
| |
|
|
| ����ƻ� -> �Ƽ�֪ʶ -> ��һ˵һ����������paddlepaddle (�ɽ�) �� -> �����Ķ� |
|
|
[�Ƽ�֪ʶ]��һ˵һ����������paddlepaddle (�ɽ�) �� |
| [�ղر���] �����ر��ġ� |
|
������ǰٶ�Ա������������أ������˻�������������pytorch��1.3�˰���tensorflow����̬ͼ�ˡ�Ҫ˵Ӳ�����������ĸ�����Ӳ������ܣ��� |
|
�����Ŀ�����иж�������һ�θо��ٶ������Ǯ+kpi��������Դ��ģʽ�߲�Զ�� ȷʵ��paddle���������������Ĺ��ܿ������dz�ǿ����Ϊ���ƹ��ܴ�����ѧcolab��Ѹ��û��á������㼫��̶ȵؽ�������������ʹ��aiѵ��ģ�͵��ż�������Ҳ�������ż��ˡ������������ʹ�õ�ʱ��ͻ���ָ��ֵ��۵����⣬�����̶���ȫ�Ȳ��ϸ��ڵ�pytorch�� �������һ����Ŀ��������3d��ctӰ��ָ����paddleseg�����е�ҽ�Ʒָ�ͱȽ��������֣������̵������˹ٷ�ѵ���õ�һ��vnetģ�ͣ����ŰѲ�����ǿ���д�ˡ�Ȼ����paddle2onnx������ʱ����ʾconv3d_transpose���Ӳ�֧�֡� ��һ��ʼ����Ϊģ�ͺ��£������Ӳ�֧�ֺ������������������ò��ԣ���arxivһ��ģ�Ͷ���2016����Ϲ���ģ���ˡ���ȥpaddle2onnx�ٷ���һ�飬2021������������ͬ��issue���ٷ����˸������Եı�Ǿ�û�������ˡ�Ȼ�������ֿ⣬�����ƺ��Ŷ���æһ��fastdeploy����Ŀ������ǽ������Ҫkpi�ɣ���������paddle2onnx�����︴����һ�ݡ�����ȥ�������˸�issue������û�˴��������fastdeploy��Ŀ����һ���Ǹ�beta�汾��ʹ�ñ��������ӡ��аɣ������ɽ��ٷ�����·�������������� Ȼ���ڶ������IJ�����ͻ��������github���������ķ����������ѵ�����ôһ��Ұ���⣬��paddleocr2pytorch���������������ǰ���ͬ��ģ����pytorch��������Ȼ�ɽ���ģ��Ȩ�ض���pytorchģ�����档 �ұ�������������ҽ���뷨��ôһ�ԣ�������ô�ţ���ľ���import paddle as torch������������api����˵��ȫһ������Ҳ�������ǰ������ɵ����𣬰�paddle��ģ���ļ��ù����ؼ����滻�Ͱ�ģ�ʹ���ˡ� ������ĥȨ�ص����⣬��Ѱ˼�������˿϶��ÿ��ܾã�������ô����Ҳ����������ȫһ�°ɡ��Ұ�Ȩ�ص��ֵ�key�������滻��һ�£�����Ȩ�غ���һ���˶����������Ȼ���Һܿ췢������һ����ʡ�ˣ�ƴװģ�������paddlepaddleһģһ���� ���ž���˿��������torch.onnx.export��trtexec��ȥ��pytorch��issue������ȷʵҲ�е������Ӳ�֧�ֵ����⣬���������ǹٷ��ظ�����汾���¼ƻ�or���°��ѽ�������۹�����ߣ�paddle2onnx��open issue����һ���Ǻǵ��ˣ����Ʋ��������Ŀ�Ѿ��Ƴ��ٶȹ�˾kpi���������ˡ��������������С����ǣ��������ѵ���õ�ģ�͵Ļ��ͱ�ɵ�ȹٷ������ˣ�����������������ɣ�˳���̶ȳ��������� ��лpaddlepaddle���ҶԹ�����Դ�������ָ���һ�㣬��ô�����أ�һ���Ѿ�+����ף���ɡ� |
|
