
| |
|
|
| 首页 淘股吧 股票涨跌实时统计 涨停板选股 股票入门 股票书籍 股票问答 分时图选股 跌停板选股 K线图选股 成交量选股 [平安银行] |
| 股市论谈 均线选股 趋势线选股 筹码理论 波浪理论 缠论 MACD指标 KDJ指标 BOLL指标 RSI指标 炒股基础知识 炒股故事 |
| 商业财经 科技知识 汽车百科 工程技术 自然科学 家居生活 设计艺术 财经视频 游戏-- |
| 天天财汇 -> 科技知识 -> 有没有人解释下Sora原理? -> 正文阅读 |
|
|
[科技知识]有没有人解释下Sora原理? |
| [收藏本文] 【下载本文】 |
|
为什么Sora能够生成这么长视频,且没有明显bug了。有哪些技术革新。 |
|
这几天被OpenAI释放出重磅模型 Sora刷屏, 它可以生成1分钟的视频,效果秒杀现有的视频生成模型,大家都惊呼其效果,但是从披露的信息来看, OpenAI并未使用新的模型架构,类似GPT一样, 这个Sora模型基于 Diffusion和Transformer 结构, 扩大模型规模,并提供更加丰富的训练数据,像另一个GPT3一样,大力出奇迹的搞出了Sora这个大杀器,下面根据披露的信息尝试解读下 Sora背后的原理 Transformer 结构 大家都知道Transformer被Google(Attention is all you need)整出来后, 被证明理解Language能力是无比有效的。先面大致介绍下这个结构: ? 句子先转化成一个个单词的Token(可理解为语言的寓意最小单位, 比如Loves 对应成love) ? 然后把这个token序列转换成Embeding的向量加上token的位置信息,输入到模型中 |

|
|
图1: 文本如何从Token输入到Transformer结构 ? 如图所示的Transformer结构, ? 每个token外加token的位置编码信息组成的embeding矩阵X,就是对句子的数学表示 ? 后续基于X 生成的 QKV是三个矩阵加上前向网络是著名的Header结构 ? 用多个Header结构,从而生成对X充分理解 ? 多个Header最终concat 成最后的向量,得到最后向量 ? 这个向量可以做很多事情, 比如语义分类,比如情感分析,比如作为另一个Decoder的输入等 ? 模型被提出来时是两个部分, Encoder + Decoder, 图2 表示的是两部分都包含的Transformer核心组件, Attention机制。 Encoder用于对上下文的理解, Decoder可以生成内容 |
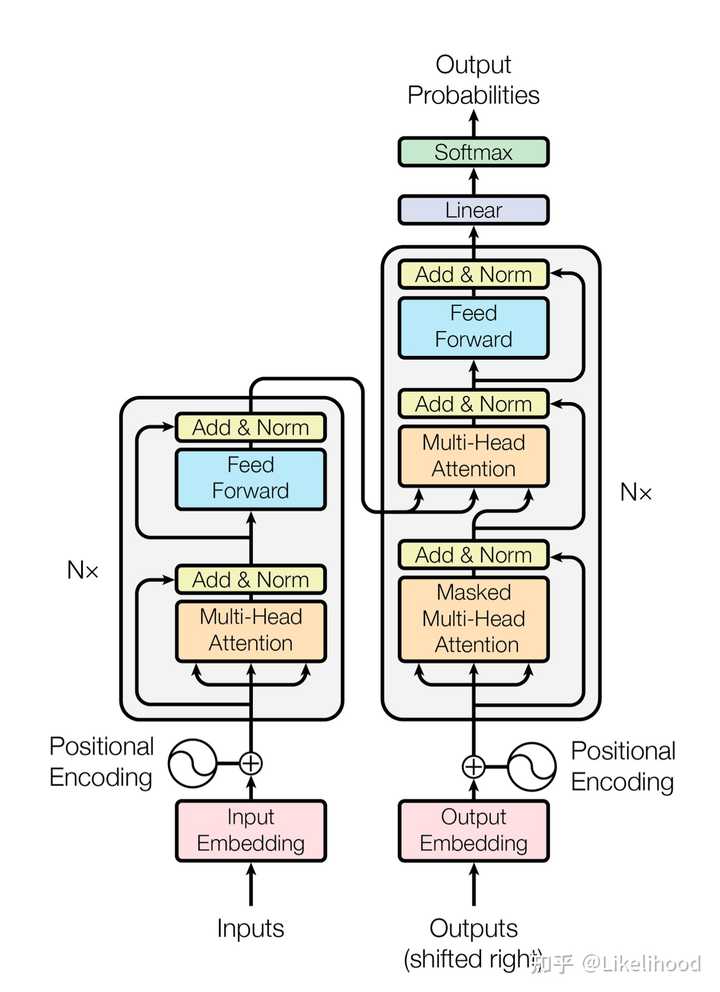
|
|
图2: Transformer整体Encoder+Decoder结构, 左侧Encoder 右侧Decoder ? 比如Encoder输入是中文, Deocoder输出是英文, 这样就能完成翻译 ? GPT正是利用Decoder部分,直接基于上文生成下文,创造了强大的生成模型。这也充分证明了Transformer结构对理解人类语言的惊人能力 ? 人类的语言的特点是有上下文, 视频天生具有上下文的特性。Transformer被证明对语言有效后, 研究人员也就开始用该结构来理解任何人类产生的内容, 如图片,视频等。 Diffusion过程 Diffusion是一个迭代过程: ? 先向一个图片中增加噪声,那么对每个图片, 清晰图片X + Noise_x = X' (含有噪声的图片) ? 如果训练一个模型(通常用UNet模型), 能够预测X'中噪声Noise_x, 那么用X' - Noise_x 就能恢复到X |

