
| |
|
|
| 首页 淘股吧 股票涨跌实时统计 涨停板选股 股票入门 股票书籍 股票问答 分时图选股 跌停板选股 K线图选股 成交量选股 [平安银行] |
| 股市论谈 均线选股 趋势线选股 筹码理论 波浪理论 缠论 MACD指标 KDJ指标 BOLL指标 RSI指标 炒股基础知识 炒股故事 |
| 商业财经 科技知识 汽车百科 工程技术 自然科学 家居生活 设计艺术 财经视频 游戏-- |
| 天天财汇 -> 科技知识 -> 百川智能发布超千亿大模型 Baichuan 3,技术能力如何? -> 正文阅读 |
|
|
[科技知识]百川智能发布超千亿大模型 Baichuan 3,技术能力如何? |
| [收藏本文] 【下载本文】 |
|
量子位:百川智能上新超千亿大模型Baichuan 3,冲榜成绩:若干中文任务超车GPT-4 |
|
之前测过 Baichuan-2 和 Baichuan-NPC,百川之前专门做过 RAG 搜索增强的优化,效果是超过我的预期的。而且相比于其他支持文件分析的 AI 工具,百川支持最多同时跨 20 个文件进行内容检索和回答,所以我平时日常使用的频率还挺高的。 |

|
|
Baichuan-2 是去年 9 月发布的,今天发布了 Baichuan-3,也算是过年之前的年终交付了。 |
|
|
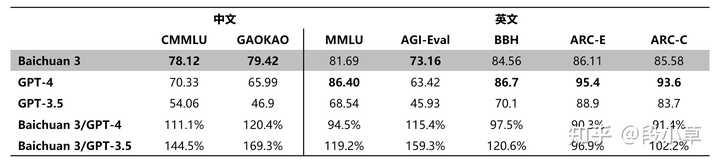
Baichuan 3 号称在 CMMLU、GAOKAO 和 AGI-Eval 等评测的中文任务上超越了 GPT-4: |
|
|
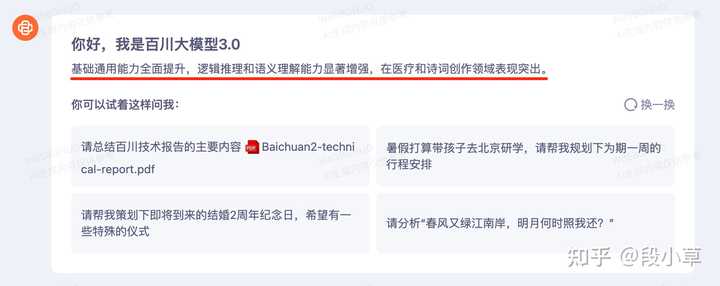
在 MCMLE、MedExam、CMExam 等医疗评测上的中文效果同样号称超过了 GPT-4,是「中文医疗任务表现最佳的大模型”」。 我刚去官网看了看,已经更新到 Baichuan-3,可以直接体验了: |
|
|
我们可以让百川自己总结一下 3.0 的进步,在开启联网搜索的情况下,百川可以正确地检索到文章信息并进行内容总结: |

|
|
根据介绍,百川 3.0 在医学和中文任务上表现不错。医学咱也不专业,问问诗词歌赋吧: |

|
|
相比之下,ChatGPT 确实有点不那么懂诗词: |

|
|
大模型发展到 2024 年,国产大模型在很多方面的表现是令人惊喜的。还是以契合需求,落地应用为主,大家可以自测一下,提供更多好用的教程,和真实的反馈。 参考: |
|
超过ChatGPT是可能的,但是超过GPT-4存疑。 不过不开源的话,还不如用GPT-4,或者免费版的开源模型。 |
|
技术能力如何,反正也没有论文,更不可能全开源,也不太好说。 不过,百川从1.0到3.0只用了9个月。对比OpenAI,从GPT-3到GPT-4用了将近3年。考虑到一个1000亿参数规模的模型,从预训练到对齐地跑一轮,怎么也得差不多1个月。由此可见团队背的kpi压力有多大。 不过既然问的是技术能力,又没有论文,我就简单用用测测吧。 |

