
| |
|
|
| ����ƻ� -> �Ƽ�֪ʶ -> �������OpenAi��������Ƶ����ģ��Sora? -> �����Ķ� |
|
|
[�Ƽ�֪ʶ]�������OpenAi��������Ƶ����ģ��Sora? |
| [�ղر���] �����ر��ġ� |
|
Text2Vid: Sora: Creating video from text |
|
Sora�ļ��������Ѿ������ˣ�Video generation models as world simulators OpenAIû�з���GPT-5�������������µ�����������Ƶ��OpenAI�·�����������Ƶģ��Sora������DALLE-3�кܺõij��ı��������������ҿ������ɳ�����Ӽ���ĸ�������Ƶ���ӹٷ�ʾ���Ͽ������ɵ���ƵЧ��ȷʵ���ޡ�Sora�������ɿ��� 1920x1080 ��Ƶ����ֱ 1080x1920 ��Ƶ�Լ���������֮���������Ƶ�� |

|
|
0 |

|
|
0 |

|
|
0 |

|
|
0 |

|
|
0 |

|
|
0 �Ӽ����Ͽ���Sora��DALLE-3һ�����Dz�����ɢģ�ͼܹ�������һ�����������ʼ��ȥ������һ����Ƶ�����һ���Ƚϳ���ļ�����������������ȸ�ļ�����Ƶ���ɹ�����VideoPoet�Dz��û���Transformer���Իع鷽����������ͼ������ɢģ������������ô����Ƶ���������Իع����ʤһ�������д�δ������֤�� |

|
|
ͬʱSora��ģ�Ͳ���Transformer����ViTһ����ͼ�������Ƶת��patches�������ı�tokens������Transformerģ�͡�����Transformer��һ���������кܺõ�scaling���ܡ��ҹ�������Ϊ�˼��ټ������������ܻ����latent diffusion������Meta֮ǰ��DiT�������µļ��������Ͽ���ȷʵ������Visual Encoder����Ƶת��latent�ռ䣬Ȼ���ٷֽ��patches�� |

|
|
��ɢģ��֮DiT����Transformer�ܹ�139 ��ͬ �� 5 �������� |

|
|
Sora��ѵ�������в�����Ƶ��ԭʼ�ֱ��ʽ���ѵ������������ͨ�������ü���������ͼƬѵ��������ѵ���ĺô��ǿ��Ա���ü�ЧӦ�� |

|
|
0 |

|
|
0 ������Ҳ��Sora֧�����ɱ�ֱ��ʵ���Ƶ��1920x1080��1080x1920 ��Ƶ�Լ���������֮���������Ƶ����������ʱ��ֻ��Ҫ������֯�����ʼ����noisy patches��grid��С��������ͨ��λ�ñ��������ƣ��Ϳ��Կ���������Ƶ�ĵķֱ��ʺ�ʱ���� |

|
|
0 |

|
|
0 |

|
|
0 Sora��ʹ�� DALL��E 3 ��recaption���ɣ���Ϊ�Ӿ�ѵ���������ɸ߶������Ե�caption������Sora�ܹ�����ʵ����ѭ������Ƶ���û����ı�ָ����һ�֧�ֳ��ı������Ӧ����OpenAI���е����ơ� DALL-E 3���������Ķ��ʼ�155 ��ͬ �� 19 �������� |

|
|
���⣬��OpenAI������ϸ�ڿ���Sora������֧��������Ƶ����֧��ͼ����Ƶ������һ��ͼƬ����������Ƶ��ȷ�ض���ͼ������ݲ���עСϸ�ڡ�Sora�����Ի�ȡ������Ƶ�����������չ�����ȱʧ��֡�� �������������DALLE-3����һ��ͼ��Ȼ����Soraת����Ƶ�� |

|
|
|

|
|
0 |

|
|
|

|
|
0 Sora֧�ֶ����е���Ƶ������չ����������ǰ�������ͼ����Ƶ������������Ƶ��չ��ֻ�����ǵ�֡��Ƶ����չ���� |

|
|
0 |

|
|
0 |

|
|
0 ����˵Sora��һ��������Ƶ��ģ�ͣ��������Ƶ��չ���������������ģ�ͣ����Dz�����Ƶinpainting�ķ�ʽ��ʵ�֣���������ͼ��inpainting���� ��������ͼ��ͼ��ͼ����Ҳ����ͨ�����Ƶ���Ƶת��Ƶ����ʵ����Ƶ�ı༭�� |

|
|
0 |

|
|
0 �����ͨ����������Ƶ���֡������������Ƶ�� |

|
|
0 |

|
|
0 |

|
|
0 �ر�أ�Sora���������ɷֱ��ʸߴ�2048x2048��ͼ����Ϊͼ����Կ���ֻ��һ֡��ͼ�� |

|
|
Close-up portrait shot of a woman in autumn, extreme detail, shallow depth of field |

|
|
Vibrant coral reef teeming with colorful fish and sea creatures ���ף��OpenAI������AGI�ֽ���һ���� Sora serves as a foundation for models that can understand and simulate the real world, a capability we believe will be an important milestone for achieving AGI. OpenAI��ΪSora���Գ�Ϊ���������ģ������world simulators������Ҫ����Ϊ��Ƶ����ģ���ڴ��ģѵ��ʱ���ֳ�������Ȥ���¹��ܣ���Щ����ʹ Sora �ܹ�ģ����ʵ�������ˡ�����ͻ�����ijЩ���档 3D consistency��Sora�������ɴ��ж�̬������˶�����Ƶ��������������ƶ�����ת���˺ͳ���Ԫ������ά�ռ���һ���ƶ��� |

|
|
0 Long-range coherence and object permanence��Sora�ܹ���Ч�ضԶ��ںͳ���������ϵ���н�ģ�����磬ģ�Ϳ��Ա����ˡ�����������һ���ԣ���ʹ���DZ��ڵ����뿪��ܡ�ͬ�����������ڵ�������������ͬһ��ɫ�Ķ����ͷ������������Ƶ�б�������ۡ� |

|
|
0 Interacting with the world��Sora�����üķ�ʽģ��Ӱ������״���Ķ��������磬���ҿ����ڻ����������µıʴ���������ʱ������ƶ��������ڡ� |

|
|
0 Simulating digital worlds��Sora ���ܹ�ģ���˹����̣�һ����������Ƶ��Ϸ�� Sora ����ͨ���������Կ��ơ��ҵ����硷�е���ң�ͬʱ�Ը߱������Ⱦ���缰�䶯̬�� |

|
|
0 ��Щ����˵��Sora��ǿ����ϣ��ģ����ʵ�������磺 These capabilities suggest that continued scaling of video models is a promising path towards the development of highly-capable simulators of the physical and digital world, and the objects, animals and people that live within them. OpenAI�����³�����Ƶ�������������Խ��Խ�������ƶ�Runway��Pika�ȹ�˾�бȽϴ�ij����δ��AIGC˵������������PK�� |

