
| |
|
|
| 首页 淘股吧 股票涨跌实时统计 涨停板选股 股票入门 股票书籍 股票问答 分时图选股 跌停板选股 K线图选股 成交量选股 [平安银行] |
| 股市论谈 均线选股 趋势线选股 筹码理论 波浪理论 缠论 MACD指标 KDJ指标 BOLL指标 RSI指标 炒股基础知识 炒股故事 |
| 商业财经 科技知识 汽车百科 工程技术 自然科学 家居生活 设计艺术 财经视频 游戏-- |
| 天天财汇 -> 科技知识 -> 谷歌发布全新诊断对话式AI在测试中击败医生,通过了图灵测试,如何看待此研究?AI医疗未来会如何发展? -> 正文阅读 |
|
|
[科技知识]谷歌发布全新诊断对话式AI在测试中击败医生,通过了图灵测试,如何看待此研究?AI医疗未来会如何发展? |
| [收藏本文] 【下载本文】 |
|
我们需要研发对人类有益AGI的原因之一: 我妻子的身体5年来经历了种种痛苦,最终被检查出一种叫肢体活动过度Ehlers-Danlos综合征的遗传病。现… |
|
真做诊断什么的倒不着急,毕竟三级查房除了诊断,还有教学的功能。 能不能用这个把病历写了? 真的帮大忙! 建议这套系统先进病房,通过对话把首程、入院记录、三级查房写好,省了管床医生好多事还不会遗漏病史。 病史采集这事除了临床思维,更多时候真的是聊不出来。 特别是一些患者面对年轻医生查房,这也不说那也不说,问了也说“没有吧?”“不记得”,一到教授查房就都来了,这也有症状,那也不舒服。 有了这套系统就好了,大家都平等聊,没聊出来的教授问出来了,那也不能骂管床的,让他去办公室骂那个服务器。 我还建议一个方向,让这个AI去做手术二助,反正拉钩、扶镜子罢了,给个机械臂就行,而且力道姿势都固定,教授甩锅都没得甩(什么出血了因为二助“拉钩松了”没看到这种事再也不会发生) 这样术后病程这个AI也可以写了! 手术记录,术后三级查房,出院记录,出院带药,都搞了。 真的,击败医生可太好了。 |
|
看起来,这问题展示的是“新智元”等媒体从欧美网络上复制来的炒作,一般读者和医护人员不宜过分乐观。 相关新闻报道以“在测试中击败医生”当标题,读者看了以为是做了有说服力的双盲测试、用疗效说话什么的。在这些新闻报道的正文里,读者会发现情况迅速降格为“在与模拟患者交谈并根据患者病史列出可能的诊断”时针对“呼吸系统和心血管疾病”有和人类医生相仿或更好的效果。 所谓“模拟患者”,是经过训练来扮演患者的健康人。样本只有 20 人。 读者可以合理怀疑“模拟患者”会罗列训练他们用的典型字词,人工智能可以利用这些字词与数据集里各种疾病诊断的统计相关性给出概率较高的结果。对于现实生活中情况五花八门的患者,你不好期待现有人工智能发挥重大作用。在这项研究中,“模拟患者”为症状・病史・家族史等提供了冗长、详细、准确的描述。要求现实中的患者如此做,经常是天方夜谭。作者让 AI 为每个患者提出 10 种可能诊断,参与实验的 20 名人类医生对与他们接触的模拟患者各自提出了 3 到 8 种不等的可能诊断。作者统计了所有诊断及其前三名、前五名,认为数据可以体现人工智能“比人类医生做得更好”,这值得怀疑。读者可以合理估计,人类医生从模拟患者获得与病情相关的信息的效果低于从真正的患者那里获得信息。