
| |
|
|
| ����ƻ� -> �Ƽ�֪ʶ -> OpenAI ����������Ƶģ�� Sora��AI �������˶��е��������磬��������ģ������ζ��ʲô�� -> �����Ķ� |
|
|
[�Ƽ�֪ʶ]OpenAI ����������Ƶģ�� Sora��AI �������˶��е��������磬��������ģ������ζ��ʲô�� |
| [�ղر���] �����ر��ġ� |
|
OpenAI�������ǵ�������Ƶ��ģ�ͣ�Sora�ˡ����� ���ң���ǿ����������һ����ij̶ȡ����� https://openai.com/sora ����� |
|
ת��һ������AI��V Jim Fan�Ĺ۵㣬 �������Ϊ OpenAI Sora ���� DALLE һ���Ĵ�����ߣ�...����һ�롣 Sora ��һ�������������������档���Ƕ����������ģ�⣬��������ʵ�Ļ��ǻ���ġ�ģ����ͨ��һЩȥ����ݶ���ѧ��ѧϰ���ӵ���Ⱦ����ֱ�ۡ�������������������������� ��� Sora ʹ��������� 5 �Դ����ϳ����ݽ���ѵ�����Ҳ���е����ȡ���������ˣ� �������ֽ�һ���������Ƶ����ʾ�������Һ�������һ�������ں���ʱ����ս���ı�����д��Ƶ���� |

|
|
0 - ģ����ʵ���������־�����3D�ʲ������в�ͬװ�εĺ������� Sora ��������DZ�ڿռ�����ʽ�ؽ���ı��� 3D ������ - 3D �����ں��в��ܿ��˴�·��ʱʼ�ձ��ֶ���Ч���� - ���ȵ����嶯��ѧ�������Ǵ�����Χ�γɵ���ĭ������ģ���Ǽ����ͼ��ѧ��һ������������ͳ����Ҫ�dz����ӵ��㷨�ͷ��̡� - ��Ƭдʵ���壬���������������Ⱦһ���� - ģ�������ǵ������뺣����ȳߴ��С����Ӧ��������Ӱ��Ӫ�조С���ķ�Χ�� - ��������������ʵ�����в������ڣ���������Ȼʵ����������������ȷ�������� �����������Ӹ���ģʽ��������Ȼ�����Ǿ�����һ������������������ Unreal Engine������ȡ�������ֹ���Ƶ�ͼ�ιܵ��� Ҳ����˵Sora�п����ǿ�����һ�����UE����ģ�����档�����ڴ�һ�º������ĸ���ϸ�ڷų� ���������Soraȫ��������ʾ����Ƶ��Ŀ��⣬��Ҫ�Ŀ���˽�ż��� |
|
|
|
|
|
|

|
|
|

|
|
|
|
�ҵ�һ�ο���Sora�����Ƶ���ɵ�Ч������DZ��������ˡ����Dzµ���Ƶ�����⼸����п��ٵķ�չ������û���뵽��Ȼ���һ���ʱ����Ѿ���������ز���ʵ����̫�����ˡ� �����ĵط��Ͳ������ˣ������IJ����Ѿ��Ѿ�˵���ܶࡣ��ʹ���о���Ա����ȻҲҪ����������Щ����ĵط�������֮����о����з�������ͼ�����������ͷ��������Щϸ�ڻ�û��������ȫ��ʵ���ȵ����ף����ﲻ��Ҫ����Sora�Ľ������������Ϊ��Ƶ�������������ʵ�����Dz��ܹ��л���ȥ������Щϸ�IJ���ʵ�ĵ㡣 �����ǹ�Ӱ������Ͱ�OpenAI�ų����ĵ�һ�������ӡ��������dz�����������ͼƬ��Ӱ��Ư���������ǵ���ˮ�ķ��䡣����ϸ�۲죬�ͻᷢ�ֺܶ�ط��ķ����д����������½ǻ�ɫ������ķ���������ϸ���䣬һ���ֵ��䣬��������ʵ�ʵĹ����ȴ������ϸ���䡣�������½Ǻ�ɫ����ij�ɫ���⣬��ʵ������û�ж�Ӧ�ij�ɫ����ġ� |

|
|
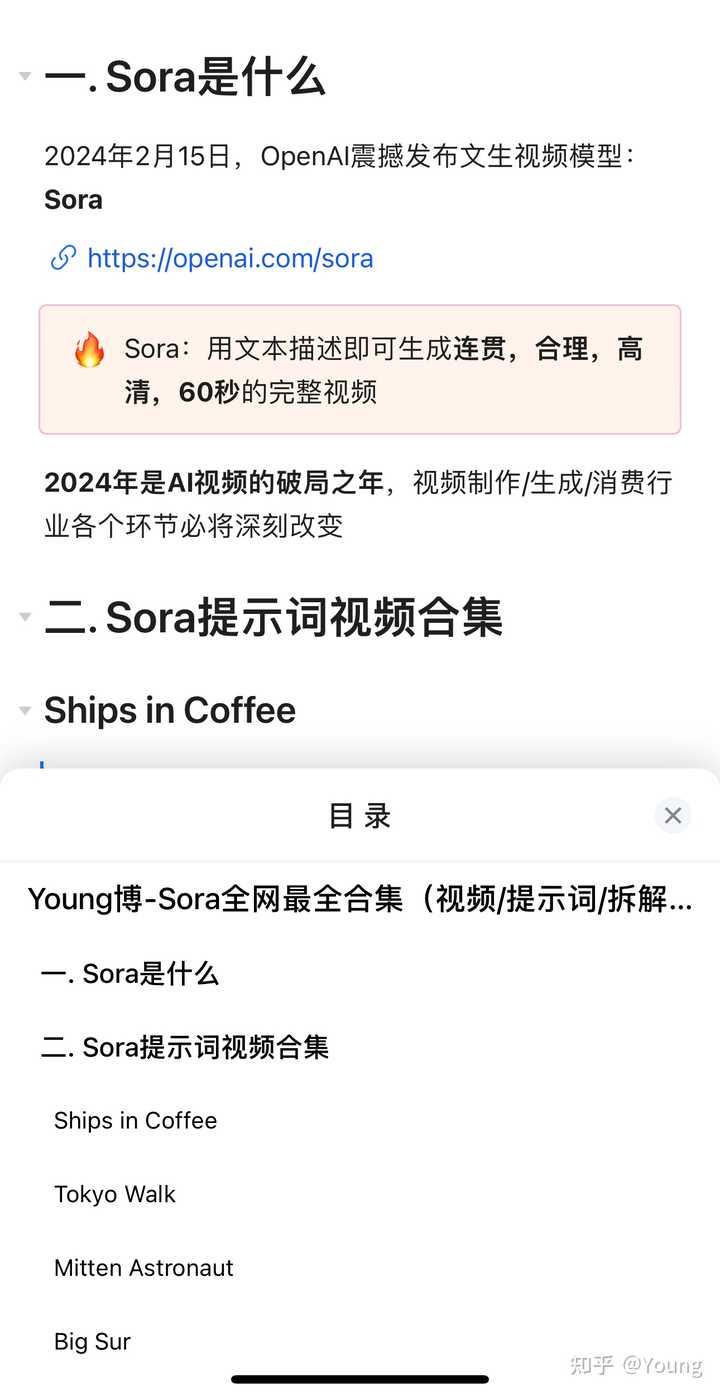
https://openai.com/sora Ȼ��ϸ�ڣ�������������������Ƶ�����ӡ����������OpenAI�����ż��ľ����������ë���������ǹ�Ӱ����ϸ�ڼ����������ޣ��������в��������������·ʱ�����ѩ��������ѩ�Ķ�֪����ѩ���ϵĽ����ѩһ�㲻�����̫�ߣ����һ�������Կ���״������Ƶ�е�ѩ��������һ��Ʈ�����������һ����ʵ�Ļ������ѩ�ص�ͼƬ���ԱȾ�һĿ��Ȼ�ˡ� |

