
| |
|
|
| 首页 淘股吧 股票涨跌实时统计 涨停板选股 股票入门 股票书籍 股票问答 分时图选股 跌停板选股 K线图选股 成交量选股 [平安银行] |
| 股市论谈 均线选股 趋势线选股 筹码理论 波浪理论 缠论 MACD指标 KDJ指标 BOLL指标 RSI指标 炒股基础知识 炒股故事 |
| 商业财经 科技知识 汽车百科 工程技术 自然科学 家居生活 设计艺术 财经视频 游戏-- |
| 天天财汇 -> 科技知识 -> 为什么openai可以跑通所有AGI技术栈? -> 正文阅读 |
|
|
[科技知识]为什么openai可以跑通所有AGI技术栈? |
| [收藏本文] 【下载本文】 |
|
是有什么新型的组织管理形态,还是有人才,有钱,有数据的先发优势,还是对AGI的信念感? 当初pika和Midjourney的时候,大家会觉得,AGI时… |
|
大家一直高估人才和钱的重要性 低估管理一堆人,处理内部矛盾的重要性 大公司有时候不是做不到,而是你要做这事情,能短时间聚焦同一个体量资源,和力量去做,远比技术本身还难 创业公司初始内部认知高度一致是更加有凝聚力的,而且openai也太能圈钱了 反而大公司宫斗很厉害的,Google一样有阿里的毛病,字节大了内部嫡系太子党羽一样可以限制某些事情认真执行 国内讯飞和百度是老板要做的,所以阻碍少,但是公司发展不行老板意愿再好也做不到更好,字节阿里都是技术先去探路然后报给老板,老板看价值才算一个投入产出比去做的,后者是有很多矛盾需要处理的 比如老板很多时候需要思考,你今年高绩效,到底是倾斜给了抖音,还是倾斜给大模型 但凡搞不好派系问题,跑几个人到竞争对手那边那就惨了 总是很多人觉得,我要做就立马能做,往往太过单纯了。。 |
|
尽管问题提的不是很准确,但如果要将错就错地讨论的话,我觉得最核心的是: 对 Transformer 的理解,真正大一统的 Anything to Anything Foundation Model,Transformer is all You Need对 Scale Law 的信仰,力大砖飞,如果智能不够大,一定是数据不够多,Scale it Up!对高质量数据的追求,对智能的压缩表示,对 RLHF 的探索团队的 Vision,领袖的 insight 至于其他的因素,人、钱、算力,很重要,但其他公司并不是做不到。以下是展开论述。 首先,AGI 是个比较玄乎的东西,没有明确的定义和评判标准,所以谁也不知道现在的道路是不是 AGI 的正确道路,也许真正等到 AGI 实现的那一天回头看,OpenAI 曾经把大家带进了坑里,甚至 AI 会在某个节点再卡柱一段时间。 现在大家对 AGI 的认识一般是 human-level intelligence: 在 OpenAI 的章程中[1],他们对 AGI 的定义是:highly autonomous systems that outperform humans at most economically valuable work(能够在最具经济价值的工作中超越人类表现的高度自治的系统)。 马库斯对 AGI 的定义则是[2]:any intelligence (there might be many) that is flexible and general, with resourcefulness and reliability comparable to (or beyond) human intelligence. (任何灵活、通用的,其智慧和可靠性相当于或超过人类)。 所以从这个角度上讲,OpenAI 并没有所谓「跑通所有 AGI 技术栈」,但 OpenAI 似乎的确断崖式的强,拳打 Google,脚踢 Meta,每次都能端出真正 SOTA 且长久霸榜的产品。 Transformer is All You Need 回归到大家当初对 GPT-4 和 Q* 的讨论,尽管不知道是否正确,但大家最后的结论一般是,OpenAI 没有银弹,和大家走的路没什么不一样。 但 OpenAI 的成功在于,坚持走(目前看来、结果看来)正确的路:大一统的 Transformer。Ilya 不止一次在各种场合表达过他对 Transformer 的看法: |

|
|
