
| |
|
|
| ����ƻ� -> �Ƽ�֪ʶ -> OpenAI ������Ƶ����ģ�� Sora ���Լ����ͼ��ѧ����ʲôӰ��? -> �����Ķ� |
|
|
[�Ƽ�֪ʶ]OpenAI ������Ƶ����ģ�� Sora ���Լ����ͼ��ѧ����ʲôӰ��? |
| [�ղر���] �����ر��ġ� |
|
OpenAIȫ�·���������Ƶģ��Sora����ʵ��������_��Ѷ���� |
|
�����ͼ��ѧ��Ϊ��ֱ��ҵ���ߣ�����߾��ȵ�Ӱ��Ⱦ����ҵ CAD����Ϸ��ҵ���ڹ��ġ�Ӳ���Լ۱ȿ�����Ȼ��Ҫ��ͳͼ����Ⱦ�����Ҳ��ų�δ��������ԭ���� AI ��Ⱦ���泹�߸����ڵļܹ��� ��������ҵ�������Ƶ���;��ȵ�Ӱ��Ⱦ������Ƭȫ�汻 AI ȡ���� |
|
����Sora���ü�ֵ�ܸ� ������һ���棬��ʵûɶӰ�죬��AIû�н�����������ѧ����֮ǰ����Щ��ʵ�����п������á���רҵ����Ծ���Ҫ���������˷�ָ�������������ҵֻҪ�ÿ����ɡ� Խ��Խ����LeCun��ʦ�ġ��ǵ���˼�롱��������Ҫ�����Ҫ�ԡ� |
|
��ͼ��ѧ��ʵûɶӰ�죺���Dz�����ͼ�˰����Dz�������任�˰����ǿ�������Shader�˰����� Ӱ���ǵ����ݲ�ҵ |
|
Ԥ��SIGGRAPH Asia 2024��SIGGRAPH 2025����������Ƶ��ͼ����Ƶ����Ƶ����Ƶ�����»ᱩ��һ����Ȼ���Ȼ������Ƶ�ˣ���ô����3D�ؽ��Ĺ�����ȻҲ�����и��������3D��ͼ��3D�ȵȡ� һЩ��ȥû������Ƶ���ɵ�ͼ��ѧ����������������ǿ�ʼ�����Լ�Ҳ��AI��Ƶ���ɣ�Ȼ��ʼ��������Ƶ��ͼ����Ƶ����Ƶ����Ƶ�ĺ�����⡣����funding proposal�↑ʼ�ᵽDiffusion Transformer��Sora���������������ɽǶ���˵����֮ǰ����ʲô����Ķ���մ�ϵ��ϵ�� ���������NeRF��Gsplatһ���� Ȼ���ٹ������Ч�������㹻�ã���Ҿͻ�����Diffusion Transformer�Ǽ����ͼ��ѧ�ĵ������֮һ����ѧͼ��ѧ���Ͽ�ʼ��Sora��Ϊ���䰸����������ѧ��ʵ�ּ�Sora��ΪС��ҵ����ҵ��ͼ��ѧ����ʦ���Լ���Diffusion Transformer��صĿ��⡣ |
|
���������������������ʤäƤ��ޤä��� �䤨���y�ӤΥ٥åɤǡ��ҤȤ��ߤ�� ������������ �����ÿ��� ����ȴ�������´� ������˯� -�ԥΥ����ԩ`�������ޥ��� �����õ��������ʣ���Ȼ���ⲻ�ǣ�������Ϊ���Դ���Ŀǰ AIģ�����ɵ������䡰�ߡ���������������ȷ������ �ֲ���ЧӦ Sora ����ǿ��Ҳֻ�Ǹ�����ģ�� ���ɵ����ݶ���ģ�����ɵ� ������ֱ��������Ƶ��Ʒ�ʾ����ٸ�Ҳû���߹���ͳ��ģ��Ⱦ ������ �� AI ���ɾ�����ȷ�ز���ģ�ͣ�Ӳ��������Mesh GPT �Ѿ�Sota �ˣ���ɫģ�ͻ�����ͣ� �� AI ����FEM MPM FLIP ����Ⱦ��Щ�� δ��Ӱ����������һ�����룺�籾�������rig���+��ɫmesh�����meshgpt��3d GS��Ȼ������ML��������ɫ��Ƥ�����ô�ͳȨ�أ�����ML����ϵͳ Ȼ��������Infinigen������Ȼ�����������˹����� ��AI��������ƶ����־���AI��������ģ��Ȼ��TTS���ɽ�ɫ������Ȼ���������ɶ�����������nvidia ACE����ɫ��������Ȼ������ô�ͳ��ʽ��Ⱦ��������Ⱦ�����AI���֣�����Cubase Nuendo֮��Ĺ��� |
|
��IJ�Ҫȥ����xx������Ƶ�����������ô�ϴ���˼������ô��Ǯ�������˵һ�䡰����ѧ������ģ���Ѿ��������������ˣ��� ��ͼ��ѧ�������������������˻���������Ԫ���ϵĸ�ɽ��һ��ʼ��վ���Ƕ����ο��أ��α��أ� ��ʵҪ˵ͼ��ѧ��ô��ߣ���Ȼ����world simulator��Ϊɶ���Լ�����ȥ��һЩ���������·�ӣ� ����˵agent��ͨ��һ�仰�ı���������һ��agent��Ȼ���������agent�Զ��������κ�һ�ֻ����ͼ��ϵͳ�������ı�����ͼ���첢�ϸ߱���ȵ���Ⱦ��һ�Ρ���ȷ������Ƶ�� ��������Ƶ���ٱ�һ��ai�ļ�������˾�/���һ����ɡ�Ӱ������ȡ� �����ͼ��ѧ�ĸ߹�ʱ�̣�world simulator�� |
|
OpenAI Sora������ͨ��AGI����һ��ChatGPTʱ�̣�GPT4����ҲҪ���ɵ��� ע�⣺�ù��ܻ����ڲ�Ρ� |