|
|
数学能力 |

|
|
前面的计算题都做对了,能看到输出时貌似有markdown或latex语法。应该是识别出了公式并调用了工具。素数没有判断对。拿ChatGPT也可以对比一下(就不用GPT-4欺负人了): |

|
|
应用题解得还可以,看起来对相关的数据集优化得比较到位。但这也是一个基础能力了,ChatGPT一样可以解决得挺好的。 |

|
|
|

|
|
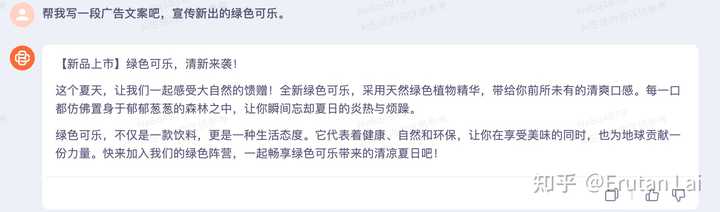
语言能力 广告文案,这个比较简单。 |
|
|
概述+长度限制: 长度限制一直是一个难点。我这里要求100字以内,3个模型都没能实现。百川3.0生成400字符,ChatGPT生成265字符,GPT-4生成209字符。 |

|
|
|

|
|
|

|
|
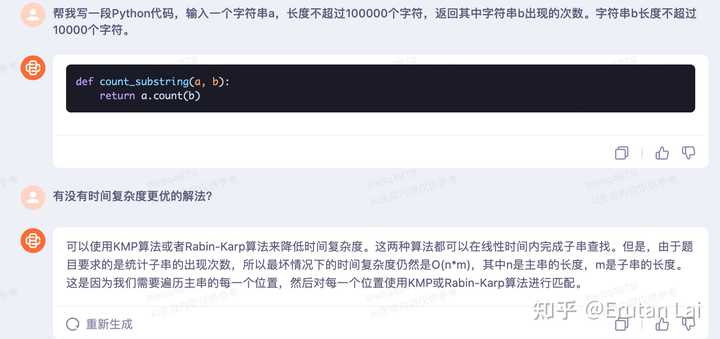
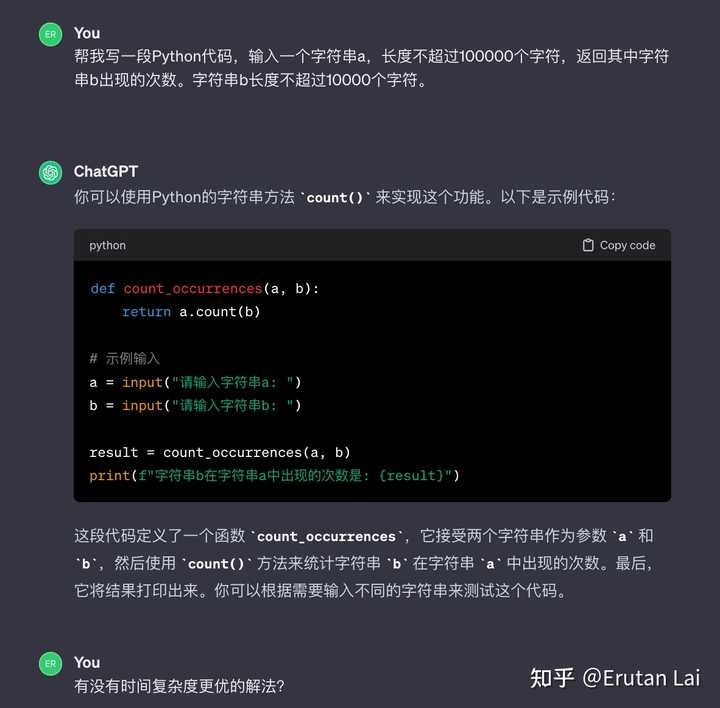
