
| |
|
|
| ����ƻ� -> �Ƽ�֪ʶ -> Ϊʲô�Կ����ô�С�ˣ��Ͼ������ֻ���ƽ�壬���ԣ�CPU���Ǵ�С�˽ṹ�ˣ� -> �����Ķ� |
|
|
[�Ƽ�֪ʶ]Ϊʲô�Կ����ô�С�ˣ��Ͼ������ֻ���ƽ�壬���ԣ�CPU���Ǵ�С�˽ṹ�ˣ� |
| [�ղر���] �����ر��ġ� |
|
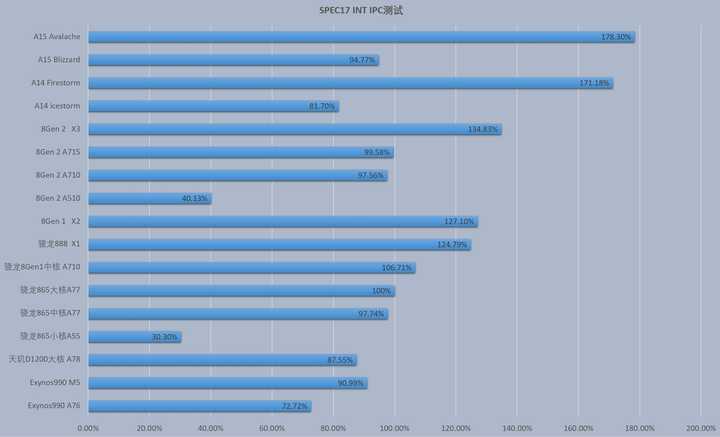
Ϊʲô�Կ����ô�С�ˣ��Ͼ������ֻ���ƽ�壬���ԣ�CPU���Ǵ�С�˽ṹ�ˣ� ��ע����?д�ش� [img_log] �ֻ� ���봦���� (CPU) ƽ����� �Կ� �����Կ� Ϊʲô�Կ����ô�С�ˣ��Ͼ������ֻ���ƽ�壬���ԣ�CPU���Ǵ�С�˽ṹ�ˣ� Բ����¼ �����ξ��� #����������ָ�� |
|
�������Ϊ�Կ������������Ѿ���С�ˡ��� |
|
|
|
|
|
���������ڲ������涼û�У�ȫ�Ǽ���ģ�飬������������ |
|
�Կ�������������������Ϊһ��ѵij���С�� |

|
|
��CPU��һ�����Ĺ�ģҪ��ܶ� |
|
|
�������������ͼ�������ˣ��Ǿ���ʵ��ʵ�����Zen4���ĶԱ�AD102���ĵ�ͼ������������̨����5nm�ڵ��оƬ ����һ��AD102���ĵ�ͼ�� |

|
|
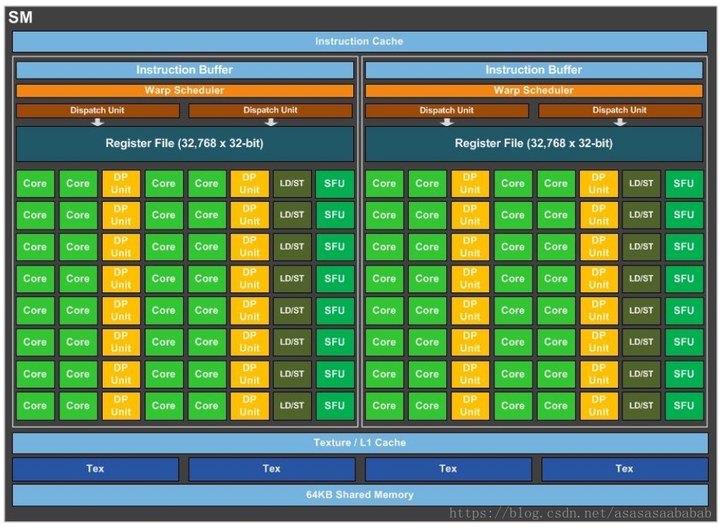
AD102�������Ϊ609mm2��ӵ��12��GPC��72��TPC��144��SM��Ԫ��4090������128�飩 ��ÿ��SM��Ԫ���������ģ� |

|
|
Ҳ����˵һ��SM��Ԫ����128��FP32��Ԫ����128ALU��Ҳ���Խ�128CUDA ��������ƽ��˵���Կ����ٶ�������������Ԫ��������˵�ľ�������SM����ĵ���ALU���� ����ALU����������һ��SM��2%���ҵ��������AD102����ӵ��144��SM�������609mm2 ��������һ��SM��Ԫ����������1.1154mm2��������ALU�����ԼΪ0.00218mm2 ������dz��dz�С����CPU�أ� ����Zen4��CCD����Ƭͼ�� |

|
|
��AMD�ٷ����ĵ��Zen4����CCD���Ϊ70mm2 |
|
|
�����������Dz���L3���������ĵ����Ҳ���ﵽ��4.79mm2 |

