
| |
|
|
| 首页 淘股吧 股票涨跌实时统计 涨停板选股 股票入门 股票书籍 股票问答 分时图选股 跌停板选股 K线图选股 成交量选股 [平安银行] |
| 股市论谈 均线选股 趋势线选股 筹码理论 波浪理论 缠论 MACD指标 KDJ指标 BOLL指标 RSI指标 炒股基础知识 炒股故事 |
| 商业财经 科技知识 汽车百科 工程技术 自然科学 家居生活 设计艺术 财经视频 游戏-- |
| 天天财汇 -> 科技知识 -> 阿里云大模型「让照片跳舞」刷屏朋友圈,有哪些信息值得关注? -> 正文阅读 |
|
|
[科技知识]阿里云大模型「让照片跳舞」刷屏朋友圈,有哪些信息值得关注? |
| [收藏本文] 【下载本文】 |
|
只要一张照片就能生成一段舞蹈视频,又一个大模型应用出圈! 2024年第一个工作日开始,阿里云通义千问APP上线免费功能,兵马俑、马斯克以及各地网友跳科… |
|
最近我的朋友圈被阿里通义千问APP的“全民舞王”占领了,朋友圈和微信群里都是魔性的“科目三”,先看看究竟是什么效果吧! |

|
|
0 |

|
|
0 |

|
|
0 而这神奇的视频只需要简单几步,就可以免费体验到这款神奇的AI视频。 下面,我来给大家分享下如何进行操作吧! 一、APP安装 我以安卓手机为例,首先通过手机自带的软件商城,搜索找到“通义千问”(下图第一个) |
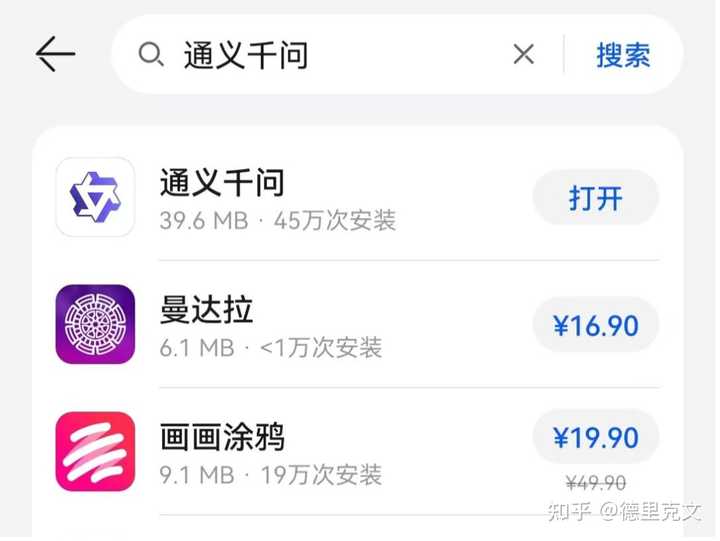
|
|
然后点击进入,进行下载安装 |

|
|
进入主页后,点击第一个“一张照片来跳舞”就可以进入,如果没有跳出这个画面,也可以在输入框输入“全民舞王”,然后点击右下角的小箭头就可以顺利进入了。 |
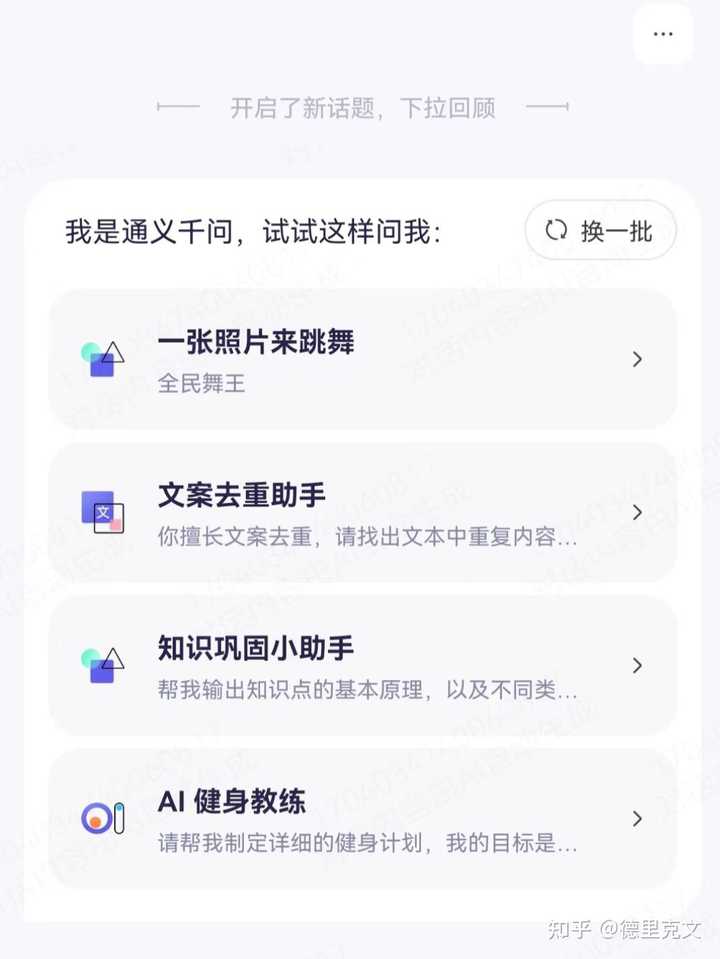
|
|
二、合成视频 进入这个应用后,可以看到引导界面,点击“立即体验热舞”,就可以进入下面的界面了 |

|
|
接下来进入界面我们可以看到有好多不同的舞蹈模板,让我们选择其中一个进行舞蹈创建 |

|
|
我选择了兔子舞看下效果,点进界面,点击右下角“舞同款” |

|
|
我们可以选择系统默认形象也可以选择自定义形象。 |
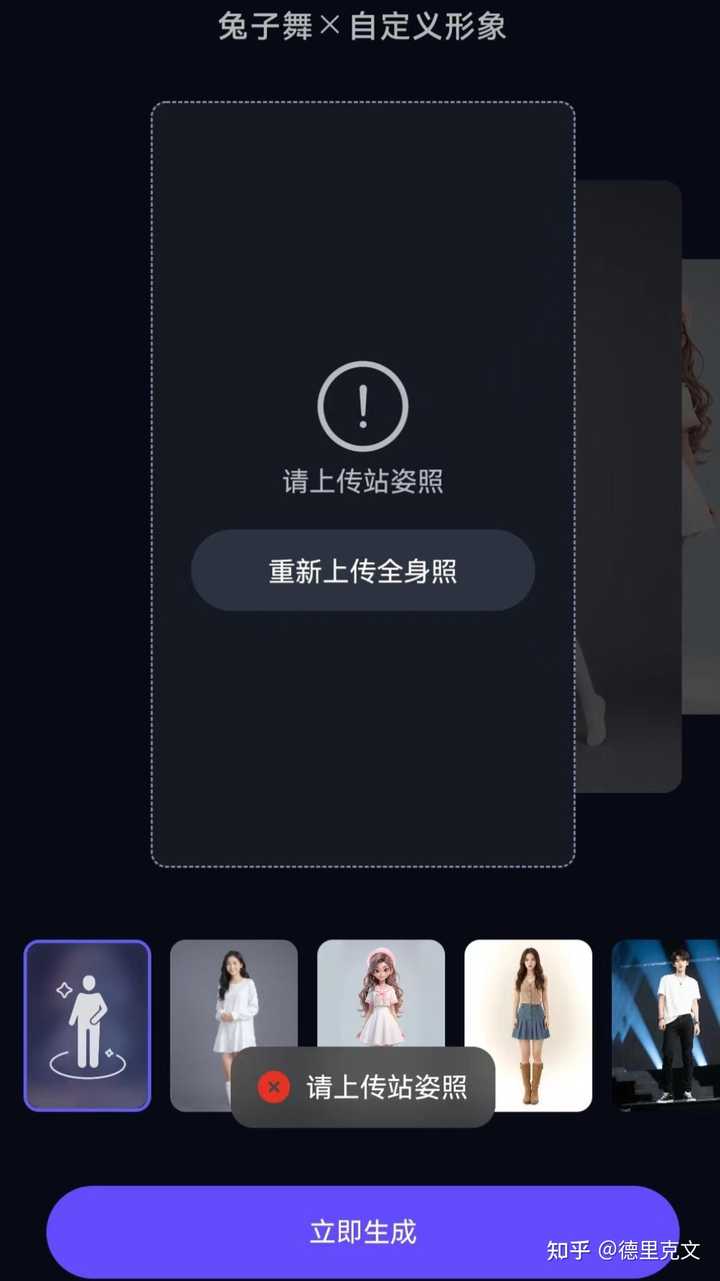
|
|
如果是自定义形象,需要上传站姿全身像,我选择的是自定义,我试着上传我用AI生成的阳光美女。 |

