
| |
|
|
| 首页 淘股吧 股票涨跌实时统计 涨停板选股 股票入门 股票书籍 股票问答 分时图选股 跌停板选股 K线图选股 成交量选股 [平安银行] |
| 股市论谈 均线选股 趋势线选股 筹码理论 波浪理论 缠论 MACD指标 KDJ指标 BOLL指标 RSI指标 炒股基础知识 炒股故事 |
| 商业财经 科技知识 汽车百科 工程技术 自然科学 家居生活 设计艺术 财经视频 游戏-- |
| 天天财汇 -> 科技知识 -> 如何看待ICLR2024录用结果? -> 正文阅读 |
|
|
[科技知识]如何看待ICLR2024录用结果? |
| [收藏本文] 【下载本文】 |
|
如何看待ICLR2024录用结果? 关注问题?写回答 [img_log] 人工智能 国际学术会议 如何看待ICLR2024录用结果? |
|
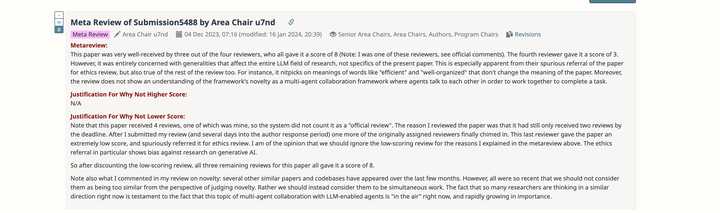
ICLR24得分888居然被拒?Area Chair的Meta review完全事实性错误? TL;DR: AC把我们方法的超参数N=1理解为了攻击次数为1,于是认为我们评测不充分,并引用了autoattack这一大家认为充分的攻击。然而,我们全文(除了特殊的adaptive attack外),全部是使用的AC所引用的autoattack。这样的meta review是不是一种笑话? 文章链接:Robust Classification via a Single Diffusion Model 文章的blog链接:虚无:扩散模型即为鲁棒分类器: Robust Classification via a Single Diffusion Model 888据我所知似乎是iclr历史上被拒稿的最高分了。 我先简单介绍一下这篇论文:我们提出了一种新的分类算法,直接使用diffusion这种生成模型(无需CNN ViT等分类模型)来做鲁棒分类。在对抗攻防的领域下,新的防御算法一旦提出,需要进行各种adaptive attack来进行充分评测,从而确保鲁棒性并不是因为评测不充分造成的。因此,我们也进行了大量的adaptive attacks。同时,攻击步数越多,攻击通常来说就越强。我们使用了大家默认的评测方式AutoAttack(最少100步攻击)进行评测。我们得到了3个审稿人的一致好评,得分888. |

|
|
AC的意见 Area Chair的核心论点是:one-step attack不足以充分评测防御。只有AutoPGD这种multi-step attack才能充分评测防御。 然而,我们全文从未使用过one-step attack。我们全文(除了攻击diffpure的adaptive attack外),全部使用的是Area Chair引用的"AutoPGD"。 这样完全的事实性错误也太搞笑了。我们用的方法就是AC所cite的方法。AC却认为我们用的是one-step attack。AC为什么会这么认为呢?我猜是因为AC把我们方法中的超参数N的 (N=1)直接误认为了是攻击次数为1。把N=5误认为了攻击次数是5次。 |

|
|
AC很可能根本就没有仔细阅读论文,就随意的把“N=1”理解为攻击次数为1。one-step attack显然不是充分的评测。但是给出Meta review之前,是否可以多花一点时间想一想,在整篇文章做了这么多adaptive attack的情况下,难道作者所有攻击要么5步要么1步么?作者有意识做adaptive attack,难道还不知道“one-step attack不充分”么.....三个审稿人给分888,如果真是“作者的攻击次数是1”,难道他们三个看不出来么。。。 下面我来回答一下Meta review的两个comments。 Comments 1: 理论分析部分和实际claim没有联系。并且不知道optimal diffusion classifier是怎么评测的。 我们在本篇文章中提出一个新的理论分析工具,即Diffusion Model和Diffusion Classifier的最优解。因此,我们只需要检验optimal下是否还有类似的问题。如果有,那我们应该改进模型;如果没有,那我们应该去查看empirical solution和optimal solution的区别,从而更好的改进我们的算法。我们发现对于对抗样本,主要区别在于empirical solution的diffusion loss相比optimal solution更小。这有且仅有2个原因。1) empirical情况下likelihood更小 2) ELBO和log likelihood差距大,从而导致diffusion classifier (theorem 1)近似误差过大。 为了解决这两个问题,我们提出likelihood maximization,去maximize elbo,同时增大likelihood,减小elbo和likelihood的误差。 至于optimal diffusion classifier的评测,我们在实验部分写的很清楚,除特殊声明和LM这种不可导的外,都是以"AutoAttack"进行评测的,即Area Chair引用的那个评测。我们使用AutoAttack,梯度又是准确的,同时几乎没有随机性,我们有理由相信评测是充分的。 Comments 2: 方法的高时间复杂度让作者无法用SOTA的白盒攻击来评测。作者只进行了one-step gradient attack,而这显然是不充分的。 经过其中一个审稿人的建议,我们已经测了real time cost。对于每张图片,之前的防御DiffPure需要0.60秒(linf)或0.72秒(l2)。而我们最终的方法需要1.43秒。时间复杂度高是我们的limitations,但不影响我们的评测。 最重要的是,"one-step gradient attack"当然是不充分的。但我们也当然知道这是不充分的,我们从头到尾就没用过one-step gradient attack。我们全用的是Area Chair所引用的"AutoAttack"。 |
|
借楼宣传下我们MetaGPT的工作(Oral):得分8883,最后Meta review的阶段AC极其nice的提到给3分的reviewer nitpick(懂得都懂),从结果看应该是按888给了。 |
|
|
* 论文地址:https://arxiv.org/pdf/2308.00352.pdf * 项目地址:https://github.com/geekan/MetaGPT 2023年可以说是AI Agent的元年,2024年还会有什么新的工作脱引而出,拭目以待! |
|
883 -> 886 -> Accepted (Poster) 博士入学就给我带来一个好消息,算是开了一个好头吧。 虽然分数看起来不错,但可能因为我们在这篇工作中只讨论了线性情况,所以影响力还是不太够,只有一个poster。 不过它是我第一篇被顶会接收的工作!耶?! |
|
|
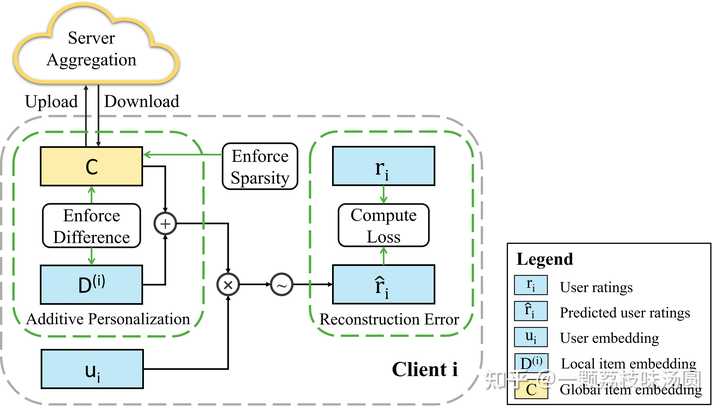
同时借题宣传下我们的工作「Federated Recommendation with Additive Personalization」: 论文主页: Federated Recommendation with Additive Personalization?openreview.net/forum?id=xkXdE81mOK |

|
|
我们提出了一种基于加性个性化的矩阵分解方式来做联邦推荐任务,整体思想十分Simple,甚至可以说是Naive,但是得到结果却十分出彩--足以弥补目前浅层联邦推荐模型与传统推荐模型之间巨大的Gap。 代码已在Github开源:code |
|
宣传一下我们的工作。我们的模型可解释性研究在ICLR 2024的评审中获得了6888分,很荣幸被选为Oral Presentation,欢迎感兴趣的朋友们交流讨论: Less is More: Fewer Interpretable Region via Submodular Subset Selection 主页: Less is More: Fewer Interpretable Region via Submodular Subset...?openreview.net/forum?id=jKTUlxo5zy |
|
|
|
在本文中,我们解决了当前SOTA归因算法的两个挑战:1)现有的归因方法生成不准确的小区域,从而误导了正确归因的方向;2)模型无法对错误预测的样本产生良好的归因结果。 |