|
|
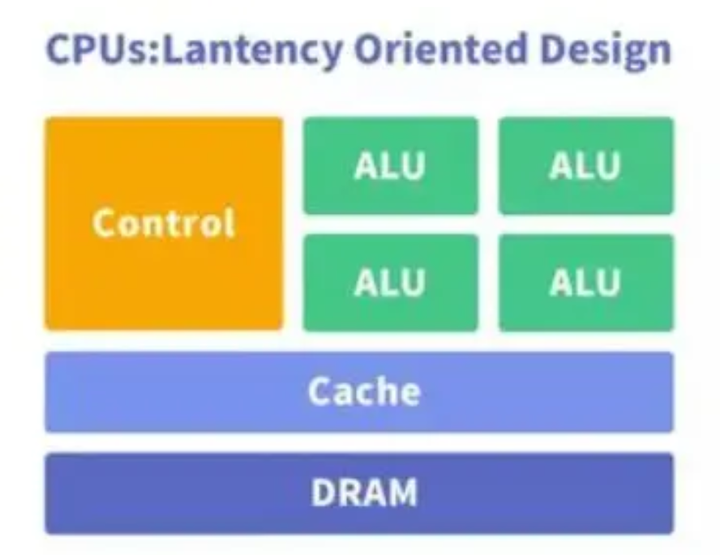
����һ�Ƚ��������Dz��Ǻ�ֱ�Ӿ��ܿ��ó�����һ��CPU�ĺ������ҪԶ��һ���Կ���ν������������öࣿ ����˵�Կ����Ӵ������������ģ������������������CPU����������˵��ʵ����һ�����ܼ��͵ļ��㵥Ԫ��������ȣ�A55�����㳬���ˣ�ֻ����GPUӵ�м����Ӵ������������ģ�����м������ܷdz�ǿ�� CPU�ڲ�����ˮ�߸��Ӷ�ԶԶ����GPU���������ƺͻ��沿λ���˺ܴ�Ŀռ䣬CPU��Ҫ��ǿ��ͨ�������������ֲ�ͬ���������ͣ�ͬʱ���ж��ֻ���������ķ�֧��ת���жϵĴ��� ��GPU��Ե��������߶�ͳһ�ġ���������Ĵ��ģ���ݺͲ���Ҫ����ϵĴ����ļ��㻷�� CPUʲô�����������ǹ�ģС��GPU��ģ���ǶԴ�������������Ӷ���Ҫ���һ�Ҫ�����ݶ��� CPU֮���Ի��д�С�˵ļܹ���ƣ�����ΪҪ����ͬ��ʹ�ó���������˵�ֻ��˵Ĵ�С�ˣ���˸�������ܱ�������С������һЩ����Ӧ�ó��� ��Ϊ�ֻ���ƽ�����ڶԹ���Ҫ�������еij�����Ҫ�dz�����������20%���Ƕ�������Ӱ�춼�Ƿdz������� ƻ����ARM�����С�˶����ڹ��ĺܵ͵Ĵ��ڣ�����������Ҳ������㼸�ߵĴ��ڣ�ֻ����ƻ����С��IPC��ARM����С�˵ĺü��� |
|
|
����IPC�ܽӽ�������к�ˮƽ��ARM�����С�˾�ֻ�е�����һ����ȡ֮�� ��Intel���õĴ�С�������Ϊ����ߵ�λ����ĸ�ǿ�Ķ����������ܣ����ڴ�һ�����֪��Intel���С����ʵ�㲻��ʡ�磬������Ҳ�ȹ����ǿ�ܶ࣬���Դﵽ��˵�1/2����ˮƽ |
|
|
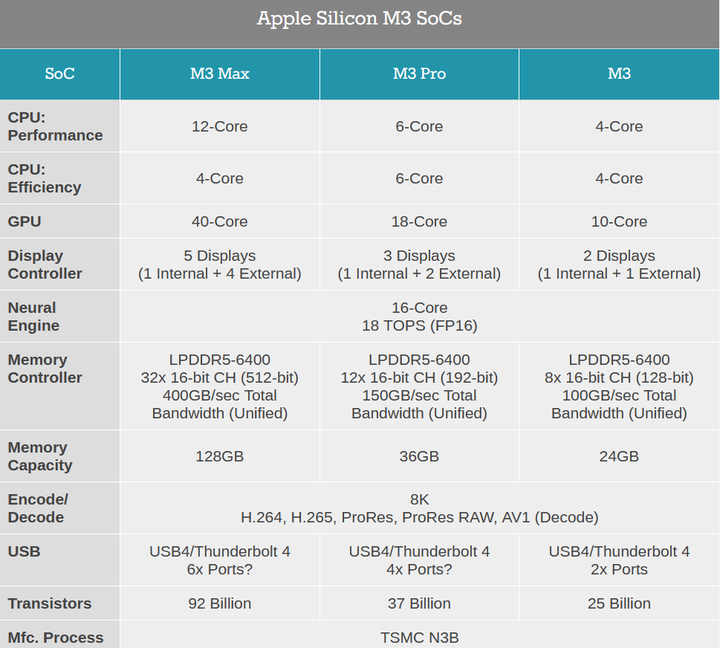
�ĸ�С��һ�����ۺ�����Ҫ����һ����˿����̵߳����ܣ������Intel��Ҫ��Ч�� AMD��С���������;Ҳ�����ƣ��ٺ˵���;����Ƶ�ʸ��ߵĴ���ϣ���Ҫ�����������ʱ��С��������æ�� ˳��һ�ᣬ��ƻ������Լ���GPU�ؽк� |
|
|
����˵M3 Max��GPU��˵40�ˣ���ʵ������ˡ���˵��������ǰ��AD102�����һ��SM��Ԫ����CPU�Ķ��ٶ��ٺ��Dz�һ���ģ� M3 Max��40��GPU�أ�����5120ALU�� |
|
CPU���Կ��Ĺ�������ͬ CPU���������DZȽϸ��ӵ������㣬���Կ����Ĵ����ͨ�ü��㡣 ������һ�������dz�ǡ���� ��һ����ʿ����1+1=2 �����ϸ�1000���� ����1000��Сѧ����1+1=2��ÿ��һ���ᣬ������ĸ���Ŀ죺 ��1000��Сѧ���ͺñ��Կ��Ĺ������� �Կ���һ������Ҫ��ָ��������������������� |
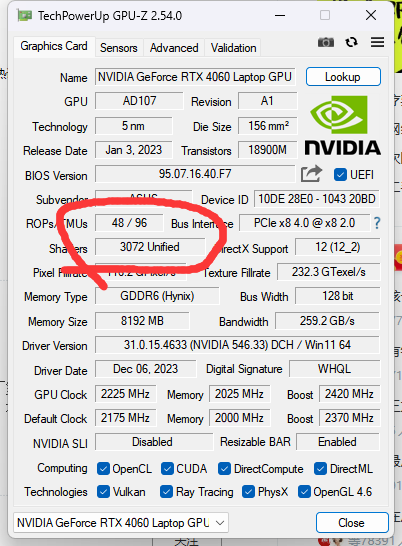
|
|
��������̨4060 laptop����3072����������������Կ�����ȫ��С�ˡ� �������Ҫ�����ȼ��㲢�Ҵ������ظ�����Ĺ��̣�������Խ����Կ�����������Խǿ�����Կ��������������Ч��ҲҪ��CPUǿ�Ķࡣ CPU��ͬ��CPU����ͬһ��ʱ������Ҫ�����ܶิ�ӵĶ���������ĵ��Կ��ţ���һ�߿���ҳ��һ�߹���QQ�ź��˳������DZ����������֡� |

|
|
��Щ����ĸ��ز�����ͬ��CPU���ô�С�˵���ƣ������ö������е�ʱ�ؼ�������ô�ˣ�С������С�����Ƶ������Ż��ܺıȺ��õķ������ܡ� ���Կ�����Ҫ�����仰˵���Կ��õ���ţ���籾���ͺñ�һ�������˵ij�����ˮ�ߣ��������Ĺ���һ�쵽����š��˿һ���£���ôһ���������������Ǿ��˵ģ������ʱ��Ҳ����Ҫ��Щ���˻�ʲô��ļ��ܣ���Ͱ���˿š�ã����仰˵��������ӹ�š��˿���������С� ��������£�ȫС�˶���ǧ����������Ȼ��һ��ɻ���ڵ�λʱ�����������������ݡ� �Կ��Ĺ���ԭ�����������ġ� �پٸ����ӣ��Կ�һ�㶼�ǽ���ͼ����ص��������ģ�����������ͼ˵�£� ÿһ�ŵ���ͼƬ��������ʵ�豸�϶���һ��һ�����ص���ɵ�ɫ�飺 |
|
|
�Կ�������������ͼ��ͼƬ��ʱ��ÿһ��������������������ôһС��ɫ�飬������Ⱦ���ɵ�Խ��Խ�ࣺ |

|
|
Ȼ�����ղ�ͬ��ɫ�����ص�����һ��ͼƬ�� |

|
|
��ÿһ����������ͬʱ��������ɫ�飬��ô��ǧ��������һ�����ɼ�������ɫ�����һ��ͼƬ�ˣ��������վ�����ô��Ⱦ�ɹ��ˡ� ���Կ���CPU��������Ĺ�ģ�����ڴ��ڴ����ӣ��ò��ϣ�һ̨�Կ�Ҳ����������ǧ����ˣ��Ǿ����ս�����Կ��ˡ��������졣 |
|
��Ϊ���������Ͳ���һ�����µļܹ��Լ���ģҲ��һ������С��Ϊ����ʲô������Ĵ�С�ˣ������жȵ������Ӧ���ǣ� С�˸�����ع�������˸���߸��ع����ڱ�Ҫ��ʱ���С��һ���������Ӷ������ �����ĺô�һ���ǵ��ģ���ΪС�˹���С����̨ʽ������ʵ������ܲ������ص㣬ֻ���㸽�����档����PC�˵ġ�С�ˡ����������ֻ�����С��С�ˡ� ������Ŀ�Ļ���Ϊ��ʵ�ָ���ĺ��Ŀ���ͬʱ������㡣�Ͼ�����һ��оƬ��˵�������ν���������������������Ľ��������С�˶�һЩ���Ϳ��Զ����ȥһЩ�����������i9 13900K��1��P�˾�ռ���˽ӽ�4��E�˵������ |

