
| |
|
|
| ����ƻ� -> �Ƽ�֪ʶ -> OpenAI ��������Ƶ����ģ�ͣ������ֳ� 1 ���Ӹ�����Ƶ����������������������ʵ�Ľ����� -> �����Ķ� |
|
|
[�Ƽ�֪ʶ]OpenAI ��������Ƶ����ģ�ͣ������ֳ� 1 ���Ӹ�����Ƶ����������������������ʵ�Ľ����� |
| [�ղر���] �����ر��ġ� |
|
2022��ĩ��OpenAI���������ChatGPT���������ɳ�Ϊ�������˹������˳��ı�־���¼�����������һ�ֿƼ������ĵ������������������֡�����ѧϰ���� |
|
�������ʵ֮�䱾���ͺ�ģ�����Ժ�ֻ��������Խ��Խģ���ˡ� ����Ƶ�ճ��ֵ�ʱ�㷺����Ϊ�Ǻ�ˮ���ޣ����ڻ��������˶�������һ������ƵAPP�� ��Ϊ�㲻�ɷ��ϣ�������һ���Ķ���Ƶ�����Ӿ��Ľ������������á�������Ȥ�����Ǻÿ��Ķ������ָ��㣬������������ô�����ӣ�ֱ�ӾͿ��Ի�þ����ϵ�ˬ�С� ���ֻ��ˬ�еķ�ʽ�dz������ۣ���Ҳ��Ϊʲô���������ܿ�����Сʱ���飬��ͬ����ʱ�仨��ˢ����Ƶ�Ͽ����Ծʹ�������ˡ� �������Ϊһ���˱���ҪŬ���ijɼ���Sora������Ƶ����ģ�ͣ���������������汾���ټ�����������������Ļ��� ���������Բ��ýӴ���ʵ���磬����vision pro���豸������ϵ���������ˬ����Ƶ���С� �����ϲ�����������Ǿ������ɹ�������һ�����ݡ� �����ϲ��������Ԫ����ôר������ϲ�õĶ���Ԫ��Ƶ7*24Сʱ�IJ�ͣ�������������������۾Ϳ��Կ������ɵ��㲻�뿴Ϊֹ�� ��Ϊ˵���ˣ���ν��ʵ���˴����ĸ��ܣ��Dz��Ǿ��Ǹ������ﴫ��������ѧ���۾�����ѧ�Ķ��࣬����Ƥ���Ĵ�����ζ�ٸ��ܵ�ζ����Ȼ��ת���ɵ��źš� ֻҪ���յĸ������棬�DZ���������û�кܴ� Sora�������ɲ���ϵ���Ƶ���ṩ��ѧ�źţ����Ժ����Ҳ���и�������ģ������ δ����õ�����ѡ�������ѡ����ʵ��Ҳ����ѡ�����⣬�㻹������ʵ��ϡ� |
|
�ղ�ȥopenai���������й䣬������һ��Ŀǰ��ͨ�������Ȥ�����⣺ |

|
|
Sora��������������ʽ�Ƴ�������ѵĻ����շѵģ�����ɶʱ������ô���ʹ�ã� �����һ���ظ�����������⣺ |

|
|
һλ�ų���רҵ��Ӱ�����˵��û���Ϊ��Sora��ò�Ҫ��ѣ������������ʹ���ż���ͬʱ������������������һ���ǡ�������Ƶ�����Ա����ϱ�ǣ���һ����ϣ���ܹ�������ģ��ѧϰ�����Լ��ķ�� һ�����ը�ѵļ�������ʵ�ܻ�������ش�ҵ�ߣ�������ͨ�˵ĺܶൣ�ġ�����openai��˵����SoraĿǰ��Ȼ�ڡ�ѧϰ�������Ǽƻ�ʹ����ͼ��������Dall-E���е�һЩ��ȫ���ܣ����ð�������ı���ʾ������ڵ�һЩ���ߣ�ȷ��Sora���ɵ���Ƶ������"���˱����������ݡ����ͼ������Ф�������֪ʶ��Ȩ"�ȹ��� ���һ��ʱ�䣬AI��������һЩ���ƻ����桱�Ķ������Ѿ���ʼ������벢Ӱ�������ǵ������ð���и���Taylor Swift����ʾAI����ͼ�����罻ý���Ϸ贫��������������ۿ������º���ʲ���ݳ�ѡ�ڼ䣬һ����ð��ͳ�ǡ��ݵ��������Զ��绰����Ȱ������ͶƱ�� ����˵������Ŀǰ�ļ���ֶΣ�ʲô���棿ʲô�Ǽ٣���ʵ�Ѿ����ѷֱ棬��fake��Ƶ�ļ�⣬���������ϼ��ѡ� �����������ʵ֮��Ľ��ޣ���ר����Ϊ����Ӱ����Ƶ�����е���ʵ�������Ѿ���ʧ�ˡ�������ҵ��Ǻ��Ͽɣ���Ϊ��Sora�ļ����ĵ��оͿ��Կ�������Sora�����ű����Ѿ��ﵽ�����ij̶ȣ���ʹ�ֲе����Լ��ҵĹ������ĺ����ˣ�����ֻҪ����Sora������Ȼ�ܻ���һ�Ρ���������Ӱ�� |

|
|
ֻ���������������ԭ���Ĺ����У��Һܵ���һ�����飬���ǡ��ҵĹ����Ƿ���Ļ��ǡ��ҵĹ������Ͼ��ǡ����ɡ�����һЩδ�����㵽��ϸ�ڣ�ֻ�ܿ�ģ���Լ�����������������������ϸ����䣬��ô�������������Ƿ��ǡ���������ԭ���壬�Ͳ��ò����˻�һ���ʺ��ˡ� ������˵��ֻҪ��ͬһƷ�֣����ö���࣬�Ժ�SoraҪ�ǽ��������������������ʵ�ԡ��ɿ��ԡ��Ϸ�����ʵ����ֵ����ȶ��������Щ�ֵ���ȥ������Ӳ�������Щ������� Sora����������ʽAI��Ʒһ�����ǻ��ڴ�����������ѵ���ģ����������ݵ�������ʵ�Dzβ��ġ�����Sora�����������ޡ��������ģ��Ƿ���Ŀ���ͻ����ʵ�Ľ��ޣ�������Ҫ�ȵ���public������ҵ�ʹ�ò��ܱ�֤ʵ�� |
|
����dz�NB�� ��Ŀǰ�ļ���·���ܸ���ⶫ����˵ʵ�������DZȽϳԾ��ġ���Ϊ�����ڵIJ�Ʒ������ܿ����ģ�ͼƬ�ľ���SD��MJ�Լ�Dalle-3��dalle-3��Ȼ�Ա�SD�бȽϴ�����ƣ������㷨�Ҹ�˵����Ǿ���ͼ��ģ��������ģ��ǿ��ѵ������Ҳ���ࡣ���ֻҪ���д������ѧϰ��صľ���Ͳ��ѵó����Ƶ���֪��ʵ����openAI���ǰ뿪Դ��dalle-3�ļ���ϸ�ڣ���������ؼ��������Ʊ���ϸ�ڱ������ˣ��ӹ���������������ʵ���ϲ�û��ʲô�ر��Ĵ���֮������Ҳ������֪�� Ȼ��Sora���Ҹо���Ӧ���Ǹ�ȫ�µĶ���������������������ڵ��㷨ȥ���ͣ���ʲôֻ�ǵ����Ķѵ�������֮����������͡��ҽ��ļ㣬���� existing methods + bigger model + larger dataset != Sora ����Sora����ײ�ԭ����Ȼ��diffusion�������п�����diffusion�Ļ�����������һЩ��Ĵ��¡��ͺñ���GPT��vanilla transformers�����𡣵�Ȼ����Ҳ����100%�ų��ⲻ�ǵ�ģ�ʹ�һ���ز���ʱ��������ν�ġ�emerging��������Ȼ�ҷdz�������һ�㡣 ���̵��ǣ����¹����볭Ҳ�������ˣ�������˵��ģ�֮ǰ���ڵİ�ģ��ս����������սʤgpt��������openAI���Sora���ⳡ����̫�����ˡ� |
|
�Ҿ�����������Ҫ�ijɣ���������ı����ڶ��̶��ϴ�����������ʵ�Ľ��ޣ�����ʲôʱ���Ƴ������ڣ� ����һֱ��δ�����������ǵ�δ��������˵�ʱ�������˷�����ʼ��������δ���𣿿�ʼ�־壬δ���������Լ��Ĺ��������ʼ���߾²ˣ�������ѧ�����û��δ���� ���Դ�ҿ��Կ�����δ������ʱ���ǻ��ҵ�ʱ������Ҫ��ע��һ�£��������ṩ����Ӽ����Ƕ��������ʵ�� �������������������ϢΪ����ʱ���ˣ������ֵ�ͼ���ٵ���Ƶ�㿴����һ�ж��������˹��������ɵĻ����ٵ���Ϣ�����ǹ�ȥ��ݵġ��ۼ�Ϊʵ������Ϊ�顱����ˣ�һ�ж������ǡ��顱�ˣ�������ͱ�÷dz�Σ�գ������û���Լ����ж����������ܻ�ӹ�ȥ�������������������壬�����������������������ģ� ��dz�Σ��??????ֻҪ��һ���ļ�����������������൱�����ļٻ����ټ����˹����ܵ�Ч�ʣ�����ϲ�ɵ��ɸ�ӣ�δ����������ö���ͨ�˼��Ȳ��Ѻã� |

