
| |
|
|
| 首页 淘股吧 股票涨跌实时统计 涨停板选股 股票入门 股票书籍 股票问答 分时图选股 跌停板选股 K线图选股 成交量选股 [平安银行] |
| 股市论谈 均线选股 趋势线选股 筹码理论 波浪理论 缠论 MACD指标 KDJ指标 BOLL指标 RSI指标 炒股基础知识 炒股故事 |
| 商业财经 科技知识 汽车百科 工程技术 自然科学 家居生活 设计艺术 财经视频 游戏-- |
| 天天财汇 -> 科技知识 -> 为什么现在的LLM都是Decoder only的架构? -> 正文阅读 |
|
|
[科技知识]为什么现在的LLM都是Decoder only的架构? |
| [收藏本文] 【下载本文】 |
|
相比encoder-decoder架构,只使用decoder有什么好处吗? |
|
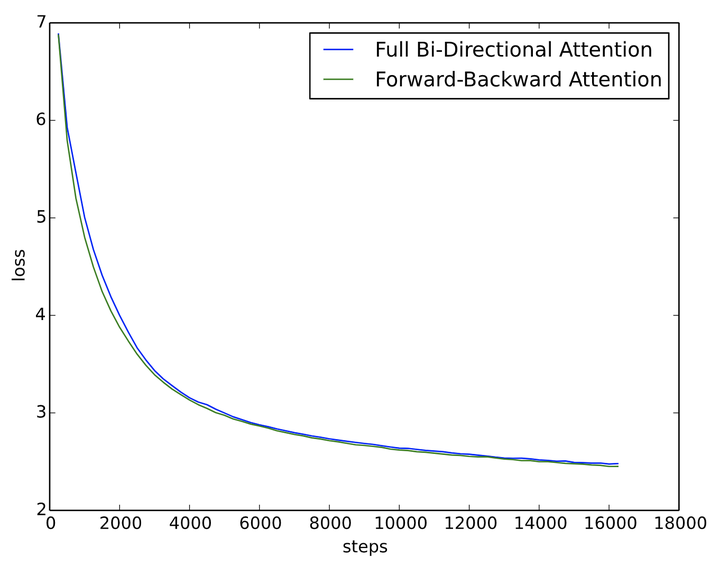
从理论视角强答一波,大部分结论源自个人实验,可能会有偏差。 原文链接: 为什么现在的LLM都是Decoder-only的架构? - 科学空间|Scientific Spaces?kexue.fm/archives/9529 结论: LLM之所以主要都用Decoder-only架构,除了训练效率和工程实现上的优势外,在理论上是因为Encoder的双向注意力会存在低秩问题,这可能会削弱模型表达能力,就生成任务而言,引入双向注意力并无实质好处。而Encoder-Decoder架构之所以能够在某些场景下表现更好,大概只是因为它多了一倍参数。所以,在同等参数量、同等推理成本下,Decoder-only架构就是最优选择了。 统一视角 需要指出的是,笔者目前训练过的模型,最大也就是10亿级别的,所以从LLM的一般概念来看是没资格回答这个问题的,下面的内容只是笔者根据一些研究经验,从偏理论的角度强行回答一波。 我们知道,一般的NLP任务都是根据给定的输入来预测输出,完全无条件的随机生成是很少的,换句话说,任何NLP任务都可以分解为“输入”跟“输出”两部分,我们可以把处理“输入”的模型叫做Encoder,生成“输出”的模型叫做Decoder,那么所有任务都可以从“Encoder-Decoder”的视角来理解,而不同模型之间的差距在于Encoder、Decoder的注意力模式以及是否共享参数: Encoder注意力Decoder注意力是否共享参数GPT单向单向是UniLM双向单向是T5双向单向否" role="presentation" style="font-size: 100%; display: inline-block; position: relative;">注意力单向双向双向注意力单向单向单向是否共享参数是是否Encoder注意力Decoder注意力是否共享参数GPT单向单向是UniLM双向单向是T5双向单向否\begin{array}{c|ccc} \hline & \text{Encoder注意力} & \text{Decoder注意力} & \text{是否共享参数} \\ \hline \text{GPT} & \text{单向} & \text{单向} & \text{是} \\ \text{UniLM} & \text{双向} & \text{单向} & \text{是} \\ \text{T5} & \text{双向} & \text{单向} & \text{否} \\ \hline \end{array}\\ 这里的GPT就是Decoder-only的代表作;UniLM则是跟GPT相似的Decoder架构,但它是混合的注意力模式;T5则是Encoder-Decoder架构的代表作,主要是Google比较感兴趣。 Google在T5和UL2两篇论文中做了较为充分的对比实验,结果均体现出了Encoder-Decoder架构相比于Decoder-only的优势,但由于从LLM的角度看这两篇论文的模型尺度都还不算大,以及多数的LLM确实都是在做Decoder-only的,所以这个优势能否延续到更大尺度的LLM以及这个优势本身的缘由,依然都还没有答案。 对比实验 从上表可以看出,其实GPT跟UniLM相比才算是严格控制变量的,如果GPT直接跟T5相比,那实际上产生了两个变量:输入部分的注意力改为双向以及参数翻了一倍。而之所以会将它们三个一起对比,是因为它们的推理成本大致是相同的。 相比GPT,既然T5有两个变量,那么我们就无法确定刚才说的Encoder-Decoder架构的优势,究竟是输入部分改为双向注意力导致的,还是参数翻倍导致的。为此,笔者在10亿参数规模的模型上做了GPT和UniLM的对比实验,结果显示对于同样输入输出进行从零训练(Loss都是只对输出部分算,唯一的区别就是输入部分的注意力模式不同),UniLM相比GPT并无任何优势,甚至某些任务更差。 假设这个结论具有代表性,那么我们就可以初步得到结论: 输入部分的注意力改为双向不会带来收益,Encoder-Decoder架构的优势很可能只是源于参数翻倍。 换句话说,在同等参数量、同等推理成本下,Decoder-only架构很可能是最优选择。当然,要充分验证这个猜测,还需要补做一些实验,比如Encoder和Decoder依然不共享参数,但Encoder也改为单向注意力,或者改为下一节介绍的正反向混合注意力,然后再对比常规的Encoder-Decoder架构。但笔者的算力有限,这些实验就留给有兴趣的读者了。 低秩问题 为什么“输入部分的注意力改为双向不会带来收益”呢?明明输入部分不需要考虑自回归生成,直觉上应该完整的注意力矩阵更好呀?笔者猜测,这很可能是因为双向注意力的低秩问题带来的效果下降。 众所周知,Attention矩阵一般是由一个低秩分解的矩阵加softmax而来,具体来说是一个n×d" role="presentation">n×dn\times d的矩阵与d×n" role="presentation">d×nd\times n的矩阵相乘后再加softmax(n≫d" role="presentation">n?dn\gg d),这种形式的Attention的矩阵因为低秩问题而带来表达能力的下降,具体分析可以参考《Attention is Not All You Need: Pure Attention Loses Rank Doubly Exponentially with Depth》。而Decoder-only架构的Attention矩阵是一个下三角阵,注意三角阵的行列式等于它对角线元素之积,由于softmax的存在,对角线必然都是正数,所以它的行列式必然是正数,即Decoder-only架构的Attention矩阵一定是满秩的!满秩意味着理论上有更强的表达能力,也就是说,Decoder-only架构的Attention矩阵在理论上具有更强的表达能力,改为双向注意力反而会变得不足。 