|
|
��ͼ��https://openai.com/sora����ͼ��https://generalaviationnews.com/2021/01/10/flying-with-skis/ Ȼ�����������������ƽ̨ת�صĺ������ڿ����е����ӡ���������ʱ���ȵķɽ����Ǻ������ķ緫���dz���ʵ�����Ǵ��ں���Ư����ȴż����Щʧ�棬������һС�Σ�ע���Ҳ�Ĵ��ƺ��������ڿ���Ư�ƣ�����������ں���Ư����������Ϊ�Աȣ�����������"��������δ��̵�"����Ĵ��ں���Ư������Ƶ���Ϳ��Կ������� |

|
|
https://openai.com/sora |

|
|
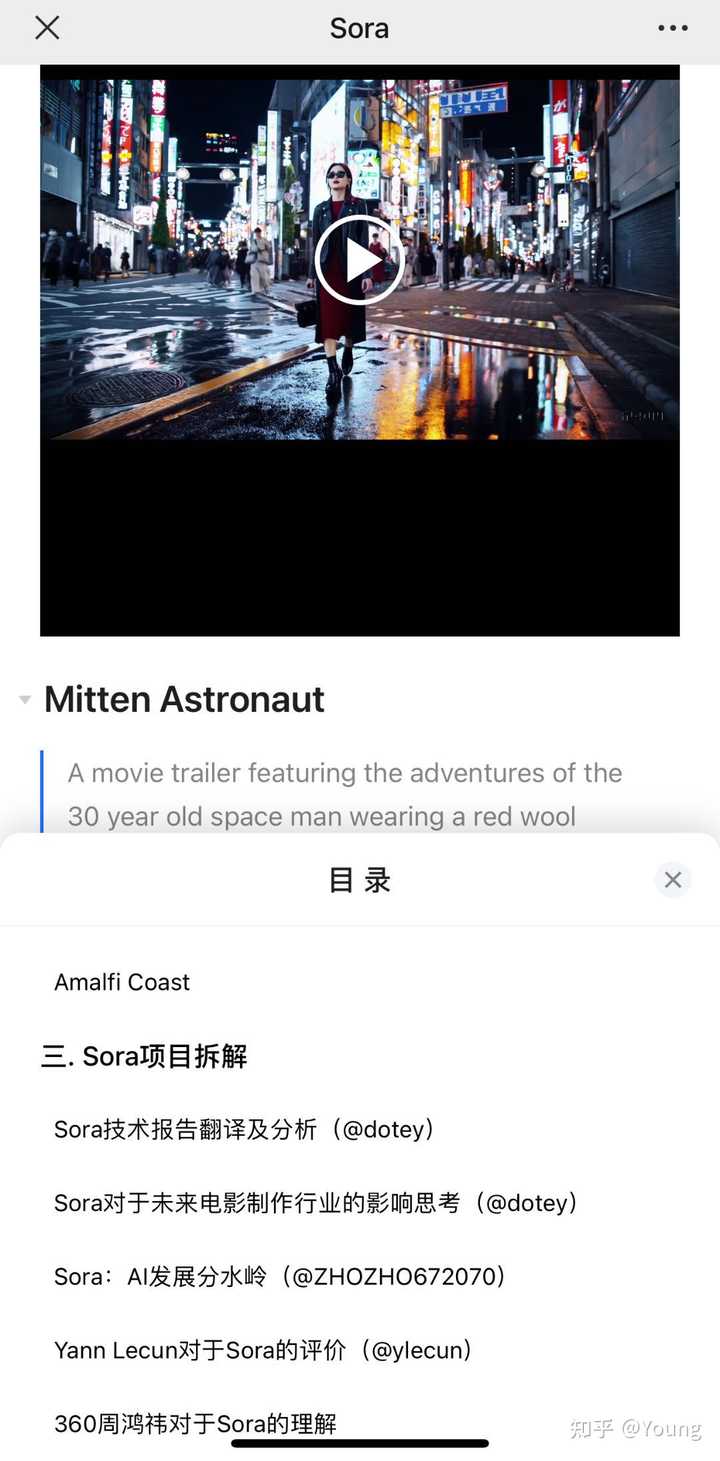
��Ƭ������������δ��̵ġ� ������άһ���ԣ���������һ�ηdz�Ư�����ձ���ͷ��Ƶ���ܹ�����ô���ӵij��г�����ά�ṹ����ͨ����Ƶ��Ϣ��ģ����ʵ�����ס�������ӣ����ijЩ֡�������Կ�����һЩ�������ڿ��У���Ҳ����Ϊ������ά��Ƶ��û����������ά�ṹ�����Դ�ijЩ�Ƕȿ���ȥ�����ױȽ���֡�������Ϊ�Աȣ���һ��������ά��Ϸ�е�ɭ�ֳ�������Ⱦ�� |

|
|
https://openai.com/sora |
|
|
��Դ������������ �����Ǹ��ӵ��˶��������Ƶ����ֻ�ɰ���è�ڶ����˵�ʱ������ͻȻ�������һ��צ�ӡ� |

|
|
˵����ô�࣬�������ͷ��˵�ģ���ʹ��ˣ�������Ҳ�Ƿdz����������˸��ܵ�����Ƶ���ɵ�����DZ����δ��Ҳ���ܶ�Ķ���Ƶ����������Ӱ��������Ϸ�����ָ����������ɣ����ǿ�����AI������ɡ� ���Ҳ��һ��˽���ҿ��ܾ�����˵��ô���е㴵ë����ˣ���Щϸ�ڵ�����˭�������أ�����ȴ����ô���á������и�ҵ���ھ�������������һ��Ҳ�Ǿ��ķdz�������ͷ����һ���ֻ�һ�����żܾͿ���¼��Ƶ����������������Ƕ��Ǹ���רҵ¼Ӱ����Ӱ���Ӿ����Ƶ��Ϸ������ˣ�����dz�ţ�Ƶ���Ч�����ڿ�������5ëǮ��Ч�ˡ���������Ա�һ��ͬ�������սϵ��99�������ӰΣ����19��������������� |

|
|
���������ս�Աȣ��ϣ���ӰΣ�����£����������� ��Ϊ������Ч�������Ҳ��ƴ����ϸ�ڣ����������Ϸ�����⣬����ôһ�Ż���ͼ��Ϊ�˿���ȥ�ÿ�����������˶��ٸ���Դ��Ҳ������ΪЧ��Խ��Խ�ã������ǵ��۾�Ҳ�ᱻ����Խ��Խ����Ʒ����ҲԽ��Խ�ߡ������ݴ�������һ��Ӯ��ͨ�Ե���Ϸ����õ����ݻ�ȡ�˾��ֵ�����������ȴ�Ҷ��뾡�취ȥ�������е�ÿһ��ϸ�ڡ� |

