
| |
|
|
| ����ƻ� -> �Ƽ�֪ʶ -> UUID�����ȫ��Ψһ�� -> �����Ķ� |
|
|
[�Ƽ�֪ʶ]UUID�����ȫ��Ψһ�� |
| [�ղر���] �����ر��ġ� |
|
32λuuid�����ݿ�ÿһ��uuid����ȫ��Ψһ�� |
|
ȫ��Ψһ�����ڷֲ�ʽһ�������⣬�������⡣ ��������д������Ϊ�˽������ģ�����������ţ�Ǽ�ġ��� |
|
���ǡ� ���������ij�ͻ�����Ǻܵ͵ġ� �͵�ʲô�̶��أ� ���Ⱦ���һ�㣺UUID������32λ���ǽ�32λ16�������֣����߽�128λ�����ơ�ϰ�������ǻ�˵����128λ������32λ�� 128λ�����ƵĿ���ȡֵ��2^128��������3.4X10^38���� ��������������ֱ�۵�֪�����ж����ô���������ʵ���ԭ������Լ��10^50�����������ÿ������ϸ����Լ��10^14��10^17��ԭ�ӡ� ���������е�һ��ϸ���ж��ٸ�ԭ�ӣ���������ԭ�ӣ���ԭ�Ӿ����ˣ���5 ��ע �� 1 �ش����� ������ܰѵ������ɺ�����ϸ��һ����Ŀ������ٰ���̯����̯�ɱ�����һ�㡪�������ͷ��˿��Ҫ���öࡪ��ʹ��ÿ��ϸ������������ѵ�����һ��֮�ϣ�Ȼ��ӿռ�վ�������롣 �������ӵ����ȸ��ʵ�����ÿһ��ϸ������ôuuid��ͻ�ĸ��ʾ��൱����ӿռ�վ�ӵ�������������ͬһ��ϸ���� ���ߣ���һ��˵�����������ڶ����ϴ��˸�������������ͷ��һ�ܷɻ��ɹ���Ȼ�����˴ӷɻ�������һ���롣�����ոպô���������۵ĸ��ʣ���Ҫ��uuid��ͻ�ĸ��ʴ��������ڱ����������ˣ�ֻ�ٲ��ࣩ�� ��ˣ�uuid��Ȼ������ȫ��Ψһ�ġ���ȷ�п��ܴ��ڳ�ͻ�����Ե�������˵����ȫ�����ڹ�������Ϊ������Ψһ�ġ� ��������ʹ���������ֻ꣬Ҫ���ǻ��Ǹ��벻��̫��ϵ��������������ô�����ϾͲ��ÿ���uuid��ͻ�Ŀ��ܡ� |
|
https://en.wikipedia.org/wiki/Universally_unique_identifier?en.wikipedia.org/wiki/Universally_unique_identifier ժ��һ�£� In the case of standard version-1 and version-2 UUIDs using unique MAC addresses from network cards, collisions are unlikely to occur ��ΪUUID V1��UUID V2ʹ��������������ַ����ͻ�����ܴ��ڡ�����������������Ψһ��mac��ַ��ǰ����������������ַ�����ֶ����õģ����dz����Զ�������ɵģ��������ɽկ�������������壩�� hash-based version-3 and version-5 UUIDs, and random version-4 UUIDs, collisions can occur even without implementation problems ����Hash�㷨��V3��V5�������������V4����ͻ���ܻᷢ���� Thus, the probability to find a duplicate within 103 trillion version-4 UUIDs is one in a billion. ��ˣ���103���ڸ�V4 UUID���ҵ�2���ظ�UUID�ĸ���Ϊʮ�ڷ�֮һ�� |
|
