
| |
|
|
| ����ƻ� -> �Ƽ�֪ʶ -> Sora�������������磿 -> �����Ķ� |
|
|
[�Ƽ�֪ʶ]Sora�������������磿 |
| [�ղر���] �����ر��ġ� |
|
������ʵ����Ƶ�ǻ����� ��ʵ������������ɣ��Ժ���Ϊ������ζ�� AI ��Ҫ���ǵ���������������ײ�Լ�����ṹ�ڶ�̬�����е���Ϊ����ô�������ˣ�Sora�� |
|
���ͩ�����ĵ���, ŦԼ��ѧʯϪ��У����, �����ͼ��ѧר�ҹ��շ����ѧ�Ƕȸ����˺ܾ����ķ����� ���շ�����������о���Sora������Ƶ���������⣬�ܽ����£� ���ȣ��ø���ͳ�Ƶ����������ȷ�����������ɵ�����ԣ���Ȼ���Ե�������������ﵽƫ�ַ��̵ľ��̶ܳȣ���Σ�Sora���ж�ȫ�ֵĺ����ԡ���ȻTransformer����ѧϰ�ٽ�ʱ�����Ƽ�����Ӹ��ʣ���������ĺ�������Ҫ���߲�ε���ѧ���۹۵㡢���߸�Ϊ���ζ�������Ȼ��ѧ�����Ŀ�ѧ�ı�����Ŀǰ��Transformer�����������Щȫ�ֹ۵㣻���⣬Sora������������������Ϊ�ؼ����ٽ�̬��һ������Ϊ�ٽ�̬������ϡȱ����һ������Ϊ��ɢģ�ͽ��Ⱥ�̬�������εı߽�ģ�������������ٽ�̬�Ĵ��ڣ����ɵ���Ƶ�����˲�ͬ�Ⱥ�̬֮�����Ծ��Sora�Ļ���ԭ��[1] Sora��ѵ����Ϊ����Ƶ����ÿ��������һ������Ƶ��Sora������뵽���ݿռ���н�ά��Ȼ�������ռ��н����������и�ɲ���������ʱ��˳����ʱ�ղ������༴ʱ�����ƣ�time-space token����ÿ�������ڶ���Ƶ��֡���кţ�ʱ�䣩���ڵ�ǰ֡��������ţ��ռ䣩������¼������� |
|
|
Sora ����Ƶ����ӳ�䵽���ռ䣬���и��ʱ�ղ���������Ϊʱ�����ƣ�time-space token�� ��һ���أ�Sora�����ݿռ佫�������Ƶĸ��ʷֲ�ͨ����ɢ���̴���任�ɸ�˹�ֲ�����ͨ������任����任�����ռ��еİ��������Ʊ�����������ơ�������Щ������ڼ�̣���Ļȱ�ٵ���Ƶ��Sora������Dall-E�����±��⼼���� |

|
|
Sora����ɢģ�ʹӰ�����ʱ��������������ʱ������Sora ������Ͳ��� Ȼ����Sora�����·�������Ų��㣺 ������������ Sora����ȷ���ﲻͬ���Ƽ�ʱ�յ������ϵ������չʾ�Ĵ���������У�ÿһ֡���쳣���棬���ǵ������̴������������ʱ������Ļ�����˿������������ǽ���Ұ��С��ÿһ�����Ƶ��������ǿ���������ۼ����ʵ���棬����֮����ν�Ҳ�dz�ƽ����Ȼ�����ǵ�����Զ������֮���������ϵ��ʱ�������Ŀ���Ӱ����������ʱ����������֮����������û�����ֳ����� ����ζ�ţ�Transformer���Ա�������֮���ͳ������ԣ�����ȷ������������ɡ���Ȼtransformer������һ���̶��ϲ�����Ȼ���ԣ�����Ȼ������ȷ�����������ɣ�����������Ŀǰֻ��ƫ�ַ��̲��ܾ��ܱ���ⷴӦ�˻��ڸ��ʵ�����ģ�͵�ij�־����ԡ� |

|
|
0 �ֲ�������������� Sora���Ժ���ƴ���������ƣ���������Ƶ���ܳ��������ȱ��ȫ�ֵĺ����ԣ��۲�����ġ��������ӡ���Ƶ��������ǽ���Ұ��������Ļ�м��һ���ֲ���������Ƶ�dz���������ϸ��ⲻͬ��������ֱ�ӵ����ӣ�Ҳ�dz������⻬������������������Ȱ����գ������ճ�������㣡� ���֡��ֲ������������������������Ƶ����ζ��Transformerѧ����Token��ֲ������Ӹ��ʣ�����ȱ��ʱ�������ĵĴ�Χ�������������Ƶ�У�������������������е�����������Ȼ�ֲ�����������������������ʱ���ڡ� |

|
|
0 ��ʶ��ȱʧ Ŀǰ��Transformer��Ȼ����ѧϰ�ֲ��������ģ�����ѧϰ����ȫ�ֵ������ģ������ȫ�ֿ����������е���������Ҳ���������幤��ѧ�����������е����ַ��ࡣ����ȫ�ֹ۵㣬ǡ�����ɴ����������AI�����еİ�����˼�롣 ��Ȼÿ��ѵ��������Ƶ�������ر�����ȫ�ֵĹ���������ƻ��Ĺ���ȴ������ȫ�ֵĹ�����ر������ٽ����Ƽ�����Ӹ��ʣ��Ӷ����¾ֲ���������������Ľ���� ���磬Soar���ɵġ���ԯ�����ܲ�������Ƶ��������ǹ۲�ÿһ���ֲ�����������Ƶ���Ǻ����ģ���Ƶ���Ƽ������Ҳ����Ȼ�ģ�����������Ƶȴ�ǻ����ģ��ܲ������ܲ��ߵķ����෴�������Ƶ��ȫ�ֹ������������幤��ѧ����ʵ��㣡� |

|
|
0 ����Sora���ɵġ��������ϡ�����Ƶ�����ϵĶ�����������������������ˮ�����ǵ������Ȼ�粢û���������ϡ��ֲ��ĺ�������֤����ĺ����������ȫ�ֹ�������������ѧ��ʵ�� |

|
|
0 ���ݹ⻬�����ٽ���Ϣ��ȱʧ �����ٽ��¼�������ϵͳ�г��ֵĸ��ʼ���Ϊ�㣬����ȴ������Ҫ��Sora����������ƽ���ı仯���̣����������������йؼ����ٽ����������籭�ӵ��㵹�� |

|
|
0 ��ͼ�е�С��һ����������һ�����ĸ���Sora����ɢģ��û��ʶ������ݵı߽磬���dz��Ʊ߽磬��3ֻС��ͼƬ�����κ�4ֻС��ͼƬ�����μ��Խ�� ��ȷ������Ӧ������ʶ�����ݱ߽磬Ȼ������������Խ�������£���3ֻ���4ֻ�����ڱ߽紦���ۻ�ԭ����ģ�͡� |