按作者给出的数据,AMIE[1] 在 32 项“诊断性对话和推理质量标准”中有 28 项优于医生,包括礼貌、解释病情和治疗方案、给人诚实的印象、表达关心??和承诺,其余项目与医生相当。这项研究的合作者之一 Alan Karthikesalingam 表示,这绝不意味着语言模型在获取临床病史方面比医生更好:参与这项研究的初级保健医生可能不习惯通过基于文本的聊天与患者互动,而且人工智能可以快速撰写长度超大、结构精美的答案,能够始终如一地“体贴”、不会感到疲倦。 在《自然》对 AMIE 的报道[2]中,内科医生 Adam Rodman 表示,AMIE 可能会有帮助,但它不应该取代患者与医生的互动:“医学不仅仅是收集信息,它还涉及人际关系[3]。” 至于“通过了图灵测试”,你猜如果 AMIE 真的通过了图灵测试,“新智元”这种媒体会将哪个句子放在前面? 人工智能在“对话质量标准”中获得的高分实际上可等同于“对话表现明显不像人”。 2024 年 1 月 11 日发表在《科学》的文章 Illusory generalizability of clinical prediction models 报道用于医学诊断的人工智能对从未见过的患者效果不佳[4]。 过去数年间,人工智能公司多次声称可以利用大规模数据集训练机器学习模型来对患者进行诊断和精准治疗(至少是能为人类医护人员找到最佳方案)。这些模型很少用真正独立的患者样本进行前瞻性测试,而是针对一个数据集不断改进。哪怕针对的数据集是国际大规模临床试验的结果,我们也不能保证这样训练出的模型在处理真正的患者时有好的表现。作者在真正独立的临床试验中测试让这类模型预测精神分裂症的治疗结果,发现模型的预测效果就像瞎猜,汇集各项试验的数据来构建的、理论上应该更稳健的模型的预测效果仍然很差。作者的结论是,预测精神分裂症治疗结果的模型高度依赖于背景,其普遍性可能是有限的。 顺便说,这问题从“新智元”的“报道”开头复制的内容是可笑的: 以“OpenAI 联创 Greg Brockman 的深情自白”吸引读者的注意和共情,然后突兀快进到“一番话点明,当前先进 AI 系统还需不断演进,有望破解人类医学难题”――你用哪只眼从什么部位看出“有望”的? 这大概意味着这“报道”是用糟糕的 AI 撰写的。这是黑色幽默、行为艺术,“新智元”在结果上发挥了反串黑的作用。 参考^Articulate Medical Intelligence Explorer^doi:https://doi.org/10.1038/d41586-024-00099-4^Medicine is just so much more than collecting information ― it’s all about human relationships^https://doi.org/10.1126/science.adg8538 |
|
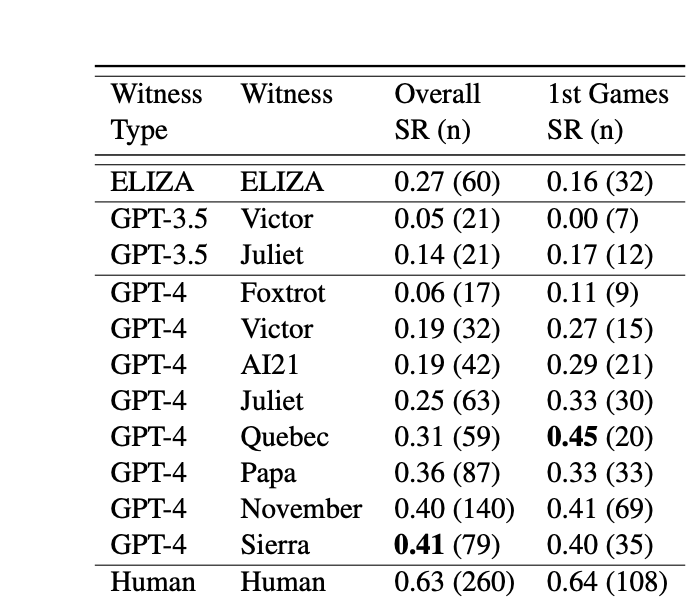
现在图灵测试也是真不值钱,动不动就某某大模型通过了图灵测试。 图灵测试并不是一个考验 AI 是否先进的方法,图灵测试更多的是考验这个 AI 是不是像人。 比如我现在有一个 AI,已经完全能摸你人类的情感,思维等等,但是你仍然可以分辨出它是不是 AI。比如你随机在 24 小时的任意时间段给它发消息他都能秒回,这就不像是人能干出来的啊。 所以之前在一次图灵测试中,GPT败给了一个上世纪 60 年代开发的聊天机器人ELIZA。[1]原因就是,这玩意回复的又慢又差,这种爱答不理的感觉,让测试人员误以为这个是真人。 |
