
| |
|
|
| 首页 淘股吧 股票涨跌实时统计 涨停板选股 股票入门 股票书籍 股票问答 分时图选股 跌停板选股 K线图选股 成交量选股 [平安银行] |
| 股市论谈 均线选股 趋势线选股 筹码理论 波浪理论 缠论 MACD指标 KDJ指标 BOLL指标 RSI指标 炒股基础知识 炒股故事 |
| 商业财经 科技知识 汽车百科 工程技术 自然科学 家居生活 设计艺术 财经视频 游戏-- |
| 天天财汇 -> 科技知识 -> 从技术原理上分析,为什么OpenAI发布的sora模型会碾压pika和runway? -> 正文阅读 |
|
|
[科技知识]从技术原理上分析,为什么OpenAI发布的sora模型会碾压pika和runway? |
| [收藏本文] 【下载本文】 |
|
从技术原理上分析,为什么OpenAI发布的sora模型会碾压pika和runway? 关注问题?写回答 [img_log] 技术原理 OpenAI AI视频生成 从技术原理上分析,为什么OpenAI发布的sora模型会碾压pika和runway? 圆桌收录 拥抱AGI:从Gemini到Sora |
|
答案其实很简单,就藏在 OpenAI 的核心价值观里 |

|
|
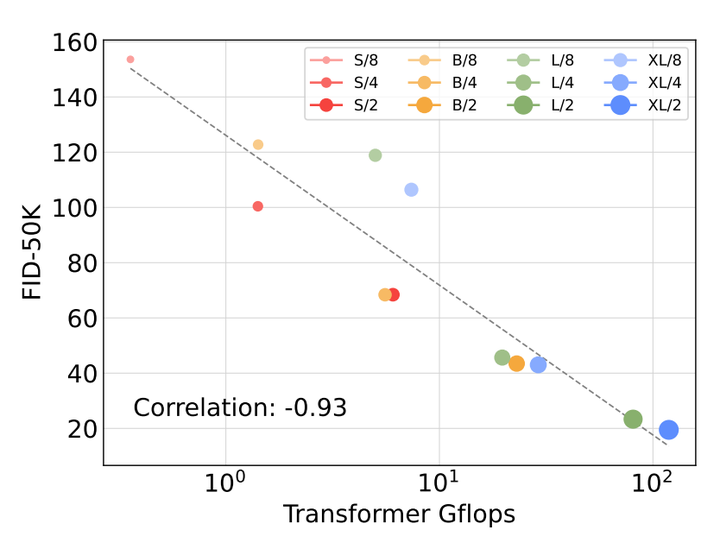
OpenAI 核心价值观,红框的部分:我们相信规模是一种魔法,当我们困惑时,我们就扩大规模 具体的架构 OpenAI 没有公布,但在 Technical Report 中明确说了 sora 是基于 Diffusion Transformers,也就是 DiT 的,这是 Meta 发表在 ICCV2023 上的一篇工作,Diffusion Transformer 的特点就是用 Transformer 替代了传统扩散模型中的 U-Net 结构,造就了其强大的 scalability |
|
|
随着计算量的增大,FID-50K 呈现出log下降趋势 DiT 的细节这里就不展开了,感兴趣可以自己去看论文:https://arxiv.org/abs/2212.09748 读完这篇文章,个人感觉 Sora 在 DiT 基础上主要做了这些改进: 用自行训练的 Video Encoder 替换掉了 DiT 中的 VAE从对图像的 patchify 泛化到了对视频图像序列的 spacetime patchify基于 GPT-4V 对视频分片的 Re-captioning 技术大幅提升了模型的自然语言理解能力Scale up,Scale up,Scale up 最后不得不吐槽 OpenAI 真是越来越 Close 了,Meta 这篇论文是模型代码全开源的,OpenAI 用了那么多别人家的学术成果,自己搞点新东西出来,模型不开源就算了大家不会说啥,代码不开源隐藏训练细节也行大家并不强求,现在连论文都不想发了,就发个技术报告 |
|
首先,OpenAI没有发布技术细节,所以很难详细解释。 但是有一点儿很明确,Sora的母公司OpenAI还有一个地表最强的大语言模型GPT4。 记得最开始GPT4怎么出圈的吗? 是它可以做各种题,物理,数学,化学等等。 你给他一些涉及到物理规律的题,它是真的能理解,也能比较准确的展开它的思考以及计算过程。 这就说明了一点儿,那就是OpenAI这个公司,在做一些对于现实世界的一些规律捕捉上,非常有心得。 他们对于AI的理解真的是超过平均线太多了。 有点儿做到了一法通 万法通的那种感觉。 我估计在Sora生成视频的时候,会用到GPT4+Dalle-3这俩它自己的工具,GPT4对于各种定理、规律的理解,如果用过的都知道有多惊艳。 再者还有一个细节,OpenAI每次发布产品基本上都是已经精雕细琢过的。 GPT4去年年中发布,它实际上训练完毕是一年前,也就是说,它打磨了一年多才放出来。 Sora据说是23年3月做好的,24年2月中发布,也差不多打磨了一年多。 这非常的OpenAI,要放出来的都是可以炸街的水平。 厚积而薄发吧这就是。 |
|
我个人的感受是以后的AI视频生成领域,恐怕真的只有 Sora 和其他模型了。 但比较遗憾的是,OpenAI 发布的 Sora 报告中不包含模型和训练的细节,所以在技术原理上来讲还是一个黑帽。 不过之前已有不少研究过视频数据的生成建模技术方向,其中主要包括:循环网络、生成对抗网络、自回归 transformer 和扩散模型。 推测 OpenAI 是从大型语言模型中汲取了灵感,大型语言模型有文本 token,而 Sora 是视觉 patches 数据的通用模型。 |