还有个间接支持这一观点的现象,那就是线性Attention在语言模型任务上(单向注意力)与标准Attention的差距,小于它在MLM任务上(双向注意力)与标准Attention的差距,也就是说,线性Attention在双向注意力任务上的效果相对更差。这是因为线性Attention在做语言模型任务时,它的Attention矩阵跟标准Attention一样都是满秩的下三角阵;在做MLM任务时,线性Attention矩阵的秩比标准Attention矩阵更低(线性Attention是n×d" role="presentation">n×dn\times d的矩阵与d×n" role="presentation">d×nd\times n的矩阵相乘,秩一定不超过d" role="presentation">dd,标准Attention是n×d" role="presentation">n×dn\times d的矩阵与d×n" role="presentation">d×nd\times n的矩阵相乘后加softmax,softmax会有一定的升秩作用,参考《Transformer升级之路:3、从Performer到线性Attention》中的“低秩问题”一节及评论区)。 反过来,这个结论能不能用来改进像BERT这样的双向注意力模型呢?思路并不难想,比如在Multi-Head Attention中,一半Head的Attention矩阵截断为下三角阵(正向注意力),另一半Head的Attention矩阵截断为上三角阵(反向注意力);又或者说奇数层的Attention矩阵截断为下三角阵(正向注意力),偶数层的Attention矩阵截断为上三角阵(反向注意力)。这两种设计都可以既保持模型整体交互的双向性(而不是像GPT一样,前一个token无法跟后一个token交互),又融合单向注意力的满秩优点。 笔者也简单做了对比实验,发现正反向混合的注意力在MLM任务上是比像BERT这样的全双向注意力模型效果稍微要好点的: |
|
|
好消息是看得出略有优势,间接支持了前面的猜测;坏消息是这实验的只是一个base版本(1亿参数)的模型,更大模型的效果尚未清楚。 |
|
先问是不是:GLM130B和UPalm-540B不是decoder-only,但是确实大家都在做decoder-only 三个原因 工程:模型10B的时候还好,各种骚操作都能上,scale效果也很好,但是再大以后,很多东西的scalability都会出问题。举个例子,如果你不是Google的话,基本上需要pipeline parallelism,如果你看过megatron的codebase,你就能看到t5的模型是不支持pipeline的,你自己写的话就很麻烦。而且现在所有的非Google系的都在用Megatron。现在再加上flashattention,t5的relative positional bias也有问题了,除非你花很大力气去解决,或者用rope。同样的原因现在训练GLM也不是throughput最优的,因为里面的attention mask不是causal的。总之scale一大,任何一个小问题都会被放大,非常的困难非常的吃工程。这个bigscience的人在reddit的ama里面提过。zero-shot的表现:有篇paper专门讲这个,decoder-only的模型zero-shot的performance是最强的,而zero-shot是最秀的一个feature,不要这个还能干啥,这个也是bloom的paper里面提过的没有对应的scaling law:GPT-3当时敢scale到175B是因为之前有Kaplan做了scaling laws,大家知道如何scale能budget-efficient,再加上后面chinchilla,也对scaling law这件事情有了加强。相比之下其他架构的nlp模型没有scaling law,也没有人做过。 我自己是认为bi-directional的肯定是更强的,但是没人做啊,而且decoder-only参数上去了也够了。话又说回来,AlphaCode就是enc-dec,而且明说了enc很重要。 另外现在就只说gpt-like和t5-like的模型了,bert的模型因为做的东西是这俩的子集,确实没太多人用了,类似说法源于ul2。 |
|
跟风也答一波,大家胡乱看看一起讨论。摘自我最近文章的第4部分: CastellanZhang:【大模型慢学】GPT起源以及GPT系列采用Decoder-only架构的原因探讨343 赞同 ・ 4 评论文章 |

|
|
4. 关于Decoder-only架构的思考 GPT为什么从始至终选择Decoder-only架构?GPT-1,包括之后的2,3系列全都如此。我不知道答案,ChatGPT给出的回答也很泛泛,并不能说服我。 4.1 各种架构能否训练语言模型 我们不妨先想想用Encoder-Decoder或者Encoder-only架构能不能训练语言模型?如果不是按照标准的语言模型目标训练,而只是利用大规模未标注预料无监督学习,肯定是可以的,比如BERT就是Encoder-only架构的代表,Google T5[4]是Encoder-Decoder架构的代表。BERT输入为句对,学习目标有两个:Masked LM(随机遮盖句子中若干token让模型恢复)和Next Sentence Prediction(让模型判断句对是否前后相邻关系);T5借鉴了BERT的Masked LM(或者称作denoising目标),只不过输入输出都是text的形式,如下图: |

|
|
BERT和T5通过这种完形填空式的学习目标加强模型在语义理解上的能力,但这个训练目标和文本生成并不直接对应。如果非要按照标准语言模型目标的训练方式,即将一个文本段从头到尾依次基于上文预测下一个token,则对于Encoder-Decoder和Encoder-only架构很别扭且无法并行。T5的对比实验部分给出了另一种替代方案:采样一段文本,然后选择一个随机点将其拆分为前缀和目标部分,前缀作为输入,目标作为输出。只不过为了防止信息泄露,Encoder-only架构要换成论文中的Prefix LM架构,三种架构的对比如下图,实现上也很容易,设置不同的掩码矩阵即可: |

|
|
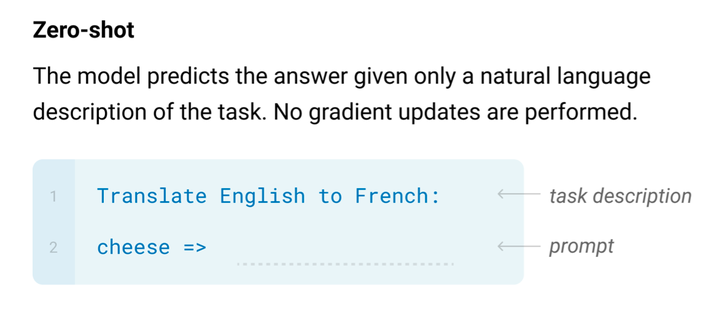