|
|
|
|
�dz�ͬ����AI��Ƶ��������Ĵ�ҵ��˾��OPENAI��һ̨���ٷɱ��Ļ�һ�������������ϵij���ȫ�������ˡ� ��� OPENAI��X�Ϸų�����Ƶ�ǿ��ŵģ���ôSora������Ƶ��ˮƽʵ����̫ǿ�ˣ����ִ�ҵ��˾���AI��Ƶ������ȣ�������˻����õ�������ʱ��OPENAIͻȻ�ͳ��˳��ǹ�����������˵������ϡ� ���ָо�����ǰ��ChatGPT��ճ���һ����һ���־�ֱ��������һ��ʱ����2024��Ź���2���£�OPENAI�Ͷ�����Ӳ���ˣ����ڴ����꽫������GPT-5�� |
|
������ǰNeurIPS����ʱ����Χ���˲�����cv������ģ�͵�С��飬��������LLM+video ����ս�Ϳ���·��������ҵĹ�ʶ�������ǡ��ѡ������ر��ǶԳ�ʱ�䡢�߷ֱ��ʣ��ͱ�֤���غ���������������ԡ�һ����ǰpika ˢ��һ��������������ࡣ����Ƶ����openai �·�Ҳ�������aigc ��С����ָ�����ľ������ݡ� ����sora �ȳ���ʲôѧ��ǰ�أ�ʲôopen problem ��ʲô��������� һ�����ѣ���ѹ������ |
|
֮ǰpika����·ý�崵�������OpenAIһ���־ͱ���ſ�ˡ� ������Ӹ������ǣ���ҵ����Ҫ�IJ��Ǵ��⣬����ʵ�����ֽ����� ����Ƶ��ҵҪ��ʼ�����ˣ���������ȥ��ai�ᴴ������������Ƶ�� �ֽ�������õIJ��Ծ�������������Ǯ����Ȼ��һ����OpenAI�Լ���һ������Ƶapp��ר�Ų���ai��Ƶ������Ƶ��ͷ��β������ҵ�����ᱻ������� AI�ܸ��õ�����������Եij����ƣ����OpenAI���������ҵ���ܿ���ܰ�������ҵ���OpenAI��һ����Ŀ�� �ٶ�Ե�������ҵ��û����������ܿ�ʼ���ϰ뵼���ҵ�� |
|
��Ը��Ϊ����Ƶ���������iPhone moment |
|
|
0 Ŀǰ�ų���demo��Ƶ�����������ȣ��ȶ��ԣ������ԣ���������Ƶʱ�����Ǿ����걬Ŀǰ�κ�����ai��Ƶ���ɹ��ߡ�runway��pika��pixverse��Щ��˾���Թ����ˣ���ȫû�о������� ���̶��Ҿ��ñ�ȥ��ChatGPT�������͡���ΪChatGPT����ʱ����blog����һ���˳����������ͷ����gpt+alignment������������������Sora�Ƴ��ͺñ����Ƕ�������ô�о��Ľ���ͳ������������õ�Ҳ���Ǹ��Ϲ���OpenAIֱ�ӿ��ź���ĸ��������������ˡ��������ȫ�벻������ô�����ġ���OpenAI���ܹ�������Ҳ��̫���ˣ�ǰ����Sam���������������ų�һЩgpt5��С��Ϣ��ԭ��ƭ�������ˣ����ű�����أ� Ŀǰ������ֻ����ʹ������ģ�ͣ��ܹ�����ģ��������˶�������Ԥ�⡣���Դ�Ŀǰ�ų�demo���������Ӧ��������һ������ģ�͵���Ҫ�Ľ������ǿ϶�û��silver bullet���������ԭ����Ҳ˵������һ�꣬���е������Ѽ�/ģ�ͼܹ�/�����ط����϶����Ǽ��ܸ����ġ� Sora���Ƴ�Ӧ�������������Ƶ�������� |
|
|
���ݴ����Ѿ���Զ�ı��ˡ� �Ⲣ�����š� �ҽ��� YouTube �����Ѿ� 15 ���ˣ�Open AI �ո�չʾ��������������� ��ʱ�뷨/Ԥ�⣺ - ����ʦ/3D ���������鷳�� - �ز���վ������ؽ�Ҫ - �κ��˶�����������þ��ʵ�Ļ���� - �������ݣ�ʵ�������������ŵIJ�ֵ - ��ÿ���˶���������������Ƶ�������У����ݱ���ġ��뷨�����±�ø�����Ҫ - �����������ҽ���/��Ƶ����/�����ߵ������г� ���Խ�����Ӧ�ù���Ҳ��Ӧ�����ˣ���ʲôLLM��ģ�ͣ��Ͻ���AI��Ƶ��ҵ��˾�ˡ������ò��²���һ��Ҫ��ʼ�ϣ�ϣ��������ܴﵽ95%��ˮƽ������ ���������Soraȫ��������ʾ����Ƶ��Ŀ��⣬��Ҫ�Ŀ���˽�ż��� |
|
|
|

|
|
|

|
|
|
|
���и�Ԥ�У�Sora��ʽ����ChatGPT����һ�죬Ҳ��GPT5��������һ�졣 �ٷ��������ӣ�Sora: Creating video from text ˵ʵ����Ƶ����ģ�����ù��������٣�����֮ǰ����Runway�� ������ʲô�����ܹ�AI�Զ�������Ƶ��106 ��ͬ �� 2 ���ۻش� |
|
|
����OpenAI�����ģ��һ������˵ʵ�����е����Ϊ�����ˣ����������ͼ��Sora�ķ�����Ƶ�� |

|
|
�㿴�������������ξ��� |

|
|
��Ȼ˵���������Ʒ������ʱ������õĽ�����������ɺ�ǣ����������ҵ���Ƶ��������ͼ����IJ���Sora�� �������� �����������м�����dz���ǿ���㿴����������ӡ� |

|
|
|

|
|
0 |

|
|
1 �����ڸ���Prompt���������� �������������Ƶ��Prompt���ܸ��ӵ�һ��Prompt�� Prompt: A stylish woman walks down a Tokyo street filled with warm glowing neon and animated city signage. She wears a black leather jacket, a long red dress, and black boots, and carries a black purse. She wears sunglasses and red lipstick. She walks confidently and casually. The street is damp and reflective, creating a mirror effect of the colorful lights. Many pedestrians walk about. ��ʾ��һλʱ�е�Ů�����ڶ����Ľֵ��ϣ��ֵ��ϵ���������ů�ķ�����ƺͶ������б�־����������ɫƤ�пˣ���ɫ��ȹ����ɫѥ�ӣ�����һ����ɫǮ����������ī����Ϳ�ź�ɫ�ں졣�����Ŷ��������·���ֵ���ʪ�����⣬Ӫ���������ɫ�ĵƹ�ľ���Ч�������������Ĵ��߶��� ������ù�AI�滭�Ļ���֪�������prompt���е�Ԫ����ʵ�кܶ࣬AI�滭��һ���������ĸ��֣������㿴��Ƶ�г��ֳ�����Ԫ�أ������ֵ���������ƣ����Ŵ�磬���dz������ϡ� ����Ҫ���ǣ��������Ŷ����⡹���ֶ������ƺ��dz������ϣ��������Sora������ˮƽ���һ�����������̫�ֲ��ˡ� 2 ʱ�� �����Ƶ������59�룬����ܻ����һ������1���ӵ���Ƶ���ѡ� �����Ҹ���˵��������������Ƶ����ģ��һ�������ʱ����10����֮�ڣ������Dz������ɳ��ģ����Ƕ̶̼����ܿ��Ƶ�ס��һ��ʱ�䳤�ˣ��Ͳ�֪��������ʲô���ι�״�Ķ��������ˡ� �����Ƶ���Ⱥʹ�����ģ�͵������������һ������ʵҲ�ǻƽ���� һ����ģ���ܴ���10���֣���һ��ֻ��1���֣���ˮƽ���Զ����ˡ� 3 ����ľ�ϸ�� �㿴��Ȧ�����ģ�����˵�����ϸ���ж��٣�ʲôȸ�ߣ�����ɫ��ʲô�ģ��Dz��Ǻܶ࣬����ʵûʲô�� |