|
|
图3: 生成噪声图,预测噪声图里的噪声 ? 当对一个完全是噪音的图片,逐渐去掉噪声的时候, 就能得到一个清晰的图片 |

|
|
图4: 循环迭代预测噪声过程, 从而得带清晰图 ? 一般会引入一个Condition, 比如文字的condition, 这样基于这个condition,就能得到一个该Condition下清晰的图片,这就是Text 2 Image的大致原理 |
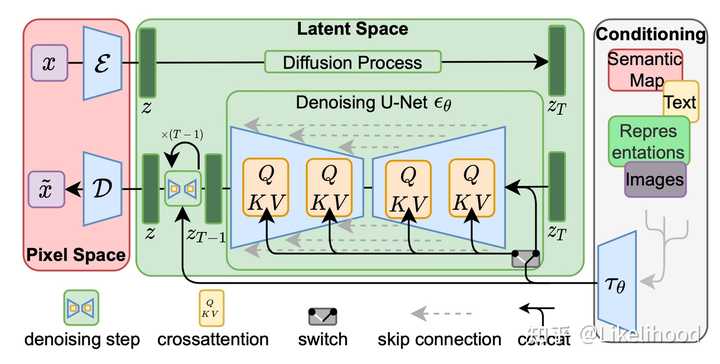
|
|
图5: 引入TextCondition,这样基于Text能生成和Text描述一致的图片 ? 为了加速过程, 先会对图片做Encoder从而得到图片的一个 Latent 表示, 然后对Latent做diffusion过程 Sora的原理 基于以上Diffusion的原理, 如果基于Condition条件,比如Text输入,从一个完全噪声的视频帧,生成清晰的视频帧,就能实现Text2Video了。那具体是怎么做的呢? ? 为了更好的处理和理解视频, 把视频中的每一帧,用一个模型Encoder, 转换成Latent tokens ? 有了Token,就能用Transfomer结构去理解视频,处理视频 |
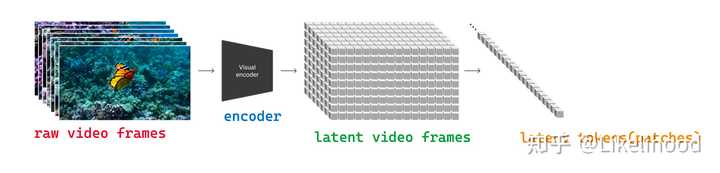
|
|
图6: 视频帧转成Token ? 通过Encoder把视频的帧转换成了latent 表征, 后续diffusion过程,都是基于这个这个 latent的 ? 基于Latent 表征,可以加入噪声,然后是训练预测噪声的模型,这个预测噪声的模型不是StableDiffusion里的Unet, 而是换成了 Transformer架构,这是最先提出TransformerDiffusion论文,基于这个论文提到的结构如下图 |

|
|
图7: 基于Token,利用Transformer模型理解视频并预测噪声 ? 左侧输入有两个部分, 被加了噪声的Latent表征(灰色部分), 还有是condition, 因为要做text 2 image or video, condition必不可少, 论文提到的是把Noise和Condition分别处理, 最后输出成一个向量 ? DiT Block 就是基于Latent Tokens的Transformer结构 ? 图上给出的是Encoder部分, 另有也是Transformer结构的Decoder部分预测噪声,这样就实现了Diffusion过程, 从一个噪声视频帧得到清晰视频帧 |

|
|
图8: 去除噪声,得到高清视频 ? 以上过都是基于Latent 表征做的, 所以需要把Latent 表征, 通过类似VAE的结构, 生成出原始高清视频帧 Sora 训练细节 官方披露的报告中提到几点讨论 ? 基于原始视频的大小,不做裁剪会有跟多好处 ? 不同尺寸的素材直接用作采样目标,用作训练数据 ? Sora也能为能生成不同尺寸的视频 ? 裁剪后会使得生成的视频不完整, sora不会 ? 利用基于DALL-E3提到的标注技术,训练了标注模型, 为大量视频生成丰富的文本解释,提高了文字准确度也提高了视频整体质量, 还用GPT把简短的提示转化成详细的文字说明 ? Sora 不仅能Text2Video, 也能Image2Video, ? Video的编辑 ? 无缝转场能力 ? 合并两个风格视频的能力 Sora 讨论 ? 无法精确模拟像玻璃破碎的物理互动能力, 吃东西 ? 视频样本出现的不一致和物体突然出现 写在最后: 官方披露的信息还很少, 以上根据披露信息做了些许解读,Diffusion Transformer华人作者Xie 最近也被自媒体标题党,自己出来辟谣说和Sora这个产品无关,他自己应该也不在OpenAI。 AI就这样, 大家都站在前人的肩膀上,从Transformer的提出开始,就迸发出了无限的潜能,人类的技术的进步不断改善着人类生活的世界。 愿世界和平,AI技术欣欣向荣持续改善人类世界,向所有为技术进步作出贡献的科学家,公司致敬! 看到这里了, 求个关注,感谢!! 参考文献: ? Transformer Model (Attention is all you need) ? GPT1(Improving Language Understanding by Generative Pre-Training ) ? Diffusion model (Denoising Diffusion Probabilistic Models ) ? OpenAI官方报告(https://openai.com/research/video-generation-models-as-world-simulators) ? Scalable Diffusion Models with Transformers(https://arxiv.org/pdf/2212.09748.pdf) ? What are Diffusion Models(https://lilianweng.github.io/posts/2021-07-11-diffusion-models/) ? https://medium.com/@taran.lan/2023-summary-of-diffusion-models-2370a264d6f1 ? https://www.assemblyai.com/blog/diffusion-models-for-machine-learning-introduction/ ? https://encord.com/blog/diffusion-models/ |
|
相信大家这几天已经被 AI 生成的雪中猛犸象视频刷屏了,小鲤琢磨了一下午,尝试用大白话和大家聊聊:Sora 背后的技术究竟是如何实现的呢?Sora 的出现会对产品设计带来哪些影响呢? 我的目标是,让普通人一听就懂~ |

|
|
视频中,几只巨大的毛茸茸的猛犸象穿越雪地中的草地,它们的长毛在微风中轻轻飘扬。远处是被雪覆盖的树木和壮丽的雪山,午后的阳光透过薄雾的云层,营造出一种温暖的光芒。 而这一切,都是由 OpenAI 的最新重磅产品――Sora 自动产生的。 |

|
|
Sora 是一种能够根据用户的文本描述生成视频的 AI 产品。想象一下,将来你只需要给 Sora 一个大致的故事描述,比如“一只小怪兽在玩蜡烛”,Sora 就能够制作出对应的视频来讲述这个故事。 |

|
|
简而言之,Sora 通过学习大量的视频数据,理解不同场景、动作和物体在视觉上的表现方式,然后利用这些学习到的知识,根据文本提示生成新的视频内容。这就像是让一位电影导演根据你的提示创作电影,只不过这位导演是人工智能。 尽管目前 Sora 生成的内容还存在一些瑕疵,但整个影视行业已经感受到了前所未有的冲击,正如 23 年初 Midjourney V5 版本发布时对设计行业所产生的影响。 |

|
|
但是,乐观一点,正如那句老话所说,新技术的出现必然会带来新职业的诞生。汽车的出现淘汰了马车夫,但同时也催生了汽车司机一职。Sora 目前还处于内测阶段,让我们一起来好奇和展望一下: 好奇的是,Sora 背后的技术究竟是如何实现的呢? 展望的是,Sora 的出现会对产品设计带来哪些影响呢?( 我的本行是产品经理) 一、超级大白话聊聊 Sora 背后的技术实现 这两天,我也阅读了很多文章,深感对于我们这些不懂技术的普通人,试图通过专业术语(而且还是英文)来理解技术,是一件相当困难的事情。因此,我结合了官方论文和一些文章的解释,尝试用最简单直白的语言来为大家拆解 Sora 的技术原理。 |