因此我们首先可以肯定,理论上各种架构都是可以训练语言模型的。 4.2 不同架构推理对比 再看推理过程,即训练完毕后用于生成文本的过程,2L层的Encoder-Decoder架构和L层的Decoder-only架构的推理时间差不多,但前者参数多了一倍;同样参数规模的Decoder-only和Prefix LM对比,前者只有前向过程,推理应该能更快一些。因此假设2L层Encoder-Decoder、L层Decoder-only、L层Prefix LM三者模型效果差不多,则对比下来,Decoder-only是存储和计算上效率最高的。当然这只是假设,按照T5论文的结论,2L层Encoder-Decoder效果才是最好的,不过T5参数量才110亿,当参数规模达到GPT-3级别的千亿规模,不知道结果如何。 4.3 低秩问题是原因吗 在调研过程中,发现知乎上有相关讨论[5]:“为什么现在的LLM都是Decoder only的架构?相比encoder-decoder架构,只使用decoder有什么好处吗?”在苏剑林的最高赞回答中提到双向注意力会带来低秩问题,想通过理论视角给出答案。我顿感兴趣,但苏剑林的回答在理论分析上写得还是不够详尽,于是按图索骥,找来回答中提到的两篇论文。 先说第一篇[6] Attention is not all you need: pure attention loses rank doubly exponentially with depth,纯纯的理论分析,结论是如果没有残差连接和MLP兜着,self-attention网络的输出会随着网络深度迅速朝秩为1的矩阵收敛。self-attention网络的输出就是每个token表示在所有token上的权重分配矩阵,秩为1就是说attention矩阵每一列都相同了,即每个token最后的表示都一样了,网络就废了。但在Transformer实际使用中没有谁会这么干,所以我的总结是这篇论文很NB,但和这个问题并无关系,先留个坑,以后有时间单开一篇文章写它。 第二篇论文[7] Low-Rank Bottleneck in Multi-head Attention Models就有点意思了。理论分析表明了标准Multi-head Attention的一个固有缺陷:当head size小于输入序列长度时,会带来所谓低秩瓶颈,降低模型表达能力。这个分析有点复杂,我们需要详细描述一下。 设定Transformer的输入为 n" role="presentation">nn 个token序列,每个token用 d" role="presentation">dd 维向量表示,则可以用矩阵 X∈Rd×n" role="presentation">X∈Rd×n\mathbf X\in\mathbb R^{d\times n} 统一表达输入序列。 回顾一下Transformer block架构(本论文只针对Encoder分析),每一个block包含一个Self-Attention子层和一个FFN子层。每个子层还包含一个残差连接和LN操作。Self-Attention子层可以是Single-Head Attention,也可以是Multi-head Attention,当然也可以把前者看作后者的特例。 (1)Single-Head Attention情况 先从简单的单头分析。Self-Attention的计算如下: (1)Attenion(X)=WvX⋅Softmax[(WkX)⊤(WqX)dk]=WvX⋅P" role="presentation">(1)Attenion(X)=WvX?Softmax[(WkX)?(WqX)dk]=WvX?P \text{Attenion}(\mathbf X)=\mathbf W_v\mathbf X\cdot\text{Softmax}\left[\frac{(\mathbf W_k\mathbf X)^\top(\mathbf W_q\mathbf X)}{\sqrt{d_k}}\right]=\mathbf W_v\mathbf X\cdot\mathbf P\tag{1} 其中三个分别对应query、key、value的投影矩阵形状为 Wq∈Rdq×d,Wk∈Rdk×d,Wv∈Rdv×d" role="presentation">Wq∈Rdq×d,Wk∈Rdk×d,Wv∈Rdv×d\mathbf W_q\in\mathbb R^{d_q\times d},\mathbf W_k\in\mathbb R^{d_k\times d},\mathbf W_v\in\mathbb R^{d_v\times d},且对于单头情况有 dq=dk=dv=d" role="presentation">dq=dk=dv=dd_q=d_k=d_v=d。矩阵 P∈Rn×n" role="presentation">P∈Rn×n\mathbf P\in\mathbb R^{n\times n} 就是所谓的Attention矩阵,每一列是一个归一化的权重向量,对应一个token,表示该token的Attention向量可以通过n个输入的value向量加权求和获得,n个权重值就是这一列向量。 接下来Self-Attention子层的输出为 (2)LN(X+Wo⋅Attention(X))" role="presentation">(2)LN(X+Wo?Attention(X)) \text{LN}(\mathbf X+\mathbf W_o\cdot\text{Attention}(\mathbf X))\tag{2} 我们仔细想想公式(1),真实的语料中self attention权重任意情况都可能存在,Attention矩阵 P" role="presentation">P\mathbf P 可能的取值应该是任意的(只要满足非负性和列归一),但是通过这种softmax函数形式是否能保证取值范围足够大,从而覆盖任意的 P" role="presentation">P\mathbf P 呢?更准确地说就是,给定任意的输入 X" role="presentation">X\mathbf X 和 Attention矩阵 P" role="presentation">P\mathbf P,是否一定存在 Wq" role="presentation">Wq\mathbf W_q 和 Wk" role="presentation">Wk\mathbf W_k,满足如下等式(3)呢? 如果理论上都不成立,那么再怎么训练都无济于事,也就是说模型表达能力不足,无法拟合真实的Attention矩阵。 (3)Softmax[(WkX)⊤(WqX)dk]=P" role="presentation">(3)Softmax[(WkX)?(WqX)dk]=P \text{Softmax}\left[\frac{(\mathbf W_k\mathbf X)^\top(\mathbf W_q\mathbf X)}{\sqrt{d_k}}\right]=\mathbf P\tag{3} 论文中给出定理1回答这个问题。 