|
|
|

|
|
������������ͺֲܿ��ˣ�����һ����ͷԶһЩ����ƵƬ�Σ�����ϸ������������ |
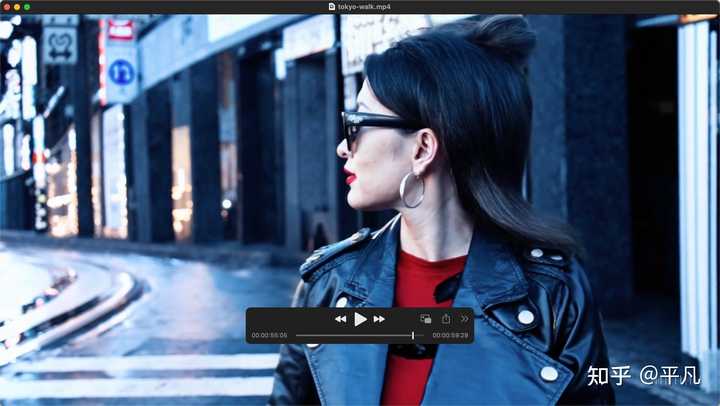
|
|
�Dz��Ƿ��������ϵ���Щϸ�ڻ����϶����ڣ��ر��������м���Ǹ�ȸ�ߣ� |

|
|
�����Ǿ仰�������Ƶ����ģ�ͣ���Ҳ�ù���������ϸ�ڱ������ô�õģ�Sora������Top1�� ������Ҫ �����ʵû��̫����Խ��͵ģ���Ϊ���ļ������滹û�зų����� ȷ������Ҳ����Diffusion model���ģ���˵�����Ǹ�һ��ͼƬ����ѩ��һ����������Ȼ���ٻ�ԭ��ȥ�Ĺ��̣����ı����������ϵ���ɢģ�͡� |

|
|
��ԭ�����������ɵ���ͼƬ�ģ�������Ƶ����������ͼƬ��ɵģ�����һ��=24֡��ÿһ�ž���һ��ͼƬ�� |

|
|
Sora����10����Ƶ��˵���˾�������10*24 = 240��ͼƬ��Ȼ���������������һ����Ƶ�� ԭ��������ô�ļ����Ҳ���õIJ����㷨����������Ч���ã�������ѵ�����ݺã��Լ���OpenAI�Ķ���ѵ�������� �ܽ�һ��?? �������ģ� Sora��һ����ɢģ�ͣ�ͨ����ȥ����ʼ��̬������Ƶ�е�����������������Ƶ�� �����ص㣺 һ��������������Ƶ���������Ƶ������չ��ʹ�������ͨ��ͬʱԤ���֡������˱�����Ƶ������һ���Ե���ս��ʹ��transformer�ܹ����ṩ���������չ���ܡ� ���ݴ�����ʽ�� ��Ƶ��ͼ�ֽ�Ϊ����������С���ݵ�Ԫ����������GPTģ���е����ơ��������ݱ�ʾ������չ��ģ�ʹ�����ͬ����ʱ�䡢�ֱ��ʺ��ݺ���Ӿ����ݵ������� �������£� �����DALL��E��GPTģ�͵��о��ɹ�������DALL��E 3�����±��⼼����Ϊ�Ӿ�ѵ���������������Ա��⣬�Ը�ȷ����ѭ�û����ı�ָ� Ӧ�ó����� �����ı�ָ��������Ƶ���Ӿ�ֹͼ�����ɶ�̬��Ƶ����ȷ������ͼ�����ݡ���չ������Ƶ�����ȱʧ֡������ 1 �ܹ����ɾ��ж����ɫ���ض����͵��˶��Լ�����ͱ�����ȷϸ�ڵĸ��ӳ�������ģ�Ͳ����˽��û�����ʾ��Ҫ������ݣ����˽���Щ���������������еĴ��ڷ�ʽ�� �������������Ƶ��ͼ |

|
|
Prompt: A close up view of a glass sphere that has a zen garden within it. There is a small dwarf in the sphere who is raking the zen garden and creating patterns in the sand. ��ʾ��һ�����������д��ͼ��������һ�����ڻ�����������һ��С���ˣ����������ڻ���ҵأ���ɳ���ϴ���ͼ���� ���ɳ�������Ƶ�����ǵ����������Ļ���������������䣬�dz��ľ�ȷ�˻�ԭ��Prompt�� 2 �������ɾ��ж����ɫ���ض����͵��˶��Լ�����ͱ�����ȷϸ�ڵĸ��ӳ�������ģ�Ͳ����˽��û�����ʾ��Ҫ������ݣ����˽���Щ���������������еĴ��ڷ�ʽ�� ���������ף���ڵ���Ƶ�����治����������������������ˣ��dz���ȷ�Ļ�ԭ��prompt�����ݣ� Prompt: A Chinese Lunar New Year celebration video with Chinese Dragon. ��ʾ���й������й�ũ��������ף��Ƶ�� |

|
|
ȱ�� ����ȷģ�⸴�ӳ������������ԣ����ҿ��������������ϵ�ľ���ʵ�������磬һ���˿��ܻ�ҧһ�ڱ��ɣ���֮���ɿ���û��ҧ�ۡ� ��ģ�ͻ����ܻ�����ʾ�Ŀռ�ϸ�ڣ����磬���һ��������ҿ������Ծ�ȷ������ʱ�����Ʒ������¼���������ѭ�ض�������켣�� �㿴�������Щ���ӣ���ƾ�յij��֡� |

|
|
һЩ���� |

|
|
0 |

|
|
0 |

|
|
0 |
|
һ�������������ը�ˡ� Sora������Ч��̫���ˣ����ٹ����¹ٷ��ļ������档 �ҹ���2���㣬 Scaling transformers for video generation����ָʲô�������ᵽSora����diffusion�ģ�����transformer�Ľṹ������scaling����������û�п���һ��scaling�����ߣ���������ӿ�ֵ��������� |