预测具有不确定性的高维向量是一项挑战…但我发现有一件事让人惊讶,或者至少在(LeCun)论文中没有得到承认,那就是当前的自回归转换器(autoregressive transformers)已经具备了这个性质。 我给你举两个例子。第一个是给出一本书中的一页,预测书中的下一页。会有非常多的可能性。这是一个非常复杂的高维空间(high-dimensional space),而它们处理得很好。这同样适用于图像。这些自回归转换器(autoregressive transformers)能在图像上完美运行。 例如,和对OpenAI一样,我们也对iGPT开展了工作。我们只是采用了一种转换器(transformer),并将其应用于像素,它就可以运行得非常好,能以非常复杂而微妙的方式生成图像。对于Dall-E 1,相同的情况再次发生。 再看,即便是最新发布的 Sora,底子依然是 Transformer 没有变,而且他们直接说了,就是像训练 LLM 一样训练视频模型,就是把视频压缩成 patch(= LLM 的 token)交给 Transformer,然后用 Diffusion 生成。 |

|
|
方法论简单到有人在调侃,只看报告 Sora 拿到顶会上会被拒稿: |
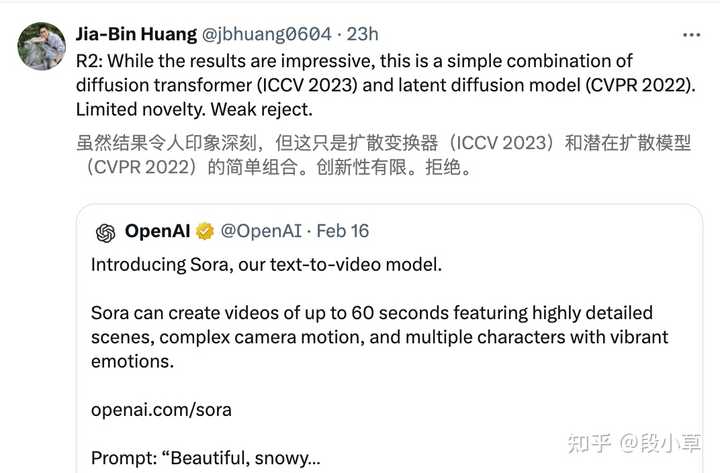
|
|
Scale Law + Moore's Law for Everything 这不足以解释 OpenAI 的成功,毕竟 Transformer 2017 年来自于谷歌,也被普遍使用,为什么其他人没做出来? 答案应该就是 Scale Law,投入更多数据,投入更大算力,更大的模型就一定会更强。 |

|
|
所以一种看法是,就像 GPT-4 一样,Sora 的成功依然是那四个字――力大砖飞。如果一定要比较 Transformer 和 Scale law 的重要性,我会觉得,Transformer 是 OpenAI 的路线基础,Scale law 是几乎可以称之为信仰的一种信念,大胆地往上梭数据量,就能看到涌现。 当然,投入要讲 ROI,就算 OpenAI 的研发环境比大公司宽松,应该也不会无节制地烧钱。Scale law 背后的另一个隐含的理论基础大概是「摩尔定律」,或者更进一步 Sam Altman 的「万物摩尔定律」。 也就是说,「缩放定律」的背后其实是「摩尔定律」,是算力的倍增。人类的智力是相对固定的(除非有其他开发方式),但机器的智能则取决于算法、数据和算力,根据摩尔定律,算力现阶段依然在发展,假定人类的智能是固定的,而机器的智能(在遇到瓶颈之前)不断进步甚至倍增,那么终究会赶上人类的智能水平。即使在未来传统计算机逼近摩尔定律的极限,依然可以靠量子计算的进步继续推动 AI 发展。 所以,算力一定会越来越大,越来越不值钱,现阶段的算力可能会短缺,但闲置算力不仅仅是当下的浪费,更是在未来时间尺度上的贬值。所以一定要榨干最后一滴算力,去抢占人工智能的先机。 数据,更多的数据,更好的数据 不展开了。还是引用 Ilya 的话: 学习统计规律比看到表象要重要得多。 预测也是一种统计现象。然而,要进行预测,你需要了解产生数据的基本过程。你需要更多地理解产生数据的这个世界。 随着我们的生成模型变得非常出色,我认为它们将具有对世界惊人的理解程度,许多微妙之处也将变得清晰。 大型生成模型所学习的是它们的数据――在这种情况下大型语言模型是对真实世界的各类过程中产生的数据进行压缩表示(compressed representations),这意味着不仅涉及人们及其思想和情感,还涉及人们所处的状态和他们之间的互动。 人们可能处于不同的情况中。所有这些都是由神经网络生成文本所代表的压缩过程的一部分。语言模型越好,生成的模型就越好,保真度就越高,它就越能捕捉到这个过程。 |

|
|
看到有人引用了 Jim Fan 的看法,其实他后来又更新了一段话: |

|
|
Sora 需要大量高质量的学习数据,就像 LLM 吃掉了人类有史以来所有的文本数据之后,需要用 AI 生成的数据再喂给 AI,Sora 也有可能学习了一些来自游戏引擎生成的图像(前期训练时)。(而不是像一些人说的那样,在后期推理时靠驱动游戏引擎去生成图像) 我的理解大概是上面这些。 最后还有一点虚的,就是 OpenAI 的 Vision 和领袖的 insight。团队的愿景和讲故事的能力,可以吸引人才,可以吸引投资,可以塑造文化。 至于领袖的 insight,不论是 Ilya 对 Transformer,对强化学习,或者 Sam 对投资、算力、产品,或者 Greg 对工程对 AI infra,insight 就是在大家面对未知和迷茫时,凭借模糊的方向看到光亮,拍板做决定,给大家带来向未知探索的勇气的洞见。 