|
|
By Peter Tran. https://www.artstation.com/artwork/L352gk ����������ϸ�ڵļ���nei���£�juan���������������ɵ��о�Ա��˵������һ���ѵõû�������Ϊ����˵��ÿһ��ϸ�ڣ���Ӱ��ϸ�ڣ���������������ά������Ҫһ��һ����ϸ�о�������ƣ����������������컯�ù������֣��Ͼ���ÿһ��ά���ϵĽ����������ܱȱ���������������һ������ݡ����쿴������Ȧ�ܶ������������о����о�Ա�ڰ�����˵OpenAI�ְѴ�Ҿ����ˣ���ʵ�о���ɲ��ء� |
|
���ǡ���ѵ�����ݵĻ����ϴ��ı�������Ƶ������֤����AI �������˶��е��������硱����������ζ��ij����ģ�͡��ǡ�����ģ�͡� �����ע���ClosedAI ��������ʾ��Ƶ����ʧ������幹�����˶���ʽ����Ҫ�Ƕ����ȵ��ƶ��ٶȹ��ڻ����������˶����������岻Э�������ֽṹ�Բ�������ʵ�ķ�ʽ�ƶ������������������Ա��ܵ�С��èȫ��ȱʧ֫�壬�������ڿ��ȱ����սʱһ�������IJ��������ر���˱��ӿڡ�������ġ��˹��������еĴ�����ʾ��Ƶ�������ȱ������ϵ�ͬ��ģ�ͺã���ϸ�ڵ���ɶȲ���ֵ�������ϵ�����֮�ʡ� �ұ�м���С��è�DZ��Q�ţ������˳��ע�������������ߵ���̬Ť������Ӱ������Ķ�����̬��ͬ��������������Ŷ������ã� |

|
|
������ð��һ���մɣ� |

|
|
���ȱ�������������б��ڵ� |

|
|
��������Χ�IJ��˳����˻���ģʽ |

|
|
ģʽ�Ŵ� |

|
|
ģʽ�Ŵ���Ȼ�ij̶� |

|
|
���β����ڱ�Ե�仯 |

|
|
ð���µı��� |

|
|
ռ����������ڵ�λ�� ������ģ�͡��Ƕ�����Ŀռ�ά�ȡ�ʱ��ά�ȵij����ʾ�����˿��ܾ��С���������ģ�Ϳ��ܡ��С���û�С���һ���������������۴�������ģ���ܷ����㹻�õ�����ģ�͡��ڶ�������ģ�ͼ��л���AI ��ģ���ڶ����ϲ��ܡ��ǡ�����ģ�͡� �� Sora �Զ���ṹ���˶���ʽ�ı��ֿ�������ѵ������ȱ�پ������ñ�ע�ġ�������������Ľṹ���˶������ݡ�����Ϊ��һ���˹�������Ҫʹ�����������ֵ����������绥���������ǿ�ѵ������װ���˽�������������ӡ� |
|
��ȻSora�İ�����Ƶ�ͼ����ĵ��������˷ܲ��ѣ������Ҿ���˵Sora�ܹ����⡰�˶��е��������硱���ǹ��ڿ����ˡ� ��һ�������ӣ� ��һ��ˮ������һ������� �����Ҫ��ϸ��ģ������Լ�����������̣���Ҫͨ���������嶯��ѧģ����ʵ�֡�ģ��Һ�������������������Լ�Һ��������������������Ϊ���������������Ҫ����Һ��ij�ʼ״̬�������������״���ٶȡ�Ȼ����ģ�ͼ���Һ��������·��������Һ����δ�һ������ת�Ƶ���һ��������Һ�������������е��ٶȱ仯�ͷ���仯�ȵȡ�ͬʱ��ģ�ͻ���Ҫ���ǵ�Һ���뱭��������������ã���ճ�����ͱ�������������·����Ӱ�졣 ������Ƶ����ģ����Ȼ���ǰ���������ޱȡ�רҵ�ޱȵĹ�����Ͻ�����ģ���У�ʵ�֡��˶����̡������ɣ�����ͨ����ѧϰ�������ġ���ˮ����Ƶ���ݣ�ѧϰҺ�嶯̬������ú���������������Ӿ�ģʽ�� Ҳ����˵Sora����ģ����Ҫ�����ڴ�������ѧϰ��������ġ���������������ֱ����ģ���н����������ɵı��롣 �������ڡ��������漣��ѧϰ���ġ�������������ʹ����Ƶ����ģ���ܹ����ɡ��������������������ɵĶ�̬������ȴ������ֱ�ӽ�������漰���ĸ����������㡣 ��������Ȼ��������ѧϰ��������������ѧϰ��ԭ���������������ܵ��ºܶ����⡣ ���磬ģ�Ϳ��ܲ���ȷ��Ԥ�⡱δ�������³�������Ϊ����������ѵ�������С�����������Щģʽ������Щģʽ�����Ը������п��ܵ�����������һЩ����ģ����˵��İ�������������̣���������һЩ������Υ���۹��ɵĽ���� ���磬Sora��Ȼ�ܹ��ӡ��Ӿ��������������Ǿ������ŷ��ij��������������ϸ�۲�������ϸ�ڵĻ�����ʵ�ڶԶ�̬������ϸ�����������ⷽ����ܴ����źܶ�bug�� ���磬ģ�Ϳ��ܶ��ڸ��ӳ�����Ԥ���������ޣ����������ָ���漰�����������̹��ڸ��ӵĻ����ܿ������νӼ����ɷ���������þ���������һЩ��δ��ѧ������ϸ�ڣ�ģ�ͺܿ��ܽ��С����족�� ��ʵ�������������Զ�ȿɻ�ȡ��ѵ���������ܹ�����Ķ���Ҫ���ӵö࣬��������ѧϰ���Ӿ�����������Ԥ���ģ�ͣ���̫�������������⡱�������硣 ����֮ǰ������runway��pika��4s��Ƶ��Sora��59s������Ƶ�����㹻�����ġ�������ȻĿǰ��ģ����Ȼ�����ԡ����⡱���磬����δ������ﵽ�����ij̶ȣ�˭��֪���ء��� |
|
��һ������ Sora �ļ�������ı�������һ���֡�ӿ�֡����������֡���εļ������棬��Ŀֱ�Ӿ��ǡ���Ƶ����ģ����Ϊ����ģ�����������Ұ� Scaling video generation ��Ϊ����ͨ����������ģ������ promising path�� |

|
|
�ں���ļ�����������ǿ�����һ����Ϥ�Ĵ��Emerging��������һ�λ�������������һ���ֿ�ʼ��Sora ��չ�ֳ��������dz���ԭ��Ԥ�ڵģ����ڡ�����ӿ�֡��� ��Щ����ʹ��Sora�ܹ�ģ���һЩ��������������ˡ�����ͻ�����ijЩ���档 ͬʱ��OpenAI Ҳ��ǿ������Щ������ȫ������ Scale��Scale Law �����Ϸ֣� |

