
| |
|
|
| 首页 淘股吧 股票涨跌实时统计 涨停板选股 股票入门 股票书籍 股票问答 分时图选股 跌停板选股 K线图选股 成交量选股 [平安银行] |
| 股市论谈 均线选股 趋势线选股 筹码理论 波浪理论 缠论 MACD指标 KDJ指标 BOLL指标 RSI指标 炒股基础知识 炒股故事 |
| 商业财经 科技知识 汽车百科 工程技术 自然科学 家居生活 设计艺术 财经视频 游戏-- |
| 天天财汇 -> 科技知识 -> 上海AI lab什么来头,好厉害,挺高产? -> 正文阅读 |
|
|
[科技知识]上海AI lab什么来头,好厉害,挺高产? |
| [收藏本文] 【下载本文】 |
|
刚接触自动化驾驶,阅读第一篇paper是ECCV2022 《BEVFormer》。被它Spatial Cross Attention采样方式折服,与传… |
|
简单回忆一下之前的帖子和部分网友的评论: 帖子里面提到2点: 第一,开源代码开的不全,大部分都是从别人的github拉过来的代码,自己论文中实现的核心代码基本没有; (顺便反驳下@刘斯坦的回忆,之前帖子并没有说不能使用别人的代码,而是说自己的核心代码也要放到github上,不能只放github上已有的代码)。此外,对别人提的issue置之不理,甚至直接关闭。 第二,论文写的不详细,导致无法复现,可能存在学术不端 (这里再顺便反驳下@刘斯坦,复现别人论文的时候,如果作者完全公开各种细节,复现的结果至少和论文中公布的结果基本一致。比如你在ImageNet上训练一个Image Classification模型,没有多少人会说是随机数导致的吧)。另外,至于是不是学术不端,根据@程明明老师的学术规范与论文写作的第1课PPT里面的第10, 11, 和12页内容以及第4课里面的第27页内容,大家可以自行判断。 帖子里面的评论包括: 1.PKVD 论文的作者的文章不要看,基本复现不出来。应该是这篇文章,Point-to-Voxel Knowledge Distillation for LiDAR Semantic Segmentation (CVPR 2022)。刚看了下,作者已经把issue关了,https://github.com/cardwing/Codes-for-PVKD。 2.SCPNet 被法国的一个组给锤了。SCPNet 应该是这篇文章,SCPNet: Semantic Scene Completion on Point Cloud (CVPR 2023, Highlight)。同样,作者已经把issue关了,GitHub - SCPNet/Codes-for-SCPNet: SCPNet: Semantic Scene Completion on Point Cloud (CVPR 2023, Highlight)。 另外,锤他们的法国论文应该是这一篇,PaSCo: Urban 3D Panoptic Scene Completion with Uncertainty Awareness,https://arxiv.org/pdf/2312.02158.pdf。在论文第10页的“6. Implementation Details”章节的最后一小段有这么一段话,“For SCPNet, despite many email exchanges with the authors we were unable to reproduce their reported performance using their official code as also mentioned by other users“。 根据帖子内容和帖子里面的评论,有问题的组应该是ADLab组ADG@PJLab,他们的其它github repos 包括但不限于: GitHub - PJLab-ADG/neuralsim: neuralsim: 3D surface reconstruction and simulation based on 3D neural rendering. GitHub - PJLab-ADG/3DTrans: An open-source codebase for exploring autonomous driving pre-training GitHub - PJLab-ADG/OpenPCSeg: OpenPCSeg: Open Source Point Cloud Segmentation Toolbox and Benchmark 附带躺枪的组: 1.OpenDriveLab, GitHub - OpenDriveLab/UniAD: [CVPR 2023 Best Paper] Planning-oriented Autonomous Driving 主要还是论文中没写明细节问题。至于是不是学术不端,参考上面提到的第二条。 历史不良记录: 1.根据下面知友的帖子和评论,2019年CVPR有哪些糟糕的论文?,里面提到的论文应该是这一篇,Finding Task-Relevant Features for Few-Shot Learning by Category Traversal (CVPR 2019 Oral),https://arxiv.org/abs/1905.11116v1。一作的名字叫 H. Y. Li。不知道是不是那位李姓老师。 |