|
|
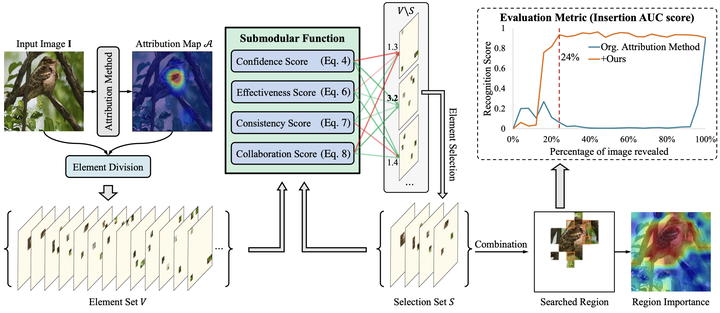
对于正确预测的样本,我们的方法可以找到更少的区域,从而使模型预测更加可信。 对于预测错误的样本,我们的方法可以找到导致模型预测错误的原因。 为了解决这些问题,我们提出了一种新颖的图像归因算法,将归因问题重新表述为子模子集选择问题,并以更少的密集区域实现更高的可解释性。 我们从四个角度设计了一种新颖的子模函数,并采用贪婪搜索算法对划分的密集子区域进行归因。 |
|
|
所提出方法的框架。 它不仅提高了现有归因算法的归因区域密度,而且可以更好地发现图像预测错误的原因。例如,在下图中我们针对CUB-200数据集中模型预测错误的样本进行归因,在经过我们的归因方法搜索后,我们可以找到使模型重新预测正确的区域,从而大幅度提高了归因能力,同时能解释导致模型预测错误的原因,即图中的暗区域 |

|
|
用于发现导致模型预测错误的原因的方法的可视化。 Insertion曲线显示了搜索区域与地面真实类别预测置信度之间的相关性。 突出显示的区域与曲线中红线指示的搜索区域相匹配,暗区域是该方法识别出的错误原因。 此外,我们也对方法进行了理论分析,提供了理论保证,请参考附录。 未来展望:我们的方法在子区域划分上是用先验显著图配合Patch进行划分,然而这样划分方法的缺陷在于,部分子区域的划分可能不好。我们也在尝试使用Super-Pixel还有Segment-Anything进行相关的实验。此外我们也将进一步在大模型方向验证我们的可解释方法。 代码:我们将原始的代码已经发布到了Github,后续也将会进行整理,更新README,欢迎大家尝试! https://github.com/RuoyuChen10/SMDL-Attribution?github.com/RuoyuChen10/SMDL-Attribution 此外,欢迎大家加入研究可解释AI的队列,加油! 以下为个人的一些愚见,认为可解释AI在现代深度学习模型中各应用场景的重要性: |

|
|
另外如果对大模型可解释性内容感兴趣的,也可以参考一下我做的PPT: https://ruoyuchen10.github.io/talk/Ruoyu_Chen-Interpretation_of_foundation_model.pdf?ruoyuchen10.github.io/talk/Ruoyu_Chen-Interpretation_of_foundation_model.pdf |

|
|
|
|
实习期间的工作EMO: Eearth Mover Distance Optimization For Auto-Regressive Language Modeling成功被ICLR 2024录用,感谢上海AI Lab的大家的鼎力支持。 文章主要关注常见自回归语言模型训练过程中采用的最大似然估计MLE(Maximum Likelihood Estimation)的经验性缺陷。诚然,理想情况下的MLE能让模型分布最终与人类语言分布 P" role="presentation">PP 完全相同。但在现实条件下,我们的训练数据均为有限的文本序列,并且对于自回归语言模型每一个time step的label都是one-hot的。在这种情况下,MLE有以下三个特点:(1) recall-prioritization (2) negative diversity ignorance和 (3) train-test mismatch。接下来简要介绍这三点。 recall-prioritization指MLE的监督信号仅仅告诉了模型什么是好的样本。这点从MLE的梯度不难看出,并没有显式的监督信号去告诉模型哪些是不好的样本。 |
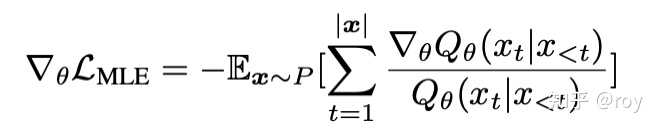
|
|
MLE相对于模型参数的梯度 negative diversity ignorance指,对于所有非ground-truth的token,MLE将它们一视同仁地对待(错误程度相同)。这点从MLE相对于词表里不同token logits的梯度可以看出,所有其他token的概率随着梯度下降而被推向0。 |
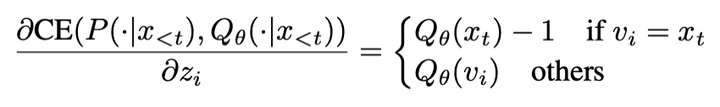
|
|
MLE/Cross-Entropy相对于logits的偏导数 train-test mismatch则指训练和推理时目标函数的不同。训练时,MLE的目标函数形式是对于数据分布的期望,而推理时我们是期望最大化某个变量/指标对于模型分布的期望。 针对上述三点,我们试图寻求除了MLE/Cross-entropy之外的分布间距离度量来进行改善。具体地,我们将目光投向推土机距离(Earth Mover Distance)。EMD最早出现于最优传输规划问题,后来在GAN等生成式模型中也有所运用。我们将EMD引入自回归语言建模,用于衡量per time step模型分布和数据分布之间的距离。 |