|
|
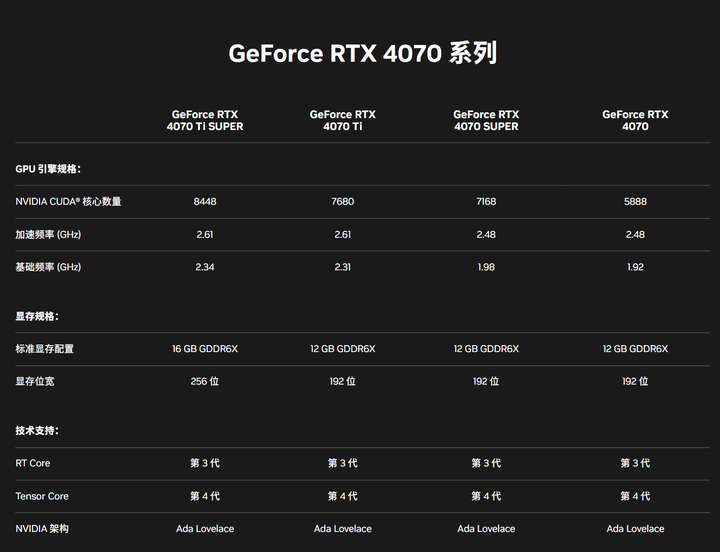
i9 13900K�IJ���ͼ �ڼ����ϵͳ�CPU������һ��ȫ�ܵĽ��ڣ����������һЩ���ӵ����ݣ����縴�ӵĿ����������еļ�������ȵȣ������ܹ�ʤ�Σ���GPU��������һ��Ⱥ����������ֻ�����ļ��㣬��������������㣬��Ȼ������ʵ��CPU�Ľ����������������������Ҫ��Ķ����ǡ������������Ѷȡ�����ôһȺ���������ǻ��һ��������Ŀ죨8������vs.1000����������������CPUֻ���Ǿ����ܵ�����һЩС���ģ����Ӿ���������һ���̶��ϻ������������ϵ�ƿ���� ���ĵ�������Ҳֻ����ʱ�ģ���AMDδ��Ҳ����칹��֪�����������ȷʵ�����õģ��������ؽ�Ҫ�ġ������²�һ�䣬����������һ�����Ҫ��Ӳ���������Ͼ�Ӳ�������DZ����ȵ�һ��������Ӳ���Ķ���Win12�� ����GPUǡǡ�ȱ�ľ�����ν��������ܡ����������������㣬�����GPU����Ҫ���ô�С�˵ĺ���ԭ������ԱȵĻ�����˵�۸�߰���RTX4090�ˣ������Ǻ�ͬ��i9�۸������RTX4070��CUDA����Ҳ��5888���� |
|
|
������Ҳ�������Եؿ����������������������Կ����ָ��еͶ˵�����Ҫ����֮һ�� ��չһ�»��⣬�պ�AMD�����ӿ��Խ��Ƶ���Ϊ�����ᵽ�ġ�С�ˡ���AMD��Nvidia������Ͼ���ȫ��ͬ����ȥAMD���ϼܹ�GCN��ÿ4������һ�������Ƶ�Ԫ��������Ȼ���ֺܴ���ʵ���߲�����ȫֱ�ӶԱȣ�Nvidia��CUDA������ÿ�����Ķ���һ�������Ƶ�Ԫ������������RDNA�ܹ�����Ȼ�Ѿ����˺ܴ�仯���������֡��칹����Ȼ�õ��˱����� |

|
|
|
|
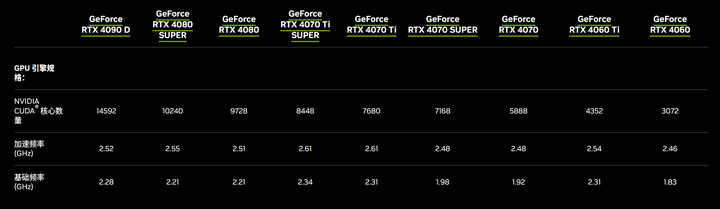
�����Կ���Ҫ��С�����������������ڸ���FP32���ȣ��������С�������������Ӵ� |
|
|
��40ϵ����Ͷ˵Ķ�������3072�������CPU�ĺ�����������˵ңң��������ȫ��ѹ�ơ� ����Ϊʲô�Կ�Ҫ��ô����������أ� ���ҿ���������Խ��Խ������Ҳ���ǣ������ޣ����������ˣ����������Ҫ�˽��Կ��Ĺ���ԭ���ˡ��Һܾ�֮ǰд��һƪ�ش�����Բο���չ�Ķ��£��ܰ�������ԭ�� �Կ���ʲô���Կ������������Կ�Ӱ����Ե���һ��ܣ�470 ��ͬ �� 35 ���ۻش� |
|
|
���ڷֱ���Խ�ߣ������ܶ�ҲԽ����Ҫ������ͼ�ξ����� |

|
|
����������һ��ģ����ͼ����С�Ժ����Ը��õĿ������������ݣ���������4�Ų�ͬ��С��ͼ�������Կ���˵���������һ�µģ�����Ҫ����С������ͼ�Ŵ������������ȣ���ô�����ͻ�Խ��Խ�ߡ�����ˢ����Խ�������������������Ҳ��Ҫ������Դ棺 |
|
|
������ʱ���㻹�Dz����⣬�Ҹ�����һ�Ŷ�ͼ�����������Կ���Ⱦ��ʱ������һС��һС��Ĺ����ģ������������Խ�࣬�Ϳ��Ը���IJ��м��㣬�����ٶȾ��죺 |

|
|
����������C4D��Ѫ�߾�����Ⱦ�����Ծ�ϸ�Ⱥܸߣ����Ժ�������Ϊ��Ҳ�������㿴�����Ĺ������̡������ǵ�ͼƬ�Ͳ���Ҫ��������Ⱦ��ֱ������������ˣ���������CPU�ͼ��Զ����������������������Ϸ����ô�������������ˣ�������Ҫ��ǧ��С�˲��й�������������ʵʱ������ߴ�60֡�����û��濴����ʮ�����̣������ܴﵽ2000֡���ϵ������� |