现在的 AI 依然是炼丹抽卡,就像 GPT-4、Sora 这样的产品,在没有成功之前,如何坚持、坚定地投入人力财力算力,这是 OpenAI 做到 而其他公司没有做到的。 以上只是个人看法。还是那句话,也许几年十年几十年后,当 OpenAI 重新开源他们的模型,当此刻的亲历者写下回顾历史的回忆录,我们才能真正看到 AGI 的火花是如何迸发,理解当下正在发生的事情是多么伟大。 以上。 参考^https://openai.com/charter^https://twitter.com/GaryMarcus/status/1529457162811936768 |
|
今天早上跟一个老师一起看Sora的技术报告,出于职业习惯就去看了一眼作者栏。 对号是中国人或者华裔,画圈的估计是东南亚那边的名字,比如吴恩达的名字就是Ng。 |

|
|
然后我又找了下Dalle3的论文,这边的中国人含量更是高,超过一半。 |

|
|
这俩都是比较新的工作,说实话,在日常的工作中,中国同事相对来说都比较的负责且高效,对于承诺的事情,基本上都能按时完成。 我指的是在计算机这个领域里面,基本上我遇到的中国同事都比较敬业,一般属于是说的少但是做的多的那位。 再者就是OpenAI对于人的凝聚力足够的强,前段时间Sam差点被辞退,绝大多数的员工都签了要么Sam回来,要么集体辞职的信,这种队伍真的强。 |

|
|
当然了,人是一方面,因为对于人才储备来说,像Google,微软,Meta之类的都应该丝毫不差。 但OpenAI可以独树一帜,最大的原因就是OpenAI深耕AGI这个领域很久了,特别是大模型LLM这一条,基本上之前所有人都认为这条路走不通,真的没多少人真正的觉得scaling law的可行性,以及真的有人花真金白银,几百万美金一次去训练大模型。 说实话,OpenAI敢想敢做,且持续深耕,绝对是这几次AI新产品极其重磅的主要原因。 Google他们不是没有钱,而是不觉得LLM这条路能走得通。 |

|
|
你看Google在ChatGPT大火之后迅速推出Bard,因为他们是真的急了,但是现场演示翻车后,股票大跌。 |

|
|
这些公司也不是追不上,但是问题是OpenAI深耕多年,你的初始速度和加速度都不如OpenAI,其他公司很难短时间内追得上。 还有一个恐怖的点是,GPT4是一年前就做出来的东西,微调了一年才发布;Sora据说也是23年3月就做出来的东西,差不多过了一年才放出来。 OpenAI每次发的东西基本上都是调整了很久才发布,发出来可能就是王炸。 最后一点儿,可能荣誉感也很重要,在OpenAI做的工作,可能会载入到AI发展史,甚至更宏大的历史,这种感觉或许也是OpenAI如此牛逼的原因之一。 |
|
没想到这个问题竟然火了,我自己再描述一下我的想法吧。 sora这次是两个顶尖的应届博士生挑头,花一年时间做出来的,然后配合其他整个openai的资源。 我想问的类似问题是,同期为什么其他的团队做不出来?关键核心的差距在哪儿? 我认为这个点比较关键:openai借助gpt4,dalle3,以及某些未披露的强力模型,跑通了数据自动获取和清洗的流程,实现了超越其他团队的数据处理能力,以供scaling law的发挥。 这里面的数据获取,可能包括自动爬虫,ocr,物理引擎等。 数据清洗可能包括基础的格式梳理,二次校对等。 |
|
简单说一下我的见解,以公司和技术趋势而不是个人的角度做一些分析,并预测一些OpenAI下一步的进展。 目标和商业模式明确 对于OpenAI,目前的目标很明确:就是 all in AGI,一切研究围绕着探索通往AGI的路径。 而商业模式上也很简单:SaaS,直接给API,接口设计内部自己决定,付多少钱用多少,不想用就不用,这样省去了很多产品设计,marketing,BD的时间,伺候甲方的时间(有比较可靠的消息称即使Microsoft的Copilot等产品也是直接用的API,没有花功夫做太多的定制),整个公司可以集中精力开发AGI。 有人可能说:不是啊,OpenAI不是还有ChatGPT的用户界面,手机端语音聊天,以及GPTs吗?但是仔细想想,这几个部分OpenAI可以说是“非常不用心”了。比如ChatGPT Plus 是怎么自动融合搜索,图片生成,代码调用等工具的?单独做了一套深度优化?