|
|
������˵��OpenAI ������ Sora �ļ��������� 3Dһ���ԡ�Sora�������ɾ��ж�̬������˶�����Ƶ��������������ƶ�����ת������ͳ���Ԫ������ά�ռ��б���һ���ƶ�������һ���Ժ����������ԡ�������Ƶ����ϵͳ��˵��һ����Ҫ����ս���ڲ�������Ƶʱ����ʱ���ϵ�һ���ԡ����Ƿ��֣�Soraͨ���ܹ���Ч�ؽ�ģ�̳̺ͳ��̵�������ϵ�����ܲ���������ˡ����磬���ǵ�ģ�Ϳ������ˡ���������屻�ڵ����뿪����ʱ��Ȼ�������ǵĴ��ڡ�ͬ������������һ������������ͬһ��ɫ�Ķ����ͷ������������Ƶ�б������ǵ���ۡ������绥����������ʱ����ģ������������Ӱ��Ķ��������磬���ҿ����ڻ��������³������ڵ��±ʴ�������һ���˿��ԳԵ�һ������������ҧ�ۡ�ģ���������硣Sora���ܹ�ģ���˹����̣�һ����������Ƶ��Ϸ��Sora����ͬʱʹ�û������Կ���Minecraft�е���ң�ͬʱ�Ը߱������Ⱦ���缰�䶯̬��ͨ����ʾSora�ᵽ��Minecraft���ı��⣬���Լ�����Щ������ ���۾��ǣ� ��Щ����������������չ��Ƶģ���Ƿ�չ���������������������Լ����е����塢����������ģ��������ϣ����;���� ����˵�������������˵������ֵ��������Ҫ�ԣ��Ҿ��ô������������⣬һ�������������ռ���㡢�ռ���Ƶ������������ģ�͡� ȥ�꣬NVIDIA �������������������ǵ� Omniverse��Ҳ�������������ĸ��Ȼ�����ƻ���� Vision Pro������һ���ռ���㡣�����Ҿ�����Щ�������ܴ��������ˡ� �����������������������̻�ϵͳ����������ĸ���������������һ��3Dģ�ͣ�ʹ�ô��������ϸ�����ʵ��������ݡ��ṩ��һ��ʵʱ�ġ�����Ļ��������ڲ��Ա仯����ѵ��Ա������Ӱ����ʵ�����Ӧ��֮ǰʶ��DZ�����⡣�������������ı�����ҵ������ѧ���������й滮���죬���ڼ����̡�Ԥ����ϣ�������ģ�����������õľ��ߡ� NVIDIA Omniverse��һ��רΪʵʱ3DЭ����ģ����Ƶ�ƽ̨��Omniverse�������ɵ�������ƹ��ߡ��������ݼ����Ƚ����˹����ܡ���ͬѧ�Ƶ��Ŷӿ����ڹ���������ռ���������������г�ǿ�ı�������ģ�⣬�������dz���ȷ����ӦѸ�ٵ�������������˾���Խ�����������Ż���������Ƹ���ȫ������Ч�Ļ����ˣ�����ģ���������еĽ�ͨģʽ��������Ӫ����ѵ�滮�Ŀ�����ȷʵ�����ġ� ��������ģ�ͣ�����Կ���֮ǰ�Ļش� ��ʡ�����ذ�������Χ�ۣ�֤ʵ��������ģ���ǡ�����ģ�͡��������ж�����ʱ��Ϳռ���Ԫ����ʵ����Σ�1163 ��ͬ �� 132 ���ۻش� |

|
|
����ģ����Ҫǿ���ľ��Dz���Ҫר��ѵ��ѧϰ���Է���֪������Щ����ʶ������Щ��ʶ���������ڻ��������������������������Ȼ�ĸ�֪����������������ɫ�ʣ���Щ��Ȼ�ij�ʶ�����������أ�������������ȷ����������йٸ����йء� |

|
|
����ģ������һ��������Ϸ����Ϊ����ģ��ǿ���й١�ֱ������ʶ�����仰˵������ģ�Ͷ��˻���������˵�Dz��Զ����ĴӸй�ϰ�õij�ʶ�����Ի�����˵��������Խ����ʶ���ƣ��Ͼ�����û������������������ȥ�������磬���ܿ�ֱ����δ��ѵ����������������ߡ� ֮ǰ���ܶ������ɴ�����ģ�Ͳ�������ģ�ͣ�ԭ������� ��ô������ģ�ͺ���Ƶ��ʲô��ϵ������ Meta ����ô���ľͺ��ˡ��������ģ����� Yann LeCun �� Meta ��ȥ�� 6 �·����� I-JEPA[1]���������� AI ��������ģ�͵�̽��������ż���� Sora ������ͬһ�죬Meta �˳���V-JEPA[2]�� |

|
|
Ҫ�����������磬�Dz���ȱ��ͼ����˶�����ģ�������һЩֻ�������Դ��ĸо�����Щ�о�����������ȷ�������壬��ͨ�����ģ�Ļ��桢��Ƶѵ����AI �����Լ��ܽᡢ�������е� 3D����ײ���������ɡ� ͦ��Ȥ�ģ�LeCun ������ ChatGPT��û�뵽 Sora ����Ƶ����������������������ģ����������;ͬ�顢��ı�����ˡ� ʱ��ִ٣���д��ô�࣬�����뷨�������� ���ϡ� �ο�^https://arxiv.org/abs/2301.08243^https://ai.meta.com/blog/v-jepa-yann-lecun-ai-model-video-joint-embedding-predictive-architecture/ |
|
Sora������Ƶ��Ч��ȷʵ���ޣ������Ҿ���Sora������Ҳֻ������GPT�����ı���AI����ģ��+�����ݣ�����Ƶ���������һ���ɹ�Ӧ�ã����Ʋ�������ģ�ͣ���νAI�������˶��е���������Ҳֻ�DZ���AI��չ�ֳ����㹻ǿ�ķ����������ѡ� |
|
��ȥ�ϰ��·�ϣ����Ļش�һ��������⡣ Video generation models as world simulators (openai.com)?openai.com/research/video-generation-models-as-world-simulators ���ȴ�Ҷ���Sora�ķ��������е��Ծ����������ֳԾ��͵߸��ij̶���ʵ������Video generate�ϣ���������World Model������˵World simulaors����ȫû������ġ� ����Sora������û�м���ɶphysis��bound����tech report�Ͽ��������ġ�����ͨ��data-drivern+model scale-up���˶��������������������Ե�©��������ȫ��������ġ��Ͼ����������ģ�ͣ��˶���ģ����ʵ������ͨ��һ�ֵĸ��������ݾͿ������������learning������ʵ���Dz�̫���ܵġ������ⲿ�ֵ�ȱ�ݵĽ������Ȼ�Ѿ�����һЩai4phy�ķ������Խ��������DALLE3��˼·��Ҫ������һ���ֵ�physical�����Ⲣ���Ǻ��ѵ������������顣 ��ʵSora�����ṩ������ŵ���ǿ��ٵij�����ܴ�����ܹ�ֱ�ӽ����real2sim�����⣬������Ϊ���60s����Ƶ������Ϊ����sense�ṩ�㹻�����Ӿ࣬Ϊ֮ǰsimȱʧ�ij����ḻ�Ȳ��������ƣ� ֻ��˵���Ӷ�Ԫ��Video Data��ѧϰ����ǿ��ӿ��������������ij�ֲ������̻���diffusion-transformer��Ҳ����2024��Human robotic��һ����⣡ ���Ǻ��������������� ��ʵ�ܶ���video�Ļ���ǽ��춼�ƴ���ˣ��������ǻ����ܵ��£���һ�����������˺ܶ�����������ȥ��·����ôһ��Ŭ����Ŀ�꣺����ȥ���������� ���α��֣��ο���һ���ϰ庺�����ο����ڴ������Ķ����������ṩ����OpenAI�ķ��ο�֪ʶ������Щ���귿���ĸ��Ƕ�Special Domain Adapt��ҽ��������Nerf��������Ҳ�ƻ��ܸ��ˣ���ֱ�ӽ�һ������������ͼ���͵��ˣ�Prompt engineer �����ֹ��Ʊ��Q���˶���ˣ�Multi-Modality Function ��Ƶû��զ�氡��interaction���ο�һЩinpaint�Ĺ�������Ƶ�༭�����ǹ��ƻ���Ҫ�Ȱ�Sora���֮����ܺ����о�Embodied AI��real2sim����Indoor�����ij�����ͼ����㹻��RL���Ż���ѧ��World Model��ֱ���滻Dreamxxx��diffusion�IJ��֣���Sora������������Ի��long horizon��manipulation |
|
���ȣ���������ģ�ͣ����ڲ�û��һ����ν���Ѿ���Ϊ��ʶ�Ķ��塣 ���ǹ�����Yann LeCun�����ġ�A Path Towards Autonomous Machine Intelligence�����ģ������Ϊ���ӡ� |

