
| |
|
|
| 首页 淘股吧 股票涨跌实时统计 涨停板选股 股票入门 股票书籍 股票问答 分时图选股 跌停板选股 K线图选股 成交量选股 [平安银行] |
| 股市论谈 均线选股 趋势线选股 筹码理论 波浪理论 缠论 MACD指标 KDJ指标 BOLL指标 RSI指标 炒股基础知识 炒股故事 |
| 商业财经 科技知识 汽车百科 工程技术 自然科学 家居生活 设计艺术 财经视频 游戏-- |
| 天天财汇 -> 科技知识 -> 如何评价CVPR2024的审稿结果? -> 正文阅读 |
|
|
[科技知识]如何评价CVPR2024的审稿结果? |
| [收藏本文] 【下载本文】 |
|
如何评价CVPR2024的审稿结果? |
|
占了个坑,AAAI分数不高就投CVPR,CVPR分数不高就投IJCAI,IJCAI拒了就投NIPS 主打一个学术黄巢 |
|
今年一口气投了20篇,都是开创性的工作,审稿意见和得分都很满意。 现在交不起注册费,考虑撤稿了 |
|
提供581个分数投票统计(投票还在继续,预计将获得1000+真实样本),祝大家rebuttal顺利! |
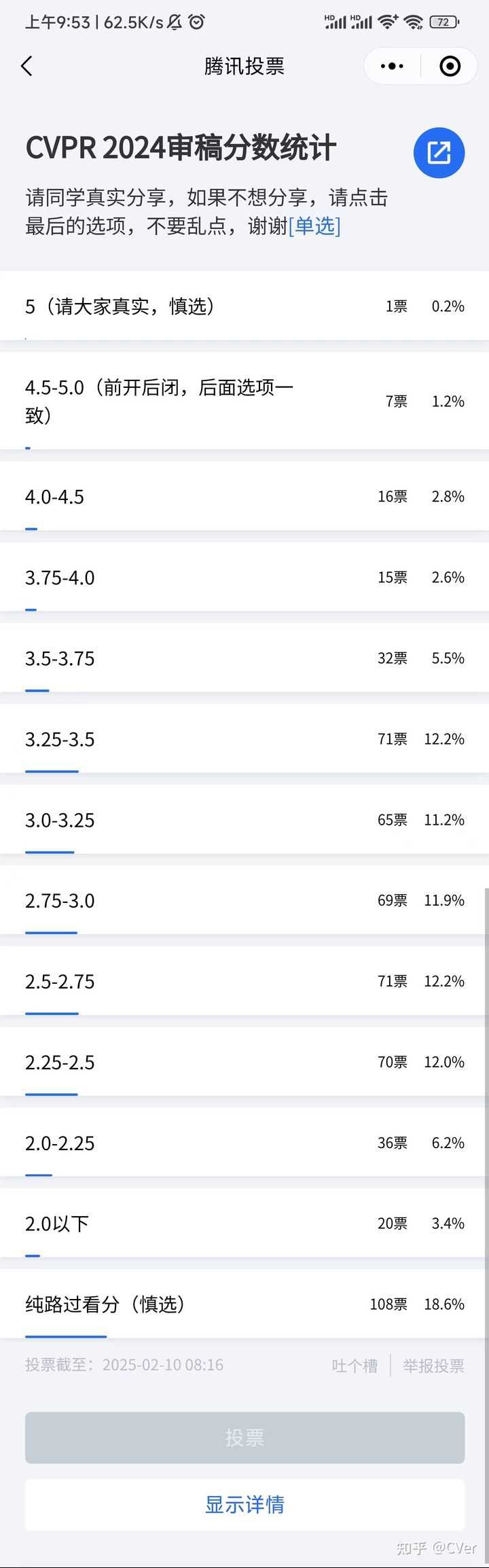
|
|
|
|
更新:2024.01.24 呜呜 方差好大 一个审稿人看得出来对我们的工作很感兴趣,并十分热情地给了许多未来工作的建议,最后给了5; 一个审稿人质疑我们的motivation,最后给了2; rebuttal只能好好向给2的审稿人解释我们的工作了。 好事多磨,希望最终能让给负面意见的审稿人回心转意!求求了!!一定要中啊!!! 2023.10.30 cvpr 我的cv梦!再冲一波!! 希望能有好结果!! |
|
先来占坑。 论文主题是physics-based image warping,在unsupervised domain adaptation上的应用。主要实验还没跑完,正在全力赶进度。 硕士期间最后一篇论文了,希望能中。 |
|
果然就是凌晨开奖hhh 理论的开奖时间是周三下午四点(1.24 16:00) |
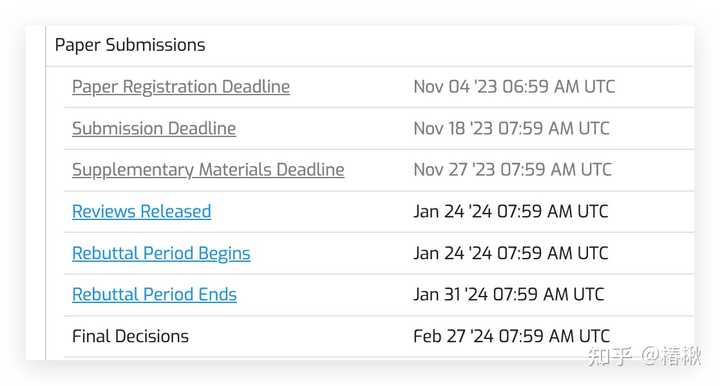
|
|
但是去年是本该下午四点出的那天的凌晨出的(给你们增加点焦虑哈哈) review都很友善,拿了555,希望能拿个oral 审的几篇最低给的wa,质量都挺高的 |

|
|
↑梦里啥都有 |

|
|
|
|
出分了 4332 都改好格式和paper要转ICML了(写太赶了,投的时候是draft),现在出这个分就处在一个很尴尬的位置。 占坑,实验跑完准备开写,给reviewer们一点学术垃圾的震撼 |
|
屎上雕花,让审稿人感受下学术垃圾的震撼 |
|
2 2 3主打一个让补实验和细节。。。 许愿!!! 看倒计时应该明天下午会开奖 许愿! 隔壁iclr出结果了。希望cvpr reviewer对我好点,谢谢了。 |
|
好想去西雅图 求一波好运 |
|
本次投稿体验良好,已经转投ECCV24,下次还投! |
|
第一次投稿CVPR,希望有好事发生 |
