
| |
|
|
| ����ƻ� -> �Ƽ�֪ʶ -> 2024�꣬���ѧϰ������Ŀ�е�top10�㷨��ʲô�� -> �����Ķ� |
|
|
[�Ƽ�֪ʶ]2024�꣬���ѧϰ������Ŀ�е�top10�㷨��ʲô�� |
| [�ղر���] �����ر��ġ� |
|
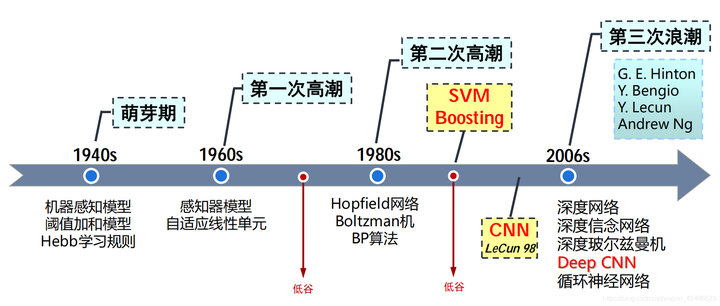
�������ھ������У�2006 �� 12 �� IEEE ICDM ѡ��top10�㷨��C4.5��k-Means��SVM��Apriori��EM��PageRa�� |
|
���������Ⱥ� Wide & Deep Word2Vec FastText BERT GPT Transformer AlexNet YOLO Diffusion Whisper 1. Wide & Deep�� - ģ�ͼ�Ҫ������Wide & Deep��һ�ֻ���ѧϰģ�ͣ����������ģ�ͣ������֣�����������磨��֣������ڴ������ģϡ�������� - ����ҵӰ�죺��ģ��Ϊ�Ƽ�ϵͳ��涨�������ṩ���µķ�����ͨ����Ͽ���������ƣ������ģ�͵ķ���������Ԥ��ȷ�ԡ� 2. Word2Vec�� - �����ˣ�Tomas Mikolov - ģ�ͼ�Ҫ������Word2Vec��һ���������ɴ�������ģ�ͣ�����CBOW��Skip-gram����ʵ�ַ�ʽ���ܹ����ʻ�����������ϵ�� - ����ҵӰ�죺Word2Vec������ƶ�����Ȼ���Դ�������Ľ�����Ϊ�����Ĵ�Ƕ�뼼����Ԥѵ������ģ�͵춨�˻����� 3. FastText�� - ����������Facebook AI Research (FAIR) - ģ�ͼ�Ҫ������FastText��һ���ı���ʾģ�ͣ�ͨ�����ʷֽ�Ϊ�ַ�n-grams��ѧϰ�ʻ��֮����ַ���ϣ��Ӷ����õش��������ʺʹ���Ϣ�� - ����ҵӰ�죺FastText�����˺����ʺ�����ʵ��ʶ������ܣ��ر����ڴ�����Ӣ������ʱ���ֳ�ɫ���Զ�����NLP��������˻���Ӱ�졣 4. BERT�� - ����������Google AI Language - ģ�ͼ�Ҫ������BERT�ǻ���Transformer��Ԥѵ�����Ա�ʾģ�ͣ�ͨ��Masked Language Model��Next Sentence Prediction����Ԥѵ�������Ժܺõ��������������塣 - ����ҵӰ�죺BERT�ij�����������˸�����Ȼ���Դ�����������ܣ����ı����ࡢ����ʵ��ʶ���ʴ�ϵͳ�ȣ�������NLP������о����ơ� 5. GPT�� - ����������OpenAI - ģ�ͼ�Ҫ������GPT��Generative Pretrained Transformer����д����һ�ֻ���Transformer������ʽԤѵ��ģ�ͣ��ܽ�����������Ȼ�������ɡ� - ����ҵӰ�죺GPTϵ��ģ�ͣ���GPT-3������Ȼ������������ɷ���ȡ�����ش�ͻ�ƣ��㷺Ӧ������������ˡ��ı����ɡ�������������� 6. Transformer�� - ����������Google AI Language - ģ�ͼ�Ҫ������Transformer��һ�ֻ�����ע�������Ƶ����ѧϰģ�ͣ������˴�ͳ��ѭ���;����ṹ�������ڴ����������ݡ� - ����ҵӰ�죺Transformer�ܹ����ı�����Ȼ���Դ�����������������Ϊ���������Ƚ�ģ�ͣ���BERT��GPT���Ļ����� 7. AlexNet�� - �����ˣ�Alex Krizhevsky, Ilya Sutskever, Geoffrey Hinton - ģ�ͼ�Ҫ������AlexNet��һ����Ⱦ��������磬������ReLU�������Dropout����GPUѵ������ImageNet��ս����ȡ����ͻ���Գɹ��� - ����ҵӰ�죺AlexNet�ijɹ�֤�������ѧϰ��DZ�����������˼�����Ӿ���������ѧϰ�����������˺�����������ģ�ͣ���VGGNet��ResNet���� 8. YOLO�� - �����ˣ�Joseph