|
|
�������������ֽ����60FPS�����ˣ���ȫû�б�Ҫ���������ɵ�2065FPS��ֻ��ͽ�����ġ���Ҳ���Կ�������ǧ��С�˵��Կ�������ש�ɡ� Ϊʲô����ש���أ� ��ΪGPU�������ӵĹ��������Ĺ������䵥һ��ֻ��ȷ���ֱ����µ�ÿһ�����������ɫ������Խǿ֧�ֵķֱ���Խ�ߣ�Խ�ܸ��ܵ��Ľ���IJ��죻����ԽǿҲ��֧�ָ��ߵ�ˢ���ʡ� ������������С���ľ��ˣ�С���IJ���Ҫ��ߵ�Ƶ�ʡ� �㻻�ɴ�ˣ����ò��ϰ� ��ֻ���ò��ϰ����ò��Ͼ͵������˷��ˣ�����CPU�Ĺ��������෴��������Ҫ�����临�ӵĹ��������Ը��������ƵԽ��Խ�ã����ܱ�֤�ȶ�����������£���ȻҲ�Ǻ���Խ��Խ�á� �������չ����������ƿ������Ҫ���ϵ�ͻ�ƣ��������ͻ����ø����ԭ���� ����ͻ������ֿ������ܿ��ǵ��뷨��ʵ���ط����Ѿ����ˡ� |
|
���ȴ��ڡٺ��������ٶ���������˵ ��˵��С�˵ij�����Ϊ��ʲô����С�������dz������ƶ����豸�ϵģ�Ҳ����armƽ̨������ƽ̨��һ���ص����Ҫ��Ҫ�ͣ���������һ��������������ô���أ��������˴�С�ˣ��������������������ܣ�һ�������С���� �ܵ���˵��С�˵Ĵ��ھ�����һ������Ҫ���½��������������ڵ� ��Ϊʲô������ᱻ���ϵ���cpu�أ�����Ͳ��ò��ᵽ����amd5000ϵ��intel10����11��cpu֮�����ħ��ս�����濪ʼ����ʷ�� intel��pc��cpu�г���������˺ö���Nɪ�ˣ�8����ʼ�ͼ����࣬ÿһ����ֻ��һ��������������Ȼѹ��amd��ֱ��10����ʱ��amd5000ϵ�����ˣ�ȫϵ����intel10����5800x��ֱ�Ӹɵ�i9�������������intel���һ����Ϳ��ֻ�ܿ����˵�һ�������Ƴųų��� intel���ˣ������ذ��Ƴ���11����������Ȼ����Ȼ�����������༷���˵��µģ�������amd��粽�������5950x��pc�˵��컨�壬5600x���Լ۱���u��intelȫϵ�������д�硣���ò������һ�����amd�ĺ��ԣ���Ȼ��1060��ˮƽ�����ʱ����a�Ҵ��i���Ҳ��ű�������ü������һ��ʱ�� intel�����Լ��Ѿ���ͨ�������ľ�������սʤamd�ˣ����պô�ʱ��ǡ���ֻ�cpu����ʽ��չʱ����ǰ������870��������9000����ʱintel�뵽��һ������а������Ȼ���С������һ�������������������ģ���ô���Dz���Ҳ�����ô�С�˵ļܹ�����һ�����ĵ������������ܣ� ���ǣ�����cpu��չʷ�ϣ���ƽ��һ���磬��С�������cpu�������ˣ� ����ʷ�鵽��Ϊֹ�������С�˼ܹ��ͳ���intel�������ܹ����������ⶫ��Ҳ�й�Ϊڸ����һ�㣬�Ǿ��ǣ���intelȷʵ�����ˣ�һ�������£�������С�ˣ����������ˣ������Ҹɻ���ܷ֣�����ָܷ���ʲô�ã����ڴ��������������ʱ�϶���cpuȫ�������ģ�Ȼ����������Ǽ��������ȵ�С���Ǹ�ʲô���⣿���ܷ���ɶ�ã� ��С����ǿ������������ȵġ��ֻ�ƽ�������������Ⱥܺý�����Ͼ��û���ǰ��Ļ�µ�Ӧ�þ������������ڴ���ϣ���̨Ӧ�þ��Dz���Ҫ��������С���ϡ��������ô���������⣿����һ������Ļ����ͬʱ�����Ӧ�ã���һ�߹�֪��һ��ˢbվͬʱ���и�ǰ��html�IJ������ܣ��Һ�̨���˸����������迪�˸��ٶ����������أ�ͬʱ������������һ�����ѧϰģ��ѵ�����DZ���һ��vscode����Զ������һ̨���������ܳ�����߿��˸�ģ����ˢ���Σ��һ����˸��������ˢ���ϱ�������ʲô�������ܵĵ����㷨���ֱܷ���Щ��������ػ����� ��С�˸ճ���ʱ����Щ���ⶼ���������ʵģ����ڵ����㷨��������Լ��Ѿ��ж������ˣ�������Щ������ע��������ģ�����һ�����ѵ��ģ������Ҫ������Ҫ������ȥ�ܣ���һ���ҷ�������������ò�������ҲҪ������ȥ�ܣ�ʲô�����㷨��Ԥ��ҵ�����������ԣ��������������ض��������û�������һЩ������������Ҫ�����ܵ�����intel i9��Ƶ���ɻң�ֱ�Ӱ�С��ȫ�����ε���ֻ�ð˸���ˣ�����������һɫamdȫ��˴����� ��һ���������˵�ʼDZ������и��������Ѵ�С�˰���ȥ��Ҳ�����⣬����pc�ˣ�����ҽ�ʡ�磬���Ц�أ� �ȿȣ����潲��ô�࣬��Ҫ���ڻظ�һ�����⣬�Ǿ��ǣ��ֻ���ƽ�塢���ԣ�cpu���Ǵ�С�˼ܹ�������±�����һ�����������¡���ǰ�����Ǻ����ģ��Ժ����Dz������ġ��������ںܶ���ͨ�û��Ѿ���֪������С�˵��ȵ������ˣ����Ƕ����������û�����Щ������Ǵ��ڣ�����������û����������DZ���Ҫ����˲��� �ص����⣬Ϊʲô�Կ������С�ˣ����ȸ�����Կ���ʲô�ܹ����Կ���ȫС�˼ܹ���Ӧ�ó���Ϊ�����ģ�IJ��м��㣬�����ǵ��������������������Ϊһ���Сѧ����Ӽ��˳����Կ���ѹ����Դ��Сѧ��ѧ��̫����һ���Сѧ�����û������죬��������Ŀ̫������Сѧ���ⲻ���������Ǹ��������Կ����������ƹ����𣿲����ơ��������𣿲����ӡ���Ϊʲô��Ҫ��С�˵ļܹ�����С�˼ܹ����Կ����ٵ�������ν�Ƿ���ţ���༰�����Զ����� |
|
�Կ��Ĺ���ѹ�����ֻ���ƽ�壬���ԣ�CPU�Ĺ���ѹ������Ŀǰ�ġ�ȫС�ˡ���ƣ��Ѿ���Ŀǰ����µ����Ž⡣ CPU�Ĵ�С�˽ṹ�������Dz������ܹ�ƽ����������ܺ��ģ������ܵؽ��͡����ƴ����������幦�ġ���ʵ�������������Ҳ��һ����ѡ���Ӣ�ض���12���������������������+Ч�ܺ��ĵĴ�С����ƿ������dz��ã���ʵ����Ҳ��һ�ִ��ţ����Ǵ�С���������Ϸ�л���ڴ�С���ķ��������������ʹ�ò����û���������BIOS�йر���С���ģ���˵��Ϸ���ܻ��ǿ���ȶ��� |

|
|
�Կ�������������Ϸ������ͼ��ʱ��3D���涼����һ����һ�����ص���ɵģ�����������������Щ���ص����Ⱦ���������꣬���ռ������ҵ��һ����Ȩ�������״���DX10�Ĺ����������ͳһ��Ⱦ�ĸ����Ϊͼ�δ����������쳧�̣�����AMD����Ӣΰ��Ʊ�Ҫ�����з�˼·���ɴ˳�����ר�ŵ�ͳһ����Ⱦ���㵥Ԫ����SP������������������Ӣ��ƴдΪ��stream processors������дΪSP�������кܶ�����֣�������Ⱦ�ܡ���ɫ���ȡ� |

|
|
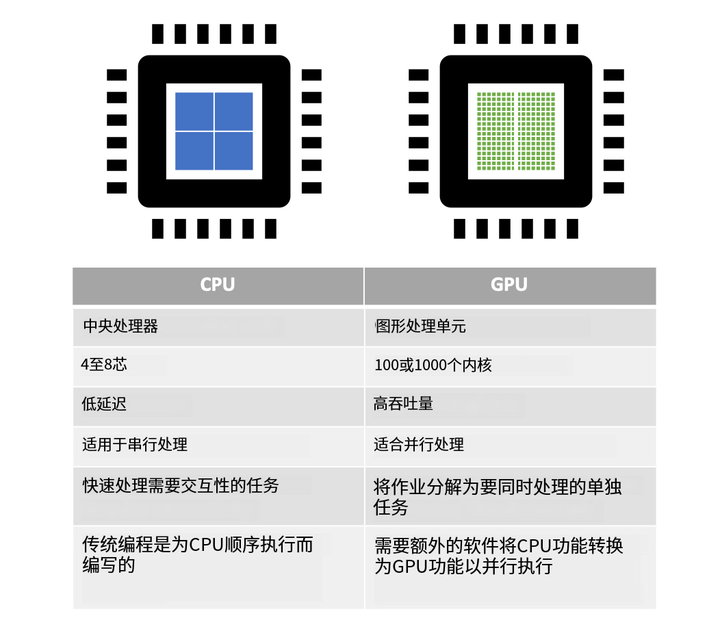
CPU����רΪ˳���д������Ż��ļ���������ɣ���GPU������ɼ�ǧ���ĸ�С������Ч�ĺ���(רΪͬʱ����������������)��ɵĴ��ģ���м���ܹ���ʹ��GPU���ó��Դ����ݽ��м��ظ��������ܶ��С���������о����������ڰ����һ��������ǧ�����������Ĺ�ͬЭ�����������ᶯһ�������壨��ͼ��������ֻ��Ҫ�������У�������Ҫȥ�ɱ��ʲô���飬���Է��乤������ͺܼ��ˣ�CPU��Ҫ��Ը�������������������ѣ����������С����Ⱥ�Ĺ�����ʽ����������˵����õġ� |
|
|
GPU�����CPU��GPU�߱�����ļ�����ĺ��ߵIJ��м�������������ܹ���ͬ��ʱ������ɸ���ļ����������ǿ��Կ���GPU����������GPU�IJ��м���������������������䵽������������ͬʱ���д������봫ͳ��CPU���м�����ȣ�GPU���ٿ��Դ����������Ⱦ���ٶȡ����������漰�����ģ�����ݴ��������ӵ�ͼ��Ⱦ�Լ�����ѧϰ������GPU���ٸ��������� |

|
|
GPU�����CPU��ͬ�Ĺ�����ʽ�����������Dz��ò�ͬ�Ľṹ�� |
|
�Կ������沢�м���ĸ��˸�ɶ��˭��������GPU�е��������Ǵ��ģ���м��㣬Ҫ��Dz��еĵ��߳�����Ϊɶ������CPU�� |
|
��ͳ��Ϸ�Կ���ȫС�˴���������ͳ��Ϸ�Կ���ȫС�˴���������ͳ��Ϸ�Կ���ȫС�˴������� NVIDIA��AMD�������Կ��������ڸ�IDCר�õ�AI���㿨��ARM/ZEN4C���ģ�������IDCר�õ�AI���㿨���㿨����˴�С�˴������� ��ο���AMD����Instinct MI300X GPUоƬ���Ƿ��ڴ�ģ��ʱ����вNvidia��λ?254 ��ע �� 35 �ش����� |