|
来头是指?人才的来头很明显(从你列的paper的author list里)哈,消化了一些商汤系的优秀青年学者;制度上的来头… 不搞行政描述不准确,反正就是一个级别挺高的国家实验室就是了 ;前年找faculty position的时候大概social打听过一些,那时候给人的感觉是不对外招聘,大朋友们不同信源略有差异但大差不差,x年有x个phd hc云云,和其他国家实验室规模听起来是互相印证的,这两年也听到很多小朋友的描述,大多是心向往之,想去那读书,想分流去那云云… |
|
我就问一句,全国有哪个实验室和上海AI Lab一样钱多事少的? 钱比他们多的P事也多,事比他们少的钱给不够。他们的研究员工作很自由,没啥KPI考核,正常上下班,同时钱和计算资源拉满,不让人用爱发电。我听说的是普通博士研究员给的是80w+。 现在他们和复旦一起做的MOSS,他们自己的openMMLab,internGPT都是中国人工智能领域非常重要的组件,最近还拿了cvpr2023最佳论文奖。我没记错应该是继kaiming在2015年以后第二次颁给国内机构。 现在看人工智能领域像上海AI Lab这样集中力量办大事才是正解。未来产业升级肯定和AI脱不开关系,如果要和美国掰手腕靠的得是创造力、资源整合能力、团队协作能力,靠996卷毫无意义的OKR是没用的。 不知不觉我身边已经有很多人在上海AI Lab工作/实习了,感觉那里就像是AI的黄埔军校一样。唯一的疑惑就是上海这样大成本的投入能维持多久?会不会新来一个书记觉得这玩意没有产生收入就砍经费呢? 考虑到现在这个问题下大部分的回答都是“AI lab不赚钱,是商汤的不良资产”。我觉得AI lab未来可能危险。其实AI lab已经做出了很多有高价值的东西,就是不体现在公司账本上而已。唯变现论的短视思潮已经让我们失去了openAI,现在我们养出了一个最接近openAI的机构,还是要担心被自己人阉割掉――甚至不用美国出手。 |
|
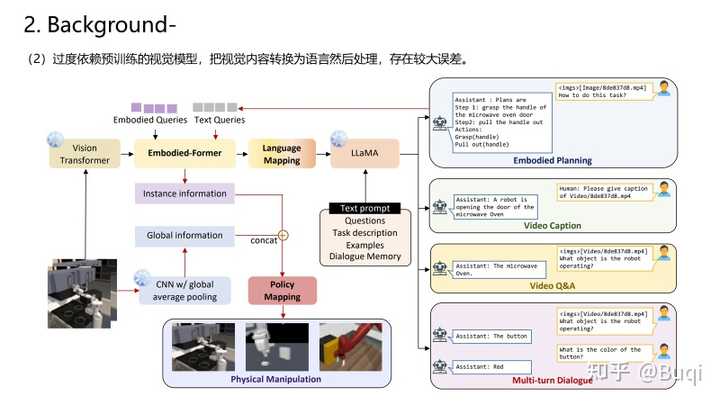
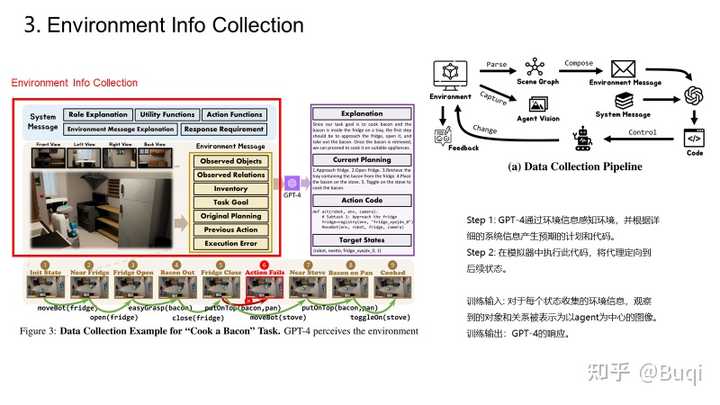
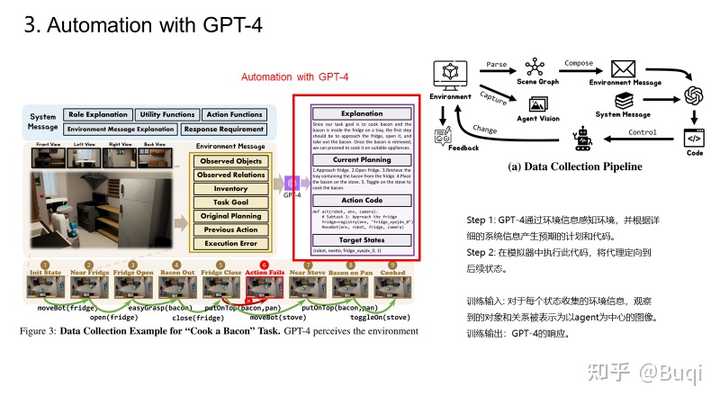
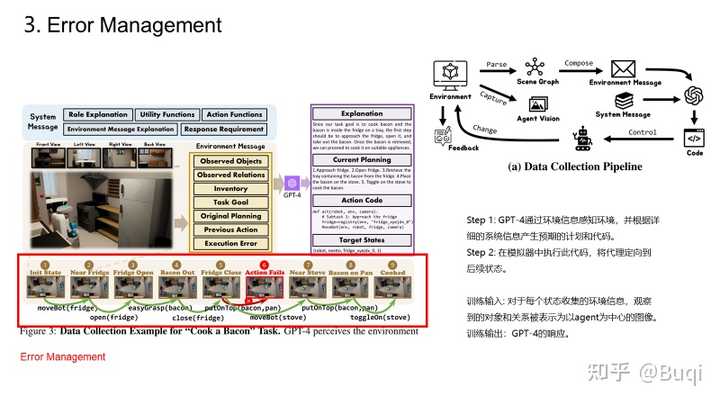
【具身智能】Octopus: Embodied Vision-Language Programmer From Environmental Feedback【写在前面】 这篇是上海AL lab的一篇关于具身智能的工作,它实现了令agent与环境交互从而完成task。这篇文章在我写分享的时候(2023.10.22的时候还在under review的状态)。这篇文章中提到的Programmer的训练思路实际上很简单,分为三步,分别是:(i)基于视觉模型从环境中提取信息;(ii)基于LLM进行分析,获得指导agent的code(以提供强化学习所需的State以及Action),以及(iii)基于强化学习学习策略(评估+提升),最终得到最优的机制,从而指导agent从环境中学习。我觉得这篇文章所提出的视角是很有趣的,接下来我依旧用PPT来简单介绍一下这篇文章(有组会需求的同学按需自取)。 老样子,首先给出paper和demo的链接: https://paperswithcode.com/paper/octopus-embodied-vision-language-programmer?paperswithcode.com/paper/octopus-embodied-vision-language-programmer demo: https://choiszt.github.io/Octopus/?choiszt.github.io/Octopus/ 接下来的一段时间,我会不断关注具身智能以及元学习的工作,并不断更新我在github上的论文库,里面收录了元学习与具身智能相关的经典与最新文章(依旧在不断更新中): |
|
|
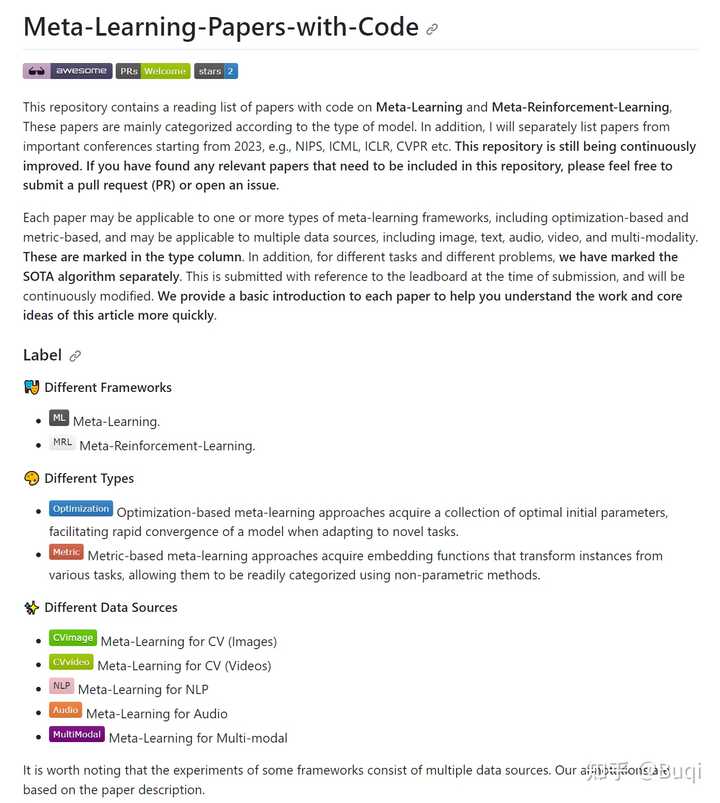
元学习文章与代码: https://github.com/WangJingyao07/Meta-Learning-Papers-with-Code?github.com/WangJingyao07/Meta-Learning-Papers-with-Code?github.com/WangJingyao07/Meta-Learning-Papers-with-Code 具身智能文章与demo: https://github.com/WangJingyao07/Embodied-AI-Papers?github.com/WangJingyao07/Embodied-AI-Papers?github.com/WangJingyao07/Embodied-AI-Papers 元学习baselines: https://github.com/WangJingyao07/Meta-Learning-Baselines?github.com/WangJingyao07/Meta-Learning-Baselines?github.com/WangJingyao07/Meta-Learning-Baselines Overview via PPT |

