
| |
|
|
| 首页 淘股吧 股票涨跌实时统计 涨停板选股 股票入门 股票书籍 股票问答 分时图选股 跌停板选股 K线图选股 成交量选股 [平安银行] |
| 股市论谈 均线选股 趋势线选股 筹码理论 波浪理论 缠论 MACD指标 KDJ指标 BOLL指标 RSI指标 炒股基础知识 炒股故事 |
| 商业财经 科技知识 汽车百科 工程技术 自然科学 家居生活 设计艺术 财经视频 游戏-- |
| 天天财汇 -> 科技知识 -> OpenAI 发布文生视频模型 Sora,将对 AI 视频行业、传统的影视公司等造成哪些影响? -> 正文阅读 |
|
|
[科技知识]OpenAI 发布文生视频模型 Sora,将对 AI 视频行业、传统的影视公司等造成哪些影响? |
| [收藏本文] 【下载本文】 |
|
OpenAI,发他们的文生视频大模型,Sora了。。。 而且,是强到,能震惊我一万年的程度。。。 https://openai.com/sora 如果… |
|
投资人:悬着的心终于死了。 |

|
|
|
|
又到了用干货给各位大V好好拨冷水的时候了,让大家看看这回OpenAI到底是怎么翻车的。 首先,把官网给大家贴出来,让大家可以自己去看看到底这些成品是怎么个质量 Sora: Creating video from text?openai.com/sora |

|
|
接下来,我们先拿出OpenAI的头牌,也就是那个美女逛东京街头的短片来看看。 |

|
|
0 Prompt: A stylish woman walks down a Tokyo street filled with warm glowing neon and animated city signage. She wears a black leather jacket, a long red dress, and black boots, and carries a black purse. She wears sunglasses and red lipstick. She walks confidently and casually. The street is damp and reflective, creating a mirror effect of the colorful lights. Many pedestrians walk about. 大多数人看到这个视频,第一个感觉就是真,就是非常惊艳。 说实话,从0和1做到现在这个水平,真的是难如登天,OpenAI是很不容易的,但我们要实事求是,这成片细节上的毛病非常多,根本还没有到能用的水平。 先来看C位的美女 |

|
|
粗看之下找不出什么毛病,但是看久一点,就会发现她每8步就会出现走错脚的问题,美女会鬼畜重置,而且这个问题在其它人物上也有。 其次,画面中的井盖会神秘消失 |

|
|
第1秒的帧上有井盖 |

|
|
第24秒的帧上已经没有井盖了 接下来是美女背后的红衣女与便装男神秘消失 |

|
|
第1秒的帧上有红衣女与便装男 |

|
|
第4秒的帧上红衣女与便装男被C位美女掩盖 |

|
|
到第13秒的帧上红衣女与便装男已经完全消失了 然而,这个问题并非是必然的,例如在便装男后面那对男女就没有消失 |

|
|
第2秒的帧上出现的男女 |

|
|
第9秒的帧上这对男女被完全掩盖 |

|
|
到第12秒的帧上这对男女又重新出现了 之后,我们又能发现乱标的斑马线 |

|
|
再接下来是一只数不清多少只脚的类似女人的怪物 |

|
|
|

|
|
还有会凭空换裤子的多脚男 |

|
|
第12秒的帧上多脚男是穿黑裤子 |

|
|
第13秒的帧上多脚男换了一条浅色的裤腿 |

|
|
第14秒的帧上多脚男另一脚的裤腿也换了,而且后面的脚也出来了 接下来是背景人物的大小比例不协调感比较明显 |

|
|
再来,是美女眼镜里乱画的斑马线 |

|
|
|

|
|
最后,这个C位美女的连衣裙也换了,皮甲也变形了 |

|
|
第1秒的帧上美女穿的皮甲下面是一条纯红色的连衣裙 |

|
|
第56秒的帧上连衣裙出现了黑斑 |

|
|
第58秒的帧上皮甲严重变形 就这一分钟的小短片上就能找到这么多个穿帮点,放到2个小时的电影片长上恐怕能注释出几十万字的方案了。 连头牌的问题都这么多,其它展品自然也就难免有一大堆毛病,就这质量离好莱坞水准还是有非常大的距离的。 在我看过的展品当中,最难挑问题的就是下面这个近似静态的小短片 |

|
|
0 Prompt: Drone view of waves crashing against the rugged cliffs along Big Sur’s garay point beach. The crashing blue waters create white-tipped waves, while the golden light of the setting sun illuminates the rocky shore. A small island with a lighthouse sits in the distance, and green shrubbery covers the cliff’s edge. The steep drop from the road down to the beach is a dramatic feat, with the cliff’s edges jutting out over the sea. This is a view that captures the raw beauty of the coast and the rugged landscape of the Pacific Coast Highway. 当然,问题少不等于没有,最明显的就是那一线波浪,在碰到礁石之后波浪没有任何变化,根本就是穿模了。 最后,给大家穿帮得最显眼的一个――新年舞龙,有龙没有杆,龙是漂在空中的,真不知道是不是中西方文化差异造成的忽视。 |