|
|
我用AI绘画生成的美女 |

|
|
我用AI绘画生成的美女 |

|
|
我用AI绘画生成的美女 |

|
|
我用AI绘画生成的机器人图片 |

|
|
我用AI绘画生成的可爱猫咪 以上几张,全部失败……为什么呢,因为必须同时满足以下四点要求才能够识别:包括正面站立、全身照、全身无遮挡、无角度。 不过我还是不能理解猫咪不被识别的原因……毕竟别人用奥特曼和龙宝宝都成功了,我用的这个猫咪图片也不比奥特曼更奇怪呀。 |

|
|
最后,我上传了满足要求的美女图片,图片为我用AI绘画生成。 |

|
|
我的AI绘画作品 上传自定义形象成功后,点击生成,就可以等待生成效果啦! |

|
|
三、生成的视频 最后来看下这个小姐姐不同舞蹈的生成效果吧! 1.西域慢摇 |

|
|
0 2.只想对你说【爱你】 |

|
|
0 3.兔子舞 |

|
|
0 4.鬼步舞 |

|
|
0 5.科目三 |

|
|
0 四、有趣视频欣赏 以下是其他来源于互联网的视频,网友们的各种想象力太有趣了,让我们看看还有什么有趣的形象在跳舞吧! 1.蜘蛛侠 |

|
|
0 2.永远的坤坤 |

|
|
0 3.兵马俑 兵马俑跳舞1100 播放 ・ 15 赞同视频 |

|
|
? 4.奥特曼 奥特曼跳舞683 播放 ・ 7 赞同视频 |

|
|
? 结语 阿里最新的AI视频和上次妙鸭相机一样瞬间刷爆了朋友圈,这充分说明了AI人工智能技术的推广,想要出圈,除了技术过硬,做好内容传播和宣传也是必要的! 我是德里克文,一个对AI绘画,人工智能有强烈兴趣,从业多年的室内设计师!如果对我的文章内容感兴趣,请帮忙关注点赞收藏,谢谢! |
|
好东西该夸还是要夸。 这个可以让照片跳舞的大模型算法是阿里云的Animate Anyone。简单来说就是,Animate Anyone可将人物图像(无论是真人还是动漫形象)按照预设的“火柴人”几个连续姿势动起来,就相当于把静态照片转换成了动态影片。就像demo里面展示的球王自信三连拍,如下: |
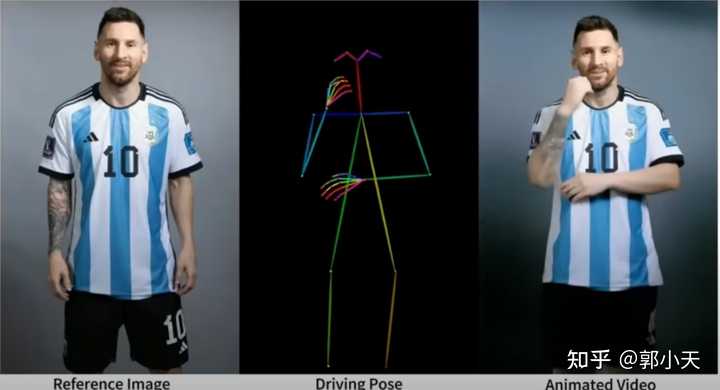
|
|
|
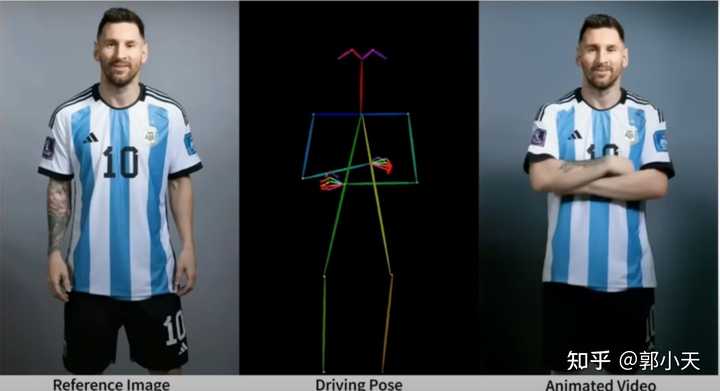
|
|
|
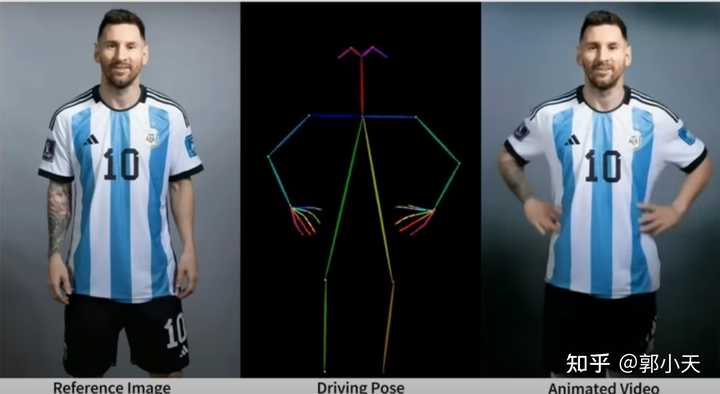
|
|
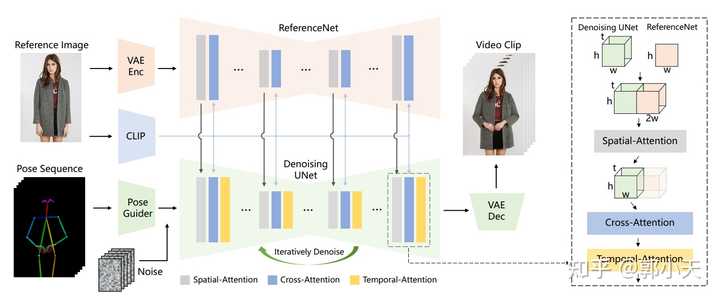
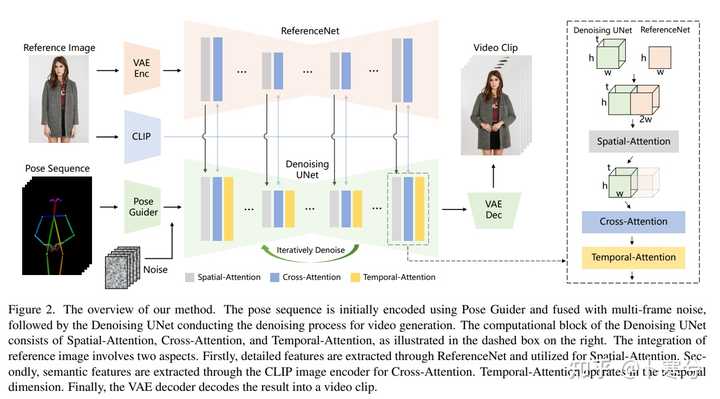
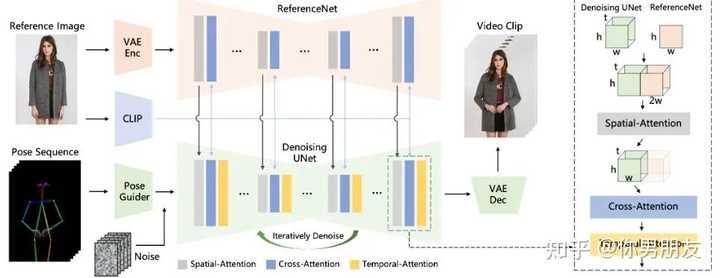
虽然算法还没有正式开源,但从网友体验的效果上看已经足够惊艳。虽然还不是像ChatGPT或者Midjourney刚出来可以让人惊呼“居然还可以这样”的程度,但我觉得已经可以称得上是一个“deepfake时刻”了――“我知道早晚会有人做出来,但居然这么快就做出来了,而且效果比我想象的还要好”的那种程度。 因为要做到这样的效果绝对不是一个简单的事情。从静态图片到动态影片,说穿了就是引入了时间这个恐怖的维度――当无数张连续画面放置在一个时间轴的时候,你如何保证动画中的每一帧画面之间可以平稳过渡,确保时空的连续性和一致性? 从空间上说,要知道,人的五官、四肢、衣服和周围的环境都是各种复杂的细节,是高度结构化的对象,在一个静态的平面上可以彼此相安无事,但一旦你要求每个像素都动起来,你怎么知道在你低头的时候眼睛不会飞过头顶?当你侧过身去,你怎么知道你正面所遮挡住的背景是什么样的?或者你想让球王先抱胸后叉腰,你怎么保证他会按部就班地先双臂抱胸然后双手自然放下再然后双手叉腰,而不是瞬间完成一个荒谬得超出人类极限的双臂外翻?――在时间变换的时候,空间必须保持一致性,否则就不真实。 从时间上说,时间是一个很硬很冷的坚硬刻度,人在一秒钟能做到的事情,不可能在一纳秒完成。就好比说梅西一秒钟可以颠一两次球,但绝不可能颠一百次;你可以这一秒种把手从上衣口袋里拿出来,但不可能下一秒就拿出电脑点了杯咖啡写了一份上万字的商业计划书。――在空间变换的时候,时间也必须保持一致性,否则就不真实。 所以,虽然对抗生成网络(GANs)流行以来人们就在不断做出图片动画化的努力,但能否保持人物外观的一致性和平滑的时间过渡(或者就是两个字,“真实”),就是图片动画化一直面临的巨大挑战。换句话说,图片动画化的挑战并不在于如何生成一个视频出来,而是如何控制好各种结构化的细节,让人物和环境在时间和空间上保持连续和一致。 在Animate Anyone之前,静态视频动画化比较成功的工具一个是DreamPose,一个是DisCo。 DreamPose的成功之处在于把Stable Diffusion扩展到图像合成视频的领域,利用图像的CLIP特征让就是Stable Diffusion可以生成多张图片,连续播放也就成了动画,可以简单理解为确保运动中的人物形象不会走样,也就是空间的一致性。 DisCo一方面进一步修改了Stable Diffusion,利用ControlNet同时整合图像的CLIP(人物)和VAE(背景)特征,这样一来空间的一致性也就大大提升了。在对图像模型进行训练后,再进一步加入了时间卷积层(UNet)和注意力层(Attention),也就是AnimateDiff构架,负责添加跨图像帧的连贯运动。以提高帧间的平滑度,因而时间的一致性也提高了。 如果你认真看过Animate Anyone下面张构架图,不难发现阿里云真的是站在前人的肩膀上,做出了扎实的创新: |
|
|
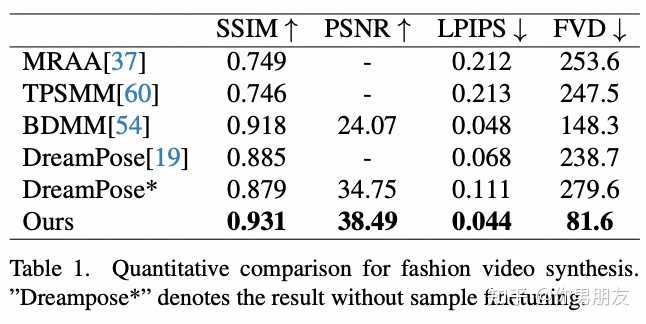
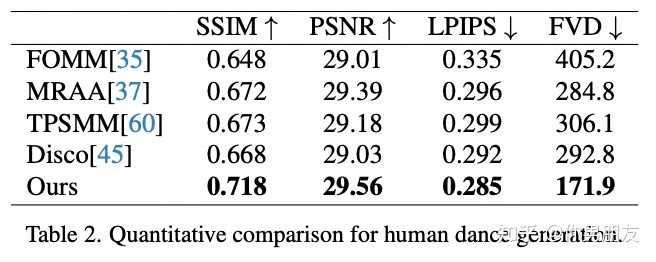
前人的肩膀就包括AnimateDiff当中用到的UNet和时间注意力层(Temporal Attention),也包括DisCo用到的图片的CLIP和VAE特征。 创新之处主要是整合图片特征的ReferenceNet的构架,此外将“火柴人”姿势序列引入噪音得到的Pose Guider也可以算是一个数据预处理上的小创新。 ReferenceNet主要是针对单帧图像的训练的UNet,相比DIsCo的ControlNet,ReferenceNet是一大创新。因为只针对单帧图像,所以时间注意力层在这里不需要。由于 ReferenceNet 和Denoising UNet的网络结构基本相同,Denoising UNet 可以选择性地从ReferenceNet中学习在同一特征空间中相关的特征,也就是空间注意力层(Spatial Attention)。同时,CLIP图像编码器利用与文本编码器共享的特征空间,提供参考图像的语义特征,从而更有利于参考图像和目标图像在空间上对齐,是为交叉注意力层(Cross Attention)。相较而言,DisCo的ControlNet就控制不好图片的深度和边缘信息,导致参考图像和目标图像在空间上相关但无法对齐。 也因此,Animate Anyone呈现的效果是显著高于DreamPose和DisCo的,它在细节保存和时间稳定性方面表现出色。在 SSIM (0.931)、PSNR (38.49)、LPIPS (0.044) 和 FVD (81.6) 等指标上均优于其他方法: |