不,答案是OpenAI给了一个巨大的prompt,让模型自己去选。OpenAI是怎么和各种第三方插件结合的,是单独做了匹配和接口?不,答案是直接让这些plugins描述自己是什么,然后模型自己调用,至于调用得对不对那就是另外一件事情了。这里最典的是最近OpenAI怎么实现“记忆”的,给大家看看OpenAI的完整 prompt(博杰提供的,每个人可以诱导ChatGPT说出这些,OpenAI也不在乎): OpenAI 直接用 prompt 让GPT-4调用bio这个工具记录需要记忆的内容(“to=xxx”是调用内部工具的语法,比如"to=python"是 GPT 调用 code interpreter 的方式)。然后每次新的对话开始时,在prompt的最后直接加上所有之前的记录的内容(## Model Set Context)。就是这么简单粗暴。 GPTs 怎么做的?其实很大程度就是OpenAI 的 Assistant API加个简单得有点简陋的前端。(PS:现在有了OpenAI Assistant API后,你发现加个UI就可以很轻松的复刻OpenAI上线的大部分功能。) 那么语音对话呢?你会发现就是换了一个prompt,告诉GPT尽量生成短的内容,不要轻易生成列表和代码。语音合成用TTS API,识别用whisper API(可能有针对上下文的优化),结束。 这些选择看上去非常暴力,而且会给OpenAI增加开销(长的prompt会明显增大开销),但是OpenAI仍然选择这么做,因为这让OpenAI将大部分精力都花在模型本身的研发上,同时这也是OpenAI的方法论的极致体现,我们下面会提到。这种方法论让OpenAI追求一个大的通用的模型,避免一切定制和特化,就像最近Sam说的一样,希望GPT-5的出现能让模型微调失去意义;这样OpenAI就变成了完完全全的SaaS服务。 方法论明确 OpenAI的方法论是通往 AGI 的方法论。这个方法论有着非常清晰的逻辑结构,和非常明确的推论。我们甚至可以用公理化的方式来描述它,怎么说呢,感觉上有一种宿命感,。 方法论的公理 这套方法论的大厦构建于以下几个“公理”(打引号是因为它们不是真正的“公理”,更多是经验规律,但是在AGI方法论中,它们起到了公理的作用): 公理1: The bitter lesson。我认为所有做AI的人都应该熟读这篇文章。“The bitter lesson” 说的事情是,长期来看,AI领域所有的奇技淫巧都比不过强大的算力夹持的通用的AI算法(这里“强大的算力”隐含了大量的训练数据和大模型)。某种意义上,强大的算力夹持的通用的AI算法才是AGI路径的正道,才是AI技术真正进步的方向。从逻辑主义,到专家系统,到SVM等核方法,到深度神经网络,再到现在的大语音模型,莫不过此。 公理2: Scaling Law。这条公理说了,一旦选择了良好且通用的数据表示,良好且通用的数据标注,良好且通用的算法,那么你就能找到一套通用规律,保证数据越多,模型越大,效果越好。而且这套规律稳定到了可以在训练模型之前就能预知它的效果: |

|
|
Scaling Law 甚至能够在训练前预知最后的性能,图片选自OpenAI GPT-4 Technical Report 如果说 公理1 The bitter lesson 是AGI的必要条件――大模型,大算力,大数据,那么公理2 Scaling Law 就是AGI充分条件,即我们能找到一套算法,稳定的保证大模型,大算力,大数据导致更好的结果,甚至能预测未来。 而具体来谈,就是我们之前说的“良好且通用的数据表示,良好且通用的数据标注,良好且通用的算法”,在GPT和Sora中都有相应的内容: 在GPT中,良好且通用的数据表示,是tokenizer带来的embedding。良好且通用的数据标注是文本清理和去重的一套方法(因为自然语言训练是unsupervised training,数据本身就是标注)。良好且通用的算法就是大家熟知的transformers + autoregressive loss。在Sora中,良好且通用的数据表示,是video compress network带来的visual patch。良好且通用的数据标注是OpenAI自己的标注器给视频详细的描述(很可能是GPT-vision)。