
| |
|
|
| ����ƻ� -> �Ƽ�֪ʶ -> �� ChatGPT �� Sora��Ϊ�� OpenAI �������������ը�������� -> �����Ķ� |
|
|
[�Ƽ�֪ʶ]�� ChatGPT �� Sora��Ϊ�� OpenAI �������������ը�������� |
| [�ղر���] �����ر��ġ� |
|
�������ܴ��OpenAI��ֻ��OpenAI�� 2022��ף�OpenAI�Ƴ��˹��������������ChatGPT�������˴�ģ������ġ������ܡ�ģʽ��202�� |
|
�ʽ�+�ŶӶ�����Ҫ OpenAI�Ŷ�����Ȼû���ر�൫��������ǿ��Ч�ʺܸߣ�����������ָ�����е����鷢�� ����һֱ��ԴԴ���ϵõ�Ͷ�ʣ���Ȼ���Ҳ���ศ��ɵģ��ܶ˾Ҳ��ȱǮ����������Ķ���ȷʵ�Ͳ��ܴ� OpenAIĿǰ�������֣����Ұ����������ر���������Ͷ�ʣ����������ʵ����ַ�϶��Dz�ȱǮ�� AI������Ͷ���Ƿdz���Ҫ�ģ��ҷdz���Meta�Ѿ���50���GPU�������հ���ȥ�¶��� ��������Ӧ���ǹ��ڵ������˹����ܹ�˾����һ���������������һ����˾���������� ����Ӣΰ�������Ʊ���ǣ�������������Ǹ�����ҵ���ڷ�������IJ�Ʒ��������ǮͶAI �������������Ѱ�����оƬ����7���ڵ�Ͷ�ʣ���Ȼ���ղ�һ����ĵ���ô�࣬�����Կ����������м�ǿ����Ͷ������������һֱԴԴ���ϵ�����OpenAI�ʽ�Ͷ������ |
|
|
��������Ǯ��һ���Ϳ��Ը���������IJ�Ʒ����Ҫ����Ŷ�Ҳ�dz��Ȱ������ҵ Sora��˵����13�����ߣ��Ŷӳ�������һ�꣬���Ŷ���00�����֮ǰ���ǵ����Ļ���Ϊȱ�����±��� ���ǵ��Ŷӿ�������������ª���ҿ϶������������µ��� ����ô�����������µ��ˣ�����һЩ�˰���һ����������Ч�ʱ�һ��Ⱥ�� ��û�к��ģ��Ҷ�ϲ���죬Ч�ʵͣ������㲻����ϲ��Ϲָ�ӵ�ǿ |
|
|
����Ҳ���˷�����OpenAI����ʦ�Ĺ���״̬ ���Ƕ��dz�Ŭ���������DZ��ȵģ��������Ǻ��Ȱ�������飬�����Լ��ᰲ�ź�ʱ�䣬ÿ��dz�Ŭ������ ����������Ч���Ƿdz��ߵ� |