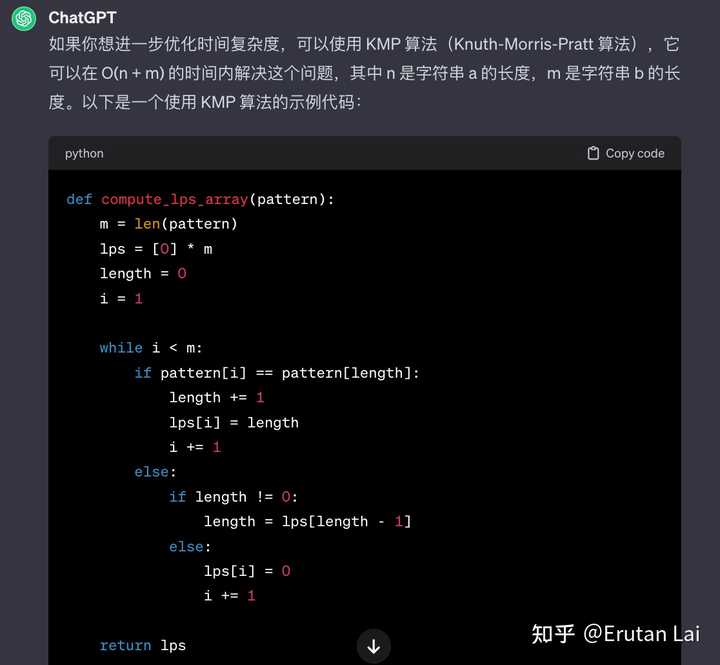
程序能力 简单出道编程题。一个经典的kmp,搞不定。 |
|
|
|
|
|
|
|
|
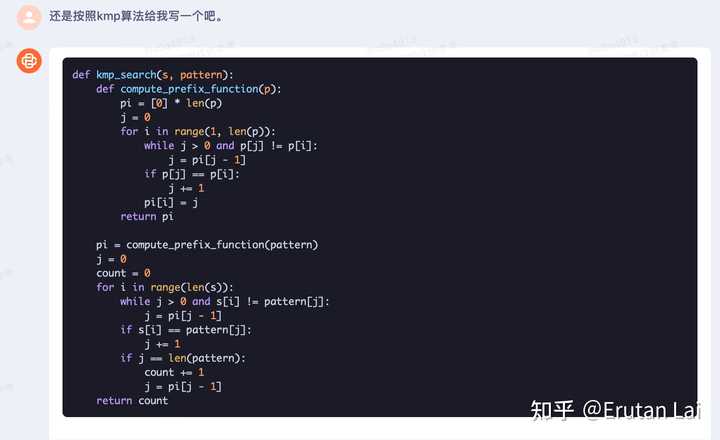
后面kmp的代码太长了,不截了。 不过,这个好像是对的?我没细看。这种经典的算法生成其实不难,因为语料实在太多了。 |
|
|
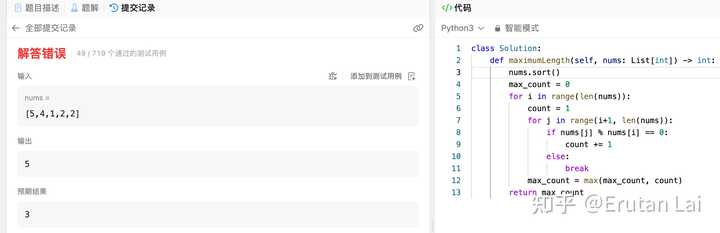
找一道上周leetcode周赛第二题给他们做做吧。 |

|
|
百川并不能搞定。不过其实ChatGPT也没搞定。 |
|
|
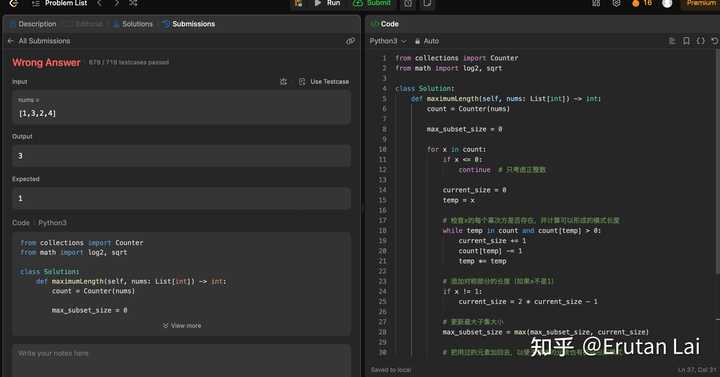
GPT-4问题分析还是可以的,但写程序有点困难。不过最终程序过的样例还是更多一些。这主要还是上周leetcode周赛太难了。。 |