|
|
0 Prompt: A Chinese Lunar New Year celebration video with Chinese Dragon. 总结来说,这次Sora的效果是很惊艳,但展品肯定都是筛选过的,质量都只有这个水平,想用到电影工业上恐怕还有很大距离。 而OpenAI现在的说法是未来还要在物理引擎上下功夫,希望能逐步完善其产品,但我个人并不看好这一前景。 OpenAI的这种改进方案实质上就是较真,在虚构的图上去较真肯定会产生矛盾的,不穿帮才是怪事。 可是说到底现在的AIGC还是离不开贴图怪的圈子,只不过它贴得更好而已,AI并没有真正理解图片的逻辑,所以有穿帮是难免的。 更进一步来说,如果继续沿着现有的技术原理发展下去,恐怕永远也不可能达到好莱坞水平,因为理论上来说完全符合物理逻辑的模拟与现实无异,或者说那就是现实,而反过来只要现实不存在的,它就生成不出来。 电影戏剧本来就是虚构的,如果AIGC真的把现实场景给模拟出来了,那就不再是戏了,而是历史回放。 这样的AIGC或许很难在电影行业上应用,或者只有那些有大才的导演能用,其他人恐怕真的控制不了。 更理想的应用场景应该是刑侦,或者是科学模拟研究,对真实进行模拟或许才是最好的出路。 |
|
简单来说,生成效果非常好,技术力非常强。但依然需要创意、审美、构图,创作者会有更加趁手的工具,而不是被替代。很多人晒了各种场景的视频,我觉得效果最好的反而是这一个: |

|
|
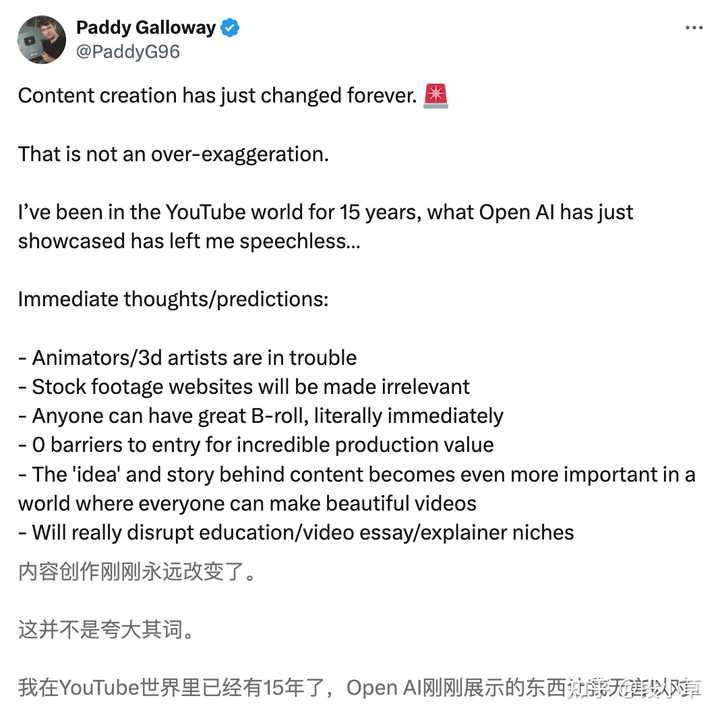
0 Sora 对一些工作肯定是有影响的,比如前期的分镜创作、远景里不重要的群演、一些视频画面的插帧特效…将来有可能不再需要那么多的实拍和人力,甚至是一些风格化的改变,类似于调色一样,直接给视频套一个 LoRA…等等。 AI 能很大程度上填补这些工作,具体的影响还要看圈内人的反应,至少我们看到了希望。(我记得郭帆对这些新技术非常感兴趣,考虑到流浪地球3 说的是 2027 年,按照现在的进度,我觉得大概率会用到很多人工智能技术了) 现在外网已经有各种看法了,YouTube 上最著名的内容顾问 Paddy Galloway(Mr. Beast 合伙人)是这么表达他的看法的: |
|
|
即时的想法/预测: 动画师/3D艺术家陷入困境 素材网站将变得无关紧要 任何人都可以立即拥有出色的B-roll素材 令人难以置信的生产价值,没有任何门槛 在一个每个人都能制作出精美视频的世界中,内容背后的“想法”和故事变得更加重要 将真正打破教育/视频论文/解释者领域 我担心人工智能内容农场 这不会取代内容背后的策略、个性和思考 文本转视频 prompt = 高价值技能 制作价值从来都不是YouTube上最重要的事情,所以不要太担心! 但同时,他也强调,这些只是直觉的反应,还在进一步思考中。而且这里的「产生巨大的影响」...并不是「这对YouTuber来说会很糟糕 」而是会更加强调了内容背后的想法、愿景和战略。 |