|
|
在我看来,Sora 有点像是玩拼图游戏 。当我们玩拼图时,一幅完整的画面是由许多小块图像拼接而成的,官方将这些小块称为“patches”(这个词可以翻译为补丁、斑块、小方块或图像块等,具体含义根据上下文而定)。 首先,Sora 会将视觉数据转化为许多这样的图像块。每个图像块包含了关于时间和空间的信息,比如颜色、形状、位置和运动等。这些图像块就像是拼图中的碎片,可以被重新组合成各种不同的画面。 |

|
|
注:图中的Visual encoder意为视觉编码器 第二,Sora 利用一个称为视频压缩网络(Video compression network)的特殊网络来“压缩”视频,这一过程会将图像块转换成一种统一且信息量更小的形式。这样的压缩为什么重要呢?因为压缩后的图像块可以大幅降低计算负荷,使得 Sora 能够在训练过程中更加高效地处理大量数据。 当视频数据被压缩之后,Sora 接着生成所谓的时空潜在图像块(Spacetime latent patches)。顾名思义,这种图像块蕴含了时间与空间的信息,它们是 Sora 核心技术的一部分。这种技术使得 Sora 在处理视频数据时,能够保持三维空间的一致性,就像艺术家在绘制移动物体时确保其在三维空间中的移动是连贯且合理的一样。 如果你对“图像块”的概念还是有些模糊,可以将其类比于 GPT 中的“token”概念。这种处理方式实际上受到了处理文本数据的大型语言模型的启发。在这里,图像块就像是 GPT 处理文本时使用的 token。这可以被视为 OpenAI Transformer 架构的一种延续和发展。不同于主流视频生成模型多采用的 U-Net 架构,OpenAI 在经验和技术路线选择上展现了其独到之处。 第三,Sora 利用扩散模型(Diffusion model)来生成视频,这个过程被称为“扩大变换器用于视频生成”(Scaling transformers for video generation)。扩散模型是一种生成模型,其核心原理是通过学习如何从数据中去除噪声来生成新的数据样本。 因此,当我们向 Sora 提供一个提示后,Sora 最初生成的图像实际上是充满“噪声”的,每个像素点都被随机赋予颜色值,看起来类似于老电视中的雪花屏幕。通过训练,Sora 会不断调整图像块的位置、大小、角度、亮度等参数,最终预测出这些噪声图像背后的“干净”状态。通过逐步去除噪声,视频最终看起来会更加自然和流畅。 这个过程可以比作是艺术家首先绘制一个大致的草图,然后逐步添加细节,使画作从模糊逐渐变得清晰。对视频而言,这意味着一次性地预测多帧画面,将这些带有噪声的多帧图像转换为清晰的图像,这些清晰的图像连续起来,就形成了最终的视频。 |

|
|
注:图像生成过程示意 总结来说,Sora 的工作原理与 GPT 学习并生成新句子的方式颇为相似。Sora 通过将视频数据分解成图像块(类似于拼图的方式),观察和学习大量的视频和图片数据。同时,它也掌握了如何将这些图像块重新组合起来,以创造出全新的视频内容。 例如,如果你给 Sora 一个简单的图像提示,比如“一群活泼的金毛在雪地上嬉戏”,Sora 将结合这些文字提示和它学到的视频数据知识,像拼图一样,一块块构建出视频的每一帧。如下图,细节丰富到炸裂,看不出一丝一毫的破绽。 |

|
|
使 Sora 成为 AI 视频领域的第一产品的原因,不仅仅在于上述生成技术的优势,还包括三个关键的功能: 1、图像和视频的扩展提示能力: 与 MJ 和 SD 能够从文本生成图像,以及从图像生成图像的能力类似,清晰的图像和视频也可以作为提示输入给 Sora,实现从图生成视频、从视频扩展到更多视频的效果。 |

|
|
注:小狗图片生成小狗动图 2、更高的灵活性 Sora 创新性地选择以视频的“原始尺寸和时长”进行训练,而不是将视频裁剪到预定的标准尺寸和时长。这使得 Sora 生成的视频不仅构图质量更高,内容也更加灵活,允许自定义视频的时长和尺寸。 |

|
|
注:(左图)正方形尺寸训练的模型有时会生成仅部分显示主题的视频,而(右图)Sora的视频有很大的改进 3、更好地理解提示:考虑到用户给出的提示词可能参差不齐,Sora 利用 GPT 技术将简短的提示转化为更长、更详细的提示。这样做能够让 Sora 生成高质量的视频,准确地遵循用户的意图。 二、Sora 的出现对产品设计会产生什么影响呢? Sora的出现不仅降低了视频内容生成的技术门槛,即便没有专业的视频制作背景,普通人也能创作出高质量的视频内容。 这也有助于产品经理等互联网从业者加快创意的实验和迭代过程,促进创新,同时也为产品和服务的未来发展打开了新的可能性。Sora必将对产品经理和产品设计领域将产生深远的影响,小鲤我畅想一下,主要有几个方面: 1. 加速营销内容创作 在需要快速生成营销视频,比如推广产品的视频,产品内页中其他的营销视频时,产品经理可以直接使用文本提示来生成产品使用场景的视频,而无需聘请专业的视频制作团队,Sora可以显著缩短制作周期,提高效率。 2. 增强个性化和定制化能力 由于Sora能够基于文本提示生成视频,产品经理可以设计更加个性化的用户体验,为用户提供定制化的视频内容。这种能力特别适合内容驱动的平台,如在线教育、社交媒体和娱乐应用。 3. 提升用户体验和互动性 利用Sora,产品经理可以设计出更加丰富和互动性强的用户体验,甚至可以改变现有用户与产品的互动方式。例如,在游戏或教育应用中,可以让用户通过简单的文本输入来创造或修改视频内容,为用户提供独一无二的体验。 这种能力将推动产品设计向更加动态和个性化的方向发展,新的互动方式也可以为产品带来更多的用户参与度和满意度,开辟新的市场机会。 三、结尾 Sora 正在打开一扇门,让我们能够以前所未有的方式与内容互动,无论是作为创作者、普通人还是大公司。 想象一下,对于个人,未来我们在发朋友圈发小红书时,可以直接通过简单的文本描述,创造出丰富多彩的视频内容,分享自己的故事。对于大公司,例如在线教育平台,也可以通过提供定制化的视频教程,让学习变得更加生动有趣。 随着技术的进步,我们对于创意的实现方式也将不断革新。让我们一起期待,Sora 在 2024 年将如何继续改变我们的世界,以及将如何激发出更多创新的灵感和想象吧。 |