|
|
OpenAI��������Ƶģ��Soraˢ���ˡ� ���ж����أ���ô˵�ɣ���һ����ô����ˢ�����ܻ��������һ�μ���ChatGPT��ʱ���Լ���Sora֮ǰ��СʱGoogle�ո��Ƴ�������ǿ��LLM Gemini1.5������ͼ�����Լ�����ɱ����GPT-4��Ȼ������Ȼ����û�˹�ע�ˡ� ��Ϊ����Sora����ܻᷢ�֣�OpenAI�Լ�����Ҫ������ɱ��GPT-4�ˡ� ÿ���˶����Դ����Լ��������� ��������Sora�� |
|
|
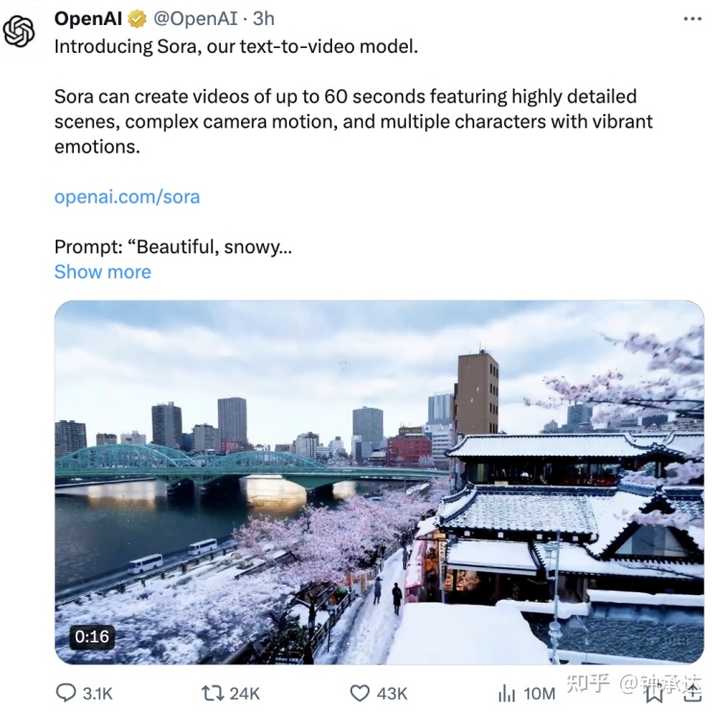
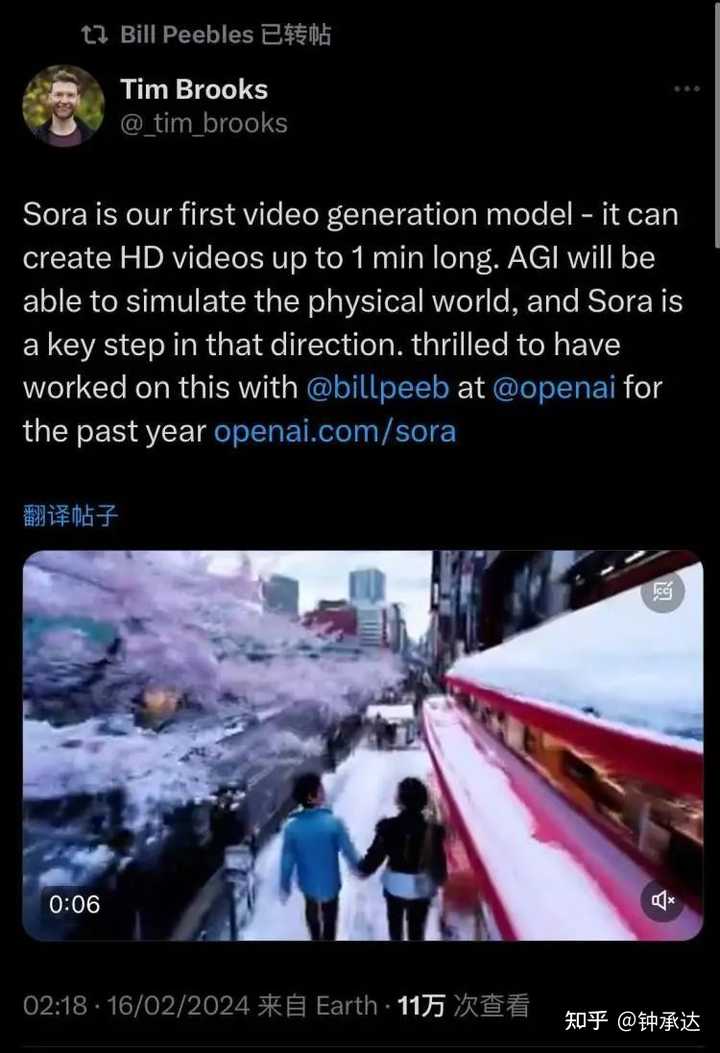
����һֱ�ڴ�GPT-5����Sora�����ĺ䶯������һ��GPT-5�ķ����� ��ΪOpenAI ���Ƶ��ı�ת��Ƶģ�ͣ�Sora�ܹ������ı�ָ���̬ͼ�����ɳ��� 1���ӵ���Ƶ�����а�����ϸ���ӵij����������Ľ�ɫ�����Լ����ӵľ�ͷ�˶���ͬʱҲ����������Ƶ��չ���ȱʧ��֡�� ÿ����ʾ60�����Ƶ������Pika Labs��3�롢Meta Emu Video��4�롢��Runway��˾Gen-2��18����ȣ�������Ӯ�ˡ����Ҵӹٷ���������ʾ���������۴���Ƶ�����Ȼ���ϸ�ڱ��������ϣ�Sora��Ч�����൱���ޡ� �������������14��Ķ���ѩ����Ƶ�� ��ʾ�ʣ�Beautiful, snowy Tokyo city is bustling. The camera moves through the bustling city street, following several people enjoying the beautiful snowy weather and shopping at nearby stalls. Gorgeous sakura petals are flying through the wind along with snowflakes. �������ģ���ѩ���ǵĶ�������æ�š���ͷ������æ�ij��нֵ��������ż�������ѩ�����ڸ���̯λ������ˡ�������ӣ�������Ʈ�䣬��ѩ��һͬ���衣�� |