|
|
�Dz������Ҳ²�������ɹ���������unreal������ȥ����һЩ���壿 |
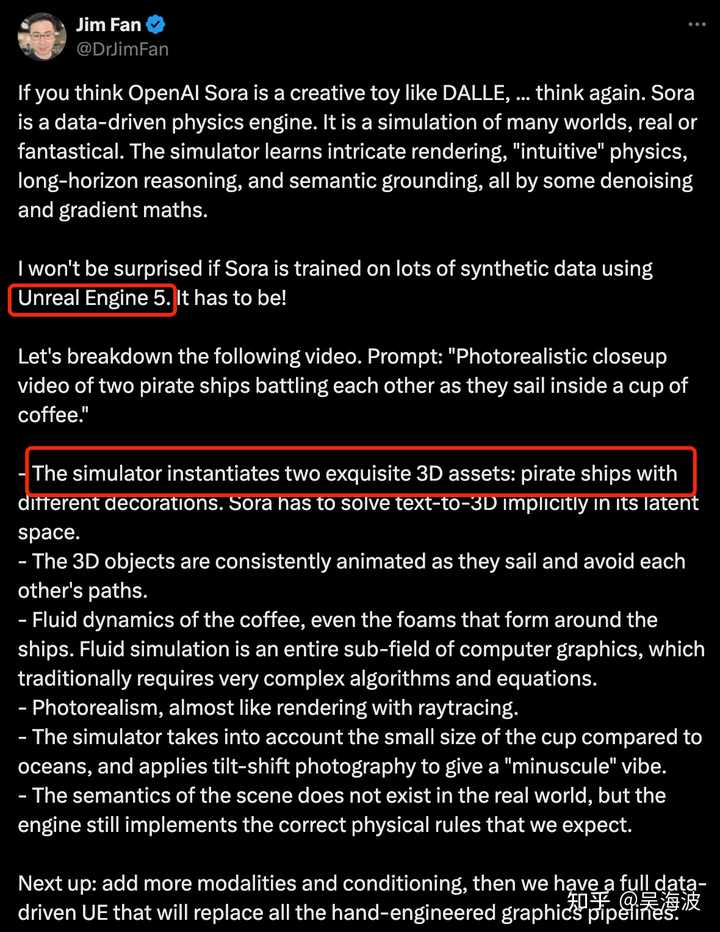
|
|
���Openai����������ҵ���ꣿ |
|
��һ����������һ���ط����Ļش���һ�α�֪����֧�ֺϲ�������ˣ�����ο���openai���·�����sora�� |
|
����NLPer��ChatGPTɱ�������Ŀ־� �����ֵ�CVer����� |
|
�����賿�����Ĺ�ˤ��ȥ��������ˢ��������⣬ϣ��ai������չ�����������ְ�ƽ�����ӵ���Ƶ |
|
���� Sam Altman ˵�Ļ�����Ҫվ�� OpenAI ǰ�棬ȥ��Ӧ�ðɣ� ����öഴҵ�߶�Ͷ���˵Ļ������DZ� ChatGPT ǿ�ĵط���û�����ã� Sora: Creating video from text ����������ģ��뿴������������Ƶ���Ұѹٷ���49 ����Ƶ�ϲ���һ���ˣ���� 10 �뵽 1 ���ӵ���Ƶ��û����������� AI ���������̵ģ� �ŵ��ֱ������ AI ���ɹ�������ѹʽ�ģ�ʱ���������е����ɹ���֡����˼����ȶ���û�з������������ı��μ��컯��ͷ�����ܹ����ɾ��ж����ɫ���ض����͵��˶��Լ�����ͱ�����ȷϸ�ڵĸ��ӳ�������ģ�Ͳ����˽��û�����ʾ�������Ҫ���˽���Щ���������������еĴ��ڷ�ʽ�������ڵ�??�����ɵ���Ƶ�д��������ͷ��ȷ�ر�����ɫ���Ӿ����ȱ�㣺����������ȷģ�⸴�ӳ���������ԭ�������ҿ��������������ϵ�ľ���ʵ�������磬һ���˿���ҧ��һ�ڱ��ɣ���֮����ɿ���û��ҧ�ۡ� ��ģ�ͻ����ܻ������ʾ�Ŀռ�ϸ�ڣ�����������ң����ҿ������Ծ�ȷ��������ʱ�����Ʒ������¼���������ѭ�ض�������켣���������ܣ�Sora ��һ����ɢģ�ͣ������ϸ� StableDiffusion ��û�в�̫�࣬�ǴӾ�̬��������Ƶ��ʼ������Ƶ��Ȼ��ͨ��������������������������ת����Sora �ܹ�һ������������Ƶ����չ���ɵ���Ƶ��ʹ�������ԭ����ͨ��һ��Ϊģ���ṩ���Ԥ��ؼ�֡�������һ��������ս�Ե����⣬��ȷ�����⼴ʹ��ʱ�뿪��ҰҲ���ֲ��䡣�� GPT ģ�����ƣ�Sora ʹ�á��任��/Transformer���ܹ������ǽ���Ƶ��ͼ���ʾΪ��Ϊ������/Patch���Ľ�С���ݵ�Ԫ�ļ��ϣ�ÿ��Patch������ GPT �е�Token��ͨ��ͳһ���DZ�ʾ���ݵķ�ʽ�����ǿ����ڱ���ǰ���㷺���Ӿ������ϡ��任��/Transformer�������Dz�ͬ�ij���ʱ�䡢�ֱ��ʺ��ݺ�ȡ�������Ӧ����һ����ʼ���� ViT �ļܹ������Ǻ��������ģ�͵�ѵ�������������Ը��ӣ�û�м�����˾���������������֡�Sora �����ڹ�ȥ�� DALL��E �� GPT ģ�͵��о�֮�ϡ���ʹ�� DALL��E 3 ��recaptioning�������ü����漰Ϊ�Ӿ�ѵ���������ɸ߶������Եı��⡣��ˣ���ģ���ܹ�����ʵ����ѭ������Ƶ���û����ı�ָ������ܹ��������ı�ָ��������Ƶ֮�⣬��ģ�ͻ��ܹ���ȡ���еľ�̬ͼ����������Ƶ��ȷ�ض���ͼ������ݲ���עСϸ�ڡ���ģ�ͻ����Ի�ȡ������Ƶ�����������չ�����ȱʧ��֡�� Sora ���ܹ������ģ����ʵ�����ģ�͵Ļ���������������һ���ܽ���Ϊʵ�� AGI ����Ҫ��̱��� Ҳ���Ǵӽ���Ͽ�����������ܲ��������ɣ�������һ��������ʵ����ġ���������ͬʱ�����ᵽ�ˡ����硱���Dz��Ǹ��� Yann LeCun ������ģ�͵�δ���أ� �Ҳ�֪�� ��������֪�� ��������Ƶ���ɵĹ��߳��̱����ˣ��������������ȥ��Ķ����������� |