|
|
内容创作正在加速,但这只是可以通过文本提示来生成的视频游戏技术。 即时的想法/预测: 动画师和3D艺术家将专注于新的、更复杂的动画 库存素材仍然具有价值。人工智能使事物变得普遍。价值在于难以获得的东西。库存素材将专注于新事物和独特事物。 对于这个新领域没有任何进入的障碍,但是创造真正独特的事物仍然需要努力。 |

|
|
A)实际的创作者(艺术家、作家等)因为盗版/人工智能内容的兴起而放弃了这个平台。 B) GAI的内容水平趋于稳定,平庸的海洋统治着YouTube C) 观众收视率下降,因为他们对重复/冗余的作品感到厌倦 D) YT恳求(A)回归并限制GAI使用 无论如何,内容创作者们都要开始学习如何和 AI 相处了,只是没想到这一天来的这么快,过去一年文字工作者承受的苦痛这么快就来到了视频行业头上… |
|
1. 还是使用的是Transformer 架构,建立在 DALL・E 3 和 GPT 模型之上。 重大的突破在于一分钟,多机位。 2. 同样的, Sora有世界模型的特质。 这里需要解释一下,我们在使用GPT这类的模型时经常会遇到复读机的情况,又或者AI不能很好的画手的问题。 这是因为多数的LLM是运行在『自回归』这个框架下的: 文字模型用上文预测下文,反卷积很多是以图像像素作为输入输出的。 这就导致了出现了很多反常识的情况的存在,比如你可以问之前很多大模型这样的一个问题: 鲁迅为什么暴打周树人 回答的内容看起来很正确,说了鲁迅和周树人是谁,也提到了打人是不对的,但是他就是没有意识到,鲁迅就是周树人。 |

|
|
而且目前很多的AI视频生成,其实就是静态主题在动态的背景,画面十分单调,除了推拉之外,几乎没有什么复杂的运镜。 所谓世界模型,就是要让AI像人类一样,对世界形成一个全面的认知,人类的思考能力其实是有层级的,通过不同的层级去理解这个世界。 所以世界模型,具有抽象,预测,模拟,和交互的能力。 在Sora上,不仅运镜手段更加丰富,多机位也给你添上了。 |

|
|
0 3. 当然,目前的 Sora 还是存在很多的问题: 比如处理不好碰撞,有一些反常识的情况出现,就像魔术一样。 也很难理解因果。 |

|
|
但是他就是这么流畅,一点都没有闪烁。 4. 毫无疑问,还在AI视频生成这个赛道上的公司,如果生成能力还停留在4s左右的,那么现在基本上已经可以宣告死刑,凉透了。 这个赛道的投资逻辑也会发生大的变化,有可能昨天还有投资人计划继续给你打钱,今天一条邮件过来,我们不打算投了。所谓的明星企业,不管是之前的Pika、Runway,必将也会成为一个短命企业,而且这个短命在之前几乎是无法预料的。 所谓的降维打击。 5. 对于影视行业,其实也是一个较大的打击。 因为之前需要的美术布景,布光摄影,剪辑调色,这些以前需要很多人完成的工作,现在只需要一个人,外加一点电费和订阅费用。 6. 要知道,这只是第一版。 |
|
|
视频学术界也快进到只能做prompt了,我先占个坑, “Chain-of-Thought Prompting Elicits Reasoning in Large Video Model” |
|
我觉得对做视频生成的创业团队是好事。 只要sora不开放,pika们就还有机会。 而且投资人也不会只投一家,这种技术路线,多投几家本来就是常有的事儿。 现在sora把路走通了,大力就能出奇迹,更应该是多投钱了 |
|
|
0 |
|
目前来看效果非常不错,肯定会辅助很多视频,影视创作者更好的完成自己想要的作品 也会导致很多混饭吃的影视公司失业,如果你的东西拿出来毫无灵气,完全比不过AI生成,那肯定会被淘汰 OpenAI发布的这个视频模型Sora,可以一句话生成1分钟视频,效果接近实拍 Sora的优势是图像的真实感,其他对手的产品真实感不如Sora 而且Sora能够生成比其他模型更长的视频片段,最长可达一分钟 未来或许会有更强的功能 OpenAI做了一些演示,大家也可以看看效果 东京街头的时尚女性 |

