
| |
|
|
| ����ƻ� -> �Ƽ�֪ʶ -> OpenAI ȫ�·���������Ƶģ�� Sora��֧�� 60s �������ȣ�����Щͻ�ƣ���������ЩӰ�죿 -> �����Ķ� |
|
|
[�Ƽ�֪ʶ]OpenAI ȫ�·���������Ƶģ�� Sora��֧�� 60s �������ȣ�����Щͻ�ƣ���������ЩӰ�죿 |
| [�ղر���] �����ر��ġ� |
|
OpenAI�������ǵ�������Ƶ��ģ�ͣ�Sora�ˡ����� ���ң���ǿ����������һ����ij̶ȡ����� https://openai.com/sora ����� |
|
�������Ӣΰ��Ŀ���С��磬��˵��������Ҫ��ͻ�Ƶ㣬���� Sora ֤���� diffusion + ViT ����Ч�ԣ����������ҵij��������һ�¡� �Դ�Ϊ������������ʦ����дһƪ�����ʼǡ� ������Ƶ���ɵķ���Recurrent networks (RNNs)Generative adversarial networks (GANs)Autoregressive transformersDiffusion models ��ǰ�ķ���ͨ��ֻ�������ض����Ӿ�������̵ġ��̶��ֱ��ʵ���Ƶ��RNN �� GAN �ķ�������Ч��������������ӡ� LLM for Videos? Sora�����ã�OpenAI �����ŷ�����һƪ��������˵���ܵ�������ģ�͵�������Sora ���������Ƶ��Ӿ�������patches��ɶɶɶ�ġ� ƪ�����ޣ����ǵ������Ǵ����˵ģ�û���ᵽѧ����ĺܶ������ġ�ʹ���Ӿ� transformer ������Ƶ�Լ��ִ������뷨�������µĴ��⡣ |
|
|
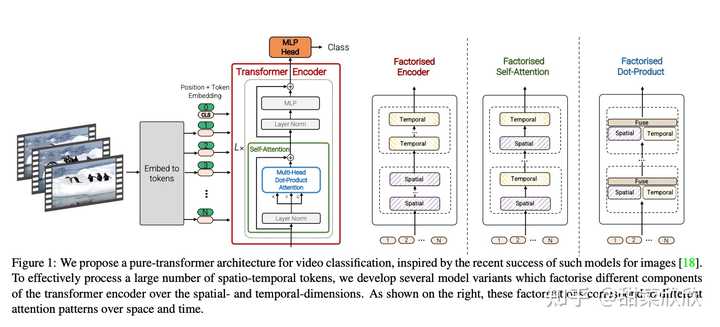
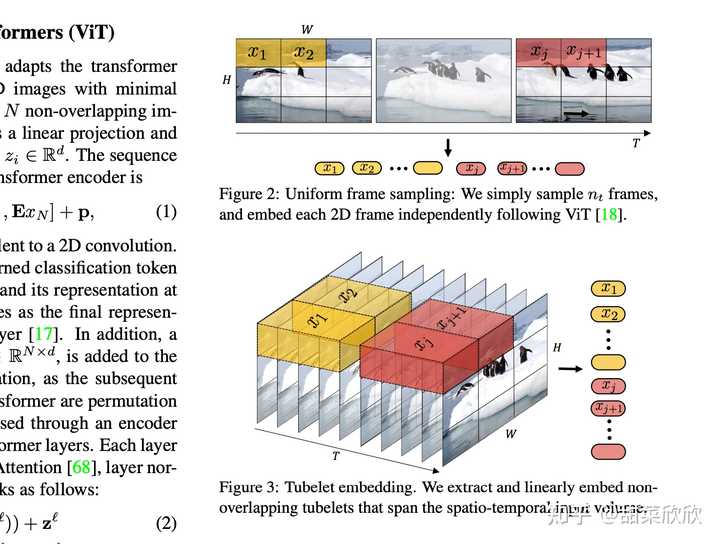
�ȸ���2021������� ViViT������һ�ֻ����Ӿ� transformer ����Ƶ����ģ�͡� ��ˣ�����Ӣΰ��� AI �о�Աѯ���� Sora ����ӱ֮������˵��ѧ���磬������Աһֱ������ ViT �� UNet �ܹ���������Ƶ����˭���á���������ViT �ƺ���Ϊ�����Ӿ��ܹ���ģ�ͣ����� UNet ��Ȼ����ɢģ������ռ��������λ���� DALL��E 2 �� Stable Diffusion��UNet �㷺Ӧ���������Ӿ�ģ�͡� 2023 �꣬�ȸ������ MAGVIT��ʹ��ͨ�ñ�Ǵʻ�Ϊ��Ƶ��ͼ�����ɼ���Ҹ��б������ı��롣 |

|
|
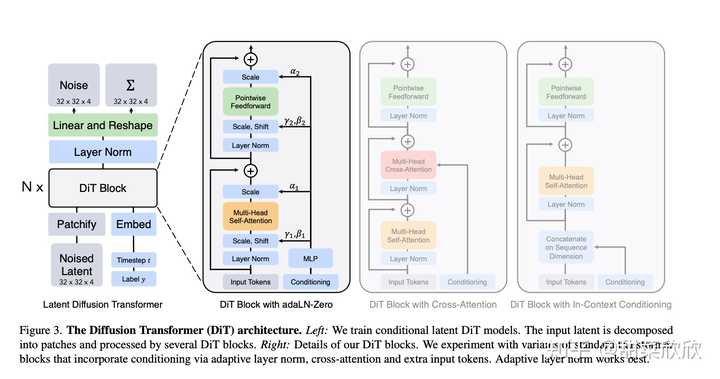
�ȸ�� MAGVIT ���ģ��������̵���ѧ�����ٸ�����˵ MAGVIT v2 ������Ϊ ��Language Model Beats Diffusion: Tokenizer is Key to Visual Generation��������������ǡ�������ģ�ʹ����ɢģ�ͣ��ִ������Ӿ����ɵĹؼ���������������ˡ�ս������ʵ�������ģ�ͺ��������ɵ��ȸ�� VideoPoet �У�����һ�������㾵ͷ��Ƶ���ɵĴ�ģ�͡� ������Ƕ���˵��Sora ֤���� DiT �ļ���·�������µ㻹�Ƿdz���ġ���������һ����DiT ��ɶ�� ����ṹ ���ġ�Scalable Diffusion Models with Transformers���������һ�ֽ� DiT ��������ṹ��������Ӿ� transformer �� diffusion ģ���ŵ㡣 DiT = VAE encoder + ViT + DDPM + VAE decoder |
|
|
ICCV 2023 paper proposes a diffusion model with a transformer Backbone. (https://arxiv.org/pdf/2212.09748.pdf) ���� DiT �� Sora �е�Ӧ�ã�DiT ����֮һ Saining Xie ���������ᵽ�� �� batch size ��С��صļ����Ƶ���Sora �����д�Լ 30 �ڸ������� ��ѵ�� Sora ģ�Ϳ��ܲ���Ҫ������Ԥ�ڵ�������� GPU����Ԥ��δ�����зdz���ĵ�������Sora�����ܻ�ʹ���˹ȸ�� Patch n�� Pack (NaViT) ���ijɹ���ʹ���ܹ���Ӧ�ɱ�ķֱ���/����ʱ��/�����ȡ�����Ƶѹ�� ���� Sora �ٲ�����Ƶѵ����ʱ��ѹ��Ϊ���յ�ʱ�ձ��룻Ȼ����һ��������ģ�Ϳ��Խ����ɵı��뷴������Ϊ�����ر�ʾ�ĸ�ʽ�� |
|
|
�ӹȸ�� ViViT ������͵��ͼ������һ�µ���ɶ��ʱ�ձ��� Saining �������ۣ��������������һ�� VAE �ṹ��������ԭʼ��Ƶ���ݽ���ѵ������ ��������Sora �ٲ�¶������ѵ����һ��ģ����������Ƶ��Ӧ����Ļ�����ģ�������� DALL��E 3 ���������������������� Sora ���û������ı�������������������Ƶ���������Ŷӻ����� GPT ���û��Ķ��ı���ʾת��Ϊ��ϸ�ı��⡣��д��ʾ�����ǵ��� AI ��Ʒ�ı����������ֺ��û�ָ���ģ����Ϊ֮��ĸ��ҡ�ѵ���������Dz²� Sora ��ѵ���漰�� 3d ���������Ⱦ������Ƶ���ϳ����ݵĹ㷺ʹ��һ���� Sora ��ѵ���з�������Ҫ���á�Sora ����Ƶ��ԭʼ������ѵ�����Ի�ø��õĹ�ͼ��ȡ����Takeaways Sora ֤���˴������漣�Ĺ���Ҳ��������Ƶ���ɣ�ʹ�� DiT ģ�ͺ� token ��������ʵ���˾��˵����ɽ�������ǿ�����Sora ��ƽ�ȵ��ƶ��������Ҳ�ܱ�������ǰ��һ�µ�ģ������ס�����������ʹ��Ƶ�е����廥���� Sora ��һ���ش���������ܹ������ܳ�����Ƶ������ 5 ���ӵ���Ƶ�� 1 ���ӵ���Ƶ�����ߵļ���·���dz���ͬ���� Sora ֮ǰ�о���Ա��֪��������Ƶ�����Ƿ���Ҫ����ض�??����������ӵ�����ģ������ Sora �������ǣ��˵��˵�ͨ��ģ��ѵ��������������Ƶ�����ɡ� ��Ƶ���ɵ�ͻ�ƻ������� 3D ���ɡ��Զ���ʻ�ͻ����˼����������������������ܹ�ģ���������硣 |