|
|
这里的 patches 是指训练生成各种类型视频和图像的模型的可扩展且有效的表示。 从上面的图我们可以更加直观的看到,需要先把视频压缩到较低维的空间,然后将表示分解为 patches,从而将视频转换为 patches。 另外 Sora 是一个扩散 Transformer,给定输入噪声 patches(以及文本提示等调节信息),训练出的模型来预测原始的「干净」patches。 |

|
|
OpenAI 发布 Sora 的时候也展示了训练过程中具有固定种子和输入的视频样本的比较。随着训练计算的增加,我们可以看到下面的狗狗样本质量显着提高。 |

|
|
以上是基于OpenAI发布的Sora技术报告和一些媒体的分析得出,具体的内容大家也可以进一步的参考OpenAI发布的 报告原文 。 |
|
不是...他们的技术路线也没完全放出来啊,只是给了个大概,好多细节都是网友脑补的,而且有些脑补一眼就是错的(你看那个一条狗变成好几条狗的failure mode就能排除掉好多错误答案) 那我也瞎猜一波,不要光看他们report放出来啥,要看他们没放出来啥,关于这个的training set长啥样他们是一点信息没漏,甚至连大概的大小都未知 那么很有可能最关键的点是数据牛逼,毕竟微软能access到的训练视频应该远多于创业公司 |
|
前年我也讲了很多篇了,现在依旧看来,Sora是后起之秀! 我们先看一张图: |

|
|
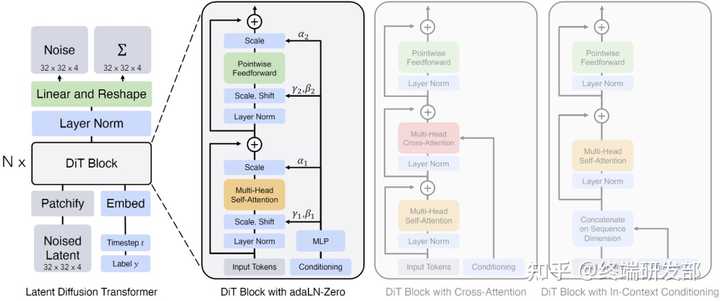
对于OpenAI 核心价值观: 红框的部分:我们相信规模是一种魔法,当我们困惑时,我们就扩大规模! Sora 训练过程获得了大语言模型的灵感,采用扩散型变换器模型,通过将视频转换为时空区块的方式,实现了在压缩的潜在空间上的训练和视频生成。 Sora的整体架构 |
|
|
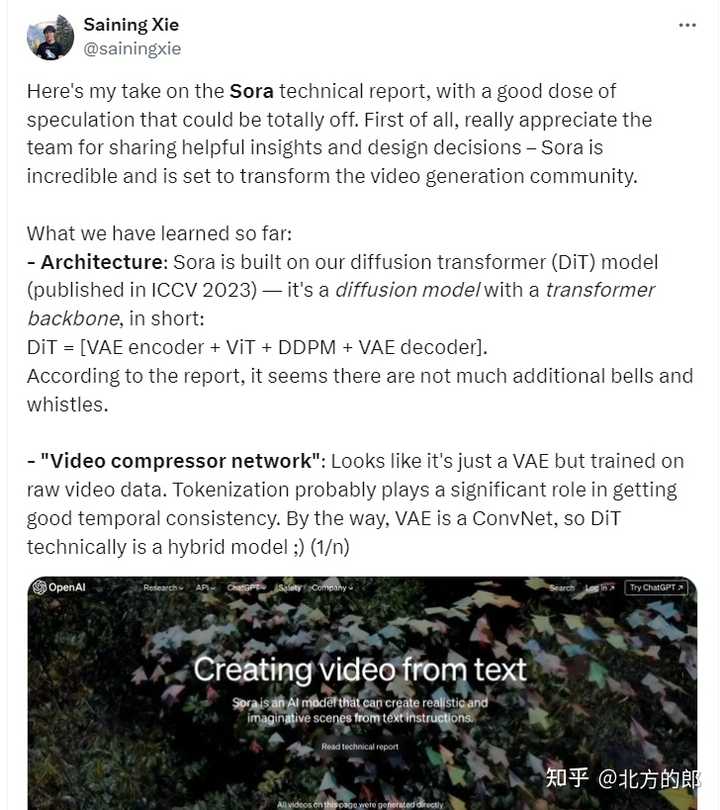
其实open ai并没有发布具体的大规模素材生成的原理 之前看过网上一位大神的分析: 作者:谢赛宁分析 1、Sora应该是建立在DiT这个扩散Transformer之上的。 简而言之,DiT是一个带有Transformer主干的扩散模型,它= [VAE 编码器 + ViT + DDPM + VAE 解码器]。 谢赛宁猜测,在这上面,Sora应该没有整太多花哨的额外东西。 2、关于视频压缩网络,Sora可能采用的就是VAE架构,区别就是经过原始视频数据训练。 而由于VAE是一个ConvNet,所以DiT从技术上来说是一个混合模型。 |