|
|
|

|
|
|
|
���ȣ�GPU����������CPU���������������Ͳ��С� ��һ��GPU��NVIDIA �����ģ�geforce 256����֮ǰ�Կ���ʹ��ڣ�ֻ��û����ȷ�ġ�ͼ�δ�����������ѡ���GPU��û���뱻����������������֮ǰ��������CPU��Э����������������CPU���и���Ԥ�㡪��������㶥���������ɫ������ʵʱ��Ⱦ��3D��Ϸ��������ĵ����� ���û���Կ��� ����CPU���㣬Ҳ�ǿ��������Ϸ�ġ����°빦�������ˣ�linus�������ѹµ�Σ��������ȫ�ŵ�threadripper ��5950x�����У���Ⱦ�ٶ������ﵽ�ˡ���ǿ��������ij̶ȡ� |

|
|
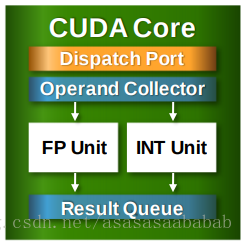
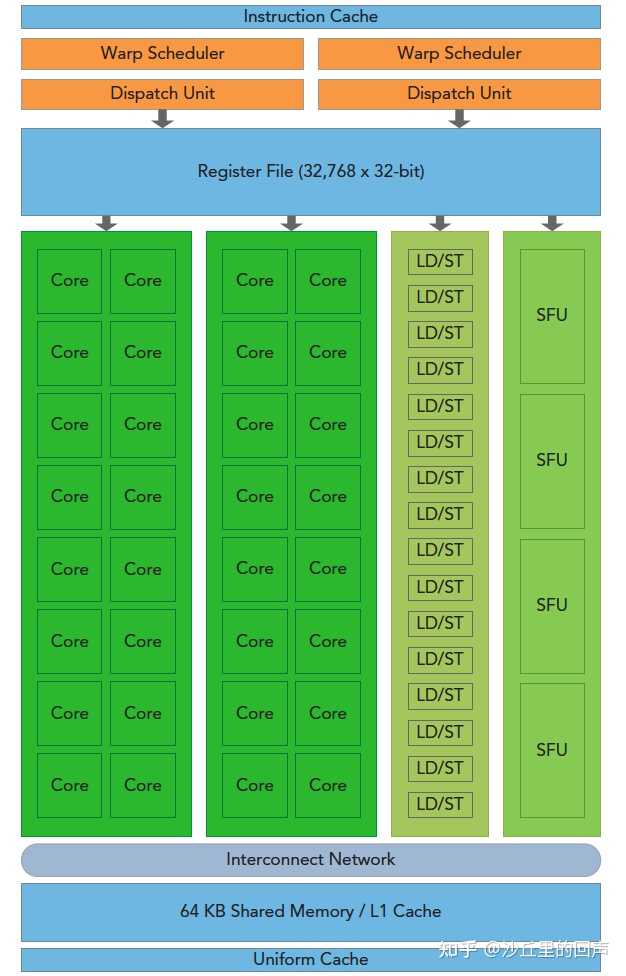
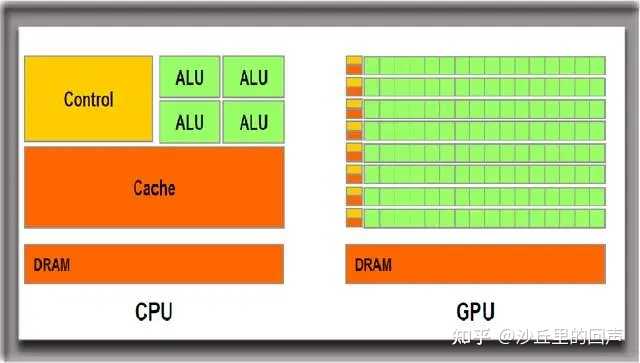
��Σ�CPU��ע�������㣬�Կ�ע�ز��е���Ⱦ�� CPU��GPU�ṹ�ж�����ALU��FPU(CPU�ڵ�FPU��486ʱ�����ɽ����ģ����ֱ�����������㣬��GPU��Ҫ�������Ǵ��ģ�ĸ�����㲢�У���һ���㵥Ԫֻ�ܴ����ض����ȵ����ݡ� CPU�Ľṹͼ���������Ǵ����Ļ���Ϳ�����������Э��ALU��FPU������㸴��ά�ȵ����ݣ�������Ҫ�Ǵ��еģ������������䣩������������ALU���û�и����FPU�����GPU�Ľṹͼ����������һɫ�ļ�FPU+��ALU��ɻ���������������CUDA��Ԫ���߽�SP��Ԫ����������Ƶ�����·ֻ�к�Сһ���֣�ͬʱ�ҿ�����������������CPU���Ķ�Ӧ�ĸ������������Ҫ���Ӻܶ࣬��λ����൱��һ������������NVIDIA��SM��Ԫ��AMD��CU��ƻ���Ķ���ͼ�κ��ģ��� |
|
|
|
|
|
|
|
|
���CPU�Ĵ�С�������ֺˣ������ܺĺ����������Э�� ��Ŀǰ���Ƴ̺ͼܹ������£�Intel ��ringͨѶ�����¹ҿ���������̫��ᵼ��Ч���½���intel��mesh ͨѶ�����£����������������ŵø��࣬������ܺıȱ�ը���Ǽ��㳡�ϵ�����Ҳ�����á� ����Intel ���������������ƺͻ����С���ģ����������Ѽ��������Ͻ�ʡring����ͨѶ�ڵ㣬ͬʱ��ʡ��������������;����ܺģ������ܺĹ̶���ǰ��������������߳����ܡ� ƽ����ֻ�����ͬһ��ARM��ϵ�����������Ϊ�����ƹ������������伫��Ƕ��ʽ����������ģ���С��һ��ʼ���DZ�������͵Ĺ�������������ķ����Ż��ġ� GPU ����Ҫ���֡�����������Ⱥ������Ϊ��Ҫ�ľ��Dz��л���û�п��Կ������������Ƶ�Ԫ������ͷ�֧Ԥ�����õľ���ܡ��������ܺġ��������ء��������������Ľṹ���Ƿdz�����ģ��������������Ⱥ�ļܹ���Ȼ���Ǽֱ��ģ���ӦCPU��˵�������ɿ�����������Ҳ������FPU˫���ȵĵ�Ԫ��ȣ�������Ϸ���ͼ��㿨�����𣬵������߲���Ҫ����һ�𣩡� |
|
ǰ������ͨ���Կ���CPU�ļܹ������ˣ��Dz�����һЩ����ֱ��������С�������š� ��˱����ǿ�����Ӳ�ˣ����˰�ʮ���Ϊʲô�� ��ǰ�и��ر�õı���������ΪʲôGPU�����ڿ�CPU���У���ʵ��������������Ҳ�����á� CPU��Ե��Ǹ��ӣ������������⣬���ÿһ�����Ŀ�������Ϊһλ���ڡ� |

|
|
ʲô�д�С�����أ� �������⽻�����ڣ�����ô���ӵĽ����о����Ǵ�������������ܺ��ģ�P�ˣ���ˣ�������Ч���ģ�E���ģ�С�ˣ����ٸ����ӣ�Ӣ�ض�13500F�����ڷdz�������һ��CPU��6P+8E��һ��14�����ġ� |

|
|
������ǰ̨����Ҫ��������ģ��������ܺ��ģ�Ҳ���Ǵ������������̨�������Ǽ���������С���⣬������Ч���������� ��ô�Կ��ĺ�����ʲô�� �ܼ��־�֢��ɢ�� |