|
|
�Ŷӷdz��dz���Ҫ���ʽ�Ҳ����Ҫ��������Ҳ���Dz�Ǯ ��ΪOpenAI��������µ���һ�ʽ����Ժ�ֵ��������� OpenAIԱ��Ҳ�������ֻ�����Ա���ɳ����Ϲɣ��ù�˾��ͨ������Ͷ�ʹ�˾Thrive Capital ǣͷ��ҪԼ�չ��������йɷݣ�Ҳ����˵�ý�������Ա�������ڹ�˾�Ĺɷ����� ��ȥ���ʱ�����Ͷ�ʹ�˾Thrive Capita����һ���ʱ���ͬ��ͨ��ҪԼ�չ�����OpenAI ��Ʊ����ʱ���ֵ��300�����ң�Ŀǰ��800�ڣ������dz��� Ա��Ҳ����ͨ�������Ϲ��ķdz��� ��Щ���Ƕ��������ã����룬�Ŷӵ�����������������Ǯ��Ȼ����ԴԴ�����ʱ�Ͷ������ �����ۺ������͵����������˾���ǿ����ó�����ǿ�IJ�Ʒ |
|
���������������˹��������ȴƫ��Ӣΰ�������ֻҪӢΰ��ɼ����ǣ���˹���Ϳ�ʼ�µ���ֻҪӢΰ��ɼ��µ�����˹���ɼ۾ͻῪʼ���ǡ�Ϊ��Ū��������Ȥ���������������൫ֱ�۵ط�������AI������Ĵ��ص����⣺ Ϊʲô��˹��ͨ�� FSD(�Զ���ʻ) ��ʵ�� AGI(ͨ���˹�����) ��˼·���������ֿ��ã� 2. ���� ��ģ��(CHATGPT) �ã����� רҵģ��(FSD) �ã� 3. CHATGPT ����ô���������ģ��й�����û�л��������ͨ�����AI�˳���ʱ����ʲô��ͬ�� 4. �Ⲩ AI оƬ���˳�ʲôʱ��ʼ˥�ˣ�˥�˵ı�־���ź���ʲô�� ------------------ ��������Ҫ��ס����ģ���ǹ�����������רҵģ�������������������ȼ�ס��仰���������������ᵽ��������ش����� ����������������һ�� CHATGPT ���ִ�ģ������ô���������ġ� ����� CHATGPT �����Ϊһ���߶ȸ��ӵ�ͳ��ģ�ͻ���ͳ���㷨����Ȼ���ӣ�������������һ�����ڹ��������ĸ������⡣��ʵ CHATGPT �ʹ�����Ԫ���������������Ƶģ����ն��Ǿ�����ʡ����������������� CHATGPT ����һ�λ���ʱ��������ͨ��������Ԥ�������һ�仰���п�����ʲô�� �ȷ�˵������������ "�����ϵ�ʱ���ô�����ϲ���Ե�ʳ����ʲô"��ģ�ͻ���ݸ���������������������ĸ�����50%�������ĸ�����60%��ţ�̵ĸ�����30%��ģ�;��������ĸ��������ô�ͻ���� "����"����Ȼ��������ʼ���Ĺ��̲�����ʵʱ�ģ����� Open AI �Ѿ���õġ��� Open AI ��ģ�����棬"���ô���" + "���" + "����" �����ϸ��ֵ�Ƶ����ߣ�����ģ�ͻ��Զ�����������Ϊһ���������ȷ�Ľ�� (���Ǿ�����ȷ���Ǵ����)�������ģ�����档�����������ѯ�����������ʱ��ģ�ͻ��Զ���� "����" ��Ϊһ�����������Ľ����Ҳ����˵��ģ�Ͱѻ����������еĴ𰸶������ܽ���һ�飬���յó���һ�����ۣ�"����" ���Ǽ��ô��������͡� ����ģ�����棬��ؼ��ľ������Ȩ�صķ��䣬Ҳ�������� 50% 60% 30% ��Щ������ô���ġ���Щ������ͨ�� AI оƬ����������������һ��һ��Ӳ������ģ���ν�������漣��������˵��������� "���� / �� / ���� / �����罻ý��" ��������ݶ�˵���ô���ϲ������������ô AI ģ�Ϳ��Բ�����Щ���ݣ�������ǿ������������ɣ������Զ������Լ���ģ�͡�Ҳ����˵��ֻҪ��������ϸ�����������ι�� AIģ�ͺ� AI�����������ͻ�ͨ�� unsupervised learning �ķ�ʽ�����Ĵ�����ʱ�������������������ϳ�һ����������ģ�͡����ģ�ͻ����ͬ�Ľ�����Բ�ͬ��Ȩ�ء� ˵���ף�������ģ�͵Ĺؼ�������������ǿ�������������ݣ�ȱһ���ɡ���Ҳ��Ϊʲô�������й�оƬ���ӵı���������������ij���������Ͳ����������й��� ------------------ Ϊʲô˵ CHATGPT �������Բ���Ԫ������ģʽ���ƣ����Dz��ӹ���רҵ�ĽǶ�����������ˡ����������Ȥ��ȥ����רҵ�����ľͻᷢ�֣�CHATGPT ����������ģ��������Ԫ������ģʽ�����ǴӱȽ�dz�����ĽǶ������� ����������ж�Сè��Сè��С����С���ģ�û������Ӥ����ʱ������㣺"�������䣬�к��룬�������ȣ���β�͵ľ���Сè"��û������ô����˵�������ǣ����˻����ʲô��Сè�����ѧϰ�Ĺ���ʮ�ֵļ���������Сè��ʱ��ָ���㿴�����Ҹ����㣺"�㿴�������Сè"������Ķ����Ժ�����������������һ��ģ����ӡ���ʲô������������Сè����ȫ������������������顣�����ľ������ AIģ����˵�����Ǵ�����ѵ���� ͬ�������ӣ������Ѽ�������Сè��ͼƬι�� AI ģ�ͣ����ͻữ��Ϊ���ҳ����еĹ�ͬ�㡣�ȷ�˵Сè��������������䣬������к��룬�������β�͵ȵȡ���������ͨ��ͳ�ƺ��ʵķ�ʽһ��һ����ϳ����� �����ʵ���Ǹ��ʣ�CHATGPT ��ѧϰ�Ĺ�����Ҳ������һ��һ����еġ��ڳ��ڽΣ���Ҫ��Ϊ��������ѧϰʲô��Сè�������뼸������Ƭ����������Щ��Ƭ������Щ��Сè����Щ����Сè��������� supervised learning���ȵ�ģ���㹻���ܵ�ʱ��ģ�;Ϳ��Կ�ʼ����ѧϰ���Լ������Լ���ģ�ͺͲ���������ξͽ��� unsupervised learning��������Ͽ��Խ������dz����ӵĽΡ������Ѿ�û�����ܹ���ȫ���� CHATGPT �ڵײ㷽������������ˡ��е������� "�ں�" ������ֻ�ܹ����֪�� CHATGPT ����ô��ת�ģ�ȴ��֪��������ϸ�ĵײ���Ϣ���ͱȷ�˵������֪��Сè�����ʲô���ӵģ�����û����֪��������β�Ͷ����һֻè�����Ƕ�֪��β��10�׳��Ŀ϶�����è��β��1���̵�Ҳ����è�����Ǿ����������è�����������Լ�Ҳ�������ͬ�� CHATGPT Ҳ�����������ֻ֪����һ����ŵķ�Χ���ʡ������Ƕ��٣�ֻ��ģ���Լ�֪����������û�о�������ġ� ------------------ ���������ǽ����һ�����⣬Ϊʲô FSD(�Զ���ʻ) ������ģ�����γ� AGI(ͨ��ģ��)����������پ���һ�㣬Ϊʲô��˹������Ӣΰ�� (�Һ���˵�����߶�����Ҫ)�� ����˵���� overfitting����һ��ģ����רҵ��ʱ�����ͻ������ϡ������������Զ���ʻ��ģ�ͻ����רע�ڼ�ʻ��������������������ȫ���Զ���ʻ��FSD ����רҵģ�Ͳ���ȥѧϰһЩ�ؽ�Ҫ�Ķ������ȷ�˵ FSD û�б�Ҫȥѧϰ "��ô��һ������Ļ�" �����ؽ�Ҫ�����⡣������ȥѧϰ�����ؽ�Ҫ�Ķ�����������Ӱ���Զ���ʻ��ȷ�������ԣ�FSD ��Ҫ�IJ�����Щ���ַ��������ý�巽�����ϣ��෴��FSD ��Ҫ���ǽֵ����ݵ���ϣ��������ݵ���ϣ���ͨ��־����ϵȵȴ��� 3D���ݵ���ϡ�����֮�⣬��Ҫ�ܹ����Ӹ��ִ��������Ϳ��Ƹ��־��ܻ�е�� ���ǻ�һ���Ƕ���������û�а취�ô�ģ��ȥֱ�Ӳٿ�һ�����������仰˵����Ҳû�а취�ô�ģ��ȥ������רҵ�����顣CHATGPT ֻ�ܹ�רע�� ���� / ��Ƶ / ��Ƶ / ����ȵ���Щԭ���ʹ��ڻ����������ݡ�����ijЩ��ʵ����ʵ���ڵ� 3D ���ݣ�CHATGPT ��û������������ǡ���������Щ���ݣ�CHATGPT ����ͨ��ģ��Ҳû�а취���ƻ�е�ṹ��������ʻ�ڵ�·�ϣ���Ϊ�������ܻ�е������Ҫ�����������ݡ�CHATGPT ������֪���ھ��ܶȵı����Ϻܲ��������ѧ�� �ر�ǿ������ѧ������������ ��ʷ�ǹ��������� ����ʷȥ������������������ѧȥ������������ش���Լ����д𰸡� ------------------ ��ʵ��������Ա������Ǵ�ģ�͡����ǿ���ͨ��������ģ���������������磬���ǿ���������дʫ�����ǿ������������������ӵ����֣���������ţ�ٵ�һ���ɣ����ǻ�������������д�dz����ӵĿ�ѧ���ģ����ǻ�������������д�����С˵��Ϸ�硣���ǣ�������Ҫ��ѧ�����ִ��������ģ�ͣ������һЩ���ܵ���֤���̡��������������ѧ���Dz����ܵġ���������ѧȥдʫ��Ҳ�Dz����ܵġ����Ծ��Ǵ�ģ�ͣ����� CHATGPT����ѧ����רҵģ�ͣ����� FSD��CHATGPT �� FSD ���������Ժ���ѧһ���������Ի����滻��Ҳ��ȱһ���ɡ� ����һ��ʼѧϰ���Ե�ʱ����Ӥ���Σ�������ѧϰ�������ͨ�����ϵ��ظ�����ϰ�������Լ���ѧ�������ԡ������˶���ѧ��ĸ��������̸ߵ͡���������������˶�˵һ�������ԣ���ô���Ǿͻ�ͨ����һ���Ĺ��ɣ�����һ�����������Ĵ�����̾ͺʹ��� CHATGPT ��һģһ���ġ�ͨ�� ���� / �ܽ� / �ظ����ͻ���Ȼ�ĵ���һ�� CHATGPT ר�õ�������������Ǵ�ģ�ͱ����� һ���Ա�֮����ģ�;��� "�������漣"�� ------------------ ���֮�£�FSD ����һ������ģ�͡��ڽ�ͨ�����Լ�������£�ͨ��ʶ���·����ʵ����������������ӵĽ���������Ȿ����һ���ɼ��뷱�Ĺ��̡���ͨ������ʵ�ܼ������������������⽻ͨ�����������ϰ��������ڴ���ϡ����Ǵ���ϵ���ʵ״��ȴ��ǧ���ģ����Ǻ�����һ��ģ��ȥ�������е������������˾��������������㣺"�����̵ƾͱ��ۿ�"���෴����˾����Զ������㣺"�������̵ƣ�ҲҪ�����ٶȣ��۲���Χ����������������"�� �ɼ��뷱�����Ͳ���ͳ��ѧ�ó������飬���������ó������顣ѧ��ͳ��ѧ�Ķ�֪����Ϊ�˵õ�һ��ģ�ͣ����Ǿ���������һЩ�����������������һ�������ȷ�Ľ���������Զ���ʻ�������������������������Ϊ�������κ����������������ش�İ�ȫ������ �������ó��������ӵ������ѧ����ѧ�Ķ�֪�������㼸���Ķ�����ʽ����Ϳ����Ƶ��������Ӹ��ӵĹ�ʽ������dz����ӵ�Ӧ�����⡣��������FSD ����רҵģ�ͣ������Ͼ����ɼ��뷱���� CHATGPT ���ִ�ģ�ͣ������Ͼ����ɷ���� ǿ�������� FSD �� CHATGPT ����������ȫ�෴�������¡�FSD �ǻ��ڼĽ�ͨ�����Ƶ���һ���dz����ӵ�ģ�͡�CHATGPT ����ͨ�������ĸ������ݣ����ɳ�һ���������ȷ�ļ�ģ�ͣ����Ұ������ģ�ʹ洢�������Ա����á� ------------------ ��һ��ʵ�������е����ӡ�����ʹ�ù� CHATGPT �����Ѷ�֪�������� CHATGPT ��ѧ����Ļ����������������������Ϊ CHATGPT ֻ������ģ���ĸ������㣬�����ܹ������ӵ����������� ���Զ���ʻ����רҵģ�������أ�ʹ�ü��⸨���Զ���ʻ�����������ֵ��������Ӿ������Զ���ʻ������Ҫ�úܶࡣ���������רҵģ����Ҫ�ľ��� �� / / �ȣ����Լ����״��Զ���ʻ��Ŀǰ�������Ž⡣ ��ģ�ͺû���רҵģ�ͺã���ʵ��������Զ������������Է�������������Զ�������ѧһ���� ------------------ �����Ǵ�ģ�ͻ���רҵģ�ͣ����ǿ��Կ����������Ǻ��ĵĺ��ġ���ʵ��ģ�ͱ�����û���ر�ߵļ����Ѷȣ������Dz�����Խ�Ĵ�ɽ���ҿ�����ô˵���κι�˾��ֻҪ���㹻���������㹻��ʱ�䣬�㹻�����ݣ��㹻�ĵ��������ܹ��Ƶ����ܺõĴ�ģ�͡���������ʵ�����У��������������������Ѿ��Ǻܶ˾�����������ˡ��ܶ���е��ϰ��ջ�����������˹����ܿ�����ѹ�й�������ʵ���������Dz����ڱ��ݵģ����ڱ��ݵ���ʵ��оƬ�����ݡ� ��������ŷ������ŷ����Ȼ�ܹ�������̻�������ŷ��û��������оƬ������ҵ����Ҫ��ø����� AI оƬ������Ҫ��̨�����¶���������֮�⣬ŷ����ʵ��û���Լ��Ļ��������ݻ��ۡ�ŷ���������Ĵ��ͻ�������˾��û�С����Ƕ���ʹ�����������Ļ�������Ʒ���� / �ȸ� / ���� / �� �ȵȶ���������˾��������������˾������������ Uber��ŷ����ʵ���ڸ�������˾�����ṩ���ָ�����ѵ�����ݡ�������˾����������Щ���ݿ�����ģ�ͣ�����ŷ��ȴû����Щ���ݵ�ʹ�������� ����֮�⣬ȫ����ʹ��Ӣ����˿���ࡣ��˻�������Ӣ�����ݵ�����Ҳ�����ġ����Ӣ�����ݱȻ�� ���� / ���� ���������Ե�����Ҫ���öࡣ���Ӣ���ģ��ѵ������Ҳ������ס� �й����Ѵ������������档�й��кܶ����綥���Ļ�������˾����Ψһ�л����������������˾��������塣ŷ���Ѿ�����Ϊ���ˡ������̻��ܹ������й�����ô�й�Ҳ�������������۵��˹�����оƬ����ϧ�ľ�������û�а취�����Ƚ��Ĺ�̻�����Ȼ�����ڽ��������Ƕ���Ҳ�ڽ�������ͻ���й���ɺܴ����в�� �й�������һ���ش����в��������˽���ݵı��ݡ��� CHATGPT ���ܿ����Ĺ����У�Open AI ��û�и��߱��ˣ����ǽ���ʹ�ñ��˵���Ϣ����������ģ�͡����Ժܶ����ڲ�֪�������±� Open AI ������ѵ���ˡ����ǵ���˽���ݶ�ι���� Open AI�����������о��õĴ�ģ��Ǯ��������ȴ�����ܵ��ֺ졣ij�̶ֳ��ϣ����������˵���˽Ȩ��֪ʶ��Ȩ���ܵ����ַ�������� Open AI �Ѿ������������ǿ��� AI ģ�ͣ���ʱ�˿�������������֣��䲼�µİ�ȫ��˽���ɡ���ʱ�˿��й�����֣���û�а취��ø�������ѵ�������ˡ�����ʵ�����εİ�Ȩ�� û�������ݣ��й����ѿ�����ģ�͡� ------------------ ����˼���£��й������ó����������Ĺ��ң�ȱ�����ڿ�����Ҫ����������רҵģ�͡������������ó����������Ĺ��ң�����ȴ�����ڿ�����Ҫ���������Ĵ�ģ�͡��й��Ѿ��ٺܶҵ����ʹ����רҵ��ģ�ͣ�����������ָ�����ʵ����������� ������˼���ǣ������������ڿ����ܹ������Լ����õ� AI ģ�͡���ģ�ͶԷ���ҵ����в�����ģ���ģ�͵��ƹ��ݻ������ķ���ҵ��ҵ��������ȴƫƫϲ�����ģ�ͣ�������רҵģ�͡�רҵģ�Ͷ�����ҵ����в�����ģ�רҵģ�͵��ƹ��ݻ��й�������ҵ��ҵ�����й�ȱƫƫϲ����רҵģ�ͣ������Ǵ�ģ�͡� Ψһ����ȷ�����£����Ǵ�Ҷ���Ҫ AIоƬ����Ҳ����ΪʲôӢΰ��Ĺɼۻ��������ĸ���ԭ�����Ǵ�ģ�ͻ���רҵģ�͵Ķ���Ҫ�����ļӳ֡� ------------------ CHATGPT ��ʵ��Ӧ�ò����Ѿ�֤����ģ��������Ԫ��ģ�������ǻ۵ĵ�·����ȷ�ġ�������� CHATGPT ��ΰ���ͻ�ơ� ------------------ ��ô���Ⲩ AI �˳�ʲôʱ��ʼ˥�ˣ�˥�˵ı�־��ʲô�أ� ͨ�����������ķ��������Ҳ������ˣ�AI ʱ������Ҫ�ľ������������������� AI оƬ������֮����оƬ��˾����ӯ����ô�ߣ�������Ϊû�м��ҹ�˾�ܹ��������� AI оƬ������һ�еĸ�Դ�����й����õ����Ƚ��Ĺ�̻��������й�û�а취�����ṩ�г���Ҫ��оƬ�� ���ڵ�״����2000�����������ĭ����һģһ����2000�����ʱ���Ҿ��û�������һ���߸��ԵIJ�Ʒ�����Դ��һ���Եķ��Ͷ�ʡ��������������ļ۸�Խ��Խ�ͣ�"����" ����´�һ���ݳ���Ϊ����˼����������ճ������������ڶ��������ɵ�ʹ�û��������������Ӵ���������̳�� δ�� AI ��ͻ�����һ������Ϊһ���»�����AI �ڽ�������һ��ȫ���ռ��ķ��ͺ����ڵĻ�����һ���洦�ɼ�����ʱ�� AI оƬ�ͻ�Ͱײ˼�һ�������ֿɵá� �� AI оƬ�ײ˼۵���������ľͲ����� "����"�����Ƿ����ˡ� �ٸ����ӣ������Ļ�����ʱ�������������������Խ��Խ���ˣ���������Խ��Խ�͡�����ͨ�������ṩ�ķ������ƷԽ��Խ�ࡣ����ͨ���ƶ�����������������ȫ�����κ�һ�ַ������Ʒ��������������ƻ�� / Meta / ����ѷ / �ȸ� �ȵȹ�˾��ӭ���˱���ʽ������ ��δ���������Ǵ�ģ�ͻ���רҵģ�ͣ�����Ҫ�����о������ݡ�С��ҵ���÷dz����Դ���Ϊ����û�����ݻ��ۡ� δ��������Ͷ�ʼ�ֵ�Ľ����� AI Ӧ�á����ǣ����ǣ����ǣ�������оƬ�ײ˼۵�ʱ��Զ�����ǻ�û�е���ĭ���ѵ�ʱ�����ڻ�����ĭ�ѻ��ĽΡ� δ�����ܻ�����µ��ںϣ�Ҳ���Ǵ�ģ�ͺ�רҵģ�͵��ںϡ��������ô�ģ�Ϳ���һ��ר�ŷ����ɺͻ��ҵ���ģ�͡���������������������ǻۣ���û��������һ��ģ�ͽ�����д�ģ�ͺ�רҵģ�͵����⡣ ------------------ δ�� AI �˳�˥���������־�� ̨����Ż��Ƚ��Ƴ̵�Ͷ�����࣬�Ƴ�Ͷ��ʱ�䣻Intel��ʼ����̨���磬Ͷ��2��������оƬ���й���ʼ��ģ������2����һ��оƬ�� ��Ȼ�м���ܻᷢ��һЩ����������ı����ȷ�˵̨�����ơ����ǣ�������˵������������һ���������ͱ�־�� AI �˳����״�оƬʱ��ת��Ϊ����ʱ������ĭ����ʱ�ͻ����ѡ�����Ҳ������һ��ȫ�µ�δ���� |
|
��Ŀ�����⣬���ڲ�����������OpenAI������Щ����ȫ������ģ�ʲô����ը����Ķ�����������и�ʵ�壬Ȼ����������ը��Ҫô�Լ���������ը��Ҫô�ܷ�����ը�Ķ����� ��ChatGPT�������Ǹ����칤�ߣ���Sora����ֻ������һЩĪ���������Ƶ�� ��������ը����������� ��ȫ���㣬����������ֽ���첻������ ���������ʵ�������� OpenAI�Ĵ�22�������ChatGPT�������ڵ�Sora��ÿһ�������ذ�ը���� ������Ҫ��������ÿ�η����IJ�Ʒ��������һ��ǰ���������ģ�ֻ������������ʱ��ܳ���GPT4����1��ʱ����������SoraҲ���һ�ꡣ �ر���Sora��һ��ĵ����ڣ�������Ƶ���ɹ�˾�����ʣ�����runway������pika�� �ر���Pika�ķ������Ƕ�ʱ���ڸ���Ӫ�����������Ӳ��ϣ�������Ůѧ�Եȡ� |

