
| |
|
|
| 首页 淘股吧 股票涨跌实时统计 涨停板选股 股票入门 股票书籍 股票问答 分时图选股 跌停板选股 K线图选股 成交量选股 [平安银行] |
| 股市论谈 均线选股 趋势线选股 筹码理论 波浪理论 缠论 MACD指标 KDJ指标 BOLL指标 RSI指标 炒股基础知识 炒股故事 |
| 商业财经 科技知识 汽车百科 工程技术 自然科学 家居生活 设计艺术 财经视频 游戏-- |
| 天天财汇 -> 科技知识 -> 为什么央视把 Sora 称为首个视频生成大模型? -> 正文阅读 |
|
|
[科技知识]为什么央视把 Sora 称为首个视频生成大模型? |
| [收藏本文] 【下载本文】 |
|
之前不是有很多吗? [图片] [图片] |
|
央视将Sora 称为OpenAi首个视频生成大模型,那是因为确实是OpenAi的文生视频产品首发。 而且目前的文生视频产品,只有Sora做到了与真实世界一致,从真正意义上理解并进行视频生成,而不是二维图像动态填补。 |

|
|
0 Sora这几天的爆炸性新闻,让所有人工智能相关从业者及对应用感兴趣的人群都感到沸腾,震撼到央视也在进行相关的讨论,简直可以和2023年初ChatGPT讨论带来的热潮一般。 我整理了下最近两天的相关内容给大家做一个回顾参考。 先看下Sora最新的视频效果及和其他文生视频的对比。 一、什么是SORA? Sora 是OpenAI最新发布的文本生成视频模型,不仅可以生成长达一分钟的视频,且能完全遵照用户的 Prompt 并保持视觉质量。 OpenAI 这个公司的格局非常大,他想要做 World Simulators(世界模拟器),做通用AGI,而不仅仅是文字或者图像视频领域的内容,他希望的是帮助人们解决需要现实世界交互的问题。 1.Sora官网 |

|
|
2.Sora 论文 OPENAI对于Sora的论文可以详见下列链接: Video generation models as world simulators?openai.com/research/video-generation-models-as-world-simulators |

|
|
我挑选大众关心的重点内容翻译: |
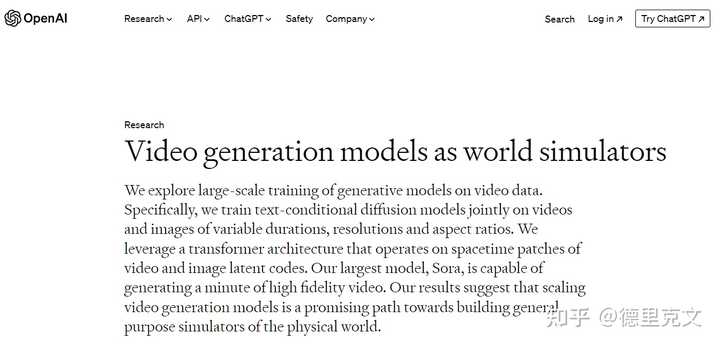
|
|
图片中文翻译: 视频生成模型作为世界模拟器 我们探讨了在视频数据上对生成模型进行大规模训练。 具体来说,我们共同训练了文本条件扩散模型,这些模型能够处理不同时长、分辨率和宽高比的视频和图像。 我们利用了一种变压器架构,该架构能够处理视频和图像潜在代码的空间时间块。我们最大的模型,Sora,能够生成一分钟的高保真视频。 我们的结果表明,扩展视频生成模型是构建通用物理世界模拟器的有希望的道路。 |

|
|
中文翻译: 语言理解 训练文本到视频生成系统需要大量的带有相应文本字幕的视频。 我们将DALL・E330中引入的重新字幕技术应用到视频中。我们首先训练一个高度描述性的字幕模型然后使用它为训练集中的所有视频生成文本字幕。 我们发现,高度描述性的视频字幕训练提高了文本保真度以及视频的整体质量。 与DALL・E3类似,我们还利用GPT将简短的用户提示转换为较长的详细字幕,并发送给视频模型。 这使得Sora能够准确地按照用户提示生成高质量的视频。 而关于论文内部详细的内容,网上有整理好的资料,建议可以参考这个飞书文档,有对这个论文的翻译及详细的解析,分享给大家,不用花冤枉钱去购买。 https://caaiartlab.feishu.cn/docx/LgmFdXTRwo0m5yxkQRIcO6RGnRf?caaiartlab.feishu.cn/docx/LgmFdXTRwo0m5yxkQRIcO6RGnRf |