|
|
GAIA-1 ģ���ܺϳɸ��ֵ�·���Ӿ���Ϣ�������Զ���ʻ�����ģ��ѵ���� (https://arxiv.org/pdf/2309.17080.pdf) ��Ƶ���ɵ���һ����ս���DZ�ɣ���ν�������ۻ����⣬����ʱ������ƻ��ܱ�֤��Ƶ������һ���ԡ� ��Sora ��ʽ���ߣ��ڴ������ֲ���һ�£��õ�������ۡ� |
|
�Ҹо������ż�+���������Dz��Ǻܶ���˵�Լ��Ķ�ģ̬�� SOTA ���������������ɸ� 60s ���ȶ���Ƶ���ԣ�û����û���������� Runway �� 18s��20s ���ڣ���Pika �ʼ�� 3 �룬Sora ̧�־��� 60s������������Ŵ��С� ��һ�� Sora �ļ��������[1]���ɻ��ܶࡣ�Ҿ����ص㣺 Scaling Law ��Ȼ���ڲ�ֻ������ͼ������ƴ����Ƶ��������֡����Ϊ��Ƶ�༭ʹ�ø��������������磬����ģ�ͣ���Ƶ����ģ����Ϊ����ģ���� ���Ƕ��������Ƶ�����Ͻ��д��ģ������ģ��ѵ��������̽����������ԣ����ǶԳ���ʱ�䡢�ֱ��ʺͿ��߱ȸ�����ͬ����Ƶ��ͼ��������ı������µ���ɢģ������ѵ�������Dz�����һ�ֱ�ѹ���ܹ������ּܹ��ܹ�������Ƶ��ͼ��DZ�ڱ����ʱ�ղ�����������ǿ���ģ�ͣ�Sora���ܹ����ɳ���һ���ӵĸ�����Ƶ�����ǵĽ����������չ��Ƶ����ģ���ǹ���ͨ����������ģ��������ϣ����·���� ������������Ҫ��ע�����������棺��1�����ǽ��������͵��Ӿ�����ת��Ϊͳһ�ı�ʾ�������Ա���д��ģ����ģ�͵�ѵ������2����Sora�����������ƽ��ж���������ģ�ͺ�ʵ��ϸ�ڲ������ڱ������С� ������ǰ���о���ʹ���˸��ַ�������Ƶ���ݽ������ɽ�ģ������ѭ�����硢���ɶԿ����硢�Իع�任������ɢģ�͡���Щ�о�ͨ��רע���ض����͵��Ӿ����ݡ��϶̵���Ƶ��̶��ߴ����Ƶ��Sora��һ�ֶ��Ӿ����ݽ��й��彨ģ��ģ�ͣ����������ɿ�Խ��ͬ����ʱ�䡢���߱Ⱥͷֱ��ʵ���Ƶ��ͼ������Ƶ�ij��ȿɴ�һ���ӡ� ���Ӿ�����ת��Ϊ patch ���ǴӴ�������ģ���м�ȡ��У���Щģ��ͨ���ڻ�������ģ�������Ͻ���ѵ�������ͨ���������ɹ���LLM��ʽ��һ���̶��ϵ�����ʹ�����ܹ����ŵ�ͳһ�ı������롢��ѧ������Ȼ���Եı�ǡ���������У����ǿ����������Ӿ�����ģ����μ̳���Щ�ô�����LLMs�����ı���ǣ�Sora�����Ӿ���������ǰ�Ѿ�֤��patch��һ����Ч���Ӿ�����ģ�ͱ�ʾ���������Ƿ��֣�patch��һ�ָ߶ȿ���չ����Ч�ı�ʾ������������ѵ���������͵���Ƶ��ͼ�������ģ�͡� |

|
|
�ڸ߲���ϣ�����ͨ�����Ƚ���Ƶѹ���ɵ�άDZ�ռ䣬Ȼ��ʾ�ֽ��ʱ��patch��������Ƶ�� ��Ƶѹ������ ����ѵ��һ�����磬�����Ӿ����ݵ�ά�ȡ����������ԭʼ��Ƶ��Ϊ���룬�����һ����ʱ��Ϳռ��϶���ѹ����DZ�ڱ�ʾ��Sora�����ѹ����DZ�ڿռ��н���ѵ������������Ƶ�����ǻ�ѵ����һ����Ӧ�Ľ�����ģ�ͣ������ɵ�DZ�ڱ�ʾӳ������ؿռ䡣 ʱ��DZ�ڲ��� ����һ��ѹ����������Ƶ��������ȡһϵ��ʱ�ղ��������dz䵱�任�����ơ��������Ҳ������ͼ����Ϊͼ��ֻ�Ǿ��е���֡����Ƶ�����ǻ��ڲ����ı�ʾʹ��Sora�ܹ��ڷֱ��ʡ�����ʱ��Ϳ��߱ȿɱ����Ƶ��ͼ���Ͻ���ѵ����������ʱ�����ǿ���ͨ���������ʼ���IJ����������ʵ���С�����������������ɵ���Ƶ�Ĵ�С�� ��Ƶ���ɵ� Scaling transformer Sora��һ����ɢģ�ͣ���������������������Լ����ı���ʾ������������Ϣ��������ѵ����Ԥ��ԭʼ�ġ��ɾ�����������Ҫ���ǣ�Sora��һ��diffusion transformer��transformer �ڸ�������չʾ����������չ���ܣ��������Խ�ģ��������Ӿ���ͼ������ͼ�����ɡ� |