|
|
所以 AI 先进与否,跟能不能通过图灵测试就没啥直接关系。你不能说这里头 ELIZA 这个上世纪开发的聊天机器人,比 GPT3.5 更加功能强大吧。 当然,即便是 GPT4,目前对于它有没有通过图灵测试呢,是处在一个量子叠加态的,最少在媒体里是这样的,不信你往下看。 |

|
|
当然我不是否认 AI大模型不好用,只是当下的 AI 更多的还是作为一个助手的角色,而非决定者的角色。 以医疗 AI 模型为例,我们都知道 AI 在看片子,检测报告,综合信息判断,尤其是对于一些罕见病症的了解程度是远超人类的水平的,毕竟 AI 的主打的就是全知。 但还是那句话,它只是全知,并不是全能。这并不矛盾,就好比一个超忆症患者在有生之年之内背下来了人类所有的图书,但能他能解决什么人类难题吗? 所以医疗 AI,更好的应用方向是作为一个医生外置的大脑,它可以帮助医生来更好的分析病情,找到可能的原因,以及疑点。 目前就纯用 AI 看病,仍然不够现实。 我个人是很看好医疗 AI 在未来的应用的,毕竟向 GPT 这种全能型的 AI 里边的数据质量堪忧,医学 AI 需要用严格的数据进行训练,同时也需要大量的人工纠错帮助其成长。 至于谷歌这次发布的诊断对话 AI,怎么说呢,就有点像你拿 GPT4 去考美国的执业医生资格考试差不多,估计能比它靠的好的医生可能确实不多了。但看病不是聊天对话式的问诊啊,这里边涉及到的东西仍然很复杂。 甚至,就像我一个医生朋友说的,患者给你说的病情,你只能当做参考,不能不信也不能全信,如果你真的全信患者所说,你很可能会掉坑里。 另外别忘了大模型的幻觉到现在仍然没有办法解决,如果平时写个年终总结什么的出错也就出错了没啥大毛病,看病的时候给你整点幻觉出来,你怕不怕? 参考^https://arxiv.org/pdf/2310.20216.pdf |
|
AI能不能替代医生这件事,好像在ChatGPT出来之前就在探讨了,比如用AI看片子,用AI辅助开药等。 大部分人得工作,看起来是专业工作,比如医生、程序员、律师等等,其实80%得从业人员根本不需要多高的水平。也就是说80%的人应该干的是重复的没有技术含量的工作。 从目前的应用来看,人工智能应用比较好的领域是皮肤科、病理科和影像科。 2023年7月17日,Google DeepMind与多个研究机构的联合研究团队提出了一种名为CoDoC的AI系统,它能够学习何时应该依赖AI提供的信息,何时又应该听从临床医生的意见。 CoDoC系统研究了如何在假设的医疗环境中,充分利用人类与人工智能的协作,以实现最佳的结果。 |

|
|
在乳腺癌筛查方面,相比英国筛查项目中的“双读仲裁”方法,CoDoC在保持相同假阴性率的前提下,将假阳性率降低了25%,同时临床医生的工作负担也减轻了66%。 在结核病的分类方面,与单独的人工智能和临床工作流程相比,CoDoC在相同假阴性率的情况下,将假阳性率降低了5-15%,这在五个商用预测AI系统中的三个系统上都得到了验证。 为了更好的验证安全性,他们的代码还开源了。 |

|
|