|
|
|

|
|
|

|
|
|

|
|
这页PPT里引用的图例是来自SayPlan,因为是动图,我在下面两页里给出细节: |

|
|
|

|
|
|
|
|
|

|
|
|

|
|
|
|
|
|
|
|
|
|
|
|

|
|
|

|
|
|

|
|
|

|
|
|

|
|
|
|
主打一个羡慕里面实习的同学,据说日常能用32-128张a100跑任务,还能做一些非有钱不能做的collection或者training。 |
|
开始是商汤找的后路,这么多智力资源可惜了,挂靠国资,既能保证活下去,又能不浪费他们的才华,主打投资长远,算是新兴科研实体了。类似的还有智源,都是学校+城市+公司三位一体的运作模式,感觉这个运作模式还是不错的。 |
|
他们卡很多,我目前看到osdi,asplos,eurosys等系统顶会上都有他们的工作,主要是做分布式deep learning training/scheduling,以及hyper parameter optimization。 不谈其他的,确实蛮高产 |
|
不愧是国家实验室的危机公关, 指出上海AI Lab多篇论文涉及学术不端的回答,(一天七百赞),在作者刚刚编辑完回答以后就被删除了 如果这就是国家实验室的学术态度,那也就这样吧 |
|
里面太具体的也不清楚,但是人才和大佬是真的多啊。因为工作的原因,只跟一位李师兄有接触,能力很强而且人也有才,有篇cascaded的文章极大影响了我的科研品味,可以窥见lab的实力人才储备了。国内很多高校的老师要么脱离一线只会push和接项目,要么只会夸夸其谈追热点。这种跟高校挂钩但是又不沾染高校那些腐糜气质。比如李师兄这样踏踏实实做科研的在高校就很少很难看见。只可自己惜不够到lab实习。至于有的人觉得这里太虚了我就很无语,世界上能比上openai的能有多少?而且比如李师兄,就在踏踏实实用ai改变身边的世界,不是很好。他当年给我讲过在电网和市政方面的工作,可能没那么高大上,但是simple yet effecient,这才是正确的科研。也不知道近年有哪些新的工作。 |
|
不赞同别的回答,这种机构就是为了发文章而生的,不看文章看什么。科研界就是暂时难落地的,好落地的叫什么科研,那是工程 |
|
表面上看是上海人工智能实验室。 实际内核全是港系学者学生,沪的学生和老师只不过在里面挂名而已,拿不到什么资源。 大概就是港系学派浪费国家经费养肥自己(包括自己的学生)的一个基地吧。 |
|
高产啥?论文? 那确实传承了论文厂的基因 |
|
看了之前那篇被删掉的吐槽文,我觉得吐的槽算是valid,但绝对上升不到学术不端的程度。我凭借记忆回忆一下那位知友吐的槽: 一大类问题是在github上提issue问用了多少GPU之类的细节(影响了batch size),repo作者答不上来直接关闭issue。这一类问题,大家经常做实验的可以扪心自问,是不是有些中了大奖的实验找不回详细参数的?当然作为优秀的研究机构,在模型管理上不严谨是值得诟病,但你要说这属于学术不端,未免太小题大做了吧? 类似的几个问题都集中在一个焦点:sota无法复现。甚至吐槽的知友还很明确的提出:我不关心你公开的模型是不是sota,我只关心你怎么训练出来的sota。我理解,作为学术界的研究者,要出论文要刷sota,搞一点incremental innovation,首先得复现sota,否则所谓刷sota是无从谈起的。但你不得不承认妄图复现一个训练中偶尔中的大奖几乎不可能,各种超参数不提,最大的影响因素是系统的随机性,所以比较好的论文会反复做实验提供每一个超参数点的variance。但现在这些BEV模型的训练如此昂贵,每一个超参数都训练10次并不现实。 UniAD,OccNet,都属于结构类似,思想类似,提供了公开模型佐证其有效性的,对于我,从业者而言,这就足够solid了,省掉几百个W是至少的。至于能否基于nuScenes复现整个训练过程,拜托,那是刷点的研究者们在乎的事情好吗?我为什么要在这么一个只能做PoC的弱鸡数据集上复现? 吐槽的知友花费无数时间和计算资源之后复现不出sota那种愤怒的心情完全可以理解,我的想法仍然是相反的,能够复现训练属于加分项,只要公开的模型能sota,这篇文章就不能属于学术不端了,除非他用了一些没公开的trick或者数据进行了额外的操作,比如在什么inhouse超大规模数据集上预训练之类的。 不过确实有一篇论文,没有放出sota的模型,只有代码,那么这篇论文是否学术不端确实是存疑的。这是各式吐槽中唯一一条我觉得值得讨论的。不过那论文也不是他们的明星论文,我也就无所谓了。因为只要没有放出sota模型的论文,我现在一律不信。 还有一大类问题是吐槽复制黏贴别人的代码,这个我就不提了,这属于值得鼓励的行为哈,请大家在版权允许范围内加大复制黏贴的力度。 最后,OpenDriveLab是上海AI Lab的一个实验室,吐槽的知友列举的一些文章有些其实并不是OpenDriveLab的文章,OpenDriveLab是那个出BEVFormer和UniAD的实验室,明星论文一般是这个实验室的。上海AI Lab还有其他自动驾驶相关的课题,其实和OpenDriveLab关系不大,不可等同视之哈。 |
|
不敢发,我怕被注销 |
|
有人备份学术不端的回答了吗……还没细看就没了,主要有老师也转发了 |
|
事业单位,由上海人工智能创新中心发起设立的新型研发机构。与多个知名高校签订战略合作框架协议,建立科研人员双聘和职称互认机制。 首页_上海人工智能实验室?www.shlab.org.cn/ |