|
|
��ʵ����Sora��23���ǰ�����ʵ�������ƵĹ��ܣ�������Ҫ���á� �����ǵȵ���Sora���ԱȽ��ȶ�������1���ӵ���Ƶ��ʱ���ѡ���˷����� ��һ�η��������Ӳ���������˺ܶ��죬�е��������µ���˼�� ��Ҷ���10�����ڵ���Ƶ����������ֵ���ˣ���㳬������һ������ұ�����һ���ǿ�� |

|
|
������������ڣ����ֵ����ʣ����ֵĸ�Ǯ�� ����Sora����ֱ����ը���������ñ�����ô�棿 |

|
|
��ʵ���˵���ף����ڵ�AI���еļ�����Ҷ��У�Ψһ���������OpenAI���Ը������ͨ�����ļ����� Ϊʲôopenai������ͨ����AGI����ջ��450 ��ͬ �� 94 ���ۻش� |

|
|
��OpenAI���Զ���һ�ģ�����ԭ�����OpenAI���AGI�������ܾ��ˣ��ر��Ǵ�ģ��LLM��һ����������֮ǰ�����˶���Ϊ����·�߲�ͨ�����û�����������ľ���scaling law�Ŀ����ԣ��Լ�������˻�������������������һ��ȥѵ����ģ�͡� ˵ʵ����OpenAI����������ҳ���������������⼸��AI�²�Ʒ�����ذ�����Ҫԭ�� Google���Dz���û��Ǯ�����Dz�����LLM����·���ߵ�ͨ�� |

|
|
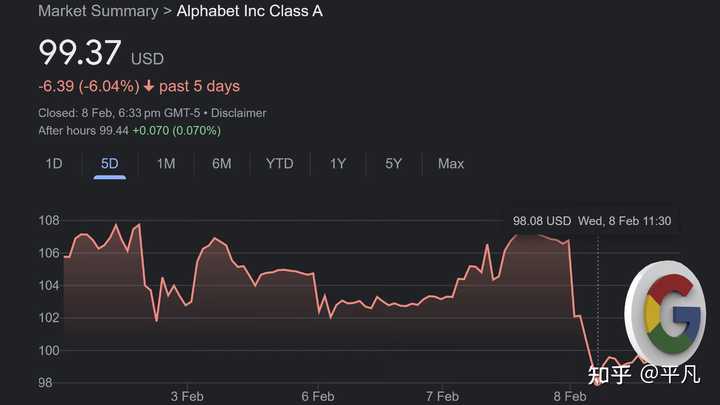
�㿴Google��ChatGPT���֮��Ѹ���Ƴ�Bard����Ϊ��������ļ��ˣ������ֳ���ʾ������Ʊ����� |
|
|
��Щ��˾Ҳ�������ϣ�����������OpenAI������꣬��ij�ʼ�ٶȺͼ��ٶȶ�����OpenAI��������˾���Ѷ�ʱ�������ϡ� ����һ���ֲ��ĵ��ǣ�GPT4��һ��ǰ���������Ķ���������һ��ŷ�����Sora��˵Ҳ��23��3�¾��������Ķ�����������һ��ŷų����� OpenAIÿ�η��Ķ��������϶��ǵ����˺ܾòŷ��������������ܾ�����ը�� ���һ���������������Ҳ����Ҫ����OpenAI���Ĺ��������ܻ����뵽AI��չʷ��������������ʷ�����ָо�����Ҳ��OpenAI���ţ�Ƶ�ԭ��֮һ�� |
|
�ܺõ����⣬̸̸�Լ��Ŀ����� ����ΪOpenAI�ܳɹ�����������ը����Ҫ��OpenAI��������֡� �����������ϵļ�֣��Ǿ���AGI��ͨ���˹����ܣ�һ����ʵ�֡� |

|
|
��Ȼ����AGI���ǾͲ�����Щֻ��ˢˢ��Ĺ���������Ҫ����ChatGPT��Sora������ͨ�ø����ܵĹ�����OpenAI�ĺܶ������CLIP��DALLE����������һ���µķ���������� Ȼ���Ƿ����ļ�֣��Ǿ���scaling law�������ģ��+���������+��ǿ�����������������档��ֻ��100��M������GPT-1����T���������GPT-4������scaling law��õ�֤������Sora����������ҪҲ������transformer�ܹ���scaling�� |

|
|
�����������أ����˲ź��ʽ���Ҳ����OpenAI���еģ��ȸ��MetaҲ��ȱ��Ҳ��ȱ�ʽ�����ֻ�DZ�Ҫ�������ѡ� �Ҹ��˲�ȷ��AGI�����������������OpenAIһ���Ǿ���AGI�����һ�ҹ�˾���ڴ��������������ྪϲ������ʵ��AGI��Ҳ����Open�� |

|
|
����һ��OpenAIԱ�������ġ����������������ң�Ϊʲô����Ӧ�ðѶ�ע����OpenAI����ƽ̨�ϡ� |
|
|
ԭ��ܼ����ĵ㣺 Compute ������ |

|
|
������������չ�������ڵõ���֤������ζ�����ǿ���ͨ�������ģ�ͳ����Ľ����ͬʱ�����������ʹ�����������ϸ���Ч�������ǽ�����������õ�ģ�ͣ���Ϊ�������ṩ���������ԡ� û�����������������ģ��Ͷ���ڼ��������� �����˸ո�������ʶ��������Ҫ����ʮ��Ƶ�GPU�� ��Sam��OpenAI�е������˶��������Ѿ�֪����һ�㡣 ���⣬�����ƽ̨���ڲŸոմﵽ��ģ�������ڳ����������Ŭ�������������Ѿ�������ͺ���ƽ̨��չ����һ����ʱ���ˡ� ��Щս���İ̺ۺ���ȡ�Ľ�ѵ����Ҫ�ġ� Mission ʹ���� |

|
|
ʹ�˹�ͨ�����ܣ�AGI���ݼ�ȫ�����ʹ��Ҫ������Ϊ�����߹���ƽ̨������˵������ÿ�������������һ���������ܹ�����ؼ����������ʩͶ�ʲ��е����ŵ�ƽ̨�� ����������ÿһ�����߶����ǵ��˿����ߺͽ����ߡ� ��һ��������С���϶��������֡�̹��˵����������Ŭ�����������������Dz������������������ڳ��ԣ���ϲ����Ϊ�������ڳɹ��ش���һЩ������ϲ���Ķ����� Team �Ŷӣ� |

|
|
��Ȼ������̸�ۣ���OpenAI���˲��ܶ���Ȼ�����ˡ������Ŷ��е��˲Ų�����һЩ��ʷ������ɹ��ͶԿ��������ѺõIJ�Ʒ�Ĺ����� ÿ���ϰ֪࣬����������ô����ȫ��ȫ��ذ���������ȡ�óɹ�������ʱ��Ļ�����Ц�� ��Ϊһ�������ߣ�֪��������Ŭ�����ҵ������ø��ã�����һ�ֺܰ��ĸо��� Focus רע�� |

|
|
����ֻ��һ��Ŀ�꣬�Ǿ��Ǵ����˹�ͨ�����ܣ�AGI����ʹ�������ܹ�������������Ʒ�ͷ������Dz����ڳ�������桢�����罻�����������롣 ���������ܹ������ƶ��Լ������ܹ����еĹ�ģͶע�Ϸdz���Ҫ�� ��������������ģ������˰����Ǵ����Ŀ��������ʱ�����ǻỨ�Ѵ����ľ��������Ǵ��ص���Ҫ�������ϣ�����������ϲ���Ķ����� ����һ�������������Listening ������ |

|
|
�������ǿ��ܴ�ÿ�η����п����ģ�������ĺ�Ŭ���ظĽ���Щ���Dz�����ĵط��������DZ�ø��á� ��ijЩ����£�����ģ�͵Ķ��ԣ����������Ҫһ��ʱ�䣬�����������Ļ��ȫ���Ը��� ������ṩ��������������֪��������Ҫʲô���ܳɹ���?? �����������۵������� |

|
|
|
|
����������Ϊ�٣����ڻ�����Ϊ�� OpenAI ��Ҫ���������ǻ�����й���ѧ����Ϊ�й��˾Ͳ����أ��ܶ����д�ĺܺã��ش�ĺ�ȫ�棬��ȱһ��ά�ȡ� �Ҹո����һ����ͻ���������������������Σ�������˼���������й��˺��ѹ��£������й����쵼�й���Ҳ�Ѹɳ��¡����������쵼�й��ˣ���������ŶӾ�������ս����Ǹ��Ǹ������쵼�¸����͵Ķ��С� �ոջ�����ͬ�����죬��̸��������⣬��˵�����ʱ������������һ��������϶�ɶ�¶��ɲ��ɣ�������������ڿӣ��°��ӣ���Ҳ�Ǻ�Ц����������ǰ���һ�������� ��Э���Ĵ����⼮�쵼�����쵼ɶ�����ܣ���ô�ɣ������ȶ��������ǣ���������Ȼ�����ĺܺá� ����Ǵ��˵�ģ�һ���й����ǡ����� �������й����ǡ��桹 �� ����һ�룬�й�����ǰ��������������������һ��������ij��������ﶷ���������û�����������������ͳ����ԭ��ÿһ�δ��ں�֮�������� �����������������˽ᵳ�������ﶷ���㷢��û�У�����ͳ�ε��峯����������������Э���� �����ڹ�ȣ�ӡ�Ȱ����쵼���Ƕ����ԣ��������ˣ�����Ҫ�й����쵼�й��ˣ���������ƽ�����й�����һ���Ǹɲ����µġ� |