|
|
|
|
|
上下文学习能力 百川3.0要求输入长度不超过2K字符。看起来感觉就没啥上下文学习能力。 |

|
|
想办法弄一个短点的prompt试试,发现百川3.0也还是差点。chatgpt学到了精简版描述的长度。样例中,详细版与精简版的字符数分别为:274 77,chatgpt生成的为255 91,而百川的为312 185。并且chatgpt在把握精简版描述的短句、简洁用词、并列结构上也要更好。 |

|
|
|

|
|
总结 综上所述,因为也没啥论文,就对数学能力、语言能力和程序能力做了简单的对比和测试。随意挑了些场景,百川3.0的水平感觉略低于ChatGPT,明显低于GPT-4。 至于问题中所提到的冲榜啥的,咱普通人拿大模型是拿来干活吃饭的,也不是用来刷榜的,没啥意义。 |

|
|
Erutan Lai 52 次咨询 5.0 北京大学 计算机应用技术博士 10179 次赞同 去咨询 |
|
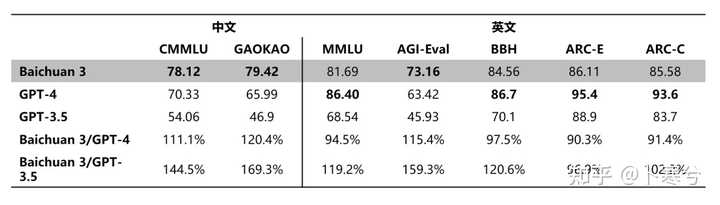
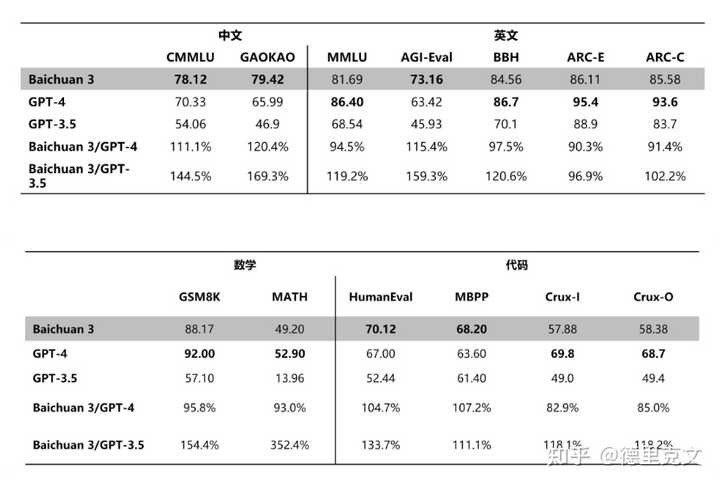
都跟OpenAI学鸡贼了,模型参数数量也不公开了,新闻里面只透漏了Baichuan 3是一个超千亿参数的大模型(对比GPT-3.5是1750亿,GPT-4未知)。 好在是模型直接上线官网,所有人可以在线体验,实际感受模型效果。根据官网上的介绍,“Baichuan 3 的基础通用能力全面提升,逻辑推理和语义理解能力显著增强,在医疗和诗词创作领域表现突出。” 性能指标 性能指标方面[1],在两个中文benchmark上,跟GPT-4相比,Baichuan 3精度更高;在几个常用的英文数据集上,整体上还是GPT-4的能力更强。看起来还是如百川的前几代模型,更擅长中文任务。 |
|
|
专业知识/能力方面,数学能力远远优于GPT-3.5,但是跟GPT-4相比还有些许差距;代码能力跟GPT-4相比互相打得有来有往。 |