UUID����32λ�ģ����ڵĿ�����������רҵ����λ���ֽ����ַ����ֲ������ UUID��128λ��ÿ8λ��һ��ʮ�����Ƶ��ַ���ʾ��32���ַ����ѡ� ������˵û���κ�������ȫ��Ψһ�ģ�ֻ���ظ��ĸ����ж�ߡ� UUID 128λ��Ҳ����2��128�η���֮һ���ظ����ʣ�2^128������̼������Ŀǰ�������Ĵ� ��֮ǰ��һƪ�ĵ�������UUID�ظ��ĸ��ʺ͵����̫����ײ�ĸ��ʲ�ࡣ |
|
���ǣ�����������ݿ�����϶���Ψһ�� |
|
�ǻ�����Լ����Ψһ�������Ǽ���ʵ�ֵ�Ψһ�� |
|
uuid���治��ѩ��ID����Ȼ�����Ψһ���⣬����ȱ��Ҳ�����ԡ� ȱ��һ��û�취�����������ɵ�IDû��˳�� ȱ�����uuid�ij���̫�����洢��չʾ������ô���㡣 ��Ȼѩ��ID��ֻҪע��ʱ��������⣬����ĿǰΪֹ��������ΨһID�� ѩ��ID���ŵ����£� �ŵ�һ��ӵ����uuidһ����Ψһ���Լ�ʹ�ֲ�ʽϵͳҲ���ظ��� �ŵ���������uuid������������⣬��ID��ʹ�ڲ�ͬ�ĵ�����������Զ�Ⱦ�ID�� �ŵ������̶����ȣ����ȱ�uuid�� |
|
��ô˵����ʹ��uuid�ظ��ĸ��� ������һ���������5�Σ������㻹���� �������������˷�ʱ�� |
|
�����˵������Ψһ�ġ��п��ܻ���ͬ�����������ͬ�ĸ����Ǻܵͺܵ͵ģ�������Ϊ��Ψһ�ġ� |

|
|
���ںţ������� ǰ�� ��һ�����ԣ����Թ����� UUID ����ظ����ҵ�ʱֻ֪�� UUID ��ͨ��Ψһʶ���룬��Ȼ��Ψһ���ǿ϶��Ͳ����ظ�ѽ����ʵ֤����ǰ���һ���̫�����ˣ��������һ�ν���� UUID ��֪ʶ�� ����ʲô�� UUID? ͨ��Ψһʶ���루Ӣ�Universally Unique Identifier����д��UUID�������ڼ������ϵ����ʶ����Ϣ��һ�� 128 λ��ʶ���� UUID ���ձ���������ʱ����ʵ��Ӧ���о���Ψһ�ԣ��Ҳ��������������ע��ͷ��䡣UUID �ظ��ĸ��ʽӽ��㣬���Ժ��Բ��ơ� ��ˣ������˶��������н�����ʹ�� UUID�����Ҽ�������ȷ���䲻������еı�ʶ���ظ���Ҳ��Ϊ��ˣ��ڲ�ͬ�ط������� UUID ����ʹ����ͬһ�����ݿ��ͬһ��Ƶ���У����Ҽ����������ظ��� UUID ��Ӧ���൱�ձ飬�������ƽ̨���ṩ�˶������ɺͽ��� UUID ��֧�֡� ���ǰٿ������ UUID ��������������˶��� UUID ���������Ҳ�͵������ˣ�����Ϊʲô���ظ����ʽӽ��㣬�����Ǿ��Բ����ظ��أ�UUID �İ汾 UUID Ŀǰ�������� 5 ���汾������汾����˼����ʵ�������ɹ���ͬ�汾���ɹ���ͬ�� �汾 1 �� UUID �Ǹ���ʱ��ͽڵ� ID��ͨ���� MAC ��ַ�����ɣ� �汾 2 �� UUID �Ǹ��ݱ�ʶ����ͨ��������û� ID����ʱ��ͽڵ� ID ���ɣ� �汾 3���汾 5 ���������ռ䣨namespace����ʶ�������ƽ���ɢ������ȷ���Ե� UUID�� �汾 4 �� UUID ��ʹ������Ի�α��������ɡ� ���ʶ�� UUID �İ汾 |
|
|
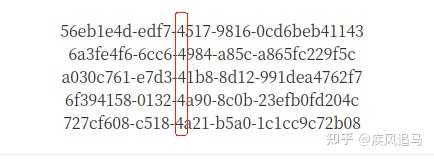