|
出分会发邮件提醒吗? 有没有知道的大佬 |
|
占坑占坑~好运 ICML是完全赶不上了,手里这个idea一直不可行(哭死了 |
|
今年CVPR分我的稿子Image and video synthesis and generation; Computational imaging; Low-level vision; 3D from multi-view and sensors四个方向的都有。 人临毕业,其心也善。我给分偏高 。不想刁难作者。好好Rebuttal。 祝大家好运 ,早日上岸 。 |
|
本文独家改进:DCNv4更快收敛、更高速度、更高性能,完美和YOLOv8结合,助力涨点 DCNv4优势:(1) 去除空间聚合中的softmax归一化,以增强其动态性和表达能力;(2) 优化存储器访问以最小化冗余操作以加速。这些改进显著加快了收敛速度,并大幅提高了处理速度,DCNv 4实现了三倍以上的前向速度。 难点:如何编译DCNv4,提供windows编译环境。 ? 1.DCNv4介绍 |

|
|
? 论文: https://arxiv.org/pdf/2401.06197.pdf 摘要:我们介绍了可变形卷积v4 (DCNv4),这是一种高效的算子,专为广泛的视觉应用而设计。DCNv4通过两个关键增强解决了其前身DCNv3的局限性:去除空间聚合中的softmax归一化,增强空间聚合的动态性和表现力;优化内存访问以最小化冗余操作以提高速度。与DCNv3相比,这些改进显著加快了收敛速度,并大幅提高了处理速度,其中DCNv4的转发速度是DCNv3的三倍以上。DCNv4在各种任务中表现出卓越的性能,包括图像分类、实例和语义分割,尤其是图像生成。当在潜在扩散模型中与U-Net等生成模型集成时,DCNv4的性能优于其基线,强调了其增强生成模型的可能性。在实际应用中,将InternImage模型中的DCNv3替换为DCNv4来创建FlashInternImage,无需进一步修改即可使速度提高80%,并进一步提高性能。DCNv4在速度和效率方面的进步,以及它在不同视觉任务中的强大性能,显示了它作为未来视觉模型基础构建块的潜力。 图1所示。(a)我们以DCNv3为基准显示相对运行时间。DCNv4比DCNv3有明显的加速,并且超过了其他常见的视觉算子。(b)在相同的网络架构下,DCNv4收敛速度快于其他视觉算子,而DCNv3在初始训练阶段落后于视觉算子。 |
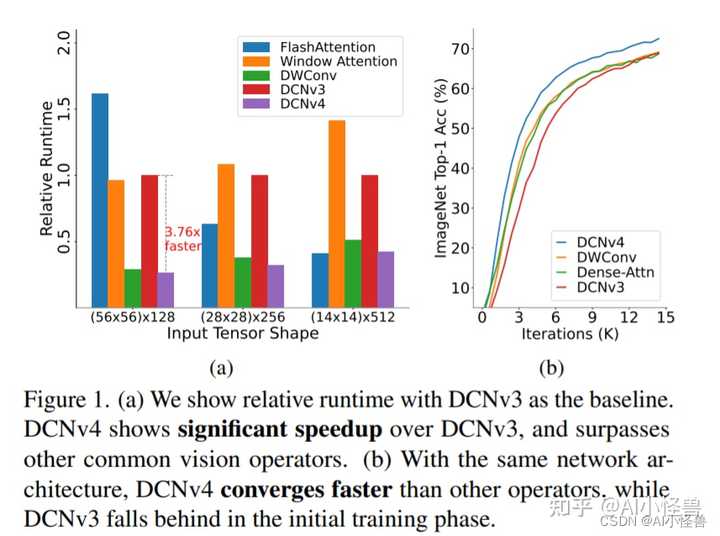
|
|
为了克服这些挑战,我们提出了可变形卷积v4 (DCNv4),这是一种创新的进步,用于优化稀疏DCN算子的实际效率。DCNv4具有更快的实现速度和改进的操作符设计,以增强其性能,我们将详细说明如下: 首先,我们对现有实现进行指令级内核分析,发现DCNv3已经是轻量级的。计算成本不到1%,而内存访问成本为99%。这促使我们重新审视运算符实现,并发现DCN转发过程中的许多内存访问是冗余的,因此可以进行优化,从而实现更快的DCNv4实现。 