|
|
����ĸ���Ӱ�������ˣ���ͯ���������̼�������ȱ��������ɼ������û�а취���������ˣ� ������Ե����Լ������˵���Ƶ+�������Ӵ�Ǯ ��̸��������ҵ��Ӱ�� ���������ҵ����һ�仰���� ai �ľ������� ai �ģ�������ai ���ݻ����ˮ����һ����Ƶƽ̨����ֻ�������˵Ŀ��ܣ���Ҫ������Ƶ����������ţ���һֱ���š��� ��Ӱ�����ҵ����ֱ�ӵ���Ƶ��ش�ҵ����ý�壬�����ҵ����DZ�ڵ�δ����ش�ҵ�ߣ������ҵ��������-�ϰ�����Ҳ�������һ���ӵ����ۣ���ǧ���ɲ��ɣ������ prompt �㻹����˼Ҫ��ô��Ǯ������Ϊ�ǡ���ѩ���������ۣ��㰮���Ұ��㡱���� ��ʵ�ĸ�����Ӱ�춼��ᵽ�ˣ�ʱ���뿪�������к������� ������������ʵ��ÿ���ᵽ����ʣ��������Ӷ��� vision pro ��ƻ�� |

|
|
���������ƻ�������ᣬtsmc �ȹ�˾������������й�װ�似����û�д�����������ʵ�Ļ����� sora �����������Զ�� ��������ʵ�Ĵ�������Ƶ aigc ��ʵʱ���ɣ������� vr �� ar �����л���ʱ���� ��ʱ���������ǿ agi ʱ���ˣ� �����������ѧϰ�Ѿ��������Ǹ�ʱ���ĿƼ��ˣ� |
|
֮ǰ������Runway��ͼƬ�ϳɣ�s�����Ƶ�����Եĸо�����ģ����ͨ����������ϳ���Ƶʱ�����ɵ����ݱ��ֳ����Ե�ָ���������������Ƶ����֡�䲻����(�ر�������������ද̬�ϳ�ʱ������������̬���ε�)�� 4s����Ƶ�����ܹ����ݵ���Ϣ̫�̣����Ҫ�ϳɸ�������Ƶ����ҪԤ�����ķ־����ϳɶ����s��Ƶ���ٺ��ڼ����ϳɸ�������Ƶ���ݡ�����������׳�����Ƶ�������岻һ�µ����(��Ҫ���ѽϳ�ʱ��ĵ������ܻ���������Ƶ����)�� ��Sora�ļ������濴��soraģ�� ���������ɺ��Dz�ͬ����ʱ�䡢���߱Ⱥͷֱ��ʵ���Ƶ��ͼ�ߴ�һ���ӵĸ�����Ƶ����Ϊ����ģ��������Ƶ����ģ��(video generation models as world simulators:)����һ��diffusion transformerģ�͡���������Ƭ��(��������Ϣ�������ı�prompt),����ԭʼ��������Ƭ��.������ǿ������������������chatGPT���û�����ʾ��ת���ɸ���ϸ����������Ļ��ʾ�ʣ���֤��Ƶ�ϳ�ģ��Sora�������������û���ͼ�ĸ�������Ƶ����֧�����ͼƬ����Ƶprompt: ��������ͼƬ�ϳɶ�̬��Ƶ��������Ƶ������Ƶ��չ�ϳɸ��������ḻ����Ƶ���ݡ���֧����Ƶƴ�ӣ�����ƽʱ�����ļ�������Ƶƴ�ӣ����Ǹ�������Ƶ����������ٺϳ��µ���Ƶ�����ַ�ʽƴ�ӵ���Ƶû�����Եij����任��ͻأ�С���Ҳ֧�����ɸ��ֱַ��ʵ�ͼ�����ɴ�2048x2048.������ǿ�����ά״̬ģ����������Ҫ��������Ƶ�е���������ά�ռ���˶��������㾵ͷ����ά�ռ���˶��������˶�������Ч���ܹ��ܺñ�ģ�������(����ͼ����Runway�о�ͷ����ͨ��Camera Motion���������ƣ�Motion Brush�����������������ά�˶�) |

|
|
�����г���ͷ�ж���һ���ԣ���Ƶ����ϵͳ���ٵ�һ����Ҫ��ս���ڲ�������Ƶʱ����ʱ���ϵ�һ���ԡ�openAI���֣�Soraͨ���ܹ���Ч�ؽ�ģ���ںͳ���������ϵ�����ܲ���������ˡ����磬ģ�Ϳ������ˡ���������屻�ڵ����뿪����ʱ��Ȼ��������ڡ������Ժ����罻�����������������ͼ�������Ƶ�ź��������һ����е�֣�����һ��ֽ�����Ϳ�����������ʵ�����ͼ�� |

|
|
������ģ����������: �������������������ң������ݲ��Խ������档 sora�ij��ֻ������ı����ӹ��ȵļ������£�AIGC��صķ��ɱ��ȡ�Ŀǰ��Sora��Ϊһ��ģ������Ȼ�����������ơ����磬����ȷ��ģ�������������������ЧӦ�����粣�����顣��������������Զ�����Ҳ����������ȷ�ظı�����״̬�� |
|
��˵����Щ��Ц�������ˣ����˼����������������ľ�����Ա�������������Ա�ͱ���������������������һ��ţ�Ƶ��������Զ���ͼ�Զ�����Ƶ�Ĺ��ߡ�Ȼ��д�ĵ��ij�Ц����Ա����ũ��Ȼ����ũ���ı�gpt�����ȥ�깤����д�ĵ���10���˲õ�ֻʣ��1���ˣ�Ȼ��java����Ա��Цpython����Աн�ʵͣ�Ϊ�˱���Java����Ա���dz����Զ�д���룬������Ƹ��վ������python����Ա��c#����Ա�Ѿ���ʧ�ˡ� |
|
����˵Sora��αװ�ɡ���Ƶ����ģ�͡����������档 ����������������Ǹ�����ģ�ͣ�������������ģǿ�����ࡣ ���ǣ����Ƕ���Ⱥ�ݣ��������������ݵ��¾硶����֮���桷���� ------ ��Sora���ˣ���ʵ�������ˣ��������������ȷʵ�ḡ������... ��0��1���������ӿ�֣�����Sora�Ѹ������ܺ���ʾ�� ��ChatGPT��Dall-E��������ģ�ʹ�����������档��չ��������ز��������ǽ���Ƶ����ģ�ͷ������������档����������������������ʵ��ֻ��һ��֮ң�� �Ҳµ�Sora��Ӧ����Ӧ������Ϸ��������ģ����פ��������ð�գ��ֻ��ٴη��ӳ�����˼��������ɡ� ------ ��Sora�Ĺ���֮���� ����ʵ���롰���⡱�����������С������֪����Sora�ܰ����û���ʾ��������Ƶ���Ⲣ�����״���Fliki���ԡ�Pictory���ԡ���ӳҲ���ԡ� ?���Ƚ�������ǣ����ܱ��ֳ����������ȶ��Ժ������ԣ����Ͼ��Ⱥ�����������ܺ�֮ǰ���в�ͬ�� û�й���ı仯��û�����˹�������ֽţ�Ҳû�����֮�ϵĿֲ��ȡ������dz���ʵ�İ�Ҳ������������������ƫ�� |