|
|
3.Sora怎么使用 需要强调给大家的一点是,截止至2024年2月17日,Sora目前没有公开测试,也没有内测申请渠道,国内是没有渠道可以去尝试的,因此大家千万不要相信现在所谓的Sora课程,这些人都自己没有操作过。 |

|
|
二、关于Sora的讨论1.各方观点 下面从互联网上收集了部分信息,供大家参考 |
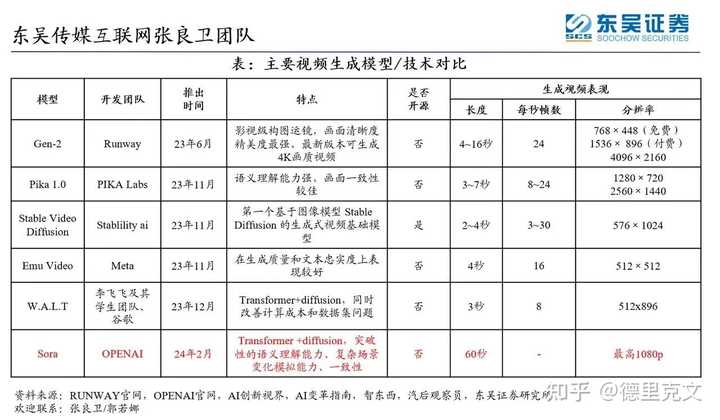
|
|
|

|
|
2.Sora会议小结 而在2月6日晚上,有一个人工智能论坛讨论关于Sora之后,生成视频往何处去的内容,我征得记录者同意,将晚上讨论的内容分享给大家, |

|
|
三、详细解读 我认为这是AI视频领域的原子弹!“60s超长长度”、“超强语义理解”和“世界模型”每一条都足以震撼人工智能应用! 对比现在文生视频的一流团队RUNWAY 、PIKA、SVD的生成效果,简直是造成了跨时代的碾压震撼效果!Runway 和Pika目前生成的视频时长都较短只有几秒,需要通过不断的拼接。 |

|
|
00:17 而且画面稳定性不强,如果需要呈现好的效果,需要创作者本身有非常强的视频剪辑及相关基础。 而SORA这次最逆天的是,通过非常简单的文字描述,就可以生成画面稳定,理解能力强的长视频! Sora本次展示的是技术思路不同所带来的完全碾压。 从关注二维像素的变化,变成关注语义理解的变化,从视频画面的生成,变成故事逻辑的生成。 |

|
|
00:10 之前无论是Runway、Pika、SVD等等文生图、文生视频都是在二维平面上对图像进行调整和组合,但是Sora的视频,显示它能像人一样理解一些基础的物理规律,这是 OpenAl利用它的大语言模型优势进行的超强语义理解,是真正层面的世界模型。 只有实现对现实世界的理解和对真实世界的模拟,这样产生的图像和视频才是更加真实的效果。 这次Sora带来的震撼或许不仅仅是影视行业,而是未来可能扩展到其他行业,视频展示的是对真实世界物理规律的再现! |

|
|
00:20 英伟达的高级科学家Jim Fan认为 Sora 的实现原理,这不仅仅是一个视频生成模型这么简单,还是一个基于数据驱动的虚幻 5 引擎。 可以把 Sora 看作是一种可学习的模拟器,或者说是一个能模拟现实世界的“世界模型”。 这种方法可以让 Sora 更好地理解和模拟现实世界的物理现象。 |

|
|
00:08 1、世界模拟器 OpenAI目前开发的Sora视频生成模型技术,将完全超越现有的视频生生成模型,如Runway和Pika。 这项技术的核心是一个创新的“世界模拟器”,它是一个基于文本条件的扩散模型,通过从大量的视频中学习,这些视频涵盖了不同的时长、宽高比和分辨率。 这个模拟器的训练过程涉及吸收和处理海量的视觉数据,使其能够根据文本描述生成相应的视频内容。 例如,当输入“太空人的冒险故事,他戴着一顶红色羊毛编织的摩托车头盔”这样的描述时,模型能够理解含义,并且生成与之相符的视频画面。 |