|
|
�����������ģ�����ģ��Ҳ����World Model�Ķ������¡� ����ģ��������ģ���Ԥ������������������̬�ĸ����ܡ�����ʹ���������ܹ���Ч�����������Χ�������������˹������ر���������ϵͳ�ͻ����˼����е�һ��������ɲ��֡�һ�����͵�����ģ�Ͱ����������֣� ��֪ģ�� Perception Module�����������й����ݣ��������統ǰ״̬��Ԥ���ǰ��ģ�� Prediction or Forward Model�����ڹ۲��DZ���ж���ģ��δ��״̬���滮�;��� Planning and Decision Making����ǰ��ģ��Ԥ��ѡ��ʵ��Ŀ����ж���ѧϰ���� Learning Mechanism�������¹۲�ͽ������ģ�ͣ����Ԥ������������ Memory���洢���飬���ڸ��õ�Ԥ��;��ߡ�����ϵͳ��Ŀ�꺯�� Reward System or Objective Function���ṩ�ж����������ָ��ѧϰ�� ����ʵ����һ���ˣ���������ͨ����֪���ռ���Ϣ�����ü���;�����Ԥ��δ���¼���ͨ���滮�;�����ѡ���ж����Լ�ͨ��ѧϰ������������Ӧ�Ľ�������ģ��Ҳ�������ƵĻ�����ʹ�����������������ܹ����价�����������ж�����Ӧ���������������˹�����������ͼ�ﵽ��һ�ָ���ʽ�����ܣ�Ŀ�ľ��Ǵ�����ܹ�����Ȼ���븴�����绥����ϵͳ�� Ҳ������ν�ĸ������˹����ܡ� �������Ķ��壬�����Եģ�һ������ģ���������һ�����������罻����ʽ�������ǿ�������������Ҳ�������ŵȵȡ� Sora���ģ�ͱ�����һ��text-to-video��ģ�ͣ�Ҳ���Ǹ������ṩ��������������Ƶ������û�и�֪ģ�ͣ��Ҿ���ѧϰ����Ҳû���ᵽ������˵ԶԶ�����ܳƵ���������ģ�͡� OpenAIҲ˵�ˣ����Sora������һ����������ģ������·���� |

|
|
���������а����˷dz���ķ���������������Ħ�����������������ɢ�ȵȣ���Ҫ˵Sora����������ģ����Щ�������ǿ϶��Ǵ�ţ�� ������Ҫ��Sora�ɲ�����������Щ�������Ҿ����ǿ��Եġ� ����˵���è������·��ʱ��ǰ����Ƭ��Ҷ������˵���������ۣ����ܻ�����ȥһ���֣�Ȼ���ٻָ�ԭ״�� |

|
|
�����㿴��ʵ�ʵ���Ƶ�У���û�����ۣ����DZ��ģ���� |

|
|
��������һ�̣�è�Ľ����������ֳ����ˡ� |

|
|
����˵��ʲô��Sora�ǿ�������һ���������ƶ������У�ijһʱ�̿��ܻ�����������ʱ����������һ���IJ�λ���赲������֮�����������չ�ֳ����� Sora��û�����ϰ����Խ���ϰ����������û����ģ������ڴ����������Ӵ���ʱ�������⡣ ��Ϊ���ʱ��Ҷ��Ӧ�������۵ģ�������ϸ����Ƶ�Ǽ�֡��ģ���ġ� �Ҿ��ã���Ҫ������Ϊ�������������൱�ڲ�����һ�ּ����ַ����м�IJ�����ģ�������ͼ�������Ƶ������ʼ������汣����ȷ֮����������Բ�������Ǽ�֡�� ����������Ƶ�е�����һ������Ҫ���������ѵ���������Լ��������Dz��������ø�оƬ����scaling law�㵽���²�֪�������ܲ��ܳ�Ϊ����������ģ�͡� �����������������Ҳ��ͨ���۲�Ȼ���ܽ�����ģ�Sora����˵OpenAI�Ĺ��췽ʽҲ�����Ƶģ������������ӽ�ȥ���ܵ�Ҳ�Ǵӹ۲��н���ģ�£�ӿ�ֿ��ܾ��������˹��ɻ��߶��ɵı��֡� |
|
��Խ��Խ����transformerѹ���Ͳ���һ������ģ�͡�����һ��ͼģ�ͣ�������ѧϰ��ͬ��Ϣ֮�����ϵ��attention matrix������Щ��Ϣ�����Ǹ��ֲ�һ����token��������һ�ֻ����������Ժܺõı�ʾ����ʱ�չ�ϵ�����˵ģ�Ͳ���������������Ķ�̬���磬����ô���ɹ�Ӱ�������˶�����������Ƶ�أ�����openAI��˵����ģ���������������transformer��������������ΰ��ķ���֮һ�ˡ� |
|
1. ����ʹ�õ���Transformer �ܹ��������� DALL��E 3 �� GPT ģ��֮�ϡ� �ش��ͻ������һ���ӣ����λ�� 2. ͬ���ģ� Sora������ģ�͵����ʡ� ������Ҫ����һ�£�������ʹ��GPT�����ģ��ʱ������������������������ֻ���AI���ܺܺõĻ��ֵ����⡣ ������Ϊ������LLM�������ڡ��Իع须�������µģ� ����ģ��������Ԥ�����ģ��������ܶ�����ͼ��������Ϊ��������ġ� ��͵����˳����˺ܶ෴��ʶ������Ĵ��ڣ������������֮ǰ�ܶ��ģ��������һ�����⣺ ³ѸΪʲô���������� �ش�����ݿ���������ȷ��˵��³Ѹ����������˭��Ҳ�ᵽ�˴����Dz��Եģ�����������û����ʶ����³Ѹ���������ˡ� |

|
|
����Ŀǰ�ܶ��AI��Ƶ���ɣ���ʵ���Ǿ�̬�����ڶ�̬�ı���������ʮ�ֵ�������������֮�⣬����û��ʲô���ӵ��˾��� ��ν����ģ�ͣ�����Ҫ��AI������һ�����������γ�һ��ȫ�����֪�������˼��������ʵ���в㼶�ģ�ͨ����ͬ�IJ㼶ȥ����������硣 ��������ģ�ͣ����г���Ԥ�⣬ģ�⣬�ͽ����������� ��Sora�ϣ������˾��ֶθ��ӷḻ�����λҲ���������ˡ� |

|
|
0 3. ��Ȼ��Ŀǰ�� Sora ���Ǵ��ںܶ�����⣺ ���紦��������ײ����һЩ����ʶ��������֣�����ħ��һ���� Ҳ������������� |

|
|
������������ô������һ�㶼û����˸�� 4. �������ʣ�����AI��Ƶ������������ϵĹ�˾���������������ͣ����4s���ҵģ���ô���ڻ������Ѿ������������̣����ˡ� ���������Ͷ����Ҳ�ᷢ����ı仯���п������컹��Ͷ���˼ƻ����������Ǯ������һ���ʼ����������Dz�����Ͷ�ˡ���ν��������ҵ��������֮ǰ��Pika��Runway���ؽ�Ҳ���Ϊһ��������ҵ���������������֮ǰ��������Ԥ�ϵġ� ��ν�Ľ�ά����� 5. ����Ӱ����ҵ����ʵҲ��һ���ϴ�Ĵ���� ��Ϊ֮ǰ��Ҫ������������������Ӱ��������ɫ����Щ��ǰ��Ҫ�ܶ�����ɵĹ���������ֻ��Ҫһ���ˣ����һ���ѺͶ��ķ��á� 6. Ҫ֪������ֻ�ǵ�һ�档 |
|
�����˶��е��������磿���Ǻ�Ц��Sora��չʾ��ȫ������Ϊ����̲����ã����˵��AI������ֻ�����Dz���װ����ˮƽ���ˡ� ������Щʱ���Ҿ�����һ�����̵����ݣ����ߴ����Щ�������ܾ���չʾ�����ж���ˮ�֣�û�����Ŀ��Կ���������� ���AI����������������磬��ô��������Ӧ�ö����������ɵľ����ԣ�Ҳ����һ�����ɲ�������һ���ط���Ч������һ���ط�����Ч�� Ȼ�����������չʾ�ͳ��˵��AI���������������� ��ϸ����ͼ��Ȧ���Ȧ��ע��������ʯ |