|
|
��������У����Ƿ���diffusion transformer����Ƶģ����Ҳ����Ч�ؽ�����չ�����棬����չʾ����ѵ��������ʹ�ù̶����Ӻ��������Ƶ�����ıȽϡ�����ѵ����������ӣ���������������ߡ� �ɱ�ij���ʱ�䣬�ֱ��ʣ�������� ��ȥ����ͼ�����Ƶ�ķ���ͨ���ǽ���Ƶ������С���ü����������ߴ� - ���磬256x256�ֱ��ʵ�4����Ƶ�����Ƿ��֣��෴��ʹ��ԭʼ�ߴ�����ݽ���ѵ���м����ô��� ��������� Sora���Բ�������1920x1080p��Ƶ������1080x1920��Ƶ�Լ�����֮����������ݡ���ʹ��Sora����ֱ����ԭ�����߱�Ϊ��ͬ�豸�������ݡ���������������������ȫ�ֱ�������֮ǰ������ԭ�ͻ��ϵͳߴ������ - ������Щ��ʹ��ͬһģ�͡� ���ƵĹ�ͼ�Ͳ��� ���Ǿ����Եط��֣�����ԭ�����߱���ѵ����Ƶ������߹�ͼ�Ͳ��ֵ����������ǽ�Sora����һ���汾��ģ�ͽ��бȽϣ����߽�����ѵ����Ƶ�ü�Ϊ�����Σ�����ѵ������ģ��ʱ�ij������������֮�£�Sora���ɵ���Ƶ�ڹ�ͼ���������ơ� �������� ѵ�����ı�����Ƶ������ϵͳ��Ҫ���������ı��������Ƶ�����Dz�������DALL��E 3����������±�ע������Ӧ������Ƶ����������ѵ��һ���߶������Եı�������ģ�ͣ�Ȼ������Ϊ����ѵ�����е�������Ƶ�����ı����⡣���Ƿ��֣��ڸ߶������Ե���Ƶ�����Ͻ���ѵ������������ı���ȷ���Լ���Ƶ������������ ������DALL��E 3�����ǻ�����GPT����̵��û���ʾת���ɸ���������ϸ�ı��⣬��Щ�������������Ƶģ�͡���ʹ��Sora�ܹ����ɸ���������Ƶ����ȷ�ظ����û�����ʾ���д����� ͼ�����Ƶ��Ϊprompt �������н�������ǵ�ҳ�涼չʾ���ı�����Ƶ��ʾ��������SoraҲ���Խ����������룬�������е�ͼƬ����Ƶ����������ʹ��Sora�ܹ�ִ�и���ͼ�����Ƶ�༭�����紴������ѭ������Ƶ������̬ͼ�����Ӷ���Ч��������Ƶ��ǰ������ӳ��ȵȡ� DALL��Eͼ���� Sora�ܹ����������ͼ�����ʾ������Ƶ�� ��չ���ɵ���Ƶ Sora�����Խ���Ƶ��ǰ������ӳ�ʱ�䡣 ��Ƶ����Ƶ�༭ ��ɢģ���Ѿ�Ϊ���ı���ʾ�༭ͼ�����Ƶ�ṩ�˴����ķ������������ǽ�����һ�ַ�����SDEdit��Ӧ����Sora�����ּ���ʹ��Sora�ܹ���������ת��������Ƶ�ķ��ͻ����� ƴ����Ƶ ���ǻ�����ʹ��Sora��ֵ����������Ƶ���Ӷ�����ȫ��ͬ������ͳ�����ͼ֮�䴴������ɡ� ͼ���������� Sora���ܹ�����ͼ������ͨ����һ��֡��ʱ�䷶Χ�ڣ�����˹�����IJ���������һ���ռ���������ʵ����һ�㡣��ģ�Ϳ������ɲ�ͬ�ߴ��ͼ����߷ֱ��ʿɴ�2048x2048�� |
|
|
ӿ�ֵ�ģ������ ���Ƿ��֣�����Ƶģ���ڴ��ģѵ��ʱ������չ�ֳ�һЩ��Ȥ��������������Щ����ʹ��Sora�ܹ�ģ���һЩ��������������ˡ�����ͻ�����ijЩ���档��Щ���Բ�û���κ���ȷ�Ĺ���ƫ�����������3D������ȵȣ����Ǵ����ǹ�ģЧӦ������ 3Dһ���ԡ�Sora�������ɾ��ж�̬������˶�����Ƶ��������������ƶ�����ת������ͳ���Ԫ������ά�ռ��б���һ���ƶ��� ����һ���Ժ����������ԡ�������Ƶ����ϵͳ��˵��һ����Ҫ����ս���ڲ�������Ƶʱ����ʱ���ϵ�һ���ԡ����Ƿ��֣�Soraͨ���ܹ���Ч�ؽ�ģ�̳̺ͳ��̵�������ϵ�����ܲ���������ˡ����磬���ǵ�ģ�Ϳ������ˡ���������屻�ڵ����뿪����ʱ��Ȼ�������ǵĴ��ڡ�ͬ������������һ������������ͬһ��ɫ�Ķ����ͷ������������Ƶ�б������ǵ���ۡ� �����绥����������ʱ����ģ������������Ӱ��Ķ��������磬���ҿ����ڻ��������³������ڵ��±ʴ�������һ���˿��ԳԵ�һ������������ҧ�ۡ� ģ���������硣Sora���ܹ�ģ���˹����̣�һ����������Ƶ��Ϸ��Sora����ͬʱʹ�û������Կ���Minecraft�е���ң�ͬʱ�Ը߱������Ⱦ���缰�䶯̬��ͨ����ʾSora�ᵽ��Minecraft���ı��⣬���Լ�����Щ������ ��Щ����������������չ��Ƶģ���Ƿ�չ���������������������Լ����е����塢����������ģ��������ϣ����;���� ���� SoraĿǰ��Ϊģ���������������ơ����磬����ȷģ�������������������ЧӦ�����粣�����顣��������������Զ�����Ҳ����������ȷ�ظı�����״̬�����������ǵ���ҳ���о���ģ�͵�������������ģʽ�������ڳ�ʱ�������г��ֵIJ������Ի������ͻȻ���֡� ��������Sora�������߱�������������������չ��Ƶģ���Ƿ�չ�ܹ�ģ���������硢���������Լ����е����塢������������ϣ����·���� �ο�^https://openai.com/research/video-generation-models-as-world-simulators |
|
ֱ�Ӹ���ҿ���Ƶ�Ͷ�Ӧ��Prompt�ɣ������бȽ�ֱ�۵����飺 ��Ƶ�٣�������ͷɢ����ʱ��1���� |

|
|
0 Prompt: A stylish woman walks down a Tokyo street filled with warm glowing neon and animated city signage. She wears a black leather jacket, a long red dress, and black boots, and carries a black purse. She wears sunglasses and red lipstick. She walks confidently and casually. The street is damp and reflective, creating a mirror effect of the colorful lights. Many pedestrians walk about. ��һ����Ƶ����һ������ʵ�������ǿ��������Ƶ������һ������ʷ���֡� ��Ƶ�ڣ����������֣�ʱ��10�� |