|
|
该模型还具备生成视频的灵活性和多样性,支持不同的时长和分辨率设置,其最大输出规格可达1920*1080的分辨率和30帧/秒的帧率。 2、视觉数据转换 简单来说,OpenAI在视觉数据处理领域,将视觉数据转换为“patch”这一个个单元体,它可以将图像和视频帧分割成“补丁”状的小块。 这些“补丁”作为视觉模型的基本输入单元,使得模型能够学习和理解如何表示以及重建视觉场景。在此基础上,模型能够在特定条件,如文本描述的引导下,生成新的图像或视频内容。 |

|
|
这种处理方式与大型语言模型中的“token”概念相似,token是文本数据的基本处理单元。 在语言模型中,文本被分解为较小的片段以实现语言的理解和生成。同样地,视觉模型的训练过程涉及将不同类型的视频和图片转换成patch,作为模型输入的基本单位。 这个过程可以理解成首先将视频压缩到一个较低维的潜在空间,然后将视频转换为patch,并进一步分解为“spacetime patches”(时空补丁)。 3、视频压缩 研究者开发出一种专门的视频压缩网络。 该网络的核心是一个经过训练的神经网络,其设计宗旨在于降低视觉数据的多维度复杂性。 而所谓的“降低维度”,指的是将数据从高维空间――例如原始视频数据,包含了海量的像素信息――转换到低维空间。这一过程的目的是对数据进行简化,提取关键特征,同时减少后续处理所需的计算资源。 |

|
|
这个神经网络接受原始视频作为输入,并输出一个在时间和空间上都经过压缩的潜在表示(latent representation)。 时间上的压缩意味着减少了表示视频动态变化所需的信息量; 空间上的压缩则意味着减少了表示视频中每一帧图像所需的信息量。 在这个压缩的潜在空间中,Sora模型首先进行训练,学习如何理解和控制这种形式的数据。经过训练,Sora能够在这个潜在空间内生成新的视频数据。 |

|
|
为了将Sora生成的潜在表示转换回原始的像素空间,研究者还训练了一个解码器模型。 解码器的作用是将压缩的视频数据还原成可以直接观看的视频格式。 4、时空补丁(Spacetime Laten Patches) 在视频数据压缩完成后,接下来的关键步骤是提取一系列的“Spacetime Latent Patches”,这些Patches包含了视频在特定时间和空间范围内的信息。 这些Patches在transformer模型中扮演的角色类似于自然语言处理中的单词token。 这种方法不仅适用于视频数据,也适用于图形数据,使得不同分辨率、时间和宽高比的视频和图像能够作为Sora模型的训练集。 |

|
|
在模型推理,即生成新的视频内容时,可以通过在适当大小的网格中排列随机初始化的Patches来控制生成视频的大小。 这个过程类似于在自然语言处理中,模型根据给定的token生成新的文本内容。通过这种方式,Sora模型能够根据需要生成不同大小和格式的视频,为视频生成和编辑提供了更大的灵活性和多样性。 5、视频生成扩展变压器 Sora模型的根基是建立在Transformer架构之上的扩散模型。 该模型通过接收输入的噪声Patches和文本提示等调节信息,能够有效地预测出“干净”的Patch。 |

|
|
这种架构在大型语言模型、计算机视觉和图像生成等领域都有着广泛的应用。 在训练过程中,使用固定的种子和输入,随着计算量的增加,生成样本的质量会显著提高。 这种训练方式使得Sora模型能够逐步学习并优化其生成能力,从而在处理视频和图像数据时,能够输出更加精细和逼真的结果。 四、原理讨论1.个人理解 首先说下我个人的理解,Sora呈现的效果,只需要知道需求和结果,中间的原理并不是机器学习的内容。 也就是说,人工智能不需要知道中间的过程,中间的过程可能如同量子力学一样不可琢磨,它不需要知道具体的物理规律,而是如同孩童观察世界一样。 |

|
|
孩童并不需要知道牛顿三大定律,而看到苹果从树上掉下来,就知道苹果必然会落地,而不是飞向天上。 下面是根据群友讨论的推测内容: 2.原理推测 而Sora让视频看起来符合物理规律主要依赖于其训练过程中使用的大量数据和先进的学习算法。 |