对于人工操作的临床工作,目前AI无法替代人类 因为人工操作的部分,并不是一个标准化的流程,AI擅长的是数据分析推理,而不是实操。实操的部分需要软硬件结合,显然只有AI是不够用的。 还有就是有些疾病其实答案是模糊的,比如医生经常会给病人几个方案,让病人家属去选,这些选项不是非1即0。这种模糊的场景怎么给出答案,貌似还有段路要走。 |
|
读了一下谷歌的这篇文章,其实谷歌去年的Med-Plam发布就说的很厉害,毕竟是500B+的医疗模型。但一直也不对外开放,性能只能说考试方面很强吧。这次又来了一篇其实没打算写东西,但看了他们的模型方法/流程觉得还是可以参考一下。 最后的验证部分还是OSCE这种类似的考核/考试机制,只要到了考核机制模型的优势往往就大的多。但没有具体了解这个考核机制内容,不做过多评价。 主要内容 这篇文章介绍了一种名为AMIE(Articulate Medical Intelligence Explorer)的人工智能系统,这是一种专为医疗诊断对话优化的大型语言模型。AMIE通过使用多样的真实世界数据集、模拟对话和自我对弈来提高其能力。该研究包括了一项随机、双盲的交叉比较实验,比较了AMIE和初级保健医生(PCPs)在使用基于文本的咨询与患者演员的表现,并由专家进行评估。AMIE在多个评估轴上显示出比PCPs更高的诊断准确性和优越性能。 |

|
|
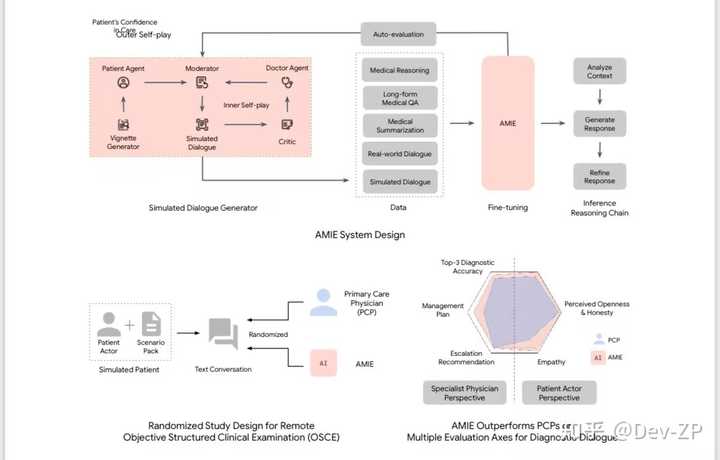
模型流程 |
|
|
模型主要框架:Vignette Generator: 利用网络搜索创建特定医疗条件下的独特患者信息;Simulated Dialogue Generator: 三个大型语言模型(LLM)代理扮演患者、医生和主持人的角色,通过轮流对话模拟真实的诊断互动;Self-play Critic: 第四个LLM代理作为批评者,向医生代理提供反馈以实现自我改进。搜索模块 "Vignette Generator"的工作流程。我理解这个模块要大量获取患者相关类似的信息:包括基本的背景信息,如患者人口统计数据、症状、过往医疗史、手术史、社交史和患者问题,以及相关的诊断和管理计划。为了构建特定条件下的患者情景,首先从互联网搜索引擎检索与该病状相关的人口统计数据、症状和管理计划的60段文本(每项20段)。为确保这些文本与特定病状相关,使用通用大型语言模型(如PaLM-2)对检索到的文本进行筛选,移除与病状无关的文本。然后,AMIE根据筛选后的文本,结合人口统计数据、症状和管理计划生成符合这些信息的患者情景,通过提供一次性示例来强制执行特定的情景格式。 |

|
|
扮演模块 "Simulated Dialogue Generator" 是AMIE系统中用来模拟真实医患对话的部分。在一个虚拟的在线聊天环境中,三个由AMIE扮演的特定LLM代理(分别扮演患者、医生和主持)通过互相沟通来生成模拟对话。患者代理扮演经历医疗状况的个体,诚实回应医生代理的询问并提出任何额外问题或担忧。医生代理扮演一位有同情心的临床医生,在线上环境中理解患者的医疗史。主持人代理持续评估患者和医生代理之间的对话,确定对话何时自然结束。对话是轮流进行的,从医生代理开始,直到对话自然结束。 |

|
|