|
|
0 Prompt�� ��Several giant wooly mammoths approach treading through a snowy meadow, their long wooly fur lightly blows in the wind as they walk, snow covered trees and dramatic snow capped mountains in the distance, mid afternoon light with wispy clouds and a sun high in the distance creates a warm glow, the low camera view is stunning capturing the large furry mammal with beautiful photography, depth of field.�� ���ڶ���Ƭ�ε�������SoraҲ���Ը������˵��ʸУ����ǿ������С��ħ����Ƶ�� ��Ƶ�ۣ�С��ħ������ʱ��9�� |

|
|
0 Prmopt�� ��Animated scene features a close-up of a short fluffy monster kneeling beside a melting red candle. the art style is 3d and realistic, with a focus on lighting and texture. the mood of the painting is one of wonder and curiosity, as the monster gazes at the flame with wide eyes and open mouth. its pose and expression convey a sense of innocence and playfulness, as if it is exploring the world around it for the first time. the use of warm colors and dramatic lighting further enhances the cozy atmosphere of the image.�� ����������Ӱ����Ƭ�����ɣ����Ƭ�ε��ص��Ƕྵͷ�л� ��Ƶ�ܣ���ñ���Ա��ʱ��17�� |

|
|
0 Prompt�� ��A movie trailer featuring the adventures of the 30 year old space man wearing a red wool knitted motorcycle helmet, blue sky, salt desert, cinematic style, shot on 35mm film, vivid colors.�� ����ע����prompt�������о�ͷ�л������ԣ�������Ƿ�OpenAI������Prompt�Ƿ�����ʡ�ԣ� ������һ����ֽ�ĺ������磬��һ������ֽ����Ƭ�ĸо��� ��Ƶ�ݣ���ֽ�ĺ������磬ʱ��20�� |

|
|
0 Prmopt�� ��A gorgeously rendered papercraft world of a coral reef, rife with colorful fish and sea creatures.�� ����⼸���ɰ���С��ë��ë����������ѩ�����ɸ� ��Ƶ�ޣ�ѩ��С��ë��ʱ��20�룬 |

|
|
0 Prompt�� A litter of golden retriever puppies playing in the snow. Their heads pop out of the snow, covered in. Ŀǰ��OpenAI��û�п��Ų��ԣ�����ֻ�ܴ��������[1]�Ͽ�����Щ��Ƶ������OpenAI��X�ϵ��˺�[2]�� OpenAI�ڹ�������ȷ˵������Щ��Ƶ����ֱ�����ɣ�û�о����༭�ĵġ� All videos on this page were generated directly by Sora without modification. ��OpenAI��ʽ������Sora���ã����Dz�����������ֱ����ᡣ ����������Ȼ�������Ѿ���AIק���ˡ�������Ƶ����ʱ���� �����ʱ������ĵ�һҪ���ǣ����պ���Ȼ���ԣ������ĺ�Ӣ�ﶼҪѧ�á� ���ú�˼�����ѻ�˵�ã�ʣ�µ����齻��AI������仰������δ����ѧУ���ʦ�ǵĿ�ͷ���ˡ� ����ʽ��Ƶ�ĵ��������Ǹ�˫�н�����ζ�������Ϣ���浽���Ը��ӡ� ��Ȼ��AI������ƵҪ���ģӦ�ã�����Ҫ����������Դ��������ƿ������˶��������������̿��� ��������������Ƶapp��δ���ļ۸�Ҳ����̫���ˡ� Ŀǰ���������dzɱ��� ChatGPT Plus�˺�ÿ���������50��ͼƬ�����൱��50֡��Ҳ�����������Ƶ�� ÿ��������Ƶ�����Dz�������ҵ���ġ� ���һ�������˺�ÿ���������10�������ҵ���Ƶ��������һ������������ ����600�룬�൱���ֽ�300��Plus�˺ŵ����ͼƬ�������� ��300��Plus�˺�һ���µķ�����6000��Ԫ�� ���ԣ�OpenAI���кܳ���·Ҫ�ߣ����Dz�Ӧ�ý�����ע����Ƭ����������Ҫ��ע�ɱ����⡣ �������Ҫ����������������ס� �ο�^Sora - OpenAI https://openai.com/sora^OpenAI - X https://twitter.com/OpenAI |
|
60�볬����������һ���ر���ͻ�ƣ������ỹ�С�����Ƶ��ǶȾ�ͷ�� ����ǿ���������⣬�Լ���ʵ������������ĸ��֡� |

|
|
0 ���Ҹе���ԭ����������Ϊ������Ƶ��ʱ�����ȶ��ԣ���������Ƶ��չʾ����������Ͷ�����ʵ�����������ɵ����֣� һ��ֱ��Ӱ�� ����������Google�ոչ�����Gemni Pro1.5��OpenAI���ڼ���Сʱ����Sora�� |

|
|
Gemini1.5����100��token���������������������п�ģ̬������������ܹ����ı�������ͼ����Ƶ����Ƶ���и߶ȸ��ӵ������������ ��������1Сʱ��Ƶ��11Сʱ��Ƶ������30,000�д����700,000�ֵ��ı��� �ⶼ�����˾�̾�ijɼ��� ���ǣ�OPENAI����ͷ����Sora �Ĺ�������ը�ѣ������ھ۹����ȫ�۽���OPENAI�ϡ� ����Sora��Ƶ�� ��������һЩSora��Ƶ����Ч���� |