|
|
在视频生成方面,OpenAI训练了一个专门的网络,用于将视频数据的维度降低,并在压缩后的潜在空间中训练模型以生成视频。 |

|
|
同时,通过训练解码器模型,将潜在表征还原为像素级的视频图像。这一过程类似于将复杂的视频数据简化为易于处理的小方块,从而使得视频生成更加高效。 由于个人没有有体验过pika,但runaway感觉还不错,从整个感受而言,Sora可能支持更加长的视频支持,所以依然看好! |
|
这个其实也是大家都很想知道的。 我在 OpenAI 全新发布文生视频模型 Sora,功能有多强大?将带来哪些影响? - higgaraa的回答 - 知乎 OpenAI 全新发布文生视频模型 Sora,功能有多强大?将带来哪些影响? 这个回答里面我简单猜测了sora的整体结构。实际上大致的结构就是diffusion换掉了unet换成了DiT,并且使用3d conv。sora似乎有个绕不开的问题,就是token数量会极其庞大。实际上在reddit相关的原理讨论帖中,不止有一个小伙伴也指出了类似的问题。 文生视频这个领域一直都不是非常完善。之前的所有工作对比sora就像是原始人对比三体人那样。所以真的说不好sora到底是大力出奇迹,还是真有什么独门杀手锏。但是就算是大力出奇迹,这次的力似乎对于哪怕有机器的研究者也“太大”了一些。因此我有些悲观,对于开源社区能否复现sora这件事情上来讲。希望openAI心善,给大家开源了吧。。。 顺便还有个事情可能要和大家提一下。。因为sora是基于diffusion的,所以一堆diffusion的技巧其实可以直接用上去:例如CFG(条件生成),instruct2pix,包括controlnet,稍微改下网络结构都可以直接用。。。所以不要觉得说现在生成不可控之类的,openAI想要让它可控,可以说是易如反掌,别说openAI了,给我源代码让我加个controlnet我都能在1个月内给它加出来。 |
|
介绍 在Sora发布后,各路大佬纷纷猜测它的技术细节。例如:谢赛宁就认为Sora是基于他在ICCV 2023发布的DiT(Diffusion Transformer)技术(或思路)构建的。 |
|
|
在Sora技术报告里面披露的技术内容包括: 将视觉数据转化为补丁(Turning visual data into patches) 研究人员受到大型语言模型的启发,它们通过在互联网规模的数据上进行训练而获得了通用能力。LLM范式的成功部分得益于优雅地统一了文本、代码、数学和各种自然语言等不同形式的令牌。在这项工作中,研究人员考虑了生成视觉数据模型如何继承这些优势。而LLMs具有文本令牌,Sora则具有视觉补丁。研究表明,补丁是模型视觉数据的一种有效表示。研究人员发现,补丁是用于训练生成模型的多种类型视频和图像的高度可扩展且有效的表示。 |

|
|
在较高层面上,研究人员通过首先将视频压缩到低维潜空间,然后将表示分解为时空补丁来将视频转换为补丁。 视频压缩网络(Video compression network) 研究人员训练了一个降低视觉数据维度的网络。这个网络以原始视频为输入,并输出一个在时间和空间上都被压缩的潜在表示。Sora在这个压缩的潜在空间上进行训练,并在此空间内生成视频。研究人员还训练了一个相应的解码器模型,将生成的潜在表示映射回像素空间。 时空潜在补丁(Spacetime Latent Patches)(译者:应该翻译成“潜在”还是“潜空间”?) 给定一个压缩的输入视频,研究人员提取一系列时空补丁,这些补丁充当Transformer令牌。这种方案对图像也适用,因为图像只是具有单帧的视频。研究人员基于补丁的表示使得Sora能够训练各种分辨率、持续时间和长宽比的视频和图像。在推理时,研究人员可以通过将随机初始化的补丁排列成适当大小的网格来控制生成视频的大小。 扩展Transformers用于视频生成(Scaling transformers for video generation) Sora是一个扩散模型;给定输入的噪声补丁(和文本提示等条件信息),它被训练来预测原始的“干净”补丁。重要的是,Sora是一个扩散Transformer(diffusion transformer)。Transformers已经在各种领域展现出了显著的扩展性能,包括语言建模、计算机视觉和图像生成。 |

|
|
因为在Sora的技术报告里面有这么一句“Importantly, Sora is a diffusiontransformer.” 而且在Reference里面有: Peebles, William, and Saining Xie. "Scalable diffusion models with transformers."Proceedings of the IEEE/CVF International Conference on Computer Vision. 2023.?? 所以大佬的话是对的,的确使用了DiT技术。那么DiT技术到底是什么呢? 以下内容来自论文 论文链接:Scalable Diffusion Models with Transformers |

|
|
官网:Scalable Diffusion Models with Transformers |

|
|
随着人工智能技术的不断发展,图像生成领域正经历着一场深刻的变革。近年来,扩散模型在图像生成领域取得了令人瞩目的进展,其中尤以基于变分自编码器(VAE)的隐变量空间的扩散模型最为出色。本文将为您介绍一种全新的基于Transformer的扩散模型,它不仅能够实现媲美GAN的图像生成质量,而且具有更好的扩展性和计算效率。 |
|
|
扩散(Diffusion)模型是一类基于深度学习的图像生成模型,它通过学习噪声图像到真实图像的逆过程,从而生成高质量的真实图像。传统的扩散模型通常采用卷积神经网络作为其主干网络,但本文提出了一种基于Transformer的新型扩散模型,即Diffusion Transformer(DiT)。 DiT(Diffusion Transformer)基础概念: Denoising Diffusion Probabilistic Models (DDPMs):通过逐步添加噪声来模拟数据分布,然后学习逆向过程去除噪声,以生成新的数据。DiT是DDPM在图像生成中的应用。 Latent Diffusion Models (LDMs):使用变分自编码器将图像压缩到低维表示,然后在低维空间中训练DDPM。这样可以降低计算成本,并使DiT成为基于Transformer的DDPM的适用框架。 DiT的架构: |
|
|
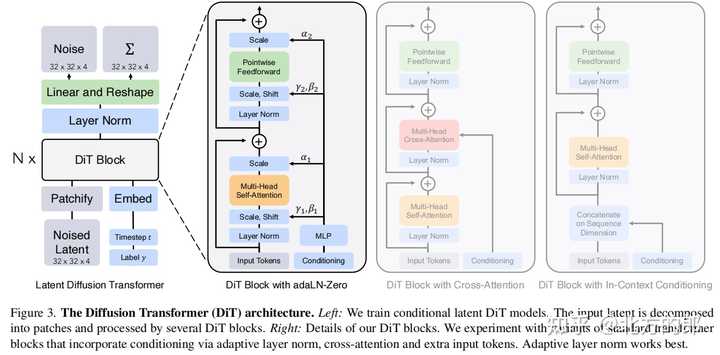
Patchify层:将图像切分成多个大小为p x p的patches,并转换为长度为T的序列作为Transformer的输入。具体来说,当图像大小为I x I x C时,Patchify层将图像切分成大小为p x p的patches,并将每个patch转换为长度为T的序列。序列长度T的计算公式为:T = (I/p)2。例如,当图像大小为32 x 32 x 4,patch大小为2时,T为1024;当patch大小为8时,T为16。 |