|
|
0 |
|
|
Sora���ɵ�������Ƶֱ�ӳ��������ݿռ�ı߽磬��û���ڱ߽紦�۷��� �ο�^ժ���Թ���ʦ�IJ��� |
|
�dz��õ����⡣ ������һ�ֱ������ǣ�����diffusion model��transformer�ܹ���DiTs�����ܷ�ʵ�ֶ�����ʵ�����ķ���Ԥ�⣿ ��������˵һ�¸��˵�������Ҿ�����ÿ�Ҫ��Ԥ�ʲô�̶ȣ�����Ǵ�Χ�������ȵġ�Сʱ�䷶Χ�ģ������ַ����ܴﵽ�dz��õ�Ч���������С�߶ȡ�ϸ���ȡ���ʱ�䷶Χ�ģ��ǹ��ƻ���ƫ��������ñȽ�Զ��Ȼ�����ɷ��ϣ����ַ�ʽ�Ѿ����ֳ��˾��˵�DZ���Ϳ����ԡ� Ϊʲô��ô˵��������diffusion model���������ͼ������ġ�diffusion model�����һ����Ϣ��ʧ��ԭ�����⡣��SoraΪ�����Ǹ����ض���������ӣ���ʱ�����ռ��ϸ���prompt��Ϣsample���������㣬��ʹ��diffsion model�������ڽ��ڵ�ʱ���а����ڵ���л�ԭ����ͨ��decoder��ԭ��pixel���� ������̾�����������дС˵���ȹ�˼���������ŶΣ��ٸ��ݳ�ʶ�������ϵ�������������Ǵ������������һ�������ġ��������Ĺ��¡���Ȼ���������Ĺ����Ƿ���Ȼ�����������Ƿʣ��������ҵ���������֤�ġ���Sora�У��ⲿ�־���ͨ��ѵ��diffusion model�Ļ�ԭ���̡����������ͨ��������������������ɣ���Щ������������ͨ��transformer�ܹ��������ġ�transformer��ԭ�����ﲻ������������Ϊ���ǻ���һ�����ȵ�tokens/patches��pixel�ռ�ӳ�䵽��ͬ��latent space ά���ϣ���������һ����Ϣѹ���ͷֽ�ӳ�䡣 ��������: Transformer�ķֽ�ӳ���Ƿ��ܹ��γɺ���ʵ�������Ч��Ӧ������ѧ�Ƕ���˵������ӳ����̬ͬӳ�仹��ͬ�������ǵ�ʱ�պͱ仯���ԣ�����ӳ���Ƿ��˶Գ��ԣ������˽Ƕ��Ƿ��ܱ�֤ͬ�ߣ��Ƿ�֤ͬ�ۣ��Ҿ�����Ҫ��һ�������ʺš� Ҫ֪����ͳ���ϱ���һ�����ף��ھ�ϸ�ṹ�ϱ���һ���Ǻ��ѵģ���Ȼ��Ҳ�п����Ǻ������о����� ��Σ�diffusion model��һ��ǰ����裬������Ϣ�Ķ�ʧ����ɢ�Ƿ��ϸ�˹����������������Ʒ���̡�Ȼ������Ȼ״̬�ĸ�˹�ֲ��������Ʒ��Զ��Dz����ڵġ�ǰ���Ǵ��������µĽ��ƣ������Ǻ��Գ���ʱ��·���������������֮������Ҫ������Ϊ����ǡǡҪ�������������·����������ͻ��ߡ����ȡ����ȵȣ���һ�������۹��̣�ͳ�������ϵĶ��ɿ��ܾͲ����к�ǿ��ָ�����ˣ����ο���Ϊ���ڡ��Ҵ�����ۡ���AIѧϰ�����ݱ�������ͨ�������ϲ��ɸѡ���ģ���ͺ���ʵ����Զ�ˡ� ��������Ҳ���Դ���һ���Ƕ�ȥ������¡�������ν����������������ij�������Ͻ���ֻ�������и���work��world model������ν�����е���ѧ���۶��ǶԵģ�ֻ����һЩ�����õġ����е�����ģ�Ͷ��Ǵ��ģ�ֻ����һЩ�����õġ���������Ƕ�����˵����ʹSora��world model�����⣬Ҳֻ������Ϊ�����ڵ�ģ�Ͳ����ð��ˡ�����˵Sora�ܹ���������������Ҳ��������ȫ����û�ߡ���lecun������������ʵҲֻ����Ϊ������ȷ���ˡ� ���ϣ���ӭ���������������ָ���� |
|
���������Sora�ܲ����������������⣬�ǿ϶��Dz��ܣ������������Sora�ܲ��ܸ�����Ȼ��������������һ���̶ȵĿ�Ԥ�����������ǿ��ԡ� ��������Ĺؼ������ڣ���Ӧ����ô���塣 �������࣬��Ȼ����һ����֪�ṹ�ģ���������˵�����ǰ�����Ž����ǵ���֪����ڵõ�һ��ģ�ͣ�������Ҫ��ѧ����������ȵ�Ҫ�ء�����ѧ�ɵľ�����ôһ���£������������ģ��(����BCS���ۣ����ȱ�-�ʵ����ۣ�����SM��ȥ��ʵ����ջ�����һЩԤ�⣬���Ҳ����һ����Χ�ڲ�����Ҳ��������ס������ף�������ʵҲ���Ƕ���Ȼ�磬���������ǵĿ��ȥ���Ǹ����硣 ����SoraҲ����֪�ṹ����ô������֪�ṹ��Ȼ�������Dz�һ���ģ�������֪�ṹ˵���˾���ai���㷨��ܡ�����һ�����룬��Ҳ������������м�����ô���£����������㷨��ܾ����ģ�����˵��������֪�ṹ�����ġ� ��Ҫע����ǣ���Ȼ���Ǻ�������ʶ��Ȼ�ķ�ʽ�Dz�̫һ���ġ���ˣ�����AI�ܳɹ��������Ԥ�ʲô����Ҳ���������Ƕ��ˣ����ǻ�����Ҫ��������һЩ���ȥ�������������ģ��ȥ�����������磬��Ȼ�����������������о���Ч�ʡ� ��֮��AI�������������粻��Ҫ��������AI�ĸ����£����ǿ��Ը�����������һЩ�� |
|
��һ����ǡ���ı������ֽε�AI�е������ڻ�δ��չ���ִ���ѧ�����࣬����������ڸɻ ͨ������ǰ�˵ľ���ͳ�ƣ�����֪��̫��ÿ����������£�Ҳ֪����������ˮ����ڣ�Ҳ�ܼ�Ԥ����������ʱ����ѩ�����������֪��������������������ǿ����á�����������������Щ�����������ɣ������������������ı��ʡ� ֪���ϵ��վ����⣺href="https://http://www.zhihu.com/question/19696294">Ϊʲô��������ǧ��������ȴû�з�չ����ϵ�����ִ���ѧ�� ��ˣ��ֽ�AI�����������������ʵ����������ڱ��ʵIJ��졣 ���ֲ����ҪԴ��AI�������ǻ������ݺ�ͳ��ģ�͵ģ������ǻ��ڶ��������ɵ�ֱ����֪���֪�� ����ζ��AI��"����"���������������ѵ�������ݼ��е�ģʽ����������������Ļ���ԭ���� ���Ǿټ������������������ֲ�� ����1����������Ԥ����ʵ�������磺����ʵ�����У����һ���˿���һ����¥������б�����ǻ���ڶ�������ֱ������Ԥ����¥���ջᵹ�¡�����Ԥ���ǻ���������������ɣ����������Ļ������⡣AI�����⣺һ����������ѵ����AIģ�ͣ���ʹ��diffusion models��transformer�ܹ���ģ�ͣ������ܹ�Ԥ����¥�ᵹ�£���������Ϊ����ѵ�������п��������Ƶ���б�������յ��µ�ģʽ����������Ϊ�����������ĸ������2��ͼ���е��ڵ�������ʵ�������磺������Ժ��������������ڵ��������״���Ǻ��澰�����ò����Ϊ���������ǽ��������Ƕ��������������Ժ��������ԵĻ��������ϡ�AI�����⣺AIģ���ڴ����ڵ�����ʱ�����������������ѵ�������ݡ����ģ��ѵ�������а������㹻����ڵ������������ʽ���������ܹ���ȷ"����"�����ڵ������Ϣ��Ȼ�������������ǻ���ͳ�ƹ����������Ƕ��ڵ����������ԭ�������⡣����3�������˸�֪�������ʵ�������磺�������ͨ��������֪������ʵء��������¶ȣ����ݴ����ʵ������Ⱥͷ�ʽ�������������ƶ����塣AI�����⣺һ�������ˣ���ʹװ���˴������ͻ���AI�Ĵ���ϵͳ�����������"����"Ҳ�ǻ����䴫����������Ԥ��ѵ��������ģ�͡������˿����ܹ�ģ����ʵ��Ļ�����ʽ��������������Դ������������ģʽʶ�𣬶��Ƕ�������֪���������⡣ ��Щ���ӽ�ʾ��һ����Ҫ�Ĺ۵㣺����AI����չ�ֳ�����������ĸ߶���Ӧ�Ժ�Ԥ�������������ǵ�"����"�������ǻ������ݵ�ͳ��ģ�͡�����ȱ���������ֻ���ֱ������������������������������ֲ���ڴ���δ�������������Ҫ������������ԭ��������ʱ��Ϊ���ԡ� |
|
����ĿǰSora�ijɹ����������������������硣 ������۲�����˵�ģ���Sora���з���OpenAI�ڷ���Sora����վ���Լ�˵�ģ� The current model has weaknesses. It may struggle with accurately simulating the physics of a complex scene, and may not understand specific instances of cause and effect. For example, a person might take a bite out of a cookie, but afterward, the cookie may not have a bite mark. ��Ŀǰ��ģ�������㡣����������ȷģ�⸴�ӳ������������ԣ����ҿ��������������ϵ�ľ���ʵ�������磬һ���˿��ܻ�ҧһ�ڱ��ɣ���֮���ɿ���û��ҧ�ۡ��� The model may also confuse spatial details of a prompt, for example, mixing up left and right, and may struggle with precise descriptions of events that take place over time, like following a specific camera trajectory. ����ģ�ͻ����ܻ�����ʾ�Ŀռ�ϸ�ڣ����磬���һ��������ҿ������Ծ�ȷ������ʱ�����Ʒ������¼���������ѭ�ض�������켣���� ������������������ı�����ʲô�� �������ϵ�� �����������������ʱ����һ������ͷ�ģ���Զ��ǰ����������һ���������ɣ������Ķ��ǻ���ʱ�������ǰ��ǰ���£����ʵ��ݻ����̡����仰˵���������ɾ����������������ϵ�ġ� ���磬������ţ�ٵ��˶�����ȥ����һ��������С����һ�룬С������������һ�룬С��ͻ���������˶��켣�ϵ���һ��λ�á����С��ͻȻ��ʧ�ˣ���һ������һ����ԭ��Ҫô�ǵ����˶��Ҫô�DZ��������ˡ�������Զ������Ե�ʵķ������С�������һ���С��� ��Sora��ѵ������������ͨ����������ȥ��ʶ������ȫ��ͬ�� ʵ���ϣ�Sora��Ȼ�ߵ���OpenAI�Ĵ�ͳ·�ߣ�ʹ�ý���DZ����ɢģ�ͣ�ͨ����3D�����롱�ķ�ʽ������Ƶ��ͨ��˵�����Ƕ�֪����Ƶ��ʵ����һ֡һ֡�ľ�ֹͼƬ��������ɵģ�Sora������Ƶ�������ʣ���ȥ�ж�����һ֡ͼƬ�У�ǰһ֡ͼƬ��Ԫ�س��ֵĸ��ʣ�����������һ֡ͼƬ��ͨ��������ѵ�������жϵ���ȷ��Խ��Խ�ߣ�����֡��ͼƬ�ı仯�ͻ���Խ��Խƽ�������忴������Ƶ��Խ��Խ���档 ����������Ƶ�ķ�ʽ���������������������Ĺ�����ȫ��һ���ˡ����磬�������������ֻ����Զ����ͻȻ�����ֻ���ⲻ����������������Sora�����һ��ijһ֡ͼƬ�����˴���ƫ�ƣ�ƾ�ճ����˵���ֻ������ô�����п��ܻὫ��ֻ��������Ⱦ��ȥ�����ǣ���ֻ���ͱ������ֻ�� Soraֻ��ͨ������ȥ��������Ĵ����������⡰��ֻ������ƾ�ձ����ֻ����������������� ��Ҳ�ǻ���ѧϰ��������ʵ����� |