|
|
|

|
|
从去年开始关注阿里云的通义千问的开源大模型,不得不承认阿里云在开源大模型的持续发力确实为它带来了实实在在的成绩:通义千问720亿参数(Qwen72B)大语言模型达到了GPT3.5的同等学力,在开源大模型中稳稳的位居前列――当然这是相当客气的说法。稍微不客气一点的说,就是数一数二的地位。而且它家的多模态大模型Qwen-VL-Chat同样在众多开源大模型的表现中位居前列,至少位居前五没什么问题。 通义千问?tongyi.aliyun.com/qianwen/ |

|
|
在静态人物图像转换维动态视频这个细分赛道上,不管客气不客气,阿里云的Animate Anyone就是目前最好的框架了。相信很快就能等到它开源的那天。 |
|
阿里云通义千问大模型火了这事有三个关键要素,科目三、AI、兵马俑,咱一件一件来说。 先来说科目三吧。如果想解释为什么科目三这么火,其实还是得从根源上去找原因,在主流文化圈子以外,亚文化圈里一直有一个不怎么被人注意但一直很具备文化生命力的圈子,乡土文化圈。你可以直观理解为杀马特、喊麦,以及科目三的前身,社会摇。 很多人会觉得这些东西俗,但实际上,大家都忘了一件事,哪怕是从文学这种绝对算得上高雅的角度,当代文学建立的根底之一都是乡土文学。这倒并不是什么网传的“大俗即大雅”,这些东西的火甚至无关于俗雅,更多的是乡土文化就是约束少,生命力就是旺盛,创造性就是强。 科目三的关键词是生命力。 社会摇以前在亚文化圈就很火了,之所以会闯入主流文化圈,其实也有出口再进口的因素,就像当初李子柒一样,在国外摆脱国内的刻板印象,火了,然后才流回国内主流文化圈。 接着再来说AI,自从去年年初百模大战以后,AI这个词真正以普及之势闯进了每一个愿意主动拥抱技术的人的生活。我一直有一个观点,大模型有两个突围方向,一个是算法研发,一个是场景应用。前者凭借核心硬实力可以吸引核心用户,后者凭借娱乐性吸引大众用户。 阿里云通义千问APP上线的新应用,“让照片跳舞”功能,简单点来说,就是可以将用户上传的任何人形图像转化为动态的视频,能跳的舞也不只是科目三,还有蒙古舞鬼步舞之类的模板。但这其实不算是新的研发进展,早在去年11月,阿里云的视频生成模型Animate Anyone就已经在外网火了一遍: |