|
|
通过在广泛的视频数据上训练,Sora学习到了世界如何运作,包括物体如何移动、互动和受到物理规律(比如重力和惯性)的影响。这个过程类似于人类学习物理规律:观察、学习和模仿。 3.数据和训练 Sora通过分析和理解大量包含物理互动的视频,学习到了物理规律的表现形式。 例如,它可以观察到苹果从树上落下来的视频,学习到重力的效应; 看到球在地面上滚动的视频,理解到惯性和摩擦力如何影响物体的运动。 通过这些观察,Sora能够生成新的视频,其中的物体和人物遵循现实世界的物理规律。 4.算法和模型架构 Sora使用的算法和模型架构(如扩散模型和变换器)使其能够在视频生成过程中考虑时间和空间的连续性。 |
|
|
这意味着它不仅能够理解单个画面中物体的位置和状态,还能够理解这些物体随时间如何变化和移动。 这种时空连续性的理解是让生成的视频看起来符合物理规律的关键。 结语 Sora通过分析大量的视频数据、学习物理规律的表现,并利用先进的算法理解和模拟时空连续性,从而能够生成看起来符合物理规律的视频。 这一过程涉及到复杂的计算和大量的数据处理,最终使得Sora生成的视频在视觉上既真实又符合逻辑。 AGI的未来或许真的不远了! 我是德里克文,一个对AI绘画,人工智能有强烈兴趣,从业多年的 设计师!如果对我的文章内容感兴趣,请帮忙关注点赞收藏,谢谢! |
|
震撼,NB,央视虽然不是科研机构,但合作了很多厉害的AI大佬,这个论点可能来自于那些专业人员。我认为Sora的能力还不止这个定义,甚至可以叫做矩阵原型,就是AI理解和提供了1个世界模型,视频只是这个世界模型的表象。即使考虑Altman只是为了响应皮衣黄教主的RTX本地gpt甩出来的一个小炸弹, 并不打算让公众现在就用它, 也足够震撼了。 国外学术界已经有些大佬发现Sora的潜在威力了, 替代短视频作者和电影产业的一部分工作人员是表象, 真相是,Sora是真的在理解地球物理世界的规律,而且取得了巨大的进展。这和短视频制作和图像插帧完全不是一个当量的成就。 本来我正在备课,计算机图形学游戏方向,去年教得还挺好的。 但是看完Sora之后,都有点不想教了, 二维图像原理、透视、碰撞、骨骼、光追等等图形学的基石技术和公式模型, 本质就是为了输出符合物理世界或人感知规律的图像。到光线追踪这一层,计算机图形学的物理计算本质已经和真实世界的视觉原理一样了(其实和数值仿真、材料设计、风洞水洞模拟原理一样) 但是,真正编程的都知道, 光追的实现有很多tricks,根据不同环境和需求进行光线的简化和合并和近似, 没有任何一款游戏或图形学软件可以做到真实事件一样的光子数量追踪。而这些tricks可能就是我在计算机图形学上的最高造诣了。 但是,Sora不讲武德啊,它偷袭啊。它不用物理公式计算啊,它也不惧怕高密度计算, 甚至我还知道它的底层多半也是概率模型蒙特卡洛网络,但是它的维度太高,抽象机制复杂,我根本无法得知或表述它是如何理解粒子系统、物体碰撞、透视等等的, 但是, 它的连续图像已经做到了, 无论是我的世界的渲染视频还是类似极品飞车的渲染视频,真的是光线追踪的顶级效果了。问题是它还不需要场景搭建和交互调试,一句话就有连续的视频。 这是我之前的备课提纲,不但感觉专业水平很高,甚至感觉十分生动有乐趣。 《超级马里奥兄弟》与2D图形渲染:介绍基础的2D图形绘制技术,包括像素、颜色和图层。《俄罗斯方块》与图形变换:探讨图形的平移、旋转和缩放等基本变换。《雷曼》系列与2D动画技术:学习2D关键帧动画和精灵动画的制作。《我的世界》与3D建模基础:介绍三维坐标系、基本几何形状和建模技巧。《塞尔达传说》系列与3D世界导航:探索三维世界中的摄像机控制和视角变换。《辐射》系列与纹理映射:学习纹理映射技术,如UV映射和纹理过滤。《半条命2》与光照模型:介绍光照的基本原理,包括环境光、漫反射和镜面反射。《地铁》系列与高级光照技术:探讨全局光照、阴影映射和HDR渲染。《荒野大镖客2》与实时渲染技术:学习游戏引擎中的实时渲染技术,如着色器编程和后处理效果。《最后的生还者》与3D动画技术:探索骨骼动画、蒙皮和动作捕捉的应用。《刺客信条》系列与物理模拟:介绍刚体动力学、布料模拟和碰撞检测等物理模拟技术。《古墓丽影》系列与场景管理:学习如何组织和管理复杂的三维场景,包括场景图和遮挡剔除。《战地》系列与粒子系统:探讨粒子系统的原理和应用,如烟雾、火焰和爆炸效果。《光环》系列与后处理效果:介绍后处理技术,如景深、运动模糊和色彩校正。《生化奇兵》系列与水面模拟:学习水面的渲染技术,包括反射、折射和波纹效果。《星际争霸》系列与实时策略游戏图形:探讨实时策略游戏中的图形渲染需求和技术。《模拟城市》系列与城市建模:学习如何创建和渲染复杂的城市景观和建筑。《孤岛惊魂》系列与自然环境渲染:探讨如何模拟和渲染自然环境,包括植被、土壤、环境效果。 但是看了Sora表现能力的现在。。。。 毁灭吧,计算机图形学毁灭吧,游戏引擎毁灭吧,游戏从业岗位,地编、特效、动作、动物、测试等等等 学术界的震动更大, SIGGRAPH,一直有AI渲染的论文,AI小模型一般用于替代基于概率或特定环境的光线积分方法, 现在Sora面前, 玩不下去了, 问题是Sora那一套我们都大概知道原理,就是没法玩,缺设备、缺数据、缺办公楼、缺电费、缺考核指标。。。真的是量级差太多了,邹市明碰到泰森的感觉。 |