其次,从卷积的无界权值范围中得到启发,我们发现在DCNv3中,密集关注下的标准操作――空间聚合中的softmax归一化是不必要的,因为它不要求算子对每个位置都有专用的聚合窗口。直观地说,softmax将有界的0 ~ 1值范围放在权重上,并将限制聚合权重的表达能力。这一见解使我们消除了DCNv4中的softmax,增强了其动态特性并提高了其性能。 因此,DCNv4不仅收敛速度明显快于DCNv3,而且正向速度提高了3倍以上。这一改进使DCNv4能够充分利用其稀疏特性,成为最快的通用核心视觉算子之一。 我们进一步将InternImage中的DCNv3替换为DCNv4,创建FlashInternImage。值得注意的是,与InternImage相比,FlashInternImage在没有任何额外修改的情况下实现了50 ~ 80%的速度提升。这一增强定位FlashInternImage作为最快的现代视觉骨干网络之一,同时保持卓越的性能。在DCNv4的帮助下,FlashInternImage显著提高了ImageNet分类[10]和迁移学习设置的收敛速度,并进一步提高了下游任务的性能。 图2。(a)注意力(Attention)和(b) DCNv3使用有限的(范围从0 ~ 1)动态权值来聚合空间特征,而注意力的窗口(采样点集)是相同的,DCNv3为每个位置使用专用的窗口。(c)卷积对于聚合权值具有更灵活的无界值范围,并为每个位置使用专用滑动窗口,但窗口形状和聚合权值是与输入无关的。(d) DCNv4结合两者的优点,采用自适应聚合窗口和无界值范围的动态聚合权值。 |
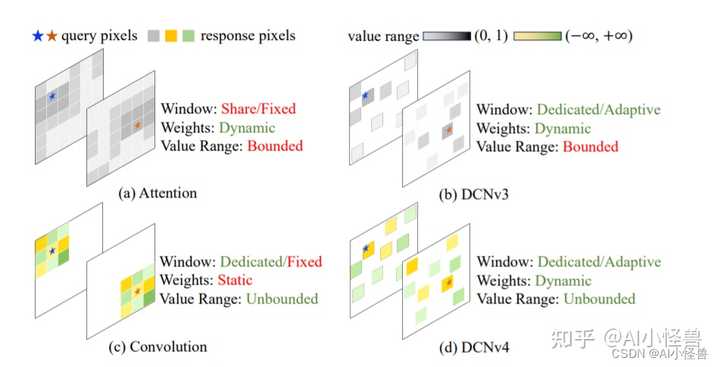
|
|
图3。说明我们的优化。在DCNv4中,我们使用一个线程来处理同一组中的多个通道,这些通道共享采样偏移量和聚合权重。可以减少内存读取和双线性插值系数计算等工作负载,并且可以合并多个内存访问指令。 |
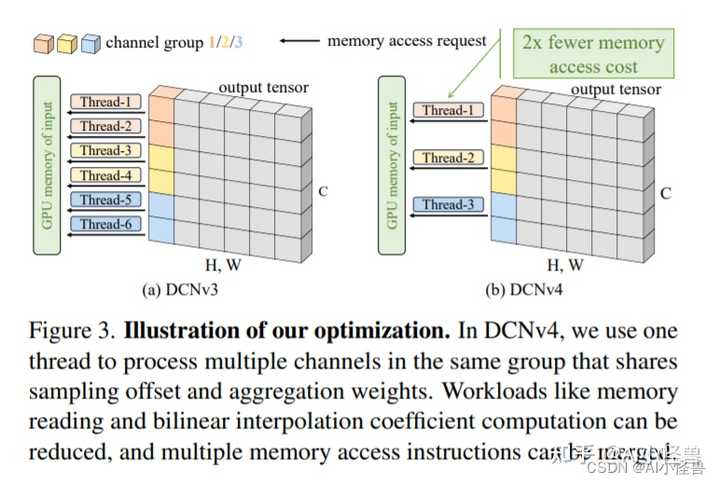
|
|
表2。具有各种下采样率的标准输入形状的运算级基准。当实现可用时报告FP32/FP16结果。在不同的输入分辨率下,我们的DCNv4可以超越所有其他常用运算符。 |
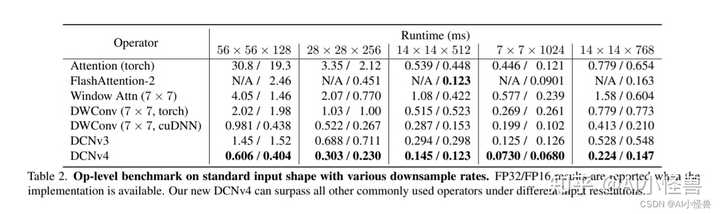
|
|
表3。具有各种下采样率的高分辨率输入形状的运算级基准。DCNv4作为稀疏算子表现良好,优于所有其他基线,而密集的全局关注在这种情况下速度较慢。 |
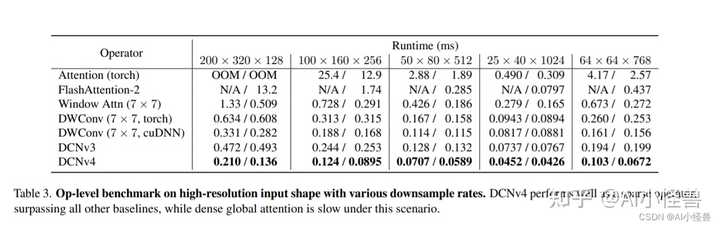
|
|
表4。ImageNet-1K上的图像分类性能。我们展示了FlashInternImage w/ DCNv4和它的InternImage对应版本之间的相对加速。DCNv4显着提高了速度,同时显示了最先进的性能。 |

|
|
2.如何将DCNV4将入到YOLOv8 2.1 源码下载 下载链接:https://github.com/OpenGVLab/DCNv4 将 DCNv4_op文件夹放入ultralytics\nn目录下 ? |

|
|
