
| |
|
|
| ����ƻ� -> �Ƽ�֪ʶ -> Linus ΪʲôҪ fuck NVIDIA �� -> �����Ķ� |
|
|
[�Ƽ�֪ʶ]Linus ΪʲôҪ fuck NVIDIA �� |
| [�ղر���] �����ر��ġ� |
|
[ͼƬ] �������ѧϰѵ�������� NVIDIA ���Կ��𣿶��Ҷ������� linux �� Ϊʲô˵ linux �ϵ� NVIDIA ���У� ��Ϊ NVI�� |
|
�������Ӧ�ù�Ϊ��ʷ�� linus fucked nvidia����2012�ꡣ��ʱlinus��ij��ѧ���������ʴ��У������²����ڱʼDZ��������ܸ���ͼ�ν����linux���鷳��linus���ֳ��˼����ͬ�飬��˵nvidia������г���������оƬ�����ֲ������linux�ṩ֧�֣��dz��Ѳ���ԭ����the single worst company�������linus�ڼ���֮�¶�����Ӱ�������ָfuck��nvidia�� �����������Ѿ��������ٷ����ˡ� ��һ��linus����֮��ʼ��˼�Լ��Ĺ����������Լ�������������������أ�ȱ��ͬ���ģ��Dz��Եģ�Ҳ���������档��������������ص�therapy���˱�ñȽ��º͡���������֮����Ҳ�ɲ������ž�ͷfuck���˵������ˡ� �ڶ���2012��Alex��Ilya���ǻ����ִ�AlexNet����GPU��AI���ڱ�����ǰҹ��nvidia�Լ����ܶ���û�뵽��������ô��һ��ҵ����ȻҲ���ø�linuxͶ�뾫������nvidia������Щ�꿿AI���ˣ�nvidia��linux��֧��Ҳ��Խ��Խ�ࡣ��Ȼ�ֺ��ľ�����������������cuda֮��Ķ����DZ�Դ������������˵��������Ϳ�Դ������������һ���ϣ�linus����Ҳ��ʾ����ͬ�� |
|
Ӣΰ����Linux�²�������Դ�������������е���̬ һ��ʼ��optimus˫�Կ��л���NVIDIA����������������AMDҲ�У�����AMD��Linux�¿��������л���Ӣΰ��ֻ������������Ĵ�Ʒ䣬���ǰ��û���/usrɾ�����Ǹ� �پ���CUDA������һֱ�DZ�Դ�ģ�����ƺ���Դ�˲�������������CUDA�����ǵ��ò��ٱ�Դ�Ķ��������� ���о��������û�Ҫ�õ���X11��wayland�ȵ�֧�֣��Լ���ƵӲ���֧�֡�������NVIDIA������Լ��ķ����̬��������Щ��Դ�Ķ�������мһ�ˣ�bugһ��� ����Ӣΰ���Լ���Դ�Ķ�����Linux��Ҳ����ô���á���ǰ����Linux�û���װϵͳ���һ������װ������������װ���Ļ����ȵö࣬��ΪӢΰ����Կ������������¸������⣬��ʱ��������ÿ����˻���ÿ�θ����ں�ҲҪ���ûع�����������Ҫ��һ�����Էŵ��ºü����ں˺�initramfs��/boot �Լ��ںܳ�һ��ʱ���ڣ�n���������ᵼ��splash���ܲ���ͼƬ��tty�ֱ��ʺܵ͡�����˯�߲��� NVIDIA����û����ô��Linux���濪Դ���������ף���Դ������������ȫ����������ġ���ΪNVIDIA�DZ߲��ṩʲô�������ܶ�������ܶ������� |
|
һ�仰���ͣ�Linus���ֵ��Ǹ��£������ѧϰ����DZ������£�������Ҫ�硣��ʱNV��Linux��������ͦ�����ġ� |
|
nVidia����һֱ����Դ���ǵ�������������Linux��nVidia�Ĺٷ��������õ�һ������linus����nVidia����Ȼ���Ѿ�������ǰ�ˡ� |
|
Nvidia������Ȼ֧��Linux���ͳ��Ķ��DZ�Դ�棬��ֻ���ڷ������ܱ�֤�������������Ͼ�û��ͼ�ν��档 һ�����滷�����Ǿ��������ˡ�����Linus��Nvidia������Ϊ�бʼDZ���ʼ����˫�Կ�����˫�Կ���ҪOptimus������������Nvidia�Կ����㡣����Windows��Ȼ�������⣬��Linux��ܵ�֧��Ҫ�ü����ų��֡� ����Linux��Ⱥ��������X��ת��Wayland���ȫ�µ���ʾЭ������ʵ�������ѳ���10���ˣ�����а��������ΪĬ��ѡ�Nvidia�ı�Դ�������ڶ�Wayland֧�ֲ�(��˵�������Լ���һ�ױ�)�����������Կ���������Linux������ά������˵���Wayland��Nvidia�Կ��²�ʱ�Ļ�������ʹ����2022����Wayland֧�ֱȽ������ˣ���������Dz�ʱ����������KDE WaylandΪ���� ��ʹLinux��Ⱥ������˿�Դ��nouveau���������Կ����ܿ��룬CUDA���ϣ������װ�� 2022��Nvidia��Դ��һ���ֺ����������Ŀǰ����û�����á� ��ʱ��Nvidia�����ϳɵ�X11֧�ֶ�������⡪����������ҵ�Arch Linuxһ����������X11����Ķ������0.75���٣��л���Intel���ϻָ�˿��˳��(���������ֺ���Orz)������Ϊ��ʹ���������룬������̨ʽ����������prime-run�IJ��ԣ���Ļ��ʾ��Intel���ԣ���ҪNvidia����prime-run��Ӧ����Nvidia�Կ����У������������Ϸս��������ʱ�� |
|
�ִ��Կ����ں�����ֻ������ͨ������Ҫ�ĺ��ļ������������û��ռ������� ������ô�����������ܿ��Ե��ں�������nvidiaҲ��Ը��ű�̽ӿڣ���fxxk��������Ȼ�ġ� |
|
LinusӦ����Ҫ��ҵ���ϵ����ţ���ͬ��Ƶ��������NVIDIA���ڵIJ������Ͳ����������̬�������dz������⡣ �����ҵ�����������֡����������� �Ҵ�ѧ�������̨�ʼDZ��ʹ���NVIDIA���Եġ� ��ʱ���Linux����Ȥ����װ�˸�Ubuntu��һ������ѧϰ��һ����Ҳ�ǽ����Ǹ�Unity������װ�ơ����Ͼ����ú����ص㡣 һ��ʼ�õ���wubi��װ����Ϊ�¸㻵���ԡ��������Ӵ��ˣ����ݺ����ݺ�Ҳ�Ϳ�ʼ����˫ϵͳ���ʼ�õ�Ҳ���С�ֱ����һ�죬�������п���һƪ���£�˵����ô��ubuntu��ͷװNVIDIA������˵�DZ�Ĭ�ϰ�װ�ġ���Դ��Nouveau������ǿ��ȵȣ������Ҿ�ԾԾ���ԡ� ���UbuntuҪװ���������㿪ϵͳ�����ҵ���������ֱ��ѡ��Ӧ�ļ��ɡ����Ǹ�ʱ���Dz������������������û��ȷ�����Ͼ���ƪ����Ҫ��ȥ��������һ��ѹ������Ȼ��ͨ��һϵ�����װ������Ҫж�ص�Nouveau��Ȼ�����ø�һЩgrub����֮��ġ��ٺ��漸��ȫ�������������̨�����Ȳ�̫�е�ŵ�������������е����Ȼ������ʱ����è������ ��Ȼ���ܿ��Ҿͷ��ֽ����������ˣ�ֻ�ܽ���tty�������������һ�����ֵ�������ⲻȷ�������Ǵ���ƪ���������ƺ�����ж�ص���������������������Ҽ������ڣ�������ȵط��֣�tty�����е������û�Ŀ¼����ȫ���������Ρ����������ص�ѹ������������Ŀ¼�У������һ����� ���������ʾ�����ߣ�Ȼ��Ϳ��������ϣ�������Ķ������Ǿ����ƺ����ִ�����ˣ���������ʼ�ս���ȥ���Ҳ�֪����ô�죬��ͼ�����еIJ����ظ�һ�飬�������û�á� �һ��ǵ����ǹ�����ڣ��Ҿ�����ڿ���һ�˵Ľ���Ū������һ��Ҳû��������������ƫƫ�ҵ��ֻ�ֻ����������Wifi����ͼ���ֻ��ҵ�ԭ�̳�Ҳû�ɹ��� ��Ȼ���£��ϸ���˵�����Լ�û�е������ף���ûŪ���һЩϵͳ�Ļ���������óȻ���֡����Ǹ�ʱ��Ĵ�ܸл�������ӡ����̣���Fuck NVIDIA��֮���ͬ�����ҿ϶����˺ü��飬˳����UbuntuҲ����Fuck�ˡ� ������һ��û��Ubuntu������������Ϊ���ԭ���Ƿ��������IJ����Ubuntu���ò��ˣ��ִ���Ϸ��������װ���˾Ͷ���������������װ��Ʒ����ʱ����װ���ĸ�ϵͳ��8/7/XP/Ubuntu����ú��ռ��һ��( *�@?�A)???? |