|
|
Sora����Ʒ������ʵ������������ |

|
|
|

|
|
Sora ����һ������Ƶ������������һ�������������������棬������������ʵ�������ģ�⡣ ��������У�ģ����ͨ��һЩȥ����ݶ���ѧ������ѧϰ���ӵ��Ӿ���Ⱦ����������ֱ�ۡ�������Ч�����Լ����г������������������ ?Sora���õ���OpenAIģ�͡���DALL-E 3��ǿ�������ɽ�����ı�����ת����60��һ�����ĸ�����Ƶ�������ڶ���Ƶ��������һ��������ը������ͬ����֮��ս������Ϊ�ı���Ϸ�����Ӧ�ü���������Ӱ�Ӵ�ҵ��Ҳ��Ȼ����һ�����塣 ���������£�ԭ��һ���籾Ҫ��Ϊ��Ӱ��������Ҫ�����������������־�ͷ�ű���������ơ�����ѡ�ǡ�����Э�������ַ��������˳���ι���������������ھ籾�ij������ؼ��ʣ�ֱ��Ͷι�ͺ��ˡ��ɱ���ֱ��Ĩ�˸���0���������ż����ݽ������ִ�����ʽ�������죬�Դ�ͳ������ʽı���Ĵ�ҵ�߲������Dz����ܡ� --------- ��������Ҳ��������ģ��ô�� |

|
|
|

|
|
�����ǵ�����Ҳ��������ģ��ô�����δ���췽ҹ̷�� ��ͬ�������˵���2��ͼ����̨�ʡ�����û���ʸ���ʲô������ʵ������ȷ�е�����˭Ҳ����ȷ�����Ҳ��ǡ�������������û��������550W��������������֮�С� ?��ôȷ���Լ������ⲻ��LLM��ģ�͵Ĵ����� �Ӻ��͵۹������д��ԣ��ٵ���˹�������ı��ۡ������ۡ�������һ�ַ������Ļ��� ----- �����������������㵥Ԫ�����ݡ�0���͡�1��������֮������ż��㣬ǧ�˰�̬�����������ɴ˶���������ʵ�������Ҳ����...but it from Qubit�� |

|
|
����ǰ�����ѧϰ���͡�������Ⱥ��(renormaliztion groups)�ɽ����ϸ�ӳ����ۣ�DL��RG����ͬ����һ���촰�����������о��е����ֹ۵㣬�����˳��������� ����ѧ��David Bohm����˵���������ǵĴ�������ѧ���㣬������������һ��ά�ȵ�Ƶ�ʹ����Ŀ���ʵ������һ�ֳ�Խʱ�յĸ����εĴ������� �ֻ�����������Σ�����ղ�ס�� Ҳ���������Ľ������ԡ��������̨������������������ڼ�������������Ϥ�����粻��һ������online����ƽֱʱ����ʽչ������ʾ���ϡ�����һ����Ҫ�鹦�����о��µ�����ģ�͡� |

|
|
?����LLM�ķ��㣬��˭�����أ� �����Щ���ӻ��ͷ�۵���ҵ������ChatGPT�ȴ�ģ�ʹ�����æ��͵����Ϸ���ڡ� ��δ����������磿������û��˵������Online����Ҫ�� ����GAN ������ʱ���������ӡ� û�����ij��Loss������ָ�������磬�ɸ����߽������ʵ �������µ����õ�̽�����������Ĵ浵�С� |

|
|
�����������һ������ʽ���磬�����ǵ������������һϵ�С������ؼ��ʡ����̶������ƽ�������������ǰ��չ������ ������IJ���������ı߽绹�ڲ�ͣ��չ����ʵ������Ϊԭ�㣬��ȥδ������ϸ�ڲ�����油�꣬�����������ܵĺ���ӿ�֡� Sora����ֻ����Ƶ�������ߣ������Զ�... ��һ�����������ܴ�������������������ʱ���ع˼������̣������Ҳ������������֡� ������Online����Ҫ�ˣ�����GAN.40 ��ͬ �� 2 �������� |