|
|
OpenAI ������ AGI ��δ���������������˹����ܴ�ҵ��˾��ج�Σ� |

|
|
|
|
�����Ӷ������������ˣ� |

|
|
���ҿ���Soraչʾ��OpenAI��Ҫ��һ������ģ�͵�һ����ͼ��Ұ�ģ�AGI��IJ�Զ�ˡ� |

|
|
����AI�滭���ɵ�ͼƬ ���������˽���Sora������ʲô�ɣ� һ��Ч��չʾ �ȿ�������59��ȫ�����������ɵ�Ч���� ��ʾ�ʣ�һλʱ�е�Ůʿ�߹�������һ���ֵ����ֵ��ϳ�������ů�������ƺͶ������б�־��������һ����ɫƤ�пˣ�һ������ɫ����ȹ����ɫѥ�ӣ���Я��һ����ɫ�������������̫������Ϳ�ź�ɫ�ں졣�����Ŷ���������š��ֵ���ʪ�ҷ��⣬�������ɫ�ƹ�ľ���Ч���������������ڽ��ϡ� ����һ�������ַ������Ұ����˶��λ�� �����ǻ�����Ƶ��ǰ�������Ů���ǡ����DZ����е������ʶ�ƣ����ﵽ�˾��˵�һ���ԡ����Ҹ��־�ͷ���������л������ﶼ�DZ����˷�ͬһ����ȶ��ԡ� ��Ա�ԭ��Runway �� Pika��ͼƬ����ȫ�ǽ�ά����� �������ٿ���������Ƶ�� ��Щ��Ƶ����һ����ͬ�ص㣬ͼƬ�ľ��Ⱥ��ȶ��������������ⲻ����ʵ����ġ� ����������� Sora����չʾ���Ǽ���˼·��ͬ����������ȫ��ѹ�� �ӹ�ע��ά���صı仯����ɹ�ע��������ı仯������Ƶ��������ɣ���ɹ����������ɡ� |

|
|
֮ǰ������Runway��Pika��SVD�ȵ�����ͼ��������Ƶ�����ڶ�άƽ���϶�ͼ����е�������ϣ�����Sora����Ƶ����ʾ��������һ������һЩ�������������ɣ����� OpenAl�������Ĵ�����ģ�����ƽ��еij�ǿ�������⣬���������������ģ�͡� ֻ��ʵ�ֶ���ʵ���������Ͷ���ʵ�����ģ�⣬����������ͼ�����Ƶ���Ǹ�����ʵ��Ч���� ���Sora������������������Ӱ����ҵ������δ��������չ��������ҵ����Ƶչʾ���Ƕ���ʵ�����������ɵ����֣� Ӣΰ��ĸ���ѧ��Jim Fan��Ϊ Sora ��ʵ��ԭ�����ⲻ������һ����Ƶ����ģ����ô������һ������������������� 5 ���档 ���� Sora ������һ�ֿ�ѧϰ��ģ����������˵��һ����ģ����ʵ����ġ�����ģ�͡��� ���ַ��������� Sora ���õ������ģ����ʵ������������� ���ڽ���OpenAI������������Ƶ��ģ��Sora��360���Ŵ�ʼ�ˡ����³���CEO�ܺ�t����һЩ�۵㡣 ����Ϊ������Sora���ܸ����ҵ����ӰԤ��Ƭ������Ƶ��ҵ������߸���������һ����ô�����TikTok�������ܳ�ΪTikTok�Ĵ������ߡ��� ��̸��Sora�ļ���˼·��ȫ��һ����ͨ���Ѵ�����ģ�ͺ���ɢģ�ͽ�ϣ�ʵ���˶���ʵ���������Ͷ������ģ������������������������Ƶ������ʵ�ġ� һ��AI��������ͷ�������е�Ӱ��YouTube��TikTok�ϵ���Ƶ��һ�飬����������⽫ԶԶ��������ѧϰ���������AGI��ľͲ�Զ�ˣ�����10��20������⣬����һ����ܿ�Ϳ���ʵ�֡��� �ܺ�t����OpenAI���ﻹ����һЩ���������� |

|
|
������Ϊ��Ϊֱ�ӳ������ҵ����Ӱ����ҵ��˵��δ���ĵ�Ӱ���������㡢������������̬��������AI�������� AI��ɫ�����Դ�����ģ��Ϊ������������������ʵʱ���жԻ��ݳ������ַ�ʽ������������������ݵ�Ч�ʣ�ʹAI��Ϊ�����Ĵ������ߣ���ɹ��¡���ɫ���Ĵ���������ʵ�����˶�����ͨ��AI��Ƶ�����������Լ���Ӱ��Ч���� ����ԭ����� |

|
|
�����Ҹ���OPENAI���������ӣ�����Ȥ�Ŀ���ֱ���Ķ��� ������˵���Ҷ����µ����⣺ 1������ģ���� OpenAIĿǰ������Sora��Ƶ����ģ�ͼ���������ȫ��Խ���е���Ƶ������ģ�ͣ���Runway��Pika�� ������ĺ�����һ�����µġ�����ģ������������һ�������ı���������ɢģ�ͣ�ͨ���Ӵ�������Ƶ��ѧϰ����Щ��Ƶ�����˲�ͬ��ʱ�������߱Ⱥͷֱ��ʡ� ���ģ������ѵ�������漰���պʹ����������Ӿ����ݣ�ʹ���ܹ������ı�����������Ӧ����Ƶ���ݡ� ���磬�����롰̫���˵�ð�չ��£�������һ����ɫ��ë��֯��Ħ�г�ͷ��������������ʱ��ģ���ܹ����⺬�壬����������֮�������Ƶ���档 |

|
|
��ģ�ͻ��߱�������Ƶ������ԺͶ����ԣ�֧�ֲ�ͬ��ʱ���ͷֱ������ã������������ɴ�1920*1080�ķֱ��ʺ�30֡/���֡�ʡ� 2���Ӿ�����ת�� ����˵��OpenAI���Ӿ����ݴ��������Ӿ�����ת��Ϊ��patch����һ������Ԫ�壬�����Խ�ͼ�����Ƶ֡�ָ�ɡ�������״��С�顣 ��Щ����������Ϊ�Ӿ�ģ�͵Ļ������뵥Ԫ��ʹ��ģ���ܹ�ѧϰ��������α�ʾ�Լ��ؽ��Ӿ��������ڴ˻����ϣ�ģ���ܹ����ض����������ı������������£������µ�ͼ�����Ƶ���ݡ� |

|
|
���ִ�����ʽ���������ģ���еġ�token���������ƣ�token���ı����ݵĻ���������Ԫ�� ������ģ���У��ı����ֽ�Ϊ��С��Ƭ����ʵ�����Ե���������ɡ�ͬ���أ��Ӿ�ģ�͵�ѵ�������漰����ͬ���͵���Ƶ��ͼƬת����patch����Ϊģ������Ļ�����λ�� ������̿�����������Ƚ���Ƶѹ����һ���ϵ�ά��DZ�ڿռ䣬Ȼ����Ƶת��Ϊpatch������һ���ֽ�Ϊ��spacetime patches��(ʱ�ղ������� 3����Ƶѹ�� �о��߿�����һ��ר�ŵ���Ƶѹ�����硣 ������ĺ�����һ������ѵ���������磬�������ּ���ڽ����Ӿ����ݵĶ�ά�ȸ����ԡ� ����ν�ġ�����ά�ȡ���ָ���ǽ����ݴӸ�ά�ռ䡪������ԭʼ��Ƶ���ݣ������˺�����������Ϣ����ת������ά�ռ䡣��һ���̵�Ŀ���Ƕ����ݽ��м���ȡ�ؼ�������ͬʱ���ٺ�����������ļ�����Դ�� |