定理1: 如果 dq=dk=d≥n" role="presentation">dq=dk=d≥nd_q=d_k=d\ge n,那么给定任意的列满秩矩阵 X∈Rd×n" role="presentation">X∈Rd×n\mathbf X\in\mathbb R^{d\times n} 和任意的正列随机矩阵(positive column stochastic matrix,即每个元素为正,且每一列元素之和为1,都是一个概率分布)P∈Rn×n" role="presentation">P∈Rn×n\mathbf P\in\mathbb R^{n\times n},则总是存在 d×d" role="presentation">d×dd\times d 的矩阵 Wq" role="presentation">Wq\mathbf W_q 和 Wk" role="presentation">Wk\mathbf W_k 满足如下等式(即有解) (3)Softmax[(WkX)⊤(WqX)dk]=P" role="presentation">(3)Softmax[(WkX)?(WqX)dk]=P \text{Softmax}\left[\frac{(\mathbf W_k\mathbf X)^\top(\mathbf W_q\mathbf X)}{\sqrt{d_k}}\right]=\mathbf P\tag{3} 如果 dq=dk=d<n" role="presentation">dq=dk=d<nd_q=d_k=d\lt n,则存在 X" role="presentation">X\mathbf X 和 P" role="presentation">P\mathbf P,对于所有的 Wq" role="presentation">Wq\mathbf W_q 和 Wk" role="presentation">Wk\mathbf W_k 都无法满足等式(3),即无解。 证明有解是通过构造法,不在这里详述。证明无解是通过给出一个例子: 假设 d=1" role="presentation">d=1d=1,n=2" role="presentation">n=2n=2,则 X∈R1×2" role="presentation">X∈R1×2\mathbf X\in\mathbb R^{1\times 2},Wq" role="presentation">Wq\mathbf W_q 和 Wk" role="presentation">Wk\mathbf W_k 退化成了 1×1" role="presentation">1×11\times 1 的矩阵即标量。令 X=[1,0]" role="presentation">X=[1,0]\mathbf X=[1,0],则有 \text{Softmax}\left[\frac{(\mathbf W_k\mathbf X)^\top(\mathbf W_q\mathbf X)}{\sqrt{d_k}}\right]=\text{Softmax}\left[\frac{[1,0]^\top\mathbf W_k^\top\mathbf W_q[1,0]}{\sqrt{d_k}}\right]=\text{Softmax}\left[\begin{bmatrix}\mathbf W_k\mathbf W_q&0\\0&0\end{bmatrix}\right]\\ 注意Softmax是在列上操作,而上式Softmax内的矩阵第二列全0,经过Softmax后只能变成 [0.5,0.5]^\top,必然无法生成第二列元素不相等的 \mathbf P,比如 \mathbf P=\begin{bmatrix}0.5&0.75\\0.5&0.25\end{bmatrix}. 论文在这里说,当 d\lt n 时就造成了低秩瓶颈,但并没有解释为何叫低秩瓶颈,和“秩”这个概念有啥关系?我们不妨自己理解一下。令Softmax函数里的矩阵为 \mathbf S,当 d\lt n 时,有 \text{rank}(\mathbf S)=\text{rank}\left[(\mathbf W_k\mathbf X)^\top(\mathbf W_q\mathbf X)\right]\le\min\left[\text{rank}(\mathbf W_k\mathbf X),\text{rank}(\mathbf W_q\mathbf X)\right]\le d\lt n\\ 即 \mathbf S 的秩的上限只能到 d,低于 n,而考虑到 \mathbf P 的任意性,秩的上限是 n。即便经过Softmax函数后 \mathbf S 的秩可能会升高一些,但也无法保证能够到 n。因此公式(3)左右两边的秩都无法保证相等,要保证矩阵相等自然更是妄想。秩相等是矩阵相等的必要条件,这便是低秩瓶颈的由来。定理1的 d\ge n 部分无非是证明了当秩能保证相等时矩阵也一定能够保证相等,必要条件变成了充要条件。 (2)Multi-Head Attention情况 再看标准的Multi-Head Attention,假设一共 h 个head,每个head都是一个Self-Attention: \text{head}(\mathbf X)_i=\mathbf W_v^i\mathbf X\cdot\text{Softmax}\left[\frac{(\mathbf W_k^i\mathbf X)^\top(\mathbf W_q^i\mathbf X)}{\sqrt{\frac{d}{h}}}\right]\in\mathbb R^{\frac{d}{h}\times n}\tag{4} 然后 h 个head通过concat拼接起来: \text{MultiHead}(\mathbf X)=\text{Concat}[\text{head}(\mathbf X)_i,...,\text{head}(\mathbf X)_h]\in\mathbb R^{d\times n}\\ Multi-Head Attention层的输出如下,其中 \mathbf W_o\in\mathbb R^{d\times d}: \mathbf Z=\text{LN}(\mathbf X+\mathbf W_o\cdot\text{MultiHead}(\mathbf X))\\ 标准的做法将每个头的投影矩阵 \mathbf W_q^i,\mathbf W_k^i,\mathbf W_v^i 的维度都弄成了 \frac{d}{h}\times d,在论文中 d/h 被称作head size,因为 \text{head}(\mathbf X)_i 输出的每个token向量维度就是 d/h。一般认为增加head数量 h 能够提升性能,但同时也导致了head size变小。对照公式(4)和定理1可以发现,当 h 过大超过 d/n 时,有 d/h\lt n,出现了低秩瓶颈问题,带来性能下降。论文实验也证明了这一点。h 过大超过 d/n 很常见,比如BERT-LARGE在pre-training阶段大部分情况 d=1024,n=128,当 h 超过8时就会发生。因此为了增加head数又不出现低秩问题,就必须增大 d,带来计算和存储的成本,得不偿失。 (3)Fixed Multi-Head Attention 论文给出了破解之法,修改标准的Multi-Head Attention,命名为Fixed Multi-Head Attention。其实分析清楚了原因,解法也比较好想,无非将head size和head数 h 解耦。 令 d_p 表示head size,新的投影矩阵 \mathbf V_q^i,\mathbf V_k^i,\mathbf V_v^i 的尺寸改为 d_p\times d,有 \text{fixedhead}(\mathbf X)_i=\mathbf V_v^i\mathbf X\cdot\text{Softmax}\left[\frac{(\mathbf V_k^i\mathbf X)^\top(\mathbf V_q^i\mathbf X)}{\sqrt{d_p}}\right]\in\mathbb R^{d_p\times n}\\ \text{FixedMultiHead}(\mathbf X)=\text{Concat}[\text{fixedhead}(\mathbf X)_i,...,\text{fixedhead}(\mathbf X)_h]\in\mathbb R^{hd_p\times n}\\ Fixed Multi-Head Attention层的输出如下,其中 \mathbf V_o\in\mathbb R^{d\times hd_p}: \mathbf Z=\text{LN}(\mathbf X+\mathbf V_o\cdot\text{FixedMultiHead}(\mathbf X))\\ 我们只要让 d_p\ge n,就可以消除低秩问题。缺点是投影矩阵的参数规模上去了,但相比需要增大 d 的破解之法,这种方法可以保持较小的embedding size d,最终能减少参数总量。 (4)MultiHead vs. FixedMultiHead Attention 如果 d_p\lt n 会怎么样?会比MultiHead更差还是更好?论文还贴心地对比了任意情况下二者的表现力,我们简述一下,不是本文重点。 当 d_p\ge d/h 时,给定一个MultiHead层,一定可以用一个 FixedMultiHead层表达它。原因很简单,MultiHead中Softmax内两个相乘的矩阵维度为 n\times d/h 和 d/h\times n ,换成两个更大的矩阵 n\times d_p 和 d_p\times n 相乘,自然是可以完全表达的。但是否有更强的表达能力呢?这个并不是很直观的结论,需要证明。论文给出定理2证明在一定条件下确实如此,这就表明FixedMultiHead Attention的优越性,即便在低秩瓶颈的情况下,FixedMultiHead依然有更强的表现力。 (5)总结思考 回到Decoder-only的思考,前面说明了Encoder存在低秩问题,限制表达能力。Decoder-only情况如何?苏剑林认为因为是单向注意力,有mask矩阵的存在,softmax函数后就变成了一个三角阵,且对角线都是正数,所以是满秩的,意味着有更强的表达能力,改成双向反而会变弱。 我觉得这里如果当作理论分析的话,严谨性有待商榷,原因有两点: 首先,根据我们前面对等式(3)的分析,满秩只是等式成立的必要条件,不一定是充分条件,也就是说满秩不能天然得出可以完全表达Attention矩阵 \mathbf P,甚至不一定就比低秩矩阵表达能力强,如果认为是充分条件或者一定比低秩矩阵强都需要给出证明。 其次,即便证明满秩确实可以完全表达Attention矩阵 \mathbf P,但这里Decoder-only的 \mathbf P 也是一个三角矩阵,是我们人为构造的单向注意力限制而成。如果改成Encoder双向注意力的话, \mathbf P 也将发生变化,变成了任意的矩阵 \mathbf P' (只要符合非负性和列归一),满秩三角阵必然无法完全表达 \mathbf P' 。梳理一下逻辑:Decoder-only满秩三角阵可以完全表达单向的 \mathbf P ,无法完全表达双向的 \mathbf P';Encoder低秩矩阵同样无法完全表达双向的 \mathbf P';不能推导出Decoder-only满秩三角阵和Encoder低秩矩阵谁强谁弱。 绕了一圈依然没有答案,除非真实的世界就是单向注意力的天下,即虽然我们对 \mathbf P' 不做限制,但它在真实语料上的分布大概率就是三角阵,也就是当语料大到一定规模根本不需要双向注意力,不然的话我感觉低秩问题并不是根本原因,而且Encoder低秩问题并非无解。 4.4 实验对比最靠谱 理论分析没有满意结果,那不妨实际对比一下,正好看到知乎上其他几位答主提到了这篇2022年的论文[8]:What Language Model Architecture and Pretraining Objective Work Best for Zero-Shot Generalization? 这篇论文真是大手笔,在50亿参数1700亿tokens预训练的模型上排列组合做了各种对比实验,有钱任性。论文背景是目前公认大模型(准确说为大型预训练Transformer语言模型)具有零样本(zero-shot)泛化能力,但是大模型各种各样,从模型架构到预训练目标差异很大,以及有没做adaptation,有没有fine-tuning,都不相同。门派众多到底哪家强,不妨对所有因素做个排列组合,公平PK一把。 (1)zero-sho介绍 先说一下什么是zero-shot,意思就是我们在大规模语料上训练出一个大模型之后,直接就可以通杀一切,在下游任务上不需要做任何微调。是不是有点“学好数理化,走遍天下都不怕”的味道了?说明模型已经具备了全部知识,不需要专项培训就可以直接上手干活,这不就是梦寐以求的通用人工智能(AGI)能力吗?当然在具体提问上需要告诉模型任务是什么,这一点在GPT-3的论文[9]里给出很形象的示例: |
|
|
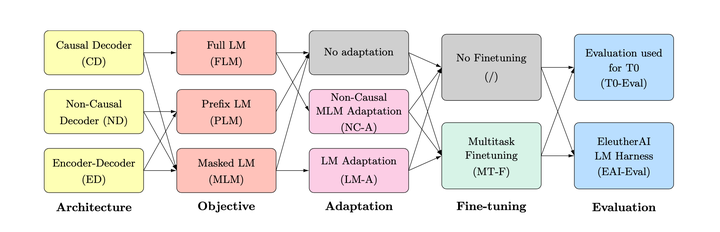
(2)四个变量的排列组合 然后论文[8]做的事就是如下图的排列组合,考虑模型架构、预训练目标、Adaptation、Multitask Fine-tuning四个变量,最后在两种评测数据上对比。我们分别介绍一下这四个变量都是何方神圣,有些内容跟前文重复,就不再详述。 |
|
|
(3)模型架构 Causal decoder-only,简称CD,就是我们前文一直说的Decoder-only架构,只有前向注意力,最适合训练标准的语言模型。 Non-causal decoder-only,简称ND,就是我们前文说的Prefix language model,当前输入的前一部分(给定的条件信息,比如问句部分)为双向注意力,后一部分为单向注意力。 Encoder-decoder,简称ED,原始Transformer的架构。 三种架构跟前文4.1部分介绍的三种架构本质上一回事,同样依靠不同的掩码矩阵实现,对比如下图: |