|
|
|
|
因为这确实是OpenAI发布的首个视频生成大模型。。。 |
|
ChatGPT是首个摆脱“人工智障”的语言生成大模型。虽然在GPT4时代还有不少人在用GPT3,甚至GPT2来写诗写文,但是ChatGPT(GPT3.5)相对于前者有质的飞跃,核心点在于它具有很强的理解世界知识的能力,前后问答能保存很强的逻辑一致性。 Sora的地位与ChatGPT一样,它不仅能画出来,还能体现出对空间物理逻辑的理解。较长时间内保持物体运动逻辑上的一致性,这与其他模型只能生成局部或短暂动图有着本质区别。(网上有很多对比图我就不贴了)。 然而,这种“理解”也有局限性,与文字生成一样,上下文窗口大小问题和幻觉问题很难解决,还有持续学习的问题,一定会出现在有些地方始终画不出你需要的效果,而且暂时教不会。但这不影响其在短视频生成方面的强大地位。但又由于其学习和运行成本比文字生成高得多,其影响力多半不如ChatGPT,跟风企业也更少。 |
|
不是首个。但是叫首个也没问题。之前那些和sora比都不配叫视频生成大模型。 |
|
|
| [收藏本文] 【下载本文】 |
| 科技知识 最新文章 |
| 百度为什么越来越垃圾了? |
| 百度为什么越来越垃圾了? |
| 为什么程序员总是发现不了自己的Bug? |
| 出现在抖音评论区里边的算命真不真? |
| 你认为 C++ 最不应该存在的特性是什么? |
| 为什么 Windows 的兼容性这么强大,到底用了 |
| 如何看待Nvidia禁止使用翻译工具将cuda运行 |
| 为何苹果搞了十年的汽车还是难产,小米很快 |
| 该不该和AI说谢谢? |
| 为什么突破性的技术总是最先发生在西方? |
| 上一篇文章 下一篇文章 查看所有文章 |
|
|
|
| 股票涨跌实时统计 涨停板选股 分时图选股 跌停板选股 K线图选股 成交量选股 均线选股 趋势线选股 筹码理论 波浪理论 缠论 MACD指标 KDJ指标 BOLL指标 RSI指标 炒股基础知识 炒股故事 |
| 网站联系: qq:121756557 email:121756557@qq.com 天天财汇 |