Redmon, Ali Farhadi - ģ�ͼ�Ҫ������YOLO��You Only Look Once����һ��ʵʱĿ����ϵͳ��ͨ����ͼ��Ϊ�����е���Ԥ��������ʶ��ͼ���еĶ��� - ����ҵӰ�죺YOLO�����ٶȿ��ʵʱ���ܶ�������������ƶ���Ŀ���⼼�����Զ���ʻ����Ƶ��ص������Ӧ�á� 9. Diffusion�� - ����������OpenAI - ģ�ͼ�Ҫ��������ɢģ����һ������ģ�ͣ�ͨ������������Ȼ����ȥ��������������������������ͼ����Ƶ���ı�������ȡ������Ч���� - ����ҵӰ�죺��ɢģ��Ϊ����ģ���ṩ��һ���µĿ����ԣ���������ͼ�����Ƶ���ɷ�����ʾ��ǿ���DZ�������ܳ�Ϊδ������ģ�͵���������֮һ�� 10. Whisper�� - ����������Google AI - ģ�ͼ�Ҫ������Whisper��һ���������ı���ת��ϵͳ��ʹ�����ѧϰģ����ʶ������ⲻͬ���������ٺͱ��������µ��������ݡ� - ����ҵӰ�죺Whisper�Ľ�������ʶ������ȷ�ԺͿ����ԣ��������ϰ��������Զ���Ļ���ɺͶ���������ʶ������������Ҫ��ֵ�� |
|
ʵ��Ч����һ������õģ�����������ۿ϶�����������̵ģ���������ϲ���� Top10 Word2vec ��һ�νӴ�����ѧϰʱ���������е����ӡ��й�-���� = ����-���衹���о������˵���֪�����߸��ˣ��Ӵ�̤���˻���ѧϰ����ӡ� Variational Autoencoder (VAE) ����ƶ����Ա������������ںϣ��봫ͳ�Ա�������ȣ�ͨ����������ķ�ʽǿ����������ѧ���ı���߱��ֲ��ռ�ṹ�����ַ�ʽ����������ģ�������������Զ��Ӱ�졣 Generative Adversarial Network (GAN) �����ڴ�ͳ Encoder-Decoder �ṹ���߳���һ��ȫ�µ�·���� min-max �Ż�����ת��Ϊ������������б�������ĶԿ�ѧϰ���̡� Graph Convolutional Network (GCN) ����ָ���ǹ����ͼ�������磬һ������ Spectral Networks and Locally Connected Networks on Graphs��Convolutional Neural Networks on Graphs with Fast Localized Spectral Filtering��Semi-Supervised Classification with Graph Convolutional Networks ��ƪ���ġ� Spectral CNN �ǿ�ɽ֮����������ͼ�����״ν������ƹ㵽��ͼ���硣 Chebyshev Spectral CNN ��������˹�����Chebyshev����ʽ�������˲���������������˼������� GCN ���Ǽ�����ߣ����������������ս�ͼ����Ũ����һ�������������˼��¡� ��ϧ�Դ�֮��� GNN ����ͼ������ֻʣ��Ϣ���ݡ� PointNet �������紦�����ƵĿ�ɽ֮��������˵������ݵ������ԺͲ������ԣ��Ӵ���ά�Ӿ��������ѧϰʱ���� Neural Radiance Field (NeRF) ��������ѧϰ�ռ���ÿһ��Ĺⳡ��Ȼ��������Ⱦ���ֳ�ͼ��ֱ�DZ�����ѧ�� ��˵��ά�Ӿ������ֶ��˸��·����������ͷ���ܿ졣 Deep Q-Network (DQN) ��ӹ���ɵľ��䣬�� Q-learning ���츳�������ѧϰ�������˺ܺõĻ�ѧ��Ӧ��ǿ�ò���˼�顣 AlphaGo ���ؿ���������+���ѧϰ�����ܿ½�������� AI �������ʷ��ʱ�̡� Proximal Policy Optimization (PPO) Schulman �� TRPO ��������������������ѧϰ���ȶ������⣬���Ǽ��㿪��̫���������ֽ������ PPO����Ȼ���������ָĽ��������ײ���������ûͶ���ģ�����Arxiv�ϡ� û�뵽���� PPO ̫�����ˣ����ȶ���Ч����Ӧ�õ�����һ�������� ChatGPT Ҳ�õ� PPO�� Neural Tangent Kernel (NTK) �����������磨������������£���ѵ��Ϊʲô���ȶ�������Ϊʲô������������ij�ʼ���أ���������Ľṹ�йء� ���� NTK �Ľ��� �Ҷ� NTK �о��ò�����̣�����ֻ��һ��ֱ�۵����⣺ ��������������������ʱ���� NTK ��ѵ��ʱ�Ǽ�������ģ�Ҳ����˵��������ݶ��½����̣����Խ��Ƴ�һ������ODE ���ݻ����̡� ����ֱ��ʹ�ý��ۣ����� Understanding the Neural Tangent Kernel �IJ��� |

|
|
����� w0" role="presentation">w0w_0 ������ij�ʼȨ�أ� u(t)=y(t)−y¯" role="presentation">u(t)=y(t)?y��u(t)=y(t)-\bar{y} ��ʾ��ground truth�IJ��죬���Կ������۳�ֵ u(0)=y(w0)−y¯" role="presentation">u(0)=y(w0)?y��u(0)=y(w_0)-\bar{y} ��ôȡ��������Ӱ�쵽 u(t)" role="presentation">u(t)u(t) ������ 0. �����ʾ��һЩ��̵����� ����ij�ʼ��������Ӱ������������NTK���ȶ��ԣ������ѵ������Ҳ���ȶ��� ����ο� Some Math behind Neural Tangent Kernel |

|
|
��ʹ���������ع��Ȳ�����ʱ��ģ����Ȼ�ܹ�ѧϰ�������������������û�д�仯��ͬʱ��loss Ѹ���������㡣 |
|
�������ޣ�ֻ��ѡ���Լ�ϲ����10���� GAN, ResNet, Transformer����������ǰ��û��˵����Ϊ��֪����work����ͨ�������䣬�������� CV�ģ�Diffusion(DDPM)��MVSSNet��LoRA�� Speech�ģ�VITS��Conformer�� ʱ�����еģ�AnomalyTransformer�� ǿ��ѧϰ�ģ�PPO�� |
|
�ӹ�ȥ��������� 1. word2vec����ɽ֮��û��˵�������bert��gpt��������Ӱ�� 2. resnet��������yyds 3. transformer����Ȼattention����transformer��������ģ�����̬Ȩ��Ӱ����Զ 4. BERT��transformer��encoder 5. GPT��transformer��decoder��Ҳ����gpt3ֱ�ӿ�����ģ��ʱ�� 6. CLIP����ģ̬�ij���֮�� 7. MoCo���Ա�ѧϰ 8. stable diffusion������ͼ 9. ViT 10. RWKV�����Դ�ģ�ͣ�����RNN |
|
0 Word2Vec 1 ResNet 2 Transformer 3 CLIP 4 Expert Systems (GPT4) 5 Diffusion Model 6 Encoder->Decoder Structure 7 Reinforcement Learning (DDPO) 8 LSTM 9 Object Detector (R-CNN, Fast R-CNN, Faster R-CNN, YOLO) |
|
վ��2024��Ľ��죬�����е�Top10���㷨��ʱ��˳����˵�ֱ��� AlexNet�� Word2vec��GAN��ResNet��Transformer��BERT��GPT-3��CLIP��StableDiffusion��InstructGPT�� AlexNet�������˹������˳��� AlexNet��ʹ���Ǽ�ʶ�������ѧϰ�㷨ģ�ͶԱȴ�ͳ����ѧϰ�㷨��ǿ�� Word2Vec: ����NLP��һ����ʱ�� GAN������������ͬ�����������ѵ�����㷨���ܹ����ɷdz������ͼƬ ResNet������һ�쿪ʼ�����������Ӿ����������ϵ�Ч����Խ�����ࡣ������� ResNet �о���IJв����� Transformer��Transformer �ṹ����Խ��ʹ�ú��������Ķ�������������˸Ľ������߽�ԭ����ģ�ͽ�������ֻ�����죬��û�г����ܹ������������ṹ��ģ�͡� BERT����ɨ�� 11 �� NLP �������˴�ģ��ʱ������Ļ������һ�쿪ʼ��ѧ���о���ʼ��ƴ�Կ���ƴ�����ľ��������� GPT-3����ζ�Ŵ�ģ�ʹӡ�Ԥѵ��-�����ķ�ʽ����ʾ��ѧϰ���ķ�ʽ����ת�䡣 CLIP��ʹ��ͼ����ı�����ѵ���Ķ�ģ̬ģ�ͣ�����������ѧϰ�����������Դ���Ȼ��������Ч��ѧϰ�Ӿ��źţ���Ӧ�õ��κ�ͼ��������� StableDiffusion����һ�ֻ�����ɢ���̵�ͼ������ģ�ͣ��ܹ��ڸ����κ��ı��������������ɱ������Ƭͼ��ʹ��ʮ�����ܹ��ڼ������ڴ��������˾�̾��������Ʒ InstructGPT��ChatGPT��ǰ����������ȫ��AI�˳�������ʱ���� �ر���ϸ����Ϣ�ҷ�������ƪ�����У���ӭ���ȥ�鿴�� ��ɣ�AI ʮ���꣬�̵�������ģ��ؿ��˹����ܵ�����֮· ��������а��������Ե��ޡ��ղء���עһ�£�лл~ |
|
NLP��Transformer����Seq2Seq�㷨����GPT4��Decoder-only�컨�壩��Word2Vec��Skip-gram Embedding˼������RLHF������������ͼ����ģ������Ҫ���㷨����MoE��������ģ�Ͳ������ܣ� CV��ResNet����˼���ǵ�һ����MAE��������ֱ����CV��BERT����Nerf��Ч���ܺã���Diffusion����ͨ����ͼ��flexible & tractable����Swin Transformer��ƴͼidea��� |
|
0 AlexNet: �Ҿ����Ǿ�����������ߴ����Ĺ����� 1 ResNet: ���ٲ���֮ǰ� 2 Transformer: Attention is all your need; 3 GAN����ģ�ʹ��ģ�ͣ� 4 LSTM��ʱ��������㷺���͵����磬�����ŵ���ƣ� 5 GPT: Decoder-Only����һ����ģ��ʱ����־�����磻 6 BERT��Encoder-Only�����ģ�ͻ����Ķ������� 7 Diffusion������������ͼ��ʱ���� 8 YOLO: You Only Look Once; 9 Gemini: ���һ�������ɣ��������漣����������Ķ�ģ̬������˫ģ̬����Agent��Ŀǰģ�ͻ��ڳ����ĵ���ѵ����δ�����ڣ� �кܶྫ�ɵ��뷨��LoRA, FastSpeech, FastText, Word2Vec, RLHF��������VGG, VAE��U-Net����������籾Ӧ�ó�����ǰʮ������������һЩ����ɫ�ʣ��ڴ�δ�������ܹ������������ɫ�ʵİ�ȫ�������� |
|
Transformer Diffusion GAN Nerf BEV Gaussian splatting Vit Resnet |
|
0 Auto Regression 1 Self Attention 2 ResNet 3 CNN 4 Reinforcement Learning 5 DDPM 6 Contrastive Learning 7 Lora 8 GCN 9 VAE -������������������ ���������Ⱥ� |
|
��д������ô�࣬���������е���һ�Űɡ� 1.Transformer��ת����ģ�͡���Ч��ģ�����������Ԫ��Ӧ���ƣ���������֮ǰ���ѧϰ�㷨��Transformer�ܹ�ͨ������ע�������ƺ���֪�������ƣ������������ģ�͵IJ�����ģ���ƣ�����Ч�����ƣ�ΪChatGPT�ij��ֵ춨������Ҫ�Ļ����������Ľ��죬��������̸��Transformerʱ�����Ѿ����˹����ܵľ����ܣ��γ���һ������塣Transfomer�� NLP �����˹ؼ��ķ�ʽת�ƣ�2018�꿪ʼ���������Transformer����ģ��ELMo��BERT��RoBERTa��XLNet��T5��ALBERT��GPT-3�ȣ�����ˢ����Ȼ���Դ������������SotA��State of the Art�����֡� |