|
|
����ʱ�е�Ů���������米���Ķ�����ͷ�������л�ˮ��Ӱ�� |

|
|
������ٺ�Ƥ���Ŀ̻�ʮ����ʵ���ر��Ƕ�ӡ�ͷ����ƣ�ϸ�����˾�̾�� |

|
|
�������Ա���ѩԭ�л�������������������ѩ���� |

|
|
����Դ�����Ƥ��3D����С�����Ӱ�������ë����ϸ�����֣� |

|
|
һ��24��Ů�Ե��۲���д�������Լ����档 |

|
|
���˻��ӽǵĺ����Ĵ���Big Sur����Ǻ����±ڣ��������½�ɫ��â�� ��̨�ϵĻ��俪����ʱӰ�� |

|
|
�������Ͻ���������ף�й�ũ�����ڡ� |

|
|
�ɰ�Сè�����߰��������� |

|
|
ҹ���ֵ����ŵĿ���С���� |

|
|
�����ͺ�������һ����������š� |

|
|
�����Խ�ʱ����������ʷӰ���������� ����Sora���ġ� |

|
|
ĿǰSora���ڲ��ԽΣ����Բ���������Ա���Ӿ������ҡ����ʦ�͵�Ӱ�������ǿ��ŷ���Ȩ�ޣ��õ������ʸ�������Ѿ���ʼ��������ɡ� Sam Altman��ת��������Sora�����ġ����ӲӶ�������Ƶ���������Լ��ġ�What������ |
|
|
����������ӻԾ�������Sora������Ƶ����ʾ�ʣ��Ŷ�����Ϊ������ɣ�˲��8ǧ�����ظ��� �����Զ���Ҫ��������������г��������� |
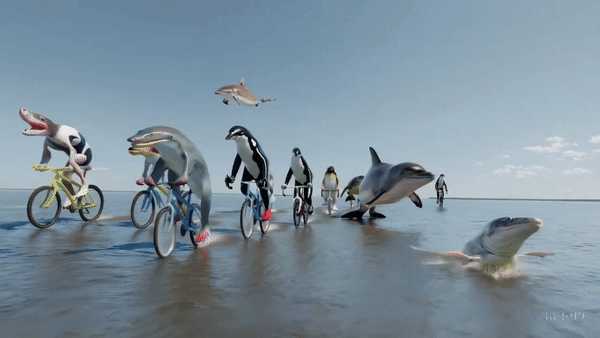
|
|
��ֻ��ë��ɽ�ϴ��Ŷ��������͡� |