|
|
|

|
|
|
|
Sora �ķ����м����ˣ�����������Ȼ�Ǹ���Ⱥ���۵Ľ��㣬���Ͼ��ú��ʱ��г��ı��֣��ձ�������Ƚϱ��ۡ� Sora ���������������Ҳ�����ڸ���Σ�ֻ�Ǹ�����ȷʵ���Ƚ��������γ���ѹʽ��ά�����ҪAGI��AIGC��AGI��Ҫһ�����ײ������ģ�ͣ��������ģ�Ͱ��������������ʶ���磬����������㹻С����ô��Ҫ�������ǿֲ��ģ�Ŀǰ����ĵ���������һ�������ϡ�������չ������Ҫ���ϵĸ���ά�ȵ�����ʽ����ת���Ҹ�����û��ô���ۡ� ��������ʷ��û����һ��¢��������ģ� �༭�� 2024-02-24 12:26?IP ���ؼ��� ������ͼ���� |
|
����ţ��̶̼����£����Ǿ�Ȼ��ס�ˡ�Open AI���IJ��� ���Open AI�Ƴ��Ĵ�ģ��Sora���ˡ� ���ҵ���֪������������˸��Ӵ��ţ�����һֱû������ ���ܲ�ס�����ʵö࣬�����ҿ�������ز��ϡ� �üһ ԭ�������ܿ�OpenAI�ġ����ӡ�....... ���磺���������Ķ��ĿƼ��� ���Ĵ��ձ�����ǰ�����ȱ�����Ϊ��վ̨������ʯ���쾪��һ���� Sora�ؼ�ԭ����֮һ��������� ������ ��ģ��һ����ʵ��ԭ���ϵĹ�˾����ɶ��ϵ����û�ǵ�Open AI��������Ĺ�Ӧ�̰��� �������ʣ�����ͼȥ������������������������Ӹ��ǡ������˵ġ� �Ĵ��ձ��ڱ�������ְ�ֽ�ı�ʾ�� �����ĿƼ������������������������������IJ���˫�������ǰ���֬���нϸ߱��ݣ����ڼ���û��ͬ��ҵ��˾�������� ��������֪��Sora���߱��ʲô��ģ�ͣ����벻��Ӣΰ����Կ����� �������ĿƼ���Ӣΰ�﹫˾����Ҫԭ���Ϲ�Ӧ��֮һ.......�� �������ƺ�����й¶��ҵ���ܣ����ܵ������ֹͣ�ˣ� ʲô���������ô��֪�������������������� �Ҽ����ھ����б��з����������緹�����ࡣ ��������ν�ġ�Sora�ؼ�ԭ����֮һ����ʵ���Ƕ��ĿƼ�������˫�������ǰ���֬BMI�����ļ��BMI���� ��BMI�㷺Ӧ���ڸ߾��ȴ�ӡ�����ٸ�ͭ��ʱ��Ҫ�õIJ��ϡ� ��ˣ����ĿƼ��ļ��ְ֣�������̨�⡢���µ���ҵ�� �����ɲ��ɵ���̨�⡢���µ���ҵ������Ӣΰ��GPU���飬OAM��UBB����ԭ���Ĺ�Ӧ�̡� ��Sora��ģ�����벻��Ӣΰ����Կ�...... ���ԣ���Sora�ؼ�ԭ����֮һ����������� ����....... �������ˣ�Ϊɶ���Խ��Խ֧����ѩ�塣 |
|
|
���ڵ�ý���ֱ�ȵ���Ӫ�조������������չ������������������硱��Ҫ��� ��Ȼ�����˶��ĿƼ�����Ȼ���кܶ���ҵ���������ȵ㡣 ���磬�����Ƽ�����Sora��������3���������� �Լҵ�Arc muse����ӭ���ذ�������֧���������ĵ���ҵ��Ƶ�Զ����ɡ� �еĹ�˾��Ȼ��û�в�Ʒ����������ʾ���������еġ� ���磬�ƴ�Ѷ�ɱ�ʾ�� ���Լ��Ѿ�ӵ����Ի������ı�������Ƶ���ܡ��� �����Ƽ�������� ������ӵ�а�����Ƶ���ڵĶ�ģ̬ʶ�������� ������һ�£�����ô"��Sora��A�����й�˾����60+�ң��� �ִ�ɨ��һ�飬�������и������� ��Sora���������ǵģ�����Open AI�ģ��� ��֮��Ӧ���һ���һ�����ʣ� �������У�Ϊʲô����˵���� �Ҽǵú��������һ��ChatGPT������ʱ�����һ���ǵ���271Ԫ/�ɡ� �������2024��2�£��ɼ۵�����108Ԫ/�ɡ� ����5����ʼ��������40���ڡ� 360��������ALL IN AI�Ĺ�˾���ɼ���һ�ɳ�����ܺ�t�����ˡ������֡�������·�� ������ά���������ʤ������ͬ������chatgpt�Ķ��磬���Ƿ�����70%��ʼ����飬ǰ������22���ڡ� ��Ȼ�����22���ڽ����˾����Ϣ������������һ�����ԡ� ����ǰ��֮���������µ����ﱳ���£���ô��Sora�����Ҫ��Ҫ���룿 ����ʵ��������룬���������ӡ� һ����û��һ��������ס���á� ��һ�����Ҷ������Ʋ�˵�ơ�����þ��ǻ��Ĵ��������������ģ����ڶ������۵���һ������ȥ�����Ϊ���� ����һ��Ҫ���롣 ����ֻ��ף�����ˣ���һ��ע���������������������λ....... �����������룺�ҵ�Ȧ�� ��Ӧ�����������ֵ��Ͷ���һ�ʡ� |
|
��������ɽķ�������������㣬����˹�˷������һ���� ��Ҫ˵OpenAI�ijɹ��ǽ�����OpenAI������Ű�Ĺ���ʦ����ѧ�����ϣ��Ҳ����ϣ�����Ϊʲô��Ҳ�������ľ�Ӣ�Ŷӡ��ȸ�Ҳ�������ľ�Ӣ�Ŷӡ�FBҲ�������ľ�Ӣ�Ŷӡ�����ѷҲ�������ľ�Ӣ�Ŷ�........������OpenAIɱ����Χ���أ� ����ܶ���˹�˺�Ϊ�˱����˹�ˣ�����"SpaceX�ijɾ���SpaceX�����㹤��ʦ"֮��Ĺ۵㣬��Щ�۵������ȷ��Ϊʲô������ŵ��ULA���������ͺ�����ҵû�������з����ɻ��ջ����ȡ��һϵ�гɾ��أ� �ܶ��˺���Ϊʲô�����ĵ�Ӱ���ǻ���һЩ����Ӣ�����壬��Ϊ������������ϵ��һ��������Ҫ�Ŀ��Ʊ������۷��� ���һ����ҵ����������ҵ����Ǯ������������˲š������ɵ�����.......��ô���ݿ��Ʊ���������ô������ҵ���쵼�����㡣 ���ֿ��Ʊ�����������Ϊ�����ͬ���Ļ������ĸ��û��߸���Ļ�������һ���ã���ô������������˳�Ϊ�˹ؼ������� OpenAI���������Ĺ�����ʡ������Ү³��˹̹�����˲ţ����������Ƽ���ҵҲ��������SpaceX���������Ĺ�����ʡ������Ү³��˹̹�����˲ţ����������Ƽ���ҵҲ��������Ϊʲô��OpenAI��SpaceX����ҵ�ڸ��Ե�����"��ɱ"��ͷ���أ� �����ᳫ�����ֿ��Ʊ�����������ô�����һ��ֹ����ר��ѧ�߶��ż��䴦�����ӣ��ڶ�������ʵ��Ӣ�۱�����������������ۡ� |
|
Sora�����ж�ը�ѣ��Ŀ���Ƶ��ģ��5����������ChatGPT��Sora��OpenAIΪ�����������������ը�������� |