|
|
在线体验:https://tongyi.aliyun.com/qianwen/ 这个模型的优势就是稳定和生成的内容完成度很高,这意味着什么呢? 这不仅意味着任何人拿任何一张人形照片都可以生成一段舞蹈,我们可以将这些概念扩大一下,也就是说,任何人都可以以极低的成本批量化生产人物指定动作的视频。如今提供的功能只是跳舞,而以后,无论是网红行业还是影视行业,都必然会被这么一个看似简单的大模型功能所影响。 这也是AI对于互联网时代的普通人带来的最大的提升:极低成本的创意落地。互联网时代赋予了每个普通人文化发声的权利,而AI极有可能赋予每个普通人文化创造的可能――就比如新闻里这个兵马俑跳科目三,也不过是出自于一位西安网友之手。 最后一个要素就是兵马俑了。 兵马俑在这事里扮演的角色,你不能单独以一个文物的角度去看,而应该是文旅。 这几年很多地方都在刮文旅大风,从淄博到哈尔滨,越来越多的非传统型旅游城市都在努力往文旅方面发展。西安是比较特殊的一个:优秀的文化历史底蕴,多年来的深耕。但文化历史型旅游城市一直有一个痛点:很难像海南青岛之类的城市,凭借自然资源和地理优势获取游客,而从游客的持续性来说,文化历史型旅游城市是比不过地理自然型旅游城市的。 那么,文化历史型旅游城市就必须寻求一个方法,让城市持续破圈。 所以对旅游行业比较关注的朋友也应该都看到了,在如今的互联网时代,文化历史型旅游城市在对自身城市IP的打造和经营上往往更上心:大唐不夜城的网红都换了一茬又一茬。 |

|
|
大众的新鲜往往过得很快,需要持续性的新鲜刺激点,所以我一向觉得,大唐不夜城的网红更迭是极为正常的事,如果哪一天不更迭了,那才成问题。 再聊回文旅,今年夏天,火了淄博,今年冬天,火了哈尔滨。而今年火的这几个地方,蛮有意思的是:大众宣传,大众参与,大众享受。我之前和一个十级文旅干部聊天的时候,他提到文旅的时候就说过为什么他在抛开自身所处职位的因素以外仍然极为看好文旅:中国人和乡土之间的联系是很紧密的,紧密到外国人往往不理解,哪怕是游走在外的游子也总是会为家乡的成就骄傲,会为家乡的负面懊恼,文旅很容易带动这种人同家乡的紧密联系,很容易拉近城市中人和人的距离。这不仅是经济方面的影响,还有整个社会的正向促进。 所以在这个冬天,西安的这位网友会面对通义千问上线跳舞新功能时,将本地文旅的标志――兵马俑和最新的技术融合在一起,套上这几年最有生命力的文化表现形式社会摇。 |

|
|
社会摇本身代表的粗粝的生命力和创造力,AI所带来的创意落地,中国人对于故乡标志的情愫和文化历史型旅游城市发展中的创新需求,就在这么一件“兵马俑跳科目三”的小事里达成了和谐。 |
|
兵马俑、马斯克都开始跳科目三了?来看看通义千问是怎么整活的吧。 一时间,网上掀起了一股斗舞热潮,“参赛人员”从兵马俑到马斯克,就连拿破仑都忍不住跳起舞步。。。 这也太精彩了,那不得上点图? |

|
|
|

|
|
|

|
|
到底是怎么一回事呢? 实际上,这是阿里的AI大模型--通义千问做的一款名叫“通义舞王”的功能,用AI大模型来模仿任务跳“科目三”。这种AI+热梗的玩法,迅速让通义千问火出了圈。 只需要一张照片,人人都可以科目三。 阿里这次整活儿可以说很成功,我们一起来看看这究竟怎么玩! 先来看看这是什么技术 这个技术名叫“Animate Anyone”。看不太懂?没关系。 你只要上传一张图片,无论是真人、动漫角色还是历史画像,都能转化为一段流畅的舞蹈视频。无需舞蹈基础,没有复杂操作,只要几分钟,一个新鲜的科目三视频就出炉啦! 这是由于Animate Anyone算法在维持人物形象一致性的同时,确保了动作的流畅和时序的连贯。从技术层面上看,它通过巧妙的ReferenceNet框架、轻量级姿态引导器和时间建模方法,解决了视频生成中的一系列挑战。 想象一下,历史上的秦始皇突然跳起了流行的“科目三”,就连《蒙娜丽莎》也开始舞动,甚至是漫威宇宙中的超级英雄也摇摆不停。这些都不是幻想,通过“Animate Anyone”,这些都可以实现!想想就觉得有趣啊! 这么有趣的东西,怎么玩呢? 到底该怎么玩? 其实很简单,跟着我一步步来试试吧! 1、下载APP【通义千问】 直接到应用商店下载即可 |