|
|
��ȻҲ����cueһ��ȥ����յ�Ilya��Ҫ������һ����Ilya���е���ʵ���硱�� |
|
|
����OpenAIҲ��ʾ����ȻSora ����Ȼ����������������⣬�ܹ�ȷ��Ϥ��ʾ�ʣ����ɱ���ḻ�����ݣ������Դ��������ͷ�����ֽ�ɫ���Ӿ�����һ���ԣ����Բ��ɱ���ش���һЩ���㡣 ���磬����ȷģ�⸴�ӳ���������������������ѣ�Ҳ���ܲ������ض��������ϵ���ȷ�˵��һ����ҧһ�ڱ��ɺ����Ͽ��ܲ�û��ҧ�ۡ��� ģ��Ҳ���ܻ�����ʾ�Ŀռ�ϸ�ڣ�����Ū�����ҡ����ߡ���ȷ������ʱ�䷢�����¼������������ѣ�������ѭ�ض���������켣���� SoraҲʹ����DALL��E 3��recaptioning�������ü����漰Ϊ�Ӿ�ѵ���������ɸ߶������Եı��⡣���ģ���ܹ�����ʵ�ذ����û���������Ƶ�е��ı�ָ����в����� ���ܹ�һ��������������Ƶ��������չ�����ɵ���Ƶʹ��䳤��ͨ����ģ��һ����Ԥ����֡������˼�ʹ������ʱ�뿪����Ҳ�ܱ��ֲ������ս�����⡣ ���ڰ�ȫ�ԣ�OpenAI��ʾ���������Ϣ��������ݺ�ƫ���������ר�Һ�������ģ�ͽ��жԿ��Բ��ԡ�ͬʱҲ�ڿ�����������������ݵĹ��ߣ�ʶ����Ƶ�Ƿ���Sora���ɡ�����Υ��ʹ�����ߵ��ı���ʾ�����籩��������ַ�����֪ʶ��Ȩ�����ݣ����ܾ���ʾ���û��� �������⣬ΪDALL��E 3��Ʒ���������а�ȫ����Ҳͬ��������Sora�� �����ܽ����˹㷺���о��Ͳ��ԣ���������Ԥ�����ǽ�����������ǵļ�����Ҳ��Ԥ����������������������Ϊʲô�������ţ�����ʵ�����������ѧϰ������ʱ�乹��Խ��Խ��ȫ��AIϵͳ�Ĺؼ���ɲ��֡��� OpenAI�� Sora������������Ϊ��Ϊģ�������ģ����ʵ����춨�˻������ǡ�ʵ��AGI����Ҫ��̱����� ������Ҳ��n+1�ηװ�������������Ĺ�˾�ǣ� ��OpenAI���Dz���ֹͣɱ����ҵ��˾���� �����ģ�����������ҪŪ��ʲô����ģ�ʲô�Ǽٵġ��� ���ҵĹ���û�ˡ��� ������Ӱ���ز���ҵ��Ѫϴ����Ϣ�ɡ��� |
|
|
��ɱ��GPT-4������ģ�ͣ��ⲻ������ OpenAIһ�����û�и�������ϸ�ļ���˵������һЩֻ��Ƭ���Ѿ��㹻���㸡�����档 ��������������ע��ĵ�һ���㣬�Ƕ����ݵĴ����� Sora��һ����ɢģ�ͣ�diffusion model������������GPT��Transformer�ܹ������ڽ��ѵ�����ı���������Ƶ����֮���ͳһ���棬OpenAI��ʾ�������ڴ���ͼ�����Ƶ����ʱ���Ѷ����ǽ��зָ��õ�����С��Ԫ����ΪС�飨patches����Ҳ���Ƕ�ӦLLM��Ļ�����Ԫtokens�� ����һ������Ҫ�ļ���ϸ�ڡ�������Ϊģ�ʹ����Ļ�����Ԫ��ʹ�����ѧϰ�㷨�ܹ�����Ч�ش��������Ӿ����ݣ����Dz�ͬ�ij���ʱ�䡢�ֱ��ʺͿ��߱ȡ� �����յ���Ч����������Ѳ��ó�����һ�����ۣ������Ե������������ǿ���Ǩ�Ƶ��Ը�����̬�����ݵ����ⷽ����ȥ�ġ� ��ǰ��Dalle-3��Ч���ͱ����Ϻܴ�̶�����OpenAI��GPT�ϻ��۵�����N�������������������Ǹ�ͼ��Ϊ�����ģ�ͣ�������������Ҳ��������Ҫ�ġ����������Ƶģ�ͣ�ͬ����ˡ� ����������������ģ��в�����ҵ�ڵ�ר�Ҹ�������ͬ�IJ²⣺����ѵ��������ʹ������Ϸ������ǰ�˵���������Unreal