|
|
注:视频由sora生成,意为中国龙年街景参考文章: https://openai.com/research/video-generation-models-as-world-simulators --全文完-- 希望本文能帮助到你,或者给你也带来启发,欢迎关注我的公众号“产品小鲤 AI 冲浪”,一起交流呀 我会持续分享:AI 助力产品设计提效方法、ChatGPT\MJ\SD 等主流 AI 工具玩法、prompt 助力工作提效方法~让 AI 帮我们干活! |
|
常规的计算机CG没有几个月是做不出来的,Pika、Runway为什么做不出这样的效果?这两天网上介绍所有的视频已经非常多了,大家都在说sora好,到底为什么好,它是怎么做的呢? 我特别对三个场景印象深刻:一群金毛小狗在雪地里打滚,其真实感让人惊叹;一个咖啡杯中的海盗船战斗场景,展现了惊人的特效;以及无人机穿越城市古迹的画面,其3D效果和一致性维护得非常好。这些效果展现了目前技术的极限,以及为何传统的CG方法无法轻易复制这些效果的原因。 |

|
|
Pika和Runway,那为什么做不出这样的效果? 我理解Pika和Runway实际上还是基于这种图形图像本身的操作来进行的生成,在一个画面上选定一两个目标,一两个对象。让这一、两个对象要么保持不动,背景在动,要么背景不动,这一两个对象在动,就形成一种比较简单的计算机动画的效果,它是肯定做不到刚才的三个画面的能力。 ( PS:目前,OpenAI 尚未公开开放 Sora 的灰度测试。然而,借鉴之前 DALL・E 图像模型的案例,我们可以预见首先会向 ChatGPT Plus 的付费用户提供这一服务。对于有意体验此服务的用户,如果您尚未注册或希望了解如何升级至 GPT Plus ,可以参考: 快速开通 ChatGPT Plus 在CG领域,创建真实感强的画面,比如毛茸茸的动物或是动态的水面,需要极其复杂的建模和粒子效果模拟。这不仅涉及到每一根毛发的建模,还包括每一个水滴的物理建模,以及如何表现出毛发随风飘动的感觉和雪花的质感。这样的工作量是巨大的,使用常规的电影工业特效手段,可能需要几个月的时间才能完成。 如果用电影特效来表示咖啡杯里的那个波动,这个就需要给粒子特效来模拟多少个水分子,把每个水分子看成是一个粒子,然后利用水的这种物理方程来模拟流体的特质,一帧帧的把它渲染出来。阿凡达为了做水的特效,据说花了好几年的时间才完成了大量的海浪,水波纹这些特效镜头。 那么像无人机飞跃一个城市,所有飞跃的地方,都要需要做真实的3D建模,3D的贴图和3D的渲染,在镜头飞跃的每一个观察点上,都要对这个3D的画面做若干次的渲染。对一个城市的3D建模的工作量特别大,所谓叫数字孪生还是非常昂贵的一个技术。 但是到了sora这里,这些东西都变得非常的简单,只要给一堆文字的提示要求,它就能给你非常逼真的描绘出来。 sora到底做3D建模没有? 我觉得答案应该是没有,因为sora如果也只是3D建模在进行渲染,和传统的电影工业走一样的路,那就它就不具备颠覆性和革命性了。 sora怎么做到的呢?第一点 sora应该还是模拟了我们人类去观察世界、描绘世界和表现世界的这种方法,比如说如果要我们人类一个有经验的画师用笔画出来看才3个场景,我们人类在大脑里并不需要3D建模。 因为人类已经对世界有了一个基本的认知,我们知道透视的原理,我们知道随着这个镜头的移动,每个物体的视觉画面会发生改变,我们知道如何去画毛茸茸的毛发,如何去画这个雪,当狗转身的时候,我们知道整个画面会有什么样的变化,我们不需要懂粒子特效,不需要3D建模,不需要懂物理定律,我们靠着对世界的观察,我们也能画出惊涛骇岸的这种海浪的感觉。 sora应该通过大量的训练,掌握了人类这种观察世界、描绘世界、表现世界的这种能力,所以就使得他通过表面看的是2D画面的这种生成,完全理解了这个3D世界的物理规律。 第二点 我觉得sora在学习的过程中,不光是用了很多视频电影的内容来作为训练的输入,当你输入一些画面给sora模型做训练的过程中,你不仅要解读出画面有什么元素,你还要解读出来这里面反映的一些物理定律。 openai在对他的论文。你提到一个叫recaptioning技术,很多人把它翻译错了,翻译成叫字幕技术,像recaptioning的意思是说对每一帧画面能够把它变成用文字来描述,这点也非常符合人人类认知世界的方法。 比如说一个见过大海的人,向一个没有见过大海的人,用语言来描述这个海浪的效果,让他来进行学习,进行想象。所以这一点说明openai的多模态技术已经达到一个新的空间,我估计Google的Gemini看来短期内是很难赶上了。 第三点 大胆的猜测一下,openai应该是自己产生了很多3D的内容,也不排除他用现在的游戏引擎做了很多这种实时3D模型的渲染,利用这种3D模型来把更多的物理知识训练给sora。 为什么人类对AIGI的突破可能就剩下最后一步了? sora表面上看起来是一个刮胡刀,实际上它是一个吹风机,或者它看起来像一个吹风机,它实际上是个刮胡刀,它表面上看来是一个记录文字生成视频AIGC的工具。 它反映了AI对我们这个世界的理解,已经从文字进到图像,已经从图像进成视频,对这个世界3D模型的理解,对物理定律的理解,还有些人在吹毛求疵,我看到一个sora翻车的视频,比如一个杯子没有碎掉,水就流出来了,还比如说从土里挖出一个凳子,那个凳子没有表现出重力的感觉。 s我恰恰觉得有这些问题呢,非常正常,就像大模型会产生幻觉一样,在梦中不也是会让很多物理定律失效吗? sora所谓的失效,我觉得有两种可能,一种是这种模型先天具备的,这种也有幻觉的问题,会产生一些魔幻的效果,还有一种,是物理知识训练的不够,所以我们面对一个新的东西,不要老是盯着它的弱点,这些弱点都是可以被改进的。 原文转载:https://haogonju.com/2049.html |
|
首先,不是没有明显的bug,只是优点太明显,大家忽略了其依然存在的bug而已。 等到热度下来了,有人开始大范围使用的时候才会有人指出问题来。 目前的Sora依旧是通过数据学习来模拟一个“世界模型”的,跟真正的物理世界模型还有较大的差距。从目前Sora发布出来的视频可以看到,虽然质量很高且很逼真,但是在一些特殊的场景下依然能看到AI的影子以及AI常犯的错误。 这里举几个例子: 海盗船这个Demo视频中出现的圆弧海浪: |