|
|
DiT block:DiT block包含自注意力层、层规范层、前馈网络层。文档中提到了四种变体,分别为: in-context conditioning:将噪声时间步和类别标签的嵌入向量作为额外的输入token,与图像token一起输入。cross-attention:将噪声时间步和类别标签的嵌入拼接为一个长度为2的序列,与图像序列分开,并在block中增加一个cross-attention层。adaptive layer norm (adaLN):使用自适应层规范层代替标准层规范层,并从噪声时间步和类别标签的嵌入向量中回归出尺度参数和偏置参数。adaLN-Zero:在adaLN的基础上,对每个block的最后一个层规范层进行初始化,使其初始为恒等函数。 |

|
|
最有效的是adaLN-Zero。 模型大小: |
|
|
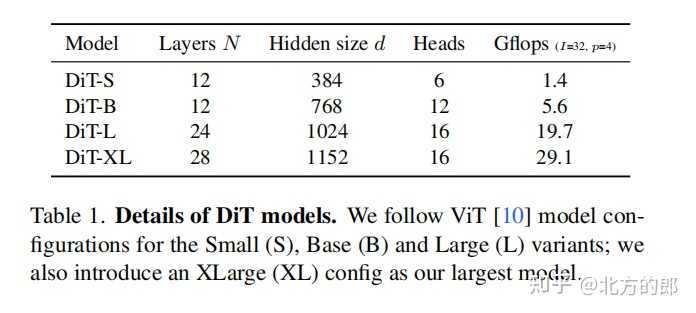
DiT有四种配置,分别为DiT-S、DiT-B、DiT-L和DiT-XL。 DiT-S包含12层,隐藏维度为384,6个注意力头,计算量为1.4 Gflops。DiT-B包含12层,隐藏维度为768,12个注意力头,计算量为5.6 Gflops。DiT-L包含24层,隐藏维度为1024,16个注意力头,计算量为19.7 Gflops。DiT-XL包含28层,隐藏维度为1152,16个注意力头,计算量为29.1 Gflops。 实验设置 |
|
|
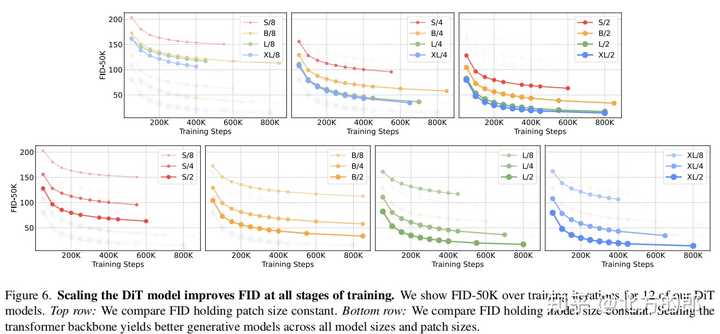
训练: 在ImageNet数据集上训练类条件DiT模型,分辨率为256 x 256和512 x 512。使用AdamW优化器,学习率为1 x 10^-4,权重衰减为0,批量大小为256。数据增强仅使用水平翻转。训练过程中维护DiT权重的指数移动平均(EMA),衰减率为0.9999。 扩散: 使用预训练的变分自编码器(VAE)将图像编码为低维表示。在VAE的潜在空间中训练DiT模型。使用ADM的扩散超参数。 评估指标: 使用Fréchet Inception Distance (FID)评估模型性能。使用Inception Score、sFID和Precision/Recall作为辅助指标。 计算资源: 使用JAX实现所有模型,并在TPU v3 pods上进行训练。实验结果 |
|
|
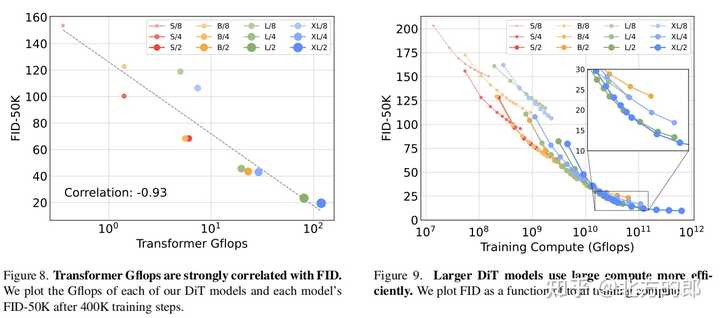
DiT block设计:在相同计算量下,adaLN-Zero block的FID明显低于其他三种block设计,性能最优。模型大小和patch size:增加模型大小和减小patch size都可以显著提升DiT的性能。模型计算量(Gflops)与FID负相关,与参数数量相比,模型计算量是影响性能的关键。计算效率:大模型在使用更多计算资源时能获得更好的性能提升,小模型即使使用更多计算资源也难以赶上大模型。256x256分辨率:DiT-XL/2获得state-of-the-art的FID 2.27,优于LDM的3.60。 |