|
|
还有龙年春节的景象 |

|
|
宇航员的冒险之旅 |

|
|
蜥蜴在树枝上的各种动作 |

|
|
|

|
|
该图片有可能会引起不适 继续查看 五只灰狼幼崽 |

|
|
从以上AI生成画面可以看出来,效果确实不错,已经非常超预期了 虽然很多专业人士认为还有很多细节不够完美,但对于普通人来说,就我个人而已,我认为AI的水平已经非常非常好了,足够应对普通人创作者的需求,且非常超预期 目前Sora正面向部分成员开放,以评估关键领域的潜在危害或风险 OpenAI也邀请了一批视觉艺术家、设计师和电影制作人加入,需要可以获得更多反馈 未来OpenAI还会把Sora不断的加强,让他表现的更加真实 从AI目前的发展来看,头部企业,比如说OpenAI,谷歌他们的发展确实高出其他企业好几个版本,好几个身位 他们拿出来的东西每次都可以震撼到大家,并且还在不断的更新更强的产品 全世界这么多大模型,但目前最强的就是这两个 AI行业确实有很大的发展潜力,但目前领跑的企业不多 头部企业技术垄断非常明显 |
|
题目引用的这个文章里一惊一乍的什么“现实不存在了”、“跪下来叫爸爸”之类的言论,要么说明这个作者从来对AI视频就没有过任何思考,要么说明其对视频行业本身就没有多少了解,只会看到一个新技术就动辄说“吊打”、“颠覆”之类――包括现在很多人对ChatGPT之类的态度皆是如此。 对于视频AI技术,其实在20年前我刚上大学的时候我就有过设想。那个时候,我们拍摄用的还是磁带机,需要经过一系列的采集、转换才可以导入非线性编辑系统中。而当时做后期特效也很麻烦,不仅对电脑的配置要求很高,也需要长期的练习才能掌握相关技术。但那个时候,我已经明白了一点,那就是在非线性编辑系统中,数字信号实际上是一个可以随意组合编辑的东西。因此,你可以根据自己的需求任意组合数字信号。这样,很多现实中不存在的东西、不存在的场景,无需经过任何特效处理,也可以通过数字信号的组合展现出来。 而从历史上看,自上世纪90年代以来,CG技术在影视行业中的大规模应用,就已经预示着未来有一天“虚拟”将全面在影视领域中普及。而AI的出现,只是让一个过程不断提速,它降低了没有专门学习过技术的普通人制作影视作品的门槛,让整个影视制作的周期变得更多。但对整个行业来说,只要是有一定从业年限的,都早已经预见到了这一天的到来。 如果说AI制作视频就代表了“现实不存在”,那“现实不存在”历史其实非常久远。往远了说,在古代,宗教壁画、天顶画等就是通过描绘其构想的世界中的种种来吸引受众,而往近了说,CG技术的出现曾经就让很多人把虚拟误以为现实――比如我小时候,在看到《侏罗纪公园》之后就一直认为实际上真存在着这么一个恐龙乐园。 但是过去强调商业领域的技术影响,其实意义也不大。因为当年我在意识到可以通过视频剪辑和特效技术随意创造一个虚拟世界的时候,进而意识到的另一个问题就是,当技术已经不能成为瓶颈的时候,作品的上线就取决于创作者本身的创作能力――或者说想象力。 说的直白一点,就算几年后,单纯靠着AI技术就可以生成《流浪地球5》,但是到底能拍出什么样的《流浪地球5》则取决于人的想象――你想出来的《流浪地球5》和郭帆想出来的《流浪地球5》肯定不是一个东西。之于郭帆而言,AI带来的最大价值,在于可以省略非常多的拍摄成本、创造出那些在当下技术环境中不可能排出的镜头。在这个层面上,准确的说法是,“AI帮助导演去掉了‘现实枷锁’”,这恰恰不是什么颠覆,而是前所未有的助力。对于观众而言,大家欣赏的也就是这个人的创造力。 其实,这一点在文学领域也早已得到了验证。因为如果说视频技术还由于存在技术门槛,普通人难以全面掌握的话,那么在文字领域,人人都识字的情况下,就算没有AI技术,每个人也都可以把自己想到的东西写下来。但是,能真正称得上有创造力的创作者,依然只是极少数。AI的出现,只是提升了普通人的下限,也让优秀的创作者可以提升上限――在后者眼里,这绝非什么颠覆。 回顾人类的文明史而言,其实任何一项看起来颠覆性的技术,最后的带来的结果往往都是拉大了人与人之间的差距。因为,很多新的技术的“颠覆性”,在于降低了这个行业低端岗位的入门门槛,导致很多基础性岗位消失。如在影视剪辑中,很多原本就是简单的做点婚庆、会议等剪辑的小公司,其需要用到的技术很简单,现在很多剪辑软件的智能剪辑功能就已经可以做到智能分析素材、智能剪辑、智能配乐,效果还是可以的。再比如新闻行业,现在的很多AI新闻已经写的非常不错,甚至可以达到普通记者的水平。但是,对于优秀的记者来说,高超的采访沟通能力、独到的视角等这些高度个人化的东西目前是无法取代的。但颠覆性技术在降低入门门槛、消除基础性岗位的同时,因为技术的颠覆性,也必然会对行业带来正向的发展影响,而只有在这个行业中从事高端岗位且积极拥抱新技术的人,才可能会借助这个前所未有的新技术而为行业开辟出更广大的空间。 于此而言,动辄说什么“颠覆”、“吊打”之类,反而只能说明说这话的人对行业并没有什么了解。 |
