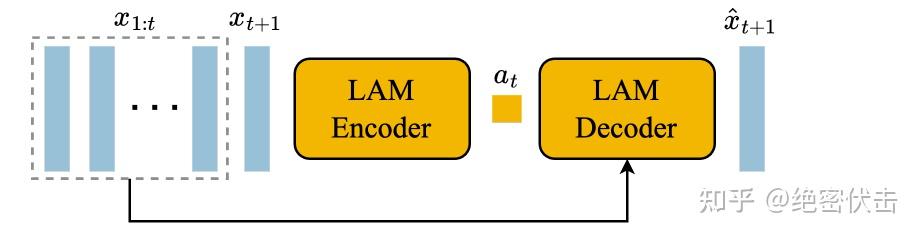
|
|
��һ��encoder-decoder�ܹ��� �ִ���ʹ�ñ���VQ-VQAE����ѵ�����������£� |

|
|
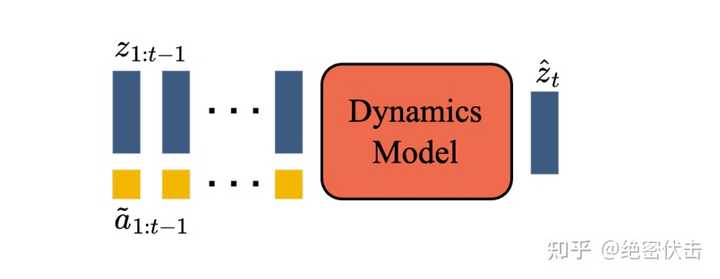
��̬ģ�ͣ���һ���������������� MaskGIT transformer������ͼ��ʾ�� |
|
|
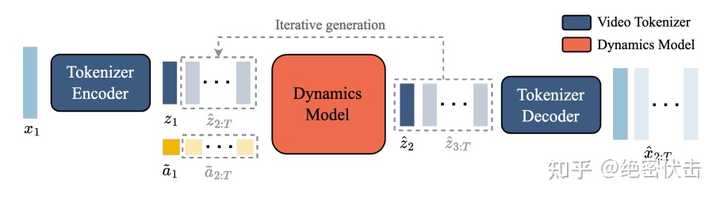
��ͼ��Genie���������̣� |
|
|
���༼������ϸ�ڣ����Բο��������ӣ� Genie: Generative Interactive Environments |
|
Sora����������ã�DeepMind�������ģ��GenieҲ�������ո¶ͷ�ǣ��� ����Genie �������죬�ȸ�DeepMind�Ŷӷ�������һ��������ģ��Genie�����ֽ�������Ψһһ����ͨ����20��Сʱ�Ĺ���������Ϸ��Ƶ���ݼ���ѵ�������Ŀ����ɽ���������ģ�ͣ���Ҳ����ζ��Genie��Ҫ���д���Ƶ��ʶ�����ͬ������������ģʽ�� |

|
|
Ҳ������Ϊ����ص�ѵ����ʽ��Genie�߱��˿������ƶ�ÿ��֮֡��DZ�ڶ�������������ԭʼ��Ƶ֡ת��Ϊ��ɢtoken�Լ������ڸ���DZ�ڶ�����ȥ֡token������£�Ԥ����Ƶ����һ֡�������������� �� ������Sora �;�������OpenAI����ǰ���ȫ���������Ƶģ��SoraͬΪ�������ģ�͡���������ʵ��Ҳ���������Ե����� ����Ƶ�������ϣ�Sora���õķ�ʽ��ֱ�ӽ�����������Ƶ������ģʽ�ͻ���������ڡ��������漣������Genie��Ŀǰ��������¶���������������������»�����Ҫ��������ͼģ����������ʼ֡ͼƬ������Genie����������Ƶ�� |
|
|
��������Ƶ���ɵ�ʱ���ϣ�Sora�������ɵ���Ƶʱ���ߴ�һ���ӣ���Genie�����ά����һ�������ң�����˵����Ƶ����ʵ�����Ƕ�ͼ�� �� Genie����ʵ���� Ȼ��������SoraҲ�ã�GenieҲ�գ�����ֻ�ǰ����ǵ���һ����ͨ����Ƶ���ɹ��߾���Щ���ڴ��С���ˡ� ʵ���ϣ���Ϊ������ģ�����������ǣ���Ҫ��Ҫʵ�ֵ�������������ģ����ʵ��������ĸ������ԣ�������Ħ���������ܡ��⡢�����硢���ϡ�����ȵȣ��������������вٿ����嶯�����ڷ������������������ʵ�顣 ����һ���ܹ�Ϊ���Ǵ��������ô��������ڴ�ҿ���ͨ������������Ҫ�Դ��IJ��ַ������������н��С� |
|
|