�����á� ��pytorch�����������֣������Դ�һ���������ƶ��������������棬���ܸо������ԡ� paddle��ģ�Ϳ����IJ���������paddleocr������openmmlab�Ŀɶ���ǿһ�㣬Ҳ����diy�����кܶ౾�Ʊ��輶���С��Ŀ�������Թ�������Ŀǰ�ڿ��ٿ����ȽϺ��ʡ� ȱ����ǣ��ĵ��õ�һ�ʣ�demo��ܶ�ӿ��ĵ��Ҳ���������Խ��Խ����ˡ����������� ���кܶ�bug������ѵ��ֹͣ���̲��ͷţ�ѵ�������Լ���ͷ�ֿ�ʼѵ����ѵ��������Ī����ס������Ҳû�б���������ʱ�Դ�������⣬ռ�ù����Դ治���ͷţ����ֽӿڹ��ܲ�û��ʵ�֣�ֻ��װװ���ӡ������� |
|
�������ʹ��paddle�ľ������Ҳ���ʹ���������ˡ� ��һ����22��4�·ݣ��μ�paddle�����ĸ���������һ���ٷ���Դpytorch�汾�Ĺ�������Ϊʶ��ģ�ij�paddle�Ϳ��ԣ��Ĵ���ȷʵû��ʲô�ѵģ����ܳ���������DZ�ԭpytorch�汾�����0.5%~0.8%�������ȶ����飬����ǰ����̽��һ�£�paddle��Momentum�Ż�����pytorch��SGD�Ż�������������ͬ������·�������������ݶȾͲ�ͬ�ˡ�������Ϊ��������û���ٻ�ʱ�������������ˣ�û���������ʲôԭ���µġ� �ڶ�����22��11����Ѯʹ�õģ���װ���ǵ�ʱ���µ�paddle-gpu 2.3�汾��д����ʱ����������ʵʵ��bug��paddle��������ά�ȵ�inplace��������squeeze_()������ִ�����ʾ�����´���ֹͣ�����ǣ������ı�����������ȷ��ά�������ˣ������룺 ���ϴ���������ȷ��squeeze()�����ǿ�������ʹ�õģ������� ����ʹ��squeeze_(2)�ͱ����ˣ�������ʾά�Ȳ���2���������ά�ȣ��� ���ǣ���������aa��ά�ȣ� ������ά�ȷ�������ȷ�Ľ������ԭ���±�2��ά�������ˣ� ��Ȼ˵�������ά���±꣬��Ҫ����-1��ָ�����һ��ά���أ��������� ���û�б����������һ��ά�������ˡ� ���bugֻ�����ڲ���Ϊ���һ��ά���±������£����ά����[3, 1, 2]Ȼ����squeeze_(1)���������ġ� ����pytorch�ᆳ��ʹ�����Ƶ�inplace������û�г��ֹ�����bug������paddle������ô���õĺ����������ô���صĴ���չ����ô���꣬��IJ�Ӧ���ˡ��ѵ�֮ǰ��û�˷������bug��������ȥgithub�Ͽ��˿�paddle�ֿ��issues���ҵ��������Ѿ������bug��issues�� 2021��2�£�paddle 2.0.0 https://github.com/PaddlePaddle/Paddle/issues/30935 2021��8�£�paddle2.1.0 https://github.com/PaddlePaddle/Paddle/issues/34589 �ظ���˵������������һ����˶�û���ޡ��ղſ���һ��������µ�paddle 2.4������־��ò��Ҳû���ᵽ����bug�� ��ǰϲ�����ڴ��룬������ʵ�鷢�ֻ�����ô������ȶ���ô����ʡ�£���ʱ����ڵ�����Щ��֪����Сbug�ϲ�ֵ���ġ������һ����źú�ѧһѧpaddle֧��֧�ֹ�����ܣ������ڱ�Ȱ���ˡ�Paddle�ҵ�ǰ��δ����һ��ʱ���Dz��������ˣ������������bug֮ǰ���Dz����ˡ� ���£� ��paddle��AI Studio�������ԣ�2.5�汾�Ѿ�����squeeze_()��bug����л���������и��ɽ��ķ����� |