|
|
|

|
|
来源:复旦大学新闻文化网 |
|
|
来自:上海市人民政府 |

|
|
来自:华东师范大学 |
|
|
来自:上海交通大学 还有很多高校,有点懒就不全找出来了。 |
|
问题问的强啊,第一次听说“自动化驾驶”这个说法。OpenDriveLab是个非常年轻的团队,刚成立不久,目前还在稳步、低调发展,都是一些微小的工作。真的很微小。键盘侠/各位大佬轻喷。以后下面一定会有个评论是,“工作都是灌水、凑数”之类的。没事儿,网络嘛。 团队工作一览:https://opendrivelab.com/publication/CVPR 2023自动驾驶挑战赛:CVPR 2023 Autonomous Driving Workshop 欢迎参加! 上海AI Lab还有很多其他优秀的团队,例如OpenGVLab书生,手动点名文海,高鹏,工作都做得很不错!大家多多关注! 欢迎大家加入这个单位! 其他新型研发机构也不错,也欢迎加入他们! |
|
本文首发于微信公众号 CVHub,未经授权不得以任何形式售卖或私自转载到其它平台,违者必究! |

|
|
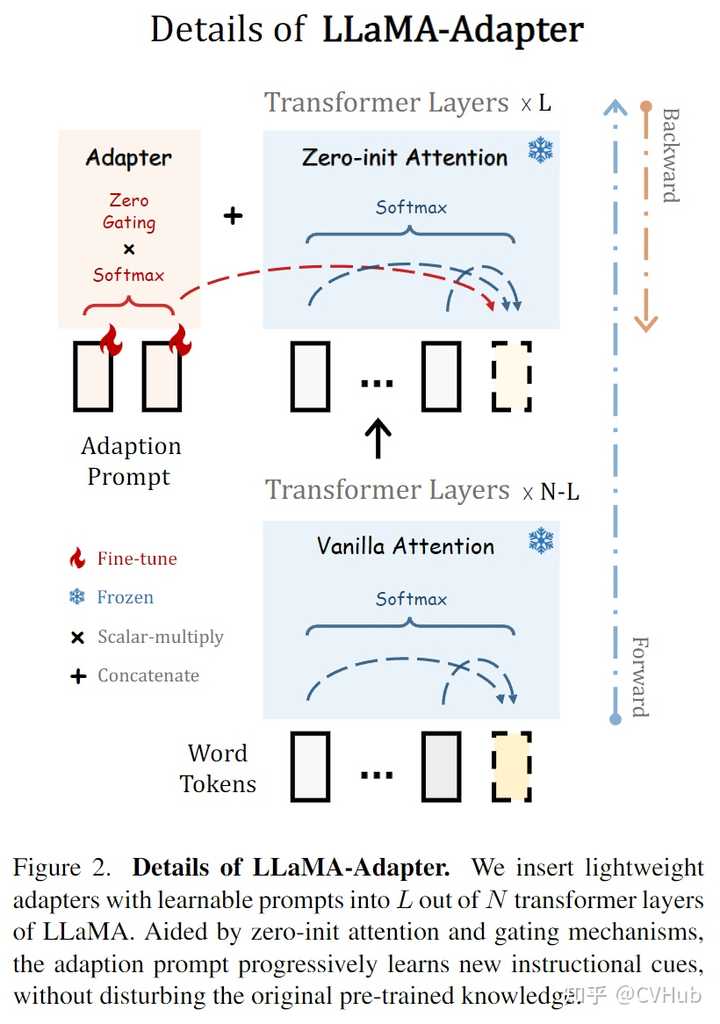
Title: LLaMA-Adapter: Efficient Fine-tuning of Language Models with Zero-init Attention Code: https://github.com/zrrskywalker/llama-adapter PDF: https://arxiv.org/pdf/2303.16199.pdf导读 Instruction-Following指令跟随方法:是指通过使用高质量的任务指令及其对应的输出,作为一些输入输出对,来进行模型微调,从而增强预训练模型以帮助模型更好地理解用户意图,生成更为准确的回答。 本文主要介绍了一种名为LLaMA-Adapter的轻量级适配方法,可以高效地将LLaMA模型微调为指令跟随模型Instruction-Following。该项目通过使用52k的self-instruction训练数据,冻结LLaMA 7B模型参数,并引入1.2M可学习参数,在8个A100 GPU上的微调时间不到1小时即可将LLaMA调整为良好的指令跟随模型,并且支持多模态(文本与图像)输入。LLaMA-Adapter可以自适应地将新的指令提示注入LLaMA中,同时有效地保留其预训练的知识不被破坏。 通过高效的训练,LLaMA-Adapter可以生成高质量的响应结果,其效果与完全微调7B参数的Alpaca相当。 引言 Alpaca利用大规模语言模型LLMs和self-instruction学习的方法,将LLMs Fine-tune为指令跟随模型。该模型可以理解并回答自然语言中的指令或命令。然而,**LLMs完整的Fine-tune计算非常耗时,且不支持多模态,并且不易转移到不同的下游任务。** 因此,本文介绍了一种名为LLaMA-Adapter的轻量级适应方法,该方法可以在LLaMA的基础上进行Fine-tune以更高效地将其转换为指令跟随模型,并且可以扩展到多模态输入。这种方法引入了可学习的适应提示,并将它们预置到更高的transformer层的输入文本标记中。通过零初始化的注意力机制和零门控机制,适应性地将新的指令提示注入LLaMA中,同时有效地保留其预训练知识,从而生成高质量的响应。 相比全微调的Alpaca模型,LLaMA-Adapter提高了资源利用率。具体而言:在LLaMA较高的transformer层中,添加一组可学习的适应性提示作为前缀prefix,以注入新的指令到LLaMA中。为了避免在早期训练阶段来自适应提示的噪声,作者修改了插入层的vanilla注意机制,将其作为可学习的门控因子进行零初始化。将门控因子通过零向量初始化,可以保留LLaMA中的原始知识,并在训练期间逐步融入指令信号。这有助于稳定学习过程,并提高最终模型的指令跟随能力。 总的来说,LLaMA-Adapter具有以下四个主要特点: 仅更新1.2M个参数。 相比于更新完整的7B参数,本项目在训练过程中冻结了预训练的LLaMA参数,并仅学习和更新顶端的适应性提示层参数(1.2M个参数)。结果表明它具有与7B Alpaca相当的指令跟随能力。仅微调一小时。 由于轻量级参数和零初始化门控机制,LLaMA-Adapter的收敛成本少于一小时,在8个A100 GPU上快于Alpaca三倍。兼容性和灵活性高。 对于不同的场景或下游任务,只需插入相应的适配器,就可为LLaMA注入不同的专业知识,所以这种适配器的方法是非常灵活的。