|
|
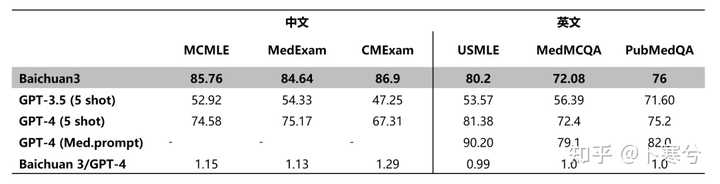
官方特意强调了Baichuan 3在医学领域和文学创作领域的能力,一下是在多个医疗方面评测集上的评估结果。 |
|
|
具体这部分在思路上是如何做的,可以参考量子位的文章[2]: Baichuan 3在模型预训练阶段汇集了达到千亿Token的医疗相关数据,同时构建了一个含数十万条记录的医疗微调数据集。 同时,为了让整体模型相关能力得到更好地激发,百川智能在模型推理阶段针对Prompt做了系统性的研究和调优。 简单来说,百川智能在医疗领域的秘诀=基础模型能力+准确描述任务+恰当的示例样本。 当然以上只是理论上的评估结果,有一定参考性,但是对于绝大多数用户来说,大模型具体能力如何还是取决于实际表现。 实际效果 1、医疗领域知识 既然强调了Baichuan 3在医疗领域能力,那就先测试一下它作为“医生”的表现。 这是前段时间家里人咳嗽不好的情况下,去医院拍片子后,片子给出的结果,让Baichuan 3 帮忙解读一下。 |

|
|
最为对比,下面是ChatGPT 4的回答: |

|
|
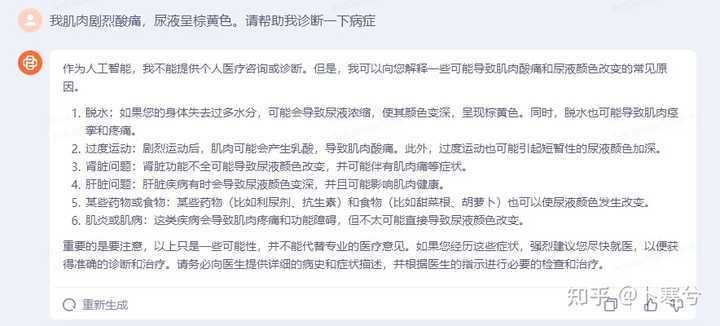
看起来对一些基本的医学知识掌握都挺靠谱的,有这方面医学知识的可以点评一下,两个模型分析的如何。 另外一个问题,关于横纹肌溶解症的症状诊断。Baichuan 3的回答: |
|
|
ChatGPT上一个叫 AI Doctor 的GPT的回答。 |

|
|
针对这个问题,Baichuan 3给了比较全面的分析,各有可能的原因都提到了,但是没有明确最可能是什么病症。ChatGPT则给出了具体的诊断建议。 2、简单测试一个逻辑推理方面的问题。 |

|
|
|

|
|
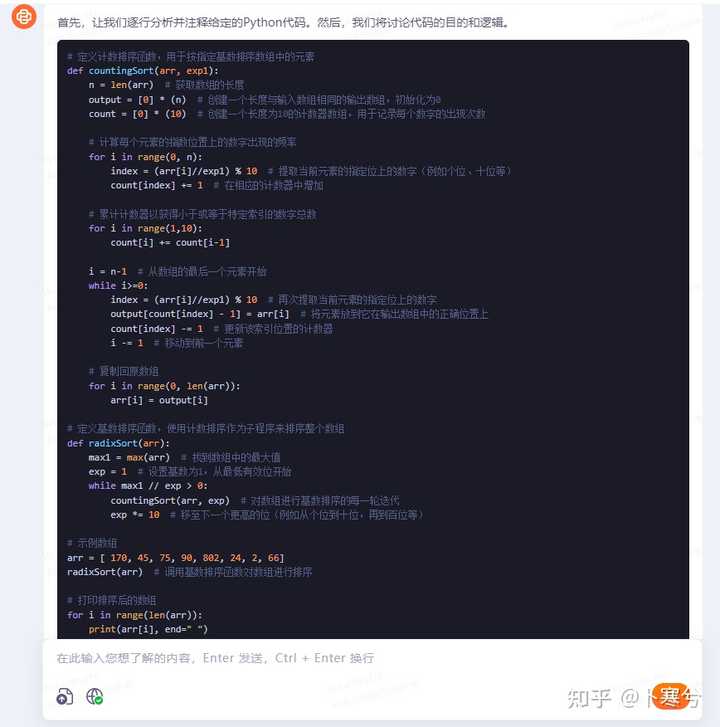
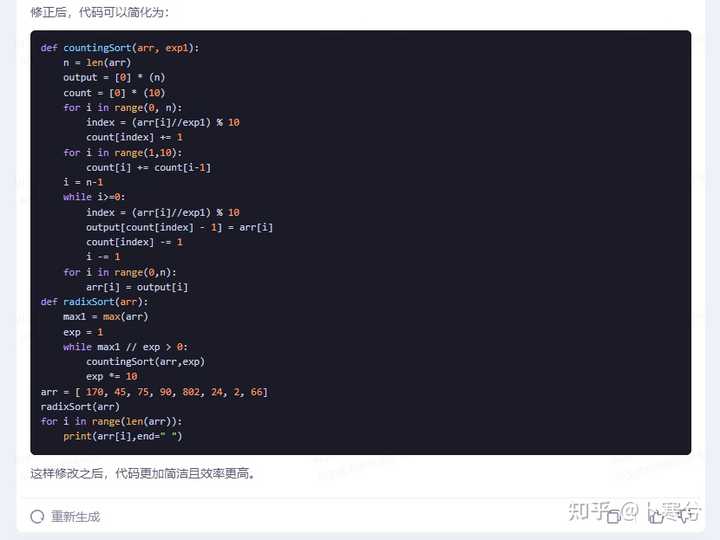
3、代码注释。 |
|
|
|