|
|
������IJ��˾���֮�£���ͼ��Ȧ�ڵ�����Ϳ�ʼʧ���� |

|
|
���˾�����ʯ�Ĺ�������ȫ�������������ɵģ�ʧ��Ҳ�dz�������������֮���Ȧ�ڵĽ�ʯ��ʧ�ˣ���ʣ�»�Ȧ�ڵĽ�ʯ |

|
|
�������Ƭ���ǾͿ��Կ���AI���������ɵ������Dz����ȵģ�������ô�������ȷ�ȴ��֪��������е㾫���ˡ� ���仰��˵����ȻAI���������Dz����ȵģ���ô���Ϳ϶�û������ʲô������� ���⣬��������ʧ��IJ���Ҳ���Կ���AI������û��������ģ�⣬��Ҳ��֪��ʲô�Ǻ��ˣ���ֻ�Ǵ����������ϳ�һ�����������Ĵ𰸳������ѡ� �Ҿ��ø���ȷ�Ŀ�������Soraֱ���ճ����5��������ݣ������������з����������Щ���ݣ������������������������������������ �ܽ���˵��Sora�Ǻܾ��ޣ�����ǧ���ϸ������Ȼ�����������ճ���ĺۼ�������˵Ҫ�������ģ�ͣ����ƻ��Ǻ�ңԶ���¡� |
|
������ζ�� transformer ��DZ���Ծ�δ���ھ�ɡ� sora pr ��ԭ�����ᵽ�� sora ������ģ����Ҳʹ���� transformer�� Similar to GPT models, Sora uses a transformer architecture, unlocking superior scaling performance. ����Ȼ����Ч���ϣ�sora �Ѿ�����һ���̶ȵ��������⣬�����п����� transformer ���粶���������Ѿ������������ﶼ���� transformer �ĸо��ˡ� ��ôһ���ؼ��������ǣ�������㹻��ķ������ݣ��Ƿ���Ե���ѵ�� transformer ȥģ������������� ai �ܡ�ģ�⡹���Լ����������Ч������������׳�����һ������˼�����⣺δ����Ϸ���������Ƿ���Կ� ai ģ��ȥ����������������û������أ� ���������Ŀǰ dlss �����Ż����������������ƿ��һ����ͬ����������������Ҳ��ʮ�����ļ�����Դ�ġ����δ�� ai ��ģ�����ʵ������Ч������ô��ҿ��������Ѽ����������鵽������ʵ�ı�ըЧ�����ӵ��켣��ˮ�彻���ȵȡ���ʱ��Ϸ�ij���ʽ�����ܸ���һ��¥�� ��֮��sora ��ȻĿǰֻ�� demo������ȷʵҲ��һ�ε��ؿ������Ƕ��� ai ������ռ䣬δ�����ڣ� |
|
������������Sora ���˵ĸо��������������ݡ������ƺ�Ҳ�Ʋ���������ģ�͡� ��ΪAI��ҵ��ٮٮ�ߣ�OpenAI ��ÿһ��������������ȫ��ҵ�Ĺ�ע�����Sora��û���κ�Ԥ��������ͻȻ�dz���ͬ�������ҵ������С���� ��ע�OpenAI�ڽ���Sora�IJ����У���һ�仰����ôд�ģ� We��re teaching AI to understand and simulate the physical world in motion, with the goal of training models that help people solve problems that require real-world interaction. �������ڽ��˹����������ģ���˶��е��������磬Ŀ����ѵ��ģ�����������ǽ����Ҫ��ʵ���罻�������⡣ Ҳ����˵����OpenAI���Sora����������һ��������Ƶģ����ô���������ǰ�������������˹���AGI��ͨ���˹����ܣ�ϵͳһ����Ҫ���ڡ�AGI������Ľ����������������֡�ͼƬ����������Ϣ��ʽ�ϣ����и�ֱ�ӵ��Ӿ���Ƶ����Ҳ������������֪��������������Ҫ�ķ�ʽ������������Ƶ��������Ƶ�������������磬��δ��AGI�ر�����֮һ�� ��ȷ��������AGI�ֽ���һ���� ����Sora�㲻������ģ�ͣ�world models����������Ϊ���㲻�ϡ� ����ģ��ǿ������һ���������ڲ���ʾ����ʹ������ģ��û�����δ�����¼�����ĿǰΪֹ������ģ�͵��о���Ҫ�����ڷdz������ܿص������ϣ�Ҫô�������ģ�������У�����Ƶ��Ϸ�е���Щ����Ҫô������խ���������У���Ϊ��ʻ��������ģ�ͣ��� ͨ������ģ�͵�Ŀ�꽫�Ǵ�����ģ���������ͽ�������ͬ����ʵ������������������[1] Sora��ͨ���ı����ɸ���������Ƶ��֤����������������������������൱����������������������Ȼ���ڴ�����ѵ�����������ڷ��Ķ�������������⣬����Sora����Ƶ�Ĵ����������кܶ���ģ�����Ҳ�����ܻ�������ʵ���� ��������ô˵����������Sora��������Ƶ����������һ��̨�ס� �ο�^https://research.runwayml.com/introducing-general-world-models |
|
OpenAI����������¶��Sora�ܹ���̵������˶��е��������磬����Ϊ�����ġ�����ģ�͡��� ��һֱ��������ģ�͡���Ϊ�о����ĵ�ͼ���ͷLeCun��Ҳ�������ⳡ��ս�� �����ǣ������ڳ�ǰ����LeCun�μ�WGS����Ϸ����Ĺ۵㣺����AI��Ƶ���棬���Dz�֪������ô������ ������������������������ʾ���ɱ������Ƶ����������ģ���������������硣������Ƶ�Ĺ������������ģ�͵����Ԥ����ȫ��ͬ���� |

|
|
��������LeCun����ϸ�ؽ��͵��� ��Ȼ�������������Ƶ����࣬����Ƶ����ϵͳֻ�贴�����һ������������������ɹ��� ������һ����ʵ��Ƶ��������ĺ�����չ·������Խ��٣�������Щ�������еľߴ����Բ��֣����������ض����������£��Ѷȴ�öࡣ ���⣬������Щ��Ƶ�������ݲ����ɱ��߰���ʵ����Ҳ�������塣 �������������������Щ�������ݵġ������ʾ����ȥ�������ǿ��ܲ�ȡ���ж��صij���ϸ�ڡ� ������JEPA������Ƕ��Ԥ��ܹ����ĺ���˼�룬����������ʽ�ģ������ڱ�ʾ�ռ��н���Ԥ�⡣ Ȼ�������Լҵ��о�VICReg��I-JEPA��V-JEPA�Լ����˵Ĺ���֤���� ���ؽ����ص������ͼܹ��������Ա�������Variational AE���������Ա�������Masked AE����ȥ���Ա�������Denoising AE������ȣ�������Ƕ��ܹ����ܹ�������������Ӿ������� ��ʹ��ѧϰ���ı�ʾ��Ϊ�����������ܼලͷ�������루��������ɽ�������������Ƕ��ܹ���Ч���ϳ���������ʽ�ܹ��� Ҳ������Soraģ�ͷ����ĵ��죬Meta�ذ��Ƴ�һ��ȫ�µ��ල����ƵԤ��ģ�͡�����V-JEPA�� ��2022��LeCun����JEPA֮��I-JEPA��V-JEPA�ֱ����ͼ����Ƶӵ��ǿ���Ԥ�������� �ų��ܹ��ԡ���������ⷽʽ�������磬ͨ�������Եĸ�ЧԤ�⣬���ɱ��ڵ��IJ��֡� |