|
|
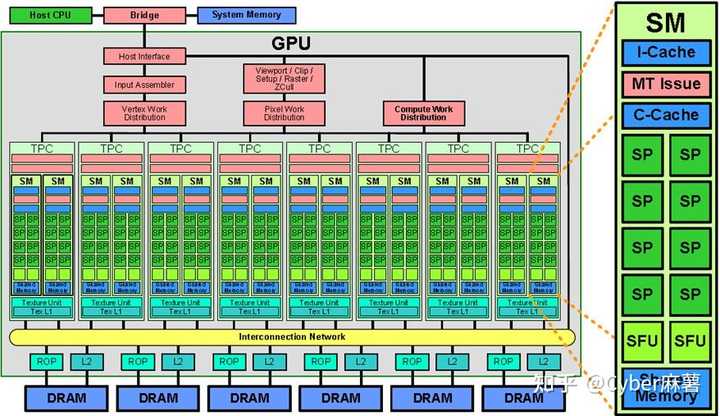
ãã���Сѧ���� ��������������GPU�ļܹ�ͼ |
|
|
�������ڰ����GPU�����һ��ר�Ź�ӶСѧ��ͯ����Ѫ�������� һ��GPU�������������кܶ�TPC�����䣩�������ֳַ��˺ܶ�SM�����飩��SM��һ������SP��Ԫ��Сѧ������ɡ� ��Ȼ���м仹�и��ֻ��棬���Ƶ�Ԫ�ȵȣ�̫�����˲��ᡣ ������GPU�����˸���Ŀ���ָ��������䣨TPC����ͬ�����䣨TPC������ַ������飨SM�������飨SM������ÿ�����ʵ���ɻ��Сѧ����SP�����ϣ���������ݲ��ѣ�ȫ���������㡣 ����֮�������ܣ��������������Ŀ�� GPU���Ѫ������һ���ʲô���أ� ������Ⱦ������һ��3D�ṹ��CPU����GPU�����������λ��������Ͻ�Ū��һ������Ļǰ�����ӽǵĶ�λ�Ļ����������GPU��Ⱦ���˽�����CPU���ٽӵڶ���� ��û��GPU��ʱ����Ⱦ������CPU�Լ���ɣ�����һ���ر��������û�м��������Ĺ�����������6����8�о������Ŷӹ������ĸ�����ܵ����¶���������ͬʱ����CPU�Լ��ĸ��Ӽ��㹤���� ��˿�����ͼ�δ���оƬ��ר�Ÿ�����Ⱦ����������CPU�Ϳ��Դӷ��ص�ͼ�μ����н��ѳ����� GPUΪͼ��ͼ��ר����ƣ�ר�Ÿ������������ӵ����⣩���ھ������㣬��ֵ���㷽����ж������ƣ��ر��Ǹ���Ͳ��м�����������CPU����ʮ���ٱ������ܡ� ��GPU��չ�����У���ҷ��ֺܶ��ѧ����������������㣬��CPU��̫���ˣ���������һ���ӿڣ���OpenCL��ƻ������������Ҹ�����������Ϊ�˹����Ľӿڹ淶�� ��һ�仰˵�����ǵ�����̫���������ʱ��CPU��С���Ķ���ֵ��Ϊ���˷�ʱ�䣬�ͻ�Ѽ��㹤�������Կ�����Ϊû�б����С�ĺ����ˡ� ���ˣ�GPU�����ӶСѧ��Ѫ���������ϼҼ�����CPU���漸������ |
|
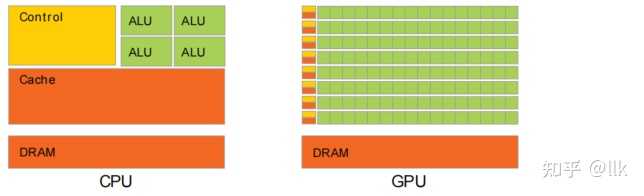
1 ���� ��˵���ۣ���Ϊ�Կ�����˵GPU����ļ�����ģ����CPU�ĺ��ģ��������Ѿ��㹻С�ˣ���ʹ��CPU�ϵ�С��С�ȡ���ͼ��NVIDIA��CUDA���ָ����˵��CPU��CPU�����һ��ͼ�����Ժ����������죺 |
|
|
����ֱ���NVIDIA��Volta GPU����о��3A5000Ϊ��˵���� 2 Volta Volta��NVDIA�Ƴ��ĵ�����Tesla�ܹ���GPU������CUDA core��ɵ����������������㵥Ԫ�ˣ���������Tensor Core������ͼ��ʾ�� |

|
|
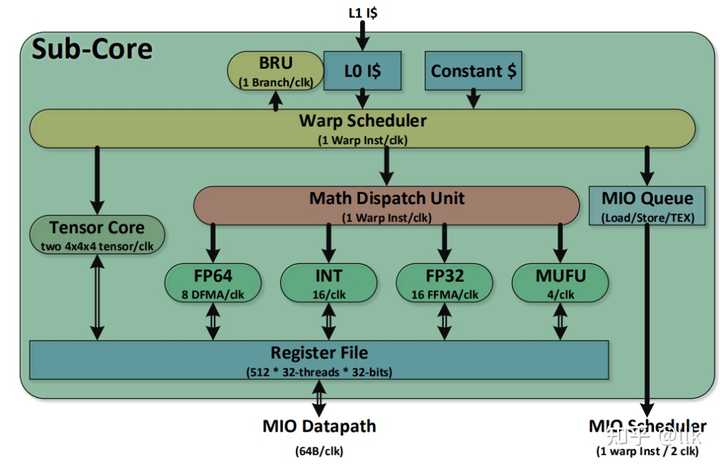
2.1 Sub Core һ��SM��4��Sub Core��ÿ��Sub Core�ܹ�����ͼ��ʾ�� |
|
|
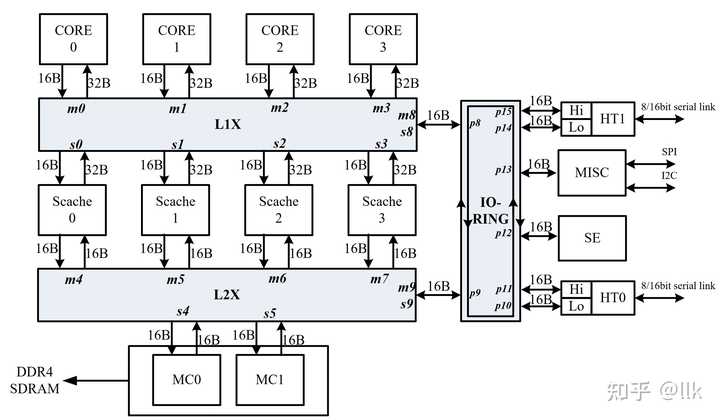
���Կ�����Tensor Core���Կ���һ��Э��������ר������ִ�о�������ģ���˫���ȸ��㣬�����������ȵȱ������㶼��Sub Core���һ��������ִ�е�Ԫ�ˡ����ʱ���Ѿ�û��cuda core�ˣ������������ָ��Ҳ����ͬʱִ���ˣ����Կ���һ���������������ˡ�ֻ�����������Ⱥܿ���16������ָ�16�������ȸ���˼�ָ�8��˫���ȸ���ָ���ͨ�ô�������ȣ�ȱ�ٸ��ӵķ�֧Ԥ������ָ��Ԥȡ�����Ĵ�����������������ִ�еȿ������� 3 ��о3A5000 ��о3A5000���ú���о3A4000�Ĵ�����ͬ����GS464EV, ����12nm������Ƭ, ��Ƶ������2.5GHz����о3A5000��Ȼ��4�˴�����������о3C5000����һ��16�˴���������о3A5000/3B5000��������˼����������������Ϣ�������ͨ�ô�������������о����ָ��ϵͳLoongArch��LA464�ṹ���ĺ˴�������������о3A4000�������������ż��ݵĻ����ϣ�Ƶ��������2.5GHz�����Ľ���30%���ϣ���������50%���ϡ���о3B5000����о3A5000�Ļ�������HT0�ӿ���֧��һ���Ի����Ա�֧�ֶ�·��������ͼչʾ����оƬ�ܹ��� |
|
|
��һ����������5x5�Ľ��濪�أ�����4���������ˣ�4����������ģ���һ��IO�˿ڵ����ӡ��ڶ�����������5x3�Ľ��濪�أ�����4�������Ļ���ģ�飬�����ڴ��������һ��IO�˿ڡ�IO������һ��8���˿ڣ��ֱ�����4��HT�������������������ģ�飬��ȫģ���Լ��������濪�ء�����HT����������16��HT���ߣ�������Ϊ����8λHT��һ��16λHTʹ�á� ���������ṹ�����ö�д���������ͨ����λ��128���أ��봦����ͬƵ���������˺͵�һ�����濪�ض�ͨ����256���ء� 3.1 LA464�������� LA464��һ��4����ij���������������4�����㵥Ԫ��2��256λ��������Ԫ��2���ô浥Ԫ��ÿ��������Ԫ֧��8�������Ȼ�4��˫���ȳ˼����㣻�ô浥Ԫ֧��256λ�洢����.��ͼչʾ��LA464�������˵��ܹ��� |