|
|
�߆�AI�Σ�AIӢ��ϵ�С���Transformer0 ��ͬ �� 0 �������� 2.GPT��Generative Pre-trained Transformer��������ʽԤѵ��ת��ģ�͡�GPT�ܹ��ڻ������۶���Դ�ڹȸ������£�ͨ���������漣������˵�ǰAI���ȵ�λ�á���ȻGoogle��Deepmind������BERT��T5��Gopher��PaLM��GaLM��Switch�ȴ�ģ�ͣ��ٶȷ��������ģ�ERNIE��ϵ��Ҳ�����о������� |

|
|
�߆�AI�Σ�AIӢ��ϵ�С���ChatGPT0 ��ͬ �� 0 �������� 3.Hallucinate�������þ�����Ȼ������������������㷨������Ӱ�����Ѿ���������һ��AI�㷨�ȼ磬�ŵ�����λ�ɣ��������˹����ܻþ����뷢չ�˹�����ģ��ͬ�������ش����OpenAI��ѧ��Andrej Karpathy˵��������ģ�͵�ȫ������ǡǡ��������þ�����ģ�;��ǡ����λ�������ģ���ܹ�����ѵ����ʹ�õ�֪ʶͼ�ʹ����ݼ���֪ʶͼ���У�ѧϰ��ȥ�ش���˴��ڡ�Hallucination�þ����⡹����õ�LLM�㷨�Ƿ����ͨ���л���������ʹ��ģʽ��������������ʱ���Σ���ʱ�����Σ� |

|
|
�߆�AI�Σ�AIӢ��ϵ�С���Hallucinate0 ��ͬ �� 0 �������� 4.Stable Diffusion����ɢģ�͡�����ʮ�����ڼ������ڴ�����������̾������Ʒ�����ٶȺ��������棬��������ͻ�ƣ�����ζ����������������� GPU �����У�ʹͼ�����ɼ���������ڡ� |

|
|
�߆�AI�Σ�AIӢ��ϵ�С���Stable Diffusion��ɢģ��0 ��ͬ �� 0 �������� 5. Midjourney���е���ʹ�õ�Ҳ��Diffusion��ɢ�㷨Ϊ��������������Ƭ������������LOGO�����裬MJ������ͼ���������˾�̾�Ҹ��д��⣬MJȷʵ���һЩ����������ר�ŵ�ѵ������������ʦ�й㷺Ӧ�á� |

|
|
�߆�AI�Σ�AIӢ��ϵ�С���Midjourney0 ��ͬ �� 0 �������� 6.Artificial Neuron Network���˹������硣�������㷨��һ���˲����ͻ�ƣ�������ʵ����Ҫ�����ļ�����Դ�ͼ���ɱ�����2012�����������ķ���10������˳����������Դ�����������ݣ���ǿʽѧϰ�㷨�ļӳ֣�����ʽAI��������ģ�Ͳŵ��Խ��˹������ƶ������ڵ�ˮƽ�� |
|
|
�߆�AI�Σ�AIӢ��ϵ�С���ANN �˹��������㷨0 ��ͬ �� 0 �������� 7. RLHF����ǿʽѧϰ���ɹ�ģ��������������̣����趨�����㷨�Ͳ�����Ȼ����㷨������ʦģ���ֻ��ڣ�ͨ�����ϴ�ֶ�gpt��������з������Զ����������������̼�GPT������õĴ𰸣����ճ�Ϊ������ߵ�ѧ������Ҳ�������ˡ� |
|
|
�߆�AI�Σ�AIϵ��Ӣ�ġ���RLHF��ǿʽѧϰ������ѧϰ�Ĺ���0 ��ͬ �� 0 �������� ���ǡ��߆�AI�Ρ���ϲ���ҵ���������ޡ���ע���ղء�רעAI����ѧϰ���˹����ܡ�Ӣ��ѧϰ��Դ�� |
|
�������лش�IJ���ˣ���˵һ��û���ᵽ�ģ�dreamerϵ�У�ǿ��ѧϰmodel-baseĿǰ��sota��v3�Ѿ���ʵ��Minecraft����ʯ�ˡ� ������Ϊǿ��ѧϰ���ر���model-base�������Ϊ��һ��ChatGPT��������Ʒ�Ĺؼ� |
|