���ǰ汾 4 �� UUID���ڶ���-���һλ�������İ汾����~ Java �е� UUID java �е� UUID ��λ�� java.util ���� randomUUID ������������� 4 ����������ɵģ�Ҳ��������õ� nameUUIDFromBytes ����������� 3 �����������ɵ� ������ͨ��������֤һ�� �� nameUUIDFromBytes ������������������ַ�������ͬ����ô���� UUID Ҳ����ͬ ���� randomUUID ���������������ͬ�� UUID ��ͻ���� UUID �ı���ʽ���� 32 �� 16 �������֣������ֺŷ�Ϊ��Σ���ʽΪ 8-4-4-4-12 �� 32 ���ַ���ʾ����550e8400-e29b-41d4-a716-446655440000 ��Ϊ�� 16 ���ƣ�ÿ��λ���� 16 ��������� 32 ���ַ��������������ɲ��ظ��Ľ���ܹ��� 16^32=2^128 �֣�Լ���� 3.4 x 10^38 ����һ���dz��dz�������֣����뿴��һ��Ҳֻ�� 10^8 �������������ͻ�ĸ��� �����Ѿ������� 1 �� UUID����ô��һ�����ɷ�����ͻ�ĸ����� 1/3.4 x 10^38 �����Ѿ������� 2 �� UUID����ô��һ�����ɷ�����ͻ�ĸ����� 2/3.4 x 10^38 ... ���������Ѿ����ɵ� UUID ���ϱ�࣬�´η�����ͻ�ĸ���Ҳ�ڲ��ϱ������Ϊ����ʵ��̫�����Ծ��ܸ���һֱ�ڱ��Ҳ������ȫ���Բ��� �ܽ� �Ͻ�������UUID ���ܻᷢ����ͻ����Ϊ����������ͻ�Ŀ����Լ�С�����Ժ��Բ��� �ŵ�: �������� ID������Ҫ����Զ�̵��ã�û�������ʱ���٣�û���������� ȱ��: �ɶ��Բ�ȹ��������ɵ� UUID ͨ���� 36 λ (���� -)�����ʺ���Ϊ���ݿ������������Ϊ�������������� (����������) ��ռ�úܴ�Ŀռ䡣����֤���Ƶ������� MySQL �� InnoDB �����£��²������ݻ����������Ѱ�Һ���λ�ã��ᵼ��Ƶ�����ƶ�����ҳ�����˺ܶ���� |
|
ʹ���� mac ��ַ�� uuid����ȫ��Ψһ�� ��������˹���������� mac ��ַ������ uuid, �Dz���Ψһ���Ͳ���˵�ˡ� ��������������Լ�д�ij����Լ��ܿ��Ƶ����ɷ������������Χ�ڣ�uuid ��Ŀ���Ψһ�� ��ʵ������ uuid ȫ��Ψһ��û�����塣 �Ͼ��������������ϵͳ�ӿ�ʱ���㲻�ܰ���� uuid �������������Է��ϲ��ˡ� |
|
��uuid���ɣ� Mac��ַ+ʱ���+�������� ǰ�����������ģ����������ڲ�ͬ��������������֤Ψһ��û�о��Ե�Ψһ������ҵ��Ϳ����ˡ��������ֲ�ʽ���ݿ�mycat_plus����������һƪUUID���£���ӭ��עmycat_plusר����https://zhuanlan.zhihu.com/c_177209637 |
|
���ʷ������⣬�Ҹ���һ�����Ͳ�Ψһ�ˣ� ��ʹ�����ɹ��̣�Ҳ����˵�ϸ�Ψһ�� ��������� |
|
UUID ͨ��Ψһʶ���루Ӣ�Universally Unique Identifier����д��UUID�� UUID �� 16 �� 8 λ�ֽڱ�ʾΪ 32 ��ʮ�����ƣ�����16�����֣���ʾ�������ַ��ָ� '-' ��������У�"8-4-4-4-12" �ܹ� 36 ���ַ���32 ����ĸ�����ַ��� 4 �����ַ��� UUID�ṹ�ֽ� ��UUID�汾1Ϊ�� ʾ����58e0a7d7�Ceebc�C11d8-9669-0800200c9a66 