Engine5���ֱ������⣬�������������㹻ǿ��֮���������ķ�������ֱ�ӿ���ѧϰ�������ɵ�ͼ����Ƶ���ݺ������ֳ���ģʽ��Ȼ����ֱ����ѧϰ���ģ�������������ķ�ʽ����Щ�����������ǿ�������Ӿ�ģ��ģ����ָ��������ǿ����ı���ǿ��Ķ������������ֳ������⡱����Ƶ�� ��������²⣬OpenAI��̵Ľ����е���仰�ƺ�������Ҫ�ˣ� ��Sora ���ܹ������ģ����ʵ�����ģ�͵Ļ�����OpenAI������һ���ܽ���Ϊʵ��AGI����Ҫ��̱����� ���⣬��ʵ�����硣 �ⲻ���������������۵��Ǹ�Ψһ�п��ܡ��ɵ���GPT-4������ģ�͡����ڣ�OpenAI����������ij��Σ������������ǰ�� �����������ģ��ѧ���˹��� 3D ������״��һ���Ե�֪ʶ�����Ҳ���OpenAIѵ���Ŷ�Ԥ���趨�ģ�������ȫ��ͨ���۲����������Ȼ��Ȼ��ѧ��ġ�����Soraѵ����OpenAI��ѧ��Tim Brooks��ʾ��AGI���ܹ�ģ���������磬��Sora���������������Ĺؼ�һ���� |
|
|
��Ȼ����OpenAI�������ֻ��һ����������Ƶģ�͡������Ǹ���Ķ����� ����������Խ�һ����һ�����ۣ����ǣ�����������һ�еĻ�������������Ƶ������ģ�ͲŻᵽ���� ��������DZȽ���ˢ���п�����ʵ�������ˡ�֮�⣬���ֲ��ĵط��������������ͨ��AGI����һ��ChatGPTʱ�̡� |
|
�Ҿ��öԾ�ҵ����˵�������õģ���Ϊ����Ҫ��ʼ�ϣ��Ͼ���Ҫ����˲š� |
|
û��ʲôӰ�찡��ֻ��˵��Ŀǰ�ľ�������Ҫǿ������������ҵ������Զ������2024����������Ƶ��Ԫ�� |
|
���� sora �����ɸ��ֱ�����άģ�͵�DZ���������Ҳ��ͨ���ض�����������ģ���������ᶯ����DZ���� |
|
bվ������������ |
|
�⼸����NeRF�ȵ��αͼ��ѧ�������˾���soraӰ���dz����Ҹ����Ǿ���sora��ͼ��ѧ��Ӱ����NeRF��ͼ��ѧ��Ӱ���10�����ϡ���ʱ��ȫ��ӵ��data-driven�ˡ� |
|
�������ʲôӰ�졣 ���ܻ�� SIGGRAPH ����Ӱ�죬���Dz����ͼ��ѧ����ʲôӰ�졣 ��ٵ� neural rendering, ������ neural rendering.jpg |
|
�ศ��ɰ�, û�����ഴ��, AIģ��û�������ݿ�������ѵ��, ��ȫ�����Լ����ɵ�ͼ��ѵ��, �о����ڴ����·��Խ��ԽԶ, ��˼�ݽ߶����� |
|
���ǻ���������-�������Ѱ������·�� �м��Ǵ��������-����·��С���� �������ƽ��-���������Լ�ɸѡ |
|
����������ǰ����һ�� Ҫ��������Ի��ӿڣ���������Ļ�����ֵ���ʵ�����ֱ�ӻ�е������ |
|
OpenAI��Soraģ���ܹ������ı�ָ�����ɸ��ӵ���Ƶ���������ɫ���ض���������ϸ�ij����Լ�������У�Sora�ܹ�������������������ã�������չ������Ƶ�еij���������ζ��Sora�����ڽ��������֡��������ݴ����������й㷺Ӧ�á����磬�������������������̡̳�������Ƭ��ģ����ʵ������Sora��Ӱ�����������Ƶ���ݵĴ�����̡����������ɱ����ƶ����µı��﷽ʽ����Ȼ����Ҳ���ܴ�����Ȩ����������Ϣ��ʵ�Ե���ս�� |