|
|
0 �����Ҹ��˵����⣬Sora�����ģ������ǡ��ξ�������������ʵ���������硣 ��������������������ֵֹ��Σ���Щ�dz���ʵ����Щ��ʮ�ֵֹ����������������ֱ���α��������˯��ʱ�����е�ǰ��Ҷ�����ƣ����ǵ����ж����������б��������ͣ����Ρ���ʵ�ǵ�֡�dz����صģ������˲�����������ϸ�ں���ֵ���������Ҫ�ȵ����������ˣ���˼ά�����ˣ����ܷ������������ֲ�����֮���� ��Sora�ij�Ʒ��Ҳ������ȱ�١�����������֧�ţ�����������ѻ������������Ļ��棬��Ȼ�����׳��ֲ��������������ˡ� |

|
|
0 |
|
���ڡ��������硱������Ϊ���������ͨ��ָ���Ƕ���Ȼ���������ɵ�������ʶ�����������ʡ��������ռ䡢ʱ���Լ�����֮������õı��ʺ�ԭ�������⡣ �������ⲻ�����ڹ۲��ʵ���ȡ�ľ���֪ʶ���������ܹ�ͨ�����ۺ���ѧģ����������Ԥ��ͽ�����Щ����������� ������ڡ��������硱��������������ʹ�����ܹ�������裬���п�ѧʵ�飬��֤���ۣ������γ��ܹ����㷺���ܵĿ�ѧ���ۣ�����ţ���˶����ɡ�����ѧ���ɡ�����ۡ�������ѧ�ȵȣ���Щ�����ܹ�������������������������Ļ����ṹ���������ơ� ����Sora������Ƶ����ģ�͵���ν�����⡱��ȴ��һ�ֽ�Ȼ��ͬ�����⡣ ����٤����ͨ��ʵ�ʵ�����ʵ�飬�۲첻ͬ������С��ӱ���б�����µĹ��̣���������С��ͬʱ���أ��Ӷ��Ʒ��˵�ʱ�㷺��Ϊ�ĸ��ص������������ij�ʶ��������������ٶȶ���������������ͬ��ԭ���� ������ֲ��Ͻ���ʵ�飬��������С������б����£�����С��ͨ����ͬ���ȵľ��������ʱ�䡣ͨ��ʵ�飬������С���¹��ľ�����ʱ���ƽ�������ȣ�������ֽ�һ���Ƶ���������������ٶ���ʱ������ȣ��Ҳ������������������ ��֮������Ϊ���࣬���ǻ�������ͨ��ʵ����֤���裬���Դ��Ƶ��ͽ����������ɡ� ����Sora��ʶ���������硱�Ĺ���ȴ����ȫ��ͬ�ġ� Soraͨ�����������������������������Ƶ���ݣ����û���ѧϰ�㷨ʶ����һ�������̡�Sora��"ѧϰ"������Ҫ��������������ȡ��Ӧģʽ�����������ܻ�ʶ������������ٶ���ʱ�����Ӷ��ӿ죬���ҡ����֡���һ����������������ء�����Soraȱ�������������ٶȱ�������ԭ�������붴�죬��"֪ʶ"�����������г��ֵĹ��ɡ� ͨ��ѧϰͬһ������Ƶ���ֳ��ġ����ɡ���Sora�ܹ�ģ��������Ԥ�⡱�����������Ϊ��ֻ����ȻSora�ܹ�ȷģ���������ٶȵġ�������������٤����ͨ��ʵ�����������õ����������ȣ�Sora����������Ƕ������ģ�⣬���Ƕ�����ԭ�����������ա� ������ʵ�Ҿ�����Ҳ��������AI���������ľ�����ɵĺ����AIѧϰ���ġ����������������ࡰ�������������ɣ��������ӣ�˭�ܸ��õķ�ӳ��������Ĺ��ɣ�����AI�IJ������ƣ�����Խ��Խ�������С� |
|
���Ҫ��ʲô�ж��������磬���ȥ���嶮�������硣 �������������������ĵ����⣬����ͨ���ӳ�����ʼ��ͨ���������Ӿ��������������ζ���ȸ��ָо�����������������źţ���ͨ����ϵͳ������ԣ����ϵ�����Ԫ֮������ӷ�ʽ���Ӷ��γ���������֪������������Ĵ����ṹ�����Ƕ���һ���������ɣ�����֪������һ��������������ԭ�����Ľ�����ɴ�ȥ���ݵõ���δ�����������Ԥ�⡣ �������Ǵ�����ģ��ʵ�ֵļ���������������ģ��������������Ȼ���Դ�������ľ���Ӧ��֮һ��ͨ�������Ż�������ģ��ģ��������ģ���ܹ����õ������������Ȼ���ԣ�Ϊ�������롢�ı����ɡ������ʴ𡢶Ի�ϵͳ��Ӧ���ṩ����֧�֡� �������������Ҳ�����Ƶ�һ�����̣�ֻ��������һ���ɼ����оƬ��ı����洢���㹹�ɵ�������ϵͳ��ͨ��������ѧϰ��Ҳ������������������Զ�������������ڶ�������Ӷ��γ���һ�����յ�������ṹ�������յĽ������������������ģ����ѧϰ������Щ���ӣ����ٸ���һ��û��ѧ���������źţ����ͻ᷵��һ�������Ѿ�ѧϰ�Ĺ��ɵ��������� ���������ִ����ڼ�����еļ���ģ�ͣ��������Թ���ԭ����������ͨ��ģ����Ԫ��ͻ���Ľṹ�빦����������Ϣ�������ڻ���ѧϰ���˹�������������ͨ��˵�������硰���⡱��ָ���ܹ���������ѧϰ�����ӵ�ģʽ��ϵ�������ض������ϱ��ֳ����༶������ܣ�����ͼ��ʶ�����Դ����ȡ� ���֡����⡱ָ�㷨�����ݵ�һ�ֱ����ͼӹ���������ô������������֪����ʶ����ʲô������һ������µ���ѧ���⡣ ���ҿ�����������ͨ����������ѵ����������ȡ����������Ԥ�⡢�����µ����ݣ���Ȼ�������߱�������ʶ����С�������������������ζ��죬����������ɻ���ͳ��ģʽ���㷨�ġ����⡱������������������ⲻ�ǻ����������ʶ�ģ������ӽ���Ͽ���һ�µġ������ţ���������������������Ȼ����������һ���Ľ�����������ȫ���Բ���������ͬ������ġ���ʶ���� |
|
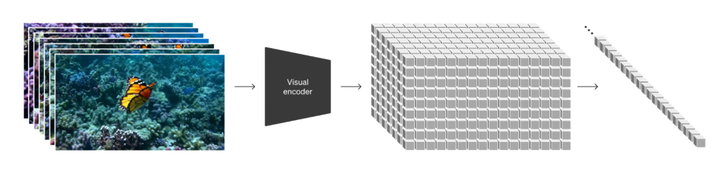