|
|
在继续扩大以后变成了杯子的杯口: |

|
|
这明显是不符合常理的。 以及在另一个展示视频中,时而两条腿,时而四条腿的小动物: |

|
|
|

|
|
所以,目前的Sora是很惊艳,但是还没有到能够“无bug”的地步,还是有很长的路要走的。 |
|
1. Sora 是什么? 2024年2月16日,OpenAI 在其官网上面正式宣布推出文本生成视频的大模型 Sora: https://openai.com/sora PS:目前 openai 官方还未开放 sora 灰度,不过根据文生图模型 DALL・E 案例,一定是先给 ChatGPT Plus 付费用户使用,需要注册或者升级 GPT Plus 可以看这个教程: 升级 ChatGPT Plus 的教程 ,一分钟完成升级 Sora能够根据简单的文本描述,生成高达60秒的高质量视频,使得视频创作变得前所未有的简单和高效。 本文将为您提供关于如何使用Sora的最新详细教程。 2. Sora 视频案例 Sora的应用范围非常广泛,从教育教学、产品演示到内容营销等,都可以通过Sora来实现高质量的视频内容创作。 下面是 OpenAI 官方发布的应用案例: 1.Prompt: A stylish woman walks down a Tokyo street filled with warm glowing neon and animated city signage. She wears a black leather jacket, a long red dress, and black boots, and carries a black purse. She wears sunglasses and red lipstick. She walks confidently and casually. The street is damp and reflective, creating a mirror effect of the colorful lights. Many pedestrians walk about. 翻译:一位时尚的女性走在东京街头,周围是温暖闪亮的霓虹灯和活力四射的城市标识。她穿着一件黑色皮夹克,一条长长的红色连衣裙,搭配黑色靴子,并背着一个黑色手提包。她戴着墨镜,涂着红色口红。她步履自信,悠然自得地走着。街道潮湿而反光,呈现出丰富多彩的灯光的镜面效果。许多行人在街上走动。 |

|
|
2.Prompt: Several giant wooly mammoths approach treading through a snowy meadow, their long wooly fur lightly blows in the wind as they walk, snow covered trees and dramatic snow capped mountains in the distance, mid afternoon light with wispy clouds and a sun high in the distance creates a warm glow, the low camera view is stunning capturing the large furry mammal with beautiful photography, depth of field. 翻译:几只巨大的长毛猛犸象踏过一片雪白的草地,它们长长的毛发在微风中轻轻飘动着,远处覆盖着雪的树木和雄伟的雪山,午后的光线下有些薄云,太阳高悬在远方,营造出温暖的光芒。低角度的摄影视角令人惊叹,捕捉到了这些大型毛茸茸的哺乳动物,画面景深感强烈。 |

|
|
3.Prompt: Historical footage of California during the gold rush. 翻译:加利福尼亚淘金热时期的历史影像。 |

|
|
4.Prompt: A close up view of a glass sphere that has a zen garden within it. There is a small dwarf in the sphere who is raking the zen garden and creating patterns in the sand. 翻译:放大观看一个玻璃球,里面有一个禅宗花园。球内有一个小矮人,他正在用耙子整理禅宗花园,并在沙地上创造出图案。 |

|
|
5.Prompt: A cartoon kangaroo disco dances. 翻译:一只卡通袋鼠在迪斯科舞厅跳舞。 |

|
|
6.Prompt: The camera follows behind a white vintage SUV with a black roof rack as it speeds up a steep dirt road surrounded by pine trees on a steep mountain slope, dust kicks up from it’s tires, the sunlight shines on the SUV as it speeds along the dirt road, casting a warm glow over the scene. The dirt road curves gently into the distance, with no other cars or vehicles in sight. The trees on either side of the road are redwoods, with patches of greenery scattered throughout. The car is seen from the rear following the curve with ease, making it seem as if it is on a rugged drive through the rugged terrain. The dirt road itself is surrounded by steep hills and mountains, with a clear blue sky above with wispy clouds. 翻译:摄像机跟随一辆白色老式SUV,顶部有黑色行李架,它加速通过一条陡峭的土路,周围是松树,地势陡峭,车轮卷起了尘土,阳光照射在SUV上,它沿着土路飞驰,给场景增添了温暖的光芒。土路在远处轻轻弯曲,看不到其他车辆。路边的树是红杉,绿色的植物点缀其中。汽车从后方的镜头中轻松地跟随着曲线,使其看起来好像在崎岖的地形中轻松驾驶。土路周围是陡峭的山丘和山脉,天空晴朗,偶有薄云飘过。 |

|
|
7.Prompt: Reflections in the window of a train traveling through the Tokyo suburbs. 翻译:一辆列车穿越东京郊区时,窗户上的倒影。 |

|
|
8.Prompt: Tour of an art gallery with many beautiful works of art in different styles. 翻译:参观一个艺术画廊,展示了许多不同风格的精美艺术品。 |

|
|
9.Prompt: A grandmother with neatly combed grey hair stands behind a colorful birthday cake with numerous candles at a wood dining room table, expression is one of pure joy and happiness, with a happy glow in her eye. She leans forward and blows out the candles with a gentle puff, the cake has pink frosting and sprinkles and the candles cease to flicker, the grandmother wears a light blue blouse adorned with floral patterns, several happy friends and family sitting at the table can be seen celebrating, out of focus. The scene is beautifully captured, cinematic, showing a 3/4 view of the grandmother and the dining room. Warm color tones and soft lighting enhance the mood. 翻译:一位头发整齐梳理的祖母站在木制餐桌后面,桌上摆放着一个五彩缤纷的生日蛋糕,上面点着许多蜡烛,她的表情洋溢着纯粹的喜悦和幸福,眼中闪烁着快乐的光芒。她向前倾身,轻轻吹灭了蜡烛,蛋糕上涂着粉红色的糖霜和彩色糖粒,蜡烛的火焰也熄灭了,祖母穿着一件淡蓝色的上衣,上面点缀着花卉图案,可以看到几位快乐的朋友和家人坐在餐桌旁庆祝,但是他们处于焦点之外。这个场景被美丽地拍摄下来,有电影般的感觉,展示了祖母和餐厅的三分之四视角。温暖的色调和柔和的光线增强了氛围。 |
|
|
10.Prompt: A Chinese Lunar New Year celebration video with Chinese Dragon. 翻译:一个有中国龙的中国农历新年庆祝视频。 |