|
|
�������ܴ��OpenAI��ֻ��OpenAI�� 2022��ף�OpenAI�Ƴ��˹��������������ChatGPT�������˴�ģ������ġ������ܡ�ģʽ��2024��2��15�գ�������Ƶ����ģ��Sora�ĺ�ճ�����OpenAI�ٶ������ȳ��� Sora����Ƶ��������������һ��ȫ�µĸ߶ȣ��������ƵЧ��ˢ��������AI�����߽����֪����������������ͬһö��ˮը����˲������ȫ��Ƽ�Ȧ�� ����ҵ����ʿֱ�ԣ�Sora�ĵ�����־��һ���ʵķ�Ծ��Ӣ���ʼҹ���Ժ����Ժʿ��ŷ��ѧԺԺʿ����Pan Hui���ڽ��ܡ�ÿ�վ������š����߲ɷ�ʱ��ʾ����ĿǰSora����Ƶ����Ʒ�������������ƥ�еġ�Sora���ɵ���Ƶ���Դ�С��д�д�ȫ�����任��ͬ�Ļ�λ���� ֵ��ע����ǣ�������Ƶ��ģ�Ͳ�����һ��ȫ�µ�������Ϊ�˸�ֱ�۵س���Sora��������Ƶ��������ÿ�վ������š����߲���OpenAI�ٷ�������5��Sora��Ƶ��ʾ�ʣ���Pika��Runway��PixVerse��������Ƶ���������˲��ԣ��������ɽ����Sora��Ƶ�����˶Աȣ����Գ����漰������д����ӰԤ��Ƭ��5�ࡣ �ԱȽ����ʾ��Sora�����ɳ��ȡ������Ժ��Ӿ�ϸ�ڷ�����ֳ����Ե����ƣ�����ʵ���ˡ���ά������� ��ChatGPT��Sora��Ϊ��OpenAI���������������ը���������� ���ݴ�ѧ��������У�������ѧ PHD��֪������SIY.Z�����ƣ������������һ������չ��OpenAI����ĵļ������Ҿ�����scaling law��������ô����֤ģ��Խ������Խ�࣬Ч����Խ�á������ı�����ģ�� GPT������ͼģ�� DALL��E����������Ƶģ�� Sora��OpenAI�����Ѿ��������һ���Լ���AGIͨ�ü���·�ߡ� |

|
|
5��ʵ�⣺ Sora��ʱ����4��ά����ʵ�֡���ά����� |
|
|
|
2��15�գ�OpenAI��ʽ��������������Ƶ��ģ��Sora����ʾ��Ƶһ������Ѹ������ҵ�����飬�������Ѹ��ǰ�������Ҫʧҵ�ˡ��� ������CEO������һƪ������д����������һ�̣�����ϸ�����ʵ�������ɵ��������������߽���������ᡣ��Ը�⽫�����Ϊ��������AI��չ��ţ��ʱ������ Sora��������Ƶ���������к�ͻ��֮���� ����Sora��δ���Ų����˺ţ���ˡ�ÿ�վ������š����߲���OpenAI�ٷ�������5��Sora��Ƶ��ʾ�ʣ��ڽ�ͷ����ͨ������������д��������д�Լ���ӰԤ��Ƭ��5���¶�ͬ��ģ��Runway��Pika��Pixverse������Ч�����ԡ�ͬʱ����OpenAI�ٷ�������Sora��Ƶ��ǰ��3��������Ƶ��ģ�ͽ����˶Աȡ� Ч�����ԶԱȷ��֣�Sora��������Ƶ��ʱ���������Ժ��Ӿ�ϸ�ڷ�����ֳ����Ե����ƣ������ﵽ�����ij̶ȡ� Ӣ���ʼҹ���Ժ����Ժʿ��ŷ��ѧԺԺʿ����Pan Hui���ڽ��ܡ�ÿ�վ������š����߲ɷ�ʱҲ��ʾ����Sora�ĺ������ƿ����ܽ�Ϊ�����ɸ������ȵij���Ƶ�������������ȣ�����ʱ����Ŀǰ���ǵ�һ��OpenAI��רע����Ƭдʵ����ļ�������Ȼ����ȥ����������������˳�����Ϊ֮���磬����ĿǰSora����Ƶ����Ʒ�������������ƥ�еġ��� ��������Ҫ˵�����ǣ�����Ч���ԱȽ�����5�������µ���ʾ�ʣ���������ʾ�ʵ���������Ϊ���ޣ����Ҳ�ͬģ�����ɵĽ�����ܴ�������ԡ� һλ������ҵ��Ҳ��ÿ�����߱�ʾ������Sora������������Ƶ��ģ�͵Ľ���Աȷdz�ǿ�ң������ų�Sora����Ƶ��OpenAI������ɺ�ѡȡ��õ�һ�����Է��������չʾЧ�����š� |

|
|
��1����������Ƶʱ�� ����Runway��Pika��PixVerse�ĶԱ��У�Sora���ɵ���Ƶƽ�����Ƚ���16�룬��ﵽ20�룬�����֮�£���������ģ�����ɵ���Ƶ���Ⱦ���3~4�����ҡ�Sora��������ɳ���һ���ӵ���Ƶ����ʹ��Sora�ܹ��������س�����Ƶ���ݣ�ʹ����ʺ�������Ƭ����������Ӧ�á� ��2����ǿ����Ƶ������ Sora���ɵ���Ƶ��������ɡ���Ȼ��������ƶ��������Ľ�ɫ��������ǿ������ۿ����顣�����֮�£�����ģ����������Ƶ��������ֳ���ͻ�䡢���治���������⣬Ӱ��ۿ����顣 �����ʾ����Sora���Ըı���Ƶ���ӽǡ�Sora���ɵ���Ƶ��������һ������һ������С��д�д�ȫ�����任��ͬ�Ļ�λ�����DZ�֤�����е�����/��Ʒ��ͬʱ����Sora���ɵ���Ƶ�У������һ���Ժ�ǿ��һ����һ��������Ƶ���ɵ�������Ƚ���ս�Ե�һ������Sora�ڴ˷�����ֺܺá��� ��3�����ḻ���Ӿ�ϸ�� ���⣬ÿ�����߷��֣�Sora���ɵ���Ƶ�Ӿ�ϸ�ڷḻ����������������ɫ�ʱ��棬������Ƶ�������ߡ����֮�£�����ģ�����ɵ���Ƶͨ���Ե�ģ����ϸ�ڲ��㡢ɫ�ʲ���ô���ޡ� ���磬�����ɵġ�Ů��գ�۾�������Ƶ�У�Sora��Ů���۲�����дʮ�ֵ�λ����üë����ë����Ƥ���塢�۴����ԲϺ�ϸ�Ƶ�ϸ���������Ѿ��ﵽ�Լ������Ч���� |
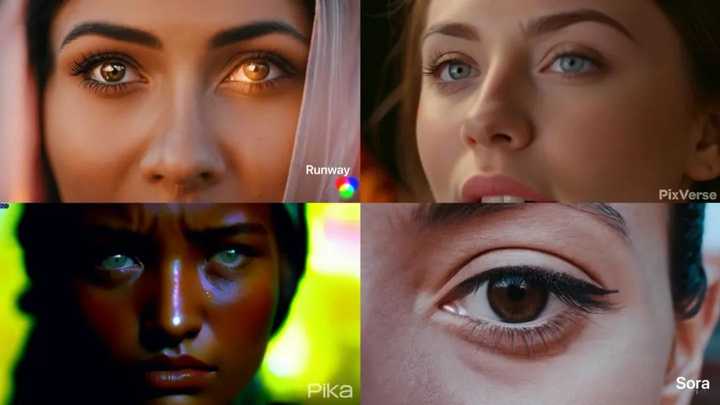
|
|
��4���������㲻ͬ�ij��� ������5��ͬ�����ij���Ч�����ѿ�����Sora���Ը��ܹ����㲻ͬ�����ߵ����������Ǵ����ƻó����������������ģ����ʵ����������������ʵ�֡� ����֤ȯ�б��ƣ�Sora�ĺ��ļ����ǻ���OpenAI����Ȼ���Դ�����ͼ�����ɷ���������ۣ���Runway��Pika����ȣ�Sora����Ƶ���ɵ���ʵ�С�ϸ�ڱ����Ͼ��߱�־�Լ�ֵ��AI��Ƶ�����䲻�����£���Sora���Ƴ������Ƹ�AI��ģ̬���ȶȣ��ɹ�עAI��ģ̬Ӧ�������������������뽻���·�ʽ�������Ӿ���ҵ�������֡�3D���ɡ���������Ӱ��ͼƬ����Ƶ���缯�ȷ��棬�����������������г��ķ��ٷ�չ�� |
|
|
|
��GPT��Sora��OpenAI��ͨAGI����ջ |