|
����һ��֮ǰOCR�����ɹ� ���˲����ģ���ײ����ĩddl�������ͦ������ ����������ʶ�������´��� - �ٶ�AI Studio - �˹�����ѧϰ��ʵѵ����?aistudio.baidu.com/aistudio/competition/detail/75 |

|
|
|

|
|
ȥ�꣨2020��11�¿�ʼ��paddlepaddle�������ǰٶȵ�PaddleOCR PaddlePaddle/PaddleOCR?github.com/PaddlePaddle/PaddleOCR |
|
|
�����˻���two-stage����ʵ���з����⣩��OCRģ�ͣ�ѵ����������������ֽű����Ѿ�д�ã��������ݾͿ���ֱ���á����Ҵ�����ܹ淶�����Խ�������һЩģ�ͺʹ��� ����֤��һ�£�����ֿ����Һ�����Դ�ģ������û��ô��עPaddleOCR�������Բֿ�һֱû�����µĹ��ܣ�֮��ż��п�Ӧ�û����һ�� caopulan/PaddleOCR_Utils?github.com/caopulan/PaddleOCR_Utils |
|
|
�����ֵ�ʱ����paddlepaddle1.8�����ڶ��Ѿ�2.1�ˣ������������pytorchһ�� ������paddle�ĵ���ʱ������һ��ģ�Ϳ⣺ ģ�Ϳ�_�ɽ�-Դ�ڲ�ҵʵ���Ŀ�Դ���ѧϰƽ̨?www.paddlepaddle.org.cn/modelbase |
|
|
|
����ȥ����ûʲôģ�ͣ���ʱ�����ſ϶���paddle�Ŀ�Դ��������һЩ������ܣ����»����ܶ࣬��һ���ģ�Ͷ�û�е��Լ�д����������������� PaddlePaddle/PaddleClas?github.com/PaddlePaddle/PaddleClas |
|
|
�ŷ���Github��PaddlePaddle����˻��¿�Դ�˺ö����Paddle�Ķ��������ݷdz�ȫ�����ҵ������ǹ��ڵĹ�˾�����вֿ���Gitee�϶��У�ֻ�ǿ��ܸ��²�ͬ��������ͬ�汾��Ӧ������һ�µ� ������PaddleOCR��ʱ���ҷ��ָ����ٶȷdz��죬Issue��Ӧ��ʱ��Ҳ�б�֤���������ǰٶ��Լ��ٷ���С�鸺��ά��������Ǹ��˿����ߵĻ�һ��IssueӦ�����һЩ�� ���Ҳ����һЩ��������Ŀ��backbone���ֲ�����PaddleClas�Ĵ��룬�������黹���� �������ܽ�һ��paddlepaddle������ д����ǰ���ٶȾ��Զ�paddle����Ұ�ĵģ���������Ѫ�� һ������̬���� ����Ϊpaddle����̬��������ܣ���pytorch��TFΪ�����Dz�̫һ���ġ� ������ܵ���̬�ǿ����������� ��̬����������ʹ������������һЩ�µ�����û�и������paper��ʱ����п�������GitHub�Ͻ��п�Դ paddle����̬�ǰٶ��������� Ŀǰ��״̬���ǻ����ɰٶ��Լ����и��ֿ�Դ�������������ᵽ��PaddleClas���ǰٶ��Լ����ŶӲ���ͨ��������ȤС�����PPDE������һЩ���˿����ߣ�������Ҫ�ػ��ǰٶȹٷ����Ŷӣ�������ٶ��йص��Ŷӱ���AgentMaker������鿪ʼ�����ǻ�����Ȥ�齨�ģ���������Ӧ�ø��ٶ����к����ģ��ٶ�Ҳ������һЩ�ƹ㣩 ��������Ϊ���кû� ��������������̬����ӡ��ࡱ��һЩ����û��ôţ�ƻ���Сһ�������paperҲ���п����߽��и����о����Ͼ��ٶȲ����ܶ��������Ľ��и��� ���ٶ��Լ���Դ�ĺô��Ǵ������ȶ��������뼸����û��bug�ģ�������û�����صؽṹ��bug�����˿������ڿ�Դ������汾��ʱ������һЩģ�ͽṹ��bug�������Ҽ����������Ԥѵ��Ȩ�ء�������Ҳ�Զ���������ֻ��һЩ���ŵķ����Լ�ţ�Ƶ����Ľ��и��֡� ����ʹ�ø��� paddle��pytorch�Ĵ������Ǻ����Ƶģ��ٶ����������paddleӦ��Ҳ�Ǵ����ο���pytorch������Ϊ��һ��dz��ã���������������Ѷȡ� ����paddle1.x��paddle2.xû����TF�����ļ������ԵĶϵ���������һ��Ҫ�²�һ��TF����2.x��������1.x�����ֱ�����Ѽ����Ĵ����ܸ�һ�꣬����Զ��֪��һ�������ڲ�ͬ�汾�µ�api��ʲô������ΪʲôҪ��2.x����1.x���룬��Ϊ30ϵ�Կ�ֻ����cuda11+����TF1.x��֧��cuda11+�������С���֪����ʲô�취������30ϵ�Կ�����������TF1.x��һ�������ҡ�30ϵ�Կ�Ӧ����װ����cuda10����docker�� ˵��30ϵ�Կ���cuda11�����ﻹҪǿ���£�paddlepaddle���ҿ�ʼ����������û���Ĺ�cuda11������� ��֪���ҵ�����Ҫ��TF�����˶���Ŭ�� �������� ���������ĺ��㣬V100+32G�Դ棬���������ʱ����Ҫ�Ŷӣ�Ŀǰ���û�Ŷӳ���1�죩��ƽ�����л���or�μ�һЩ�����������������л�������ͬѧ�����˵��˺ţ��꣬��û�� doge�� ǰ��������ڿ�paddle������Ҳ˵һ���ҵĵ��� ��Դ��AI������һ����Ҫ�л�Ծ������������ֻ���ٶȱ�����Ŭ����˵��ģ���Ҫpaddle��Ϊ������ܣ������ٵ���researcher�ڸ�ʵ�鷢paper��ʱ����paddle�����ܣ�����ֻ�ǰٶȸ��ں��渴�ֱ��˵����ġ� ��˵�����Ҫ���Ϊ������Ҫôռסѧ���г���Ҫôռס��ҵ�г�������paddle��ѧ��������˵��ȫû�зݶ�ڹ�ҵ��һ��������ȫֻ�������ٶ��Լ���Դ��һЩ��Ŀ��ռסһ���ݶ����϶��Dz����ġ�����paddleĿǰ���ڹ���ռ��һ���г��������Ҫ��ij�Ϊ������ܣ�����ҪӮ��ȫ����Ŀ����ߵ������� ֻ��˵��Ŀ�Դ��ɣ������˽�paddle�����������ڵĿ�����DZȽ�����ģ�δ������ ���Ҷ���ô���˰ٶ��ܲ��ܸ��ҽ�һ��Ǯ�����߰�����֤��PPDE�£� |
|
����������ˣ��ٶ�ȷʵ��ѷɽ������й��İ����ܶ����������star����ǧ�ˣ����ϰٶȹ�ҵ�����Ļ��ۣ����ܺ��ȶ��Զ����á�����ٶȳ���Ͷ������꣬���˾���δ�����ڣ��о�����tf������pp�Dz����ġ� |
|
23.08.29 ���� ��ɢ�˰ɣ���ʼ��Ǯ�ˣ��Ҳ���С�� |
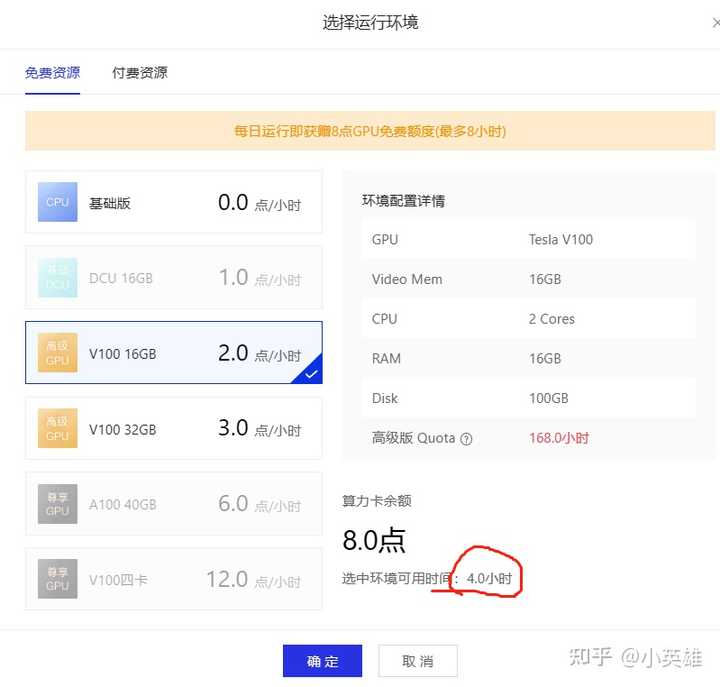
|
|
ԭ��16G����ÿСʱ1�� |

|
|
���ڿ�ͨ���ѷ���ԭ���⼸�ſ�������ͨ������㿨�һ� |

|
|
����С�� ��ʵ���ҵ�ʦ����ì�ܣ� ��ʦ�������������������� �ã� ��ı��·�� ѡ��Baidu AI Studio�� ��������� ֮ǰ��PyTorch�� Paddle ������졣 Github �ϻ��� ����ģ�͵� Paddle ʵ�֣� �������������⡣ Ч�������ڷ���������PyTorch�ܵ�Ч������˵��ƫ��ɣ� ֻ��˵һģһ���� |
|