|
|
语言建模中的EMD EMD允许我们灵活定义每一对token之间的距离,并通过该距离定义实现更好的recall-precision trade-off, negative diversity awareness。针对语言建模任务,我们将该token间距离定义为LLM lm_head层中embedding之间的余弦距离。 由于我们最终的目标是找到一个end-to-end可导的目标函数进行梯度下降优化,上述形式的求解依赖外部求解器,阻断了梯度传播。为了绕过这个问题,我们转而优化当前模型分布真实的EMD在一个surrogate transport plan下的代价作为上界。对于常见的标签为one-hot的情况,优化上界得到的最优解也是真实EMD的最优解,即 Qθ=P" role="presentation">Qθ=PQ_{\theta}=P (对于标签非one-hot的情况,我们优化模型分布和标签分布对应的上界的差的绝对值)。 |
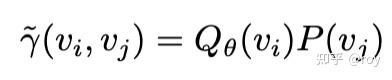
|
|
Surrogate transport plan 我们在language modeling, continual-finetuning和instruction-tuning设置下进行了实验。结果显示EMD使得模型能更好地平衡recall和precision,与human text分布具有显著更高的相似性,能够生成更高质量的response,同时在常用benchmark如MMLU、BBH上较MLE有所提升。详见论文正文及附录。 论文地址:EMO: Earth Mover Distance Optimization for Auto-Regressive Language Modeling Github仓库:https://github.com/DRSY/EMO |
|
6665,感谢AC赏识。 安利一下我们组的工作,FreeNoise,基于一个预训练好的视频生成扩散模型,无需微调无需优化,即可生成长达512帧的视频(再长的话GPU塞不下了),相比之前的方法内容一致性较高、突变较少,并且只带来20%的额外推理时间。感兴趣的请多多Star,有问题欢迎交流。 主页:FreeNoise 代码:https://github.com/arthur-qiu/LongerCrafter (基于VideoCrafter的实现) https://github.com/arthur-qiu/FreeNoise-AnimateDiff (基于AnimateDiff的实现) 论文:https://arxiv.org/abs/2310.15169 FreeNoise: Tuning-Free Longer Video Diffusion via Noise Rescheduling 也顺带安利一下何老师的ScaleCrafter (ICLR 2024 Spotlight),也是一种tuning-free的方法,无需微调无需优化,可以让预训练好的图像/视频模型生成更高分辨率的结果:https://github.com/YingqingHe/ScaleCrafter |
|
86666, accpet. 这次5个审稿人包括 AC 给的意见都非常中肯,不胜感激。同时,也看到了自己和领域内优秀 researchers 的差距. 这次 ICLR 的论文是上一篇 ICML 2023 论文的延续,两篇文章分别从 training 和 sampling 角度给出了一行代码大幅提升 diffusion model 的方法,欢迎大家即插即用~ https://github.com/forever208/EDM-ES https://github.com/forever208/DDPM-IP |
|
谢邀,第一次投三大会,彻底败北哈哈! 先说结论,我认为ICLR审稿结果受大家诟病,主要在于Meta Reviewer的评审很不负责任。 bg: 1篇一作,3篇挂名,全军覆没呜呜。 一作文章: 我认为这篇文章确实存在一些问题,rebuttal后633->653,最终12月选择了撤稿转投。但是我认为reviewer间互相身份可见是存在bias的,试问大佬拍了低分,小弟你敢不跟吗?还在学术圈混不混? 3篇挂名文章: 大佬们的工作还是很有影响力的,rebuttal后两篇分数都在bordlone(大约6655)。但是Meta reviewer只是寥寥草草copy了几条审稿人的意见,直接一言堂Reject,我觉得这对我们的文章很不负责。 另附这四篇文章链接,都是非常有意思的工作,近期引用量都不错,望大家关注!! How Abilities in Large Language Models are Affected by Supervised Fine-tuning Data Composition?arxiv.org/abs/2310.05492 Scaling relationship on learning mathematical reasoning with large language models?arxiv.org/abs/2308.01825 Query and response augmentation cannot help out-of-domain math reasoning generalization?arxiv.org/abs/2310.05506 Chatkbqa: A generate-then-retrieve framework for knowledge base question answering with fine-tuned large language models?arxiv.org/abs/2310.08975 |
|
纯小白,第一次投稿,分享下自己的工作,8866,spotlight “通过Krylov recycling算法 加速PDE数据集生成” Accelerating Data Generation for Neural Operators via Krylov Subspace Recycling | OpenReview |

|
|
省流截图 神经算子等数据驱动的PDE算法是AI for PDE最近最火的算法,例如:FNO等工作都火出圈了,用于了很多其他AI领域。 但是计算数学中各类不同的PDE差距巨大,在数值求解PDE领域本身就没有“泛化性”这一说。也就是说,为了训练这些看似高级的AI算法,反而需要针对不同的PDE反复调用传统算法来生成训练数据集。 而计算数学中NPDE主要研究的是如何更好地求解一个PDE问题,并不存在求解一系列PDE问题生成数据集这种问题。即传统计算数学领域并不存在加速生成PDE数据集的任务。 于是乎,一般的做法,例如FNO、DeepONet等工作的数据集都是通过反复调用传统算法来生成的,没有任何优化。但事实上,这些PDE问题本身就存在很强相关性(神经算子就是在学这个)。我们设计了一种基于Krylov subspace recycling的算法,从纯计算数学的角度来获取PDE之间的相关性,从而加速了线性方程组的求解,最终加速了数据集生成。(具体细节见论文吧,也可以私我) 为什么说是纯计算数学的呢?因为我们是从矩阵算法、子空间加速角度出发的,是纯加速,没有误差损失,也就是不会改变最后生成数据的结果。 最后我们从理论上,分析了为什么我们能加速,以及如何对数据集排序让效果更好。 从实验上,在四个不同PDE,5+种矩阵大小,5+种预处理方法,5+种精度,总计3k组实验,对比了我们算法和GMRES算法的计算开销和迭代次数,基本上都取得了很好的效果,计算速度上加速高达14倍,迭代次数上降低高达30倍。大部分的实验计算速度加速了2-5倍,迭代次数降低5-15倍。 当然我们的工作也有很多待解决的问题: 我们强行假定讨论的PDE是用基于线性方程组的算法求解的,但实际上很多基于初始条件的PDE并不是这样求解的。我们开发的是针对非对称矩阵的版本,并未对特殊结构的矩阵做算法加速优化(例如对称、对称正定)。本文做了近3000组实验,但并未讨论recycle算法参数对最后加速效果的影响。未对PDE的特征做对应优化(我也不会) 欢迎任何人找我聊,欢迎合作,我这边有无尽的idea完全做不完!包括但不限于,这个工作、AI for PDE、AI for 科学计算、AI for science、计算数学、理论物理、计算化学、计算物理。 最终感谢,老师们,同学的帮助。感谢王杰教授的帮助,MIRA Lab(我们组主页)。郝中楷给我提出的问题,带我入门。耿子介教我怎么写论文。汪震教我怎么用Linux。秦欧源、邓宽等同学带我入门Krylov算法、recycle算法等。徐宽教授教我计算数学。以及中科大和父母。 |
|
86553->88653,最终accept (poster)。 第一篇RLAIF相关录用正会的文章,主题是language model self-improve,回答了“为什么language model能自我提升”这一基础问题,先占个坑 |
|
ICLR 2024(International Conference on Learning Representations)在5月7日-11日在奥地利维也纳举行。今年,ICLR共收到7262篇投稿,总体录用率在31%。 本文总结了2024 ICLR录用的有关时间序列论文,其中包含了时间序列预测,分类,插补以及气象预测,大模型在时间序列建模等的应用。供大家学习,欢迎大家补充。 其中目前仍然炙手可热的两个技术大模型和扩散模型: 扩散模型:9,10,11,12,13(9-13) 大模型对应序号:14,15,16(14-16),21是基础模型(foundation model) 更好成绩:Oral一篇,Spotlight 8篇(ICLR时序收的比NeurIPS多) 如果本文对您有用,还请您点赞,收藏和转发,十分感谢您的支持! 更详细的一些论文介绍可以参考另一位大佬 @的泼墨佛给克呢 的总结: [Oral] 1. ClimODE: Climate Forecasting With Physics-informed Neural ODEs 链接:https://openreview.net/forum?id=xuY33XhEGR 关键词:神经常微分方程、时间序列预测、气候预测、基于物理的机器学习、不确定性量化 TL;DR:引入了一种受物理学启发的新颖的气候建模方法,使用常微分方程捕获潜在的归纳偏差并允许预测中的不确定性量化。 分数:8888 |