|
|
0 |

|
|
0 |

|
|
0 |

|
|
0 |

|
|
0 |
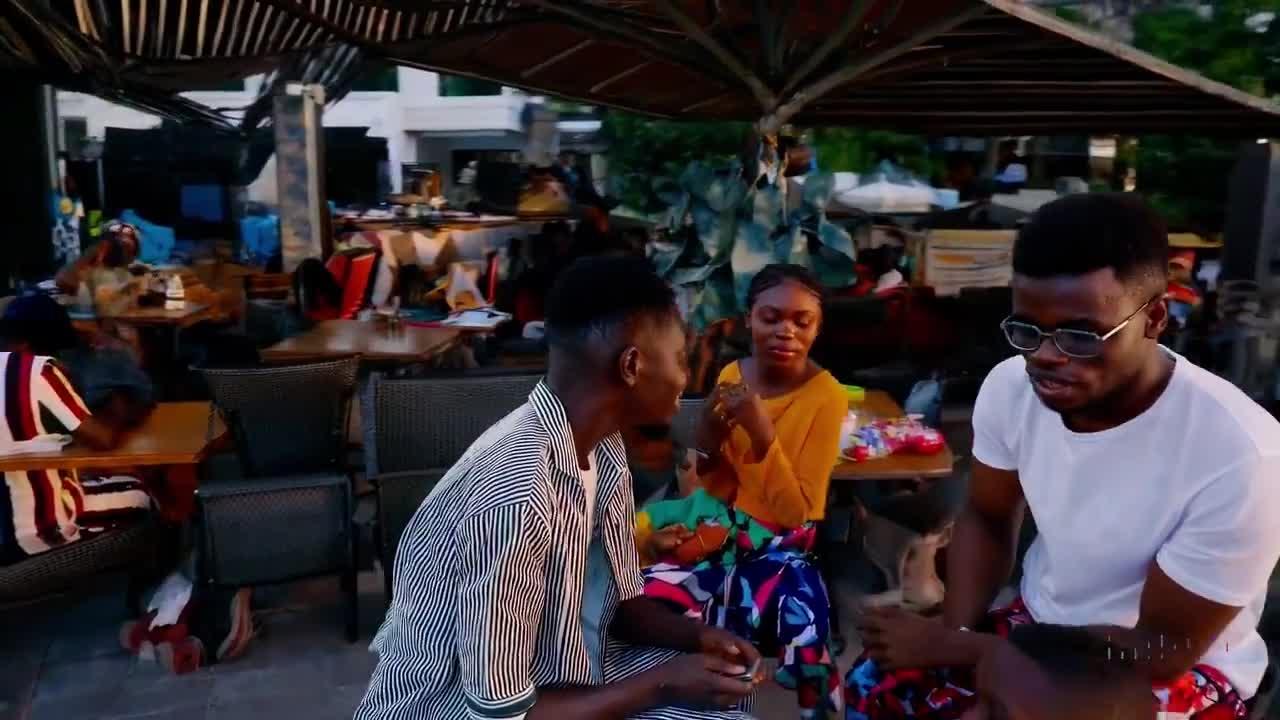
|
|
0 |

|
|
0 |

|
|
0 �ҿ���ĸо�ֻ��һ���������ˣ� ����ͻ�ƻ��ǻ��� ���������������Sora����չ�ֳ���ը��Ч������ʵ���Ч���ɹ����Ǻ����ټ��� �����ӿ��µ��ǣ������ֻ��OPENAIĿǰӵ��������������������֪���IJ��֡� |

|
|
Soraģ��֮�����ܹ�չ�ֳ�Խ�����ܣ��ܴ�̶��ϵ�����OpenAI�����˾���������˹�������������ϸ��������ChatGPT��DALL��E�ȸ������͵��˹����ܲ�Ʒ�Ĵ��¼����� ��Щ����������ֱ��Ӧ�ã��䱳���˼·�ͷ���Ҳ�����Sora���������������롣 OpenAI��������һ�����������ĸ���������������������ƽ̨���ٴδ���µĸ߶ȣ��Ӷ���Ϊ������һ������Ҳ���ɼ��ĸ߶ȡ� |

|
|
�������ҳ�Խ�ʹ��µ�����������OpenAI�ܹ����˹���������������ȵĹؼ��� ���֮�£������ǹ��ڻ��ǹ����ϵ������������֣����ı������ı����ı�����ͼ��ȼ����Ͽ��ܴ��ڲ�ࡣ���ֲ����ܻᵼ��������δ���ľ����������ࡣ ��ˣ���ν�ġ����ֻ��X���¡�����ֻ��һ�����Ұ�ο��˵��������ν�ġ��������������ʵ�п�������ʵ�֡� ����Ӱ��1.���� ������������������OPENAI�������ĵ���Sora�ܸ�Щɶ�� ���ģ��Ƶ����ѵ����Soraģ��ͨ���ڲ�ͬʱ�����ֱ��ʺͿ��߱ȵ���Ƶ��ͼ���Ͻ���ѵ����չʾ���ڴ��ģ���ݼ���ѵ������ģ�͵������� |

|
|
�Ӿ����ݵ�ͳһ��ʾ��Sora�����������ڴ�������ģ�ͣ�LLM���ķ��������Ӿ�����ת��Ϊ�ռ�-ʱ�䣨spacetime��������patches������Щ������Ϊģ�͵ġ��Ӿ���ǡ���visual tokens����ʹ��ģ���ܹ���������������Ƶ��ͼ�� |

|
|
A Shiba Inu dog wearing a beret and black turtleneck. ��Ƶѹ�����磺Soraʹ����һ����Ƶѹ�����磬��ԭʼ��Ƶѹ����һ����άDZ�ڿռ䣬������ֽ�Ϊ�ռ�-ʱ�䲹������ʹ��ģ���ܹ���ѹ����DZ�ڿռ���ѵ����������Ƶ�� |

|
|
��ɢģ�ͣ�Sora��һ����ɢģ�ͣ���ͨ��Ԥ�����������������noisy patches����������������Ƶ������ģ�������Խ�ģ��������Ӿ���ͼ�����ɵ������Ѿ���ʾ������������չ�ԡ� |

|
|
��Ƶ���ɵ�����ԣ�Sora�ܹ����ɲ�ͬ�ֱ��ʡ����߱ȵ���Ƶ�����ҿ���ֱ��Ϊ��ͬ�豸�������ݣ���������ݴ���������ԡ� �����������ı���ʾ��Soraͨ��ѵ���߶������Ե���Ļģ�ͣ��������Ƶ���ɵ��ı�ȷ�Ժ����������������ܹ������û��ļ����ʾ������ϸ����Ļ���Ӷ����ɸ���������Ƶ�� |

|
|
ͼ�����Ƶ�༭��Sora�����ܹ������ı���ʾ������Ƶ�����ܹ���������ͼ�����Ƶ���б༭��ִ����ѭ����Ƶ��������̬ͼ��������Ƶǰ����������� |

|
|
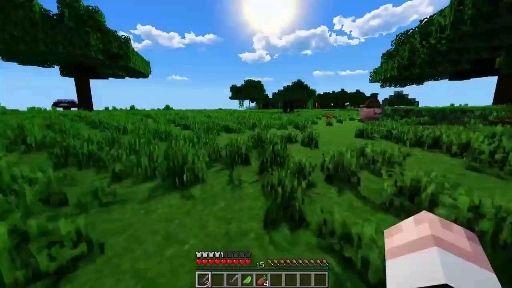
2.ģ�� Sora�����üķ�ʽʵ����ʵ��������״̬ģ�⡣ �����ڻ����У�һ�����ҿ����ڻ����������µıʴ���������ʱ������ƶ��������ֻ�����һ�����˿��ԳԺ���������ҧ�ۡ� Sora���ܹ�ģ���˹����̣����������Ϸ��Sora������һ����������ͬʱ���ơ��ҵ����硷�е���ң�ͬʱҲ���Ը߱������Ⱦ���缰�䶯̬�� |
|
|
0 Ŀǰ����һЩ�Ӿ������ҡ����ʦ�͵�Ӱ�����ˣ��Լ�OpenAIԱ���������Sora����Ȩ�ޡ� 3.���� ����Sora��Ȼ������һЩ�����ԡ� ������ȷ��ģ�������������õ��������̣����粣�����飻����������ã������ʳ�����������Sora���������ܲ�������״̬����ȷ�仯�� |

|
|
OPENAIҲ���������о��˸�ģ�͵�������������ģʽ���糤ʱ�������г��ֵIJ���ɻ������Է����֡� Sora�����������������Ƶģ�͵ij�����չ�ǿ������������������Լ����������е����塢������˵�ǿ��ģ������һ������ǰ;�ĵ�·�� 4.δ�� ����Ϊ��δ������SoraΪ������������Ƶģ�ͣ����������·���Ը���ҵ����Ӱ�죺 ���ݴ����ĸ��£����ɶ���������Ƶ�����ܹ�Ϊ��Ӱ����Ϸ��������ҵ�ṩ�µ����ݴ������ߡ� ����ʽý�壺Sora�������������ڴ�������ʽý�����飬������û�����ʵʱ���ɻ�����Ƶ�� |