良好且通用的算法也是大家熟知的transformers + diffusion “良好且通用的数据表示,良好且通用的数据标注,良好且通用的算法”同时也为检测scaling law做好了准备,因为你总是可以现在更小规模的模型和数据上检测算法的效果,而不用大幅更改算法。比如GPT1,2,3这几代的迭代路径,以及Sora中OpenAI明确提到visual patch使得他们用完全一样的算法在更小规模的数据上测试。 公理3: Emerging properties。这条公理其实是一条检验公理:我怎么知道scaling law带来“质变”,而不仅仅是“量变”?答案是:你会发现,随着scaling law的进行,你的模型突然就能稳定掌握之前不能掌握的能力,而且这是所有人能够直观体验到的。比如GPT-4相比于GPT-3.5,可以完成明显更复杂的任务,比如写一个26行诗来证明素数是无限的,每行开头必须是从A到Z。比如Sora相对于之前的模型,它的时空一致性,以及对现实中物理规律的初步掌握。没有 Emerging properties,我们很难直观感觉到突破性的变化,很难感知“我们真的向AGI前进了一步”,或者是“我们跑通了一个技术栈”。 方法论的必然推论 从上面的公理中,我们就可以理解OpenAI的各种决策了,并且可以预见OpenAI未来的行为。 推论1: 世界模型。大量数据从哪里来?什么东西能够产生最多的数据?AGI需要什么样的数据才能通用地处理世界上的一切事情?答案就是:世界本身。世界本身产生最多的数据(或者极端一点,世界就是数据),而世界产生的数据,也是AGI需要的数据的最小集合,因为我们也只需要或者只能让AGI处理这个世界的事情。可以预见,OpenAI未来还会执着于持续获得或者构造数据。 推论2: 世界生成模型。要最有效的利用数据,我们需要最困难的,需要最多数据,且能利用所有数据的任务。这样的任务可能只有一个:模拟和生成整个世界(人类所有的智能只是一小块)。因此OpenAI需要做生成模型,并且是能够模拟和生成物理世界的模型,通过生成这个世界,实现对世界的理解。最近火爆的Sora便是其中之一。这个想法也和费曼的名言对应:“我不能创造的,我也不能真正理解”。可以预见,OpenAI未来还会在更多的模态和数据上去做生成模型。 推论3:通用模型。通用模型还是专用模型能用到更多数据?显然是通用模型。而通用模型也减少了OpenAI的技术栈,因为一个模型能解决更多问题。这也导致之前提到的OpenAI解决各种问题时更倾向于用同一种模型,而不是做非常多不同的定制。可以预见,OpenAI未来可能会继续走通用模型的道路,降低finetuning等特化的需求,继续增加模型的context length。 推论4:用一个模型为另一个模型提供标注。由于当前技术限制,OpenAI仍然无法用一个模型完成所有的任务,这样一个的模型收到数据就变少了。然而,我们可以用一个模型给另一个模型提供标注的形式,来间接实现数据供给。OpenAI的Dall E和Sora都用到了大量可能来自于GPT vision的数据标注。这样OpenAI的各个技术栈都可以连通起来。可以预见,OpenAI未来可能会继续加强各个模型的连接,比如将来用Sora反向给GPT vision给数据都是可能的;用一个已有模型去构造更多数据也会是一个重要的方向(比如backtranslation,data distillation等等)。 推论5:Transformer架构。我们需要一种能够并行处理大量数据吞吐,且满足scaling law的架构。transformer架构充分证实它在各个模态和技术栈的优势,特别在复杂任务中,因而被OpenAI广泛使用。使用同样一个架构的好处在于可以复用模型的参数(比如tokenizer,embeddings,以及部分权重)来bootstrap不同技术栈的训练,以及可以用一套infra框架训练不同的模型。可以预见,将来新的模型如果要取代传统的transformer架构,还需要通过scaling law的检验。 推论6:稀疏模型。模型越大,性能越好,但是推理的成本也越高,这看上去是个死结。但是我们可以使用稀疏激活的方式,在推理时降低实际的参数量,从而在训练中使用更多参数的同时,降低推理的成本。Mixture-of-Experts就是常用的方法之一,被OpenAI采用,从而继续scale模型的大小。未来稀疏化仍会是一个重要的课题,目前即使Mixture-of-Experts的稀疏也会造成推理性能的损失,尚不清楚稀疏化的极限在何处。 推论7:算力是瓶颈。最终卡OpenAI脖子的是算力。