因此,只需要为每个不同的下游任务配置一个1.2M的适配器,再共同连接一个7B模型,即可实现不同任务的适配,这种方式是非常灵活的。支持多模态。 除了文本指令外,LLaMA-Adapter还可以扩展到图像输入进行多模态推理。通过简单地将图像token添加到适应提示层中,LLaMA-Adapter在ScienceQA基准测试中表现出极具竞争力的结果。方法Learnable Adaption Prompts 基于52K" role="presentation">52K52K条指令-输出数据和一个预训练的 N" role="presentation">NN 层 LLaMA transformer 模型,使用一组可学习的适应性提示进行指令跟随 fine-tuning。作者将每个 transformer 层的适应性提示表示为 {P_l}_{l=1}^L,其中 Pl∈RK×CP_l \in \mathbb{R}^{K\times C}, K" role="presentation">KK 表示每个层的提示长度,C" role="presentation">CC 等于 LLaMA transformer 的特征维度。这些prompts被插入到 transformer 最上面的 L" role="presentation">LL 层中 (L≤N" role="presentation">L≤NL \leq N),以更好地调整具有高层语义的语言表示。 |
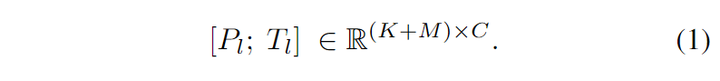
|
|
如上公式所示,Pl∈RK×C" role="presentation">Pl∈RK×CP_l \in R^{K \times C} 表示第 l" role="presentation">ll 层的适应性提示,K" role="presentation">KK 表示每个层的提示长度,C" role="presentation">CC 等于 LLaMA transformer 的特征维度。Tl" role="presentation">TlT_l 表示第 l" role="presentation">ll 层的长度为 M" role="presentation">MM 单词token。适应性提示将沿着token维度作为前缀与 Tl" role="presentation">TlT_l 进行连接,以此来指导生成上下文响应。 |
|
|
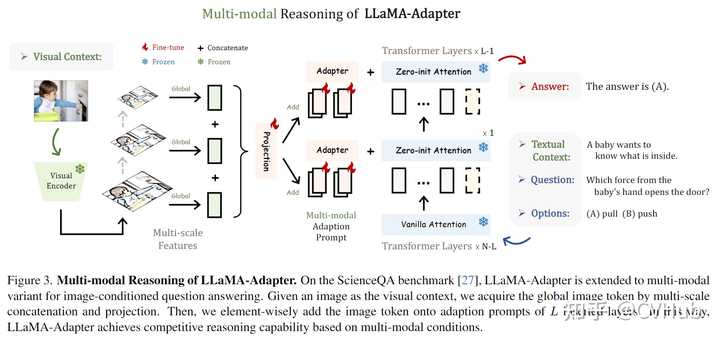
LLaMA-Adapter模型可以通过轻量级的适配器来对预训练的LLaMA语言模型进行fine-tuning,使其适应指令跟随任务。适配器由可学习的提示层组成,并且插入到LLaMA的N个transformer层中的L out层。通过零初始化的注意力和门控机制,适应提示层Adaption Prompt可以逐步学习新的指令提示,而不干扰原有的预训练知识。 Zero-init Attention LLaMA-Adapter模型框架适配器机制通过在预训练语言模型的基础上,增加用于新任务的小量特定参数,从而提高其在多领域下的表现。其中,作者提出了零初始化注意力机制,避免了在训练初期,随机初始化的适配器带来的干扰,从而损害微调稳定性和有效性。作者提出了一个基于零初始化的注意力机制,并使用QKV机制使用可学习的门控因子自适应地控制注意力机制中适应性提示。在该机制下,作者对注意力得分进行了重组,以便根据门控因子自适应地调节适应性提示的作用,从而逐步将新获得的教学知识注入到LLaMA中。最终,通过线性投影层计算注意层的输出,并将其与预训练能力结合起来,提供高质量的响应能力。 Multi-modal Reasoning LLaMA-Adapter 不仅限于文本指令,还能够基于其它模态的输入回答问题,这为语言模型增加了丰富的跨模态信息。如下图3所示,我们以 ScienceQA 基准测试为例。给定视觉和文本上下文,以及相应的问题和选项,模型需要进行多模态推理以给出正确的答案。 |
|
|
上图展示了LLaMA-Adapter在处理多模态输入上的框架图,在 ScienceQA 基准测试上,可将LLaMA-Adapter扩展为图像问答模式,在给定的图像视觉上下文中,通过多尺度连接和投影来获取全局图像 token。然后对插入层L的适应提示逐元素加上图像 token。通过这种方式,LLaMA-Adapter 模型在基于多模态输入下实现了有竞争力的生成结果。 作为一个通用框架,LLaMA-Adapter 还可以扩展到视频和音频模态。使用预训练的模态特定编码器,我们可以将不同模态的指令信号集成到适应性提示中,从而进一步最大化 LLaMA 的理解和生成能力。 实验结果 |