|
|
3. Sora 怎么使用 (PS:目前 openai 官方还未开放 sora 灰度,不过根据文生图模型 DALL・E 案例,一定是先给 ChatGPT Plus 付费用户使用,需要注册或者升级 GPT Plus 可以看这个教程: 升级 ChatGPT Plus 的教程 ,一分钟完成升级) 3.1 使用Sora前的准备工作 在开始之前,确保您已经拥有了OpenAI账目,并获得了Sora的访问权限。准备好您想要转化成视频的文本描述,记住越详细越好。 3.2 Sora使用步骤一:文本描述 登录您的OpenAI账户,找到Sora的使用界面。在指定区域输入您的文本描述,可以是一个故事概述、场景描述或是具体的动作指令。 3.3 Sora使用步骤二:生成视频 完成文本描述和自定义设置后,点击“生成视频”按钮。Sora将开始处理您的请求,这可能需要几分钟时间。完成后,您可以预览生成的视频。 需要注意的是,截止2024年2月18日,OpenAI只向部分专业用户开放了Sora的访问权限。普通用户只能观看其发布的演示视频。4. Sora 常见问题 OpenAI的Sora开启了视频创作的新纪元,无论是专业人士还是爱好者,都可以轻松创作出高质量的视频内容。尽管仍有一些限制,但随着技术的不断进步,相信这些问题将会逐渐被解决。立即尝试Sora,开启您的AI视频创作之旅吧 5. Sora技术原理 OpenAI近日发布了一项重要的里程碑技术――Sora,它是基于文本生成视频的AI模型。通过简单的文本描述,Sora能够生成连贯的长达1分钟的视频。那么,Sora是如何实现这一壮举的呢?我们来揭开它的技术原理。 基于Transformer架构 Sora模型与GPT模型类似,都基于Transformer架构,这使得Sora具有极强的扩展性。Transformer是一种基于自注意力机制的神经网络架构,它能够同时处理输入文本中的所有位置信息,使得模型能够捕捉到全局的上下文信息。这样的架构使得Sora在生成视频时能够更好地理解文本描述。 扩散模型和训练稳定性 Sora模型采用了扩散模型的方法,与传统的GAN模型相比,具有更好的生成多样性和训练稳定性。扩散模型通过逐步消除噪声来生成视频,这样可以有效地提高生成的视频质量。同时,通过采用扩散模型,Sora还能够生成更加逼真的视频场景。 生成视频的数据处理和压缩 生成视频需要处理大量的数据,对于这一问题,Sora模型采用了数据处理和压缩的技术。通过对视频数据进行处理和压缩,Sora能够在保持视频质量的同时,减少存储空间的占用。 视频质量和逼真度 Sora模型在生成视频的过程中,注重保持视频质量和逼真度。通过采用Transformer架构和扩散模型的方法,Sora能够生成更加连贯、且具有很高逼真度的视频场景。这使得Sora在应用领域具有广泛的潜力,比如可以用于影视制作、游戏开发等方面。 参考链接:https://www.openai.com/research/sora/ 6. openai sora如何使用的常见问答Q&A问题:Sora是什么?Sora是由OpenAI开发的AI视频生成模型。Sora可以根据用户提供的描述性文字生成长达60秒的高质量视频。Sora的视频包含精细复杂的场景、生动的角色表情和复杂的镜头运动。问题:Sora怎么使用?登录OpenAI账户并找到Sora的使用界面。在指定区域输入您的文本描述,可以是一个故事概述、场景描述或是具体的动作指令。点击生成按钮,OpenAI Sora会根据您的文本描述生成视频。问题:Sora的优势有哪些?Sora具有极强的扩展性,基于Transformer架构,可以应用于各种场景。Sora能够生成高质量、高清的视频,展现复杂场景的光影关系、物体的物理遮挡和碰撞关系。Sora可以创造出包含多个角色、特定动作类型以及与主题和背景相符的详细场景。问题:Sora的训练原理是什么?Sora的训练分为两个阶段。首先,使用一个标注模型为训练集中的视频生成详细描述。标注模型生成的描述能够更好地指导Sora生成视频。Sora利用稳定扩散(Stable Diffusion)技术将静态噪声转换为连贯图像。Sora模型采用初步的扩散模型生成视频长度,并逐步消除噪声完成视频。最后:需要注册或者升级 GPT Plus 可以看这个教程: 升级 ChatGPT Plus 的教程 ,一分钟完成升级 |
|
对于人来说,文字是文字,图像是图像,视频与图像有关但差异很大。 对计算机来说,文字,图像,视频,没有本质区别,都是2进制编码。 只不过,曾经,文字和多媒体有巨大的区别,以至于计算机要处理视频必须有专门的视频加速卡。 现在的计算机配合常规操作系统,在记录和播放层面,数字-文本-图形-视频,已经没有太大的区别,都能轻松处理,区别只是人觉得它们有区别,算力消耗有区别,但对电脑来说,都是二进制编码的不同处理而已。 但是,在目前的生成式ai出现之前,在创造信息层面,这几种主要的信息类型(文本,图像和视频),差异是巨大的,需要不同的软件,以及不同的专业创作者。 写文字的,画画的,拍视频的,做动画的,天差地别。 但现在,随着深度学习、GPT 、transformer、diffusion这些算法模型的发展,这些差别被抹平了。 对ai程序来说,所有这些不同的信息类型,创造过程的本质都一样,这才是最令人震惊的。 创造空间三维视频和创造文字,居然可以用类似的算法,这是sora带来的新震撼。 仅仅在大半年前,我跟做视频的同学讨论文本直接生成 长视频时,还觉得这比较难实现。 在GPT阶段,大家还会觉得文本相对容易处理,图像跟文本有本质区别,量变会引起质变。后来有了stablediffusion,又觉得图像没问题,但视频有恐怖的数据量,量变会造成质变。 然而sora证明了,视频和文字仍然没有本质区别,仍然可以用类似的大模型算法生成。只不过根据有关分析,这个算力消耗确实是比较惊人的。 这确实意料之外,但又情理之中。人脑不也是一套软硬件解决所有创造问题。 但还是挺惊人的。 就像解析几何抹平了所有图形的区别一样,用统一的形式实现原本各不相同的图形。 之前的计算机软硬件抹平了各种媒体信息在记录层面的差别,全都是0和1可以解决的。 生成式人工智能大模型则抹平了这些不同媒体信息在创造层面的差别,全都是可以用大规模数据训练后,以特定的文本(以自然语言或带格式的自然语言的形式)进行提取重组然后生成新的内容信息。以后显然还可以以图或视频来生成新视频,没有本质区别。 从我目前看到的一些有限的信息,sora似乎抹平了3d模型和视频的区别。 从我们3d图形工作来说,以往的方式,要创造合理的视频,需要首先建立三维模型,再通过三维图形学生成二维图像序列(视频),其中三维模型的矢量数据格式是核心。 但我们也知道,对于有经验的创作者,可以根据一段视频,和自己的经验,逆向创建出相当准确的3d模型,然后进行任意角度动线的视频输出,这是业内比较常规的流程。 sora似乎超越了这个过程。 大量的视频素材,经过数据训练形成了大模型,就可以直接生成各种各样新的视频,这个大模型内部的数据结构,显然达到了提取三维模型的效果,这是sora跟过去的视频图像生成ai最不一样。 但sora提取的三维模型,很可能未必是那个人所理解的三维模型,毕竟三维模型也只是人的理解,本质仍然是有一定特征的数据包。 只能说,sora处理后的大模型基本等效于三维模型提取-组合-生成的过程,但内在数据特征到底是什么个情况,目前的信息很难说清楚。 我倾向于它训练出来的是比三维模型更本质更基础的数据结构,其过程应该比人脑对三维空间和视频的理解更抽象,就好像01000111这种数据包比具体的图片更抽象一样,解析几何也比立体几何更抽象但更具泛用性。 但其中一定包含了大部分三维模型必须有的结构特征,否则输出的视频不会给人类以经验合理性。 这种三维模型数据的结构特征,应该就是sora与之前的stable diffusion和chatGPT不同的地方。 但之前的gpt只是没有去做,还是sora加入了新针对三维空间信息的算法,目前还不得而知。 再扯远一点,就是冯诺依曼架构的计算机,跟人脑结构,到底能不能等效,或者是,ai到底能不能实现真正的强人工智能,学界是有分歧的。 但从目前来看,从深度学习开始的ai,似乎真的与人脑思维机制没有本质区别,两者可以实现等效,只是目前的ai的算法和效率还需要优化。 sora比起chatGPT又进了一步,只不过我对它的商业前景还不乐观, 就像当初那些大型机一样,技术原理上早就没问题了,但要到像pc真正深入各行各业的阶段,甚至像手机互联网那样深入到每个人,还需要不小的工程学上的大革命才行。 目前来说ai内部算法的意义还很难被人脑理解,半类似于黑箱,所以,确实说不清楚。 既然同一套算法下,文字和图像没区别,图像和视频没区别,那么具象信息和抽象情绪能否等同处理?理性推演和感性表达能否本质相同?自我意识和视觉形态是否也没有本质区别?欲望动机意义价值,和文字图像视频模型,是不是也可以用同一套算法实现和创造? 不好说,但概率已经不是太小。 |
|
Sora也没什么高深的技术含量,只是在图片生成的基础上加了游戏引擎而已。 Sora先把接收到的文字- prompt转化成代码(chatgpt很擅长这个),再用代码驱动游戏引擎生成初始三维画面,然后对初始画面每一帧进行高清渲染,颜色和细节补充(时空补片(Space Patch)),最后输出结果。 因为Sora生成的初始三维画面是引擎驱动的,所以可以有任意角度的摄影效果。 Sora的基本单元是patch,每个patch包含了原本的token,以及新加入的每个三维物体的顶点,颜色,纹理,运动矢量等元数据。 Sora视频中的文字都是鬼画符,因为是后期渲染的,其实类似加上了随机生成的2d纹理。如果在prompt中指定了要显示的文字,那么该段文字会生成3d模型,就是真正的文字了。 从Sora视频引擎的原理可以知道其用了大量游戏代码和3d模型文件进行训练,甚至还有好莱坞电影特效的原始工程文件,通过额外的物理引擎的加持,Sora对真实世界的模拟也就更加逼真了。 |
|
在 OpenAI 的技术报告里并没有提供更多的细节,大家只能在大方向上猜测一下:基于 OpenAI 的大规模算力资源的 Transformer + Diffusion 技术的合并优化是一个最大的可能。 Video generation models as world simulators 但是从这个名字上看,又不太像是一个简单的 Tranasformer+Diffusion 的东西,因为你很难想像它们综合起来后,可以做为一个 world simulator 。这不太符合生成式的认知,要不然 ChatGPT/GPT4 也会被称为一个 world simulator 的。 所以很多人猜测有物理引擎,也是有可能的。 如果是 物理引擎 + Transformer 共同生成 Noise, 然后 Diffusion 对 Noise 做一个解码生成图像,那就有点能说得通了。网上也有大量的人猜测,是存在 unreal 这个物理引擎的。不过在上面的 report 里,反而完全没有提到。这是一个故意的操作吗? 只能从给出的信息上看一下了, 先看一下引用吧 LSTM 对视频进行无监督学习 RNN 模拟器 世界模型 动态场景生成视频 分解运动及内容生成视频 VQ-VAE与 Transformer 生成视频 Diffusion 生成视频 如果从引用来看,应该真的就是 Transformer 与 Diffusion 一类的综合应用,再加上 OpenAI 一贯的信念,“在人工智能领域永远是一个可以大力出奇迹的工作”! 所以 OpenAI 称自己的 Sora 是 LargestModel 。 所以就可以想当然的认为,Sora 就是一个大力出奇迹的模型了! Transformer+Diffusion 。 然后加上 OpenAI 自己的数据处理、对齐方式这些密而不宣的 Trick,造就了现在的 Sora. 大模型: |