|
|
���Ժ�����������LA464���Volta ��Sub Core��ִ�е�Ԫ���٣�������Ӧ�Ŀ������ܶ࣬�и��ӵķ�֧Ԥ������ָ��Ԥȡ�����Ĵ�����������������ִ�еȿ������� �ο�����CUDA C PROGRAMMING GUIDE J. Choquette, O. Giroux and D. Foley, "Volta: Performance and Programmability," in IEEE Micro, vol. 38, no. 2, pp. 42-52, Mar./Apr. 2018, doi: 10.1109/MM.2018.022071134.Loongson 3A5000/3B5000 Processor Reference Manual - Multicore Processor Architecture, Register Descriptions and System Software Programming Guide, n.d.Wang H., Wang W., Wu R., Hu W., 2015. ��оGS464E�������˼ܹ����. Sci. Sin.-Inf. 45, 480�C500. https://doi.org/10.1360/N112014-00292 |
|
л���� �����Կ����dz����С�ˣ�3060��12400���������ܶ�Ҳû�в��ر�ࡣ 3060��3840��cuda���ģ�12400ֻ��6��cpu���ġ� �����Կ���˵�������С���ıȶѴ���ĸ����Լ۱ȡ� ��������һ���Ƕ��룬nvҲ�ڿ������칹����cuda���ڱ��������칹������ġ� N���У�������int32��fp32��fp64�ļ��㵥Ԫ����һ����������cuda core���ģ������ר���ھ�������tensor core���ġ� ������ǶȽ��������Կ��е��칹������cpu��С�˵��칹����Ϊ���ף���Ϊר�ã���Ϊ��Ч�� |
|
���Ͻ��ۣ�����ͼܹ������ġ� ���������Ǹ������⣬��Ϊ�Կ�������DZŷ����㣬�������ݱȽϵ�һ����cpu֧����������Ҫ�������㣬��Ҫ�չ�ϵͳ����Ҫ�չ˸��������� ͨ����˵��cpu�Ĺ������ݣ�����Կ�Ҫ���Ӻܶ࣬cpu�չ˵���һ����ӣ����Կ�֧�ֵ���һ���ˡ� ���൱�ڣ�cpu�ǽ������Կ���С���� ��������������ʱ������������Կ��ܾͻ���뿨�١�ʧ���״̬�˰ѡ� cpu���Բ�Ҫ�Կ������Կ�����û��cpu���Ǿ���ζ�ţ��Կ�����һ����ǰ�س�棬ѹե�����ܣ���cpu����Ҫ��������������ָ�ӣ��ô�������ǿ�ĺ�ܡ� CPU�Ĵ�С���ľ���Ϊ�˶Ը�������������� ��������������ô����ǽ���cpu�ܺģ�����豸���������ֻ���Ϊ�ƶ�ʹ����䷶�Ĵ�������С���ľ������ڸ��跶�룬�ʼDZ������õ㣬���û����Բ���á� CPU�ֶ�����ĺ��̣߳�һ������ͼ�� |
|
|
���ڵ�cpu����������ԣ�ȵģ� �ճ�����칫������office�����ף���ҿ�����������߿���Ƶ���������˿��ܶ��Բ��������ʱ��ѹ����㣻���ǵ������ƣ�����ps��cad��ͼ����ЩӦ�ã�Ҳ�����̫����ģ����⣬��Щ3d��ģ������revit��3dsmax�����ģ����س�������ֻ��һ������.�����������ģ�Ҳ��PR�����Ƶ��C4d���ͼ�ģ���Ⱦ��Ƥ��Ӧ�ã�����matlab���ݷ��������������cpu�Ż������ �Կ��أ��������ż������Σ�����LOL�����ģ����ܳԲ����Կ���������3A����������3d���Σ��������ܰ��Կ����� ŶŶ�������ڽ�ģ����Ч������չʾ���ʺϣ��Կ�����һ��Ҳ�Բ����� |

|
|
�����Ӳ��˼ά���ˣ�������˼ά���һ����Բ���㡣 ϵͳ�ϵ�����������������windowsϵͳ��Ϊƽ̨�����Կ���ƽ̨��һ��������Կ�����������ǻ���ϵͳ֮�ϵģ�ϵͳ������cpu�ϡ� |

|
|
��С�����ǽ���������cpu��һ�飬AMD��Ȼ���ϴ�ͳ�� intel���Ǵ�С���ļܹ����ˣ�����2024��ultraϵ�У��ر���2������С���ģ���һ���չ������� |
|
���ġ���С�ˡ���������������ȱ�� �����ǰ�й�ע���������������������ݣ�����ܻ�ǵã����Ƕ����PC�������ϵġ���С�ˡ������ʵ�������ʵġ������ڲ���ǰ�����ǻ�ר�����ڳ���һ̨û�С���С�ˡ���Ƶ�11�����+����DDR4ƽ̨������������˴������ԣ���չ�������������ܱ��֡� Ϊʲô���Dz�̫ϲ��ĿǰPC�������ġ���С�ˡ���ƣ�������Ϊ�ۺ���֪�������Ϣ����������С�ˡ����������������Իرܵ�ȱ�ݡ� ���ȣ��������������Ч�ġ�С�ˡ���֧��һЩ�Ƚϸ��ĸ������ָ�������AVX-512��AMX�ȣ������Ե��²����ˡ���С�ˡ���Ƶ�12����13��������ò��ڡ���ˡ���Ҳ���ζ�Ӧ��ָ����������ʹ������ָ������Է��棬����������ġ�����ˡ���Ʒ�����������ˡ� |

|
|
��Σ����ڡ���ˡ��͡�С�ˡ������˼·�ϴ��ڼ�����죬���Ե������ǵķ�ֵ���ܲ�������仰˵����ij�����ͳ���ͬʱ��Ҫ���ߵ�������+�㹻�����������ʱ����ʱ��Щ�������Ʋ��ٵġ�С�ˡ����������ܻ���Ϊ�������ܲ���ǿ���Ӷ���Ϊ��Լ����Ч�ʵ�ƿ����ͨ����˵�����Ǵ���Ѿ���ռ������С���ִ�����������ġ��Ե����������ߵ��̣߳�����һ�㣬��ʵ������߶��������������ǿ�йر����С�С�ˡ���ֻ�ô�����г������ν����Ϸģʽ�������ܿ������ߡ� ��������Ϊ���ּܹ����죬�����ˡ���ˡ�����Ч������Զ������С�ˡ������仰˵���������������ೡ����������Ҳ���ǡ��д������������У�����ʵ������Ҫ��ǿ�������ܡ�ʱ��һ��С���ϵ��̱߳�ռ�����������Զ������á����ʱ�����ľͱ�Ȼ�ᶸ������Ч�Ȼ����½�����������ӷ��ȡ��������ᱡ�ͱʼDZ�������˵����Ȼ���Ǽ����¡� ��Royal Core��й¶��������еĸ������� ˵����ô�࣬�������ѿ����Ѿ����������ˡ�����ĿǰPC�������ġ���С�ˡ������˵�������Ķ̰���ʵ�����ڴ����С��֮����ڹ���ļܹ����������Լ����ܲ����ϡ� |
|
|
˵���ˣ������뵽�ģ������������ͬʱ���С�����͡�С��������һ�ߴ���Ϸһ�߿�ֱ��������һ������Ƶһ��д���£�����ô��С�˸�˾��ְ�����Ծ��ܼ����������Ч������ʵ��ʹ�ó����У�������������治���þͺܶ࣬���Ե��ˡ�ȫ�ظ��ء���ȫ�Ḻ�ء���ʱ�����С��֮���������Ķ̰���չ¶���š� ��ô��������ˣ���û�а취�á���С�ˡ�֮��ʵ������������ת�����á���ˡ�����Ҫ��Ч�ȵ�ʱ����Ա���롰С�ˡ�һ��ʡ�硢һ���������ͣ���С�ˡ�����Ҫ����ʱ�����������롰��ˡ�������ͬ����Ƶ������أ� ��ʵ�����С�������Ǻ���ǰ�ͱ��ع⣬�����ղ��������˸���ϸ�ܹ���Ϣ�ģ�Intel�������´�������û��������������Royal Core���� |