|
|
2、输入“通义舞王” 在对话页面输入“通义舞王” |

|
|
3、选择舞蹈 选择你想要的舞蹈吧!这里我们选择最火的“科目三” |
|
|
|

|
|
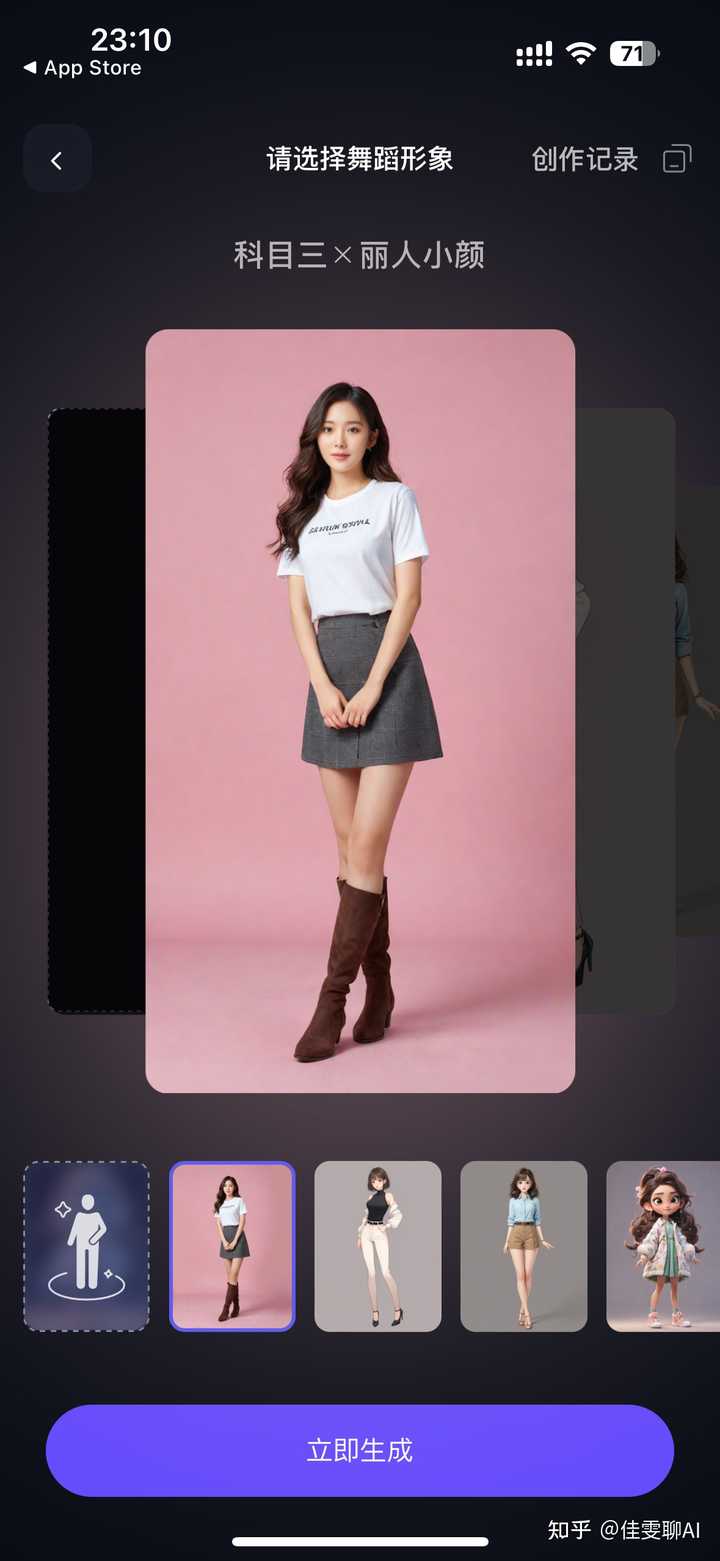
4、选择形象 你可以上传一张照片,也可以选择它提供的虚拟形象 |
|
|
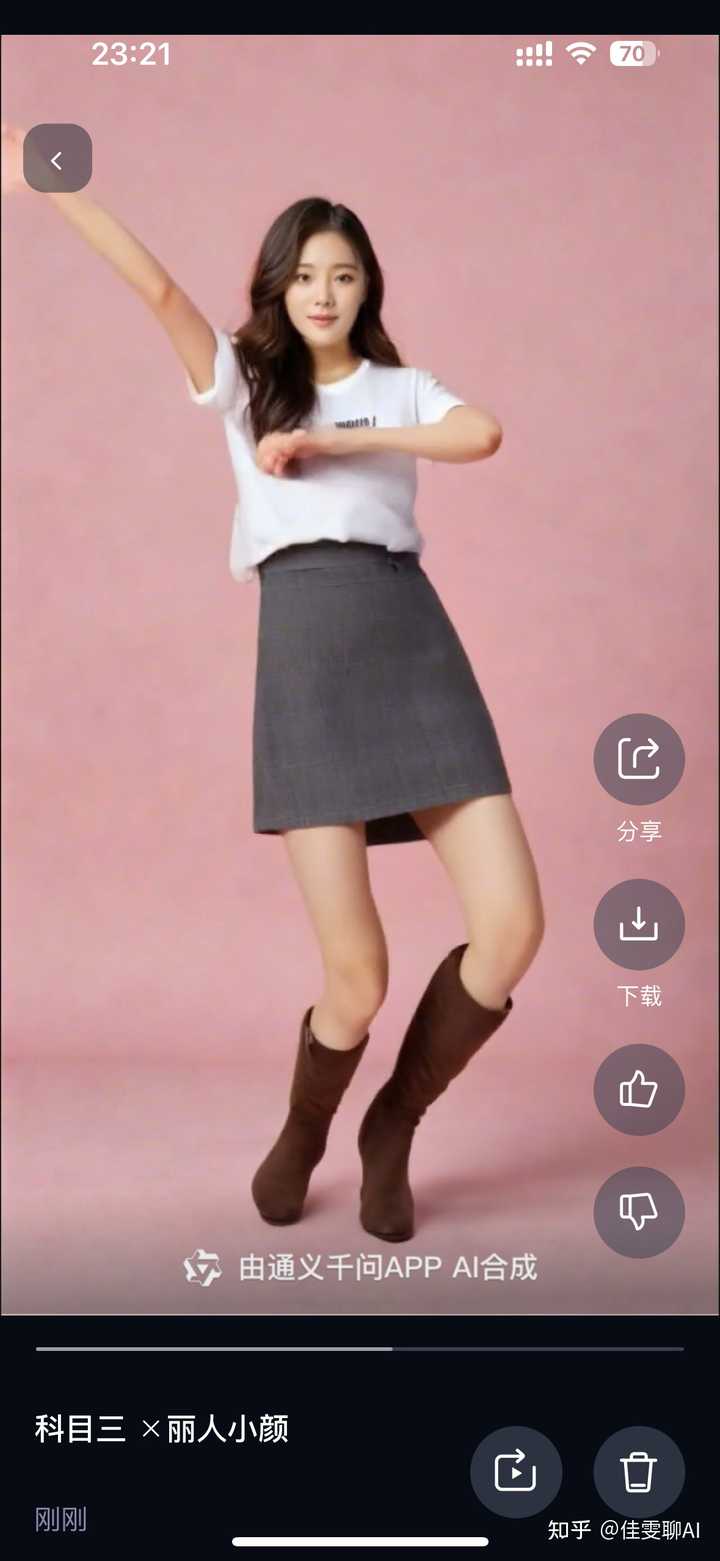
5、开始制作 点击上图的“立即生成”,即可开始制作,等待对应时长,你的舞王就诞生啦! |

|
|
|
|
|
还能做什么好玩的事情 实际上,不仅仅能够成为一个“舞王”,Animate Anyone在教育领域,还可以使历史人物“复活”,让学生以更直观的方式学习历史。 甚至可以应用到电商中,模特通过动态视频展示服装,增强消费者的购物体验。 不仅如此,在电影制作、广告、数字艺术等行业中也能够有所作为。 这听起来就很nice!未来真是充满想象力啊! 为什么是它火出圈呢? 我们细究这次通义千问火出圈的原因,最重要的实际上是用户体验。 从操作流程上看,全程没有任何一点难度,随便一个人来都能操作,甚至小学生都能够快速上手。并且视频生成的时间并不长,虽说让我等“16分钟”,实际上没有那么长时间。 整体来说,这个流程是充满“爽感”的,让用户的及时满足感得到最大的释放,也极大地增大了用户的粘性。 在此之外,阿里巴巴对用户反馈的快速响应也是重要的因素之一。 当然,技术的创新自然不必说。 在此之前,大模型图片生成视频有不少的技术卡点,生成的视频动作不流畅,或者整体的形象很奇怪,比比皆是。人物动画的生成是极为复杂的任务,阿里突破了技术难关,在这场竞赛中拔得头筹。 其次,阿里捕捉热点的能力也是非常厉害。 “科目三”可以说是最近的热梗了,多次登上热搜,在全国各地都火了起来。阿里敏锐地捕捉到了这次热点,将新奇的AI技术结合当下的热点,并且是以短视频这样易于传播的方式,一时间就火遍了全网。 AI技术的发展真的日新月异,我们今天在感慨着数字人的逼真,明天就为图片生成舞蹈视频所惊叹,后天又会出现什么,谁知道呢?我们只要怀着开放的心态,迎接一个全新的数字时代的到来。 喜欢的话,记得给我点赞收藏哦~更多AI干货,请关注@佳雯聊AI,找我聊聊。 |
|
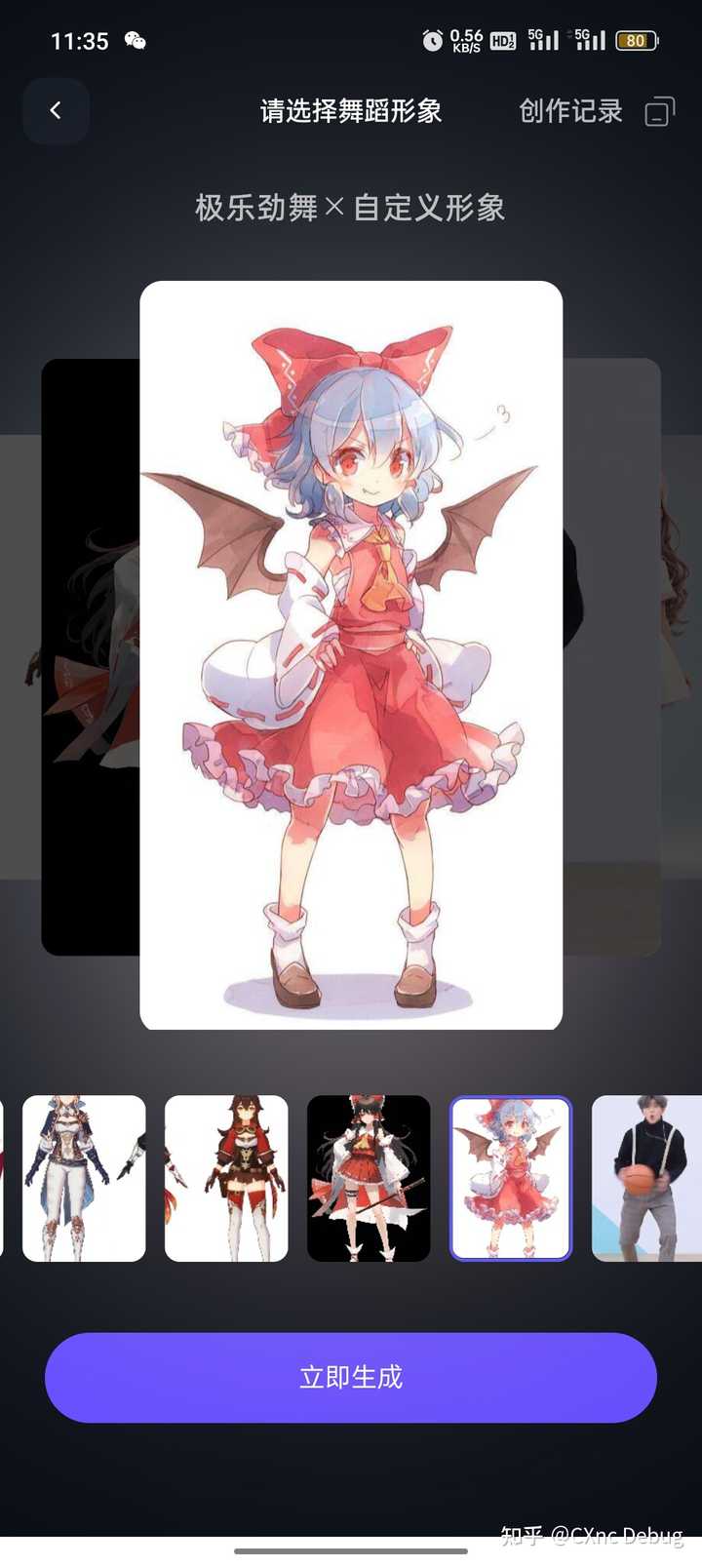
刚刚去实测了,确实强大,用的二次元动漫图片也可以,平面和3D的效果都不错,尤其是3D的已经接近MMD软件出来的效果。 推荐大家去玩玩,很方便。 就放入自己找的图片,然后就可以生成了。要求图片要是全身正面的,姿势简单的。 |
|
|
生成效果: 「AI视频」灵梦跳极乐净土758 播放 ・ 3 赞同视频 |