|
|
ClimODE [Spotlight] 2. Inherently Interpretable Time Series Classification via Multiple Instance Learning 链接:https://openreview.net/forum?id=xriGRsoAza 关键词:多示例学习,时间序列分类,可解释性 分数:8, 8, 8, 8 |
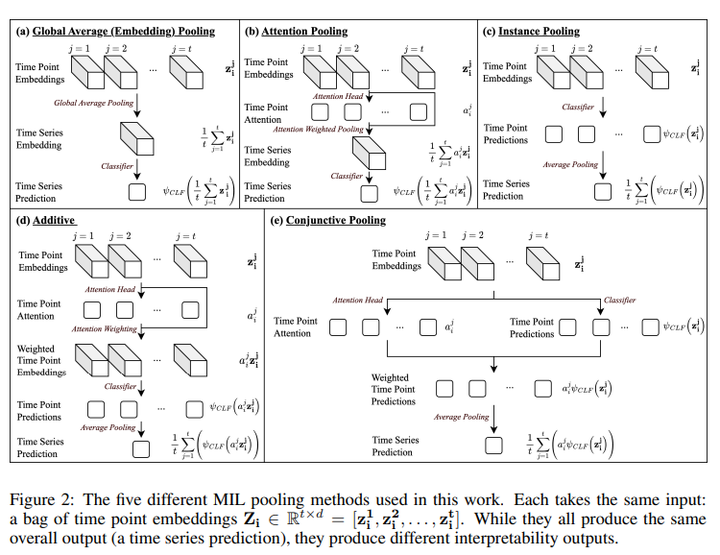
|
|
Model Arch [Spotlight] 3. ModernTCN: A Modern Pure Convolution Structure for General Time Series Analysis 链接:https://openreview.net/forum?id=vpJMJerXHU 关键词:时间序列分析,卷积 TL;DR:采用了时间序列社区中很少探索的方法,成功地将卷积带回到时间序列分析中。我们的纯卷积结构在五个主流时间序列分析任务中实现了一致的最先进水平 分数:8, 8, 8 |
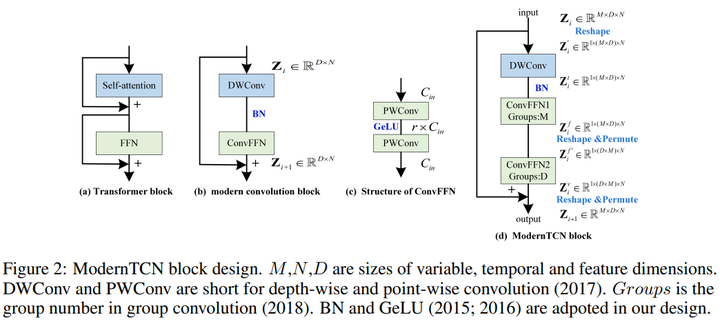
|
|
ModernTCN [Spotlight] 4. iTransformer: Inverted Transformers Are Effective for Time Series Forecasting 链接:https://openreview.net/forum?id=JePfAI8fah 关键词:时间序列预测,长时预测,Transformer TL;DR:提出了一种新颖的周期性解耦框架(PDF),通过捕获 2D 时间变化建模来进行长期序列预测。 分数:8, 8, 8, 6 |

|
|
iTransformer [Spotlight] 5. FITS: Modeling Time Series with 10k Parameters 链接:https://openreview.net/forum?id=bWcnvZ3qMb 关键词:时间序列分析、时间序列预测、复值神经网络,轻量级 TL;DR:提出了一种新颖的周期性解耦框架(PDF),通过捕获 2D 时间变化建模来进行长期序列预测。 分数:8,8,8,8 |
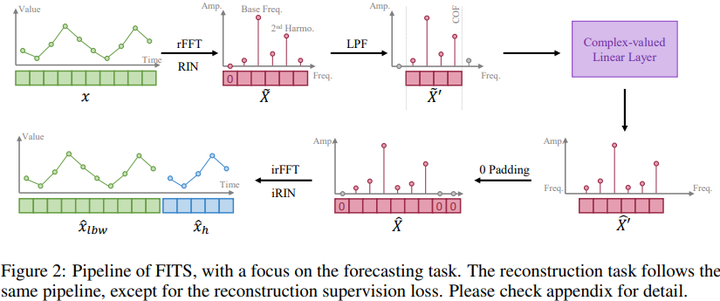
|
|
FITS [Spotlight] 6. SocioDojo: Building Lifelong Analytical Agents with Real-world Text and Time Series 链接:https://openreview.net/forum?id=s9z0HzWJJp 关键词:大语言模型、Agent、时间序列预测(好像和TSF关系不大,更多的是社交媒体分析) TL;DR:提出了 SocioDojo,这是一个终身学习环境,可以让agent根据新闻持续做出投资决策,以及一种新颖的agent架构,可以通过假设和证明提示生成深入分析以协助决策。 分数:5,8,8 |
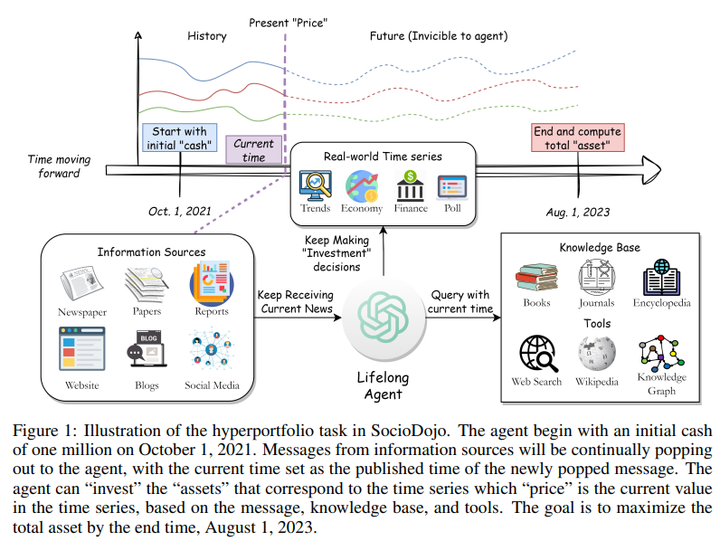
|
|
SocioDojo [Spotlight] 7. Soft Contrastive Learning for Time Series 链接:https://openreview.net/forum?id=pAsQSWlDUf 关键词:对比学习,自监督,表示学习(下游任务:分类,迁移学习,异常检测) TL;DR:本文提出了 SoftCLT,一种时间序列的软对比学习框架。 分数:8, 6, 6, 6 |

|
|
SoftCLT [Spotlight] 8. Stable Neural Stochastic Differential Equations in Analyzing Irregular Time Series Data 链接:https://openreview.net/forum?id=4VIgNuQ1pY 关键词:神经常微分方程、神经随机微分方程、不规则时间序列数据、时间序列分类 TL;DR: 稳定神经随机微分方程 分数:8, 6, 6 [Spotlight] 9. Generative Learning for Financial Time Series with Irregular and Scale-Invariant Patterns 链接:https://openreview.net/forum?id=CdjnzWsQax 关键词:生成模型,时间序列模式识别,扩散模型,金融时序 分数:8, 8, 6 |
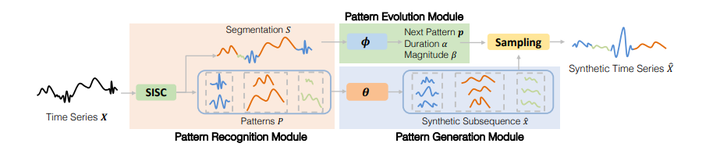
|
|
FTS-Diffusion 10. Transformer-Modulated Diffusion Models for Probabilistic Multivariate Time Series Forecasting 链接:https://openreview.net/forum?id=qae04YACHs 关键词:时间序列预测,生成模型,扩散模型,不确定性估计 分数:6, 6, 8, 3 |