|
|
512x512分辨率:DiT-XL/2同样获得state-of-the-art的FID 3.04,优于ADM的3.85。 |

|
|
|

|
|
DiT的出现为图像生成领域带来了新的思路和可能性。它不仅展现出媲美GAN的生成质量,而且还具有更好的扩展性和计算效率。对比Sora与其他视频生成模型,感觉DiT的确是它效果胜出的一个原因。 |
|
sora是一个出色的产品。 openai的领导者是ilya sutskever,他是hinton的弟子,和hinton,alex一起开创alexnet之后依然锐意进取的 真正的远见者。 不要说华为和国内高校不如openai,谷歌也在其ceo劈柴哥管理下也被碾压。 |
|
pika是在图像生成基础上添加时间层,本质是逐帧生成,而sora的patch是跨帧的,所以他能比较好地学到物体的运动 |
|
大家生图模型距离dalle3还很遥远的情况下,sora是没可能赶上的,别分析了。。。首先生图准确了再说。 |

|
|
图 0 2024开年第一王炸,OpenAI发布Sora视频生成模型,可以实现1min长视频,多机位,任意比例,任意分辨率的视频内容生成。 |

|
|
Sora和其他模型相比 |
|
|
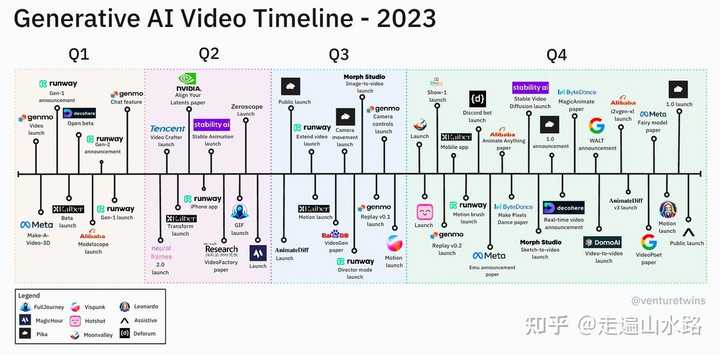
alt text 2023年是视频生成领域爆发的一年,可以看到大公司、头部高校全部投入了人力物力来研究视频生成技术,但是这些产品却都没有取得突破性的进展。 “真正”的长视频 Sora之于视频生成领域有多大的进步呢?单单从生成长度来说,就已经是吊打之前所有的模型了。可以看下图: |
|
|
图 2 之前大火的Pika、Runway等模型只能生成3秒上下的视频,而Sora可以实现1分钟的视频生成。 虽然1min对于抖音来说,也就是平常的短视频,但是对于学界来说已经是突破的进展了。 多机位、任意比例、任意分辨率 Sora的另一个突破性的地方在于,它可以实现多机位、任意比例、任意分辨率的视频生成。 多机位 |

|
|
任意比例 |

|
|
|

|
|
|

|
|
Sora的技术解析 针对openai的官网的技术报告,我们在这里对Sora的技术细节进行初步解析。 参考文献:官网技术报告 该技术细节主要包括以下: 如何统一地表示多种类型的视觉数据?Spacetime patch的信息关于其架构的一些信息大家的猜想?如何统一地表示多种类型的视觉数据? 作者团队从LLM的快速发展中受到启发,因为各种类型的语言都可以表示成token,因此,对于不同类型的视觉数据能否也采用token的表示呢?Sora使用的是patch,即图像或者视频帧的小块,这样可以更好地表示视觉数据。如下图所示: |

|
|
图 3 此外,Sora还将训练一个视觉编码器去压缩输入的视觉数据(包括图像和视频),最终将得到包含了空间和时间的视觉token representation。而Sora的训练都将在此represeantation空间上进行。当然,Sora也会有一个decoder,对其进行解码,得到pixel space。这个流程是否似曾相识? Spacetime patch 在处理压缩后的视频时,Sora会提取一系列spacetime patch,类似于LLM中的token。这种方法同样适用于图像,因为图像本质上就是只有一帧的视频。通过这种基于补丁的表示方式,Sora能够适应训练过程中视频和图像的各种分辨率、时长和宽高比的变化。在生成视频时,我们可以通过在合适大小的网格中随机排列这些补丁来调整生成视频的尺寸。 Sora架构信息 作者团队并没有给出架构的详细信息,但是已知的是Sora是基于Tranbsformer的Diffusion模型。它将带有噪声的patch(以及像文本提示这样的条件信息)作为输入时,训练用来预测原始的“干净”patch。 |

|
|
图 4 大家的猜想 在X和知乎等平台上,Sora引起了众多大佬的讨论和猜想,这些猜想和讨论主要包括以下三部分: Sora的架构细节Sora的训练数据Sora之于AGISora的架构细节 |

|
|
图 5 谢赛宁分析: Sora应该是建立在DiT这个扩散Transformer之上的。 简而言之,DiT是一个带有Transformer主干的扩散模型,DiT = [VAE 编码器 + ViT + DDPM + VAE 解码器]。 谢赛宁猜测,在这上面,Sora应该没有整太多花哨的额外东西。关于视频压缩网络,Sora可能采用的就是VAE架构,区别就是经过原始视频数据训练。 而由于VAE是一个ConvNet,所以DiT从技术上来说是一个混合模型。 Sora的训练数据 |