�ɽ����ĺܺã��������ڴ��������ĵĿ�Դ������ pytorch �ģ����� pytorch �Ƚ����� ���������Ĵ����Ƿɽ��ģ����ƻ������ |
|
�����ˣ�paddle�ܲ��ܰ�һЩ��������úô���һ�£����ݼ����ص�dataloader�ڴ�й©����ô���ص����⾹Ȼ�������ȶ��汾�У�2.2.2.post111�����ſ���ȥ��һ�£����µ��ȶ��棬�ڴ��һ��һ��й¶��ֱ��oom�� paddle������ô���issue��ϣ���ٷ��������Ӱɣ���Ҫ��ʲô����num of worker���������������˵ķ�ʽ�ġ��ײ⣬worker����Ϊ1������Ϊ8�������6�����ҡ� ��Ϊ��Щ�Ƚϻ��������⣬��֪����Ȱ�˶������ء����� |
|
�С� �Դ�paddlehub����stable diffusion֮���û��������� ��֪������˵ʲô�� |
|
�鷳��λ�ڹ�˾��paddle�ı�һ�¹�˾���֣��Ժ��ò�Ʒ�����ܿ��������Ͽ϶�һ��һ�ѵ�so����������ڴ�й©���⡣ |
|
��֪��Ϊʲô��Ҷ�paddle��ô��Ķ��⡣ �ٶȺͰٶ��з��Ŷ������������� ��Դ��Ʒ�����ͻ��кܶ����⣬�����˼��ǿ�Դ�İ��� ����㲻�ã�����bug��ô������ torch�Ǻ��ã�����torch��û��bug�� ������˵������������ļң�����Լ���torch����һ��һ���� ������paddle����tf����openmmlab �Dz��Ǹ���ü��ȡ� ���߾��ǹ��� �����ڽ�����������ҵ���ڡ� Ӧ�ð���_��ҵ����_�ɽ�-Դ�ڲ�ҵʵ���Ŀ�Դ���ѧϰƽ̨ �����ң����Ѿ���������С��˾�㷨��ȫ����paddlenlp���� ������paddleҪ�þ�Ҫ��һ�ס� ��һ�����������DZȽ�����ġ� ����paddle��������pytorch������Ҳ��� |
|
cpp���в�������paddle inference demoû�������еģ��ĵ��ʹ�����ȫ�ѽڡ�github�ϵ�issue�����ʽ��кܶ�����û�д�close�ˡ����˸��ٷ�Ⱥ�ģ��ʸ�����ٷ�û�˽����ֱ��׳���ң��ҷ���һ��ͱ������Ⱥ�ġ����� |
|
���ù�paddle��ocr������Ч���������������Ҳ�֪���⼸��������⣬paddle��֧��pytorch�°汾�ģ��ҿ������°汾�ܡ� |
|
��˵paddle2.0��torch�ģ���ʵ�������dz�tf2.0��(�Ͼ�tf2.0Ҳ�dz�torch��)�� Ϊʲô��ô˵��?��Ϊtorchû���Ҹ�API���ȱ�㣬��˭����? |
|
�ڿ�����ѡ��������˭���ã� |
|
�ܶ����AIоƬ��PyTorch��TF�����ݡ�����Paddle���ԣ����ٿ��Լ��ݰٶ��Լҵ�AIоƬ����Щ�ط�����ֻ���ù���оƬ����ôPaddle������Ψһ��ѡ�� |
|
���dz�����ѵ�V100��A100ȥ�� ǰ��ʱ�䲻��һֱ�������ţ�PP����Ѿ���ȫ���һ�������û�ȫ���һ���������и��ֵ�һ �������ģ���ô���������д��ˡ� |
|
��һ��������DETR��������pytorch��Դ�룬Ȼ���ְٶ�paddlepaddle��������Ӿ�Ȼ��һģһ���ģ���torch���˶��ѡ� |

|
|
|
|
|
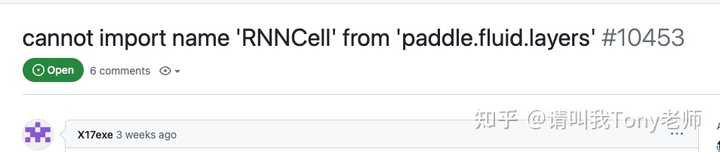