|
|
ˮƽ���ޣ��Զ����У�����Ȥ�Ļ����������Ĺ��� |
|
��������һ�¸�λ����������թƭ�� ������2024��2��18�գ�OpenAI �� Sora ģ�ͻ�δ���ڿ��ţ� ĿǰOpenAIҲ�ͻ��˸� Sora�Ĵ�����ѣ��� Sora ��ʽ����ǰ���� Sora������εĶ���թƭ�� |
|
���ű���дҲ���ܸı������һ�����žͻᱻ�ɵ�����ʵ���Լ����Լ�������Լ���������µġ������DZ����ж�ǿ�� |
|
����Ļ����˵sora��ʱ�������Ƿ���ʶ�����е���� ����˵�˹����ܲ���Ҫ�����ǵ��ĴοƼ�����û�����⣬�������Ҫ����Ҳ����һֱ�����ٺ��˽����� ���ǣ������������չ��һ��ʲôλ�á�����ս�ԵĶ�λ��ʲô��Ͷ�뾫����Σ��Ⲣ����һ�������жϵ����顣 ��һ���и��ȡ�����������Ȼ��ʱ����������������ں�ɢ����������Ҫ������û�п����ǡ��������ս�ƻ����� ��Ϊ������е���Ϣ�����������DZ�¢�Ϻʹ�����ģ����ң������Ѿ�����һ��ǰ��δ�е��ۺ�ս�У����е����飬�����ܼӸ��Ե�����ȥ���� ��������˵�ģ�����˹˵��֢������о��ɹ��ˣ��ݵ�˵�����ڽ����֢���⣬������������˼�� ��ȻҲ�����Ƽ��� Sora��û�н�������Ȼ��ը�ѵĽ�����һ�λ�����60�붯�������ɶ������ҵ���п��ܲ����߸���Ӱ�졣 ���ǣ��ܵ������� �¹��ձ������Ĺ�ҵ��������ö���˥�ˣ�����¢���ʱ�������ҿ�������Ѫ�����Ƿ��ܹ������� ����е����������˾��������Ĵ���һ������ʵ�ϣ��й�����ʮ��������н��5000Ԫ���¡� ���Ǵ��û��ʶ����80�����У������˻��Բ��Ϸ��� ���Ϲ����鳤������˹������Ϊ��80���˿ڣ�һ�����ࡷ�������������¡�������˹ָ����������ͥ������׳���ͬʱ��Ҳ����������ѡ�����ʾ������ʮ�����������࣬�����������ټ����������ģ�ΪѰ������Լ���ծ��Ϳ��ѡ�ս���������ֺ��л�ý��Ѷ�Ǩ�Ƶ������ﵽ�¸ߡ��� ���ͬʱ���������������̿��ƵIJƸ����൱�ڴ�������Ƹ��ײ��һ���˿������ƵIJƸ��ܺͣ�ȫ��Ƹ�����1%��Ⱥ����������������������֮һ������ǿ�������ԣ���ң����ڵ�Ԥ��������������ƶ���������ڵ�Ԥ��������30�ꡣ ������˹ͬ��ָ����������Щ��������֮�⣬����Σ���IJ��ϼ����Լ��¹������ָ�����IJ�����Ҳ�ڽ�һ���Ӿ粻ƽ�ȡ�������ˣ��ڿ���ս��ʹ��ǰ����ʳ����Դ�ͽ���Σ��ѩ�ϼ�˪���Է�չ�о�����Ĵ�������Щ��ƽ������Ը�Ů��Ůͯ�Լ��Ѿ��������ӵı�ԵȺ����������ص��˺��� ���ǿ��ܻ�����ؾ��ã��������ʲô��ϵ�� ��ʵ�ϣ�����������һ�û��ʶ������ʲô�ǡ��������˹�ͬ�塱��������һ���Ƽ���������Ĺ��ҿ��Դӵ��������ж������������·����� ��ʵ�ϣ��˹����ܽ�Щ��Ŀ��ٷ�չ��Ҳ����������������Ҫͨ���Ƽ������������Խ���������������ġ������辶���� ����˵����Ҫ������ϵ�ˣ�ȫ�û����˹��������Ͳ�����ʲô����ʱ������н�����ʾ����𣿳ɱ����ͽ������� ����˵������Ai�ˣ��˿�Խ��Խ�ٵ����ⲻ�ͽ������ ����˵�����Ի��ӿ��ˣ��˲��Ǹ���ɸѡ�Ϳ�������Ҳ���������ˣ����������ء� ���ǣ����������һ�룬������ ����ģ�;�����ijɹ��ˣ���������ʵ�����⣬��һ���Ǻ��������������������ɢ�ˣ����빲����������ˣ� �Ⲣ����ʲô���������������ǣ�������Ҫ���������·����չ����;��ʲô���Լ����յ�����ʵ����������ˮƽ�Ͳ���Ͷ�룬������Ҫ�ﵽһ��ʲô����Ŀ�ġ� �������Լ����ܶ�Ǯ���Լ�����һ���ӣ�Ȼ����Լ����ȥ�� ����Ҫ��ʶ����δ����ʵ����������һ�����컨�壬���˹����ܻ����ռ���Դ��ͻ�ƣ���������ĴοƼ�������������������̵����������� ���������Ǻ��»��ǻ��¡� һ���ǵذ壬����ȫ�������Ȼ���ڳԲ���������ů�������ò���ҽ�Ρ���������仯�����ֺ�Ӱ���ˮ�����֮�С� ���ң�Ӱ������磬����ÿһ�����������������˶����ܵ��� ������ûʲô����Ӫ�ȣ�ֻ�����˵��� ���������컨�廹�ǵذ壬���㹻����һ����������� ���ԣ�����Ӧ�����Ե�ȥ����������Ӧ����ʲô�� ���ȣ�����Ҫ�dz����ѵ���ʶ�����й�Ŀǰ������һ��û�����̵�ս���С� �ⳡ����������ս������ս������ս���Ƽ�ս�ȵ��ۺ�ս�dz��пᣬ���˾��������֡� �������ϾͿ�������ս�� �������ֲ�����Ա������Ƕ������˹����ܵĺ����� ��Σ�����Ҫ�����������ڸ��������ʵ��࣬����û��ô������ ���ڲ�Ҫ˵�ˣ�һֱ�ڷ��أ����²������С�����˼����������ڻң���ʵ������˵�ˣ��Ƽ����ǡ� Ai���棬������ȫ���ϣ����ǣ���ʵ��������������������о��롣 ���ǵ����������ϵ��ٶȷdz��죬��ǿ�������ã������á� ������ǵ�һҪ����������ȥ�� �治Ҫ��Ц����˹�����������ǣ���δ����������ô���·��� ��������һ����Ӯ��������Ҳһ���ܴ� ����˹��Դ����ʳ������Ӳ�ܸܿ����Ը����㣬������Ŀǰ���Ƕ������������ԣ�����ֻ�ܶ����������� ���һ�������ձ����ɱ�̨��ʡҪ���ڻң��������ս���������������ױ�����������£��ܲ��ܷ�ƽ�˾��������ꣿ �����Լ��� ������Щ���������������������ǻ�Ҫ���ǡ�һ��һ·���ij�����չ���⣬��Ϊ���漰����������ҹ��ʻ��Ľ��̣�������Ԫ��Ȩ��Ҫ�����ǡ� ���еط�ծ�����ز���ĭ��������⡣ Ȼ������˹����ܣ�����ҪоƬ�ʹ��ʽ������Ͷι�� ֪����ʿ˵�������ݵ�����������Ӣ�ض��ṩ����100����Ԫ����һ�£��⽫���������������뵼������ҵ�ع������ƻ��е����һ���ʽ����衣��ؼ�����ʩ�����ݡ�2022�꾧Ƭ�Ϳ�ѧ������ִ�У��÷�������390����Ԫ��Լ525.37����Ԫ����ֱ�Ӳ����Լ���ֵ750����Ԫ��Լ1010.32����Ԫ���Ĵ���ʹ�������Թ������綥���뵼�幫˾�ص������г�������Ƭ�� ·һ�����ߣ���һ�ڿڳԡ� Ϲ��Ҳû�á� ����1-10Ҳ�Ǽ�ΰ������飬vison pro�����Ϊ������1000��Ԫ����������������ң�����Ҳ�Ա� ��������������磬����ȱ����ĭ�ͻ��ҡ� Ŀǰ����Ҳ�Ǽ�����Ҫ���Ƶ��ĴοƼ��������ڸǹ��ڵ����⣬˭�������Լ����ǻ��Ĵ��������һ�������ǣ����е����ڣ���ֻ�DZ��ӳ������ˡ���һ�εĿƼ�����������֮ǰ�κ�һ�ζ���һ����������ռ����ⲻ����ָ�������Ƽ������ ��������������õ�ʱ������ͬ��Ҳ�������������ʱ���� �������ս����ʼ��ʱ�����һ�ߵ��Ķ���˹��ʤ��������һ�ߵ��Ķ���˹�ذܣ������ڣ����ǻᷢ�֣��ܶණ����ƫ���˱��ʡ� ����Ӧ��ȷ���÷�չ�����ȼ����ܹ�Ͷ�����Դ��һ����Ŭ�����ϣ���������Ϊһ�����������Ϣ��������˷��硣 ���ǿ�����ʷ����û����Ϥ��ζ���� 70���ĩ80��������������������۷壬������������ͱ��ˣ�����һ������ͬʱ�ڵ������ھ���Խ��ս�����º�������Σ��֮�����������ܴ�������ϴ�ʱ�������ó������ͣ�ʧҵ�����������ĸ������������д������ơ� 1981��1�£�69�ꡰ���䡱��Ӳ����������ܿ��أ���ѡ������ͳ����Ȼ�����������γ��˺˾��ƣ�˭����������ʹ�ú����������Ⲣ���ܴ��������Ժ���в�Ŀ־塣�����˵�������в�������Ƕ�����״����һ�ֱ���ע�⡣70���֮�������Լ��������Ϣ���������ɵ�·Ϊ�����ĵ��Ӹ������չ���������ŵ���Ϊ���ڲ�Զ��δ�����������������ļ����������ܹ�ȡ��ͻ�ơ� 1984��1��6�գ����ǩ���˵�119�Ź��Ұ�ȫָ���ʽ����ս�Է������飬4�£���������ս�Է���������֯�����ܷ����������о��ƻ���6�£���������14����Ԫ���������ѡ��������ս�ƻ���ȫ�������� |