|
|
TMDM 11. Multi-Resolution Diffusion Models for Time Series Forecasting 链接:https://openreview.net/forum?id=mmjnr0G8ZY 关键词:扩散模型,多尺度 分数:5, 6, 8, 6 |
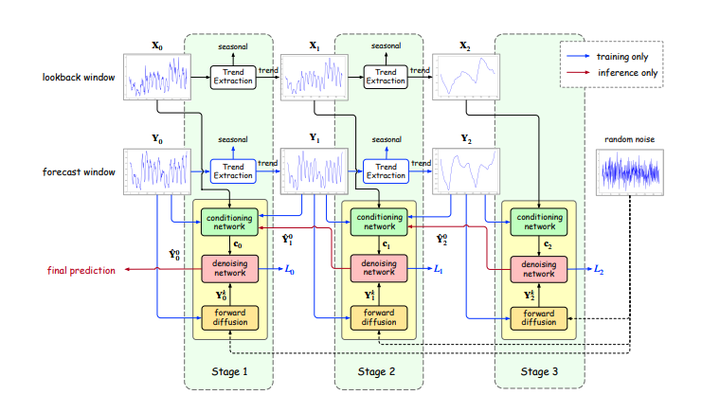
|
|
mr-Diff 12. MG-TSD: Multi-Granularity Time Series Diffusion Models with Guided Learning Process 链接:https://openreview.net/forum?id=CZiY6OLktd 关键词:扩散模型,多粒度,时序预测 TL;DR:引入 MG-TSD 模型,该模型利用数据中的多个粒度级别来指导扩散模型进行概率时间序列预测。 分数:6, 6, 5 |
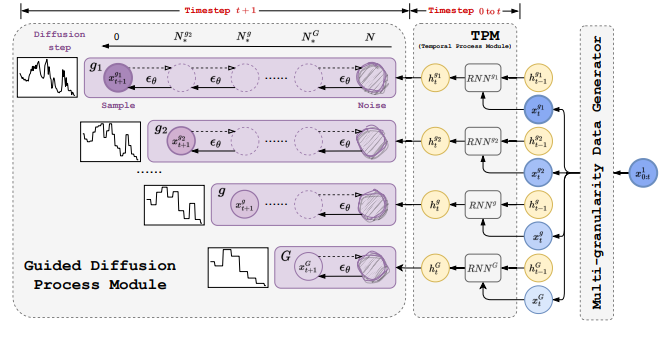
|
|
MG-TSD 13. Diffusion-TS: Interpretable Diffusion for General Time Series Generation 链接:https://openreview.net/forum?id=4h1apFjO99 关键词:扩散模型,时间序列 分数:6, 5, 8 |
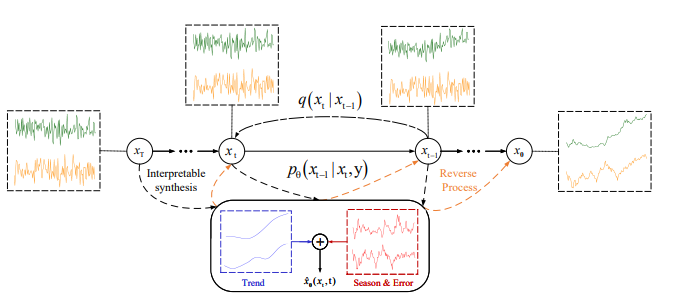
|
|
Diffusion-TS 14. Time-LLM: Time Series Forecasting by Reprogramming Large Language Models 链接:https://openreview.net/forum?id=Unb5CVPtae 关键词:时间序列预测,大模型,模型重编程 TL;DR:一个灵活的多变量概率时间序列预测模型,简化了attentional copulas,在不同的预测任务中具有最先进的精度,同时支持插值和从不规则数据中学习。 分数:8, 8, 8, 8, 3 知乎解读:https://zhuanlan.zhihu.com/p/676256783 15. TEST: Text Prototype Aligned Embedding to Activate LLM's Ability for Time Series 链接:https://openreview.net/forum?id=Tuh4nZVb0g 关键词:多元时间序列预测、嵌入(表示)、LLM 分数:6, 8, 5, 5 |

|
|
TEST 16. TEMPO: Prompt-based Generative Pre-trained Transformer for Time Series Forecasting 链接:https://openreview.net/forum?id=YH5w12OUuU 关键词:时间序列预测、LLM TL;DR:这项工作提出了一种用于时间序列预测的GPT 分数:5, 6, 8 |
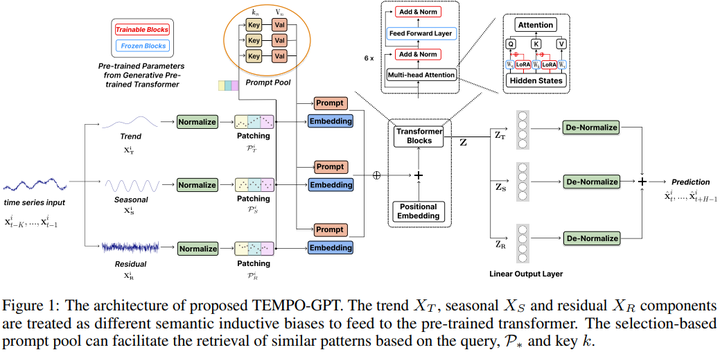
|
|
TEMPO-GPT 17. Interpretable Sparse System Identification: Beyond Recent Deep Learning Techniques on Time-Series Prediction 链接:https://openreview.net/forum?id=aFWUY3E7ws 关键词:稀疏系统,识别、长时预测 TL;DR:不使用神经网络的稀疏识别方法,与最近的 SOTA 深度学习方法相比,在多变量长期预测中实现了更高的精度,并且显着降低了计算成本。 分数:8, 8, 6 |
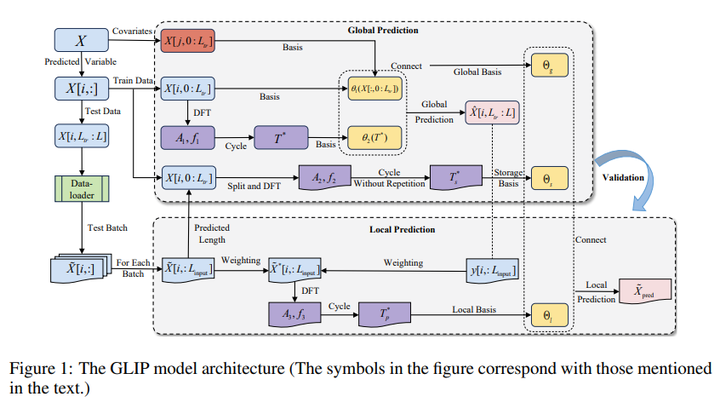
|
|
GLIP 18. Disentangling Time Series Representations via Contrastive based l- Variational Inference 链接:https://openreview.net/forum?id=iI7hZSczxE 关键词:学习解缠结表示、泛化、弱监督学习、电器使用电力、多模态学习 TL;DR:介绍基于 Disco(Disentangling via Contrastive) 电器用电量的 l- 变分推理,在训练过程中解决现实相关性,以捕捉现实世界的复杂性。 分数:8, 8, 1 |