|
��˵��������ģ�6��ǰ��nvidia�Կ�����nvidia���ڵ�525/535/545������bug������ͬ������һ���á����ֻ���跨�ƹ�ȥ�� ���Կ�4090����535�п��ã�545�ֳ�bug�������AI���ȣ�Ͷ�������Դ��ע�ȵ�����¡� ����Linuxϵͳ�Լ�GNU�����У�������������С� �����NVIDIA��Linuxд����������û������ʹ�ù��� |
|
���¶��һᡣ��ʱ�Ҿ���nvidiaʵϰ��D3Dдdriver�� ��ʱnvidia��driver�dz��D3D���Ѿ����Ǻõ��ˣ�����Ȼ�dz��IJBUG���࣬design���������windows����������������������kernelģʽ��user ģʽ��ֻҪkernel���ң��Ͳ��������� D3D������ҵ�Լ��ߵķ�������ˣ�������˵opengl��Щ�ˡ��м����˸���дdriver�Ͳ����ˡ���ʱƻ����nvidia����nvidiaר������һЩ������ƻ����opengl��������bug���ࡣ���ܹ�Ҫ����Ұ����linux�� linux�Կ��г�����С������nvidia�����ӣ�����ѭ����ʵ��������linux�ϴ���Ϸ��Ҳ���ࡣ linus�������ܶԣ�nvidia������linux�г���nvidia����Ҳ�ԣ�����ҪǮ�ģ��Ȱ�windowsҪ�ź�ò��С� |
|
���� ����·�����ʱ��ͦ��ģ�2012����¡�������Щ���е������ˣ�AIɶ�Ķ��Ǻ� ��ʱ��NVIDIA��Unix��Linux��FreeBSD��Solaris���������ر��Ū�£���ž��������������ܵ�����GLX�����ˡ� ����ʱ�ʼDZ���˫�Կ��л������Ѿ����ˣ�Windows��ֻ��Ҫ�Ҽ��˵���ѡһ�¾����ˣ�Linux�ϣ��Բ����У���ֻ������������������ֻ����ȫ�ö��Ի�����ȫ�ú��ԡ����ң������Linux������ȫû�ж�Ƶ�ʹ���ɶ�������������гɶ����ˣ�������ȫ�����С� ��������Ϊ�˽��������⣬��Bumblebee��PRIME������ǰ����Ϊ��װ�ű���д�˸��ո��»���ɾ��/usr�������ļ������ֹ�Ц���� ���ң�Linux������������Unix��ͬ�����ں˽ӿ��Dz��ȶ��ģ��°汾Ҳ�����ܿ죬���ʹ���㼴�������µ���������Ҳû�취��װ�ڱȽ��°汾���ں��ϣ�����ʱֻ��openSUSE�����ܵ�NVIDIA�ٷ��������Ȩ������Ubuntu��Ȼ�Լ�Ҳά����Դ��NVIDIA��������������Լ����õ��ں�Ҳ�ṩ���Լ���patchset���Ͼ����ں˽������ⲿ�ִ���һ�����ṩԴ����ģ������Լ��ġ�Ҳ����˵NVIDIA��Ȼ�ṩ�����������ǻ�Ҫ�����Լ���������������ǿ�����á� ��������Ҳ����Դ�������Ŀ�Ҳ���У�����A��I�����ٿ�Դ��û��Ū���� ������Ȼ����NVIDIA����ٷ��Ŀ�Դ����Ҳ�ǽ�����NVIDIA�Ѿ��ֵ���������Ų������RISC-V��GSP���������ˣ�����ֻ��Ҫ��GSP���������ˣ��������û��ô�����ˣ�����Դ��Nouveau�������Ͽ���Ҳ���ǿ������ij̶ȡ� �ͣ��ڼ������ùٷ��ṩ�ı�Դ����������£�Linux��ʹ��N����������Ȼ�����д�磬���ο���������Դ�������г�ռ����ȴ����ߣ��Dz�fuck��fuck˭�� |
|
��Ȼ���Ǻܹ���������ˣ� ����NvidiaҲ��ͦ��ϵģ��Ͼ�����ȵ�ϵͳ��������Linux. ���Ǿ�ƾ�����Ͽ�Դ�����ӿڣ� ������һ��Linux����Wayland������֧��N���� ��˭��Ҫf..k�� |
|
�����Ͽ�����nv����Դ����ʵ��ʱ��nv��Ʊ���������꣬linus���������Ʊ������ |
|
ʱ������2023�꣬Ubuntu 22.04 ��װ���µ�CUDA�������汾�Ѿ���Ӧ������װ��Ҫ��rootfs������ִ�У�ok���Ҳ�˵��Ҫ��recovery��rootfs�У������װʧ���ˣ���Ȼ��������noveau�Ӻ�������ȥ��������nvidia�������ϣ�noveau���������أ�ֱ�����涼����ȥ�� ���㰲װ���ˣ�Ubuntu 22.04��CUDA���õ�������װ���Ժ����е�WiFi����ģ��ȫ����ʧ���� ��20.04�����⡣���Ե���fuck˭��Ҳ��֪���ˡ� ���⣬ֻҪLinux�������ѧϰһ���õľͲ���������Դ������Ҫô��nvidia�Ĺٷ�kernel driver��Ҫô�ǹٷ�open kernel�� �����⣬nvidiaһֱ��ȫ�ߵ��Կ���CUDA����֧�֣��������Ѽ��Կ�GTX��RTX�� |
|
�����Ҽ��������˵ıʼDZ���ΪӢΰ���������ͼ�θ���ˣ�������kernel panic |
|
�ϻƵķ����Ǹ��Դ��̬����ĺ���fuck�� N�ҵ�ʲô�������¿�Դ��Ҳ��Ϊ�˰��������� ������ȥ��nvidia��github��star������Ŀ: instant-ngp����ȫ���Ǹ�ʵ���Ҳ�Ʒ����������ʵ�ã��˼Ҿ͵��Ű���������Щcontributor�ء�NVIDIA�Լ��ڲ������õĿ϶���������instant-ngp�����������죬�϶������Լ��ı�Դ��̬�� N���Լ��õĺö�����������Դ�� ���Ա�һ�������ң����������pytorch���ȸ��android��tensorflow����Щ��Դ��Ŀ�����浶��ǹ�������ã�������Щ��˾�Լ�Ҳ���õģ��϶���������������һ��ʺ��ȥ��Ū�˵ġ� ���֮�£�NVIDIA�����ڸ�����ιʺ�� |
|
��˵Linus������һ����ҪFcuk Nvidia��Fcuk Ƥ��� |
|
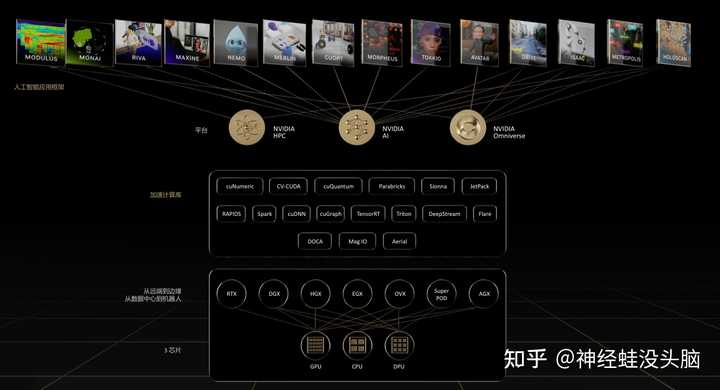
������AI��ģ�͵Ļ��ȣ�������NVDIA��Ϊ���ֿ��ȵ����ǡ�����ԭ��������GPUΪ���ĵ�һЩ����Ӳ����Ʒ����̬��AI��ģ���а����ź������á����Ǿ�������A100��H100��A800��GPU�ͺţ���ô���Ǿ�����ʲô��ϵ���Լ�{BANNED}��ѽ�NVDIA���Ƴ���DGX HG200����ʲô�������������ݾ��ǽ���NVDIA AI��ص�Ӳ����صIJ�Ʒ��ϵ���ô��������Щ���ʱ�������ĺ��塣 ��Ӳ������̬��Ұ�� ���ȿ��������Ŵ�ͼ����������NVDIA��������Ʒ����̬������{BANNED}���������Ӳ������GPU��CPU��DPU����оƬ��ϵΪ����������GPU��NVDIA�ķ��Ҳ�Ʒ��Ҳ�Ǻ��ģ���DPU��NVDIA����ɶ���ɫ��MLX�չ���bluefieldϵ��������������ΪDPU��չ�����ģ�û�����Ǹ������ѡ�����NVDIA��������ϻ���ͦ��һ�ģ�ʱ�����պܶ�����������������������DPU�����������������飬Ҳȷʵ�����ĵģ�ͬ����һ��bluefield 2����NVDIA�չ�ǰ�������������չ����DPU����˵��ʲô���� ���ˣ��ص�ͼ�У�������оƬ֮����DGX��HGX��EGX��һЩ��Ӳ��ƽ̨�������е��ǽ�GPU�Լ�NVlink�������Ӳ��ģ���飬�е��ǽ�GPU��DPU��CPUͨ��NVlink��PCIe�Ȼ���ֱ����ɷ��������е�����ʹ�÷��������Ͻ�������IB����ֱ�ӹ��ɼ�Ⱥ�����仰˵NVDIA�IJ�Ʒ��������оƬ�����ǻ���ͨ���Լ���һЩ����������������������������������оƬ���а�װ��ƽ̨��Ʒ�� |
|
|
|