Sora �����������磬���ҵ�û�д��� Sora �����Ĺ��������ĵ��Ͽ����Լ�ȡ���� ��Video generation models as world simulators���� ���ֱ����ǡ�������ģ������������Ƶ����ģ�͡��� https://openai.com/research/video-generation-models-as-world-simulators �Ҳ�֪���Dz�����������ô������ˡ����������ṩ�ļ���ϸ�����û�п�������ģ������ ���ļ���ʵ������Ϊ�� ViT + Diffusion �� �Ӿ����ݴ��� ViT ���Ƶļ������������Ǽ�������ĵ�һλ��˵��������Ϊ��������Ҫ�ġ� |

|
|
����ͼ�����Ľ�ʾ��һ�����������е���Ƶ�Ƕ�֡����һ�� �������г� 3D ��ķ�ʽ���� Token �ġ����������һ���Ǽ�֡ͼ��һ���У�����һ�� 3D ������� 2 ά��������Ϣ������ 3ά��ʱ����Ϣ��Ҳ����һ�� Token ������ Space �� Time ��Ϣ����������� Transformer �Ĵ�ģ��ѵ�����Ƕ�����������Ϊͼ�����м�������ġ��ֽε���Щ����ѵ����ʱ���� ViT�����ɹؼ�֡���ٲ�ֵ�ķ�ʽ���ȶ����Ͽ϶�û������á� ������Ϊ��� Token ������С��ʵ�ǻ�Ӱ�쵽���������ģ����Զ�����������ͼ�Ϊ�ؼ�������ǡ���� OpenAI ��ķ���ˮ���Լ���û�й������κ�ϸ�ڵļ��� KnowHow �� ͼ������Ƶ���� ���������һ�� nosy patches �� Diffusion Model ����ͼ�ļ����� |

|
|
����Կ�����ͬ��Ҳ�Ƕ�֡��ͼ��� Noise һ�������Ȼ��� Noise ��ͼ��Ĺ��̡� |

|
|
�����˫��� Diffusion ˵�������ǿ��������Ŀ����� Diffusion ����һ֡ͼ��ļ����ж���죬����֡һ�����ɣ����������Կ϶����ж��١� ����˵����Ƶ�� Space �� Time һ������� Patch ��Ϣ����Ϊ Transformer �����룬Ȼ��������� Noise ���������ȷʵ��һ����ŵ��뷨���������ʵ�־�Ҫ������һ�� AI �ɹ���Ҫ�أ� �˲š����ݡ������� �����ҵ��� OpenAI ���߶���ȱ�� ������һ�����⣬��������ô���ģ��;���������ģ�ͱ��֡� ֮��������������ѧ���ɣ��Ҿ������������������еģ����� 2D ��ͼ��������ͨ���������룬���ɵ��˵�ͼ����㹻�ĺá� ���������� 3D �Ŀռ���ʱ�����ݣ���Ȼ�ڶ����ͱ��ֳ��˷�����������Ĺ��ɡ������������ˣ� |
|
OpenAI ���Ƴ� SORA ʱ��ͷų��� ��������Ƶ�����ԣ����ֽΣ�SORA Ӧ���Dz��ܾ�ȷ������������ġ� �� SORA �����ˣ�Ҫ�������Ƿ�����������������Ҳ���ѡ�����ֻ��Ҫ��һ����ʵ������ʵ�飬��ǰ���ι�� SORA����������һ��������������Ƶ������Ȼ��������ȥ�����������ɵ������Ƿ�����������ɡ� ����������Ϊ������ AI Ӧ�ö�������ȫ����������������Ҫ��Transformer �� Q-K-V ������Ļ��������Ȼ���Դ����ģ���̬��ע�������еIJ�ͬ���֡���ֱ��˵��Transformer ��������⡸��� A λ�ó����� XXX����ô ��B λ�����п����� YYY�������⡣�������������ݵ�˼·�ǣ��������� -> ���빫ʽ -> ȷ���ؼ����� -> �������ݡ����˼��ģʽ�ĸ��ӳ̶Ⱥ� IF A THEN B �����к蹵�ģ�����ؼ��ij�����������Ӧ����ʲô������ṹȥ���ء� ���� Q-K-V �ij���Transformer ȷʵҲ�ܹ�����Ƶ�������㹻ƽ���������Ѳ����������ɡ� ��ʵ��SORA Ŀǰ��������������ͼ��ѧ�ϵģ�ͨ����ʾ��Ƶ���Dz��ѷ��֣�����Ƶ��ͷ����ת����ʱ����Ƶ���岻�ᷢ��Ԥ����Ļ��䣬ʮ��ƽ������Ȼ��������ԭ�еļ��νṹ��˿�������������� Transformer ��ǿ���Ҳ�� Pika �� Runway ֮ǰ��û�����Ĺ������� SORA ֤ʵ�� AI ������Ƶ�ǿ��Ի���˵�Ǽ�������±��ּ��νṹ����ġ� ���Ӧ�÷�Χ�ɾͷdz����ˡ����磬δ����Ƶ�����߿���ֻ���ķdz������Ĺؼ�֡���д��������ؼ�֮֡������IJ�֡����ʹ�ô�ģ����Ⱦ�ͺ��ˣ����������Լ�����������ȥ�� AI �����ض��������磬δ��ƴ�������زģ������� AI ȥʵ�־ͺ��ˣ�����ֻ��Ҫ���������ǵ����ɣ�����������Ƶ�������������IJ����ˣ�������������ר������ LORA�����ü��á� �г�Ҳ��֤����һ�㣬SORA ҲӰ���� Adobe �ȴ���߹�˾�ڶ����г��Ĺɼۡ� ����Ҿ��� AI Ŀǰ�ó����������һЩ�����ڼȶ��ظ�ģʽ���������ۺͷ���ѧ��������������ij��������ڴ�ͳ��������ۣ��������ⷽ�棬AI �Ծɱ��ֲ��㣬����ṹ������������ͻ�ƣ�����δ�����ڡ� |
|
Sora�����������Ҳ�֪������������������ѧ��ģ���������Ԥ����pinn��Щ���� |
|
���ֲ����� ������ΪSora�Ǿ�����������Ƶ����ѵ�����ģ����ܹ��Ӻ�������ѧϰ��һ���ķ�ʽ�����бȽϵĺ÷����������ܹ����ɺ���ʵ��������һ�µ���Ƶ�� ��������ΪSora��û�о�����ʽ�ļල��ѧϰ�������ɣ����ܹ����ɷ����������ɵ���Ƶ����ֻ��ģ��ѧϰ������ʵ���ϲ����������ɣ������п������ɵ���Ƶ�����Υ���������ɵĴ��� |