|
非常棒,之前AI能生成图片,就应该料到它有一天能生成视频,未来说不定还能独立创作长视频。 别的不说,就说我们码字的,难道不知道大家都爱看视频么?我还经常被人抄来抄去,其实我也想做视频,但视频耗费的精力要大得多,关键是这些精力损耗都不在原创环节,而是在一些无新观点生产的重复劳动环节,也就是说,当我写出文章来,观点表达就已经完成了,表达欲获得了满足,再去做视频就不是很有动力。 有人说请团队。 那就会为盈利目标所困,因为要养活团队,于是很多“心里话”就会变成要迎合流量的“场面话”。 我看到很多喜欢的大v,之前没火的时候,写的东西还能看,后来火了,全平台推广,就明显感觉到后面的写手都不是ta本人了。 现在有了视频模型,做视频的成本大大降低,那大家拼的就不再是你有视频但我没有了,而是观点、逻辑、表达思路等灵性的东西。 那么在内容创作端,什么东西最重要也就不言而喻了――依然是原创能力! 所以奉劝抖音、b占上某些抄袭家们,赶紧趁早锻去炼自己的原创能力,别后面我们都去做视频,你也没得抄了,账号也就废了。 再一个就是,估计会有一些眼疾手快的人出一波AI视频教程,教人怎么用ai做视频,我觉得不用太急,不差这一天两天的。 出教程割韭菜的,当然得急,一旦镰刀下晚了,地里就只剩下根了,而且还是被市场教育过的。 但咱搞学习的,不用太急着报课,这玩意儿有长期用途,风口没那么快就过,再说那些讲师们也是摸索着自学的,比你强不到哪里去,他们只是更擅长贩卖焦虑罢了。 以上,AI视频是个好东西,以后咱有好点子、好脚本,都可以轻松地自己做动画了,很兴奋! |
|
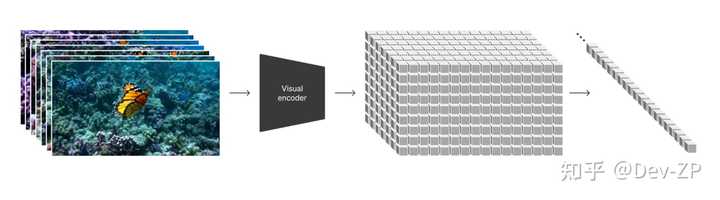
先读一下OpenAI提供的“技术文档”。这次竟然不是PDF是web了,估计因为很多视频展示吧。 技术文档链接: Video generation models as world simulators?openai.com/research/video-generation-models-as-world-simulators 技术文档主要内容Sore如何将各类视觉数据转换为统一表示的方法,该方法使得生成模型的大规模训练成为可能;虽然具体模型和落地方法都没有提及,但有说过他们对于视频进行了编码、数据尺寸的应用及高质量的标注数据;对Sora能力和限制的定性评估。这部分它也说了很多模型的应用方法,比如图生视频,视频-视频生成或者优化;视频编码 大量先前的工作已经研究了使用各种方法对视频数据进行生成建模,包括循环网络、生成对抗网络、自回归变换器和扩散模型。在技术文档罗列了一批文章,其实我见过最多的是用双流网络,cnn,vit处理图像,rnn,lstm处理时间轴;还有类似现在很多的controlnet抽取股价,生成不同风格的相同舞蹈的视频。 该Sora是一种视觉数据的通用模型――它能生成持续时间、纵横比和分辨率各异的视频和图像,最长可达一分钟的高清视频。 其实这里也说明了,Openai是吧时间轴一起进行的编码,算是有一个zero-shot工作。而且对于时间,视频比例和分辨率都可以适配,后面内容也可以看出就是文本语句Mask类似的方式的应用。 视频编码 从大型语言模型(LLM)中获得灵感,NLP模型通过在互联网规模的数据集上训练获得了通用语言能力。LLM范式的成功部分归功于使用tokens,这些tokens统一了不同的文本模态――编码、数学以及各种自然语言。 在Sore工作中,OpenAI考虑视觉数据的生成模型如何继承这样的好处。与LLM拥有文本tokens不同,Sora拥有视觉Patch。先前的研究已经证明,Patch是视觉数据模型的一种有效表示。我们发现,Patch是一种高度可扩展并且有效的表示形式,适用于在多种类型的视频和图像上训练生成模型。 |
|
|
在高层次上,通过首先将视频压缩到一个低维潜在空间中,然后将该表示分解成时空Patch,从而将视频转换成Patch。 视频压缩网络 训练了一个降低视觉数据维度的网络。这个网络将原始视频作为输入,并输出一个在时间和空间上都被压缩的潜在表示。Sora在这个压缩的潜在空间内进行训练,并随后生成视频。我们还训练了一个相应的解码器模型,将生成的潜在表示映射回像素空间。 时间轴编码 在给定一个压缩后的输入视频的情况下,提取一系列的时空Patch。这一方案同样适用于图像,因为图像可以被视为只有单一帧的视频。 基于Patch的表示使得Sora能够在不同分辨率、时长和纵横比的视频和图像上进行训练。在推理时,我们可以通过在适当大小的网格中排列随机初始化的Patch来控制生成视频的大小。 扩散模型 Sora是一种扩散模型;给定输入的噪声Patch(以及像文本提示这样的条件信息),它被训练来预测原始的“干净”Patch。 |

|
|
在这项工作中,Sore被证明扩散变换器作为视频模型同样可以有效地扩展。上面展示了训练进度中,使用固定种子和输入的视频样本比较。随着训练计算的增加,样本质量显著提高。 训练尺寸 Sora能够采样宽屏1920x1080p视频、垂直1080x1920视频以及介于两者之间的所有内容。这使Sora可以直接以不同设备的原生纵横比创建内容。它还让视频能够在生成全分辨率内容之前,快速原型较小尺寸的内容――所有这些都使用同一个模型。 |

|
|
具体图像视频刷不出来,但基本说明模型训练使用统一尺寸 按照视频原始纵横比进行训练能够改善构图和镜头框架。团队将Sora与我们的另一个版本模型进行了比较,后者将所有训练视频裁剪成正方形,这是训练生成模型时的常见做法。在正方形裁剪训练的模型中,有时会生成视频的主题只是部分可见。相比之下,Sora的视频则展示了改进的镜头框架。 训练数据质量 在训练文本到视频生成系统时,需要大量带有相应文本标题的视频。我们将在DALL・E 3中引入的重新标注技术应用到视频上。首先,训练一个高度描述性的标注模型,然后使用它为训练集中的所有视频生成文本标题。训练时使用高度描述性的视频标题可以提高文本的准确性以及视频的整体质量。 与DALL・E 3类似,OpenAI还利用GPT将简短的用户提示转换成更长的详细标题,然后发送给视频模型。这使得Sora能够生成高质量的视频,准确地遵循用户的提示。 性能评估 之前大部分人展示的所有结果是登陆页面上的都是文本到视频的示例。 但是,Sora也可以通过其他输入进行提示,例如已存在的图像或视频。这一能力使Sora能够执行广泛的图像和视频编辑任务――创建完美循环的视频、给静态图像添加动画、在时间上向前或向后延伸视频等。 Dall-E扩展 Sora能够基于提供的图像和提示生成视频。下面我们展示了基于DALL・E 2和DALL・E 3图像生成的示例视频。 |
|
|
上面图里原本Dalle生成的图会伴随视频效果; Sora还能够扩展视频 无论是向前还是向后都可以进行延伸。 web提供了四个视频,它们都是从生成视频的一个片段开始向后延伸的。因此,这四个视频的开头各不相同,但所有四个视频都有相同的结尾。 风格迁移 扩散模型已经使得从文本提示编辑图像和视频。 这些方法中的一种,SDEdit,应用于Sora。这项技术使得Sora能够零次学习地转换输入视频的风格和环境。 插帧 还可以使用Sora逐渐插值两个输入视频之间,创建在完全不同的主题和场景构成之间的无缝过渡。在web的示例中,中间的视频在左右两边相应视频之间进行插值。 生成图片 Sora也能够生成图像。我们通过在具有一个帧的时间长度的空间网格中排列高斯噪声Patch来实现这一点。模型能够生成不同大小的图像――分辨率可达2048x2048。 相关能力 当在大规模训练时,视频模型展现出许多有趣的新兴能力。这些能力使Sora能够模拟物理世界中人、动物和环境的某些方面。这些属性是在没有任何针对3D、推理等针对训练的情况下出现的――它们完全是规模效应的现象。 3D效果 Sora能够生成具有动态相机运动的视频。随着相机的移动和旋转,人物和场景元素在三维空间中一致地移动。 对于物体保持连贯性 对于视频生成系统来说,一个重大的挑战一直是在采样长视频时保持时间上的连贯性。Sora通常(虽然不总是)能够有效地模拟短期和长期依赖性。例如,模型即使在人物、动物和物体被遮挡或离开画面时,也能保持它们的持续存在。同样,它能够在单个样本中生成同一角色的多个镜头,贯穿整个视频保持他们的外观一致。 有效的推理 Sora有时能够模拟以简单方式影响世界状态的行为。例如,一个画家可以在画布上留下随时间持久的新笔触,或者一个人吃汉堡时可以留下咬痕。 局限性 Sora目前作为模拟器展示了许多限制。 例如: 它不总是能够准确模拟许多基本互动的物理效应,比如玻璃破碎。其他推理互动,比如吃食物,不总是产生正确的物体状态变化。比如在长时长样本中发展的不连贯性或物体的突然出现。总结 技术文档的内容确实太少了,管中窥豹。但比较关键的信息,数据质量和大力出奇迹吧。对于真实世界的物理推导过程还需要很多工作吧。 GPT走了三代半才能到了能用; Dalle走了两代才能到了能用; Sore现在走了一代,我们还是可以期待一下。 另外现在在哪里可以测试?不会又要再等半年吧?估计这个不便宜吧 |
|
实际效果还没看到,毕竟还没有真实的体验机会。现在大家看的仅仅是Sora的「宣传片」,参考其他公司,比如谷歌、百度之前宣传片的经验,实际效果估计是要比宣传片差蛮多的。 毕竟,OpenAI虽然在文本上非常强大,傲视群雄、一览众山小,但在图像处理方面,可绝对称不上是最好的。 目前来看,text2video里,最好的还是heygen。 |