|
|
������������ԭʼ��Ƶ��Ϊ���룬�����һ����ʱ��Ϳռ��϶�����ѹ����DZ�ڱ�ʾ��latent representation���� ʱ���ϵ�ѹ����ζ�ż����˱�ʾ��Ƶ��̬�仯�������Ϣ���� �ռ��ϵ�ѹ������ζ�ż����˱�ʾ��Ƶ��ÿһ֡ͼ���������Ϣ���� �����ѹ����DZ�ڿռ��У�Soraģ�����Ƚ���ѵ����ѧϰ�������Ϳ���������ʽ�����ݡ�����ѵ����Sora�ܹ������DZ�ڿռ��������µ���Ƶ���ݡ� Ϊ�˽�Sora���ɵ�DZ�ڱ�ʾת����ԭʼ�����ؿռ䣬�о���ѵ����һ��������ģ�͡� �������������ǽ�ѹ������Ƶ���ݻ�ԭ�ɿ���ֱ�ӹۿ�����Ƶ��ʽ�� 4��ʱ�ղ�����Spacetime Laten Patches�� ����Ƶ����ѹ����ɺ������Ĺؼ���������ȡһϵ�еġ�Spacetime Latent Patches������ЩPatches��������Ƶ���ض�ʱ��Ϳռ䷶Χ�ڵ���Ϣ�� ��ЩPatches��transformerģ���а��ݵĽ�ɫ��������Ȼ���Դ����еĵ���token�� ���ַ���������������Ƶ���ݣ�Ҳ������ͼ�����ݣ�ʹ�ò�ͬ�ֱ��ʡ�ʱ��Ϳ��߱ȵ���Ƶ��ͼ���ܹ���ΪSoraģ�͵�ѵ������ |

|
|
��ģ���������������µ���Ƶ����ʱ������ͨ�����ʵ���С�����������������ʼ����Patches������������Ƶ�Ĵ�С�� �����������������Ȼ���Դ����У�ģ���ݸ�����token�����µ��ı����ݡ�ͨ�����ַ�ʽ��Soraģ���ܹ�������Ҫ���ɲ�ͬ��С��ʽ����Ƶ��Ϊ��Ƶ���ɺͱ༭�ṩ�˸��������ԺͶ����ԡ� 5����Ƶ������չ��ѹ�� Soraģ�͵ĸ����ǽ�����Transformer�ܹ�֮�ϵ���ɢģ�͡� ��ģ��ͨ���������������Patches���ı���ʾ�ȵ�����Ϣ���ܹ���Ч��Ԥ������ɾ�����Patch�� |

|
|
���ּܹ��ڴ�������ģ�͡�������Ӿ���ͼ�����ɵ��������Ź㷺��Ӧ�á� ��ѵ�������У�ʹ�ù̶������Ӻ����룬���ż����������ӣ�����������������������ߡ� ����ѵ����ʽʹ��Soraģ���ܹ���ѧϰ���Ż��������������Ӷ��ڴ�����Ƶ��ͼ������ʱ���ܹ�������Ӿ�ϸ�ͱ���Ľ���� ���� Sora�����ҵ���ʵ��̫����Ҫ�ú��������������뷨�����ҷ��� ���ǵ�����ģ�һ����AI�滭���˹�������ǿ����Ȥ����ҵ����� ���ʦ��������ҵ��������ݸ���Ȥ�����æ��ע�����ղأ�лл�� |
|
������ǰ����һƪ���ڴ�ģ��ʱ����ҵ·�ߵĻش𣬼������ǣ� ��˽�����ݣ���˽�����ݣ���˽�����ݡ� �����Ķ�����ס�� |
|
���ڻ�������˵������һ���dz��õ�������Դ�������������˶�ģ̬������ѵ������ȱ����������Ƶ-���Զ�������ݼ���Ҳ���ܿ����Ǿ��ܿ�������Sora��������ѵ���Ļ����˲�������ģ���ˣ� |
|
������죬����ʵ�������ˡ���ʼȫ��ˢ�����ܶ��˸�̾��������ô��Ͳ�����һ��ʱ���ˣ�Sora ��ֱ̫ը���ˡ�����ǵ�Ӱ������δ���� �ȸ�� Gemini Pro 1.5 ��û������Сʱ�ķ�ͷ����һ����ȫ����ľ۹�ƾͼ������� OpenAI �� Sora ���ϡ�Soraһ������ǰ����Ƶ����ģ��ֻ�г����� |

|
|
���ݽ��ܣ�Sora ͨ����̻���ϸ�� prompt����һ�ž�̬ͼƬ�������������Ƶ�Ӱ�ı��泡�������������1�������ҵ� 1080P ������Ƶ�� ����������һ�£� ���� prompt����ʾ�ʣ���һ����ʵ������������Ŵ�ء���������������硣 |
|
|