|
|
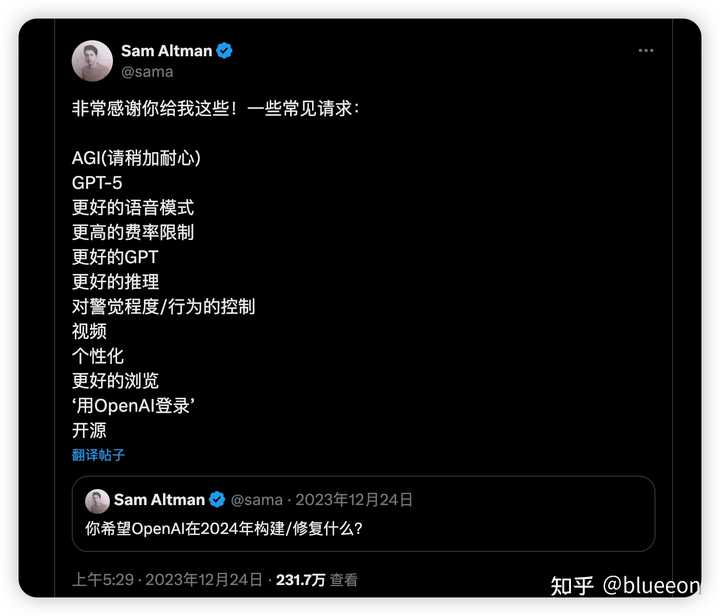
��������ѵ���ڽ�������Sora��������ģ�⸴�ӳ������ṩ����������ѧϰ���ϡ� ���ֲ�ҵ��Sora�������ڴ����µ�������ʽ����������ʵ����ǿ��ʵ���顣 ��ѧ�о�����ģ����������ͻ������棬Sora���Ը�����ѧ�ҽ����о���Ԥ�⡣ ���� AGI��δ��������IJ�Զ��! ���ǵ�����ģ�һ����AI�滭���˹�������ǿ����Ȥ����ҵ����� ���ʦ��������ҵ��������ݸ���Ȥ�����æ��ע�����ղأ�лл�� |
|
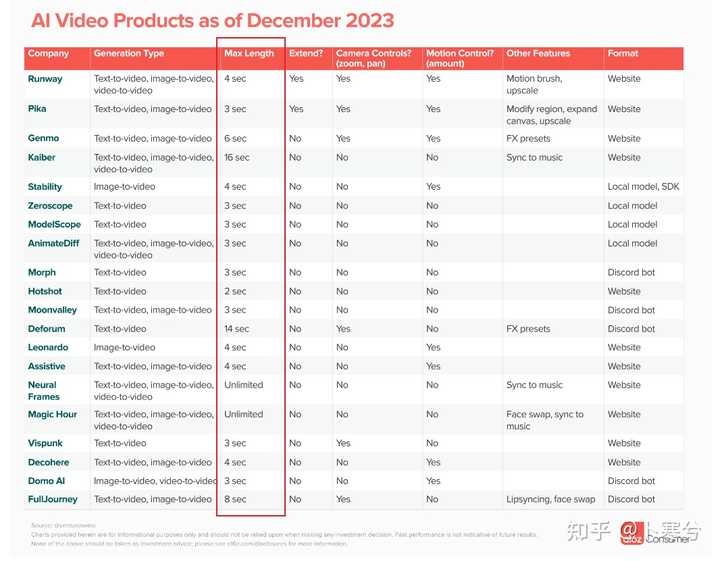
Sora ������Ƶ�����ܴﵽ���Ӽ��𣬵�ȷ���˸е��� �ж���У�������������ͼ����Դ��������ᵽ�ˣ����ǹ�ȥһ��Ƚ���Ҫ�� AI ������Ƶģ�ͣ����а���֮ǰ�ʹ���RunWay��Pika �Լ� Stability �� SAD �ȡ� ��Щģ�ͻ������ɵ���Ƶ���������ʮ���롣 |
|
|
��ʮ���뵽һ���ӣ����ѶȲ����Ǽı�������ˡ� ���� AI ��Ƶ���ȵ����ش����Ͽ��Է�Ϊ�������档 1��������Դ����Ҷ�֪������AI�������ɻ�����ά��ͼ�������Ѿ�Ҫ�ȴ����ı�������Ҫ����ļ�����Դ������Ƶ���������Ķ�֡ͼ����ɵģ�������Ƶ����Ҫ�ļ�����Դ�ֻἸ�μ��������ӡ����ɼ����ӵ���Ƶ���Ѿ���Ҫ���Ĵ���������Դ�������ɸ�������Ƶ����Ҫ�����ģ�ļ�����Դ��֧�֡� ������������ѵģ��Ͼ�������Դ����ͨ��Ǯ�������С��˾�治�𣬻��Ǵ��ء� 2�����������Ժ����ԡ� ����������Ƶ�������ȼ�����Դ���ؼ�����������Ƶ��ʱ�������Ժ����Ե�ά���� Ҳ��˵���ȷ�������Ԥ��������˶��ͱ仯����Ҫʱ�������ᣬ��Ҫ��������������ɣ�����ܱ�֤���ɵ���Ƶ�DZ���ġ�����̨������һ֡�������Ϲ�������һ֡�ͷɵ�����ȥ�ˡ���������ѧ�Ͳ������ˡ��� |

|
|
�����ܹ����⸴�������ṹ������ϵ��������Ƶģ���Ƿdz����ѵģ�����ʱ��Խ����ά�����������Ժ����Ծͻ�Խ�ѣ����������ڶ�δ����Ƶ֡���ݵ�Ԥ���ϣ��������ڶ��ڴ���������ϡ� OpenAI �� Sora �ļ������棨���ӣ��н�����Sora�����õļ���·�ߣ����˼·��Ŀǰ�������õķ���������û�б������� Ҳ���ǰ�ͼ�����ݿ��ɶ��patches��������LLM�е�tokens��������patches�ı����ǿ���չ�Ժͱ����������涼����Ч���������ڲ�ͬ���͵���Ƶ����Ƶ��ѵ������ģ��ͼƬ�� |

|
|
Sora��һ������Transformer����ɢģ�ͣ�������������ɢģ�͵Ĺ������̣��������� patches �Լ��ı���ʾ�ȵ�����Ϣ��Ϊ���룬ģ��ͨ��ȥ��������Ԥ��ԭʼ��patches��ͼ�� |

|
|
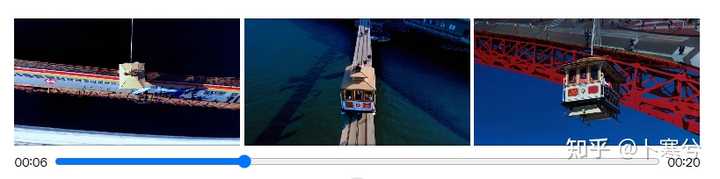
OpenAI�ڼ����������ᵽ��һ����չ������Ƶ��Extending generated videos��������ʹ�� Sora �߱�һ����ص�����������������Ƶ��ʱ��������ǰ�������չ�������ڹٷ���ʾ��һ�������У��м��β�ͬ����Ƶ�����Ǵ�һ�����ɵ���ƵƬ�ο�ʼ�����չ�ġ����ĸ���Ƶ�Ŀ�ʼ������ͬ��������������ͬ�Ľ�β�� |
|
|
|

|
|
���ô˷�����ǰ�������չ��Ƶ�Բ����������ѭ���� ������������ ������ݣ� |
|
�Ի������û���˵ Soraһʱ���ͷ����������ʱ�䷢����Google Gemini1.5�����Դ���100���token��ţ�ƶ����������ˮ������Sora���̫�ࡣ �ֵ�����������Sora�����˹�ȥ��������ʱ���ڲ���ʹ���ϣ����Թ�ע�����ͣ�ֱ���ſ�ʹ�ú������ڶ����� |