2.2 编译DCNv4 在DCNv4_op文件夹下执行以下命令: 编译通过 |

|
|
2.3 新建ultralytics/nn/conv/dcnv4.py 核心代码: ??2.4 yolov8_C2f_DCNv4.yaml ? 2.6 开启训练 |

|
|
? ?原文链接:https://blog.csdn.net/m0_63774211/article/details/135640743 ? ? |
|
今天同时作为审稿人和投稿人,期待有个好结果 |
|
记录一下自己第一次投稿的经历,学术垃圾绝赞生成中 2023/11/12 今天看知乎发现 CVPR 序列号已经到18000了,听说去年投稿量只有9000?这么多投稿想必审稿质量不会太高。 今天已经基本上完成了 Method,已经是5页多的篇幅,希望明天能够写完 Experiment,这样后天完成初稿后或许还有时间多润色几遍论文或者添加一些实验。 昨天和老师交流论文的时候发现我们的想法都是一致的,写够8页,能够投出去就是胜利^ 2023/11/13 离DDL又近了一天。 今天一直在写实验,参考别人论文中实验部分得措辞时发现大部分 CVPR 2023 的主会论文确实都做了非常详实的实验。相比之下我的实验确实没有那么有说服力。 还是会忍不住感慨,如果时间再充足一些或许可以做的更好。不过看到身边的师兄一直帮忙润色论文,还是决定充分的用好剩下的这几天。希望最终提交的论文不至于让审稿人认为是废纸吧。 4个月前第一次进实验室,直到一个月前搭好才刚刚第一个 idea 的 pipeline。到了现在最终的论文写作润色环节还是偶尔会有一种不真实感:我居然真的在写自己的一作论文。尽管目前的paper是CV方向,也不是什么需要 solid mathematical proof 的工作,但是还是感觉有所收获。 我已经抱着会被拒稿的心态来投这篇论文了 2023/11/13 虽然我也明白数据当然比 fancy 的可视化更有说服力,但是论文提出的问题没有很合适的 datasets 可以做 evaluation,所以相对而言实验部分并不充实,想必是很容易被攻击的点。而且文章中提出的module 是不需要 learning 的,相比之下论文的结构也与大部分 learning 的论文不同。 也许我该考虑一下要不要写一个 Future work/Limitation 的模块 2023/11/15 骑车回宿舍的路上在听Olafur Arnalds的3055。晚上太冷了所以我戴着帽子,帽子外面戴着耳机,这样我就有了一个替代性的耳罩。 今天修改了很多论文的措辞,也修改了很多图片上的caption。之前看到一种评价论文可读性的方式:单看图可以看懂,单看文字也可以看懂。 不过我暂时还做不到这一点,只希望审稿人和未来的读者能够结合我的图文理解我想表达的就好。 2023/11/18 今天是 CVPR 论文提交的日子。 这两天一共睡了5个小时,但是还是很精神,不会是我回光返照了吧( 2023/11/18 14:20 submit! |
|
|
然后睡觉 |
|
占坑,抽奖 分了一个很久之前做的topic的文章审稿。。。都忘的差不多了 |