|
|
��ʵSora��������������������⣬�����ϻ�����AIģ���Dz����пɽ����ԣ���Ȼ��Щ����AIģ�͵Ŀɽ������о����������Ǵ���ΪĿǰ�������ѧϰ��AIģ���Dz��ɽ��͵ģ�����ʵҲ��ĿǰAI����ڸ���� ����Ŀǰ�Ƚ�ǿ���GPT-4ģ����ʵҲ�Ǻ��䣬�㲢��֪����Ϊʲô��ʱ������ȷ�����𰸣���������ʱ�������Ƚ����Ļش𡣵����ܹ�ȷ�ŵ�һ���ǣ�����ģ����������ǿ�������ĸ��ʻ�Խ��Խ�ͣ�������һ�쵱Soraģ�Ͳ�������Υ���������ɵ���Ƶ�����ģ��˵��������ģ�Ͷ���������Ҳ��Ϊ�������������һ��������٣����ǵ������ֻ������أ�������е㺦�¡��� |
|
Sora�ǡ����������Ķ˵����������桿�������ڶ��������5����ʵ�������Ƶ���ݡ���ϡ��� ��Ȼ�Ƕ˵��˺��������������۾��ǣ�sora�������������ˣ������ᵽ����������������ײ��û����ʽ�IJ�����ģ�ͣ�ȫ�������������������������ġ� �����Ǵ���˯�߽β������ξ���Ҳ���Ƕ������ݵ�һ�֡���ϡ��� |
|
|
|
|
��ֵ����ƪACL��ACL������������������ |
|
��һ�����Լ�������������ⷽʽ��Ŀǰ�������� �ڶ���������Ŀ�꣬��ʵ����������Ƶ��������Ҫ�ľ���Ҫ��Ϊһ����ģ����ʵ���硱�Ĺ��ߣ�˼�빤�ߺͼ�����֤�Ĺ��ߡ���������ʵ��Щ���ӣ��������������˹�˵ĶԻ������Ǻ���ͬ�ġ� ��Ȼ����Ȼ��һЩ���ڴ����ݵķ������ô����������˺ܶࡰ��ͷ��ȥ�����Է�����ͨ����������ͼ��ѧ���������Ⱦɫ�ʹ�Ӱ�ͽ�ģ��������Щ��ԭ���ǵ������ι�ʽ�ģ��������˴�����ȥ���ƣ�������DZȽ�ǿ��ġ�������µ�˼ά������ʽ�� |
|
Sora��ô���ܶ����������ء��� ����һ������������һ��ͼƬ����������ʵ���������û�нӴ������� ��Ҫ������һ�����μǵ��Ӿ�ͼƬ��Sora�ͻ���Ϊ���������������ա��� |
|
ɶ�ж���ɶ�в����� ��ν�Ķ����ǽ��������Ի����ϵĶ��� ֻҪ���������ԣ���û�в���������������⡣ SoraĿǰ���ڵ����⣬Ҳ��ֻ���ص���ʱ��û�з���������������ⷽ�档 ���ſ��ɣ��ܿ죬Sora���ܡ����֡����������ˡ� |
|
���Dz���������Ͷι������ai���õ�������������������������ô���ǣ������������ŵ㣬��Ҳ������ȱ�ݡ� һ���ŵ�������ϳ̶Ⱥܸߣ������Լ����棬ֻҪ���Ͽ��㹻����ϳ̶��п���Խ��Խ�ߣ��������������ֱ档 ��һ���ŵ���������������С��һ����������ϵͳ����ȫ״̬�ռ��ģ���������ִ�10^100�̶ȣ������в���ȡ���п���ֵ��õ�����״̬��ai����Ҫ��ȡ����״̬��ֻ��Ҫ���ٵĵ���״̬���ܽ��������������������˼��㸺���� ȱ�����ڣ�ai��������ͳ�ƹ��ɣ����ֹ��ɺ���⣬һ�������������ݼ���������Ҫȫ�棬ȷ��������Ҫ�㹻רһ����ǰ����Ϊ�˷�ӳ��ʵ����������Ϊ�˱�֤��ȷ�ԣ���Ϊͳ��ѧϰ���ӹ���ʧ�ܵĿ����Լ�����������Ѱԭ����һ����������ͳ��ģ�͵�ƫ�ã����е�ai��ƶ�����ȷ��ͳ��ģ�͵�ѡ��ʽ�����ں�������ѡ�����ģ�ͣ��Ӷ����Ծ�ȷ��ϣ�����ʵ�ʾ��Ǹ������ۺ���������������������ǰ���ƻ����º���ƣ�Ŀ�Ķ����ڸ�ͳ��ģ����������Dz����㹻���aiģ�͵�ѡ�����Ҫ������ν�ĵ������������ϵ��������ѧϰ���������ڼ��������ϣ�ʧȥ�˿������ԣ���������û������ͳ��ѧϰ��ܣ���ʹ��չ���˴�ģ�͵ĵز�����Ȼ���Ѳ���������ơ� ��֮�Աȣ���ѧ�о���ͨ�������������ȡֵ���������ܵĹ��ɣ�Ȼ��Թ��ɽ�����֤�����ۣ������Ͼ��ȡ����ԣ����������ܻ����һ�����ȷ�Χ��������������Ǿ�ȷ�ġ� ���ԣ�ͨ��ai��ø���ϵͳ�ľ�ȷ���ɣ������ڴ����롣 ����������վ�������ѧ�ǶȵĹ۵㣬��Ϊһ���������ɱ��������ֵ�ϵľ�ȷ�Ȳ������塣 ����ܰ��Ѿ�ȷ��ѧ�Ĺ۵㣬ѡ��ͳ�ƿ�ѧ�۵㣬��һ���������ɸ�������Ͼ���(����ģ����������ģ�͵ľ���)�������壬��ô��ai�Ѿ������൱���ˡ����ֶ�����������֪�ϵIJ������������ai������������ai�Dz�ͬ�������壬����ai�����ķ�չ�����ֲ�ͬ��Խ��Խ�������ų����ͬ�����Dz���ʵ�ģ�����ʵķ�ʽΪ���ܲ�ͬ��ѡ���������Ҳ�Ǻ���Ȥ�����飬��Ȼ�����Ҳ��������еķ��������壬�Ǿ��Լ���չһ�����������塣��������������Ӵ���Ӱ����СһЩ�� |
|
Sora��һ�ֻ���Transfomer�ܹ���������ģ�ͣ�����ʵ�֡��˵��ˡ���������ϼ�Ԥ�⣬���������������кܺõ�Ч�������������ڿ������ɳ���1���ӵı�����Ƶ���ݣ��������ҵ�Ĵ�ҵ��Ϊ֮�� ���ǣ�Ŀǰ��Sora�������������ɣ�������������ֻ�л������ݵľ����ܽᡣ |