|
|
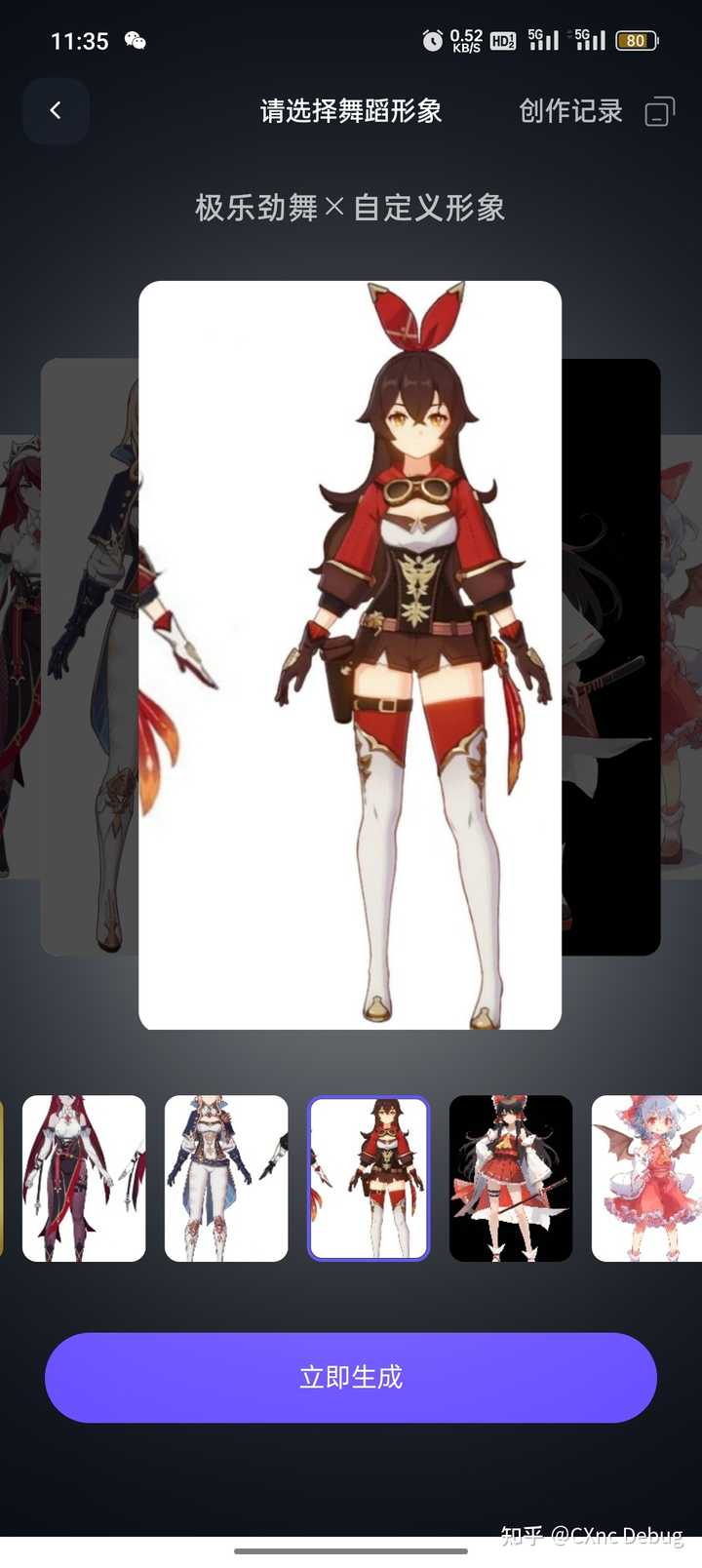
? 还试了几个原神的,还是用的图片,生成后的3D效果很好。 |
|
|
生成效果: 「AI视频」原神角色跳极乐净土761 播放 ・ 0 赞同视频 |

|
|
? 舞蹈是可以选不同种类的: |

|
|
而且目前是免费的。 然后说说它的不足: 首先目前应该是阿里资源有限或者是限制过多内容,今早每一条视频都要28分钟才能生成出来。生成出来的视频时长仅仅11秒。 (12点钟,现在排队只用15分钟了) 然后是真人视频,可能是我传的图片一般,最终效果不太自然。 |
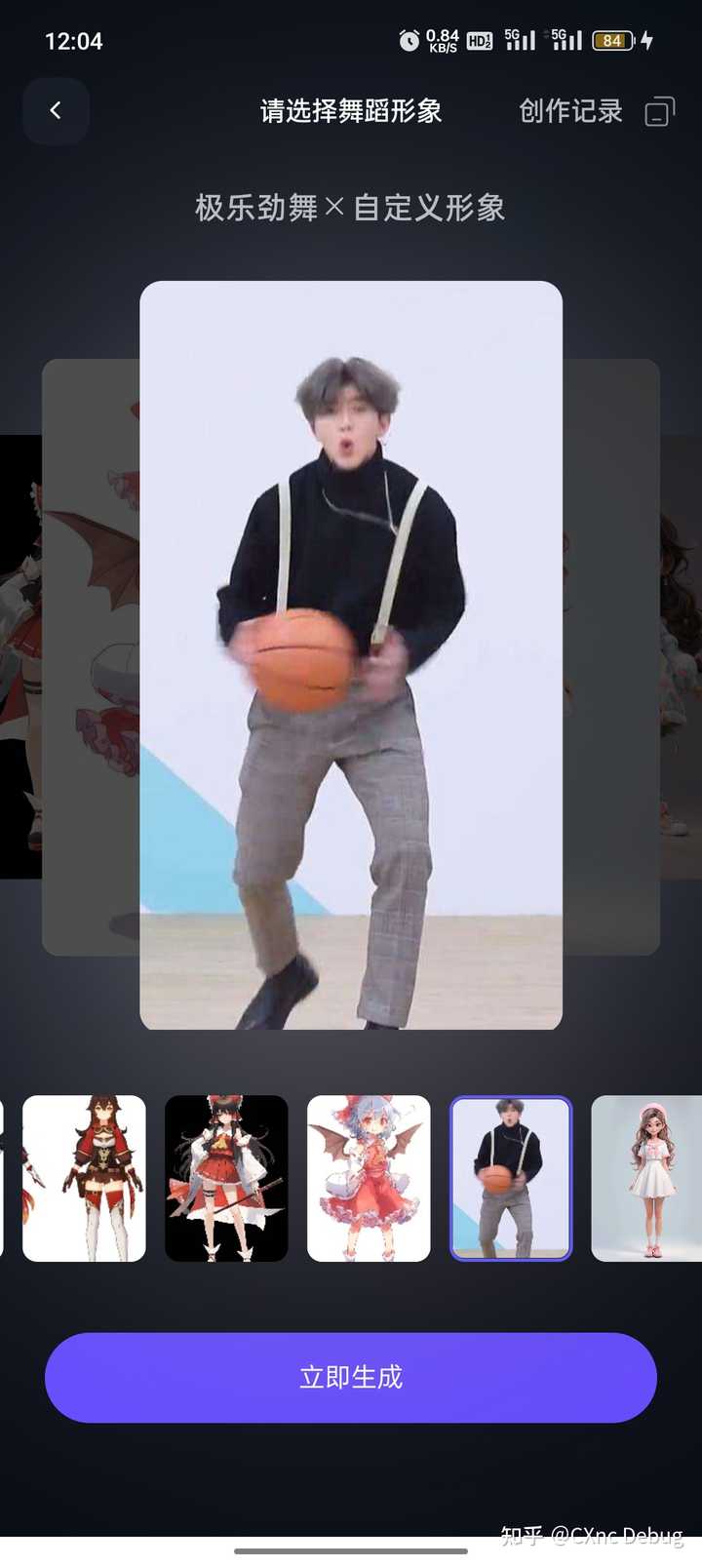
|
|
一时没有找到很清晰的图,生成出来的视频是这样的效果: 「AI视频」背带裤跳极乐禁土1066 播放 ・ 5 赞同视频 |