���ǵ�����Ͳ���ֻ�������ô�����鵽�Լ�������Ϸ/��Ƶ����Ȥ�������������ѵ��ͨ�õ�Agents�� ͨ���ڸ�����Ƶ����ֻ�Ǻ����Ϸ��Ƶ����ѧϰ�£�����Agents������ģ�´�δ��������Ϊ����������ʼ֡��Ԥ�ⲻ��ѧϰ�����еĻ���������Ϊ����Ϊδ��ͨ��Agent��ѵ����ƽ��·�� ˵���ˣ���Genie��Sora��������ģ�����Ƴ�֮��Ҳ����ζ�ŵ��µ��˹��������ڲ���һ����Ϊ���IJ�������� |
|
������·ͨ�� AGI������ͬ�㶼�ǡ���ģ������Ҫ�ܶ�ܶ�����ݣ�ʹ�úܴ�ܴ��ģ�ͣ��ú�ǿ��ǿ������ȥ��ģ��ѵ���������ڱ�ע�ܶ�������ʵ������� ��˵�����Genie�����������⣨�ලѵ�����������µ���Ƶ��������Ƶ������������ţ����ʵ��Ч���д���֤�� ������Genie �ij��֣������Ͽ���ȷ���� ȥ���������ģ�� �������Ƶģ�� ȥ���Ӯ���� nvidia �����Ӯ�һ��� nvidia �����أ�ȥ��û��Ӯ�ң���������ǻ�Ϊ ������ģ�͵ļ�Ҫ���� Genie��һ���ɴ���Ƶ����ѵ�������ɽ���ʽ������Genie�ܹ��еļ�����������Ӿ��任�����磨ViT����Vaswani���ˣ�2017 ��; Dosovitskiy���ˣ�2021����ֵ��ע����ǣ��任���Ķ����ڴ�ɱ�����Ƶ��������ս����Ƶ�������ߴ���ĸO?��10^4����Ԫ��token������ˣ����Dz����˾����ڴ�Ч�ʵ�ST�任���ܹ�����ͼ������ģ�������ƽ��ģ�������ͼ���Լ���� |
|
|
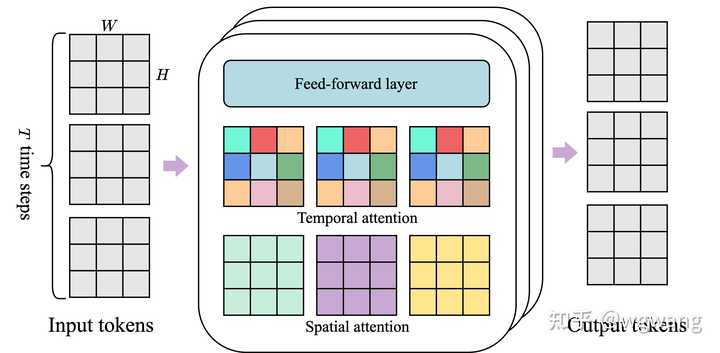
st�任������ ��ÿ����Ԫ����ע����������Ԫ�Ĵ�ͳ�任�����粻ͬ��ST�任�����������ĸLʱ�տ��뽻���Ŀռ��ʱ��ע�����㣬Ȼ����ǰ���㣨FFW����Ϊ��ע�����顣ÿ��ʱ�䲽���ڣ��ռ������ҹ�ע����1��H��W��Ԫ����Tʱ�䲽�裬��ʱ���μ�T��1��1��Ԫ��������ת�������ƣ�ʱ�����ô���������������ṹ��������Ҫ���ǣ����ǵļܹ��м��㸴���Ե��������أ����ռ�ע�����㣩��֡�������Թ�ϵ�����Ƕ��η���ϵ����ʹ����Ƶ��������չ�����Ͼ���һ�µĶ�̬�Ը��Ӹ�Ч�����⣬��ע�⣬�� ST ���У������ڿռ��ʱ�����֮�������һ�� FFW��ʡ���˺�ռ� FFW ����������ģ�͵�������������ǹ۲쵽�����Ÿ����˽���� 2.1ģ����� ����ͼ��ʾ��ģ�Ͱ��������ؼ������ |
|
|
1���ƶ�DZ�ڶ�����DZ�ڶ���ģ�� ��ÿ��֮֡�䣬 2)��ԭʼ��Ƶ֡ת��Ϊ��ɢ��ǵ���Ƶ����� 3������ѧģ�ͣ�����DZ�ڶ�����ȥ��֡��ǣ�Ԥ����Ƶ����һ֡�� ��ģ�Ͱ��ձ��Իع���Ƶ���ɹܵ��������ν���ѵ������������ѵ�����ڶ�̬ģ�͵���Ƶ�ִ�����Ȼ�����ǹ�ͬѵ��DZ�ڶ���ģ�ͣ�ֱ���������أ��Ͷ�̬ģ�ͣ�����Ƶ����ϣ��� DZ�ڶ���ģ�ͣ�LAM��Ϊ��ʵ�ֿɿ���Ƶ���ɣ����Ǹ���ǰһ֡��ȡ�Ķ�����Ԥ��ÿ��δ��֡��Ȼ�������ද����ǩ�����Ի���������Ƶ�к��ٿ��ã����һ�ȡ����ע�͵ijɱ����ܸܺߡ��෴����������ȫ�ල�ķ�ʽѧϰDZ�ڶ��� |