���ѧϰ�������㷨��Deep Learning Neural Networks��2. ���������磨Convolutional Neural Networks��CNN��3. ѭ�������磨Recurrent Neural Networks��RNN��4. ����ʱ�������磨Long Short-Term Memory��LSTM��5. �Ǽලѧϰ�㷨��Unsupervised Learning Algorithms��6. ǿ��ѧϰ�㷨��Reinforcement Learning Algorithms��7. ���ɶԿ����磨Generative Adversarial Networks��GAN��8. ע�������ƣ�Attention Mechanism��9. Ǩ��ѧϰ�㷨��Transfer Learning Algorithms��10. �Լලѧϰ�㷨��Self-supervised Learning Algorithms�� |
|
�������Ⱥ�ʮ�����ۣ�ƫ�����ӽǣ� Alexnet/CNN �˲���ƽ�� Transformer/RNN �Իع�ǿЧ���� Dropout NN���е�����ͬʱ�Ǵ���ȸ�˹���̳�������Ҷ˹���ڿ� word2vector NN��negative sampling�������ϣ����ڱ���ѧϰ�ͶԱ�ѧϰӰ����Զ�������DZ���Ӱ�죩 Residual Connection ������ VAE/diffusion NN��ͼģ�͵������� GAN NN�벩���� Deep RL ��Χ�Դ������������Ϊ������ML�ϵĽ�� LLM ��Χ����ȷʵĿǰ����AGI����ϣ���ķ�������Ȼ������Ϊͨ�÷��ţ�����ij�������ϰ�ʾ��������ǣ����ʣ������� Pre-training + Fine-tuning Ӥ���Ƿ����һ��pretrained�����أ� |
|
Transformer���磺Transformerģ���ѳ�Ϊ��Ȼ���Դ��������������������ؼ�����������ע������self-attention�����ƣ���Ч�����������ݣ���������˻������롢�ı����ɵ���������ܡ�BERT������壺BERT��Bidirectional Encoder Representations from Transformers��ģ��ͨ��˫��Transformer�ڴ��ģ������Ԥѵ����ʵ���˶��NLP�����������������������壬��RoBERTa��GPT-3�ȣ���һ����չ��ģ�͵�Ӧ�÷�Χ�����ܡ����������磨CNN������ȻCNN�Ļ����ṹ��1990����������������������ͼ��ʶ����Ƶ���������Ӿ�����������ʾ��ǿ������ܣ����������������Ͳв�������ƶ��¡�ѭ�������磨RNN��������壺��LSTM��Long Short-Term Memory����GRU��Gated Recurrent Unit�����ڴ���ʱ���������ݣ�������ʶ����ı���������Ȼռ��һϯ֮�ء����ɶԿ����磨GANs������2014�����������GANs��ͼ�����ɡ����Ǩ�ơ�������ǿ������ȡ���������ɹ���Capsule Networks��������ʵ��Ӧ���л�����CNN�ձ飬��Capsule Networks�ڴ���ͼ���еĿռ��ι�ϵ������ʾ����������ơ�AlphaGo Zero��������㷨����Щ�㷨ͨ��ǿ��ѧϰ�����ѧϰ���ϣ���Χ�塢���������ﵽ�˳�Խ�����ˮƽ��ͼ�����磨GNNs����GNNs�ڴ���ͼ�ṹ���ݷ�����ʾ����DZ����Ӧ�����罻���������֪ʶͼ�ס�ҩ��ֵ�����AutoML��������ܹ�������NAS���������Զ�����Ƹ�Ч��������ܹ����������ֹ���Ƶ���Ҫ��Attention���Ƽ�����չ��������Transformer�е�Ӧ�ã�Attention����Ҳ���㷺���ڸ������ѧϰ�ܹ��У������ģ�Ͷ���Ҫ��Ϣ�����жȡ� |
|
ֻ˵CV��صģ������˽ⲻ�� ���������Ⱥ� resnet vitrepvgg�ز���ϵ��faster-rcnnyolodetrbevnerfganldm |
|
�������Զ�һ�� |
|
ResNet�����ţ���Ч��³�� Transformer�����ģ����/��ģ̬ CLIP����ģ̬�������������Ժ��Ӿ��� GPT��AGI��� PPO�������Ϲ�RL MAE���Ӿ��ԼලԤѵ�� BERT���ı��ԼලԤѵ�� ���кܶ��㷨/˼���Ѿ�DZ��Ĭ���������ѧϰ�Ŀ���У���������ݶ��½���BatchNorm֮��ģ�����һ����û�����������Ǿ���Ҳ��NB�� |