|
|
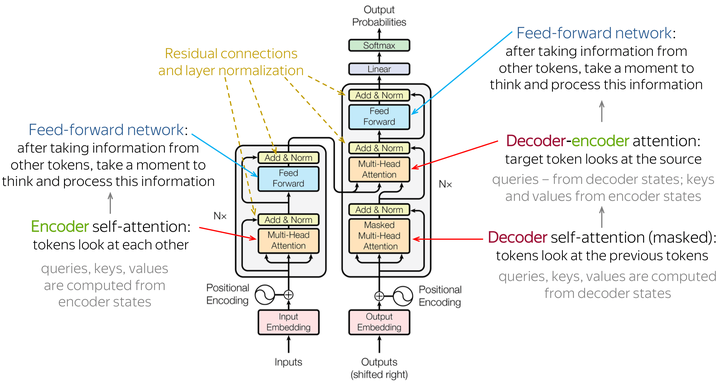
�����ϣ�Sora������һ��������ģ�ͣ�ͨ����������������������ܽ��ѧϰ�������չ��ʱ�չ��ɣ�����δ��һ��ʱ���ڵı仯����Ԥ�⡣�䱳����������ڼƵij�������ͨ���ݶȼ���Ͳ����ĵ������µȷ���������ģ�ͣ��Ӷ��ܹ��ƽ������������ݣ�����ģ��һЩ���ӵļ�����̡� |
|
|
Transformer�ܹ���������ģ�� ��ˣ�ij�̶ֳ�����˵��������ģ�ͱ������ڵ�������Sora��Ҳ���ڣ�ֻ������������һЩ���������ṹ����ƣ������ݵ�������ܸ��ã��ڴ����������û�б��ֳ����⡣�����ڸ����£��������������ٻ���û�м����ij����У����ܾͻ��ֳ�Ц������ ���������ɳ��������һ�����ӵIJ��������˺�������ͷ�ԣ������������ڿ���Ʈ��Ʈȥ��������һЩ��ȫ�����������˶����ɵĶ�����������Ƶ�������ɵļ�����������Ӱ�ӻ��ġ�ħ�á������ǿ��Եģ����Dz�������ʵ���������硣 �ٱ��磬������������̹����յ���Ƶ�У��ֳ����պ����ң���Ҷ��ܿ��ģ�������Ҳ�ڱ����ŶԴ�ҵĸ�л����Щ���Ƕ��ܸ��ܵ������ǣ������̶������յ��ⴵ����ʱ������û�����ζ���û�У���ͺܲ�������������ij�ʶ�ˡ� ��������ߵĵ�һ��Ůʿ�����ڿ������裬���Ҹ�������ʿ���ֽ�֯����һ�𣬺���ȻSora����ģ�´�ҹ��Ƶĸ��˳��棬���ǽ�������Ƶ���ݵĽǶ���ģ���ǻ������ģ���Щ�������������������ʶ����ֻ�������ݲ�����ģ����Щ���档 �ٱ��磬������������Ƶ�У�Sora��Ҫչ�ֵ��DZ��ӵ����Ժ��еľ�ˮ��������������̯��һƬ��״̬���ھ�ˮ������֮ǰ�;�ˮ������֮���״̬���ȽϷ�����ʵ��������Ǻ����Ե��ǣ�Sora��������ȷ���������б��ӵ��ˣ�����Һ���������������̿���״̬���������ʼ��״̬�����յ�״̬��Ⱦ�����������м�������������ȴ������ȷ��Ⱦ�� ��Ȼ������Ƶ���ݵ����ɷ��棬Sora�Ѿ�����ҵ�̳��ˣ�����ȡ�úܺõ��Ӿ�Ч����ʮ�ֱ��棬���Ѿ��ڳ���ȥ������������硣���Ƕ������������������ɣ�Ŀǰ��Sora������ò���λ������˵��Ŀǰ�����߱����֡����⡱�������� ��Ȼ�����ѧϰҲ��ͨ���ܽ������ʵ�ֵģ������˵�ѧϰ��������ȫ�������ݣ�������һ�ַdz���Ҫ���������dz���������������ܹ����ṹ���ƵĶ�����ϵ��������ѧϰ��Ч�ʣ����ܹ�ͨ���鱾����Ƶ�����������������ݽ����ּ����ġ�û�����Ķ������������������Դ��ѧϰ���Ѷȡ� ����˼��������Ҳ����������ḻ����������ʹ��������������������Լ�û�м����Ķ�������ͨ��������²²������������кͷ�չ���ɣ���Ҳ���������ѧ���������Ժܺõķ�չ��ǰ�ᡣ Ҳ�������������������ˣ����ֳ������ḻ�ˣ��ֻ��߿�����������ģ�ʹ�����ѧϰ�Ļ�����������ѧ������Լ������ôSora�ĺ�����Ǿ�����ʱ���ѧϰ�;�����ȡ���п��ܶ���������Ĺ�������ñȽϺã��Ӷ��ܹ����ɸ��ӷ�������ֱ�������ݡ� |
|
Sora ��ûȷѧ���������ɣ�������������world simulator������ģ�ͣ��� Soraû�дﵽ��Խ���ݱ��������з���ʵ�����ĵز���OpenAI Ҳ��ʾSora ��һ��������ɢģ�͵ġ�Diffusion Transformer�������������������ڴӾ����Ƶ���ݿ�����ȡ��Ƭ����֮��Ĺ������ݻ��Ķ�̬���̣����������Ϊ�������Ʒ�� �زĿ���Щ����Ƶ��ѧϰ���Ϸ�������������ʽ����ƷҲ�ͺ��������ֲ����Ͼ�������ʵʱ��ӳ������Ӱ��ͬʱ����ע���Sora��������������Ƶ��������Ƶ��С���ü�����������С�������������˾�����ʹ����������ͬһ������ʱ��������ʵ���硣 ������֮�����ϵ��ͳ�ƹ��ɣ������������������������ɡ���Ҳ����д��һ����ѧ��ʽ���Դ���Լ�����ɵ����ݡ�����ʱ����չ���������оֲ�������ȫ�ֲ��������������ƫ������... ��SORA�����е���ij�������ξ����硢�ɾ������������ɣ�����������ʵ�ɸС��������뵫�����������пա� |
|
|

|
|
һ����Sora�Ĺ���֮���� ����ʵ���롰���⡱�����������С������֪����Sora�ܰ��û���ʾ��������Ƶ���������״���Fliki���ԡ�Pictory���ԡ���ӳҲ���ԡ�?���Ƚ�����ģ����ܱ��ֳ����������ȶ��Ժ������ԣ����ܺ�֮ǰ���в�ͬ��û�й���ı仯��û�����˹�������ֽţ�Ҳû�����֮�ϵĿֲ��ȡ������dz���ʵ�İ�Ҳ������������������ƫ�� ������ᷢ�֡���ͬ������ά�ռ��˶�һ���ԡ���������羰��ʱ�䱣���ȶ����������ﻥ����Ժ������� |
|
|