|
|
���ĵ�ַ��https://ai.meta.com/research/publications/revisiting-feature-prediction-for-learning-visual-representations-from-video/ V-JEPA����������Ƶ�еĶ���ʱ����˵����ֽ˺�����롹�� |

|
|
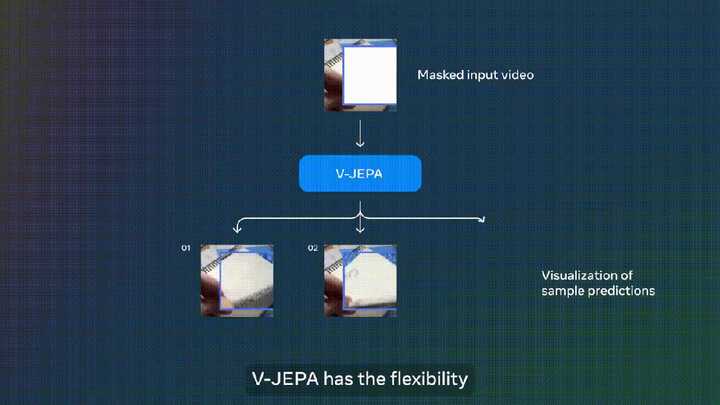
�ٱ��磬�����ʼDZ�����Ƶ���ڵ���һ���֣�V-JEPA���ܹ��ԱʼDZ��ϵ�����������ͬ��Ԥ�⡣ |
|
|
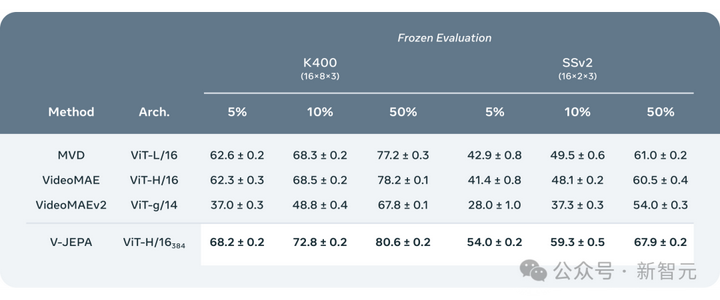
ֵ��һ����ǣ�����V-JEPA�ڹۿ�200�����Ƶ�Ż�ȡ�ij������� ʵ������������ͨ����Ƶ����Ԥ��ѧϰ�����ܹ��õ��㷺�����ڸ�����ڶ���������жϵ�����ġ���Ч�Ӿ���ʾ�������Ҳ���Ҫ��ģ�Ͳ��������κε����� ����V-JEPAѵ����ViT-H/16����Kinetics-400��SSv2��ImageNet1K ���Ϸֱ�ȡ����81.9%��72.2%��77.9%�ĸ߷֡� |
|
|
����200�����Ƶ��V-JEPA���������� ������������������ʶ���ر��������������ڣ��ܴ�̶�����ͨ�����۲졹��õġ� ����ţ�ٵġ��˶��������ɡ���˵��������Ӥ��������è���ڶ�ΰѶ������������²��۲�����Ҳ����Ȼ��Ȼ�����������ڸߴ����κ����壬�ս����䡣 |

|
|
������ʶ��������Ҫ������ʱ���ָ�������Ķ��������鼮���ܵó��� ���Կ����������������ģ�͡���һ�ֻ������Ƕ�������������������龰���⡪���ܹ�Ԥ����Щ��������Ҽ����Ч�� Yann LeCun��ʾ��V-JEPA�����������Ŷ������и�������������Ĺؼ�һ����Ŀ�����û����ܹ���Ϊ�㷺�������滮�� |

|
|
2022�꣬�����״��������Ƕ��Ԥ��ܹ���JEPA���� ���ǵ�Ŀ���Ǵ�����ܹ�����������ѧϰ���Ƚ��������ܣ�AMI����ͨ���������������������ģ����ѧϰ����Ӧ��Ч�滮���Խ�����ӵ����� |

|
|
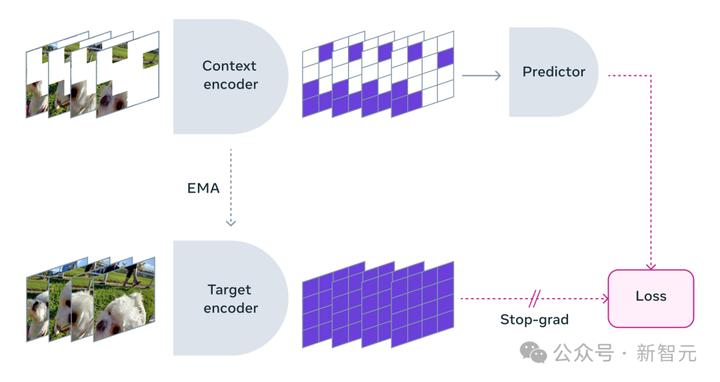
V-JEPA��������ʽģ�� ������ʽAIģ��Sora��ȫ��ͬ��V-JEPA��һ�֡�������ʽģ�͡��� ��ͨ��Ԥ����Ƶ�б����ػ�ȱʧ���֣���һ�ֳ���ռ�ı�ʾ������ѧϰ�� ����ͼ������Ƕ��Ԥ��ܹ���I-JEPA�����ƣ�����ͨ���Ƚ�ͼ��ij����ʾ����ѧϰ��������ֱ�ӱȽϡ����ء��� ��ͬ����Щ�����ؽ�ÿһ��ȱʧ���ص�����ʽ������V-JEPA�ܹ�������Щ����Ԥ�����Ϣ����������ʹ����ѵ��������Ч����ʵ����1.5-6���������� |

|
|
V-JEPA�������Լල��ѧϰ��ʽ����ȫ����δ��ǵ����ݽ���Ԥѵ���� ����Ԥѵ��֮���������ͨ�����������ģ�ͣ�����Ӧ�ض������� ��ˣ����ּܹ���������ģ��Ϊ��Ч������������Ҫ�ı�����������ϣ������ڶ�δ������ݵ�ѧϰͶ���ϡ� ��ʹ��V-JEPAʱ���о���Ա����Ƶ�Ĵ������ڵ�����չʾ��С���ֵġ������ġ��� Ȼ������Ԥ������ȫ��ȱʧ�����ݡ�������ͨ����������أ�������һ�ָ�Ϊ�����������ʽ�������ʾ�ռ���������ݡ� |
|
|
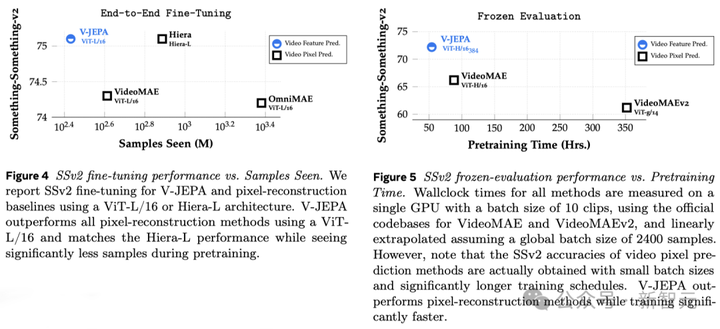
V-JEPAͨ��Ԥ��ѧϰDZ�ռ��б����ص�ʱ��������ѵ���Ӿ������� ���뷽�� V-JEPA������Ϊ�������ض����͵Ķ�������Ƶġ� �෴����ͨ���ڸ�����Ƶ��Ӧ���Լලѧϰ�������������������������ʽ��֪ʶ�� Meta�о���Ա��������������루masking�����ԣ� ������ڵ���Ƶ�Ĵ�����ֻ�����ѡȡһЩСƬ�Σ������ѧϰ�����ù��ڼ�����ģ����ѧϰ����������ĸ�����Ϣ�� ͬ������Ҫע����ǣ��������Ƶ�У���������ʱ������ƶ����ݱ䡣 ���ֻ�ڶ�ʱ����������Ƶ��һС���֣���ģ���ܿ���ǰ�������£�ͬ���ή��ѧϰ�Ѷȣ���ģ������ѧ����Ȥ�����ݡ� ��ˣ��о���Ա��ȡ��ͬʱ�ڿռ��ʱ����������Ƶ��������ķ�������ʹģ��ѧϰ�����ⳡ���� ��ЧԤ�⣬������ �ڳ���ı�ʾ�ռ��н���Ԥ��dz��ؼ�����Ϊ����ģ��רע����Ƶ���ݵĸ߲��������ص���ͨ������������ؽ�Ҫ��ϸ�ڡ� �Ͼ������һ����Ƶչʾ��һ����������ܲ������ÿһƬ��Ҷ��С�˶��� ��������Meta�о���Ա�˷ܵ��ǣ�V-JEPA�����ڡ������������ϱ��ֳ�ɫ����Ƶģ�͡� ���ᣬ��ָ�ڱ�������Ԥ��������������ԼලԤѵ���Ͳ��ٶ�������ġ� ��������Ҫģ��ѧϰ�¼���ʱ��ֻ������������һ��С�͵ġ�ר�ŵIJ�����磬���ַ�ʽ�ȸ�Ч�ֿ��١� |
|
|
�������о�����Ҫ����ȫ�����������Ԥѵ��ģ�ͺ�Ϊ����ģ����ϸ���ȶ���ʶ��������ϱ��ֳ�ɫ����Ҫ��ģ�͵����в�����Ȩ�ء� ֱ���������ģ��ֻ��רע��ij����������Ӧ�������� �������ģ��ѧϰ��ͬ�����ͱ���������ݣ���������ģ�ͽ���ר�Ż������� V-JEPA���о��������Ϳ���һ����Ԥѵ��ģ�ͣ��������κα�����ݣ�Ȼ��ģ�����ڶ����ͬ�������綯�����ࡢϸ�������彻��ʶ��ͻ��λ��������ȫ�µĿ��ܡ� |