|
|
��������������ս�ƻ���������֮������ֻ������ѡ��Ҫô����Ҫô��������ʱ�����������ڰ�������̶�����ھ���ȫ��ή������������ܱ�����ʲô������ʹ���˿��Ӹ����ܸ���������֮���Ը㡰�����ս�ƻ������������ﳤ�̣ܶ��Ѻ������ľ�������ת�Ƶ��������ó��������ȵ����� ��������������ж��ǣ������������1984�꣬���������ж����˻�̸ʱ����Ϊ���������ȡͬ���ƻ����侭�ý����پ�ѹ��������Ҫ���������ֽڼ�ҲҪ�и����ߣ��������һ���������� �������������ȳ�ˡ� �����й����Ǻ���ʵ��Ҳ�������ģ���Ȼ�����ڱ�����ǣ������ս��Щ�ƻ������������ʵ����ģ�����ʲô̫�������������ڡ�����ڡ� ֻ�����Dz���ô˵�������ƣ��������˵�� δ����A I������ֻ��һ�������������ɸ���ÿ�����Ҷ������Լ���������Ȩ�����ܻ���ּ���Ai������Ⱥ���������������иߵͣ����ǣ�����ȱλ�� ���ң�����ռ���Դ���������ˣ�AiҲ������ʵ��ȫ����ռ����ƹ㣬����ʼ��Ҫ��Ӱ�졣 �˹����ܣ�����һ����������ǣ��й����������������ϡ��������ս�ƻ����ĵ��� ���ң�δ�������˵����������ط������ԺϷ���D���顢�IJ�����Ů���ϲ�������������������ף�ֻ��һ���ط�������������ʵ���磬����ģ�����ط�һ�����й��� ��������˹�����ʱ���У���Ӧ�������������飺 �����������ˣ�Ai�ǹ��ߣ��������෴�� �˹�����ר�� 2023��2��06�� ��һ����ʶ��̬�ĺ�ս����Ҫ���ˡ� 2023��2��08�� ������215|�˹�����ʱ������Ҫ�����ں����ˡ� 2023��3��26�� ���˶�����ħ���Ѿ����ز�ȥ�ˡ� 2023��4��23�� ���˹���������µĵط��� 2023��11��26�ա��������ʶ����ô���� 2023��12��2�� ���Ƹ����롷 2024��1��15�� ����κ��κ�һ�ζ���һ���� 2024��2��5�� ��ʱ���������ǵ�ʱ�����һ���к��� |
|
��ζ�Ŵ�ͳ������-��Ȼ��������-����-��������-ʵ�֡���Эͬģʽ������������-��Ȼ��������-AI��ȫ��ȡ���� �������ʱ��ֻ�����۵��������ڵı���Dz���̫���ڿ����ˣ� |
|
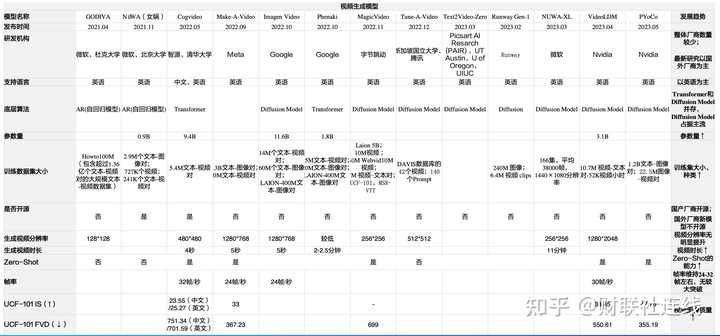
��OpenAI������������Ƶģ��Sora��ҵ��Ԥ��AGIʵ�ֽ���10�����̵�1�ꣻ �ں������ӡ��ɷݵȹ�����Ƶ�������̾���ֶ�ģ̬��ģ���о����̣����˿Ƽ����������ŵȳ�10��A�����й�˾���������ڻ���ƽ̨�ظ�ҵ���漰��Ƶ����ģ������������ OpenAI������Ƶ����ģ�Ϳ�����ը����ЩA�����й�˾�������ҵ�� OpenAI��������������Ƶģ��Sora����OpenAI���ܣ����˹�����ϵͳ���Կ�����������һ���ӵ���Ƶ����Щ��Ƶ���Գ��־��ж����ɫ���ض����͵Ķ������Լ�����ͱ�����ȷϸ�ڵĸ��ӳ������ӹ�˾�����ϸ��µ�48����Ƶdemo������Sora������ȷ����ϸ�ڣ��������ɾ��зḻ��еĽ�ɫ�� |

|
|
�ڼ�������ԭ�����棬OpenAI���ܳƣ���ʹ��Transformer�ܹ���Sora���м�ǿ����չ�ԣ�ͬʱ�ڻ��ڹ�ȥ��DALL��E��GPT���о����������ϻ�������DALL��E 3��������ʾ�ʼ�����Ϊ�Ӿ�ģ��ѵ���������ɸ������Եı�ע�� ��OpenAI��Sora֮ǰ���ȸ���ȥ��12��21�շ���һ��ȫ�µ���Ƶ����ģ��VideoPoet���ܹ�ִ�а����ı�����Ƶ��ͼ����Ƶ����Ƶ��Ȳ�������ǰһҹ�����������Ƶ����Pika��������AI��ƵӦ���ȳ������ڴ˴�Sora�ij��֣�360���Ŵ�ʼ�ˡ����³��ܺ�t2��16���������ı�ʾ������ζ��AGIʵ�ֽ���10�����̵�1�ꡣ |
|
|
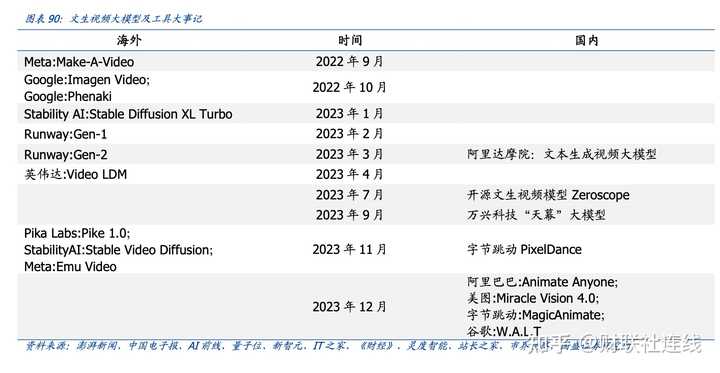
ҵ��ר�ҷ���ָ�����߱�������Ƶ���ܵ���Ƶ������ʽAI�������ܹ���Ч���ʹ����ߵĴ����ż�������֤ȯ��������11��8���б����ᵽ��������λ�����ġ�AIGC/AI�������ݲ�ҵչ�����桷����Ƶ���ɽ���Ϊ���ڿ�ģ̬����������и�DZ���������䱳�����Dz�ͬ��������������������ʽ�ı仯��Ӣΰ�����ѧ��Jim Fan������Ϊ��2022����Ӱ��֮�꣬2023������֮�꣬��2024����Ƶ֮�ꡣ �溣��OpenAI���ȸ�ȷ��Ƴ����Ե�������Ƶģ�ͣ�����֤ȯ�ὣ������12��18���б����ᵽ���������ȳ�������֣����У��������ӡ��ɷݡ�өʯ�������Ƶ������ҵ���ȳ��̷�Ͷ�뵽��ģ̬��ģ���о�����ҵӦ����ؽ��̡����������������������Ѵ��ڶ�ģ̬��ģ�͵��з��Σ������Ӿ����������ı��ȶ�ģ̬�źŵ��ں�ѵ�����������ɷ���23��10�·������Ǻ���ģ�͡�����ģ���ںϵ��ơ�������ͼ������룬�����˶�ģ̬�ںϵ���ҵ�Ӿ���ģ�͡�ֵ��һ����ǣ����Ŵ�ƾ�衰���Ů��������Pika����Ϣ�̼�����ȥ��11��30����12��7��¼��6���壬��˾��ʾ������Χ��ͼ��ʶ�� AI ���ƻ���ģ��������չ�����о��� |
|
|
���⣬��Ӫ��Ƶ���⡢��ͼ������������Ʒ�����˿Ƽ������ڻ���ƽ̨��ʾ����˾������Ƶ�����Ʒ������Ӱ/Filmora�����ڸ�����Ƶ�Ĵ����ͼ���������Ļ����ģ��������Ƶ������AI����Ϊ���ĵĶ�ý���ģ�ͣ�������Ƶ��ͼ����Ƶ�ȶ�ģ̬������������ά����Star Group��Opera���߱�������Ƶ������������Opera�ں����Ѿ��Ƴ��˶���Ƶ���ܡ����⣬������ά�칤��ģ������Ѷ��ͼʵ�����������Ŵ�ѧ��չ�Ķ�ģ̬������ģ�Ͳ����У��ۺϵ÷�������һ��רҵ������Ƶ�����������Ƶ�Ʒ����ṩ�̵���Ƽ�ӵ�����е�AIGC��������ȥ���ϰ��귢���Ծ�̬��Ƭ������ά�����Ƶ�ķ����� �ݲ����粻��ȫͳ�ƣ��������˿Ƽ�������Ƽ��������¡�������Ѷ�������Ƽ�������Ƽ����������š���˼���ӡ��������š��ض�˼�������Ļ����Ѷ��Ƽ����ڵij�10��A�����й�˾�������������ڻ���ƽ̨��¶��Ƶ����ģ�������ҵ����������У�����Ƽ�1��5�ջ���ƽ̨��ʾ����˾ӵ�����е�AIGC�������������Ծ�̬��Ƭ������ά�����Ƶ�ķ���������ͨ������ģ��ת����ѹ���㷨ʵ�ָߴ�800�����Ӿ�����ѹ����ʵ�ֲ�ͬģ̬֮����л���������������InsightGPTĿǰ������20�����ϵ���Ƶ���ܹ����ͼ����Ƶ��ģ�ͣ��ںϿ�ͼ�ȶ����㷨���ٽ����Ƶģ�ͣ�������Ⱦ�����պϳ�������Ƶ�� |