|
ֻѡһ����ѡgan |
|
Transformer �� Google Brain �Ŷӵ� Ashish Vaswani ������2017���������ƪ���ı���Ϊ���ѧϰ��Ȼ���Դ����������Ҫ��̱�֮һ�����Ľ����� Transformer ģ�͵Ļ����ṹ����������ע�������ƣ�Self-Attention���������������еij�����������ϵ��Transformer ģ�͵ijɹ��ƶ�����Ȼ���Դ�������ķ�չ����Ϊ����Ӧ���еĻ���ģ�ͣ���������롢�ı����ɵȡ��ĸ�GPT�ײ㲻���⣿(���һ�䲻һ����) Attention Is All You Need?arxiv.org/abs/1706.03762 |

|
|
2. BERT �� Google AI Language��2018�������BERT�ǻ���Transformer��Ԥѵ�����Ա�ʾģ�ͣ�ͨ��Masked Language Model��Next Sentence Prediction����Ԥѵ�������Ժܺõ��������������塣��������˸�����Ȼ���Դ�����������ܣ����ı����ࡢ����ʵ��ʶ���ʴ�ϵͳ�ȣ�������NLP������о����ơ� BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding?arxiv.org/abs/1810.04805 |
|
|
|
3. Wide&Deep Wide&Deep �� Google �� DLRS 2016�������ģ��һ������ģ�������ģ�ͽ�ϵIJ������ֻ��4ҳ��˼·Ҳ�ܼ��ۺ�����dz��ģ�͵ļ������������ģ�͵ķ���������ʵ�ֵ�ģ�Ͷ��Ƽ�ϵͳȷ�Ժ���չ�Եļ�ˡ��Ӵ˳����˸���ģ������(���һ�䲻һ����) https://arxiv.org/abs/1606.07792?arxiv.org/abs/1606.07792 4. YOLO �� Joseph Redmon �� Santosh Divvala ��2016�������YOLO ��һ��ʵʱĿ�����㷨�����ص����ڵ���ǰ����ֱ��Ԥ��ͼ�������б߽�������λ�á��������ʹ�� YOLO ���ٶ��Ϸdz���Ч������ʵ��ʵʱ��Ŀ���⡣�����汾�� YOLOv2��YOLOv3 ��YOLOv5 YOLOv8��һ���Ľ����㷨�����ܡ���һ��Ŀ���ⲻ֪��YOLO��(���һ�䲻һ����) https://arxiv.org/abs/1506.02640?arxiv.org/abs/1506.02640 5. ResNet �� Kaiming He��Xiangyu Zhang��Shaoqing Ren��Jian Sun��2016�������ResNet ����˲в�ѧϰ�ĸ��ͨ������в�飨Residual Block����������������ѵ�������е��ݶ���ʧ���ݶȱ�ը���⡣���ֽṹ������ѵ���dz����������ʱȡ������������������ͬʱ�������Ż���ResNet �����Ӱ�������ѧϰ������Ϊ�����Ӿ������еĻ���ģ�͡� Deep Residual Learning for Image Recognition?arxiv.org/abs/1512.03385 |
|
|
|
����ѧdz��ֻ�ܸ���TOP5����Ȼ���־�����Щģ������Ѿ���ȥ�ܶ����ˣ������λ���м��¡� |
|
�����⣬mark |
|
resnet |
|
|
| [�ղر���] �����ر��ġ� |
| ��һƪ���� ��һƪ���� �鿴�������� |
|
|
|
| ��Ʊ�ǵ�ʵʱͳ�� ��ͣ��ѡ�� ��ʱͼѡ�� ��ͣ��ѡ�� K��ͼѡ�� �ɽ���ѡ�� ����ѡ�� ������ѡ�� �������� �������� ���� MACDָ�� KDJָ�� BOLLָ�� RSIָ�� ���ɻ���֪ʶ ���ɹ��� |
| ��վ��ϵ: qq:121756557 email:121756557@qq.com ����ƻ� |