|
|
Ч�������� ���ڼ�Сʱ��OpenAI Sora �ļ�������Ҳ�����ˡ����У�����̱���Ҳ��Ϊ�����еĹؼ��ʡ� �����ź����ǣ����治����ģ�ͺ�ʵ��ϸ�ڡ�OpenAI �����Ǹ� Close AI��������Ȼû��ģ��ϸ�ڣ��������ǴӼ��������л����ܴ���˽� Sora �Ĺ���ԭ�������������Ǿ������һ����ƪ�������档 ��������ؼ���Ϣ �Ӿ����ݵ�ͳһ��ʾ���ܵ���������ģ�ͣ�LLM������������Щģ��ͨ���ڻ�������ģ��������ѵ����ʹ��tokens��ͳһ��ͬģ̬���ı���Sora ģ�Ͳ������Ӿ��飨visual patches����Ϊ���Ӿ����ݵı�ʾ����Щ�飨patches����ѵ����������Ƶʱ���dz���Ч�� ��Ƶѹ�����磺OpenAI ѵ����һ�������������Ӿ����ݵ�ά�ȣ�������罫ԭʼ��Ƶѹ����һ��ʱ��DZ�ڿռ��У�Sora �����ѹ����DZ�ڿռ���ѵ����������Ƶ��ͬʱ����ѵ����һ����Ӧ�Ľ�����ģ�ͣ������ɵ�DZ�ڱ�ʾӳ������ؿռ䡣 �ռ�ʱ��飨spacetime patches����ͨ����ѹ�������Ƶ�ֽ�Ϊһϵ�� spacetime patches����Щ patches ��Ϊ transformer �� token�����ֻ��� patches �ı�ʾ���� Sora �ڲ�ͬ�ֱ��ʡ�ʱ���Ϳ��߱ȵ���Ƶ��ͼ���Ͻ���ѵ�� diffusion-transformer��Sora ��һ����ɢģ�ͣ���ͨ��Ԥ��ԭʼ�ġ��ɾ���patches��ѵ������Щ patches ������ʱ����������diffusion-transformer ����Ƶģ����Ҳ��ʾ������Ч����չ�ԡ� �ɱ�ʱ�����ֱ��ʺͿ��߱ȣ�������ͨ������Ƶ���������ߴ�ķ�����ͬ��OpenAI ������ԭʼ�ߴ���ѵ�������ṩ�˶��ֺô���������������ԺĽ��Ĺ�ͼ�� �������⣺Ϊ��ѵ���ı�����Ƶ������ϵͳ����Ҫ�������ж�Ӧ�ı��������Ƶ��OpenAI Ӧ���� DALL��E 3 ����������±��⼼����re-captioning technique��������ѵ��һ���߶������Եı�������ģ�ͣ�Ȼ��Ϊѵ�����е�������Ƶ�����ı����⡣ ͼ�����Ƶ prompt��Sora ��������ͨ���ı���ʾ������Ƶ��������ͨ��Ԥ�ȴ��ڵ�ͼ�����Ƶ��Ϊ���롣��ʹ�� Sora �ܹ�ִ�й㷺��ͼ�����Ƶ�༭���� ������Ƶ��������Sora ���ܹ�����ͼ��ͨ���ڿռ����������и�˹������ patches����Щ patches ����һ֡��ʱ�䷶Χ��ģ�Ϳ������ɲ�ͬ��С��ͼ�ֱ��ʸߴ� 2048��2048�� ģ������������Ƶģ���ڴ��ģѵ��ʱ��չ�ֳ�һЩ��Ȥ���������������� 3D һ���Ժ�����־��ԣ��Լ������绥����������Sora �����ܹ�ģ���������磬������ Minecraft ��ͬʱ������Һ���Ⱦ���硣 ������������¼��������ϸ�ڡ� ��Ƶ����ģ����Ϊ����ģ�� OpenAI ̽������Ƶ��������ģ�͵Ĵ��ģѵ����������˵��������˵���о���Ա�ڿɱ����ʱ�䡢�ֱ��ʺͿ��߱ȵ���Ƶ��ͼ��������ѵ����һ���ı�������ɢģ�ͣ�text-conditional diffusion models��������һ��transformer�ܹ���������Ƶ��ͼ��Ŀռ�ʱ��飨spacetime patches����������ģ�� Sora �ܹ����ɳ���һ���ӵĸ�������Ƶ�� OpenAI ��Ϊ����չ��Ƶ����ģ���ǹ�����������ͨ��ģ������һ����Ч;���� ���������ص� ����������Ҫ��ע�������棺 ��1�����������͵��Ӿ�����ת��Ϊͳһ�ı�ʾ��ʽ���Ա���д��ģ������ģ��ѵ���� ��2���� Sora ģ�͵������;����Խ��ж��������� ���������о��У��Ѿ��������ʹ�ø��ַ�������Ƶ���ݽ������ɽ�ģ������ѭ�����磨RNN�������ɶԿ����磨GAN�����Իع� transformer ����ɢģ�ͣ�diffusion models������Щ�о�ͨ���������ض������Ӿ����ݡ��϶̵���Ƶ��̶���С����Ƶ�ϡ� ���֮�£�Sora ��һ��ͨ�õ��Ӿ�����ģ�ͣ����������ɿ�Խ��ͬʱ�������߱Ⱥͷֱ��ʵ���Ƶ��ͼ�������ܹ����ɳ���һ���ӵĸ�����Ƶ�� �Ӿ�����תΪ Patches ��������ģ�ͣ�LLM��ͨ���ڻ�������ģ�������Ͻ���ѵ��������˳�ɫ��ͨ�������У�OpenAI ����һ�㼳ȡ����С�LLM ����ȷ���·�ʽ�����ֵ����ڴ����� token ʹ�õķ������о���Ա����ؽ��ı��Ķ���ģ̬ ���� ���롢��ѧ������Ȼ����ͳһ�������� ��������У�OpenAI �����Ӿ����ݵ�����ģ����μ̳���Щ�ô����� LLM ӵ���ı� token ��ͬ��Sora ӵ���Ӿ��飨visual patches�����飨patches���Ѿ���֤�����Ӿ�����ģ�͵���Ч��ʾ��OpenAI ���� patches ��ѵ����Ƶ��ͼ������ģ�͵���Ч��ʾ�� |

|
|
�ڸ��߲����ϣ�OpenAI ���Ƚ���Ƶѹ�����ϵ�ά��DZ�ڿռ䣬Ȼ��ʾ�ֽ�Ϊʱ�� patches���Ӷ�����Ƶת��Ϊ patches����Ƶѹ������ OpenAI ѵ����һ�������������Ӿ����ݵ�ά�ȡ����������ԭʼ��ƵΪ���룬���һ����ʱ��Ϳռ��϶���ѹ����DZ�ڱ�ʾ��Sora ��ѹ����DZ�ڿռ���ѵ����������Ƶ��OpenAI ��ѵ����һ����Ӧ�Ľ�����ģ�ͣ������ɵ�DZ�ڱ�ʾӳ������ؿռ䡣 ʱ��DZ�� patches ����һ��ѹ����������Ƶ��OpenAI ��ȡһϵ��ʱ�� patches���䵱 Transformer �� tokens���÷���Ҳ������ͼ����Ϊͼ�����Ϊ��֡��Ƶ��OpenAI ���� patches �ı�ʾʹ Sora �ܹ��Բ�ͬ�ֱ��ʡ�����ʱ��ͳ����ȵ���Ƶ��ͼ�����ѵ����������ʱ��OpenAI ����ͨ�����ʵ���С�����������������ʼ���� patches ������������Ƶ�Ĵ�С�� ������Ƶ���ɵ����� Transformer Sora ��һ����ɢģ�ͣ������������� patches���Լ��ı���ʾ������������Ϣ����ѵ������ģ����Ԥ��ԭʼ�ġ��ɾ��� patches����Ҫ���ǣ�Sora ����һ����ɢ Transformer��Transformer �ڰ������Խ�ģ��������Ӿ���ͼ���������ڵĶ������չʾ����������չ���ԡ� |

|
|
��������У�OpenAI ������ɢ Transformers Ҳ������Ч������Ϊ��Ƶģ�͡����棬OpenAI չʾ��ѵ������������ѵ�������������ӣ���Ƶ����������������ߡ� |
|
|

|
|
�ɱ�ij���ʱ�䣬�ֱ��ʣ����߱� ��ȥ��ͼ�����Ƶ���ɷ���ͨ����Ҫ������С�����вü������ǽ���Ƶ���е����ߴ磬���� 4 �����Ƶ�ֱ���Ϊ 256x256���෴����ԭʼ��С�������Ͻ���ѵ���������ṩ���¼����ô��� ��������� Sora ���Բ���������Ƶ 1920x1080p����ֱ��Ƶ 1920x1080p �Լ�����֮�����Ƶ����ʹ Sora �ܹ�ֱ��������Ȼ�ݺ��Ϊ��ͬ�豸�������ݡ�Sora ������������ȫ�ֱ��ʵ�����֮ǰ���Խ�С�ijߴ���ٴ�������ԭ�� ���� �������ݶ�ʹ����ͬ��ģ�͡� |
|
|

|
|
����˹�ͼ�Ͳ��� �о���ͨ��ʵ�鷢�֣�ʹ����Ƶ��ԭʼ�����Ƚ���ѵ�����Ը������ݺͲ��֡��� Sora ������ģ�͵ıȽ��У����߽�����ѵ����Ƶ�ü��������Σ�����ѵ������ģ��ʱ�ij������������������βü�ѵ����ģ�ͣ���ࣩ���ɵ���Ƶ�����е���Ƶ����ֻ�Dz��ֿɼ������֮�£�Sora ���ɵ���Ƶ���Ҳࣩ���и��õĹ�ͼ�� |
|
|