|
|
������Ҫ˵�����ǣ���CPU tiles������17����ļܹ����ƣ�����������Ŀ���š����嵽�������ܹ�����ϣ���Royal Core������ʹ��һ�ַdz��ر�ġ�����Ϊ��CPU tiles�����ں˹��졣 ���ظ��س����£���ÿһ����CPU tiles������������һ�������ġ�����ġ�����ӵ���㹻�ߵIJ����������ṩ���ߵ�ִ��Ч�ʣ�Ҳ���dz�ǿ�ĵ������ܡ� |
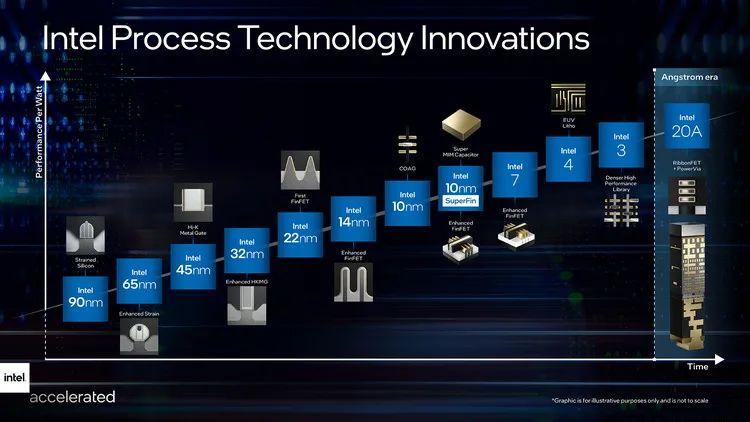
|
|
�������Ḻ�س�����ÿһ����CPU tiles�����ܱ��Զ�����֡������š�С���ġ���������ʱ������ʵ�ָ��ߵ���Ч�ȣ�ͬʱ������Ϊ�����ṩ����IJ����̡߳� ��ʱ������ƣ�������17��ǰ�������·��� ���ѷ��֣����Ŀǰ�ع�������Ϣ��ʵ����ô��������2024���°�����dz���17�����Nova Lake�����壬�������ǰ��δ�еļܹ���ƣ�ͬʱ����������С���С�ˡ�֮����ܹ���������µ����ּ����Ժ��������⡣ Ȼ�������ġ�ȫ����ơ�������ǡ�ǰ��δ�С����� |
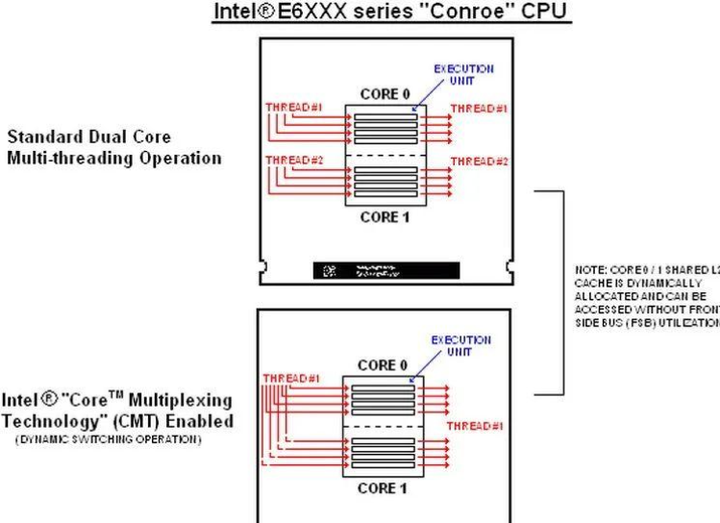
|
|
��ʵ����2006�����С�Ҳ���Dz��17��ǰ����ʱ����Ƽ�ý��ͱ�����һ����Ϊ�������̡߳��Ĵ������������ݳƣ������Խ��������������ġ��ϲ���Ϊһ�����Ӷ��������ߵĵ������ܡ��ر��Ƕ��ڵ�ʱ�������ĺ˴�������˵����һ�����������������ںܶࣨ��ʱ��ֻ֧��˫�˵�Ӧ���У���þ��˵����������� ��Ȥ���ǣ���������������Ƿ��֣�����2006�����У�Intel����������ǵĸ߶����壨i975X���ϣ�������һ������Ϊ��Core Multiplexing Technology�����Ķ�·���ü��������Ŀ��ء���ý�巢�֣�����������ܺ�ԭ����˫�˴������ͻᱻʶ��Ϊ��������������Ԫ�ĵ��ˡ���Ҳ���ǽ������������������桰�ϲ����ˡ� |

|
|
����������Ϊ������ڵ�ʱ���ڳ�ǰ���ֻ���Intel�ж϶�˲����Ǹ����CPU��չ����ȷ������֮����Core Multiplexing Technology��������ܽ���ֻ��Intel�ٷ������BIOS�������һ���£��ͱ������ĸ��°汾���ε����Ӵ���Ҳ���������ա��� ��ô�����Ƿ���ζ����оƬ����Jim Keller���Բٵ��ġ�Royal Core�����ڻ����������ܵ���Intel 17��ǰ������������أ������е��ع���Ϣ������ȷʵ��������ܡ�������Ȼ����Royal Core���ĺ��ĺϲ����ƻ�����ף�Ҳ���������һЩ������δ�����Ѽ��������ϳ��ֹ����¼����������ij��̣߳��� ����������ʵ��Ч����Σ��ܷ���������PC�������ܹ���Ƶ�һ��ȫ��ʱ�������ܾ�Ҫ�ȵ�2024����ܼ������ˡ� |

|
|
ͬ�����칹����Ȼ����ͬ������Ŀ��ȴ��һ���ģ�����Ϊ����ߴ�������������Ч�ʣ���ϵͳ���Ը����ķ�������͵��ã������칹��ͬ��Ҳȷʵ���Ų�һ�����ó���������˵˵�칹��Ӣ�ض��Ĵ�С������ڹ����ϵ����ƽ�Ϊ���ԣ����������ڵ�ʹ���ʵ�����£������ṩ����Ĺ��ļ����ȱ��֣�ʮ���ʺ��ƶ��˺�С��PC�� ��ôͬ����С���أ�������칹��С�ˣ�ͬ����ƵĹ���������Ȼ��С�ܶ࣬���ǶԱȴ�ͳ��ȫ��������Ȼ�����������ƣ����һ����Ÿ�����߳�������Զ��ԣ��ڸ߸��ɵĴ��������У�ͬ����С�˵��������ܱ��ֻ������һЩ�����ճ�ʹ��ʱ�����ߵı��ֻ�����ʮ�����ƣ����ڸ߸�������ʱ��AMD�����ƻ��������ֳ����� ���������������IJ��Խ����������Ȼ�칹��Ƶ�Ч�ʺ����ܲ������ܺˣ�����Ӣ�ض��ĵ�������һֱ����AMD������Windowsϵͳ������Ե����Ż�����ʹЧ�ʺ˵����ܽ����������ȴ�ܸߣ�һ���̶���Ҳ�ֲ������е����ƣ���������¹��˭�֣�������˵�� ������Ϊ����AMD������˴�С�˴�������δ����������£���ʵ�������ж�Ӣ�ض���AMD�ķ���˭��˭�ӣ����ǣ����ٿ��Կ϶���AMD�����£�Ӣ�ض�Ӧ��Ҳ���ٴ����٣��ô������������ٶ��ٴμӿ죬������������˵����������AMD��Ӣ�ض�˭ʤ����������������ġ� |
|
|
| [�ղر���] �����ر��ġ� |
| ��һƪ���� ��һƪ���� �鿴�������� |
|
|
|
| ��Ʊ�ǵ�ʵʱͳ�� ��ͣ��ѡ�� ��ʱͼѡ�� ��ͣ��ѡ�� K��ͼѡ�� �ɽ���ѡ�� ����ѡ�� ������ѡ�� �������� �������� ���� MACDָ�� KDJָ�� BOLLָ�� RSIָ�� ���ɻ���֪ʶ ���ɹ��� |
| ��վ��ϵ: qq:121756557 email:121756557@qq.com ����ƻ� |