|
|
�������Ͽ�����һ�������ķ�����������CUDA��DOCAΪ�����������⣬����CUDA����GPU���Ϊ���ĵ������⣬��DOCA����DPUΪ���ĵ������⡣��Ȼ��������һЩ������RAPIDS��NVDIA�Ƴ���һ̨��Դ���ݿ�ѧ�ͻ���ѧϰ���ٹ��ߡ���֮����NVDIA���Լ���Ӳ����ϵ�ܹ��ϣ��Լ���������һЩ��������̬���Ӷ�����ϲ�Ӧ�ò��ṩ�������û���Ȱ�����Ӳ������Ұ�IJ���ν���� GPU�ķ��ٷ�չ GPU��ΪNVDIA�ĺ��IJ�Ʒ�������ڴ�ģ��ѵ���������ܼ��㣬AI������ͼ����Ⱦ��������Ϸ�ȳ����� |

|
|
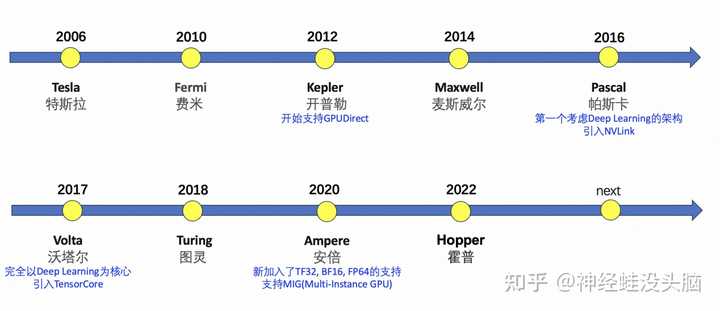
�������ǿ�һ��NVDIA��GPU�ķ�չ���̡�NVDIA������û�����Ƴ�һ��GPU�ܹ�������ͼ��ʾ����{BANNED}������Tesla����ǰ��Hopper�ܹ�������Ͳ�����ϸչ��������Ȥ���Բο���ƪ���� �� |
|
|
��һ���棬NVDIA���Կ�Ŀǰ������Ӧ��������·�Ϊ�������ͣ� GeForce���ѿ���������Ϸ����������GeForce RTX? 3090��GeForce RTX? 3080�ȡ� Quadroרҵ��������רҵ��ƺ����⻯������NVIDIA RTX? A6000��NVIDIA? T1000�ȡ� Tesla��ҵ�������������ѧϰ���˹����ܺ����ܼ���������NVIDIA A100\A30 Tensor Core GPU�ȡ� |