ǰ3�ηֱ���Timestamp�ĵ͡��С��ߺ�UUID�汾(��3�ε�1λ)��4��Clock sequence��Ϊ����TimestampijЩ˲�䲻Ψһ��14bits number 08:00:20:0c:9a:66 ��5��NodeIdΪMac��ַ���������48bits Number�ŵ�UUID����ȫ��Ψһ�ԣ��ظ�UUID����ʽӽ��㣬���Ժ��Բ������ܸ�ʹ�ü�������������������ȱ�㲻�ʺ���Ϊ���ݿ���������״洢����ʹ��36�����ַ����洢�����ȹ������������洢������Ч������MySQL InnoDB�����ڲ�������ʱ�������������������������λ��Ƶ���䶯������I/O������Ӱ��insert����UUID V1�汾 ���Ķ�ʹ��Mac Address����ȫ������������������Ӧ�������������·TraceId�û��Ự sessionIdһ����ǩ������ַ���MySQL InnoDB���Ƽ�ʹ��UUID���� InnoDBʹ�þ۴����������������ٶ�������������˳��ʹ��UUIDʹ�þ۴ز�������ȫ�����ʹ������û���κξۼ����� UUID���������ܽ� ��������(Secondary index ����������)�б�����������У���������кܴ�����������������ܴ�д��Ŀ��page�����Ѿ�ˢ�������ϲ��ӻ������Ƴ��������ǻ�û�б����ص������У�InnoDB�ڲ���֮ǰ���ò����ҵ����Ӵ��̶�ȡĿ��ҳ���ڴ��У��⽫���´��������I/O����Ϊд��������ģ�InnoDB���ò�Ƶ������ҳ���Ѳ������Ա�Ϊ�µ��з���ռ䡣ҳ���ѻᵼ���ƶ��������ݣ�һ�β���������Ҫ������ҳ������һ������������Ҷ�ӽڵ��һ�����ڵ㡣����Ƶ����ҳ���ѣ�ҳ����ϡ�貢�����������䣬�����������ݻ�����Ƭ������ҳ���Ѻ���Ƭ�IJ���������ռ�ÿռ�Ҳ������Page��Innodb�洢��������ṹ��Ҳ��Innodb���̹�������С��λ�Ż����� �˷���ֻ��Ի���timestamp��UUID�汾1��Ч��UUID�汾�ڵ������ֵĵ�1λ�� Time-Base UUID���ɵ�һ����ʱ������仯�ڶ�����ʱ��������仯�������������µ��Ķ�ʱ����͵����Mac��ַ�ڵ������൱�ڳ����Ż�����ɾ�����õķָ���timestamp �ߵ�λ�������������UNHEX()��16�����ַ���ת��ΪBianry(16)MySQL 5.7 MySQL 8.0���ϰ汾 ����UUID_TO_BIN(UUID() , swap_flag) �������ǽ�UUIDת��Ϊ������Binary(16) UUID�� �ڶ�����������Ϊ1����UUID��timestamp �����θ�λ�͵�һ�ε�λ����λ�ã��ܱ�֤UUID�ĸ���ʱ��仯���������������InnoDB�ľ۴������������Ѻã���ø��õ����� |
|
�����ܱ�֤ȫ��Ψһ�� ��ȫ��Ψһûɶ̽�����塣 |
|
�����´���һɫ����˵��ײ���ʺܵͣ�������ȷʵ��ˣ���Google��һ�¾��ܿ������ָ����������ײ������ �����Ͻ��������ǽ���ʹ�����ݿ����������� |
|
�Լ�ʵ�ֵĻ��������ú���ʱ���ת16���ƷŽ�UUID���棬�ظ����ʾͽ�һ������... |
|