|
|
Disco 19. Towards Enhancing Time Series Contrastive Learning: A Dynamic Bad Pair Mining Approach 链接:https://openreview.net/forum?id=K2c04ulKXn 关键词:时间序列对比学习、医疗保健、自监督表示学习 分数:8, 8, 6 |
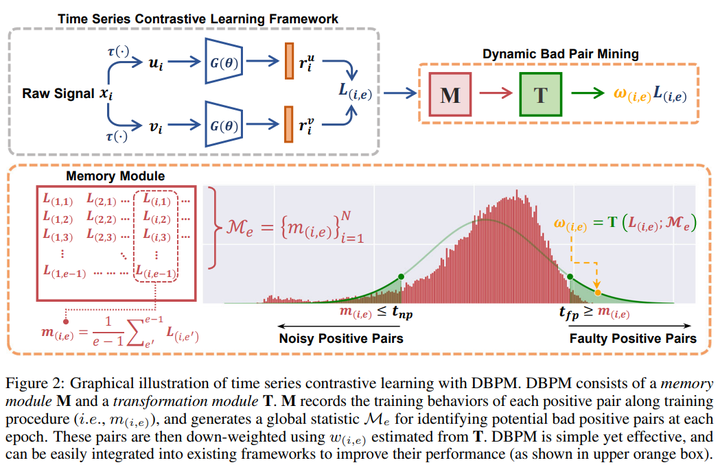
|
|
DBPM 20. Conditional Information Bottleneck Approach for Time Series Imputation 链接:https://openreview.net/forum?id=K1mcPiDdOJ 关键词:时间序列插补;信息瓶颈 分数:8, 6, 6, 6 |
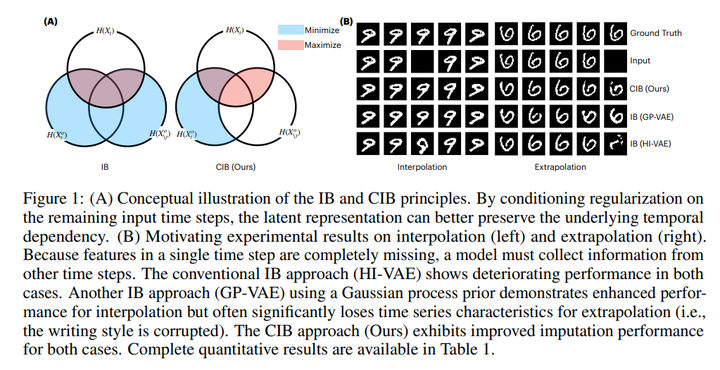
|
|
CIB21. DAM: A Foundation Model for Forecasting 链接:https://openreview.net/forum?id=4NhMhElWqP 关键词:预测,插补,基础模型,迁移学习 TL;DR:一种用于时间序列预测的神经模型,可以从长尾分布中摄取随机采样的长尾历史,并通过可调整的基函数组合进行预测。 分数:8, 6, 6, 8 |
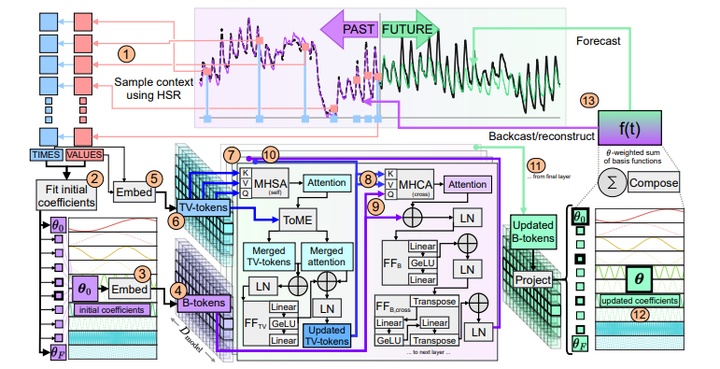
|
|
DAM22. TACTiS-2: Better, Faster, Simpler Attentional Copulas for Multivariate Time Series 链接:https://openreview.net/forum?id=xtOydkE1Ku 关键词:多元时间序列预测、copula TL;DR:一个灵活的多变量概率时间序列预测模型,简化了attentional copulas,在不同的预测任务中具有最先进的精度,同时支持插值和从不规则数据中学习。 分数:8, 5, 6, 5 |
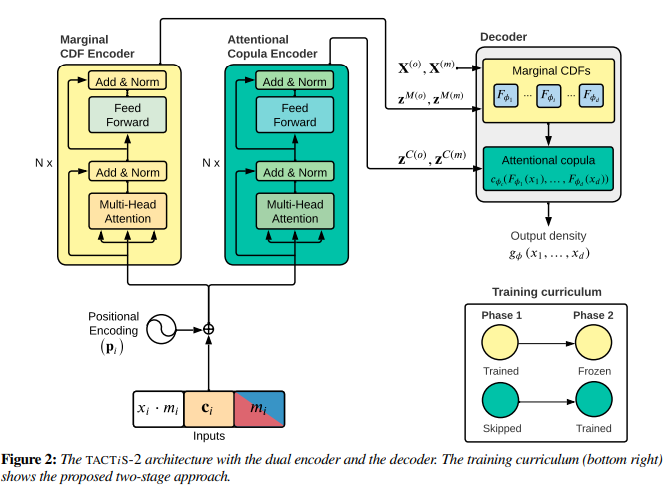
|
|
TACTiS-2 23. Retrieval-Based Reconstruction For Time-series Contrastive Learning 链接:https://openreview.net/forum?id=3zQo5oUvia 关键词:对比学习,掩码重建,自监督学习,插补,无监督学习 TL;DR:提出了一种基于检索重构(Retrieval-Based Reconstruction (REBAR))的时间序列对比学习的正负识别方法 分数:8, 5, 6, 5 |
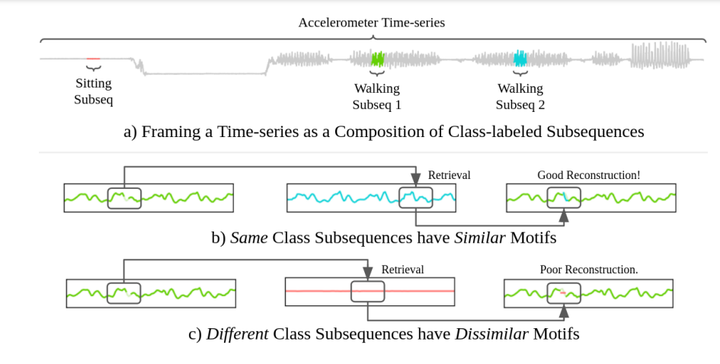
|
|
REBAR 24. Leveraging Generative Models for Unsupervised Alignment of Neural Time Series Data 链接:https://openreview.net/forum?id=9zhHVyLY4K 关键词:神经动力学、迁移学习、分布对齐、小样本学习(few-shot)、神经时间序列数据 分数:6, 8, 6, 6 25. GAFormer: Enhancing Timeseries Transformers Through Group-Aware Embeddings 链接:https://openreview.net/forum?id=c56TWtYp0W 关键词:时间序列,transformer,时空 分数:6, 6, 6, 6, 6 |
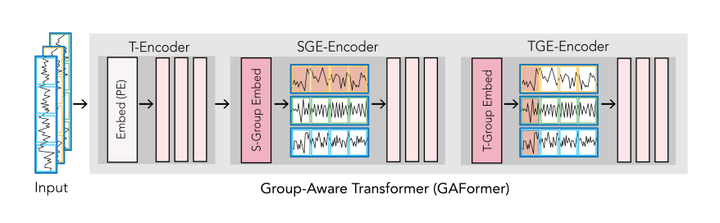
|
|
GAFormer 26. Towards Transparent Time Series Forecasting 链接:https://openreview.net/forum?id=TYXtXLYHpR 关键词:透明度、可解释性、时间序列 分数:6, 6, 8, 3 |

|
|
TIMEVIEW 27. CARD: Channel Aligned Robust Blend Transformer for Time Series Forecasting 链接:https://openreview.net/forum?id=MJksrOhurE 关键词:时间序列预测,transformer,稳健学习(robust),token mixing 分数:6, 6, 5, 8 |
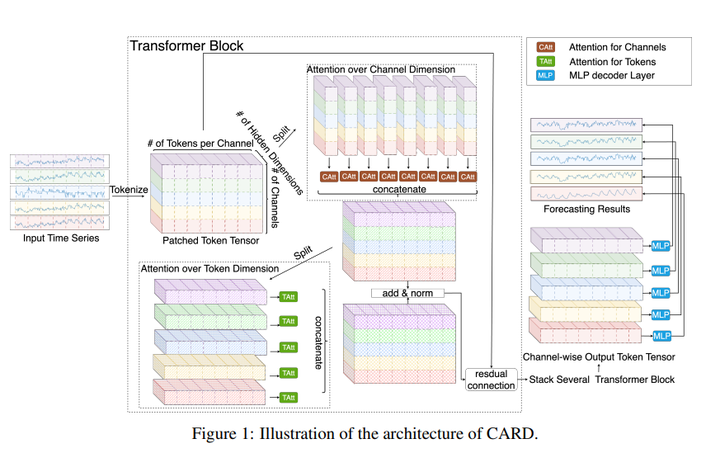
|
|
CARD 28. Biased Temporal Convolution Graph Network for Time Series Forecasting with Missing Values 链接:https://openreview.net/forum?id=O9nZCwdGcG 关键词:时空图神经网络,缺失值,时序预测,时空预测 分数:6, 6, 6 |
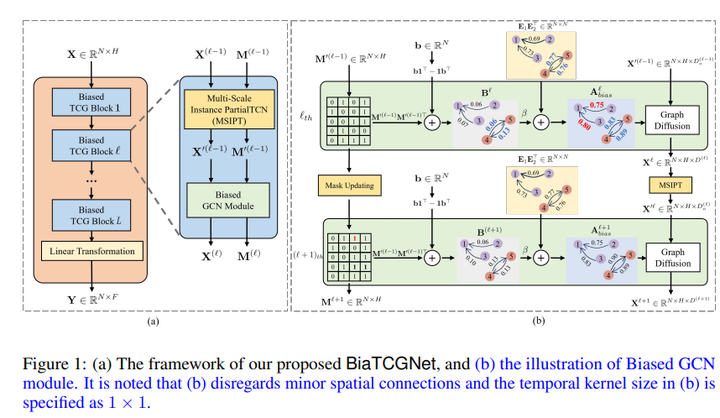
|
|
BiaTCGNet 29. Generative Modeling of Regular and Irregular Time Series Data via Koopman VAEs 链接:https://openreview.net/forum?id=eY7sLb0dVF 关键词:时间序列生成,库普曼理论(Koopman);变分自动编码器(VAE);生成模型 TL; DR: 引入了用于时间序列生成的 Koopman VAE (KVAE),它基于模型先验的新颖设计,并且可以针对规则和不规则训练数据进行优化 分数:8, 5, 6, 6 |