|
|
���������ص�����һ����������GPU��ͬ������������GPU��ͬһ���ܹ�NVDIAҲ�Ƴ��˶��ֲ�ͬ��Ʒ���ڲ�ͬ��������Ampereϵ�в�ƷΪ��������ͼ��ʾ�� |

|
|
�������ǽ�һ�¾��������ļ���GPU�ͺţ�V100��A100��A800��H100��H800�Ĺ�ϵ�����������V��A��H�ֱ��Ӧ����ͼ�е�����GPU�ܹ���Volta��Ampere�Լ�Hopper�� l V100 V100��NVDIA�Ƴ��ĸ����ܼ�����˹����ܼ�����������Volta�ܹ�ϵ�С�������16nm FinFET���գ�ӵ��5120��CUDA���ĺ�16GB��32GB��HBM2�Դ档V100���䱸Tensor Cores�����������ṩ�ߴ�120�������ѧϰ�������������⣬V100֧��NVLink������ʵ�ָ��ٵ�GPU��GPUͨ�ţ����ٴ��ģģ�͵�ѵ���ٶȡ�V100���㷺Ӧ���ڸ��ִ��ģAIѵ��������������������Ȼ���Դ�����������Ӿ�������ʶ������� l A100 A100��NVDIA�Ƴ���һ��ǿ�����������GPU������ȫ�µ�Ampere�ܹ�����ӵ�иߴ�6,912��CUDA���ĺ�40GB�ĸ���HBM2�Դ档A100�������ڶ���NVLink������ʵ�ֿ��ٵ�GPU��GPUͨ�ţ���������ģ�͵�ѵ���ٶȡ����⣬A100��֧��Ӣΰ�������з���Tensor Cores�����������ṩ�ߴ�20�������ѧϰ����������A100�㷺Ӧ���ڸ��ִ��ģAIѵ��������������������Ȼ���Դ�����������Ӿ�������ʶ������� l H100 ��H100��NVDIA����{BANNED}�����һ��Hopper�ܹ��������Ƚ���̨����4nm�������죬ӵ�г��� 800 �ڸ�����ܡ�NVIDIA Hopper �ܹ�ͨ�� Transformer �����ƽ� �ķ�չ��Hopper Tensor Core �ܹ�Ӧ�û�ϵ� FP8 �� FP16 ���ȣ��Դ������ Transformer ģ�͵� AI ���㡣����һ����ȣ�Hopper ���� TF32��FP64��FP16 �� INT8 ���ȵ�ÿ�븡������ (FLOPS) ����� 3 ����ͬʱHopper�ܹ�֧�ֵ��Ĵ� NVLink��NVLink Switch ϵͳ���ڿ��Կ�����������ÿ�� GPU 900 GB/s ��˫�������չ�� GPU IO���� PCIe 5.0 �Ĵ����� 7 ����NVLink Switch ϵͳ֧���ɶ�� 256 ������ӵ� H100 ��ɵļ�Ⱥ���Ҵ����� Ampere �ܹ��ϵ� InfiniBand HDR �� 9 ����{BANNED}��Ѻ�Hopper֧�ֵڶ���MIG��������ʵ�� GPU (MIG)��GPU ���Էָ�ɶ����С�ġ���ȫ������ʵ������ӵ���Լ����ڴ桢����ͼ�����ġ�Hopper �ܹ�ͨ����� 7 �� GPU ʵ�������⻯������֧�ֶ��⻧�����û����ã���һ����ǿ�� MIG����Ӳ����������ʹ�û��ܼ��㰲ȫ�ظ���ÿ��ʵ���� ��ôA800��H800����ʲô�أ�A800��H800��Ҫ���������������ƣ���ֱ�����A100��H100���Ӷ��Ƴ����˸��Ʒ�ֱ���ΪA100��H100�Ĵ���Ʒ����ͼ���������A100��H100��A800��H800��������Щ���졣���Կ���������NVlink�����IJ��죬�Լ�FP64�������ϡ� |

|
|
��������⳧����ȣ����������ﵽͬ�������ܣ�����Ҫ����ijɱ��� Ӳ��ƽ̨�Ŀ�֦ɢҶ ���Ǿ���������DGX��HGX��EGX��ʵ��NVDIA�ṩ�����ַ������ο��ܹ������ּܹ������ú����ܶ��нϴ���죬Ӧ�ó���Ҳ��ͬ�����������ij��õ���DGX��HGX��EGX�����ڱ�Ե����Ҳ���Ǵ�ҳ�˵�ġ����ܡ��͡��ڹ��ܡ�������Щ�ܹ�ͨ������ӵ���оƬ���ƣ���DGX A100���ǻ���A100�Ƴ���DGX�������ܹ�����HGX A100���ǻ���A100�Ƴ���HGX�������ܹ����������Ƿֱ���DGX 100��HGX 100Ϊ������DGX��HGX�IJ�ͬ�� DGX A100 DGX A100��Nvida��DGX-1��DGX-2֮���Ƴ��ĵ�����AI������ƽ̨����̨�������Ϳ�������AIѵ�����������Լ������ݷ������������������ͼ��ʾ������8��A100 GPU��6��NVswitch��15TB�� NVMe SSD��9��CX-6DX 200Gb�������Լ�˫·64 core��AMD Rome CPU��1TB�ڴ档 |