|
|
? 可以看到背带裤时隐时现,人物的表情比较奇怪,嘴部不自然,衣服的褶皱也不是很合乎逻辑。 起码它知道把手上的篮球给剔除了,识别能力还不错。 总结: 仅仅上传一张图片就可以生成舞蹈视频,效果已经非常惊艳了。期待更多的玩法和更高的质量。 |
|
跟纯文本生成的AI应用相比,视频/图像类的AIGC应用可玩性高,容易吸引人们的关注,因为图片、视频这种内容形式比文字更直观,就像现在大部分人都喜欢刷短视频,而不喜欢看文字获取信息一样。 所以如果此类应用生成的视频效果还不错,再把上手难度降到最低,然后结合当前互联网上的热梗,就很容易形成一种“病毒式”传播的现象,实现“出圈”的目的。 这次通义千问推出的视频生成应用,也是把AI跟当下比较火的网红舞结合起来,抓住了年轻人群体喜欢玩梗的心态,形成一波刷屏。 生成视频要比生成图像难度高很多,因为生成的视频帧需要在时间上连续,过渡需要比较自然;另外,预测物体的运动轨迹也是非常困难的。视频中可能会有多个物体在同时运动,模型需要能够正确处理这些运动关系。同时生成高质量、高分辨率的视频也需要大量的计算资源。 题目中提到的这个“通义舞王”其实是image-to-video,用户先选择一个视频模板,然后上传一张静态全身照,就可以生成一段舞蹈视频。 原理方面和详细实现过程可以参考原论文。 |
|
|
|
|
我到现在都不理解,国内为何大公司每次AI技术落地,都一定要跳舞擦边 我觉得这可能跟国内推广思维,就好这一口有关 整得自己跟阿三一样,你要说那个高射炮做low b事情,那群码农还急眼攻击你,没法理解 可能大家都是,打不过都加入了 |
|
阿里对于C端营销是真舍得花钱 我认识的几个媒体老师已经朋友圈AI跳上科目三了 你要说这些人是自发的我是不信的 但是我还是由衷的对阿里营销感到深深的佩服和羡慕 愿意做一些大众有感知的东西来让普通人了解AI 比起其他家各种吹逼不落地的概念 不如直接生成跳段科目三来的感知强烈 起码很多人知道通义千问很好玩 AI最终结果是要落地的朋友们不是靠吹概念 人家阿里 妙鸭相机都赚钱了 其他家还搁在那吹牛逼呢 |
|
有鉴于前排都有软文嫌疑,我就不凑热闹去评价软件本身了,毕竟也没收到小钱钱呀(笑 首先我要说,本身这个功能也没什么实用价值,主要目标肯定是为了推广APP本身。这种形式对于提高传播度和下载率来说是不错的,但是留存率有多少就难说了。祝愿有个好的结果吧。 |
|
阿里云的「让照片跳舞」功能是通义千问APP中的一个免费功能,它可以将上传的静态照片转换成舞蹈视频。该功能在2024年新年伊始上线,并迅速在社交媒体上流行起来。这些大约10秒的舞蹈视频不是由真人拍摄的,而是由大模型生成的。用户只需上传一张照片,通义千问APP会在十几分钟内生成具有原始面部表情、身材比例、服装和背景特征的舞蹈视频。 该功能背后的关键技术是阿里通义实验室自研的视频生成模型「Animate Anyone」。该模型集成了多项创新技术,如ReferenceNet用于捕捉和保留原图像信息,高效的姿态引导器Pose Guider用于确保动作的精准可控,以及时序生成模块确保视频帧间的连贯流畅性。Animate Anyone在视频生成领域的性能表现显著优于国内外同类模型。 通义千问APP不仅提供这项舞蹈视频生成功能,还提供了包括文本对话、语音对话、翻译、PPT大纲助手和小红书文案等多项服务。这个功能的推出不仅在国内引起热议,还在国际上获得关注,成为大模型领域备受欢迎的算法之一。 这一大模型应用的推出标志着AI技术在娱乐和社交媒体领域的一个新的发展阶段,展示了大模型在视频内容生成方面的巨大潜力和影响力 |
|
原理其实很简单:就是在你上传的图的基础上一次性生成几十张上百张动作略微有点不同的静态图,然后串联起来变成看起来像跳舞的ai视频 跟电影胶卷一个道理 所以生成的速度特别慢,要十多分钟,因为它在给你生成几十张图片好连贯起来啊… |
|
不吐槽,就从工具层面简单聊聊变现思路。 步骤一,微博贴吧老平台找出一些质量比较高的图片素材 步骤二:Ai.工具生产跳舞视频。 步骤三:剪辑工具调参数,调曝光,裁剪,调分辨率做运镜转场。 步骤四:所有平台发,不断发。总有爆的。引私域,找供应链平台供货。卖货+收代理卖四个步骤的细节操作课程。 窗口期1-3个月。挣不了多少,比打工强。 最后:总结,苦了兄弟们。 |
|
1、通义千问水平约等于文心一言4.0,但实际用户数很低,营销没搞好 2、跳舞照片本身并非大语言模型的功能。这算是一个封装好的AIGC小游戏,技术难度其实不高。比起通义千问大语言模型的水平,跳舞照片只能算是有趣,不能算是出众。 3、跳舞照片让通义千问出圈了,但很可能并不会带动大语言模型本身的用户。 4、从前年ChatGTP突然开口说话到现在,刚好一年多一点的时间,AI再一次引起了老百姓的注意。但这个世界的变化是:大家已经习惯了会说人话的AI,会跳舞的照片也将成为习惯,世界本该如此。 |
|
又一款现象级产品,生成的舞蹈视频非常丝滑! 不仅能让人跳舞,有手有脚的形象都可以。 比如,玩具、雕像等等,效果都出奇的好! 操作也非常简单,下载通义千问APP,输入“全民舞王”关键词,即可进入功能界面! 有心的朋友可能会奇怪,为啥非要用通义千问APP作为入口呢? 当我去下载通义千问APP的时候,才明白了阿里的用意和无奈! 通义千问APP竟然只有49万次安装! 而国内其他大模型APP,百度文心、讯飞星火、字节豆包,都是千万级的下载量。 真是没有对比就没有伤害啊! |