|
|
大数据: |

|
|
更大的训练数据(相比其它人,因为 OpenAI 的算力资源比别人好太多了, GPU 自由谁不想啊!!!): |

|
|
大模型涌现??这个我不太信,更相信它是个大数据相关性! |

|
|
差不多是这个样子吧,不过这个工作真的是让一众小创业团队的优秀工作绝望的项目。 |

|
|
|
|
Sora引发的思考 一点碎碎念,如有错误,请大力指出,不胜感激。 1. ai生成图片的进化永不停止。从GAN到CNN,再到Lantern Space,再到U-Net,以及Sora的纯Transformers架构,效果越来越惊艳。 2. 很多东西需要实际操作才能下结论。《Scalable Diffusion with Transformers》论文刚出的时候收到群嘲,说是灌水。直到Sora一鸣惊人才受到大家的重视,要知道论文发表于2022年,Sora在2024年开年王炸。(2023年这一年大家都在折腾U-Net) 3. 意料之外,情理之中。Sora提出的时空补片(Space Patch)真是一个创新,意料之外,情理之中。论文认为使用CNN的做法,即收集偏置的做法(acquisition bias),并不比纯Transformer的做法效率高,效果好。而Trasformer通用架构的好处,就是可以集成很多现成的研究成果,比如类似informer的稀疏注意力等等。 4. 时间的维度。最近在研究time series模型,感觉Space Patch在空间这一维度信息基础上,又增加了时间的维度信息,而input升维这一操作,在Transformer里再合适不过了。这样也彻底转化了视频生成的思路,原来靠图片生成单帧,再合并帧为视频,想尽各种办法在condition层面保证图片稳定性。而现在直接在训练的最小输入单位,Space Patch(也可以理解为token)本身就包含了时间,空间,像素的信息,可以无缝直接生成视频。 5. 巨人的肩膀。当然LatentSpace技术可以继续使用。SpacePatch转化为SpaceLatentPatch,等价于StableDiffusion使用PixelSpace=>LatentSpatch。当然这个Vae过程可以做很多优化。技术永远不是一蹴而就的,ai领域需要大量的前人的肩膀,就比如Transfoemer也是一路从RNN,RNN变体,Seq2Seq,Attention一路进化而来 6. 维度的思考。维度是在ai领域永恒的话题,遇事不决,特征不明,升维降维就完事了。Transform为什么是版本答案,因为万物皆可Embedding,笑~。只要信息是可编码的,关联性的,非混沌的,就一定有一种方式可以Embedding,再用transformer去找寻这一规律。从Stable Diffusion到Sora,有点符合我们认知物理规律的过程。从最开始的经典物理一维的小滑块,到二维的牛莱公式,以及对于三维空间的计算,四维空间的想象,这也在ai领域一一体现,也越来越坚信随着技术的迭代,算力的进化,ai对真实世界的模拟,越来越趋近真实。 |
|
因为Sora的原理并没有公布,所以只能推测一个方向。 我认为Sora原理并不难,是结合了DALLE3(官方确认的)和OPENAI自己现成的某个世界模型,所以合并开发速度才能如此之快,一年就完成了。 我复制了SORA实例视频的描述,然后放到DALLE(没钱搞DALLE3)里面做了生成尝试 对比一下DALLE和SORA的图像,很容易发现: 1)DALLE自己画的两张图时空上本身就有一定逻辑关系 2)SORA对画面要素和构图模式的理解,和DALLE是完全一样的 3)二者对色彩的理解完全一致(东京美女视频调了色温) 4)SORA比DALLE多了一些细节和真实感,估计是DALLE和DALLE3的差距所致 |