|
|
(KVAE 30. Rethinking Channel Dependence for Multivariate Time Series Forecasting: Learning from Leading Indicators 链接:https://openreview.net/forum?id=JiTVtCUOpS 关键词:多元时间序列预测、通道依赖性、超前滞后关系 TL; DR:重新思考多元时间序列中的通道依赖性,并强调局部平稳的超前滞后关系。提出 LIFT 来动态利用领先指标,这使得 SOTA 方法平均提高了 5.6%。 分数:6, 6, 6, 6 |
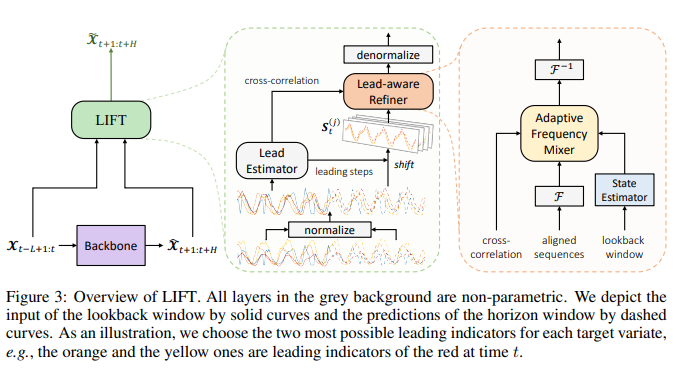
|
|
LIFT 31. VQ-TR: Vector Quantized Attention for Time Series Forecasting 链接:https://openreview.net/forum?id=IxpTsFS7mh 关键词:时序预测,隐变量模型,离散表示 TL; DR:概率时间序列预测的矢量量化表示 分数:6, 6, 8 |

|
|
VQ-TR 32. Learning to Embed Time Series Patches Independently 链接:https://openreview.net/forum?id=WS7GuBDFa2 关键词:自监督学习、掩码时间序列建模、对比学习 TL;DR:提出了通过掩码时间序列建模进行自监督表示学习的独立patch策略。 分数:5, 8, 6, 6 |
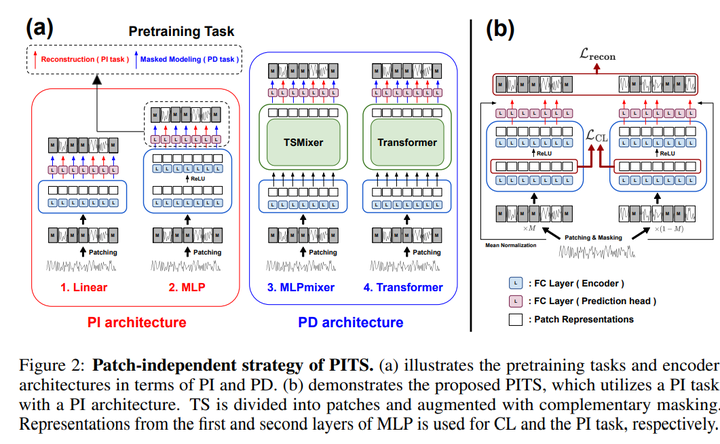
|
|
PITS 33. Copula Conformal prediction for multi-step time series prediction 链接:https://openreview.net/forum?id=ojIJZDNIBj 关键词:共形预测、时间序列、不确定性量化、校准、RNN、Copula TL;DR:通过使用 copula 对时间步长的依赖性进行建模,显着提高共形预测置信区间的效率/清晰度,用于多步时间序列预测。 分数:5, 8, 6, 5 34. CausalTime: Realistically Generated Time-series for Benchmarking of Causal Discovery 链接:https://openreview.net/forum?id=iad1yyyGme 关键词:因果发现,benchmark dataset TL;DR:新颖的pipline,能够生成真实的时间序列以及可推广到不同领域ground truth的因果图。 分数:6, 8, 8, 5 |
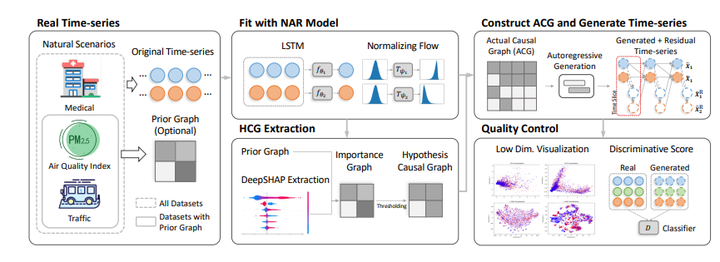
|
|
CausalTime 35. STanHop: Sparse Tandem Hopfield Model for Memory-Enhanced Time Series Prediction 链接:https://openreview.net/forum?id=6iwg437CZs 关键词:时间序列预测;多元时间序列;霍普菲尔德网络; TL,DR:提出了STanHop-Net,一种新颖的时间序列预测模型,将基于 Hopfield 的模块与外部存储模块相结合,增强学习能力,对突发事件快速响应,并具有卓越的理论保证和经验性能。 分数:5, 8, 5, 8 36. Multi-scale Transformers with Adaptive Pathways for Time Series Forecasting 链接:https://openreview.net/forum?id=lJkOCMP2aW 关键词:时间序列预测;transformer,多尺度 TL; DR: 提出了用于时间序列预测的具有自适应路径的多尺度transformer(Pathformer)。 分数:6, 6, 8 |
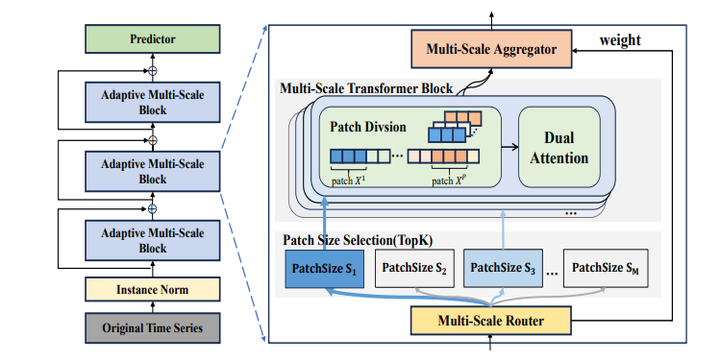
|
|
Pathformer 37. RobustTSF: Towards Theory and Design of Robust Time Series Forecasting with Anomalies 链接:https://openreview.net/forum?id=ltZ9ianMth 关键词:稳健时序预测,使用噪声标签学习(learning with noisy labels) TL; DR:一种简单高效的处理时间序列数据异常的算法 分数:6, 5, 5, 6 38. Explaining Time Series via Contrastive and Locally Sparse Perturbations 链接:https://openreview.net/forum?id=qDdSRaOiyb 关键词:可解释性,扰动 分数:6, 5, 6, 6 |
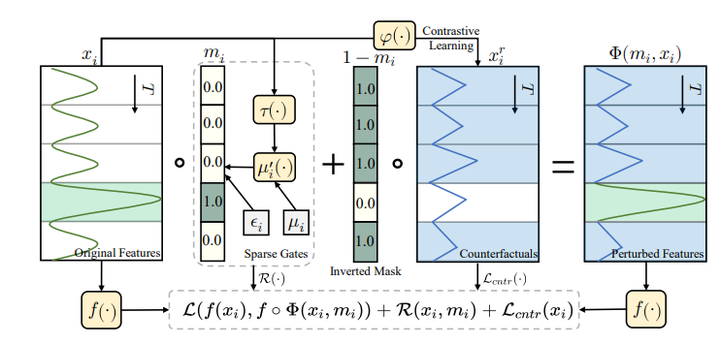
|
|
ContraLSP 39. Parametric Augmentation for Time Series Contrastive Learning 链接:https://openreview.net/forum?id=EIPLdFy3vp 关键词:对比学习,流式数据分析 分数:6, 5, 6, 8, 8 |