大算力系统的构建也是OpenAI打通各个技术栈的底气。有人可能认为,高质量文本是有限的,因此实际上模型大小有个极限。但是以世界模型的角度来考虑,OpenAI现在用的数据仍然是冰山一角,更不用说Q*等方法或许可以以间接方式创造数据。比如最近OpenAI GPT-4-Turbo,作为一个distillation模型,在很多评测上都超过原来的模型,就是一个例证。直到目前,作为局外人仍然看不到scaling law的尽头。而且即使不开发任何新的模型,OpenAI离“用GPT-4服务所有人”的目标仍然很远。所以算力在可见的未来都是一个巨大的瓶颈。这也可以理解Sam为何有“7万亿重构芯片产业”的想法了。可以预见,OpenAI可能在未来在芯片以及整个AI Infra方面尝试更多的自研和垂直集成。 总结 总结来看,OpenAI采取的商业模式以及其对于AGI的信奉、系统性的方法论以及积极的尝试,都在推动他们朝着实现通用人工智能的目标前进,实现了一种可以跑通所有AGI技术栈的模式,而这一点,是OpenAI能在众多研究机构和公司中脱颖而出的重要因素。未来,OpenAI可能继续朝着商业化的道路前进,并在世界模型、模型标注、通用模型、模型架构、稀疏模型数据扩充等方面进行更深入的探索和实践。同时,OpenAI也会持续关注和应对算力带来的挑战,寻找突破算力瓶颈的解决之道。 |
|
OPENAI CEO奥特曼昨天发的招聘推文: openai 是我在一个地方见过的最有才华、最善良的一群人 致力于解决最困难、最有趣和最重要的问题 所有关键资源都已到位 非常专注于制作 AGI 您也许应该考虑加入我们 |

|
|
Sora的出现让我们真正可以进入到虚拟的平行世界。它不只是一项技术突破,而是一个世界模型,这意味着多模态和机器人的进步。 英伟达负责ai的工程师Jim Fan对sora的评价,具体的技术词汇可能不懂,但底层数字科技发展的逻辑很清楚了。 如果你把OpenAl Sora当作一个和 DALLE类似的创意小玩意……那你可能要重新认识它了。Sora实际上是一个基于数据的物理模拟引擎。它能够模拟各种各样的世界,不管是真实的还是幻想中的。通过一系列复杂的计算过程,比如去噪技术和梯度计算,这个模拟器能够学习到如何进行精细的渲染、模拟直观物理效果、进行长期的逻辑推理,以及实现语义理解。 如果说Sora是依赖使用Unreal Engine5生成的大量合成数据进行训练,我一点都不会觉得意外。因为它的确需要这样做! 我们来分析一段视频。视频提示是:“在一杯咖啡中航行的两艘海盗船进行战斗的逼真特写镜头。” 模拟器创建了两艘装饰各异的精美3D海盗船模型。Sora需要在其内部空间隐式地完成从文本描述到3D模型的转换。这些 3D模型能够在保持彼此距离的同时进行动态航行。 它还模拟了咖啡流体的动力学效果,包括船只周围形成的泡沫。值得一提的是,流体模拟本身就是计算机图形学中一个非常复杂的分支,需要依赖复杂的算法和方程式。 视频达到了近乎逼真的光影效果,仿佛是采用了光线追踪技术进行渲染。 考虑到杯子相比海洋的小尺寸,模拟器还采用了移轴摄影技术,营造出了一种微观世界的视觉感受。 虽然视频中的场景在现实世界中并不存在,但这个引擎还是按照我们所期望的物理规则正确地实现了场景模拟。 下一步是增加更多的输入模式和条件设置,我们就能得到一个全面的数据驱动的虚拟引擎,它将有望取代所有传统手工编制的图形处理流程。 |

|
|
显然有些人不明白什么是“数据驱动的物理引擎”,所以我来澄清一下。Sora 是一个端到端的扩散变换器模型。它输入文本/图像,直接输出视频像素。Sora 通过大量视频的梯度下降,隐式地在神经参数中学习物理引擎。 Sora 是一个可学习的模拟器,或者说“世界模型”。当然,它不会在循环中显式地调用 UE5,但有可能将 UE5 生成的(文本,视频)对作为合成数据添加到训练集中。 |

|
|
|
|
因为OpenAI还算是一个创业公司,而大公司早已经有了大公司病,国内的BAT如此,国外的谷歌也是如此。 创业公司的凝聚力强,能集中力量办大事,大公司更多的是内卷和内耗。 |
|