|
|
笔者自己用DALLE生成的图像 |

|
|
|

|
|
|

|
|
也就是说,DALLE3为SORA提供了分镜,而SORA借助世界模型描绘了各帧之间的时空关系。 这个串联的世界模型具体为何物,暂时未知。但其实多年游戏产业积累下来,这个东西应该有相当多现成引擎代码可用。 世界模型(World Models)是一种深度学习和强化学习结合的方法,旨在让计算机或机器人通过对其环境的观察来构建一个内部表示(即“模型”),进而能够预测未来的状态或动作的结果。这种方法受到了人脑如何理解和互动世界的启发。 世界模型通常包含几个关键组件 感知模型(或视觉模型):用于从原始输入(如图像或传感器数据)中提取有用信息,并可能将其压缩为更高级别的特征表示。这个过程类似于人类如何从视觉场景中提取关键信息。 记忆模型:存储过去的观察和行动,帮助预测未来的状态。这可以通过各种形式的网络来实现,如循环神经网络(RNN)或长短期记忆网络(LSTM)。 控制模型(或决策模型):基于当前的环境状态和内部模型预测,制定行动策略来达成目标。这个模型试图优化某个目标函数,比如最大化奖励或最小化成本。 通过这些组件的交互,世界模型能够在没有直接环境反馈的情况下内部模拟和预测未来事件,从而使得算法能够在复杂环境中做出更加智能的决策。这种方法已经被用于各种应用中,包括自动驾驶汽车、视频游戏中的AI角色,以及机器人的导航和任务规划等。 去年DALLE3放出的时候,好像没有引起这么大的热度,可能因为OPENAI在图像方面相对落后,比起竞品并没有绝对的优势。 chatGPT自己对DALLE的解释如下,其中TRANSFORMER是核心关键 DALL・E(和它的后续版本如DALL・E 2)是由OpenAI开发的一个人工智能程序,旨在根据用户提供的文本描述生成相应的图像。它基于一个叫做Transformer的深度学习架构,这是一种特别适用于处理序列数据(如文本或图像像素)的模型。DALL・E的工作原理可以概括为以下几个关键点: 1. Transformer 模型 Transformer是一种深度学习模型,最初是为了改善机器翻译任务而设计的。它能够处理序列数据,并通过注意力机制关注序列中的不同部分,这使得它非常适合文本和图像生成任务。 DALL・E使用了一种特别调整的Transformer架构,能够处理文本和图像数据,实现从文本描述到图像内容的转换。 2. 大规模数据训练 为了使DALL・E能够理解复杂的文本描述并生成相应的图像,它需要在大量的文本-图像对上进行训练。这些数据包括各种主题、风格和上下文的图像及其描述。 训练过程中,模型学习到如何根据文本描述的内容、情感和细节来生成图像。 3. VQ-VAE DALL・E 2等后续版本采用了一种名为VQ-VAE(Vector Quantized Variational Autoencoder)的技术来处理图像数据。VQ-VAE能够将图像编码为一个紧凑的、离散的表示形式,这使得Transformer模型能够更有效地处理图像数据。 通过这种方式,DALL・E能够在保持图像质量的同时,有效地生成与文本描述相匹配的图像。 4. Attention 机制 Transformer模型的核心是它的注意力机制,它使模型能够在生成图像时集中于文本描述的特定部分。 这意味着DALL・E可以理解文本中的复杂结构和细节,并在生成的图像中精确地反映这些细节。 5. 创造力和多样性 通过训练,DALL・E不仅能够生成与文本描述直接相符的图像,还能展现出一定程度的创造力和多样性,生成在合理范围内变化的图像,这些图像既符合描述,又具有独特性和新颖性。 DALL・E展示了人工智能在理解自然语言和视觉艺术创作方面的前所未有的能力。通过将先进的机器学习技术与大规模数据训练结合,它能够在各种主题和风格上创造出令人印象深刻的图像。 至于说SORA还有什么缺陷,那就是偶发的物理规律模仿有误差,或者图片逻辑清奇,这个在官方文档里有比较详细的描述,这里就不抄了。 我认为最重要的还是创意的自由性。专业的高水平作者如果过于依赖SORA,必然影响创意的发挥。 SORA应该主要用于降低图像视频制作的门槛,以及绕开现有图像专利。 |
|
|
| [收藏本文] 【下载本文】 |
| 科技知识 最新文章 |
| 百度为什么越来越垃圾了? |
| 百度为什么越来越垃圾了? |
| 为什么程序员总是发现不了自己的Bug? |
| 出现在抖音评论区里边的算命真不真? |
| 你认为 C++ 最不应该存在的特性是什么? |
| 为什么 Windows 的兼容性这么强大,到底用了 |
| 如何看待Nvidia禁止使用翻译工具将cuda运行 |
| 为何苹果搞了十年的汽车还是难产,小米很快 |
| 该不该和AI说谢谢? |
| 为什么突破性的技术总是最先发生在西方? |
| 上一篇文章 下一篇文章 查看所有文章 |
|
|
|
| 股票涨跌实时统计 涨停板选股 分时图选股 跌停板选股 K线图选股 成交量选股 均线选股 趋势线选股 筹码理论 波浪理论 缠论 MACD指标 KDJ指标 BOLL指标 RSI指标 炒股基础知识 炒股故事 |
| 网站联系: qq:121756557 email:121756557@qq.com 天天财汇 |