�ڰ�װ PaddleHub �����ʱ�����dz������������ִ����������û���ģ�飬�����ĸ���û������ԣ�ÿ�����������ͷʹ������Ҳû�� PaddleHub �� PaddlePaddle ��Ӧ�İ汾��ֻ���Լ��������ԣ�ͨ�����ϲ�����ҵ���������ͨ�ķ����������������ڽ��г����е�һЩ���飬ϣ���Դ������������ ��װ PaddlePaddle �� PaddleHub Ŀǰ�������������¼��ݰ汾�ǣ�paddlehub 2.3.1��paddlepaddle-gpu 2.4.2 ���ݰ汾��ʹ�õĻ����Ǿس��� CUDA 11.7 ������Ԥװ��Ubuntu20.04, Python 3.9, CUDA 11.7, cuDNN 8, NVCC, VNC�ȡ� |
|
|
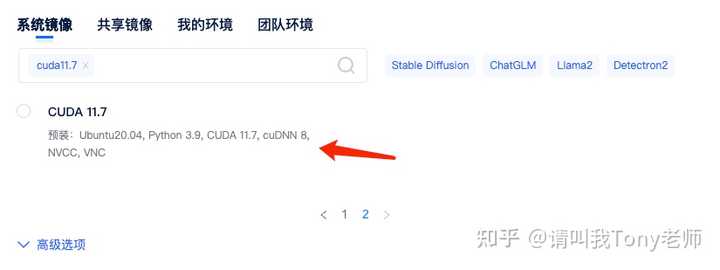
���û�����ʱ�����ڸ�ѡ��-�Զ���˿�������һ���Զ���˿ڣ����ڲ��� hub serving ���� |
|
|
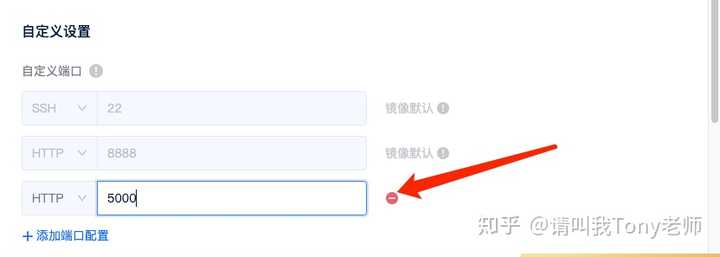
���������� Jupyterlab���½�һ�� Terminal��������������ָ�װ����. |
|
�����ϲ��谲װ�� Paddle ��ذ��汾�� Ȼ���½�һ��notebook���Ϳ�������ʹ���ˡ� ���Ի��� |
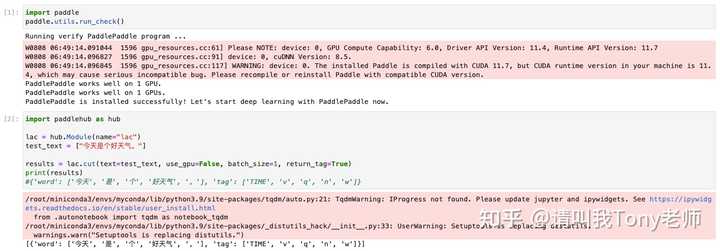
|
|
���� lac ������ Terminal ����������ָ������ hub serving �������в����������£� -m ָ��ģ�ͣ�����ʹ�õ��� lac-p ָ�����������˿ڣ�����ʹ�õ��� 5000 |

|
|
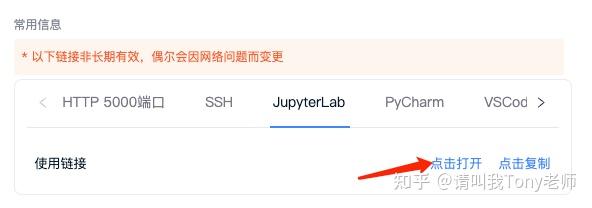
�����ɹ������Ǽ����ڱ���ʹ�ô�������ƶ˲���õķ����ˣ����������£� ���������URL��Ҫ�滻�����Լ�������ҳ���5000�˿ڶ�Ӧ����(token���ֿ��Բ�Ҫ) �������н�����£� |

|
|
�������ʻ�ӭ�;س���С���ֽ����� |
|
��һ˵һ�����á�����ѧ���������ǻ���ϵ�ģ��ͼ�����Ĵ�����������⺺���Ҿ�˵һЩ�Լ������顣 ���ù�TensorFlow��Pytorch��Ŀ����tf��1.x��2.x�Ľ����������ڽ����������õ���ȴԽ��Խ���ˣ�pytorch���Ҹ�����һ��ʱ��û�������ã�������ҵ��ʱ��ȫ��pytorch��һ��ʼ��������ʵ����ʦ�ֵ�Ӱ�죬ѧϰ��TensorFlow����ѧû��ã������µ���2.0������1.13�汾��2.0�汾��������һ����������ǰ�Ĵ���ȫ���ˣ��ҵ�ʱ��һ�о��Ǽ�����Ķ��������Ǹ߰汾���ݵͰ汾�𣬹ȸ�Ҳ̫��ˡ���������һ��ʱ��2.0�����ֻ��治��������һ������github��̵IJ���GitHub�����ĵĴ���ʵ�ֶ���pytorch���Ƶ�����ѧϰ��pytorch����Ϊ��ֻ����tfʵ��u-net���������磬���ӵ��ʵ���������dz����⡣pytorch����Դ��ĺܶ࣬APIȷʵ���ı�tf�ã�tf��API�е��ң��ܶ����Keras���У��ڱ�����滹�С�������ϲ��tf��ԭ��ܼ���һ��tf�dz����������tf�����˽���ѧϰ����һ���˼�Ҳ��ʵ�����ѧϰ����ĺ��гɾС��ڶ���˵�����ܶ��ˣ���Ϊtf�ľ�������padding���������ѡ��same����pytorchȴ���У���һ�����⺺��ϲ��ɵ��ʽ�Ķ����������� ��paddle��Ե����Ϊ�Լ�С������һ�����磬��tf��pytorch����ʵ�֣�����ѵ��һֱ�����⣬��������Ҳ����������������ʵ����ʦ�ܸ���˵paddle��ר�ŵ�Ⱥ���������ȥȺ�������˻ش��Ҿ�����һ���tf�Ĵ�������д