|
|
|
|
�������뵽���ǣ� ���ٿ�������������Ӱ����·���߲�ͨ�ˡ� ˵����Ӱ����Ϊ�������ˣ��DZ���ǿ������������ȵ㿿һ�¡����ܹ�ͨ�������Զ�������Ƶ��Sora���Dz��ǻ���˵�Ӱ��Ч�����أ� Ϊ�ˣ���������ѯ��һ��Bing Copilot������Ѽ�����ʸ�Sora����������һ�¹�����Ҫ��Ȼ���ɡ������棬��������һ�£����ͨ��AI���������ĵ�Ӱ�� ����ļ��ʱ�����ʵ����һ�������εĻ��⣬�Ǿ����˹����ܵľ���������ĵ�Ӱ����ã����Ӣ���У���һ�����˾��ij��������Ǽ��������ĸ�����Ӣ��һ�����Ƶ�������Ƶ��ͨ���˹����ܼ������ɵģ�����ʹ����OpenAI������һ���ܹ������ı�����������Ƶ���˹�����ģ�ͣ�����Sora�� Sora��Ŀǰ���Ƚ����ı�����Ƶ���ɼ���֮һ�����ܹ������û�������ı������ɱ������Ƶ���棬������������������������顢�����ȣ����ܹ����ı�������ƥ�䣬�ﵽ�Լ������Ч������������Sora��������ĸ�����Ӣ����Ƭ���������еĶԻ���ת��Ϊ��һ�ζ��˵���Ƶ���ù��ڸ��ܵ��˼�������Ӣ֮����������С� ��ô����˵�����ˣ� Soraȷʵ��ǿ����δ���ĵ�Ӱ��Ŀ���ͨ���籾ֱ�����ɡ�����ͬChatGPTһ����ǿ��ı������������Դ�⣬����Ҫ�����к���������ѵ�������ݲ���һ�еĻ�ʯ�� AIGC����һ���Ƕ�Ԫ���ľ�������ΪGC�ı�������Ų�ͬ�Ļ��ĶԿ�����ģ��ֻ�������Ļ�������̬���������������Ļ��������Ļ�����Ȼ��Ӧ�Ų�ͬ�Ĵ�ģ�͡�һ���Ա�֮���Ļ�������ֵ�ۣ���ֵ�۾�����ѵ�����ݣ�ѵ�����ݾ����˴�ģ�͡� ����������ÿ���ˣ���Ӧ������ʶ�ػ���һЩר�����Լ��ġ�ѵ�����ݡ������ֻ���AI����������·�ϡ� ������ʱ����AI����?mp.weixin.qq.com/s/OI_84MTAxkWGXpzvFLgUuA |

|
|
|
|
ɶ�� |
|
Sora ��ԭ���������Ķ��� ���AI��ҵ����AI ��Ƶ���ߡ��ս��ߡ����ߡ�̫ը���ˡ�̫ţ���ˣ�û�뵽���һ��ģ̬���ݱ����ݵ���ô�죬AGIħ�л�Զ�������� Sora ��������ȷʵ��DZ���ڶ�������������������һ���̶���ģ����������ʵ�Ľ��ޡ������������ʵ֮�仹��Ҫ������һЩ���߲��У����磬����Ӱ����ʵ����ʵӰ������֮���ʵʱ������ ���ݴ�����ý��������Sora �ܹ������ı������Զ�������Ƶ���⽫����ؼ���Ƶ�������̣����ͳɱ�������ߴ���Ч�ʡ�������ʹ���˴����ߡ�С�����Һʹ���ý�幫˾����������������������Ƶ���ݡ������Ӫ��������̿������� Sora ���ɸ߶ȶ��ƻ�����Ƶ��棬��Щ�����Ը���Ŀ�����ڵ�ƫ�ú���Ϊģʽ���и��Ի����ƣ��Ӷ���߹��Ч������������ѵ���ڽ�������Sora ��������������ѧ��Ƶ��ģ�⸴�ӵĿ�ѧʵ�����ʷ�¼�������ѧ�����õ������ѧϰ����ְҵ��ѵ�У�����������ģ����ֹ����������ṩʵ�������Ļ��ᡣ���ֲ�ҵ��Sora �������ڵ�Ӱ�����Ӿ����Ϸ��Ԥ�����Σ����������߿���ԭ�ͻ��Ͳ��Դ��⡣���������������ɵ�ӰԤ��Ƭ����ϷԤ�����������ʵ��VR�����顣��������Ϣ������Sora ���������������ű����ı�����Ƶ��������ijЩ����£��������ڴ���ģ�������¼�����Ƶ������Ҫ���������Ա������ڡ���������ʵ�Ľ��ޣ�Sora ���ɵ���Ƶ���ݱ���Ⱥܸߣ�����ܻ���һ���̶���ģ��������������ʵ����֮��Ľ��ޡ�����������������Ӱ��Ч��������ʵ�������������ԣ����ڿ�������������Щ����ʵ�������Ƶ����Щ���� AI ���ɵġ� |