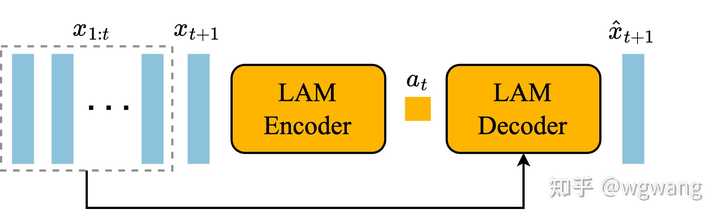
|
|
��Ƶ�ִ�������Ƶѹ��Ϊ��ɢ����Խ���ά�Ȳ�ʵ�ָ�����������Ƶ���ɡ�����ʹ�� VQ-VAE��Ϊÿһ֡������ɢ��ʾ���ִ�����������Ƶ������ʹ�ñ� VQ-VQAE Ŀ�����ѵ���� |

|
|
����ѧģ�� ����ѧģ���ǽ���������MaskGIT����DZ����Ϊ��Ϊ DZ����Ϊ�Ͷ���ѧģ�͵ĸ���Ƕ����������߸����Ŀɿ��ԡ� |
|
|
��ͼ��Genie ������ʱ���ɶ����ɿص���Ƶ�Ĺ��� |
|
|
|
|
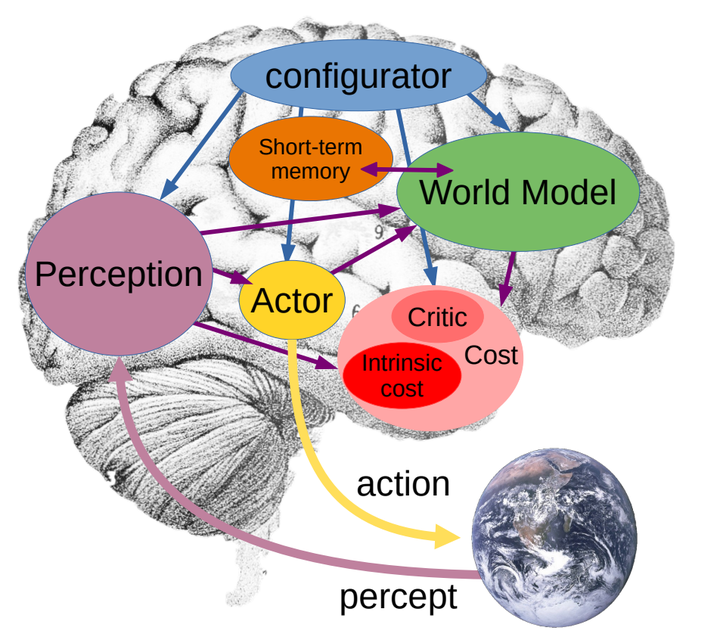
ÿһ�ο�������� AI ��չ���Ƕ�����ֱ�ӷ��ʣ��Ҿͻ���һ�£������IJ��������ǵ� AI �Dz�����Զֻ���ں�����棿 ��̸����ģ�ͣ���������һ������ܽ��ܵ�����ģ�͵Ķ��壺������ Yann LeCun �����ģ� �������ԣ�����ģ�Ϳ��Ը��ݵ�ǰ����IJ�ͬ����������ã����������ܴ����ڲ�ͬ�龳��������ͬ��ģ�͡�Ԥ���ԣ�����ģ���ܹ�Ԥ��δ��������״̬���������Ȼ�ݱ���ɴ�����Ϊ����ı仯����λ�������ģ���ܹ��ڶ���������ϱ�ʾ��֪���ж��ƻ�����ʹ�ô����ܹ��ڲ�ͬ��ʱ��߶��Ͻ��������滮���Լලѧϰ�����������һ���Լලѧϰ��ʽ������ѵ������ģ�ͣ�ʹ���ܹ�ͬʱ������Ϣ�ḻ�ҿ�Ԥ��ı�ʾ������ģ�ͣ�����ģ�͵�ѵ���漰������ģ�ͣ�Energy-Based Model, EBM��������һ��ͨ��ѧϰ����������������֮��������Ե�ģ�͡�����Ƕ��ܹ������������һ�ַ������Ե�Ԥ��������ģ�ͼܹ�����Ϊ����Ƕ��Ԥ��ܹ���Joint Embedding Predictive Architecture, JEPA������ͨ��ѧϰ����֮���������ϵ������Ԥ�⡣��λ��滮�����»����������ʹ������ģ�ͽ��в�λ��滮�����ڲ�ȷ���Ի����½��ж༶�滮�� https://openreview.net/pdf?id=BZ5a1r-kVsf |
|
|
��������ǿ����ġ�Genie���� ���ܱȵ������ı�������Ƶ��һ��ĸ��ӽ� ����ģ�͡� ����һ��������������ˡ��ɽ������ģ����������ȷ��·��������Ȼ���ж��������� Wolrd ���Լ���ģ�⣬���Ǻ��ź����ǣ��������ֻ����������Ч�����ڼ���·�ߣ�����û��ʲôϸ�ڿ��ԡ� ���Ǽ����������ͨ��һ��������ģ�ͣ���� Agent ����ɵģ��ǿ������������ʵ����������һ������ͨ����������ʵ���ģ��ﵽ������һ��Ч���� ���⣬������һ������ȷ�����ķ�ʽ��ͨ��ģ�����еĴ�������ɣ���ȷ���������ļ��������û��һ���ر�����ķ�ʽ����������ʵ�á� ���Dz���������һ����δ�� AGI �ľ�����̽�� ����� SORA �Ŀ����ԵĴ������漣���Ҹ�ϲ�� Genie ���ַ�������Ϊ�����������漣����ֻ�ܵ��Ƕ�������������������ܴﵽģ���˵����ܣ��������ijɱ�Ӧ���Ǽ��ߵģ������е�����/��Դ�ɱ��£���̫���ܴﵽ���˶�ӵ���Լ����˹����ܵij̶ȡ� ������� Genie ���������һ������ȫģ��������硣�������Ǿ����˷dz����������ģ�ͣ�����������ϣ����ǿ�������������ľ���Ӧ�ã����ı����ǵ���� |
|
google �� Gemini ħ������ʩչ��������� Genie ����һ�� Gemini ������չ���Դ� google ���ԼҴ�ģ�� Gemini "����" ֮����֮�� Brad ����Ϊ Gemini���Ƴ���Դ��ģ�� Gemma���ڴ�ģ��Ӧ����������Ƕ���ƵƵ������� Genie ������Ϊ "�ɽ�������ʽ����ģ��"���� Sora ���������ͬ��Sora ����һ�� text-to-video ����Ƶ����Ӧ�ã��� google �� Genie ���ص��� "����"���� "�����ɿ�"������ Gemini �����Ĺ�����һЩЧ����ʾ��ƵҲ��Ҫ�������Ƴ�������µ���Ϸ�������ɣ���˵�� google ��Ϊ Gemini Ŀǰ��С��Ϸ���������������Ǻ������Ƶġ� |

|
|
��Ȼ��"�����ɿ�" �Dz��Ǻ��������뵽Ӧ�õ���е�ˣ�ȷʵ��google Ҳ�ڷ������������������չ��һ�£���Ϊ Gemini �����ֽ���ʽ�����ɶ��ڶ�����������ĵ�����λҲ�а���������ʾ�����ԼҵĻ�е�� RT1 �ϵ�Ӧ�ã�������������DZ�ڵĻ�е�ֶ����� |

|
|
ֱ�ӶԱ� Sora������Ƶ����Ч�������� Sora ����Ӻã��� Gemini ������ǿɿأ�������ͬ������Ƶ��������Ӧ�ã������ص�������ͬ����ȻӦ�ó���Ҳ��������ͬ�� ���Ҹ��룺���� google �ڿ��� Sora ��ô������Ƶ����Ч��֮��Ҳ֪��Ҫ��Ӳ����Ƶ���ݵĸ��������������ڣ������âѰ���λ�IJ��ص��Ǹ�������ѡ�� |
|
һЩ�����Ѿ��ܽ��ˣ�Genie��һ������Ƶѵ�������ġ����ڿɽ�����������ɵ��������� ��ô��Ϊʲô������ʵ�����н���ֱ�ӵĽ���ʽѵ�����������������������֪����Ƶ��Ϸ��������������ʵ�����н����˽���ʽѵ��֮���������������������ù��߷�չ�����ġ���Ϊ��Ϊ�������ʵ����ġ�����ģ�͡��û�����֤�ֶ���������ģ����������ڵ��˹������������ֶΡ�����������ɱ�����ʵ����ʵ����Դ��ɱ����ܸߡ���Ϊ�����ճ�������صĻ��������磬�ڳ��ڵ���������ʵ�����Ѿ������˺����ı�����Ƶ����Ȼ������Ϊѹ�����Ķ�����˵���ܶȵ���Ϣ�����ܺù�����ʵ��������������Լ�ȥ��ȡ��Ϣ�ˣ���ι�Ͳ������Լ��ҳԵģ�����Ǵ����ݡ���ģ������AI����·�ߵ�˼·��Sora��Genie�����߾ȹ���������߱���������������������ڸ��õ�AIѵ����Ī������Ǵ�˵�еġ������ݡ�����ͣ��һ�Ų�����һֻ����Ȼ�����죿��������ô˵�����Ƕ�����������������ɽ���ϳ���ȥ�ɵķdz���ʵ�ļ���·�ߣ�Ӧ�ö�����Ҳϣ�������и���ķ�չ�� ���������Ƚ�ϲ����һ��·�ߣ�AI�ͻ����������ϡ�����������һ�����ʣ�ʲôʱ��AI�����ܺͻ����˺úý�ϣ�ֱ������ʵ������ѧϰ�����ܻ����˻�����һ������������ ������֮���������֪������·���п��ܴ��ڵ�����Ҳ�dz��ࡣ��Щ��˵�ñȽϼ��ˣ���ӭ��ש������ |
|
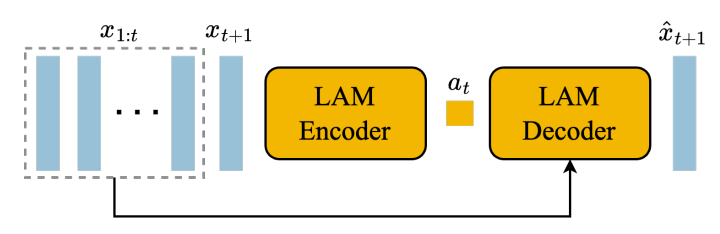
��һ������Action�������ɻ���Ľ���ʽģ�͡������ Idea ����ܶ��˶��뵽�������ںܾ�֮ǰ�������Ƶ��뷨�� ���ҵ�ʱ�������У����ģ�ʹ���������ģ� �����������һ�������ı���ͼ��������������ͼ���ģ�ͣ���Ϊ����ġ��ı���ʵ��Ҳ���������������Action��Action��ʵ�����������û���ÿ��������wasd space jkl ��Ӧ�Ķ�����һ��ѭ����ÿ�������н���һ�� Action ��Ϣ��Ȼ�����Action�͵�ǰ�Ļ���Ԥ�����һ֡�Ļ������ѭ�������ͳ���һ����Ϸ�� �Զ�����Ҫѵ����������ģ�ͣ�ѵ�������е�ÿ������һ����������input �� Action �� LatestFrameImages��Label �� NextFrameImage �����Dz��ò��ش�һ�����⣬������ѵ�����ݴ�����������������������Ȼ�к�������Ϸ��Ƶ�����ƺ���û��������Ϊ���ĵġ���ÿ��������������Ӧ�� Action ���Լ��ռ�����Ȼ�������߲�ͨ�ģ���Ϊ�Լ����ռ���������̫�����ˣ�������ͨ���Զ�������������Ҫ �� DeepMind �����Ĵ𰸾���������ѵ��һ���ܻ�������֡����õ� Action ��ģ�ͣ�Ȼ���������ģ�ͽ�ϻ������ϵ���Ϸ��Ƶ�������ɳ��������������� ��ô���ѵ����������������֡�������Action��ģ���أ��ѵ�����Ҫ���ռ� Input �� CurrentFrameImage �� NextFrameImage��Label �� Action �������� DeepMind ��ʱ�ָ������ǣ����Dz�����Ҫ֪�� Action ��ʲô�����ǿ���ֱ�ӻ��� LatestFrameImages �� NextFrameImage ѵ����һ���� Latent Space �� Action�����ǽ��� Latent Action Model |