|
|
所以,看到大家的评价,什么「现实不存在了」、「什么这回影视人焦虑了」,有点还是太过了……连实际上手都没达到,就吹到了天际,是不是……不够谨慎? 比如下面这一段: 我的脑海中,突然冒出了《三体》中杨冬的一句话: “物理学,不存在了” 套用这句话。 那就是。 “现实,不存在了” 文本、图片都已经被AI攻占,而现在,AI视频,这个人类最后的最坚固的堡垒,在OpenAI的Sora攻势下,也已经很难再分清,AI和现实的界限了。 什么以前的AI视频工作流,全部成了往日泡影,全都滚犊子吧。 都TM跪下,都给OpenAI喊爸爸。 说回那三个最核心的特点: “60s超长长度”、“单视频多角度镜头”,还有那个最核心的,“世界模型” 从跪下给OpenAI喊爸爸的角度看…… 奥特曼绝对是一个营销大师,把自己产品的每一次发布,都搞成了世界性的大热点、大爆点。我们这些做营销的的,是要膜拜的。 但这种实用科学,还是严谨些好。 |
|
先放上两个刚刚更新的关于 Sora 的回答。 很多人都把 2023 年当作生成式人工智能/AIGC 元年,作为一个重要分支,生成式 AI 视频在 2023 年也迎来了小爆发。从去年下半年开始相继出现了几款比较火的 AI 视频应用,比如 RunwayGen、Pika、Stability 的 SVD 等等。它们都能根据文字描述或参考图片生成一段几秒钟的视频。由于这种技术在娱乐、视频创作和游戏等领域都有很大的应用潜力,再加上其效果非常直观,所以很受关注。下面这张图(来源)整理了过去一年最主要的AI视频应用或技术。可以看到在这个领域,大厂和创业公司可谓齐头并进。 |

|
|
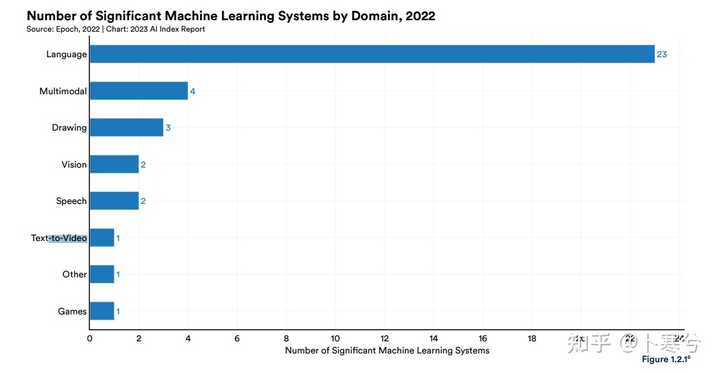
在众多的生成式AI技术中,相较于文生文(如ChatGPT为代表的各类chatbot)、文生图(如SD,midjourney),文生视频或者图生视频技术算是比较少,且发展相对缓慢的。从下图的统计数据也看出文生视频工作的数量之少。(来源:Artificial Intelligence Index Report 2023) |
|
|
原因不仅仅在于视频数据需要更大的计算资源上,还在于其本身的技术难度就很高。 OpenAI突然发布Sora,从初步的演示视频来看,其效果是非常好的,相比于当前已经存在的一些文生视频技术,比如Runway Gen 2、Pika等,不论是在内容质量上,还是在视频长度上,都是一个质的飞跃。 是不是碾压我不敢轻易下结论,但势必会让AI视频行业上了一个新的台阶。 至于对传统影视行业,甚至游戏等行业的影响,个人认为短期内不会产生什么实质性的影响,AI生成视频目前还有很多问题存在。 包括OpenAI自己也提到了Sora还有很多局限,比如 它可能难以准确模拟复杂场景的物理世界的变化,并且可能无法理解因果关系。例如,一个人咬了一口饼干,但之后的视频中显示饼干根本没有咬痕。还可能混淆提示的空间细节,例如混淆左右。 |