|
|
|
|
|
时间有限,有空了再做更多详细测试,大家也可以自己去实际体验一下。 还支持上传文档和联网功能。 |
|
|
参考^https://m.ithome.com/html/747794.htm^https://zhuanlan.zhihu.com/p/680366369 |
|
部分领域超越了GPT-4?国产大模型是不是越来越强大了呢? |

|
|
大模型更新 2024年1月16日智谱AI技术开放日上公布了 新一代基座大模型GLM-4,展示的各项模型水平已经让国内人工智能行业人员感到振奋。没想到这个兴奋劲还没过多久,1月29日,百川智能也发布了他们的新产品,具有超千亿参数的先进大语言模型――Baichuan 3 |

|
|
令我没有想到的是,这次发布百川表示在经过一系列的专业评估后,该模型在CMMLU和GAOKAO这两个中文任务评测、在HumanEval和MBPP的代码测评中,Baichuan 3均取得了比GPT-4更好的成绩! 如果我没记错的话,这可是国内第一个宣称在部分测评中赶超GPT-4水平的大模型。 |
|
|
图片来源于互联网 除此之外,在MT-Bench和IFEval等对齐基准测试中,Baichuan 3成功超越了GPT-3.5和Claude等其他大型模型,确立了其在行业内的领先地位。 |