|
|
|

|
|
NVDIA DGX A100 �䱸 8 �� NVDIA A100 Tensor Core GPU���ɰ����û���ɫ����ɼ�������ͬʱҲ��� NVIDIA CUDA-X? �����Ͷ˵��� NVIDIA �������Ľ�� ������ջ������ȫ���Ż���NVDIA A100 GPU ʵ���� �� FP32 ԭ����ͬ��ȫ�¾��ȼ��� TF32���������һ�� ��Ʒ�����ṩ�ߴ� 20 �� FLOPS �� AI ���ܡ���{BANNED}�����Ҫ ���ǣ�ʵ�ִ����������Ķ��κδ��롣ͨ�� NVDIA �Զ���Ͼ��ȹ��ܣ�ֻ��Ҫ����һ�д��� A100 �Ϳ��� �ṩ���������� FP16 �������ܵ�������ͬʱ��A100 GPU ӵ���������ȵ��Դ���� (1.6 TB/s)������һ�� ��Ʒ��ȣ��������� 70%�����⣬A100 GPU �г��� Ƭ���ڴ棬���� 40 MB �Ķ������棬����һ����Ʒ�� �� 7 �����ɸ����ȵ������������ܡ�DGX A100 �� �Ƴ��ٶ�Ϊ��һ�� 2 ����ȫ�� NVDIA NVSwitch �� ��һ�� NVDIA NVLink? ���������߿ɽ� GPU ֮��� ֱ����������һ�����Ӷ��ﵽ 600 GB/s�����⼸���� PCIe Gen 4 �� 10 ��������ǿ��Ĺ��ܿ������û����� ������⣬�Լ�Ӧ�Դ�ǰ����������⡣ ����DGX����NVDIA���õ�һ���ֳɵķ�������������NVDIA���̱꣬��������Լ����ã������Լ�������Ӳ����װ�� HGX A100 HGX A100�ǵ��������������̣����˳���H3C�ȣ�����NVDIA�ṩ��specification��Ƶ�GPU���������ҷ���������ǰ�ᾭ��NVDIA�����ϸ����֤��Ϊʲô��������һ����̬�أ���Ҫ��NVDIA��û��NVlink�Ľӿ���Ʊ�¶�����������̣�����PCIeһ�����������̿���������ƻ�����������NVDIA�Լ���GPUͨ��NVlink��NVswitch���Ӻõ�һ��ģ�齻�����������̣����������̾�������������ģ�鼴�ɡ�������ˣ����DGX��HGXҲ���˲�ͬ���̸��ඨ�ƿռ䣬��������Ƴ��̲�����ʹ��NVDIA����������ʹ���Լ���DPU�� ���⣬���DGX A100��HGX A100�ṩ�˸�������ã������Ʒ����4 GPU��ģ�飬Ҳ��8GPU��ģ�顣�������Խ�����8��GPUͨ��NVSwitch���ӣ�ʵ��16GPUȫ����������A100 GPU��ѡ���Ͽ�����40GB����80GB����ѡ�ͣ�Ҳ����ѡ��NVlink����PCIe�ӿڵ�GPU�����ڴ棬CPU������û��ͳһ�ı��涨���������������̿����Լ���ƣ�ֻҪ��ͨ��NVDIA�Ĺٷ��Ͽɼ��ɡ� |
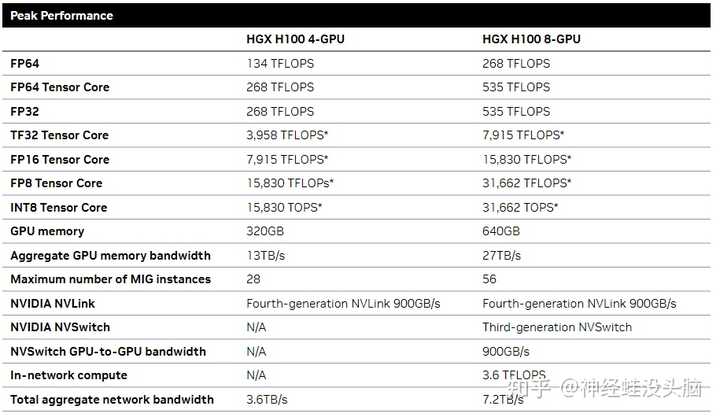
|
|
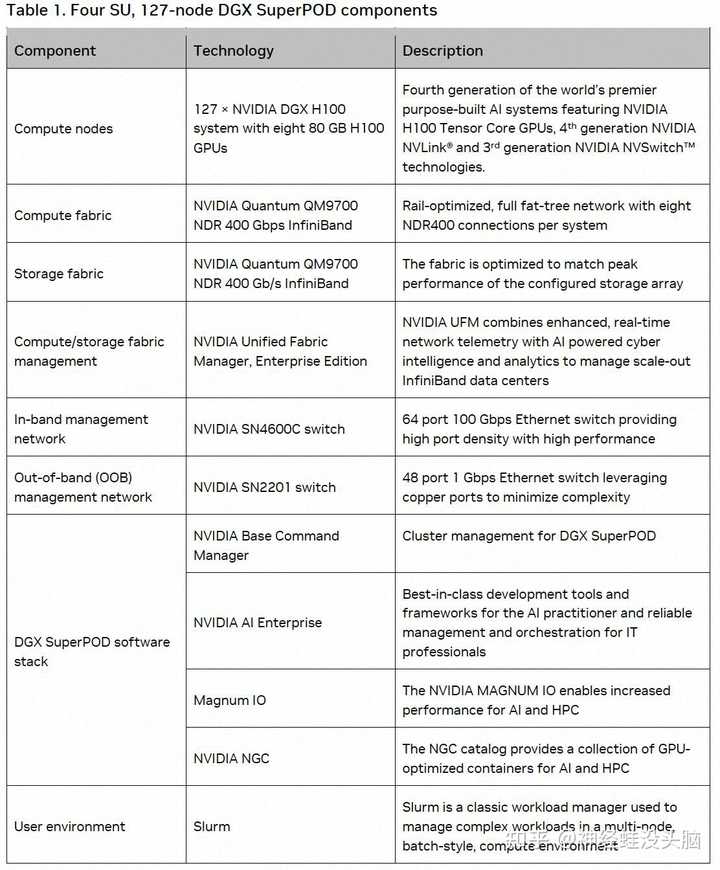
֪����DGX A100��HGX A100����������ٿ���HGX H100���־Ͳ��������ˣ�����һЩ���������Եı仯�� DGX SuperPOD DGX SuperPOD������DGX��Ʒ��ɵĴ������POD������ͼ��ʾ��Ϊ��DGX H100���ɵ�DGX H100 SuperPOD�Ĺ��ɡ� |
|
|
ͨ��NVDIA�ṩ��DGX H100����ش洢��������Ӳ�����һ������POD���ڸ�����AI���㡣 Grace Hopper�ܹ� ��GTC 2022�ϣ�NVDIA������Grace Hopper Superchip�ܹ�������Ҫ����һ�¼������µ㡣Grace��ֻNVDIA���е�Grace CPU����Hopper����Hopper�ܹ���GPU�� |