|
|
图 6 有些人认为Sora的训练数据应该包含了使用游戏引擎例如虚幻5,制作的游戏视频,但是作者团队并没有给出具体的训练数据。 Sora之于AGI |

|
|
图 8 本文使用 Zhihu On VSCode 创作并发布 |
|
因为openai有性能最好的图像标注模型DALLE 3和效果最好的llm gpt 4.5 |
|
大力出奇迹。 |

|
|
在分析为什么OpenAI发布的Sora模型在技术上领先于Pika和Runway之前,我们先来概述一下这些模型的基本功能和定位。Pika和Runway也是在人工智能领域的重要作品,它们各自在图像生成、视频编辑等方面有着显著的应用和成就。而Sora模型,作为OpenAI最新发布的文生视频模型,其技术优势主要体现在以下几个方面: 技术架构和算法优化 更深层次的自然语言理解(NLU):Sora模型在自然语言理解方面采用了最新的深度学习算法,这使得它能够更准确地解析复杂的文本指令,转化为视频内容的具体参数。与Pika和Runway相比,Sora在处理复杂文本描述到视频内容转换的准确度和灵活度方面有明显优势。 高效的视频渲染技术:Sora模型在视频渲染方面引入了创新的算法,优化了渲染流程,不仅提高了视频生成的速度,也保证了输出视频的高质量。这一点在与Pika和Runway的比较中尤为突出,尤其是在处理高分辨率视频内容时的性能表现。 丰富的预训练模型和数据集:OpenAI为Sora模型提供了庞大且多样化的预训练模型和数据集,这使得Sora在学习和理解各种视频内容创作规则方面更为高效和精准。相比之下,Pika和Runway虽然也使用了预训练模型,但在数据的丰富度和多样性方面可能不如Sora。 应用和创新能力 更广泛的应用场景:Sora模型的设计考虑了更多的应用场景,包括但不限于教育、娱乐、广告等领域。这种广泛的适用性是基于其强大的技术基础和灵活的内容生成能力,使其在多领域应用中相对于Pika和Runway展现出更大的潜力。 用户交互和实时反馈:Sora模型支持更加丰富的用户交互功能,能够根据用户的实时反馈快速调整视频内容,这一点对于实时内容创作尤为重要。而Pika和Runway在这方面的功能可能更加有限,主要集中在内容的初步生成和后期编辑。 综合性能和生态支持 更强的综合性能:综合上述技术优势,Sora模型在自然语言理解、视频渲染效率、内容生成的准确性和多样性等方面,都展现出了较Pika和Runway更优越的性能。 强大的生态支持:作为OpenAI的产品,Sora模型得到了强大的技术和社区支持,这包括不断更新的算法、广泛的合作伙伴网络以及丰富的开发资源。这种生态支持为Sora的持续优化和应用扩展提供了有力保障。 总结来说,OpenAI发布的Sora模型之所以能在技术上领先于Pika和Runway,主要得益于其在自然语言理解、视频渲染技术、预训练模型和数据集、应用场景设计、用户交互能力以及综合性能和生态支持等方面的全面优化和创新。Sora模型的技术架构和算法优化确保了其在视频内容生成的准确性和效率上的领先地位,而其对于应用场景的广泛覆盖和对用户交互的深度支持,则进一步扩大了其在各领域应用的可能性和实际效果。 此外,Sora模型背后的强大生态支持,包括OpenAI的技术积累、合作伙伴网络以及开发者社区的贡献,也是其能够持续领先并推动行业发展的关键因素。这种生态支持不仅为Sora提供了丰富的数据和算法资源,也促进了技术的快速迭代和应用的广泛推广。 尽管Pika和Runway各有特点和应用成就,Sora模型在综合技术创新、性能表现以及应用领域的拓展性方面展现出了更加突出的竞争力。随着人工智能技术的不断进步,我们有理由期待,Sora模型及其后续版本将继续引领视频内容生成技术的发展,为用户提供更加丰富、高效和个性化的视频创作工具。 在未来,随着技术的进一步发展和应用场景的不断拓展,Sora模型及类似技术的影响力将进一步加深。对于技术开发者和内容创作者来说,了解和掌握这些先进工具的特点和应用方法,将是把握未来内容创作趋势的关键。同时,对于技术的负责任使用、伦理问题的深入探讨以及相关法律法规的完善,也将是伴随这些技术发展不可或缺的部分。 |
|
关于Sora的技术细节,OpenAI介绍的不多,但是也有一些说明。 首先Sora这玩意儿是个扩散模型,就和AI会话的Stable Diffusion差不多,它从类似静态雪花点的视频起步,然后一步步把那些杂乱的噪声清理掉,生成一段完整的视频。不仅能够一次性生出一整段视频,还能把生成的视频接续拉长。 |

|
|
就像GPT那种大语言模型一样,Sora也用上了Transformer架构,解锁了超强的延展能力。怎么做的呢?首先,把视频和图像像切豆腐一样分成好多小块,每一块叫它“patch”,就相当于在GPT里的“token”。这样一来,不管是多长时间的、多大分辨率还是各种不同比例的视觉数据,都能以统一的格式喂给扩散Transformer去训练,让它变得无所不能,实际生成的视频布局也有明显的改善。 |