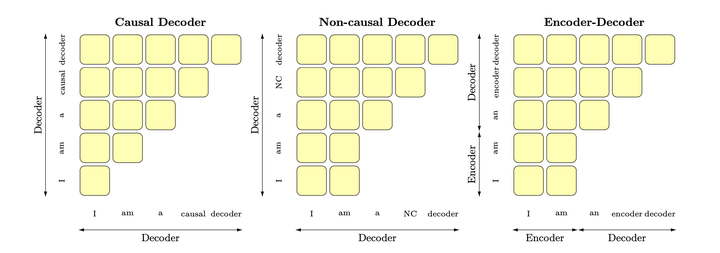
|
|
(4)预训练目标 full language modeling,简称FLM,就是训练标准的语言模型,完整一段话从头到尾基于上文预测下一个token,如GPT系列。跟CD模型架构是绝配。 prefix language modeling ,简称PLM,一段话分成两截,前一截作为输入,预测后一截。跟ND、ED架构配合都很自然。 masked language modeling,简称MLM,就是训练BERT时候用的完形填空,遮盖住文本中的一部分token,让模型通过上下文猜测遮盖部分的token。可以像Google T5模型一样将任务改造成text-to-text形式,即input和target都是一段文本,就可以适配ND和ED。如果将input和target拼接起来,就可以适配CD。 (5)adaptation 简单来说就是对大模型做改造。比如T5模型的预训练目标是MLM,不是一个很好的生成模型,那就继续预训练,不过目标改成PLM或FLM,注意这里跟微调不一样,再次预训练用的数据不是下游的任务数据,而是额外的无监督文本数据。反过来也一样,FLM预训练好的CD模型,通过切换掩码变为ND模型,再使用MLM目标改造,就可以用于完成完形填空任务。论文将前者称为Language modeling adaptation (LM-A) ,后者称为non-causal MLM adaptation (NC-A)。 (6)Multitask finetuning 多任务微调multitask finetuning (MT-F) ,照搬了T0模型[10]的做法,在一百多个已知任务的prompt数据上做微调,能极大提升预训练模型在未知任务上的zero-shot泛化能力。这其实属于Instruction Tuning做法,后续讲到的时候再细聊。 (7)实验结论 通过排列组合后,总结出三个发现: 发现1:如果大模型只做无监督预训练,则CD架构+FLM目标的zero-shot泛化能力最佳。这和当前大模型的主流做法一致。 发现2:无监督预训练+Multitask finetuning后,则ED架构+MLM目标的zero-shot泛化能力最佳。 发现3:鉴于发现1和发现2,加上Multitask finetuning后,ED架构zero-shot泛化最佳,但可能不适合某些CD架构更擅长的开放式生成任务。当我们想获得两个不同模型:一个是利用Multitask finetuning后的最佳zero-shot性能模型,一个是用于生成任务的高质量语言模型,则可以利用adaptation方法更加快速的生成,减少计算成本。方案是:从CD架构模型开始,使用FLM预训练,获得最佳语言模型;然后经过non-causal MLM adaptation,最后通过Multitask finetuning,获得最佳zero-shot多任务模型。一箭双雕,完美。 (8)总结 让我们回到GPT为什么从始至终选择Decoder-only架构这个问题,发现1可以作为一个很好的旁证,说明这条道路的选择是正确的。但这篇论文是22年的工作,GPT-3都出来两年了。作为“外人”,我们可能永远无法获悉OpenAI当初决策的原因,或许做了很多未公开的对比实验,或许单纯就是一种信仰,认定了bigness is betterness,只要模型足够大,选择decoder-only还是其他都不是问题,那何不选择一个和语言模型目标最契合、参数存储和推理计算效率最高的呢? |
|
从面试者的角度认真答一下^_^。 我想起了大半年前第一次在面试中遇到这个问题的窘况: 面试官 :“为什么现在的大模型大都是decoder-only架构?” 懵逼的我TAT:“呃呃,和encoder-only相比,它既能做理解也能做生成,预训练的数据量和参数量上去之后,GPT这样的decoder-only模型的zero-shot泛化能力很好,而BERT这样的encoder-only模型一般还需要少量的下游标注数据来fine-tune才能得到较好的性能。” 面试官礼貌地说有点道理^_^,然后开始发威→__→:“那T5这种encoder-decoder也能兼顾理解和生成啊?像FLAN那样instruction tuning之后zero-shot性能也不错呢?为啥现在几十几百B参数量的大模型基本都是decoder-only呢?” 更加慌张的我QaQ:“呃呃,确实有encoder-decoder和PrefixLM这些其他架构,现在大家对哪个更好好像还没有统一的定论,但到几十B这个规模还没人进行过系统的比较,大概是OpenAI先把decoder-only做work了,形成了轨迹依赖,大家都跟上了,之后或许会有更系统的探索。” 当时是面暑期实习,面试官还是放过了我,但我当时的内心是这样的: |

|
|
半年前差点被这个问题挂在面试现场的我 现在想来,这个回答既不全面(没有主动提到T5那样的encoder-decoder架构,也忘了GLM、XLNET、PrefixLM等等其他架构),也没涉及到问题的科学本质:都知道decoder-only好,为啥好呢? 这个没有统一答案、却又对LLM的发展极其重要的问题,在24届算法岗面试热度颇高,我找工作的一路上就被不同公司的面试官们问了四五次,从面试官的反馈和贵乎各位大佬的回答中总结了一套目前来看比较完备的回答,希望能帮到有需要的各位: 首先概述几种主要的架构:以BERT为代表的encoder-only、以T5和BART为代表的encoder-decoder、以GPT为代表的decoder-only,还有以UNILM为代表的PrefixLM(相比于GPT只改了attention mask,前缀部分是双向,后面要生成的部分是单向的causal mask),可以用这张图辅助记忆: |

|
|