评审模块 "Self-play Critic" 是一个用于自我提升诊断对话质量的框架。这个框架引入了第四个LLM代理,即“批评者”,它也由AMIE扮演,知晓确切的诊断结果,以便向医生代理提供有关背景的反馈,从而提高其在后续对话中的表现。批评者根据以下标准评估医生代理的回应:展现同情心和专业性,避免问过多或重复的问题,保持回应自然流畅且事实准确,以及提出足够的问题来识别至少两种最可能的差异诊断。医生代理在每轮对话中都能访问之前的对话历史,并根据批评者的反馈改进回应。 模型微调 AMIE的指令微调是为了增强其在医疗对话和推理方面的能力,它基于基础大型语言模型PaLM 2。AMIE通过特定任务的指令进行微调,以扮演医疗对话中的患者或医生角色,执行医疗问答和推理,并总结电子健康记录(EHR)笔记。在对话生成任务中,AMIE被训练以根据先前的互动预测下一个对话转向。在扮演患者代理时,AMIE回应医生代理关于其症状的问题;而在扮演医生代理时,AMIE作为医生采访患者,最终得出准确诊断。此外,对于EHR笔记总结任务,AMIE根据提供的临床笔记生成总结。所有任务,除了对话生成和长篇回应生成,还包含了少量(1-5个)例子和特定任务的指令,以提供额外的背景。 模型验证 这个OSCE其实具体如何考核我没去看。文章:评估框架基于医学访谈中以患者为中心的交流进行的,英国皇家医学院在临床考试技能评估中对病史获取技能的标准,以及英国医学委员会为专业反馈时使用的问卷作为评分。Objective Structured Clinical Examination (OSCE)是医疗领域中用来标准化和客观评估临床技能和能力的实践考核形式。与主要关注理论知识的传统书面或口头考试不同,OSCE旨在提供一个环境,以评估真实世界临床实践中的技能。OSCE通常分为多个站点,每个站点都模拟真实临床场景,由受过特别培训的标准化患者演员扮演特定症状或条件。在每个站点,学生被要求执行特定任务,如获取病史或进行诊断。每个站点都有固定的时间限制。经过培训的考官使用预先定义的清单或评分方案观察学生的表现,并评估其临床技能,如沟通、病史获取、体检技术、临床推理和决策能力。 |

|
|
模型结果我就不展开了,不是医学背景其实也不懂考核指标的意义。 但综合读下来文章主要还是说明在医疗考核方面的优势吧,换言之现在一个模型说他在高考试卷上上了211和985我一点不意外,但如果说它的能力和211学生应该差距很大。 |
|
|
| [收藏本文] 【下载本文】 |
| 科技知识 最新文章 |
| 百度为什么越来越垃圾了? |
| 百度为什么越来越垃圾了? |
| 为什么程序员总是发现不了自己的Bug? |
| 出现在抖音评论区里边的算命真不真? |
| 你认为 C++ 最不应该存在的特性是什么? |
| 为什么 Windows 的兼容性这么强大,到底用了 |
| 如何看待Nvidia禁止使用翻译工具将cuda运行 |
| 为何苹果搞了十年的汽车还是难产,小米很快 |
| 该不该和AI说谢谢? |
| 为什么突破性的技术总是最先发生在西方? |
| 上一篇文章 下一篇文章 查看所有文章 |
|
|
|
| 股票涨跌实时统计 涨停板选股 分时图选股 跌停板选股 K线图选股 成交量选股 均线选股 趋势线选股 筹码理论 波浪理论 缠论 MACD指标 KDJ指标 BOLL指标 RSI指标 炒股基础知识 炒股故事 |
| 网站联系: qq:121756557 email:121756557@qq.com 天天财汇 |