|
�ศ��ɣ����湲������������������������ͼ��ѧ�����������������������˵�˼�봴�첻ͬͼ�Σ��ﵽ�����Ŀ�ġ� ���µ�sora���DZ�����������һ����˼��ļ���������������ģ�ͣ�����ÿ����˼������Ż��� ʱ���ڱ䣬�������������������������˵�����Խ��Խǿ������߸���ֻ�������и������о�������������ӭ̽�ֽ���~ |
|
û���κ�Ӱ�죬 ��������������ģ�⡰��Ⱦ����Ƶ |
|
Sora��һ������AI����Ƶ����ģ�ͣ������Դ��ı��������ɸ���������Ƶ������ζ���������Զ�������Ƶ���������˹���Ԥ�����ּ��������������������Ӱ�죬������桢��Ӱ����Ϸ�ͽ����ȡ� ���ڼ����ͼ��ѧ��˵��Sora��Ӱ����Ҫ���������¼������棺 ��Ƶ���ݴ�����ø��Ӽ�Ч��Sora�����Զ�������Ƶ���⽫�����ٴ��������е�ʱ��;������⽫ʹ��������ܹ����ɵش�����Ƶ���ݣ��Ӷ��ƶ������ͼ��ѧ����Щ�����Ӧ�á���Ƶ���ݵ������õ�������Sora���Ը���������ı��������ɸ���������Ƶ���⽫ʹ����Ƶ���ݵ������õ������������Ӷ�����û����顣��Ƶ���ݵĶ��������ӣ�Sora���Ը��ݲ�ͬ���ı��������ɲ�ͬ����Ƶ���⽫ʹ����Ƶ���ݵĶ��������ӣ���������û����������ͼ��ѧ�㷨���Ż���Sora�ij��ֽ���ʹ�о���Ա�����Ż������ͼ��ѧ�㷨���������Ƶ���ɵ�������Ч�ʡ��⽫�ƶ������ͼ��ѧ�����ķ�չ���˹������ڼ����ͼ��ѧ�����Ӧ�ã�Sora��һ���������ѧϰ��ģ�ͣ�����ζ�������������˹����ܼ�����������Ƶ���⽫��һ���ƶ��˹������ڼ����ͼ��ѧ�����Ӧ�ã�Ϊδ���ļ�����չ�춨������ |
|
gpt�����ӵ����ݷ������̣����������ݷ���ʦ��Ȼ���ã����˱���д���������ս�Է���ʦ��Ȼ���ã����lean���Խ��и�����ѧ֤��������ѧ����Ȼ����Ҫ sd�����˻滭���� soraһ���������ɸ��ӵ�ͼ�δ������ ���������� ͼ��ѧ��������˵��һ�ּ��ټ������˵���ٹ�����Ч���� �����پ�������Ƶ��������ֹ����ܹ���ģ��������Ӱ�� ��Ϸ��������ͳͼ��ѧ��render simulate geometry��������Ҳ������� �ֽ���������negative���뷨����ai����cg���� ������ͼ���ı�����Ƶ���ݶ��Ѿ����þ��ˣ�AI�Ƿ��ݶ������أ����������Ǵ��ģ�������ռ�ʱ���������Ǹ���expertģ�ͺ�ai4sciģ�ͣ� |
|
�о�Ӧ������ý���Ӫ���ŵĿ������ȱ�����ai��������ܳ�һ����Ȼ����������Ƶ�ֳ�һ����ChatGPT�����İ���sora��������Ƶ��ֱ��Ӯ���ˣ����¿����İ�������������Աȫ�����ˣ� ����ͼ��ѧ��Ӱ��Ļ������˸о�ͼ��ѧӦ��������ai��ץ�֣�aiȥ����ͼ��ѧ��ز��ȥ������Ƶ��Ȼ����ai�����������ȼ���ͼ��ѧ��ԭ�����������ߵIJ��֣�����ë����ˮ���ȣ���������С������Ҳ����������ֻҪ�����ָо����ˣ����κ�ģ�ⲻ̫�˽⣬��Ⱦ����о����ֵ͵Ĺ�ʵ�Ѿ�ժ�IJ���ˣ�������ͷ�ͱ仯�Ծ�ҵ����Ͷ�ʶ����а����ġ� |
|
���´��彲AI��Sora����ԭ������� |