这里的causal decoder就是GPT这样的decoder-only,non-causal-decoder就是指Prefix-LM。图片来自[1] 然后说明要比较的对象:首先淘汰掉BERT这种encoder-only,因为它用masked language modeling预训练,不擅长做生成任务,做NLU一般也需要有监督的下游数据微调;相比之下,decoder-only的模型用next token prediction预训练,兼顾理解和生成,在各种下游任务上的zero-shot和few-shot泛化性能都很好。我们需要讨论的是,为啥引入了一部分双向attention的encoder-decoder和Prefix-LM没有被大部分大模型工作采用?(它们也能兼顾理解和生成,泛化性能也不错) 铺垫完了,相信这时候面试官已经能感受到你对各种架构是有基本了解的,不至于太菜,接下来是主干回答: 第一,用过去研究的经验说话,decoder-only的泛化性能更好:ICML 22的What language model architecture and pretraining objective works best for zero-shot generalization?. 在最大5B参数量、170B token数据量的规模下做了一些列实验,发现用next token prediction预训练的decoder-only模型在各种下游任务上zero-shot泛化性能最好;另外,许多工作表明decoder-only模型的few-shot(也就是上下文学习,in-context learning)泛化能力更强,参见论文[2]和 @Minimum 大佬回答的第3点。 第二,博采众家之言,分析科学问题,阐述decoder-only泛化性能更好的潜在原因: @苏剑林 苏神强调的注意力满秩的问题,双向attention的注意力矩阵容易退化为低秩状态,而causal attention的注意力矩阵是下三角矩阵,必然是满秩的,建模能力更强; @yili 大佬强调的预训练任务难度问题,纯粹的decoder-only架构+next token predicition预训练,每个位置所能接触的信息比其他架构少,要预测下一个token难度更高,当模型足够大,数据足够多的时候,decoder-only模型学习通用表征的上限更高; @mimimumu 大佬强调,上下文学习为decoder-only架构带来的更好的few-shot性能:prompt和demonstration的信息可以视为对模型参数的隐式微调[2],decoder-only的架构相比encoder-decoder在in-context learning上会更有优势,因为prompt可以更加直接地作用于decoder每一层的参数,微调的信号更强;多位大佬强调了一个很容易被忽视的属性,causal attention (就是decoder-only的单向attention)具有隐式的位置编码功能 [3],打破了transformer的位置不变性,而带有双向attention的模型,如果不带位置编码,双向attention的部分token可以对换也不改变表示,对语序的区分能力天生较弱。 第三,既然是工业界面试嘛,肯定要提效率问题,decoder-only支持一直复用KV-Cache,对多轮对话更友好,因为每个token的表示只和它之前的输入有关,而encoder-decoder和PrefixLM就难以做到; 第四,务虚一点,谈谈轨迹依赖的问题:OpenAI作为开拓者勇于挖坑踩坑,以decoder-only架构为基础摸索出了一套行之有效的训练方法和Scaling Law,后来者鉴于时间和计算成本,自然不愿意做太多结构上的大改动,继续沿用decoder-only架构。在工程生态上,decoder-only架构也形成了先发优势,Megatron和flash attention等重要工具对causal attention的支持更好。 最后,跳出轨迹依赖,展示一下你的博学和开放的眼光,谈谈GLM、XLNet这些比较另类的模型结构,表示到了几十几百B这个参数规模,还没有特别系统的实验比较说明decoder-only一定最好,后面值得继续探索。当然了,“咱们”公司如果有相关机会,我特别愿意过来和老师们结合具体业务需求来探索(手动狗头)。 相信这一套回答下来,原本可能昏昏欲睡的面试官会精神一振奋,大概率给你痛快通过: |

|
|
我是 @Sam多吃青菜 ,一枚即将从北大毕业的NLPer,日常更新LLM和深度学习领域前沿进展,也接算法面试辅导,欢迎关注和赐读往期文章,多多交流讨论: |

|
|
Sam多吃青菜 北京大学 前沿交叉学科研究院硕士在读 1614 次赞同 去咨询 #大模型 #大语言模型 #GPT #ChatGPT #NLP #自然语言处理 #深度学习 #算法岗面试 #面经 参考文献 [1] Wang, Thomas, et al. "What language model architecture and pretraining objective works best for zero-shot generalization?."International Conference on Machine Learning. PMLR, 2022. [2] Dai, Damai, et al. "Why can gpt learn in-context? language models secretly perform gradient descent as meta optimizers."arXiv preprint arXiv:2212.10559(2022). [3] Haviv, Adi, et al. "Transformer Language Models without Positional Encodings Still Learn Positional Information."Findings of the Association for Computational Linguistics: EMNLP 2022. 2022. |
|
这个问题还挺值得思考的。在这里从一个NLP从业者的角度来说一说decoder-only的优点,也讨论一下encoder-decoder模型会不会有翻身的空间。 1. 更好的Zero-Shot性能、更适合于大语料自监督学习 首先,对encoder-decoder与decoder-only的比较早已有之。咱们先把目光放放到模型参数动辄100B之前的时代,看看小一点的模型参数量下、两个架构各有什么优势――Google Brain 和 HuggingFace联合发表的 What Language Model Architecture and Pretraining Objective Work Best for Zero-Shot Generalization? 曾经在5B的参数量级下对比了两者性能。 (之前我写过对该论文写过一篇解读,有兴趣的读者可以看看) 论文最主要的一个结论是decoder-only模型在没有任何tuning数据的情况下、zero-shot表现最好,而encoder-decoder则需要在一定量的标注数据上做multitask finetuning才能激发最佳性能。 而目前的Large LM的训练范式还是在大规模语料上做自监督学习,很显然,Zero-Shot性能更好的decoder-only架构才能更好地利用这些无标注数据。 此外,Instruct GPT在自监督学习外还引入了RLHF作辅助学习。RLHF本身也不需要人工提供任务特定的标注数据,仅需要在LLM生成的结果上作排序。虽然目前没有太多有关RLHF + encoder-decoder的相关实验,直觉上RLHF带来的提升可能还是不如multitask finetuning,毕竟前者本质只是ranking、引入监督信号没有后者强。 2. 大数据训练+大参数模型的涌现能力替代了multitask finetuning 前面说到,5B参数量+170B token数据量时,在做multitask finetuning后encoder-decoder相比decoder-only反而在新任务上会有一定的优势。 那么,在参数量再上一个台阶后,我们知道了LLM大模型表现出了涌现能力 (emergent abilities)。关于涌现能力,爱丁堡大学的Yao Fu博士有一篇很好的博客详细阐述: 简言之,在模型参数量足够大时,模型的能力提升不再遵守以往的log-linear的提升法则,而是突然急速增强性能。 |