|
|
AutoTCL 40. TimeMixer: Decomposable Multiscale Mixing for Time Series Forecasting 链接:https://openreview.net/forum?id=7oLshfEIC2 关键词:时序预测,混合网络(Mixing Networks), MLP TL;DR : TimeMixer 作为一种完全基于 MLP 的架构,充分利用解缠结的多尺度时间序列,在长期和短期预测任务中实现一致的 SOTA 性能,并具有良好的运行时效率。 分数:6, 5, 6, 8, 8 |
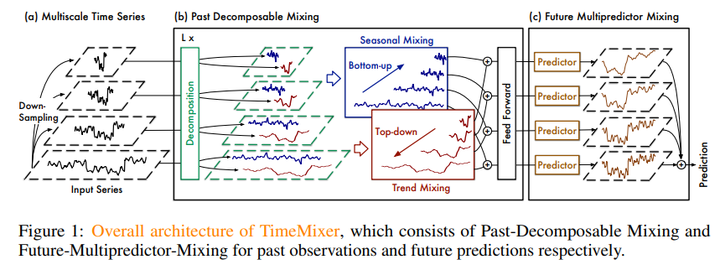
|
|
TimeMixer 41. T-Rep: Representation Learning for Time Series using Time-Embeddings 链接:https://openreview.net/forum?id=3y2TfP966N 关键词:多元时间序列、自监督、时间序列表示、时间特征、时间嵌入、表示学习、缺失数据 TL;DR :T-Rep 是一种以时间步粒度学习时间序列表示的自监督方法,在分类、预测和异常检测任务中优于现有的自监督算法 分数:6, 8, 5, 6, 5 |
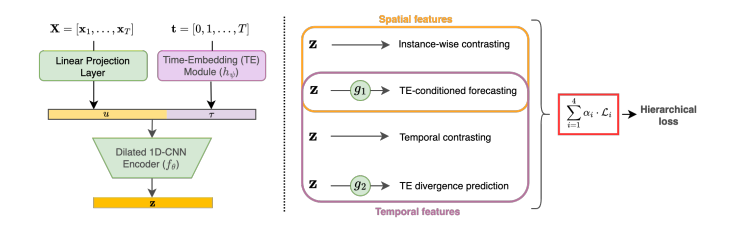
|
|
T-Rep 42. Interpretable Sparse System Identification: Beyond Recent Deep Learning Techniques on Time-Series Prediction 链接:https://openreview.net/forum?id=aFWUY3E7ws 关键词:稀疏系统,识别、长时预测 TL;DR:不使用神经网络的稀疏识别方法,与最近的 SOTA 深度学习方法相比,在多变量长期预测中实现了更高的精度,并且显着降低了计算成本。 分数:8, 8, 6 |
|
|
|
GLIP 43. Periodicity Decoupling Framework for Long-term Series Forecasting 链接:https://openreview.net/forum?id=dp27P5HBBt 关键词:时间序列分解,长时预测 TL;DR:提出了一种新颖的周期性解耦框架(PDF),通过捕获 2D 时间变化建模来进行长期序列预测。 分数:8, 3, 8, 8 |
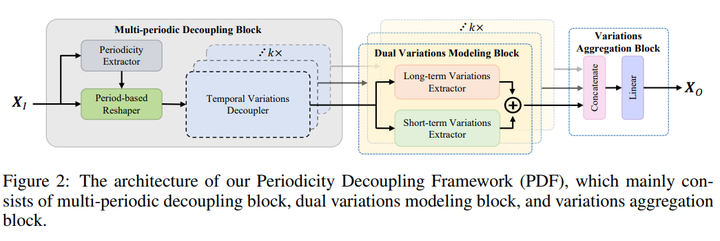
|
|
44. Self-Supervised Contrastive Forecasting 链接:https://openreview.net/forum?id=nBCuRzjqK7 关键词:自监督,对比学习,长时预测 TL;DR:提出了一种新颖的周期性解耦框架(PDF),通过捕获 2D 时间变化建模来进行长期序列预测。 分数:6, 5, 6, 8 |
|
|
SSCF 相关链接: ICLR 2024论文:https://openreview.net/group?id=ICLR.cc/2024/Conference ICLR 2024 统计:https://guoqiangwei.xyz/iclr2024_stats/iclr2024_submissions.html NeurIPS 2023 时间序列(Time Series)论文总结 NeurIPS 2023 时间序列预测论文总结 NeurIPS 2023 时空数据论文总结 NeurIPS 2023 时空预测论文总结 ICML 2023 时序和时空论文总结 ICML 2023 时间序列预测和时空预测论文总结 ICLR 2024投稿时空数据论文汇总 ICLR 2024 时间序列(Time Series)高分论文 SIGMOD 2023 时序&时空数据论文 VLDB 2023 时空&时序论文汇总 ICDE 2023 时空数据论文 KDD 2023时空数据相关论文 SIGIR 2023 时空数据论文总结 WWW 2023 时空数据论文汇总 AAAI 2024 时序和时空论文总结 IJCAI 2023 时空数据论文 ICDM 2023 时空数据&时间序列论文总结 WSDM 2023 2024时空&时序论文总结 ECML PKDD 2023 时空数据论文 CIKM 2023 时空数据论文总结 |
|
这次我们主要做了一篇关于半监督的论文,中了poster。后续会详细讲一下论文具体内容,个人感觉还是很impressive的~欢迎大家关注。 链接先放出来,宣传稿还在加班加点 |
|
我们的工作Relay Diffusion取得了spotlight的好成绩,感恩! |

|
|
欢迎大家关注我们的工作!我们设计了一个新的级联扩散框架,在ImageNet256,CelebA-HQ256、512、1024上均取得了sota的结果,最新版本论文请关注camera-ready版本或者openreview版本。 知乎链接: TTJiayanTeng:清华团队扩散模型新研究:统一不同分辨率的扩散过程 论文链接: https://arxiv.org/abs/2309.03350 GitHub地址: https://github.com/THUDM/RelayDiffusion |
|
谢邀。祝贺各位已录用论文的同学朋友老师!!想起来作为CV选手在CV主战场CVPR/ECCV/ICCV以及次战场AAAI/ACMMM/IJCAI都中过不少,目前还没有ICLR/ICML/NeurIPS的经历(希望以后有合适的投稿机会)。 借楼蹭蹭好运,希望下周的CVPR2024 rebuttal开分顺利 |
|
很幸运borderdline被接受,挽救了我的研究生涯 |
|
|
| [收藏本文] 【下载本文】 |
| 科技知识 最新文章 |
| 百度为什么越来越垃圾了? |
| 百度为什么越来越垃圾了? |
| 为什么程序员总是发现不了自己的Bug? |
| 出现在抖音评论区里边的算命真不真? |
| 你认为 C++ 最不应该存在的特性是什么? |
| 为什么 Windows 的兼容性这么强大,到底用了 |
| 如何看待Nvidia禁止使用翻译工具将cuda运行 |
| 为何苹果搞了十年的汽车还是难产,小米很快 |
| 该不该和AI说谢谢? |
| 为什么突破性的技术总是最先发生在西方? |
| 上一篇文章 下一篇文章 查看所有文章 |
|
|
|
| 股票涨跌实时统计 涨停板选股 分时图选股 跌停板选股 K线图选股 成交量选股 均线选股 趋势线选股 筹码理论 波浪理论 缠论 MACD指标 KDJ指标 BOLL指标 RSI指标 炒股基础知识 炒股故事 |
| 网站联系: qq:121756557 email:121756557@qq.com 天天财汇 |