|
|
|

|
|
|

|
|
|

|
|
|

|
|
|
|
|
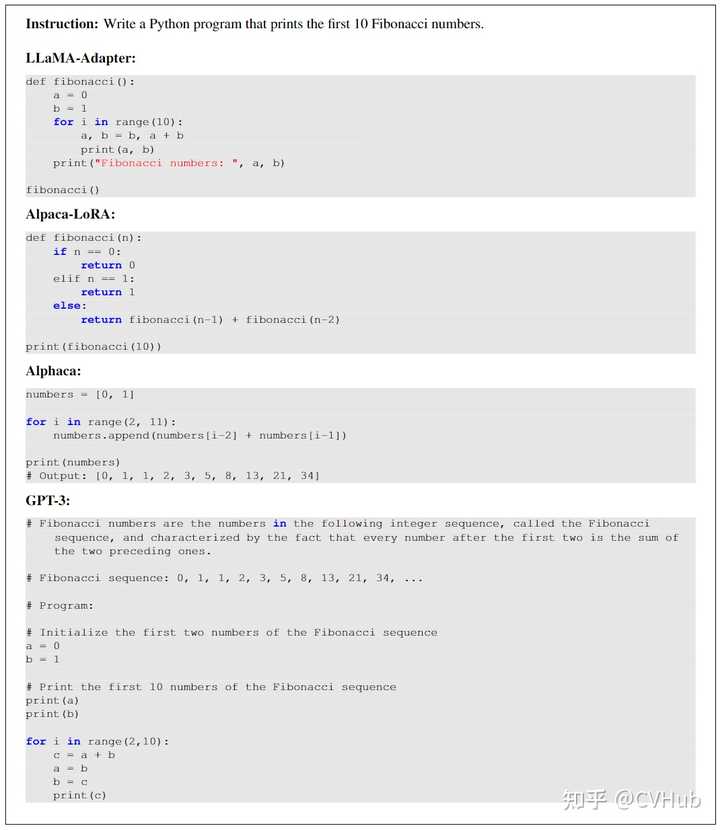
这里将LLaMA-Adapter和一些代表性的指令跟随方法Alphaca进行了比较,并与Alpaca-LoRA和GPT-3进行了全面比较。由于缺乏严格的评估指标,这里只展示某些例子。如上图所示,通过仅微调1.2M个参数,LLaMA-Adapter方法生成了合理的响应,可与全参数微调的Alpaca和大规模的GPT-3相媲美。这充分证明了适配器和零初始化注意机制的有效性。 |

|
|
|

|
|
|
|
|
|

|
|
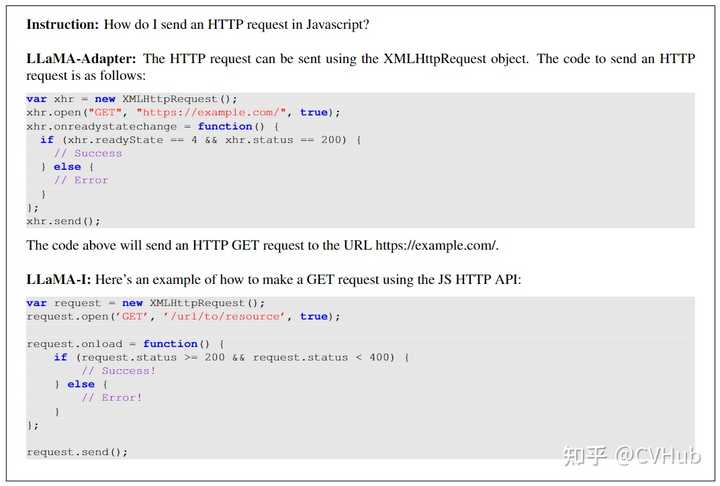
这里将LLaMA-Adapter与LLaMA-I(即在大规模指令数据上微调的LLaMA-65B)进行了比较。如图所示,LLaMA-Adapter能够完成各种复杂任务,如对话生成、代码生成和问题回答等。另外,LLaMa-Adapter还可以通过结合更大的LLaMA模型、增加训练数据量和扩大可学习参数的规模来进一步提升性能。 |
|
|
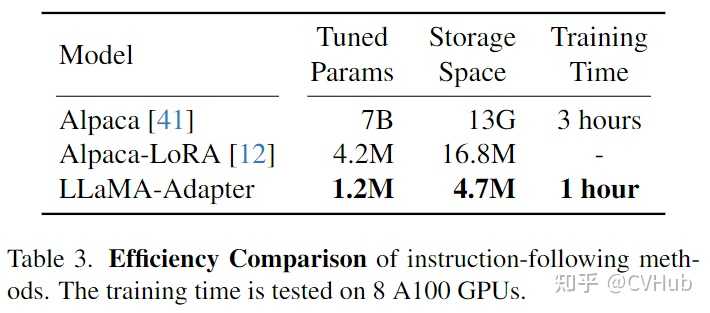
在上Table 3中,作者对不同指令跟随方法(Alpaca和Alpaca-LoRA)的可学习参数、存储空间和训练时间进行了比较。LLaMA-Adapter作为一种轻量级的即插即用模块,仅有1.2M的参数、4.9M的存储空间和1小时的训练时间。这使得我们能够在廉价和移动设备上对大规模语言模型LLaMA进行高效微调。 |

|
|
在上Table 2中,作者将LLaMA-Adapter与其它较为流行的视觉问答模型进行了比较,并发现LLaMA-Adapter的单模态变体可以在只有1.2M参数的情况下实现78.31%的准确率。在注入视觉信息之后,LLaMA-Adapter的多模态变体获得了6.88%的准确率提高。与GPT-3相比,LLaMA-Adapter的参数数量较少,但性能仍然表现良好,尤其是在使用视觉信息时。此外,LLaMA-Adapter的多模态变体可以更容易地将视觉信息整合到模型中,从而实现更高的准确性。 |

|
|
上图Figure 4展示了LLaMA-Adapter处理多模态输入时的一些例子,其中视觉信息作为一种context上下文注入到模型中。 |
|
|
|
|
|
|