|
|
Sora这家伙背后站着DALL・E和GPT这些前辈的研究成果,特别是吸收了DALL・E 3的一种牛x技术――能为图片生成超详细的标题描述,这在视频模型训练和文生视频时否发挥了重要的作用。所以,这模型超级听话,用户给啥文本指令,它就能精准地在生成视频时照着来。 不仅如此,Sora还能拿一张静止的照片,让它瞬间活起来变成视频,而且动画效果那叫一个逼真又细致。另外,你要是有现成的视频,它也能帮你加长或者填补丢失的画面。更多细节,可以看看它们的技术报告。 最后说一句,Sora这种对现实世界的理解和模拟,我认为是朝着通用人工智能(AGI)迈进的一大步,意义重大! |
|
Openai去年ChatGPT就非常热门,占据了主要的Ai领域关注度!每次更新都会带来新的关注热度,所以这次Sora是生成视频功能,更加会吸引人的眼球! 从官网放出来生成的视频来看,确实很丝滑,比其他任何工具都有优势,加上本身ChatGPT的热度和关注度,今年会让Sora和之前的ChatGPT一样碾压全部Ai同类工具, 也会让大家有新发展空间, |
|
1、模型结构上抛弃了传统路线Unet,patchify+transformer-base让模型的涌现效应更显著。缺点是推理成本会更大,可能后期的API价格比竞品贵很多。 2、训练数据质量很高。生成视频质量可能比其他厂收集数据的质量都要高,那些还在用Webvid-10M的直接破防,而且OpenAI的传统应该是用了不少人肉清洗。 OpenAI已经把路趟好了,国内的大厂是时候招兵买马跟进(狗头) |
|
sora的视觉部分采用类似stable diffusion的结构,传统的方法是text作为condition,但是很难生成长视频。sora应该是在gpt的监督下闭环训练出来的,这样才能维持长视频的稳定性,说白了就是给传统diffusion增加一个大脑。如果真是这样,这种gpt+的模式很快就会渗透到AI的各个领域,谁拥有最强大脑,就拥有AI的话语权。 一种可行的方法是先利用gpt根据用户提示词生成prior,然后视觉部分经过gpt产生output,通过训练使得output的风格更加接近prior,从而实现gpt监督下的视觉生成,类似模仿学习的思想。实际上Dall-E本身就包含了物体空间信息,比如不同光源下物体的投影;也能理解某些物理过程,比如输入“玻璃杯从高空落地,与地面碰撞”,就会生成一个杯子破碎的图,这些都是通过gpt实现的,难点在于如何生成一个连续的物理过程? |
|
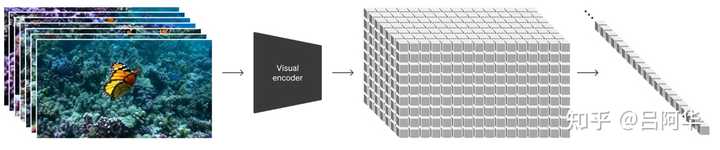
在OpenAI公开的Sora技术文档《Video generation models as world simulators》 中提到了: “与LLMs使用文本token不同,Sora使用的是视觉patch。” |
|
|
如何来理解patch这个名词呢?《How Sora Works (And What It Means)》这篇文章中有一段形象的描述: 想象一下,如果我们把《黑暗骑士》的一段电影胶片拿出来,就像在老电影院里,一位年轻人把那种绕在金属盘上的透明胶卷装进放映机一样。假设我们从这卷胶片上切下前100帧,然后开始一个奇妙的实验:在每一帧上剪出一个变形虫状的小片段,就像用精细的工具从精密的机械中取出零件一样,然后把这些片段一层层叠起来。 这样就得到了一个沿着Y轴延伸的多彩的“变形虫”,如果通过放映机播放,它将展示《黑暗骑士》中一个很小的片段,仿佛是有人在放映机前挥动着手,只让一束微弱的光线穿过。 将这个过程想象成将电影的每一个瞬间转换成了一个个小色块,“patch”在Sora中的角色,就像在GPT-4中单词的“token”一样。Token代表文字的片段,而块则代表电影的片段。 就像GPT-4能够根据一系列token预测下一个token,Sora也被训练来根据一系列的patch预测下一个patch。这种方法之所以革命性,是因为它允许OpenAI利用海量的图像和视频数据来训练Sora,想象一下,把存在的每一个视频都剪成无数个patch,然后堆积起来喂给模型。 之前的文本到视频技术需要将所有训练用的图像和视频调整到同一尺寸,这需要大量预处理工作。但Sora通过训练"patch”而非完整的视频帧,可以直接处理任何尺寸的视频或图像,无需剪裁。 这意味着可以使用更多的数据进行训练,从而获得更高质量的输出。这种技术不仅令人震撼,而且将对电影制作等领域带来深远的影响。 |
|
OpenAI 总结起来就是 大力出奇迹 他自己说的 Scale Up, 什么Whisper, CLIP都是数据规模和模型规模都很大, GPT更是了,把Transformer Decoder搞的很大,数据量也大, 结果就 Emerge了智能。 啥模型到它那里,就是把模型规模搞的大大的, 数据量搞的多多的, 数据质量尽量搞的高高的,卡也是用的多多的, 当然人才要搞的最优秀的! 这次Sora, 要说模型架构有什么创新, 倒也没有特别的创新(不是鄙视它的意思,人家搞的多, 搞的大那也是技术实力的体现),连大佬都说Sora 参考的论文(Diffusion Transformer)投稿因为缺乏新颖性还被拒,另投另一个会被接收的。公开的信息里提到的,为了更多的数据和高质量数据,专门训练模型描述视频, 用GPT丰富文字描述等。据有经验的观察说, 似乎也用了Engine去生成数据来训练。总之以GPT的经验,数据规模和数据质量对效果有非常高的影响。 |
|
OpenAI发布的sora模型之所以能碾压pika和runway,主要原因可以归结为以下几点: 1. 模型架构和训练策略的差异:sora模型采用了更先进的架构和训练策略,如Transformer结构和自监督学习方法。这些方法可以提高模型的学习能力,使其更好地理解和生成自然语言。而pika和runway可能采用的是较老的模型架构和训练方法,导致其性能不如sora。 2. 数据量和质量的差异:sora模型所使用的训练数据量和质量可能更高。这意味着模型有更多的机会接触到各种各样的语言样本,从而提高其泛化能力。而pika和runway所使用的训练数据可能较少或质量较低,导致其性能不如sora。 3. 计算资源的差异:sora模型可能使用了更多的计算资源进行训练,如更高的计算能力、更多的GPU等。这使得模型在训练过程中能更好地优化参数,提高模型的性能。而pika和runway可能受限于计算资源,导致其性能不如sora。 4. 研发投入和技术积累的差异:OpenAI作为一个专注于AI技术研究的组织,具有丰富的技术积累和研发投入。这使得他们在开发sora模型时能充分借鉴前人的研究成果,提高模型的性能。而pika和runway可能受限于研发投入和技术积累,导致其性能不如sora。 5. 应用场景和目标的差异:sora模型可能针对某些特定的应用场景进行了优化,如自然语言处理、机器翻译等。这意味着在这些应用场景中,sora模型的表现可能会更加出色。而pika和runway可能没有针对特定应用场景进行优化,导致其在某些任务上的性能不如sora。 总之,sora模型之所以能碾压pika和runway,主要是因为其在模型架构、训练策略、数据量和质量、计算资源、研发投入和技术积累等方面的优势。 |
|
Sora 基于的transformer diffusion 模型,有更好的理解能力。openai 对于transformer 架构的逆天的理解和应用能力,是无人能敌的。 而仅仅是diffusion模型,是缺乏理解能力的。 |
|
一个一个来说 |