|
|
�������� ѵ���ı�����Ƶ����ϵͳ��Ҫ�������ж�Ӧ�ı��������Ƶ���о��Ŷӽ� DALL?E 3 �е����±��⣨re-captioning technique������Ӧ������Ƶ�� ������˵���о��Ŷ�����ѵ��һ���߶������Եı�������ģ�ͣ�Ȼ��ʹ����Ϊѵ������������Ƶ�����ı����⡣�о��Ŷӷ��֣��Ը߶���������Ƶ�������ѵ����������ı�������Լ���Ƶ������������ �� DALL?E 3 ���ƣ��о��Ŷӻ����� GPT ����̵��û� prompt ת��Ϊ�ϳ�����ϸ������Ȼ�����뵽��Ƶģ�͡���ʹ�� Sora �ܹ�����ȷ��ѭ�û� prompt �ĸ�������Ƶ�� ʹ��ͼ�����Ƶ��Ϊ��ʾ �����Ѿ��������ı�����Ƶ���������ʾ����ʵ���ϣ�Sora ������ʹ���������룬�����е�ͼ�����Ƶ����ʹ Sora �ܹ�ִ�и���ͼ�����Ƶ�༭���� �� ����������ѭ����Ƶ����̬ͼ������ǰ������ӳ���Ƶʱ��ȡ� Ϊ DALL-E ͼ���������� Sora �ܹ�����ͼ�����ʾ������Ƶ����������չʾ�˻��� DALL��E 2 �� DALL��E 3 ͼ�����ɵ���Ƶʾ���� |
|
|

|
|
����ͼƬ+һֻ���ű���ñ�ͺ�ɫ����ë�µIJ�Ȯ |
|
|

|
|
����ͼƬ+д�С�SORA������ͼ����չ���ɵ���Ƶ Sora���ܹ���չ��Ƶ�������ǿ�ͷ���ǽ�β������ʹ�����ַ��������ӳ���Ƶ�����ݣ�ʵ�֡���Ƶ�������������� |
|
|

|
|
��Ƶ����Ƶ�༭ ��ɢģ�ͼ����˶��ָ����ı� prompt �༭ͼ�����Ƶ�ķ�����OpenAI ���о��Ŷӽ�����һ�ַ��� ����SDEdit Ӧ���� Sora��ʹ�� Sora �ܹ�����������zero-shot�������¸ı�������Ƶ�ķ��ͻ����� ������Ƶ���£� |
|
|

|
|
�������� |
|
|

|
|
������Ƶ ���ǻ�����ʹ�� Sora ������������Ƶ֮������ת��������������ȫ��ͬ����ͳ�����ͼ��Ƶ֮�������ɡ� ͼ���������� Sora Ҳ�ܹ�����ͼ��Ϊ�ˣ�OpenAI ����˹���� patches �����ڿռ������У�ʱ�䷶ΧΪһ֡��ģ�Ϳ������ɲ�ͬ��С��ͼ����߷ֱ��ʿɴ� 2048x2048�� |

|
|
ӿ��ģ������ OpenAI ���֣���Ƶģ���ھ������ģѵ������ֳ�������Ȥ������������Щ����ʹ Sora �ܹ�ģ�����������е��ˡ�����ͻ�����ijЩ���档��Щ������û�ж�3D������ȵ��κ���ʽ����ƫ�������³��� ���� ���Ǵ����ǹ�ģ���� 3D һ���� Sora �������ɴ��ж�̬������˶�����Ƶ��������������ƶ�����ת���˺ͳ���Ԫ������ά�ռ���һ���ƶ��� |
|
|

|
|
�����������Ժ�Ŀ��־��� ��Ƶ����ϵͳ���ٵ�һ���ش���ս���ڶԳ���Ƶ���в���ʱ����ʱ��һ���ԡ�OpenAI ���֣���Ȼ Sora ������������Ч��ģ��̾���ͳ������������ϵ�������ںܶ�ʱ����Ȼ��������һ�㡣���磬��ʹ�ˡ���������屻�ڵ����뿪���棬Sora ģ��Ҳ�ܱ������ǵĴ��ڡ�ͬ�����������ڵ�������������ͬһ��ɫ�Ķ����ͷ������������Ƶ�б�������ۡ� |
|
|

|
|
�����绥�� Sora ��ʱ����ģ���Լ�ʽӰ������״̬�Ķ��������磬���ҿ����ڻ����������µıʴ�����Щ�ʴ�������ʱ������ƶ�����������һ���˿��ԳԺ���������ҧ�ۡ� |
|
|

|
|
ģ���������� Sora ����ģ���˹����̣���Ƶ��Ϸ����һ�����ӡ�Sora ����ͨ����������ͬʱ���� Minecraft �е���ң�ͬʱ�߱���س������缰�䶯̬��ֻ���� Sora �� prompt ���ἰ ��Minecraft��������������������Щ���ܡ� |
|
|

|
|
��Щ���ܱ�������Ƶģ�͵ij�����չ�ǿ������������������Լ����е����塢������˵ĸ�����ģ������һ�����п�Ϊ�ĵ�·�� ������ ��Ϊһ��ģ������Sora Ŀǰ��������������ԡ����磬������ȷģ������������������������粣�����ѡ��������������ʳ��������ܲ�����ȷ������״̬�仯���������о��� Sora ģ�͵���������ʧЧģʽ�����糤ʱ�������г��ֵIJ������Ի�������Է����֡� |
|
|

|
|
|
|
|

|
|
������Sora Ŀǰ��չ�ֵ�����֤���˳���������Ƶģ�͵Ĺ�ģ��һ������ϣ���ķ��� �ܽ� OpenAI �ļ������濴�����������ż���ûʲô�ɻ������������Һ�ţ��Ϊʲô��ţ�����Լ�ȥ���⡣�������һ������ģ��ģ����Ч���� �ο� Video generation models as world simulators SORA��OpenAI�����ı�������Ƶ���ɴ�ģ�ͼ���������-CSDN���� OpenAI��ըģ�������Ƽ�Ȧ���ٷ���������˵��ʲô�� �ȸ跢����һ����ģ̬��ģ�� Gemini 1.5������Щ���������� ����ģ�����磡OpenAI�ոչ���Sora����ϸ�ڣ������������������� �����ּ��� ǿ��ѧͽ��SORA��������ȫ�ķ���-��Ϊ����ģ��������Ƶ����ģ�� |
|
|
| [�ղر���] �����ر��ġ� |
| ��һƪ���� ��һƪ���� �鿴�������� |
|
|
|
| ��Ʊ�ǵ�ʵʱͳ�� ��ͣ��ѡ�� ��ʱͼѡ�� ��ͣ��ѡ�� K��ͼѡ�� �ɽ���ѡ�� ����ѡ�� ������ѡ�� �������� �������� ���� MACDָ�� KDJָ�� BOLLָ�� RSIָ�� ���ɻ���֪ʶ ���ɹ��� |
| ��վ��ϵ: qq:121756557 email:121756557@qq.com ����ƻ� |