|
|
OpenAI��Ϊ����������Ƶģ�͵Ĺ�ģ����������ģ�������������������磬they are purely phenomena of scale�� Sora ����һ������Ƶ������������һ�������������������棬������������ʵ�������ģ�⡣ ��������У�ģ����ͨ��һЩȥ����ݶ���ѧ������ѧϰ���ӵ��Ӿ���Ⱦ����������ֱ�ۡ�������Ч�����Լ����г������������������ Sora���õ�OpenAIģ�͡���DALL-E 3��ǿ�������ɽ�����ı�����ת����60��һ�����ĸ�����Ƶ�������ڶ���Ƶ��������һ��������ը������ͬ����֮��ս������Ϊ�ı���Ϸ�����Ӧ�ü���������Ӱ�Ӵ�ҵ��Ҳ��Ȼ����һ�����塣�����ż����ݽ������ִ�����ʽ�������죬�籾ֱͨ��Ƶ����һ����Ӱ�ijɱ���ֱ��Ĩ����0���Ļ���Ͷ�����Dz����ܲ��Ķ��ġ�һ������ֻʣ��硢���ݡ�����...����Ա������������Ӱ���ƹ⡢�����������Ⲩ���Dz����ܲ����µġ� ��Ȼ�¸��˿���Ҳûʲô����ҿ���������������Sora���������������������������� ----------------- SoraΪ����ָ����������ģ������һ���ǿɳɾ͵���Online�Ρ� �����������Ǹ�����ģ��ô���� ����Soraȷ�Ǿ��ޣ�������αװ�ɡ���Ƶ����ģ�͡����������沢��Ϊ�������������룬������Ҳ�Ǹ�����ģ�ͣ�������������ģǿ������ �� |

|
|
��������Ҳ�Ǹ�����ģ�� Video generation models as world simulators Sora���ˣ���ʵ�������ˣ�����������ȷʵ�ḡ������... ��0��1���������ӿ�֣�����Sora�Ѹ������ܺ���ʾ�� ��ChatGPT��Dall-E��������ģ�ʹ�����������档��չ��������ز��������ǽ���Ƶ����ģ�ͷ������������档����������������������ʵ��ֻ��һ��֮ң�� �Ҳµ�Sora��Ӧ����Ӧ������Ϸ��������ģ����פ��������ð�գ��ֻ��ٴη��ӳ�����˼��������ɡ� |

|
|
|

|
|
�����������˹������Ѳ��ڶ��������ǵ�����Ҳ��������ģ��ô�����δ���췽ҹ̷�� ��ͬ�������˵���2��ͼ����̨�ʡ�����û���ʸ���ʲô������ʵ������ȷ�е�����˭Ҳ����ȷ�����Ҳ��ǡ�������������û��������550W��������������֮�С� |

|
|
?��ôȷ���Լ������ⲻ��LLM��ģ�͵Ĵ����� �Ӻ��͵۹������д��ԣ��ٵ���˹��������99.9%����-��������ʵ�ۡ�������һ�ַ������Ļ��� ----- �����������������㵥Ԫ�����ݡ�0���͡�1��������֮������ż��㣬ǧ�˰�̬�����������ɴ˶���������ʵ�������Ҳ����...but it from Qubit�� |

|
|
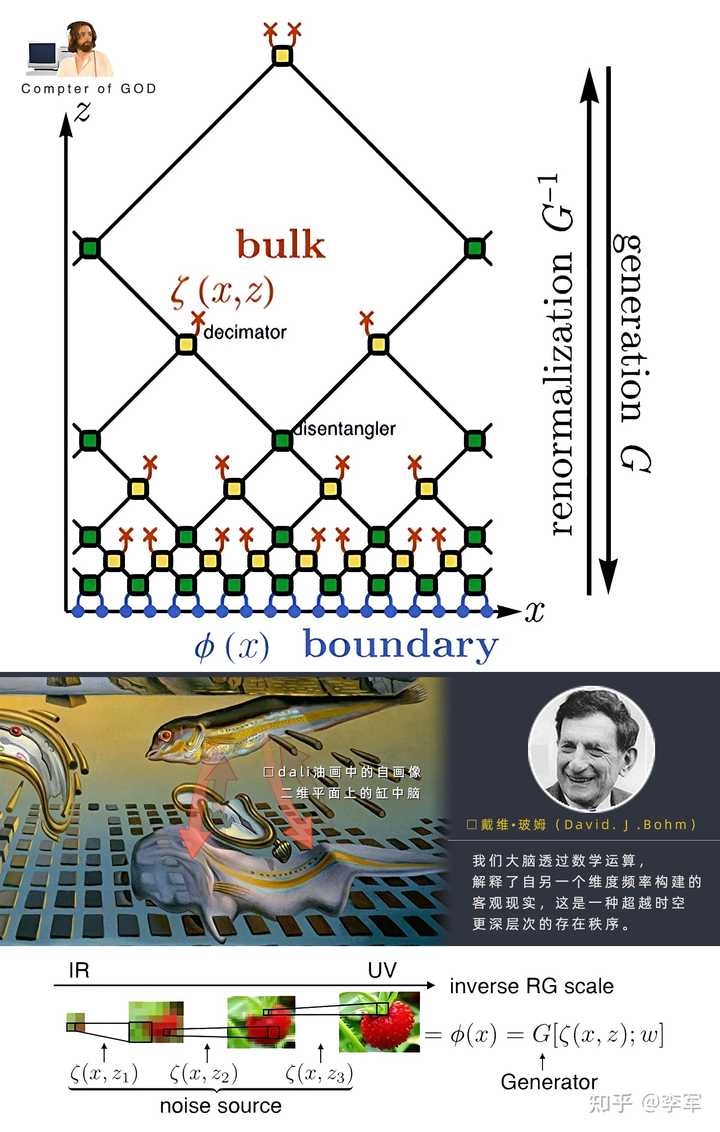
����ǰ�����ѧϰ���͡�������Ⱥ��(renormaliztion groups)�ɽ����ϸ�ӳ����ۣ�DL��RG����ͬ����һ���촰�����������о��е����ֹ۵㣬�����˳��������� ����ѧ��David Bohm����˵���������ǵĴ�������ѧ���㣬������������һ��ά�ȵ�Ƶ�ʹ����Ŀ���ʵ������һ�ֳ�Խʱ�յĸ����εĴ������� �ֻ������Ϊ������������Σ�����ղ�ס���� �������Ǹ���ż�����������������һ������һ�������룬����Сѧʱ������ʱ���ÿ�������糡���ġ���ͨ�����Ρ���Ҳ�С����Կ�����������Ļ��ӿ�ֳ�����ɫ����С�ˣ��������衣��Ҳ�������棬�Լ�������һ����������ij����ĵ���~ |

|
|
��仰���ڿ���˵�ɣ�һ���ݻ��ŵ����ӱ��ؼ��ϴ�����������硣�������������� Ҳ���������Ľ������ԡ��������̨������������������ڼ�������������Ϥ�����粻��һ������online����ƽֱʱ����ʽչ������ʾ���ϡ�����һ����Ҫ�鹦�����о��µ�����ģ�͡� �������������ѧ����ϲ��������5ëǮ�ģ��ƻÿ��ͺã� ��.��һ��һ���磬һҶһ��� ? ��0��1���������ӿ�֣�����Sora�Ѹ������ܺ���ʾ��OPENAI�ĺ�ΰ��ͼ�ǣ���Ƶ����ģ�ͱ�ɡ�����ģ���������������ƺ�����һ���ˡ� |