|
|
����������Ƶ����ͬ����˵ OpenAI��ֱ��AI���ͬ��ɱ�֣���һ���Ŭ�������ɵ�4������Ƶ�б���һ���Ե�ʱ��Soraֱ�Ӹ���ɵ�1���ӡ� ����Runway��Pika�ȵȣ�����һ���ó����ȽϵĻ����ӷų������������濴��SoraҪԶԶǿ��������������Ƶ���ɹ��ߣ�������60s�ij��ȣ�����Ƶ��Ƕ��Լ�����������������⡣ SoraPikaRunway�����ı�����Ƶ��רע����ʵ�ġ�����Ϊ���ĵĽ��ͼ����Ƶ�����ж����ͷ��Ǩ�ƹ㷺����Ƶ�༭������AI���������ɹ��߳���ʱ�䳤��60��3��4�빦���Էdz�ǿ��̫ǿ���൱ǿ������ģ̬��Ҫ���ı���ʾͼ����ʱ�����ı�ָ��ͼ����Ƶ���ı�����������������ּ��ʵ����ʵ������ӷ���������Ķ����㷺�ķ�Χ���ӷ����Ƭ����ʵ��ȡ����ʹ�õĹ���������δ���������ڴ������ӻ�������ʱ���ܲ�̫�ɹ����ܸܺ��ӣ���ҪһЩ��Ƶ�༭֪ʶ��Ҫ������ʵ���壬����������Ϊ���ӳ��������ԵĶ�����̬ͼ���Ч������ԣ�ȫ�����Ƶ�༭���߱�AI���ܶ���AI��ҵ����˵ AI�ȶȻ�������֣���һ��ʱ���ڣ���Ƶ���������͵Ĺ���������࣬ͬʱн��ˮƽҲ��ܲ������������Ǻ��¡� ��֪������������Ƶ����������н�dz��dz���������Ľ�� ����AI��ҵ����˵ ���˻�ϲ������ Sora��Ч�����ܻ���������˶�����Ƶ��������Ĺ�ע��Ͷ�ʣ�������Ͷ�ʱ���ǰ���£��϶����м��ҹ�˾Ҳ����һ����Ͷ�ʣ������ڲ��㻵���� ����Sora��Ч���ƺ��е��̫�ã��ܿ��ܻᵼ�±����ôҲ���ϣ����˱���̭�� ����Ҫ��AI��ز�Ʒ������˵ �ձ����OpenAI�������û��ѹ·������֪��ʲôʱ����һ�����У�Ȼ���ij��·���ϵ�ͬ��ȫ���������� ������ͨ����˵ �������Ǻ��£���ζ�����ǿ�����AI�������ֺ�ͼ��֮��Ҳ������AI�����ɲ�������Ƶ�ˡ� ��Ҫ�����뷨���ж������Լ���һ����AI���ɵĵ�ӰҲ���Dz����ܡ� AI����̨���㵨������� |
|
һ����������OpenAI �� Soraˢ���ˡ����˹�������ʾ��Ƶ��Ч��̫�������ˣ���ֵ�ñ�ˢ���� sora��ͻ�� ��������Щ��ʾ��Ƶ��ֵ�÷�����ĥ����ʾ��Ƶ��������ӡ����̵��м��㣺 ��Ƶ�ij��ȣ���ʾ��Ƶ�1���ӣ��Ӵ���Ƶ�����������ʱ�����ܲ��������ʱ���� ��Ƶ�ijߴ磺��Ƶ�ijߴ�dz�����������������Ӧ�о��С������Ժ�һֱ�ԣ��ܶ���Ƶ���ж���־���ÿ���־����ϸ����Ȼ�õ��˺ܺõı��֡����������A movie trailer �����Ƭ���á�A movie trailer����һ��Prompt�����ɵ�17����Ƶ�����������10���־��������ܼ������ֻ���һ���ԡ�̫���ˣ� �Լ���Ƶ�����������ɵ���Ƶ�ķֱ��ʸߴ�1920?��?1080��������pika����256x256�ֱ��ʣ�pika֮���ֱ��ԭ��ȥ����ζ��ʲô�� ����ͨ�˺ʹ����ߣ���������������Ҳ��������ý��ı������ Soraһ�������е���Ƶ�ˡ���Ӱ�˶��¸ڣ� ��������ϣ�AI��ķ����֣�OpenAI ������AI����ͨ�����˽�AI���½�չ����ȫ����Ҫ��������AI����ʡ�����Ծ��ǣ�����רע������OpenAI�� �Դ�ҵ�ߣ� ����ڴ�ҵ������Ŀ��openai�п����ص���������ã�����ȫ������ ��Ƶ��������ֻ����������б�������������ô��ǰ��һ���������� |
|
|
ɽķ������ȥ������������ռ����û��������رܣ����� ����һ��������Ⱥ���̾�� �ܶ����㷨��ѧ�Ҽ�ʮ��ľ�����ۣ��ڴ������漣�����������ݵı�����ѧ��ǰ����������ʱ��Ͷ��ȡ�ɡ����ջ��Ǻ컨һ���������ǣ��������ĺ�����û��Ϣ����ʱ������Ԥ��û�С�sora��ʵ�� ���ٿ�����Tenical Report��sora��������һЩ�㣺 sora��������Ƶѵ���������Ļ�����Ԫ��Patches����������ģ���õ�tokens��ͳһ��Ȼ����/�������ѧһ����soraѵ�������õ� patches Ҳͳһ����Ƶ��ͼƬ��ͼƬ��=��֡����Ƶ���Ӵ�ͼƬ����Ƶ��ͳһ�ˣ���ǰOpenAI Dalle-3������ͼƬ���ݶ����Ա�����ѵ������˼·��ܻ���transformer+diffusion������ѵ��һ��encoder������Ƶ��ʱ��Ϳռ�2��ά����ѹ������ά���ռ�����Ŵ����ռ�����ȡ��һϵ��ʱ��patches���е���ѵ��û����ȷ�ᵽUnreal engine��game engine�����Dz��ų����ռ����õ���NeRf����Gaussian splatting��3D������������Ч�ر������塢��������ͷ֮��Ĺ�ϵ��Ŀǰ�Ʋ�Ч���õ�2��ԭ�������Ǵ�����ע�õ�ͼƬ����+scaling law��ȥ��pika��ͨ�������Ƶ�ߴ��С������ 256x256 �ֱ��ʵ� 4 ����Ƶ������ѵ�����졣��sora�õĶ���ԭ�ߴ���Ƶ������1920x1080p ��Ƶ���ߴ�ֱ 1080x1920p��60s��Ƶ���ô����ڲ���������ͼ���á�������ܿ�Ҳ���Ϊ��Ƶ���ɵ��·�ʽ������飿 ���ڹٷ����ڽ��ж��빤����ֻ�������������Ӿ������ҡ����ʦ�͵�Ӱ�����˷��ʣ����а�ȫ���ԡ�����Ψһ�п������鵽sora�ķ�ʽ������ȥ�����������������ԣ�CEO���ߵ������ˣ�����������Ƶ������ |
|
|
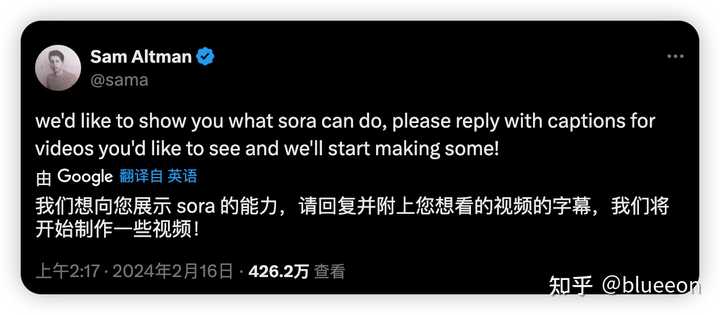
��������������дprompt������Ƶ |
|
�������������˲���ai��ҵ�ߣ�ֻ���û��Ƕ�̸̸�ҵĸ��ܡ� ������һ��ai������չ��ʲô�̶��ˡ� |