|
|
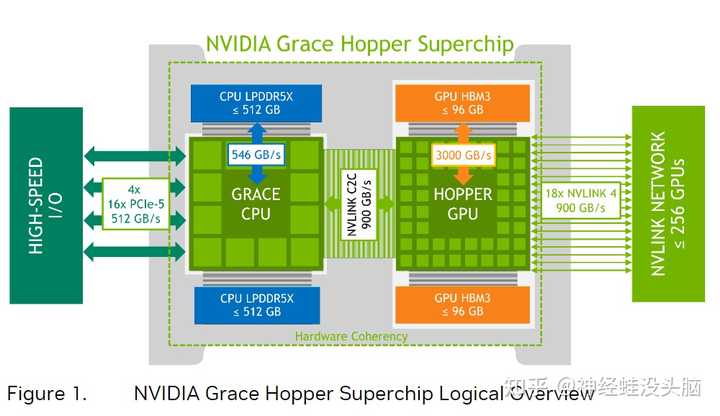
Grace CPU��Ӣΰ���{BANNED}�й���һ����������CPU��ӵ��{BANNED}��Ѷ�72��Arm Neoverse V2���ģ�֧��{BANNED}��Ѷ�512GB��LPDDR5X�ڴ棬ÿ��CPU���ڴ�����ɴ�546GB/s�� Hopper��Ӣΰ��ھŴ���������GPU���������һ��Ampere �кܶ�������ǰ���Ѿ����ܹ�������Ͳ��ٽ����ˡ� Grace Hopper Superchip��Grace CPU��Hopper GPU�ŵ���һ���·���ϣ���һ��CPU��GPU����ô����ʱ���Ǽ����Կ�����������CPUʱ������ͼ��ʾ���ڵ�������оƬ�У�Grace��Hopper֮��ͨ��һ����NVLink Chip-2-Chip(C2C)�Ļ�������������һ���ṩ�ߴ�900 GB/s���ܴ�����������450GB/s������x16��PCIe Gen5��7��������Ϊ����оƬ�ṩ�ڴ�һ���ԡ��ߴ����͵��ӳٵ�ͨ�š�NVLink C2C���ṩ���ڴ�һ�������ƣ�������߿����ߵ�������������������ܣ��������GPU�Ŀɷ��ʵ��ڴ���������NVLink C2C�İ����£�CPU��GPU���ڿ���ͬʱ�����ط��ʶԷ����ڴ棬��ʹ�ÿ����߿���רע���㷨��ƣ������û�ʱ�����ڴ������NVLink C2C���ṩ���ڴ�һ���ԣ�����������ֻ����������Ҫ�����ݣ�������Ҫ������ҳ������Ǩ�Ƶ�GPU���GPUǨ���� |
|
|
��NVLink C2C�İ����£�Ӧ�ó���ɷ��ʵ��ڴ治ֹGPU���ṩ��96GB�����õĻ�������Grace CPU���ڴ棬ÿһ��Grace Hopper Superchip���ṩ{BANNED}��Ѷ�512GB��LPDDR5X��CPU�ڴ档����������512+96=608GB! |
|
|
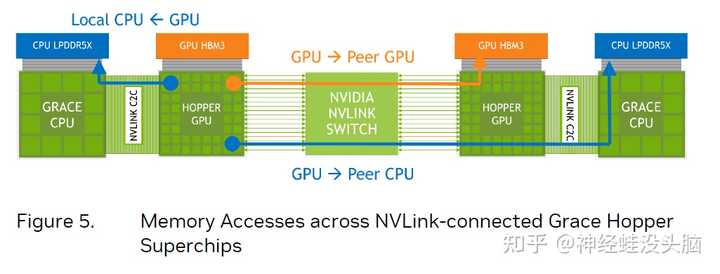
���⣬NVLink C2C��֧��NVLink Switch System����ʹ��һ��Hopper GPU�������Է��ʱ���Grace CPU���ڴ棬����������������Զ�˵�Hopper GPU�Լ�Զ�˵�Grace CPU���ڴ档Ҳ����˵��ÿһ��Hopper GPU�����Է��ʼ�Ⱥ��������ڴ档ֵ��ע����ǣ�NVLink Switch��NVLink C2C�Ĵ���һ����900GB/s�ģ���Ϊ��ڵ���ڴ����һ�����ṩ�˻���������NVLink������{BANNED}��Ѷ�256��Grace Hopper Superchip����������{BANNED}��Ѷ���Է���150TB��256x608GB�����ڴ档 ��֮��NVLink C2C����Ӧ�ó����ܹ�������ֱ�Ӷ�ȡ���������ݣ�������ؽ���ԭ�Ӳ����������ڴ����������ӵ����⡣����Grace Hopper����оƬ����֮��Ӧ�ľ�����ص�DGX��HGX��Ʒ�� DGX GH200 NVIDIA��ǰ�� DGX A100 ϵͳֻ�ܽ��˸� A100 GPU ����������Ϊһ����Ԫ���������ʽ�˹����ܴ�ģ�Ͷ��������ı�ըʽ������NVIDIA�Ŀͻ�������Ҫ����ǿ���ϵͳ��DGX GH200����Ϊ���ṩ{BANNED}��Ѵ���������Ϳ���չ�Զ���Ƶġ� ����ͼ��ʾ��DGX GH200ͨ�����Ƶ�NVLink Switch System������ 36 �� NVLink switch����256��GH200����оƬ�ߴ�144TB�Ĺ����ڴ����ӳ�һ����Ԫ���������Ⱥ����ѡ��� InfiniBand ����̫���������ƣ������µĻ�����ʽʹDGX GH200ϵͳ�е�256��H100 GPU��Ϊһ������Эͬ���У�ʹ���Ϊ��רΪ{BANNED}��Ѹ߶˵��˹����ܺ����ܼ��㹤�����ض���Ƶ�ϵͳ�Ͳο��ܹ�����֧�������ڲ���AI��ģ��ѵ���� |

|
|
DGX GH200ϵͳ�е�ÿ��Grace Hopper Superchip ����һ��NVIDIA ConnectX-7������������һ��NVIDIA BlueField-3 NIC��ԡ�DGX GH200 ӵ�� 128 TBps �Էִ����� 230.4 TFLOPS �� NVIDIA SHARP ���ڼ��㣬�ɼ��� AI �г��õļ����������ͨ�����ټ��������ͨ�ſ������� NVLink ����ϵͳ����Ч�������һ����ConnectX-7 �����������Ի������DGX GH200 ϵͳ������չ������256��GPU�ĸ���Ľ������������NVIDIAҲ{BANNED}�й���һ��ʹ�� NVLink Switch ���˽ṹ���������������������Ⱥ��֮ǰNVlink switchֻ����оƬ��ʽ�������ڣ�����DGX GH200��NVlink switchҲ��ʵ��Ϊ��������ʽ������༶GPU���������ֽṹ�ṩ�˱�ǰһ��ϵͳ�߳�10����GPU��GPU�������Լ�7����CPU��GPU�Ĵ����� |

|
|
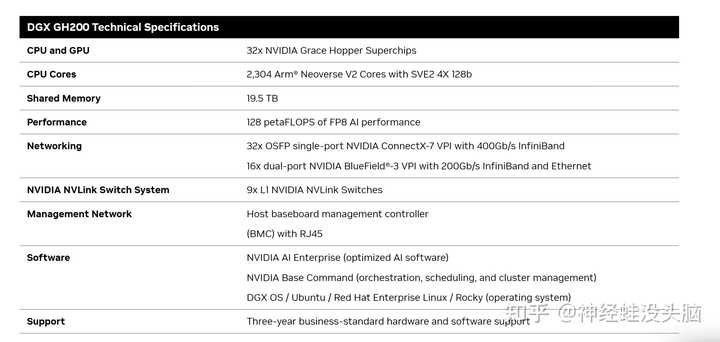
�±���DGX GH200�����ã���֮DGX GH200�Ա��DGX A100�����Խ�DGX GH200����һ�����GPUоƬ�� |
|
|
��ôDGX GH200�����Ľ��ܵ�DGX SuperPOD�ڲ�Ʒ��λ��ʲô��ͬ�أ���ͼ��һ���ܽᣬ������DGX GH200ֻ��GPU�Ĺ̶���ϣ�256������DGX SuperPOD��һ����Ⱥ�� |