Ŀǰ���е�UUID����ISO/IEC 9834-8:2014����涨��UUID���� �汾(version)��ʱ�䡢����(variant)��ʱ�����С��ڵ�(node) ��ɵġ� ���а汾һ����5�֣�����ʱ�䡢DCE��ȫ������ʱ�䣩���������֣�MD5����������������������֣�SHA-1�� Ȼ����Ȼ��һ��ʼ˵��˵��ʱ�䡱����ʱ�����С�������������ֵ�UUID�����������node����ʹ���������ɵģ����������������������ɡ� ������ʱ���UUID���ǣ�node��shall������mac��ַ�����������ӿڡ�usually����host��ַ�� ����豸û��mac��ַ����ô����������� ��������uuid�Ƿ�ȫ��ΨһҪ�ֺü�������� ���ȣ�����ǻ����������uuid����ô��ľ�����ȫ�����Ψ��Ψһ��ȫ��������Ȼ������ʿ��Ժ��Բ��ƣ�������Ҳ���ܱ�֤˵����ʷ�������ɳ�������version4��uuidȫ���ù�����һ��û��һ���ġ� ��Σ��������ֵ�uuid����Ŀ�ľ����÷ֲ��Ļ�������ͨ����ͬ������������ͬ��uuid����ͬ��������Ŀ�ġ�����Ҳ������Ψ��Ψһ���˵���ˡ� ����ǻ���ʱ���uuid��Ҳ�������uuid����������������£�ʱ��+ʱ����������ͬһ̨����������������ͬ�ģ���mac�����˲�ͬ�Ļ���������ͬ�������Ѿ������졣 ����ע�⣬����ֻ�������������ʵ�����п��ܻ���ͬ�ģ������豸ʱ�����ص��ˣ��Ҷϵ���ʱ�����й����ˣ���ΪijЩԭ����̨�豸������node����һ���ˣ����綼ûmacȻ�����һ���ˣ����߲��Ϲ���豸�����̣���Ȼ����ǡ��ͬһʱ��ʱ��������ͬ����������ࡣ ����������˵������ʱ���uuid������������Ŀ��ܻ��������ڣ����Կ�����Ϊȫ��Ψһ�� |
|
UUID��ͨ��Ψһ��ʶ������һ�������ı�ʶ��ϵͳ��Ŀ�����ڷֲ�ʽ���㻷����Ψһ�ر�ʶ��Ϣ��UUID �ı�����涨�����ʽ�����ɹ�����������˵��UUID ��ȫ��Ψһ�ġ� |

|
|
UUID ��ͨ���㷨���ɵ� 128 λ���֣����а���ʱ������ڵ���Ϣ���������Ԫ�ء����� UUID ʹ�� MAC ��ַ��Ϊ�ڵ���Ϣ����ȷ���ڱ������ɵ� UUID ����ȫ��Ψһ�ԡ� Ȼ������ʵ��Ӧ���У����� UUID �����ɷ�ʽ�ͻ����IJ�ͬ������������¿��ܴ����ظ��Ŀ����ԣ�������������dz��������ظ��ķ���������ͨ���������¼������棺 1.������ظ��� UUID �а������������������˵����ʹʹ��ǿ�������������������ڼ����������Ҳ����������ͬ������������� UUID �ظ��� 2.�ڵ���Ϣ��ͻ�� ��һЩ��������£����ʹ�� MAC ��ַ��Ϊ�ڵ���Ϣ���������豸��������� MAC ��ַû����ȷ���û���������ܻᵼ�½ڵ���Ϣ��ͻ������������ͬ�� UUID�� 3.�����ϱ��淶�����ɣ� ��ijЩ����£������߿���ʹ���Զ�������ɷ�ʽ���㷨������ UUID������Щ�Զ��巽ʽ���ܲ�δ�ϸ���ѭ UUID �ı��淶�������ظ��ķ��ա� |

|
|
���ܴ��ڼ������Ŀ����ԣ�����ʵ���У�UUID ���ظ������Ƿdz��͵ģ������������������µ�Ψһ��ʶ����Ϊ�˱�����ܵ��ظ������Բ��������ֶ���ȫ��Ψһ�����ݿ��ʶ�������������������������á� |

|
|
|