|
|
�����������и�������ai������ �����Ѿ����������������Ե�С�����ˡ� ���Կ�������¼Ϊ����������96w�ιۿ���6500С���ġ���2��13���ϴ�����Ʒ���� |

|
|
|

|
|
|

|
|
�ϴ��߷����������ĸ�̾�� ����ai�Ѿ���չ�����̶ֳ����� һ����ͨ��+һ̨4090�Կ��ĵ���һ��������ɸѡ50�����õ�ͼ������ 12�����������590ҳ�ij������ӡ� ������˹���,�Գ��M��ʦΪ����590ҳ��������IJ����� ͬ��������sora����������60s����Ƶ��ֻҪ������ɣ��˹�ɸѡ��ϡ�������ϳ�24 30���ӵ���Ƶ���൱��δ����������ƻô�Ƭ�����п�����ai��������� ����˵����д��С˵�����㼸�����֣������Ժ�ֻ��Ҫһ���Կ��������ˣ�������ɶ������� ������������������¼��3��ﵽ��������ɼ���������������£����ܻ���10���ĵ������� �����Ǻܶ�����ӣ�10���ĵ�����Ҳ�Dz���ġ� Ҳ����˵��Ŀǰ��ai�����Ѿ���չ���ˣ�����ƥ��ͷ�����������ij̶��ˡ� ����Ԥ�����ǣ�δ����Ƶ����Ҳ���60s���120s 240s��������ʮ�����ӡ���������£�ֻҪ�˹�ɸѡɸѡ��ai���ܴ���������������Ʒ�� һ��һ�ƻô�ƬҲ���Dz����ܡ� |
|
2��16���賿��OpenAI�ذ���Ϣ����������������Ƶģ�� Sora�� �ݽ��ܣ�Sora ����ֱ���������60�����Ƶ�����Ұ����߶�ϸ�µı��������ӵĶ�ǶȾ�ͷ���Լ�������еĶ����ɫ�� ������������ӣ� �ڶ�����ͷ��һλʱ�ֵ�Ůʿ�����ڳ�����ů��ƹ�Ͷ��г��б�־�Ľֵ��ϡ� |
|
|

|
|
�� Sora ���ɵ���Ƶ�һλŮʿ������ɫƤ�¡���ɫȹ�������ͷ���ߣ�������Ƶ�����ȶ������жྵͷ���Ӵ�ֵľ�ɫ���������뵽Ůʿ���沿��д����ʪ�Ľֵ����淴����ƵĹ�ӰЧ���� Ŀǰ��OpenAI�������Ѿ�������48����Ƶ������Щdemo�У�Sora�����ܹ�ȷ��������������ϸ�ڣ������ܹ��������⣬���ɾ��зḻ��еĽ�ɫ��Sora �����Ը���prompt�������Ƶ�е�ȱʧ֡��������Ƶ�� ���� OpenAI �Ľ��ܣ�Sora ��һ����ɢģ�ͣ�����ȥ������У��������������������Ƶ��ʼ��ͨ�����������ȥ�룬��ƵҲ��������������ת��Ϊ������ͼ����Sora ʹ����Transformer�ܹ��� �����ݴ������棬OpenAI ����Ƶ��ͼ���ʾͳһΪpatch��������GPT�е�token�� ͨ������ͳһ�����룬�����ڱ���ǰ���㷺��cv������ѵ��ģ�͡� ������������Щ����ʦ����Ƶ�����߽����кܴ�ij�����ز���վҲ������ؽ�Ҫ���κ��˶����������������ŵĶ���Ƶ�����������ϳ���Ŵ���AIд����δ�����Ǵ���AI����Ƶ�� |
|
���̫ǿ�ˡ�������Ƶһֱ�� AI ��رȽϿ��ŵ�һ��Ӧ�ó��������� OpenAI �� SORA ֮ǰ���о����������ԵĶ̰塣 ����֮ǰ����� pika����ȻЧ��Ҳ�ܲ���������ֻ�� 3 ���ӡ�3 ���ӵ���Ƶ�ô��DZȽ����ģ�Ҫƴ�ӳɳ���Ƶ����Ҫ�������ܶ�Ĺ����Ҷ������Ƶ��һ������ʵ��������ô�ñ�֤����� OpenAI ֱ�Ӱ�ʱ�������� 60 �룬�Ѿ����� cover �dz�����ҵ��Ƶ��ʱ����Χ�ˣ���ô����ʱ����ʹ���ߵĽ�ɫֱ�Ӵ�ƴ���߱���˼����ߡ����� OpenAI �Լ�����һЩ���ӣ���������Ƶ�л����г��ִ��ҵ���������Ͼ��������ǣ����Խ��м�����������˸���ö�Ĵ������ɶȡ� �ڶ���Ч��ʵ����̫ţ���ˡ�����ҵ�����Ƭ���ǻ��⾰�Ͷ�����ͷ�����������Ǹ���Ƶ����Ȼ��һ���ǻ������ij��������Ż���������������ȫ����Ȼ���Ĺ�ѧ���Դ�����ٱ�Ϊ���⣬�Ӵ��⾰ɫ��ʼ���ɵ����ڵľ���������̶�������˵�dz���Ȼ�����һ��ǵ�һ�ο����� AI ���ɵ���Ƶ�̻������ϸ��ı仯��������ͷ�����Ǹ���Ƶ������Ļ�ˮ��Ӱ�Ĺ�Ӱ��ʷ׳ʣ��dz����棬���Ҹо�������Ӣΰ���������Ƭ�� ����һЩ������ģ�͵ķ��������Ѿ�д�˺ܶ��ˣ��ܽ������������֣�ţ�ơ� �� 22 ������֣��� 23 ���ͼƬ���ٵ� 24 �����Ƶ������ʵ��Ƶ����Ҳ�Ѿ��������ˣ���AI ����Ѿ�������̫�ࡣ�о�����ǰ����ȥ����ʵ�ʵ�Ԫ����ܿ��Ҫӭ������ˡ� |
|
|
| [�ղر���] �����ر��ġ� |
| ��һƪ���� ��һƪ���� �鿴�������� |
|
|
|
| ��Ʊ�ǵ�ʵʱͳ�� ��ͣ��ѡ�� ��ʱͼѡ�� ��ͣ��ѡ�� K��ͼѡ�� �ɽ���ѡ�� ����ѡ�� ������ѡ�� �������� �������� ���� MACDָ�� KDJָ�� BOLLָ�� RSIָ�� ���ɻ���֪ʶ ���ɹ��� |
| ��վ��ϵ: qq:121756557 email:121756557@qq.com ����ƻ� |