��paddle�Ĵ��롣˵ʵ��������tf��pytorch��ѧϰ������������������paddle��paddle��pytorch���������ͽ���ˣ�����Ϊ�����Ա�ʵ�飬���˽��paddle��Ȼ�п��ӻ���ѵ������paddlex����ͳ���������ѵ�������ˣ�������ѧϰ���ָ���Ķ�������Ѱ�����ռң������˶���ѵ�����磬��������ʵ�����ѧϰ�����������Ŀ��֡� �����˽�ĸ��࣬paddle�IJ�Ʒȷʵ�ܷḻ�����Ǻ�ȫ���������̿���ʹ��ʱ�䣬�����ĵ��������ĵģ�����Ҳ�У������������������˵�����Ǹ�985��˶ʿ������Ӣ��ˮƽ���ܻ�û���Ϻ����ַ��������������ˮƽ�ߡ� �һ��ǵ�����github���ύ�����⣬paddle�ŶӺܿ����˾ͻش��ˣ��������֮���Ҹ����ǻظ���һ�仰��paddle�Ŷ�����һ��ΰ������顣��������Ȼ������۵㣬�ٶ������˾ȷʵ�кܶ�ڵ㣬����paddle�Ŷ�ȴ����ΰ������飬��������tf��pytorch���й�����paddle�� |
|
�����д����裬�������úõĻش�һ��������⡣��ʵ�ʼ�Ĵ������õ�pytorch�����淢���Լ��Ļ�����ģ��ʵ����̫���ˣ�Ȼ��ij���paddlepaddle(������GPU��ǰ�����˴��700��Сʱ��GPU�ɣ�Ҳû��ϸ�㣬�㱬�ˣ����տ�ʼ������ʵ������ԣ�ÿ���������õĺ���ȥpaddle�ĵ���һ��Ϳ��Եõ��ˡ�����paddle������һ���ܴ�����⣬������̬�����ر��(ʹ�õ��˲����ر�࣬������Щ������ͨ��������鵽,����paddle��ģ�Ϳⲻ���ر����ƣ���һЩdensenet��efficientnet֮��Ķ���ͨ��������Ŀȥʵ�֣����������Ͼ�������GPU������ͦˬ�ġ��ر��ǰ����Ѳ��õĺ�һ��������ģ�ͣ������Ҳ���ر�ࡣ |
|
��������+�Ƚ��㷨������ģʽ��Ϊ����оƬ��Ӧ�ÿ����̴���ȫ���Ż��Ľ������ �й�������2022��5��20�� �C Imagination Technologies�ڽ���¡�ؾ��еġ�Wave Summit 2022�������������Я�ְٶȷɽ���PaddlePaddle������Һ�����鹲ͬ����Ӳ����̬�����ƻ������������������Ƽ������г�Ӧ�þ��鹲ͬ������Ч����Ӳһ��ƽ̨���������ٶȷɽ��������Ƚ��㷨���������Imagination�칹����IP�������ϣ�֧������оƬ��Ӧ�ÿ������ڴ˻����Ͽ��ٴ���ȫ���Ż��Ľ�������� �����˹����ܼ����ڸ���ҵ�Ĺ㷺Ӧ�ü����ٷ�չ��ҵ���ѴӸ��Զ�����Ӳ�������������㷨�����������뵽�㷨��Ӳ��Эͬ���½Ρ���Ӳ����̬�����ƻ��У�˫�����ڰٶȷɽ���PaddlePaddle����δ��Ӳ������ƽ̨�������Imagination ��GPU, CPU, AI���칹����IP���������㷨ģ�͵��������ٵ��뵼��IP����ͨ�������Ż��ķ�����������Ч��������ջ������ΪоƬ�����ṩ���ָ����Benchmark�ο��� ������ҵӦ�ù���Model Zoo��Ϊƽ̨���ն˿ͻ��ṩ�ο�����������ȫ�µ���̬����ģʽ��Ϊ˫���Ŀͻ������������������ֵ��δ����˫��������ʹ��Imagination NC-SDK�ķɽ������߹�ͬ������ѵ�γ̣�����������ѵ��֤�� |
|
|