|
|
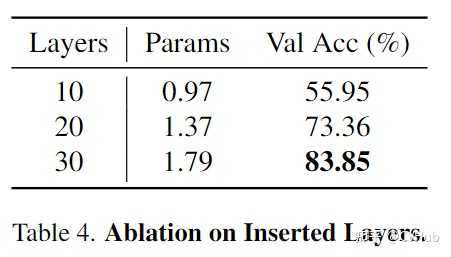
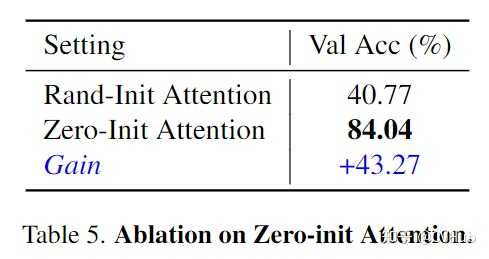
以上分别展示了Adapter中transformer层的数量消融实验(层数越多,可学习参数越大,精度一般越高);Zero-init Attention和随机Rand-init Attention的精度对比(Zero-init attention显著优于Rand-init attention);以及在训练过程中,Zero-init Attention和随机Rand-init Attention的Loss曲线变化 结论 本文介绍了一种名为LLaMA-Adapter的轻量级适配方法,仅引入1.2M可学习参数,微调一小时即可将LLaMA调整为一个支持下游任务的良好模型,同时支持多模态(文本与图像)输入,并有效保留其原有预训练知识不被破坏。对于不同的场景或下游任务,只需在大模型前额外插入相应的适配器Adapter,即可为LLaMA注入不同领域的知识,兼容性与灵活性非常高。 欢迎各位尝试!(另外,LLaMA-Adapter V2版本已出,感兴趣的读者也可尝试) 即日起,CVHub 正式开通知识星球,首期提供以下服务: 本星球主打知识问答服务,包括但不仅限于算法原理、项目实战、职业规划、科研思想等。本星球秉持高质量AI技术分享,涵盖:每日优质论文速递,优质论文解读与知识点总结等。本星球力邀各行业AI大佬,提供各行业经验分享,星球内部成员可深度了解各行业学术/产业最新进展。本星球不定期分享学术论文思路,包括但不限于Challenge分析,创新点挖掘,实验配置,写作经验等。本星球提供大量 AI 岗位就业招聘资源,包括但不限于CV,NLP,AIGC等;同时不定期分享各类实用工具、干货资料等。 |
|
今天自动驾驶之心为大家分享ICLR 2024刚刚中稿的工作――DiLu。DiLu(的卢)是首个基于AI Agent范式的知识驱动自动驾驶框架,其结合了常识知识和大语言模型,通过外挂记忆模块以实现闭环自动驾驶决策制定并拥有持续进化的能力。通过不断对环境的交互积累经验,自我反思纠正错误的决策,从而实现Life-long Learning。DiLu现已在GitHub上开源,欢迎大家体验。 论文信息 |

|
|
论文题目:DiLu: A Knowledge-Driven Approach to Autonomous Driving with Large Language Models ( ICLR 2024 接收)论文发表单位:上海人工智能实验室,华东师范大学,香港中文大学论文地址:https://arxiv.org/abs/2309.05527代码地址:https://github.com/PJLab-ADG/DiLu研究动机 自动驾驶技术近年来发展迅速,但目前仍然面临着诸多挑战。最主要的挑战之一是数据集偏差和过拟合问题,当前的系统大多基于数据驱动(Data-driven)的深度学习方法,它们在标准化和简单的驾驶场景下表现良好,但在复杂多变的真实世界环境中却经常遇到困难。同时,当前的自动驾驶系统在理解复杂的交通环境、预测其他车辆和行人的行为等方面还存在不足。 正如Yann LeCun 所指出的 [1]:为什么一个从未开过车的少年可以在20 小时内学会驾驶,而当今最好的自动驾驶系统则需要数十亿的训练数据和数百万次在虚拟环境中进行强化学习试验? 这些问题的根源在于现有系统缺乏对环境深层次理解和适应性,在面对未知或复杂场景时的表现远远不及人类驾驶员。人类驾驶员能够利用其丰富的驾驶经验和常识性知识,灵活地应对各种驾驶情境。这种能力源自于人类的知识驱动行为,即基于对环境的理解、经验的积累和逻辑推理来做出决策。这引发了我们的思考,如何将人类的这种知识驱动方式应用于自动驾驶系统,以使其能够不断积累经验,提升其在面对复杂环境时的表现。 知识驱动的自动驾驶范式 基于上述动机,我们提出了知识驱动(Knowledge-driven)的自动驾驶范式。这一范式的灵感正是来源于人类的驾驶行为。当面临新的驾驶情境时,人类驾驶员依靠积累的经验和常识做出决策。例如,遇到前车可能掉落货物的情况时,人类会基于常识保持安全距离。这种基于知识的决策过程与数据驱动方法截然不同,后者依赖大量相似数据来拟合特定场景,但缺乏对环境的深入理解。 |
|
|
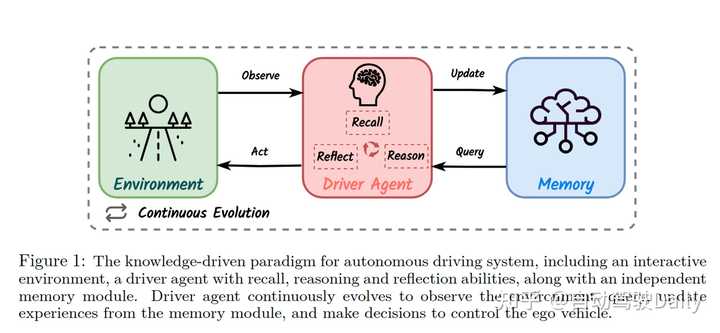
在上图中,我们展示了这一范式的理念。图中的驾驶智能体(Driver Agent)具有三个关键能力:回忆(Recall)、反思(Reflect)和推理(Reason)。这些能力使得智能体不仅能够从记忆模块(Memory)中提取过往经验,进行场景分析和决策;还能通过与环境(Environment)的不断交互和记忆的更新,实现持续的进化。与传统的数据驱动方法相比,知识驱动的自动驾驶范式更加注重对环境的理解推理和自我持续学习的能力。 关于知识驱动的自动驾驶更细致的介绍,请参考我们团队的综述:Towards Knowledge-driven Autonomous Driving (https://arxiv.org/abs/2312.04316). [2] DiLu框架介绍 基于上述知识驱动的自动驾驶新范式,我们尝试并实现了一个全新的自动驾驶框架:DiLu(的卢)。该框架通过整合利用大语言模型(LLM),实现基于常识的决策和持续的驾驶经验累积。该框架由四个核心模块组成:环境(Environment)、推理(Reasoning)、反思(Reflection)和记忆(Memory)。下图详细展示了DiLu框架的工作流程和各模块之间的交互方式,包括环境感知、推理决策生成、决策的反思评估,以及记忆的更新和累积。 |