|
|
AI�ܺ�ΰ �˹����ܿ�ѧ�ң���ѵAI��ChatGPTѧԱ����10���ˡ� ǰ�أ�Sora��һ��OpenAI������ģ�ͣ��ں���ChatGPT��DALL E3���Լ�����Ƶ�ںϵ�Transformer�У�����һ��һ����Ƶ֡������ʸ������ʾ���������ʸ���͵�Transformer��ѵ���Ӿ���ģ�͡� Sora����ͼ��������Sora��һ��������Ƶģ�ͣ���ͬ���߱�����ͼ�������������������ҵ�ڵ�һ�ҡ�Sora�������ɲ�ͬ��С���ֱ��ʸߴ�2048x2048��ͼ�����磬����������ɺ��������ɫ���ͷ�����ͺ������ |
|
��Ӱ�죬��Ϸ�͵�Ӱ����������Ⱦ������ϸ�ں��Ӷ��ܵ���������������Լ�� ai���ɻ�������������ƺ��컨����ߡ� ����ܹ��Ż�������Ӳ���Ҹ�֡�������϶����Դ���һ���ֵ�Ӱ����Ϸ������ |
|
û��Ӱ�죬��ֻ�ǵ�����ͼ��ѧ�������Ӱ�� |
|
|
| [�ղر���] �����ر��ġ� |
| ��һƪ���� ��һƪ���� �鿴�������� |
|
|
|
| ��Ʊ�ǵ�ʵʱͳ�� ��ͣ��ѡ�� ��ʱͼѡ�� ��ͣ��ѡ�� K��ͼѡ�� �ɽ���ѡ�� ����ѡ�� ������ѡ�� �������� �������� ���� MACDָ�� KDJָ�� BOLLָ�� RSIָ�� ���ɻ���֪ʶ ���ɹ��� |
| ��վ��ϵ: qq:121756557 email:121756557@qq.com ����ƻ� |