|
|
Overall workflowVideo to patch:通过一个visual encoder对video进行编码,这里编码是把时空关系给混合了的。这一步独立于sora,是另外的模型Latent space generation:sora的全部操作位于latent space上,操作对象就是这个由video编码得到的一堆patch。对于sora这个模型本身而言,它只是一个普通的DiT,不过他被scale up到了很大Patch to video:这一步依靠另一个visual decoder把通过sora生成的patch给生成回video技术细节1. Visual Encoder Visual Encoder的作用是将video转化为latent space中patch,然后交由sora进行操作。这里的Visual Encoder和后面的Decoder都是独立于sora的另外的模型,同时注意这个模型是同时对time space进行的操作,能做到这一点,粗略猜测有三种实现路线: 三维卷积(很有可能)CNN+TCN(很有可能)序列模型,RNN(概率不大)或Transformer(概率中等)2. sora sora操作的是通过visual encoder得到的patch,这些patch被rearrange成了一个sequence,然后输入到sora中。sora实质上是一个DiT sora使用clip训练范式,使用了dall・e-3中的captioner对视频进行文本描述生成,然后再最终进行对齐 3. 如何控制视频大小、时长、帧数在技术报告中提到通过random init的patch来填充对应位置,同时也提到了inference时用gpt对prompt进行扩写,猜测此处应该是两者混用控制视频的尺寸和时长,报告中的方法是“把这些patch放在对应的位置上”帧数的做法没有看到提及,猜测是一种二维位置编码,其中一维对应着秒,另一维对应这一秒内的帧4. 为什么sora这么强 scale up |
|
为什么sora碾压runway? runway的团队明显是懂视频的,而且他们推出的更新一直是以视频编辑为核心:从镜头的推拉功能到控制图生视频的运动轨迹。他们只要再把运动形变的问题解决好就完美了 而sora目前来看还是一群程序员的作品。sora介绍的功能都不是视频编辑过程中需要的,而且20s的案列明显这个模型不实用,一般使用的话一个镜头也就2-3s,runway4s的时间正好。我生成10个一组看效果选出一个能用的也就10分钟搞定。而20s一个的视频生成10个估计至少1小时,看openai对于sora模型的介绍2小时也有可能,这里面的时间成本太高了 生成式ai的核心卖点永远是解决精准控制,sd就是靠各种各样的controlnet赢过mj。而sora在精准控制方面来看目前还是0 |
|
OpenAI: 规模是一种魔法! 人话: 力大飞砖 |
|
|
| [收藏本文] 【下载本文】 |
| 科技知识 最新文章 |
| 百度为什么越来越垃圾了? |
| 百度为什么越来越垃圾了? |
| 为什么程序员总是发现不了自己的Bug? |
| 出现在抖音评论区里边的算命真不真? |
| 你认为 C++ 最不应该存在的特性是什么? |
| 为什么 Windows 的兼容性这么强大,到底用了 |
| 如何看待Nvidia禁止使用翻译工具将cuda运行 |
| 为何苹果搞了十年的汽车还是难产,小米很快 |
| 该不该和AI说谢谢? |
| 为什么突破性的技术总是最先发生在西方? |
| 上一篇文章 下一篇文章 查看所有文章 |
|
|
|
| 股票涨跌实时统计 涨停板选股 分时图选股 跌停板选股 K线图选股 成交量选股 均线选股 趋势线选股 筹码理论 波浪理论 缠论 MACD指标 KDJ指标 BOLL指标 RSI指标 炒股基础知识 炒股故事 |
| 网站联系: qq:121756557 email:121756557@qq.com 天天财汇 |