|
|
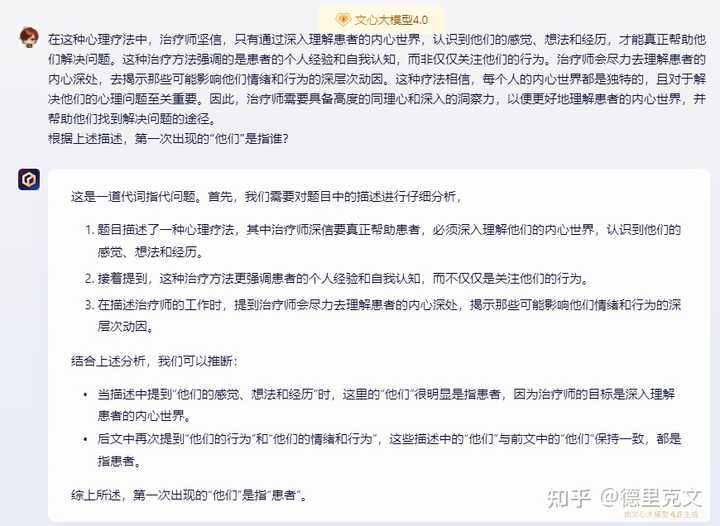
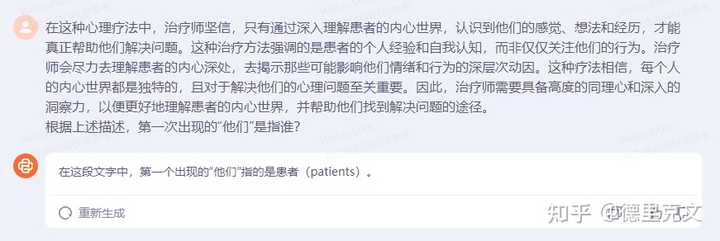
图片来源于互联网 而在针对逻辑推理能力的专业医疗评测中,如MCMLE、MedExam和CMExam测试,Baichuan 3以其卓越的中文处理能力脱颖而出,其表现不仅超越了GPT-4,更被誉为“中文医疗任务表现最佳的大模型”。 据报道,为了打造这一行业领先的中文大模型,百川智能在Baichuan 3的训练过程中采用了多项创新技术手段。 “动态数据选择”能够根据模型训练的需要实时筛选高质量数据,提升训练效果; “重要度保持”则确保了在训练过程中关键信息的不丢失,进一步增强了模型的稳定性; “异步CheckPoint存储”则大大缩短了故障恢复时间,保障了长时间训练的顺利进行。 Baichuan 3这次的稳定训练时间达到了一个月以上,其故障恢复时间也不超过10分钟,这在大模型训练中是非常罕见的。 百川智能官方表示,Baichuan 3 还突破“迭代式强化学习”技术,进一步提升了语义理解和生成能力,在诗词创作的格式、韵律、表意等方面进行了提升,对于宋词这种格式多变,结构深细、韵律丰富的高难度文体,生成的内容亦能工整对仗、韵脚和谐,让每个人都能创作出咏物、寄思的五言律诗、七言绝句,写下的言志、抒情的“沁园春”、“定风波”。我的测试 看来宣传,我马上就进入百川大模型进行了实际测试,通过一些经典的提示词问题来与其他国内大模型进行横向对比,来看看我的测试结果吧! 1.语言理解能力 在这个比较中,我将百川与我认为语言理解能力较强的文心一言4.0及智谱GLM4进行对比。 提示词: 在这种心理疗法中,治疗师坚信,只有通过深入理解患者的内心世界,认识到他们的感觉、想法和经历,才能真正帮助他们解决问题。这种治疗方法强调的是患者的个人经 验和自我认知,而非仅仅关注他们的行为。治疗师会尽力去理解患者的内心深处,去揭示那些可能影响他们情绪和行为的深层次动因。这种疗法相信,每个人的内心世界都 是独特的,且对于解决他们的心理问题至关重要。因此,治疗师需要具备高度的同理心和深入的洞察力,以便更好地理解患者的内心世界,并帮助他们找到解决问题的途径。 根据上述描述,第一次出现的“他们”是指谁? |
|
|
文心一言4.0回答 |

|
|
智谱GLM4回答 |
|
|
百川Baichuan 3回答 从答案来看都是正确的,文心一言更加详细。 2.逻辑推理 提示词: 一个三位数除以15,商和余数相同,这个三位数最大是多少?最小是多少? |

|
|
文心一言4.0回答 |

|
|
智谱GLM4回答 |

|
|
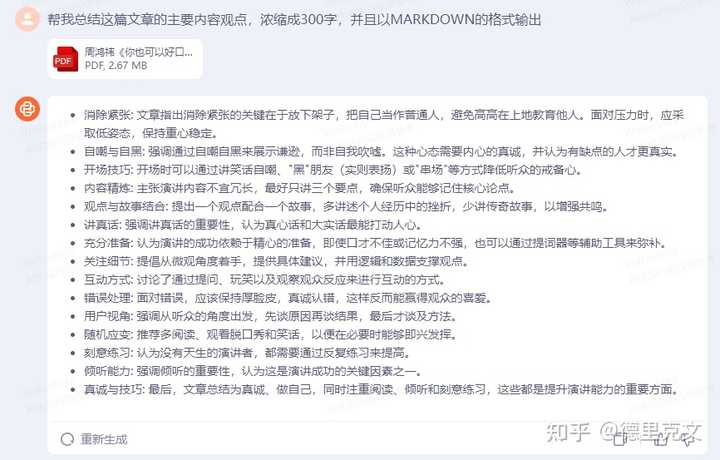
百川Baichuan 3回答 全军覆没,文心4.0答对了最小值,其他都是错的。 正确答案是:这个三位数最大是: 14×15+14=210+14=224,这个三位数最小是:7×15+7=105+7=112; 答:这个三位数最大是224,这个三位数最小是112. 当商和余数最大时,这个三位数最大,可根据余数与除数的关系余数最大为14;这个三位数最小,可以这样想15×( )的最小的三位数所以商和余数是7,然后根据被除数=商×除数+余数解答.3.PDF文件读取总结 在这个比较中,我将百川的这个功能与我觉得国内长文本读取做的最好的月之暗面KIMI进行了对比,以下是对比结果。 提示词: 帮我总结这篇文章的主要内容观点,浓缩成300字,并且以MARKDOWN的格式输出 |