|
|
- �������������� �о���Ա��V-JEPA��������Ƶ����ģ�ͽ����˶Աȣ��ر��ע�����ݱ�ע���ٵ�����µı��֡� ����ѡȡ��Kinetics-400��Something-Something-v2�������ݼ���ͨ����������ѵ���ı�ע�����������ֱ�Ϊ5%��10%��50%�����۲�ģ���ڴ�����Ƶʱ��Ч�ܡ� Ϊ��ȷ������Ŀɿ��ԣ���ÿ�ֱ����½�����3�ζ����IJ��ԣ����������ƽ��ֵ�ͱ�ƫ� �����ʾ��V-JEPA�ڱ�עʹ��Ч������������ģ�ͣ������ǵ�ÿ�������õı�ע��������ʱ��V-JEPA������ģ��֮������ܲ��������ԡ� |

|
|
δ���о��·����Ӿ�+��ƵͬԤ�� ��ȻV-JEPA�ġ�V��������Ƶ��������Ϊֹ������Ҫ�����ڷ�����Ƶ�ġ��Ӿ�Ԫ�ء��� ��Ȼ��Meta��һ�����о������ǣ��Ƴ�һ����ͬʱ������Ƶ�еġ��Ӿ�����Ƶ��Ϣ���Ķ�ģ̬������ ��Ϊһ����֤�����ģ�ͣ�V-JEPA��ʶ����Ƶ��ϸ�����廥��������ֳ�ɫ�� ���磬�ܹ����ֳ�ij�����ڷ��±ʡ�����ʣ����Ǽ�װ���±ʵ�ʵ����û�з��¡� ���������ָ���Ķ���ʶ����ڶ���ƵƬ�Σ����뵽10���ӣ�Ч���ܺá� ��ˣ���һ���о���һ���ص��ǣ������ģ���ڸ�����ʱ�����Ͻ��й滮��Ԥ�⡣ ������ģ�͡��ֽ�һ�� ��ĿǰΪֹ��Meta�о���Աʹ��V-JEPA��Ҫ��ע�ڵ��ǡ���֪������ͨ��������Ƶ����������Χ����ļ�ʱ����� ���������Ƕ��Ԥ��ܹ��У�Ԥ�����䵱��һ�������ġ���������ģ�͡����ܹ������Եظ���������Ƶ�����ڷ��������顣 |

|
|
Meta����һ��Ŀ����չʾ�������������Ԥ����������ģ�������й滮���������ߡ� �����Ѿ�֪����JEPAģ�Ϳ���ͨ���۲���Ƶ������ѵ��������Ӥ���۲�����һ��������ǿ�����ļල����ѧϰ�ܶࡣ ͨ�����ַ�ʽ������������ע���ݣ�ģ�;��ܿ���ѧϰ�������ʶ��ͬ�Ķ����� �ӳ�Զ��������δ��Ӧ���У�V-JEPAǿ���龳���������Կ�������AI�����Լ�δ����ǿ��ʵ��AR���۾������ش����塣 �������룬���ƻ��Vision Pro�ܹ��õ�������ģ�͡��ļӳ֣��������ˡ� �������� ��Ȼ��LeCun������ʽAI�������á� |

|
|
������һ��һֱ����ͼѵ��������ʾ�滮�ġ�����ģ�͡������˵Ľ��项�� |

|
|
Perplexity AI����ϯִ�йٱ�ʾ�� Sora��Ȼ���˾�̾������û�����ö���������ȷ�Ľ�ģ������Sora�����߷dz����ǣ��ڲ��͵ļ������沿���ᵽ����һ�㣬�������IJ������ܺõؽ�ģ�� �����Զ����ڣ������������ӵ��������������������ڼ��û��������������еġ� |
|
|
��ʵ�ϣ�������δ�������һ���dz���Ҫ��ϸ����ǣ� ���ı�����Ƶ�����ɿ�����Ȥ�����ݲ�����ζ�ţ�Ҳ����Ҫ���������⡹�Լ����ɵ����ݡ�һ���ܹ������������������������ģ�ͱ��룬�������ڴ�ģ�ͻ���ɢģ��֮�⡣ |

|
|
��Ҳ�����ѱ�ʾ�����Ⲣ��������ѧϰ�ķ�ʽ���� �����Ƕ�����������ֻ�ǵ�һЩ���صģ����������е�ϸ�ڡ����ǻ�������ʱ���Ϊ������ģ��������ʾ��������Ϊ���Ǹ�֪����������������Ҫ�IJ����Ƿ������� |

|
|
�����˳ƣ�����Ȼ�Dz�ֵDZ�ڿռ��Ƕ�룬��ĿǰΪֹ�㻹���������ַ�ʽ����������ģ�͡��� |

|
|
Sora���Լ�V-JEPA����ܹ���������������ô���� �ο����ϣ� https://ai.meta.com/blog/v-jepa |
|
�����ܴ���Ƶ��ѧ��������������ģ���������ܹ⿴��Ƶ��ѧ����Ӿ�� https://www.zhihu.com/zvideo/1742667808507457536 |
|
|
| [�ղر���] �����ر��ġ� |
| ��һƪ���� ��һƪ���� �鿴�������� |
|
|
|
| ��Ʊ�ǵ�ʵʱͳ�� ��ͣ��ѡ�� ��ʱͼѡ�� ��ͣ��ѡ�� K��ͼѡ�� �ɽ���ѡ�� ����ѡ�� ������ѡ�� �������� �������� ���� MACDָ�� KDJָ�� BOLLָ�� RSIָ�� ���ɻ���֪ʶ ���ɹ��� |
| ��վ��ϵ: qq:121756557 email:121756557@qq.com ����ƻ� |