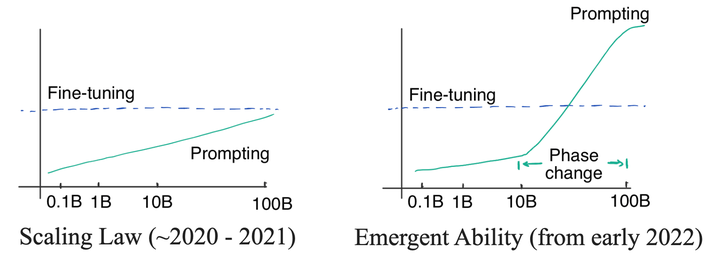
|
|
左图是传统的对数-线性性能曲线,而右图的LLM大模型在参数量突破某一量级后会急速提升性能、突破以往的对数-线性曲线。图源自Yao Fu博士的博客。 我们迄今还没有办法解释涌现能力为何出现。涌现能力的一个表现是,参数量达到一定量级后,模型具有了"复杂的推理能力"――譬如从非结构化的文本中自动地提取结构化的知识。 那么,LLM也可以自动地从大数据里面做self multitask finetuning。具体来讲,大数据里面本身天然蕴含了许多任务:比如 双语网页数据-机器翻译、论文(摘要+正文)数据-文本摘要、维基百科数据-命名实体识别等等。 因此,对于常见的NLP任务、LLM可以视为已经self finetuning过了;对于复杂问题,LLM的推理能力可以把这些问题转换成几个基本任务的”和“。譬如Closed-book question-answering任务,模型可以将其转换为 Knowledge Graph Completion + Reading Comprehension + Question Answering的组合。 由此,encoder-decoder在multitask finetuning上的优势在大参数量时被LLM的推理能力给拉平了。 3. In-context learning对LLM有few-shot finetune的作用 最后,在实际使用LLM时,我们经常会加入Chain-of-Thought或者In-Context信息来作为prompt进一步激发模型潜力――例如加入一些例句让GPT类模型来模仿、生成更好的结果。 |

|
|
无In-context的生成 |

|
|
有In-context的生成 以上两个例子是我使用GPT-2的demo生成的,可见GPT类模型In-Context Learning能力很强(虽然后者后面也生成错了一些case,但远强于前者的non-sense)。 近期有论文指出In-Context信息可以视为一种task finetuning 论文的数学推导是定性的,大体上是将prompt信息归为对Transformer Attention层参数的微调。 |
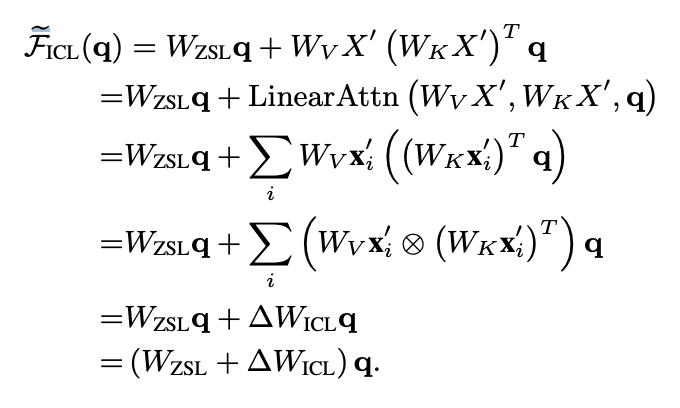
|
|
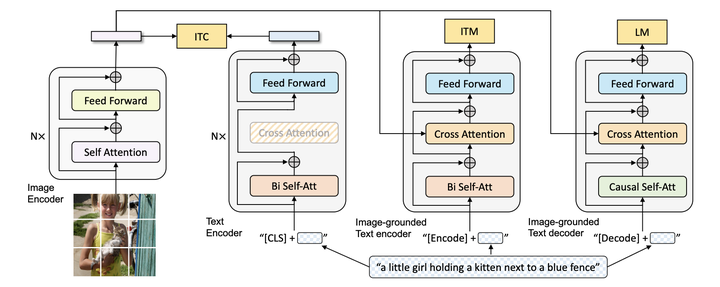
作者推导的核心步骤 按照这篇论文的思路,decoder-only的架构相比encoder-decoder在In-Context的学习上会更有优势,因为前者的prompt可以更加直接地作用于decoder每一层的参数,微调信号更强。也因此,更适合ChatGPT这类开放域的对话模型作为基础模型。同理,在总数据量少的情况下,In-Context + Decoder-only也更具有few-shot的优势――Google近期的论文在机器翻译上也观察到了类似现象,即中等量的单语数据+大模型+In context就能学习出很好的翻译效果: 小结,以及encoder-decoder的未来 总言之,decoder-only在参数量不太大时就更具有更强的zero-shot性能、更匹配主流的自监督训练范式;而在大参数量的加持下,具有了涌现能力后、可以匹敌encoder-decoder做finetuning的效果;在In Context的环境下、又能更好地做few-shot任务。 我在这里说些个人看法:decoder-only架构其实也更天然地符合传统的Language Model的模式,前几年encoder-decoder模型的火爆更多是依赖于在特定标注数据上的训练――比如Transformer论文中经典的WMT机器翻译任务。 在未来,Large Language Model+自监督训练应该还是会继续采用decoder-only的架构。encoder-decoder有两个特点可能会使得它在以下两类任务上有优势: encoder的多样性。许多多模态工作(BLIP、ALBEF、SimVLM)上可以看见encoder-decoder的影子,因为encoder可以用来encode多种模态的信息,而decoder-only的多模态工作相对较少(微软近日的visual-ChatGPT更多偏向模型级联pipeline)。 |
|
|
BLIP模型:每个模态可以有一个encoderDeep Encoder+Shallow Decoder的推理优势。Encoder-decoder架构本来在计算效率上(以FLOPs衡量)就是优于其他LM的,且工业界目前常使用Deep Encoder+Shallow Decoder的组合,由于encoder本身并行度高,这类encoder-decoder的infer速度远超大型的decoder-only。在有较多标注数据的任务上,encoder-decoder还是具有成本优势的。 |
|
|
| [收藏本文] 【下载本文】 |
| 科技知识 最新文章 |
| 百度为什么越来越垃圾了? |
| 百度为什么越来越垃圾了? |
| 为什么程序员总是发现不了自己的Bug? |
| 出现在抖音评论区里边的算命真不真? |
| 你认为 C++ 最不应该存在的特性是什么? |
| 为什么 Windows 的兼容性这么强大,到底用了 |
| 如何看待Nvidia禁止使用翻译工具将cuda运行 |
| 为何苹果搞了十年的汽车还是难产,小米很快 |
| 该不该和AI说谢谢? |
| 为什么突破性的技术总是最先发生在西方? |
| 上一篇文章 下一篇文章 查看所有文章 |
|
|
|
| 股票涨跌实时统计 涨停板选股 分时图选股 跌停板选股 K线图选股 成交量选股 均线选股 趋势线选股 筹码理论 波浪理论 缠论 MACD指标 KDJ指标 BOLL指标 RSI指标 炒股基础知识 炒股故事 |
| 网站联系: qq:121756557 email:121756557@qq.com 天天财汇 |