|
刚把补的也都提交了,感觉论文分配系统有问题,我选的兴趣和方向明明都不是low-level vision,但是: 分给我稿件的都是low-level task, 而且也都是low-level quality的, 因此我都给了low-level evaluation, 误伤知友请原谅… |
|
之前一篇顶会没有,现在有了,感谢审稿人(不知道朝哪边拜能遇到心软审稿人)。 |
|
吓了我一跳。看到这问题我还以为错过了deadline |
|
挺乐子人的,越不confident的人给分越低。还有个大哥说的跟论文写的完成反过来,论文写现有方法会有A和B两方面问题,我们用a解决A,B呢不用直接解决可以通过一个 操作b绕过去。这个大哥说,文章写了A,B 两问题,可以用b解决A, 没写怎么处理B. 我?????然后,放supp里的结果图一个都没看, 好,这个确实是我的锅,但正文确实放不下了啊,咱也没办法。 |
|
占坑. 一篇really awesome paper正在生成中.. |
|
占坑,希望能有个好结果~ |
|
占坑,希望能中 |
|
更:333该怎么re,在线等,挺急的 |
|
占个坑,人生第一次投顶会,注入了很多的心血,放弃了很多的休假,希望到时候会有好消息 ――― 出分更:G,转投了 |
|
更新,两篇分别是5 4 3,4 4 3 low level,占坑 |
|
2 3 5(533) 哎 给负分的确实了解这个领域,开始补实验。 _________________________________________________________ 第一次投稿,不知道结果会怎么样,焦虑啊 时而感觉自己做的还不错应该会好评吧,时而又觉得哎太简单了,可能会被喷。T.T |
|
第一次rebuttal,有点紧张 |
|
谢谢啊,我是穿越者,刚刚中了2000篇,审稿人都很好,意见中肯,孩子很爱吃,谢谢。 |
|
谢谢大家,中了100篇 |
|
分给我的6篇完成度都相当高,也反映了现在是越来越卷了。 |
|
|
| [收藏本文] 【下载本文】 |
| 科技知识 最新文章 |
| 百度为什么越来越垃圾了? |
| 百度为什么越来越垃圾了? |
| 为什么程序员总是发现不了自己的Bug? |
| 出现在抖音评论区里边的算命真不真? |
| 你认为 C++ 最不应该存在的特性是什么? |
| 为什么 Windows 的兼容性这么强大,到底用了 |
| 如何看待Nvidia禁止使用翻译工具将cuda运行 |
| 为何苹果搞了十年的汽车还是难产,小米很快 |
| 该不该和AI说谢谢? |
| 为什么突破性的技术总是最先发生在西方? |
| 上一篇文章 下一篇文章 查看所有文章 |
|
|
|
| 股票涨跌实时统计 涨停板选股 分时图选股 跌停板选股 K线图选股 成交量选股 均线选股 趋势线选股 筹码理论 波浪理论 缠论 MACD指标 KDJ指标 BOLL指标 RSI指标 炒股基础知识 炒股故事 |
| 网站联系: qq:121756557 email:121756557@qq.com 天天财汇 |