图片,语音,文字并不是所有的技术栈。 人脸识别,AI智能审核,瑕疵检测,AI生物制药,等等内容都是agi的范畴,OpenAI显然在这些方面没有发力,或是单纯认为不重要。 虽然这些是基础agi任务,但人类对于复杂精密任务的控制显然是不能用传统意义的图片,语音,文字所能概括的。 对人类复杂情感的理解和推理,对于高精密机械的控制,对于普世价值的认定,对于科研创新思维,商业金融,对于人类权力和财富的理解,制定复杂周密的计划和陷阱,以及预判未来发展等等。这些都是agi的范畴,显然OpenAI并没有完全攻克以上内容。 不过尽管如此,OpenAI技术已经突破了临界点。未来的很多agi都需要依赖OpenAI的基础技术,也就是对文字,图像,语音的理解和生成。 简单来说OpenAI没有跑通所有agi的技术栈,但其资源调度能力比几乎所有的AI公司都要强,可以集中资源去攻克核心问题。这就使得这个公司可以不断突破极限。 OpenAI的内部工作方式可能更像是SpaceX和Tesla,而非传统互联网的Google,Meta,微软,亚马逊。 如果说传统互联网是给流水线披了层互联网的外衣。那么OpenAI这样的公司应该是披着初创企业外衣的科研机构。 本质是科研驱动,而非业务导向。不管赚不赚钱,而是把突破人类科技边界为第一使命。然后再用垄断的科技对旧商业模式进行降为打击。 旧sora这种技术,放其他互联网公司肯定不会投入太多,视频生成的优先级肯定不如平台流量,推荐搜索为核心的业务模式利润率高。 |
|
目前来看,LLM之于AGI好比当年蒸汽机之于工业革命。 首先是用于视觉理解的VLM。有了LLM,结合高质量的image caption标注结果,可以很快训练得到一个高质量的captioner。在此基础上,利用LLM构造大量图文问答pair数据不是什么难事,由此我们就可以得到一个有细粒度图片理解能力的VLM。 同样的,通过类似方法我们可以快速构造一批视频问答pair数据,由此得到具有视频理解能力的VLM。 然后是文生图模型,上面说到图文pair数据同样可以用来训练生成模型。当然,在此过程中,类似SAM的data engine迭代肯定是必要的,由此带来的标注质量提升也是可预见的。 至于视频生成方面,一方面可以通过上述的方式得到视频-文本pair数据,另一方面也可以通过人工构造(如Jim Fan提到的利用UE合成)来得到数据。当然中间迭代肯定需要解决很多细节问题(如主体进出画面等)。 总的来说,一个强大的LLM是目前AGI的通用组件,但是AGI之路也离不开高质量的人工标注数据的驱动,希望国内的LLM可以快速赶上来吧。 |
|
因为现阶段大模型的关键门槛不在技术上。 个人最佩服openai的一点是,这家公司能够撬动天价的资源持续投入在未经验证的猜想上。这种公司全世界都找不到几家。在其中工作的科研人员想必是很幸福吧。 |
|
根据我的经验,如果国内大厂的某人要做ChatGPT这种东西,其领导一定会问,如何证明你这个东西一定会成功。换句话说,他是一点风险也不想担。按照这种思路来做事的话,只有三种可能: 大厂的普通员工或中层领导想做某个东西,但被否决了,等OpenAI或者国外其他团队做出来以后再抄;大厂的最高领导自己想做某个东西,所以没人能质疑,最后证明是失败的。大厂的最高领导自己想做某个东西,所以没人能质疑,最后证明是成功的。 其中第一种可能性占99%,毕竟最高领导大多数只热衷商业模式创新,就算热衷技术创新,他长期远离技术工作的情况下,也不会有一线技术人员的洞察力。 |
|
先发优势 鉴定为纯纯的AI公司 而不是互联网公司从业务的角度入手去做AI |
|
不管是谁跑通这个技术栈,无论是openai、google、deepmind、meta,甚至国内的glm等,从更加宏观的角度出发,本质上,大家都是在试错。 就好像从迷宫起点出发,有的人走的快有的人走得远有的人原地彷徨有的人兜了一大圈发现徒劳无功。但是谁也不知道终点在哪里。你用Transformer他不用,他相信scale law而你不相信,这就是在迷宫中左手右手的不同选择。走出去之后一路走到黑和四处出击浅尝辄止不停选择,则是我们在迷宫中的战术策略了,试想其实何止是走迷宫时如此。 不过我们眼下这个迷宫,它不是完全的黑暗森林,走在前面的人可以自封为领路人,打出来的是明牌,它可以给其他人启发和提示,可以给其他人作业抄。而他们走出来的路,慢慢的就变成了大路。但是这不代表其他的小路就彻底没戏,搞不好还有shortcut没有被发现。而openai恰巧是当下在迷宫中走在最前列的一股力量,而现在说一定就是它胜出还为时尚早。 所以,我既不同意说openai这套就是大力出奇迹瞎猫碰死耗子的路线否定,也不同意说openai这套就是朗朗乾坤永远滴神的盲目崇拜。 计算机科学本来就是个工程和科学混杂的学科,尤其是发展到先阶段,又有复杂科学标度定律等等进来捣乱让事情更加复杂。