|
|
HGX GH200 ����DGX��Ʒ��HGX Grace Hopperÿ���ڵ㶼��һ��Grace Hopper����оƬ����Bluefield-3 NIC��OEM�����I/O�Լ���ѡ��NVlink switchϵͳ��ԡ� |

|
|
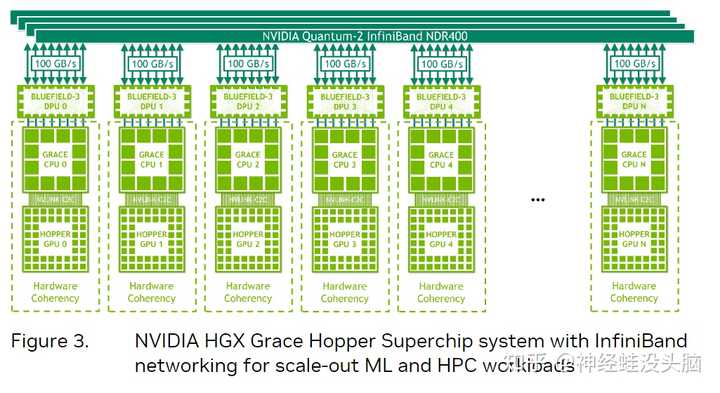
��ͼչʾ���ǻ���Grace Hopper Superchip��һ��HGX Grace Hopper Superchip�ڵ㣬���ڵ��TDP�ߴ�1000�ߣ�����ɢ�Ⱥ�ˮ��ɢ�ȶ��С���ôһ������Ҫ��ô���أ���������������֯��ʽ�� |
|
|
{BANNED}�й���һ����ֻ��InfiniBand�����Ӣΰ���Bluefield-3 DPU�������ϻ��Ǵ�ͳ��RDMA�������磬�����ʺϺ�����չ�Ļ���ѧϰ�����ܼ��㹤�����ء�ÿ���ڵ����һ��Grace Hopper Superchip��һ������PCIe�豸������NVMe��̬��������BlueField-3 DPU��NVIDIA ConnectX-7 NIC ��OEM�����I/O��NDR400 InfiniBand NIC����16��PCIe Gen 5ͨ�������ڳ���оƬ���ṩ�ߴ�100 GB/s���ܴ��������NVIDIABlueField-3 DPU����ƽ̨���ڹ����Ͳ��𣬲�ʹ�ô�ͳ��HPC��AI��Ⱥ����ܹ��� |
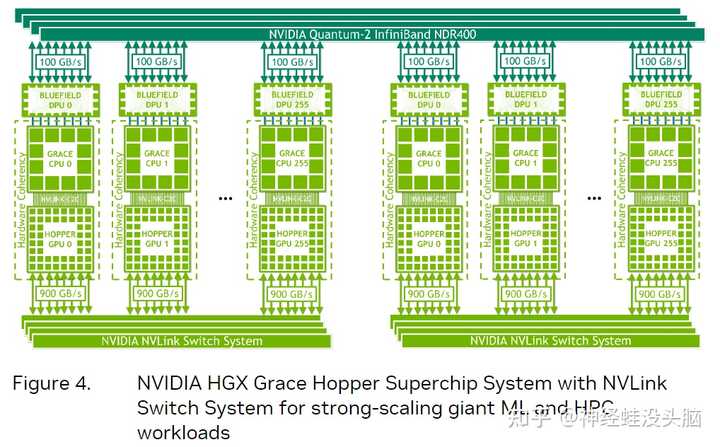
|
|
��һ�֣�������InfiniBand�Ļ����ϣ������Կ���һͷ��NVLink Switch System���Կ�������һ����������256��Grace Hopper Superchip����ȫ���ʺ�������������Ϲ�ģ{BANNED}��Ѵ�{BANNED}��Ѿ���ս�Ե�AIѵ����HPC�������ء� |
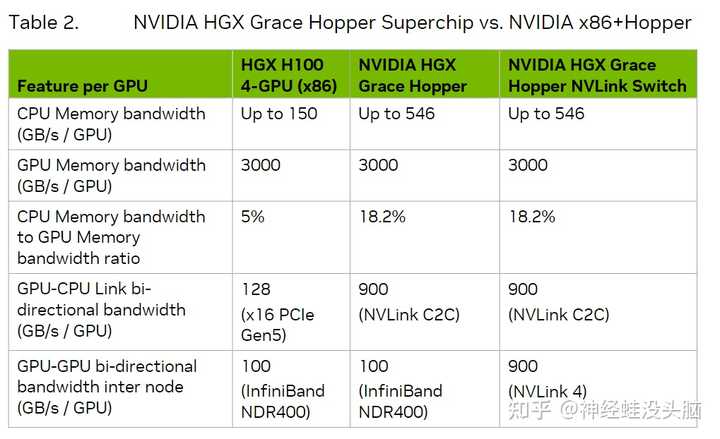
|
|
��ͼ�Ա���CPU+�Կ���ͳ��ϣ�Grace Hopperһ�������Լ�������NVLink Switch��Grace Hopper����֮��ĶԱȡ��Ա�֮�£�CPU-GPU��16ͨ����PCIe 5.0���ӵ��ٶ�������NVLink C2C��Grace Hopper���ʵ����̫���ˡ���GPU-GPU֮��ͨ��InfiniBand�Ĵ����ٶȸ�����NVLink 4��NVLink Switch��ȣ�Ҳ�����Զ�� ��֮��HGX GH200���˷���������һ������ԣ�ѡ���Ƿ�ʹ��NVlink Switch���Լ����ö��ٸ��ڵ㡣 MGX NVIDIA DGX ����{BANNED}��Ѹ߶��г���AIϵͳ��HGX ϵͳ���������ģ�������ģ��˴�NVIDIA�����Ƴ��˽���������֮��ĵ�NVIDIA MGX ϵͳ�� NVIDIA ��ʾ����OEM���������Ϊ AI ������Ʒ�����ʱ�������µ���ս����Щ��ս���ܻ������ƺͲ�����ٶȡ�NVIDIA ��ȫ�� MGX �ο���Ƽܹ�ּ�ڼ�����һ���̣����Խ�����ʱ������2/3������6���£������ɱ�Ҳ���Լ���3/4�� |

|
|
�ݽ��ܣ�MGX ϵͳ��ģ�黯�����ɣ������� NVIDIA �� CPU �� GPU��DPU ������ϵͳ�����з��棬��Ҳ��������ͨ�� x86 �� Arm ����������ƣ�ӵ��100 ���ֲο���ơ�NVIDIA ���ṩ�����Һ�����ѡ�����Ӧ����Ӧ�ó����� |