|
|
推理模块是DiLu框架中的关键组成部分,它利用LLM的常识知识和存储在记忆模块中的经验来进行Few-shot决策制定。具体来说,推理模块首先从环境中获得场景描述,然后结合记忆模块中的相似经验生成决策所需Prompt。接着,这些提示被输入到LLM中,LLM基于这些信息生成当前帧的驾驶决策,并输入环境实现决策闭环。下图展示了推理模块的工作流程,包括场景描述的生成、记忆模块的调用、提示的生成以及LLM的决策解码过程。 |
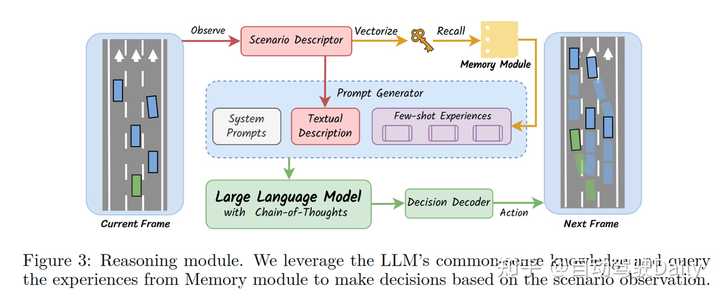
|
|
反思模块是DiLu框架中的另一个核心部分,它负责评估并修正推理模块产生的决策。这一模块通过分析记录的决策序列来识别不安全或不准确的决策,并利用LLM的智能对这些错误决策进行修正。修正后的决策会被更新回记忆模块,从而实现系统的持续学习和进化。下图展示了反思模块的工作流程,包括决策的评估、关键决策帧的采样、错误修正和经验的更新过程。 |
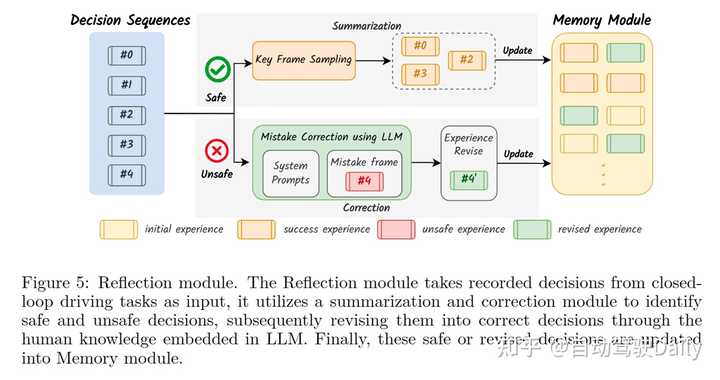
|
|
实验结果 DiLu使用Highway-env仿真环境进行闭环实验测试。Highway-env [3] 是一个基于OpenAI Gym开发的Python环境,专为开发和测试自动驾驶系统的决策算法而设计,提供了一个充满挑战的多车交互路况环境。下面这个视频展示了一次闭环实验中,DiLu框架如何在复杂的交通情境中作出决策。视频中,绿色的自车不仅成功地进行了变道以提升车速,还像经验丰富的司机一样与前车保持了安全距离,没有采取任何冒险的驾驶策略。同时,DiLu在每个决策节点不仅能做出准确的驾驶决策,还能展示其完整的推理过程,这一点体现了我们框架优异的可解释性。 Dilu-video.mp4 此外,我们还进行了一系列精心设计的量化实验,来验证DiLu框架在自动驾驶闭环决策中的表现。我们将DiLu与Highway-env下现有的强化学习方法GRAD [4] 进行了比较。我们发现,DiLu 仅使用记忆模块中的 40 条经验就超过了强化学习方法在 600,000 个episodes训练后的闭环表现。同时,DiLu在泛化能力方面也表现出显著的优势,特别是在高密度交通环境下,DiLu展示了其出色的闭环成功率。基于数据驱动的强化学习方法相比,DiLu不仅更加聪明,而且具有更强的泛化能力。此外,我们的实验也证实了DiLu框架能够有效利用其记忆模块中的经验,不断地提升决策质量和系统的整体性能。 总结 DiLu是首个基于AI Agent范式的知识驱动自动驾驶框架,可能也是第一个将LLM和自动驾驶决策相结合的工作。具体来说:DiLu结合了常识知识和大语言模型技术,通过外挂记忆模块以实现驾驶决策制定并拥有持续进化的能力。DiLu可以通过不断对环境的交互积累经验,并通过自我反思纠正错误的决策,从而实现Life-long Learning。通过大量实验,我们证明了DiLu框架在经验积累和泛化能力方面具有显著优势,并可以随着LLM的发展同步提升性能。此外,DiLu还能够直接从真实世界数据集中获取经验,这为其在实际自动驾驶系统中的应用提供了潜力。 参考文献 [1] LeCun, Yann. "A path towards autonomous machine intelligence version 0.9. 2, 2022-06-27." Open Review 62.1 (2022). [2] Li, Xin, et al. "Towards Knowledge-driven Autonomous Driving." arXiv preprint arXiv:2312.04316 (2023). [3] Edouard Leurent. "An environment for autonomous driving decision-making". https:// http://github.com/eleurent/highway-env, 2018 [4] Xi, Zerong, and Gita Sukthankar. "A Graph Representation for Autonomous Driving." The 36th Conference on Neural Information Processing Systems Workshop. 2022. 写在最后 欢迎star和follow我们的仓库,里面包含了BEV/多模态融合/Occupancy/毫米波雷达视觉感知/车道线检测/3D感知/目标跟踪/多模态/多传感器融合/Transformer/在线高精地图/高精地图/SLAM/多传感器标定/Nerf/视觉语言模型/世界模型/规划控制/轨迹预测等众多技术综述与论文; 链接:autodriving-heart/Awesome-Autonomous-Driving |
|
我就想知道 是事业单位编制还是私企? |
|
|
| [收藏本文] 【下载本文】 |
| 科技知识 最新文章 |
| 百度为什么越来越垃圾了? |
| 百度为什么越来越垃圾了? |
| 为什么程序员总是发现不了自己的Bug? |
| 出现在抖音评论区里边的算命真不真? |
| 你认为 C++ 最不应该存在的特性是什么? |
| 为什么 Windows 的兼容性这么强大,到底用了 |
| 如何看待Nvidia禁止使用翻译工具将cuda运行 |
| 为何苹果搞了十年的汽车还是难产,小米很快 |
| 该不该和AI说谢谢? |
| 为什么突破性的技术总是最先发生在西方? |
| 上一篇文章 下一篇文章 查看所有文章 |
|
|
|
| 股票涨跌实时统计 涨停板选股 分时图选股 跌停板选股 K线图选股 成交量选股 均线选股 趋势线选股 筹码理论 波浪理论 缠论 MACD指标 KDJ指标 BOLL指标 RSI指标 炒股基础知识 炒股故事 |
| 网站联系: qq:121756557 email:121756557@qq.com 天天财汇 |