|
|
凭空出现的狼。 |

|
|
|

|
|
这些固有的缺陷在任何AI模型中都会存在,就像LLM中的幻觉无法彻底消失一样。 所以在从技术到工业化,还有很长的路要走。 |
|
对于我这种原纪录片创作人员,现科幻小说作家来说。 太牛逼、太颠覆、太炸裂了。 大概率到了2025年,我一个人花一个月,就可以把自己的长篇小说搞成电影了。 |
|
大多数人的“创意”水平真心不如AI,文创领域人类劳动力被AI取代,之前被认为是天方夜谭,或者所谓“替代门槛很高”,但自从AIGC越来越多的爆点出现,这已经越来越像成为一个既成事实了。 Sora的出现是极其震撼的,这两天财经界已经遍地都是“新科技商业周期”、“未来经济增长的范式已经改变”的论调。甚至流露出对新冷战的悲观,“所谓错过时代,就是让你固守的那些曾经占优资产(也包括产业)发生持续的大幅通缩。资产负债表衰退说到本质 还是被人类的新工业技术革命所甩出了时代差”。不管相关定性和判断准确与否,sora作为生成式AI发展史上的一个里程碑、新科技革命的一个重要节点,是毫无疑问的。 但从(对全人类)负面的角度看,新一代的AI(AIGC及各种先进的自动化技术等)很可能系统性压缩人类的工作岗位,并重构人类经济活动模式与价值链条,降低人类劳动者工作岗位的数量和质量。在没有外部调控和二次分配的情况下,人类劳动者经济回报在整个经济产出中的比例,可能会被AI明显挤压。 到头来,人类劳动力可能只在部分偏重体力而非脑力、中低技能且使用AI成本比使用人类劳动力更高的领域。届时,决定大多数人类劳动者经济回报的,可能不再是知识技能(这些都已被AI替代),而是工作强度、肮脏度、体面度等,高收入将属于吃得起苦、忍受得了脏、不在乎“体面”的劳动者,“高性价比”工作会越来越少。 如果AI技术达到一个奇点,可能导致常规脑力劳动岗位的批量化甚至灭绝式损失,引爆新时代的卢德运动,甚至从分配制度、生产资料所有制等方面导致资本主义基本运行模式的根本性危机。马列经典作家所谓的“生产无限扩大的趋势与劳动人民有支付能力的需求相对缩小的矛盾”将会愈发尖锐,并且在技术层面构成真正的危机。事实上,关于AI技术的进步将导致资本主义制度走向末路的可能性已经有很严肃的讨论。 实际上,如果AI技术的社会历史后果能类似原子弹,反而是比较好的结局。原子弹固然导致了毁灭整个世界的战争可能性的出现,但原子能相关技术也为人类提供高效便捷的能源,原子能技术也和空间技术、信息技术一样成为第三次工业革命的代表性技术,极大提升了人类的生产力水平。同时,在后来的历史中,“核恐怖平衡”极大限制了大国之间的战争,保持了几十年的世界总体和平,人类死于战争的比例,比起原子弹出现前,反而下降了。 |
|
MIT Technology Review对Sora进行了报道,称其为“令人惊叹的新型生成视频模型”, Sora目前还没有对外开放,只有少数安全测试人员可以使用。OpenAI表示,Sora还需要进行更多的安全和道德评估,以确保其不会被滥用或造成伤害。 我上网查了一些资料,给大家分享: Sora是一个能够根据文本指令生成逼真和富有想象力的场景的AI模型。它可以生成长达一分钟的高清视频,同时保持视觉质量和对用户提示的遵循。 Sora的技术原理是基于变换器(transformer)架构,它将图像和视频表示为小块(patches),这些小块是数据的更小的单元。通过这种方式,Sora能够在不同的持续时间、分辨率和纵横比的数据上进行训练。 Sora的研发团队以日语的“空”(sky)为名,寓意其“无限的创造潜力”。Sora的目标是训练能够理解和模拟运动中的物理世界的模型,从而帮助人们解决需要与现实世界交互的问题。 对视频行业的影响,我觉得应该是机会和风险并存, 一方面,用AI生成视频,可以大大缩短制作过程并降低成本,提高效率和利润空间,降低制作的门槛,更好的个性化和创意有了发挥的空间。应当可以为用户带来更多的乐趣,丰富大家的体验。 另一方面,版权、真实性、隐私和安全等问题也是公众关注的焦点。AI生成视频如果被滥用的话,也是会对社会秩序造成负面的影响,甚至引发道德风险和违法犯罪。 目前来说,AI生成视频还需要持续的发展,我个人也非常期待能够使用Sora来创作视频节目。 |
|
|
| [收藏本文] 【下载本文】 |
| 科技知识 最新文章 |
| 百度为什么越来越垃圾了? |
| 百度为什么越来越垃圾了? |
| 为什么程序员总是发现不了自己的Bug? |
| 出现在抖音评论区里边的算命真不真? |
| 你认为 C++ 最不应该存在的特性是什么? |
| 为什么 Windows 的兼容性这么强大,到底用了 |
| 如何看待Nvidia禁止使用翻译工具将cuda运行 |
| 为何苹果搞了十年的汽车还是难产,小米很快 |
| 该不该和AI说谢谢? |
| 为什么突破性的技术总是最先发生在西方? |
| 上一篇文章 下一篇文章 查看所有文章 |
|
|
|
| 股票涨跌实时统计 涨停板选股 分时图选股 跌停板选股 K线图选股 成交量选股 均线选股 趋势线选股 筹码理论 波浪理论 缠论 MACD指标 KDJ指标 BOLL指标 RSI指标 炒股基础知识 炒股故事 |
| 网站联系: qq:121756557 email:121756557@qq.com 天天财汇 |