|
����������⣬���뵽�˱�ѩ����2�������ļ�ѹ�������ʽ�� ������ļ����Ĺ�ϣ������ظ�����ô�죿 �±�+1 ϣ���ش���������� |
|
ȡ���������㷨 |
|
Ӧ�ò��ܱ�֤ |
|
��������ȫ��Ψһ���Ҷ���ײ��1��2���ˡ����� |
|
�������Ŀ���ϵͳ��������UUID�ظ��ģ����³ɼ�������һ�졣�����Ҹ��UUID��64λ�� UU+UUID+ID�����ظ���Ҳû�취�� |
|
һ��id�����ô�������dzԱ����Ź�Ū���飡128λ�����������256λ����512λ��ʲô����Ӧ�����ˣ� ����ô��ɱ�ȥ��ֹһ�������ʷ��������⣬������ɴ��������ⷢ����Ȼ���ߴ���������������ϵͳ�����������豸���ü����������õ�ȫ��id����128bit�㹻�ˣ������ͻ�����·��䣬�ڴ��������Ҳ���죡 |
|
At32 ��ǰһ��mcu�ͳ���uuid�ظ������⡣�������ˡ����һ������� |
|
������ID�����Դ����۲�����ȫ���ⲻΨһ���⣬ÿ�����ӵ�ID�����ID+1�������ݿ�ִ����IDʱ��������һ������ID������ʹ�á� ��֪��ǿ��֢���Ƿ����⡣ |
|
����ѧ��˵�����ǣ���Ϊ�и��ʳ�ͻ������������ʶ�С���ӹ�����˵���ڴ���������£��ǣ���Ϊ�����㹻С�� Ҫ���ڹ����ϡ���֤��uuidû�г�ͻ����ôͨ����Ҫ��һ���º��飬���������ݿⲢ�Ҽ���Ψһ��Լ�������������ظ���Ҳ�����������ȷ�Բ�����ͻ�����ǵ����������ܶ�ʱ������ԾͿ����ˡ���������ǰ���Ǹ����㹻С����Ȼ����ϵͳ�ͻᱻ���ϵ������Ͽ塣��uuidͨ��������һ�㡣 uuid��ͻ��С����������һЩ����ģ����磺 1. �ڵ���ϵͳ��ʹ�á������Ļ���ʹ������ͬ��ϵͳ����ͬ����uuid��Ҳ���ụ��Ӱ�졣 2. ͬʱ����ͬһ��ϵͳ��uuid�Ļ�����Ҫ̫�࣬����MAC��ַ�����ɿء� ��֮ǰ����������ġ�uuid�ظ����ij�������ǰ��������Զ�����uuid����δ��¼�û���������ͳ�ƣ����һ����������渶��ͳ�ƻ�������ֳɡ�����uuid����������̨�����������Dz��ܵ�����˾���ƵĻ�����MAC���ܱ�֤���ظ���ʱ���û����֤��ȷ�������Ե���uuid���ܻᷢ����ͻ�������ʽ���ö��uuid�������ʾ�����û����������uuid�������uuid���û�uuid�ȣ������Ͼ��ǰ�uuid�ij��ȱ䳤����С��ͻ����ֱ����ҵ�Ͽɺ��Գ�ͻ���ʡ� |
|
�����ϼ����ǣ����϶����ǣ� ��ʵ��������һ���ظ�����ʱ���ֱ�Ǿ����ˣ�����������һ�Σ� |
|
ֻҪ�Ƕ����ģ��ͱ�Ȼ������Ψһ�����Ǽ���ѧ������ʵ��ʹ����ֻҪ������ij�������ϵIJ��ظ��Ϳ��� |
|
ȫ��Ψһ�Ǵӹ�������ϱ�֤��uuid��������ֻ��һ��Ψһid�ı�������ɷ�ʽ����������Թٵ����㣬��߽�����ֱ���������㶮����� |
|