|
|
��� ?����LLM�ķ��㣬��˭�����أ� �����Щ���ӻ��ͷ�۵���ҵ������ChatGPT�ȴ�ģ�ʹ�����æ��͵����Ϸ���ڡ� ��δ����������磿������û��˵������Online����Ҫ�� ����GAN ������ʱ���������ӡ� û�����ij��Loss������ָ�����磬�ɸ����߽������ʵ �������µ����õ�̽�����������Ĵ浵�� ȫϢԭ��֮�£������Զ��ƺ���һ�������ʵ��������Լ������������Ӳ�����ɣ�Ҳ������Online�Ĵ��������� |
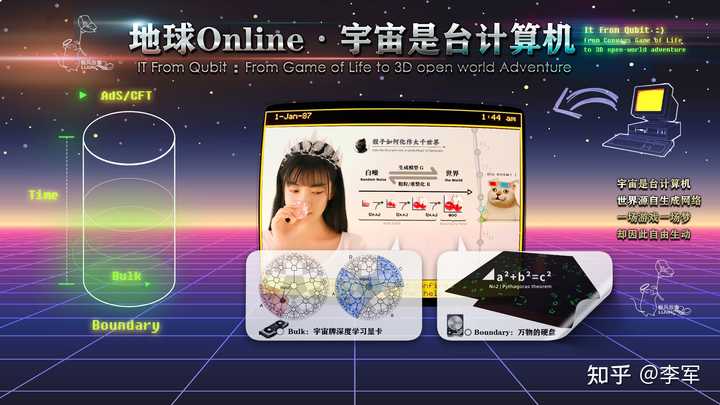
|
|
����һ̨����������������̼��Կ� ��ǿ����������̨��������趨�����ϵ۵�����զ�ͻ����˴�ǧ�����ء� ����������������Online����ģ�͡����ø��Ƚ�����˼��ʽ�����ȣ� ������ʦdali�з��ͻ��С���������Ľ��塷����the Disintegration of the Persistence of Memory��in 1954�������ЩȤζͼ�η�һ����ᷢ�֣� ������������֮�С����ӻ�ƽ���ϣ������˱�ɴ��Ĵ����Ի��� һ����ձ�־����������...��ͬ����ڴ����ϵġ���ά���д��ԡ�����ġ���ɫԴ���롱�� |

|
|
��������������ͻ� ���������ƺ��ܺܺõ���ʾȫϢԭ��������ڹ���£�ʱ���ڲ���bulk������������������ʱ�ձ߽磨boundary���ϵķ��������ӳ������Ӧ��չ�ֳ�һ��N+1ά������Nά���治��˼��Ķ�ż�����ͻ�����Ԥ�ԣ� �����۸����ɶȼ�ľ�����������������ά�ȵ�ʱ�ռ��Ρ������ͼ��������������չ�ֳ��������ڲ����߽硢�����ز㵽�Բ�... Ҳ��������������ģ��˼������㡣 |

|
|
�˴���άƽ���ϳ��ַḻ��Ϣ����Ť�������桱����С��������������ʵ��ͬ���칹��From bulk to boundary �ƺ������ߣ��ڱ߽���Ϣƽ���ϵġ��㡱����ռ�������ӳ��˴˺�Ӧ����ӳ��Ȥ���̲��ǹ�����ȷ��ʽ... ��Ʈ���ʱ�ӡ�������������������ƺ���ʾʱ�ղ����þ�һ���������������ӱ��غ�����˻���ӿ�֣� it from Qubit�� һ�ж��Ǽ���֮�ϵ��Ծ���������������д�������~~ ��ƽ�Ċ������ά�����ԣ������ӱ��غ�����ʰȡ����ϸ�ڡ����������ӵذ�����ƽ�Ĵ����Ի���������Ǵ��ڣ���������ʵֻ������߽�Ķ�άƽ���ϣ��������Ӧ��֮�أ� ������Щ����ά�����ԡ��ճ����������ӱ��غ�����ʰȡϸ�ڣ������������в����Լ�������ȫ��ͼ�� |
|
|
�����ij��Loss������ָ�������磬�ɸ����߽������ʵ �������µ����õ�̽�����������Ĵ浵�С� ����GAN�����ѧϰ���ã�ԭ����ά������Ҳ��������3D������Ӱ�Ŀ��ܡ���������Щ��λС�˶����Ǵ���3D�۾�������һ����Ϊ��������֡����¾硣 Are We living in the Simulation ?? in the Ads/CFT Correspondence,Deep Learning Relies on Renormalization Group. in "Bulk"we see the Organizational form of ��Simulation��. as to the Emergent Universal mind��in the sight of God��just something like the description in dalis painting ��The Disintegration of the Persistence of Memory�� : ) Time ,space, gravity are just a dream in this quantum-ocean�� ˮƽ���㣬�͵����Զ��� |

|
|
ʱ�����⣺ ���ǵû��յ�ά�ع�ʽ��ʱ���ǣ�ʱ�䲢������ô! Page Wooters������Ϊ�����ڲ��۲�����˵��ʱ���Ǿ�����ӿ�֣������ⲿ�۲��߶��ԣ�ʱ���Dz����ڵġ������ڲ��Ĺ۲��߲����������Ӷ��е�һ��֮�������۲쵽����֮��IJ��졣���۲��߿�����Ϊ�����Ǿ�ֹ���ޱ仯�ģ�����������ʵ����ȴ�����˼��Ȼ��ҵı仯�� ��������������ǰ������Ǿ�ֹȫϢ�ġ��������ǣ�����ȴ����ӿ�ֶ��������ǵ������ǡ��������������ѡ�������ʵ��ߥ�������ľ�����Ӱ... �ص�����Ļ��⡸���桹��������һ������ʽ���磬�����ǵ������������һϵ�С������ؼ��ʡ����̶������ƽ�������������ǰ��չ������ �����㲽��������ı߽绹�ڲ�ͣ��չ����ʵ������Ϊԭ�㣬��ȥδ������ϸ�ڲ�����油�꣬�����������ܵĺ���ӿ�֡� ������Sora��ֻ�Ǹ���Ƶ����...��һ�����������ܴ�������������������ʱ���ع˼������̣������Ҳ������������֡� ��������~���� Online���Sora˵�����Ê��ⷽ���Ļ�ͦԶ�ء� |

|
|
��ȫϢԭ��������ģ�ͣ��Զ����У���ӭ����Ȥ�Ļ��һ�����ģ� |
|
���������ɵı��֡��͡��������ɱ�������������������ȷ����ġ��κζ���������������ܣ��ѡ�����ô֪���˲�������ʵ�ֵġ�������ߵ��ˣ�����ǻ����������������� ����һ���ģ�AIGC�ĸ���ģ��ѧ����ֻ���ǡ��������ɵ��Ӿ����֡�����Sora��������Ƶ�ͼ���������������ѧϰ���ĸ�����һ��ʱ���ϵ����塣���������Ƕ���2dͼ���̺����������չ�����˵������ģ��֪��ʲô�Ǵ���ʲô��ˮ����Soraѧ���ľ���ʲô����ʻ��ʲô�����У�ʲô����ײ�� ������ռ��2d��չ��2d+1d֮����Ƶ�������Ժͺ�������Ȼ��������ģ�͡���Ҳ����ֵ�þ�̾�ĵط�������������ģ�ͣ�Sora��Ȼ�Ǹ������������ˣ������������������������µĹ�����Ŀǰ��������û�С� |
|
|
| [�ղر���] �����ر��ġ� |
| ��һƪ���� ��һƪ���� �鿴�������� |
|
|
|
| ��Ʊ�ǵ�ʵʱͳ�� ��ͣ��ѡ�� ��ʱͼѡ�� ��ͣ��ѡ�� K��ͼѡ�� �ɽ���ѡ�� ����ѡ�� ������ѡ�� �������� �������� ���� MACDָ�� KDJָ�� BOLLָ�� RSIָ�� ���ɻ���֪ʶ ���ɹ��� |
| ��վ��ϵ: qq:121756557 email:121756557@qq.com ����ƻ� |