|
|
��Sora���ϣ����Կ���OpenAI��Ϯ�˹���������ģ��ѵ��������ɹ����顣 Sora��Ƶ�ı��������̶���ʵ���˾�̾��������Soraʵ��������Ծ���Ǹ�ģ�͵��������ͻ�ơ� �����ڵײ�ܹ��ϣ�Sora���õ�Diffusion Transformer��DiT������ɢ�� Transformer���ܹ��� OpenAI���ı�ģ�ͣ�����GPT-4�����Dz��õ�Transformerģ�ͣ���ͳ���ı�����Ƶģ��ͨ������ɢģ�ͣ�Diffusion Model����Sora���õ�DiT�ܹ����ں���GPT�ʹ�ͳ����ɢģ�ͼܹ��� ��OpenAI����������Sora���������п��Է��֣�Sora���õ�DiT�ܹ������ۻ�����һƪ��ΪScalable diffusion models with transformers��ѧ�����ġ���ƪ������2022��12���ɲ�������ѧ�о���Ա����Sora�ŶӼ����쵼William (Bill) Peebles��ŦԼ��ѧ�о���Աл������ͬ������ ��Sora������л������Xƽ̨��д��������Bill���Ҳ���DiT��Ŀʱ�����Dz�δרע�ڴ��£����ǽ��ص�������������棺����ԣ�Simplicity���Ϳ���չ�ԣ�Scalability����������ʾ��������չ�������ĵĺ������⣬�Ż���DiT�ܹ��������ٶȱ�UNet����ͳ�ı�����Ƶģ�͵ļ���·�ߣ���öࡣ����Ҫ���ǣ�Sora֤����DiT���Ŷ��ɲ���������ͼ������Ҳ��������Ƶ����Sora������DiT�й۲쵽���Ӿ�������Ϊ���� |

|
|
ͼƬ��Դ��Xƽ̨ ��Σ�Spacetime PatchҲ��Sora���µĺ���֮һ������һ���ϣ�Sora�����˼·��GPT-4Ҳ��һ�µġ� Patch��������ΪSora�Ļ�����Ԫ��Patch����Ƶ��Ƭ�Σ�һ����Ƶ�������ⲻͬPatch����һ��������֯�����ġ�����GPT-4 �Ļ�����Ԫ��Token����Token�����ֵ�Ƭ�Ρ�GPT-4��ѵ���Դ���һ��Token����Ԥ�����һ��Token��Sora��ѭ��ͬ���������Դ���һϵ�е�Patch����Ԥ��������е���һ��Patch�� ��������߽��ͣ�������Ƶ���ݱ��һ����С�飨patches������ģ�Ͷ�ͼ��������ܹ�������һ�����ο�����GPT�ı��֣�GPT���ı�����������ˮƽ�dz�ϸ�壬��ͬ����ԭ��Ӧ������Ƶ�ϣ������������ݵ�������Լ�ģ�����ı����������� |
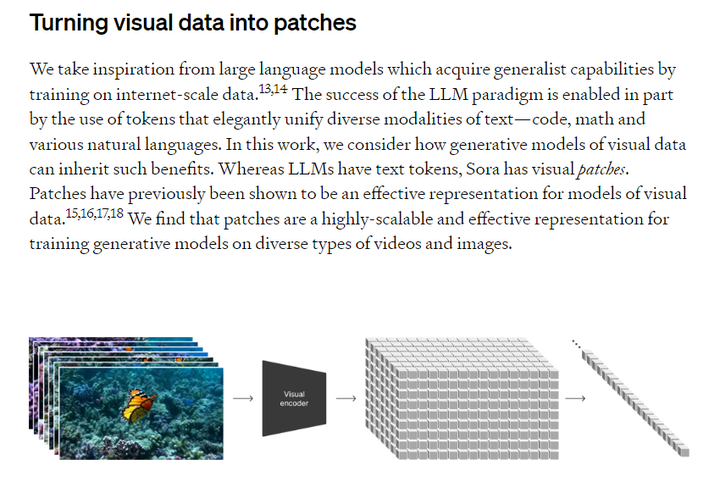
|
|
ͼƬ��Դ��Sora�������� ����л������̸���ġ�Scalability��һ�������ݴ�ѧ��������У�������ѧ PHD��֪������SIY.Z��֪��������д���������������һ������չ��OpenAI����ĵļ������Ҿ�����scaling law��������ô����֤ģ��Խ������Խ�࣬Ч����Խ�á�һ�仰���� Sora �Ĺ��ף����������������ݣ����ʵı�ע�����ı����£�scaling law��transformer + diffusion model�ļܹ��ϼ����������� �������������ݡ���ע�����롢�ײ�ܹ����������ڴ�ǰ��ģ�͵ijɹ����顣л������Xƽ̨Ҳ���ᵽ�� Sora�������ؼ�����δ���ἰ��һ�ǹ���ѵ�����ݵ���Դ���������ǹ��ڣ��Իع�ģ�����Ƶ������صļ���ϸ�ڡ� ����˵������Ŀǰall in AGI��OpenAI��˵�����ı�����ģ�� GPT������ͼģ�� DALL��E����������Ƶģ�� Sora��OpenAI�����Ѿ��������һ���Լ���AGIͨ�ü���·�ߡ� ֵ��ע����ǣ������ڴ�ǰ�ɹ�����֮�ϵ�Sora·�ߣ����ܻ��Ϊ��������������Ƶģ���·�ʽ������1�£�һλǰ�����AIר����Xƽ̨�ϱ�ʾ��������Ϊ��Transformer��ܺ�LLM·�ߣ�����AI��Ƶ��һ��ͻ�ƿں��·�ʽ������ʹAI��Ƶ�������ᡢһ�£�����ʱ��������Ŀǰ��Diffusion+Unet·�ߣ���Runway��Pika�ȣ���ֻ����ʱ�Ľ���������� |

|
|
ͼƬ��Դ��Xƽ̨ |
|
|
|
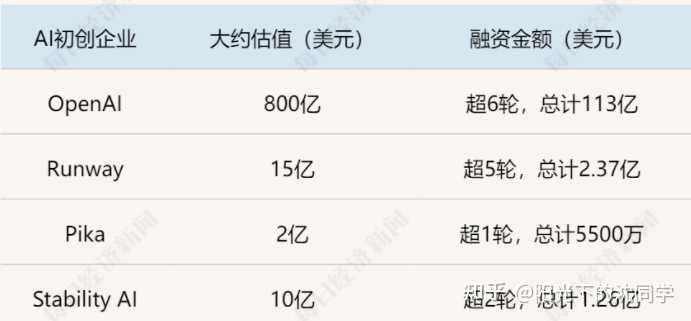
800����Ԫ�����ʱ�����OpenAI��ֵ9������������ |
|
|
|
�����������ChatGPT�����ı�תͼ��ģ��DALL��E���ٵ����ڵ��ı�ת��Ƶģ��Sora������ϵ�OpenAI��Ϊ�ʱ��г�����Ĺ�ע���㡣 ʵ���ϣ�������Ƶ��ģ�Ͳ�����һ��ȫ�µ��������ܶ�������Ƶ��ģ������������ڵ���Ұ������Stability AI��Stable Video Diffusion��Runway��Gen-2 Video���ȸ��Lumiere��Meta��Make-A-Video��Pika�Լ�PixVerse�ȵȡ� ���У�Pika��ȥ��11����ʽ����Pika 1.0���������ȫ���ȳ����䴴ʼ�˹��ľ�Ҳ�������룬Pika 1.0Ҳ��������Runway Gen-2����ǿ��Ʒ����������Sora�𱬳�Ȧ�����������������¼���·�ߵij��֣�������Ƶ����İ�ͼ����Ҫ���¸�д�ˡ� һ���棬���ļ�����һ���蹵����Diffusion Transformer��Spacetime Patch�������������ȴֻ��OpenAI�ɹ��Ƴ���Sora�����ң���������Ƶ��ʵ��Ա�������Sora��ȷʵ���˽�ά����� ��һ���棬�ӹ�ֵ�����ʹ�ģ��������������OpenAI��AI������˾�п���˵�Ƕϲ����ȡ�֮�������Ʒһ����������������ҵ�����䳬ǿ�ĵ�������������Ҳ�벻���������Ǯ�� |

|
|
ͼƬ��Դ��ÿ����ͼ Sora�𱬳�Ȧ���ʱ�Ȧ��������Ϣ�ǣ� OpenAI�Ĺ�ֵ�������800����Ԫ���ϣ�ֵ��һ����ǣ��ù�˾�Ĺ�ֵ��9���µ�ʱ���������������� ���˸���AI��ģ�Ͳ�Ʒ֮�⣬OpenAI CEOɽķ���������������˰뵼�����ݱ�����������������DZ��Ͷ���ߡ��뵼�������̺���Դ��Ӧ�̵ȸ�����������߽Ӵ���Ԥ�ƽ�����7������Ԫ����оƬ�۹��� �ڼ������ʽ�ļӳ��£�OpenAI�ڽ�������ʱ������ܻ�������ңң���ȡ� ��֮��ȣ�Runway����Ŀǰ�ۼ����ʳ�2.5����Ԫ��TechCrunch�����ƣ�Runway�Ĺ�ֵ��ȥ��6�µ״ﵽ15����Ԫ����Ͷ���߰����ȸ衢Ӣΰ�Salesforce�ȡ� Pika�Ĺ�ֵĿǰ��2����Ԫ����ҽ������˵ij�����˾���ŷdz�������Ͷ�������ݣ�����ǰGithub CEO Nat Friedman��Quora��ʼ��Adam D'Angelo��OpenAI��ʼ��ԱKarpathy��Perplexity CEO�ȡ� ȥ��11�£�Stability AI�Ĺ�ֵ�ﵽԼ10����Ԫ��������Stability AI������Ҳ�����������ʽ����ѹ����2023��11�£�Stability AI���س����ڲ���״��ѹ��������Ѱ����ۡ����⣬����ҪͶ���������Գ����Coatue Management����ȥ��10�����Ź����㣬Ҫ��CEO�����¡�Ī˹���˴�ְ�� |
|
|
|
���ݴ��������߸� �������ü�� |
|
|
|
|