|
|
���� LAM Encoder�����Ǿ��ܵõ� Latent Action ��������ĵط����ڣ����ģ�͵�ѵ����һ���ල�Ĺ��̣���������ֻҪ�ռ�������Ƶ���ݾ��У���Ƶ�����ѵ���ȱ���ල�� ����� Genie ����ĵ���� ��Ȥ���ǣ���ͬ�� Latent Action ���ܶ�Ӧ����ǰ�ߡ�����������ߡ�������������� Latent Action ��������������Ķ�������֮���ӳ���ϵ��ѵ����ʱ���Dz���֪���ģ�ֻ�е�����ʹ�ò�ͬ�� Latent Action ʵ���� LAM ��������֮�����Dz���ͨ���۲�֪����ͬ�� Latent Action ����Ӧ��ʲô���� ������� Latent Action Model���Ϳ���ѵ�����ܻ�����ʷͼ��Ͷ�������������һ֡��ģ�ͣ�Dynamics Model |
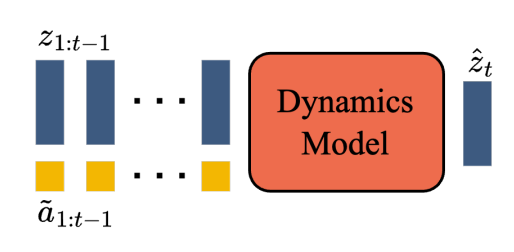
|
|
������� Dynamics Model���Ϳ��Ի�������һ��ͼ����Ϊ��ʼ�����룬Ȼ������һ�� Latent Action ���ܳ�����Ԥ�����һ֡��ͼ�� Genie ���ģ���Ǻ���Ȥ�ģ�����˵����һ���� Sora ���ӽ�ʵ�� AGI ֮·�յ��ģ�ͣ���Ϊ Sora ��ͻ����һ�ٽ�������Ƶ��10��������60�֣����ı仯������Ͷ�������Զ��֮ǰ��ģ�ͣ��� Genie ȴ�Ǹ�����һ��ȫ�µ��ල�ɽ�������ģ�͵Ŀ�ܣ����������������һ�� scale ���ܻ���ֺ�ֵ���ڴ��Ľ�� ����һ�£�������Dz���������Ϸ��Ƶ�Ļ�����ѵ�����ģ�ͣ������ں����ĵ�һ�˳���ʵ������Ƶ�Ļ�����ѵ���أ���ô����ͱ���ˣ� ���ں����ĵ�һ�˳���ʵ������Ƶѵ��һ�� Latent Action Model�������ͬ�� Latent Action ����Ӧ���˵�ʲô��Ϊ���������ҿ���̧ͷ��ǰ�������ˡ����֡���ȭ��˵�����ȵȵȵȻ��� LAM �ͺ����ĵ�һ�˳���ʵ������Ƶ��ע����Ƶ��Ӧ�� Latent Actionѵ����һ������� Dynamics Model �ȵȣ�������Ӧ���ټ������� Dynamics Model �ˣ�����Ӧ�ó���Ϊ������ģ���� |
|
|
| [�ղر���] �����ر��ġ� |
| ��һƪ���� ��һƪ���� �鿴�������� |
|
|
|
| ��Ʊ�ǵ�ʵʱͳ�� ��ͣ��ѡ�� ��ʱͼѡ�� ��ͣ��ѡ�� K��ͼѡ�� �ɽ���ѡ�� ����ѡ�� ������ѡ�� �������� �������� ���� MACDָ�� KDJָ�� BOLLָ�� RSIָ�� ���ɻ���֪ʶ ���ɹ��� |
| ��վ��ϵ: qq:121756557 email:121756557@qq.com ����ƻ� |