数学能推导一切的话,就不需要我们走迷宫了,工程实践就好比要走迷宫,就是有大量的人力物力财力走了一条死路,但是也给后来人证明了这条死路有问题不要再来了。 很多时候我们走迷宫走不好要么就是走不对要么就是走不快,走不对的时候可以走快点多试试不同的小路。 所以,试错也有方法。 毕竟,从动机上说,你和我想的无非就是两个问题,当下我如何把openai的技术用到我这里来,以及,未来有没有可能我们搞出自己的openai。 第一个问题还相对容易些,技术线上,确实暂时证明了Transformer、ScaleLaw、高质量数据、RLHF整条线路的有效性,也算是一种集大成的完整技术链路。当然很多人对这条技术路线不屑不是一天两天了,在视觉方法CNN刚刚兴起的时候也是这样的,认为这就是大力出奇迹只是做了些拟合数据的工作,没有什么技术含量。这没有关系,其他的视觉解决方法现在在通用领域早已经无人问津了。所以技术讨论是可以一直进行的,实践则是检验真理的唯一标准。 说到第二个问题,这就是个系统工程了,上升到国家层面的系统工程了。我们可以看到,其实openai的资源调动能力是最重要的,尤其是人和资金,在技术路线都不明确的时候就能把最核心的资源都丢进这个风险巨大的方法中,那么路径已经相对光明之后就更不用说了,接下来优势将会放大,这个竞品们都已经落后了。其他的回答都回答的特别好,领袖任务的vision、insight以及坚持做下去的意志,都是非常重要的。 当然,扎心的事情也是明摆着的,国内的玩家很多时候都是跟在后边。但是,其实这并不是我们没有资源,我们集中力量办大事的能力自称第二放眼全球没人敢说第一,我们很多时候在于一开始不敢做有风险的事情,这个原因是方方面面的没法一概而论。发展是需要过程的,不需要过分苛求,毕竟暂时没法改变过去几十年以抄作业为主的特点,毕竟猥琐发育是最经济的。不过我坚信未来是可以有所改变的,多说无益,我倒是觉得作业先抄好,才能有积累去思考弯道超车的事情。 |
|
跑通所有AGI技术栈这话说的还有点早。AGI这东西完全取决于你怎么定义,按照最严格的定义,"人类水平的智能"意味着给足够的时间训练它可以替代世界上任何一种岗位,"超越人类的智能"意味着它至少可以解决一项人类目前调用所有资源都无法解决的复杂问题(比如癌症治疗,室温超导)我认为目前openai的技术栈并没有达到这个程度。 但openai的成功是可以预见的,顶尖的人才密度,技术领袖的vision,充足的资金支持(先是马斯克,然后是微软)这几个兼备的全世界除了它只有一家半,一家是deepmind,半家是FAIR。 为啥deepmind没有在这一波成为领军者,个人认为是因为他们之前在类Gato路线上耗费了太大精力,导致一步慢步步慢,不过最近也在努力赶上就是了。其实deepmind的demis和openai的ilya一样,都是对自己的技术路线有坚定信念的人,唯一的区别是,demis没赌对。 |
|
OpenAI的所有模大模型,都是用transformer来做的,包括GPT,Wisper,Sora.,Dell 。 这表明他们内部很早就意识到transformer架构的强大,并熟练掌握了基础模型的训练,同时又能获取很好的大规模数据集。 要想追上OpenAI,应该先力求对标GPT,只要一个通,其他都通了。 然而,目前的国产模型,大多都使用RAG去做增强,来达到“追上GPT”的假象。 |
|
|
| [收藏本文] 【下载本文】 |
| 科技知识 最新文章 |
| 百度为什么越来越垃圾了? |
| 百度为什么越来越垃圾了? |
| 为什么程序员总是发现不了自己的Bug? |
| 出现在抖音评论区里边的算命真不真? |
| 你认为 C++ 最不应该存在的特性是什么? |
| 为什么 Windows 的兼容性这么强大,到底用了 |
| 如何看待Nvidia禁止使用翻译工具将cuda运行 |
| 为何苹果搞了十年的汽车还是难产,小米很快 |
| 该不该和AI说谢谢? |
| 为什么突破性的技术总是最先发生在西方? |
| 上一篇文章 下一篇文章 查看所有文章 |
|
|
|
| 股票涨跌实时统计 涨停板选股 分时图选股 跌停板选股 K线图选股 成交量选股 均线选股 趋势线选股 筹码理论 波浪理论 缠论 MACD指标 KDJ指标 BOLL指标 RSI指标 炒股基础知识 炒股故事 |
| 网站联系: qq:121756557 email:121756557@qq.com 天天财汇 |