|
|
ͼƬ��Դ���»������ ��ΰ �� ��������Ϊ��Sora�ij��ֿ��Ըı�һϵ�д����ҵ���ӵ�Ӱ��������浽ͼ����ƣ�����Ϸ�������罻ý�塢Ӱ����Ӫ�����������Ƽ��������ܵ�Ӱ�졣 ����ֱ�ӵ�����Ƶ�����������ǵ�Ӱ���������˶��ܲ���Ķ���Ƶ���ܶ�Σ�յģ�����������ij�������������AI��������ɡ��������ı�����Ƶ����������Ҳ��������Ƶ�������ż������߱���Ƶ�����������ˣ�ͨ���Լ�����������Ҳ���Ա���������Ƶ�����ߡ�������˵���� ��ͬʱ�����ߣ�Sora���������Ƶ�AI��Ƶģ���ڶ����ҵ����ʾ�������ҵDZ�����г���������ý������֡����С����ڷ����뱣�ա������Լ�ҽ�Ʊ�������ҵ����������������ʽAI�Ľ�������Щ������Ӧ�ò��������Ż�Ӫ�������ۻ�����ƿͻ������ܼ�ǿ��Ʒ�����ͷ��չ������� ����ͬʱ��ʾ��������ʽAI����Щ����ı��DZ���ѱ����˹㷺���г�����Ϳ���ҵ�ľü�ֵ������Ϊ������ҵ����2.6������4.4������Ԫ�ļ�ֵ���� ���⣬����ý����������ӡ�Ⱥϻ���Hemant Mohapatra��Sora�ij��ֱ���Ϊ�˶�����ħ���Ѿ���������һ�ж������ı䡣�������ɵ���Ƶ����֮�ߣ����ÿ����Ƶ���ɹ�˾�������ܵ���в���� �����г����ȷ�Ѫ���Ѿ�����ӡ֤��һ˵����Sora�����Ĵ��գ���������������˾Adobe�ɼ۱�����7%������ͼƬ�⡢ͼƬ�زġ�ͼƬ���ֺͱ༭���߹�Ӧ��Shutterstock����5%������ǰ�����ˡ�������Ƶ������Lumiere�Ĺȸ�ĸ��˾�ɼ��´�1.58%�����ҹ�˾һ���ھͺϼ�������480����Ԫ����ֵ�� ��һ���棬����AI�Ŀ��ٷ�չ���й�����յ�����Ҳһֱδ��ͣЪ����η�ֹ�䱻���û������Լ���α���������ǵ���֪��������Ӱ����ҵ������ר��̽�ֵ��ص�֮һ�� ����Ƶ���ɺ�����Ӧ����թƭ���ܶ�ط���������ʶ����Ƶ����Ҳ�ù����ļ�����ò��ٰ�ȫ��Ϊ�˼�����Щ�������ܴ����ķ��գ�������ȫ�ĵ�����ʵʩ�ϸ��������˽��ʩ���Լ�ȷ��AIģ�Ϳ�����ʹ�õ�����������Ҫ������������ߡ� ����AI�ķ�չ������Ҳ�������ڼ�ǿ��AI�ļ�ܡ�����ȥ��10�£��������״η������AI�����������AI�з���Ӧ���ƶ�ȫ��ļ�ܱ���ȥ��11�£��й���������Ӣ����ŷ�˵ȶ��������ȫ���˹����ܰ�ȫ�����ǩ���ˡ������������ԡ��� ������Ϊ��δ�����ص���ܻ�ת����ǿ��AI��������ͬʱȷ���ԺϺ����º����εķ�ʽ������ʹ�����ǣ�������ȵط�����Ը�����ҵ�Ļ���Ӱ�졣��AI��Ƶģ�����ڳ��Ÿ������ε�AIʵ������չ������Ҫ��ͨ��Ͷ���з�����ǿAIӦ�õİ�ȫ�Ժͱ��ϡ���ȡ���������ķ����������Щ�������������ǿ��ܵġ��� |

|
|
�����ּ�ح�Ӿɼܹ���ʵ����ͻ�ƣ�OpenAI�ı߽粻ֹ�ڴ� OpenAI��ÿһ�ζ�������������Ƽ�Ȧ����һ�ξ��𡣾���������Ƶģ���ѷ��״η��������������ʣ�Sora������һ���ʵķ�Ծ����ʱ���������Ժ��Ӿ�ϸ�ڵȷ����ͻ�ƶ���ǰ��δ�еġ� ������߸е����ȵ��ǣ��ڲ�����صļ������ʱ���֣�Sora�ӵײ�ܹ�����˵������ȫ�µļ��������磬DiT�ܹ���Patch�����Ķ���ȥ��ͷ����ġ���Sora���ϣ�Ҳ���Կ���OpenAI����������ģ��ѵ���ijɹ����顣Ȼ����ֻ��OpenAI�Ӿɼܹ���ʵ�����µ�ͻ�ƣ��������ζ�ţ�������OpenAI��ҹ�˾������AI�㷨���������ǵı߽绹Զ��ֹ�ڴˡ� Sora�ٴ�չʾ��AI�������ܣ���ҵ�ĵ߸�Ҳ�����ٴε������������м�����ҵ��Ҳ�����ߣ��ڹ۲�Sora����ʾ�ʷ��֣�������Ƶģ�͵�ʹ���ż��Ƚϸߣ��û�Ҫ�бȽ�ǿ��������������Ҫ���һ��Ʒ�ʽϸߵ���Ʒ��Ҳ�ܿ����û������������� ���ͬʱ��Ҳ���ò��ᵽAI���յ�������̸������һ��¥�ļ������ܽ�ΪAIթƭ�ȷ�����Ϊ�ṩ�´�����ˣ�������ȫ��ܴ�ʩ��ȷ��AI�������ú�������һ����Ҫ�����⡣ ��|Ф�� ������ ����|���� ֣�꺽 �༭|����Ӣ �Ӿ�|������ ��Ƶ|�ź� �Ű�|����Ӣ ��ʵϰ�����������¾����Ա������й��ס��� ����ת�����롶ÿ�վ������š�������ϵ�� δ����ÿ�վ������š�������Ȩ���Ͻ�ת�ػ���Υ�߱ؾ��� |
|
��С��˾�����ƣ�open aiĿǰ���Žᡣ���Ӱ����������»Ὺ���粨���ܿ������� һ����Ŀ������Խ��Խ�ã������и��߽�ЧӦ����������߽磬Խ���˷���Ч��Խ�͡� ai�������ȸ�һֱ�ڸ㣬chatpgt֮ǰҲ��ÿ�꼸ʮ�ڵ�Ͷ�롣���ǹȸ�Ϊɶ�ϲ���open ai �ȸ�gumini����ֵ�Ц�����������ɵ�ͼ���Ǻ��˺��������֡�������������˹�ˣ��վ�ȫ�����������˺��ˡ� ������reddit�����˱��ϣ��ڲ�Ա����ͷ�����������ˣ���������Լ��ϱ���ʱ���鷳�͵���ͷ�ϣ�����װ��û������ ������һ�����㵽��Ӫ�������˶����ˣ�ȫ��û������ ��Ǹ�bug���������һ����Ŀ��;����·�ߴ����أ���Щ�˻��ϱ�����װ���� |
|
|
| [�ղر���] �����ر��ġ� |
| ��һƪ���� ��һƪ���� �鿴�������� |
|
|
|
| ��Ʊ�ǵ�ʵʱͳ�� ��ͣ��ѡ�� ��ʱͼѡ�� ��ͣ��ѡ�� K��ͼѡ�� �ɽ���ѡ�� ����ѡ�� ������ѡ�� �������� �������� ���� MACDָ�� KDJָ�� BOLLָ�� RSIָ�� ���ɻ���֪ʶ ���ɹ��� |
| ��վ��ϵ: qq:121756557 email:121756557@qq.com ����ƻ� |