UUID��ͨ��Ψһ��ʶ����ּ���ܹ�����ȫ��Ψһ�ı�ʶ������ʵ�ϣ����� UUID ���ݵ���һ���dz�������ֿռ䣬ȷ�������ǵ�Ψһ�ԣ���ʹ����û�м���ʽЭ�����Ƶ�����¡� UUID ���� RFC 4122 ��������ͨ���� 128 λ��ֵ���� 5 �ֲ�ͬ�İ汾����õ��ǰ汾 4������汾�� UUID ʹ��������ɵ����֣���Ψһ�Ի�������ԡ����ڿ��õ���ֵ��Χ�dz��Ӵ�21222122 �����ܵ�ֵ����Ϊ�汾 4 UUID �� 122 �����λ���������������ϣ������ظ��� UUID �Ŀ����Լ��͡� Ȼ����"ȫ��Ψһ" ������ζ�Ų����ܳ����ظ���ֻ����ʵ��Ӧ�����ظ������ĸ��ʷdz��dz��͡����ָ���������������������ײ����ij���в�Ʊ�ĸ������ƣ��ǿ��ܵ��������ܷ����ġ����ָ���С��ͨ�����Ժ��Բ��ơ� ��������Ҫע����ǣ�UUID ��Ψһ�Ի�ȡ�����������ǵ��㷨�����������磬�����������������������ߣ���ô�����ظ��ĸ��ʿ��ܻ����ӡ����⣬���ʵ�ֲ����ϱ�����ôҲ���ܻ�Ӱ�� UUID ��Ψһ�ԡ� ��ʵ��Ӧ���У����������ظ� UUID �Ŀ����Լ��ͣ�������Ψһ�Ի��Dz�����ȫ��֤�������ϵͳʱ�������������µ�Ψһ�Գ�ͻ�ᵼ���������⣬�������Ҫ�������������DZ�ڵ��ظ������ |
|
ȷʵ����ײ���ܣ�������ײ��Ū2��uuidƴ�ӣ�����������4������������������һ�졣 |
|
UUID��Universally Unique Identifier������ͨ��Ψһʶ���룬���֮������ּ�����ܹ�����ȫ��Χ�����ɵı�ʶ������Ψһ�ԡ��������ϣ�UUID�Ķ����Եõ������õı�֤��ͨ�����㷨�����ĸ����Գ�ͻ�dz�С��С�����Ժ��Բ��ơ� ����UUID����128λ���֣�����ζ����ӵ�� 2^{128} �����ܵ�ֵ�����������������ϵ�ɳ��������ȣ�����ԼΪ7.5 x 10^{18}�����ɼ�UUID�Ķ�����ȷʵ�dz�֮�ߡ������������ÿ���˶�������UUID������ÿ��������1�ڸ�UUID��Ҫ��ʹ����UUID��ײ�������Ҫ����3600�ꡣ���ʱ���ȱȹŰ����Ľ�������Ҫ��Զ����ˣ���ʵ��Ӧ���У�UUID�ij�ͻ�����Ǽ��͵ġ� �����ϵ�ȫ��Ψһ������ζ�ž��Բ��ᷢ����ͻ���ڼ��亱��������£��ر��ǵ�UUID���ǰ��չ淶����ʱ����ͻ��Ȼ�п��ܷ�������ˣ����ʵ������ϵͳ���ʱ��Ҫ���ǵ�����С�����¼�����Ԥ���������ơ� �����ָ����32λʮ����������ʵ������128λ�����ƣ�����ôÿһ��UUID��ȫ��Χ����Ψһ�ġ����������ֻ��32λ��������ɣ�������֤ȫ��Ψһ����Ϊ��ֻ���ṩԼ42�ڸ���ͬ��ֵ�� |
|
UUIDֻ��2^128����Ҳ����10^38�����������ڿ�ѧ�ҹ������������������10^80��ÿ�����ӷ�һ��UUID���ͱ��ˡ� �����������������������Ҽǵ����Ŀ������������Ϊ������ѧ��ԭ���bug�ĸ��ʶ��к�����10^-38������������ô���������¡� |
|
|
| [�ղر���] �����ر��ġ� |
| ��һƪ���� ��һƪ���� �鿴�������� |
|
|
|
| ��Ʊ�ǵ�ʵʱͳ�� ��ͣ��ѡ�� ��ʱͼѡ�� ��ͣ��ѡ�� K��ͼѡ�� �ɽ���ѡ�� ����ѡ�� ������ѡ�� �������� �������� ���� MACDָ�� KDJָ�� BOLLָ�� RSIָ�� ���ɻ���֪ʶ ���ɹ��� |
| ��վ��ϵ: qq:121756557 email:121756557@qq.com ����ƻ� |