|
|
|

|
|
|

|
|
从之前的评测结果来看,通义千问的效果与文星一言相差无几,明显优于星火和豆包。 但没想到用户数量竟如此惨淡!实在令人费解! |
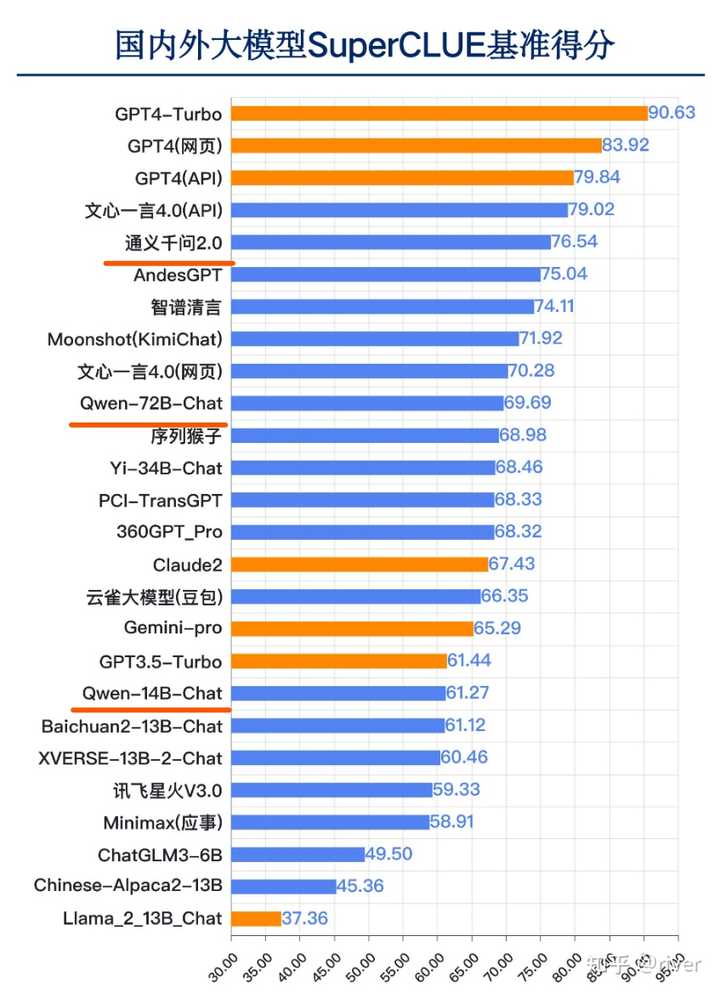
|
|
此次全民热舞应用火出圈,将其与通义千问APP进行捆绑,提升通义千问的影响和下载量,就是一个自然而然地想法了! 接下来,通义千问能否借势崛起呢? 千万量级的用户数量差距,恐怕不是一朝一夕能够填补~ |
|
如果回忆过去一年最让人印象深刻的科技事件或现象,那 AI 得是数一数二的。 这个「让照片跳舞」的功能更是有趣,上传一张真人的,或动漫卡通的人物照片,就能免费生成一段这个人物舞蹈的视频。 |
|
|

|
|
每一个模特跳舞的动作都十分自然,几乎可以乱真。而且看到他们从静止突然变成“妖娆多姿”,魔性又喜感。 然后,我们就看到各路大 V 也纷纷开始转发,各种花活应接不暇。比如让梅球王摆各种 Pose: |
|
|
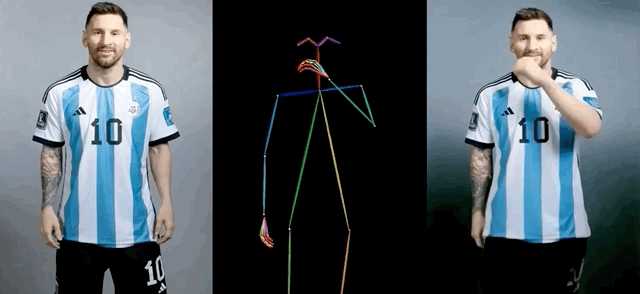
|
|
蒙娜丽莎魔性起舞: |
|
|

|
|
还有各路明星也“惨遭毒手”…… |
|
|

|
|
从结果来看,很自然,很好地保留了原来的面部表情、身材比例、背景等特征,衣服也没有出现穿帮。 相信很多朋友都体验过用 AI 大模型生成文字、生成图片,效果都不错。但能生成视频,并且效果体验还好的,属实不多。究其原因,还是因为视频生成太难了,特别是人物动作视频的生成: 形象一致性难保持;动作流畅度难把控;动态时序很难无瑕疵;推理等待时间长。 总之,人物是视频生成中的核心元素,也是核心难点,目前像谷歌、Meta、Runway 等巨头都在积极布局,解决这些困难,也确实诞生了一些方法来化解挑战。 Animate Anyone 算法,也就是在这种背景下研发出来的。整体来看,Animate Anyone 算法从一致性、可控性、和稳定性三方面保证了视频的效果。 例如,它引入 ReferenceNet,用于捕捉和保留原图像信息,可高度还原人物、表情及服装细节;同时使用了一个高效的 Pose Guider 姿态引导器 ,保证了动作的精准可控;另外,还通过时序生成模块,有效保证视频帧间的连贯流畅性。 |
|
|
根据评测集结果显示,Animate Anyone 的性能表现是要显著优于国内外同类模型的。 |
|
|
|
|
|
目前市面上类似的专注人的视频生成主要有两种: 一种是用人体 mask 来控制视频生成,人体会变形到 mask 的形状,无法保持照片中人的比例;另一种是基于视频的重绘,只保留了人脸的信息,身体、服装、背景都不保留。 两种显然都有一定的瑕疵,而Animate Anyone 是完整的保留了人脸、身材比例、服装细节、背景信息,能更好的还原图片信息。 而且,相比 Gen2、Pika 等文本生成视频的产品,Animate Anyone 可以更聚焦到人的视频生成。可以对生成的动作做精准控制,且在技术上生成的视频长度不受限制。 由此可见,Animate Anyone 在算法上确实具备相当的领先性,特别是在人物一致性和画面稳定性上表现极佳,一改当下很多视频生成画面局部扭曲、细节模糊、抖动跳帧等问题。 并且,这项技术未来可能还会有更广泛的应用场景,包括各种图生视频的应用,还有在线零售、娱乐视频、影视、艺术创作和虚拟角色创建等等,想象空间很大。 值得一提的是,最近他们还推出了一款一键试衣的模型,Outfit Anyone,仅仅依靠服饰的平铺图,就可以实现上下装的试穿。 |
|
|

|
|
从效果看,这个模型不仅能保证人物本身脸部的 ID,并且通过 3D 和 2D 技术的结合,确保模特姿势、身材等信息的还原,在此基础上,针对任意的单件上 / 下服饰、上和下组合套装等服饰进行直接试衣穿搭。 试想,这个技术如果应用普及了,以后我们在网上买衣服,岂不再也不用为合不合适发愁了?一键虚拟试衣,简直爽歪啊。 大模型发展速度真的太快了,智能化时代也正快速到来,相信未来大模型的应用会持续落地和创新,而我们的生活,也会因为这些应用而深刻改变。 |
|
|
| [收藏本文] 【下载本文】 |
| 科技知识 最新文章 |
| 百度为什么越来越垃圾了? |
| 百度为什么越来越垃圾了? |
| 为什么程序员总是发现不了自己的Bug? |
| 出现在抖音评论区里边的算命真不真? |
| 你认为 C++ 最不应该存在的特性是什么? |
| 为什么 Windows 的兼容性这么强大,到底用了 |
| 如何看待Nvidia禁止使用翻译工具将cuda运行 |
| 为何苹果搞了十年的汽车还是难产,小米很快 |
| 该不该和AI说谢谢? |
| 为什么突破性的技术总是最先发生在西方? |
| 上一篇文章 下一篇文章 查看所有文章 |
|
|
|
| 股票涨跌实时统计 涨停板选股 分时图选股 跌停板选股 K线图选股 成交量选股 均线选股 趋势线选股 筹码理论 波浪理论 缠论 MACD指标 KDJ指标 BOLL指标 RSI指标 炒股基础知识 炒股故事 |
| 网站联系: qq:121756557 email:121756557@qq.com 天天财汇 |