Imagination����ҵ���ܲ�Shreyas Derashri��ʾ�����ܸ����ܹ���ٶȷɽ����ڶ��������ٴ�Я�֣�������Ӳ����̬�����ƻ�������Ϊҵ�繹����Ӳһ��ļ��㷽����2020�꣬Imagination����ٶȷɽ�Ӳ����̬Ȧ��2021�꣬Imagination�Ͱٶȷɽ���ȫ���˹����ܣ�AI����̬ϵͳ���濪չ�������˴κ�����˫�����ú��������������������㷨�������Ƶ�����ںϣ���Ϊ��ҵ�ṩ���Ż��Ľ���������� �ٶȷɽ���Ʒ�ŶӸ���������˵������Imagination��Ϊȫ�����ȴ�����������IP��Ӧ�̣��ٶȷɽ��ڼ�������̬ϵͳ���涼�����˼����֧�֡��ܸ������˫���ܹ����ڶ�AIӦ��������к������ɽ�һ�����Ӱٶ������ѧϰ��ܡ��㷨������ƽ̨�ȷ�����������ƣ�������Щ������õ�֧�����οͻ����� ����Imagination TechnologiesImagination��һ���ܲ�λ��Ӣ���Ĺ�˾�������ڴ���뵼�������֪ʶ��Ȩ��IP����ʹ�ͻ��ھ������ҵ�ȫ�����г��л���㹻���ơ���˾��ͼ�δ�������GPU�������봦������CPU�����˹����ܣ�AI����������ʵ�ֳ��ڵ�PPA�����ġ����ܺ������ָ�ꡢ���ٵ�����ʱ����͵�����ӵ�гɱ���TCO��������Imagination IP�IJ�Ʒ��ȫ����ʮ�����������ǵ��ֻ���������סլ���������� ������Ϣ������ʣ�https://www.imaginationtech.com/�� ���ڰٶȷɽ��ɽ�(PaddlePaddle)�ٶȶ�������ѧϰ�����о���ҵ��Ӧ��Ϊ�����������ѧϰ����ѵ����������ܡ�����ģ�Ϳ⡢�˵��˿��������ḻ�Ĺ��������һ�壬���й��������з������ܷḻ����Դ���ŵIJ�ҵ�����ѧϰƽ̨��Ŀǰ���ɽ�������406���ߣ����ڷɽ���Դ���ѧϰƽ̨����47.6���ģ�ͣ�����15.7�������ҵ��λ���ɽ����������߿���ʵ��AI�뷨������AIӦ�ã���Ϊ����ƽ̨֧��Խ��Խ����ҵʵ�ֲ�ҵ���ܻ������� ������Ϣ����ʣ�http://www.paddlepaddle.org.cn�� |
|
������ã���Ϊ֪ʶ������2.0֮���˾��û���������Ȼ��torch����Щ���룬�����Ͼ��ǹ�����������չ�� ��������ս��ʱ��paddle�ؽ������� ��һ���Լ���Դ��paddle��Ŀ�ɣ����£� |
|
���ȣ��ɽ�2��ʹ�÷�����pytorch�dz����������ף������ ��Σ��ɽ��ṩ��ѵ�GPU����ƾ��һ��ҲҪȥѧ�ɽ� ����Ҫ���ǣ��ɽ������ķ����������ڹ��ڵģ����������ֲ����ѧ����������˵��ֱ���ܾܾ����Ͼ�����pytorch����������ʵ�ڸ��� ���⣬�ɽ�������api�ĵ����ÿ϶��ȹ���Ŀ�ܺã������ʺ������Ķ� |
|
֮ǰ�ڰٶȣ���ʱ�����Ʒɽ���ֻ�ǵ�ǿ���˰��꣬��һ�����tf�Ƚ϶࣬�ĵ�̫�ѷ����������⣬�����Ų顭����д�ɽ��ij�Ա�������� |
|
|
| [�ղر���] �����ر��ġ� |
| ��һƪ���� ��һƪ���� �鿴�������� |
|
|
|
| ��Ʊ�ǵ�ʵʱͳ�� ��ͣ��ѡ�� ��ʱͼѡ�� ��ͣ��ѡ�� K��ͼѡ�� �ɽ���ѡ�� ����ѡ�� ������ѡ�� �������� �������� ���� MACDָ�� KDJָ�� BOLLָ�� RSIָ�� ���ɻ���֪ʶ ���ɹ��� |
| ��վ��ϵ: qq:121756557 email:121756557@qq.com ����ƻ� |