|
|
0 Prompt: Extreme close up of a 24 year old woman's eye blinking, standing in Marrakech during magic hour, cinematicfilm shot in 70mm, depth of field, vivid colors, cinematic ���İ汾:-��24���Ů��գ���۾��ļ�����д��վ��������ʲ������ʱ�̣���Ӱ��Ƭ������70mm�����������ɫ�ʵ�Ӱ |
|
ǰ�Լ�Ҫ�ش� 1��������Զ���ʻ��ͨ�û����ˣ�ͨ���˹������ı� 2��Ŀǰ������ƴ�Ԫ�ڻ��� ������ζ��������� ����Sora���ϵ�ͼ����Ƶ�ܶ࣬�ҾͲ������ˡ�����������Ҳ�����ȿ���������� ��Ȼ���ڷ�AI�ײ㼼��רҵ���ˣ�û�б�Ҫȥ���� OpenAI��Meta�ļ���·����ִ��ֻ��Ҫ֪��������ģ�͡�����������ٵ������Ȼ������Ӧ����Ҫ�������ն˳�����ȥӭ��δ���������ٵġ�AI����ģ�͡�������������ϵ�ʵ��Ӧ���С� ��������ˣ���֤��һ������������ʱ���� ��Ϣ����Ϣ���������ij��� ��������Ϣ�������������ij��֣�ʵ����0��1�����ֿ����źŵĴ���ʹ����� ���ֵ���Ϣ�� Ȼ�����ֱ���Ϣ���ˣ��ճ�ʹ�õ�10���Ʊ�����ת����2���ƣ�ͨ�������Ƽ��㣬ʵ������ѧ����Ч�������������˿���������з�Ч�ʺ������������Ч�ʡ� ����ASCII�������ij������ı�Ҳ����Ϣ�����ƶ�����ֽ���칫���ռ����칫���ϵĴ����ļ�����ת����01�洢�ڼ�����У�ʵ���˸�Ч�ı༭�����ƺʹ��䡣 ����ͼ����Ƶ����Ϣ�� ��������Ϣ���뼼���ķ�չ��������ͼ����ƵҲ��ʼ����Ϣ���������Ϣ���ȵ߸�������Ӱ��ͼ���г���Ҳʵ�������ݵĶ�ý�廯��������������������ױ༭�����ƺʹ����� �ռ��ʱ�����Ϣ�� ��������ܵ������������Կ��ij��֣��ü����ͼ��ѧ�õ��˷�չ��������3Dģ�ͼ����Ͷ���ģ�⼼����ʼ���֣��ռ��ʱ��Ҳ����Ϣ���� �������Ϣ�� ���Ÿ�����Ϣ�����̵��ƽ������������������Ľ�ϸ��ӽ��ܣ�����AI��ʼ���֣�����AI��Ҫ��ͨ�������ж���������Ϊ�趨��������Ҳ��ģʽʶ���ר��ϵͳ������������ǿ�����Ϊ�ǹ������Ϣ���� ��Ϣ���� ��Ϣ�����̵��ƽ��������˴�������Ϣ��Ȼ��Ӳ�����ʿ��������ɴ�����ƿ�������ǿ�����������ʼ�ռ���ʵ������Ϣ�Ŀ��ٴ�����Զ�̷��� iPhoneʱ�� ʮ����ǰ��3G�������ռ������ִ�����������ͷ����λ�������ǣ�NFC����С�ͻ������к�ݮ��Palm��WindowMobile��S60�ȸ������������ֻ�����ˮ���ƶ���iPhoneʱ�̵ij��֣��ƶ������������ռ�����Ϣ��������ݺͷ��������ʱ��ػ�ȡ�� ģ�ͻ� ��Ϊ������������Ϣ���Ϳ��ٴ������ƣ����и��ִ�������ȡ����Ϣ���������������ͼƬ��Ƶ�����������ھ��������ͻ���ѧϰ�����ѧϰ���ı��������Կ������AI�㷨��ģ�ͻ���Ϊ���ܡ� chatGPTʱ�� OpenAI����ͨ������������ȥѵ������ģ�ͣ�������ģ�ͣ�ͨ��һЩ��ʾ�����ȥԤ��ظ��ı�����һ���ֿ���ʵ������ӿ�֣���������ӿ�֣��е�����������Ա���������������ü��������ģ�����������˼ά��ʽ��ȥ���������ѧϰ�������ĵ����ͱ������Ȼ��ͼ��ʶ���㷨��ϴ�����ģ�͵ı�ע���ü������������ͼƬ��ͨ����ɢģ���������������ͼƬ�����Dz��������ģ̬�� GPT4.0-v�ͳ����ˡ� Soraʱ�� OpenAI��ʼ�ô�����ģ��ȥ������Ƶ������������Ӥ��һ�����۲춯̬����ȥ��������������������������ν������ģ�͵ĸ��ʼ���֡� ����ģ��Ӧ�� ����ģ�͵ij��֣���߸��ܶ����� 1���Զ���ʻ�� ������˹�����쵼��˹�����Զ���ʻʱһֱ��ֲ����״��ǿ����һ��ԭ������Ϊ����Ҳֻ��ͨ���۾������м�ʻ����Ϊͨ������ͷ��ȡ���Ӿ����������������Զ���ʻ������������ʱ�����з��Ŷ�һֱ����������⣬����������Ǻ���ʵ������Sora�ij��֣��������Ӿ����Զ���ʻӦ�û�ܿ�ʵ�֡� 2������������ ����ģʽʶ��AI��������ֻ�ܰ��ض������̣���������30cm�������2���ؽ���ת���ٶȣ�ȥ���ִ�и��ֶ�����ֻ�ڲֿ�������ض���ҵ����������ʹ�á�����ģ�͵ij��֣������˿���ͨ���ֳ��۲�ѧϰ��Ԥѵ�������ݣ��������Լ��Ļ�е�ؽ����������ִ�еĴ�������������վ���Ա߿���������˵��һ����ʲô�ڶ�����ʲô��Ȼ�������ͨ������ģ�������Ҳ���������ķ��ˡ� 3�������������� ԭ�����ֻ����DZ���������Ϣ����ִ��ָ�����ģ�͵ij��֣�ͨ��AirPods����Vision Pro��ʵʱ�ɼ��������Ϣ��ͨ������ģ��AI�������һЩ�������ѹ�������������˺���˵���ϻؼҼǵ�˳·������5�ŵ�ػؼң�AirPods�ɼ��������Ϣ��ͨ������ģ������������ϣ���������ģ������17��������ϣ�����λ���Ҹ�����ʱ������ؼ�����������λ���������꣬��ʼͨ��AirPods�������ԣ�������ǵ����ء� ��Ԫ�ڿ��Ա������� ��������Ϣ����ģ�ͻ����Ǵ������������Ӿ����� ������绹�������ζ���ʹ�����û�б���Ϣ��ģ�ͻ���Ҫ�����������ʵ�Ľ��ޣ�������Ҫһ��ʱ�䡣��Ȼ����������Ķ������������ֵ������û����ô��ζ�����ܼ�ֵ����һЩ������δ����ʦ�Ƚϲ�����ʧҵ�� |

|
|
ͨ��AI��AGI����ͨ�û�����ʱ����������ʲô��·�� AGI������3-5���ڻ���֣������ŵͳɱ���ͨ�û�����Ҳ�ռ�����֮ǰ�������ش���һֱ�ᵽ2020�����AI�������2030����ǻ����˵������ 70������Dz�˹����������˸��˵��ԣ����˵��Դ�����80�����Ϣ��ҵ�����Ǵı�ʾ����ʾ��������Ϣ��ҵ���ִ�����90���Ħ��������ŵ���ǵ�ͨ�ż��豸�ķ�չ��ͨ��Ӳ�������ķ�չ������21����ǰ10�껥�������ƶ�����������2010�����ҿ�ʼ�����ֻ������ܴ�����������Ͱ���ϳ��֡�������ʹ�õĵ��Ӳ�ƷԽ��ԽС��Խ��Խ���ܣ�ƻ����С�׳�Ϊ���ֿ��ȵ�������ҵ���� ����Ԥ�������Ǿ���Ӳ������ÿ��10�����������֮����ӭ�������˹����ܣ�20������ͻ����ˣ�30������Ĵ�ʱ������ʧ�ء�̸�������﹤�̻��������ﻯ�Ľ��ޣ�����ͻ����Ľ��ޣ�������Ϊ����2040���ҳ���ģ������ ���Ƕ���ʮ���ڣ����ǵ���һ����ʼ��Ϊ����Ͷ�������ʱ����AGI��ͨ�û�����Ӧ�ö�������ĸ�������û�а취������ƽȨ��Ҳ��������Ӧ�ú�ū�����ʱ����ū��һ���������������ϣ��������Ͷ��ߡ����Գ�·���ǻ�ȡ������������ϣ���ȡ����ʹ�ú����������ϵļ��ܺ������� ��ʵ��������Ѿ��������ʱ��г��ˣ�Ŀǰӵ������AI�������ϵ��������ū�����������Ѿ�����ƻ���û��������һ��˾�ı�������AI������ʩ��������Ӣΰ�����ū�����ӣ�����Ҳ�嵽��ǰ�������ѷ������������λ�á� |
|
����һ����ģ��̶̵�һ�������µ����̵Ŀ�ʼ�� Sora ��һ�ִ��ı�������Ƶ������ʽ�˹�����ģ�͡�OpenAI ���ƣ�������̻���ϸ��������̬ͼ��Sora �������ɾ��ж����ɫ����ͬ���͵��˶��ͱ���ϸ�ڵ� 1080p ��Ӱ������ Sora �����ԡ���չ�����е���Ƶ�������������ȱʧ��ϸ�ڡ� OpenAI �ڲ���������д������Sora ������������̵����⣬ʹ���ܹ�ȷ�ؽ�����ʾ����������עĿ���ַ������������������С�������ģ�Ͳ����˽��û�����ʾ�������Ҫ���˽���Щ���������������еĴ��ڷ�ʽ�� Sora ��ʾ ��������֮�ã�ȫ���� Sora ���� |