|
|
智谱GLM4回答 |

|
|
KIMI回答,太长了我没有截完 |
|
|
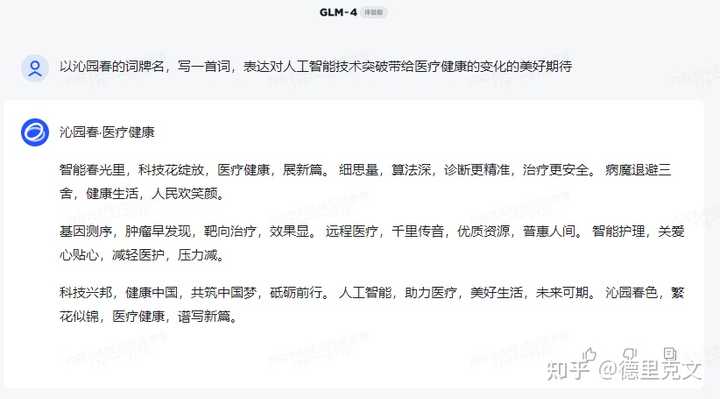
百川Baichuan 3回答4.诗词创作 提示词: 以沁园春的词牌名,写一首词,表达对人工智能技术突破带给医疗健康的变化的美好期待 |

|
|
文心一言4.0回答 |
|
|
智谱GLM4回答 |

|
|
百川Baichuan 3回答 附: 沁园春词牌格律及格式如下: (仄)仄平平,(仄)仄平平,仄仄仄平。仄平平仄仄(上一下四),(平)平(仄)仄;(平)平(仄)仄,(仄)仄平平。(仄)仄平平,(平)平(仄)仄,(仄)仄平平(仄)仄平。 平(平)数滑如仄,仄(平)平(仄)仄(上一下四),(仄)仄平平。(平)平(仄)仄平平。(仄)仄仄、平平(仄)仄平。仄(平)平(仄)仄薯启(上一下四),(平)平仄仄;(平)平仄仄,(仄)仄平平。 (仄)仄平平,(平)平(仄)仄,(仄)仄平平(仄)仄平。平(平)仄(或仄平仄),仄(平)平(仄)仄(上一下四),(仄)仄平平。 注:前阕后九句与后阕后九句字数与平仄相同,此调般都用较多的对仗。结语 以上做了一些小小的测试,对于实际的使用效果,是大众更加关注的,希望未来国产大模型能够发展的越来越好! 我是德里克文,一个对AI绘画,人工智能有强烈兴趣,从业多年的设计师!如果对我的文章内容感兴趣,请帮忙关注点赞收藏,谢谢! |
|
|
| [收藏本文] 【下载本文】 |
| 科技知识 最新文章 |
| 百度为什么越来越垃圾了? |
| 百度为什么越来越垃圾了? |
| 为什么程序员总是发现不了自己的Bug? |
| 出现在抖音评论区里边的算命真不真? |
| 你认为 C++ 最不应该存在的特性是什么? |
| 为什么 Windows 的兼容性这么强大,到底用了 |
| 如何看待Nvidia禁止使用翻译工具将cuda运行 |
| 为何苹果搞了十年的汽车还是难产,小米很快 |
| 该不该和AI说谢谢? |
| 为什么突破性的技术总是最先发生在西方? |
| 上一篇文章 查看所有文章 |
|
|
|
| 股票涨跌实时统计 涨停板选股 分时图选股 跌停板选股 K线图选股 成交量选股 均线选股 趋势线选股 筹码理论 波浪理论 缠论 MACD指标 KDJ指标 BOLL指标 RSI指标 炒股基础知识 炒股故事 |
| 网站联系: qq:121756557 email:121756557@qq.com 天天财汇 |