|
|
ASRock Rack�����棩����˶��GIGABYTE�����Σ�����˶��QCT������Supermicro������ʹ�� MGX �ο��ܹ����������ڽ�����Щʱ�����������е�ϵͳ�� ��������ת�Բ���lvyilong316 |

|
|
����ûͷ�� 9 ����ѯ 5.0 1933 ����ͬ ȥ��ѯ 2023��һ��ԭ�����з���������������ƽ̨�Ƽ� - ֪�� (zhihu.com) ���������������ܣ������ָ�У������Ϣѧ���ģ� - ֪�� (zhihu.com) |
|
|
������Ϣѧ�ر���վ��ȫ - ֪�� (zhihu.com) ������Ϣѧ��ʷ - ֪�� (zhihu.com) Llama-2 LLM�����汾GPU������������Ҫ����ʲô�� - ֪�� (zhihu.com) �˹�����ѵ������������վ������������ȺӲ�������Ƽ� |

|
|
������һЩ���ѧϰ���˹����ܷ�������ϣ����Կ��� һ�Ŀ���Ӣΰ��A100��A800��H100��H800�����汾��ʲô���� - ֪�� (zhihu.com) ����ѧϰ�����ѧϰ��ǿ��ѧϰ�Ĺ�ϵ��������ʲô�� - ֪�� (zhihu.com) �˹����� (Artificial Intelligence, AI)��ҪӦ�������������̬�����˹����ܡ�ǿ�˹����ܺͳ����˹����ܡ� ��Ӳ�����������㻹�����Ʒ��������㣿 - ֪�� (zhihu.com) ���ѧϰ����ѧϰ֪ʶ��ȫ���ܽ� - ֪�� (zhihu.com) ��ѧ����ѧϰ�����ѧϰ���˹����ܵ���վ������ - ֪�� (zhihu.com) 2023�����ѧϰGPU�����������Ƽ��ο���3�� - ֪�� (zhihu.com) |

|
|
������һֱרע�ڿ�ѧ�������������Χ����ƽ̨��H100��A100��H800��A800��L40��L40S��RTX6000 Ada��RTX A6000����̨˫·256���ķ������ȡ� |

|
|
|

|
|
|
|
�ܼ�linus���˾��������ģ��ر�ϲ������ָ��fuck���������ء���ʦүô����Ƣ���������� ����nvidiaȷʵ��linux��֧�ֲ������ƣ����һ����Ǹ������֧�ָ������� ������ʦү�������������˵���Ǻ������������� ����һ�䣬��ȥ����Ķ���Ӱ��1650s�����ų�ת�ֺü��ң����Dz�̫�����ǿ���kali��ʱ��Ʈ�����������ŵã�����ն�װ�����Ž�����⡣��Ubuntu������������֪��centos����debian����ô���� |
|
��һ����ʱ��linux desktop user�ĽǶȻش𡣷����רҵ�� ��˵˵Ϊɶ��2023���ˣ�nvidia��wayland�ļ����Ի���ô���amd�����Ǽ��弴�õġ� û��wayland�͵��ó�ʺ��xorg��xinput�ڱʼDZ�������֧�����ơ�������ͬ�ֱ�����ʾ��������֡�����⡣����ʾ�����и�wine session����Ϸ�������� �������xwayland�Ļ��ܶ����������gnome �ܶര�ڶ���cpu���ܣ������ʹ���������30w�Ĺ��ʡ� fedora���Ѿ�Ĭ��wayland session�ˣ�nvidia ��kde����gnome��bug��Ȼһ�ѡ� firefox����n�����뻹�ð�װ����lib����һ�����ز����� |
|
ͻȻ�뵽�����Կ��ܲ����Կ�Դ֧��linuxΪͻ�ƿڡ� ������������Ϸ���Ǻ��и�ͷ�� |
|
FN�����A��FA����ֻ��˵���Լ������� |
|
�Ҽǵõ�ʱnvidiaһֱ���ṩgpu������ ����Linus����ں˵���ү�ǣ������������ں�API�� ���Ծ�������nvidia��������������ˣ�Linus���fuck���Լ��� ��ʱ�ҿ�������ʱ�����ܹ�ȥ����һ�٣��ҵ�ʱ�;���������������������š� ����һ�²�ͬ�汾libcʵ��ij�����ܵĺ�������������������ʧ�� ��˭�����⣿����ʹ��libcд������˵����⣬��Ȼû�н���libc�ı仯�� Ϊÿ���汾��libc��дһ�����Ȼ�����ÿһ���libc�����Ӧ�Ķ����ư汾�� |
|
��ѽ����֪���𣬵���Linus˵"fuck NVIDIA"������Ϊ�����ú�NVIDIA�Ĺ�ϵ������Ů����һ����������������Linus����NVIDIAһ�������ڰ��г�������оƬ��һ����ȴ�ڸ�Linux�ṩ֧����ĥĥ��������š�͵����ˡ� ����ԭ�����ǡ�the single worst company�������������Ĺ�˾�����ͺ�����������ȫ����˾�Ĺھ�һ������������ΪLinus����дLinux������ֱ��дLinux�ں˻��ѣ�������һ������NVIDIA��������ָ�� ��������ʱ���ȥ�ˣ�����Linus���ú�NVIDIA�Ĺ���Ҳ��������ʱ�Ա�����Ե�ѡ��һ������ʱ��������ʢ�ľ����������ڵ�Ҫ�����Ͼ����������ѧϰ��NVIDIA��GPU�ܵ÷ɿ죬Linus����������ĬĬΪ�����ġ���������NVIDIA�¾�������˵��"fuck"������ȴ˵��"thank you for the CUDA cores"���������һ�����۵ĸ�����£�˭��û�뵽�����ߵ�һ�� |
|
��Ϊ���Լ���macbook pro ���Dz����������ö����Կ�����. |
|
ӡ����Ӧ����Ӣΰ����linux������һЩ���Ӳ��Ե��µġ� |
|
�Ƕ���ɶ�������Ƶ�ˣ��Ҽǵõ�ʱlinus˵�⻰��dlûɶ��ϵ�ɡ� |
|
���ͼ�ҾͲ����ˣ�Ӣΰ��֮ǰһֱ�������Կ�����API��Linux�ں�û������Ӣΰ���Կ�����������Ӧ�������ˡ� |
|
��Ҫ��ʮ����ǰ��linux�������ù�nvidia��Դ���߿�Դ�����Ļ�����Ҳ��fxxk�� |
|
|
| [�ղر���] �����ر��ġ� |
| ��һƪ���� ��һƪ���� �鿴�������� |
|
|
|
| ��Ʊ�ǵ�ʵʱͳ�� ��ͣ��ѡ�� ��ʱͼѡ�� ��ͣ��ѡ�� K��ͼѡ�� �ɽ���ѡ�� ����ѡ�� ������ѡ�� �������� �������� ���� MACDָ�� KDJָ�� BOLLָ�� RSIָ�� ���ɻ���֪ʶ ���ɹ��� |
| ��վ��ϵ: qq:121756557 email:121756557@qq.com ����ƻ� |