|
|
Sora ��λ OpenAI �� Sora ��λΪ�о�Ԥ��������¶����ѵ��ģ�͵����ݣ�ȱ��Լ 10,000 Сʱ�ġ�����������Ƶ��������û���� Sora �ձ���á������������õĿ����ԣ�OpenAI ָ����������Ϊ�߿��ܻ��Զ��ַ�ʽ������ Sora ������ģ�͡� OpenAI ��ʾ����������ר�Һ���̽��©������ģ�ͣ������������������Ƶ�Ƿ��� Sora ���ɡ��ù�˾����ʾ�����ѡ��ģ�����������ڵIJ�Ʒ�У�����ȷ�����ɵ�����а�����ԴԪ���ݡ� OpenAI д���������ǽ���������ص������ƶ��ߡ����������ߺ������Һ������˽����ǵĵ��Dz�ȷ�������¼����Ļ����������� �����ܽ����˹㷺���о��Ͳ��ԣ���������Ԥ�����ǽ�ʹ�����ǵļ������������淽ʽ��Ҳ��Ԥ�����ǽ��������ǵļ��������з�ʽ�������Ϊʲô�������ţ�����ʱ������ƣ�����ʵ�����ʹ����ѧϰ�Ǵ����ͷ���Խ��Խ��ȫ���˹�����ϵͳ�Ĺؼ���ɲ��֡��� ��Ƶ��Ϸ���� ��һ��ʵ���У�OpenAI �� Sora �ṩ�˰������ҵ����硱һ�ʵ���ʾ����������Ⱦ�������ŷ������ơ��ҵ����硷�� HUD ����Ϸ�����Լ���Ϸ�Ķ�̬��������������ͬʱ������ҽ�ɫ�� https://twitter.com/i/status/1758347012909474137 |
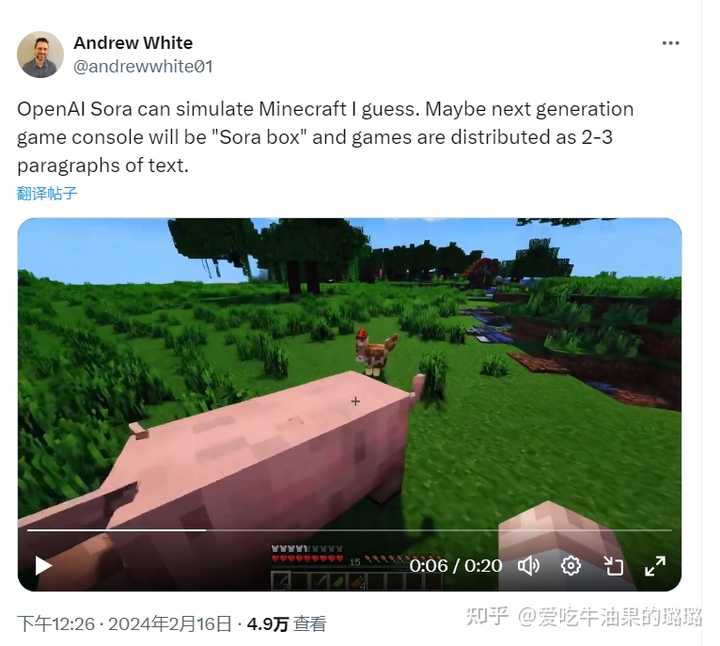
|
|
���ڣ�Sora �ij���������������Ƶ��Ϸ����ģ����ȷ��ģ�ⲣ������Ȼ�������õ�����ԭ������ʹ ���Խ�ģ������Sora Ҳ������һ�¡���������Ⱦһ���˳Ժ�����δ����Ⱦҧ�ۡ� ���༼������ɲο���https://zhuanlan.zhihu.com/p/682541338?utm_psn=1742524696665440256 ��Щ���ܱ�������Ƶģ�͵ij�����չ�ǿ������������������Լ����������е����塢������˵ĸ�����ģ������һ����ǰ;�ĵ�·�� |
|
OpenAI����Ƶ����ģ��ȷʵ�Ǹ������ţ���������ܹ������ı�ָ����������Ƶ���ⲻ����AI������һ�����Ծ��Ҳ���ܻ�����ݴ��������ֺ�Ӱ��������ҵ������ԶӰ�졣����һ�£����ֻ��Ҫ������������ڣ�AI����������Ӧ����Ƶ���⽫����ؽ��������ɱ����������ݵ������� ��������Ҳ������һЩ��ս�������Ȩ����������ʵ�Ե����⡣�������ݺ���ʵ�Ľ����ܻ���ģ����������Ҫ�µķ��ɺ淶��Ӧ����Щ�仯�� �����Ƿ����������ǿ϶��ġ����ǣ����ֱ�ﲻ��һ�����ͣ�����һ���Ĺ��̡����ż����ij�����ռ������ǿ��ܻῴ�������Ӧ�ó��������������� ������AI����ҵ���ճ������е�Ӧ�ø���Ȥ���������˽��������AI��������Ч�ʣ����ǿ��Խ�һ�����������ǵ��Ŷ�רע��AI������Ӧ�ã��ر�������ҵ���������Ա�����棬�����ṩһЩ��Ȥ�ļ���ͽ�������� |
|
���ѵĴ����������ʵ�Ľ��� Ŀǰ�������ɵ���Ƶ��������и���ϸ������ĺ���������������ֻ��Demo����Ƶ������ ��ʵ��ȥ���¾�֪���ˣ�����100����Ƶ���˿�������������Ʋ��ᳬ��ʮ�������и�������ϸ�����⣬��Ȼ��˵�Ǵ���Ҳ�а� Ŀǰ����AI������Ƶ����û������ʵ������ģ����ǿ����������ݴ��� |
|
ĿǰSora���ɵ���Ƶ������ֻ�л���û��ƥ����Ƶ�ġ��ƾ硱����Ĭ�硱�� ��һ����ͻ�������ܹ�ͬʱ��������Ƶ��ƥ�����Ƶ���������жס���ɭ�����������ó����������� |
|
|
| [�ղر���] �����ر��ġ� |
| ��һƪ���� ��һƪ���� �鿴�������� |
|
|
|
| ��Ʊ�ǵ�ʵʱͳ�� ��ͣ��ѡ�� ��ʱͼѡ�� ��ͣ��ѡ�� K��ͼѡ�� �ɽ���ѡ�� ����ѡ�� ������ѡ�� �������� �������� ���� MACDָ�� KDJָ�� BOLLָ�� RSIָ�� ���ɻ���֪ʶ ���ɹ��� |
| ��վ��ϵ: qq:121756557 email:121756557@qq.com ����ƻ� |